[GitHub] [carbondata] asfgit closed pull request #3781: [CARBONDATA-3839]Fix rename file failed for FilterFileSystem DFS object
asfgit closed pull request #3781: URL: https://github.com/apache/carbondata/pull/3781 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] kunal642 commented on pull request #3781: [CARBONDATA-3839]Fix rename file failed for FilterFileSystem DFS object
kunal642 commented on pull request #3781: URL: https://github.com/apache/carbondata/pull/3781#issuecomment-636648360 LGTM This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] CarbonDataQA1 commented on pull request #3781: [CARBONDATA-3839]Fix rename file failed for FilterFileSystem DFS object
CarbonDataQA1 commented on pull request #3781: URL: https://github.com/apache/carbondata/pull/3781#issuecomment-636647973 Build Success with Spark 2.4.5, Please check CI http://121.244.95.60:12545/job/ApacheCarbon_PR_Builder_2.4.5/1390/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] CarbonDataQA1 commented on pull request #3781: [CARBONDATA-3839]Fix rename file failed for FilterFileSystem DFS object
CarbonDataQA1 commented on pull request #3781: URL: https://github.com/apache/carbondata/pull/3781#issuecomment-636645771 Build Success with Spark 2.3.4, Please check CI http://121.244.95.60:12545/job/ApacheCarbonPRBuilder2.3/3114/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] sraghunandan commented on pull request #3781: [CARBONDATA-3839]Fix rename file failed for FilterFileSystem DFS object
sraghunandan commented on pull request #3781: URL: https://github.com/apache/carbondata/pull/3781#issuecomment-636610478 LGTM This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] akashrn5 opened a new pull request #3781: [CARBONDATA-3839]Fix rename file failed for FilterFileSystem DFS object
akashrn5 opened a new pull request #3781: URL: https://github.com/apache/carbondata/pull/3781 ### Why is this PR needed? Rename file fails in HDFS when the FS object is of FilterFileSystem, (which basically can contain any filesystem to use as basic filesystem) ### What changes were proposed in this PR? While rename force, have a check for this FS object ### Does this PR introduce any user interface change? - No ### Is any new testcase added? - No(Tested in cluster) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (CARBONDATA-3839) Rename file fails in hdfs for FilterFileSystem Object
Akash R Nilugal created CARBONDATA-3839: --- Summary: Rename file fails in hdfs for FilterFileSystem Object Key: CARBONDATA-3839 URL: https://issues.apache.org/jira/browse/CARBONDATA-3839 Project: CarbonData Issue Type: New Feature Reporter: Akash R Nilugal Assignee: Akash R Nilugal Rename file fails for FilterFileSystem Object -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (CARBONDATA-3838) Select filter query fails on SI columns of different SI tables.
Chetan Bhat created CARBONDATA-3838:
---
Summary: Select filter query fails on SI columns of different SI
tables.
Key: CARBONDATA-3838
URL: https://issues.apache.org/jira/browse/CARBONDATA-3838
Project: CarbonData
Issue Type: Bug
Components: data-query
Affects Versions: 2.0.0
Environment: Spark 2.3.2
Reporter: Chetan Bhat
Select filter query fails on SI columns of different SI tables.
*Steps :-*
0: jdbc:hive2://10.20.255.171:23040/default> create table brinjal (imei
string,AMSize string,channelsId string,ActiveCountry string, Activecity
string,gamePointId double,deviceInformationId double,productionDate
Timestamp,deliveryDate timestamp,deliverycharge double) stored as carbondata
TBLPROPERTIES('inverted_index'='imei,AMSize,channelsId,ActiveCountry,Activecity,productionDate,deliveryDate','sort_columns'='imei,AMSize,channelsId,ActiveCountry,Activecity,productionDate,deliveryDate','table_blocksize'='1','SORT_SCOPE'='GLOBAL_SORT','carbon.column.compressor'='zstd');
+-+--+
| Result |
+-+--+
+-+--+
No rows selected (0.153 seconds)
0: jdbc:hive2://10.20.255.171:23040/default> LOAD DATA INPATH
'hdfs://hacluster/chetan/vardhandaterestruct.csv' INTO TABLE brinjal
OPTIONS('DELIMITER'=',', 'QUOTECHAR'=
'"','BAD_RECORDS_ACTION'='FORCE','FILEHEADER'=
'imei,deviceInformationId,AMSize,channelsId,ActiveCountry,Activecity,gamePointId,productionDate,deliveryDate,deliverycharge');
+-+--+
| Result |
+-+--+
+-+--+
No rows selected (2.357 seconds)
0: jdbc:hive2://10.20.255.171:23040/default> CREATE INDEX indextable1 ON TABLE
brinjal (channelsId) AS 'carbondata'
PROPERTIES('carbon.column.compressor'='zstd');
+-+--+
| Result |
+-+--+
+-+--+
No rows selected (1.048 seconds)
0: jdbc:hive2://10.20.255.171:23040/default> CREATE INDEX indextable2 ON TABLE
brinjal (ActiveCountry) AS 'carbondata'
PROPERTIES('carbon.column.compressor'='zstd');
+-+--+
| Result |
+-+--+
+-+--+
