[GitHub] spark issue #22639: [SPARK-25647][k8s] Add spark streaming compatibility sui...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/22639 @mccheah and @skonto Do you have suggestion how to go forward from here? I wanted to write more tests, like how to recover from checkpoints etc... --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22639: [SPARK-25647][k8s] Add spark streaming compatibil...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/22639#discussion_r229218791
--- Diff:
resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/StreamingCompatibilitySuite.scala
---
@@ -0,0 +1,214 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.deploy.k8s.integrationtest
+
+import java.net._
+
+import scala.collection.JavaConverters._
+import scala.concurrent.ExecutionContext.Implicits.global
+import scala.concurrent.Future
+
+import org.scalatest.concurrent.{Eventually, PatienceConfiguration}
+import org.scalatest.time.{Minutes, Span}
+
+import org.apache.spark.deploy.k8s.integrationtest.KubernetesSuite._
+import org.apache.spark.deploy.k8s.integrationtest.TestConstants._
+import org.apache.spark.internal.Logging
+import org.apache.spark.util
+
+private[spark] trait StreamingCompatibilitySuite {
+
+ k8sSuite: KubernetesSuite =>
+
+ import StreamingCompatibilitySuite._
+
+ test("Run spark streaming in client mode.", k8sTestTag) {
+val (host, port, serverSocket) = startSocketServer()
+val driverService = driverServiceSetup
+try {
+ setupSparkStreamingPod(driverService.getMetadata.getName)
+.addToArgs("streaming.NetworkWordCount")
+.addToArgs(host, port.toString)
+.endContainer()
+.endSpec()
+.done()
+ Eventually.eventually(TIMEOUT, INTERVAL) {
+assert(getRunLog.contains("spark-streaming-kube"), "The
application did not complete.")
+ }
+} finally {
+ // Have to delete the service manually since it doesn't have an
owner reference
+ kubernetesTestComponents
+.kubernetesClient
+.services()
+.inNamespace(kubernetesTestComponents.namespace)
+.delete(driverService)
+ serverSocket.close()
+}
+ }
+
+ test("Run spark streaming in cluster mode.", k8sTestTag) {
+val (host, port, serverSocket) = startSocketServer()
+try {
+ runSparkJVMCheckAndVerifyCompletion(
+mainClass = "org.apache.spark.examples.streaming.NetworkWordCount",
+appArgs = Array[String](host, port.toString),
+expectedJVMValue = Seq("spark-streaming-kube"))
+} finally {
+ serverSocket.close()
+}
+ }
+
+ test("Run spark structured streaming in cluster mode.", k8sTestTag) {
+val (host, port, serverSocket) = startSocketServer()
+try {
+ runSparkJVMCheckAndVerifyCompletion(
+mainClass =
"org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount",
+appArgs = Array[String](host, port.toString),
+expectedJVMValue = Seq("spark-streaming-kube"))
+} finally {
+ serverSocket.close()
+}
+ }
+
+ test("Run spark structured streaming in client mode.", k8sTestTag) {
+val (host, port, serverSocket) = startSocketServer()
+val driverService = driverServiceSetup
+try {
+ setupSparkStreamingPod(driverService.getMetadata.getName)
+.addToArgs("sql.streaming.StructuredNetworkWordCount")
+.addToArgs(host, port.toString)
+.endContainer()
+.endSpec()
+.done()
+
+ val TIMEOUT = PatienceConfiguration.Timeout(Span(3, Minutes))
+ Eventually.eventually(TIMEOUT, INTERVAL) {
+assert(getRunLog.contains("spark-streaming-kube"),
+ "The application did not complete.")
+ }
+}
+finally {
+ // Have to delete the service manually since it doesn't have an
owner reference
+ kubernetesTestComponents
+.kubernetesClient
+.services()
+
[GitHub] spark issue #22639: [SPARK-25647][k8s] Add spark streaming compatibility sui...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/22639 Jenkins, retest this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22639: [SPARK-25647][k8s] Add spark streaming compatibility sui...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/22639 Jenkins, retest this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22639: [SPARK-25647][k8s] Add spark streaming compatibility sui...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/22639 Jenkins, retest this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22639: [SPARK-25647][k8s] Add spark streaming compatibility sui...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/22639 Jenkins, retest this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22639: [SPARK-25647][k8s] Add spark streaming compatibil...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/22639#discussion_r225105051
--- Diff:
resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/StreamingCompatibilitySuite.scala
---
@@ -0,0 +1,214 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.deploy.k8s.integrationtest
+
+import java.net._
+
+import scala.collection.JavaConverters._
+import scala.concurrent.ExecutionContext.Implicits.global
+import scala.concurrent.Future
+
+import org.scalatest.concurrent.{Eventually, PatienceConfiguration}
+import org.scalatest.time.{Minutes, Span}
+
+import org.apache.spark.deploy.k8s.integrationtest.KubernetesSuite._
+import org.apache.spark.deploy.k8s.integrationtest.TestConstants._
+import org.apache.spark.internal.Logging
+import org.apache.spark.util
+
+private[spark] trait StreamingCompatibilitySuite {
+
+ k8sSuite: KubernetesSuite =>
+
+ import StreamingCompatibilitySuite._
+
+ test("Run spark streaming in client mode.", k8sTestTag) {
+val (host, port, serverSocket) = startSocketServer()
--- End diff --
Please correct my understanding, a custom source has to either live in
examples, or a separate image has to be published with the class path of the
custom source.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22639: [SPARK-25647][k8s] Add spark streaming compatibility sui...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/22639 Jenkins, retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22639: [SPARK-25647][k8s] Add spark streaming compatibility sui...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/22639 @mccheah Thanks for taking a look. Overall nice suggestion, I am okay with idea of having a pod, I am struggling with creating a pod for socket server, I can only think of non trivial options. Can you please suggest how to go about it? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22564: [SPARK-25282][K8s][DOC] Improved docs to avoid running i...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/22564 I am sorry for the trouble, @liyinan926 and @srowen. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22564: [SPARK-25282][K8s][DOC] Improved docs to avoid running i...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/22564 Looks like this is working without making a release. It is not clear what change could have fixed the problem. Closing the PR for now. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22564: [SPARK-25282][K8s][DOC] Improved docs to avoid ru...
Github user ScrapCodes closed the pull request at: https://github.com/apache/spark/pull/22564 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22639: [SPARK-25647][k8s] Add spark streaming compatibility sui...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/22639 Jenkins, retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22639: [SPARK-25647][k8s] Add spark streaming compatibil...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/22639#discussion_r222942209
--- Diff:
resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/KubernetesTestComponents.scala
---
@@ -120,7 +120,7 @@ private[spark] object SparkAppLauncher extends Logging {
appConf.toStringArray :+ appArguments.mainAppResource
if (appArguments.appArgs.nonEmpty) {
- commandLine += appArguments.appArgs.mkString(" ")
+ commandLine ++= appArguments.appArgs
--- End diff --
Space separated single argument or, multiple different argument. If we do
`.mkString(" ")` then, it takes multi arguments as space separated single
argument.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22639: [SPARK-25647][k8s] Add spark streaming compatibil...
