svn commit: r28068 - in /dev/spark/2.4.0-SNAPSHOT-2018_07_11_20_01-5ad4735-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Thu Jul 12 03:15:51 2018 New Revision: 28068 Log: Apache Spark 2.4.0-SNAPSHOT-2018_07_11_20_01-5ad4735 docs [This commit notification would consist of 1467 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-24529][BUILD][TEST-MAVEN] Add spotbugs into maven build process
Repository: spark
Updated Branches:
refs/heads/master 3ab48f985 -> 5ad4735bd
[SPARK-24529][BUILD][TEST-MAVEN] Add spotbugs into maven build process
## What changes were proposed in this pull request?
This PR enables a Java bytecode check tool
[spotbugs](https://spotbugs.github.io/) to avoid possible integer overflow at
multiplication. When an violation is detected, the build process is stopped.
Due to the tool limitation, some other checks will be enabled. In this PR,
[these
patterns](http://spotbugs-in-kengo-toda.readthedocs.io/en/lqc-list-detectors/detectors.html#findpuzzlers)
in `FindPuzzlers` can be detected.
This check is enabled at `compile` phase. Thus, `mvn compile` or `mvn package`
launches this check.
## How was this patch tested?
Existing UTs
Author: Kazuaki Ishizaki
Closes #21542 from kiszk/SPARK-24529.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/5ad4735b
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/5ad4735b
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/5ad4735b
Branch: refs/heads/master
Commit: 5ad4735bdad558fe564a0391e207c62743647ab1
Parents: 3ab48f9
Author: Kazuaki Ishizaki
Authored: Thu Jul 12 09:52:23 2018 +0800
Committer: hyukjinkwon
Committed: Thu Jul 12 09:52:23 2018 +0800
--
.../spark/util/collection/ExternalSorter.scala | 4 ++--
.../org/apache/spark/ml/image/HadoopUtils.scala | 8 ---
pom.xml | 22
resource-managers/kubernetes/core/pom.xml | 6 ++
.../kubernetes/integration-tests/pom.xml| 5 +
.../expressions/collectionOperations.scala | 2 +-
.../expressions/conditionalExpressions.scala| 4 ++--
.../spark/sql/catalyst/parser/AstBuilder.scala | 2 +-
8 files changed, 44 insertions(+), 9 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/5ad4735b/core/src/main/scala/org/apache/spark/util/collection/ExternalSorter.scala
--
diff --git
a/core/src/main/scala/org/apache/spark/util/collection/ExternalSorter.scala
b/core/src/main/scala/org/apache/spark/util/collection/ExternalSorter.scala
index 176f84f..b159200 100644
--- a/core/src/main/scala/org/apache/spark/util/collection/ExternalSorter.scala
+++ b/core/src/main/scala/org/apache/spark/util/collection/ExternalSorter.scala
@@ -368,8 +368,8 @@ private[spark] class ExternalSorter[K, V, C](
val bufferedIters = iterators.filter(_.hasNext).map(_.buffered)
type Iter = BufferedIterator[Product2[K, C]]
val heap = new mutable.PriorityQueue[Iter]()(new Ordering[Iter] {
- // Use the reverse of comparator.compare because PriorityQueue dequeues
the max
- override def compare(x: Iter, y: Iter): Int =
-comparator.compare(x.head._1, y.head._1)
+ // Use the reverse order because PriorityQueue dequeues the max
+ override def compare(x: Iter, y: Iter): Int =
comparator.compare(y.head._1, x.head._1)
})
heap.enqueue(bufferedIters: _*) // Will contain only the iterators with
hasNext = true
new Iterator[Product2[K, C]] {
http://git-wip-us.apache.org/repos/asf/spark/blob/5ad4735b/mllib/src/main/scala/org/apache/spark/ml/image/HadoopUtils.scala
--
diff --git a/mllib/src/main/scala/org/apache/spark/ml/image/HadoopUtils.scala
b/mllib/src/main/scala/org/apache/spark/ml/image/HadoopUtils.scala
index 8c975a2..f1579ec 100644
--- a/mllib/src/main/scala/org/apache/spark/ml/image/HadoopUtils.scala
+++ b/mllib/src/main/scala/org/apache/spark/ml/image/HadoopUtils.scala
@@ -42,9 +42,11 @@ private object RecursiveFlag {
val old = Option(hadoopConf.get(flagName))
hadoopConf.set(flagName, value.toString)
try f finally {
- old match {
-case Some(v) => hadoopConf.set(flagName, v)
-case None => hadoopConf.unset(flagName)
+ // avoid false positive of DLS_DEAD_LOCAL_STORE_IN_RETURN by SpotBugs
+ if (old.isDefined) {
+hadoopConf.set(flagName, old.get)
+ } else {
+hadoopConf.unset(flagName)
}
}
}
http://git-wip-us.apache.org/repos/asf/spark/blob/5ad4735b/pom.xml
--
diff --git a/pom.xml b/pom.xml
index cd567e2..6dee6fc 100644
--- a/pom.xml
+++ b/pom.xml
@@ -2606,6 +2606,28 @@
+
+com.github.spotbugs
+spotbugs-maven-plugin
+3.1.3
+
+
${basedir}/target/scala-${scala.binary.version}/classes
+
${basedir}/target/scala-${scala.binary.version}/test-classes
+ Max
+ Low
+ true
+ FindPuzzlers
+ false
+
+
+
+
+
spark git commit: [SPARK-24761][SQL] Adding of isModifiable() to RuntimeConfig
Repository: spark
Updated Branches:
refs/heads/master e008ad175 -> 3ab48f985
[SPARK-24761][SQL] Adding of isModifiable() to RuntimeConfig
## What changes were proposed in this pull request?
In the PR, I propose to extend `RuntimeConfig` by new method `isModifiable()`
which returns `true` if a config parameter can be modified at runtime (for
current session state). For static SQL and core parameters, the method returns
`false`.
## How was this patch tested?
Added new test to `RuntimeConfigSuite` for checking Spark core and SQL
parameters.
Author: Maxim Gekk
Closes #21730 from MaxGekk/is-modifiable.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/3ab48f98
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/3ab48f98
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/3ab48f98
Branch: refs/heads/master
Commit: 3ab48f985c7f96bc9143caad99bf3df7cc984583
Parents: e008ad1
Author: Maxim Gekk
Authored: Wed Jul 11 17:38:43 2018 -0700
Committer: Xiao Li
Committed: Wed Jul 11 17:38:43 2018 -0700
--
python/pyspark/sql/conf.py| 8
.../scala/org/apache/spark/sql/internal/SQLConf.scala | 4
.../scala/org/apache/spark/sql/RuntimeConfig.scala| 11 +++
.../org/apache/spark/sql/RuntimeConfigSuite.scala | 14 ++
4 files changed, 37 insertions(+)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/3ab48f98/python/pyspark/sql/conf.py
--
diff --git a/python/pyspark/sql/conf.py b/python/pyspark/sql/conf.py
index db49040..f80bf59 100644
--- a/python/pyspark/sql/conf.py
+++ b/python/pyspark/sql/conf.py
@@ -63,6 +63,14 @@ class RuntimeConfig(object):
raise TypeError("expected %s '%s' to be a string (was '%s')" %
(identifier, obj, type(obj).__name__))
+@ignore_unicode_prefix
+@since(2.4)
+def isModifiable(self, key):
+"""Indicates whether the configuration property with the given key
+is modifiable in the current session.
