[GitHub] [spark] AmplabJenkins commented on pull request #31989: [SPARK-34891][SS] Introduce state store manager for session window in streaming query
AmplabJenkins commented on pull request #31989: URL: https://github.com/apache/spark/pull/31989#issuecomment-811665311 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41375/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31989: [SPARK-34891][SS] Introduce state store manager for session window in streaming query
SparkQA commented on pull request #31989: URL: https://github.com/apache/spark/pull/31989#issuecomment-811665284 Kubernetes integration test status failure URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/41375/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32019: [SPARK-34881][SQL][FOLLOW-UP] Use multiline string for TryCast' expression description
SparkQA commented on pull request #32019: URL: https://github.com/apache/spark/pull/32019#issuecomment-811665027 **[Test build #136797 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136797/testReport)** for PR 32019 at commit [`f83d4e2`](https://github.com/apache/spark/commit/f83d4e22034831c07fb213272d7dc4f35ca4dc29). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32019: [SPARK-34881][SQL][FOLLOW-UP] Use multiline string for TryCast' expression description
HyukjinKwon commented on a change in pull request #32019: URL: https://github.com/apache/spark/pull/32019#discussion_r605393073 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/TryCast.scala ## @@ -30,10 +30,12 @@ import org.apache.spark.sql.types.DataType * session local timezone by an analyzer [[ResolveTimeZone]]. */ @ExpressionDescription( - usage = "_FUNC_(expr AS type) - Casts the value `expr` to the target data type `type`. " + -"This expression is identical to CAST with configuration `spark.sql.ansi.enabled` as " + -"true, except it returns NULL instead of raising an error. Note that the behavior of this " + -"expression doesn't depend on configuration `spark.sql.ansi.enabled`.", + usage = """ +_FUNC_(expr AS type) - Casts the value `expr` to the target data type `type`. + "This expression is identical to CAST with configuration `spark.sql.ansi.enabled` as + "true, except it returns NULL instead of raising an error. Note that the behavior of this + "expression doesn't depend on configuration `spark.sql.ansi.enabled`. Review comment: ```suggestion This expression is identical to CAST with configuration `spark.sql.ansi.enabled` as true, except it returns NULL instead of raising an error. Note that the behavior of this expression doesn't depend on configuration `spark.sql.ansi.enabled`. ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32019: [SPARK-34881][SQL][FOLLOW-UP] Use multiline string for TryCast' expression description
HyukjinKwon commented on a change in pull request #32019: URL: https://github.com/apache/spark/pull/32019#discussion_r605392992 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/TryCast.scala ## @@ -30,10 +30,12 @@ import org.apache.spark.sql.types.DataType * session local timezone by an analyzer [[ResolveTimeZone]]. */ @ExpressionDescription( - usage = "_FUNC_(expr AS type) - Casts the value `expr` to the target data type `type`. " + -"This expression is identical to CAST with configuration `spark.sql.ansi.enabled` as " + -"true, except it returns NULL instead of raising an error. Note that the behavior of this " + -"expression doesn't depend on configuration `spark.sql.ansi.enabled`.", + usage = """ +_FUNC_(expr AS type) - Casts the value `expr` to the target data type `type`. + "This expression is identical to CAST with configuration `spark.sql.ansi.enabled` as Review comment: Oops -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32017: [SPARK-34923][SQL] Metadata output should be empty by default
SparkQA commented on pull request #32017: URL: https://github.com/apache/spark/pull/32017#issuecomment-811662206 **[Test build #136796 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136796/testReport)** for PR 32017 at commit [`ce3ac0e`](https://github.com/apache/spark/commit/ce3ac0e5465b158e70ec317c403203511c96568a). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on a change in pull request #31451: [SPARK-34338][SQL] Report metrics from Datasource v2 scan
viirya commented on a change in pull request #31451: URL: https://github.com/apache/spark/pull/31451#discussion_r605392105 ## File path: sql/catalyst/src/main/java/org/apache/spark/sql/connector/read/PartitionReader.java ## @@ -51,7 +51,8 @@ T get(); /** - * Returns an array of custom task metrics. By default it returns empty array. + * Returns an array of custom task metrics. By default it returns empty array. Note that it is + * not recommended to put heavy logic in this method as it may affect reading performance. Review comment: If the iterator is not consumed to the end, doesn't it mean we will produce inaccurate metrics if it stops in the middle of 100? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a change in pull request #32019: [SPARK-34881][SQL][FOLLOW-UP] Use multiline string for TryCast' expression description
gengliangwang commented on a change in pull request #32019: URL: https://github.com/apache/spark/pull/32019#discussion_r605391951 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/TryCast.scala ## @@ -30,10 +30,12 @@ import org.apache.spark.sql.types.DataType * session local timezone by an analyzer [[ResolveTimeZone]]. */ @ExpressionDescription( - usage = "_FUNC_(expr AS type) - Casts the value `expr` to the target data type `type`. " + -"This expression is identical to CAST with configuration `spark.sql.ansi.enabled` as " + -"true, except it returns NULL instead of raising an error. Note that the behavior of this " + -"expression doesn't depend on configuration `spark.sql.ansi.enabled`.", + usage = """ +_FUNC_(expr AS type) - Casts the value `expr` to the target data type `type`. + "This expression is identical to CAST with configuration `spark.sql.ansi.enabled` as Review comment: shall we remove the leading `"` in these 3 lines? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] karenfeng closed pull request #31975: [WIP][SPARK-34527][SQL] Resolve duplicated common columns from USING/NATURAL JOIN
karenfeng closed pull request #31975: URL: https://github.com/apache/spark/pull/31975 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31179: [SPARK-34113][SQL] Use metric data update metadata statistic's size and rowCount
AmplabJenkins removed a comment on pull request #31179: URL: https://github.com/apache/spark/pull/31179#issuecomment-811660012 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41376/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31179: [SPARK-34113][SQL] Use metric data update metadata statistic's size and rowCount
AmplabJenkins commented on pull request #31179: URL: https://github.com/apache/spark/pull/31179#issuecomment-811660012 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41376/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31179: [SPARK-34113][SQL] Use metric data update metadata statistic's size and rowCount
SparkQA commented on pull request #31179: URL: https://github.com/apache/spark/pull/31179#issuecomment-811659972 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31989: [SPARK-34891][SS] Introduce state store manager for session window in streaming query
SparkQA commented on pull request #31989: URL: https://github.com/apache/spark/pull/31989#issuecomment-811659949 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/41375/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31179: [SPARK-34113][SQL] Use metric data update metadata statistic's size and rowCount
SparkQA commented on pull request #31179: URL: https://github.com/apache/spark/pull/31179#issuecomment-811659269 **[Test build #136795 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136795/testReport)** for PR 31179 at commit [`70e7425`](https://github.com/apache/spark/commit/70e74254acc17ca02ba90c70a7b097b39308ee65). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32010: [SPARK-34908][SQL][TESTS] Add test cases for char and varchar with functions
