[GitHub] [spark] LuciferYang commented on a change in pull request #29434: [SPARK-32526][SQL] Pass all test of sql/catalyst module in Scala 2.13
LuciferYang commented on a change in pull request #29434:
URL: https://github.com/apache/spark/pull/29434#discussion_r471064312
##
File path:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/StarJoinCostBasedReorderSuite.scala
##
@@ -351,6 +351,18 @@ class StarJoinCostBasedReorderSuite extends PlanTest with
StatsEstimationTestBas
.join(t5.join(t6, Inner, Some(nameToAttr("t5_c2") ===
nameToAttr("t6_c2"))), Inner,
Some(nameToAttr("d2_c2") === nameToAttr("t5_c1")))
.select(outputsOf(d1, t3, t4, f1, d2, t5, t6, d3, t1, t2): _*)
+} else {
Review comment:
Maybe we can add a Manual sort like
```
while (k <= lev - k) {
val oneSideCandidates =
existingLevels(k).values.toSeq.sortBy(_.itemIds.head)
for (i <- oneSideCandidates.indices) {
val oneSidePlan = oneSideCandidates(i)
val otherSideCandidates = if (k == lev - k) {
// Both sides of a join are at the same level, no need to repeat
for previous ones.
oneSideCandidates.drop(i)
} else {
existingLevels(lev - k).values.toSeq.sortBy(_.itemIds.head)
}
..
```
to ensure the candidates plan input order, but the results tend to be expect
plan in Scala 2.13
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #29434: [SPARK-32526][SQL] Pass all test of sql/catalyst module in Scala 2.13
LuciferYang commented on a change in pull request #29434:
URL: https://github.com/apache/spark/pull/29434#discussion_r471061359
##
File path:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/StarJoinCostBasedReorderSuite.scala
##
@@ -351,6 +351,18 @@ class StarJoinCostBasedReorderSuite extends PlanTest with
StatsEstimationTestBas
.join(t5.join(t6, Inner, Some(nameToAttr("t5_c2") ===
nameToAttr("t6_c2"))), Inner,
Some(nameToAttr("d2_c2") === nameToAttr("t5_c1")))
.select(outputsOf(d1, t3, t4, f1, d2, t5, t6, d3, t1, t2): _*)
+} else {
Review comment:
I think the difference is caused by the 'toMap' method, and `HashMap`
is rewritten in Scala 2.13, the code affected for this case includes:
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L153-L155
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L163-L166
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L208-L236
The **Iteration order** of `existingLevels(k).values.toSeq` and
`existingLevels(lev - k).values.toSeq` in Scala 2.13 different from in Scala
2.12
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #29434: [SPARK-32526][SQL] Pass all test of sql/catalyst module in Scala 2.13
LuciferYang commented on a change in pull request #29434:
URL: https://github.com/apache/spark/pull/29434#discussion_r471067768
##
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/Row.scala
##
@@ -314,7 +314,7 @@ trait Row extends Serializable {
*
* @throws ClassCastException when data type does not match.
*/
- def getSeq[T](i: Int): Seq[T] = getAs[Seq[T]](i)
+ def getSeq[T](i: Int): scala.collection.Seq[T] =
getAs[scala.collection.Seq[T]](i)
Review comment:
The return type or convert type?There are some things that need to be
discussed. There are 2 major changes related to scala 2.13:
- Seq` alias representative `scala.collection.immutable.Seq`, not
`scala.collection.Seq`
- `WrappedArray.make` method produce `mutable.ArraySeq` instance, not
`WrappedArray`
Explicit use cast type as `getAs[scala.collection.Seq[T]](i)` because
`ArrayTpye` all mapped to `scala.collection.Seq` in `RowEncoder`, otherwise,
the cast will fail because of the actual data type is `mutable.ArraySeq`, the
affected cases are `RowEncoder should support primitive arrays` and `RowEncoder
should support primitive arrays` in `RowEncoderSuite`.
Explicit appoint return type to `scala.collection.Seq` because we promise a
`scala.collection.Seq` in Scala 2.12 and use `Seq` alias in Scalal 2.13 will
trigger a `toSeq` operation, but it can be removed if we are sure covert to
`scala.collection.immutable.Seq` doesn't affect the caller's perception.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #29434: [SPARK-32526][SQL] Pass all test of sql/catalyst module in Scala 2.13
LuciferYang commented on a change in pull request #29434:
URL: https://github.com/apache/spark/pull/29434#discussion_r471067768
##
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/Row.scala
##
@@ -314,7 +314,7 @@ trait Row extends Serializable {
*
* @throws ClassCastException when data type does not match.
*/
- def getSeq[T](i: Int): Seq[T] = getAs[Seq[T]](i)
+ def getSeq[T](i: Int): scala.collection.Seq[T] =
getAs[scala.collection.Seq[T]](i)
Review comment:
The return type or convert type?There are some things that need to be
discussed. There are 2 major changes related to scala 2.13:
- Seq` alias representative `scala.collection.immutable.Seq`, not
`scala.collection.Seq`
- `WrappedArray.make` method produce `mutable.ArraySeq` instance, not
`WrappedArray`
Explicit use cast type as `getAs[scala.collection.Seq[T]](i)` because
`ArrayTpye` all mapped to `scala.collection.Seq` in `RowEncoder`, otherwise,
the cast will fail because of the actual data type is `mutable.ArraySeq`, the
affected cases are `RowEncoder should support primitive arrays` and `RowEncoder
should support primitive arrays` in `RowEncoderSuite`.
Explicit appoint return type to `scala.collection.Seq` because we promise a
`scala.collection.Seq` in Scala 2.12 and use `Seq` alias will trigger a `toSeq`
operation, but it can be removed if we are sure covert to
`scala.collection.immutable.Seq` doesn't affect the caller's perception.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #29434: [SPARK-32526][SQL] Pass all test of sql/catalyst module in Scala 2.13
LuciferYang commented on a change in pull request #29434:
URL: https://github.com/apache/spark/pull/29434#discussion_r471067768
##
File path: sql/catalyst/src/main/scala/org/apache/spark/sql/Row.scala
##
@@ -314,7 +314,7 @@ trait Row extends Serializable {
*
* @throws ClassCastException when data type does not match.
*/
- def getSeq[T](i: Int): Seq[T] = getAs[Seq[T]](i)
+ def getSeq[T](i: Int): scala.collection.Seq[T] =
getAs[scala.collection.Seq[T]](i)
Review comment:
The return type or convert type?There are some things that need to be
discussed. There are 2 major changes related to scala 2.13:
- Seq` alias representative `scala.collection.immutable.Seq`, not
`scala.collection.Seq`
- `WrappedArray.make` method produce `mutable.ArraySeq` instance, not
`WrappedArray`
Explicit use cast type as getAs[scala.collection.Seq[T]](i) because
`ArrayTpye` all mapped to `scala.collection.Seq` in `RowEncoder`, otherwise,
the cast will fail because of the actual data type is `mutable.ArraySeq`, the
affected cases are `RowEncoder should support primitive arrays` and `RowEncoder
should support primitive arrays` in `RowEncoderSuite`.
