Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/22124
Thanks @cloud-fan I updated it in description.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22124#discussion_r210832045
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/rules.scala
---
@@ -490,7 +490,8 @@ object DDLPreprocessingUtils
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22124#discussion_r210831619
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
---
@@ -901,6 +901,12 @@ class Analyzer(
// If the
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/22124
cc @gengliangwang
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h
GitHub user wangyum opened a pull request:
https://github.com/apache/spark/pull/22124
[SPARK-25135][SQL] Insert datasource table may all null when select from
view
## What changes were proposed in this pull request?
How to reproduce:
```scala
val path = "/tmp/
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21734
Thanks @vanzin If there is a problem with a filesystem, it will take a long
time to retry when get the delegation token.
The new approach is:
- Get all the delegation tokens by default
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22078#discussion_r209954635
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala ---
@@ -626,6 +626,14 @@ object SQLConf {
.stringConf
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22078#discussion_r209934062
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/InsertIntoHadoopFsRelationCommand.scala
---
@@ -261,4 +273,67 @@ case class
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/22038
**Teradata**:
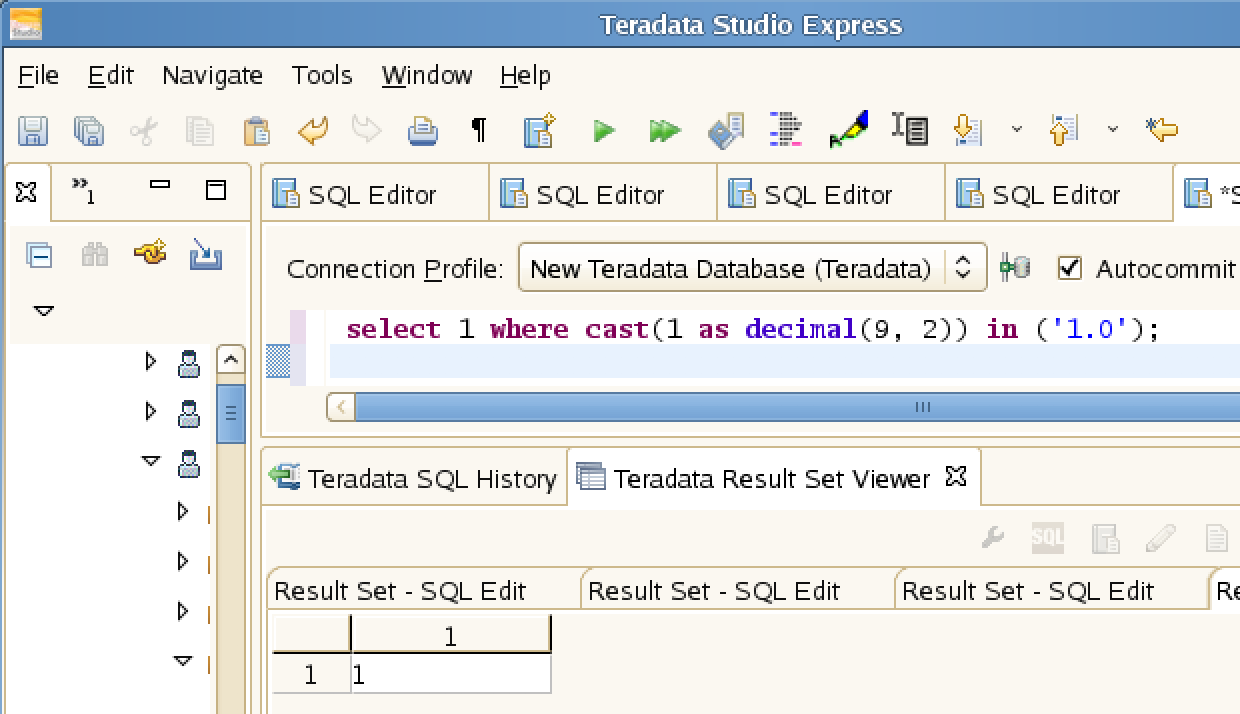
**Oracle**:
 | Truncate
directory elapsed time(milliseconds)
-- | -- | --
200 | 7 | 319
5000 | 48 | 7810
1 | 90 | 16427
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/22038
retest this please
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/22077
retest this please.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/22077
retest this please.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/22077
retest this please
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h
GitHub user wangyum opened a pull request:
