[GitHub] spark issue #19955: [SPARK-21867][CORE] Support async spilling in UnsafeShuf...
Github user ericvandenbergfb commented on the issue: https://github.com/apache/spark/pull/19955 @sitalkedia Added comment in test section on some benchmarks. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19955: [SPARK-21867][CORE] Support async spilling in UnsafeShuf...
Github user ericvandenbergfb commented on the issue: https://github.com/apache/spark/pull/19955 @cloud-fan In this case it reverts to the existing behavior, it will spill synchronously, free memory and then continue inserting. In addition, it would re-tune (down) the spill threshold so as it likely not hit this condition next time. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19955: [SPARK-21867][CORE] Support async spilling in UnsafeShuf...
Github user ericvandenbergfb commented on the issue: https://github.com/apache/spark/pull/19955 @cloud-fan I think this could be enabled for other sorters (mentioned that at end of design spec), just wanted to get this in incrementally. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19955: [SPARK-21867][CORE] Support async spilling in Uns...
GitHub user ericvandenbergfb opened a pull request: https://github.com/apache/spark/pull/19955 [SPARK-21867][CORE] Support async spilling in UnsafeShuffleWriter ## What changes were proposed in this pull request? Add a multi-shuffle sorter which supports asynchronous spilling during a shuffle external sort. The benefit is that we can insert and sort/spill in parallel, reducing the overall latency for jobs that are heavy on shuffling (as are many ads jobs). The multi-shuffle sorter is added between the UnsafeShuffleWriter and ShuffleExternalSorter such that few changes are needed outside of this component, and as such, we can see clearly there is little room for regressing other code paths. The multi-shuffle sorter is enabled via a configuration flag, spark.shuffle.async.num.sorter (default 1) If the value is 1, then the multi-shuffle sorter is not used, it must be configured to have multiple sorters (>=2) There is a design spec here attached to the jira. ## How was this patch tested? Added unit tests specifically for the MultiShuffleSorter to exercise under various spill and insert conditions. Extended the UnsafeShuffleWriterSuite to run against a single ShuffleExternalSorter or multiple via the MultiShuffleSorter to ensure no regressions. Ran against production work loads and observed gains and validated based on logging. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ericvandenbergfb/spark async.multi.shuffle.sorter.2 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/19955.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #19955 commit 7f751ec23ba6d8c53c009edb7d62a460e9166d7f Author: Eric Vandenberg <ericvandenb...@fb.com> Date: 2017-12-12T02:23:26Z [SPARK-21867][CORE] Support async spilling in UnsafeShuffleWriter Add a multi-shuffle sorter which supports asynchronous spilling during a shuffle external sort. The benefit is that we can insert and sort/spill in parallel, reducing the overall latency for jobs that are heavy on shuffling (as are many ads jobs). The multi-shuffle sorter is added between the UnsafeShuffleWriter and ShuffleExternalSorter such that few changes are needed outside of this component, and as such, we can see clearly there is little room for regressing other code paths. The multi-shuffle sorter is enabled via a configuration flag, spark.shuffle.async.num.sorter (default 1) If the value is 1, then the multi-shuffle sorter is not used, it must be configured to have multiple sorters (>=2) There is a design spec here attached to the jira. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19770: [SPARK-21571][WEB UI] Spark history server leaves...
Github user ericvandenbergfb closed the pull request at: https://github.com/apache/spark/pull/19770 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19770: [SPARK-21571][WEB UI] Spark history server leaves incomp...
Github user ericvandenbergfb commented on the issue: https://github.com/apache/spark/pull/19770 @vanzin I took a look at your pr, it looks good overall and covers the same cases from what I can tell. I don't think there's anything additional needed here unless I missed something. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19770: [SPARK-21571][WEB UI] Spark history server leaves incomp...
Github user ericvandenbergfb commented on the issue: https://github.com/apache/spark/pull/19770 Fixed scalastyle issues. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18791: [SPARK-21571][Scheduler] Spark history server leaves inc...
Github user ericvandenbergfb commented on the issue: https://github.com/apache/spark/pull/18791 See continuation of pull request at https://github.com/apache/spark/pull/19770 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18791: [SPARK-21571][Scheduler] Spark history server lea...
Github user ericvandenbergfb closed the pull request at: https://github.com/apache/spark/pull/18791 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19770: [SPARK-21571][WEB UI] Spark history server leaves incomp...
