[GitHub] orc pull request #316: Fix a table row ending markup
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/316 ---
[GitHub] orc pull request #316: Fix a table row ending markup
GitHub user dongjoon-hyun opened a pull request: https://github.com/apache/orc/pull/316 Fix a table row ending markup Currently, a table in ORC website is broken. This PR aims to fix it. - https://orc.apache.org/docs/hive-config.html **Before** 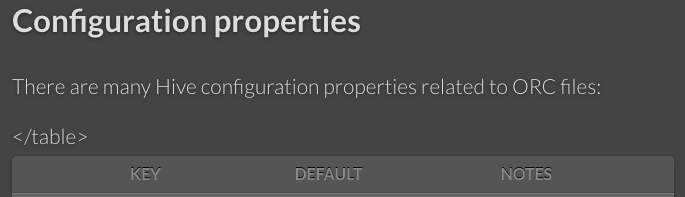 **After** 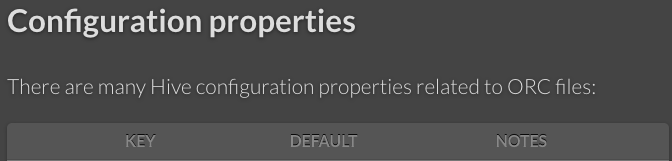 You can merge this pull request into a Git repository by running: $ git pull https://github.com/dongjoon-hyun/orc fix_doc Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/316.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #316 commit 4e27f293afabe866c4be2c9e52cc069089d019ca Author: Dongjoon Hyun Date: 2018-10-05T03:05:49Z Fix a table row ending markup ---
[GitHub] orc pull request #311: ORC-407 - Lowerbound and upperbound support in JsonFi...
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/311 ---
[GitHub] orc pull request #312: fix ORC-237 OrcFile.mergeFiles
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/312 ---
[GitHub] orc pull request #313: ORC-409: Changes for extending MemoryManagerImpl
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/313 ---
[GitHub] orc pull request #314: ORC-410: Fix a locale-dependent test in TestCsvReader
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/314 ---
[GitHub] orc pull request #315: ORC-411: Update pom file to work with openjdk 10.
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/315 ---
[GitHub] orc pull request #315: ORC-411: Update pom file to work with openjdk 10.
GitHub user omalley opened a pull request: https://github.com/apache/orc/pull/315 ORC-411: Update pom file to work with openjdk 10. You can merge this pull request into a Git repository by running: $ git pull https://github.com/omalley/orc orc-411 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/315.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #315 commit 6be929f239dadd18ff35bff9c072fd315008354f Author: Owen O'Malley Date: 2018-09-30T04:58:29Z ORC-411: Update pom file to work with openjdk 10. ---
[GitHub] orc pull request #314: ORC-410: Fix a locale-dependent test in TestCsvReader
GitHub user kotarot opened a pull request: https://github.com/apache/orc/pull/314 ORC-410: Fix a locale-dependent test in TestCsvReader ## Problem `testCustomTimestampFormat` in `TestCsvReader` fails in some environments because the test is locale-dependent. In this test, we try to parse a DateTime string (such as '21 Mar 2018 12:23:34') with a given timestamp format. The problem is that English month abbreviations (such as 'Mar') are locale-dependent. When the locale of Java Virtual Machine is a locale where the language is English (e.g., en_US and en_GB), this test passes without any problems. However, when the locale of JVM is a locale where the language is non-English (e.g., ja_JP and zh_CN), the test fails as follows. ``` [INFO] Running org.apache.orc.tools.convert.TestCsvReader [ERROR] Tests run: 5, Failures: 0, Errors: 1, Skipped: 0, Time elapsed: 0.237 s <<< FAILURE! - in org.apache.orc.tools.convert.TestCsvReader [ERROR] testCustomTimestampFormat(org.apache.orc.tools.convert.TestCsvReader) Time elapsed: 0.143 s <<< ERROR! org.threeten.bp.format.DateTimeParseException: Text '21 Mar 2018 12:23:34' could not be parsed at index 3 at org.apache.orc.tools.convert.TestCsvReader.testCustomTimestampFormat(TestCsvReader.java:189) ``` ## Solution The following two solutions can be considered to fix this problem by updating the test: (1) Make this test be locale-independent. (2) Set the locale to en_US in this test. (1) is better, but it's not an easy task to construct a DateTime string which can be successfully parsed in all existing locales. Thus, I adopt (2) and modify the test. You can merge this pull request into a Git repository by running: $ git pull https://github.com/kotarot/orc ORC-410 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/314.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #314 commit 43ae8b80783c2af8e155c2fbbfb724bf86b9a5f2 Author: Kotaro Terada Date: 2018-09-27T03:45:31Z Fix a locale-dependent test in TestCsvReader ---
[GitHub] orc pull request #313: ORC-409: Changes for extending MemoryManagerImpl
GitHub user prasanthj opened a pull request: https://github.com/apache/orc/pull/313 ORC-409: Changes for extending MemoryManagerImpl You can merge this pull request into a Git repository by running: $ git pull https://github.com/prasanthj/orc ORC-409 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/313.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #313 commit 9cc833d560da188fd48ece42c31d1daa9ea6bc08 Author: Prasanth Jayachandran Date: 2018-09-28T00:51:57Z ORC-409: Changes for extending MemoryManagerImpl ---
[GitHub] orc pull request #312: fix ORC-237 OrcFile.mergeFiles
GitHub user yiyezhiqiu233 opened a pull request: https://github.com/apache/orc/pull/312 fix ORC-237 OrcFile.mergeFiles -set buffer size You can merge this pull request into a Git repository by running: $ git pull https://github.com/yiyezhiqiu233/orc ORC-237 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/312.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #312 commit b09a1652a3cbfbe44245a673cedcb26c16875e3b Author: yiyezhiqiu233 Date: 2018-09-27T15:20:08Z fix ORC-237 OrcFile.mergeFiles -set buffer size ---
[GitHub] orc pull request #310: ORC-406: First padded version with 3 failing tests
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/310 ---
[GitHub] orc pull request #310: ORC-406: First padded version with 3 failing tests
Github user t3rmin4t0r closed the pull request at: https://github.com/apache/orc/pull/310 ---
[GitHub] orc pull request #310: ORC-406: First padded version with 3 failing tests
GitHub user t3rmin4t0r opened a pull request: https://github.com/apache/orc/pull/310 ORC-406: First padded version with 3 failing tests This implementation always pads the CHAR() columns, which is undone by the reader codepath (causing the current failures). Will fix test-case when it is clear whether the padding is necessary or not. You can merge this pull request into a Git repository by running: $ git pull https://github.com/t3rmin4t0r/orc ORC-406 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/310.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #310 commit 8330bc77fc85573dd30c9f6ae5e401acb13ba44b Author: Gopal V Date: 2018-09-19T08:49:23Z ORC-406: First version with 3 failing tests ---
[GitHub] orc pull request #309: ORC-403: [C++] Add checks to avoid invalid offsets in...
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/309 ---
[GitHub] orc pull request #309: ORC-403: [C++] Add checks to avoid invalid offsets in...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/309#discussion_r218244811
--- Diff: c++/src/Reader.cc ---
@@ -498,6 +498,12 @@ namespace orc {
const proto::Stream& stream = currentStripeFooter.streams(i);
uint64_t length = static_cast(stream.length());
if (static_cast(stream.kind()) ==
StreamKind::StreamKind_ROW_INDEX) {
+if (offset + length > fileLength) {
--- End diff --
This check is really good, but it would also be nice to check that the
stream is within the stripe, although you'd need to pass that in also. We could
pass the whole proto::StripeInformation in.
---
[GitHub] orc pull request #303: fix ORC-375
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/303 ---
[GitHub] orc pull request #309: ORC-403: [C++] Add checks to avoid negative offsets i...
GitHub user stiga-huang opened a pull request: https://github.com/apache/orc/pull/309 ORC-403: [C++] Add checks to avoid negative offsets in InputStream You can merge this pull request into a Git repository by running: $ git pull https://github.com/stiga-huang/orc check-offsets Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/309.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #309 commit 3a0e6ebc149375e424ef8d8155a774a910875a83 Author: stiga-huang Date: 2018-09-15T07:35:22Z ORC-403: [C++] Add checks to avoid negative offset in InputStream ---
[GitHub] orc pull request #306: ORC-363: Enable zstd for java writer/reader
Github user wgtmac commented on a diff in the pull request:
https://github.com/apache/orc/pull/306#discussion_r217867721
--- Diff: java/pom.xml ---
@@ -68,8 +68,8 @@
${project.build.directory}/testing-tmp
${project.basedir}/../../examples
-2.2.0
-2.7.3
+2.9.0
--- End diff --
That makes sense. Will do. Thanks!
---
[GitHub] orc pull request #306: ORC-363: Enable zstd for java writer/reader
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/306#discussion_r217801734
--- Diff: java/pom.xml ---
@@ -68,8 +68,8 @@
${project.build.directory}/testing-tmp
${project.basedir}/../../examples
-2.2.0
-2.7.3
+2.9.0
--- End diff --
We shouldn't bump the minimum version of Hadoop to 2.9. Let's instead put
it into the shims. We'll need to add a method like createZstdCodec to
HadoopShims. We'll also need a new implementation for HadoopShimsPre2_9 that
handles variable length blocks, but not zstd. You'll also need a graceful
message if they don't have the native libraries available.
---
[GitHub] orc pull request #308: Deliver a lower-case schema to OrcFile
GitHub user ddrinka opened a pull request: https://github.com/apache/orc/pull/308 Deliver a lower-case schema to OrcFile Mixed-case struct field names don't work in Hive. There should be a way to convert a camel-cased JSON document into ORC without having to pre-process the JSON. This pull request is a proof-of-concept which generates two schemas, one using the default case which is provided to the JsonReader as usual, and another schema which is lower cased and is provided to OrcFile. TypeDescription is immutable and non-trivial to manually clone using public accessors, so to make the idea clear, I do the conversion at schema ingest rather than where it's provided to OrcFile. The downside of this approach is that automatic schema detection doesn't benefit from these changes. A more experienced implementer could certainly do better. You can merge this pull request into a Git repository by running: $ git pull https://github.com/ddrinka/orc ddrinka-pr-lowercase-schema Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/308.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #308 commit cc7e909725d059b69f9a8c384aca2691b52ce0ff Author: Douglas Drinka Date: 2018-09-13T22:59:11Z Deliver a lower-case schema to OrcFile ---
[GitHub] orc pull request #307: ORC-401. Fix typing error in document
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/307 ---
[GitHub] orc pull request #299: ORC-203 - Update StringStatistics to trim long string...
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/299 ---
[GitHub] orc pull request #307: ORC-401. Fix typing error in document
GitHub user xuchuanyin opened a pull request: https://github.com/apache/orc/pull/307 ORC-401. Fix typing error in document fix typing error in document and site Corresponding reference looks like below: https://github.com/apache/hive/blob/trunk/ql/src/protobuf/org/apache/hadoop/hive/ql/io/orc/orc_proto.proto#L107 https://github.com/apache/hive/blob/trunk/ql/src/protobuf/org/apache/hadoop/hive/ql/io/orc/orc_proto.proto#L122 You can merge this pull request into a Git repository by running: $ git pull https://github.com/xuchuanyin/orc typing_error Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/307.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #307 commit 8d8a0b888dd414f317ead41c2ef45846af934786 Author: xuchuanyin Date: 2018-09-13T08:10:46Z Fix typing error in document fix typing error in document ---
[GitHub] orc pull request #301: ORC-395: Support ZSTD in C++ writer/reader
Github user xndai commented on a diff in the pull request:
https://github.com/apache/orc/pull/301#discussion_r215486726
--- Diff: c++/src/Compression.cc ---
@@ -899,6 +907,166 @@ DIAGNOSTIC_POP
return static_cast(result);
}
+ /**
+ * Block compression base class
+ */
+ class BlockCompressionStream: public CompressionStreamBase {
--- End diff --
Stream compression is not in this change yet?