No rows selected (1.895 seconds)
0: jdbc:hive2://10.20.255.171:23040/default> select * from brinjal where
ActiveCountry ='Chinese' or channelsId =4;
Error: org.apache.spark.sql.catalyst.errors.package$TreeNodeException: execute,
tree:
Exchange hashpartitioning(positionReference#6440, 200)
+- *(6) HashAggregate(keys=[positionReference#6440], functions=[],
output=[positionReference#6440])
+- Union
:- *(3) HashAggregate(keys=[positionReference#6440], functions=[],
output=[positionReference#6440])
: +- Exchange hashpartitioning(positionReference#6440, 200)
: +- *(2) HashAggregate(keys=[positionReference#6440], functions=[],
output=[positionReference#6440])
: +- *(2) Project [positionReference#6440]
: +- *(2) Filter (cast(channelsid#6439 as int) = 4)
: +- *(2) FileScan carbondata
2_0.indextable1[positionReference#6440,channelsid#6439] PushedFilters:
[CastExpr((cast(channelsid#6439 as int) = 4))], ReadSchema:
struct
+- *(5) HashAggregate(keys=[positionReference#6442], functions=[],
output=[positionReference#6442])
+- Exchange hashpartitioning(positionReference#6442, 200)
+- *(4) HashAggregate(keys=[positionReference#6442], functions=[],
output=[positionReference#6442])
+- *(4) Project [positionReference#6442|#6442]
+- *(4) Filter (activecountry#6441 = Chinese)
+- *(4) FileScan carbondata
2_0.indextable2[positionReference#6442,activecountry#6441] PushedFilters:
[EqualTo(activecountry,Chinese)], ReadSchema:
struct (state=,code=0)
*Log -*
org.apache.carbondata.core.datastore.block.SegmentPropertiesAndSchemaHolder.addSegmentProperties(SegmentPropertiesAndSchemaHolder.java:117)org.apache.carbondata.core.datastore.block.SegmentPropertiesAndSchemaHolder.addSegmentProperties(SegmentPropertiesAndSchemaHolder.java:117)2020-06-01
12:19:28,058 | ERROR | [HiveServer2-Background-Pool: Thread-1150] | Error
executing query, currentState RUNNING, |
org.apache.spark.internal.Logging$class.logError(Logging.scala:91)org.apache.spark.sql.catalyst.errors.package$TreeNodeException:
execute, tree:Exchange hashpartitioning(positionReference#6440, 200)+- *(6)
HashAggregate(keys=[positionReference#6440], functions=[],
output=[positionReference#6440]) +- Union :- *(3)
HashAggregate(keys=[positionReference#6440], functions=[],
output=[positionReference#6440]) : +- Exchange
hashpartitioning(positionReference#6440, 200) : +- *(2)
HashAggregate(keys=[positionReference#6440], functions=[],
output=[positionReference#6440]) : +- *(2) Project
[positionReference#6440] : +- *(2) Filter (cast(channelsid#6439
as int) = 4) : +- *(2) FileScan carbondata
2_0.indextable1[positionReference#6440,channelsid#6439] PushedFilters:
[CastExpr((cast(channelsid#6439 as int) = 4))], ReadSchema:
struct +- *(5)
HashAggregate(keys=[positionReference#6442], functi
[GitHub] [carbondata] asfgit closed pull request #3780: [CARBONDATA-3836] Fix carbon store path & avoid exception when creating new carbon table
asfgit closed pull request #3780: URL: https://github.com/apache/carbondata/pull/3780 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Resolved] (CARBONDATA-3837) Should fallback to the original plan when MV rewrite throw exception
[ https://issues.apache.org/jira/browse/CARBONDATA-3837?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Jacky Li resolved CARBONDATA-3837. -- Fix Version/s: 2.0.1 Resolution: Fixed > Should fallback to the original plan when MV rewrite throw exception > > > Key: CARBONDATA-3837 > URL: https://issues.apache.org/jira/browse/CARBONDATA-3837 > Project: CarbonData > Issue Type: Improvement >Reporter: David Cai >Priority: Major > Fix For: 2.0.1 > > Time Spent: 2.5h > Remaining Estimate: 0h > -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [carbondata] kevinjmh commented on a change in pull request #3780: [CARBONDATA-3836] Fix carbon store path & avoid exception when creating new carbon table
kevinjmh commented on a change in pull request #3780:
URL: https://github.com/apache/carbondata/pull/3780#discussion_r432950129
##
File path: integration/spark/src/main/scala/org/apache/spark/sql/CarbonEnv.scala
##
@@ -328,7 +328,7 @@ object CarbonEnv {
if ((!EnvHelper.isLegacy(sparkSession)) &&
(dbName.equals("default") || databaseLocation.endsWith(".db"))) {
val carbonStorePath = CarbonProperties.getStorePath()
- val hiveStorePath = sparkSession.conf.get("spark.sql.warehouse.dir",
carbonStorePath)
+ val hiveStorePath = sparkSession.conf.get("spark.sql.warehouse.dir")
// if carbon.store does not point to spark.sql.warehouse.dir then follow
the old table path
// format
if (carbonStorePath != null && !hiveStorePath.equals(carbonStorePath)) {
Review comment:
In my case, a vanilla apache version of spark on yarn, the default
warehouse location is under the local working directory where the thrift server
launch.