GitHub user ScrapCodes opened a pull request: https://github.com/apache/spark/pull/22639 [SPARK-25647][k8s] Add spark streaming compatibility suite for kubernetes. ## What changes were proposed in this pull request? Adds integration tests for spark streaming compatibility with K8s mode. ## How was this patch tested? By running the test suites. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ScrapCodes/spark stream-test-k8s Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22639.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22639 commit 0a4e222b29368b4ff1924c0635ed8274e9e69933 Author: Prashant Sharma Date: 2018-10-05T09:12:38Z [SPARK-25647][k8s] Add spark streaming compatibility suite for kubernetes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22564: [SPARK-25282][K8s][DOC] Improved docs to avoid running i...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/22564 @liyinan926 Do you have some comments, if this will be helpful. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22339: [SPARK-17159][STREAM] Significant speed up for running s...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/22339 Thank you @srowen and @steveloughran. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22339: [SPARK-17159][STREAM] Significant speed up for running s...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/22339 Hi @srowen, would you like to take a look? Is there anything I can do, if this patch is missing something? I have tested it thoroughly against an object store. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22565: [SPARK-25543][K8S] Print debug message iff execIdsRemove...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/22565 @dongjoon-hyun Thanks for looking. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22565: [MINOR][SPARK-25543][K8s] Confusing log messages ...
GitHub user ScrapCodes opened a pull request: https://github.com/apache/spark/pull/22565 [MINOR][SPARK-25543][K8s] Confusing log messages at DEBUG level, in K8s mode. ## What changes were proposed in this pull request? Spurious logs like /sec. 2018-09-26 09:33:57 DEBUG ExecutorPodsLifecycleManager:58 - Removed executors with ids from Spark that were either found to be deleted or non-existent in the cluster. 2018-09-26 09:33:58 DEBUG ExecutorPodsLifecycleManager:58 - Removed executors with ids from Spark that were either found to be deleted or non-existent in the cluster. 2018-09-26 09:33:59 DEBUG ExecutorPodsLifecycleManager:58 - Removed executors with ids from Spark that were either found to be deleted or non-existent in the cluster. 2018-09-26 09:34:00 DEBUG ExecutorPodsLifecycleManager:58 - Removed executors with ids from Spark that were either found to be deleted or non-existent in the cluster. The fix is easy, first check if there are any removed executors, before producing the log message. ## How was this patch tested? Tested by manually deploying to a minikube cluster. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ScrapCodes/spark spark-25543/k8s/debug-log-spurious-warning Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22565.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22565 commit 6ae5569c9c0c0c55ca3320ba2eb5cc97018653ca Author: Prashant Sharma Date: 2018-09-26T09:56:41Z [SPARK-25543][K8s] Confusing log messages at DEBUG level, in K8s mode. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22564: [SPARK-25282][K8s][DOC] Improved docs to avoid ru...
GitHub user ScrapCodes opened a pull request: https://github.com/apache/spark/pull/22564 [SPARK-25282][K8s][DOC] Improved docs to avoid running into InvalidClassException. ## What changes were proposed in this pull request? Documentation changes, on client mode. A user needs to make a distribution before he can use client mode. ## How was this patch tested? Doc improvement comments are based on running locally. The patch itself is a document patch, so may not need testing. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ScrapCodes/spark SPARK-25282/docs-k8s-client-mode Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22564.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22564 commit 0a4cd605b5b872148fb4649f9b3e167125f4f653 Author: Prashant Sharma Date: 2018-09-27T06:52:25Z [SPARK-25282][K8s][DOC] Improved docs to avoid running into InvalidClassException. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22339: [SPARK-17159][STREAM] Significant speed up for running s...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/22339 For numbers, while testing with object store having 50 files/dirs, without this patch it took 130 REST requests for 2 batches to complete and with this patch it took 56 rest requests. So number of rest calls are reduced, and this translates to speedup. How much speed up is dependent on number of files, but for the particular test, I have run, it was 2x. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22339: SPARK-17159 Significant speed up for running spar...
GitHub user ScrapCodes opened a pull request: https://github.com/apache/spark/pull/22339 SPARK-17159 Significant speed up for running spark streaming against Object store. ## What changes were proposed in this pull request? Original work by Steve Loughran. Based on #17745. This is a minimal patch of changes to FileInputDStream to reduce File status requests when querying files. Each call to file status is 3+ http calls to object store. This patch eliminates the need for it, by using FileStatus objects. This is a minor optimisation when working with filesystems, but significant when working with object stores. ## How was this patch tested? Tests included. Existing tests pass. Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ScrapCodes/spark PR_17745 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22339.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22339 commit 2fba9af597349fc023e04a845d1cfacfc3ab7d9e Author: Steve Loughran Date: 2017-04-24T13:04:04Z SPARK-17159 Significant speed up for running spark streaming against Object store. Based on #17745. Original work by Steve Loughran. This is a minimal patch of changes to FileInputDStream to reduce File status requests when querying files. This is a minor optimisation when working with filesystems, but significant when working with object stores. Change-Id: I269d98902f615818941c88de93a124c65453756e --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17745: [SPARK-17159][Streaming] optimise check for new files in...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17745 It appears, there are more people using object store now, than ever. For those who are attached to old versions of spark streaming, having this would be good. Hi @steveloughran, are you planning to work on it ? or shall I take it forward from here? I am contemplating what can be done. So far the plan is we will temporarily maintain it as an experimental component in Apache Bahir, for the time it is not merged in mainstream spark. If you are willing to maintain the component, then please send a pull request to Bahir with just this patch applied. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17745: [SPARK-17159][Streaming] optimise check for new files in...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17745 Can you please reopen this? I had like to discuss, if we can merge it in the spark itself. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17745: [SPARK-17159][Streaming] optimise check for new f...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/17745#discussion_r212571984
--- Diff:
streaming/src/main/scala/org/apache/spark/streaming/dstream/FileInputDStream.scala
---
@@ -196,29 +191,29 @@ class FileInputDStream[K, V, F <: NewInputFormat[K,
V]](
logDebug(s"Getting new files for time $currentTime, " +
s"ignoring files older than $modTimeIgnoreThreshold")
- val newFileFilter = new PathFilter {
-def accept(path: Path): Boolean = isNewFile(path, currentTime,
modTimeIgnoreThreshold)
- }
- val directoryFilter = new PathFilter {
-override def accept(path: Path): Boolean =
fs.getFileStatus(path).isDirectory
- }
- val directories = fs.globStatus(directoryPath,
directoryFilter).map(_.getPath)
+ val directories =
Option(fs.globStatus(directoryPath)).getOrElse(Array.empty[FileStatus])
--- End diff --
Yes, having an object store specific version of glob, will be broadly
helpful. In the mean time, this patch seems to be saving a lot of http requests.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17745: [SPARK-17159][Streaming] optimise check for new f...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/17745#discussion_r212267619
--- Diff:
streaming/src/main/scala/org/apache/spark/streaming/dstream/FileInputDStream.scala
---
@@ -196,29 +191,29 @@ class FileInputDStream[K, V, F <: NewInputFormat[K,
V]](
logDebug(s"Getting new files for time $currentTime, " +
s"ignoring files older than $modTimeIgnoreThreshold")
- val newFileFilter = new PathFilter {
-def accept(path: Path): Boolean = isNewFile(path, currentTime,
modTimeIgnoreThreshold)
- }
- val directoryFilter = new PathFilter {
-override def accept(path: Path): Boolean =
fs.getFileStatus(path).isDirectory
- }
- val directories = fs.globStatus(directoryPath,
directoryFilter).map(_.getPath)
+ val directories =
Option(fs.globStatus(directoryPath)).getOrElse(Array.empty[FileStatus])
--- End diff --
So, on looking at the code of glob status, it does filter at the end, so
doing something like above might just be ok.
