[GitHub] spark pull request #14191: [SPARK-16217][SQL] Support SELECT INTO statement
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/14191 --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #14191: [SPARK-16217][SQL] Support SELECT INTO statement
Github user gatorsmile commented on a diff in the pull request:
https://github.com/apache/spark/pull/14191#discussion_r121592866
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/parser/AstBuilder.scala
---
@@ -395,6 +414,15 @@ class AstBuilder extends SqlBaseBaseVisitor[AnyRef]
with Logging {
}
/**
+ * Change to Hive CTAS statement.
+ */
+ protected def withSelectInto(
+ ctx: IntoClauseContext,
+ query: LogicalPlan): LogicalPlan = withOrigin(ctx) {
+throw new ParseException("Script Select Into is not supported", ctx)
--- End diff --
Why throwing an `ParseException `?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #14191: [SPARK-16217][SQL] Support SELECT INTO statement
Github user wuxianxingkong commented on a diff in the pull request: https://github.com/apache/spark/pull/14191#discussion_r71077546 --- Diff: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 --- @@ -347,6 +347,10 @@ querySpecification windows?) ; +intoClause +: INTO tableIdentifier --- End diff -- For example, the json data registed as table tbl_b is:  @hvanhovell The Logical Plan of sql "SELECT a INTO tbl_a FROM tbl_b" is: 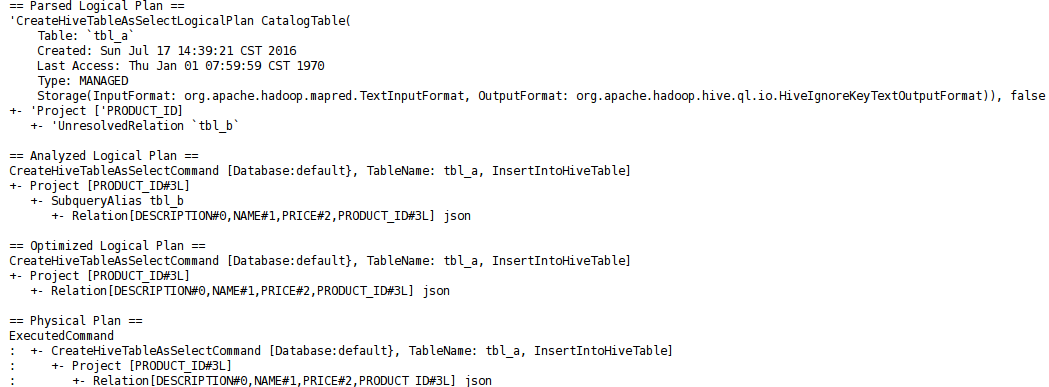 The results match the expectations --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #14191: [SPARK-16217][SQL] Support SELECT INTO statement
Github user wuxianxingkong commented on a diff in the pull request:
https://github.com/apache/spark/pull/14191#discussion_r71067943
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/SparkSqlParser.scala ---
@@ -1376,4 +1376,62 @@ class SparkSqlAstBuilder(conf: SQLConf) extends
AstBuilder {
reader, writer,
schemaLess)
}
+
+ /**
+ * Reuse CTAS, convert select into to CTAS,
+ * returning [[CreateHiveTableAsSelectLogicalPlan]].
+ * The SELECT INTO statement selects data from one table
+ * and inserts it into a new table.It is commonly used to
+ * create a backup copy for table or selected records.
+ *
+ * Expected format:
+ * {{{
+ * SELECT column_name(s)
+ * INTO new_table
+ * FROM old_table
+ * ...