If you check spark code, the default value of `spark.sql.warehouse.dir`
barely comes from Java URI implementation.
https://github.com/apache/spark/blob/6c792a79c10e7b01bd040ef14c848a2a2378e28c/sql/catalyst/src/main/scala/org/apache/spark/sql/internal/StaticSQLConf.scala#L33-L37
https://github.com/apache/spark/blob/47dc332258bec20c460f666de50d9a8c5c0fbc0a/core/src/main/scala/org/apache/spark/util/Utils.scala#L1976
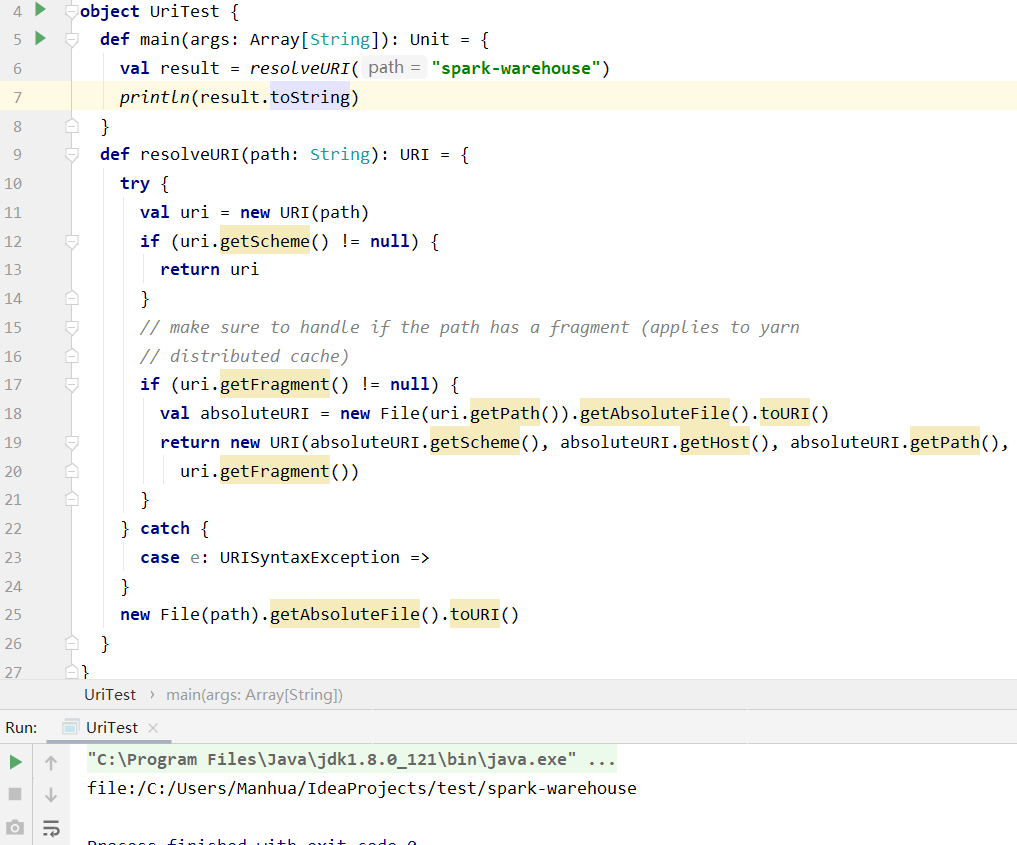
the problem of PR #3675 is :
1. carbon store path is not taken effect, default database warehouse URI
(local fs, file://...) is used. <--- this pr fix this
2. the scheme of default database warehouse URI is removed by
`FileFactiry.getUpdatedFilePath` in `CarbonEnv.getDatabaseLocation`. And this
is not an absolute URI string, so spark will make
qualified path in `SessionCatalog#createTable`. <-- #3675 fix this
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [carbondata] QiangCai commented on pull request #3780: [CARBONDATA-3836] Fix carbon store path & avoid exception when creating new carbon table
QiangCai commented on pull request #3780: URL: https://github.com/apache/carbondata/pull/3780#issuecomment-636582665 LGTM This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] kevinjmh commented on a change in pull request #3780: [CARBONDATA-3836] Fix carbon store path & avoid exception when creating new carbon table
kevinjmh commented on a change in pull request #3780:
URL: https://github.com/apache/carbondata/pull/3780#discussion_r432951870
##
File path: integration/spark/src/main/scala/org/apache/spark/sql/CarbonEnv.scala
##
@@ -328,7 +328,7 @@ object CarbonEnv {
if ((!EnvHelper.isLegacy(sparkSession)) &&
(dbName.equals("default") || databaseLocation.endsWith(".db"))) {
val carbonStorePath = CarbonProperties.getStorePath()
- val hiveStorePath = sparkSession.conf.get("spark.sql.warehouse.dir",
carbonStorePath)
+ val hiveStorePath = sparkSession.conf.get("spark.sql.warehouse.dir")
// if carbon.store does not point to spark.sql.warehouse.dir then follow
the old table path
// format
if (carbonStorePath != null && !hiveStorePath.equals(carbonStorePath)) {
Review comment:
I think he can try adding an empty carbon style option TBLPROPERTIES in
the create statement :)
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [carbondata] asfgit closed pull request #3777: [CARBONDATA-3837] Fallback to the original plan when mv rewrite throw exception
asfgit closed pull request #3777: URL: https://github.com/apache/carbondata/pull/3777 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] jackylk commented on pull request #3777: [CARBONDATA-3837] Fallback to the original plan when mv rewrite throw exception
jackylk commented on pull request #3777: URL: https://github.com/apache/carbondata/pull/3777#issuecomment-636579166 LGTM This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] kevinjmh commented on a change in pull request #3780: [CARBONDATA-3836] Fix carbon store path & avoid exception when creating new carbon table
kevinjmh commented on a change in pull request #3780:
URL: https://github.com/apache/carbondata/pull/3780#discussion_r432951870
##
File path: integration/spark/src/main/scala/org/apache/spark/sql/CarbonEnv.scala
##
@@ -328,7 +328,7 @@ object CarbonEnv {
if ((!EnvHelper.isLegacy(sparkSession)) &&
(dbName.equals("default") || databaseLocation.endsWith(".db"))) {
val carbonStorePath = CarbonProperties.getStorePath()
- val hiveStorePath = sparkSession.conf.get("spark.sql.warehouse.dir",
carbonStorePath)
+ val hiveStorePath = sparkSession.conf.get("spark.sql.warehouse.dir")
// if carbon.store does not point to spark.sql.warehouse.dir then follow
the old table path
// format
if (carbonStorePath != null && !hiveStorePath.equals(carbonStorePath)) {
Review comment:
I think he can try adding an empty carbon style option TBLPROPERTIES in