Also globStatus does a listStatus() per child directory or a
getFileStatus() in case input pattern is not a glob, each call to listStatus
does 3+ http calls and each call to getFileStatus does 2 http calls.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17745: [SPARK-17159][Streaming] optimise check for new f...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/17745#discussion_r212251757
--- Diff:
streaming/src/main/scala/org/apache/spark/streaming/dstream/FileInputDStream.scala
---
@@ -196,29 +191,29 @@ class FileInputDStream[K, V, F <: NewInputFormat[K,
V]](
logDebug(s"Getting new files for time $currentTime, " +
s"ignoring files older than $modTimeIgnoreThreshold")
- val newFileFilter = new PathFilter {
-def accept(path: Path): Boolean = isNewFile(path, currentTime,
modTimeIgnoreThreshold)
- }
- val directoryFilter = new PathFilter {
-override def accept(path: Path): Boolean =
fs.getFileStatus(path).isDirectory
- }
- val directories = fs.globStatus(directoryPath,
directoryFilter).map(_.getPath)
+ val directories =
Option(fs.globStatus(directoryPath)).getOrElse(Array.empty[FileStatus])
--- End diff --
In this approach, we might be fetching a very large list of files and then
filtering through the directories. If the fetched, list is too large, then it
can be a problem.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19096: [SPARK-21869][SS] A cached Kafka producer should ...
Github user ScrapCodes closed the pull request at: https://github.com/apache/spark/pull/19096 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18143: [SPARK-20919][SS] Simplificaiton of CachedKafkaCo...
Github user ScrapCodes closed the pull request at: https://github.com/apache/spark/pull/18143 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18143: [SPARK-20919][SS] Simplificaiton of CachedKafkaConsumer ...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/18143 @brkyvz and @zsxwing No comments on whether this will be useful or not, so far. Should I consider closing it ? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18143: [SPARK-20919][SS] Simplificaiton of CachedKafkaCo...
Github user ScrapCodes commented on a diff in the pull request: https://github.com/apache/spark/pull/18143#discussion_r162045340 --- Diff: external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/CachedKafkaConsumer.scala --- @@ -45,9 +46,6 @@ private[kafka010] case class CachedKafkaConsumer private( private var consumer = createConsumer - /** indicates whether this consumer is in use or not */ - private var inuse = true --- End diff -- Now that we have moved to using object pools, this tracking is no longer required. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19096: [SPARK-21869][SS] A cached Kafka producer should ...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/19096#discussion_r162022825
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaContinuousWriter.scala
---
@@ -112,8 +112,8 @@ class KafkaContinuousDataWriter(
checkForErrors()
if (producer != null) {
producer.flush()
+ producer.inUseCount.decrementAndGet()
checkForErrors()
- CachedKafkaProducer.close(new java.util.HashMap[String,
Object](producerParams.asJava))
--- End diff --
Since a producer is shared across threads, we maintain inuse counts and
close them separately.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19096: [SPARK-21869][SS] A cached Kafka producer should not be ...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/19096 @zsxwing, please take another look. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #14151: [SPARK-16496][SQL] Add wholetext as option for reading t...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/14151 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #14151: [SPARK-16496][SQL] Add wholetext as option for re...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/14151#discussion_r155706338
