[GitHub] [spark] SaurabhChawla100 commented on a change in pull request #29045: [SPARK-32234][SQL] Spark sql commands are failing on selecting the orc tables
SaurabhChawla100 commented on a change in pull request #29045:
URL: https://github.com/apache/spark/pull/29045#discussion_r453437981
##
File path:
sql/hive/src/test/scala/org/apache/spark/sql/hive/orc/HiveOrcQuerySuite.scala
##
@@ -288,4 +288,56 @@ class HiveOrcQuerySuite extends OrcQueryTest with
TestHiveSingleton {
}
}
}
+
+ test("SPARK-32234: orc data created by the hive tables having _col fields" +
+" name for vectorized reader") {
+Seq(false, true).foreach { vectorized =>
+ withSQLConf(SQLConf.ORC_VECTORIZED_READER_ENABLED.key ->
vectorized.toString) {
+withTable("test_hive_orc_vect_read") {
+ spark.sql(
+"""
+ | CREATE TABLE test_hive_orc_vect_read
+ | (_col1 INT, _col2 STRING, _col3 INT)
+ | USING orc
+""".stripMargin)
+ spark.sql(
+"""
+ | INSERT INTO
+ | test_hive_orc_vect_read
+ | VALUES(9, '12', 2020)
+""".stripMargin)
+
+ val df = spark.sql("SELECT _col2 FROM test_hive_orc_vect_read")
+ checkAnswer(df, Row("12"))
+}
+ }
+}
+ }
+
+ test("SPARK-32234: orc data created by the hive tables having _col fields
name" +
Review comment:
Merged the test
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on a change in pull request #28996: [SPARK-29358][SQL] Make unionByName optionally fill missing columns with nulls
viirya commented on a change in pull request #28996:
URL: https://github.com/apache/spark/pull/28996#discussion_r453447856
##
File path: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala
##
@@ -2048,19 +2088,34 @@ class Dataset[T] private[sql](
// Builds a project list for `other` based on `logicalPlan` output names
val rightProjectList = leftOutputAttrs.map { lattr =>
rightOutputAttrs.find { rattr => resolver(lattr.name, rattr.name)
}.getOrElse {
-throw new AnalysisException(
- s"""Cannot resolve column name "${lattr.name}" among """ +
-s"""(${rightOutputAttrs.map(_.name).mkString(", ")})""")
+if (allowMissingColumns) {
Review comment:
No, currently it doesn't.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] GuoPhilipse commented on a change in pull request #29056: [SPARK-31753][SQL][DOCS] Add missing keywords in the SQL docs
GuoPhilipse commented on a change in pull request #29056: URL: https://github.com/apache/spark/pull/29056#discussion_r453444219 ## File path: docs/sql-ref-syntax-ddl-create-table-hiveformat.md ## @@ -117,6 +145,21 @@ CREATE TABLE student (id INT, name STRING) CREATE TABLE student (id INT,name STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE; + +--Use complex datatype Review comment: sure, will update later This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #28833: [SPARK-20680][SQL] Spark-sql do not support for creating table with void column datatype
cloud-fan commented on pull request #28833: URL: https://github.com/apache/spark/pull/28833#issuecomment-657368732 @ulysses-you does it work before this PR? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28363: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
AmplabJenkins removed a comment on pull request #28363: URL: https://github.com/apache/spark/pull/28363#issuecomment-657368239 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28363: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
AmplabJenkins commented on pull request #28363: URL: https://github.com/apache/spark/pull/28363#issuecomment-657368239 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28746: [SPARK-31922][CORE] logDebug "RpcEnv already stopped" error on LocalSparkCluster shutdown
AmplabJenkins removed a comment on pull request #28746: URL: https://github.com/apache/spark/pull/28746#issuecomment-657367691 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28363: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
SparkQA commented on pull request #28363: URL: https://github.com/apache/spark/pull/28363#issuecomment-657367971 **[Test build #125751 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125751/testReport)** for PR 28363 at commit [`b648156`](https://github.com/apache/spark/commit/b64815622bb4e8cd8b474cb2983f2c9b78ed9342). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28746: [SPARK-31922][CORE] logDebug "RpcEnv already stopped" error on LocalSparkCluster shutdown
SparkQA removed a comment on pull request #28746: URL: https://github.com/apache/spark/pull/28746#issuecomment-657322426 **[Test build #125743 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125743/testReport)** for PR 28746 at commit [`59a0595`](https://github.com/apache/spark/commit/59a0595c8177ff801d0f7cbcc1fe6c458bcb844c). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28746: [SPARK-31922][CORE] logDebug "RpcEnv already stopped" error on LocalSparkCluster shutdown
AmplabJenkins commented on pull request #28746: URL: https://github.com/apache/spark/pull/28746#issuecomment-657367691 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28746: [SPARK-31922][CORE] logDebug "RpcEnv already stopped" error on LocalSparkCluster shutdown
SparkQA commented on pull request #28746: URL: https://github.com/apache/spark/pull/28746#issuecomment-657367130 **[Test build #125743 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125743/testReport)** for PR 28746 at commit [`59a0595`](https://github.com/apache/spark/commit/59a0595c8177ff801d0f7cbcc1fe6c458bcb844c). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28363: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