Github user ericvandenbergfb commented on the issue: https://github.com/apache/spark/pull/19770 This is a continuation of https://github.com/apache/spark/pull/18791 - the underlying code changed so had to reimplement. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19770: [SPARK-21571][WEB UI] Spark history server leaves...
GitHub user ericvandenbergfb opened a pull request: https://github.com/apache/spark/pull/19770 [SPARK-21571][WEB UI] Spark history server leaves incomplete or unreadable logs around forever ## What changes were proposed in this pull request? ** Updated pull request based on some other refactoring that went into FsHistoryProvider ** Fix logic checkForLogs excluded 0-size files so they stuck around forever. checkForLogs / mergeApplicationListing indefinitely ignored files that were not parseable/couldn't extract an appID, so they stuck around forever. Only apply above logic if spark.history.fs.cleaner.aggressive=true. Fixed race condition in a test (SPARK-3697: ignore files that cannot be read.) where the number of mergeApplicationListings could be more than 1 since the FsHistoryProvider would spin up an executor that also calls checkForLogs in parallel with the test. Added unit test to cover all cases with aggressive and non-aggressive clean up logic. ## How was this patch tested? Add test that extensive tests the untracked files getting cleaned up when configured. Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ericvandenbergfb/spark master Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/19770.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #19770 commit c52b1cfd2eee9c881267d3d4cd9ea83fb6a767eb Author: Eric Vandenberg <ericvandenb...@fb.com> Date: 2017-07-31T22:02:54Z [SPARK-21571][WEB UI] Spark history server leaves incomplete or unreadable history files around forever. Fix logic 1. checkForLogs excluded 0-size files so they stuck around forever. 2. checkForLogs / mergeApplicationListing indefinitely ignored files that were not parseable/couldn't extract an appID, so they stuck around forever. Only apply above logic if spark.history.fs.cleaner.aggressive=true. Fixed race condition in a test (SPARK-3697: ignore files that cannot be read.) where the number of mergeApplicationListings could be more than 1 since the FsHistoryProvider would spin up an executor that also calls checkForLogs in parallel with the test. Added unit test to cover all cases with aggressive and non-aggressive clean up logic. commit 08ea4ace02b7f8bf39190d5af53e7ced5e2807a0 Author: Eric Vandenberg <ericvandenb...@fb.com> Date: 2017-11-15T20:03:21Z Merge branch 'master' of github.com:ericvandenbergfb/spark into cleanup.untracked.history.files * 'master' of github.com:ericvandenbergfb/spark: (637 commits) [SPARK-22469][SQL] Accuracy problem in comparison with string and numeric [SPARK-22490][DOC] Add PySpark doc for SparkSession.builder [SPARK-22422][ML] Add Adjusted R2 to RegressionMetrics [SPARK-20791][PYTHON][FOLLOWUP] Check for unicode column names in createDataFrame with Arrow [SPARK-22514][SQL] move ColumnVector.Array and ColumnarBatch.Row to individual files [SPARK-12375][ML] VectorIndexerModel support handle unseen categories via handleInvalid [SPARK-21087][ML] CrossValidator, TrainValidationSplit expose sub models after fitting: Scala [SPARK-22511][BUILD] Update maven central repo address [SPARK-22519][YARN] Remove unnecessary stagingDirPath null check in ApplicationMaster.cleanupStagingDir() [SPARK-20652][SQL] Store SQL UI data in the new app status store. [SPARK-20648][CORE] Port JobsTab and StageTab to the new UI backend. [SPARK-17074][SQL] Generate equi-height histogram in column statistics [SPARK-17310][SQL] Add an option to disable record-level filter in Parquet-side [SPARK-21911][ML][FOLLOW-UP] Fix doc for parallel ML Tuning in PySpark [SPARK-22377][BUILD] Use /usr/sbin/lsof if lsof does not exists in release-build.sh [SPARK-22487][SQL][FOLLOWUP] still keep spark.sql.hive.version [MINOR][CORE] Using bufferedInputStream for dataDeserializeStream [SPARK-20791][PYSPARK] Use Arrow to create Spark DataFrame from Pandas [SPARK-21693][R][ML] Reduce max iterations in Linear SVM test in R to speed up AppVeyor build [SPARK-21720][SQL] Fix 64KB JVM bytecode limit problem with AND or OR ... commit aee2fd3ffb9d720d33d032fdb924e9d1f4d20a4c Author: Eric Vandenberg <ericvandenb...@fb.com> Date: 2017-11-16T20:33:39Z [SPARK-21571][WEB UI] Spark history server cleans up untracked files. The history provider code was changed so I reimplemented the fix to clean up empty or corrupt history files that otherwise would stay aroun
[GitHub] spark issue #18791: [SPARK-21571][Scheduler] Spark history server leaves inc...
