afeldman1 commented on issue #933:
URL: https://github.com/apache/hudi/issues/933#issuecomment-709716905
@LeoHsu0802, yep it's another hudi configuration option :) Where
`DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY` is the same as
`'hoodie.datasource.hive_sync.database'` and DbName is
nsivabalan commented on issue #2178:
URL: https://github.com/apache/hudi/issues/2178#issuecomment-709715455
I will try to repro tomorrow. few questions in the mean time.
1. By recordSize = 35 you mean, 35 bytes? seems too low.
2. By "IndexBloomNumEntries = 150", you meant to
bvaradar edited a comment on issue #2174:
URL: https://github.com/apache/hudi/issues/2174#issuecomment-709702300
@halkar : Do you mean you are writing to the same dataset concurrently ?
This is not supported and you need to be ingesting to the dataset by one write
a time. Can you rerun
bvaradar commented on issue #2174:
URL: https://github.com/apache/hudi/issues/2174#issuecomment-709702300
@halkar : Do you mean you are writing to the same dataset concurrently ?
This is not supported and you need to be ingesting to the dataset by one write
a time.
LeoHsu0802 commented on issue #933:
URL: https://github.com/apache/hudi/issues/933#issuecomment-709700860
Hi @afeldman1 ,
Thanks for your reply.
Yes, I found glue crawler is not support for hudi dataset.
I successfully write the data to hive store and can query in Athena now but
halkar edited a comment on issue #2174:
URL: https://github.com/apache/hudi/issues/2174#issuecomment-709654557
This is a different run. I'll add `cleans show` results later.
All partitions:
```
staff 5984 16 Oct 12:02 .hoodie
staff 224 16 Oct 12:02 graphversion=782
staff
halkar commented on issue #2174:
URL: https://github.com/apache/hudi/issues/2174#issuecomment-709697654
Commits:
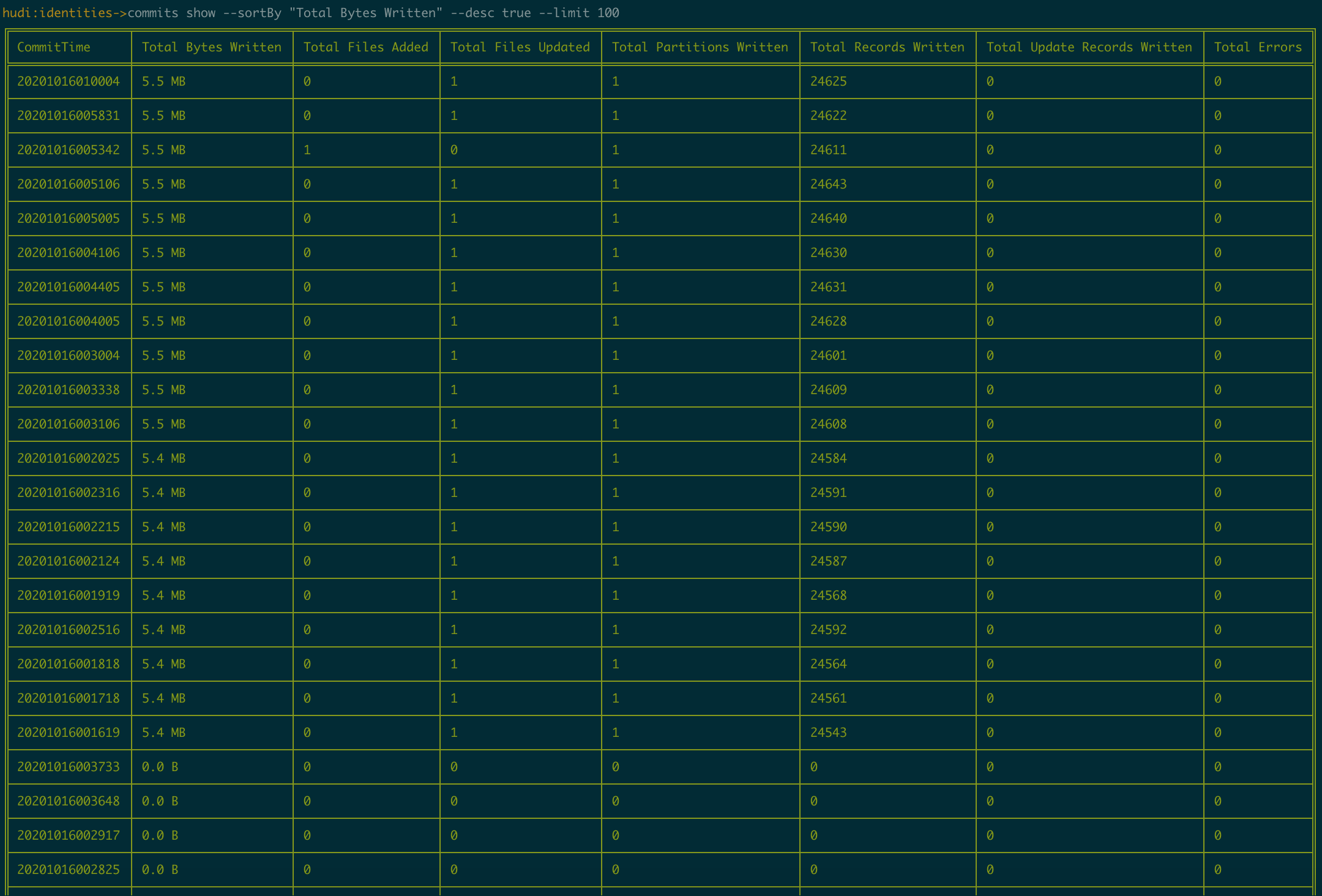
halkar edited a comment on issue #2174:
URL: https://github.com/apache/hudi/issues/2174#issuecomment-709685927
Cleans:
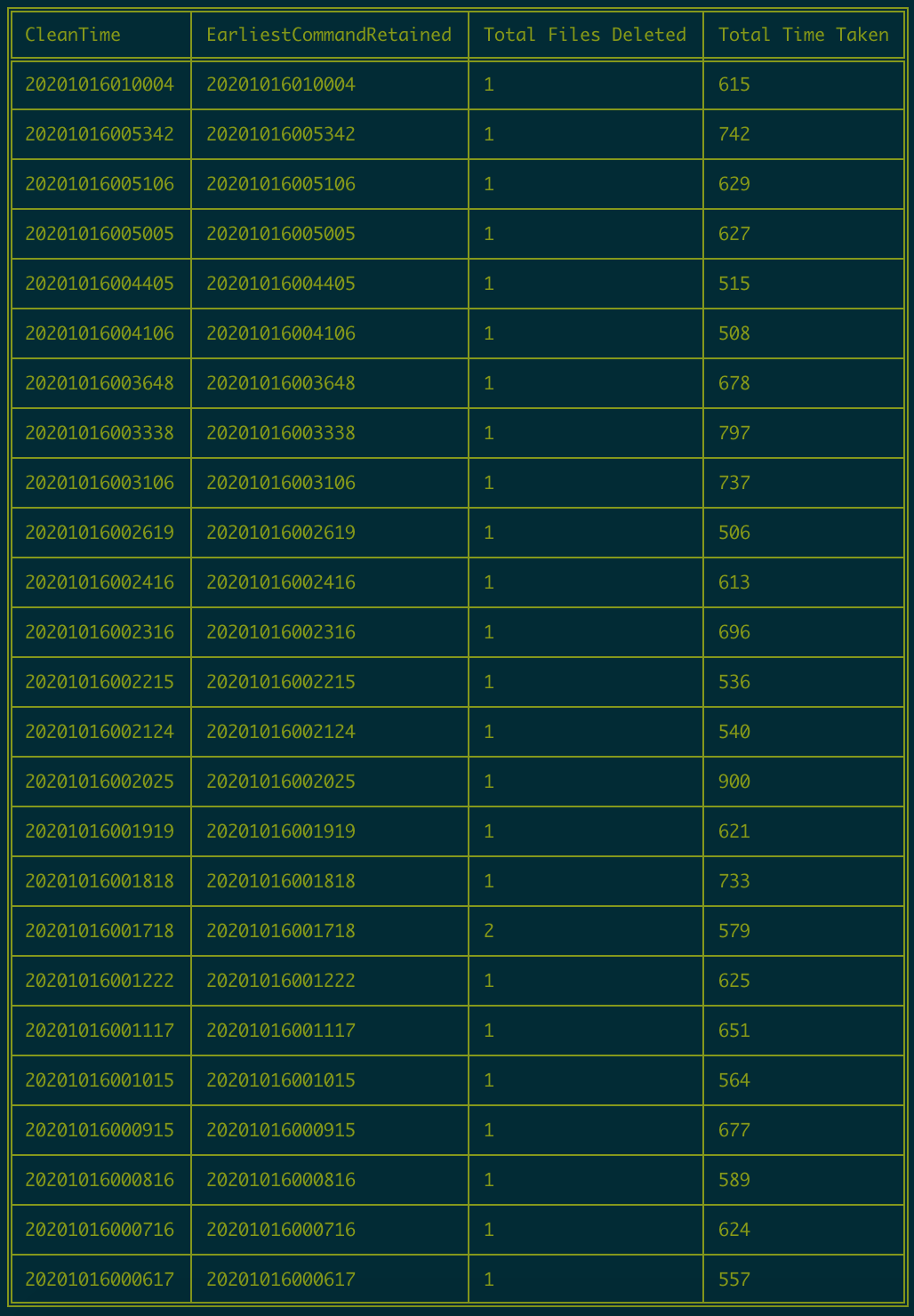
halkar edited a comment on issue #2174:
URL: https://github.com/apache/hudi/issues/2174#issuecomment-709654557
This is a different run. I'll add `cleans show` results later.