SparkQA commented on pull request #32010: URL: https://github.com/apache/spark/pull/32010#issuecomment-811658915 **[Test build #136794 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136794/testReport)** for PR 32010 at commit [`a5b9808`](https://github.com/apache/spark/commit/a5b9808eff6dded7fb2ec6032c9112d6272d5e3b). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32009: [SPARK-34914][CORE] Local scheduler backend support update token
AmplabJenkins removed a comment on pull request #32009: URL: https://github.com/apache/spark/pull/32009#issuecomment-811658544 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/136788/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32019: [SPARK-34881][SQL][FOLLOW-UP] Use multiline string for TryCast' expression description
AmplabJenkins removed a comment on pull request #32019: URL: https://github.com/apache/spark/pull/32019#issuecomment-811658545 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41374/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32019: [SPARK-34881][SQL][FOLLOW-UP] Use multiline string for TryCast' expression description
AmplabJenkins commented on pull request #32019: URL: https://github.com/apache/spark/pull/32019#issuecomment-811658545 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41374/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32009: [SPARK-34914][CORE] Local scheduler backend support update token
AmplabJenkins commented on pull request #32009: URL: https://github.com/apache/spark/pull/32009#issuecomment-811658544 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/136788/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn commented on pull request #32010: [SPARK-34908][SQL][TESTS] Add test cases for char and varchar with functions
yaooqinn commented on pull request #32010: URL: https://github.com/apache/spark/pull/32010#issuecomment-811657957 > The tests LGTM. To completely support the char feature, we may need to truly support it in the type system. For example, `upper(char_col)` should also return char type, not string type. the idea makes sense to me -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32019: [WIP][SPARK-34881][SQL][FOLLOW-UP] Use multiline string for TryCast' expression description
SparkQA commented on pull request #32019: URL: https://github.com/apache/spark/pull/32019#issuecomment-811652998 Kubernetes integration test unable to build dist. exiting with code: 1 URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/41374/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #31776: [SPARK-34661][SQL] Clean up `OriginalType` and `DecimalMetadata ` usage in Parquet related code
LuciferYang commented on pull request #31776: URL: https://github.com/apache/spark/pull/31776#issuecomment-811642573 Thanks ~ @sunchao -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn commented on a change in pull request #32010: [SPARK-34908][SQL] Add test cases for char and varchar with functions
yaooqinn commented on a change in pull request #32010:
URL: https://github.com/apache/spark/pull/32010#discussion_r605378485
##
File path: sql/core/src/test/resources/sql-tests/results/charvarchar.sql.out
##
@@ -663,6 +663,478 @@ Location [not included in
comparison]/{warehouse_dir}/char_part
Partition Provider Catalog
+-- !query
+create table str_tbl(c string, v string) using parquet
+-- !query schema
+struct<>
+-- !query output
+
+
+
+-- !query
+insert into str_tbl values
+(null, null),
+(null, 'S'),
+('N', 'N '),
+('Ne', 'Sp'),
+('Net ', 'Spa '),
+('NetE', 'Spar'),
+('NetEa ', 'Spark '),
+('NetEas ', 'Spark'),
+('NetEase', 'Spark-')
+-- !query schema
+struct<>
+-- !query output
+
+
+
+-- !query
+create table char_tbl4(c7 char(7), c8 char(8), v varchar(6), s string) using
parquet
+-- !query schema
+struct<>
+-- !query output
+
+
+
+-- !query
+insert into char_tbl4 select c, c, v, c from str_tbl
+-- !query schema
+struct<>
+-- !query output
+
+
+
+-- !query
+select c7, c8, v, s from char_tbl4
+-- !query schema
+struct
+-- !query output
+N N N N
+NULL NULLNULLNULL
Review comment:
OK, I noticed this too
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32009: [SPARK-34914][CORE] Local scheduler backend support update token
SparkQA removed a comment on pull request #32009: URL: https://github.com/apache/spark/pull/32009#issuecomment-811598016 **[Test build #136788 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136788/testReport)** for PR 32009 at commit [`8fcb62f`](https://github.com/apache/spark/commit/8fcb62fd33d07ee4cb37bc9b85118c5c4ced3b01). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32009: [SPARK-34914][CORE] Local scheduler backend support update token
SparkQA commented on pull request #32009: URL: https://github.com/apache/spark/pull/32009#issuecomment-811641059 **[Test build #136788 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136788/testReport)** for PR 32009 at commit [`8fcb62f`](https://github.com/apache/spark/commit/8fcb62fd33d07ee4cb37bc9b85118c5c4ced3b01). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #31451: [SPARK-34338][SQL] Report metrics from Datasource v2 scan
cloud-fan commented on a change in pull request #31451: URL: https://github.com/apache/spark/pull/31451#discussion_r605374302 ## File path: sql/catalyst/src/main/java/org/apache/spark/sql/connector/read/PartitionReader.java ## @@ -51,7 +51,8 @@ T get(); /** - * Returns an array of custom task metrics. By default it returns empty array. + * Returns an array of custom task metrics. By default it returns empty array. Note that it is + * not recommended to put heavy logic in this method as it may affect reading performance. Review comment: Since we can't control how frequently the underlying data source tracks the metrics, this is all about how frequently we want to update the SQL metrics. Since the actual metrics update is sent to the driver via heartbeat, it's not very useful if we update the metrics per-row. How about we do it like per 100 rows? Only update once may be problematic if the task runs for a long time. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31179: [SPARK-34113][SQL] Use metric data update metadata statistic's size and rowCount
AmplabJenkins removed a comment on pull request #31179: URL: https://github.com/apache/spark/pull/31179#issuecomment-811635011 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41373/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31989: [SPARK-34891][SS] Introduce state store manager for session window in streaming query
SparkQA commented on pull request #31989: URL: https://github.com/apache/spark/pull/31989#issuecomment-811635030 **[Test build #136793 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136793/testReport)** for PR 31989 at commit [`da08bd4`](https://github.com/apache/spark/commit/da08bd408ac74d8cdccf3ebf50d8fb3591642f5f). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31179: [SPARK-34113][SQL] Use metric data update metadata statistic's size and rowCount
AmplabJenkins commented on pull request #31179: URL: https://github.com/apache/spark/pull/31179#issuecomment-811635011 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41373/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31179: [SPARK-34113][SQL] Use metric data update metadata statistic's size and rowCount
SparkQA commented on pull request #31179: URL: https://github.com/apache/spark/pull/31179#issuecomment-811634996 Kubernetes integration test status failure URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/41373/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32019: [WIP][SPARK-34881][SQL][FOLLOW-UP] Use multiline string for TryCast' expression description
SparkQA commented on pull request #32019: URL: https://github.com/apache/spark/pull/32019#issuecomment-811634985 **[Test build #136792 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136792/testReport)** for PR 32019 at commit [`14b5968`](https://github.com/apache/spark/commit/14b59683f65316c899c866c9033e2dcb55f3a578). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #32017: [SPARK-34923][SQL] Metadata output should be empty by default