Github user ericvandenbergfb commented on the issue: https://github.com/apache/spark/pull/18791 The default is off, so people can opt-in to more aggressive clean up. Is this okay to be merged? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18791: [SPARK-21571][Scheduler] Spark history server lea...
Github user ericvandenbergfb commented on a diff in the pull request:
https://github.com/apache/spark/pull/18791#discussion_r130743830
--- Diff:
core/src/test/scala/org/apache/spark/deploy/history/FsHistoryProviderSuite.scala
---
@@ -134,7 +134,8 @@ class FsHistoryProviderSuite extends SparkFunSuite with
BeforeAndAfter with Matc
// setReadable(...) does not work on Windows. Please refer JDK-6728842.
assume(!Utils.isWindows)
-class TestFsHistoryProvider extends
FsHistoryProvider(createTestConf()) {
+class TestFsHistoryProvider extends FsHistoryProvider(
+ createTestConf().set("spark.testing", "true")) {
--- End diff --
The test suite refused to pass on my machine so decided to fix it.
Mentioned in commit comments...
Fixed race condition in a test (SPARK-3697: ignore files that cannot be
read.) where the number of mergeApplicationListings could be more than 1
since the FsHistoryProvider would spin up an executor that also calls
checkForLogs in parallel with the test unless spark.testing=true configured.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18791: [SPARK-21571][WEB UI] Spark history server leaves...
GitHub user ericvandenbergfb opened a pull request: https://github.com/apache/spark/pull/18791 [SPARK-21571][WEB UI] Spark history server leaves incomplete or unrea⦠â¦dable history files around forever. Fix logic 1. checkForLogs excluded 0-size files so they stuck around forever. 2. checkForLogs / mergeApplicationListing indefinitely ignored files that were not parseable/couldn't extract an appID, so they stuck around forever. Only apply above logic if spark.history.fs.cleaner.aggressive=true. Fixed race condition in a test (SPARK-3697: ignore files that cannot be read.) where the number of mergeApplicationListings could be more than 1 since the FsHistoryProvider would spin up an executor that also calls checkForLogs in parallel with the test unless spark.testing=true configured. Added unit test to cover all cases with aggressive and non-aggressive clean up logic. ## What changes were proposed in this pull request? The spark history server doesn't clean up certain history files outside the retention window leading to thousands of such files lingering around on our servers. The log checking and clean up logic skipped 0 byte files and expired inprogress or complete history files that weren't properly parseable (not able to extract an app id or otherwise parse...) Note these files most likely appeared to due aborted jobs or earlier spark/file system driver bugs. To mitigate this, FsHistoryProvider.checkForLogs now internally identifies these untracked files and will remove them if they expire outside the cleaner retention window. This is currently controlled via configuration spark.history.fs.cleaner.aggressive=true to perform more aggressive cleaning. ## How was this patch tested? Implemented a unit test that exercises the above cases without and without the aggressive cleaning to ensure correct results in all cases. Note that FsHistoryProvider at one place uses the file system to get the current time and and at other times the local system time, this seems inconsistent/buggy but I did not attempt to fix in this commit. I was forced to change one of the method FsHistoryProvider.getNewLastScanTime() for the test to properly mock the clock. Also ran a history server and touched some files to verify they were properly removed. ericvandenberg@localhost /tmp/spark-events % ls -la total 808K drwxr-xr-x 8 ericvandenberg 272 Jul 31 18:22 . drwxrwxrwt 127 root -rw-r--r-- 1 