All partitions:
```
staff 5984 16 Oct 12:02 .hoodie
staff 224 16 Oct 12:02 graphversion=782
staff
halkar edited a comment on issue #2174:
URL: https://github.com/apache/hudi/issues/2174#issuecomment-709654557
This is a different run. I'll add `cleans show` results later.
All partitions:
```
staff 5984 16 Oct 12:02 .hoodie
staff 224 16 Oct 12:02 graphversion=782
staff
halkar edited a comment on issue #2174:
URL: https://github.com/apache/hudi/issues/2174#issuecomment-709654557
This is a different run. I'll add `cleans show` results later.
All partitions:
```
drwxr-xr-x 187 artur staff 5984 16 Oct 12:02 .hoodie
drwxr-xr-x7 artur staff
halkar commented on issue #2174:
URL: https://github.com/apache/hudi/issues/2174#issuecomment-709685927
Cleans:
https://user-images.githubusercontent.com/1992396/96204557-520a4e80-0fb0-11eb-8205-753b60adea75.png;>
bhasudha commented on pull request #2147:
URL: https://github.com/apache/hudi/pull/2147#issuecomment-709660443
@rmpifer We might need to remove this hbase relocation from
hudi-utilities-bundle as well. Ran into this issue when using DeltaStreamer
without HBASE index and in EMR 5.31.0
halkar edited a comment on issue #2174:
URL: https://github.com/apache/hudi/issues/2174#issuecomment-709654557
This is a different run. I'll add `cleans show` results later.
All partitions:
halkar commented on issue #2174:
URL: https://github.com/apache/hudi/issues/2174#issuecomment-709655075
Is it possible that the problem is caused by two versions of the app running
in parallel? I also noticed that writing hoodie files sometimes hangs.
halkar commented on issue #2174:
URL: https://github.com/apache/hudi/issues/2174#issuecomment-709654557
This is a different run. I'll add `cleans show` results later.
All partitions:
https://user-images.githubusercontent.com/1992396/96198465-9db4fc00-0fa0-11eb-80ba-c951a64fd721.png;>
afeldman1 commented on issue #933:
URL: https://github.com/apache/hudi/issues/933#issuecomment-709642025
Hey @LeoHsu0802
Ah, yes. I've been using the 5.31 version of EMR. EMR 6.0.0 has hudi version
0.5.0-incubating which is pretty old. EMR 5.3.1 includes the latest hudi
version 0.6.0
ashishmgofficial edited a comment on issue #2149:
URL: https://github.com/apache/hudi/issues/2149#issuecomment-709557478
@bvaradar I thought that at first. To confirm the same I retried the
scenario multiple times. Im getting the same error everytime. Only during
Deletes
ashishmgofficial commented on issue #2149:
URL: https://github.com/apache/hudi/issues/2149#issuecomment-709557478
@bvaradar I thought that at first. To confirm the same I retried the
scenario multiple times. Im getting the same error everytime. Only during
Deletes
n3nash commented on a change in pull request #2092:
URL: https://github.com/apache/hudi/pull/2092#discussion_r505797510
##
File path: hudi-integ-test/src/test/resources/unit-test-cow-dag.yaml
##
@@ -17,23 +17,53 @@ first_insert:
config:
record_size: 7
guykhazma opened a new pull request #2183:
URL: https://github.com/apache/hudi/pull/2183
## What is the purpose of the pull request
* Add Documentation for Hudi support for IBM Cloud Object Storage
Hudi Support for IBM Cloud is introduced in this
[
https://issues.apache.org/jira/browse/HUDI-1344?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated HUDI-1344:
-
Labels: pull-request-available (was: )
> Support for IBM Cloud Object Storage
>
guykhazma opened a new pull request #2182:
URL: https://github.com/apache/hudi/pull/2182
## What is the purpose of the pull request
* Add Hudi support for IBM Cloud Object Storage
Documentation will be added in a separate PR
## Brief change log
- add `cos` schema in
umehrot2 commented on issue #2180:
URL: https://github.com/apache/hudi/issues/2180#issuecomment-709480582
This is strange. The exception appears to be happening at
https://github.com/apache/hudi/blob/master/hudi-spark/src/main/scala/org/apache/hudi/MergeOnReadSnapshotRelation.scala#L138
This is an automated email from the ASF dual-hosted git repository.