+ * }}}
+ */
+ override protected def withSelectInto(
--- End diff --
Reusing CTAS code path means we need to convert _IntoClauseContext_ to
_CreateTableContext_ (or construct a new _CreateTableContext_),it might be
difficult to archive. Maybe there is another way?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #14191: [SPARK-16217][SQL] Support SELECT INTO statement
Github user wuxianxingkong commented on a diff in the pull request: https://github.com/apache/spark/pull/14191#discussion_r71067768 --- Diff: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 --- @@ -338,7 +338,7 @@ querySpecification (RECORDREADER recordReader=STRING)? fromClause? (WHERE where=booleanExpression)?) -| ((kind=SELECT setQuantifier? namedExpressionSeq fromClause? +| ((kind=SELECT setQuantifier? namedExpressionSeq (intoClause? fromClause)? --- End diff -- At first, I modify grammar: 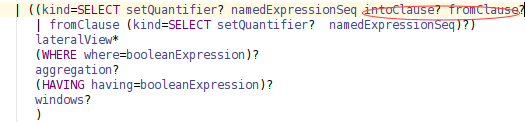 But it will affect multiInsertQueryBody rule, i.e.: ```sql FROM OLD_TABLE INSERT INTO T1 SELECT C1 INSERT INTO T2 SELECT C2 ``` The Syntax tree before adding intoClause is: 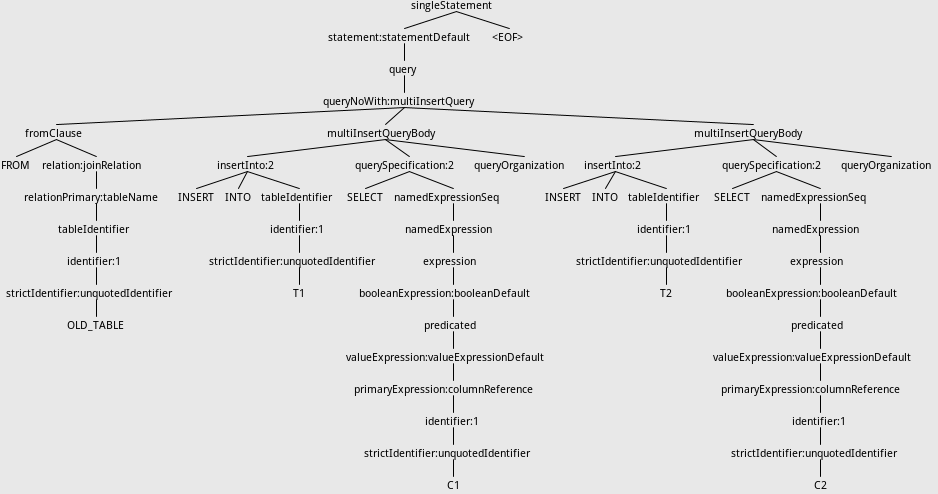 After adding intoClause ,the tree will be: 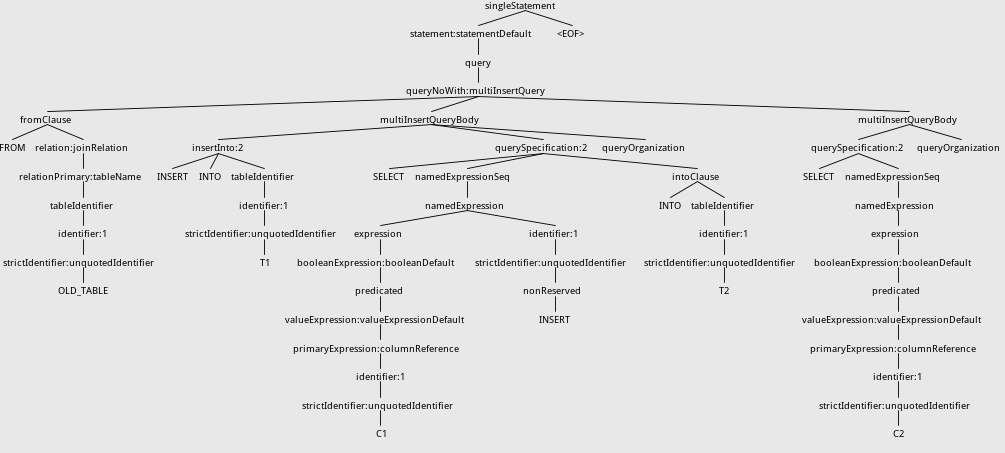 This is because INSERT is a nonreserved keyword and matching strategy of antlr. One of the ways I can think of is to change grammar like this: 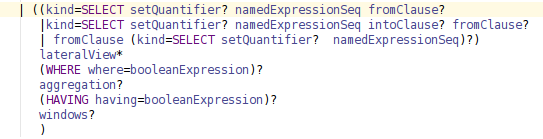 This can solve the problem because antlr parser chooses the alternative specified first. By the way, the grammar now can support "SELECT 1 INTO newtable" now. But this will cause confusion about querySpecification rule because of the duplication. Is there any way to solve this problem?Thanks. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #14191: [SPARK-16217][SQL] Support SELECT INTO statement
Github user dongjoon-hyun commented on a diff in the pull request:
https://github.com/apache/spark/pull/14191#discussion_r70935956
--- Diff:
sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 ---
@@ -338,7 +338,7 @@ querySpecification
(RECORDREADER recordReader=STRING)?
fromClause?