---
[GitHub] orc pull request #301: ORC-395: Support ZSTD in C++ writer/reader
Github user xndai commented on a diff in the pull request:
https://github.com/apache/orc/pull/301#discussion_r215486619
--- Diff: c++/src/Compression.cc ---
@@ -899,6 +907,166 @@ DIAGNOSTIC_POP
return static_cast(result);
}
+ /**
+ * Block compression base class
+ */
+ class BlockCompressionStream: public CompressionStreamBase {
+ public:
+BlockCompressionStream(OutputStream * outStream,
+ int compressionLevel,
+ uint64_t capacity,
+ uint64_t blockSize,
+ MemoryPool& pool)
+ : CompressionStreamBase(outStream,
+ compressionLevel,
+ capacity,
+ blockSize,
+ pool)
+ , compressorBuffer(pool) {
+ // PASS
+}
+
+virtual bool Next(void** data, int*size) override;
+virtual std::string getName() const override = 0;
+
+ protected:
+// compresses a block and returns the compressed size
+virtual uint64_t doBlockCompression() = 0;
+
+// return maximum possible compression size for allocating space for
+// compressorBuffer below
+virtual uint64_t estimateMaxCompressionSize() = 0;
+
+// should allocate max possible compressed size
+DataBuffer compressorBuffer;
+ };
+
+ bool BlockCompressionStream::Next(void** data, int*size) {
+if (bufferSize != 0) {
+ ensureHeader();
+
+ // perform compression
+ size_t totalCompressedSize = doBlockCompression();
+
+ const unsigned char * dataToWrite = nullptr;
+ int totalSizeToWrite = 0;
+ char * header = outputBuffer + outputPosition - 3;
+
+ if (totalCompressedSize >= static_cast(bufferSize)) {
+writeHeader(header, static_cast(bufferSize), true);
+dataToWrite = rawInputBuffer.data();
+totalSizeToWrite = bufferSize;
+ } else {
+writeHeader(header, totalCompressedSize, false);
+dataToWrite = compressorBuffer.data();
+totalSizeToWrite = static_cast(totalCompressedSize);
+ }
+
+ char * dst = header + 3;
+ while (totalSizeToWrite > 0) {
+if (outputPosition >= outputSize) {
--- End diff --
assert outputPosition not larger than outputSize.
---
[GitHub] orc pull request #306: ORC-363: Enable zstd for java writer/reader
GitHub user wgtmac opened a pull request: https://github.com/apache/orc/pull/306 ORC-363: Enable zstd for java writer/reader Use org.apache.hadoop.io.compress.ZStandardCodec in hadoop 2.9.0 You can merge this pull request into a Git repository by running: $ git pull https://github.com/wgtmac/orc ORC-363 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/306.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #306 commit c75d1fab4aa56a3dbbb935ef2f892d5502f219a4 Author: Gang Wu Date: 2018-09-04T21:42:14Z ORC-363: Enable zstd for java writer/reader Use org.apache.hadoop.io.compress.ZStandardCodec in hadoop 2.9.0 ---
[GitHub] orc pull request #304: ORC-397. Allow selective disabling of dictionary enco...
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/304 ---
[GitHub] orc pull request #305: ORC-399. Move Java compiler to version 8.
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/305 ---
[GitHub] orc pull request #305: ORC-399. Move Java compiler to version 8.
GitHub user omalley opened a pull request: https://github.com/apache/orc/pull/305 ORC-399. Move Java compiler to version 8. You can merge this pull request into a Git repository by running: $ git pull https://github.com/omalley/orc orc-399 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/305.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #305 commit f093118410710c750d84d78d18c7d952254dda09 Author: Owen O'Malley Date: 2018-08-31T22:21:49Z ORC-399. Move Java compiler to version 8. ---
[GitHub] orc pull request #304: ORC-397. Allow selective disabling of dictionary enco...
Github user wgtmac commented on a diff in the pull request:
https://github.com/apache/orc/pull/304#discussion_r213744153
--- Diff: java/core/src/test/org/apache/orc/TestStringDictionary.java ---
@@ -409,4 +411,77 @@ public void testTooManyDistinctV11AlwaysDictionary()
throws Exception {
}
+ /**
+ * Test that dictionaries can be disabled, per column. In this test, we
want to disable DICTIONARY_V2 for the
+ * `longString` column (presumably for a low hit-ratio), while
preserving DICTIONARY_V2 for `shortString`.
+ * @throws Exception on unexpected failure
+ */
+ @Test
+ public void testDisableDictionaryForSpecificColumn() throws Exception {
+final String SHORT_STRING_VALUE = "foo";
+final String LONG_STRING_VALUE = "BR!!";
+
+TypeDescription schema =
+
TypeDescription.fromString("struct");
+
+Writer writer = OrcFile.createWriter(
+testFilePath,
+OrcFile.writerOptions(conf).setSchema(schema)
+.compress(CompressionKind.NONE)
+.bufferSize(1)
+.directEncodingColumns("longString"));
--- End diff --
That makes sense. I will also port current dictionary encoding to C++
writer shortly.
BTW, we plan to do some testing about global dictionary which is shared by
all stripes in that file. Can we come up with a design in ORC V2? I can propose
a prototype after gathering certain experiment results.
---
[GitHub] orc pull request #304: ORC-397. Allow selective disabling of dictionary enco...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/304#discussion_r213566036
--- Diff: java/core/src/test/org/apache/orc/TestStringDictionary.java ---
@@ -409,4 +411,77 @@ public void testTooManyDistinctV11AlwaysDictionary()
throws Exception {
}
+ /**
+ * Test that dictionaries can be disabled, per column. In this test, we
want to disable DICTIONARY_V2 for the
+ * `longString` column (presumably for a low hit-ratio), while
preserving DICTIONARY_V2 for `shortString`.
+ * @throws Exception on unexpected failure
+ */
+ @Test
+ public void testDisableDictionaryForSpecificColumn() throws Exception {
+final String SHORT_STRING_VALUE = "foo";
+final String LONG_STRING_VALUE = "BR!!";
+
+TypeDescription schema =
+
TypeDescription.fromString("struct");
+
+Writer writer = OrcFile.createWriter(
+testFilePath,
+OrcFile.writerOptions(conf).setSchema(schema)
+.compress(CompressionKind.NONE)
+.bufferSize(1)
+.directEncodingColumns("longString"));
--- End diff --
We shouldn't change the default behavior of deciding between
direct/dictionary encoding based on the data. With the parameter being the
columns that are being forced to be direct, the default is the empty string,
which is straight-forward.
Does that make sense?
---
[GitHub] orc pull request #304: ORC-397. Allow selective disabling of dictionary enco...
Github user wgtmac commented on a diff in the pull request:
https://github.com/apache/orc/pull/304#discussion_r213542675
--- Diff: java/core/src/test/org/apache/orc/TestStringDictionary.java ---
@@ -409,4 +411,77 @@ public void testTooManyDistinctV11AlwaysDictionary()
throws Exception {
}
+ /**
+ * Test that dictionaries can be disabled, per column. In this test, we
want to disable DICTIONARY_V2 for the
+ * `longString` column (presumably for a low hit-ratio), while
preserving DICTIONARY_V2 for `shortString`.
+ * @throws Exception on unexpected failure
+ */
+ @Test
+ public void testDisableDictionaryForSpecificColumn() throws Exception {
+final String SHORT_STRING_VALUE = "foo";
+final String LONG_STRING_VALUE = "BR!!";
+
+TypeDescription schema =
+
TypeDescription.fromString("struct");
+
+Writer writer = OrcFile.createWriter(
+testFilePath,
+OrcFile.writerOptions(conf).setSchema(schema)
+.compress(CompressionKind.NONE)
+.bufferSize(1)
+.directEncodingColumns("longString"));
--- End diff --
Is it better to support specifying columns which use dictionary encoding?
---
[GitHub] orc pull request #304: ORC-397. Allow selective disabling of dictionary enco...
GitHub user omalley opened a pull request: https://github.com/apache/orc/pull/304 ORC-397. Allow selective disabling of dictionary encoding. I've forward ported the patch from Mithun. You can merge this pull request into a Git repository by running: $ git pull https://github.com/omalley/orc orc-397 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/304.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #304 commit b00a52e668efa9fb06821d7da52706ace81e31c0 Author: Owen O'Malley Date: 2018-08-28T23:12:05Z ORC-397. Allow selective disabling of dictionary encoding. ---
[GitHub] orc pull request #301: ORC-395: Support ZSTD in C++ writer/reader
Github user wgtmac commented on a diff in the pull request:
https://github.com/apache/orc/pull/301#discussion_r211793792
--- Diff: c++/src/Compression.cc ---
@@ -899,6 +900,177 @@ DIAGNOSTIC_POP
return static_cast(result);
}
+ /**
+ * Block compression base class
+ */
+ class BlockCompressionStream: public CompressionStreamBase {
+ public:
+BlockCompressionStream(OutputStream * outStream,
+ int compressionLevel,
+ uint64_t capacity,
+ uint64_t blockSize,
+ MemoryPool& pool)
+ : CompressionStreamBase(outStream,
+ compressionLevel,
+ capacity,
+ blockSize,
+ pool)
+ , compressorBuffer(pool) {
+ // PASS
+}
+
+virtual bool Next(void** data, int*size) override;
+virtual std::string getName() const override = 0;
+
+ protected:
+// compresses a block and returns the compressed size
+virtual uint64_t doBlockCompression() = 0;
+
+// return maximum possible compression size for allocating space for
+// compressorBuffer below
+virtual uint64_t estimateMaxCompressionSize() = 0;
+
+// should allocate max possible compressed size
+DataBuffer compressorBuffer;
+ };
+
+ bool BlockCompressionStream::Next(void** data, int*size) {
+if (bufferSize != 0) {
--- End diff --
Done. Please check it again when you have time. Thanks!
---
[GitHub] orc pull request #303: fix ORC-375
GitHub user LYKZZzz opened a pull request: https://github.com/apache/orc/pull/303 fix ORC-375 I have seen #281 resolve this issue, but this problem still exists in orc 1.5.2 release. add C++ header in lib/common/async_stream.h and lib/rpc/request.h You can merge this pull request into a Git repository by running: $ git pull https://github.com/LYKZZzz/orc master Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/303.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #303 commit ed1797613b39f5d0d7fdd584768138479cb3affb Author: lyk Date: 2018-08-20T05:53:46Z fix ORC-375 ---
[GitHub] orc pull request #302: ORC-396: also look for LZ4 libs in lib64 subdir
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/302 ---
[GitHub] orc pull request #302: ORC-396: also look for LZ4 libs in lib64 subdir
GitHub user timarmstrong opened a pull request: https://github.com/apache/orc/pull/302 ORC-396: also look for LZ4 libs in lib64 subdir You can merge this pull request into a Git repository by running: $ git pull https://github.com/timarmstrong/orc master Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/302.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #302 commit e1f79fbd2495ed4f09cf0930ecd36b459211477d Author: Tim Armstrong Date: 2018-08-15T18:44:37Z ORC-396: also look for LZ4 libs in lib64 subdir ---
[GitHub] orc pull request #301: ORC-395: Support ZSTD in C++ writer/reader
GitHub user wgtmac opened a pull request: https://github.com/apache/orc/pull/301 ORC-395: Support ZSTD in C++ writer/reader Support ZSTD block compression/decompression for C++ writer/reader. Test cases have been added to TestCompression.cc You can merge this pull request into a Git repository by running: $ git pull https://github.com/wgtmac/orc ORC-395 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/301.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #301 ---
[GitHub] orc pull request #300: [ORC-394][C++] Add addUserMetadata() function to C++ ...
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/300 ---
[GitHub] orc pull request #300: [ORC-394][C++] Add addUserMetadata() function to C++ ...