vinoth pushed a commit to branch asf-site
in repository https://gitbox.apache.org/repos/asf/hudi.git
The following commit(s) were added to refs/heads/asf-site by this push:
new e3b43e1 Travis CI build asf-site
e3b43e1 is
bvaradar commented on issue #2180:
URL: https://github.com/apache/hudi/issues/2180#issuecomment-709457283
@garyli1019 @umehrot2 : Can you help with this ?
This is an automated message from the Apache Git Service.
To respond
bvaradar commented on issue #2178:
URL: https://github.com/apache/hudi/issues/2178#issuecomment-709446368
@nsivabalan : Can you take a look at this ?
This is an automated message from the Apache Git Service.
To respond to
SteNicholas commented on a change in pull request #2111:
URL: https://github.com/apache/hudi/pull/2111#discussion_r505682259
##
File path:
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/action/commit/UpsertPartitioner.java
##
@@ -160,11 +174,15 @@ private
bvaradar commented on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-709445492
Yeah, I think this is a bottleneck. Is this a setup issue (are they located
across dcs) ?
This is an automated
SteNicholas commented on a change in pull request #2111:
URL: https://github.com/apache/hudi/pull/2111#discussion_r505682259
##
File path:
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/action/commit/UpsertPartitioner.java
##
@@ -160,11 +174,15 @@ private
bvaradar merged pull request #2179:
URL: https://github.com/apache/hudi/pull/2179
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to
This is an automated email from the ASF dual-hosted git repository.
vbalaji pushed a commit to branch asf-site
in repository https://gitbox.apache.org/repos/asf/hudi.git
The following commit(s) were added to refs/heads/asf-site by this push:
new d2fccc4 Adding ApacheCon talk link to site
bvaradar commented on issue #2174:
URL: https://github.com/apache/hudi/issues/2174#issuecomment-709442307
@halkar : THanks for the information. Yes, this is not expected. We would
have to see whether cleaning operations is succeeding. We have a cli "cleans
show" that lists the cleans
wangxianghu commented on pull request #2181:
URL: https://github.com/apache/hudi/pull/2181#issuecomment-709442394
@vinothchandar @yanghua @leesf please take a look when free
This is an automated message from the Apache Git
[
https://issues.apache.org/jira/browse/HUDI-1264?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17214814#comment-17214814
]
liwei edited comment on HUDI-1264 at 10/15/20, 4:20 PM:
[~satishkotha] hello , i
bvaradar commented on issue #2066:
URL: https://github.com/apache/hudi/issues/2066#issuecomment-709436915
THis looks fine to me. Just wondering instead of default implementation of
ComplexKeyGenerator which concatenates all the fields, can you try implementing
a key-generator which
[
https://issues.apache.org/jira/browse/HUDI-1264?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17214814#comment-17214814
]
liwei commented on HUDI-1264:
-
[~satishkotha] hello , i am interested to work on this. some thing want to
[
https://issues.apache.org/jira/browse/HUDI-911?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated HUDI-911:
Labels: pull-request-available (was: )
> Add Blog about Hudi-Spark decoupling and Flink integration
wangxianghu opened a new pull request #2181:
URL: https://github.com/apache/hudi/pull/2181
…design
## *Tips*
- *Thank you very much for contributing to Apache Hudi.*
- *Please review https://hudi.apache.org/contributing.html before opening a
pull request.*
## What is
bvaradar commented on issue #2149:
URL: https://github.com/apache/hudi/issues/2149#issuecomment-709424684
This is clearly the error : "Caused by: java.lang.NullPointerException: Null
value appeared in non-nullable field:"
Looking at the code, its not very clear how this can happen. Just
rahulpoptani opened a new issue #2180:
URL: https://github.com/apache/hudi/issues/2180
**Describe the problem you faced**
Hi Team,
I've written a MERGE ON READ type table and made few upserts and deletes as
mentioned in the documentation.