cloud-fan commented on pull request #32017: URL: https://github.com/apache/spark/pull/32017#issuecomment-811634868 The new behavior makes more sense to me. cc @rdblue @brkyvz @viirya -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #32017: [SPARK-34923][SQL] Metadata output should be empty by default
cloud-fan commented on a change in pull request #32017: URL: https://github.com/apache/spark/pull/32017#discussion_r605372596 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala ## @@ -466,6 +488,8 @@ case class View( override def output: Seq[Attribute] = child.output + override def metadataOutput: Seq[Attribute] = child.output Review comment: For boundary nodes like `View` and `SubqueryAlias`, I think we should not propagate as the query under them should not change during analysis after they are resolved. `ResolveMissingReferences` skips `SubqueryAlias` as well. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31179: [SPARK-34113][SQL] Use metric data update metadata statistic's size and rowCount
SparkQA commented on pull request #31179: URL: https://github.com/apache/spark/pull/31179#issuecomment-811634186 **[Test build #136791 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136791/testReport)** for PR 31179 at commit [`be37e31`](https://github.com/apache/spark/commit/be37e3153fbf07e81f0536a83b9214063fa9704e). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32015: [SPARK-34821][INFRA] Set up a workflow for developers to run benchmark in their fork
AmplabJenkins removed a comment on pull request #32015: URL: https://github.com/apache/spark/pull/32015#issuecomment-811633809 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41372/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32015: [SPARK-34821][INFRA] Set up a workflow for developers to run benchmark in their fork
AmplabJenkins commented on pull request #32015: URL: https://github.com/apache/spark/pull/32015#issuecomment-811633809 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41372/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #32017: [SPARK-34923][SQL] Metadata output should be empty by default
cloud-fan commented on a change in pull request #32017: URL: https://github.com/apache/spark/pull/32017#discussion_r605371960 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala ## @@ -270,6 +279,8 @@ case class Union( } } + override def metadataOutput: Seq[Attribute] = children.flatMap(_.metadataOutput) Review comment: Same to `Intersect` `Except` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #32017: [SPARK-34923][SQL] Metadata output should be empty by default
cloud-fan commented on a change in pull request #32017: URL: https://github.com/apache/spark/pull/32017#discussion_r605371792 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala ## @@ -187,6 +193,8 @@ case class Intersect( leftAttr.withNullability(leftAttr.nullable && rightAttr.nullable) } + override def metadataOutput: Seq[Attribute] = children.flatMap(_.metadataOutput) Review comment: shall we put it in `SetOperation`? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31179: [SPARK-34113][SQL] Use metric data update metadata statistic's size and rowCount
SparkQA commented on pull request #31179: URL: https://github.com/apache/spark/pull/31179#issuecomment-811633429 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/41373/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #32017: [SPARK-34923][SQL] Metadata output should be empty by default
cloud-fan commented on a change in pull request #32017: URL: https://github.com/apache/spark/pull/32017#discussion_r605371720 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala ## @@ -270,6 +279,8 @@ case class Union( } } + override def metadataOutput: Seq[Attribute] = children.flatMap(_.metadataOutput) Review comment: not sure about Union. It only propagates the output for the first child, and `ResolveMissingReferences` doesn't support it either. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #32017: [SPARK-34923][SQL] Metadata output should be empty by default
cloud-fan commented on a change in pull request #32017:
URL: https://github.com/apache/spark/pull/32017#discussion_r605371343
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala
##
@@ -107,6 +109,8 @@ case class Generate(
child: LogicalPlan)
extends UnaryNode {
+ val unrequiredSet: Set[Int] = unrequiredChildIndex.toSet
Review comment:
this seems not needed.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31179: [SPARK-34113][SQL] Use metric data update metadata statistic's size and rowCount
AngersZh commented on a change in pull request #31179:
URL: https://github.com/apache/spark/pull/31179#discussion_r605371258
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileFormatDataWriter.scala
##
@@ -251,7 +252,18 @@ class DynamicPartitionDataWriter(
// See a new partition or bucket - write to a new partition dir (or a
new bucket file).
if (isPartitioned && currentPartitionValues != nextPartitionValues) {
currentPartitionValues = Some(nextPartitionValues.get.copy())
-statsTrackers.foreach(_.newPartition(currentPartitionValues.get))
+val partitionSpec: Map[String, String] =
description.partitionColumns.map(attr => {
+ val proj = UnsafeProjection.create(Seq(attr),
description.partitionColumns)
Review comment:
> These `UnsafeProjection` objects can be created and reused?
Seems we don't need this, remove this now.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31179: [SPARK-34113][SQL] Use metric data update metadata statistic's size and rowCount
AngersZh commented on a change in pull request #31179:
URL: https://github.com/apache/spark/pull/31179#discussion_r605370937
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/CommandUtils.scala
##
@@ -51,6 +51,119 @@ class PathFilterIgnoreNonData(stagingDir: String) extends
PathFilter with Serial
object CommandUtils extends Logging {
+ def updateTableAndPartitionStats(
+ sparkSession: SparkSession,
+ table: CatalogTable,
+ overwrite: Boolean,
+ partitionSpec: Map[String, Option[String]],
+ statsTracker: BasicWriteJobStatsTracker): Unit = {
+val catalog = sparkSession.sessionState.catalog
+if (sparkSession.sessionState.conf.autoSizeUpdateEnabled) {
+ val newTable = catalog.getTableMetadata(table.identifier)
+ val isSinglePartition = partitionSpec.nonEmpty &&
partitionSpec.values.forall(_.nonEmpty)
+ val isPartialPartitions = partitionSpec.nonEmpty &&
+ partitionSpec.values.exists(_.isEmpty) &&
partitionSpec.values.exists(_.nonEmpty)
+ if (overwrite) {
+// Only update one partition, statsTracker.partitionsStats is empty
+if (isSinglePartition) {
+ val spec = partitionSpec.map { case (key, value) =>
+key -> value.get
+ }
+ val partition = catalog.listPartitions(table.identifier, Some(spec))
+ val newTableStats = CommandUtils.mergeNewStats(
+newTable.stats, statsTracker.totalNumBytes,
Some(statsTracker.totalNumOutput))
+ val newPartitions = partition.flatten { part =>
Review comment:
> This block seems to be the same with the `overwrite=false` case?
https://github.com/apache/spark/pull/31179/files#diff-6309057f8f41f20f8de513ab67d7755aae5fb30d7441fc21000999c9e8e8e0bfR125-R140
Done
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/CommandUtils.scala
##
@@ -51,6 +51,119 @@ class PathFilterIgnoreNonData(stagingDir: String) extends
PathFilter with Serial
object CommandUtils extends Logging {
+ def updateTableAndPartitionStats(
+ sparkSession: SparkSession,
+ table: CatalogTable,
+ overwrite: Boolean,
+ partitionSpec: Map[String, Option[String]],
+ statsTracker: BasicWriteJobStatsTracker): Unit = {
+val catalog = sparkSession.sessionState.catalog
+if (sparkSession.sessionState.conf.autoSizeUpdateEnabled) {
+ val newTable = catalog.getTableMetadata(table.identifier)
+ val isSinglePartition = partitionSpec.nonEmpty &&
partitionSpec.values.forall(_.nonEmpty)
+ val isPartialPartitions = partitionSpec.nonEmpty &&
Review comment:
> Could you move `isPartialPartitions` into L102?