--- Diff: python/pyspark/sql/readwriter.py ---
@@ -313,11 +313,16 @@ def text(self, paths):
Each line in the text file is a new row in the resulting DataFrame.
:param paths: string, or list of strings, for input path(s).
+:param wholetext: if true, read each file from input path(s) as a
single row.
>>> df = spark.read.text('python/test_support/sql/text-test.txt')
>>> df.collect()
[Row(value=u'hello'), Row(value=u'this')]
+>>> df = spark.read.text('python/test_support/sql/text-test.txt',
wholetext=True)
+>>> df.collect()
+[Row(value=u'hello\nthis')]
--- End diff --
That would fail the test, I suppose. I can give that a try though.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #14151: [SPARK-16496][SQL] Add wholetext as option for reading t...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/14151 This python pydoc style is failing at `[Row(value=u'hello\nthis')]`. I could not find a way to fix it. Any help will be appreciated. It does not like the literal `'\n'` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #14151: [SPARK-16496][SQL] Add wholetext as option for reading t...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/14151 @viirya Can you please take another look? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19785: [MINOR][doc] The left navigation bar should be fi...
GitHub user ScrapCodes opened a pull request: https://github.com/apache/spark/pull/19785 [MINOR][doc] The left navigation bar should be fixed with respect to scrolling. ## What changes were proposed in this pull request? A minor CSS style change to make Left navigation bar stay fixed with respect to scrolling, it improves usability of the docs. ## How was this patch tested? It was tested on both, firefox and chrome. ### Before 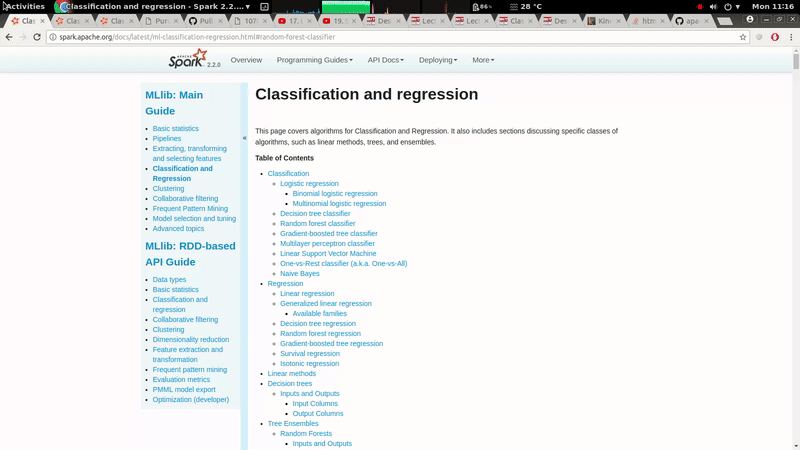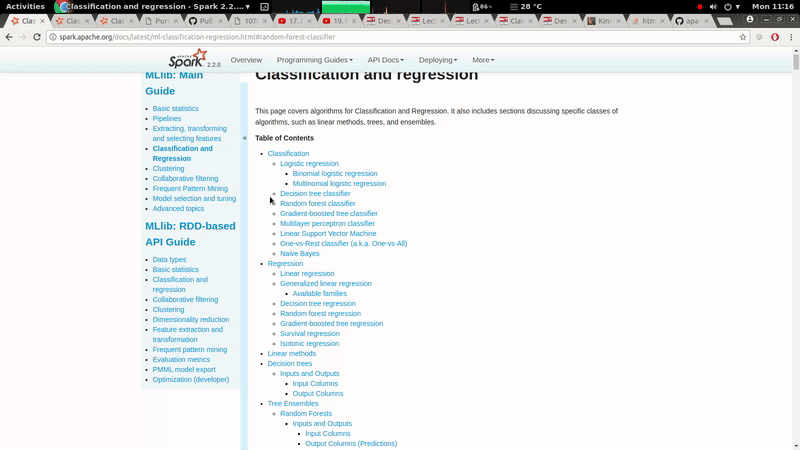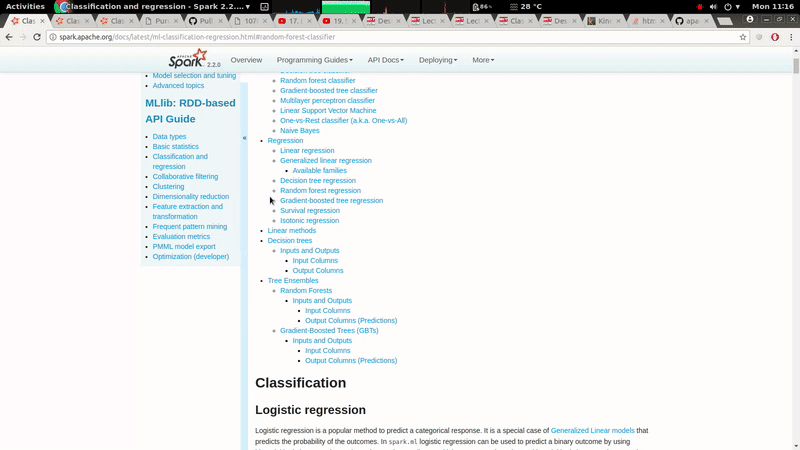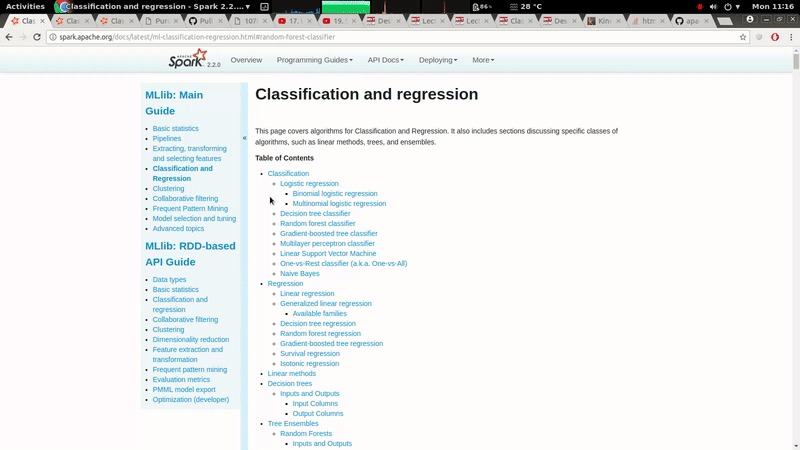 ### After 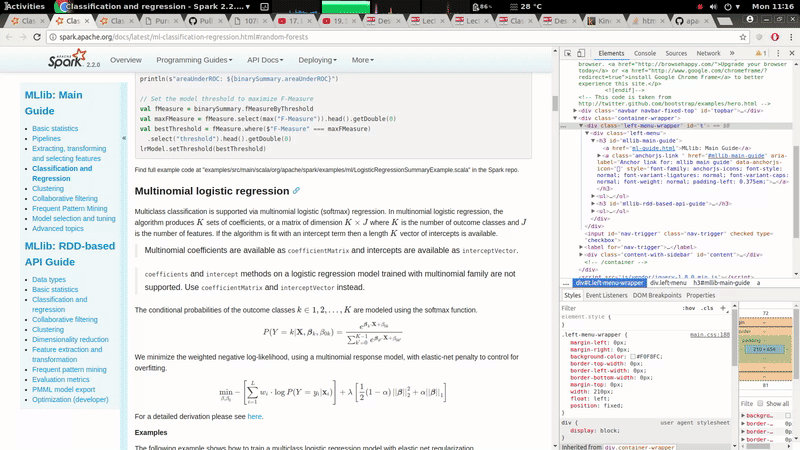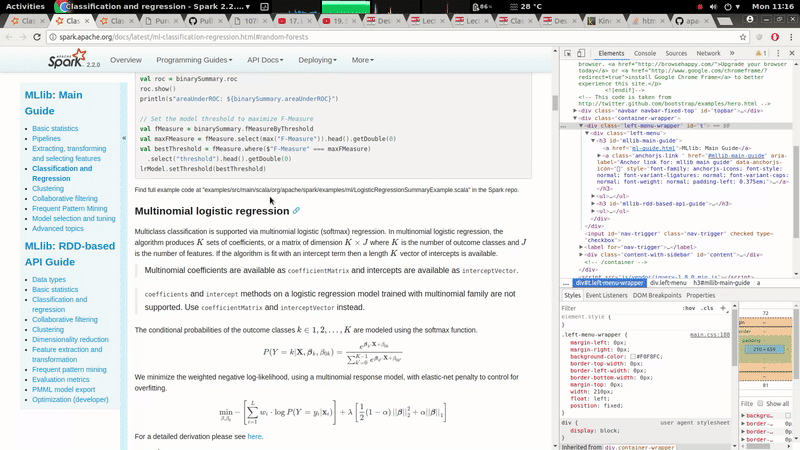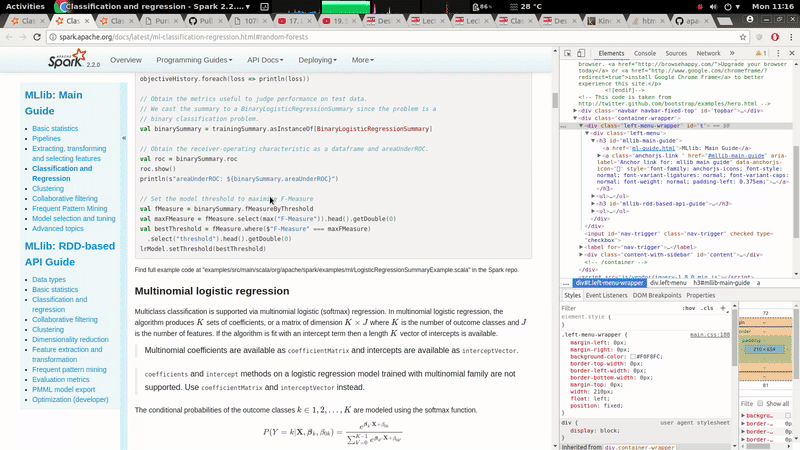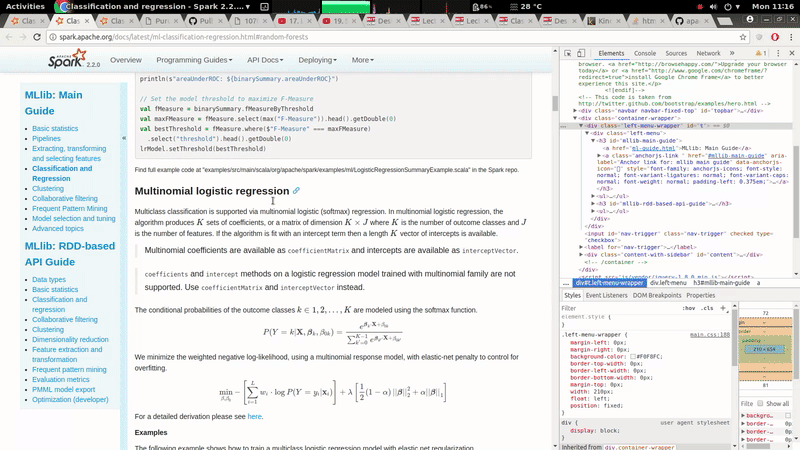 You can merge this pull request into a Git repository by running: $ git pull https://github.com/ScrapCodes/spark doc/css Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/19785.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #19785 commit 9e1f72a6db104414dae8f614777f415811569d6c Author: Prashant Sharma <prash...@in.ibm.com> Date: 2017-11-20T05:50:16Z [MINOR][doc] The left navigation bar should be fixed with respect to scrolling. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #14151: [SPARK-16496][SQL] Add wholetext as option for reading t...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/14151 @gatorsmile Ping ! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19096: [SPARK-21869][SS] A cached Kafka producer should not be ...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/19096 Hi @zsxwing, are you okay with the changes? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17357: [SPARK-20025][CORE] Ignore SPARK_LOCAL* env, whil...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/17357#discussion_r143407147
--- Diff:
core/src/main/scala/org/apache/spark/deploy/worker/DriverWrapper.scala ---
@@ -23,14 +23,15 @@ import org.apache.commons.lang3.StringUtils
import org.apache.spark.{SecurityManager, SparkConf}
import org.apache.spark.deploy.{DependencyUtils, SparkHadoopUtil,
SparkSubmit}
+import org.apache.spark.internal.Logging
import org.apache.spark.rpc.RpcEnv
import org.apache.spark.util.{ChildFirstURLClassLoader,
MutableURLClassLoader, Utils}
/**
* Utility object for launching driver programs such that they share fate
with the Worker process.