When trying to read the hudi format output
[
https://issues.apache.org/jira/browse/HUDI-1344?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17214740#comment-17214740
]
Guy Khazma commented on HUDI-1344:
--
will open PR soon
> Support for IBM Cloud Object Storage
>
leesf commented on a change in pull request #2111:
URL: https://github.com/apache/hudi/pull/2111#discussion_r505542832
##
File path:
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/action/commit/UpsertPartitioner.java
##
@@ -160,11 +174,15 @@ private void
leesf commented on a change in pull request #2111:
URL: https://github.com/apache/hudi/pull/2111#discussion_r505541446
##
File path:
hudi-client/hudi-spark-client/src/main/java/org/apache/hudi/table/action/commit/UpsertPartitioner.java
##
@@ -129,6 +131,18 @@ private int
Guy Khazma created HUDI-1344:
Summary: Support for IBM Cloud Object Storage
Key: HUDI-1344
URL: https://issues.apache.org/jira/browse/HUDI-1344
Project: Apache Hudi
Issue Type: Improvement
spyzzz commented on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-709293656
I seems that the pulling from kafka is ver slow ...
```
20/10/15 12:33:48 INFO memory.MemoryStore: Block broadcast_17 stored as
values in memory (estimated size 29.4 KB,
spyzzz edited a comment on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-709238060
@naka13 I'm already using spark.streaming.concurrentJobs with 5.
For delete i handle this by adding _hoodie_is_deleted when the field op = d
(for delete) in debezium :
spyzzz commented on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-709238060
@naka13 I'm already using spark.streaming.concurrentJobs with 5.
For delete i handle this by adding _hoodie_is_deleted when the field op = d
(for delete) in debezium :
```
nsivabalan opened a new pull request #2179:
URL: https://github.com/apache/hudi/pull/2179
##What is the purpose of the pull request
Adding ApacheCon talk link to site
## Verify this pull request
Verified by deploying the site locally.
## Committer checklist
naka13 edited a comment on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-709208973
One obvious bottleneck is the sequential processing. Since you are already
creating multiple streams, you can increase concurrency using
`spark.streaming.concurrentJobs`. You can
naka13 edited a comment on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-709208973
One obvious bottleneck is the sequential processing. Since you are already
creating multiple streams, you can increase concurrency using
`spark.streaming.concurrentJobs`. You can
naka13 commented on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-709208973
One obvious bottleneck is the sequential processing. Since you are already
creating multiple streams, you can increase concurrency using
`spark.streaming.concurrentJobs`. You can set it
KarthickAN opened a new issue #2178:
URL: https://github.com/apache/hudi/issues/2178
Hi,
I tried inspecting the parquet files produced by hudi using the parquet
tools. Each parquet file produced by hudi contains around 10MB worth of data
for the field **extra:
spyzzz commented on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-708998405
Actually Deltasteamer can't handle key in avro desirialiser that's why i
wasnt able to test it.
Its hardcoded (String Deserializer) for KEY and Avro for value.
In my case both
naka13 commented on issue #2175:
URL: https://github.com/apache/hudi/issues/2175#issuecomment-708992777
Do you think you could do the _"specific operation, such as filtering data,
converting date"_ using SMTs in kafka connect? Then you could directly use
multi table deltastreamer
[
https://issues.apache.org/jira/browse/HUDI-892?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17214511#comment-17214511
]
Vinoth Chandar commented on HUDI-892:
-
Sorry for the late response. the reason is that without any log
SteNicholas commented on pull request #2111:
URL: https://github.com/apache/hudi/pull/2111#issuecomment-708985867
> @SteNicholas Thanks for your contribution, left some comments.
Thanks for your comments. I have already followed up with your comments.
Please feel free to review
codecov-io edited a comment on pull request #2111:
URL: https://github.com/apache/hudi/pull/2111#issuecomment-708984716
# [Codecov](https://codecov.io/gh/apache/hudi/pull/2111?src=pr=h1) Report
> Merging
[#2111](https://codecov.io/gh/apache/hudi/pull/2111?src=pr=desc) into
codecov-io commented on pull request #2111:
URL: https://github.com/apache/hudi/pull/2111#issuecomment-708984716
# [Codecov](https://codecov.io/gh/apache/hudi/pull/2111?src=pr=h1) Report
> Merging
[#2111](https://codecov.io/gh/apache/hudi/pull/2111?src=pr=desc) into
LeoHsu0802 edited a comment on issue #933:
URL: https://github.com/apache/hudi/issues/933#issuecomment-708910383
Hi @afeldman1 ,
I successfully add multiple partition with ComplexKeyGenerator but still
cant not do with CustomKeyGenerator.
Try to use glue metastore but not
LeoHsu0802 edited a comment on issue #933:
URL: https://github.com/apache/hudi/issues/933#issuecomment-708910383
Hi @afeldman1 ,
I successfully add multiple partition with ComplexKeyGenerator but still
cant not do with CustomKeyGenerator.
Try to use glue metastore but not
61 matches
Mail list logo