Github user majetideepak commented on a diff in the pull request:
https://github.com/apache/orc/pull/300#discussion_r209222998
--- Diff: c++/test/TestWriter.cc ---
@@ -1170,5 +1170,52 @@ namespace orc {
}
}
+ TEST_P(WriterTest, writeUserMetadata) {
--- End diff --
can you add the user metadata check to an existing test?
---
[GitHub] orc pull request #300: [ORC-394][C++] Add addUserMetadata() function to C++ ...
GitHub user czxrrr opened a pull request: https://github.com/apache/orc/pull/300 [ORC-394][C++] Add addUserMetadata() function to C++ write You can merge this pull request into a Git repository by running: $ git pull https://github.com/czxrrr/orc ORC-394 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/300.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #300 commit a0e34f9e8091ff5e9af24b470e971023f08fe60a Author: zherui cao Date: 2018-08-10T03:54:25Z addusermetadata ---
[GitHub] orc pull request #169: [WIP] ORC-203 Modify the StringStatistics to trim the...
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/169 ---
[GitHub] orc pull request #295: ORC-389: Add ability to not decode Acid metadata colu...
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/295 ---
[GitHub] orc pull request #159: ORC-175: ORC-232: add jmh-generator-annprocess in pom...
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/159 ---
[GitHub] orc pull request #298: ORC-393. Add ORC snapcraft definition.
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/298 ---
[GitHub] orc pull request #299: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/299#discussion_r208394170
--- Diff: java/core/src/java/org/apache/orc/impl/ColumnStatisticsImpl.java
---
@@ -683,6 +787,150 @@ public int hashCode() {
result = 31 * result + (int) (sum ^ (sum >>> 32));
return result;
}
+
+/**
+ * A helper function that truncates the {@link Text} input
+ * based on {@link #MAX_BYTES_RECORDED} and increments
+ * the last codepoint by 1.
+ * @param text
+ * @return truncated Text value
+ */
+private static Text truncateUpperBound(final Text text) {
+
+ if(text.getBytes().length > MAX_BYTES_RECORDED) {
+return truncateUpperBound(text.getBytes());
+ } else {
+return text;
+ }
+
+}
+
+/**
+ * A helper function that truncates the {@link byte[]} input
+ * based on {@link #MAX_BYTES_RECORDED} and increments
+ * the last codepoint by 1.
+ * @param text
+ * @return truncated Text value
+ */
+private static Text truncateUpperBound(final byte[] text) {
+ if(text.length > MAX_BYTES_RECORDED) {
+final Text truncated = truncateLowerBound(text);
+final byte[] data = truncated.getBytes();
+
+int lastCharPosition = data.length - 1;
+int offset = 0;
+
+/* we don't expect characters more than 5 bytes */
+for (int i = 0; i < 5; i++) {
+ final byte b = data[lastCharPosition];
+ offset = getCharLength(b);
+
+ /* found beginning of a valid char */
+ if (offset > 0) {
+final byte[] lastCharBytes = Arrays
+.copyOfRange(text, lastCharPosition, lastCharPosition +
offset);
+/* last character */
+final String s = new String(lastCharBytes,
Charset.forName("UTF-8"));
+
+/* increment the codepoint of last character */
+int codePoint = s.codePointAt(s.length() - 1);
+codePoint++;
+final char[] incrementedChars = Character.toChars(codePoint);
+
+/* convert char array to byte array */
+final CharBuffer charBuffer =
CharBuffer.wrap(incrementedChars);
+final ByteBuffer byteBuffer =
Charset.forName("UTF-8").encode(charBuffer);
+final byte[] bytes = Arrays.copyOfRange(byteBuffer.array(),
byteBuffer.position(),
+byteBuffer.limit());
+
+final byte[] result = new byte[lastCharPosition +
bytes.length];
+
+/* copy truncated array minus last char */
+System.arraycopy(text, 0, result, 0, lastCharPosition);
+/* copy last char */
+System.arraycopy(bytes, 0, result, lastCharPosition,
bytes.length);
+
+return new Text(result);
+
+ } /* not found keep looking for a beginning byte */ else {
+--lastCharPosition;
+ }
+
+}
+/* beginning of a valid char not found */
+throw new IllegalArgumentException(
+"Could not truncate string, beginning of a valid char not
found");
+ } else {
+return new Text(text);
+ }
+}
+
+private static Text truncateLowerBound(final Text text) {
+ if(text.getBytes().length > MAX_BYTES_RECORDED) {
+return truncateLowerBound(text.getBytes());
+ } else {
+return text;
+ }
+}
+
+
+private static Text truncateLowerBound(final byte[] text) {
--- End diff --
You need to pass the length in here as well. The byte array may be longer
than the length of the data.
---
[GitHub] orc pull request #299: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/299#discussion_r208402722
--- Diff: java/core/src/java/org/apache/orc/impl/ColumnStatisticsImpl.java
---
@@ -683,6 +787,150 @@ public int hashCode() {
result = 31 * result + (int) (sum ^ (sum >>> 32));
return result;
}
+
+/**
+ * A helper function that truncates the {@link Text} input
+ * based on {@link #MAX_BYTES_RECORDED} and increments
+ * the last codepoint by 1.
+ * @param text
+ * @return truncated Text value
+ */
+private static Text truncateUpperBound(final Text text) {
+
+ if(text.getBytes().length > MAX_BYTES_RECORDED) {
+return truncateUpperBound(text.getBytes());
+ } else {
+return text;
+ }
+
+}
+
+/**
+ * A helper function that truncates the {@link byte[]} input
+ * based on {@link #MAX_BYTES_RECORDED} and increments
+ * the last codepoint by 1.
+ * @param text
+ * @return truncated Text value
+ */
+private static Text truncateUpperBound(final byte[] text) {
+ if(text.length > MAX_BYTES_RECORDED) {
+final Text truncated = truncateLowerBound(text);
+final byte[] data = truncated.getBytes();
+
+int lastCharPosition = data.length - 1;
+int offset = 0;
+
+/* we don't expect characters more than 5 bytes */
+for (int i = 0; i < 5; i++) {
+ final byte b = data[lastCharPosition];
+ offset = getCharLength(b);
+
+ /* found beginning of a valid char */
+ if (offset > 0) {
+final byte[] lastCharBytes = Arrays
+.copyOfRange(text, lastCharPosition, lastCharPosition +
offset);
+/* last character */
+final String s = new String(lastCharBytes,
Charset.forName("UTF-8"));
+
+/* increment the codepoint of last character */
+int codePoint = s.codePointAt(s.length() - 1);
+codePoint++;
+final char[] incrementedChars = Character.toChars(codePoint);
+
+/* convert char array to byte array */
+final CharBuffer charBuffer =
CharBuffer.wrap(incrementedChars);
+final ByteBuffer byteBuffer =
Charset.forName("UTF-8").encode(charBuffer);
+final byte[] bytes = Arrays.copyOfRange(byteBuffer.array(),
byteBuffer.position(),
+byteBuffer.limit());
+
+final byte[] result = new byte[lastCharPosition +
bytes.length];
+
+/* copy truncated array minus last char */
+System.arraycopy(text, 0, result, 0, lastCharPosition);
+/* copy last char */
+System.arraycopy(bytes, 0, result, lastCharPosition,
bytes.length);
+
+return new Text(result);
--- End diff --
A better pattern is:
Text result = new Text();
result.setCapacity(lastCharPosition + bytes.length);
result.set(text, 0, lastCharPosition);
result.append(bytes, 0, bytes.length);
return result;
---
[GitHub] orc pull request #299: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/299#discussion_r208398251
--- Diff: java/core/src/java/org/apache/orc/impl/ColumnStatisticsImpl.java
---
@@ -584,16 +630,40 @@ public void merge(ColumnStatisticsImpl other) {
if (str.minimum != null) {
maximum = new Text(str.getMaximum());
minimum = new Text(str.getMinimum());
- } else {
+ }
+ /* str.minimum == null when lower bound set */
+ else if (str.isLowerBoundSet) {
+minimum = new Text(str.getLowerBound());
+isLowerBoundSet = true;
+
+/* check for upper bound before setting max */
+if (str.isUpperBoundSet) {
+ maximum = new Text(str.getUpperBound());
+ isUpperBoundSet = true;
+} else {
+ maximum = new Text(str.getMaximum());
+}
+ }
+ else {
/* both are empty */
maximum = minimum = null;
}
} else if (str.minimum != null) {
if (minimum.compareTo(str.minimum) > 0) {
-minimum = new Text(str.getMinimum());
+if(str.isLowerBoundSet) {
+ minimum = new Text(str.getLowerBound());
+ isLowerBoundSet = true;
+} else {
+ minimum = new Text(str.getMinimum());
+}
}
if (maximum.compareTo(str.maximum) < 0) {
-maximum = new Text(str.getMaximum());
+if(str.isUpperBoundSet) {
--- End diff --
The same simplification would hold here.
maximum = new Text(str.maximum)
isUpperBoundSet = str.isUpperBoundSet
---
[GitHub] orc pull request #299: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/299#discussion_r208392941
--- Diff: java/core/src/java/org/apache/orc/impl/ColumnStatisticsImpl.java
---
@@ -543,35 +551,73 @@ public void reset() {
super.reset();
minimum = null;
maximum = null;
+ isLowerBoundSet = false;
+ isUpperBoundSet = false;
sum = 0;
}
@Override
public void updateString(Text value) {
if (minimum == null) {
-maximum = minimum = new Text(value);
+if(value.getLength() > MAX_BYTES_RECORDED) {
+ minimum = truncateLowerBound(value);
+ maximum = truncateUpperBound(value);
+ isLowerBoundSet = true;
+ isUpperBoundSet = true;
+} else {
+ maximum = minimum = new Text(value);
+}
} else if (minimum.compareTo(value) > 0) {
-minimum = new Text(value);
+if(value.getLength() > MAX_BYTES_RECORDED) {
+ minimum = truncateLowerBound(value);
+ isLowerBoundSet = true;
+}else {
+ minimum = new Text(value);
+}
} else if (maximum.compareTo(value) < 0) {
-maximum = new Text(value);
+if(value.getLength() > MAX_BYTES_RECORDED) {
+ maximum = truncateUpperBound(value);
+ isUpperBoundSet = true;
+} else {
+ maximum = new Text(value);
--- End diff --
This also needs to clear isUpperBoundSet.
---
[GitHub] orc pull request #299: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/299#discussion_r208397080
--- Diff: java/core/src/java/org/apache/orc/impl/ColumnStatisticsImpl.java
---
@@ -584,16 +630,40 @@ public void merge(ColumnStatisticsImpl other) {
if (str.minimum != null) {
maximum = new Text(str.getMaximum());
minimum = new Text(str.getMinimum());
- } else {
+ }
--- End diff --
Ok, you should keep the "else" on the same line as the "}", but I don't
think you need this new branch.
---
[GitHub] orc pull request #299: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request: https://github.com/apache/orc/pull/299#discussion_r208392060 --- Diff: java/bench/README.md --- @@ -1,3 +1,20 @@ + --- End diff -- I don't need this, even when I compile with ANALYZE_JAVA. ---
[GitHub] orc pull request #299: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/299#discussion_r208401986
--- Diff: java/core/src/java/org/apache/orc/impl/ColumnStatisticsImpl.java
---
@@ -683,6 +787,150 @@ public int hashCode() {
result = 31 * result + (int) (sum ^ (sum >>> 32));
return result;
}
+
+/**
+ * A helper function that truncates the {@link Text} input
+ * based on {@link #MAX_BYTES_RECORDED} and increments
+ * the last codepoint by 1.
+ * @param text
+ * @return truncated Text value
+ */
+private static Text truncateUpperBound(final Text text) {
+
+ if(text.getBytes().length > MAX_BYTES_RECORDED) {
+return truncateUpperBound(text.getBytes());
+ } else {
+return text;
+ }
+
+}
+
+/**
+ * A helper function that truncates the {@link byte[]} input
+ * based on {@link #MAX_BYTES_RECORDED} and increments
+ * the last codepoint by 1.