(WHERE where=booleanExpression)?)
-| ((kind=SELECT setQuantifier? namedExpressionSeq fromClause?
+| ((kind=SELECT setQuantifier? namedExpressionSeq (intoClause?
fromClause)?
--- End diff --
In the Spark Shell, please run the followings.
```
sql("select 1")
```
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #14191: [SPARK-16217][SQL] Support SELECT INTO statement
Github user wuxianxingkong commented on a diff in the pull request: https://github.com/apache/spark/pull/14191#discussion_r70935031 --- Diff: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 --- @@ -338,7 +338,7 @@ querySpecification (RECORDREADER recordReader=STRING)? fromClause? (WHERE where=booleanExpression)?) -| ((kind=SELECT setQuantifier? namedExpressionSeq fromClause? +| ((kind=SELECT setQuantifier? namedExpressionSeq (intoClause? fromClause)? --- End diff -- ```sql SELECT 1 INTO newtable ``` This won't work because we need oldtable info to create newtable. So the sql should be ```sql SELECT 1 INTO newtable FROM oldtable ``` The result from my test is: a new table called newtable was created, one column called 1 has the length of oldtable.rows.length and all elements are 1. Did you mean there is no _FROM_? --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #14191: [SPARK-16217][SQL] Support SELECT INTO statement
Github user hvanhovell commented on a diff in the pull request:
https://github.com/apache/spark/pull/14191#discussion_r70801792
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/SparkSqlParser.scala ---
@@ -1376,4 +1376,62 @@ class SparkSqlAstBuilder(conf: SQLConf) extends
AstBuilder {
reader, writer,
schemaLess)
}
+
+ /**
+ * Reuse CTAS, convert select into to CTAS,
+ * returning [[CreateHiveTableAsSelectLogicalPlan]].
+ * The SELECT INTO statement selects data from one table
+ * and inserts it into a new table.It is commonly used to
+ * create a backup copy for table or selected records.
+ *
+ * Expected format:
+ * {{{
+ * SELECT column_name(s)
+ * INTO new_table
+ * FROM old_table
+ * ...
+ * }}}
+ */
+ override protected def withSelectInto(
--- End diff --
The code below is duplicates. Why are we not using the existing CTAS code
path?
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #14191: [SPARK-16217][SQL] Support SELECT INTO statement
Github user hvanhovell commented on a diff in the pull request: https://github.com/apache/spark/pull/14191#discussion_r70754843 --- Diff: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 --- @@ -347,6 +347,10 @@ querySpecification windows?) ; +intoClause +: INTO tableIdentifier --- End diff -- Could you also check what kind of a plan the following query produces: ```SQL SELECT a INTO tbl_a FROM tbl_b ``` We might run into a weird syntax error here. If we do then we need to move the `INTO` keyword from the `nonReserved` rule to the `identifier` rule. --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #14191: [SPARK-16217][SQL] Support SELECT INTO statement
Github user hvanhovell commented on a diff in the pull request:
https://github.com/apache/spark/pull/14191#discussion_r70754573
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/parser/AstBuilder.scala
---
@@ -159,7 +159,9 @@ class AstBuilder extends SqlBaseBaseVisitor[AnyRef]
with Logging {
// Add organization statements.
optionalMap(ctx.queryOrganization)(withQueryResultClauses).
// Add insert.
- optionalMap(ctx.insertInto())(withInsertInto)
--- End diff --
We also need to check what this does with multi-insert syntax, i.e.:
```sql
FROM tbl_a
INSERT INTO tbl_b
SELECT *
INSERT INTO tbl_c
SELECT *
INTO tbl_c
```
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #14191: [SPARK-16217][SQL] Support SELECT INTO statement
Github user hvanhovell commented on a diff in the pull request: https://github.com/apache/spark/pull/14191#discussion_r70754255 --- Diff: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 --- @@ -347,6 +347,10 @@ querySpecification windows?) ; +intoClause +: INTO tableIdentifier --- End diff -- It is easier to just put this in the `querySpecification` rule. Make sure you given the tableIdentifier a proper name --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #14191: [SPARK-16217][SQL] Support SELECT INTO statement
Github user hvanhovell commented on a diff in the pull request:
https://github.com/apache/spark/pull/14191#discussion_r70754137
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/parser/AstBuilder.scala
---
@@ -159,7 +159,9 @@ class AstBuilder extends SqlBaseBaseVisitor[AnyRef]
with Logging {
// Add organization statements.
optionalMap(ctx.queryOrganization)(withQueryResultClauses).
