[GitHub] spark issue #16964: [SPARK-19534][TESTS] Convert Java tests to use lambdas, ...
Github user dahaian commented on the issue: https://github.com/apache/spark/pull/16964 @zzcclp I tried, failed. Any suggestions? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #16964: [SPARK-19534][TESTS] Convert Java tests to use lambdas, ...
Github user dahaian commented on the issue: https://github.com/apache/spark/pull/16964 hi --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #16964: [SPARK-19534][TESTS] Convert Java tests to use lambdas, ...
Github user dahaian commented on the issue: https://github.com/apache/spark/pull/16964 @srowen I want to know which IDE do you use? Eclipse or IDEA? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19503: Create myspark
GitHub user dahaian opened a pull request: https://github.com/apache/spark/pull/19503 Create myspark ## What changes were proposed in this pull request? (Please fill in changes proposed in this fix) ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/dahaian/spark master Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/19503.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #19503 commit a816a24a032944559e1af594c35b9d32d11c83f0 Author: dahaian <735710...@qq.com> Date: 2017-10-16T03:15:57Z Create myspark --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19503: Create myspark
Github user dahaian closed the pull request at: https://github.com/apache/spark/pull/19503 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #16964: [SPARK-19534][TESTS] Convert Java tests to use lambdas, ...
Github user dahaian commented on the issue: https://github.com/apache/spark/pull/16964 @zzcclp@srowen I have the same error. In JavaConsumerStrategySuite.java,error is as follows: The method mapValues(Function1) is ambiguous for the type Map I use java 8.I clean build. But the error still exist. What should I do?Any help is appreciated. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19489: The declared package "org.apache.hive.service.cli.thrift...
Github user dahaian commented on the issue: https://github.com/apache/spark/pull/19489 @srowen I closed --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19489: The declared package "org.apache.hive.service.cli...
Github user dahaian closed the pull request at: https://github.com/apache/spark/pull/19489 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19489: The declared package "org.apache.hive.service.cli.thrift...
Github user dahaian commented on the issue: https://github.com/apache/spark/pull/19489 @srowen sorry, I do not understand you said "the mailing list"?Please tell me how I ask a question?And I will close this patch. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19489: The declared package "org.apache.hive.service.cli.thrift...
Github user dahaian commented on the issue: https://github.com/apache/spark/pull/19489 @srowen sorry,I just ask a question.If someone can help me.I will close this patch. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19489: I import the spark source to eclipse. But I got some err...
Github user dahaian commented on the issue: https://github.com/apache/spark/pull/19489 @AmplabJenkins can you help me solve my problemï¼Thanks --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19489: Branch 2.2
GitHub user dahaian reopened a pull request: https://github.com/apache/spark/pull/19489 Branch 2.2 I import the spark source to eclipse. 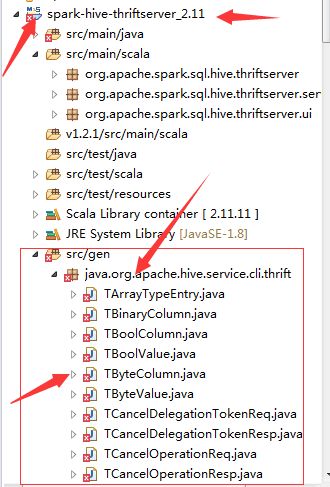 But I got some error. 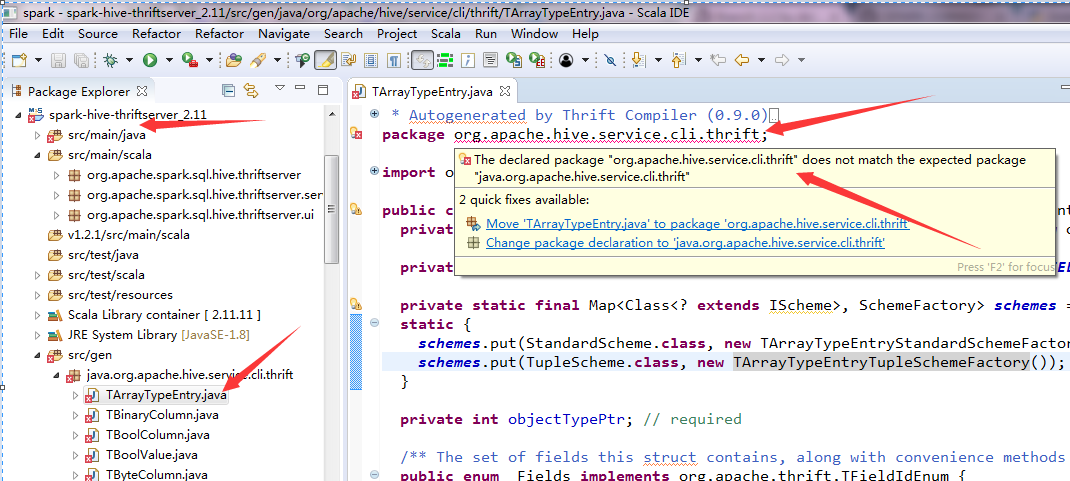 What should I do? You can merge this pull request into a Git repository by running: $ git pull https://github.com/apache/spark branch-2.2 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/19489.