+ * @param text
+ * @return truncated Text value
+ */
+private static Text truncateUpperBound(final byte[] text) {
+ if(text.length > MAX_BYTES_RECORDED) {
+final Text truncated = truncateLowerBound(text);
+final byte[] data = truncated.getBytes();
+
+int lastCharPosition = data.length - 1;
+int offset = 0;
+
+/* we don't expect characters more than 5 bytes */
+for (int i = 0; i < 5; i++) {
+ final byte b = data[lastCharPosition];
+ offset = getCharLength(b);
+
+ /* found beginning of a valid char */
+ if (offset > 0) {
+final byte[] lastCharBytes = Arrays
+.copyOfRange(text, lastCharPosition, lastCharPosition +
offset);
+/* last character */
+final String s = new String(lastCharBytes,
Charset.forName("UTF-8"));
+
+/* increment the codepoint of last character */
+int codePoint = s.codePointAt(s.length() - 1);
+codePoint++;
+final char[] incrementedChars = Character.toChars(codePoint);
+
+/* convert char array to byte array */
+final CharBuffer charBuffer =
CharBuffer.wrap(incrementedChars);
+final ByteBuffer byteBuffer =
Charset.forName("UTF-8").encode(charBuffer);
+final byte[] bytes = Arrays.copyOfRange(byteBuffer.array(),
byteBuffer.position(),
+byteBuffer.limit());
+
+final byte[] result = new byte[lastCharPosition +
bytes.length];
+
+/* copy truncated array minus last char */
+System.arraycopy(text, 0, result, 0, lastCharPosition);
+/* copy last char */
+System.arraycopy(bytes, 0, result, lastCharPosition,
bytes.length);
+
+return new Text(result);
+
+ } /* not found keep looking for a beginning byte */ else {
+--lastCharPosition;
+ }
+
+}
+/* beginning of a valid char not found */
+throw new IllegalArgumentException(
+"Could not truncate string, beginning of a valid char not
found");
+ } else {
+return new Text(text);
+ }
+}
+
+private static Text truncateLowerBound(final Text text) {
+ if(text.getBytes().length > MAX_BYTES_RECORDED) {
+return truncateLowerBound(text.getBytes());
+ } else {
+return text;
+ }
+}
+
+
+private static Text truncateLowerBound(final byte[] text) {
+
+ if(text.length > MAX_BYTES_RECORDED) {
+
+int truncateLen = MAX_BYTES_RECORDED;
+int offset = 0;
+
+for(int i=0; i<5; i++) {
+
+ byte b = text[truncateLen];
+ /* check for the beginning of 1,2,3,4,5 bytes long char */
+ offset = getCharLength(b);
+
+ /* found beginning of a valid char */
+ if(offset > 0) {
+byte[] truncated = Arrays.copyOfRange(text, 0, (truncateLen));
--- End diff --
If you do:
Text result = new Text();
result.set(text, 0, truncateLen);
return result;
you'll have 1 less copy of the bytes.
---
[GitHub] orc pull request #299: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/299#discussion_r208393137
--- Diff: java/core/src/java/org/apache/orc/impl/ColumnStatisticsImpl.java
---
@@ -543,35 +551,73 @@ public void reset() {
super.reset();
minimum = null;
maximum = null;
+ isLowerBoundSet = false;
+ isUpperBoundSet = false;
sum = 0;
}
@Override
public void updateString(Text value) {
if (minimum == null) {
-maximum = minimum = new Text(value);
+if(value.getLength() > MAX_BYTES_RECORDED) {
+ minimum = truncateLowerBound(value);
+ maximum = truncateUpperBound(value);
+ isLowerBoundSet = true;
+ isUpperBoundSet = true;
+} else {
+ maximum = minimum = new Text(value);
+}
} else if (minimum.compareTo(value) > 0) {
-minimum = new Text(value);
+if(value.getLength() > MAX_BYTES_RECORDED) {
+ minimum = truncateLowerBound(value);
+ isLowerBoundSet = true;
+}else {
+ minimum = new Text(value);
+}
} else if (maximum.compareTo(value) < 0) {
-maximum = new Text(value);
+if(value.getLength() > MAX_BYTES_RECORDED) {
+ maximum = truncateUpperBound(value);
+ isUpperBoundSet = true;
+} else {
+ maximum = new Text(value);
+}
}
sum += value.getLength();
}
+
@Override
public void updateString(byte[] bytes, int offset, int length,
int repetitions) {
+ byte[] input = Arrays.copyOfRange(bytes, offset, offset+(length));
--- End diff --
Please don't copy the array unless it is needed.
---
[GitHub] orc pull request #299: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/299#discussion_r208392855
--- Diff: java/core/src/java/org/apache/orc/impl/ColumnStatisticsImpl.java
---
@@ -543,35 +551,73 @@ public void reset() {
super.reset();
minimum = null;
maximum = null;
+ isLowerBoundSet = false;
+ isUpperBoundSet = false;
sum = 0;
}
@Override
public void updateString(Text value) {
if (minimum == null) {
-maximum = minimum = new Text(value);
+if(value.getLength() > MAX_BYTES_RECORDED) {
+ minimum = truncateLowerBound(value);
+ maximum = truncateUpperBound(value);
+ isLowerBoundSet = true;
+ isUpperBoundSet = true;
+} else {
+ maximum = minimum = new Text(value);
+}
} else if (minimum.compareTo(value) > 0) {
-minimum = new Text(value);
+if(value.getLength() > MAX_BYTES_RECORDED) {
+ minimum = truncateLowerBound(value);
+ isLowerBoundSet = true;
+}else {
+ minimum = new Text(value);
--- End diff --
This needs to set isLowerBoundSet = false.
---
[GitHub] orc pull request #299: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/299#discussion_r208398373
--- Diff: java/core/src/java/org/apache/orc/impl/ColumnStatisticsImpl.java
---
@@ -683,6 +787,150 @@ public int hashCode() {
result = 31 * result + (int) (sum ^ (sum >>> 32));
return result;
}
+
+/**
+ * A helper function that truncates the {@link Text} input
+ * based on {@link #MAX_BYTES_RECORDED} and increments
+ * the last codepoint by 1.
+ * @param text
+ * @return truncated Text value
+ */
+private static Text truncateUpperBound(final Text text) {
+
+ if(text.getBytes().length > MAX_BYTES_RECORDED) {
+return truncateUpperBound(text.getBytes());
+ } else {
+return text;
+ }
+
+}
+
+/**
+ * A helper function that truncates the {@link byte[]} input
+ * based on {@link #MAX_BYTES_RECORDED} and increments
+ * the last codepoint by 1.
+ * @param text
+ * @return truncated Text value
+ */
+private static Text truncateUpperBound(final byte[] text) {
--- End diff --
You need the length passed in here.
---
[GitHub] orc pull request #299: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/299#discussion_r208395531
--- Diff: java/core/src/java/org/apache/orc/impl/ColumnStatisticsImpl.java
---
@@ -584,16 +630,40 @@ public void merge(ColumnStatisticsImpl other) {
if (str.minimum != null) {
maximum = new Text(str.getMaximum());
--- End diff --
You'll need to copy the booleans from str also.
---
[GitHub] orc pull request #299: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/299#discussion_r208393268
--- Diff: java/core/src/java/org/apache/orc/impl/ColumnStatisticsImpl.java
---
@@ -543,35 +551,73 @@ public void reset() {
super.reset();
minimum = null;
maximum = null;
+ isLowerBoundSet = false;
+ isUpperBoundSet = false;
sum = 0;
}
@Override
public void updateString(Text value) {
if (minimum == null) {
-maximum = minimum = new Text(value);
+if(value.getLength() > MAX_BYTES_RECORDED) {
+ minimum = truncateLowerBound(value);
+ maximum = truncateUpperBound(value);
+ isLowerBoundSet = true;
+ isUpperBoundSet = true;
+} else {
+ maximum = minimum = new Text(value);
+}
} else if (minimum.compareTo(value) > 0) {
-minimum = new Text(value);
+if(value.getLength() > MAX_BYTES_RECORDED) {
+ minimum = truncateLowerBound(value);
+ isLowerBoundSet = true;
+}else {
+ minimum = new Text(value);
+}
} else if (maximum.compareTo(value) < 0) {
-maximum = new Text(value);
+if(value.getLength() > MAX_BYTES_RECORDED) {
+ maximum = truncateUpperBound(value);
+ isUpperBoundSet = true;
+} else {
+ maximum = new Text(value);
+}
}
sum += value.getLength();
}
+
@Override
public void updateString(byte[] bytes, int offset, int length,
int repetitions) {
+ byte[] input = Arrays.copyOfRange(bytes, offset, offset+(length));
if (minimum == null) {
-maximum = minimum = new Text();
-maximum.set(bytes, offset, length);
+if(length > MAX_BYTES_RECORDED) {
+ minimum = truncateLowerBound(input);
+ maximum = truncateUpperBound(input);
+ isLowerBoundSet = true;
+ isUpperBoundSet = true;
+} else {
+ maximum = minimum = new Text();
+ maximum.set(bytes, offset, length);
+}
} else if (WritableComparator.compareBytes(minimum.getBytes(), 0,
minimum.getLength(), bytes, offset, length) > 0) {
-minimum = new Text();
-minimum.set(bytes, offset, length);
+if(length > MAX_BYTES_RECORDED) {
+ minimum = truncateLowerBound(input);
+ isLowerBoundSet = true;
+} else {
+ minimum = new Text();
+ minimum.set(bytes, offset, length);
--- End diff --
Clear isLowerBoundSet.