// Add insert.
- optionalMap(ctx.insertInto())(withInsertInto)
--- End diff --
This allows for the following syntax:
```sql
INSERT INTO tbl_a
SELECT *
INTO tbl_a
FROM tbl_b
```
Make sure that we cannot have both.
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #14191: [SPARK-16217][SQL] Support SELECT INTO statement
Github user dongjoon-hyun commented on a diff in the pull request:
https://github.com/apache/spark/pull/14191#discussion_r70748362
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/SQLQuerySuite.scala
---
@@ -1755,4 +1755,97 @@ class SQLQuerySuite extends QueryTest with
SQLTestUtils with TestHiveSingleton {
}
}
}
+
+ test("select into(check relation)") {
+val originalConf = sessionState.conf.convertCTAS
+
+setConf(SQLConf.CONVERT_CTAS, true)
+
+val defaultDataSource = sessionState.conf.defaultDataSourceName
+try {
+ sql("DROP TABLE IF EXISTS si1")
+ sql("SELECT key, value INTO si1 FROM src ORDER BY key, value")
+ val message = intercept[AnalysisException] {
+sql("SELECT key, value INTO si1 FROM src ORDER BY key, value")
+ }.getMessage
+ assert(message.contains("already exists"))
+ checkRelation("si1", true, defaultDataSource)
+ sql("DROP TABLE si1")
+
+ // Specifying database name for query can be converted to data
source write path
+ // is not allowed right now.
+ sql("SELECT key, value INTO default.si1 FROM src ORDER BY key,
value")
+ checkRelation("si1", true, defaultDataSource)
+ sql("DROP TABLE si1")
+
+} finally {
+ setConf(SQLConf.CONVERT_CTAS, originalConf)
+ sql("DROP TABLE IF EXISTS si1")
+}
+ }
+
+ test("select into(check answer)") {
+sql("DROP TABLE IF EXISTS si1")
+sql("DROP TABLE IF EXISTS si2")
+sql("DROP TABLE IF EXISTS si3")
+
+sql("SELECT key, value INTO si1 FROM src")
+checkAnswer(
+ sql("SELECT key, value FROM si1 ORDER BY key"),
+ sql("SELECT key, value FROM src ORDER BY key").collect().toSeq)
+
+sql("SELECT key k, value INTO si2 FROM src ORDER BY k,value").collect()
+checkAnswer(
+ sql("SELECT k, value FROM si2 ORDER BY k, value"),
+ sql("SELECT key, value FROM src ORDER BY key,
value").collect().toSeq)
+
+sql("SELECT 1 AS key,value INTO si3 FROM src LIMIT 1").collect()
+intercept[AnalysisException] {
+ sql("SELECT key, value INTO si3 FROM src ORDER BY key,
value").collect()
+}
--- End diff --
Checking the real error message is better.
```
val m = intercept[AnalysisException] {
sql("SELECT key, value INTO si3 FROM src ORDER BY key,
value").collect()
}.getMessage
assert(m.contains("your exception message"))
```
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #14191: [SPARK-16217][SQL] Support SELECT INTO statement
Github user dongjoon-hyun commented on a diff in the pull request:
https://github.com/apache/spark/pull/14191#discussion_r70748266
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/SQLQuerySuite.scala
---
@@ -1755,4 +1755,97 @@ class SQLQuerySuite extends QueryTest with
SQLTestUtils with TestHiveSingleton {
}
}
}
+
+ test("select into(check relation)") {
+val originalConf = sessionState.conf.convertCTAS
+
+setConf(SQLConf.CONVERT_CTAS, true)
+
+val defaultDataSource = sessionState.conf.defaultDataSourceName
+try {
+ sql("DROP TABLE IF EXISTS si1")
+ sql("SELECT key, value INTO si1 FROM src ORDER BY key, value")
+ val message = intercept[AnalysisException] {
+sql("SELECT key, value INTO si1 FROM src ORDER BY key, value")
+ }.getMessage
+ assert(message.contains("already exists"))
+ checkRelation("si1", true, defaultDataSource)
+ sql("DROP TABLE si1")
+
+ // Specifying database name for query can be converted to data
source write path
+ // is not allowed right now.