https://github.com/apache/spark/pull/22078
[SPARK-25085][SQL] Insert overwrite a non-partitioned table should not
delete table folder
## What changes were proposed in this pull request?
Insert overwrite a `non-partitioned` table
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/22077
Iâd prefer the title like this: `[BACKPORT-2.3][SPARK-25084][SQL]...`
---
-
To unsubscribe, e-mail: reviews-unsubscr
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/22066#discussion_r209259163
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/hash.scala
---
@@ -778,21 +783,22 @@ case class HiveHash(children: Seq
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/22038
retest this please
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/22038
@mgaido91 what do you think about it?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands
GitHub user wangyum opened a pull request:
https://github.com/apache/spark/pull/22038
[SPARK-25056][SQL] Unify the InConversion and BinaryComparison behaviour
when InConversion's list only contains one datatype
## What changes were proposed in this pull request?
before th
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21488
It seems this commit cause `KafkaSourceStressForDontFailOnDataLossSuite`
failed:
```java
...
[info] KafkaSourceStressSuite:
[info] - stress test with multiple topics and partitions
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21883
retest this please.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews
Github user wangyum closed the pull request at:
https://github.com/apache/spark/pull/21782
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21883#discussion_r206479294
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/PartitioningUtils.scala
---
@@ -284,6 +284,11 @@ object PartitioningUtils
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21883
cc @gatorsmile @gengliangwang
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21883
retest this please
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h
GitHub user wangyum opened a pull request:
https://github.com/apache/spark/pull/21883
[SPARK-24937][SQL] Datasource partition table should load empty partitions
## What changes were proposed in this pull request?
How to reproduce:
```sql
spark-sql> CREATE TABLE
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/19635
The below SQL will throw `AnalysisException`. but it can success on Spark
2.1.x. Hope this can fix soon.
```sql
CREATE TEMPORARY VIEW t4 AS SELECT * FROM VALUES
(CAST(1 AS DOUBLE
Github user wangyum closed the pull request at:
https://github.com/apache/spark/pull/21871
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21871
Oh. It turns out that @dilipbiswal is talking about that PR. I didn't find
it in your recent PR. Letâs wait if the test can
GitHub user wangyum opened a pull request:
https://github.com/apache/spark/pull/21871
[SPARK-24916][SQL] Fix type coercion for IN expression with subquery
## What changes were proposed in this pull request?
The below SQL will throw `AnalysisException`. but it can success on
GitHub user wangyum opened a pull request:
https://github.com/apache/spark/pull/21863
[SPARK-18874][SQL][FOLLOW-UP] Improvement type mismatched message
## What changes were proposed in this pull request?
How to reproduce:
```sql
create table test1(c1 double, c2 string
Github user wangyum closed the pull request at:
https://github.com/apache/spark/pull/20866
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21827#discussion_r204019818
--- Diff:
resource-managers/yarn/src/main/scala/org/apache/spark/scheduler/cluster/YarnClientSchedulerBackend.scala
---
@@ -111,7 +111,8 @@ private[spark
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21782
Teradata has `PARTITION BY RANGE_N` option in CREATE TABLE SQL statement.