+"""
+return self._jconf.isModifiable(key)
+
def _test():
import os
http://git-wip-us.apache.org/repos/asf/spark/blob/3ab48f98/sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
--
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
index ae56cc9..14dd528 100644
--- a/sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
+++ b/sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
@@ -1907,4 +1907,8 @@ class SQLConf extends Serializable with Logging {
}
cloned
}
+
+ def isModifiable(key: String): Boolean = {
+sqlConfEntries.containsKey(key) && !staticConfKeys.contains(key)
+ }
}
http://git-wip-us.apache.org/repos/asf/spark/blob/3ab48f98/sql/core/src/main/scala/org/apache/spark/sql/RuntimeConfig.scala
--
diff --git a/sql/core/src/main/scala/org/apache/spark/sql/RuntimeConfig.scala
b/sql/core/src/main/scala/org/apache/spark/sql/RuntimeConfig.scala
index b352e33..3c39579 100644
--- a/sql/core/src/main/scala/org/apache/spark/sql/RuntimeConfig.scala
+++ b/sql/core/src/main/scala/org/apache/spark/sql/RuntimeConfig.scala
@@ -133,6 +133,17 @@ class RuntimeConfig private[sql](sqlConf: SQLConf = new
SQLConf) {
}
/**
+ * Indicates whether the configuration property with the given key
+ * is modifiable in the current session.
+ *
+ * @return `true` if the configuration property is modifiable. For static
SQL, Spark Core,
+ * invalid (not existing) and other non-modifiable configuration
properties,
+ * the returned value is `false`.
+ * @since 2.4.0
+ */
+ def isModifiable(key: String): Boolean = sqlConf.isModifiable(key)
+
+ /**
* Returns whether a particular key is set.
*/
protected[sql] def contains(key: String): Boolean = {
http://git-wip-us.apache.org/repos/asf/spark/blob/3ab48f98/sql/core/src/test/scala/org/apache/spark/sql/RuntimeConfigSuite.scala
--
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/RuntimeConfigSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/RuntimeConfigSuite.scala
index cfe2e9f..cdcea09 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/RuntimeConfigSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/RuntimeConfigSuite.scala
@@ -54,4 +54,18 @@ class RuntimeConfigSuite extends SparkFunSuite {
conf.get("k1")
}
}
+
+ test("SPARK-24761: is a config
spark git commit: [SPARK-24782][SQL] Simplify conf retrieval in SQL expressions
Repository: spark
Updated Branches:
refs/heads/master ff7f6ef75 -> e008ad175
[SPARK-24782][SQL] Simplify conf retrieval in SQL expressions
## What changes were proposed in this pull request?
The PR simplifies the retrieval of config in `size`, as we can access them from
tasks too thanks to SPARK-24250.
## How was this patch tested?
existing UTs
Author: Marco Gaido
Closes #21736 from mgaido91/SPARK-24605_followup.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/e008ad17
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/e008ad17
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/e008ad17
Branch: refs/heads/master
Commit: e008ad175256a3192fdcbd2c4793044d52f46d57
Parents: ff7f6ef
Author: Marco Gaido
Authored: Wed Jul 11 17:30:43 2018 -0700
Committer: Xiao Li
Committed: Wed Jul 11 17:30:43 2018 -0700
--
.../expressions/collectionOperations.scala | 10 +--
.../catalyst/expressions/jsonExpressions.scala | 16 ++---
.../spark/sql/catalyst/plans/QueryPlan.scala| 2 -
.../CollectionExpressionsSuite.scala| 27
.../expressions/JsonExpressionsSuite.scala | 65 ++--
.../scala/org/apache/spark/sql/functions.scala | 4 +-
6 files changed, 57 insertions(+), 67 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/e008ad17/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
--
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
index 879603b..e217d37 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
@@ -89,15 +89,9 @@ trait BinaryArrayExpressionWithImplicitCast extends
BinaryExpression
> SELECT _FUNC_(NULL);
-1
""")
-case class Size(
-child: Expression,
-legacySizeOfNull: Boolean)
- extends UnaryExpression with ExpectsInputTypes {
+case class Size(child: Expression) extends UnaryExpression with
ExpectsInputTypes {
- def this(child: Expression) =
-this(
- child,
- legacySizeOfNull = SQLConf.get.getConf(SQLConf.LEGACY_SIZE_OF_NULL))
+ val legacySizeOfNull = SQLConf.get.legacySizeOfNull
override def dataType: DataType = IntegerType
override def inputTypes: Seq[AbstractDataType] =
Seq(TypeCollection(ArrayType, MapType))
http://git-wip-us.apache.org/repos/asf/spark/blob/e008ad17/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/jsonExpressions.scala
--
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/jsonExpressions.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/jsonExpressions.scala
index 8cd8605..63943b1 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/jsonExpressions.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/jsonExpressions.scala
@@ -514,10 +514,11 @@ case class JsonToStructs(
schema: DataType,
options: Map[String, String],
child: Expression,
-timeZoneId: Option[String],
-forceNullableSchema: Boolean)
+timeZoneId: Option[String] = None)
extends UnaryExpression with TimeZoneAwareExpression with CodegenFallback
with ExpectsInputTypes {
+ val forceNullableSchema =
SQLConf.get.getConf(SQLConf.FROM_JSON_FORCE_NULLABLE_SCHEMA)
+
// The JSON input data might be missing certain fields. We force the
nullability
// of the user-provided schema to avoid data corruptions. In particular, the
parquet-mr encoder
// can generate incorrect files if values are missing in columns declared as
non-nullable.