ericvandenberg0 Jan 1 2016 local-123.inprogress -rwxr-x--- 1 ericvandenberg 342K Jan 1 2016 local-1501549952084 -rwxrwx--- 1 ericvandenberg 342K Jan 1 2016 local-1501549952084.inprogress -rwxrwx--- 1 ericvandenberg 59K Jul 31 18:19 local-1501550073208 -rwxrwx--- 1 ericvandenberg 59K Jul 31 18:21 local-1501550473508.inprogress -rw-r--r-- 1 ericvandenberg0 Jan 1 2016 local-234 Observed in history server logs: 17/07/31 18:23:52 INFO FsHistoryProvider: Aggressively cleaned up 4 untracked history files. ericvandenberg@localhost /tmp/spark-events % ls -la total 120K drwxr-xr-x 4 ericvandenberg 136 Jul 31 18:24 . drwxrwxrwt 127 root 4.3K Jul 31 18:07 .. -rwxrwx--- 1 ericvandenberg 59K Jul 31 18:19 local-1501550073208 -rwxrwx--- 1 ericvandenberg 59K Jul 31 18:22 local-1501550473508 You can merge this pull request into a Git repository by running: $ git pull https://github.com/ericvandenbergfb/spark cleanup.untracked.history.files Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/18791.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #18791 commit c52b1cfd2eee9c881267d3d4cd9ea83fb6a767eb Author: Eric Vandenberg <ericvandenb...@fb.com> Date: 2017-07-31T22:02:54Z [SPARK-21571][WEB UI] Spark history server leaves incomplete or unreadable history files around forever. Fix logic 1. checkForLogs excluded 0-size files so they stuck around forever. 2. checkForLogs / mergeApplicationListing indefinitely ignored files that were not parseable/couldn't extract an appID, so they stuck around forever. Only apply above logic if spark.history.fs.cleaner.aggressive=true. Fixed race condition in a test (SPARK-3697: ignore files that cannot be read.) where the number of mergeApplicationListings could be more than 1 since the FsHistoryProvider would spin up an executor that also calls checkForLogs in parallel with the test. Added unit test to cover all cases with aggressive and non-aggressive clean up logic. --- If your project is set up for it, you can reply to this email and have your
[GitHub] spark pull request #18673: [SPARK-21447][WEB UI] Spark history server fails ...
Github user ericvandenbergfb commented on a diff in the pull request:
https://github.com/apache/spark/pull/18673#discussion_r128051065
--- Diff:
core/src/main/scala/org/apache/spark/scheduler/ReplayListenerBus.scala ---
@@ -107,6 +107,16 @@ private[spark] class ReplayListenerBus extends
SparkListenerBus with Logging {
}
}
} catch {
+ case eofe: EOFException =>
+// If the history event file is compressed and inprogress, the
compressor will throw an
+// EOFException if there is not enough to decompress a proper
frame. This indicates
+// we're at the end of the file so we treat similarly to the
JsonParseException case above.
+if (!maybeTruncated) {
+ throw eofe
+} else {
+ logWarning(s"Got EOFException from log file $sourceName" +
--- End diff --
Agree, the message doesn't add much value since this is expected behavior.
Will remove.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18673: [SPARK-21447][WEB UI] Spark history server fails ...
Github user ericvandenbergfb commented on a diff in the pull request:
https://github.com/apache/spark/pull/18673#discussion_r128050958
--- Diff:
core/src/main/scala/org/apache/spark/scheduler/ReplayListenerBus.scala ---
@@ -107,6 +107,16 @@ private[spark] class ReplayListenerBus extends
SparkListenerBus with Logging {
}
}
} catch {
+ case eofe: EOFException =>
+// If the history event file is compressed and inprogress, the
compressor will throw an
+// EOFException if there is not enough to decompress a proper
frame. This indicates
+// we're at the end of the file so we treat similarly to the
JsonParseException case above.
+if (!maybeTruncated) {
--- End diff --
Okay, nice short syntax.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18673: [SPARK-21447][WEB UI] Spark history server fails ...