Explicit appoint return type to `scala.collection.Seq` because we promise a
`scala.collection.Seq` in Scala 2.12 and use `Seq` alias will trigger a `toSeq`
operation, but it can be removed if we are sure covert to
`scala.collection.immutable.Seq` doesn't affect the caller's perception.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29427: [SPARK-32622][SQL][TEST] Add case-sensitivity test for ORC predicate pushdown
AmplabJenkins commented on pull request #29427: URL: https://github.com/apache/spark/pull/29427#issuecomment-674480779 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29427: [SPARK-32622][SQL][TEST] Add case-sensitivity test for ORC predicate pushdown
AmplabJenkins removed a comment on pull request #29427: URL: https://github.com/apache/spark/pull/29427#issuecomment-674480779 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29427: [SPARK-32622][SQL][TEST] Add case-sensitivity test for ORC predicate pushdown
SparkQA commented on pull request #29427: URL: https://github.com/apache/spark/pull/29427#issuecomment-674480700 **[Test build #127485 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127485/testReport)** for PR 29427 at commit [`edcdb87`](https://github.com/apache/spark/commit/edcdb8795ed9b1333f568be4f42ad1e8bfd04a45). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29422: [SPARK-32613][CORE] Fix regressions in DecommissionWorkerSuite
AmplabJenkins removed a comment on pull request #29422: URL: https://github.com/apache/spark/pull/29422#issuecomment-674480317 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29422: [SPARK-32613][CORE] Fix regressions in DecommissionWorkerSuite
AmplabJenkins commented on pull request #29422: URL: https://github.com/apache/spark/pull/29422#issuecomment-674480317 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #29422: [SPARK-32613][CORE] Fix regressions in DecommissionWorkerSuite
SparkQA removed a comment on pull request #29422: URL: https://github.com/apache/spark/pull/29422#issuecomment-674470539 **[Test build #127484 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127484/testReport)** for PR 29422 at commit [`343bf8b`](https://github.com/apache/spark/commit/343bf8b4815332925116ace7217d90a641dfa96f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29422: [SPARK-32613][CORE] Fix regressions in DecommissionWorkerSuite
SparkQA commented on pull request #29422: URL: https://github.com/apache/spark/pull/29422#issuecomment-674480170 **[Test build #127484 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127484/testReport)** for PR 29422 at commit [`343bf8b`](https://github.com/apache/spark/commit/343bf8b4815332925116ace7217d90a641dfa96f). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #29434: [SPARK-32526][SQL] Pass all test of sql/catalyst module in Scala 2.13
LuciferYang commented on a change in pull request #29434:
URL: https://github.com/apache/spark/pull/29434#discussion_r471061359
##
File path:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/StarJoinCostBasedReorderSuite.scala
##
@@ -351,6 +351,18 @@ class StarJoinCostBasedReorderSuite extends PlanTest with
StatsEstimationTestBas
.join(t5.join(t6, Inner, Some(nameToAttr("t5_c2") ===
nameToAttr("t6_c2"))), Inner,
Some(nameToAttr("d2_c2") === nameToAttr("t5_c1")))
.select(outputsOf(d1, t3, t4, f1, d2, t5, t6, d3, t1, t2): _*)
+} else {
Review comment:
I think the difference is caused by the 'toMap' method because of
HashMap is rewritten in scala 2.13, the code affected for this case includes:
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L153-L155
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L163-L166
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L208-L236
The Iteration order of `existingLevels(k).values.toSeq` and
`existingLevels(lev - k).values.toSeq` in Scala 2.13 different from in Scala
2.12
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #29434: [SPARK-32526][SQL] Pass all test of sql/catalyst module in Scala 2.13
LuciferYang commented on a change in pull request #29434:
URL: https://github.com/apache/spark/pull/29434#discussion_r471061359
##
File path:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/StarJoinCostBasedReorderSuite.scala
##
@@ -351,6 +351,18 @@ class StarJoinCostBasedReorderSuite extends PlanTest with
StatsEstimationTestBas
.join(t5.join(t6, Inner, Some(nameToAttr("t5_c2") ===
nameToAttr("t6_c2"))), Inner,
Some(nameToAttr("d2_c2") === nameToAttr("t5_c1")))
.select(outputsOf(d1, t3, t4, f1, d2, t5, t6, d3, t1, t2): _*)
+} else {
Review comment:
I think the difference is caused by the 'toMap' method, and `HashMap`
is rewritten in Scala 2.13, the code affected for this case includes:
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L153-L155
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L163-L166
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L208-L236
The Iteration order of `existingLevels(k).values.toSeq` and
`existingLevels(lev - k).values.toSeq` in Scala 2.13 different from in Scala
2.12
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #29434: [SPARK-32526][SQL] Pass all test of sql/catalyst module in Scala 2.13
LuciferYang commented on a change in pull request #29434:
URL: https://github.com/apache/spark/pull/29434#discussion_r471064312
##
File path:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/StarJoinCostBasedReorderSuite.scala
##
@@ -351,6 +351,18 @@ class StarJoinCostBasedReorderSuite extends PlanTest with
StatsEstimationTestBas
.join(t5.join(t6, Inner, Some(nameToAttr("t5_c2") ===
nameToAttr("t6_c2"))), Inner,
Some(nameToAttr("d2_c2") === nameToAttr("t5_c1")))
.select(outputsOf(d1, t3, t4, f1, d2, t5, t6, d3, t1, t2): _*)
+} else {
Review comment:
Maybe we can add a Manual sort like
```
while (k <= lev - k) {
val oneSideCandidates =
existingLevels(k).values.toSeq.sortBy(_.itemIds.head)
for (i <- oneSideCandidates.indices) {
val oneSidePlan = oneSideCandidates(i)
val otherSideCandidates = if (k == lev - k) {
// Both sides of a join are at the same level, no need to repeat
for previous ones.
oneSideCandidates.drop(i)
} else {
existingLevels(lev - k).values.toSeq.sortBy(_.itemIds.head)
}
..
```
to ensure the candidates plan input order, but the results tend to be 2.13
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #29434: [SPARK-32526][SQL] Pass all test of sql/catalyst module in Scala 2.13
LuciferYang commented on a change in pull request #29434:
URL: https://github.com/apache/spark/pull/29434#discussion_r471063985
##
File path:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/StarJoinCostBasedReorderSuite.scala
##
@@ -351,6 +351,18 @@ class StarJoinCostBasedReorderSuite extends PlanTest with
StatsEstimationTestBas
.join(t5.join(t6, Inner, Some(nameToAttr("t5_c2") ===
nameToAttr("t6_c2"))), Inner,
Some(nameToAttr("d2_c2") === nameToAttr("t5_c1")))
.select(outputsOf(d1, t3, t4, f1, d2, t5, t6, d3, t1, t2): _*)
+} else {
Review comment:
In Scala 2.13, the plans level 0 ~ level 4 of `foundPlans` are
```
level 0: (t5) (d3) (d1) (f1) (t2) (d2) (t6) (t3) (t4) (t1)
level 1: {d3 f1} {t2 t1} {d2 f1} {t5 t6} {d1 f1} {t4 t3}
level 2: {d2 d1 f1} {d3 d1 f1} {d2 d3 f1}
level 3: {d1 d2 d3 f1}
```
In the level 3, the newJoinPlan produce order are:
```
Join Inner, (f1_fk2#1 = d2_pk#8)
:- Join Inner, (d1_pk#5 = f1_fk1#0)
: :- Join Inner, (f1_fk3#2 = d3_pk#11)
```
then
```
Join Inner, (d1_pk#5 = f1_fk1#0)
:- Join Inner, (f1_fk2#1 = d2_pk#8)
: :- Join Inner, (f1_fk3#2 = d3_pk#11)
```
The Cost of 2 candidates both Cost(200,9200) and we choose the first
generated one too , so the expected result change to
```
f1.join(d3, Inner, Some(nameToAttr("f1_fk3") === nameToAttr("d3_pk")))
.join(d2, Inner, Some(nameToAttr("f1_fk2") === nameToAttr("d2_pk")))
.join(d1, Inner, Some(nameToAttr("f1_fk1") === nameToAttr("d1_pk")))
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #29434: [SPARK-32526][SQL] Pass all test of sql/catalyst module in Scala 2.13
LuciferYang commented on a change in pull request #29434:
URL: https://github.com/apache/spark/pull/29434#discussion_r471063884
##
File path:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/StarJoinCostBasedReorderSuite.scala
##
@@ -351,6 +351,18 @@ class StarJoinCostBasedReorderSuite extends PlanTest with
StatsEstimationTestBas
.join(t5.join(t6, Inner, Some(nameToAttr("t5_c2") ===
nameToAttr("t6_c2"))), Inner,
Some(nameToAttr("d2_c2") === nameToAttr("t5_c1")))
.select(outputsOf(d1, t3, t4, f1, d2, t5, t6, d3, t1, t2): _*)
+} else {
Review comment:
For this case:
In Scala 2.12, the plans level 0 ~ level 4 of `foundPlans` are
```
level 0: (t4 ), (d2 ), (t5 ), (d3 ), (d1 ), (f1 ), (t2 ), (t6 ), (t1 ), (t3 )
level 1: {t5 t6 }, {t4 t3 }, {d3 f1 }, {t2 t1 }, {d2 f1 }, {d1 f1 }
level 2: {d2 d1 f1 }, {d2 d3 f1 }, {d3 d1 f1 }
level 3: {d2 d1 d3 f1 }
```
In the level 3, the `newJoinPlan` produce order are:
```
Join Inner, (d1_pk#5 = f1_fk1#0)
:- Join Inner, (f1_fk2#1 = d2_pk#8)
: :- Join Inner, (f1_fk3#2 = d3_pk#11)
```
then
```
Join Inner, (f1_fk2#1 = d2_pk#8)
:- Join Inner, (d1_pk#5 = f1_fk1#0)
: :- Join Inner, (f1_fk3#2 = d3_pk#11)
```
The Cost of 2 candidates both `Cost(200,9200)` and we choose the first
generated one, so the expected result is
```
f1.join(d3, Inner, Some(nameToAttr("f1_fk3") === nameToAttr("d3_pk")))
.join(d1, Inner, Some(nameToAttr("f1_fk1") === nameToAttr("d1_pk")))
.join(d2, Inner, Some(nameToAttr("f1_fk2") === nameToAttr("d2_pk")))
...