@@ -531,8 +532,7 @@ case class JsonToStructs(
schema = JsonExprUtils.evalSchemaExpr(schema),
options = options,
child = child,
- timeZoneId = None,
- forceNullableSchema =
SQLConf.get.getConf(SQLConf.FROM_JSON_FORCE_NULLABLE_SCHEMA))
+ timeZoneId = None)
def this(child: Expression, schema: Expression) = this(child, schema,
Map.empty[String, String])
@@ -541,13 +541,7 @@ case class JsonToStructs(
schema = JsonExprUtils.evalSchemaExpr(schema),
options = JsonExprUtils.convertToMapData(options),
child = child,
- timeZoneId = None,
- forceNullableSchema =
SQLConf.get.getConf(SQLConf.FROM_JSON_FORCE_NULLABLE_SCHEMA))
-
- // Used in `org.apache.spark.sql.functions`
- def this(schema: DataType, options: Map[String,
svn commit: r28065 - in /dev/spark/2.4.0-SNAPSHOT-2018_07_11_16_01-ff7f6ef-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Wed Jul 11 23:15:43 2018 New Revision: 28065 Log: Apache Spark 2.4.0-SNAPSHOT-2018_07_11_16_01-ff7f6ef docs [This commit notification would consist of 1467 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark-website git commit: Add ref to CVE-2018-1334, CVE-2018-8024
Repository: spark-website Updated Branches: refs/heads/asf-site a6788714a -> 85c47b705 Add ref to CVE-2018-1334, CVE-2018-8024 Project: http://git-wip-us.apache.org/repos/asf/spark-website/repo Commit: http://git-wip-us.apache.org/repos/asf/spark-website/commit/85c47b70 Tree: http://git-wip-us.apache.org/repos/asf/spark-website/tree/85c47b70 Diff: http://git-wip-us.apache.org/repos/asf/spark-website/diff/85c47b70 Branch: refs/heads/asf-site Commit: 85c47b70516aad3b04c46438b598d379121a4778 Parents: a678871 Author: Sean Owen Authored: Wed Jul 11 15:14:26 2018 -0500 Committer: Sean Owen Committed: Wed Jul 11 15:14:26 2018 -0500 -- security.md| 55 +++- site/security.html | 67 - 2 files changed, 120 insertions(+), 2 deletions(-) -- http://git-wip-us.apache.org/repos/asf/spark-website/blob/85c47b70/security.md -- diff --git a/security.md b/security.md index bd2e66f..f99b9bd 100644 --- a/security.md +++ b/security.md @@ -17,6 +17,59 @@ non-public list that will reach the Apache Security team, as well as the Spark P Known Security Issues +CVE-2018-8024: Apache Spark XSS vulnerability in UI + +Versions Affected: + +- Spark versions through 2.1.2 +- Spark 2.2.0 through 2.2.1 +- Spark 2.3.0 + +Description: +In Apache Spark up to and including 2.1.2, 2.2.0 to 2.2.1, and 2.3.0, it's possible for a malicious +user to construct a URL pointing to a Spark cluster's UI's job and stage info pages, and if a user can +be tricked into accessing the URL, can be used to cause script to execute and expose information from +the user's view of the Spark UI. While some browsers like recent versions of Chrome and Safari are +able to block this type of attack, current versions of Firefox (and possibly others) do not. + +Mitigation: + +- 1.x, 2.0.x, and 2.1.x users should upgrade to 2.1.3 or newer +- 2.2.x users should upgrade to 2.2.2 or newer +- 2.3.x users should upgrade to 2.3.1 or newer + +Credit: + +- Spencer Gietzen, Rhino Security Labs + +CVE-2018-1334: Apache Spark local privilege escalation vulnerability + +Severity: High + +Vendor: The Apache Software Foundation + +Versions affected: + +- Spark versions through 2.1.2 +- Spark 2.2.0 to 2.2.1 +- Spark 2.3.0 + +Description: +In Apache Spark up to and including 2.1.2, 2.2.0 to 2.2.1, and 2.3.0, when using PySpark or SparkR, +it's possible for a different local user to connect to the Spark application and impersonate the +user running the Spark application. + +Mitigation: + +- 1.x, 2.0.x, and 2.1.x users should upgrade to 2.1.3 or newer +- 2.2.x users should upgrade to 2.2.2 or newer +- 2.3.x users should upgrade to 2.3.1 or newer +- Otherwise, affected users should avoid using PySpark and SparkR in multi-user environments. + +Credit: + +- Nehmé Tohmé, Cloudera, Inc. + CVE-2017-12612 Unsafe deserialization in Apache Spark launcher API JIRA: [SPARK-20922](https://issues.apache.org/jira/browse/SPARK-20922) @@ -49,7 +102,7 @@ Credit: JIRA: [SPARK-20393](https://issues.apache.org/jira/browse/SPARK-20393) -Severity: Low +Severity: Medium Vendor: The Apache Software Foundation http://git-wip-us.apache.org/repos/asf/spark-website/blob/85c47b70/site/security.html -- diff --git a/site/security.html b/site/security.html index 4f30331..3e0aeac 100644 --- a/site/security.html +++ b/site/security.html @@ -210,6 +210,71 @@ non-public list that will reach the Apache Security team, as well as the Spark P Known Security Issues +CVE-2018-8024: Apache Spark XSS vulnerability in UI + +Versions Affected: + + + Spark versions through 2.1.2 + Spark 2.2.0 through 2.2.1 + Spark 2.3.0 + + +Description: +In Apache Spark up to and including 2.1.2, 2.2.0 to 2.2.1, and 2.3.0, its possible for a malicious +user to construct a URL pointing to a Spark clusters UIs job and stage info pages, and if a user can +be tricked into accessing the URL, can be used to cause script to execute and expose information from +the users view of the Spark UI. While some browsers like recent versions of Chrome and Safari are +able to block this type of attack, current versions of Firefox (and possibly others) do not. + +Mitigation: + + + 1.x, 2.0.x, and 2.1.x users should upgrade to 2.1.3 or newer + 2.2.x users should upgrade to 2.2.2 or newer + 2.3.x users should upgrade to 2.3.1 or newer + + +Credit: + + + Spencer Gietzen, Rhino Security Labs + + +CVE-2018-1334: Apache Spark local privilege escalation vulnerability + +Severity: High + +Vendor: The Apache Software Foundation + +Versions affected: + + + Spark versions through 2.1.2 + Spark 2.2.0 to 2.2.1 + Spark 2.3.0 + + +Description: +In Apache
spark git commit: [SPARK-24697][SS] Fix the reported start offsets in streaming query progress
Repository: spark
Updated Branches:
refs/heads/master 59c3c233f -> ff7f6ef75
[SPARK-24697][SS] Fix the reported start offsets in streaming query progress
## What changes were proposed in this pull request?
In ProgressReporter for streams, we use the `committedOffsets` as the
startOffset and `availableOffsets` as the end offset when reporting the status
of a trigger in `finishTrigger`. This is a bad pattern that has existed since
the beginning of ProgressReporter and it is bad because its super hard to
reason about when `availableOffsets` and `committedOffsets` are updated, and
when they are recorded. Case in point, this bug silently existed in
ContinuousExecution, since before MicroBatchExecution was refactored.
The correct fix it to record the offsets explicitly. This PR adds a simple
method which is explicitly called from MicroBatch/ContinuousExecition before
updating the `committedOffsets`.