the create statement :)
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [carbondata] CarbonDataQA1 commented on pull request #3777: [CARBONDATA-3837] Fallback to the original plan when mv rewrite throw exception
CarbonDataQA1 commented on pull request #3777: URL: https://github.com/apache/carbondata/pull/3777#issuecomment-636568738 Build Success with Spark 2.4.5, Please check CI http://121.244.95.60:12545/job/ApacheCarbon_PR_Builder_2.4.5/1389/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] CarbonDataQA1 commented on pull request #3777: [CARBONDATA-3837] Fallback to the original plan when mv rewrite throw exception
CarbonDataQA1 commented on pull request #3777: URL: https://github.com/apache/carbondata/pull/3777#issuecomment-636568643 Build Success with Spark 2.3.4, Please check CI http://121.244.95.60:12545/job/ApacheCarbonPRBuilder2.3/3113/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] CarbonDataQA1 commented on pull request #3777: [CARBONDATA-3837] Fallback to the original plan when mv rewrite throw exception
CarbonDataQA1 commented on pull request #3777: URL: https://github.com/apache/carbondata/pull/3777#issuecomment-636508600 Build Failed with Spark 2.4.5, Please check CI http://121.244.95.60:12545/job/ApacheCarbon_PR_Builder_2.4.5/1388/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] CarbonDataQA1 commented on pull request #3777: [CARBONDATA-3837] Fallback to the original plan when mv rewrite throw exception
CarbonDataQA1 commented on pull request #3777: URL: https://github.com/apache/carbondata/pull/3777#issuecomment-636507759 Build Failed with Spark 2.3.4, Please check CI http://121.244.95.60:12545/job/ApacheCarbonPRBuilder2.3/3112/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] CarbonDataQA1 commented on pull request #3774: [CARBONDATA-3833] Make geoID visible
CarbonDataQA1 commented on pull request #3774: URL: https://github.com/apache/carbondata/pull/3774#issuecomment-636504686 Build Success with Spark 2.4.5, Please check CI http://121.244.95.60:12545/job/ApacheCarbon_PR_Builder_2.4.5/1387/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] CarbonDataQA1 commented on pull request #3774: [CARBONDATA-3833] Make geoID visible
CarbonDataQA1 commented on pull request #3774: URL: https://github.com/apache/carbondata/pull/3774#issuecomment-636504454 Build Success with Spark 2.3.4, Please check CI http://121.244.95.60:12545/job/ApacheCarbonPRBuilder2.3/3111/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] ajantha-bhat commented on a change in pull request #3777: [CARBONDATA-3837] Fallback to the original plan when mv rewrite throw exception
ajantha-bhat commented on a change in pull request #3777:
URL: https://github.com/apache/carbondata/pull/3777#discussion_r432959146
##
File path:
core/src/main/java/org/apache/carbondata/core/constants/CarbonCommonConstants.java
##
@@ -1562,6 +1562,20 @@ private CarbonCommonConstants() {
public static final String CARBON_LUCENE_INDEX_STOP_WORDS_DEFAULT = "false";
+
//
+ // MV parameter start here
+
//
+
+ /**
+ * Property to enable MV rewrite
+ */
+ @CarbonProperty(dynamicConfigurable = true)
Review comment:
You wanted to make this dynamic configurable, but forgot to add in
SessionParams#validateKeyValue ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Resolved] (CARBONDATA-3835) Global sort doesn't sort string columns properly
