[GitHub] [spark] AmplabJenkins commented on pull request #29695: [SPARK-22390][SPARK-32833][SQL] [WIP]JDBC V2 Datasource aggregate push down
AmplabJenkins commented on pull request #29695: URL: https://github.com/apache/spark/pull/29695#issuecomment-730995344 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29695: [SPARK-22390][SPARK-32833][SQL] [WIP]JDBC V2 Datasource aggregate push down
SparkQA commented on pull request #29695: URL: https://github.com/apache/spark/pull/29695#issuecomment-730988720 **[Test build #131400 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131400/testReport)** for PR 29695 at commit [`7de8b20`](https://github.com/apache/spark/commit/7de8b202525bdf7b774a030da1e180ccabf66ed0). * This patch passes all tests. * This patch **does not merge cleanly**. * This patch adds the following public classes _(experimental)_: * `case class Avg(column: String) extends AggregateFunc` * `case class Min(column: String) extends AggregateFunc` * `case class Max(column: String) extends AggregateFunc` * `case class Sum(column: String) extends AggregateFunc` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30441: [SPARK-33441][BUILD][FOLLOWUP] Make unused-imports check for SBT specific.
AmplabJenkins commented on pull request #30441: URL: https://github.com/apache/spark/pull/30441#issuecomment-730980900 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30441: [SPARK-33441][BUILD][FOLLOWUP] Make unused-imports check for SBT specific.
SparkQA commented on pull request #30441: URL: https://github.com/apache/spark/pull/30441#issuecomment-730980771 Kubernetes integration test status failure URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36006/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30427: [SPARK-33224][SS] Add watermark gap information into SS UI page
SparkQA commented on pull request #30427: URL: https://github.com/apache/spark/pull/30427#issuecomment-730966978 **[Test build #131405 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131405/testReport)** for PR 30427 at commit [`d19fd10`](https://github.com/apache/spark/commit/d19fd10dab7c4fc28d1c4a893a2db74405d4ff9f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #30427: [SPARK-33224][SS] Add watermark gap information into SS UI page
HeartSaVioR commented on a change in pull request #30427:
URL: https://github.com/apache/spark/pull/30427#discussion_r527493073
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/streaming/ui/StreamingQueryStatisticsPage.scala
##
@@ -126,6 +126,53 @@ private[ui] class StreamingQueryStatisticsPage(parent:
StreamingQueryTab)
}
+ def generateWatermark(
+ query: StreamingQueryUIData,
+ minBatchTime: Long,
+ maxBatchTime: Long,
+ jsCollector: JsCollector): Seq[Node] = {
+// This is made sure on caller side but put it here to be defensive
+require(query.lastProgress != null)
+if (query.lastProgress.eventTime.containsKey("watermark")) {
+ val watermarkData = query.recentProgress.flatMap { p =>
+val batchTimestamp = parseProgressTimestamp(p.timestamp)
+val watermarkValue =
parseProgressTimestamp(p.eventTime.get("watermark"))
+if (watermarkValue > 0L) {
+ // seconds
+ Some((batchTimestamp, ((batchTimestamp - watermarkValue) / 1000.0)))
+} else {
+ None
+}
+ }
+ val maxWatermark = watermarkData.maxBy(_._2)._2
+ val graphUIDataForWatermark =
+new GraphUIData(
+ "watermark-gap-timeline",
+ "watermark-gap-histogram",
+ watermarkData,
+ minBatchTime,
+ maxBatchTime,
+ 0,
+ maxWatermark,
+ "seconds")
+ graphUIDataForWatermark.generateDataJs(jsCollector)
+
+ // scalastyle:off
+
+
+
+Global Watermark Gap {SparkUIUtils.tooltip("The gap
between batch timestamp and global watermark for the batch.",
"right")}
+
+
+{graphUIDataForWatermark.generateTimelineHtml(jsCollector)}
+{graphUIDataForWatermark.generateHistogramHtml(jsCollector)}
Review comment:
My bad. Thanks for finding!
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30428: [SPARK-28704][SQL][TEST] Add back Skiped HiveExternalCatalogVersionsSuite in HiveSparkSubmitSuite at JDK9+
SparkQA commented on pull request #30428: URL: https://github.com/apache/spark/pull/30428#issuecomment-730963890 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36005/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30428: [SPARK-28704][SQL][TEST] Add back Skiped HiveExternalCatalogVersionsSuite in HiveSparkSubmitSuite at JDK9+
AmplabJenkins commented on pull request #30428: URL: https://github.com/apache/spark/pull/30428#issuecomment-730963903 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30441: [SPARK-33441][BUILD][FOLLOWUP] Make unused-imports check for SBT specific.
SparkQA commented on pull request #30441: URL: https://github.com/apache/spark/pull/30441#issuecomment-730963366 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36007/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on a change in pull request #30427: [SPARK-33224][SS] Add watermark gap information into SS UI page
viirya commented on a change in pull request #30427:
URL: https://github.com/apache/spark/pull/30427#discussion_r527490802
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/streaming/ui/StreamingQueryStatisticsPage.scala
##
@@ -126,6 +126,53 @@ private[ui] class StreamingQueryStatisticsPage(parent:
StreamingQueryTab)
}
+ def generateWatermark(
+ query: StreamingQueryUIData,
+ minBatchTime: Long,
+ maxBatchTime: Long,
+ jsCollector: JsCollector): Seq[Node] = {
+// This is made sure on caller side but put it here to be defensive
+require(query.lastProgress != null)
+if (query.lastProgress.eventTime.containsKey("watermark")) {
+ val watermarkData = query.recentProgress.flatMap { p =>
+val batchTimestamp = parseProgressTimestamp(p.timestamp)
+val watermarkValue =
parseProgressTimestamp(p.eventTime.get("watermark"))
+if (watermarkValue > 0L) {
+ // seconds
+ Some((batchTimestamp, ((batchTimestamp - watermarkValue) / 1000.0)))
+} else {
+ None
+}
+ }
+ val maxWatermark = watermarkData.maxBy(_._2)._2
+ val graphUIDataForWatermark =
+new GraphUIData(
+ "watermark-gap-timeline",
+ "watermark-gap-histogram",
+ watermarkData,
+ minBatchTime,
+ maxBatchTime,
+ 0,
+ maxWatermark,
+ "seconds")
+ graphUIDataForWatermark.generateDataJs(jsCollector)
+
+ // scalastyle:off
+
+
+
+Global Watermark Gap {SparkUIUtils.tooltip("The gap
between batch timestamp and global watermark for the batch.",
"right")}
+
+
+{graphUIDataForWatermark.generateTimelineHtml(jsCollector)}
+{graphUIDataForWatermark.generateHistogramHtml(jsCollector)}
Review comment:
watermark-gap-histogram?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29695: [SPARK-22390][SPARK-32833][SQL] [WIP]JDBC V2 Datasource aggregate push down
SparkQA commented on pull request #29695: URL: https://github.com/apache/spark/pull/29695#issuecomment-730959298 **[Test build #131404 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131404/testReport)** for PR 29695 at commit [`0be3c95`](https://github.com/apache/spark/commit/0be3c953dfb8e7f4b483500c30e01a58eefbb4e5). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30441: [SPARK-33441][BUILD][FOLLOWUP] Make unused-imports check for SBT specific.