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #19489 commit fafe283277b50974c26684b06449086acd0cf05a Author: Wenchen Fan Date: 2017-05-26T07:01:28Z [SPARK-20868][CORE] UnsafeShuffleWriter should verify the position after FileChannel.transferTo ## What changes were proposed in this pull request? Long time ago we fixed a [bug](https://issues.apache.org/jira/browse/SPARK-3948) in shuffle writer about `FileChannel.transferTo`. We were not very confident about that fix, so we added a position check after the writing, try to discover the bug earlier. However this checking is missing in the new `UnsafeShuffleWriter`, this PR adds it. https://issues.apache.org/jira/browse/SPARK-18105 maybe related to that `FileChannel.transferTo` bug, hopefully we can find out the root cause after adding this position check. ## How was this patch tested? N/A Author: Wenchen Fan Closes #18091 from cloud-fan/shuffle. (cherry picked from commit d9ad78908f6189719cec69d34557f1a750d2e6af) Signed-off-by: Wenchen Fan commit f99456b5f6225a534ce52cf2b817285eb8853926 Author: NICHOLAS T. MARION Date: 2017-05-10T09:59:57Z [SPARK-20393][WEBU UI] Strengthen Spark to prevent XSS vulnerabilities ## What changes were proposed in this pull request? Add stripXSS and stripXSSMap to Spark Core's UIUtils. Calling these functions at any point that getParameter is called against a HttpServletRequest. ## How was this patch tested? Unit tests, IBM Security AppScan Standard no longer showing vulnerabilities, manual verification of WebUI pages. Author: NICHOLAS T. MARION Closes #17686 from n-marion/xss-fix. (cherry picked from commit b512233a457092b0e2a39d0b42cb021abc69d375) Signed-off-by: Sean Owen commit 92837aeb47fc3427166e4b6e62f6130f7480d7fa Author: Kazuaki Ishizaki Date: 2017-05-16T21:47:21Z [SPARK-19372][SQL] Fix throwing a Java exception at df.fliter() due to 64KB bytecode size limit ## What changes were proposed in this pull request? When an expression for `df.filter()` has many nodes (e.g. 400), the size of Java bytecode for the generated Java code is more than 64KB. It produces an Java exception. As a result, the execution fails. This PR continues to execute by calling `Expression.eval()` disabling code generation if an exception has been caught. ## How was this patch tested? Add a test suite into `DataFrameSuite` Author: Kazuaki Ishizaki Closes #17087 from kiszk/SPARK-19372. commit 2b59ed4f1d4e859d5987b6eaaee074260b2a12f8 Author: Michael Armbrust Date: 2017-05-26T20:33:23Z [SPARK-20844] Remove experimental from Structured Streaming APIs Now that Structured Streaming has been out for several Spark release and has large production use cases, the `Experimental` label is no longer appropriate. I've left `InterfaceStability.Evolving` however, as I think we may make a few changes to the pluggable Source & Sink API in Spark 2.3. Author: Michael Armbrust Closes #18065 from marmbrus/streamingGA. commit 30922dec8a8cc598b6715f85281591208a91df00 Author: zero323 Date: 2017-05-26T22:01:01Z [SPARK-20694][DOCS][SQL] Document DataFrameWriter partitionBy, bucketBy and sortBy in SQL guide ## What changes were proposed in this pull request? - Add Scala, Python and Java examples for `partitionBy`, `sortBy` and `bucketBy`. - Add _Bucketing, Sorting and Partitioning_ section to SQL Programming Guide - Remove bucketing from Unsupported Hive Functionalities. ## How was this patch tested? Manual tests, docs build. Author: zero323 Closes #17938 from zero323/DOCS-BUCKETING-AND-PARTITIONING. (cherry picked from commit ae33abf71b353c638487948b775e966c7127cd46) Signed-off-by: Xiao Li commit fc799d730304c6a176636b414fc15184e89367d7 Author: Yu Peng Date: 2017-05-26T23:28:36Z [SPARK-10643][CORE] Make spark-submit download remote files to local in client mode #
[GitHub] spark pull request #19489: Branch 2.2
