[GitHub] spark pull request #22758: [SPARK-25332][SQL] Instead of broadcast hash join...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22758#discussion_r228758621
--- Diff:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveMetastoreCatalog.scala ---
@@ -193,6 +193,16 @@ private[hive] class HiveMetastoreCatalog(sparkSession:
SparkSession) extends Log
None)
val logicalRelation = cached.getOrElse {
val updatedTable = inferIfNeeded(relation, options, fileFormat)
+ // Intialize the catalogTable stats if its not defined.An intial
value has to be defined
--- End diff --
> > but after create table command, when we do insert command within the
same session Hive statistics is not getting updated
>
> This is the thing I don't understand. Like I said before, even if table
has no stats, Spark will still get a stats via the `DetermineTableStats` rule.
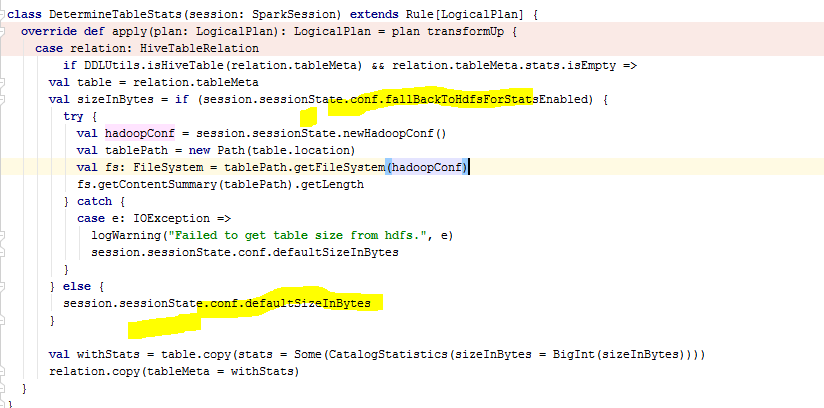
@cloud-fan DetermineStats is just initializing the stats if the stats is
not set, only if session.sessionState.conf.fallBackToHdfsForStatsEnabled is
true then the rule is deriving the stats from file system and updating the
stats as shown below code snippet. In insert flow this condition never gets
executed, so the stats will be still none.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22758: [SPARK-25332][SQL] Instead of broadcast hash join...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22758#discussion_r226515799
--- Diff:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveMetastoreCatalog.scala ---
@@ -193,6 +193,16 @@ private[hive] class HiveMetastoreCatalog(sparkSession:
SparkSession) extends Log
None)
val logicalRelation = cached.getOrElse {
val updatedTable = inferIfNeeded(relation, options, fileFormat)
+ // Intialize the catalogTable stats if its not defined.An intial
value has to be defined
--- End diff --
You are right its about considering the default size, but i am not very
sure whether we shall invalidate the cache, i will explain my understanding
below.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22758: [SPARK-25332][SQL] Instead of broadcast hash join...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22758#discussion_r226203589
--- Diff:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveMetastoreCatalog.scala ---
@@ -193,6 +193,16 @@ private[hive] class HiveMetastoreCatalog(sparkSession:
SparkSession) extends Log
None)
val logicalRelation = cached.getOrElse {
val updatedTable = inferIfNeeded(relation, options, fileFormat)
+ // Intialize the catalogTable stats if its not defined.An intial
value has to be defined
--- End diff --
The table created in the current session does not have stats. In this
situation. It gets `sizeInBytes` from
https://github.com/apache/spark/blob/1ff4a77be498615ee7216fd9cc2d510ecbd43b27/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/LogicalRelation.scala#L42-L46
https://github.com/apache/spark/blob/25c2776dd9ae3f9792048c78be2cbd958fd99841/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/HadoopFsRelation.scala#L88-L91
.