SparkQA commented on pull request #30441: URL: https://github.com/apache/spark/pull/30441#issuecomment-730957690 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36006/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30399: [SPARK-33468][SQL] ParseUrl in ANSI mode should fail if input string is not a valid url
AmplabJenkins removed a comment on pull request #30399: URL: https://github.com/apache/spark/pull/30399#issuecomment-730956904 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30399: [SPARK-33468][SQL] ParseUrl in ANSI mode should fail if input string is not a valid url
AmplabJenkins commented on pull request #30399: URL: https://github.com/apache/spark/pull/30399#issuecomment-730956904 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30399: [SPARK-33468][SQL] ParseUrl in ANSI mode should fail if input string is not a valid url
SparkQA removed a comment on pull request #30399: URL: https://github.com/apache/spark/pull/30399#issuecomment-730810816 **[Test build #131391 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131391/testReport)** for PR 30399 at commit [`d7e437b`](https://github.com/apache/spark/commit/d7e437b326dc9564a9460946bdbc0856e6876322). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30399: [SPARK-33468][SQL] ParseUrl in ANSI mode should fail if input string is not a valid url
SparkQA commented on pull request #30399: URL: https://github.com/apache/spark/pull/30399#issuecomment-730956093 **[Test build #131391 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131391/testReport)** for PR 30399 at commit [`d7e437b`](https://github.com/apache/spark/commit/d7e437b326dc9564a9460946bdbc0856e6876322). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30441: [SPARK-33441][BUILD][FOLLOWUP] Make unused-imports check for SBT specific.
AmplabJenkins removed a comment on pull request #30441: URL: https://github.com/apache/spark/pull/30441#issuecomment-730951862 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/131403/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30411: [SPARK-31962][SQL] Provide modifiedAfter and modifiedBefore options when filtering from a batch-based file data source
AmplabJenkins removed a comment on pull request #30411: URL: https://github.com/apache/spark/pull/30411#issuecomment-730920919 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/131392/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30439: [SPARK-33223][SS][FOLLOWUP] Clarify the meaning of "number of rows dropped by watermark" in SS UI page
AmplabJenkins removed a comment on pull request #30439: URL: https://github.com/apache/spark/pull/30439#issuecomment-730953402 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30441: [SPARK-33441][BUILD][FOLLOWUP] Make unused-imports check for SBT specific.
LuciferYang commented on a change in pull request #30441: URL: https://github.com/apache/spark/pull/30441#discussion_r527481555 ## File path: core/src/main/scala/org/apache/spark/SparkContext.scala ## @@ -27,6 +27,7 @@ import scala.collection.JavaConverters._ import scala.collection.Map import scala.collection.immutable import scala.collection.mutable.HashMap +import scala.collection.mutable.HashSet Review comment:  Looks like it's working in Scala 2.12 , but seems `-Wconf:cat=unused-imports:e` not working in Scala 2.13 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30411: [SPARK-31962][SQL] Provide modifiedAfter and modifiedBefore options when filtering from a batch-based file data source
AmplabJenkins removed a comment on pull request #30411: URL: https://github.com/apache/spark/pull/30411#issuecomment-730920895 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30441: [SPARK-33441][BUILD][FOLLOWUP] Make unused-imports check for SBT specific.
SparkQA removed a comment on pull request #30441: URL: https://github.com/apache/spark/pull/30441#issuecomment-730950451 **[Test build #131403 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131403/testReport)** for PR 30441 at commit [`4f4cf1a`](https://github.com/apache/spark/commit/4f4cf1acd3280596178022999a616650a0d191e1). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30437: [SPARK-33472][SQL][2.4] Adjust RemoveRedundantSorts rule order
AmplabJenkins removed a comment on pull request #30437: URL: https://github.com/apache/spark/pull/30437#issuecomment-730945642 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30437: [SPARK-33472][SQL][2.4] Adjust RemoveRedundantSorts rule order
SparkQA removed a comment on pull request #30437: URL: https://github.com/apache/spark/pull/30437#issuecomment-730823373 **[Test build #131394 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131394/testReport)** for PR 30437 at commit [`dbc38d3`](https://github.com/apache/spark/commit/dbc38d371ea3615ac6e756ade27f6fdefafa1feb). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30441: [SPARK-33441][BUILD][FOLLOWUP] Make unused-imports check for SBT specific.
AmplabJenkins removed a comment on pull request #30441: URL: https://github.com/apache/spark/pull/30441#issuecomment-730951857 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30439: [SPARK-33223][SS][FOLLOWUP] Clarify the meaning of "number of rows dropped by watermark" in SS UI page
SparkQA removed a comment on pull request #30439: URL: https://github.com/apache/spark/pull/30439#issuecomment-730830787 **[Test build #131396 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131396/testReport)** for PR 30439 at commit [`ec1fba1`](https://github.com/apache/spark/commit/ec1fba198fc8c6f2e8c50f413ef78f9a467d4c37). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30439: [SPARK-33223][SS][FOLLOWUP] Clarify the meaning of "number of rows dropped by watermark" in SS UI page
AmplabJenkins commented on pull request #30439: URL: https://github.com/apache/spark/pull/30439#issuecomment-730953396 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30441: [SPARK-33441][BUILD][FOLLOWUP] Make unused-imports check for SBT specific.