[ https://issues.apache.org/jira/browse/CARBONDATA-3835?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] David Cai resolved CARBONDATA-3835. --- Fix Version/s: (was: 2.0.0) 2.0.1 Resolution: Fixed > Global sort doesn't sort string columns properly > > > Key: CARBONDATA-3835 > URL: https://issues.apache.org/jira/browse/CARBONDATA-3835 > Project: CarbonData > Issue Type: Bug >Affects Versions: 2.0.0 >Reporter: Ajantha Bhat >Assignee: Ajantha Bhat >Priority: Major > Fix For: 2.0.1 > > Time Spent: 2.5h > Remaining Estimate: 0h > > problem: > For global sort without partition, string comes as byte[], if we use string > comparator (StringSerializableComparator) it wll convert byte[] to toString > which gives address and comparision goes wrong. > > solution: change data type to byte before choosing comparator. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [carbondata] asfgit closed pull request #3779: [CARBONDATA-3835] Fix global sort issues
asfgit closed pull request #3779: URL: https://github.com/apache/carbondata/pull/3779 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] QiangCai commented on a change in pull request #3777: [CARBONDATA-3837] Fallback to the original plan when mv rewrite throw exception
QiangCai commented on a change in pull request #3777:
URL: https://github.com/apache/carbondata/pull/3777#discussion_r432953564
##
File path:
integration/spark/src/main/spark2.3/org/apache/spark/sql/CarbonToSparkAdapter.scala
##
@@ -154,9 +154,17 @@ class CarbonOptimizer(
catalog: SessionCatalog,
optimizer: Optimizer) extends Optimizer(catalog) {
- private lazy val mvRules = Seq(Batch("Materialized View Optimizers", Once,
+ private lazy val _mvRules = Seq(Batch("Materialized View Optimizers", Once,
Seq(new MVRewriteRule(session)): _*))
+ private def mvRules: Seq[Batch] = {
+// enable mv by default
+session.conf.get("spark.carbon.mv.enable", "true").toBoolean match {
Review comment:
fixed
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [carbondata] kevinjmh commented on a change in pull request #3780: [CARBONDATA-3836] Fix carbon store path & avoid exception when creating new carbon table
kevinjmh commented on a change in pull request #3780:
URL: https://github.com/apache/carbondata/pull/3780#discussion_r432951870
##
File path: integration/spark/src/main/scala/org/apache/spark/sql/CarbonEnv.scala
##
@@ -328,7 +328,7 @@ object CarbonEnv {
if ((!EnvHelper.isLegacy(sparkSession)) &&
(dbName.equals("default") || databaseLocation.endsWith(".db"))) {
val carbonStorePath = CarbonProperties.getStorePath()
- val hiveStorePath = sparkSession.conf.get("spark.sql.warehouse.dir",
carbonStorePath)
+ val hiveStorePath = sparkSession.conf.get("spark.sql.warehouse.dir")
// if carbon.store does not point to spark.sql.warehouse.dir then follow
the old table path
// format
if (carbonStorePath != null && !hiveStorePath.equals(carbonStorePath)) {
Review comment:
I think he can try adding an empty carbon style OPTIONS in the create
statement :)
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [carbondata] kevinjmh commented on a change in pull request #3780: [CARBONDATA-3836] Fix carbon store path & avoid exception when creating new carbon table
kevinjmh commented on a change in pull request #3780:
URL: https://github.com/apache/carbondata/pull/3780#discussion_r432950129
##
File path: integration/spark/src/main/scala/org/apache/spark/sql/CarbonEnv.scala
##
@@ -328,7 +328,7 @@ object CarbonEnv {
if ((!EnvHelper.isLegacy(sparkSession)) &&
(dbName.equals("default") || databaseLocation.endsWith(".db"))) {
val carbonStorePath = CarbonProperties.getStorePath()
- val hiveStorePath = sparkSession.conf.get("spark.sql.warehouse.dir",
carbonStorePath)
+ val hiveStorePath = sparkSession.conf.get("spark.sql.warehouse.dir")
// if carbon.store does not point to spark.sql.warehouse.dir then follow
the old table path
// format
if (carbonStorePath != null && !hiveStorePath.equals(carbonStorePath)) {
Review comment:
the problem of that PR need checking of the cluster setting. I haven't
met the case local path is added hdfs prefix unconsciously.
In my case, a vanilla apache version of spark on yarn, the default warehouse
location is under the local working directory where the thrift server launch.