Done
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/CommandUtils.scala
##
@@ -51,6 +51,119 @@ class PathFilterIgnoreNonData(stagingDir: String) extends
PathFilter with Serial
object CommandUtils extends Logging {
+ def updateTableAndPartitionStats(
+ sparkSession: SparkSession,
+ table: CatalogTable,
+ overwrite: Boolean,
+ partitionSpec: Map[String, Option[String]],
+ statsTracker: BasicWriteJobStatsTracker): Unit = {
+val catalog = sparkSession.sessionState.catalog
+if (sparkSession.sessionState.conf.autoSizeUpdateEnabled) {
+ val newTable = catalog.getTableMetadata(table.identifier)
+ val isSinglePartition = partitionSpec.nonEmpty &&
partitionSpec.values.forall(_.nonEmpty)
+ val isPartialPartitions = partitionSpec.nonEmpty &&
+ partitionSpec.values.exists(_.isEmpty) &&
partitionSpec.values.exists(_.nonEmpty)
+ if (overwrite) {
+// Only update one partition, statsTracker.partitionsStats is empty
+if (isSinglePartition) {
+ val spec = partitionSpec.map { case (key, value) =>
+key -> value.get
+ }
+ val partition = catalog.listPartitions(table.identifier, Some(spec))
+ val newTableStats = CommandUtils.mergeNewStats(
+newTable.stats, statsTracker.totalNumBytes,
Some(statsTracker.totalNumOutput))
+ val newPartitions = partition.flatten { part =>
+val newStates = if (part.stats.isDefined &&
part.stats.get.rowCount.isDefined) {
+ CommandUtils.mergeNewStats(
+part.stats, statsTracker.totalNumBytes,
Some(statsTracker.totalNumOutput))
+} else {
+ CommandUtils.compareAndGetNewStats(
+part.stats, statsTracker.totalNumBytes,
Some(statsTracker.totalNumOutput))
+}
+newStates.map(_ => part.copy(stats = newStates))
+ }
+ if (newTableStats.isDefined) {
+catalog.alterTableStats(table.identifier, newTableStats)
+ }
+ if (newPartitions.nonEmpty) {
+catalog.alterPartitions(table.identifier, newPartitions)
+ }
+} else {
+ // update all
[GitHub] [spark] cloud-fan commented on pull request #32010: [SPARK-34908][SQL] Add test cases for char and varchar with functions
cloud-fan commented on pull request #32010: URL: https://github.com/apache/spark/pull/32010#issuecomment-811632116 The tests LGTM. To completely support the char feature, we may need to truly support it in the type system. For example, `upper(char_col)` should also return char type, not string type. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32015: [SPARK-34821][INFRA] Set up a workflow for developers to run benchmark in their fork
SparkQA commented on pull request #32015: URL: https://github.com/apache/spark/pull/32015#issuecomment-811631196 Kubernetes integration test unable to build dist. exiting with code: 1 URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/41372/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #32010: [SPARK-34908][SQL] Add test cases for char and varchar with functions
cloud-fan commented on a change in pull request #32010:
URL: https://github.com/apache/spark/pull/32010#discussion_r605368101
##
File path: sql/core/src/test/resources/sql-tests/results/charvarchar.sql.out
##
@@ -663,6 +663,478 @@ Location [not included in
comparison]/{warehouse_dir}/char_part
Partition Provider Catalog
+-- !query
+create table str_tbl(c string, v string) using parquet
+-- !query schema
+struct<>
+-- !query output
+
+
+
+-- !query
+insert into str_tbl values
+(null, null),
+(null, 'S'),
+('N', 'N '),
+('Ne', 'Sp'),
+('Net ', 'Spa '),
+('NetE', 'Spar'),
+('NetEa ', 'Spark '),
+('NetEas ', 'Spark'),
+('NetEase', 'Spark-')
+-- !query schema
+struct<>
+-- !query output
+
+
+
+-- !query
+create table char_tbl4(c7 char(7), c8 char(8), v varchar(6), s string) using
parquet
+-- !query schema
+struct<>
+-- !query output
+
+
+
+-- !query
+insert into char_tbl4 select c, c, v, c from str_tbl
+-- !query schema
+struct<>
+-- !query output
+
+
+
+-- !query
+select c7, c8, v, s from char_tbl4
+-- !query schema
+struct
+-- !query output
+N N N N
+NULL NULLNULLNULL
Review comment:
The indentations do not match. We need to fix the test framework.
@yaooqinn can you help with this later?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #32010: [SPARK-34908][SQL] Add test cases for char and varchar with functions
cloud-fan commented on a change in pull request #32010: URL: https://github.com/apache/spark/pull/32010#discussion_r605367754 ## File path: sql/core/src/test/resources/sql-tests/inputs/charvarchar.sql ## @@ -61,7 +61,57 @@ desc formatted char_part; MSCK REPAIR TABLE char_part; desc formatted char_part; +create table str_tbl(c string, v string) using parquet; Review comment: nit: this can be a temp view if it's only used to insert into `char_tbl4` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on pull request #32014: [SPARK-34922][SQL] Use a relative cost comparison function in the CBO
cloud-fan commented on pull request #32014: URL: https://github.com/apache/spark/pull/32014#issuecomment-811627745 The change LGTM. Can we re-generate the golden files to fix conflicts? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon opened a new pull request #32019: [WIP][SPARK-34881][SQL][FOLLOW-UP] Use multiline string for TryCast' expression description
HyukjinKwon opened a new pull request #32019:
URL: https://github.com/apache/spark/pull/32019
### What changes were proposed in this pull request?
This PR fixes JDK 11 compilation failed:
```
/home/runner/work/spark/spark/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/TryCast.scala:35:
error: annotation argument needs to be a constant; found: "_FUNC_(expr AS
type) - Casts the value `expr` to the target data type `type`. ".+("This
expression is identical to CAST with configuration `spark.sql.ansi.enabled` as
").+("true, except it returns NULL instead of raising an error. Note that the
behavior of this ").+("expression doesn\'t depend on configuration
`spark.sql.ansi.enabled`.")