---
[GitHub] orc pull request #299: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request: https://github.com/apache/orc/pull/299#discussion_r208392450 --- Diff: java/core/src/java/org/apache/orc/StringColumnStatistics.java --- @@ -33,6 +33,20 @@ */ String getMaximum(); + /** + * Get the string with + * length = Min(StringStatisticsImpl.MAX_BYTES_RECORDED, getMinimum()) --- End diff -- I would phrase this as "Get the lower bound of the values in this column. The value may be truncated to at most MAX_BYTES_RECORDED." ---
[GitHub] orc pull request #299: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request: https://github.com/apache/orc/pull/299#discussion_r208392508 --- Diff: java/core/src/java/org/apache/orc/StringColumnStatistics.java --- @@ -33,6 +33,20 @@ */ String getMaximum(); + /** + * Get the string with + * length = Min(StringStatisticsImpl.MAX_BYTES_RECORDED, getMinimum()) + * @return lower bound + */ + String getLowerBound(); + + /** + * Get the string with + * length = Min(StringStatisticsImpl.MAX_BYTES_RECORDED, getMaximum()) --- End diff -- Same here. ---
[GitHub] orc pull request #299: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/299#discussion_r208398032
--- Diff: java/core/src/java/org/apache/orc/impl/ColumnStatisticsImpl.java
---
@@ -584,16 +630,40 @@ public void merge(ColumnStatisticsImpl other) {
if (str.minimum != null) {
maximum = new Text(str.getMaximum());
minimum = new Text(str.getMinimum());
- } else {
+ }
+ /* str.minimum == null when lower bound set */
+ else if (str.isLowerBoundSet) {
+minimum = new Text(str.getLowerBound());
+isLowerBoundSet = true;
+
+/* check for upper bound before setting max */
+if (str.isUpperBoundSet) {
+ maximum = new Text(str.getUpperBound());
+ isUpperBoundSet = true;
+} else {
+ maximum = new Text(str.getMaximum());
+}
+ }
+ else {
/* both are empty */
maximum = minimum = null;
}
} else if (str.minimum != null) {
if (minimum.compareTo(str.minimum) > 0) {
-minimum = new Text(str.getMinimum());
+if(str.isLowerBoundSet) {
+ minimum = new Text(str.getLowerBound());
+ isLowerBoundSet = true;
+} else {
+ minimum = new Text(str.getMinimum());
--- End diff --
You could simplify this as:
minimum = new Text(str.minimum)
isLowerBoundSet = str.isLowerBoundSet;
---
[GitHub] orc pull request #299: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/299#discussion_r208393342
--- Diff: java/core/src/java/org/apache/orc/impl/ColumnStatisticsImpl.java
---
@@ -543,35 +551,73 @@ public void reset() {
super.reset();
minimum = null;
maximum = null;
+ isLowerBoundSet = false;
+ isUpperBoundSet = false;
sum = 0;
}
@Override
public void updateString(Text value) {
if (minimum == null) {
-maximum = minimum = new Text(value);
+if(value.getLength() > MAX_BYTES_RECORDED) {
+ minimum = truncateLowerBound(value);
+ maximum = truncateUpperBound(value);
+ isLowerBoundSet = true;
+ isUpperBoundSet = true;
+} else {
+ maximum = minimum = new Text(value);
+}
} else if (minimum.compareTo(value) > 0) {
-minimum = new Text(value);
+if(value.getLength() > MAX_BYTES_RECORDED) {
+ minimum = truncateLowerBound(value);
+ isLowerBoundSet = true;
+}else {
+ minimum = new Text(value);
+}
} else if (maximum.compareTo(value) < 0) {
-maximum = new Text(value);
+if(value.getLength() > MAX_BYTES_RECORDED) {
+ maximum = truncateUpperBound(value);
+ isUpperBoundSet = true;
+} else {
+ maximum = new Text(value);
+}
}
sum += value.getLength();
}
+
@Override
public void updateString(byte[] bytes, int offset, int length,
int repetitions) {
+ byte[] input = Arrays.copyOfRange(bytes, offset, offset+(length));
if (minimum == null) {
-maximum = minimum = new Text();
-maximum.set(bytes, offset, length);
+if(length > MAX_BYTES_RECORDED) {
+ minimum = truncateLowerBound(input);
+ maximum = truncateUpperBound(input);
+ isLowerBoundSet = true;
+ isUpperBoundSet = true;
+} else {
+ maximum = minimum = new Text();
+ maximum.set(bytes, offset, length);
+}
} else if (WritableComparator.compareBytes(minimum.getBytes(), 0,
minimum.getLength(), bytes, offset, length) > 0) {
-minimum = new Text();
-minimum.set(bytes, offset, length);
+if(length > MAX_BYTES_RECORDED) {
+ minimum = truncateLowerBound(input);
+ isLowerBoundSet = true;
+} else {
+ minimum = new Text();
+ minimum.set(bytes, offset, length);
+}
} else if (WritableComparator.compareBytes(maximum.getBytes(), 0,
maximum.getLength(), bytes, offset, length) < 0) {
-maximum = new Text();
-maximum.set(bytes, offset, length);
+if(length > MAX_BYTES_RECORDED) {
+ maximum = truncateUpperBound(input);
+ isUpperBoundSet = true;
+} else {
+ maximum = new Text();
+ maximum.set(bytes, offset, length);
--- End diff --
Clear isUpperBoundSet.
---
[GitHub] orc pull request #299: ORC-203 - Update StringStatistics to trim long string...
GitHub user moresandeep opened a pull request: https://github.com/apache/orc/pull/299 ORC-203 - Update StringStatistics to trim long strings to 1024 characters & record they were trimmed Reopening the PR. You can merge this pull request into a Git repository by running: $ git pull https://github.com/moresandeep/orc ORC-203-Truncate_Max_For_Long_Strings Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/299.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #299 commit 2e09a1fcc2bca56629b5a526b2e0df417171ceed Author: Sandeep More Date: 2018-07-18T13:31:02Z ORC-203 - Update StringStatistics to trim long strings to 1024 characters & record they were trimmed ---
[GitHub] orc pull request #292: ORC-203 - Update StringStatistics to trim long string...
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/292 ---
[GitHub] orc pull request #291: ORC-385. Change RecordReader to extend Closeable.
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/291 ---
[GitHub] orc pull request #297: Fixed Spelling.
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/297 ---
[GitHub] orc pull request #298: ORC-393. Add ORC snapcraft definition.
GitHub user omalley opened a pull request: https://github.com/apache/orc/pull/298 ORC-393. Add ORC snapcraft definition. You can merge this pull request into a Git repository by running: $ git pull https://github.com/omalley/orc orc-393 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/298.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #298 commit 9c82a14d8dd276fe4e3afcc87809c8ee9e97f843 Author: Owen O'Malley Date: 2018-08-03T19:53:37Z ORC-393. Add ORC snapcraft definition. ---
[GitHub] orc pull request #292: ORC-203 - Update StringStatistics to trim long string...
Github user moresandeep commented on a diff in the pull request: https://github.com/apache/orc/pull/292#discussion_r206636579 --- Diff: java/bench/README.md --- @@ -1,3 +1,20 @@ + --- End diff -- Thanks @omalley I updated the PR with suggested changes. ---
[GitHub] orc pull request #296: [ORC-391][c++] parseType does not accept underscore i...
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/296 ---
[GitHub] orc pull request #296: [ORC-391][c++] parseType does not accept underscore i...
Github user majetideepak commented on a diff in the pull request:
https://github.com/apache/orc/pull/296#discussion_r206153654
--- Diff: tools/test/TestCSVFileImport.cc ---
@@ -53,3 +53,33 @@ TEST (TestCSVFileImport, test10rows) {
EXPECT_EQ(expected, output);
EXPECT_EQ("", error);
}
+
+TEST (TestCSVFileImport, test10rows_underscore) {
+ // create an ORC file from importing the CSV file
+ const std::string pgm1 = findProgram("tools/src/csv-import");
+ const std::string csvFile =
findExample("TestCSVFileImport.test10rows.csv");
+ const std::string orcFile = "/tmp/test_csv_import_test_10_rows.orc";
+ const std::string schema = "struct<_a:bigint,b_:string,c:double>";
--- End diff --
Thanks for the test! can you rename `c` to `c_col`?
---
[GitHub] orc pull request #293: ORC-388: Fix isSafeSubtract to use logic operator ins...
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/293 ---
[GitHub] orc pull request #292: ORC-203 - Update StringStatistics to trim long string...
Github user wgtmac commented on a diff in the pull request:
https://github.com/apache/orc/pull/292#discussion_r205340059
--- Diff: java/core/src/java/org/apache/orc/impl/ColumnStatisticsImpl.java
---
@@ -584,16 +642,40 @@ public void merge(ColumnStatisticsImpl other) {
if (str.minimum != null) {
maximum = new Text(str.getMaximum());
minimum = new Text(str.getMinimum());
- } else {
+ }
+ /* str.minimum == null when lower bound set */
+ else if (str.getLowerBound() != null) {
+minimum = new Text(str.getLowerBound());
+isLowerBoundSet = true;
+
+/* check for upper bound before setting max */
+if (str.getUpperBound() != null) {
+ maximum = new Text(str.getUpperBound());
+ isUpperBoundSet = true;
+} else {
+ maximum = new Text(str.getMaximum());
+}
+ }
+ else {
/* both are empty */
maximum = minimum = null;
}
} else if (str.minimum != null) {
if (minimum.compareTo(str.minimum) > 0) {
-minimum = new Text(str.getMinimum());
+if(str.getLowerBound() != null) {
+ minimum = new Text(str.getLowerBound());
+ isLowerBoundSet = true;
+} else {
+ minimum = new Text(str.getMinimum());
--- End diff --
If we have found a new minimum w/o truncation, should we reset
isLowerBoundSet to false?
Same for isUpperBoundSet below.
---
[GitHub] orc pull request #295: ORC-389: Add ability to not decode Acid metadata colu...
GitHub user ekoifman opened a pull request: https://github.com/apache/orc/pull/295 ORC-389: Add ability to not decode Acid metadata columns You can merge this pull request into a Git repository by running: $ git pull https://github.com/ekoifman/orc ORC-389-branch-1.5 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/295.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #295 commit 95845239197bc3aff460eeaf53c5644f94aa10b7 Author: Eugene Koifman Date: 2018-07-26T00:44:03Z ORC-389: Add ability to not decode Acid metadata columns ---
[GitHub] orc pull request #294: ORC-389: Add ability to not decode Acid metadata colu...
Github user asfgit closed the pull request at: https://github.com/apache/orc/pull/294 ---
[GitHub] orc pull request #294: ORC-389: Add ability to not decode Acid metadata colu...
GitHub user ekoifman reopened a pull request: https://github.com/apache/orc/pull/294 ORC-389: Add ability to not decode Acid metadata columns You can merge this pull request into a Git repository by running: $ git pull https://github.com/ekoifman/orc ORC-389 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/294.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #294 commit 634404d9de38923507d0812cb3310022c03169e5 Author: Eugene Koifman Date: 2018-07-25T21:22:23Z ORC-389: Add ability to not decode Acid metadata columns ---
[GitHub] orc pull request #294: ORC-389: Add ability to not decode Acid metadata colu...
Github user ekoifman closed the pull request at: https://github.com/apache/orc/pull/294 ---
[GitHub] orc pull request #294: ORC-389: Add ability to not decode Acid metadata colu...
GitHub user ekoifman opened a pull request: https://github.com/apache/orc/pull/294 ORC-389: Add ability to not decode Acid metadata columns You can merge this pull request into a Git repository by running: $ git pull https://github.com/ekoifman/orc ORC-389 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/294.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #294 commit 634404d9de38923507d0812cb3310022c03169e5 Author: Eugene Koifman Date: 2018-07-25T21:22:23Z ORC-389: Add ability to not decode Acid metadata columns ---
[GitHub] orc pull request #292: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request: https://github.com/apache/orc/pull/292#discussion_r205179930 --- Diff: java/bench/README.md --- @@ -1,3 +1,20 @@ + --- End diff -- Let me check why this got flagged. We should have an exclusion for *.md files. ---
[GitHub] orc pull request #292: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/292#discussion_r205179439
--- Diff: java/core/src/java/org/apache/orc/impl/ColumnStatisticsImpl.java
---
@@ -621,12 +703,54 @@ public void merge(ColumnStatisticsImpl other) {
@Override
public String getMinimum() {
- return minimum == null ? null : minimum.toString();
+ /* if we have lower bound set (in case of truncation)
+ getMinimum will be null */
+ if(isLowerBoundSet) {
+return null;
+ } else {
+return minimum == null ? null : minimum.toString();
+ }
}
@Override
public String getMaximum() {
- return maximum == null ? null : maximum.toString();
+ /* if we have upper bound is set (in case of truncation)
+ getMaximum will be null */
+ if(isUpperBoundSet) {
+return null;
+ } else {
+return maximum == null ? null : maximum.toString();
+ }
+}
+
+/**
+ * Get the string with
+ * length = Min(StringStatisticsImpl.MAX_STRING_LENGTH_RECORDED,
getMinimum())
+ *
+ * @return lower bound
+ */
+@Override
+public String getLowerBound() {
+ if(isLowerBoundSet) {
+return minimum.toString();
+ } else {
+return null;
+ }
+}
+
+/**
+ * Get the string with
+ * length = Min(StringStatisticsImpl.MAX_STRING_LENGTH_RECORDED,
getMaximum())
+ *
+ * @return upper bound
+ */
+@Override
+public String getUpperBound() {
+ if(isUpperBoundSet) {
+return maximum.toString();
+ } else {
+return null;
--- End diff --
This should always return maximum.
---
[GitHub] orc pull request #292: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/292#discussion_r205180384
--- Diff: java/core/src/java/org/apache/orc/impl/ColumnStatisticsImpl.java
---
@@ -517,10 +519,14 @@ public int hashCode() {
protected static final class StringStatisticsImpl extends
ColumnStatisticsImpl
implements StringColumnStatistics {
+public static final int MAX_STRING_LENGTH_RECORDED = 1024;
--- End diff --
We should probably use the number of bytes instead of the number of
characters. I'd propose that we always truncate a whole number of characters,
with a maximum of 1024 bytes.