LuciferYang commented on a change in pull request #30441: URL: https://github.com/apache/spark/pull/30441#discussion_r527481555 ## File path: core/src/main/scala/org/apache/spark/SparkContext.scala ## @@ -27,6 +27,7 @@ import scala.collection.JavaConverters._ import scala.collection.Map import scala.collection.immutable import scala.collection.mutable.HashMap +import scala.collection.mutable.HashSet Review comment:  Looks like it's working in Scala 2.12 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30428: [SPARK-28704][SQL][TEST] Add back Skiped HiveExternalCatalogVersionsSuite in HiveSparkSubmitSuite at JDK9+
SparkQA commented on pull request #30428: URL: https://github.com/apache/spark/pull/30428#issuecomment-730952131 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36005/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30439: [SPARK-33223][SS][FOLLOWUP] Clarify the meaning of "number of rows dropped by watermark" in SS UI page
SparkQA commented on pull request #30439: URL: https://github.com/apache/spark/pull/30439#issuecomment-730952116 **[Test build #131396 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131396/testReport)** for PR 30439 at commit [`ec1fba1`](https://github.com/apache/spark/commit/ec1fba198fc8c6f2e8c50f413ef78f9a467d4c37). * This patch passes all tests. * This patch **does not merge cleanly**. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #30427: [SPARK-33224][SS] Add watermark gap information into SS UI page
HeartSaVioR commented on a change in pull request #30427:
URL: https://github.com/apache/spark/pull/30427#discussion_r527480459
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/streaming/ui/StreamingQueryStatisticsPage.scala
##
@@ -126,6 +126,53 @@ private[ui] class StreamingQueryStatisticsPage(parent:
StreamingQueryTab)
}
+ def generateWatermark(
+ query: StreamingQueryUIData,
+ minBatchTime: Long,
+ maxBatchTime: Long,
+ jsCollector: JsCollector): Seq[Node] = {
+// This is made sure on caller side but put it here to be defensive
+require(query.lastProgress != null)
+if (query.lastProgress.eventTime.containsKey("watermark")) {
+ val watermarkData = query.recentProgress.flatMap { p =>
+val batchTimestamp = parseProgressTimestamp(p.timestamp)
+val watermarkValue =
parseProgressTimestamp(p.eventTime.get("watermark"))
+if (watermarkValue > 0L) {
+ // seconds
+ Some((batchTimestamp, ((batchTimestamp - watermarkValue) / 1000.0)))
+} else {
+ None
+}
+ }
+ val maxWatermark = watermarkData.maxBy(_._2)._2
Review comment:
Nice catch! It looks to be broken while filtering out 0L. Will fix.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30441: [SPARK-33441][BUILD][FOLLOWUP] Make unused-imports check for SBT specific.
AmplabJenkins commented on pull request #30441: URL: https://github.com/apache/spark/pull/30441#issuecomment-730951857 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30441: [SPARK-33441][BUILD][FOLLOWUP] Make unused-imports check for SBT specific.
SparkQA commented on pull request #30441: URL: https://github.com/apache/spark/pull/30441#issuecomment-730951843 **[Test build #131403 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131403/testReport)** for PR 30441 at commit [`4f4cf1a`](https://github.com/apache/spark/commit/4f4cf1acd3280596178022999a616650a0d191e1). * This patch **fails to build**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30441: [SPARK-33441][BUILD][FOLLOWUP] Make unused-imports check for SBT specific.
SparkQA commented on pull request #30441: URL: https://github.com/apache/spark/pull/30441#issuecomment-730950451 **[Test build #131403 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131403/testReport)** for PR 30441 at commit [`4f4cf1a`](https://github.com/apache/spark/commit/4f4cf1acd3280596178022999a616650a0d191e1). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #30411: [SPARK-31962][SQL] Provide modifiedAfter and modifiedBefore options when filtering from a batch-based file data source
HeartSaVioR commented on pull request #30411: URL: https://github.com/apache/spark/pull/30411#issuecomment-730949018 Build failure is not related. I'll let it go and check just before the merge. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30437: [SPARK-33472][SQL][2.4] Adjust RemoveRedundantSorts rule order
AmplabJenkins commented on pull request #30437: URL: https://github.com/apache/spark/pull/30437#issuecomment-730945642 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30437: [SPARK-33472][SQL][2.4] Adjust RemoveRedundantSorts rule order
SparkQA commented on pull request #30437: URL: https://github.com/apache/spark/pull/30437#issuecomment-730943334 **[Test build #131394 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131394/testReport)** for PR 30437 at commit [`dbc38d3`](https://github.com/apache/spark/commit/dbc38d371ea3615ac6e756ade27f6fdefafa1feb). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30441: [SPARK-33441][BUILD][FOLLOWUP] Make unused-imports check for SBT specific.
LuciferYang commented on a change in pull request #30441: URL: https://github.com/apache/spark/pull/30441#discussion_r527473631 ## File path: core/src/main/scala/org/apache/spark/SparkContext.scala ## @@ -27,6 +27,7 @@ import scala.collection.JavaConverters._ import scala.collection.Map import scala.collection.immutable import scala.collection.mutable.HashMap +import scala.collection.mutable.HashSet Review comment: Expect this line to trigger compile error This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30441: [SPARK-33441][BUILD][FOLLOWUP] Make unused-imports check for SBT specific.
LuciferYang commented on a change in pull request #30441: URL: https://github.com/apache/spark/pull/30441#discussion_r527473102 ## File path: core/src/main/scala/org/apache/spark/SparkContext.scala ## @@ -27,6 +27,7 @@ import scala.collection.JavaConverters._ import scala.collection.Map import scala.collection.immutable import scala.collection.mutable.HashMap +import scala.collection.mutable.HashSet Review comment: Yeah ## File path: core/src/main/scala/org/apache/spark/SparkContext.scala ## @@ -27,6 +27,7 @@ import scala.collection.JavaConverters._ import scala.collection.Map import scala.collection.immutable import scala.collection.mutable.HashMap +import scala.collection.mutable.HashSet Review comment: Yes This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30411: [SPARK-31962][SQL] Provide modifiedAfter and modifiedBefore options when filtering from a batch-based file data source
AmplabJenkins commented on pull request #30411: URL: https://github.com/apache/spark/pull/30411#issuecomment-730920895 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30411: [SPARK-31962][SQL] Provide modifiedAfter and modifiedBefore options when filtering from a batch-based file data source
SparkQA removed a comment on pull request #30411: URL: https://github.com/apache/spark/pull/30411#issuecomment-730817075 **[Test build #131392 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131392/testReport)** for PR 30411 at commit [`ce00b6d`](https://github.com/apache/spark/commit/ce00b6dc54ed681e7172db2856fb444d51d3f75c). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30411: [SPARK-31962][SQL] Provide modifiedAfter and modifiedBefore options when filtering from a batch-based file data source
SparkQA commented on pull request #30411: URL: https://github.com/apache/spark/pull/30411#issuecomment-730917327 **[Test build #131392 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131392/testReport)** for PR 30411 at commit [`ce00b6d`](https://github.com/apache/spark/commit/ce00b6dc54ed681e7172db2856fb444d51d3f75c). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #30441: [SPARK-33441][BUILD][FOLLOWUP] Make unused-imports check for SBT specific.