"true, except it returns NULL instead of raising an error. Note that the
behavior of this " +
```
For whatever reason, it doesn't know that the string is actually a constant.
This PR simply switches it to multi-line style (which is actually more
correct). Reference:
https://github.com/apache/spark/blob/master/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/aggregate/ApproximatePercentile.scala#L52-L55
### Why are the changes needed?
To recover the build.
### Does this PR introduce _any_ user-facing change?
No, dev-only.
### How was this patch tested?
It was NOT tested yet. I opened a PR first to speed up to recover the
builds. I will use CI to verify.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #31989: [SPARK-34891][SS] Introduce state store manager for session window in streaming query
HeartSaVioR commented on pull request #31989: URL: https://github.com/apache/spark/pull/31989#issuecomment-811622439 retest this, please -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31179: [SPARK-34113][SQL] Use metric data update metadata statistic's size and rowCount
SparkQA commented on pull request #31179: URL: https://github.com/apache/spark/pull/31179#issuecomment-811619794 **[Test build #136790 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136790/testReport)** for PR 31179 at commit [`31821ff`](https://github.com/apache/spark/commit/31821ffe46ab1b95a536a1a65727448a9cd47941). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #31470: [SPARK-34354][SQL] Fix failure when apply CostBasedJoinReorder on self-join
HyukjinKwon commented on pull request #31470: URL: https://github.com/apache/spark/pull/31470#issuecomment-811619057 SPARK-34930 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #31470: [SPARK-34354][SQL] Fix failure when apply CostBasedJoinReorder on self-join
HyukjinKwon commented on pull request #31470: URL: https://github.com/apache/spark/pull/31470#issuecomment-811618571 I think we should install pandas / pyarrow in jenkins machines: ``` Skipped tests in pyspark.sql.tests.test_arrow with pypy3: test_createDataFrame_column_name_encoding (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_createDataFrame_does_not_modify_input (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_createDataFrame_empty_partition (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_createDataFrame_fallback_disabled (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_createDataFrame_fallback_enabled (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_createDataFrame_respect_session_timezone (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_createDataFrame_toggle (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_createDataFrame_with_array_type (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_createDataFrame_with_float_index (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_createDataFrame_with_incorrect_schema (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_createDataFrame_with_int_col_names (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_createDataFrame_with_map_type (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_createDataFrame_with_names (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_createDataFrame_with_schema (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_createDataFrame_with_single_data_type (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_createDateFrame_with_category_type (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_filtered_frame (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_no_partition_frame (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_no_partition_toPandas (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_null_conversion (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_pandas_round_trip (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_pandas_self_destruct (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_propagates_spark_exception (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_schema_conversion_roundtrip (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_timestamp_dst (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_timestamp_nat (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_toPandas_arrow_toggle (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_toPandas_batch_order (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_toPandas_fallback_disabled (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.23.2 must be installed; however, it was not found.' test_toPandas_fallback_enabled (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #31179: [SPARK-34113][SQL] Use metric data update metadata statistic's size and rowCount
AngersZh commented on a change in pull request #31179:
URL: https://github.com/apache/spark/pull/31179#discussion_r605358714
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/command/CommandUtils.scala
##
@@ -51,6 +51,119 @@ class PathFilterIgnoreNonData(stagingDir: String) extends
PathFilter with Serial
object CommandUtils extends Logging {
+ def updateTableAndPartitionStats(
+ sparkSession: SparkSession,
+ table: CatalogTable,
+ overwrite: Boolean,
+ partitionSpec: Map[String, Option[String]],
+ statsTracker: BasicWriteJobStatsTracker): Unit = {
+val catalog = sparkSession.sessionState.catalog
+if (sparkSession.sessionState.conf.autoSizeUpdateEnabled) {
+ val newTable = catalog.getTableMetadata(table.identifier)
+ val isSinglePartition = partitionSpec.nonEmpty &&
partitionSpec.values.forall(_.nonEmpty)
+ val isPartialPartitions = partitionSpec.nonEmpty &&
+ partitionSpec.values.exists(_.isEmpty) &&
partitionSpec.values.exists(_.nonEmpty)
+ if (overwrite) {
+// Only update one partition, statsTracker.partitionsStats is empty
+if (isSinglePartition) {
Review comment:
> Why do we need to handle the single partition case and the non-single
partition case separately?
yes
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #31470: [SPARK-34354][SQL] Fix failure when apply CostBasedJoinReorder on self-join
HyukjinKwon commented on pull request #31470: URL: https://github.com/apache/spark/pull/31470#issuecomment-811617873 Just for a bit of more contexts, ever since Jenkins were upgraded, we didn't install pandas, etc so we don't run the pandas in Jenkins. The pandas related tests only run on GA for now. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon edited a comment on pull request #31470: [SPARK-34354][SQL] Fix failure when apply CostBasedJoinReorder on self-join
HyukjinKwon edited a comment on pull request #31470: URL: https://github.com/apache/spark/pull/31470#issuecomment-811617659 I think the last trigger didn't pass in this PR: 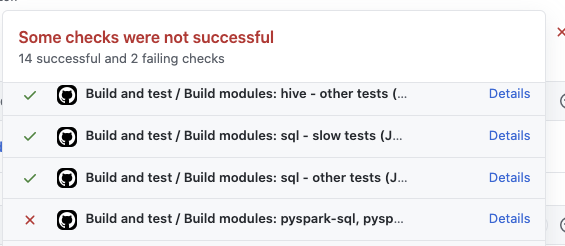 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 edited a comment on pull request #31470: [SPARK-34354][SQL] Fix failure when apply CostBasedJoinReorder on self-join
Ngone51 edited a comment on pull request #31470: URL: https://github.com/apache/spark/pull/31470#issuecomment-811617535 Is the failure from the latest run? I tested the same failed test locally yesterday and passed, and so I retriggered the GA. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #31470: [SPARK-34354][SQL] Fix failure when apply CostBasedJoinReorder on self-join