GitHub user dahaian reopened a pull request: https://github.com/apache/spark/pull/19489 Branch 2.2 ## What changes were proposed in this pull request? (Please fill in changes proposed in this fix) ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/apache/spark branch-2.2 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/19489.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #19489 commit fafe283277b50974c26684b06449086acd0cf05a Author: Wenchen Fan Date: 2017-05-26T07:01:28Z [SPARK-20868][CORE] UnsafeShuffleWriter should verify the position after FileChannel.transferTo ## What changes were proposed in this pull request? Long time ago we fixed a [bug](https://issues.apache.org/jira/browse/SPARK-3948) in shuffle writer about `FileChannel.transferTo`. We were not very confident about that fix, so we added a position check after the writing, try to discover the bug earlier. However this checking is missing in the new `UnsafeShuffleWriter`, this PR adds it. https://issues.apache.org/jira/browse/SPARK-18105 maybe related to that `FileChannel.transferTo` bug, hopefully we can find out the root cause after adding this position check. ## How was this patch tested? N/A Author: Wenchen Fan Closes #18091 from cloud-fan/shuffle. (cherry picked from commit d9ad78908f6189719cec69d34557f1a750d2e6af) Signed-off-by: Wenchen Fan commit f99456b5f6225a534ce52cf2b817285eb8853926 Author: NICHOLAS T. MARION Date: 2017-05-10T09:59:57Z [SPARK-20393][WEBU UI] Strengthen Spark to prevent XSS vulnerabilities ## What changes were proposed in this pull request? Add stripXSS and stripXSSMap to Spark Core's UIUtils. Calling these functions at any point that getParameter is called against a HttpServletRequest. ## How was this patch tested? Unit tests, IBM Security AppScan Standard no longer showing vulnerabilities, manual verification of WebUI pages. Author: NICHOLAS T. MARION Closes #17686 from n-marion/xss-fix. (cherry picked from commit b512233a457092b0e2a39d0b42cb021abc69d375) Signed-off-by: Sean Owen commit 92837aeb47fc3427166e4b6e62f6130f7480d7fa Author: Kazuaki Ishizaki Date: 2017-05-16T21:47:21Z [SPARK-19372][SQL] Fix throwing a Java exception at df.fliter() due to 64KB bytecode size limit ## What changes were proposed in this pull request? When an expression for `df.filter()` has many nodes (e.g. 400), the size of Java bytecode for the generated Java code is more than 64KB. It produces an Java exception. As a result, the execution fails. This PR continues to execute by calling `Expression.eval()` disabling code generation if an exception has been caught. ## How was this patch tested? Add a test suite into `DataFrameSuite` Author: Kazuaki Ishizaki Closes #17087 from kiszk/SPARK-19372. commit 2b59ed4f1d4e859d5987b6eaaee074260b2a12f8 Author: Michael Armbrust Date: 2017-05-26T20:33:23Z [SPARK-20844] Remove experimental from Structured Streaming APIs Now that Structured Streaming has been out for several Spark release and has large production use cases, the `Experimental` label is no longer appropriate. I've left `InterfaceStability.Evolving` however, as I think we may make a few changes to the pluggable Source & Sink API in Spark 2.3. Author: Michael Armbrust Closes #18065 from marmbrus/streamingGA. commit 30922dec8a8cc598b6715f85281591208a91df00 Author: zero323 Date: 2017-05-26T22:01:01Z [SPARK-20694][DOCS][SQL] Document DataFrameWriter partitionBy, bucketBy and sortBy in SQL guide ## What changes were proposed in this pull request? - Add Scala, Python and Java examples for `partitionBy`, `sortBy` and `bucketBy`. - Add _Bucketing, Sorting and Partitioning_ section to SQL Programming Guide - Remove bucketing from Unsupported Hive Functionalities. ## How was this patch tested? Manual tests, docs build. Author: zero323 Closes #17938 from zero323/DOCS-BUCKETING-AND-PARTITIONING. (cherry picked from commit ae33abf71b353c638487948b775e966c7127cd46) Signed-off-by: Xiao Li commit fc799d730304c6a176636b414fc15184e89367d7 Author: Yu Peng Date: 2017-05-26T23:28:36Z [SPARK-106
[GitHub] spark pull request #19489: Branch 2.2
Github user dahaian closed the pull request at: https://github.com/apache/spark/pull/19489 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19489: Branch 2.2
Github user dahaian closed the pull request at: https://github.com/apache/spark/pull/19489 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19489: Branch 2.2