HyukjinKwon commented on a change in pull request #30441: URL: https://github.com/apache/spark/pull/30441#discussion_r527472080 ## File path: core/src/main/scala/org/apache/spark/SparkContext.scala ## @@ -27,6 +27,7 @@ import scala.collection.JavaConverters._ import scala.collection.Map import scala.collection.immutable import scala.collection.mutable.HashMap +import scala.collection.mutable.HashSet Review comment: It's for testing right? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30441: [SPARK-33441][BUILD][FOLLOWUP] Make unused-imports check for SBT specific.
SparkQA commented on pull request #30441: URL: https://github.com/apache/spark/pull/30441#issuecomment-730910796 **[Test build #131402 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131402/testReport)** for PR 30441 at commit [`b9026f2`](https://github.com/apache/spark/commit/b9026f2567d8ca94ef4bc145e726554521a1099f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang opened a new pull request #30441: [SPARK-33441][FOLLOWUP] Make unused-imports check for SBT specific.
LuciferYang opened a new pull request #30441: URL: https://github.com/apache/spark/pull/30441 ### What changes were proposed in this pull request? Move "unused-imports" check config to `SparkBuild.scala` and make it SBT specific. ### Why are the changes needed? Make unused-imports check for SBT specific. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Pass the Jenkins or GitHub Action This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30430: [SPARK-33400][SQL][FOLLOWUP] Make sameOrderExpressions part of SortOrder childrens
AmplabJenkins removed a comment on pull request #30430: URL: https://github.com/apache/spark/pull/30430#issuecomment-730895924 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30430: [SPARK-33400][SQL][FOLLOWUP] Make sameOrderExpressions part of SortOrder childrens
AmplabJenkins commented on pull request #30430: URL: https://github.com/apache/spark/pull/30430#issuecomment-730895924 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30430: [SPARK-33400][SQL][FOLLOWUP] Make sameOrderExpressions part of SortOrder childrens
SparkQA removed a comment on pull request #30430: URL: https://github.com/apache/spark/pull/30430#issuecomment-730778009 **[Test build #131386 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131386/testReport)** for PR 30430 at commit [`f3a8ded`](https://github.com/apache/spark/commit/f3a8dede84aedae100e27c8344bda4d5ffa7771f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30428: [SPARK-28704][SQL][TEST] Add back Skiped HiveExternalCatalogVersionsSuite in HiveSparkSubmitSuite at JDK9+
SparkQA commented on pull request #30428: URL: https://github.com/apache/spark/pull/30428#issuecomment-730888235 **[Test build #131401 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131401/testReport)** for PR 30428 at commit [`b9dd1e4`](https://github.com/apache/spark/commit/b9dd1e40c2c4e48376417e7f0549ca976255bb51). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30430: [SPARK-33400][SQL][FOLLOWUP] Make sameOrderExpressions part of SortOrder childrens
SparkQA commented on pull request #30430: URL: https://github.com/apache/spark/pull/30430#issuecomment-730888060 **[Test build #131386 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131386/testReport)** for PR 30430 at commit [`f3a8ded`](https://github.com/apache/spark/commit/f3a8dede84aedae100e27c8344bda4d5ffa7771f). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30428: [SPARK-28704][SQL][TEST] Add back Skiped HiveExternalCatalogVersionsSuite in HiveSparkSubmitSuite at JDK9+
AmplabJenkins removed a comment on pull request #30428: URL: https://github.com/apache/spark/pull/30428#issuecomment-730881972 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30428: [SPARK-28704][SQL][TEST] Add back Skiped HiveExternalCatalogVersionsSuite in HiveSparkSubmitSuite at JDK9+
AmplabJenkins commented on pull request #30428: URL: https://github.com/apache/spark/pull/30428#issuecomment-730881972 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sarutak commented on a change in pull request #30427: [SPARK-33224][SS] Add watermark gap information into SS UI page
sarutak commented on a change in pull request #30427:
URL: https://github.com/apache/spark/pull/30427#discussion_r527463165
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/streaming/ui/StreamingQueryStatisticsPage.scala
##
@@ -126,6 +126,53 @@ private[ui] class StreamingQueryStatisticsPage(parent:
StreamingQueryTab)
}
+ def generateWatermark(
+ query: StreamingQueryUIData,
+ minBatchTime: Long,
+ maxBatchTime: Long,
+ jsCollector: JsCollector): Seq[Node] = {
+// This is made sure on caller side but put it here to be defensive
+require(query.lastProgress != null)
+if (query.lastProgress.eventTime.containsKey("watermark")) {
+ val watermarkData = query.recentProgress.flatMap { p =>
+val batchTimestamp = parseProgressTimestamp(p.timestamp)
+val watermarkValue =
parseProgressTimestamp(p.eventTime.get("watermark"))
+if (watermarkValue > 0L) {
+ // seconds
+ Some((batchTimestamp, ((batchTimestamp - watermarkValue) / 1000.0)))
+} else {
+ None
+}
+ }
+ val maxWatermark = watermarkData.maxBy(_._2)._2
Review comment:
If we access to the UI immediately after starting a streaming query,
watermarkData can be empty.