HyukjinKwon commented on pull request #31470: URL: https://github.com/apache/spark/pull/31470#issuecomment-811617659 I think the last trigger didn't pass in this PR: ![Uploading Screen Shot 2021-04-01 at 12.49.52 PM.png…]() -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 commented on pull request #31470: [SPARK-34354][SQL] Fix failure when apply CostBasedJoinReorder on self-join
Ngone51 commented on pull request #31470: URL: https://github.com/apache/spark/pull/31470#issuecomment-811617535 Is the failure from the latest run? I tested it locally yesterday and passed, and so I retriggered the GA. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32015: [SPARK-34821][INFRA] Set up a workflow for developers to run benchmark in their fork
SparkQA commented on pull request #32015: URL: https://github.com/apache/spark/pull/32015#issuecomment-811617005 **[Test build #136789 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136789/testReport)** for PR 32015 at commit [`6f17ce6`](https://github.com/apache/spark/commit/6f17ce679b43351b2744e4897a25f71c6e9b3111). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #31470: [SPARK-34354][SQL] Fix failure when apply CostBasedJoinReorder on self-join
HyukjinKwon commented on pull request #31470: URL: https://github.com/apache/spark/pull/31470#issuecomment-811616745 It seems it broke PySpark tests ... https://github.com/apache/spark/runs/2240195852 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32018: [SPARK-34926][SQL] ExternalCatalogUtils.escapePathName should support null
AmplabJenkins removed a comment on pull request #32018: URL: https://github.com/apache/spark/pull/32018#issuecomment-811616047 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41370/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32009: [SPARK-34914][CORE] Local scheduler backend support update token
AmplabJenkins removed a comment on pull request #32009: URL: https://github.com/apache/spark/pull/32009#issuecomment-811616050 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41371/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32017: [SPARK-34923][SQL] Metadata output should be empty by default
AmplabJenkins removed a comment on pull request #32017: URL: https://github.com/apache/spark/pull/32017#issuecomment-811616048 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/136784/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32018: [SPARK-34926][SQL] ExternalCatalogUtils.escapePathName should support null
AmplabJenkins commented on pull request #32018: URL: https://github.com/apache/spark/pull/32018#issuecomment-811616047 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41370/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32009: [SPARK-34914][CORE] Local scheduler backend support update token
AmplabJenkins commented on pull request #32009: URL: https://github.com/apache/spark/pull/32009#issuecomment-811616050 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41371/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32017: [SPARK-34923][SQL] Metadata output should be empty by default
AmplabJenkins commented on pull request #32017: URL: https://github.com/apache/spark/pull/32017#issuecomment-811616048 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/136784/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32009: [SPARK-34914][CORE] Local scheduler backend support update token
SparkQA commented on pull request #32009: URL: https://github.com/apache/spark/pull/32009#issuecomment-811612908 Kubernetes integration test status failure URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/41371/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32009: [SPARK-34914][CORE] Local scheduler backend support update token
SparkQA commented on pull request #32009: URL: https://github.com/apache/spark/pull/32009#issuecomment-811611447 Kubernetes integration test starting URL: https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder-K8s/41371/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32018: [SPARK-34926][SQL] ExternalCatalogUtils.escapePathName should support null
SparkQA commented on pull request #32018: URL: https://github.com/apache/spark/pull/32018#issuecomment-811610688 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon edited a comment on pull request #32015: [SPARK-34821][INFRA] Set up a workflow for developers to run benchmark in their fork
HyukjinKwon edited a comment on pull request #32015: URL: https://github.com/apache/spark/pull/32015#issuecomment-811064987 Note that I tested subset of benchmarks, verified that it works, and now I am waiting for the final results of running all benchmarks: - [Run benchmarks: * (JDK 11)](https://github.com/HyukjinKwon/spark/actions/runs/707168185) - [Run benchmarks: * (JDK 8)](https://github.com/HyukjinKwon/spark/actions/runs/707168142) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32015: [SPARK-34821][INFRA] Set up a workflow for developers to run benchmark in their fork
HyukjinKwon commented on a change in pull request #32015:
URL: https://github.com/apache/spark/pull/32015#discussion_r605349110
##
File path: core/src/test/scala/org/apache/spark/benchmark/Benchmarks.scala
##
@@ -30,44 +31,64 @@ import com.google.common.reflect.ClassPath
*
* {{{
* 1. with spark-submit
- * bin/spark-submit --class --jars
+ * bin/spark-submit --class --jars
+ *
* 2. generate result:
* SPARK_GENERATE_BENCHMARK_FILES=1 bin/spark-submit --class
--jars
- *
+ *
+ *
* Results will be written to all corresponding files under "benchmarks/".
* Notice that it detects the sub-project's directories from jar's paths
so the provided jars
* should be properly placed under target (Maven build) or target/scala-*
(SBT) when you
* generate the files.
* }}}
*
* In Mac, you can use a command as below to find all the test jars.
+ * Make sure to do not select duplicated jars created by different versions of
builds or tools.
* {{{
- * find . -name "*3.2.0-SNAPSHOT-tests.jar" | paste -sd ',' -
+ * find . -name '*-SNAPSHOT-tests.jar' | paste -sd ',' -
* }}}
*
- * Full command example:
+ * The example below runs all benchmarks and generates the results:
* {{{
* SPARK_GENERATE_BENCHMARK_FILES=1 bin/spark-submit --class \
* org.apache.spark.benchmark.Benchmarks --jars \
- * "`find . -name "*3.2.0-SNAPSHOT-tests.jar" | paste -sd ',' -`" \
- * ./core/target/scala-2.12/spark-core_2.12-3.2.0-SNAPSHOT-tests.jar
+ * "`find . -name '*-SNAPSHOT-tests.jar' -o -name '*avro*-SNAPSHOT.jar' |
paste -sd ',' -`" \
+ * "`find . -name 'spark-core*-SNAPSHOT-tests.jar'`" \
+ * "*"
+ * }}}
+ *
+ * The example below runs all benchmarks under
"org.apache.spark.sql.execution.datasources"
+ * {{{
+ * bin/spark-submit --class \
+ * org.apache.spark.benchmark.Benchmarks --jars \
+ * "`find . -name '*-SNAPSHOT-tests.jar' -o -name '*avro*-SNAPSHOT.jar' |
paste -sd ',' -`" \
+ * "`find . -name 'spark-core*-SNAPSHOT-tests.jar'`" \
+ * "org.apache.spark.sql.execution.datasources.*"
* }}}
*/
object Benchmarks {
def main(args: Array[String]): Unit = {
+var isBenchmarkFound = false
Review comment:
Actually let me just keep it. I tired few other ways just now but it
looks less readable.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon edited a comment on pull request #32015: [SPARK-34821][INFRA] Set up a workflow for developers to run benchmark in their fork