AmplabJenkins removed a comment on pull request #28363: URL: https://github.com/apache/spark/pull/28363#issuecomment-657366713 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/125744/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #28363: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
HeartSaVioR commented on pull request #28363: URL: https://github.com/apache/spark/pull/28363#issuecomment-657366988 retest this, please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28363: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
AmplabJenkins removed a comment on pull request #28363: URL: https://github.com/apache/spark/pull/28363#issuecomment-657366710 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28363: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
AmplabJenkins commented on pull request #28363: URL: https://github.com/apache/spark/pull/28363#issuecomment-657366710 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28363: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
SparkQA removed a comment on pull request #28363: URL: https://github.com/apache/spark/pull/28363#issuecomment-657332068 **[Test build #125744 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125744/testReport)** for PR 28363 at commit [`b648156`](https://github.com/apache/spark/commit/b64815622bb4e8cd8b474cb2983f2c9b78ed9342). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28363: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
SparkQA commented on pull request #28363: URL: https://github.com/apache/spark/pull/28363#issuecomment-657366383 **[Test build #125744 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125744/testReport)** for PR 28363 at commit [`b648156`](https://github.com/apache/spark/commit/b64815622bb4e8cd8b474cb2983f2c9b78ed9342). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29045: [SPARK-32234][SQL] Spark sql commands are failing on selecting the orc tables
AmplabJenkins removed a comment on pull request #29045: URL: https://github.com/apache/spark/pull/29045#issuecomment-657362237 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29045: [SPARK-32234][SQL] Spark sql commands are failing on selecting the orc tables
AmplabJenkins commented on pull request #29045: URL: https://github.com/apache/spark/pull/29045#issuecomment-657362237 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SaurabhChawla100 commented on a change in pull request #29045: [SPARK-32234][SQL] Spark sql commands are failing on selecting the orc tables
SaurabhChawla100 commented on a change in pull request #29045:
URL: https://github.com/apache/spark/pull/29045#discussion_r453437981
##
File path:
sql/hive/src/test/scala/org/apache/spark/sql/hive/orc/HiveOrcQuerySuite.scala
##
@@ -288,4 +288,56 @@ class HiveOrcQuerySuite extends OrcQueryTest with
TestHiveSingleton {
}
}
}
+
+ test("SPARK-32234: orc data created by the hive tables having _col fields" +
+" name for vectorized reader") {
+Seq(false, true).foreach { vectorized =>
+ withSQLConf(SQLConf.ORC_VECTORIZED_READER_ENABLED.key ->
vectorized.toString) {
+withTable("test_hive_orc_vect_read") {
+ spark.sql(
+"""
+ | CREATE TABLE test_hive_orc_vect_read
+ | (_col1 INT, _col2 STRING, _col3 INT)
+ | USING orc
+""".stripMargin)
+ spark.sql(
+"""
+ | INSERT INTO
+ | test_hive_orc_vect_read
+ | VALUES(9, '12', 2020)
+""".stripMargin)
+
+ val df = spark.sql("SELECT _col2 FROM test_hive_orc_vect_read")
+ checkAnswer(df, Row("12"))
+}
+ }
+}
+ }
+
+ test("SPARK-32234: orc data created by the hive tables having _col fields
name" +
Review comment:
Merge the test
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29045: [SPARK-32234][SQL] Spark sql commands are failing on selecting the orc tables
SparkQA commented on pull request #29045: URL: https://github.com/apache/spark/pull/29045#issuecomment-657361898 **[Test build #125750 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125750/testReport)** for PR 29045 at commit [`5b93849`](https://github.com/apache/spark/commit/5b9384938d9570f5b8982a6e713529f0c14d6222). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SaurabhChawla100 commented on a change in pull request #29045: [SPARK-32234][SQL] Spark sql commands are failing on selecting the orc tables
SaurabhChawla100 commented on a change in pull request #29045:
URL: https://github.com/apache/spark/pull/29045#discussion_r453438056
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/orc/OrcFileFormat.scala
##
@@ -185,10 +185,15 @@ class OrcFileFormat
isCaseSensitive, dataSchema, requiredSchema, reader, conf)
}
- if (requestedColIdsOrEmptyFile.isEmpty) {
+ if (requestedColIdsOrEmptyFile._2) {
+resultSchemaString = OrcUtils.orcTypeDescriptionString(actualSchema)
+ }
+ OrcConf.MAPRED_INPUT_SCHEMA.setString(conf, resultSchemaString)
+
+ if (requestedColIdsOrEmptyFile._1.isEmpty) {
Review comment:
done
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SaurabhChawla100 commented on a change in pull request #29045: [SPARK-32234][SQL] Spark sql commands are failing on selecting the orc tables
SaurabhChawla100 commented on a change in pull request #29045:
URL: https://github.com/apache/spark/pull/29045#discussion_r453437937
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/orc/OrcUtils.scala
##
@@ -116,47 +116,53 @@ object OrcUtils extends Logging {
}
/**
- * Returns the requested column ids from the given ORC file. Column id can
be -1, which means the
- * requested column doesn't exist in the ORC file. Returns None if the given
ORC file is empty.
+ * Returns the requested column ids from the given ORC file and Boolean flag
to use actual
+ * schema or result schema. Column id can be -1, which means the requested
column doesn't
+ * exist in the ORC file. Returns None if the given ORC file is empty.