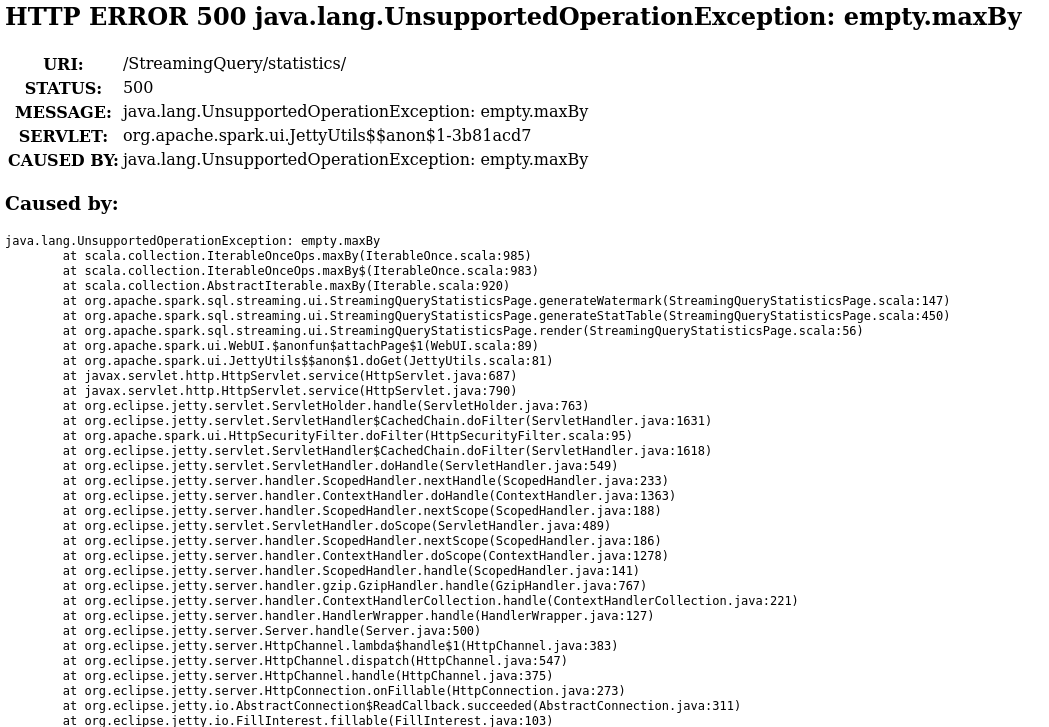
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #30428: [SPARK-28704][SQL][TEST] Add back Skiped HiveExternalCatalogVersionsSuite in HiveSparkSubmitSuite at JDK9+
AngersZh commented on pull request #30428: URL: https://github.com/apache/spark/pull/30428#issuecomment-730881488 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30428: [SPARK-28704][SQL][TEST][test-java11] Add back Skiped HiveExternalCatalogVersionsSuite in HiveSparkSubmitSuite at JDK9+
SparkQA removed a comment on pull request #30428: URL: https://github.com/apache/spark/pull/30428#issuecomment-730832673 **[Test build #131398 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131398/testReport)** for PR 30428 at commit [`b9dd1e4`](https://github.com/apache/spark/commit/b9dd1e40c2c4e48376417e7f0549ca976255bb51). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30428: [SPARK-28704][SQL][TEST][test-java11] Add back Skiped HiveExternalCatalogVersionsSuite in HiveSparkSubmitSuite at JDK9+
SparkQA commented on pull request #30428: URL: https://github.com/apache/spark/pull/30428#issuecomment-730881025 **[Test build #131398 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131398/testReport)** for PR 30428 at commit [`b9dd1e4`](https://github.com/apache/spark/commit/b9dd1e40c2c4e48376417e7f0549ca976255bb51). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29695: [SPARK-22390][SPARK-32833][SQL] [WIP]JDBC V2 Datasource aggregate push down
AmplabJenkins removed a comment on pull request #29695: URL: https://github.com/apache/spark/pull/29695#issuecomment-730878762 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/36004/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #29695: [SPARK-22390][SPARK-32833][SQL] [WIP]JDBC V2 Datasource aggregate push down
AmplabJenkins removed a comment on pull request #29695: URL: https://github.com/apache/spark/pull/29695#issuecomment-730878757 Build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29695: [SPARK-22390][SPARK-32833][SQL] [WIP]JDBC V2 Datasource aggregate push down
SparkQA commented on pull request #29695: URL: https://github.com/apache/spark/pull/29695#issuecomment-730878742 Kubernetes integration test status failure URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36004/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #29695: [SPARK-22390][SPARK-32833][SQL] [WIP]JDBC V2 Datasource aggregate push down
AmplabJenkins commented on pull request #29695: URL: https://github.com/apache/spark/pull/29695#issuecomment-730878757 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30427: [SPARK-33224][SS] Add watermark gap information into SS UI page
AmplabJenkins removed a comment on pull request #30427: URL: https://github.com/apache/spark/pull/30427#issuecomment-730865527 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
AmplabJenkins removed a comment on pull request #24173: URL: https://github.com/apache/spark/pull/24173#issuecomment-730866692 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30439: [SPARK-33223][SS][FOLLOWUP] Clarify the meaning of "number of rows dropped by watermark" in SS UI page
AmplabJenkins removed a comment on pull request #30439: URL: https://github.com/apache/spark/pull/30439#issuecomment-730866817 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30428: [SPARK-28704][SQL][TEST][test-java11] Add back Skiped HiveExternalCatalogVersionsSuite in HiveSparkSubmitSuite at JDK9+
AmplabJenkins removed a comment on pull request #30428: URL: https://github.com/apache/spark/pull/30428#issuecomment-730869986 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #30351: [SPARK-33441][BUILD] Add unused-imports compilation check and remove all unused-imports
HyukjinKwon commented on a change in pull request #30351: URL: https://github.com/apache/spark/pull/30351#discussion_r527445085 ## File path: pom.xml ## @@ -164,6 +164,7 @@ 3.2.2 2.12.10 2.12 +-Ywarn-unused-import Review comment: Sure thanks :-) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30439: [SPARK-33223][SS][FOLLOWUP] Clarify the meaning of "number of rows dropped by watermark" in SS UI page
AmplabJenkins commented on pull request #30439: URL: https://github.com/apache/spark/pull/30439#issuecomment-730872109 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30439: [SPARK-33223][SS][FOLLOWUP] Clarify the meaning of "number of rows dropped by watermark" in SS UI page
SparkQA commented on pull request #30439: URL: https://github.com/apache/spark/pull/30439#issuecomment-730872093 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36001/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30428: [SPARK-28704][SQL][TEST][test-java11] Add back Skiped HiveExternalCatalogVersionsSuite in HiveSparkSubmitSuite at JDK9+
AmplabJenkins commented on pull request #30428: URL: https://github.com/apache/spark/pull/30428#issuecomment-730869986 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30428: [SPARK-28704][SQL][TEST][test-java11] Add back Skiped HiveExternalCatalogVersionsSuite in HiveSparkSubmitSuite at JDK9+
SparkQA commented on pull request #30428: URL: https://github.com/apache/spark/pull/30428#issuecomment-730869969 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36002/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on pull request #29642: [SPARK-32792][SQL] Improve in filter pushdown for ParquetFilters
wangyum commented on pull request #29642:
URL: https://github.com/apache/spark/pull/29642#issuecomment-730869008
It seems only Parquet not well supported `In` predicate pushdown. @MaxGekk
What do you think?