## How was this patch tested?
Added new tests
Author: Tathagata Das
Closes #21744 from tdas/SPARK-24697.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/ff7f6ef7
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/ff7f6ef7
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/ff7f6ef7
Branch: refs/heads/master
Commit: ff7f6ef75c80633480802d537e66432e3bea4785
Parents: 59c3c23
Author: Tathagata Das
Authored: Wed Jul 11 12:44:42 2018 -0700
Committer: Tathagata Das
Committed: Wed Jul 11 12:44:42 2018 -0700
--
.../streaming/MicroBatchExecution.scala | 3 +++
.../execution/streaming/ProgressReporter.scala | 21
.../continuous/ContinuousExecution.scala| 3 +++
.../sql/streaming/StreamingQuerySuite.scala | 6 --
4 files changed, 27 insertions(+), 6 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/ff7f6ef7/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala
--
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala
index 16651dd..45c43f5 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/MicroBatchExecution.scala
@@ -184,6 +184,9 @@ class MicroBatchExecution(
isCurrentBatchConstructed =
constructNextBatch(noDataBatchesEnabled)
}
+ // Record the trigger offset range for progress reporting *before*
processing the batch
+ recordTriggerOffsets(from = committedOffsets, to = availableOffsets)
+
// Remember whether the current batch has data or not. This will be
required later
// for bookkeeping after running the batch, when
`isNewDataAvailable` will have changed
// to false as the batch would have already processed the available
data.
http://git-wip-us.apache.org/repos/asf/spark/blob/ff7f6ef7/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/ProgressReporter.scala
--
diff --git
a/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/ProgressReporter.scala
b/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/ProgressReporter.scala
index 16ad3ef..47f4b52 100644
---
a/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/ProgressReporter.scala
+++
b/sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/ProgressReporter.scala
@@ -56,8 +56,6 @@ trait ProgressReporter extends Logging {
protected def logicalPlan: LogicalPlan
protected def lastExecution: QueryExecution
protected def newData: Map[BaseStreamingSource, LogicalPlan]
- protected def availableOffsets: StreamProgress
- protected def committedOffsets: StreamProgress
protected def sources: Seq[BaseStreamingSource]
protected def sink: BaseStreamingSink
protected def offsetSeqMetadata: OffsetSeqMetadata
@@ -68,8 +66,11 @@ trait ProgressReporter extends Logging {
// Local timestamps and counters.
private var currentTriggerStartTimestamp = -1L
private var currentTriggerEndTimestamp = -1L
+ private var currentTriggerStartOffsets: Map[BaseStreamingSource, String] = _
+ private var currentTriggerEndOffsets: Map[BaseStreamingSource, String] = _
// TODO: Restore this from the checkpoint when possible.
private var lastTriggerStartTimestamp = -1L
+
private val currentDurationsMs = new mutable.HashMap[String, Long]()
/** Flag that signals whether any error with input metrics have already been
logged */
@@ -114,9 +115,20 @@ trait ProgressReporter extends Logging {
svn commit: r28062 - in /dev/spark/2.4.0-SNAPSHOT-2018_07_11_12_01-59c3c23-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Wed Jul 11 19:16:37 2018 New Revision: 28062 Log: Apache Spark 2.4.0-SNAPSHOT-2018_07_11_12_01-59c3c23 docs [This commit notification would consist of 1467 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23254][ML] Add user guide entry and example for DataFrame multivariate summary
Repository: spark
Updated Branches:
refs/heads/master 290c30a53 -> 59c3c233f
[SPARK-23254][ML] Add user guide entry and example for DataFrame multivariate
summary
## What changes were proposed in this pull request?
Add user guide and scala/java/python examples for `ml.stat.Summarizer`
## How was this patch tested?
Doc generated snapshot:



Author: WeichenXu
Closes #20446 from WeichenXu123/summ_guide.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/59c3c233
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/59c3c233
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/59c3c233
Branch: refs/heads/master
Commit: 59c3c233f4366809b6b4db39b3d32c194c98d5ab
Parents: 290c30a
Author: WeichenXu
Authored: Wed Jul 11 13:56:09 2018 -0500
Committer: Sean Owen
Committed: Wed Jul 11 13:56:09 2018 -0500
--
docs/ml-statistics.md | 28
.../examples/ml/JavaSummarizerExample.java | 71
.../src/main/python/ml/summarizer_example.py| 59
.../spark/examples/ml/SummarizerExample.scala | 61 +
4 files changed, 219 insertions(+)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/59c3c233/docs/ml-statistics.md
--
diff --git a/docs/ml-statistics.md b/docs/ml-statistics.md
index abfb3ca..6c82b3b 100644
--- a/docs/ml-statistics.md
+++ b/docs/ml-statistics.md
@@ -89,4 +89,32 @@ Refer to the [`ChiSquareTest` Python
docs](api/python/index.html#pyspark.ml.stat
{% include_example python/ml/chi_square_test_example.py %}
+
+
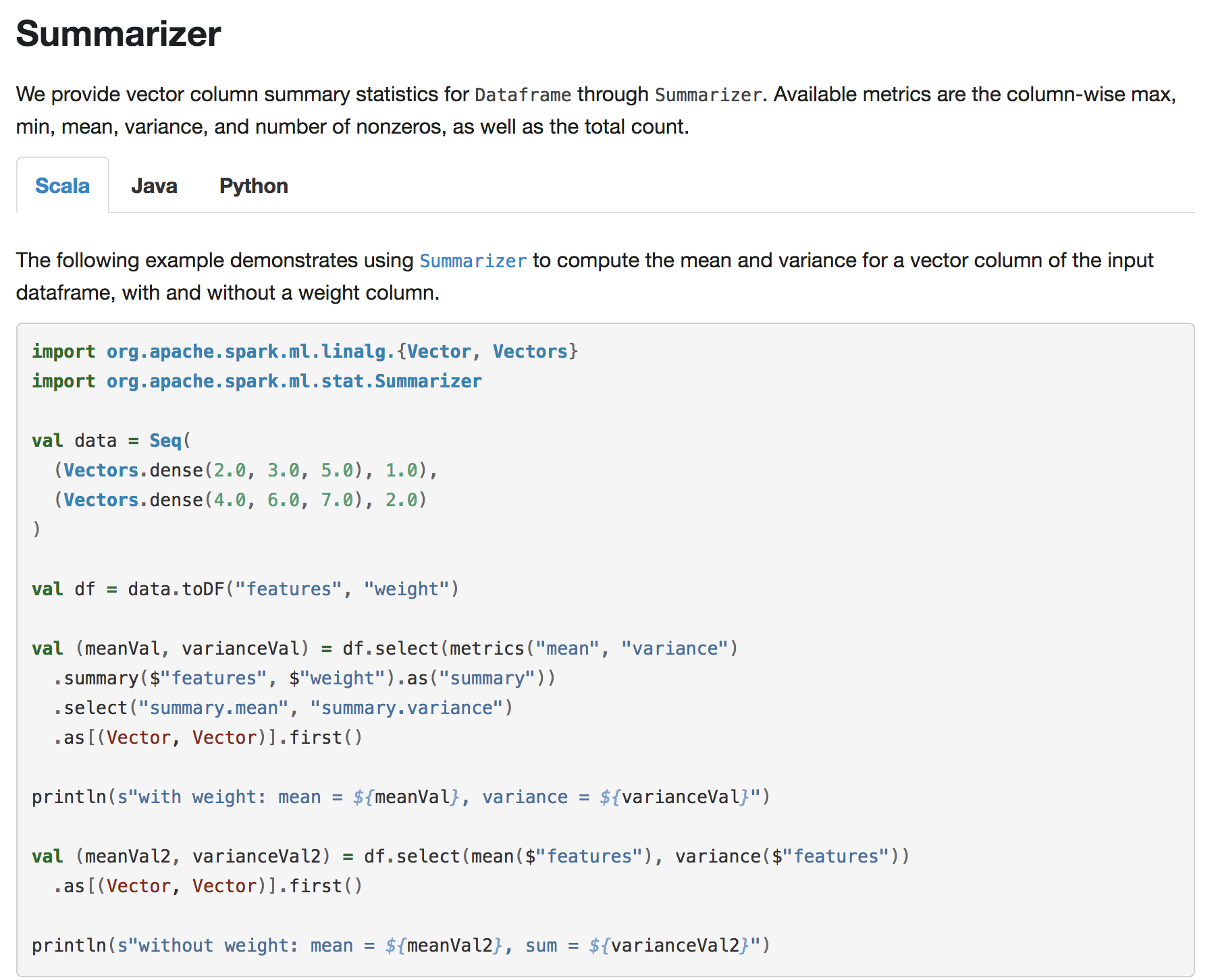
+## Summarizer
+
+We provide vector column summary statistics for `Dataframe` through
`Summarizer`.