Review comment:
done
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] PavithraRamachandran commented on pull request #28931: [SPARK-32103][CORE] Support IPv6 host/port in core module
PavithraRamachandran commented on pull request #28931: URL: https://github.com/apache/spark/pull/28931#issuecomment-657359754 thank u for merging @dongjoon-hyun This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #28996: [SPARK-29358][SQL] Make unionByName optionally fill missing columns with nulls
cloud-fan commented on a change in pull request #28996:
URL: https://github.com/apache/spark/pull/28996#discussion_r453434564
##
File path: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala
##
@@ -2048,19 +2088,34 @@ class Dataset[T] private[sql](
// Builds a project list for `other` based on `logicalPlan` output names
val rightProjectList = leftOutputAttrs.map { lattr =>
rightOutputAttrs.find { rattr => resolver(lattr.name, rattr.name)
}.getOrElse {
-throw new AnalysisException(
- s"""Cannot resolve column name "${lattr.name}" among """ +
-s"""(${rightOutputAttrs.map(_.name).mkString(", ")})""")
+if (allowMissingColumns) {
Review comment:
Does it work with nested columns?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ulysses-you commented on pull request #28833: [SPARK-20680][SQL] Spark-sql do not support for creating table with void column datatype
ulysses-you commented on pull request #28833: URL: https://github.com/apache/spark/pull/28833#issuecomment-657356505 What about view ? After this pr we have no readable exception, and also not support to create view with `NullType`. When execute `create view v1 as select null as col`, the exception is ``` org.apache.spark.SparkException: Cannot recognize hive type string: null, column: col at org.apache.spark.sql.hive.client.HiveClientImpl$.getSparkSQLDataType(HiveClientImpl.scala:999) at org.apache.spark.sql.hive.client.HiveClientImpl$.$anonfun$verifyColumnDataType$1(HiveClientImpl.scala:1021) at scala.collection.Iterator.foreach(Iterator.scala:941) at scala.collection.Iterator.foreach$(Iterator.scala:941) at scala.collection.AbstractIterator.foreach(Iterator.scala:1429) at scala.collection.IterableLike.foreach(IterableLike.scala:74) at scala.collection.IterableLike.foreach$(IterableLike.scala:73) at org.apache.spark.sql.types.StructType.foreach(StructType.scala:102) at org.apache.spark.sql.hive.client.HiveClientImpl$.org$apache$spark$sql$hive$client$HiveClientImpl$$verifyColumnDataType(HiveClientImpl.scala:1021) at org.apache.spark.sql.hive.client.HiveClientImpl.$anonfun$createTable$1(HiveClientImpl.scala:547) ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29079: [SPARK-32286][SQL] Coalesce bucketed table for shuffled hash join if applicable
AmplabJenkins removed a comment on pull request #29079: URL: https://github.com/apache/spark/pull/29079#issuecomment-657354358 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29079: [SPARK-32286][SQL] Coalesce bucketed table for shuffled hash join if applicable
AmplabJenkins commented on pull request #29079: URL: https://github.com/apache/spark/pull/29079#issuecomment-657354358 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #29079: [SPARK-32286][SQL] Coalesce bucketed table for shuffled hash join if applicable
SparkQA removed a comment on pull request #29079: URL: https://github.com/apache/spark/pull/29079#issuecomment-657287917 **[Test build #125736 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125736/testReport)** for PR 29079 at commit [`64a95d1`](https://github.com/apache/spark/commit/64a95d1a4e95ec978a00c56e97a142dedfa371c9). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29079: [SPARK-32286][SQL] Coalesce bucketed table for shuffled hash join if applicable
SparkQA commented on pull request #29079: URL: https://github.com/apache/spark/pull/29079#issuecomment-657354091 **[Test build #125736 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125736/testReport)** for PR 29079 at commit [`64a95d1`](https://github.com/apache/spark/commit/64a95d1a4e95ec978a00c56e97a142dedfa371c9). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] c21 commented on pull request #29079: [SPARK-32286][SQL] Coalesce bucketed table for shuffled hash join if applicable
c21 commented on pull request #29079: URL: https://github.com/apache/spark/pull/29079#issuecomment-657353621 > Could you show us performance numbers in the PR description, first? I think we need to check the trade-off between #parallelism and shuffle I/O. @maropu, update PR description for one test query in TPCDS (with modification). Thanks. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29078: [SPARK-29292][STREAMING][SQL][BUILD] Get streaming, catalyst, sql compiling for Scala 2.13
AmplabJenkins commented on pull request #29078: URL: https://github.com/apache/spark/pull/29078#issuecomment-657347836 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/125745/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn commented on pull request #29064: [SPARK-32272][SQL] Add and extend SQL standard command SET TIME ZONE
yaooqinn commented on pull request #29064: URL: https://github.com/apache/spark/pull/29064#issuecomment-657346567 the test case for listing all timezones is removed because it varies from different JDKs. The interval is supported and also some extensions were made too 1) offset range is [-18, +18] in spark which is bigger than ansi's, 2) the second part is supported in Spark, e.g. +14:14:14, while ansi only indicates hours-minutes, 3) multi value-units interval is much common than unit-to-unit ones, so this interval form is supported too. cc @cloud-fan This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29064: [SPARK-32272][SQL] Add and extend SQL standard command SET TIME ZONE
AmplabJenkins removed a comment on pull request #29064: URL: https://github.com/apache/spark/pull/29064#issuecomment-657346272 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29064: [SPARK-32272][SQL] Add and extend SQL standard command SET TIME ZONE
AmplabJenkins commented on pull request #29064: URL: https://github.com/apache/spark/pull/29064#issuecomment-657346272 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29064: [SPARK-32272][SQL] Add and extend SQL standard command SET TIME ZONE
SparkQA commented on pull request #29064: URL: https://github.com/apache/spark/pull/29064#issuecomment-657346056 **[Test build #125749 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125749/testReport)** for PR 29064 at commit [`3a62ecc`](https://github.com/apache/spark/commit/3a62eccedc04532e9f0841fc5f6f3f0261e252d8). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28957: [SPARK-32138] Drop Python 2.7, 3.4 and 3.5