This is the benchmark of CSV:
```scala
val rowsNum = 100 * 1000
val numIters = 3
val colsNum = 100
val fields = Seq.tabulate(colsNum)(i => StructField(s"col$i", TimestampType))
val schema = StructType(StructField("key", IntegerType) +: fields)
def columns(): Seq[Column] = {
val ts = Seq.tabulate(colsNum) { i =>
lit(Instant.ofEpochSecond(i * 12345678)).as(s"col$i")
}
($"id" % 1000).as("key") +: ts
}
withTempPath { path =>
spark.range(rowsNum).select(columns(): _*)
.write.option("header", true)
.csv(path.getAbsolutePath)
def readback = {
spark.read
.option("header", true)
.schema(schema)
.csv(path.getAbsolutePath)
}
def withFilter(filer: String, configEnabled: Boolean): Unit = {
withSQLConf(SQLConf.CSV_FILTER_PUSHDOWN_ENABLED.key ->
configEnabled.toString()) {
readback.filter(filer).noop()
}
}
Seq(5, 10, 50, 100, 500).foreach { count =>
Seq(10, 50).foreach { distribution =>
val title = s"InSet -> InFilters (values count: $count, distribution:
$distribution)"
val benchmark = new Benchmark(title, rowsNum, output = output)
Seq(false, true).foreach { pushDownEnabled =>
val name = s"Native CSV Vectorized ${if (pushDownEnabled)
s"(Pushdown)" else ""}"
benchmark.addCase(name, numIters) { _ =>
val filter =
Range(0, count).map(_ => scala.util.Random.nextInt(rowsNum *
distribution / 100))
val whereExpr = s"key in(${filter.mkString(",")})"
withFilter(whereExpr, configEnabled = pushDownEnabled)
}
}
benchmark.run()
}
}
}
```
Result:
```
Benchmark to measure CSV read performance
Java HotSpot(TM) 64-Bit Server VM 1.8.0_251-b08 on Mac OS X 10.15.7
Intel(R) Core(TM) i9-9980HK CPU @ 2.40GHz
InSet -> InFilters (values count: 5, distribution: 10): Best Time(ms) Avg
Time(ms) Stdev(ms)Rate(M/s) Per Row(ns) Relative
--
Native CSV Vectorized 13082
170771674 0.0 130815.6 1.0X
Native CSV Vectorized (Pushdown) 1172
1192 35 0.1 11719.5 11.2X
Java HotSpot(TM) 64-Bit Server VM 1.8.0_251-b08 on Mac OS X 10.15.7
Intel(R) Core(TM) i9-9980HK CPU @ 2.40GHz
InSet -> InFilters (values count: 5, distribution: 50): Best Time(ms) Avg
Time(ms) Stdev(ms)Rate(M/s) Per Row(ns) Relative
--
Native CSV Vectorized 11858
12028 237 0.0 118576.9 1.0X
Native CSV Vectorized (Pushdown) 1165
1172 6 0.1 11652.4 10.2X
Java HotSpot(TM) 64-Bit Server VM 1.8.0_251-b08 on Mac OS X 10.15.7
Intel(R) Core(TM) i9-9980HK CPU @ 2.40GHz
InSet -> InFilters (values count: 10, distribution: 10): Best Time(ms)
Avg Time(ms) Stdev(ms)Rate(M/s) Per Row(ns) Relative
---
Native CSV Vectorized11883
12180 494 0.0 118834.3 1.0X
Native CSV Vectorized (Pushdown) 1142
1156 21 0.1 11418.6 10.4X
Java HotSpot(TM) 64-Bit Server VM 1.8.0_251-b08 on Mac OS X 10.15.7
Intel(R) Core(TM) i9-9980HK CPU @ 2.40GHz
InSet -> InFilters (values count: 10, distribution: 50): Best Time(ms)
Avg Time(ms) Stdev(ms)Rate(M/s) Per Row(ns) Relative
---
Native CSV Vectorized11857
11878 19 0.0 118570.4 1.0X
Native CSV Vectorized (Pushdown) 1169
1174 7 0.1 11692.9 10.1X
Java HotSpot(TM) 64-Bit Server
[GitHub] [spark] SparkQA commented on pull request #29695: [SPARK-22390][SPARK-32833][SQL] [WIP]JDBC V2 Datasource aggregate push down
SparkQA commented on pull request #29695: URL: https://github.com/apache/spark/pull/29695#issuecomment-730868141 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36004/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30439: [SPARK-33223][SS][FOLLOWUP] Clarify the meaning of "number of rows dropped by watermark" in SS UI page
AmplabJenkins commented on pull request #30439: URL: https://github.com/apache/spark/pull/30439#issuecomment-730866817 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30439: [SPARK-33223][SS][FOLLOWUP] Clarify the meaning of "number of rows dropped by watermark" in SS UI page
SparkQA commented on pull request #30439: URL: https://github.com/apache/spark/pull/30439#issuecomment-730866805 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36000/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
SparkQA commented on pull request #24173: URL: https://github.com/apache/spark/pull/24173#issuecomment-730866683 Kubernetes integration test status success URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/35999/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
AmplabJenkins commented on pull request #24173: URL: https://github.com/apache/spark/pull/24173#issuecomment-730866692 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #30427: [SPARK-33224][SS] Add watermark gap information into SS UI page
AmplabJenkins commented on pull request #30427: URL: https://github.com/apache/spark/pull/30427#issuecomment-730865527 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wmoustafa commented on pull request #24559: [SPARK-27658][SQL] Add FunctionCatalog API