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #29434: [SPARK-32526][SQL] Pass all test of sql/catalyst module in Scala 2.13
LuciferYang commented on a change in pull request #29434:
URL: https://github.com/apache/spark/pull/29434#discussion_r471061359
##
File path:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/StarJoinCostBasedReorderSuite.scala
##
@@ -351,6 +351,18 @@ class StarJoinCostBasedReorderSuite extends PlanTest with
StatsEstimationTestBas
.join(t5.join(t6, Inner, Some(nameToAttr("t5_c2") ===
nameToAttr("t6_c2"))), Inner,
Some(nameToAttr("d2_c2") === nameToAttr("t5_c1")))
.select(outputsOf(d1, t3, t4, f1, d2, t5, t6, d3, t1, t2): _*)
+} else {
Review comment:
I think the difference is caused by the 'toMap' method, the code
affected for this case includes:
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L153-L155
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L163-L166
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L208-L236
The Iteration order of `existingLevels(k).values.toSeq` and
`existingLevels(lev - k).values.toSeq` in Scala 2.13 different from in Scala
2.12
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gatorsmile commented on a change in pull request #29064: [SPARK-32272][SQL] Add SQL standard command SET TIME ZONE
gatorsmile commented on a change in pull request #29064: URL: https://github.com/apache/spark/pull/29064#discussion_r471061698 ## File path: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 ## @@ -240,6 +240,9 @@ statement | MSCK REPAIR TABLE multipartIdentifier #repairTable | op=(ADD | LIST) identifier (STRING | .*?) #manageResource | SET ROLE .*? #failNativeCommand +| SET TIME ZONE interval #setTimeZone +| SET TIME ZONE timezone=(STRING | LOCAL) #setTimeZone +| SET TIME ZONE .*? #setTimeZone Review comment: It sounds like none of the systems are following ANSI SQL syntax completely. - https://www.ibm.com/support/knowledgecenter/SSEPEK_10.0.0/sqlref/src/tpc/db2z_sql_setsessiontimezone.html - https://www.postgresql.org/docs/12/sql-set.html - https://dev.mysql.com/doc/refman/8.0/en/time-zone-support.html - https://docs.oracle.com/cd/E11882_01/server.112/e10729/ch4datetime.htm#NLSPG263 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gatorsmile commented on a change in pull request #29064: [SPARK-32272][SQL] Add SQL standard command SET TIME ZONE
gatorsmile commented on a change in pull request #29064: URL: https://github.com/apache/spark/pull/29064#discussion_r471061698 ## File path: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 ## @@ -240,6 +240,9 @@ statement | MSCK REPAIR TABLE multipartIdentifier #repairTable | op=(ADD | LIST) identifier (STRING | .*?) #manageResource | SET ROLE .*? #failNativeCommand +| SET TIME ZONE interval #setTimeZone +| SET TIME ZONE timezone=(STRING | LOCAL) #setTimeZone +| SET TIME ZONE .*? #setTimeZone Review comment: It sounds like none of the systems are following ANSI SQL syntax. - https://www.ibm.com/support/knowledgecenter/SSEPEK_10.0.0/sqlref/src/tpc/db2z_sql_setsessiontimezone.html - https://www.postgresql.org/docs/12/sql-set.html - https://dev.mysql.com/doc/refman/8.0/en/time-zone-support.html - https://docs.oracle.com/cd/E11882_01/server.112/e10729/ch4datetime.htm#NLSPG263 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #29434: [SPARK-32526][SQL] Pass all test of sql/catalyst module in Scala 2.13
LuciferYang commented on a change in pull request #29434:
URL: https://github.com/apache/spark/pull/29434#discussion_r471061359
##
File path:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/StarJoinCostBasedReorderSuite.scala
##
@@ -351,6 +351,18 @@ class StarJoinCostBasedReorderSuite extends PlanTest with
StatsEstimationTestBas
.join(t5.join(t6, Inner, Some(nameToAttr("t5_c2") ===
nameToAttr("t6_c2"))), Inner,
Some(nameToAttr("d2_c2") === nameToAttr("t5_c1")))
.select(outputsOf(d1, t3, t4, f1, d2, t5, t6, d3, t1, t2): _*)
+} else {
Review comment:
I think the difference is caused by the 'toMap' method, the code
affected for this case includes:
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L153-L155
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L163-L166
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L208-L234
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #29434: [SPARK-32526][SQL] Pass all test of sql/catalyst module in Scala 2.13
LuciferYang commented on a change in pull request #29434:
URL: https://github.com/apache/spark/pull/29434#discussion_r471061359
##
File path:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/StarJoinCostBasedReorderSuite.scala
##
@@ -351,6 +351,18 @@ class StarJoinCostBasedReorderSuite extends PlanTest with
StatsEstimationTestBas
.join(t5.join(t6, Inner, Some(nameToAttr("t5_c2") ===
nameToAttr("t6_c2"))), Inner,
Some(nameToAttr("d2_c2") === nameToAttr("t5_c1")))
.select(outputsOf(d1, t3, t4, f1, d2, t5, t6, d3, t1, t2): _*)
+} else {
Review comment:
I think the difference is caused by the 'toMap' method, the code
affected for this case includes:
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L153-L155
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L163-L166
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L208-L236
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #29434: [SPARK-32526][SQL] Pass all test of sql/catalyst module in Scala 2.13
LuciferYang commented on a change in pull request #29434:
URL: https://github.com/apache/spark/pull/29434#discussion_r471061359
##
File path:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/StarJoinCostBasedReorderSuite.scala
##
@@ -351,6 +351,18 @@ class StarJoinCostBasedReorderSuite extends PlanTest with
StatsEstimationTestBas
.join(t5.join(t6, Inner, Some(nameToAttr("t5_c2") ===
nameToAttr("t6_c2"))), Inner,
Some(nameToAttr("d2_c2") === nameToAttr("t5_c1")))
.select(outputsOf(d1, t3, t4, f1, d2, t5, t6, d3, t1, t2): _*)
+} else {
Review comment:
I think the difference is caused by the 'toMap' method, the code
affected for this case includes:
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L153-L155
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L163-L166
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L163-L166
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #29434: [SPARK-32526][SQL] Pass all test of sql/catalyst module in Scala 2.13
LuciferYang commented on a change in pull request #29434:
URL: https://github.com/apache/spark/pull/29434#discussion_r471061359
##
File path:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/StarJoinCostBasedReorderSuite.scala
##
@@ -351,6 +351,18 @@ class StarJoinCostBasedReorderSuite extends PlanTest with
StatsEstimationTestBas
.join(t5.join(t6, Inner, Some(nameToAttr("t5_c2") ===
nameToAttr("t6_c2"))), Inner,
Some(nameToAttr("d2_c2") === nameToAttr("t5_c1")))
.select(outputsOf(d1, t3, t4, f1, d2, t5, t6, d3, t1, t2): _*)
+} else {
Review comment:
I think the difference is caused by the 'toMap' method, the code
affected for this case includes
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L153
to
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L155
and the result of `searchLevel` method
(https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L208
~
