[GitHub] spark pull request #20446: [SPARK-23254][ML] Add user guide entry for DataFr...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20446#discussion_r165578020
--- Diff:
examples/src/main/scala/org/apache/spark/examples/ml/SummarizerExample.scala ---
@@ -0,0 +1,60 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+// scalastyle:off println
+package org.apache.spark.examples.ml
+
+// $example on$
+import org.apache.spark.ml.linalg.{Vector, Vectors}
+import org.apache.spark.ml.stat.Summarizer
+// $example off$
+import org.apache.spark.sql.SparkSession
+
+object SummarizerExample {
+ def main(args: Array[String]): Unit = {
+val spark = SparkSession
+ .builder
+ .appName("SummarizerExample")
+ .getOrCreate()
+
+import spark.implicits._
+import Summarizer._
+
+// $example on$
+val data = Seq(
+ (Vectors.dense(2.0, 3.0, 5.0), 1.0),
+ (Vectors.dense(4.0, 6.0, 7.0), 2.0)
+)
+
+val df = data.toDF("features", "weight")
+
+val Tuple1((meanVal, varianceVal)) = df.select(metrics("mean",
"variance")
+ .summary($"features", $"weight"))
+ .as[Tuple1[(Vector, Vector)]].first()
--- End diff --
Good idea. This way make code easier to read.
Done.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20446: [SPARK-23254][ML] Add user guide entry for DataFr...
Github user MLnick commented on a diff in the pull request:
https://github.com/apache/spark/pull/20446#discussion_r165575680
--- Diff:
examples/src/main/scala/org/apache/spark/examples/ml/SummarizerExample.scala ---
@@ -0,0 +1,60 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+// scalastyle:off println
+package org.apache.spark.examples.ml
+
+// $example on$
+import org.apache.spark.ml.linalg.{Vector, Vectors}
+import org.apache.spark.ml.stat.Summarizer
+// $example off$
+import org.apache.spark.sql.SparkSession
+
+object SummarizerExample {
+ def main(args: Array[String]): Unit = {
+val spark = SparkSession
+ .builder
+ .appName("SummarizerExample")
+ .getOrCreate()
+
+import spark.implicits._
+import Summarizer._
+
+// $example on$
+val data = Seq(
+ (Vectors.dense(2.0, 3.0, 5.0), 1.0),
+ (Vectors.dense(4.0, 6.0, 7.0), 2.0)
+)
+
+val df = data.toDF("features", "weight")
+
+val Tuple1((meanVal, varianceVal)) = df.select(metrics("mean",
"variance")
+ .summary($"features", $"weight"))
+ .as[Tuple1[(Vector, Vector)]].first()
--- End diff --
oh ok - perhaps `select("summary.mean", "summary.variance")` would work to
extract into two columns?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20446: [SPARK-23254][ML] Add user guide entry for DataFr...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20446#discussion_r165573866
--- Diff:
examples/src/main/scala/org/apache/spark/examples/ml/SummarizerExample.scala ---
@@ -0,0 +1,60 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+// scalastyle:off println
+package org.apache.spark.examples.ml
+
+// $example on$
+import org.apache.spark.ml.linalg.{Vector, Vectors}
+import org.apache.spark.ml.stat.Summarizer
+// $example off$
+import org.apache.spark.sql.SparkSession
+
+object SummarizerExample {
+ def main(args: Array[String]): Unit = {
+val spark = SparkSession
+ .builder
+ .appName("SummarizerExample")
+ .getOrCreate()
+
+import spark.implicits._
+import Summarizer._
+
+// $example on$
+val data = Seq(
+ (Vectors.dense(2.0, 3.0, 5.0), 1.0),
+ (Vectors.dense(4.0, 6.0, 7.0), 2.0)
+)
+
+val df = data.toDF("features", "weight")
+
+val Tuple1((meanVal, varianceVal)) = df.select(metrics("mean",
"variance")
+ .summary($"features", $"weight"))
+ .as[Tuple1[(Vector, Vector)]].first()
--- End diff --
Do you mean us `.as[((Vector, Vector))]` ? It compile fails..
or Do you mean change to
```
val (meanVal, varianceVal) = df.select(metrics("mean", "variance")
.summary($"features", $"weight"))
.as[(Vector, Vector)].first()
```
? Seems also do not work because it is a "struct type" value in the
returned row. So the first row format should match Row(Row(mean, variance))
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20446: [SPARK-23254][ML] Add user guide entry for DataFr...