AmplabJenkins removed a comment on pull request #28957: URL: https://github.com/apache/spark/pull/28957#issuecomment-657343688 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/125739/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28957: [SPARK-32138] Drop Python 2.7, 3.4 and 3.5
AmplabJenkins commented on pull request #28957: URL: https://github.com/apache/spark/pull/28957#issuecomment-657343688 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/125739/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #28957: [SPARK-32138] Drop Python 2.7, 3.4 and 3.5
SparkQA removed a comment on pull request #28957: URL: https://github.com/apache/spark/pull/28957#issuecomment-657302232 **[Test build #125739 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125739/testReport)** for PR 28957 at commit [`9e8100f`](https://github.com/apache/spark/commit/9e8100fcc290d3d8f557dec59e1891879823a8d3). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28957: [SPARK-32138] Drop Python 2.7, 3.4 and 3.5
SparkQA commented on pull request #28957: URL: https://github.com/apache/spark/pull/28957#issuecomment-657343294 **[Test build #125739 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125739/testReport)** for PR 28957 at commit [`9e8100f`](https://github.com/apache/spark/commit/9e8100fcc290d3d8f557dec59e1891879823a8d3). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #27694: [SPARK-30946][SS] Serde entry via DataInputStream/DataOutputStream with LZ4 compression on FileStream(Source/Sink)Log
AmplabJenkins removed a comment on pull request #27694: URL: https://github.com/apache/spark/pull/27694#issuecomment-657340875 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #27694: [SPARK-30946][SS] Serde entry via DataInputStream/DataOutputStream with LZ4 compression on FileStream(Source/Sink)Log
AmplabJenkins commented on pull request #27694: URL: https://github.com/apache/spark/pull/27694#issuecomment-657340875 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #27694: [SPARK-30946][SS] Serde entry via DataInputStream/DataOutputStream with LZ4 compression on FileStream(Source/Sink)Log
SparkQA commented on pull request #27694: URL: https://github.com/apache/spark/pull/27694#issuecomment-657340452 **[Test build #125748 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125748/testReport)** for PR 27694 at commit [`3933018`](https://github.com/apache/spark/commit/3933018575441fca267e0a0fe93bfef7d9cf58f5). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #27694: [SPARK-30946][SS] Serde entry via DataInputStream/DataOutputStream with LZ4 compression on FileStream(Source/Sink)Log
HeartSaVioR commented on pull request #27694: URL: https://github.com/apache/spark/pull/27694#issuecomment-657340134 retest this, please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #27694: [SPARK-30946][SS] Serde entry via DataInputStream/DataOutputStream with LZ4 compression on FileStream(Source/Sink)Log
AmplabJenkins removed a comment on pull request #27694: URL: https://github.com/apache/spark/pull/27694#issuecomment-657339356 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/125737/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #27694: [SPARK-30946][SS] Serde entry via DataInputStream/DataOutputStream with LZ4 compression on FileStream(Source/Sink)Log
AmplabJenkins removed a comment on pull request #27694: URL: https://github.com/apache/spark/pull/27694#issuecomment-657339347 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #27694: [SPARK-30946][SS] Serde entry via DataInputStream/DataOutputStream with LZ4 compression on FileStream(Source/Sink)Log
AmplabJenkins commented on pull request #27694: URL: https://github.com/apache/spark/pull/27694#issuecomment-657339347 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #27694: [SPARK-30946][SS] Serde entry via DataInputStream/DataOutputStream with LZ4 compression on FileStream(Source/Sink)Log
SparkQA removed a comment on pull request #27694: URL: https://github.com/apache/spark/pull/27694#issuecomment-657294330 **[Test build #125737 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125737/testReport)** for PR 27694 at commit [`3933018`](https://github.com/apache/spark/commit/3933018575441fca267e0a0fe93bfef7d9cf58f5). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29083: debug SPARK-32250
AmplabJenkins removed a comment on pull request #29083: URL: https://github.com/apache/spark/pull/29083#issuecomment-657338929 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #27694: [SPARK-30946][SS] Serde entry via DataInputStream/DataOutputStream with LZ4 compression on FileStream(Source/Sink)Log
SparkQA commented on pull request #27694: URL: https://github.com/apache/spark/pull/27694#issuecomment-657339021 **[Test build #125737 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125737/testReport)** for PR 27694 at commit [`3933018`](https://github.com/apache/spark/commit/3933018575441fca267e0a0fe93bfef7d9cf58f5). * This patch **fails PySpark pip packaging tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29083: debug SPARK-32250
AmplabJenkins commented on pull request #29083: URL: https://github.com/apache/spark/pull/29083#issuecomment-657338929 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 closed pull request #29083: debug SPARK-32250
Ngone51 closed pull request #29083: URL: https://github.com/apache/spark/pull/29083 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29083: debug SPARK-32250
SparkQA commented on pull request #29083: URL: https://github.com/apache/spark/pull/29083#issuecomment-657338632 **[Test build #125747 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125747/testReport)** for PR 29083 at commit [`24bec3d`](https://github.com/apache/spark/commit/24bec3d09e0a4e2c12acf788cac306723714c0e7). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 commented on pull request #29083: debug SPARK-32250
Ngone51 commented on pull request #29083: URL: https://github.com/apache/spark/pull/29083#issuecomment-657337665 FYI @HeartSaVioR This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29075: [SPARK-32284][SQL] Avoid expanding too many CNF predicates in partition pruning
AmplabJenkins removed a comment on pull request #29075: URL: https://github.com/apache/spark/pull/29075#issuecomment-657337271 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 opened a new pull request #29083: debug SPARK-32250
Ngone51 opened a new pull request #29083: URL: https://github.com/apache/spark/pull/29083 ### What changes were proposed in this pull request? ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29075: [SPARK-32284][SQL] Avoid expanding too many CNF predicates in partition pruning
AmplabJenkins commented on pull request #29075: URL: https://github.com/apache/spark/pull/29075#issuecomment-657337271 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29075: [SPARK-32284][SQL] Avoid expanding too many CNF predicates in partition pruning