+Available metrics are the column-wise max, min, mean, variance, and number of
nonzeros, as well as the total count.
+
+
+
+The following example demonstrates using
[`Summarizer`](api/scala/index.html#org.apache.spark.ml.stat.Summarizer$)
+to compute the mean and variance for a vector column of the input dataframe,
with and without a weight column.
+
+{% include_example scala/org/apache/spark/examples/ml/SummarizerExample.scala
%}
+
+
+
+The following example demonstrates using
[`Summarizer`](api/java/org/apache/spark/ml/stat/Summarizer.html)
+to compute the mean and variance for a vector column of the input dataframe,
with and without a weight column.
+
+{% include_example
java/org/apache/spark/examples/ml/JavaSummarizerExample.java %}
+
+
+
+Refer to the [`Summarizer` Python
docs](api/python/index.html#pyspark.ml.stat.Summarizer$) for details on the API.
+
+{% include_example python/ml/summarizer_example.py %}
+
+
\ No newline at end of file
http://git-wip-us.apache.org/repos/asf/spark/blob/59c3c233/examples/src/main/java/org/apache/spark/examples/ml/JavaSummarizerExample.java
--
diff --git
a/examples/src/main/java/org/apache/spark/examples/ml/JavaSummarizerExample.java
b/examples/src/main/java/org/apache/spark/examples/ml/JavaSummarizerExample.java
new file mode 100644
index 000..e9b8436
--- /dev/null
+++
b/examples/src/main/java/org/apache/spark/examples/ml/JavaSummarizerExample.java
@@ -0,0 +1,71 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.examples.ml;
+
+import org.apache.spark.sql.*;
+
+// $example on$
+import java.util.Arrays;
+import java.util.List;
+
+import org.apache.spark.ml.linalg.Vector;
+import org.apache.spark.ml.linalg.Vectors;
+import org.apache.spark.ml.linalg.VectorUDT;
+import
spark git commit: [SPARK-24470][CORE] RestSubmissionClient to be robust against 404 & non json responses
Repository: spark
Updated Branches:
refs/heads/master ebf4bfb96 -> 290c30a53
[SPARK-24470][CORE] RestSubmissionClient to be robust against 404 & non json
responses
## What changes were proposed in this pull request?
Added check for 404, to avoid json parsing on not found response and to avoid
returning malformed or bad request when it was a not found http response.
Not sure if I need to add an additional check on non json response
[if(connection.getHeaderField("Content-Type").contains("text/html")) then
exception] as non-json is a subset of malformed json and covered in flow.
## How was this patch tested?
./dev/run-tests
Author: Rekha Joshi
Closes #21684 from rekhajoshm/SPARK-24470.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/290c30a5
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/290c30a5
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/290c30a5
Branch: refs/heads/master
Commit: 290c30a53fc2f46001846ab8abafcc69b853ba98
Parents: ebf4bfb
Author: Rekha Joshi
Authored: Wed Jul 11 13:48:28 2018 -0500
Committer: Sean Owen
Committed: Wed Jul 11 13:48:28 2018 -0500
--
.../deploy/rest/RestSubmissionClient.scala | 60
1 file changed, 37 insertions(+), 23 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/290c30a5/core/src/main/scala/org/apache/spark/deploy/rest/RestSubmissionClient.scala
--
diff --git
a/core/src/main/scala/org/apache/spark/deploy/rest/RestSubmissionClient.scala
b/core/src/main/scala/org/apache/spark/deploy/rest/RestSubmissionClient.scala
index 742a958..31a8e3e 100644
---
a/core/src/main/scala/org/apache/spark/deploy/rest/RestSubmissionClient.scala
+++
b/core/src/main/scala/org/apache/spark/deploy/rest/RestSubmissionClient.scala
@@ -233,30 +233,44 @@ private[spark] class RestSubmissionClient(master: String)
extends Logging {
private[rest] def readResponse(connection: HttpURLConnection):
SubmitRestProtocolResponse = {
import scala.concurrent.ExecutionContext.Implicits.global
val responseFuture = Future {
- val dataStream =
-if (connection.getResponseCode == HttpServletResponse.SC_OK) {
- connection.getInputStream
-} else {
- connection.getErrorStream
+ val responseCode = connection.getResponseCode
+
+ if (responseCode != HttpServletResponse.SC_OK) {
+val errString =
Some(Source.fromInputStream(connection.getErrorStream())
+ .getLines().mkString("\n"))
+if (responseCode == HttpServletResponse.SC_INTERNAL_SERVER_ERROR &&
+ !connection.getContentType().contains("application/json")) {
+ throw new SubmitRestProtocolException(s"Server responded with
exception:\n${errString}")
+}
+logError(s"Server responded with error:\n${errString}")
+val error = new ErrorResponse
+if (responseCode == RestSubmissionServer.SC_UNKNOWN_PROTOCOL_VERSION) {
+ error.highestProtocolVersion = RestSubmissionServer.PROTOCOL_VERSION
+}
+error.message = errString.get
+error
+ } else {
+val dataStream = connection.getInputStream
+
+// If the server threw an exception while writing a response, it will
not have a body
+if (dataStream == null) {
+ throw new SubmitRestProtocolException("Server returned empty body")
+}
+val responseJson = Source.fromInputStream(dataStream).mkString
+logDebug(s"Response from the server:\n$responseJson")
+val response = SubmitRestProtocolMessage.fromJson(responseJson)
+response.validate()
+response match {
+ // If the response is an error, log the message
+ case error: ErrorResponse =>
+logError(s"Server responded with error:\n${error.message}")
+error
+ // Otherwise, simply return the response
+ case response: SubmitRestProtocolResponse => response
+ case unexpected =>
+throw new SubmitRestProtocolException(
+ s"Message received from server was not a
response:\n${unexpected.toJson}")
}
- // If the server threw an exception while writing a response, it will
not have a body
- if (dataStream == null) {
-throw new SubmitRestProtocolException("Server returned empty body")
- }
- val responseJson = Source.fromInputStream(dataStream).mkString
- logDebug(s"Response from the server:\n$responseJson")
- val response = SubmitRestProtocolMessage.fromJson(responseJson)
- response.validate()
- response match {
-// If the response is an error, log the message
-case error: ErrorResponse =>
- logError(s"Server responded with
svn commit: r28055 - in /dev/spark/2.3.3-SNAPSHOT-2018_07_11_10_01-3242925-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Wed Jul 11 17:15:59 2018 New Revision: 28055 Log: Apache Spark 2.3.3-SNAPSHOT-2018_07_11_10_01-3242925 docs [This commit notification would consist of 1443 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-24208][SQL] Fix attribute deduplication for FlatMapGroupsInPandas
Repository: spark
Updated Branches:
refs/heads/branch-2.3 86457a16d -> 32429256f
[SPARK-24208][SQL] Fix attribute deduplication for FlatMapGroupsInPandas
A self-join on a dataset which contains a `FlatMapGroupsInPandas` fails because
of duplicate attributes. This happens because we are not dealing with this
specific case in our `dedupAttr` rules.