https://github.com/apache/spark/blob/c280c7f529e2766dd7dd45270bde340c28b9d74b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/CostBasedJoinReorder.scala#L234)
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29422: [SPARK-32613][CORE] Fix regressions in DecommissionWorkerSuite
AmplabJenkins commented on pull request #29422: URL: https://github.com/apache/spark/pull/29422#issuecomment-674470613 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29422: [SPARK-32613][CORE] Fix regressions in DecommissionWorkerSuite
AmplabJenkins removed a comment on pull request #29422: URL: https://github.com/apache/spark/pull/29422#issuecomment-674470613 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29422: [SPARK-32613][CORE] Fix regressions in DecommissionWorkerSuite
SparkQA commented on pull request #29422: URL: https://github.com/apache/spark/pull/29422#issuecomment-674470539 **[Test build #127484 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127484/testReport)** for PR 29422 at commit [`343bf8b`](https://github.com/apache/spark/commit/343bf8b4815332925116ace7217d90a641dfa96f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] holdenk commented on pull request #29422: [SPARK-32613][CORE] Fix regressions in DecommissionWorkerSuite
holdenk commented on pull request #29422: URL: https://github.com/apache/spark/pull/29422#issuecomment-674470238 Jenkins retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] holdenk commented on pull request #29422: [SPARK-32613][CORE] Fix regressions in DecommissionWorkerSuite
holdenk commented on pull request #29422: URL: https://github.com/apache/spark/pull/29422#issuecomment-674470224 PySpark failure is likely unrelated. I'm going to go ahead and said LGTM but let's give it until Monday to see if anyone else wants to review. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29342: [SPARK-32399][SQL] Full outer shuffled hash join
AmplabJenkins removed a comment on pull request #29342: URL: https://github.com/apache/spark/pull/29342#issuecomment-674467405 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29342: [SPARK-32399][SQL] Full outer shuffled hash join
AmplabJenkins commented on pull request #29342: URL: https://github.com/apache/spark/pull/29342#issuecomment-674467405 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #29342: [SPARK-32399][SQL] Full outer shuffled hash join
SparkQA removed a comment on pull request #29342: URL: https://github.com/apache/spark/pull/29342#issuecomment-674457665 **[Test build #127483 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127483/testReport)** for PR 29342 at commit [`381cdbc`](https://github.com/apache/spark/commit/381cdbc2ec393a96cab1ab611dc461dbed9d7dc2). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29342: [SPARK-32399][SQL] Full outer shuffled hash join
SparkQA commented on pull request #29342: URL: https://github.com/apache/spark/pull/29342#issuecomment-674467317 **[Test build #127483 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127483/testReport)** for PR 29342 at commit [`381cdbc`](https://github.com/apache/spark/commit/381cdbc2ec393a96cab1ab611dc461dbed9d7dc2). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] agrawaldevesh commented on a change in pull request #29342: [SPARK-32399][SQL] Full outer shuffled hash join
agrawaldevesh commented on a change in pull request #29342:
URL: https://github.com/apache/spark/pull/29342#discussion_r470892621
##
File path: sql/core/src/test/scala/org/apache/spark/sql/JoinSuite.scala
##
@@ -1188,4 +1188,53 @@ class JoinSuite extends QueryTest with
SharedSparkSession with AdaptiveSparkPlan
classOf[BroadcastNestedLoopJoinExec]))
}
}
+
+ test("SPARK-32399: Full outer shuffled hash join") {
+val inputDFs = Seq(
+ // Test unique join key
+ (spark.range(10).selectExpr("id as k1"),
+spark.range(30).selectExpr("id as k2"),
+$"k1" === $"k2"),
+ // Test non-unique join key
+ (spark.range(10).selectExpr("id % 5 as k1"),
+spark.range(30).selectExpr("id % 5 as k2"),
+$"k1" === $"k2"),
+ // Test string join key
+ (spark.range(10).selectExpr("cast(id * 3 as string) as k1"),
+spark.range(30).selectExpr("cast(id as string) as k2"),
+$"k1" === $"k2"),
+ // Test build side at right
+ (spark.range(30).selectExpr("cast(id / 3 as string) as k1"),
+spark.range(10).selectExpr("cast(id as string) as k2"),
+$"k1" === $"k2"),
+ // Test NULL join key
+ (spark.range(10).map(i => if (i % 2 == 0) i else null).selectExpr("value
as k1"),
+spark.range(30).map(i => if (i % 4 == 0) i else
null).selectExpr("value as k2"),
+$"k1" === $"k2"),
+ // Test multiple join keys
+ (spark.range(10).map(i => if (i % 2 == 0) i else null).selectExpr(
Review comment:
Oh I see you have combined it into the multiple join key code path.
Is it worth having uncorrelated nulls as a single key code test too ? (like
on line 1211)
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29437: [SPARK-32621][SQL] 'path' option can cause issues while inferring schema in CSV/JSON datasources
AmplabJenkins removed a comment on pull request #29437: URL: https://github.com/apache/spark/pull/29437#issuecomment-674460701 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29437: [SPARK-32621][SQL] 'path' option can cause issues while inferring schema in CSV/JSON datasources
AmplabJenkins commented on pull request #29437: URL: https://github.com/apache/spark/pull/29437#issuecomment-674460701 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #29437: [SPARK-32621][SQL] 'path' option can cause issues while inferring schema in CSV/JSON datasources
SparkQA removed a comment on pull request #29437: URL: https://github.com/apache/spark/pull/29437#issuecomment-674438881 **[Test build #127481 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127481/testReport)** for PR 29437 at commit [`cfc9035`](https://github.com/apache/spark/commit/cfc903551a78803cfce1ed2291bcc8a2bff09753). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29437: [SPARK-32621][SQL] 'path' option can cause issues while inferring schema in CSV/JSON datasources
SparkQA commented on pull request #29437: URL: https://github.com/apache/spark/pull/29437#issuecomment-674460559 **[Test build #127481 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127481/testReport)** for PR 29437 at commit [`cfc9035`](https://github.com/apache/spark/commit/cfc903551a78803cfce1ed2291bcc8a2bff09753). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29442: Add showSessionLink parameter to SqlStatsPagedTable class in ThriftServerPage
AmplabJenkins removed a comment on pull request #29442: URL: https://github.com/apache/spark/pull/29442#issuecomment-674459406 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29442: Add showSessionLink parameter to SqlStatsPagedTable class in ThriftServerPage
AmplabJenkins commented on pull request #29442: URL: https://github.com/apache/spark/pull/29442#issuecomment-674459509 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29442: Add showSessionLink parameter to SqlStatsPagedTable class in ThriftServerPage
AmplabJenkins commented on pull request #29442: URL: https://github.com/apache/spark/pull/29442#issuecomment-674459406 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] tianhanhu opened a new pull request #29442: Add showSessionLink parameter to SqlStatsPagedTable class in ThriftServerPage