If you check spark code, the default value of `spark.sql.warehouse.dir`
barely comes from Java URI implementation.
https://github.com/apache/spark/blob/6c792a79c10e7b01bd040ef14c848a2a2378e28c/sql/catalyst/src/main/scala/org/apache/spark/sql/internal/StaticSQLConf.scala#L33-L37
https://github.com/apache/spark/blob/47dc332258bec20c460f666de50d9a8c5c0fbc0a/core/src/main/scala/org/apache/spark/util/Utils.scala#L1976

This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [carbondata] QiangCai commented on pull request #3779: [CARBONDATA-3835] Fix global sort issues
QiangCai commented on pull request #3779: URL: https://github.com/apache/carbondata/pull/3779#issuecomment-636473791 LGTM This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] jackylk commented on a change in pull request #3777: [CARBONDATA-3837] Fallback to the original plan when mv rewrite throw exception
jackylk commented on a change in pull request #3777:
URL: https://github.com/apache/carbondata/pull/3777#discussion_r432948661
##
File path:
integration/spark/src/main/spark2.3/org/apache/spark/sql/CarbonToSparkAdapter.scala
##
@@ -154,9 +154,17 @@ class CarbonOptimizer(
catalog: SessionCatalog,
optimizer: Optimizer) extends Optimizer(catalog) {
- private lazy val mvRules = Seq(Batch("Materialized View Optimizers", Once,
+ private lazy val _mvRules = Seq(Batch("Materialized View Optimizers", Once,
Seq(new MVRewriteRule(session)): _*))
+ private def mvRules: Seq[Batch] = {
+// enable mv by default
+session.conf.get("spark.carbon.mv.enable", "true").toBoolean match {
Review comment:
please add in
https://github.com/apache/carbondata/blob/master/docs/configuration-parameters.md
conf name should start with carbon, changed to `carbon.mv.enabled`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [carbondata] jackylk commented on a change in pull request #3777: [CARBONDATA-3837] Fallback to the original plan when mv rewrite throw exception
jackylk commented on a change in pull request #3777:
URL: https://github.com/apache/carbondata/pull/3777#discussion_r432948452
##
File path:
integration/spark/src/main/spark2.4/org/apache/spark/sql/CarbonToSparkAdapter.scala
##
@@ -193,9 +193,17 @@ class CarbonOptimizer(
catalog: SessionCatalog,
optimizer: Optimizer) extends Optimizer(catalog) {
- private lazy val mvRules = Seq(Batch("Materialized View Optimizers", Once,
+ private lazy val _mvRules = Seq(Batch("Materialized View Optimizers", Once,
Seq(new MVRewriteRule(session)): _*))
+ private def mvRules: Seq[Batch] = {
+// enable mv by default
+session.conf.get("spark.carbon.mv.enable", "true").toBoolean match {
Review comment:
conf name should start with carbon, and please add in doc also
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [carbondata] ajantha-bhat commented on a change in pull request #3777: [CARBONDATA-3837] Fallback to the original plan when mv rewrite throw exception
ajantha-bhat commented on a change in pull request #3777:
URL: https://github.com/apache/carbondata/pull/3777#discussion_r432948384
##
File path:
integration/spark/src/main/spark2.3/org/apache/spark/sql/CarbonToSparkAdapter.scala
##
@@ -154,9 +154,17 @@ class CarbonOptimizer(
catalog: SessionCatalog,
optimizer: Optimizer) extends Optimizer(catalog) {
- private lazy val mvRules = Seq(Batch("Materialized View Optimizers", Once,
+ private lazy val _mvRules = Seq(Batch("Materialized View Optimizers", Once,
Seq(new MVRewriteRule(session)): _*))
+ private def mvRules: Seq[Batch] = {
+// enable mv by default
+session.conf.get("spark.carbon.mv.enable", "true").toBoolean match {
Review comment:
How user knows this property exist ? Need to add it in some document ?
And why not as carbon property ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [carbondata] QiangCai commented on a change in pull request #3777: [CARBONDATA-3837] Fallback to the original plan when mv rewrite throw exception
QiangCai commented on a change in pull request #3777:
URL: https://github.com/apache/carbondata/pull/3777#discussion_r432947870
##
File path:
integration/spark/src/main/spark2.4/org/apache/spark/sql/CarbonToSparkAdapter.scala
##
@@ -193,9 +193,17 @@ class CarbonOptimizer(
catalog: SessionCatalog,
optimizer: Optimizer) extends Optimizer(catalog) {
- private lazy val mvRules = Seq(Batch("Materialized View Optimizers", Once,
+ private lazy val _mvRules = Seq(Batch("Materialized View Optimizers", Once,
Seq(new MVRewriteRule(session)): _*))
+ private def mvRules: Seq[Batch] = {
+// enable mv by default
+session.conf.get("spark.carbon.mv.enable", "true").toBoolean match {
Review comment:
this is a runtime configuration.