For ASCII strings, it will have the same result, but larger characters may
end up at 1021 to 1024 bytes long.
---
[GitHub] orc pull request #292: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/292#discussion_r205180578
--- Diff: java/core/src/java/org/apache/orc/impl/ColumnStatisticsImpl.java
---
@@ -543,35 +549,87 @@ public void reset() {
super.reset();
minimum = null;
maximum = null;
+ isLowerBoundSet = false;
+ isUpperBoundSet = false;
sum = 0;
}
@Override
public void updateString(Text value) {
if (minimum == null) {
-maximum = minimum = new Text(value);
+if(value.toString().length() > MAX_STRING_LENGTH_RECORDED) {
+ minimum = new Text(
--- End diff --
Let's make a corresponding truncateLowerBound so that we can have one place
to change.
---
[GitHub] orc pull request #292: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/292#discussion_r205179355
--- Diff: java/core/src/java/org/apache/orc/impl/ColumnStatisticsImpl.java
---
@@ -621,12 +703,54 @@ public void merge(ColumnStatisticsImpl other) {
@Override
public String getMinimum() {
- return minimum == null ? null : minimum.toString();
+ /* if we have lower bound set (in case of truncation)
+ getMinimum will be null */
+ if(isLowerBoundSet) {
+return null;
+ } else {
+return minimum == null ? null : minimum.toString();
+ }
}
@Override
public String getMaximum() {
- return maximum == null ? null : maximum.toString();
+ /* if we have upper bound is set (in case of truncation)
+ getMaximum will be null */
+ if(isUpperBoundSet) {
+return null;
+ } else {
+return maximum == null ? null : maximum.toString();
+ }
+}
+
+/**
+ * Get the string with
+ * length = Min(StringStatisticsImpl.MAX_STRING_LENGTH_RECORDED,
getMinimum())
+ *
+ * @return lower bound
+ */
+@Override
+public String getLowerBound() {
+ if(isLowerBoundSet) {
+return minimum.toString();
+ } else {
+return null;
--- End diff --
This should always return minimum.
---
[GitHub] orc pull request #292: ORC-203 - Update StringStatistics to trim long string...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/292#discussion_r205181230
--- Diff: java/core/src/java/org/apache/orc/impl/ColumnStatisticsImpl.java
---
@@ -543,35 +549,87 @@ public void reset() {
super.reset();
minimum = null;
maximum = null;
+ isLowerBoundSet = false;
+ isUpperBoundSet = false;
sum = 0;
}
@Override
public void updateString(Text value) {
if (minimum == null) {
-maximum = minimum = new Text(value);
+if(value.toString().length() > MAX_STRING_LENGTH_RECORDED) {
+ minimum = new Text(
--- End diff --
We can even use the structure of UTF-8 to do truncateLowerBound without
forming a string. In particular you want to search from 1024 to find the first
byte of a character (0xxx or 11xx ) and truncate just before it.
---
[GitHub] orc pull request #293: ORC-388: Fix isSafeSubtract to use logic operator ins...
GitHub user wgtmac opened a pull request: https://github.com/apache/orc/pull/293 ORC-388: Fix isSafeSubtract to use logic operator instead of bit operator Both java and c++ have this issue. You can merge this pull request into a Git repository by running: $ git pull https://github.com/wgtmac/orc ORC-388 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/293.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #293 commit 3a52eeff580697db6f8d0624d6e35e4f185979ac Author: Gang Wu Date: 2018-07-24T20:35:19Z ORC-388: Fix isSafeSubtract to use logic operator instead of bit operator ---
[GitHub] orc pull request #292: ORC-203 - Update StringStatistics to trim long string...
GitHub user moresandeep opened a pull request: https://github.com/apache/orc/pull/292 ORC-203 - Update StringStatistics to trim long strings to 1024 characters & record they were trimmed This PR adds the functionality described in ORC-203. You can merge this pull request into a Git repository by running: $ git pull https://github.com/moresandeep/orc ORC-203-Truncate_Max_For_Long_Strings Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/292.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #292 commit dfb488755e0293545b5cfa364ded31b916b7d0f8 Author: Sandeep More Date: 2018-07-18T13:31:02Z ORC-203 - Update StringStatistics to trim long strings to 1024 characters & record they were trimmed ---
[GitHub] orc pull request #291: ORC-385. Change RecordReader to extend Closeable.
GitHub user omalley opened a pull request: https://github.com/apache/orc/pull/291 ORC-385. Change RecordReader to extend Closeable. You can merge this pull request into a Git repository by running: $ git pull https://github.com/omalley/orc orc-385 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/orc/pull/291.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #291 commit 903a6d6049f918566938f9621fcfadb5f146a2ac Author: Owen O'Malley Date: 2018-07-13T21:55:45Z ORC-385. Change RecordReader to extend Closeable. Signed-off-by: Owen O'Malley ---
[GitHub] orc pull request #278: ORC-251: Extend InStream and OutStream to support enc...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/278#discussion_r202473870
--- Diff: java/core/src/java/org/apache/orc/impl/InStream.java ---
@@ -401,84 +596,149 @@ private String rangeString() {
@Override
public String toString() {
return "compressed stream " + name + " position: " + currentOffset +
- " length: " + length + " range: " + currentRange +
- " offset: " + (compressed == null ? 0 : compressed.position()) +
" limit: " + (compressed == null ? 0 : compressed.limit()) +
+ " length: " + length + " range: " + getRangeNumber(bytes,
currentRange) +
+ " offset: " + (compressed == null ? 0 : compressed.position()) +
+ " limit: " + (compressed == null ? 0 : compressed.limit()) +
rangeString() +
(uncompressed == null ? "" :
" uncompressed: " + uncompressed.position() + " to " +
uncompressed.limit());
}
}
+ private static class EncryptedCompressedStream extends CompressedStream {
+private final EncryptionState encrypt;
+
+public EncryptedCompressedStream(String name,
+ DiskRangeList input,
+ long length,
+ StreamOptions options) {
+ super(name, length, options);
+ encrypt = new EncryptionState(name, options);
+ reset(input, length);
+}
+
+@Override
+protected void setCurrent(DiskRangeList newRange, boolean isJump) {
+ currentRange = newRange;
+ if (newRange != null) {
+if (isJump) {
+ encrypt.changeIv(newRange.getOffset());
+}
+compressed = encrypt.decrypt(newRange);
+compressed.position((int) (currentOffset - newRange.getOffset()));
+ }
+}
+
+@Override
+public void close() {
+ super.close();
+ encrypt.close();
+}
+
+@Override
+public String toString() {
+ return "encrypted " + super.toString();
+}
+ }
+
public abstract void seek(PositionProvider index) throws IOException;
+ public static class StreamOptions implements Cloneable {
+private CompressionCodec codec;
+private int bufferSize;
+private EncryptionAlgorithm algorithm;
+private Key key;
+private byte[] iv;
+
+public StreamOptions withCodec(CompressionCodec value) {
+ this.codec = value;
+ return this;
+}
+
+public StreamOptions withBufferSize(int value) {
+ bufferSize = value;
+ return this;
+}
+
+public StreamOptions withEncryption(EncryptionAlgorithm algorithm,
+Key key,
+byte[] iv) {
+ this.algorithm = algorithm;
+ this.key = key;
+ this.iv = iv;
+ return this;
+}
+
+public CompressionCodec getCodec() {
+ return codec;
+}
+
+@Override
+public StreamOptions clone() {
+ try {
+StreamOptions clone = (StreamOptions) super.clone();
+if (clone.codec != null) {
+ // Make sure we don't share the same codec between two readers.
+ clone.codec = OrcCodecPool.getCodec(codec.getKind());
+}
+return clone;
--- End diff --
*sigh* It is Cloneable, because it is used as a field in DefaultDataReader.
The clone is correct, I believe. We really need a better solution for
CompressionCodec than the current Cloneable and CompressionCodecPool mess. We
need to remove the compression parameters out of Codec and then they are
completely stateless again and can be trivially pooled.
---
[GitHub] orc pull request #278: ORC-251: Extend InStream and OutStream to support enc...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/278#discussion_r202471794
--- Diff: java/core/src/java/org/apache/orc/impl/writer/StreamOptions.java
---
@@ -0,0 +1,85 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.orc.impl.writer;
+
+import org.apache.orc.CompressionCodec;
+import org.apache.orc.EncryptionAlgorithm;
+
+import java.security.Key;
+
+/**
+ * The compression and encryption options for writing a stream.
+ */
+public class StreamOptions {
--- End diff --
It is org.apache.orc.impl.InStream.StreamOptions and
org.apache.orc.impl.writer.StreamOptions. I guess they should be named the same
way, but they are separate classes.
---
[GitHub] orc pull request #278: ORC-251: Extend InStream and OutStream to support enc...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/278#discussion_r202470866
--- Diff: java/core/src/java/org/apache/orc/impl/InStream.java ---
@@ -173,33 +203,208 @@ private static ByteBuffer allocateBuffer(int size,
boolean isDirect) {
}
}
+ /**
+ * Manage the state of the decryption, including the ability to seek.
+ */
+ static class EncryptionState {
+private final String name;
+private final EncryptionAlgorithm algorithm;
+private final Key key;
+private final byte[] iv;
+private final Cipher cipher;
+private ByteBuffer decrypted;
+
+EncryptionState(String name, StreamOptions options) {
+ this.name = name;
+ algorithm = options.algorithm;
+ key = options.key;
+ iv = options.iv;
+ cipher = algorithm.createCipher();
+}
+
+/**
+ * We are seeking to a new range, so update the cipher to change the IV
+ * to match. This code assumes that we only support encryption in CTR
mode.
+ * @param offset where we are seeking to in the stream
+ */
+void changeIv(long offset) {
+ int blockSize = cipher.getBlockSize();
+ long encryptionBlocks = offset / blockSize;
--- End diff --
No, we always start decryption on a block boundary and throw away the
leading bytes. See InStream.EncryptionState.changeIv(long offset) and the
"extra" and "wasted" variables.
---
[GitHub] orc pull request #278: ORC-251: Extend InStream and OutStream to support enc...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/278#discussion_r202433617
--- Diff: java/core/src/java/org/apache/orc/impl/CryptoUtils.java ---
@@ -0,0 +1,77 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.orc.impl;
+
+import org.apache.orc.EncryptionAlgorithm;
+import java.security.SecureRandom;
+
+/**
+ * This class has routines to work with encryption within ORC files.
+ */
+public class CryptoUtils {
+
+ private static final int COLUMN_ID_LENGTH = 3;
+ private static final int KIND_LENGTH = 2;
+ private static final int STRIPE_ID_LENGTH = 3;
+ private static final int MIN_COUNT_BYTES = 8;
+
+ private static final SecureRandom random = new SecureRandom();
--- End diff --
oops. Removed.
---
[GitHub] orc pull request #278: ORC-251: Extend InStream and OutStream to support enc...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/278#discussion_r202433445
--- Diff: java/core/src/java/org/apache/orc/impl/InStream.java ---
@@ -55,112 +60,137 @@ public long getStreamLength() {
@Override
public abstract void close();
+ static int getRangeNumber(DiskRangeList list, DiskRangeList current) {
+int result = 0;
+DiskRangeList range = list;
+while (range != null && range != current) {
+ result += 1;
+ range = range.next;
+}
+return result;
+ }
+
+ /**
+ * Implements a stream over an uncompressed stream.
+ */
public static class UncompressedStream extends InStream {
-private List bytes;
+private DiskRangeList bytes;
private long length;
protected long currentOffset;
-private ByteBuffer range;
-private int currentRange;
+protected ByteBuffer decrypted;
+protected DiskRangeList currentRange;
+
+/**
+ * Create the stream without calling reset on it.