tianhanhu opened a new pull request #29442: URL: https://github.com/apache/spark/pull/29442 ### What changes were proposed in this pull request? Introduced showSessionLink argument to SqlStatsPagedTable class in ThriftServerPage. When this argument is set to true, "Session ID" tooltip will be shown to the user. ### Why are the changes needed? To show "Session ID" tooltip to users. ### Does this PR introduce _any_ user-facing change? Yes. Users would be able to see "Session ID" ### How was this patch tested? Manual Test. 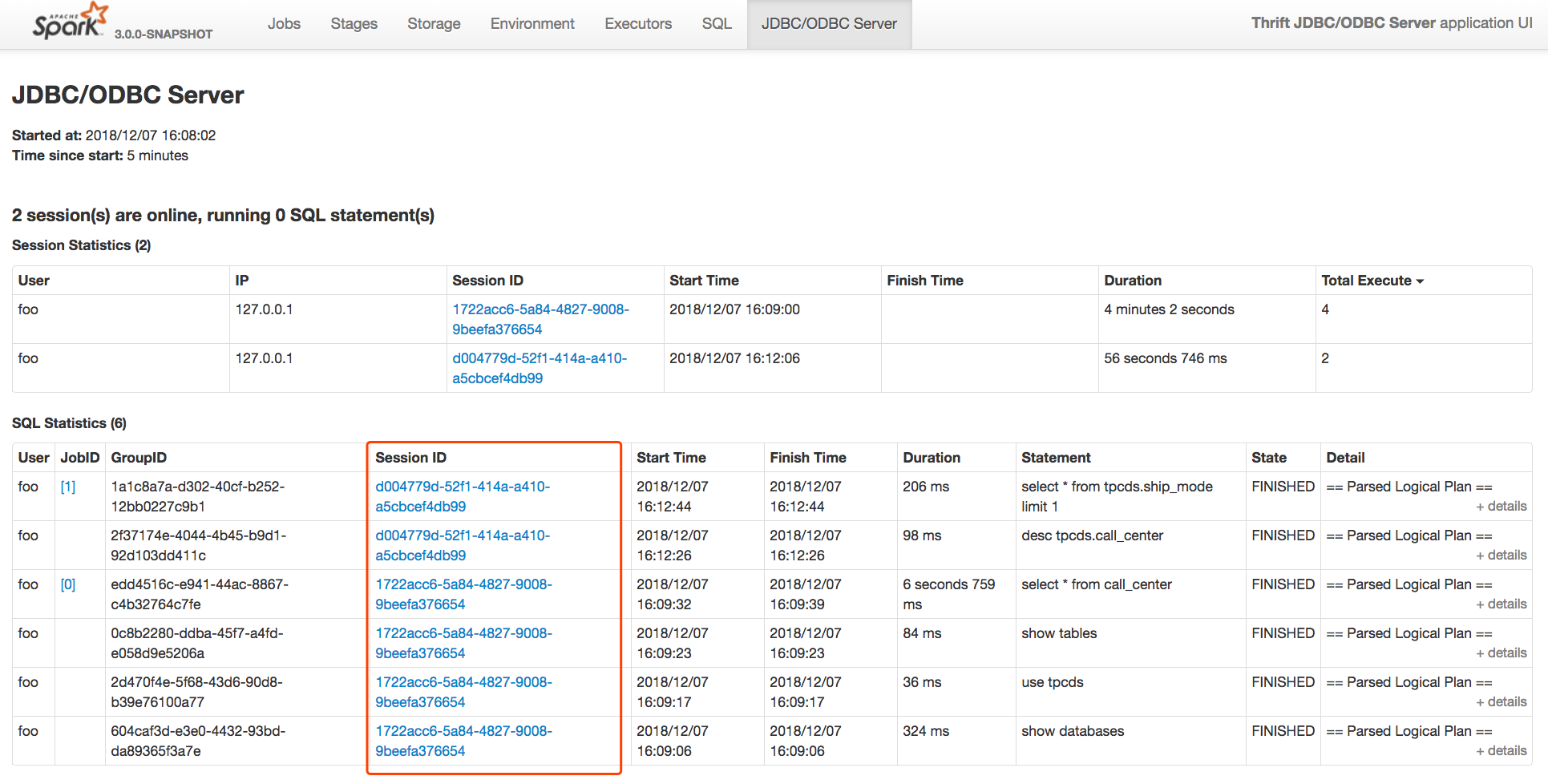 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] c21 edited a comment on pull request #29342: [SPARK-32399][SQL] Full outer shuffled hash join
c21 edited a comment on pull request #29342: URL: https://github.com/apache/spark/pull/29342#issuecomment-674457786 @agrawaldevesh - sorry for a separate irrelevant ping. It seems that `DecommissionWorkerSuite` (added in https://github.com/apache/spark/pull/29014) was kind of flaky where it failed more than 3 times in testing for this PR (both jenkins and github actions). I can confirm the test failure is irrelevant as I don't touch any logic can affect the unit test and rerun of test succeeded. An example of latest failed unit test is in https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127482/testReport/, with stack trace in https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127482/testReport/org.apache.spark.deploy/DecommissionWorkerSuite/decommission_workers_ensure_that_fetch_failures_lead_to_rerun/, thanks. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29342: [SPARK-32399][SQL] Full outer shuffled hash join
AmplabJenkins removed a comment on pull request #29342: URL: https://github.com/apache/spark/pull/29342#issuecomment-674457771 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] c21 commented on pull request #29342: [SPARK-32399][SQL] Full outer shuffled hash join
c21 commented on pull request #29342: URL: https://github.com/apache/spark/pull/29342#issuecomment-674457786 @agrawaldevesh - sorry for a separate irrelevant ping. It seems that `DecommissionWorkerSuite` (added in https://github.com/apache/spark/pull/29014) was kind of flaky where it failed more than 3 times in testing for this PR (not looking at other PR). I can confirm the test failure is irrelevant as I don't touch any logic can affect the unit test and rerun of test succeeded. An example of latest failed unit test is in https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127482/testReport/, with stack trace in https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127482/testReport/org.apache.spark.deploy/DecommissionWorkerSuite/decommission_workers_ensure_that_fetch_failures_lead_to_rerun/, thanks. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29342: [SPARK-32399][SQL] Full outer shuffled hash join
AmplabJenkins commented on pull request #29342: URL: https://github.com/apache/spark/pull/29342#issuecomment-674457771 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29342: [SPARK-32399][SQL] Full outer shuffled hash join
SparkQA commented on pull request #29342: URL: https://github.com/apache/spark/pull/29342#issuecomment-674457665 **[Test build #127483 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127483/testReport)** for PR 29342 at commit [`381cdbc`](https://github.com/apache/spark/commit/381cdbc2ec393a96cab1ab611dc461dbed9d7dc2). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] c21 commented on pull request #29342: [SPARK-32399][SQL] Full outer shuffled hash join
c21 commented on pull request #29342: URL: https://github.com/apache/spark/pull/29342#issuecomment-674457508 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29342: [SPARK-32399][SQL] Full outer shuffled hash join
AmplabJenkins removed a comment on pull request #29342: URL: https://github.com/apache/spark/pull/29342#issuecomment-674457248 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/127482/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29342: [SPARK-32399][SQL] Full outer shuffled hash join
AmplabJenkins removed a comment on pull request #29342: URL: https://github.com/apache/spark/pull/29342#issuecomment-674457245 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #29342: [SPARK-32399][SQL] Full outer shuffled hash join
SparkQA removed a comment on pull request #29342: URL: https://github.com/apache/spark/pull/29342#issuecomment-674446281 **[Test build #127482 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127482/testReport)** for PR 29342 at commit [`381cdbc`](https://github.com/apache/spark/commit/381cdbc2ec393a96cab1ab611dc461dbed9d7dc2). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29342: [SPARK-32399][SQL] Full outer shuffled hash join
AmplabJenkins commented on pull request #29342: URL: https://github.com/apache/spark/pull/29342#issuecomment-674457245 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29366: [SPARK-32550][SQL] Make SpecificInternalRow constructors faster by using while loops instead of maps
AmplabJenkins commented on pull request #29366: URL: https://github.com/apache/spark/pull/29366#issuecomment-674457154 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29342: [SPARK-32399][SQL] Full outer shuffled hash join
SparkQA commented on pull request #29342: URL: https://github.com/apache/spark/pull/29342#issuecomment-674457161 **[Test build #127482 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127482/testReport)** for PR 29342 at commit [`381cdbc`](https://github.com/apache/spark/commit/381cdbc2ec393a96cab1ab611dc461dbed9d7dc2). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29366: [SPARK-32550][SQL] Make SpecificInternalRow constructors faster by using while loops instead of maps
AmplabJenkins removed a comment on pull request #29366: URL: https://github.com/apache/spark/pull/29366#issuecomment-674457154 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #29366: [SPARK-32550][SQL] Make SpecificInternalRow constructors faster by using while loops instead of maps
SparkQA removed a comment on pull request #29366: URL: https://github.com/apache/spark/pull/29366#issuecomment-674433222 **[Test build #127478 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127478/testReport)** for PR 29366 at commit [`28f508d`](https://github.com/apache/spark/commit/28f508de56d7329b581258a5cf159c36d7fa5283). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29366: [SPARK-32550][SQL] Make SpecificInternalRow constructors faster by using while loops instead of maps
SparkQA commented on pull request #29366: URL: https://github.com/apache/spark/pull/29366#issuecomment-674457014 **[Test build #127478 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127478/testReport)** for PR 29366 at commit [`28f508d`](https://github.com/apache/spark/commit/28f508de56d7329b581258a5cf159c36d7fa5283). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on a change in pull request #29441: [SPARK-32626] Do not increase the input metrics when read rdd from cache
viirya commented on a change in pull request #29441:
URL: https://github.com/apache/spark/pull/29441#discussion_r471041575
##
File path: core/src/main/scala/org/apache/spark/rdd/RDD.scala
##
@@ -388,11 +388,9 @@ abstract class RDD[T: ClassTag](
// Block hit.