Github user MLnick commented on a diff in the pull request:
https://github.com/apache/spark/pull/20446#discussion_r165568368
--- Diff: docs/ml-statistics.md ---
@@ -89,4 +89,26 @@ Refer to the [`ChiSquareTest` Python
docs](api/python/index.html#pyspark.ml.stat
{% include_example python/ml/chi_square_test_example.py %}
+
+
+## Summarizer
+
+We provide vector column summary statistics for `Dataframe` through
`Summarizer`.
+Available metrics are the column-wise max, min, mean, variance, and number
of nonzeros, as well as the total count.
+
+
+
+The following example demonstrates using
[`Summarizer`](api/scala/index.html#org.apache.spark.ml.stat.Summarizer$)
+to compute the mean and variance for the input dataframe, with and without
a weight column.
--- End diff --
sorry, one more comment here
I think perhaps "... to compute the mean and variance for a vector column
of the input dataframe ..."
(and same below)
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20446: [SPARK-23254][ML] Add user guide entry for DataFr...
Github user MLnick commented on a diff in the pull request:
https://github.com/apache/spark/pull/20446#discussion_r165568014
--- Diff:
examples/src/main/java/org/apache/spark/examples/ml/JavaSummarizerExample.java
---
@@ -0,0 +1,71 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.examples.ml;
+
+import org.apache.spark.sql.*;
+
+// $example on$
+import java.util.Arrays;
+import java.util.List;
+
+import org.apache.spark.ml.linalg.Vector;
+import org.apache.spark.ml.linalg.Vectors;
+import org.apache.spark.ml.linalg.VectorUDT;
+import org.apache.spark.ml.stat.Summarizer;
+import org.apache.spark.sql.types.DataTypes;
+import org.apache.spark.sql.types.Metadata;
+import org.apache.spark.sql.types.StructField;
+import org.apache.spark.sql.types.StructType;
+// $example off$
+
+public class JavaSummarizerExample {
+ public static void main(String[] args) {
+SparkSession spark = SparkSession
+ .builder()
+ .appName("JavaSummarizerExample")
+ .getOrCreate();
+
+// $example on$
+List data = Arrays.asList(
+ RowFactory.create(Vectors.dense(2.0, 3.0, 5.0), 1.0),
+ RowFactory.create(Vectors.dense(4.0, 6.0, 7.0), 2.0)
+);
+
+StructType schema = new StructType(new StructField[]{
+ new StructField("features", new VectorUDT(), false,
Metadata.empty()),
+ new StructField("weight", DataTypes.DoubleType, false,
Metadata.empty())
+});
+
+Dataset df = spark.createDataFrame(data, schema);
+
+Row result1 = df.select(Summarizer.metrics("mean", "variance")
+.summary(new Column("features"), new Column("weight")))
+.first().getStruct(0);
+System.out.println("with weight: mean = " +
result1.getAs(0).toString() +
--- End diff --
ok fair enough
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20446: [SPARK-23254][ML] Add user guide entry for DataFr...
Github user MLnick commented on a diff in the pull request:
https://github.com/apache/spark/pull/20446#discussion_r165567614
--- Diff:
examples/src/main/scala/org/apache/spark/examples/ml/SummarizerExample.scala ---
@@ -0,0 +1,60 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+// scalastyle:off println
+package org.apache.spark.examples.ml
+
+// $example on$
+import org.apache.spark.ml.linalg.{Vector, Vectors}
+import org.apache.spark.ml.stat.Summarizer
+// $example off$
+import org.apache.spark.sql.SparkSession
+
+object SummarizerExample {
+ def main(args: Array[String]): Unit = {
+val spark = SparkSession
+ .builder
+ .appName("SummarizerExample")
+ .getOrCreate()
+
+import spark.implicits._
+import Summarizer._
+
+// $example on$
+val data = Seq(
+ (Vectors.dense(2.0, 3.0, 5.0), 1.0),
+ (Vectors.dense(4.0, 6.0, 7.0), 2.0)
+)
+
+val df = data.toDF("features", "weight")
+
+val Tuple1((meanVal, varianceVal)) = df.select(metrics("mean",
"variance")
+ .summary($"features", $"weight"))
+ .as[Tuple1[(Vector, Vector)]].first()
--- End diff --
nit, but `Tuple1` not required here?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20446: [SPARK-23254][ML] Add user guide entry for DataFr...