It's realy size, that why it's `broadcast join`. In fact, we should
invalidate this table to let Spark use the `DetermineTableStats` to take
effect. I am doing it here: https://github.com/apache/spark/pull/22721
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22758: [SPARK-25332][SQL] Instead of broadcast hash join...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22758#discussion_r226203075
--- Diff:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveMetastoreCatalog.scala ---
@@ -193,6 +193,16 @@ private[hive] class HiveMetastoreCatalog(sparkSession:
SparkSession) extends Log
None)
val logicalRelation = cached.getOrElse {
val updatedTable = inferIfNeeded(relation, options, fileFormat)
+ // Intialize the catalogTable stats if its not defined.An intial
value has to be defined
--- End diff --
> > but after create table command, when we do insert command within the
same session Hive statistics is not getting updated
>
> This is the thing I don't understand. Like I said before, even if table
has no stats, Spark will still get a stats via the `DetermineTableStats` rule.
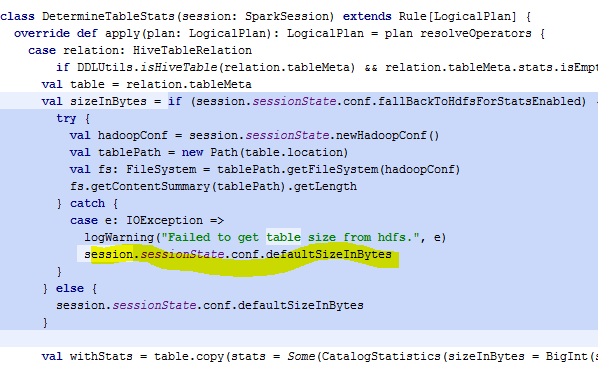
Right,but i DefaultStatistics will return default value for the stats
> > but after create table command, when we do insert command within the
same session Hive statistics is not getting updated
>
> This is the thing I don't understand. Like I said before, even if table
has no stats, Spark will still get a stats via the `DetermineTableStats` rule.
I think this rule will return default stats always unless we make
session.sessionState.conf.fallBackToHdfsForStatsEnabled as true, i will
reconfirm this behaviour.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22758: [SPARK-25332][SQL] Instead of broadcast hash join...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22758#discussion_r226201756
--- Diff:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveMetastoreCatalog.scala ---
@@ -193,6 +193,16 @@ private[hive] class HiveMetastoreCatalog(sparkSession:
SparkSession) extends Log
None)
val logicalRelation = cached.getOrElse {
val updatedTable = inferIfNeeded(relation, options, fileFormat)
+ // Intialize the catalogTable stats if its not defined.An intial
value has to be defined
--- End diff --
Yes its default setting which means false. but i think it should be fine
to keep default setting in this scenario .
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22758: [SPARK-25332][SQL] Instead of broadcast hash join...
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22758#discussion_r226199284
--- Diff:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveMetastoreCatalog.scala ---
@@ -193,6 +193,16 @@ private[hive] class HiveMetastoreCatalog(sparkSession:
SparkSession) extends Log
None)
val logicalRelation = cached.getOrElse {
val updatedTable = inferIfNeeded(relation, options, fileFormat)
+ // Intialize the catalogTable stats if its not defined.An intial
value has to be defined
--- End diff --
@sujith71955 What if `spark.sql.statistics.size.autoUpdate.enabled=false`
or `hive.stats.autogather=false`? It still update stats?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22758: [SPARK-25332][SQL] Instead of broadcast hash join...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22758#discussion_r226198591
--- Diff:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveMetastoreCatalog.scala ---
@@ -193,6 +193,16 @@ private[hive] class HiveMetastoreCatalog(sparkSession:
SparkSession) extends Log
None)
val logicalRelation = cached.getOrElse {
val updatedTable = inferIfNeeded(relation, options, fileFormat)
+ // Intialize the catalogTable stats if its not defined.An intial
value has to be defined
--- End diff --
> but after create table command, when we do insert command within the same
session Hive statistics is not getting updated
This is the thing I don't understand. Like I said before, even if table has
no stats, Spark will still get a stats via the `DetermineTableStats` rule.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22758: [SPARK-25332][SQL] Instead of broadcast hash join...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22758#discussion_r226197174
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/StatisticsSuite.scala ---
@@ -1051,7 +1051,8 @@ class StatisticsSuite extends
StatisticsCollectionTestBase with TestHiveSingleto
test("test statistics of LogicalRelation converted from Hive serde
tables") {
Seq("orc", "parquet").foreach { format =>
- Seq(true, false).foreach { isConverted =>
+ // Botth parquet and orc will have Hivestatistics, both are
convertable to Logical Relation.