case Left(blockResult) =>
if (readCachedBlock) {
- val existingMetrics = context.taskMetrics().inputMetrics
- existingMetrics.incBytesRead(blockResult.bytes)
Review comment:
Why? Based on `TaskMetrics.inputMetrics` document, it is
> Metrics related to reading data from a [[org.apache.spark.rdd.HadoopRDD]]
or from persisted data, defined only in tasks with input.
Even cached, don't we need to include its size into input size of the task?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29441: [SPARK-32626] Do not increase the input metrics when read rdd from cache
AmplabJenkins removed a comment on pull request #29441: URL: https://github.com/apache/spark/pull/29441#issuecomment-674453576 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29441: [SPARK-32626] Do not increase the input metrics when read rdd from cache
AmplabJenkins commented on pull request #29441: URL: https://github.com/apache/spark/pull/29441#issuecomment-674453576 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29441: [SPARK-32626] Do not increase the input metrics when read rdd from cache
SparkQA commented on pull request #29441: URL: https://github.com/apache/spark/pull/29441#issuecomment-674453419 **[Test build #127480 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127480/testReport)** for PR 29441 at commit [`49f9db6`](https://github.com/apache/spark/commit/49f9db6ad0efc9544f7e7e2c8286d8a394bf17fe). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #29441: [SPARK-32626] Do not increase the input metrics when read rdd from cache
SparkQA removed a comment on pull request #29441: URL: https://github.com/apache/spark/pull/29441#issuecomment-674438871 **[Test build #127480 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127480/testReport)** for PR 29441 at commit [`49f9db6`](https://github.com/apache/spark/commit/49f9db6ad0efc9544f7e7e2c8286d8a394bf17fe). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29422: [SPARK-32613][CORE] Fix regressions in DecommissionWorkerSuite
AmplabJenkins removed a comment on pull request #29422: URL: https://github.com/apache/spark/pull/29422#issuecomment-674451788 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/127479/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29422: [SPARK-32613][CORE] Fix regressions in DecommissionWorkerSuite
AmplabJenkins removed a comment on pull request #29422: URL: https://github.com/apache/spark/pull/29422#issuecomment-674451787 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29422: [SPARK-32613][CORE] Fix regressions in DecommissionWorkerSuite
AmplabJenkins commented on pull request #29422: URL: https://github.com/apache/spark/pull/29422#issuecomment-674451787 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #29422: [SPARK-32613][CORE] Fix regressions in DecommissionWorkerSuite
SparkQA removed a comment on pull request #29422: URL: https://github.com/apache/spark/pull/29422#issuecomment-674437465 **[Test build #127479 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127479/testReport)** for PR 29422 at commit [`343bf8b`](https://github.com/apache/spark/commit/343bf8b4815332925116ace7217d90a641dfa96f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29422: [SPARK-32613][CORE] Fix regressions in DecommissionWorkerSuite
SparkQA commented on pull request #29422: URL: https://github.com/apache/spark/pull/29422#issuecomment-674451584 **[Test build #127479 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127479/testReport)** for PR 29422 at commit [`343bf8b`](https://github.com/apache/spark/commit/343bf8b4815332925116ace7217d90a641dfa96f). * This patch **fails PySpark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MrPowers commented on pull request #23877: [SPARK-26449][PYTHON] Add transform method to DataFrame API
MrPowers commented on pull request #23877:
URL: https://github.com/apache/spark/pull/23877#issuecomment-674450064
@hoffrocket pointed out that this can also be accomplished with an inner
lambda (to avoid having to name the inner function):
```python
def with_funny(something_funny):
return lambda df: (
df.withColumn("funny1", F.lit(something_funny))
)
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] agrawaldevesh commented on pull request #29422: [SPARK-32613][CORE] Fix regressions in DecommissionWorkerSuite
agrawaldevesh commented on pull request #29422: URL: https://github.com/apache/spark/pull/29422#issuecomment-674447097 @holdenk ... thanks for all the feedback and suggestions. I have incorporated them all and the PR is ready for your review again. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29342: [SPARK-32399][SQL] Full outer shuffled hash join
AmplabJenkins removed a comment on pull request #29342: URL: https://github.com/apache/spark/pull/29342#issuecomment-674446372 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29342: [SPARK-32399][SQL] Full outer shuffled hash join
AmplabJenkins commented on pull request #29342: URL: https://github.com/apache/spark/pull/29342#issuecomment-674446372 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29342: [SPARK-32399][SQL] Full outer shuffled hash join
SparkQA commented on pull request #29342: URL: https://github.com/apache/spark/pull/29342#issuecomment-674446281 **[Test build #127482 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127482/testReport)** for PR 29342 at commit [`381cdbc`](https://github.com/apache/spark/commit/381cdbc2ec393a96cab1ab611dc461dbed9d7dc2). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] c21 commented on a change in pull request #29342: [SPARK-32399][SQL] Full outer shuffled hash join
c21 commented on a change in pull request #29342:
URL: https://github.com/apache/spark/pull/29342#discussion_r471022667
##
File path: core/src/main/java/org/apache/spark/unsafe/map/BytesToBytesMap.java
##
@@ -428,6 +428,68 @@ public MapIterator destructiveIterator() {
return new MapIterator(numValues, new Location(), true);
}
+ /**
+ * Iterator for the entries of this map. This is to first iterate over key
index array
Review comment:
@maropu - sure, updated.
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/joins/HashedRelation.scala
##
@@ -66,6 +66,30 @@ private[execution] sealed trait HashedRelation extends
KnownSizeEstimation {
throw new UnsupportedOperationException
}
+ /**
+ * Returns an iterator for key index and matched rows.
+ *
+ * Returns null if there is no matched rows.
+ */
+ def getWithKeyIndex(key: InternalRow): Iterator[ValueRowWithKeyIndex]
+
+ /**
+ * Returns key index and matched single row.
+ *
+ * Returns null if there is no matched rows.
+ */
+ def getValueWithKeyIndex(key: InternalRow): ValueRowWithKeyIndex
+
+ /**
+ * Returns an iterator for keys index and rows of InternalRow type.
+ */
+ def valuesWithKeyIndex(): Iterator[ValueRowWithKeyIndex]
+
+ /**
+ * Returns the maximum number of allowed keys index.
+ */
+ def maxNumKeysIndex: Int
Review comment:
@cloud-fan - per your comment in the other place, I take the current
naming is okay as well, let me know if it's not the case, thanks.