+ * This is used for the subclass that needs to do more setup.
+ * @param name name of the stream
+ * @param length the number of bytes for the stream
+ */
+public UncompressedStream(String name, long length) {
+ super(name, length);
+}
-public UncompressedStream(String name, List input, long
length) {
+public UncompressedStream(String name,
+ DiskRangeList input,
+ long length) {
super(name, length);
reset(input, length);
}
-protected void reset(List input, long length) {
+protected void reset(DiskRangeList input, long length) {
this.bytes = input;
this.length = length;
- currentRange = 0;
- currentOffset = 0;
- range = null;
+ currentOffset = input == null ? 0 : input.getOffset();
+ setCurrent(input, true);
}
@Override
public int read() {
- if (range == null || range.remaining() == 0) {
+ if (decrypted == null || decrypted.remaining() == 0) {
if (currentOffset == length) {
return -1;
}
-seek(currentOffset);
+setCurrent(currentRange.next, false);
}
currentOffset += 1;
- return 0xff & range.get();
+ return 0xff & decrypted.get();
+}
+
+protected void setCurrent(DiskRangeList newRange, boolean isJump) {
+ currentRange = newRange;
+ if (newRange != null) {
+decrypted = newRange.getData().slice();
+decrypted.position((int) (currentOffset - newRange.getOffset()));
+ }
}
@Override
public int read(byte[] data, int offset, int length) {
- if (range == null || range.remaining() == 0) {
+ if (decrypted == null || decrypted.remaining() == 0) {
if (currentOffset == this.length) {
return -1;
}
-seek(currentOffset);
+setCurrent(currentRange.next, false);
}
- int actualLength = Math.min(length, range.remaining());
- range.get(data, offset, actualLength);
+ int actualLength = Math.min(length, decrypted.remaining());
+ decrypted.get(data, offset, actualLength);
currentOffset += actualLength;
return actualLength;
}
@Override
public int available() {
- if (range != null && range.remaining() > 0) {
-return range.remaining();
+ if (decrypted != null && decrypted.remaining() > 0) {
+return decrypted.remaining();
}
return (int) (length - currentOffset);
}
@Override
public void close() {
- currentRange = bytes.size();
+ currentRange = null;
currentOffset = length;
// explicit de-ref of bytes[]
- bytes.clear();
+ decrypted = null;
+ bytes = null;
}
@Override
public void seek(PositionProvider index) throws IOException {
seek(index.getNext());
}
-public void seek(long desired) {
- if (desired == 0 && bytes.isEmpty()) {
+public void seek(long desired) throws IOException {
+ if (desired == 0 && bytes == null) {
return;
}
- int i = 0;
- for (DiskRange curRange : bytes) {
-if (curRange.getOffset() <= desired &&
-(desired - curRange.getOffset()) < curRange.getLength()) {
- currentOffset = desired;
- currentRange = i;
- this.range = curRange.getData().duplicate();
[GitHub] orc pull request #278: ORC-251: Extend InStream and OutStream to support enc...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/278#discussion_r202431172
--- Diff: java/core/src/java/org/apache/orc/impl/InStream.java ---
@@ -55,112 +60,137 @@ public long getStreamLength() {
@Override
public abstract void close();
+ static int getRangeNumber(DiskRangeList list, DiskRangeList current) {
+int result = 0;
+DiskRangeList range = list;
+while (range != null && range != current) {
+ result += 1;
+ range = range.next;
+}
+return result;
+ }
+
+ /**
+ * Implements a stream over an uncompressed stream.
+ */
public static class UncompressedStream extends InStream {
-private List bytes;
+private DiskRangeList bytes;
private long length;
protected long currentOffset;
-private ByteBuffer range;
-private int currentRange;
+protected ByteBuffer decrypted;
+protected DiskRangeList currentRange;
+
+/**
+ * Create the stream without calling reset on it.
+ * This is used for the subclass that needs to do more setup.
+ * @param name name of the stream
+ * @param length the number of bytes for the stream
+ */
+public UncompressedStream(String name, long length) {
+ super(name, length);
+}
-public UncompressedStream(String name, List input, long
length) {
+public UncompressedStream(String name,
+ DiskRangeList input,
+ long length) {
super(name, length);
reset(input, length);
}
-protected void reset(List input, long length) {
+protected void reset(DiskRangeList input, long length) {
this.bytes = input;
this.length = length;
- currentRange = 0;
- currentOffset = 0;
- range = null;
+ currentOffset = input == null ? 0 : input.getOffset();
+ setCurrent(input, true);
}
@Override
public int read() {
- if (range == null || range.remaining() == 0) {
+ if (decrypted == null || decrypted.remaining() == 0) {
if (currentOffset == length) {
return -1;
}
-seek(currentOffset);
+setCurrent(currentRange.next, false);
}
currentOffset += 1;
- return 0xff & range.get();
+ return 0xff & decrypted.get();
+}
+
+protected void setCurrent(DiskRangeList newRange, boolean isJump) {
+ currentRange = newRange;
+ if (newRange != null) {
+decrypted = newRange.getData().slice();
+decrypted.position((int) (currentOffset - newRange.getOffset()));
--- End diff --
But I'll add a comment to the code.
---
[GitHub] orc pull request #278: ORC-251: Extend InStream and OutStream to support enc...
Github user omalley commented on a diff in the pull request:
https://github.com/apache/orc/pull/278#discussion_r202430812
--- Diff: java/core/src/java/org/apache/orc/impl/InStream.java ---
@@ -55,112 +60,137 @@ public long getStreamLength() {
@Override
public abstract void close();
+ static int getRangeNumber(DiskRangeList list, DiskRangeList current) {
+int result = 0;
+DiskRangeList range = list;
+while (range != null && range != current) {
+ result += 1;
+ range = range.next;
+}
+return result;
+ }
+
+ /**
+ * Implements a stream over an uncompressed stream.
+ */
public static class UncompressedStream extends InStream {
-private List bytes;
+private DiskRangeList bytes;
private long length;
protected long currentOffset;
-private ByteBuffer range;
-private int currentRange;
+protected ByteBuffer decrypted;
+protected DiskRangeList currentRange;
+
+/**
+ * Create the stream without calling reset on it.
+ * This is used for the subclass that needs to do more setup.
+ * @param name name of the stream
+ * @param length the number of bytes for the stream
+ */
+public UncompressedStream(String name, long length) {
+ super(name, length);
+}
-public UncompressedStream(String name, List input, long
length) {
+public UncompressedStream(String name,
+ DiskRangeList input,
+ long length) {
super(name, length);
reset(input, length);
}
-protected void reset(List input, long length) {
+protected void reset(DiskRangeList input, long length) {
this.bytes = input;
this.length = length;
- currentRange = 0;
- currentOffset = 0;
- range = null;
+ currentOffset = input == null ? 0 : input.getOffset();
+ setCurrent(input, true);
}
@Override
public int read() {
- if (range == null || range.remaining() == 0) {
+ if (decrypted == null || decrypted.remaining() == 0) {
if (currentOffset == length) {
return -1;
}
-seek(currentOffset);
+setCurrent(currentRange.next, false);
}
currentOffset += 1;
- return 0xff & range.get();
+ return 0xff & decrypted.get();
+}
+
+protected void setCurrent(DiskRangeList newRange, boolean isJump) {
+ currentRange = newRange;
+ if (newRange != null) {
+decrypted = newRange.getData().slice();
+decrypted.position((int) (currentOffset - newRange.getOffset()));
--- End diff --
No, it is moving the ByteBuffer position to the correct spot so that it
matches currentOffset, which is relative to the stream.
---
[GitHub] orc pull request #278: ORC-251: Extend InStream and OutStream to support enc...
Github user prasanthj commented on a diff in the pull request:
https://github.com/apache/orc/pull/278#discussion_r202146043
--- Diff: java/core/src/java/org/apache/orc/impl/InStream.java ---
@@ -55,112 +60,137 @@ public long getStreamLength() {
@Override
public abstract void close();
+ static int getRangeNumber(DiskRangeList list, DiskRangeList current) {
+int result = 0;
+DiskRangeList range = list;
+while (range != null && range != current) {
+ result += 1;
+ range = range.next;
+}
+return result;
+ }
+
+ /**
+ * Implements a stream over an uncompressed stream.
+ */
public static class UncompressedStream extends InStream {
-private List bytes;
+private DiskRangeList bytes;
private long length;
protected long currentOffset;
-private ByteBuffer range;
-private int currentRange;
+protected ByteBuffer decrypted;
+protected DiskRangeList currentRange;
+
+/**
+ * Create the stream without calling reset on it.
+ * This is used for the subclass that needs to do more setup.
+ * @param name name of the stream
+ * @param length the number of bytes for the stream
+ */
+public UncompressedStream(String name, long length) {
+ super(name, length);
+}
-public UncompressedStream(String name, List input, long
length) {
+public UncompressedStream(String name,
+ DiskRangeList input,
+ long length) {
super(name, length);
reset(input, length);
}
-protected void reset(List input, long length) {
+protected void reset(DiskRangeList input, long length) {
this.bytes = input;
this.length = length;
- currentRange = 0;
- currentOffset = 0;
- range = null;
+ currentOffset = input == null ? 0 : input.getOffset();
+ setCurrent(input, true);
}
@Override
public int read() {
- if (range == null || range.remaining() == 0) {
+ if (decrypted == null || decrypted.remaining() == 0) {
if (currentOffset == length) {
return -1;
}
-seek(currentOffset);
+setCurrent(currentRange.next, false);
}
currentOffset += 1;
- return 0xff & range.get();
+ return 0xff & decrypted.get();
+}
+
+protected void setCurrent(DiskRangeList newRange, boolean isJump) {
+ currentRange = newRange;
+ if (newRange != null) {
+decrypted = newRange.getData().slice();
+decrypted.position((int) (currentOffset - newRange.getOffset()));
+ }
}
@Override
public int read(byte[] data, int offset, int length) {
- if (range == null || range.remaining() == 0) {
+ if (decrypted == null || decrypted.remaining() == 0) {
if (currentOffset == this.length) {
return -1;
}
-seek(currentOffset);
+setCurrent(currentRange.next, false);
}
- int actualLength = Math.min(length, range.remaining());
- range.get(data, offset, actualLength);
+ int actualLength = Math.min(length, decrypted.remaining());
+ decrypted.get(data, offset, actualLength);
currentOffset += actualLength;
return actualLength;
}
@Override
public int available() {
- if (range != null && range.remaining() > 0) {
-return range.remaining();
+ if (decrypted != null && decrypted.remaining() > 0) {
+return decrypted.remaining();
}
return (int) (length - currentOffset);
}
@Override
public void close() {
- currentRange = bytes.size();
+ currentRange = null;
currentOffset = length;
// explicit de-ref of bytes[]
- bytes.clear();
+ decrypted = null;
+ bytes = null;
}
@Override
public void seek(PositionProvider index) throws IOException {
seek(index.getNext());
}
-public void seek(long desired) {
- if (desired == 0 && bytes.isEmpty()) {
+public void seek(long desired) throws IOException {
+ if (desired == 0 && bytes == null) {
return;
}
- int i = 0;
- for (DiskRange curRange : bytes) {
-if (curRange.getOffset() <= desired &&
-(desired - curRange.getOffset()) < curRange.getLength()) {
- currentOffset = desired;
- currentRange = i;
- this.range = curRange.getData().duplicate();
[GitHub] orc pull request #278: ORC-251: Extend InStream and OutStream to support enc...
Github user prasanthj commented on a diff in the pull request:
https://github.com/apache/orc/pull/278#discussion_r202188844
--- Diff: java/core/src/java/org/apache/orc/impl/InStream.java ---
@@ -173,33 +203,208 @@ private static ByteBuffer allocateBuffer(int size,
boolean isDirect) {
}
}
+ /**
+ * Manage the state of the decryption, including the ability to seek.