+ sql("SELECT key, value INTO default.si1 FROM src ORDER BY key,
value")
+ checkRelation("si1", true, defaultDataSource)
+ sql("DROP TABLE si1")
+
+} finally {
+ setConf(SQLConf.CONVERT_CTAS, originalConf)
+ sql("DROP TABLE IF EXISTS si1")
+}
+ }
+
+ test("select into(check answer)") {
+sql("DROP TABLE IF EXISTS si1")
+sql("DROP TABLE IF EXISTS si2")
+sql("DROP TABLE IF EXISTS si3")
--- End diff --
```
withTable("si1", "si2", "si3") {
```
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #14191: [SPARK-16217][SQL] Support SELECT INTO statement
Github user dongjoon-hyun commented on a diff in the pull request:
https://github.com/apache/spark/pull/14191#discussion_r70748215
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/SQLQuerySuite.scala
---
@@ -1755,4 +1755,97 @@ class SQLQuerySuite extends QueryTest with
SQLTestUtils with TestHiveSingleton {
}
}
}
+
+ test("select into(check relation)") {
+val originalConf = sessionState.conf.convertCTAS
+
+setConf(SQLConf.CONVERT_CTAS, true)
+
+val defaultDataSource = sessionState.conf.defaultDataSourceName
+try {
+ sql("DROP TABLE IF EXISTS si1")
--- End diff --
Please consider the following convention.
```
withTable("si1") {
```
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #14191: [SPARK-16217][SQL] Support SELECT INTO statement
Github user dongjoon-hyun commented on a diff in the pull request:
https://github.com/apache/spark/pull/14191#discussion_r70748124
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/execution/SQLQuerySuite.scala
---
@@ -1755,4 +1755,97 @@ class SQLQuerySuite extends QueryTest with
SQLTestUtils with TestHiveSingleton {
}
}
}
+
+ test("select into(check relation)") {
+val originalConf = sessionState.conf.convertCTAS
+
+setConf(SQLConf.CONVERT_CTAS, true)
--- End diff --
```
withSQLConf(SQLConf. CONVERT_CTAS.key -> "true") {
```
---
If your project is set up for it, you can reply to this email and have your
reply appear on GitHub as well. If your project does not have this feature
enabled and wishes so, or if the feature is enabled but not working, please
contact infrastructure at infrastruct...@apache.org or file a JIRA ticket
with INFRA.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #14191: [SPARK-16217][SQL] Support SELECT INTO statement
Github user dongjoon-hyun commented on a diff in the pull request: https://github.com/apache/spark/pull/14191#discussion_r70747940 --- Diff: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 --- @@ -338,7 +338,7 @@ querySpecification (RECORDREADER recordReader=STRING)? fromClause? (WHERE where=booleanExpression)?) -| ((kind=SELECT setQuantifier? namedExpressionSeq fromClause? +| ((kind=SELECT setQuantifier? namedExpressionSeq (intoClause? fromClause)? --- End diff -- Hi, @wuxianxingkong . Currently, the following seems to be not considered yet. Could you modify the syntax to support this too? ``` SELECT 1 INTO newtable ``` --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #14191: [SPARK-16217][SQL] Support SELECT INTO statement
GitHub user wuxianxingkong opened a pull request: https://github.com/apache/spark/pull/14191 [SPARK-16217][SQL] Support SELECT INTO statement ## What changes were proposed in this pull request? This PR implements the *SELECT INTO* statement. The *SELECT INTO* statement selects data from one table and inserts it into a new table as follows. SELECT column_name(s) INTO newtable FROM table1; This statement is commonly used in SQL but not currently supported in SparkSQL. We investigated the Catalyst and found that this statement can be implemented by improving the grammar and reusing the logical plan of *CTAS*. The related JIRA is https://issues.apache.org/jira/browse/SPARK-16217 ## How was this patch tested? SQLQuerySuite. You can merge this pull request into a Git repository by running: $ git pull https://github.com/wuxianxingkong/spark select_into Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/14191.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #14191 commit 605634deb779a0cf0eaece8420692d9bf44dab64 Author: cuiguangfan <736068...@qq.com> Date: 2016-07-12T13:16:43Z SELECT INTO Implements --- If your project is set up for it, you can reply to this email and have your reply appear on GitHub as well. If your project does not have this feature enabled and wishes so, or if the feature is enabled but not working, please contact infrastructure at infrastruct...@apache.org or file a JIRA ticket with INFRA. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org