so the user can use the SET command to change it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [carbondata] jackylk commented on a change in pull request #3777: [CARBONDATA-3837] Fallback to the original plan when mv rewrite throw exception
jackylk commented on a change in pull request #3777:
URL: https://github.com/apache/carbondata/pull/3777#discussion_r432947210
##
File path:
integration/spark/src/main/scala/org/apache/spark/sql/optimizer/MVRewriteRule.scala
##
@@ -39,15 +39,31 @@ import org.apache.carbondata.view.MVFunctions.DUMMY_FUNCTION
*/
class MVRewriteRule(session: SparkSession) extends Rule[LogicalPlan] {
- private val logger = MVRewriteRule.LOGGER
-
private val catalogFactory = new MVCatalogFactory[MVSchemaWrapper] {
override def newCatalog(): MVCatalog[MVSchemaWrapper] = {
new MVCatalogInSpark(session)
}
}
override def apply(logicalPlan: LogicalPlan): LogicalPlan = {
+// only query need to check MVRewriteRule
+logicalPlan match {
+ case _: Command => return logicalPlan
+ case _: LocalRelation => return logicalPlan
+ case _ =>
+}
+try {
+ tryRewritePlan(logicalPlan)
+} catch {
+ case e =>
+// catch all exceptions to avoid to impact query.
+// if MVRewriteRule throw exception, here will fallback to original
plan.
Review comment:
```suggestion
// if exception is thrown while rewriting the query, will fallback
to original query plan.
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [carbondata] jackylk commented on a change in pull request #3777: [CARBONDATA-3837] Fallback to the original plan when mv rewrite throw exception
jackylk commented on a change in pull request #3777:
URL: https://github.com/apache/carbondata/pull/3777#discussion_r432947240
##
File path:
integration/spark/src/main/scala/org/apache/spark/sql/optimizer/MVRewriteRule.scala
##
@@ -39,15 +39,31 @@ import org.apache.carbondata.view.MVFunctions.DUMMY_FUNCTION
*/
class MVRewriteRule(session: SparkSession) extends Rule[LogicalPlan] {
- private val logger = MVRewriteRule.LOGGER
-
private val catalogFactory = new MVCatalogFactory[MVSchemaWrapper] {
override def newCatalog(): MVCatalog[MVSchemaWrapper] = {
new MVCatalogInSpark(session)
}
}
override def apply(logicalPlan: LogicalPlan): LogicalPlan = {
+// only query need to check MVRewriteRule
+logicalPlan match {
+ case _: Command => return logicalPlan
+ case _: LocalRelation => return logicalPlan
+ case _ =>
+}
+try {
+ tryRewritePlan(logicalPlan)
+} catch {
+ case e =>
+// catch all exceptions to avoid to impact query.
Review comment:
This line can be deleted
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [carbondata] jackylk commented on a change in pull request #3777: [CARBONDATA-3837] Fallback to the original plan when mv rewrite throw exception
jackylk commented on a change in pull request #3777:
URL: https://github.com/apache/carbondata/pull/3777#discussion_r432946953
##
File path:
integration/spark/src/main/spark2.4/org/apache/spark/sql/CarbonToSparkAdapter.scala
##
@@ -193,9 +193,17 @@ class CarbonOptimizer(
catalog: SessionCatalog,
optimizer: Optimizer) extends Optimizer(catalog) {
- private lazy val mvRules = Seq(Batch("Materialized View Optimizers", Once,
+ private lazy val _mvRules = Seq(Batch("Materialized View Optimizers", Once,
Seq(new MVRewriteRule(session)): _*))
+ private def mvRules: Seq[Batch] = {
+// enable mv by default
+session.conf.get("spark.carbon.mv.enable", "true").toBoolean match {
Review comment:
make a constant for default value
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Created] (CARBONDATA-3837) Should fallback to the original plan when MV rewrite throw exception
David Cai created CARBONDATA-3837: - Summary: Should fallback to the original plan when MV rewrite throw exception Key: CARBONDATA-3837 URL: https://issues.apache.org/jira/browse/CARBONDATA-3837 Project: CarbonData Issue Type: Improvement Reporter: David Cai -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [carbondata] QiangCai commented on a change in pull request #3780: [CARBONDATA-3836] Fix carbon store path & avoid exception when creating new carbon table
QiangCai commented on a change in pull request #3780:
URL: https://github.com/apache/carbondata/pull/3780#discussion_r432944937
##
File path: integration/spark/src/main/scala/org/apache/spark/sql/CarbonEnv.scala
##
@@ -328,7 +328,7 @@ object CarbonEnv {
if ((!EnvHelper.isLegacy(sparkSession)) &&
(dbName.equals("default") || databaseLocation.endsWith(".db"))) {
val carbonStorePath = CarbonProperties.getStorePath()
- val hiveStorePath = sparkSession.conf.get("spark.sql.warehouse.dir",
carbonStorePath)
+ val hiveStorePath = sparkSession.conf.get("spark.sql.warehouse.dir")
// if carbon.store does not point to spark.sql.warehouse.dir then follow
the old table path
// format
if (carbonStorePath != null && !hiveStorePath.equals(carbonStorePath)) {
Review comment:
ok, can you check this pr: https://github.com/apache/carbondata/pull/3675
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [carbondata] jackylk commented on pull request #3777: [WIP][Perf] Support disable mv