The PR fix the issue by adding the management of the specific case
added UT + manual tests
Author: Marco Gaido
Author: Marco Gaido
Closes #21737 from mgaido91/SPARK-24208.
(cherry picked from commit ebf4bfb966389342bfd9bdb8e3b612828c18730c)
Signed-off-by: Xiao Li
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/32429256
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/32429256
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/32429256
Branch: refs/heads/branch-2.3
Commit: 32429256f3e659c648462e5b2740747645740c97
Parents: 86457a1
Author: Marco Gaido
Authored: Wed Jul 11 09:29:19 2018 -0700
Committer: Xiao Li
Committed: Wed Jul 11 09:35:44 2018 -0700
--
python/pyspark/sql/tests.py | 16
.../spark/sql/catalyst/analysis/Analyzer.scala | 4
.../org/apache/spark/sql/GroupedDatasetSuite.scala | 12
3 files changed, 32 insertions(+)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/32429256/python/pyspark/sql/tests.py
--
diff --git a/python/pyspark/sql/tests.py b/python/pyspark/sql/tests.py
index aa7d8eb..6bfb329 100644
--- a/python/pyspark/sql/tests.py
+++ b/python/pyspark/sql/tests.py
@@ -4691,6 +4691,22 @@ class GroupedMapPandasUDFTests(ReusedSQLTestCase):
result = df.groupby('time').apply(foo_udf).sort('time')
self.assertPandasEqual(df.toPandas(), result.toPandas())
+def test_self_join_with_pandas(self):
+import pyspark.sql.functions as F
+
+@F.pandas_udf('key long, col string', F.PandasUDFType.GROUPED_MAP)
+def dummy_pandas_udf(df):
+return df[['key', 'col']]
+
+df = self.spark.createDataFrame([Row(key=1, col='A'), Row(key=1,
col='B'),
+ Row(key=2, col='C')])
+dfWithPandas = df.groupBy('key').apply(dummy_pandas_udf)
+
+# this was throwing an AnalysisException before SPARK-24208
+res = dfWithPandas.alias('temp0').join(dfWithPandas.alias('temp1'),
+ F.col('temp0.key') ==
F.col('temp1.key'))
+self.assertEquals(res.count(), 5)
+
if __name__ == "__main__":
from pyspark.sql.tests import *
http://git-wip-us.apache.org/repos/asf/spark/blob/32429256/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
--
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
index 8597d83..a584cb8 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
@@ -723,6 +723,10 @@ class Analyzer(
if
findAliases(aggregateExpressions).intersect(conflictingAttributes).nonEmpty =>
(oldVersion, oldVersion.copy(aggregateExpressions =
newAliases(aggregateExpressions)))
+case oldVersion @ FlatMapGroupsInPandas(_, _, output, _)
+if oldVersion.outputSet.intersect(conflictingAttributes).nonEmpty
=>
+ (oldVersion, oldVersion.copy(output = output.map(_.newInstance(
+
case oldVersion: Generate
if
oldVersion.producedAttributes.intersect(conflictingAttributes).nonEmpty =>
val newOutput = oldVersion.generatorOutput.map(_.newInstance())
http://git-wip-us.apache.org/repos/asf/spark/blob/32429256/sql/core/src/test/scala/org/apache/spark/sql/GroupedDatasetSuite.scala
--
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/GroupedDatasetSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/GroupedDatasetSuite.scala
index 218a1b7..9699fad 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/GroupedDatasetSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/GroupedDatasetSuite.scala
@@ -93,4 +93,16 @@ class GroupedDatasetSuite extends QueryTest with
SharedSQLContext {
}
datasetWithUDF.unpersist(true)
}
+
+ test("SPARK-24208: analysis fails on self-join with FlatMapGroupsInPandas") {
+val df = datasetWithUDF.groupBy("s").flatMapGroupsInPandas(PythonUDF(
+ "pyUDF",
+ null,
+
spark git commit: [SPARK-24208][SQL] Fix attribute deduplication for FlatMapGroupsInPandas
Repository: spark
Updated Branches:
refs/heads/master 592cc8458 -> ebf4bfb96
[SPARK-24208][SQL] Fix attribute deduplication for FlatMapGroupsInPandas
## What changes were proposed in this pull request?
A self-join on a dataset which contains a `FlatMapGroupsInPandas` fails because
of duplicate attributes. This happens because we are not dealing with this
specific case in our `dedupAttr` rules.