* This is used in standalone cluster mode only.
*/
-object DriverWrapper {
+object DriverWrapper extends Logging {
--- End diff --
I can not conceive, why that can be a problem. Can you also describe, why
do you think that it can be a problem?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19096: [SPARK-21869][SS] A cached Kafka producer should ...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/19096#discussion_r137778385
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaWriteTask.scala
---
@@ -43,8 +43,10 @@ private[kafka010] class KafkaWriteTask(
* Writes key value data out to topics.
*/
def execute(iterator: Iterator[InternalRow]): Unit = {
-producer = CachedKafkaProducer.getOrCreate(producerConfiguration)
+val paramsSeq = CachedKafkaProducer.paramsToSeq(producerConfiguration)
while (iterator.hasNext && failedWrite == null) {
+ // Prevent producer to get expired/evicted from guava
cache.(SPARK-21869)
+ producer = CachedKafkaProducer.getOrCreate(paramsSeq)
--- End diff --
Hi @zsxwing , thanks for looking, I too feel that - it seemed to be the
easiest solution though. Anyway, now in the new approach, I am tracking how
many threads are currently using the producer. Since guava cache, does not
provide a API to prevent an item from being removed. We insert an in use
producer back, instead of closing/cleaning it up.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19096: [SPARK-21869][SS] A cached Kafka producer should ...
GitHub user ScrapCodes opened a pull request: https://github.com/apache/spark/pull/19096 [SPARK-21869][SS] A cached Kafka producer should not be closed if any task is using it. ## What changes were proposed in this pull request? By updating the access time for the producer on each iteration, we can ensure that during long running task, we don't close a producer in use. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ScrapCodes/spark SPARK-21869/long-running-kafka-producer Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/19096.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #19096 commit f21bf1685a5a38d6342bb6b612247a1fac6ef2ff Author: Prashant Sharma <prash...@in.ibm.com> Date: 2017-08-31T11:51:32Z [SPARK-21869][SS] A cached Kafka producer should not be closed if any task is using it. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17357: [SPARK-20025][CORE] Ignore SPARK_LOCAL* env, whil...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/17357#discussion_r135699350
--- Diff:
core/src/main/scala/org/apache/spark/deploy/rest/StandaloneRestServer.scala ---
@@ -139,7 +139,9 @@ private[rest] class StandaloneSubmitRequestServlet(
val driverExtraLibraryPath =
sparkProperties.get("spark.driver.extraLibraryPath")
val superviseDriver = sparkProperties.get("spark.driver.supervise")
val appArgs = request.appArgs
-val environmentVariables = request.environmentVariables
+// Filter SPARK_LOCAL_(IP|HOSTNAME) environment variables from being
set on the remote system.
+val environmentVariables =
+ request.environmentVariables.filterNot(x =>
x._1.matches("SPARK_LOCAL_(IP|HOSTNAME"))
--- End diff --
Thanks!
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17357: [SPARK-20025][CORE] Ignore SPARK_LOCAL* env, whil...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/17357#discussion_r135485503
--- Diff:
core/src/main/scala/org/apache/spark/deploy/rest/StandaloneRestServer.scala ---
@@ -139,7 +139,9 @@ private[rest] class StandaloneSubmitRequestServlet(
val driverExtraLibraryPath =
sparkProperties.get("spark.driver.extraLibraryPath")
val superviseDriver = sparkProperties.get("spark.driver.supervise")
val appArgs = request.appArgs
-val environmentVariables = request.environmentVariables
+// Filter SPARK_LOCAL_(IP|HOSTNAME) environment variables from being
set on the remote system.
+val environmentVariables =
+ request.environmentVariables.filterNot(x =>
x._1.matches("SPARK_LOCAL_(IP|HOSTNAME"))
--- End diff --
@jiangxb1987 Hi I have changed it to only filter HOSTNAME and IP.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17357: [SPARK-20025][CORE] Ignore SPARK_LOCAL* env, whil...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/17357#discussion_r135187410
--- Diff:
core/src/main/scala/org/apache/spark/deploy/rest/StandaloneRestServer.scala ---
@@ -139,7 +139,9 @@ private[rest] class StandaloneSubmitRequestServlet(
val driverExtraLibraryPath =
sparkProperties.get("spark.driver.extraLibraryPath")
val superviseDriver = sparkProperties.get("spark.driver.supervise")
val appArgs = request.appArgs
-val environmentVariables = request.environmentVariables
+// Filter SPARK_LOCAL environment variables from being set on the
remote system.
+val environmentVariables =
+
request.environmentVariables.filterNot(_._1.startsWith("SPARK_LOCAL"))
--- End diff --
Alright, I will check how it is used across the project.
Just noted, In `LocalDirsSuite`, comments in `test("SPARK_LOCAL_DIRS
override also affects driver") ` seems to corroborate with my intentions here.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17357: [SPARK-20025][CORE] Ignore SPARK_LOCAL* env, whil...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/17357#discussion_r134986472
--- Diff:
core/src/main/scala/org/apache/spark/deploy/worker/DriverWrapper.scala ---
@@ -38,8 +39,10 @@ object DriverWrapper {
*/
case workerUrl :: userJar :: mainClass :: extraArgs =>
val conf = new SparkConf()
-val rpcEnv = RpcEnv.create("Driver",
- Utils.localHostName(), 0, conf, new SecurityManager(conf))
+val host: String = Utils.localHostName()
--- End diff --
Please correct me, AFAIU `spark.driver.host` may not be specified on each
node of the cluster and its value might be global(i.e. cluster wide). Since
driver is launched on a random node during a failover, it's value can not be
pre-assigned and has to be picked up from that node's local environment.