GitHub user ericvandenbergfb opened a pull request: https://github.com/apache/spark/pull/18673 [SPARK-21447][WEB UI] Spark history server fails to render compressed inprogress history file in some cases. Add failure handling for EOFException that can be thrown during decompression of an inprogress spark history file, treat same as case where can't parse the last line. ## What changes were proposed in this pull request? Failure handling for case of EOFException thrown within the ReplayListenerBus.replay method to handle the case analogous to json parse fail case. This path can arise in compressed inprogress history files since an incomplete compression block could be read (not flushed by writer on a block boundary). See the stack trace of this occurrence in the jira ticket (https://issues.apache.org/jira/browse/SPARK-21447) ## How was this patch tested? Added a unit test that specifically targets validating the failure handling path appropriately when maybeTruncated is true and false. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ericvandenbergfb/spark fix_inprogress_compr_history_file Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/18673.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #18673 commit caeac288e2285d16c327a0df6abd6c9fccecdd50 Author: Eric Vandenberg <ericvandenb...@fb.com> Date: 2017-07-18T16:58:12Z [SPARK-21447][WEB UI] Spark history server fails to render compressed inprogress history file in some cases. Add failure handling for EOFException that can be thrown during decompression of an inprogress spark history file, treat same as case where can't parse the last line. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18427: [SPARK-21219][Core] Task retry occurs on same exe...
Github user ericvandenbergfb commented on a diff in the pull request:
https://github.com/apache/spark/pull/18427#discussion_r126236401
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/TaskSetManagerSuite.scala ---
@@ -1172,6 +1172,50 @@ class TaskSetManagerSuite extends SparkFunSuite with
LocalSparkContext with Logg
assert(blacklistTracker.isNodeBlacklisted("host1"))
}
+ test("update blacklist before adding pending task to avoid race
condition") {
+// When a task fails, it should apply the blacklist policy prior to
+// retrying the task otherwise there's a race condition where run on
+// the same executor that it was intended to be black listed from.
+val conf = new SparkConf().
+ set(config.BLACKLIST_ENABLED, true).
+ set(config.MAX_TASK_ATTEMPTS_PER_EXECUTOR, 1)
+
+// Create a task with two executors.
+sc = new SparkContext("local", "test", conf)
+val exec = "executor1"
+val host = "host1"
+val exec2 = "executor2"
+val host2 = "host2"
+sched = new FakeTaskScheduler(sc, (exec, host), (exec2, host2))
+val taskSet = FakeTask.createTaskSet(1)
+
+val clock = new ManualClock
+val mockListenerBus = mock(classOf[LiveListenerBus])
+val blacklistTracker = new BlacklistTracker(mockListenerBus, conf,
None, clock)
+val taskSetManager = new TaskSetManager(sched, taskSet, 1,
Some(blacklistTracker))
+val taskSetManagerSpy = spy(taskSetManager)
+
+val taskDesc = taskSetManagerSpy.resourceOffer(exec, host,
TaskLocality.ANY)
+
+// Assert the task has been black listed on the executor it was last
executed on.
+when(taskSetManagerSpy.addPendingTask(anyInt())).thenAnswer(
+ new Answer[Unit] {
+override def answer(invocationOnMock: InvocationOnMock): Unit = {
+ val task = invocationOnMock.getArgumentAt(0, classOf[Int])
+ assert(taskSetManager.taskSetBlacklistHelperOpt.get.
+isExecutorBlacklistedForTask(exec, task))
+}
+ }
+)
+
+// Simulate an out of memory error
+val e = new OutOfMemoryError
+taskSetManagerSpy.handleFailedTask(
+ taskDesc.get.taskId, TaskState.FAILED, new ExceptionFailure(e,
Seq()))
--- End diff --
Okay
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18427: [SPARK-21219][Core] Task retry occurs on same exe...
Github user ericvandenbergfb commented on a diff in the pull request:
https://github.com/apache/spark/pull/18427#discussion_r126228623
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/TaskSetManagerSuite.scala ---
@@ -1172,6 +1172,50 @@ class TaskSetManagerSuite extends SparkFunSuite with
LocalSparkContext with Logg
assert(blacklistTracker.isNodeBlacklisted("host1"))
}
+ test("update blacklist before adding pending task to avoid race
condition") {
+// When a task fails, it should apply the blacklist policy prior to
+// retrying the task otherwise there's a race condition where run on
+// the same executor that it was intended to be black listed from.
+val conf = new SparkConf().
+ set(config.BLACKLIST_ENABLED, true).
+ set(config.MAX_TASK_ATTEMPTS_PER_EXECUTOR, 1)
+
+// Create a task with two executors.