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/joins/ShuffledHashJoinExec.scala
##
@@ -71,8 +85,217 @@ case class ShuffledHashJoinExec(
val numOutputRows = longMetric("numOutputRows")
streamedPlan.execute().zipPartitions(buildPlan.execute()) { (streamIter,
buildIter) =>
val hashed = buildHashedRelation(buildIter)
- join(streamIter, hashed, numOutputRows)
+ joinType match {
+case FullOuter => fullOuterJoin(streamIter, hashed, numOutputRows)
+case _ => join(streamIter, hashed, numOutputRows)
+ }
+}
+ }
+
+ private def fullOuterJoin(
+ streamIter: Iterator[InternalRow],
+ hashedRelation: HashedRelation,
+ numOutputRows: SQLMetric): Iterator[InternalRow] = {
+val joinKeys = streamSideKeyGenerator()
+val joinRow = new JoinedRow
+val (joinRowWithStream, joinRowWithBuild) = {
+ buildSide match {
+case BuildLeft => (joinRow.withRight _, joinRow.withLeft _)
+case BuildRight => (joinRow.withLeft _, joinRow.withRight _)
+ }
+}
+val buildNullRow = new GenericInternalRow(buildOutput.length)
+val streamNullRow = new GenericInternalRow(streamedOutput.length)
+lazy val streamNullJoinRowWithBuild = {
+ buildSide match {
+case BuildLeft =>
+ joinRow.withRight(streamNullRow)
+ joinRow.withLeft _
+case BuildRight =>
+ joinRow.withLeft(streamNullRow)
+ joinRow.withRight _
+ }
+}
+
+val iter = if (hashedRelation.keyIsUnique) {
+ fullOuterJoinWithUniqueKey(streamIter, hashedRelation, joinKeys,
joinRowWithStream,
+joinRowWithBuild, streamNullJoinRowWithBuild, buildNullRow,
streamNullRow)
+} else {
+ fullOuterJoinWithNonUniqueKey(streamIter, hashedRelation, joinKeys,
joinRowWithStream,
+joinRowWithBuild, streamNullJoinRowWithBuild, buildNullRow,
streamNullRow)
}
+
+val resultProj = UnsafeProjection.create(output, output)
+iter.map { r =>
+ numOutputRows += 1
+ resultProj(r)
+}
+ }
+
+ /**
+ * Full outer shuffled hash join with unique join keys:
+ * 1. Process rows from stream side by looking up hash relation.
+ *Mark the matched rows from build side be looked up.
+ *A `BitSet` is used to track matched rows with key index.
+ * 2. Process rows from build side by iterating hash relation.
+ *Filter out rows from build side being matched already,
+ *by checking key index from `BitSet`.
+ */
+ private def fullOuterJoinWithUniqueKey(
+ streamIter: Iterator[InternalRow],
+ hashedRelation: HashedRelation,
+ joinKeys: UnsafeProjection,
+ joinRowWithStream: InternalRow => JoinedRow,
+ joinRowWithBuild: InternalRow => JoinedRow,
+ streamNullJoinRowWithBuild: => InternalRow => JoinedRow,
+ buildNullRow: GenericInternalRow,
+ streamNullRow: GenericInternalRow): Iterator[InternalRow] = {
+val matchedKeys = new BitSet(hashedRelation.maxNumKeysIndex)
+
+// Process stream side with looking up hash relation
+val streamResultIter = streamIter.map { srow =>
+ joinRowWithStream(srow)
+ val keys = joinKeys(srow)
+ if (keys.anyNull) {
+joinRowWithBuild(buildNullRow)
+ } else {
+val matched = hashedRelation.getValueWithKeyIndex(keys)
+if (matched != null) {
+ val keyIndex = matched.getKeyIndex
[GitHub] [spark] szhem commented on pull request #19410: [SPARK-22184][CORE][GRAPHX] GraphX fails in case of insufficient memory and checkpoints enabled
szhem commented on pull request #19410: URL: https://github.com/apache/spark/pull/19410#issuecomment-674442323 @ral51 setting `spark.cleaner.referenceTracking.cleanCheckpoints` to `true` [didn't work for me too](#issuecomment-418101455). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29441: [SPARK-32626] Do not increase the input metrics when read rdd from cache
AmplabJenkins removed a comment on pull request #29441: URL: https://github.com/apache/spark/pull/29441#issuecomment-674438986 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29437: [SPARK-32621][SQL] 'path' option can cause issues while inferring schema in CSV/JSON datasources
AmplabJenkins commented on pull request #29437: URL: https://github.com/apache/spark/pull/29437#issuecomment-674439001 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29441: [SPARK-32626] Do not increase the input metrics when read rdd from cache
AmplabJenkins commented on pull request #29441: URL: https://github.com/apache/spark/pull/29441#issuecomment-674438986 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29437: [SPARK-32621][SQL] 'path' option can cause issues while inferring schema in CSV/JSON datasources
AmplabJenkins removed a comment on pull request #29437: URL: https://github.com/apache/spark/pull/29437#issuecomment-674439001 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29437: [SPARK-32621][SQL] 'path' option can cause issues while inferring schema in CSV/JSON datasources
SparkQA commented on pull request #29437: URL: https://github.com/apache/spark/pull/29437#issuecomment-674438881 **[Test build #127481 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127481/testReport)** for PR 29437 at commit [`cfc9035`](https://github.com/apache/spark/commit/cfc903551a78803cfce1ed2291bcc8a2bff09753). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29441: [SPARK-32626] Do not increase the input metrics when read rdd from cache
SparkQA commented on pull request #29441: URL: https://github.com/apache/spark/pull/29441#issuecomment-674438871 **[Test build #127480 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127480/testReport)** for PR 29441 at commit [`49f9db6`](https://github.com/apache/spark/commit/49f9db6ad0efc9544f7e7e2c8286d8a394bf17fe). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #29440: [SPARK-32625][SQL] Log error message when falling back to interpreter mode
dongjoon-hyun closed pull request #29440: URL: https://github.com/apache/spark/pull/29440 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29441: [SPARK-32626] Do not increase the input metrics when read rdd from cache
AmplabJenkins removed a comment on pull request #29441: URL: https://github.com/apache/spark/pull/29441#issuecomment-674411209 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #29441: [SPARK-32626] Do not increase the input metrics when read rdd from cache
dongjoon-hyun commented on pull request #29441: URL: https://github.com/apache/spark/pull/29441#issuecomment-674438618 ok to test This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] imback82 commented on a change in pull request #29437: [SPARK-32621][SQL] 'path' option can cause issues while inferring schema in CSV/JSON datasources
imback82 commented on a change in pull request #29437:
URL: https://github.com/apache/spark/pull/29437#discussion_r471026242
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/csv/CSVSuite.scala
##
@@ -1450,10 +1450,20 @@ abstract class CSVSuite extends QueryTest with
SharedSparkSession with TestCsvDa
val ds = sampledTestData.coalesce(1)
ds.write.text(path.getAbsolutePath)
- val readback = spark.read
+ val readback1 = spark.read
.option("inferSchema", true).option("samplingRatio", 0.1)
.csv(path.getCanonicalPath)
- assert(readback.schema == new StructType().add("_c0", IntegerType))
+ assert(readback1.schema == new StructType().add("_c0", IntegerType))
+
+ // SPARK-32621: During infer, "path" option gets added again to the
paths that have already
Review comment:
Thanks!