HyukjinKwon edited a comment on pull request #32015: URL: https://github.com/apache/spark/pull/32015#issuecomment-811064987 Note that I tested subset of benchmarks, verified that it works, and now I am waiting for the final results of running all benchmarks: - [Run benchmarks: * (JDK 11)](https://github.com/HyukjinKwon/spark/actions/runs/707148901) - [Run benchmarks: * (JDK 8)](https://github.com/HyukjinKwon/spark/actions/runs/707148688) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on a change in pull request #32015: [SPARK-34821][INFRA] Set up a workflow for developers to run benchmark in their fork
wangyum commented on a change in pull request #32015: URL: https://github.com/apache/spark/pull/32015#discussion_r605346227 ## File path: .github/workflows/benchmark.yml ## @@ -0,0 +1,68 @@ +name: Run benchmarks + +on: + workflow_dispatch: +inputs: + class: +description: 'Benchmark class' +required: true +default: '*' + jdk: +description: 'JDK version: 8 or 11' +required: true +default: '8' Review comment: OK -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32015: [SPARK-34821][INFRA] Set up a workflow for developers to run benchmark in their fork
HyukjinKwon commented on a change in pull request #32015: URL: https://github.com/apache/spark/pull/32015#discussion_r605345844 ## File path: .github/workflows/benchmark.yml ## @@ -0,0 +1,68 @@ +name: Run benchmarks + +on: + workflow_dispatch: +inputs: + class: +description: 'Benchmark class' +required: true +default: '*' + jdk: +description: 'JDK version: 8 or 11' +required: true +default: '8' Review comment: Let's just leave it ... according to the semver, the performance should stay basically same for maintenance releases. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #32017: [SPARK-34923][SQL] Metadata output should be empty by default
SparkQA removed a comment on pull request #32017: URL: https://github.com/apache/spark/pull/32017#issuecomment-811514173 **[Test build #136784 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136784/testReport)** for PR 32017 at commit [`6c3dde2`](https://github.com/apache/spark/commit/6c3dde274e36ab5665b72703435b41332ef60f65). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32017: [SPARK-34923][SQL] Metadata output should be empty by default
SparkQA commented on pull request #32017: URL: https://github.com/apache/spark/pull/32017#issuecomment-811602003 **[Test build #136784 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136784/testReport)** for PR 32017 at commit [`6c3dde2`](https://github.com/apache/spark/commit/6c3dde274e36ab5665b72703435b41332ef60f65). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32015: [SPARK-34821][INFRA] Set up a workflow for developers to run benchmark in their fork
HyukjinKwon commented on a change in pull request #32015: URL: https://github.com/apache/spark/pull/32015#discussion_r605344146 ## File path: .github/workflows/benchmark.yml ## @@ -0,0 +1,68 @@ +name: Run benchmarks + +on: + workflow_dispatch: +inputs: + class: +description: 'Benchmark class' Review comment: Let me clarify it when I document it later.. otherwise the input dialog becomes too long ;(. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32015: [SPARK-34821][INFRA] Set up a workflow for developers to run benchmark in their fork
HyukjinKwon commented on a change in pull request #32015:
URL: https://github.com/apache/spark/pull/32015#discussion_r605343992
##
File path: core/src/test/scala/org/apache/spark/benchmark/Benchmarks.scala
##
@@ -78,8 +99,12 @@ object Benchmarks {
// Maven build
targetDirOrProjDir.getCanonicalPath
}
+// Force GC to minimize the side effect.
+System.gc()
runBenchmark.invoke(null, Array(projDir))
Review comment:
Let me do it later though after checking if it is able to run in one go.
I would like to make sure it passes at least once.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32015: [SPARK-34821][INFRA] Set up a workflow for developers to run benchmark in their fork
HyukjinKwon commented on a change in pull request #32015:
URL: https://github.com/apache/spark/pull/32015#discussion_r605343862
##
File path: core/src/test/scala/org/apache/spark/benchmark/Benchmarks.scala
##
@@ -78,8 +99,12 @@ object Benchmarks {
// Maven build
targetDirOrProjDir.getCanonicalPath
}
+// Force GC to minimize the side effect.
+System.gc()
runBenchmark.invoke(null, Array(projDir))
Review comment:
Yeah .. sounds good
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #32015: [SPARK-34821][INFRA] Set up a workflow for developers to run benchmark in their fork
HyukjinKwon commented on a change in pull request #32015:
URL: https://github.com/apache/spark/pull/32015#discussion_r605343535
##
File path: core/src/test/scala/org/apache/spark/benchmark/Benchmarks.scala
##
@@ -30,44 +31,64 @@ import com.google.common.reflect.ClassPath
*
* {{{
* 1. with spark-submit
- * bin/spark-submit --class --jars
+ * bin/spark-submit --class --jars
+ *
* 2. generate result:
* SPARK_GENERATE_BENCHMARK_FILES=1 bin/spark-submit --class
--jars
- *
+ *
+ *
* Results will be written to all corresponding files under "benchmarks/".
* Notice that it detects the sub-project's directories from jar's paths
so the provided jars
* should be properly placed under target (Maven build) or target/scala-*
(SBT) when you
* generate the files.
* }}}
*
* In Mac, you can use a command as below to find all the test jars.
+ * Make sure to do not select duplicated jars created by different versions of
builds or tools.
* {{{
- * find . -name "*3.2.0-SNAPSHOT-tests.jar" | paste -sd ',' -
+ * find . -name '*-SNAPSHOT-tests.jar' | paste -sd ',' -
* }}}
*
- * Full command example:
+ * The example below runs all benchmarks and generates the results:
* {{{
* SPARK_GENERATE_BENCHMARK_FILES=1 bin/spark-submit --class \
* org.apache.spark.benchmark.Benchmarks --jars \
- * "`find . -name "*3.2.0-SNAPSHOT-tests.jar" | paste -sd ',' -`" \
- * ./core/target/scala-2.12/spark-core_2.12-3.2.0-SNAPSHOT-tests.jar
+ * "`find . -name '*-SNAPSHOT-tests.jar' -o -name '*avro*-SNAPSHOT.jar' |
paste -sd ',' -`" \
+ * "`find . -name 'spark-core*-SNAPSHOT-tests.jar'`" \
+ * "*"
+ * }}}
+ *
+ * The example below runs all benchmarks under
"org.apache.spark.sql.execution.datasources"
+ * {{{
+ * bin/spark-submit --class \
+ * org.apache.spark.benchmark.Benchmarks --jars \
+ * "`find . -name '*-SNAPSHOT-tests.jar' -o -name '*avro*-SNAPSHOT.jar' |
paste -sd ',' -`" \
+ * "`find . -name 'spark-core*-SNAPSHOT-tests.jar'`" \
+ * "org.apache.spark.sql.execution.datasources.*"
* }}}
*/
object Benchmarks {
def main(args: Array[String]): Unit = {
+var isBenchmarkFound = false
ClassPath.from(
Thread.currentThread.getContextClassLoader
).getTopLevelClassesRecursive("org.apache.spark").asScala.foreach { info =>
lazy val clazz = info.load
lazy val runBenchmark = clazz.getMethod("main", classOf[Array[String]])
// isAssignableFrom seems not working with the reflected class from
Guava's
// getTopLevelClassesRecursive.
+ val matcher = args.headOption.map(pattern =>
+FileSystems.getDefault.getPathMatcher(s"glob:$pattern"))
if (
info.getName.endsWith("Benchmark") &&
+ // TPCDSQueryBenchmark requires setup and arguments. Exclude it for
now.