+sc = new SparkContext("local", "test", conf)
+val exec = "executor1"
+val host = "host1"
+val exec2 = "executor2"
+val host2 = "host2"
+sched = new FakeTaskScheduler(sc, (exec, host), (exec2, host2))
+val taskSet = FakeTask.createTaskSet(1)
+
+val clock = new ManualClock
+val mockListenerBus = mock(classOf[LiveListenerBus])
+val blacklistTracker = new BlacklistTracker(mockListenerBus, conf,
None, clock)
+val taskSetManager = new TaskSetManager(sched, taskSet, 1,
Some(blacklistTracker))
--- End diff --
It seems all the tests in this file are using ManualClock so was following
convention here. This test doesn't validate anything specifically dependent on
the clock/time.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18427: [SPARK-21219][Core] Task retry occurs on same exe...
Github user ericvandenbergfb commented on a diff in the pull request:
https://github.com/apache/spark/pull/18427#discussion_r126228249
--- Diff:
core/src/test/scala/org/apache/spark/scheduler/TaskSetManagerSuite.scala ---
@@ -1172,6 +1172,50 @@ class TaskSetManagerSuite extends SparkFunSuite with
LocalSparkContext with Logg
assert(blacklistTracker.isNodeBlacklisted("host1"))
}
+ test("update blacklist before adding pending task to avoid race
condition") {
+// When a task fails, it should apply the blacklist policy prior to
+// retrying the task otherwise there's a race condition where run on
+// the same executor that it was intended to be black listed from.
+val conf = new SparkConf().
+ set(config.BLACKLIST_ENABLED, true).
+ set(config.MAX_TASK_ATTEMPTS_PER_EXECUTOR, 1)
--- End diff --
Yes, I added it to make the test code (configuration) inputs more explicit,
but I can remove if it's a default unlikely to change.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18427: [SPARK-21219][scheduler] Fix race condition betwe...
GitHub user ericvandenbergfb opened a pull request: https://github.com/apache/spark/pull/18427 [SPARK-21219][scheduler] Fix race condition between adding task to pe⦠â¦nding list and updating black list state. ## What changes were proposed in this pull request? There's a race condition in the current TaskSetManager where a failed task is added for retry (addPendingTask), and can asynchronously be assigned to an executor *prior* to the blacklist state (updateBlacklistForFailedTask), the result is the task might re-execute on the same executor. This is particularly problematic if the executor is shutting down since the retry task immediately becomes a lost task (ExecutorLostFailure). Another side effect is that the actual failure reason gets obscured by the retry task which never actually executed. There are sample logs showing the issue in the https://issues.apache.org/jira/browse/SPARK-21219 The fix is to change the ordering of the addPendingTask and updatingBlackListForFailedTask calls in TaskSetManager.handleFailedTask ## How was this patch tested? Implemented a unit test that verifies the task is black listed before it is added to the pending task. Ran the unit test without the fix and it fails. Ran the unit test with the fix and it passes. Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ericvandenbergfb/spark blacklistFix Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/18427.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #18427 commit 3cf068df4cb9f863b895b10d12203f3b5406a989 Author: Eric Vandenberg <ericvandenb...@fb.com> Date: 2017-06-26T22:20:42Z [SPARK-21219][scheduler] Fix race condition between adding task to pending list and updating black list state. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18369: [SPARK-21155][WEBUI] Add (? running tasks) into Spark UI...