wmoustafa commented on pull request #24559: URL: https://github.com/apache/spark/pull/24559#issuecomment-730865485 > I think we need a design doc for the UDF API. We need to think about ease-of-use and performance. @rdblue @cloud-fan What do you think of the [Transport](https://github.com/linkedin/transport) API? It is simple, wraps InternalRows in the case of Spark, and portable between Spark, Presto, Hive and Avro (and potentially other data formats, so UDFs can probably be pushed to the format layer) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30427: [SPARK-33224][SS] Add watermark gap information into SS UI page
SparkQA commented on pull request #30427: URL: https://github.com/apache/spark/pull/30427#issuecomment-730864569 **[Test build #131380 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131380/testReport)** for PR 30427 at commit [`2f1081a`](https://github.com/apache/spark/commit/2f1081a4490e62c86e80740ef9a5f0645b78fd2c). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #30427: [SPARK-33224][SS] Add watermark gap information into SS UI page
SparkQA removed a comment on pull request #30427: URL: https://github.com/apache/spark/pull/30427#issuecomment-730731852 **[Test build #131380 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131380/testReport)** for PR 30427 at commit [`2f1081a`](https://github.com/apache/spark/commit/2f1081a4490e62c86e80740ef9a5f0645b78fd2c). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on pull request #30413: [SPARK-33252][PYTHON][DOCS] Migration to NumPy documentation style in MLlib (pyspark.mllib.*)
viirya commented on pull request #30413: URL: https://github.com/apache/spark/pull/30413#issuecomment-730863277 I might be only able to look at this tomorrow or weekend. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on pull request #30411: [SPARK-31962][SQL] Provide modifiedAfter and modifiedBefore options when filtering from a batch-based file data source
maropu commented on pull request #30411: URL: https://github.com/apache/spark/pull/30411#issuecomment-730863022 > The origin PR has been open for months, and I only refactored a bit & fixed the doc. I'll merge this in early next week if there's no further comment. Yea, it looks fine to me. Thanks for the take-over, @HeartSaVioR and thanks a lot for the valuable contribution, @cchighman ! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30439: [SPARK-33223][SS][FOLLOWUP] Clarify the meaning of "number of rows dropped by watermark" in SS UI page
SparkQA commented on pull request #30439: URL: https://github.com/apache/spark/pull/30439#issuecomment-730862641 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36001/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30428: [SPARK-28704][SQL][TEST][test-java11] Add back Skiped HiveExternalCatalogVersionsSuite in HiveSparkSubmitSuite at JDK9+
SparkQA commented on pull request #30428: URL: https://github.com/apache/spark/pull/30428#issuecomment-730861444 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36002/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #30412: [SPARK-33480][SQL] Support char/varchar type
maropu commented on a change in pull request #30412:
URL: https://github.com/apache/spark/pull/30412#discussion_r527403578
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/CharVarcharTestSuite.scala
##
@@ -0,0 +1,374 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql
+
+import org.apache.spark.{SparkConf, SparkException}
+import org.apache.spark.sql.connector.InMemoryTableCatalog
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.test.{SharedSparkSession, SQLTestUtils}
+
+trait CharVarcharTestSuite extends QueryTest with SQLTestUtils {
+
+ def format: String
+
+ test("char type values should be padded: top-level columns") {
+withTable("t") {
+ sql(s"CREATE TABLE t(i STRING, c CHAR(5)) USING $format")
+ sql("INSERT INTO t VALUES ('1', 'a')")
+ checkAnswer(spark.table("t"), Row("1", "a" + " " * 4))
Review comment:
How about checking an output schema, too, in these tests?
```
scala> sql("CREATE TABLE t(i STRING, c CHAR(5)) USING parquet PARTITIONED BY
(c)")
scala> spark.table("t").printSchema
root
|-- i: string (nullable = true)
|-- c: string (nullable = true) < this check
```
btw, how do users check a char length after defining a table? In pg, users
can check a char length via some commands, e.g., `\d`;
```
postgres=# create table t (c char(5));
CREATE TABLE
postgres=# \d t
Table "public.t"
Column | Type | Collation | Nullable | Default
+--+---+--+-
c | character(5) | | |
```
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/CheckAnalysis.scala
##
@@ -94,6 +94,10 @@ trait CheckAnalysis extends PredicateHelper {
case p if p.analyzed => // Skip already analyzed sub-plans
+ case p if
p.output.map(_.dataType).exists(CharVarcharUtils.hasCharVarchar) =>
+throw new IllegalStateException(
+ "[BUG] logical plan should not have output of char/varchar type: " +
p)
Review comment:
In the case below, could we use `AnalysisException` instead?