+ !info.getName.endsWith("TPCDSQueryBenchmark") &&
+ matcher.forall(_.matches(Paths.get(info.getName))) &&
Review comment:
We could do that. I just wanted to make it matched with `testOnly` in
SBT which arguably people are more used to.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #32018: [SPARK-34926][SQL] ExternalCatalogUtils.escapePathName should support null
AngersZh commented on pull request #32018: URL: https://github.com/apache/spark/pull/32018#issuecomment-811600763 ping @MaxGekk Since your pr make partition value support value as `null`, here I think we need to handle null value and I meet this in https://github.com/apache/spark/pull/30057 's UT https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136751/testReport/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32009: [SPARK-34914][CORE] Local scheduler backend support update token
SparkQA commented on pull request #32009: URL: https://github.com/apache/spark/pull/32009#issuecomment-811598016 **[Test build #136788 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136788/testReport)** for PR 32009 at commit [`8fcb62f`](https://github.com/apache/spark/commit/8fcb62fd33d07ee4cb37bc9b85118c5c4ced3b01). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32018: [SPARK-34926][SQL] ExternalCatalogUtils.escapePathName should support null
SparkQA commented on pull request #32018: URL: https://github.com/apache/spark/pull/32018#issuecomment-811597991 **[Test build #136787 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136787/testReport)** for PR 32018 at commit [`960f2c1`](https://github.com/apache/spark/commit/960f2c10c94954e6810d3537166905b9e17f4728). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #24559: [SPARK-27658][SQL] Add FunctionCatalog API
AmplabJenkins removed a comment on pull request #24559: URL: https://github.com/apache/spark/pull/24559#issuecomment-811596875 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/136783/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #32012: [SPARK-34919][SQL] Change partitioning to SinglePartition if partition number is 1
AmplabJenkins removed a comment on pull request #32012: URL: https://github.com/apache/spark/pull/32012#issuecomment-811596876 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41369/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #32012: [SPARK-34919][SQL] Change partitioning to SinglePartition if partition number is 1
AmplabJenkins commented on pull request #32012: URL: https://github.com/apache/spark/pull/32012#issuecomment-811596876 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/41369/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #24559: [SPARK-27658][SQL] Add FunctionCatalog API
AmplabJenkins commented on pull request #24559: URL: https://github.com/apache/spark/pull/24559#issuecomment-811596875 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/136783/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn commented on pull request #32010: [SPARK-34908][SQL] Add test cases for char and varchar with functions
yaooqinn commented on pull request #32010: URL: https://github.com/apache/spark/pull/32010#issuecomment-811596632 cc @cloud-fan @HyukjinKwon thanks -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu opened a new pull request #32018: [SPARK-34926][SQL] ExternalCatalogUtils.escapePathName should support null
AngersZh opened a new pull request #32018: URL: https://github.com/apache/spark/pull/32018 ### What changes were proposed in this pull request? ExternalCatalogUtils.escapePathName should support null ### Why are the changes needed? ExternalCatalogUtils.escapePathName should support null ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on a change in pull request #32015: [SPARK-34821][INFRA] Set up a workflow for developers to run benchmark in their fork
wangyum commented on a change in pull request #32015: URL: https://github.com/apache/spark/pull/32015#discussion_r605336056 ## File path: .github/workflows/benchmark.yml ## @@ -0,0 +1,68 @@ +name: Run benchmarks + +on: + workflow_dispatch: +inputs: + class: +description: 'Benchmark class' +required: true +default: '*' + jdk: +description: 'JDK version: 8 or 11' +required: true +default: '8' Review comment: Could we use a fixed JDK version? For example: 8.0.282? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ulysses-you commented on pull request #32009: [SPARK-34914][CORE] Local scheduler backend support update token
ulysses-you commented on pull request #32009: URL: https://github.com/apache/spark/pull/32009#issuecomment-811591207 > NOte that if we decide to support this we should document exactly what is and what is not supported: http://spark.apache.org/docs/latest/security.html#kerberos thanks for the reminder, removed the word `non-local`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32012: [SPARK-34919][SQL] Change partitioning to SinglePartition if partition number is 1
SparkQA commented on pull request #32012: URL: https://github.com/apache/spark/pull/32012#issuecomment-811591016 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #24559: [SPARK-27658][SQL] Add FunctionCatalog API
SparkQA removed a comment on pull request #24559: URL: https://github.com/apache/spark/pull/24559#issuecomment-811487701 **[Test build #136783 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136783/testReport)** for PR 24559 at commit [`37439c6`](https://github.com/apache/spark/commit/37439c6069bc82c1944eb44dd2f61712d35a9e9b). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #24559: [SPARK-27658][SQL] Add FunctionCatalog API
SparkQA commented on pull request #24559: URL: https://github.com/apache/spark/pull/24559#issuecomment-811585210 **[Test build #136783 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136783/testReport)** for PR 24559 at commit [`37439c6`](https://github.com/apache/spark/commit/37439c6069bc82c1944eb44dd2f61712d35a9e9b). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on pull request #31666: [SPARK-34527][SQL] Resolve duplicated common columns from USING/NATURAL JOIN
AmplabJenkins removed a comment on pull request #31666: URL: https://github.com/apache/spark/pull/31666#issuecomment-811579868 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/136785/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #31666: [SPARK-34527][SQL] Resolve duplicated common columns from USING/NATURAL JOIN
AmplabJenkins commented on pull request #31666: URL: https://github.com/apache/spark/pull/31666#issuecomment-811579868 Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/136785/ -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on pull request #31666: [SPARK-34527][SQL] Resolve duplicated common columns from USING/NATURAL JOIN
SparkQA removed a comment on pull request #31666: URL: https://github.com/apache/spark/pull/31666#issuecomment-811535839 **[Test build #136785 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136785/testReport)** for PR 31666 at commit [`07f9ad5`](https://github.com/apache/spark/commit/07f9ad583127c19662384e3f1c31ae29cb444583). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #31666: [SPARK-34527][SQL] Resolve duplicated common columns from USING/NATURAL JOIN
SparkQA commented on pull request #31666: URL: https://github.com/apache/spark/pull/31666#issuecomment-811579710 **[Test build #136785 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136785/testReport)** for PR 31666 at commit [`07f9ad5`](https://github.com/apache/spark/commit/07f9ad583127c19662384e3f1c31ae29cb444583). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on pull request #32012: [SPARK-34919][SQL] Change partitioning to SinglePartition if partition number is 1
SparkQA commented on pull request #32012: URL: https://github.com/apache/spark/pull/32012#issuecomment-811578298 **[Test build #136786 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/136786/testReport)** for PR 32012 at commit [`1366ed3`](https://github.com/apache/spark/commit/1366ed31c2acc4ef5b6a77a5a4a5b4c4118800f4). -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org