SparkQA commented on pull request #29075: URL: https://github.com/apache/spark/pull/29075#issuecomment-657337043 **[Test build #125746 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125746/testReport)** for PR 29075 at commit [`df08390`](https://github.com/apache/spark/commit/df083906f2d9938d77b4b41878271af1826b5220). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29078: [SPARK-29292][STREAMING][SQL][BUILD] Get streaming, catalyst, sql compiling for Scala 2.13
AmplabJenkins removed a comment on pull request #29078: URL: https://github.com/apache/spark/pull/29078#issuecomment-657334091 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29078: [SPARK-29292][STREAMING][SQL][BUILD] Get streaming, catalyst, sql compiling for Scala 2.13
AmplabJenkins commented on pull request #29078: URL: https://github.com/apache/spark/pull/29078#issuecomment-657334091 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29078: [SPARK-29292][STREAMING][SQL][BUILD] Get streaming, catalyst, sql compiling for Scala 2.13
SparkQA commented on pull request #29078: URL: https://github.com/apache/spark/pull/29078#issuecomment-657333788 **[Test build #125745 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125745/testReport)** for PR 29078 at commit [`77fb2be`](https://github.com/apache/spark/commit/77fb2be3a520de1b7be9559edad7d5a21dbabc62). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LantaoJin commented on a change in pull request #29062: [SPARK-32237][SQL] Resolve hint in CTE
LantaoJin commented on a change in pull request #29062:
URL: https://github.com/apache/spark/pull/29062#discussion_r453409787
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##
@@ -200,18 +200,18 @@ class Analyzer(
val postHocResolutionRules: Seq[Rule[LogicalPlan]] = Nil
lazy val batches: Seq[Batch] = Seq(
+Batch("Substitution", fixedPoint,
+ CTESubstitution,
+ WindowsSubstitution,
+ EliminateUnions,
+ new SubstituteUnresolvedOrdinals(conf)),
Review comment:
It's hard to find which change causing it for me since 2.4 and 3.0 have
many differences that I don't know.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #28363: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
AmplabJenkins removed a comment on pull request #28363: URL: https://github.com/apache/spark/pull/28363#issuecomment-657332289 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #28363: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
AmplabJenkins commented on pull request #28363: URL: https://github.com/apache/spark/pull/28363#issuecomment-657332289 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on pull request #29078: [SPARK-29292][STREAMING][SQL][BUILD] Get streaming, catalyst, sql compiling for Scala 2.13
srowen commented on pull request #29078: URL: https://github.com/apache/spark/pull/29078#issuecomment-657332394 Jenkins retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29082: [SPARK-32288][UI] Add exception summary for failed tasks in stage page
AmplabJenkins removed a comment on pull request #29082: URL: https://github.com/apache/spark/pull/29082#issuecomment-657331978 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a change in pull request #29075: [SPARK-32284][SQL] Avoid expanding too many CNF predicates in partition pruning
gengliangwang commented on a change in pull request #29075: URL: https://github.com/apache/spark/pull/29075#discussion_r453409529 ## File path: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/PruneFileSourcePartitions.scala ## @@ -53,11 +53,17 @@ private[sql] object PruneFileSourcePartitions val partitionColumns = relation.resolve(partitionSchema, sparkSession.sessionState.analyzer.resolver) val partitionSet = AttributeSet(partitionColumns) -val (partitionFilters, dataFilters) = normalizedFilters.partition(f => +val (partitionFilters, remainingFilters) = normalizedFilters.partition(f => f.references.subsetOf(partitionSet) ) -(ExpressionSet(partitionFilters), dataFilters) +// Try extracting more convertible partition filters from the remaining filters by converting +// them into CNF. +val remainingFilterInCnf = remainingFilters.flatMap(CNFConversion) +val extraPartitionFilters = + remainingFilterInCnf.filter(f => f.references.subsetOf(partitionSet)) + +(ExpressionSet(partitionFilters ++ extraPartitionFilters), remainingFilters) Review comment: In that way, `otherFilters` can be very long, which leads to a longer codegen... I am avoiding that on purpose. Let me add comment here. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29082: [SPARK-32288][UI] Add exception summary for failed tasks in stage page
AmplabJenkins commented on pull request #29082: URL: https://github.com/apache/spark/pull/29082#issuecomment-657332189 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28363: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
SparkQA commented on pull request #28363: URL: https://github.com/apache/spark/pull/28363#issuecomment-657332068 **[Test build #125744 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125744/testReport)** for PR 28363 at commit [`b648156`](https://github.com/apache/spark/commit/b64815622bb4e8cd8b474cb2983f2c9b78ed9342). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #28363: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
HeartSaVioR commented on pull request #28363: URL: https://github.com/apache/spark/pull/28363#issuecomment-657331812 retest this, please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29082: [SPARK-32288][UI] Add exception summary for failed tasks in stage page
AmplabJenkins commented on pull request #29082: URL: https://github.com/apache/spark/pull/29082#issuecomment-657331978 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] BryanCutler commented on a change in pull request #28957: [SPARK-32138] Drop Python 2.7, 3.4 and 3.5
BryanCutler commented on a change in pull request #28957:
URL: https://github.com/apache/spark/pull/28957#discussion_r453407345
##
File path: python/pyspark/sql/types.py
##
@@ -1487,36 +1451,14 @@ class Row(tuple):
True
"""
-# Remove after Python < 3.6 dropped, see SPARK-29748
Review comment:
Yup, this looks good. I noticed you already fixed up the test cases that
if affects, so that's great!
##
File path: python/pyspark/sql/tests/test_pandas_grouped_map.py
##
@@ -139,9 +134,9 @@ def test_supported_types(self):
result3 = df.groupby('id').apply(udf3).sort('id').toPandas()
expected3 = expected1
-assert_frame_equal(expected1, result1,
check_column_type=_check_column_type)
-assert_frame_equal(expected2, result2,
check_column_type=_check_column_type)
-assert_frame_equal(expected3, result3,
check_column_type=_check_column_type)
+assert_frame_equal(expected1, result1, check_column_type=True)
Review comment:
I think the default is `True`, so not needed but no big deal to leave it.