But SELECT SQL statement not seen in other systems.
https://info.teradata.com/HTMLPubs/DB_TTU_16_00/index.html#page
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21814#discussion_r203621554
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFileFormat.scala
---
@@ -384,12 +385,10 @@ class
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21782#discussion_r203613170
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/benchmark/FilterPushdownBenchmark.scala
---
@@ -394,6 +394,41 @@ class
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21782
cc @cloud-fan
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21734#discussion_r203427395
--- Diff:
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnSparkHadoopUtil.scala
---
@@ -193,8 +193,7 @@ object YarnSparkHadoopUtil
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21734#discussion_r203425909
--- Diff:
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnSparkHadoopUtil.scala
---
@@ -193,8 +193,7 @@ object YarnSparkHadoopUtil
Github user wangyum closed the pull request at:
https://github.com/apache/spark/pull/18138
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21784
It's noisy when type something:
 64-Bit Server VM 1.8.0_151-b12 on Mac OS X 10.12.6
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21785
retest this please
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21782#discussion_r202931883
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/parser/AstBuilder.scala
---
@@ -306,44 +306,60 @@ class AstBuilder(conf: SQLConf
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21782#discussion_r202929769
--- Diff: sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
---
@@ -2813,4 +2815,87 @@ class SQLQuerySuite extends QueryTest with
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21784
cc @vanzin, @jerryshao
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21785
retest this please
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h
GitHub user wangyum opened a pull request:
https://github.com/apache/spark/pull/21785
[SPARK-24529][BUILD][FOLLOW-UP] Set spotbugs-maven-plugin's fork to true
## What changes were proposed in this pull request?
Set `spotbugs-maven-plugin`'s fork to `true`, othe
GitHub user wangyum opened a pull request:
https://github.com/apache/spark/pull/21784
[SPARK-24182][YARN][FOLLOW-UP] Turn off noisy log output
## What changes were proposed in this pull request?
[SPARK-24182](https://issues.apache.org/jira/browse/SPARK-24182) changed
the
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21782#discussion_r202622330
--- Diff:
sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 ---
@@ -340,6 +340,7 @@ queryOrganization
: (ORDER BY order
GitHub user wangyum opened a pull request:
https://github.com/apache/spark/pull/21782
[SPARK-24816][SQL] SQL interface support repartitionByRange
## What changes were proposed in this pull request?
SQL interface support `repartitionByRange` to improvement data pushdown
Github user wangyum closed the pull request at:
https://github.com/apache/spark/pull/20430
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/20430
Thanks @HyukjinKwon How about close this? `CTAS` has other issues , as
mentioned in [SPARK-24766](https://issues.apache.org/jira/browse/SPARK-24766).
I will try to fix it if there is a chance
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21556
retest this please
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21767
**Find more typos**:
- Analyze > Run Inspection by Name

- Type &q
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21556
cc @gatorsmile @cloud-fan @gengliangwang @michal-databricks
@mswit-databricks
---
-
To unsubscribe, e-mail: reviews-unsubscr
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21603#discussion_r202500542
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFilterSuite.scala
---
@@ -747,6 +748,66 @@ class
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21556#discussion_r202327362
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFilters.scala
---
@@ -37,41 +39,64 @@ import
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21603#discussion_r202302865
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFilters.scala
---
@@ -222,6 +225,14 @@ private[parquet] class
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21603#discussion_r202283085
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala ---
@@ -386,6 +386,17 @@ object SQLConf {
.booleanConf
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21741#discussion_r202277812
--- Diff: sql/core/benchmarks/FilterPushdownBenchmark-results.txt ---
@@ -578,3 +578,127 @@ Native ORC Vectorized 11622 /
12196
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21741#discussion_r202277658
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFilterSuite.scala
---
@@ -517,7 +585,6 @@ class
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21741#discussion_r202277483
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala ---
@@ -378,6 +378,15 @@ object SQLConf {
.booleanConf
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21556#discussion_r202214356
--- Diff: sql/core/benchmarks/FilterPushdownBenchmark-results.txt ---
@@ -292,120 +292,120 @@ Intel(R) Core(TM) i7-7820HQ CPU @ 2.90GHz
Select 1
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21556#discussion_r202075842