+ */
+ static class EncryptionState {
+private final String name;
+private final EncryptionAlgorithm algorithm;
+private final Key key;
+private final byte[] iv;
+private final Cipher cipher;
+private ByteBuffer decrypted;
+
+EncryptionState(String name, StreamOptions options) {
+ this.name = name;
+ algorithm = options.algorithm;
+ key = options.key;
+ iv = options.iv;
+ cipher = algorithm.createCipher();
+}
+
+/**
+ * We are seeking to a new range, so update the cipher to change the IV
+ * to match. This code assumes that we only support encryption in CTR
mode.
--- End diff --
Comment about how the bottom 8 bytes of IV will be filled (block counter)
will be helpful.
---
[GitHub] orc pull request #278: ORC-251: Extend InStream and OutStream to support enc...
Github user prasanthj commented on a diff in the pull request:
https://github.com/apache/orc/pull/278#discussion_r202189630
--- Diff: java/core/src/java/org/apache/orc/impl/InStream.java ---
@@ -401,84 +596,149 @@ private String rangeString() {
@Override
public String toString() {
return "compressed stream " + name + " position: " + currentOffset +
- " length: " + length + " range: " + currentRange +
- " offset: " + (compressed == null ? 0 : compressed.position()) +
" limit: " + (compressed == null ? 0 : compressed.limit()) +
+ " length: " + length + " range: " + getRangeNumber(bytes,
currentRange) +
+ " offset: " + (compressed == null ? 0 : compressed.position()) +
+ " limit: " + (compressed == null ? 0 : compressed.limit()) +
rangeString() +
(uncompressed == null ? "" :
" uncompressed: " + uncompressed.position() + " to " +
uncompressed.limit());
}
}
+ private static class EncryptedCompressedStream extends CompressedStream {
+private final EncryptionState encrypt;
+
+public EncryptedCompressedStream(String name,
+ DiskRangeList input,
+ long length,
+ StreamOptions options) {
+ super(name, length, options);
+ encrypt = new EncryptionState(name, options);
+ reset(input, length);
+}
+
+@Override
+protected void setCurrent(DiskRangeList newRange, boolean isJump) {
+ currentRange = newRange;
+ if (newRange != null) {
+if (isJump) {
+ encrypt.changeIv(newRange.getOffset());
+}
+compressed = encrypt.decrypt(newRange);
+compressed.position((int) (currentOffset - newRange.getOffset()));
+ }
+}
+
+@Override
+public void close() {
+ super.close();
+ encrypt.close();
+}
+
+@Override
+public String toString() {
+ return "encrypted " + super.toString();
+}
+ }
+
public abstract void seek(PositionProvider index) throws IOException;
+ public static class StreamOptions implements Cloneable {
+private CompressionCodec codec;
+private int bufferSize;
+private EncryptionAlgorithm algorithm;
+private Key key;
+private byte[] iv;
+
+public StreamOptions withCodec(CompressionCodec value) {
+ this.codec = value;
+ return this;
+}
+
+public StreamOptions withBufferSize(int value) {
+ bufferSize = value;
+ return this;
+}
+
+public StreamOptions withEncryption(EncryptionAlgorithm algorithm,
+Key key,
+byte[] iv) {
+ this.algorithm = algorithm;
+ this.key = key;
+ this.iv = iv;
+ return this;
+}
+
+public CompressionCodec getCodec() {
+ return codec;
+}
+
+@Override
+public StreamOptions clone() {
+ try {
+StreamOptions clone = (StreamOptions) super.clone();
+if (clone.codec != null) {
+ // Make sure we don't share the same codec between two readers.
+ clone.codec = OrcCodecPool.getCodec(codec.getKind());
+}
+return clone;
--- End diff --
why is this clone required? incomplete clone anyways
---
[GitHub] orc pull request #278: ORC-251: Extend InStream and OutStream to support enc...
Github user prasanthj commented on a diff in the pull request:
https://github.com/apache/orc/pull/278#discussion_r202144150
--- Diff: java/core/src/java/org/apache/orc/impl/InStream.java ---
@@ -55,112 +60,137 @@ public long getStreamLength() {
@Override
public abstract void close();
+ static int getRangeNumber(DiskRangeList list, DiskRangeList current) {
+int result = 0;
+DiskRangeList range = list;
+while (range != null && range != current) {
+ result += 1;
+ range = range.next;
+}
+return result;
+ }
+
+ /**
+ * Implements a stream over an uncompressed stream.
+ */
public static class UncompressedStream extends InStream {
-private List bytes;
+private DiskRangeList bytes;
private long length;
protected long currentOffset;
-private ByteBuffer range;
-private int currentRange;
+protected ByteBuffer decrypted;
+protected DiskRangeList currentRange;
+
+/**
+ * Create the stream without calling reset on it.
+ * This is used for the subclass that needs to do more setup.
+ * @param name name of the stream
+ * @param length the number of bytes for the stream
+ */
+public UncompressedStream(String name, long length) {
+ super(name, length);
+}
-public UncompressedStream(String name, List input, long
length) {
+public UncompressedStream(String name,
+ DiskRangeList input,
+ long length) {
super(name, length);
reset(input, length);
}
-protected void reset(List input, long length) {
+protected void reset(DiskRangeList input, long length) {
this.bytes = input;
this.length = length;
- currentRange = 0;
- currentOffset = 0;
- range = null;
+ currentOffset = input == null ? 0 : input.getOffset();
+ setCurrent(input, true);
}
@Override
public int read() {
- if (range == null || range.remaining() == 0) {
+ if (decrypted == null || decrypted.remaining() == 0) {
if (currentOffset == length) {
return -1;
}
-seek(currentOffset);
+setCurrent(currentRange.next, false);
}
currentOffset += 1;
- return 0xff & range.get();
+ return 0xff & decrypted.get();
+}
+
+protected void setCurrent(DiskRangeList newRange, boolean isJump) {
+ currentRange = newRange;
+ if (newRange != null) {
+decrypted = newRange.getData().slice();
+decrypted.position((int) (currentOffset - newRange.getOffset()));
--- End diff --
Could you leave a comment as in why positioning is done this way? Looks
like this is when 2 diskranges overlap.
---
[GitHub] orc pull request #278: ORC-251: Extend InStream and OutStream to support enc...
Github user prasanthj commented on a diff in the pull request:
https://github.com/apache/orc/pull/278#discussion_r202190526
--- Diff: java/core/src/java/org/apache/orc/impl/writer/StreamOptions.java
---
@@ -0,0 +1,85 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.orc.impl.writer;
+
+import org.apache.orc.CompressionCodec;
+import org.apache.orc.EncryptionAlgorithm;
+
+import java.security.Key;
+
+/**
+ * The compression and encryption options for writing a stream.
+ */
+public class StreamOptions {
--- End diff --
Is this duplicate class? I saw StreamOptions class above as well.
---
[GitHub] orc pull request #278: ORC-251: Extend InStream and OutStream to support enc...
Github user prasanthj commented on a diff in the pull request:
https://github.com/apache/orc/pull/278#discussion_r202147519
--- Diff: java/core/src/java/org/apache/orc/impl/InStream.java ---
@@ -55,112 +60,137 @@ public long getStreamLength() {
@Override
public abstract void close();
+ static int getRangeNumber(DiskRangeList list, DiskRangeList current) {
+int result = 0;
+DiskRangeList range = list;
+while (range != null && range != current) {
+ result += 1;
+ range = range.next;
+}
+return result;
+ }
+
+ /**
+ * Implements a stream over an uncompressed stream.
+ */
public static class UncompressedStream extends InStream {
-private List bytes;
+private DiskRangeList bytes;
private long length;
protected long currentOffset;
-private ByteBuffer range;
-private int currentRange;
+protected ByteBuffer decrypted;
+protected DiskRangeList currentRange;
+
+/**
+ * Create the stream without calling reset on it.
+ * This is used for the subclass that needs to do more setup.
+ * @param name name of the stream
+ * @param length the number of bytes for the stream
+ */
+public UncompressedStream(String name, long length) {
+ super(name, length);
+}
-public UncompressedStream(String name, List input, long
length) {
+public UncompressedStream(String name,
+ DiskRangeList input,
+ long length) {
super(name, length);
reset(input, length);
}
-protected void reset(List input, long length) {
+protected void reset(DiskRangeList input, long length) {
this.bytes = input;
this.length = length;
- currentRange = 0;
- currentOffset = 0;
- range = null;
+ currentOffset = input == null ? 0 : input.getOffset();
+ setCurrent(input, true);
}
@Override
public int read() {
- if (range == null || range.remaining() == 0) {
+ if (decrypted == null || decrypted.remaining() == 0) {
if (currentOffset == length) {
return -1;
}
-seek(currentOffset);
+setCurrent(currentRange.next, false);
}
currentOffset += 1;
- return 0xff & range.get();
+ return 0xff & decrypted.get();
+}
+
+protected void setCurrent(DiskRangeList newRange, boolean isJump) {
+ currentRange = newRange;
+ if (newRange != null) {
+decrypted = newRange.getData().slice();
+decrypted.position((int) (currentOffset - newRange.getOffset()));
+ }
}
@Override
public int read(byte[] data, int offset, int length) {
- if (range == null || range.remaining() == 0) {
+ if (decrypted == null || decrypted.remaining() == 0) {
if (currentOffset == this.length) {
return -1;
}
-seek(currentOffset);
+setCurrent(currentRange.next, false);
}
- int actualLength = Math.min(length, range.remaining());
- range.get(data, offset, actualLength);
+ int actualLength = Math.min(length, decrypted.remaining());
+ decrypted.get(data, offset, actualLength);
currentOffset += actualLength;
return actualLength;
}
@Override
public int available() {
- if (range != null && range.remaining() > 0) {
-return range.remaining();
+ if (decrypted != null && decrypted.remaining() > 0) {
+return decrypted.remaining();
}
return (int) (length - currentOffset);
}
@Override
public void close() {
- currentRange = bytes.size();
+ currentRange = null;
currentOffset = length;
// explicit de-ref of bytes[]
- bytes.clear();
+ decrypted = null;
+ bytes = null;
}
@Override
public void seek(PositionProvider index) throws IOException {
seek(index.getNext());
}
-public void seek(long desired) {
- if (desired == 0 && bytes.isEmpty()) {
+public void seek(long desired) throws IOException {
+ if (desired == 0 && bytes == null) {
return;
}
- int i = 0;
- for (DiskRange curRange : bytes) {
-if (curRange.getOffset() <= desired &&
-(desired - curRange.getOffset()) < curRange.getLength()) {
- currentOffset = desired;
- currentRange = i;
- this.range = curRange.getData().duplicate();
[GitHub] orc pull request #278: ORC-251: Extend InStream and OutStream to support enc...
Github user prasanthj commented on a diff in the pull request:
https://github.com/apache/orc/pull/278#discussion_r202187998
--- Diff: java/core/src/java/org/apache/orc/impl/InStream.java ---
@@ -173,33 +203,208 @@ private static ByteBuffer allocateBuffer(int size,
boolean isDirect) {
}
}
+ /**
+ * Manage the state of the decryption, including the ability to seek.
+ */
+ static class EncryptionState {
+private final String name;
+private final EncryptionAlgorithm algorithm;
+private final Key key;
+private final byte[] iv;
+private final Cipher cipher;
+private ByteBuffer decrypted;
+
+EncryptionState(String name, StreamOptions options) {
+ this.name = name;
+ algorithm = options.algorithm;
+ key = options.key;
+ iv = options.iv;
+ cipher = algorithm.createCipher();
+}
+
+/**
+ * We are seeking to a new range, so update the cipher to change the IV
+ * to match. This code assumes that we only support encryption in CTR
mode.
+ * @param offset where we are seeking to in the stream
+ */
+void changeIv(long offset) {
+ int blockSize = cipher.getBlockSize();
+ long encryptionBlocks = offset / blockSize;
--- End diff --
Add +1 if there is extra?
---