+ Seq(true, true).foreach { isConverted =>
--- End diff --
Right. i think some misunderstanding i will recheck into this. Thanks
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22758: [SPARK-25332][SQL] Instead of broadcast hash join...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/spark/pull/22758#discussion_r226192210
--- Diff:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveMetastoreCatalog.scala ---
@@ -193,6 +193,16 @@ private[hive] class HiveMetastoreCatalog(sparkSession:
SparkSession) extends Log
None)
val logicalRelation = cached.getOrElse {
val updatedTable = inferIfNeeded(relation, options, fileFormat)
+ // Intialize the catalogTable stats if its not defined.An intial
value has to be defined
--- End diff --
Thanks for your valuable feedback.
My observations :
1) In insert flow we are always trying to update the HiveStats as per the
below statement in InsertIntoHadoopFsRelationCommand.
```
if (catalogTable.nonEmpty) {
CommandUtils.updateTableStats(sparkSession, catalogTable.get)
}
```
but after create table command, when we do insert command within the same
session Hive statistics is not getting updated due to below validation where
condition expects stats to be non-empty as below
```
def updateTableStats(sparkSession: SparkSession, table: CatalogTable): Unit
= {
if (table.stats.nonEmpty) {
```
But if we re-launch spark-shell and trying to do insert command the
Hivestatistics will be saved and now onward the stats will be taken from
HiveStats and the flow will never try to estimate the data size with file .
2) Currently always system is not trying to estimate the data size with
files when we are executing the insert command, as i told above if we launch
the query from a new context , system will try to read the stats from the Hive.
i think there is a problem in the behavior consistency and also if we can
always get the stats from hive then shall we need to calculate again eveytime
the stats from files?
>> I think we may need to update the flow where it shall always try read
the data size from files, it shall never depend on HiveStats,
>> Or if we are recording the HiveStats then everytime it shall read the
Hivestats.
Please let me know whether i am going right direction, let me know for any
clarifications.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22758: [SPARK-25332][SQL] Instead of broadcast hash join...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22758#discussion_r226151421
--- Diff:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveMetastoreCatalog.scala ---
@@ -193,6 +193,16 @@ private[hive] class HiveMetastoreCatalog(sparkSession:
SparkSession) extends Log
None)
val logicalRelation = cached.getOrElse {
val updatedTable = inferIfNeeded(relation, options, fileFormat)
+ // Intialize the catalogTable stats if its not defined.An intial
value has to be defined
--- End diff --
I don't quite understand why table must have stats. For both file sources
and hive tables, we will estimate the data size with files, if the table
doesn't have stats.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22758: [SPARK-25332][SQL] Instead of broadcast hash join...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/22758#discussion_r226150341
--- Diff:
sql/hive/src/test/scala/org/apache/spark/sql/hive/StatisticsSuite.scala ---
@@ -1051,7 +1051,8 @@ class StatisticsSuite extends
StatisticsCollectionTestBase with TestHiveSingleto
test("test statistics of LogicalRelation converted from Hive serde
tables") {
Seq("orc", "parquet").foreach { format =>
- Seq(true, false).foreach { isConverted =>
+ // Botth parquet and orc will have Hivestatistics, both are
convertable to Logical Relation.
+ Seq(true, true).foreach { isConverted =>
--- End diff --
This is to test when the conversion is on and off. We shouldn't change it.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22758: [SPARK-25332][SQL] Instead of broadcast hash join...