About `spark.driver.port`, I am not sure, but the fact is - it might work,
even if it is global cluster wide constant.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17357: [SPARK-20025][CORE] Ignore SPARK_LOCAL* env, whil...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/17357#discussion_r134985214
--- Diff:
core/src/main/scala/org/apache/spark/deploy/rest/StandaloneRestServer.scala ---
@@ -139,7 +139,9 @@ private[rest] class StandaloneSubmitRequestServlet(
val driverExtraLibraryPath =
sparkProperties.get("spark.driver.extraLibraryPath")
val superviseDriver = sparkProperties.get("spark.driver.supervise")
val appArgs = request.appArgs
-val environmentVariables = request.environmentVariables
+// Filter SPARK_LOCAL environment variables from being set on the
remote system.
+val environmentVariables =
+
request.environmentVariables.filterNot(_._1.startsWith("SPARK_LOCAL"))
--- End diff --
You are right, but shouldn't all SPARK_LOCAL* properties be picked up from
the local environment of the node where driver is going to be started?
Not filtering them, would mean, that these local properties are common to
all nodes.
But for this particular bug, `SPARK_LOCAL_DIRS` is not required to be
filtered.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #14151: [SPARK-16496][SQL] Add wholetext as option for reading t...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/14151 @gatorsmile @jiangxb1987 ping! --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17357: [SPARK-20025][CORE] Ignore SPARK_LOCAL* env, while deplo...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17357 I will update it, soon. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #14151: [SPARK-16496][SQL] Add wholetext as option for reading t...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/14151 @jiangxb1987 @viirya your feedback has been incorporated, please take another look. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #14151: [SPARK-16496][SQL] Add wholetext as option for re...
Github user ScrapCodes commented on a diff in the pull request: https://github.com/apache/spark/pull/14151#discussion_r131100257 --- Diff: sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/HadoopFileWholeTextReader.scala --- @@ -0,0 +1,57 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + *http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.spark.sql.execution.datasources + +import java.io.Closeable +import java.net.URI + +import org.apache.hadoop.conf.Configuration +import org.apache.hadoop.fs.Path +import org.apache.hadoop.io.Text +import org.apache.hadoop.mapreduce._ +import org.apache.hadoop.mapreduce.lib.input.CombineFileSplit +import org.apache.hadoop.mapreduce.task.TaskAttemptContextImpl + +import org.apache.spark.input.WholeTextFileRecordReader + +/** + * An adaptor from a [[PartitionedFile]] to an [[Iterator]] of [[Text]], which is all of the lines + * in that file. + */ +class HadoopFileWholeTextReader(file: PartitionedFile, conf: Configuration) --- End diff -- Thank you, for catching this. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18143: [SPARK-20919][SS] Simplificaiton of CachedKafkaConsumer ...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/18143 I am currently, trying to run some performance tests and see how this change impacts performance in any case. Meanwhile, if I could get an idea if things are moving in the right direction that would be kind. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #14151: [SPARK-16496][SQL] Add wholetext as option for reading t...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/14151 @sameeragarwal Do you think this change still makes sense? Can I improve it somehow? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18143: [SPARK-20919][SS] Simplificaiton of CachedKafkaConsumer ...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/18143 @zsxwing, can you please take a look. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18562: [SPARK-21069][SS][DOCS] Add rate source to progra...
GitHub user ScrapCodes opened a pull request: https://github.com/apache/spark/pull/18562 [SPARK-21069][SS][DOCS] Add rate source to programming guide. Tested by running jekyll locally. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ScrapCodes/spark spark-21069/rate-source-docs Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/18562.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #18562 commit dd4fc3ef5c69bd5a2d9206844f0dac7a3114c54a Author: Prashant Sharma <prash...@in.ibm.com> Date: 2017-07-07T11:39:09Z [SPARK-21069][SS][DOCS] Add rate source to programming guide. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #14151: [SPARK-16496][SQL] Add wholetext as option for reading t...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/14151 Jenkins, retest this please. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18143: [SPARK-20919][SS] Simplificaiton of CachedKafkaConsumer ...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/18143 @brkyvz and @zsxwing, do you think this object pool should be bounded ? Or they can become weak reference values, incase the object pool is unbounded ? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18417: [INFRA] Close stale PRs
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/18417 15258 can also be taken out --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #15258: [SPARK-17689][SQL][STREAMING] added excludeFiles option ...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/15258 @gatorsmile Thanks for pinging this, I am closing it myself for now. And once it is ready, I will open it again. I am planning to update it soon. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #15258: [SPARK-17689][SQL][STREAMING] added excludeFiles ...
Github user ScrapCodes closed the pull request at: https://github.com/apache/spark/pull/15258 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17983: [SPARK-20738][BUILD] Option to turn off building ...
Github user ScrapCodes closed the pull request at: https://github.com/apache/spark/pull/17983 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18143: [SPARK-20919][SS] Simplificaiton of CachedKafkaConsumer ...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/18143 Thanks @koeninger for helping me. Thanks @brkyvz, please take a look again and see if what I have done is along the lines the change you wanted. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18143: [SPARK-20919][SS] Simplificaiton of CachedKafkaCo...
Github user ScrapCodes commented on a diff in the pull request: https://github.com/apache/spark/pull/18143#discussion_r119582631 --- Diff: external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/CachedKafkaConsumer.scala --- @@ -45,9 +46,6 @@ private[kafka010] case class CachedKafkaConsumer private( private var consumer = createConsumer - /** indicates whether this consumer is in use or not */ - private var inuse = true --- End diff -- Thanks, good point !, According to guava cache docs, When cache "approaches" the size limit - "The cache will try to evict entries that haven't been used recently or very often. " --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18143: [SPARK-20919][SS] Simplificaiton of CachedKafkaConsumer ...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/18143 Thanks @koeninger for taking a look. I did some testing to see if performance was impacted, and made corrections. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18143: [SPARK-20919][SS] Simplificaiton of CachedKafkaCo...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/18143#discussion_r119277567
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/CachedKafkaConsumer.scala
---
@@ -310,62 +308,45 @@ private[kafka010] object CachedKafkaConsumer extends
Logging {
private lazy val cache = {
val conf = SparkEnv.get.conf
-val capacity = conf.getInt("spark.sql.kafkaConsumerCache.capacity", 64)
-new ju.LinkedHashMap[CacheKey, CachedKafkaConsumer](capacity, 0.75f,
true) {
- override def removeEldestEntry(
-entry: ju.Map.Entry[CacheKey, CachedKafkaConsumer]): Boolean = {
-if (entry.getValue.inuse == false && this.size > capacity) {
- logWarning(s"KafkaConsumer cache hitting max capacity of
$capacity, " +
-s"removing consumer for ${entry.getKey}")
- try {
-entry.getValue.close()
- } catch {
-case e: SparkException =>
- logError(s"Error closing earliest Kafka consumer for
${entry.getKey}", e)
- }
- true
-} else {
- false
+val capacityConfigString: String =
"spark.sql.kafkaConsumerCache.capacity"
--- End diff --
This is used later to construct warning log message.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18143: [SPARK-20919][SS] Simplificaiton of CachedKafkaConsumer ...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/18143 Thanks @srowen for taking a look. I have tried to address your comments. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18143: [SPARK-20919][SS] Simplificaiton of CachedKafkaCo...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/18143#discussion_r119088849
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/CachedKafkaConsumer.scala
---
@@ -18,19 +18,19 @@
package org.apache.spark.sql.kafka010
import java.{util => ju}
-import java.util.concurrent.TimeoutException
-
-import scala.collection.JavaConverters._
+import java.util.concurrent.{Callable, TimeoutException, TimeUnit}
+import com.google.common.cache._
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord,
KafkaConsumer, OffsetOutOfRangeException}
import org.apache.kafka.common.TopicPartition
+import scala.collection.JavaConverters._
+import scala.util.control.NonFatal
--- End diff --
Got it, you mean scala imports come right after java.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18143: [SPARK-20919][SS] Simplificaiton of CachedKafkaCo...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/18143#discussion_r119085683
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/CachedKafkaConsumer.scala
---
@@ -383,19 +362,16 @@ private[kafka010] object CachedKafkaConsumer extends
Logging {
// If this is reattempt at running the task, then invalidate cache and
start with
// a new consumer
if (TaskContext.get != null && TaskContext.get.attemptNumber >= 1) {
- removeKafkaConsumer(topic, partition, kafkaParams)
- val consumer = new CachedKafkaConsumer(topicPartition, kafkaParams)
- consumer.inuse = true
- cache.put(key, consumer)
- consumer
-} else {
- if (!cache.containsKey(key)) {
-cache.put(key, new CachedKafkaConsumer(topicPartition,
kafkaParams))
- }
- val consumer = cache.get(key)
- consumer.inuse = true
- consumer
+ cache.invalidate(key)
}
+
+val consumer = cache.get(key, new Callable[CachedKafkaConsumer] {
--- End diff --
AFAIK, this is possible scala 2.12 onwards.