Github user WeichenXu123 commented on a diff in the pull request:
https://github.com/apache/spark/pull/20446#discussion_r165565121
--- Diff:
examples/src/main/java/org/apache/spark/examples/ml/JavaSummarizerExample.java
---
@@ -0,0 +1,71 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.examples.ml;
+
+import org.apache.spark.sql.*;
+
+// $example on$
+import java.util.Arrays;
+import java.util.List;
+
+import org.apache.spark.ml.linalg.Vector;
+import org.apache.spark.ml.linalg.Vectors;
+import org.apache.spark.ml.linalg.VectorUDT;
+import org.apache.spark.ml.stat.Summarizer;
+import org.apache.spark.sql.types.DataTypes;
+import org.apache.spark.sql.types.Metadata;
+import org.apache.spark.sql.types.StructField;
+import org.apache.spark.sql.types.StructType;
+// $example off$
+
+public class JavaSummarizerExample {
+ public static void main(String[] args) {
+SparkSession spark = SparkSession
+ .builder()
+ .appName("JavaSummarizerExample")
+ .getOrCreate();
+
+// $example on$
+List data = Arrays.asList(
+ RowFactory.create(Vectors.dense(2.0, 3.0, 5.0), 1.0),
+ RowFactory.create(Vectors.dense(4.0, 6.0, 7.0), 2.0)
+);
+
+StructType schema = new StructType(new StructField[]{
+ new StructField("features", new VectorUDT(), false,
Metadata.empty()),
+ new StructField("weight", DataTypes.DoubleType, false,
Metadata.empty())
+});
+
+Dataset df = spark.createDataFrame(data, schema);
+
+Row result1 = df.select(Summarizer.metrics("mean", "variance")
+.summary(new Column("features"), new Column("weight")))
+.first().getStruct(0);
+System.out.println("with weight: mean = " +
result1.getAs(0).toString() +
--- End diff --
Because spark user will usually want to get the summary result (multiple
vectors), I want to show the simple way to extract these results from the
returned dataframe which contains only one row. I think some user is possible
to get stuck here.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20446: [SPARK-23254][ML] Add user guide entry for DataFr...
Github user MLnick commented on a diff in the pull request:
https://github.com/apache/spark/pull/20446#discussion_r165362568
--- Diff:
examples/src/main/scala/org/apache/spark/examples/ml/SummarizerExample.scala ---
@@ -0,0 +1,60 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+// scalastyle:off println
+package org.apache.spark.examples.ml
+
+// $example on$
+import org.apache.spark.ml.linalg.{Vector, Vectors}
+import org.apache.spark.ml.stat.Summarizer
+// $example off$
+import org.apache.spark.sql.SparkSession
+
+object SummarizerExample {
+ def main(args: Array[String]): Unit = {
+val spark = SparkSession
+ .builder
+ .appName("SummarizerExample")
+ .getOrCreate()
+
+import spark.implicits._
+import Summarizer._
+
+// $example on$
+val data = Seq(
+ (Vectors.dense(2.0, 3.0, 5.0), 1.0),
+ (Vectors.dense(4.0, 6.0, 7.0), 2.0)
+)
+
+val df = data.toDF("features", "weight")
+
+val Tuple1((meanVal, varianceVal)) = df.select(metrics("mean",
"variance")
+ .summary($"features", $"weight"))
+ .as[Tuple1[(Vector, Vector)]].first()
+
+println(s"with weight: mean = ${meanVal}, variance = ${varianceVal}")
+
+val (meanVal2, varianceVal2) = df.select(mean($"features"),
variance($"features"))
+ .as[(Vector, Vector)].first()
+
+println(s"without weight: mean = ${meanVal2}, sum = ${varianceVal2}")
--- End diff --
Same applies here, why not just `df.select(...).show()`?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20446: [SPARK-23254][ML] Add user guide entry for DataFr...