##
File path: python/pyspark/sql/pandas/serializers.py
##
@@ -180,7 +173,7 @@ def create_array(s, t):
if len(s) == 0 and len(s.columns) == 0:
arrs_names = [(pa.array([], type=field.type), field.name)
for field in t]
# Assign result columns by schema name if user labeled with
strings
-elif self._assign_cols_by_name and any(isinstance(name,
basestring)
+elif self._assign_cols_by_name and any(isinstance(name, str)
Review comment:
We might want to think about removing this as an option as a followup.
It was mostly added because dataframe constructed with python < 3.6 could not
guarantee the order of columns, but now it should match the given schema.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a change in pull request #29075: [SPARK-32284][SQL] Avoid expanding too many CNF predicates in partition pruning
gengliangwang commented on a change in pull request #29075:
URL: https://github.com/apache/spark/pull/29075#discussion_r453408669
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/execution/PruneHiveTablePartitions.scala
##
@@ -54,9 +55,15 @@ private[sql] class PruneHiveTablePartitions(session:
SparkSession)
val normalizedFilters = DataSourceStrategy.normalizeExprs(
filters.filter(f => f.deterministic &&
!SubqueryExpression.hasSubquery(f)), relation.output)
val partitionColumnSet = AttributeSet(relation.partitionCols)
-ExpressionSet(normalizedFilters.filter { f =>
+val (partitionFilters, remainingFilters) = normalizedFilters.partition { f
=>
!f.references.isEmpty && f.references.subsetOf(partitionColumnSet)
-})
+}
+// Try extracting more convertible partition filters from the remaining
filters by converting
+// them into CNF.
+val remainingFilterInCnf = remainingFilters.flatMap(CNFConversion)
+val extraPartitionFilters = remainingFilterInCnf.filter(f =>
+ !f.references.isEmpty && f.references.subsetOf(partitionColumnSet))
+ExpressionSet(partitionFilters ++ extraPartitionFilters)
Review comment:
The `filters` here is already processed with
`splitConjunctivePredicates` in `PhysicalOperation.unapply`. That's why the
original code before #28805 doesn't call `splitConjunctivePredicates` either.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] warrenzhu25 opened a new pull request #29082: [SPARK-32288][UI] Add exception summary for failed tasks in stage page
warrenzhu25 opened a new pull request #29082: URL: https://github.com/apache/spark/pull/29082 ### What changes were proposed in this pull request? Add exception summary table for failed tasks in stage page. 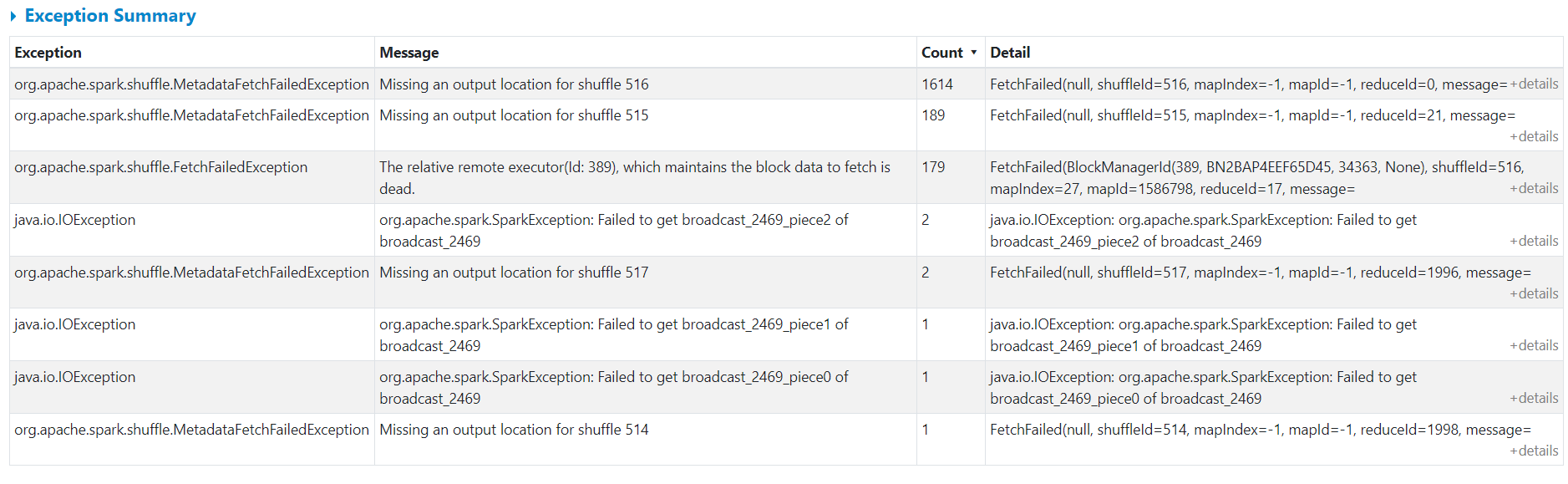 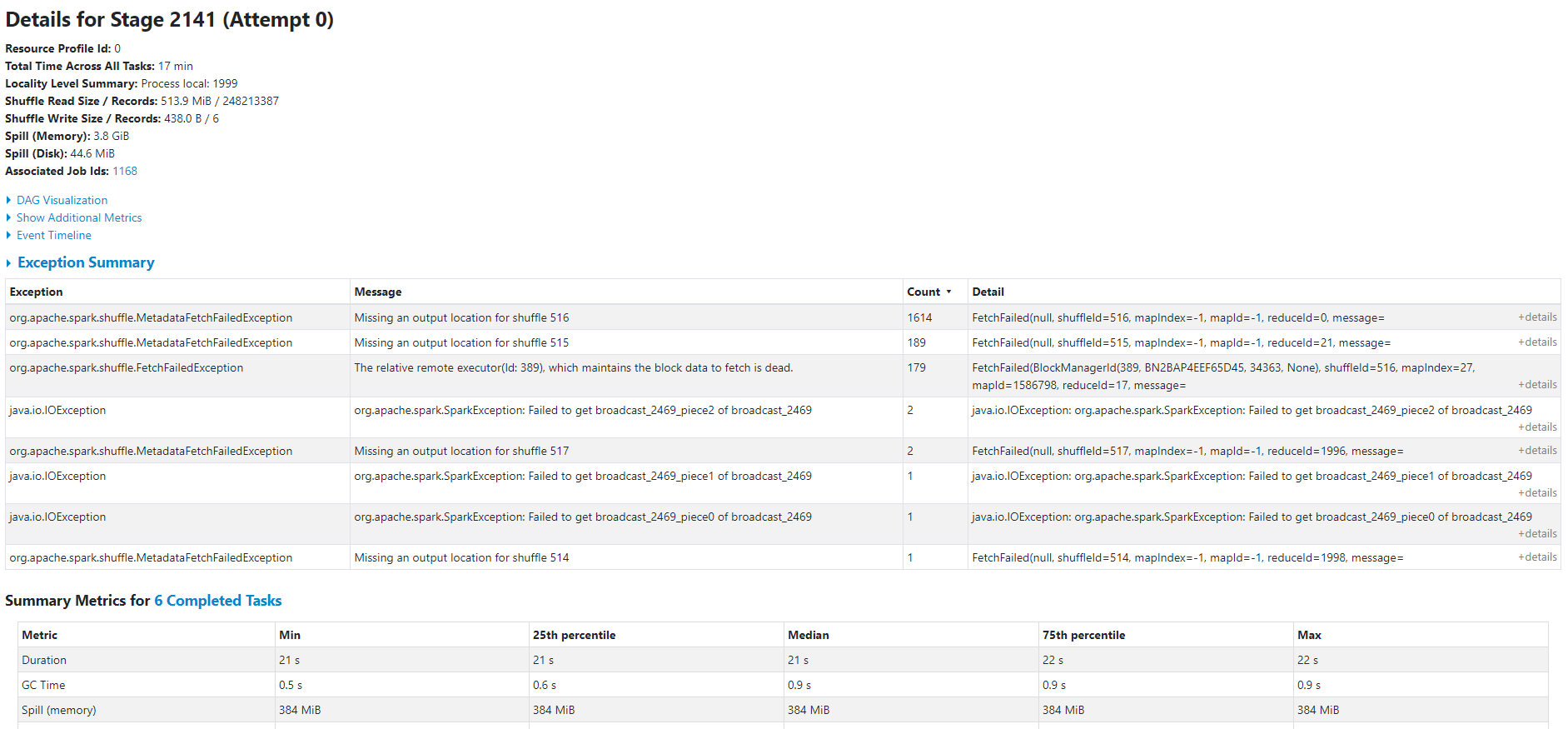 ### Why are the changes needed? When there're many task failure during one stage, it's hard to find failure pattern such as aggregation task failure by exception type and message. If we have such information, we can easily know which type of exception of failure is the root cause of stage failure. ### Does this PR introduce _any_ user-facing change? Yes ### How was this patch tested? Added UT in UISeleniumSuite This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #27620: [SPARK-30866][SS] FileStreamSource: Cache fetched list of files beyond maxFilesPerTrigger as unread files
AmplabJenkins removed a comment on pull request #27620: URL: https://github.com/apache/spark/pull/27620#issuecomment-657328854 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #27620: [SPARK-30866][SS] FileStreamSource: Cache fetched list of files beyond maxFilesPerTrigger as unread files
AmplabJenkins commented on pull request #27620: URL: https://github.com/apache/spark/pull/27620#issuecomment-657328854 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #27620: [SPARK-30866][SS] FileStreamSource: Cache fetched list of files beyond maxFilesPerTrigger as unread files
SparkQA removed a comment on pull request #27620: URL: https://github.com/apache/spark/pull/27620#issuecomment-657271647 **[Test build #125728 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125728/testReport)** for PR 27620 at commit [`0e972fc`](https://github.com/apache/spark/commit/0e972fc20fb1a77fee90200b26a824bb19a91879). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #27620: [SPARK-30866][SS] FileStreamSource: Cache fetched list of files beyond maxFilesPerTrigger as unread files