--- Diff: sql/core/benchmarks/FilterPushdownBenchmark-results.txt ---
@@ -292,120 +292,120 @@ Intel(R) Core(TM) i7-7820HQ CPU @ 2.90GHz
Select 1
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21556#discussion_r201928990
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFilters.scala
---
@@ -248,29 +371,29 @@ private[parquet] class
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21556#discussion_r201927646
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFilters.scala
---
@@ -202,6 +283,16 @@ private[parquet] class
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21556#discussion_r201925142
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFilters.scala
---
@@ -225,12 +316,44 @@ private[parquet] class
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21556#discussion_r201924695
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFilters.scala
---
@@ -225,12 +316,44 @@ private[parquet] class
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21741#discussion_r201889164
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFilterSuite.scala
---
@@ -387,6 +389,82 @@ class
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21556
retest this please.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21734#discussion_r201275550
--- Diff:
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnSparkHadoopUtil.scala
---
@@ -193,8 +193,7 @@ object YarnSparkHadoopUtil
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21734#discussion_r201271876
--- Diff:
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnSparkHadoopUtil.scala
---
@@ -193,8 +193,7 @@ object YarnSparkHadoopUtil
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21734#discussion_r201271407
--- Diff:
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/YarnSparkHadoopUtil.scala
---
@@ -193,8 +193,7 @@ object YarnSparkHadoopUtil
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21741
retest this please
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21741#discussion_r201233974
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala ---
@@ -378,6 +378,15 @@ object SQLConf {
.booleanConf
GitHub user wangyum opened a pull request:
https://github.com/apache/spark/pull/21741
[SPARK-24718][SQL] Timestamp support pushdown to parquet data source
## What changes were proposed in this pull request?
`Timestamp` support pushdown to parquet data source.
Only
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21682#discussion_r201218336
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFilters.scala
---
@@ -60,8 +62,10 @@ private[parquet] class
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21734
There is a conflict here. I configured
`spark.yarn.access.namenodes=hdfs://nameservices1,hdfs://nameservices2`, but
still fetch all.
This time I change spark.yarn.access.namenodes default to
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21734
It will spend a lot of time to fetch tokens. I add some print at
`HadoopFSDelegationTokenProvider`:
```scala
filesystems.foreach { fs =>
try {
logInfo("getting t
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21696#discussion_r201190701
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFilters.scala
---
@@ -19,187 +19,200 @@ package
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21734
@mgaido91 Yes. it's a env issue. I think it is mainly compatible with the
previous Spark. If it fails since SPARK-24149, we only can do is change the
`hdfs-site.xml`. This risk is a bi
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21734
cc @mgaido91 @vanzin
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail
GitHub user wangyum opened a pull request:
https://github.com/apache/spark/pull/21734
[SPARK-24149][YARN][FOLLOW-UP] Add a config to control automatic namespaces
discovery
## What changes were proposed in this pull request?
Our HDFS cluster configured 5 nameservices
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21556#discussion_r200813391
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFilters.scala
---
@@ -82,6 +120,30 @@ private[parquet] class
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21603
retest this please.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21603
retest this please.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21556
retest this please
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21603
retest this please.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews
Github user wangyum commented on the issue:
https://github.com/apache/spark/pull/21556
@dongjoon-hyun benchmark code:
https://github.com/apache/spark/blob/bf67f70c48881ee99751f7d51fbcbda1e593d90a/sql/core/src/test/scala/org/apache/spark/sql/execution/benchmark
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21556#discussion_r200526464
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFilters.scala
---
@@ -82,6 +120,30 @@ private[parquet] class
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21556#discussion_r200275960
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFilters.scala
---
@@ -37,26 +39,50 @@ import
Github user wangyum commented on a diff in the pull request:
https://github.com/apache/spark/pull/21677#discussion_r200262948
--- Diff: sql/core/benchmarks/FilterPushdownBenchmark-results.txt ---
@@ -0,0 +1,556 @@
+[ Pushdown for many distinct value
401 - 500 of 1006 matches
Mail list logo