Github user MLnick commented on a diff in the pull request:
https://github.com/apache/spark/pull/20446#discussion_r165362364
--- Diff:
examples/src/main/java/org/apache/spark/examples/ml/JavaSummarizerExample.java
---
@@ -0,0 +1,71 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.examples.ml;
+
+import org.apache.spark.sql.*;
+
+// $example on$
+import java.util.Arrays;
+import java.util.List;
+
+import org.apache.spark.ml.linalg.Vector;
+import org.apache.spark.ml.linalg.Vectors;
+import org.apache.spark.ml.linalg.VectorUDT;
+import org.apache.spark.ml.stat.Summarizer;
+import org.apache.spark.sql.types.DataTypes;
+import org.apache.spark.sql.types.Metadata;
+import org.apache.spark.sql.types.StructField;
+import org.apache.spark.sql.types.StructType;
+// $example off$
+
+public class JavaSummarizerExample {
+ public static void main(String[] args) {
+SparkSession spark = SparkSession
+ .builder()
+ .appName("JavaSummarizerExample")
+ .getOrCreate();
+
+// $example on$
+List data = Arrays.asList(
+ RowFactory.create(Vectors.dense(2.0, 3.0, 5.0), 1.0),
+ RowFactory.create(Vectors.dense(4.0, 6.0, 7.0), 2.0)
+);
+
+StructType schema = new StructType(new StructField[]{
+ new StructField("features", new VectorUDT(), false,
Metadata.empty()),
+ new StructField("weight", DataTypes.DoubleType, false,
Metadata.empty())
+});
+
+Dataset df = spark.createDataFrame(data, schema);
+
+Row result1 = df.select(Summarizer.metrics("mean", "variance")
+.summary(new Column("features"), new Column("weight")))
+.first().getStruct(0);
+System.out.println("with weight: mean = " +
result1.getAs(0).toString() +
--- End diff --
Why not just `df.select(...).show()`?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20446: [SPARK-23254][ML] Add user guide entry for DataFr...
Github user MLnick commented on a diff in the pull request:
https://github.com/apache/spark/pull/20446#discussion_r165360692
--- Diff: docs/ml-statistics.md ---
@@ -89,4 +89,26 @@ Refer to the [`ChiSquareTest` Python
docs](api/python/index.html#pyspark.ml.stat
{% include_example python/ml/chi_square_test_example.py %}
+
+
+## Summarizer
+
+We provide vector column summary statistics for `Dataframe` through
`Summarizer`.
+Available metrics contain the column-wise max, min, mean, variance, and
number of nonzeros, as well as the total count.
--- End diff --
Perhaps "contain" -> "are" or "include"?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20446: [SPARK-23254][ML] Add user guide entry for DataFr...
Github user MLnick commented on a diff in the pull request:
https://github.com/apache/spark/pull/20446#discussion_r165362533
--- Diff:
examples/src/main/scala/org/apache/spark/examples/ml/SummarizerExample.scala ---
@@ -0,0 +1,60 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+// scalastyle:off println
+package org.apache.spark.examples.ml
+
+// $example on$
+import org.apache.spark.ml.linalg.{Vector, Vectors}
+import org.apache.spark.ml.stat.Summarizer
+// $example off$
+import org.apache.spark.sql.SparkSession
+
+object SummarizerExample {
+ def main(args: Array[String]): Unit = {
+val spark = SparkSession
+ .builder
+ .appName("SummarizerExample")
+ .getOrCreate()
+
+import spark.implicits._
+import Summarizer._
+
+// $example on$
+val data = Seq(
+ (Vectors.dense(2.0, 3.0, 5.0), 1.0),
+ (Vectors.dense(4.0, 6.0, 7.0), 2.0)
+)
+
+val df = data.toDF("features", "weight")
+
+val Tuple1((meanVal, varianceVal)) = df.select(metrics("mean",
"variance")
+ .summary($"features", $"weight"))
+ .as[Tuple1[(Vector, Vector)]].first()
+
+println(s"with weight: mean = ${meanVal}, variance = ${varianceVal}")
--- End diff --
Same applies here, why not just `df.select(...).show()`?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20446: [SPARK-23254][ML] Add user guide entry for DataFr...