SparkQA commented on pull request #27620: URL: https://github.com/apache/spark/pull/27620#issuecomment-657328345 **[Test build #125728 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125728/testReport)** for PR 27620 at commit [`0e972fc`](https://github.com/apache/spark/commit/0e972fc20fb1a77fee90200b26a824bb19a91879). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29078: [SPARK-29292][STREAMING][SQL][BUILD] Get streaming, catalyst, sql compiling for Scala 2.13
AmplabJenkins removed a comment on pull request #29078: URL: https://github.com/apache/spark/pull/29078#issuecomment-657327850 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/125742/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #29078: [SPARK-29292][STREAMING][SQL][BUILD] Get streaming, catalyst, sql compiling for Scala 2.13
SparkQA removed a comment on pull request #29078: URL: https://github.com/apache/spark/pull/29078#issuecomment-657316041 **[Test build #125742 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125742/testReport)** for PR 29078 at commit [`77fb2be`](https://github.com/apache/spark/commit/77fb2be3a520de1b7be9559edad7d5a21dbabc62). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29078: [SPARK-29292][STREAMING][SQL][BUILD] Get streaming, catalyst, sql compiling for Scala 2.13
AmplabJenkins removed a comment on pull request #29078: URL: https://github.com/apache/spark/pull/29078#issuecomment-657327845 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29078: [SPARK-29292][STREAMING][SQL][BUILD] Get streaming, catalyst, sql compiling for Scala 2.13
AmplabJenkins commented on pull request #29078: URL: https://github.com/apache/spark/pull/29078#issuecomment-657327845 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29078: [SPARK-29292][STREAMING][SQL][BUILD] Get streaming, catalyst, sql compiling for Scala 2.13
SparkQA commented on pull request #29078: URL: https://github.com/apache/spark/pull/29078#issuecomment-657327805 **[Test build #125742 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125742/testReport)** for PR 29078 at commit [`77fb2be`](https://github.com/apache/spark/commit/77fb2be3a520de1b7be9559edad7d5a21dbabc62). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #26935: [SPARK-30294][SS] Explicitly defines read-only StateStore and optimize for HDFSBackedStateStore
AmplabJenkins removed a comment on pull request #26935: URL: https://github.com/apache/spark/pull/26935#issuecomment-657327063 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #26935: [SPARK-30294][SS] Explicitly defines read-only StateStore and optimize for HDFSBackedStateStore
AmplabJenkins commented on pull request #26935: URL: https://github.com/apache/spark/pull/26935#issuecomment-657327063 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #26935: [SPARK-30294][SS] Explicitly defines read-only StateStore and optimize for HDFSBackedStateStore
SparkQA removed a comment on pull request #26935: URL: https://github.com/apache/spark/pull/26935#issuecomment-657271662 **[Test build #125730 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125730/testReport)** for PR 26935 at commit [`9a066c1`](https://github.com/apache/spark/commit/9a066c11ee4e6a47acc2d35d17edf453657d76f6). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #26935: [SPARK-30294][SS] Explicitly defines read-only StateStore and optimize for HDFSBackedStateStore
SparkQA commented on pull request #26935: URL: https://github.com/apache/spark/pull/26935#issuecomment-657326568 **[Test build #125730 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125730/testReport)** for PR 26935 at commit [`9a066c1`](https://github.com/apache/spark/commit/9a066c11ee4e6a47acc2d35d17edf453657d76f6). * This patch passes all tests. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * ` class HDFSBackedReadOnlyStateStore(val version: Long, map: MapType)` * `abstract class ReadOnlyStateStore extends StateStore ` * `class WrappedReadOnlyStateStore(store: StateStore) extends ReadOnlyStateStore ` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29077: [SPARK-31985][SS] Remove incomplete/undocumented stateful aggregation in continuous mode