The PR fix the issue by adding the management of the specific case
## How was this patch tested?
added UT + manual tests
Author: Marco Gaido
Author: Marco Gaido
Closes #21737 from mgaido91/SPARK-24208.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/ebf4bfb9
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/ebf4bfb9
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/ebf4bfb9
Branch: refs/heads/master
Commit: ebf4bfb966389342bfd9bdb8e3b612828c18730c
Parents: 592cc84
Author: Marco Gaido
Authored: Wed Jul 11 09:29:19 2018 -0700
Committer: Xiao Li
Committed: Wed Jul 11 09:29:19 2018 -0700
--
python/pyspark/sql/tests.py | 16
.../spark/sql/catalyst/analysis/Analyzer.scala | 4
.../org/apache/spark/sql/GroupedDatasetSuite.scala | 12
3 files changed, 32 insertions(+)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/ebf4bfb9/python/pyspark/sql/tests.py
--
diff --git a/python/pyspark/sql/tests.py b/python/pyspark/sql/tests.py
index 8d73806..4404dbe 100644
--- a/python/pyspark/sql/tests.py
+++ b/python/pyspark/sql/tests.py
@@ -5925,6 +5925,22 @@ class GroupedAggPandasUDFTests(ReusedSQLTestCase):
'mixture.*aggregate function.*group aggregate pandas UDF'):
df.groupby(df.id).agg(mean_udf(df.v), mean(df.v)).collect()
+def test_self_join_with_pandas(self):
+import pyspark.sql.functions as F
+
+@F.pandas_udf('key long, col string', F.PandasUDFType.GROUPED_MAP)
+def dummy_pandas_udf(df):
+return df[['key', 'col']]
+
+df = self.spark.createDataFrame([Row(key=1, col='A'), Row(key=1,
col='B'),
+ Row(key=2, col='C')])
+dfWithPandas = df.groupBy('key').apply(dummy_pandas_udf)
+
+# this was throwing an AnalysisException before SPARK-24208
+res = dfWithPandas.alias('temp0').join(dfWithPandas.alias('temp1'),
+ F.col('temp0.key') ==
F.col('temp1.key'))
+self.assertEquals(res.count(), 5)
+
@unittest.skipIf(
not _have_pandas or not _have_pyarrow,
http://git-wip-us.apache.org/repos/asf/spark/blob/ebf4bfb9/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
--
diff --git
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
index e187133..c078efd 100644
---
a/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
+++
b/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
@@ -738,6 +738,10 @@ class Analyzer(
if
findAliases(aggregateExpressions).intersect(conflictingAttributes).nonEmpty =>
(oldVersion, oldVersion.copy(aggregateExpressions =
newAliases(aggregateExpressions)))
+case oldVersion @ FlatMapGroupsInPandas(_, _, output, _)
+if oldVersion.outputSet.intersect(conflictingAttributes).nonEmpty
=>
+ (oldVersion, oldVersion.copy(output = output.map(_.newInstance(
+
case oldVersion: Generate
if
oldVersion.producedAttributes.intersect(conflictingAttributes).nonEmpty =>
val newOutput = oldVersion.generatorOutput.map(_.newInstance())
http://git-wip-us.apache.org/repos/asf/spark/blob/ebf4bfb9/sql/core/src/test/scala/org/apache/spark/sql/GroupedDatasetSuite.scala
--
diff --git
a/sql/core/src/test/scala/org/apache/spark/sql/GroupedDatasetSuite.scala
b/sql/core/src/test/scala/org/apache/spark/sql/GroupedDatasetSuite.scala
index 147c0b6..bd54ea4 100644
--- a/sql/core/src/test/scala/org/apache/spark/sql/GroupedDatasetSuite.scala
+++ b/sql/core/src/test/scala/org/apache/spark/sql/GroupedDatasetSuite.scala
@@ -93,4 +93,16 @@ class GroupedDatasetSuite extends QueryTest with
SharedSQLContext {
}
datasetWithUDF.unpersist(true)
}
+
+ test("SPARK-24208: analysis fails on self-join with FlatMapGroupsInPandas") {
+val df = datasetWithUDF.groupBy("s").flatMapGroupsInPandas(PythonUDF(
+ "pyUDF",
+ null,
+
spark git commit: [SPARK-24562][TESTS] Support different configs for same test in SQLQueryTestSuite
Repository: spark
Updated Branches:
refs/heads/master 006e798e4 -> 592cc8458
[SPARK-24562][TESTS] Support different configs for same test in
SQLQueryTestSuite
## What changes were proposed in this pull request?
The PR proposes to add support for running the same SQL test input files
against different configs leading to the same result.
## How was this patch tested?
Involved UTs
Author: Marco Gaido
Closes #21568 from mgaido91/SPARK-24562.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/592cc845
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/592cc845
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/592cc845
Branch: refs/heads/master
Commit: 592cc84583d74c78e4cdf34a3b82692c8de8f4a9
Parents: 006e798
Author: Marco Gaido
Authored: Wed Jul 11 23:43:06 2018 +0800
Committer: Wenchen Fan
Committed: Wed Jul 11 23:43:06 2018 +0800
--
.../sql-tests/inputs/join-empty-relation.sql| 5 ++
.../resources/sql-tests/inputs/natural-join.sql | 5 ++
.../resources/sql-tests/inputs/outer-join.sql | 5 ++
.../exists-joins-and-set-ops.sql| 4 ++
.../inputs/subquery/in-subquery/in-joins.sql| 4 ++
.../subquery/in-subquery/not-in-joins.sql | 4 ++
.../apache/spark/sql/SQLQueryTestSuite.scala| 53 +---
7 files changed, 74 insertions(+), 6 deletions(-)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/592cc845/sql/core/src/test/resources/sql-tests/inputs/join-empty-relation.sql
--
diff --git
a/sql/core/src/test/resources/sql-tests/inputs/join-empty-relation.sql
b/sql/core/src/test/resources/sql-tests/inputs/join-empty-relation.sql
index 8afa327..2e6a5f3 100644
--- a/sql/core/src/test/resources/sql-tests/inputs/join-empty-relation.sql
+++ b/sql/core/src/test/resources/sql-tests/inputs/join-empty-relation.sql
@@ -1,3 +1,8 @@
+-- List of configuration the test suite is run against:
+--SET spark.sql.autoBroadcastJoinThreshold=10485760
+--SET
spark.sql.autoBroadcastJoinThreshold=-1,spark.sql.join.preferSortMergeJoin=true
+--SET
spark.sql.autoBroadcastJoinThreshold=-1,spark.sql.join.preferSortMergeJoin=false
+
CREATE TEMPORARY VIEW t1 AS SELECT * FROM VALUES (1) AS GROUPING(a);
CREATE TEMPORARY VIEW t2 AS SELECT * FROM VALUES (1) AS GROUPING(a);
http://git-wip-us.apache.org/repos/asf/spark/blob/592cc845/sql/core/src/test/resources/sql-tests/inputs/natural-join.sql
--