GitHub user dahaian opened a pull request: https://github.com/apache/spark/pull/19489 Branch 2.2 ## What changes were proposed in this pull request? (Please fill in changes proposed in this fix) ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/apache/spark branch-2.2 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/19489.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #19489 commit fafe283277b50974c26684b06449086acd0cf05a Author: Wenchen Fan Date: 2017-05-26T07:01:28Z [SPARK-20868][CORE] UnsafeShuffleWriter should verify the position after FileChannel.transferTo ## What changes were proposed in this pull request? Long time ago we fixed a [bug](https://issues.apache.org/jira/browse/SPARK-3948) in shuffle writer about `FileChannel.transferTo`. We were not very confident about that fix, so we added a position check after the writing, try to discover the bug earlier. However this checking is missing in the new `UnsafeShuffleWriter`, this PR adds it. https://issues.apache.org/jira/browse/SPARK-18105 maybe related to that `FileChannel.transferTo` bug, hopefully we can find out the root cause after adding this position check. ## How was this patch tested? N/A Author: Wenchen Fan Closes #18091 from cloud-fan/shuffle. (cherry picked from commit d9ad78908f6189719cec69d34557f1a750d2e6af) Signed-off-by: Wenchen Fan commit f99456b5f6225a534ce52cf2b817285eb8853926 Author: NICHOLAS T. MARION Date: 2017-05-10T09:59:57Z [SPARK-20393][WEBU UI] Strengthen Spark to prevent XSS vulnerabilities ## What changes were proposed in this pull request? Add stripXSS and stripXSSMap to Spark Core's UIUtils. Calling these functions at any point that getParameter is called against a HttpServletRequest. ## How was this patch tested? Unit tests, IBM Security AppScan Standard no longer showing vulnerabilities, manual verification of WebUI pages. Author: NICHOLAS T. MARION Closes #17686 from n-marion/xss-fix. (cherry picked from commit b512233a457092b0e2a39d0b42cb021abc69d375) Signed-off-by: Sean Owen commit 92837aeb47fc3427166e4b6e62f6130f7480d7fa Author: Kazuaki Ishizaki Date: 2017-05-16T21:47:21Z [SPARK-19372][SQL] Fix throwing a Java exception at df.fliter() due to 64KB bytecode size limit ## What changes were proposed in this pull request? When an expression for `df.filter()` has many nodes (e.g. 400), the size of Java bytecode for the generated Java code is more than 64KB. It produces an Java exception. As a result, the execution fails. This PR continues to execute by calling `Expression.eval()` disabling code generation if an exception has been caught. ## How was this patch tested? Add a test suite into `DataFrameSuite` Author: Kazuaki Ishizaki Closes #17087 from kiszk/SPARK-19372. commit 2b59ed4f1d4e859d5987b6eaaee074260b2a12f8 Author: Michael Armbrust Date: 2017-05-26T20:33:23Z [SPARK-20844] Remove experimental from Structured Streaming APIs Now that Structured Streaming has been out for several Spark release and has large production use cases, the `Experimental` label is no longer appropriate. I've left `InterfaceStability.Evolving` however, as I think we may make a few changes to the pluggable Source & Sink API in Spark 2.3. Author: Michael Armbrust Closes #18065 from marmbrus/streamingGA. commit 30922dec8a8cc598b6715f85281591208a91df00 Author: zero323 Date: 2017-05-26T22:01:01Z [SPARK-20694][DOCS][SQL] Document DataFrameWriter partitionBy, bucketBy and sortBy in SQL guide ## What changes were proposed in this pull request? - Add Scala, Python and Java examples for `partitionBy`, `sortBy` and `bucketBy`. - Add _Bucketing, Sorting and Partitioning_ section to SQL Programming Guide - Remove bucketing from Unsupported Hive Functionalities. ## How was this patch tested? Manual tests, docs build. Author: zero323 Closes #17938 from zero323/DOCS-BUCKETING-AND-PARTITIONING. (cherry picked from commit ae33abf71b353c638487948b775e966c7127cd46) Signed-off-by: Xiao Li commit fc799d730304c6a176636b414fc15184e89367d7 Author: Yu Peng Date: 2017-05-26T23:28:36Z [SPARK-106