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29422: [SPARK-32613][CORE] Fix regressions in DecommissionWorkerSuite
SparkQA commented on pull request #29422: URL: https://github.com/apache/spark/pull/29422#issuecomment-674437465 **[Test build #127479 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127479/testReport)** for PR 29422 at commit [`343bf8b`](https://github.com/apache/spark/commit/343bf8b4815332925116ace7217d90a641dfa96f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29422: [SPARK-32613][CORE] Fix regressions in DecommissionWorkerSuite
AmplabJenkins removed a comment on pull request #29422: URL: https://github.com/apache/spark/pull/29422#issuecomment-674436931 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29422: [SPARK-32613][CORE] Fix regressions in DecommissionWorkerSuite
AmplabJenkins commented on pull request #29422: URL: https://github.com/apache/spark/pull/29422#issuecomment-674436931 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] fqaiser94 commented on a change in pull request #29322: [SPARK-32511][SQL] Add dropFields method to Column class
fqaiser94 commented on a change in pull request #29322:
URL: https://github.com/apache/spark/pull/29322#discussion_r471023135
##
File path:
sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/optimizer/complexTypesSuite.scala
##
@@ -453,60 +453,81 @@ class ComplexTypesSuite extends PlanTest with
ExpressionEvalHelper {
checkEvaluation(GetMapValue(mb0, Literal(Array[Byte](3, 4))), null)
}
- private val structAttr = 'struct1.struct('a.int)
+ private val structAttr = 'struct1.struct('a.int, 'b.int)
private val testStructRelation = LocalRelation(structAttr)
- test("simplify GetStructField on WithFields that is not changing the
attribute being extracted") {
-val query = testStructRelation.select(
- GetStructField(WithFields('struct1, Seq("b"), Seq(Literal(1))), 0,
Some("a")) as "outerAtt")
-val expected = testStructRelation.select(GetStructField('struct1, 0,
Some("a")) as "outerAtt")
-checkRule(query, expected)
+ test("simplify GetStructField on UpdateFields that is not modifying the
attribute being " +
+"extracted") {
+// add attribute, extract an attribute from the original struct
+val query1 =
testStructRelation.select(GetStructField(UpdateFields('struct1,
+ WithField("b", Literal(1)) :: Nil), 0, None) as "outerAtt")
+// drop attribute, extract an attribute from the original struct
+val query2 =
testStructRelation.select(GetStructField(UpdateFields('struct1, DropField("b")
::
+ Nil), 0, None) as "outerAtt")
+// drop attribute, add attribute, extract an attribute from the original
struct
+val query3 =
testStructRelation.select(GetStructField(UpdateFields('struct1, DropField("b")
::
+ WithField("c", Literal(2)) :: Nil), 0, None) as "outerAtt")
+// drop attribute, add attribute, extract an attribute from the original
struct
+val query4 =
testStructRelation.select(GetStructField(UpdateFields('struct1, DropField("a")
::
+ WithField("a", Literal(1)) :: Nil), 0, None) as "outerAtt")
+val expected = testStructRelation.select(GetStructField('struct1, 0, None)
as "outerAtt")
Review comment:
@cloud-fan sorry about this but I've introduced a pretty bad bug in this
PR.
This test is wrong; `query4` should actually NOT equal to `expected`.
The optimizer rule needs to be improved.
As a result of this bug, users will get incorrect results in scenarios like
the following:
```
sql("SELECT named_struct('a', 1, 'b', 2) struct_col")
.select($"struct_col".dropFields("a").getField("b").as("b"))
.show(false)
// currently returns this:
+---+
|b |
+---+
|1 |
+---+
// when in fact it should return this:
+---+
|b |
+---+
|2 |
+---+
```
I'm working on the code to fix this. Just trying to make sure I have all the
edge cases covered before I submit a PR, hopefully by the end of the weekend.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29366: [SPARK-32550][SQL] Make SpecificInternalRow constructors faster by using while loops instead of maps
AmplabJenkins removed a comment on pull request #29366: URL: https://github.com/apache/spark/pull/29366#issuecomment-674433347 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29366: [SPARK-32550][SQL] Make SpecificInternalRow constructors faster by using while loops instead of maps
AmplabJenkins commented on pull request #29366: URL: https://github.com/apache/spark/pull/29366#issuecomment-674433347 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29366: [SPARK-32550][SQL] Make SpecificInternalRow constructors faster by using while loops instead of maps
SparkQA commented on pull request #29366: URL: https://github.com/apache/spark/pull/29366#issuecomment-674433222 **[Test build #127478 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127478/testReport)** for PR 29366 at commit [`28f508d`](https://github.com/apache/spark/commit/28f508de56d7329b581258a5cf159c36d7fa5283). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] msamirkhan commented on a change in pull request #29366: [SPARK-32550][SQL] Make SpecificInternalRow constructors faster by using while loops instead of maps
msamirkhan commented on a change in pull request #29366:
URL: https://github.com/apache/spark/pull/29366#discussion_r471021743
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/SpecificInternalRow.scala
##
@@ -192,24 +192,41 @@ final class MutableAny extends MutableValue {
*/
final class SpecificInternalRow(val values: Array[MutableValue]) extends
BaseGenericInternalRow {
- def this(dataTypes: Seq[DataType]) =
-this(
- dataTypes.map {
-case BooleanType => new MutableBoolean
-case ByteType => new MutableByte
-case ShortType => new MutableShort
-// We use INT for DATE internally
-case IntegerType | DateType => new MutableInt
-// We use Long for Timestamp internally
-case LongType | TimestampType => new MutableLong
-case FloatType => new MutableFloat
-case DoubleType => new MutableDouble
-case _ => new MutableAny
- }.toArray)
+ private[this] def dataTypeToMutableValue(dataType: DataType): MutableValue =
dataType match {
+case BooleanType => new MutableBoolean
Review comment:
Done
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] agrawaldevesh commented on a change in pull request #29422: [SPARK-32613][CORE] Fix regressions in DecommissionWorkerSuite
agrawaldevesh commented on a change in pull request #29422:
URL: https://github.com/apache/spark/pull/29422#discussion_r470889645
##
File path: core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala
##
@@ -2022,16 +2024,25 @@ private[spark] class DAGScheduler(
blockManagerMaster.removeExecutor(execId)
clearCacheLocs()
}
-if (fileLost &&
-(!shuffleFileLostEpoch.contains(execId) ||
shuffleFileLostEpoch(execId) < currentEpoch)) {
- shuffleFileLostEpoch(execId) = currentEpoch
- hostToUnregisterOutputs match {
-case Some(host) =>
- logInfo(s"Shuffle files lost for host: $host (epoch $currentEpoch)")
- mapOutputTracker.removeOutputsOnHost(host)
-case None =>
- logInfo(s"Shuffle files lost for executor: $execId (epoch
$currentEpoch)")
- mapOutputTracker.removeOutputsOnExecutor(execId)
+if (fileLost) {
Review comment:
Will do. Good idea.
Added a comment on the caller. The changes in this function are simply
tweaking the existing logic to honor the newly added flag. So I thought it
would be more interesting to describe why this unconditional forcing is
required when a host is decommissioned.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29440: [SPARK-32625][SQL] Log error message when falling back to interpreter mode
AmplabJenkins commented on pull request #29440: URL: https://github.com/apache/spark/pull/29440#issuecomment-674432427 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29440: [SPARK-32625][SQL] Log error message when falling back to interpreter mode
AmplabJenkins removed a comment on pull request #29440: URL: https://github.com/apache/spark/pull/29440#issuecomment-674432427 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #29440: [SPARK-32625][SQL] Log error message when falling back to interpreter mode
SparkQA removed a comment on pull request #29440: URL: https://github.com/apache/spark/pull/29440#issuecomment-674402253 **[Test build #127475 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127475/testReport)** for PR 29440 at commit [`cf3bf3d`](https://github.com/apache/spark/commit/cf3bf3dd184f69c6693c8ce0652f13653f9966c9). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29440: [SPARK-32625][SQL] Log error message when falling back to interpreter mode
SparkQA commented on pull request #29440: URL: https://github.com/apache/spark/pull/29440#issuecomment-674432236 **[Test build #127475 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127475/testReport)** for PR 29440 at commit [`cf3bf3d`](https://github.com/apache/spark/commit/cf3bf3dd184f69c6693c8ce0652f13653f9966c9). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29082: [SPARK-32288][UI] Add exception summary for failed tasks in stage page
AmplabJenkins removed a comment on pull request #29082: URL: https://github.com/apache/spark/pull/29082#issuecomment-674431418 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/127477/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #29082: [SPARK-32288][UI] Add exception summary for failed tasks in stage page
SparkQA removed a comment on pull request #29082: URL: https://github.com/apache/spark/pull/29082#issuecomment-674430975 **[Test build #127477 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/127477/testReport)** for PR 29082 at commit [`c10a832`](https://github.com/apache/spark/commit/c10a83251fc1f9cb7d024d52547435d89e17629f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29082: [SPARK-32288][UI] Add exception summary for failed tasks in stage page
AmplabJenkins removed a comment on pull request #29082: URL: https://github.com/apache/spark/pull/29082#issuecomment-674431416 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org