Github user MLnick commented on a diff in the pull request:
https://github.com/apache/spark/pull/20446#discussion_r165362148
--- Diff: docs/ml-statistics.md ---
@@ -89,4 +89,26 @@ Refer to the [`ChiSquareTest` Python
docs](api/python/index.html#pyspark.ml.stat
{% include_example python/ml/chi_square_test_example.py %}
+
+
+## Summarizer
+
+We provide vector column summary statistics for `Dataframe` through
`Summarizer`.
+Available metrics contain the column-wise max, min, mean, variance, and
number of nonzeros, as well as the total count.
+
+
+
+[`Summarizer`](api/scala/index.html#org.apache.spark.ml.stat.Summarizer$)
--- End diff --
Perhaps "The following example demonstrates using `Summarizer`(...) to
compute the mean and variance for the input dataframe, with and without a
weight column"?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20446: [SPARK-23254][ML] Add user guide entry for DataFr...
Github user MLnick commented on a diff in the pull request:
https://github.com/apache/spark/pull/20446#discussion_r165362440
--- Diff:
examples/src/main/java/org/apache/spark/examples/ml/JavaSummarizerExample.java
---
@@ -0,0 +1,71 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.examples.ml;
+
+import org.apache.spark.sql.*;
+
+// $example on$
+import java.util.Arrays;
+import java.util.List;
+
+import org.apache.spark.ml.linalg.Vector;
+import org.apache.spark.ml.linalg.Vectors;
+import org.apache.spark.ml.linalg.VectorUDT;
+import org.apache.spark.ml.stat.Summarizer;
+import org.apache.spark.sql.types.DataTypes;
+import org.apache.spark.sql.types.Metadata;
+import org.apache.spark.sql.types.StructField;
+import org.apache.spark.sql.types.StructType;
+// $example off$
+
+public class JavaSummarizerExample {
+ public static void main(String[] args) {
+SparkSession spark = SparkSession
+ .builder()
+ .appName("JavaSummarizerExample")
+ .getOrCreate();
+
+// $example on$
+List data = Arrays.asList(
+ RowFactory.create(Vectors.dense(2.0, 3.0, 5.0), 1.0),
+ RowFactory.create(Vectors.dense(4.0, 6.0, 7.0), 2.0)
+);
+
+StructType schema = new StructType(new StructField[]{
+ new StructField("features", new VectorUDT(), false,
Metadata.empty()),
+ new StructField("weight", DataTypes.DoubleType, false,
Metadata.empty())
+});
+
+Dataset df = spark.createDataFrame(data, schema);
+
+Row result1 = df.select(Summarizer.metrics("mean", "variance")
+.summary(new Column("features"), new Column("weight")))
+.first().getStruct(0);
+System.out.println("with weight: mean = " +
result1.getAs(0).toString() +
+ ", variance = " + result1.getAs(1).toString());
+
+Row result2 = df.select(
+ Summarizer.mean(new Column("features")),
+ Summarizer.variance(new Column("features"))
+).first();
+System.out.println("without weight: mean = " +
result2.getAs(0).toString() +
--- End diff --
Why not just `df.select(...).show()`?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20446: [SPARK-23254][ML] Add user guide entry for DataFr...