Github user ericvandenbergfb commented on the issue: https://github.com/apache/spark/pull/18369 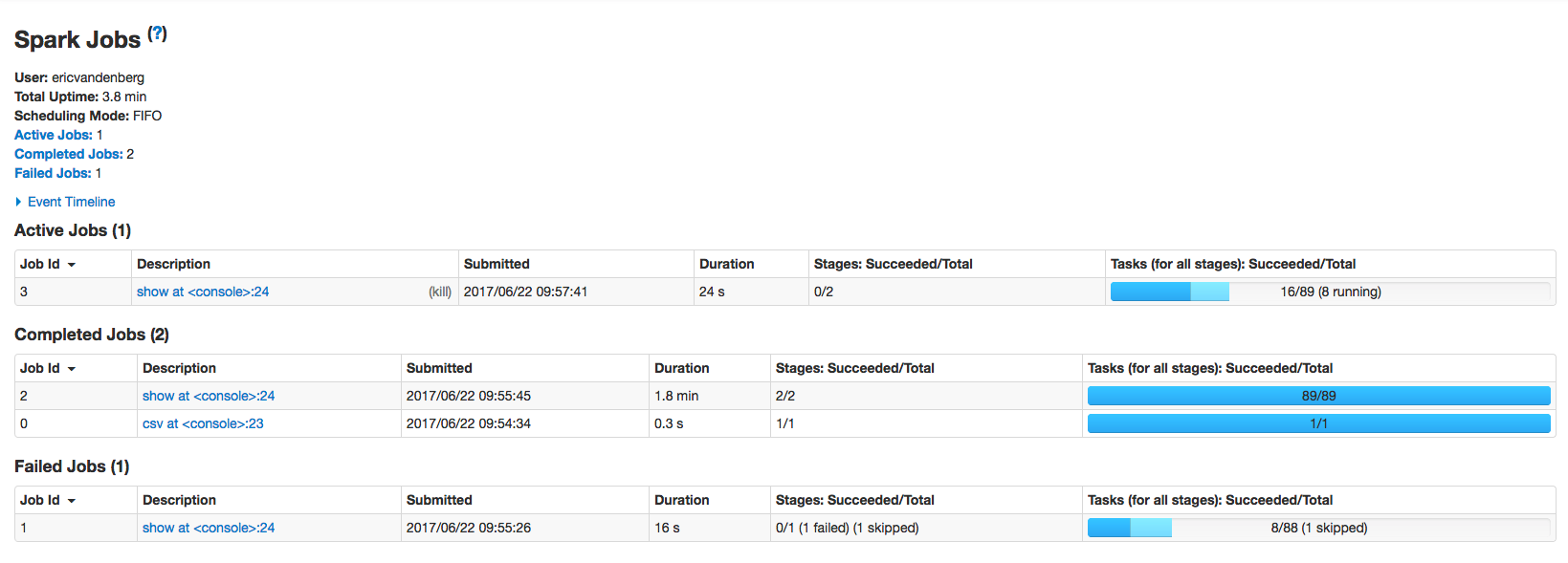 Good point, modified to only show runningTasks if no skipped or failed tasks. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18369: [SPARK-21155][WEBUI] Add (? running tasks) into Spark UI...
Github user ericvandenbergfb commented on the issue: https://github.com/apache/spark/pull/18369 before:  after:  --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18369: [SPARK-21155][WEBUI] Add (? running tasks) into S...
GitHub user ericvandenbergfb opened a pull request: https://github.com/apache/spark/pull/18369 [SPARK-21155][WEBUI] Add (? running tasks) into Spark UI progress ## What changes were proposed in this pull request? Add metric on number of running tasks to status bar on Jobs / Active Jobs. ## How was this patch tested? Run a long running (1 minute) query in spark-shell and use localhost:4040 web UI to observe progress. See jira for screen snapshot. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ericvandenbergfb/spark runningTasks Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/18369.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #18369 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18010: [SPARK-20778][SQL] Implement array_inetrsect func...
GitHub user ericvandenbergfb opened a pull request: https://github.com/apache/spark/pull/18010 [SPARK-20778][SQL] Implement array_inetrsect function. Implement array_intersect UDF for intersecting first array with set of arrays. ## What changes were proposed in this pull request? Implement a function array_intersect that computes the intersection of first array and remaining arrays. Similar to hive implementation of array intersect. ## How was this patch tested? Added unit tests to validate eval and code gen logic. Performed testing using spark-shell with similar tests to hive array intersect. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ericvandenbergfb/spark spark.array_intersect.udf Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/18010.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #18010 commit a13edcde385fd6bae83fa1d2ad4999c72456acc3 Author: Eric Vandenberg <ericvandenb...@fb.com> Date: 2017-05-16T23:45:29Z [SPARK-20778][SQL] Implement array_inetrsect function. Implement array_intersect UDF for intersecting first array with set of arrays. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18007: Test spark commit. Do not merge.
Github user ericvandenbergfb closed the pull request at: https://github.com/apache/spark/pull/18007 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18007: Test spark commit. Do not merge.
GitHub user ericvandenbergfb opened a pull request: https://github.com/apache/spark/pull/18007 Test spark commit. Do not merge. ## What changes were proposed in this pull request? (Please fill in changes proposed in this fix) ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ericvandenbergfb/spark spark.test.commit.do.not.merge Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/18007.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #18007 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org