jackylk commented on pull request #3777: URL: https://github.com/apache/carbondata/pull/3777#issuecomment-636468129 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] kevinjmh commented on a change in pull request #3780: [CARBONDATA-3836] Fix carbon store path & avoid exception when creating new carbon table
kevinjmh commented on a change in pull request #3780:
URL: https://github.com/apache/carbondata/pull/3780#discussion_r432938670
##
File path: integration/spark/src/main/scala/org/apache/spark/sql/CarbonEnv.scala
##
@@ -328,7 +328,7 @@ object CarbonEnv {
if ((!EnvHelper.isLegacy(sparkSession)) &&
(dbName.equals("default") || databaseLocation.endsWith(".db"))) {
val carbonStorePath = CarbonProperties.getStorePath()
- val hiveStorePath = sparkSession.conf.get("spark.sql.warehouse.dir",
carbonStorePath)
+ val hiveStorePath = sparkSession.conf.get("spark.sql.warehouse.dir")
// if carbon.store does not point to spark.sql.warehouse.dir then follow
the old table path
// format
if (carbonStorePath != null && !hiveStorePath.equals(carbonStorePath)) {
Review comment:
no need. Spark conf has default value
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [carbondata] QiangCai commented on a change in pull request #3780: [CARBONDATA-3836] Fix carbon store path & avoid exception when creating new carbon table
QiangCai commented on a change in pull request #3780:
URL: https://github.com/apache/carbondata/pull/3780#discussion_r432938586
##
File path: integration/spark/src/main/scala/org/apache/spark/sql/CarbonEnv.scala
##
@@ -328,7 +328,7 @@ object CarbonEnv {
if ((!EnvHelper.isLegacy(sparkSession)) &&
(dbName.equals("default") || databaseLocation.endsWith(".db"))) {
val carbonStorePath = CarbonProperties.getStorePath()
- val hiveStorePath = sparkSession.conf.get("spark.sql.warehouse.dir",
carbonStorePath)
+ val hiveStorePath = sparkSession.conf.get("spark.sql.warehouse.dir")
// if carbon.store does not point to spark.sql.warehouse.dir then follow
the old table path
// format
if (carbonStorePath != null && !hiveStorePath.equals(carbonStorePath)) {
Review comment:
need check hivestorePath is null or not
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [carbondata] QiangCai commented on a change in pull request #3780: [CARBONDATA-3836] Fix carbon store path & avoid exception when creating new carbon table
QiangCai commented on a change in pull request #3780:
URL: https://github.com/apache/carbondata/pull/3780#discussion_r432938586
##
File path: integration/spark/src/main/scala/org/apache/spark/sql/CarbonEnv.scala
##
@@ -328,7 +328,7 @@ object CarbonEnv {
if ((!EnvHelper.isLegacy(sparkSession)) &&
(dbName.equals("default") || databaseLocation.endsWith(".db"))) {
val carbonStorePath = CarbonProperties.getStorePath()
- val hiveStorePath = sparkSession.conf.get("spark.sql.warehouse.dir",
carbonStorePath)
+ val hiveStorePath = sparkSession.conf.get("spark.sql.warehouse.dir")
// if carbon.store does not point to spark.sql.warehouse.dir then follow
the old table path
// format
if (carbonStorePath != null && !hiveStorePath.equals(carbonStorePath)) {
Review comment:
need check hiveStorePath is null or not
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [carbondata] CarbonDataQA1 commented on pull request #3774: [CARBONDATA-3833] Make geoID visible
CarbonDataQA1 commented on pull request #3774: URL: https://github.com/apache/carbondata/pull/3774#issuecomment-636458697 Build Failed with Spark 2.4.5, Please check CI http://121.244.95.60:12545/job/ApacheCarbon_PR_Builder_2.4.5/1381/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] CarbonDataQA1 commented on pull request #3774: [CARBONDATA-3833] Make geoID visible
CarbonDataQA1 commented on pull request #3774: URL: https://github.com/apache/carbondata/pull/3774#issuecomment-636458681 Build Failed with Spark 2.3.4, Please check CI http://121.244.95.60:12545/job/ApacheCarbonPRBuilder2.3/3104/ This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] kevinjmh commented on pull request #3780: [CARBONDATA-3836] Fix carbon store path & avoid exception when creating new carbon table
kevinjmh commented on pull request #3780: URL: https://github.com/apache/carbondata/pull/3780#issuecomment-636454529 > Please create a JIRA for this OK This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (CARBONDATA-3836) Fix carbon store path & avoid exception when creating new carbon table
Manhua Jiang created CARBONDATA-3836: Summary: Fix carbon store path & avoid exception when creating new carbon table Key: CARBONDATA-3836 URL: https://issues.apache.org/jira/browse/CARBONDATA-3836 Project: CarbonData Issue Type: Improvement Reporter: Manhua Jiang -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [carbondata] jackylk commented on pull request #3779: [CARBONDATA-3835] Fix global sort issues
jackylk commented on pull request #3779: URL: https://github.com/apache/carbondata/pull/3779#issuecomment-636452177 LGTM This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [carbondata] kunal642 commented on pull request #3780: [HOTFIX] Fix carbon store path & avoid exception when creating new carbon table
kunal642 commented on pull request #3780: URL: https://github.com/apache/carbondata/pull/3780#issuecomment-636435451 Please create a JIRA for this This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org