[reference](http://www.scala-lang.org/news/2.12.0#lambda-syntax-for-sam-types)
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18143: [SPARK-20919][SS] Simplificaiton of CachedKafkaCo...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/18143#discussion_r119084772
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/CachedKafkaConsumer.scala
---
@@ -18,19 +18,19 @@
package org.apache.spark.sql.kafka010
import java.{util => ju}
-import java.util.concurrent.TimeoutException
-
-import scala.collection.JavaConverters._
+import java.util.concurrent.{Callable, TimeoutException, TimeUnit}
+import com.google.common.cache._
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord,
KafkaConsumer, OffsetOutOfRangeException}
import org.apache.kafka.common.TopicPartition
+import scala.collection.JavaConverters._
+import scala.util.control.NonFatal
--- End diff --
Thanks @srowen for taking a look, I am a bit unsure, how?
BTW, is this not fully covered by our scalastyle check ?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17357: [SPARK-20025][CORE] Ignore SPARK_LOCAL* env, while deplo...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17357 In essence, if environment variable SPARK_LOCAL* or config spark.driver.host or port values will not be picked up correctly without this fix. This would cause driver failover fail. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18143: [SPARK-20919][SS] Simplificaiton of CachedKafkaConsumer ...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/18143 Hi, @brkyvz as we discussed on the PR for CachedKafkaProducer that Guava cache can be used for consumer as well. May be you could take a look at this as well ? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18143: Simplificaiton of CachedKafkaConsumer using guava...
GitHub user ScrapCodes opened a pull request: https://github.com/apache/spark/pull/18143 Simplificaiton of CachedKafkaConsumer using guava cache. ## What changes were proposed in this pull request? On the lines of SPARK-19968, guava cache can be used to simplify the code in CachedKafkaConsumer as well. With an additional feature of automatic cleanup of a consumer unused for a configurable time. ## How was this patch tested? Existing tests. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ScrapCodes/spark kafkaConsumer Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/18143.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #18143 commit 710dae8851b7779936d1e1bc987567b113ae1bce Author: Prashant Sharma <prash...@in.ibm.com> Date: 2017-05-30T06:15:09Z Simplificaiton of CachedKafkaConsumer using guava cache. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17308: [SPARK-19968][SS] Use a cached instance of `KafkaProduce...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17308 Thanks @viirya and @zsxwing. I have tried to address you comments. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17308: [SPARK-19968][SS] Use a cached instance of `KafkaProduce...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17308 @marmbrus Thank you for taking a look again. Surely, shut down hook is not ideal for closing kafka producers. In fact, for the case of kafka sink, it might be correct to skip cleanup step. I have tried to address your comments. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17308: [SPARK-19968][SS] Use a cached instance of `KafkaProduce...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17308 Jenkins, retest this please ! --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17308: [SPARK-19968][SS] Use a cached instance of `KafkaProduce...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17308 Build is failing due to "Our attempt to download sbt locally to build/sbt-launch-0.13.13.jar failed. Please install sbt manually from http://www.scala-sbt.org/; --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17308: [SPARK-19968][SS] Use a cached instance of `KafkaProduce...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17308 Jenkins, retest this please ! --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17308: [SPARK-19968][SPARK-20737][SS] Use a cached insta...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/17308#discussion_r118200287
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/CachedKafkaProducer.scala
---
@@ -36,7 +36,7 @@ private[kafka010] object CachedKafkaProducer extends
Logging {
private type Producer = KafkaProducer[Array[Byte], Array[Byte]]
private val cacheExpireTimeout: Long =
-System.getProperty("spark.kafka.guava.cache.timeout", "10").toLong
+System.getProperty("spark.kafka.guava.cache.timeout.minutes",
"10").toLong
--- End diff --
Thanks, you are right !
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17308: [SPARK-19968][SPARK-20737][SS] Use a cached insta...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/17308#discussion_r118194379
--- Diff:
external/kafka-0-10-sql/src/test/scala/org/apache/spark/sql/kafka010/CanonicalizeKafkaParamsSuite.scala
---
@@ -0,0 +1,61 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.kafka010
+
+import java.{util => ju}
+
+import org.apache.kafka.common.serialization.ByteArraySerializer
+import org.scalatest.PrivateMethodTester
--- End diff --
Ahh, oversight. Thanks !
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17308: [SPARK-19968][SPARK-20737][SS] Use a cached instance of ...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17308 Jenkins, retest this please. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17308: [SPARK-19968][SPARK-20737][SS] Use a cached insta...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/17308#discussion_r117717831
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaWriter.scala
---
@@ -94,4 +94,10 @@ private[kafka010] object KafkaWriter extends Logging {
}
}
}
+
+ def close(sc: SparkContext, kafkaParams: ju.Map[String, Object]): Unit =
{
+sc.parallelize(1 to 1).foreachPartition { iter =>
+ CachedKafkaProducer.close(kafkaParams)
+}
--- End diff --
Using guave cache, we can close if not used for a certain time. Shall we
ignore closing them during a shutdown ?