GitHub user WeichenXu123 opened a pull request: https://github.com/apache/spark/pull/20446 [SPARK-23254][ML] Add user guide entry for DataFrame multivariate summary ## What changes were proposed in this pull request? Add user guide and scala/java examples for `ml.stat.Summarizer` ## How was this patch tested? Doc generated snapshot:  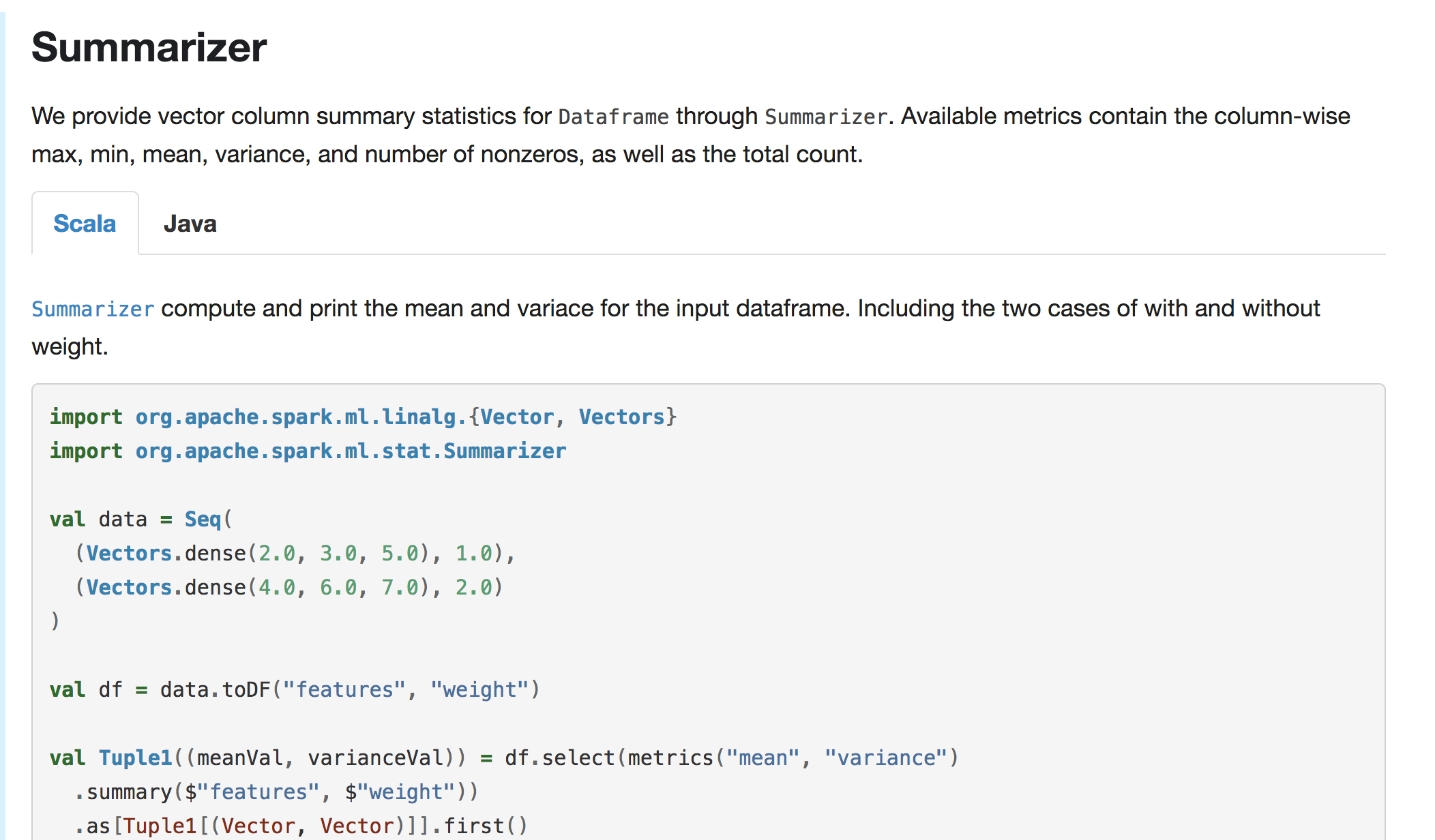 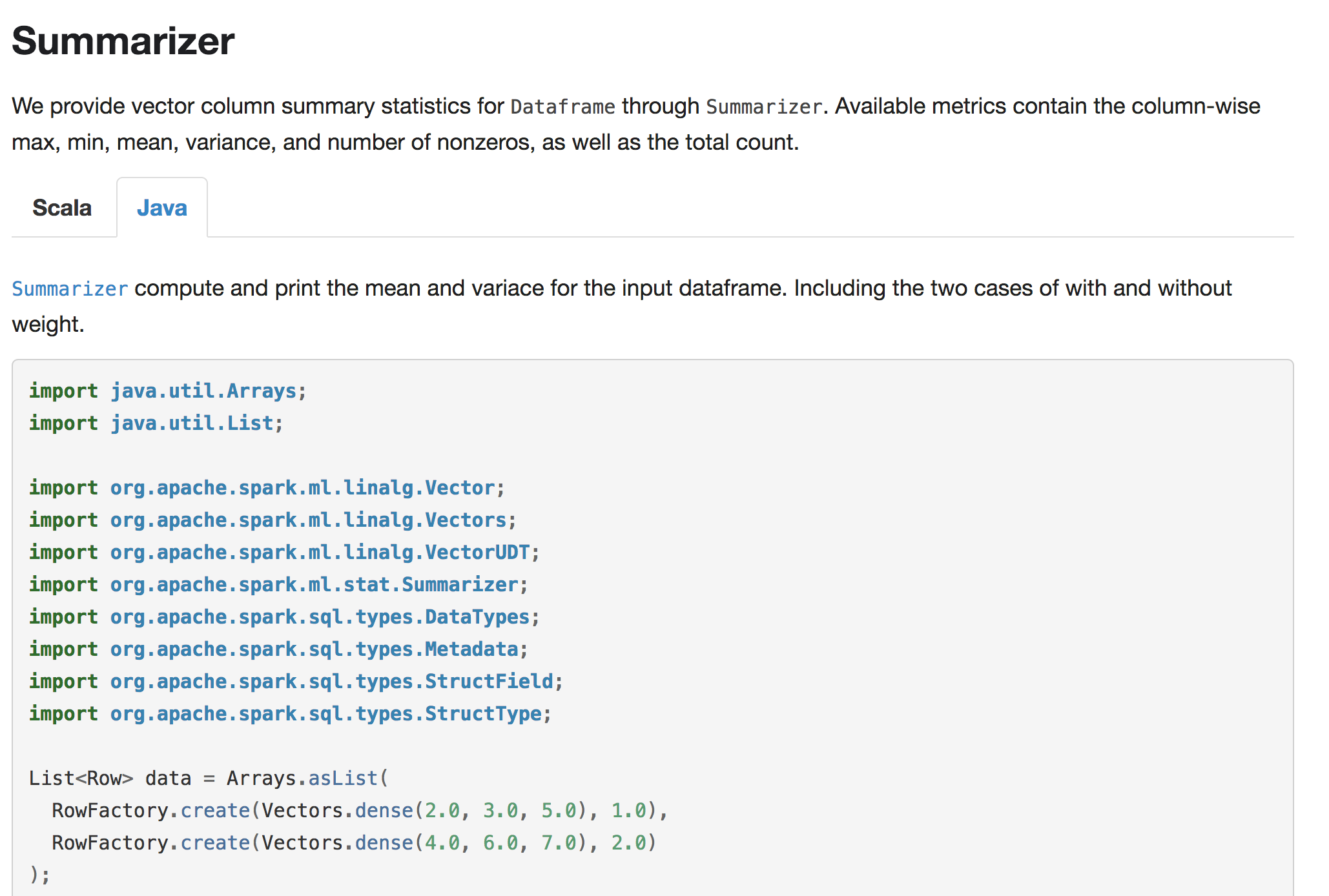 You can merge this pull request into a Git repository by running: $ git pull https://github.com/WeichenXu123/spark summ_guide Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20446.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20446 commit 307f75f4990049f78978364af4541cd20e4d5bd7 Author: WeichenXu Date: 2018-01-31T01:41:48Z init pr --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org