GitHub user sujith71955 opened a pull request: https://github.com/apache/spark/pull/22758 [SPARK-25332][SQL] Instead of broadcast hash join ,Sort merge join has selected when restart spark-shell/spark-JDBC for hive provider ## What changes were proposed in this pull request? Problem: Below steps in sequence to reproduce the issue. ``` a.Create parquet table with stored as clause. b.Run insert statement => This will not update Hivestats. c.Run (Select query which needs to calculate stats or explain cost select statement) => this will evaluate stats from HadoopFsRelation d.Since correct stats(sizeInBytes) is available , the plan will select broadcast node if join with any table. e. Exit => (come out of shell) f.Now again run **step c** ( calculate stat) query. This gives wrong stats (sizeInBytes - default value will be assigned) in plan. Because it is calculated from HiveCatalogTable which does not have any stats as it is not updated in **step b** g.Since in-correct stats(sizeInBytes - default value will be assigned) is available, the plan will select SortMergeJoin node if join with any table. h.Now Run insert statement => This will update Hivestats . i.Now again run **step c** ( calculate stat) query. This gives correct stat (sizeInBytes) in plan .because it can read the hive stats which is updated in **step i**. j.Now onward always stat is available so correct stat is plan will be displayed which picks Broadcast join node(based on threshold size) always. ``` ## What changes were proposed in this pull request? Here the main problem is hive stats is not getting recorded after insert command, this is because of a condition "if (table.stats.nonEmpty)" in updateTableStats() which will be executed as part of InsertIntoHadoopFsRelationCommand command. So as part of fix we initialized a default value for the CatalogTable stats if there is no cache of a particular LogicalRelation. Also it is observed in Test Case âtest statistics of LogicalRelation converted from Hive serde tables" in StatisticsSuite, orc and parquet both