AmplabJenkins removed a comment on pull request #29077: URL: https://github.com/apache/spark/pull/29077#issuecomment-657324893 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29077: [SPARK-31985][SS] Remove incomplete/undocumented stateful aggregation in continuous mode
AmplabJenkins commented on pull request #29077: URL: https://github.com/apache/spark/pull/29077#issuecomment-657324893 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #29077: [SPARK-31985][SS] Remove incomplete/undocumented stateful aggregation in continuous mode
SparkQA removed a comment on pull request #29077: URL: https://github.com/apache/spark/pull/29077#issuecomment-657273147 **[Test build #125734 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125734/testReport)** for PR 29077 at commit [`6a5965c`](https://github.com/apache/spark/commit/6a5965c940758caa6dc2a471fcc456633f04a2da). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29077: [SPARK-31985][SS] Remove incomplete/undocumented stateful aggregation in continuous mode
SparkQA commented on pull request #29077: URL: https://github.com/apache/spark/pull/29077#issuecomment-657324597 **[Test build #125734 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125734/testReport)** for PR 29077 at commit [`6a5965c`](https://github.com/apache/spark/commit/6a5965c940758caa6dc2a471fcc456633f04a2da). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #25965: [SPARK-26425][SS] Add more constraint checks to avoid checkpoint corruption
AmplabJenkins removed a comment on pull request #25965: URL: https://github.com/apache/spark/pull/25965#issuecomment-657323411 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #29081: Test only affected
HyukjinKwon closed pull request #29081: URL: https://github.com/apache/spark/pull/29081 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #25965: [SPARK-26425][SS] Add more constraint checks to avoid checkpoint corruption
AmplabJenkins commented on pull request #25965: URL: https://github.com/apache/spark/pull/25965#issuecomment-657323411 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #25965: [SPARK-26425][SS] Add more constraint checks to avoid checkpoint corruption
SparkQA removed a comment on pull request #25965: URL: https://github.com/apache/spark/pull/25965#issuecomment-657271688 **[Test build #125731 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125731/testReport)** for PR 25965 at commit [`d15acef`](https://github.com/apache/spark/commit/d15acef9698528239dc8a5b92d55c950cdf602b2). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #25965: [SPARK-26425][SS] Add more constraint checks to avoid checkpoint corruption
SparkQA commented on pull request #25965: URL: https://github.com/apache/spark/pull/25965#issuecomment-657323073 **[Test build #125731 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125731/testReport)** for PR 25965 at commit [`d15acef`](https://github.com/apache/spark/commit/d15acef9698528239dc8a5b92d55c950cdf602b2). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29081: Test only affected
AmplabJenkins commented on pull request #29081: URL: https://github.com/apache/spark/pull/29081#issuecomment-657322634 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #28746: [SPARK-31922][CORE] logDebug "RpcEnv already stopped" error on LocalSparkCluster shutdown
SparkQA commented on pull request #28746: URL: https://github.com/apache/spark/pull/28746#issuecomment-657322426 **[Test build #125743 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/125743/testReport)** for PR 28746 at commit [`59a0595`](https://github.com/apache/spark/commit/59a0595c8177ff801d0f7cbcc1fe6c458bcb844c). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon opened a new pull request #29081: Test only affected
HyukjinKwon opened a new pull request #29081: URL: https://github.com/apache/spark/pull/29081 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 commented on pull request #28746: [SPARK-31922][CORE] logDebug "RpcEnv already stopped" error on LocalSparkCluster shutdown
Ngone51 commented on pull request #28746: URL: https://github.com/apache/spark/pull/28746#issuecomment-657322178 @dongjoon-hyun yea, updated. Thanks! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org