```
scala> sql("""SELECT from_json("{'a': 'aaa'}", "a char(3)")""").printSchema()
java.lang.IllegalStateException: [BUG] logical plan should not have output
of char/varchar type: Project [from_json(StructField(a,CharType(3),true), {'a':
'aaa'}, Some(Asia/Tokyo)) AS from_json({'a': 'aaa'})#37]
+- OneRowRelation
```
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/CharVarcharUtils.scala
##
@@ -0,0 +1,277 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.util
+
+import scala.collection.mutable
+
+import org.apache.spark.sql.catalyst.expressions._
+import org.apache.spark.sql.catalyst.parser.CatalystSqlParser
+import org.apache.spark.sql.types._
+
+object CharVarcharUtils {
+
+ private val CHAR_VARCHAR_TYPE_STRING_METADATA_KEY =
"__CHAR_VARCHAR_TYPE_STRING"
+
+ /**
+ * Replaces CharType/VarcharType with StringType recursively in the given
struct type. If a
+ * top-level StructField's data type is CharType/VarcharType or has nested
CharType/VarcharType,
+ * this method will add the original type string to the StructField's
metadata, so that we can
+ * re-construct the original data type with
[GitHub] [spark] HeartSaVioR edited a comment on pull request #30427: [SPARK-33224][SS] Add watermark gap information into SS UI page
HeartSaVioR edited a comment on pull request #30427: URL: https://github.com/apache/spark/pull/30427#issuecomment-730855993 > If we process history data or some simulation data, the event time could be far different to processing time. For example, if we process some data from 2010 to 2019, now the gap is current time - 2010-xx-xx...? You understand it correctly, though that's just a one of use cases. Given they are running "streaming workload", one of the main goals is to capture the recent outputs (e.g. trends). Watermark would still work for such historical use cases as well, but what to plot to provide values even on the situation remains the question. (What would be the "ideal" timestamp to calculate the gap in this case?) EDIT: for that case, adjusting range on y axis would probably help, otherwise we only see the "line" plotted nearly linear like what I commented above in https://github.com/apache/spark/pull/30427#issuecomment-730701075. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #30439: [SPARK-33223][SS][FOLLOWUP] Clarify the meaning of "number of rows dropped by watermark" in SS UI page
SparkQA commented on pull request #30439: URL: https://github.com/apache/spark/pull/30439#issuecomment-730858630 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/36000/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30351: [SPARK-33441][BUILD] Add unused-imports compilation check and remove all unused-imports
LuciferYang commented on a change in pull request #30351: URL: https://github.com/apache/spark/pull/30351#discussion_r527403982 ## File path: pom.xml ## @@ -164,6 +164,7 @@ 3.2.2 2.12.10 2.12 +-Ywarn-unused-import Review comment: OK~ do it later, a little busy ## File path: pom.xml ## @@ -164,6 +164,7 @@ 3.2.2 2.12.10 2.12 +-Ywarn-unused-import Review comment: OK~ do it later, a little busy now This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR edited a comment on pull request #30427: [SPARK-33224][SS] Add watermark gap information into SS UI page
HeartSaVioR edited a comment on pull request #30427: URL: https://github.com/apache/spark/pull/30427#issuecomment-730855993 > If we process history data or some simulation data, the event time could be far different to processing time. For example, if we process some data from 2010 to 2019, now the gap is current time - 2010-xx-xx...? You understand it correctly, though that's just a one of use cases. Given they are running "streaming workload", one of the main goals is to capture the recent outputs (e.g. trends). Watermark would still work for such use cases as well, but what to plot to provide values even on the situation remains the question. (What would be the "ideal" timestamp to calculate the gap in this case?) EDIT: for that case, adjusting range on y axis would probably help, otherwise we only see the "line" plotted nearly linear like what I commented above in https://github.com/apache/spark/pull/30427#issuecomment-730701075. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR edited a comment on pull request #30427: [SPARK-33224][SS] Add watermark gap information into SS UI page
HeartSaVioR edited a comment on pull request #30427: URL: https://github.com/apache/spark/pull/30427#issuecomment-730855993 > If we process history data or some simulation data, the event time could be far different to processing time. For example, if we process some data from 2010 to 2019, now the gap is current time - 2010-xx-xx...? You understand it correctly, though that's just a one of use cases. Given they are running "streaming workload", one of the main goals is to capture the recent outputs (e.g. trends). Watermark would still work for such use cases as well, but what to plot to provide values even on the situation remains the question. (What would be the "ideal" timestamp to calculate the gap in this case?) EDIT: for that case, adjusting range on y axis would probably help, otherwise we only see the "line" plotted nearly linear like what I commented above. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #30427: [SPARK-33224][SS] Add watermark gap information into SS UI page
HeartSaVioR commented on pull request #30427: URL: https://github.com/apache/spark/pull/30427#issuecomment-730855993 > If we process history data or some simulation data, the event time could be far different to processing time. For example, if we process some data from 2010 to 2019, now the gap is current time - 2010-xx-xx...? You understand it correctly, though that's just a one of use cases. Given they are running "streaming workload", one of the main goals is to capture the recent outputs (e.g. trends). Watermark would still work for such use cases as well, but what to plot to provide values even on the situation remains the question. (What would be the "ideal" timestamp to calculate the gap in this case?) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #24173: [SPARK-27237][SS] Introduce State schema validation among query restart
SparkQA commented on pull request #24173: URL: https://github.com/apache/spark/pull/24173#issuecomment-730855964 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/35999/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30402: Spelling r common dev mlib external project streaming resource managers python
AmplabJenkins removed a comment on pull request #30402: URL: https://github.com/apache/spark/pull/30402#issuecomment-730849739 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/131390/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30440: [WIP] [SPARK-33496][SQL]Improve error message of ANSI explicit cast
AmplabJenkins removed a comment on pull request #30440: URL: https://github.com/apache/spark/pull/30440#issuecomment-730852349 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/36003/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30411: [SPARK-31962][SQL] Provide modifiedAfter and modifiedBefore options when filtering from a batch-based file data source
AmplabJenkins removed a comment on pull request #30411: URL: https://github.com/apache/spark/pull/30411#issuecomment-730849515 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/35996/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30438: [SPARK-33472][SQL][3.0] Adjust RemoveRedundantSorts rule order
AmplabJenkins removed a comment on pull request #30438: URL: https://github.com/apache/spark/pull/30438#issuecomment-730849461 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/35997/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #29695: [SPARK-22390][SPARK-32833][SQL] [WIP]JDBC V2 Datasource aggregate push down
SparkQA commented on pull request #29695: URL: https://github.com/apache/spark/pull/29695#issuecomment-730854466 **[Test build #131400 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/131400/testReport)** for PR 29695 at commit [`7de8b20`](https://github.com/apache/spark/commit/7de8b202525bdf7b774a030da1e180ccabf66ed0). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30438: [SPARK-33472][SQL][3.0] Adjust RemoveRedundantSorts rule order
AmplabJenkins removed a comment on pull request #30438: URL: https://github.com/apache/spark/pull/30438#issuecomment-730849455 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30437: [SPARK-33472][SQL][2.4] Adjust RemoveRedundantSorts rule order
AmplabJenkins removed a comment on pull request #30437: URL: https://github.com/apache/spark/pull/30437#issuecomment-730850742 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30440: [WIP] [SPARK-33496][SQL]Improve error message of ANSI explicit cast
AmplabJenkins removed a comment on pull request #30440: URL: https://github.com/apache/spark/pull/30440#issuecomment-730846807 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #30402: Spelling r common dev mlib external project streaming resource managers python
AmplabJenkins removed a comment on pull request #30402: URL: https://github.com/apache/spark/pull/30402#issuecomment-730849732 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org