diff --git a/sql/core/src/test/resources/sql-tests/inputs/natural-join.sql
b/sql/core/src/test/resources/sql-tests/inputs/natural-join.sql
index 71a5015..e0abeda 100644
--- a/sql/core/src/test/resources/sql-tests/inputs/natural-join.sql
+++ b/sql/core/src/test/resources/sql-tests/inputs/natural-join.sql
@@ -1,3 +1,8 @@
+-- List of configuration the test suite is run against:
+--SET spark.sql.autoBroadcastJoinThreshold=10485760
+--SET
spark.sql.autoBroadcastJoinThreshold=-1,spark.sql.join.preferSortMergeJoin=true
+--SET
spark.sql.autoBroadcastJoinThreshold=-1,spark.sql.join.preferSortMergeJoin=false
+
create temporary view nt1 as select * from values
("one", 1),
("two", 2),
http://git-wip-us.apache.org/repos/asf/spark/blob/592cc845/sql/core/src/test/resources/sql-tests/inputs/outer-join.sql
--
diff --git a/sql/core/src/test/resources/sql-tests/inputs/outer-join.sql
b/sql/core/src/test/resources/sql-tests/inputs/outer-join.sql
index cdc6c81..ce09c21 100644
--- a/sql/core/src/test/resources/sql-tests/inputs/outer-join.sql
+++ b/sql/core/src/test/resources/sql-tests/inputs/outer-join.sql
@@ -1,3 +1,8 @@
+-- List of configuration the test suite is run against:
+--SET spark.sql.autoBroadcastJoinThreshold=10485760
+--SET
spark.sql.autoBroadcastJoinThreshold=-1,spark.sql.join.preferSortMergeJoin=true
+--SET
spark.sql.autoBroadcastJoinThreshold=-1,spark.sql.join.preferSortMergeJoin=false
+
-- SPARK-17099: Incorrect result when HAVING clause is added to group by query
CREATE OR REPLACE TEMPORARY VIEW t1 AS SELECT * FROM VALUES
(-234), (145), (367), (975), (298)
http://git-wip-us.apache.org/repos/asf/spark/blob/592cc845/sql/core/src/test/resources/sql-tests/inputs/subquery/exists-subquery/exists-joins-and-set-ops.sql
--
diff --git
a/sql/core/src/test/resources/sql-tests/inputs/subquery/exists-subquery/exists-joins-and-set-ops.sql
b/sql/core/src/test/resources/sql-tests/inputs/subquery/exists-subquery/exists-joins-and-set-ops.sql
index cc4ed64..cefc3fe 100644
---
a/sql/core/src/test/resources/sql-tests/inputs/subquery/exists-subquery/exists-joins-and-set-ops.sql
+++
svn commit: r28052 - in /dev/spark/2.3.3-SNAPSHOT-2018_07_11_02_01-86457a1-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Wed Jul 11 09:15:28 2018 New Revision: 28052 Log: Apache Spark 2.3.3-SNAPSHOT-2018_07_11_02_01-86457a1 docs [This commit notification would consist of 1443 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
svn commit: r28050 - in /dev/spark/2.4.0-SNAPSHOT-2018_07_11_00_01-006e798-docs: ./ _site/ _site/api/ _site/api/R/ _site/api/java/ _site/api/java/lib/ _site/api/java/org/ _site/api/java/org/apache/ _s
Author: pwendell Date: Wed Jul 11 07:16:38 2018 New Revision: 28050 Log: Apache Spark 2.4.0-SNAPSHOT-2018_07_11_00_01-006e798 docs [This commit notification would consist of 1467 parts, which exceeds the limit of 50 ones, so it was shortened to the summary.] - To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org For additional commands, e-mail: commits-h...@spark.apache.org
spark git commit: [SPARK-23461][R] vignettes should include model predictions for some ML models
Repository: spark
Updated Branches:
refs/heads/master 5ff1b9ba1 -> 006e798e4
[SPARK-23461][R] vignettes should include model predictions for some ML models
## What changes were proposed in this pull request?
Add model predictions for Linear Support Vector Machine (SVM) Classifier,
Logistic Regression, GBT, RF and DecisionTree in vignettes.
## How was this patch tested?
Manually ran the test and checked the result.
Author: Huaxin Gao
Closes #21678 from huaxingao/spark-23461.
Project: http://git-wip-us.apache.org/repos/asf/spark/repo
Commit: http://git-wip-us.apache.org/repos/asf/spark/commit/006e798e
Tree: http://git-wip-us.apache.org/repos/asf/spark/tree/006e798e
Diff: http://git-wip-us.apache.org/repos/asf/spark/diff/006e798e
Branch: refs/heads/master
Commit: 006e798e477b6871ad3ba4417d354d23f45e4013
Parents: 5ff1b9b
Author: Huaxin Gao
Authored: Tue Jul 10 23:18:07 2018 -0700
Committer: Felix Cheung
Committed: Tue Jul 10 23:18:07 2018 -0700
--
R/pkg/vignettes/sparkr-vignettes.Rmd | 5 +
1 file changed, 5 insertions(+)
--
http://git-wip-us.apache.org/repos/asf/spark/blob/006e798e/R/pkg/vignettes/sparkr-vignettes.Rmd
--
diff --git a/R/pkg/vignettes/sparkr-vignettes.Rmd
b/R/pkg/vignettes/sparkr-vignettes.Rmd
index d4713de..68a18ab 100644
--- a/R/pkg/vignettes/sparkr-vignettes.Rmd
+++ b/R/pkg/vignettes/sparkr-vignettes.Rmd
@@ -590,6 +590,7 @@ summary(model)
Predict values on training data
```{r}
prediction <- predict(model, training)
+head(select(prediction, "Class", "Sex", "Age", "Freq", "Survived",
"prediction"))
```
Logistic Regression
@@ -613,6 +614,7 @@ summary(model)
Predict values on training data
```{r}
fitted <- predict(model, training)
+head(select(fitted, "Class", "Sex", "Age", "Freq", "Survived", "prediction"))
```
Multinomial logistic regression against three classes
@@ -807,6 +809,7 @@ df <- createDataFrame(t)
dtModel <- spark.decisionTree(df, Survived ~ ., type = "classification",
maxDepth = 2)
summary(dtModel)
predictions <- predict(dtModel, df)
+head(select(predictions, "Class", "Sex", "Age", "Freq", "Survived",
"prediction"))
```
Gradient-Boosted Trees
@@ -822,6 +825,7 @@ df <- createDataFrame(t)
gbtModel <- spark.gbt(df, Survived ~ ., type = "classification", maxDepth = 2,
maxIter = 2)
summary(gbtModel)
predictions <- predict(gbtModel, df)
+head(select(predictions, "Class", "Sex", "Age", "Freq", "Survived",
"prediction"))
```
Random Forest
@@ -837,6 +841,7 @@ df <- createDataFrame(t)
rfModel <- spark.randomForest(df, Survived ~ ., type = "classification",
maxDepth = 2, numTrees = 2)
summary(rfModel)
predictions <- predict(rfModel, df)
+head(select(predictions, "Class", "Sex", "Age", "Freq", "Survived",
"prediction"))
```
Bisecting k-Means
-
To unsubscribe, e-mail: commits-unsubscr...@spark.apache.org
For additional commands, e-mail: commits-h...@spark.apache.org