In the particular case of kafka producer, I do not see a direct problem
with that. Since we do a producer.flush() on each batch. I was just wondering,
with streaming sinks general - what should be our strategy ?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17308: [SPARK-19968][SPARK-20737][SS] Use a cached instance of ...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17308 @viirya Thank you for taking a look. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17308: [SPARK-19968][SPARK-20737][SS] Use a cached instance of ...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17308 @brkyvz I am toying with Guava cache, the only problem is, it does not have an in-built mechanism to do any cleanup on shutdown. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17308: [SPARK-19968][SPARK-20737][SS] Use a cached instance of ...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17308 @marmbrus and @brkyvz Please take another look, and let me know how it can be improved further. Thank you for the help so far. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17308: [SPARK-19968][SPARK-20737][SS] Use a cached insta...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/17308#discussion_r116958096
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaWriter.scala
---
@@ -94,4 +94,10 @@ private[kafka010] object KafkaWriter extends Logging {
}
}
}
+
+ def close(sc: SparkContext, kafkaParams: ju.Map[String, Object]): Unit =
{
+sc.parallelize(1 to 1).foreachPartition { iter =>
+ CachedKafkaProducer.close(kafkaParams)
+}
--- End diff --
This would cause `CachedKafkaProducer.close` to be executed on each
executor. I am thinking of a better way here.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17983: [SPARK-20738][BUILD] Option to turn off building docs in...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17983 @srowen Can you please take a look ! --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17982: [SPARK-20395][BUILD] Update Scala to 2.11.11 and zinc to...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17982 If I am not able to come up with the better alternative, then following not so ideal option exist. 1) we can do a scala version check and have two different code paths based on scala version. In scala 2.11.8+ we can hook out init just before printWelcome() In scala 2.11.11 we can do it just before `loopPostInit()`. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17982: [SPARK-20395][BUILD] Update Scala to 2.11.11 and zinc to...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17982 Actually, now I am wondering, how would it work without createInerpreter is executed. You constraint, makes things a bit tricky. I will think more before I reply. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17982: [SPARK-20395][BUILD] Update Scala to 2.11.11 and zinc to...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17982 Hi Sean, Taking a quick look at the changes that removed loadFiles. [changes](https://github.com/scala/scala/commit/99dad60d984d3f72338f3bad4c4fe905090edd51#diff-f31fa4d21a39bc6ed3c30fd38bcbc9d4) It seems `startup` is the correct alternative, i.e. just before the call to printWelcome. See [startup](https://github.com/scala/scala/blob/2.11.x/src/repl/scala/tools/nsc/interpreter/ILoop.scala#L959). --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17983: [SPARK-20738][BUILD] Hide building of docs in sbt...
GitHub user ScrapCodes opened a pull request: https://github.com/apache/spark/pull/17983 [SPARK-20738][BUILD] Hide building of docs in sbt behind an option. sbt publish-local tries to build the docs along with other artifacts and as the codebase is being updated with no build checks for sbt docs build. It appears to be difficult to upkeep the correct building of docs with sbt. An alternative is that, we hide building of docs behind an option `-Dbuild.docs=false`. This is also useful, if someone uses sbt publish and does not need the building of docs as it is generally time consuming. ## How was this patch tested? Manually running the build with and without the option. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ScrapCodes/spark build-docs-sbt Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/17983.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #17983 commit a43159e6b58dba70e11b5f2f52abbc2ab4a577dc Author: Prashant Sharma <prash...@in.ibm.com> Date: 2017-05-15T06:53:58Z [BUILD][MINOR] Hide building of docs in sbt behind an option. sbt publish-local tries to build the docs along with other artifacts and as the codebase is being updated with no build checks for sbt docs build. It appears to be difficult to upkeep the correct building of docs with sbt. An alternative is that, we hide building of docs behind an option `-Dbuild.docs=false`. This is also useful, if someone uses sbt publish and does not need the building of docs as it is generally time consuming. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17308: [SPARK-19968][SS] Use a cached instance of `KafkaProduce...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17308 SPARK-20737 is created to look into cleanup mechanism in a separate JIRA. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17308: [SPARK-19968][SS] Use a cached instance of `Kafka...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/17308#discussion_r116158469
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaSink.scala
---
@@ -30,14 +30,19 @@ private[kafka010] class KafkaSink(
@volatile private var latestBatchId = -1L
override def toString(): String = "KafkaSink"
+ private val kafkaParams = new ju.HashMap[String,
Object](executorKafkaParams)
override def addBatch(batchId: Long, data: DataFrame): Unit = {
if (batchId <= latestBatchId) {
logInfo(s"Skipping already committed batch $batchId")
} else {
KafkaWriter.write(sqlContext.sparkSession,
-data.queryExecution, executorKafkaParams, topic)
+data.queryExecution, kafkaParams, topic)
latestBatchId = batchId
}
}
+
+ override def stop(): Unit = {
+CachedKafkaProducer.close(kafkaParams)
--- End diff --
That's correct, I have understood, close requires a bit of rethinking, I am
unable to see a straight forward way of doing it. If you agree, close related
implementation can be taken out from this PR and be taken up in a separate JIRA
and PR ?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17308: [SPARK-19968][SS] Use a cached instance of `KafkaProduce...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17308 Hi @marmbrus and @brkyvz, Thanks a lot of taking a look. @marmbrus You are right, we should have another way to canonicalize kafka params. I can only think of appending a unique id to kafka params and somehow ensuring a particular set of params get the same uid everytime. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #17308: [SPARK-19968][SS] Use a cached instance of `Kafka...
Github user ScrapCodes commented on a diff in the pull request:
https://github.com/apache/spark/pull/17308#discussion_r110625538
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/CachedKafkaProducer.scala
---
@@ -0,0 +1,70 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.kafka010
+
+import java.{util => ju}
+
+import scala.collection.mutable
+
+import org.apache.kafka.clients.producer.KafkaProducer
+
+import org.apache.spark.internal.Logging
+
+private[kafka010] object CachedKafkaProducer extends Logging {
+
+ private val cacheMap = new mutable.HashMap[Int,
KafkaProducer[Array[Byte], Array[Byte]]]()
+
+ private def createKafkaProducer(
+producerConfiguration: ju.HashMap[String, Object]):
KafkaProducer[Array[Byte], Array[Byte]] = {
+val kafkaProducer: KafkaProducer[Array[Byte], Array[Byte]] =
+ new KafkaProducer[Array[Byte], Array[Byte]](producerConfiguration)
+cacheMap.put(producerConfiguration.hashCode(), kafkaProducer)
--- End diff --
It is not a good idea to do like that.
I had like my understanding to be corrected, as much as I understood. Since
in this particular case Spark does not let user specify a key or value
serializer/deserializer. So `Object` can be either a String, int or Long and
for these hashcode would work correctly. I am also contemplating a better way
to do it, now.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17357: [SPARK-20025][CORE] Ignore SPARK_LOCAL* env, while deplo...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17357 Hi @JoshRosen, can you please review this PR ? I have tested it, by running and verifying the applied configuration on the workers. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17308: [SPARK-19968][SS] Use a cached instance of `KafkaProduce...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17308 I can further confirm, that in logs, a kafkaproducer instance is created almost every instant. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17308: [SPARK-19968][SS] Use a cached instance of `KafkaProduce...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17308 @tdas ping ! --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17357: [SPARK-20025][CORE] Ignore SPARK_LOCAL* env, while deplo...
Github user ScrapCodes commented on the issue: https://github.com/apache/spark/pull/17357 Hi @rxin, I was not sure whom to ping for this PR. Would you like to take a look ? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org