are convertible but we are expecting that only orc should get/record stats Hivestats not for parquet.But since both relations are convertible so we should have same expectation. Same is corrected in this PR. ## How was this patch tested? Manually tested, attaching the snapshot, also corrected a UT as mentioned above in description which will compliment this PR changes. Step 1: Login to spark-shell => create 2 tables => Run insert commad => Explain the check the plan =>Plan contains Broadcast join => Exit  Step 2: Relaunch Spark-shell => Run explain command of particular select statement => verify the plan => Plan contains SortMergeJoin - This is incorrect result.  Step 3: Again Run insert command => Run explain command of particular select statement => verify the plan we can observer the node is been changed as BroadcastJoin - This makes the flow inconsistent. **After Fix** Login to spark-shell => create 2 tables => Run insert commad => Explain the check the plan =>Plan contains Broadcast join => Exit 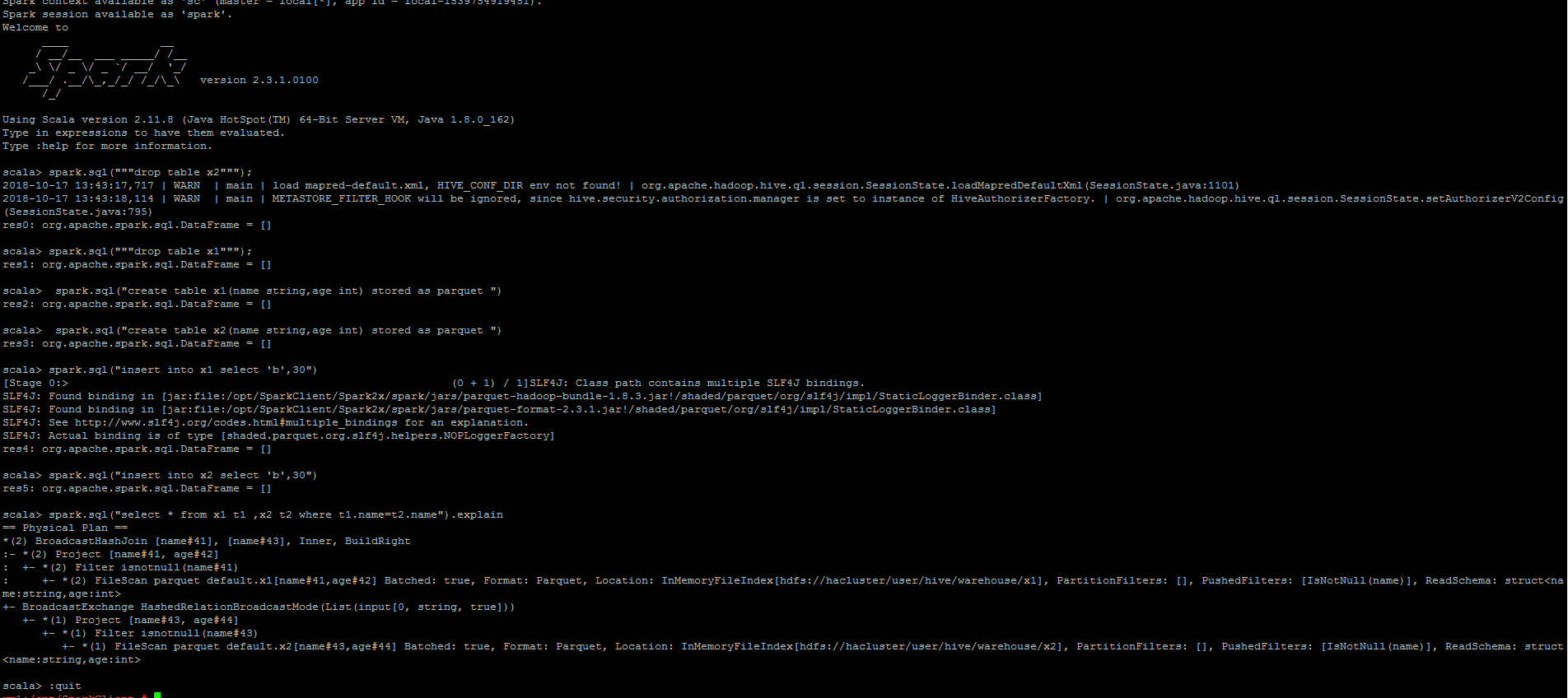 Step 2: Relaunch Spark-shell => Run explain command of particular select statement => verify the plan => Plan still contains Broadcast join since after fix Hivestats is available for the table. 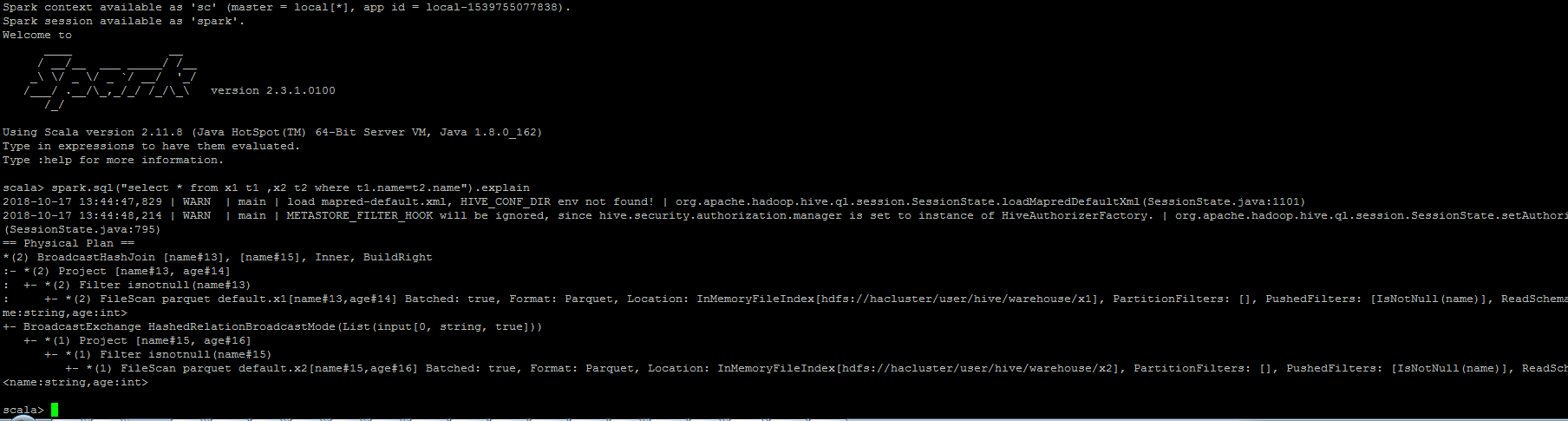 Step 3: Again Run insert command => Run explain command of particular select statement => verify the plan we can observer the plan still retains BroadcastJoin - Nowonwards the results are always consistent You can merge this pull request into a Git repository by running: $ git pull https://github.com/sujith71955/spark master_statistics Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/22758.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #22758 commit 469f3693b641dae161bbb673599f55f20a60767b Author: s71955 Date: 2018-10-17T19:43:39Z [SPARK-25332][SQL] Instead of broadcast hash join ,Sort merge join has selected when restart spark-shell/spark-JDBC for hive provider ## What changes were proposed in this pull request? Problaem: Below steps in s