[GitHub] carbondata issue #2974: [CARBONDATA-2563][CATALYST] Explain query with Order...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2974 retest this please ---
[GitHub] carbondata pull request #2974: [CARBONDATA-2563][CATALYST] Explain query wit...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2974#discussion_r239998447
--- Diff:
integration/spark2/src/main/scala/org/apache/spark/sql/execution/command/table/CarbonExplainCommand.scala
---
@@ -51,8 +51,13 @@ case class CarbonExplainCommand(
sparkSession.sessionState.executePlan(child.asInstanceOf[ExplainCommand].logicalPlan)
try {
ExplainCollector.setup()
- queryExecution.toRdd.partitions
if (ExplainCollector.enabled()) {
+queryExecution.toRdd.partitions
+// For count(*) queries the explain collector will be disabled, so
profiler
+// informations not required in such scenarios.
+if(null==ExplainCollector.getFormatedOutput) {
--- End diff --
update. thanks
---
[GitHub] carbondata pull request #2974: [CARBONDATA-2563][CATALYST] Explain query wit...
Github user sujith71955 commented on a diff in the pull request: https://github.com/apache/carbondata/pull/2974#discussion_r239998443 --- Diff: integration/spark2/src/main/scala/org/apache/spark/sql/execution/command/table/CarbonExplainCommand.scala --- @@ -51,8 +51,8 @@ case class CarbonExplainCommand( sparkSession.sessionState.executePlan(child.asInstanceOf[ExplainCommand].logicalPlan) --- End diff -- Right, line 50 we can pull down within isQueryStatisticsEnabled condition, but in line number 51 the system checks whether isQueryStatisticsEnabled is true then based on that it instantiates ExplainCollector and determines isQueryStatisticsEnabled or not. so i think 51 we cannot pull down. modified the code. thanks ---
[GitHub] carbondata issue #2974: [CARBONDATA-2563][CATALYST] Explain query with Order...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2974 @ravipesala @kumarvishal09 Please review and let me know for suggestions. ---
[GitHub] carbondata pull request #2974: [CARBONDATA-2563][CATALYST] Explain query wit...
GitHub user sujith71955 opened a pull request: https://github.com/apache/carbondata/pull/2974 [CARBONDATA-2563][CATALYST] Explain query with Order by operator is fired Spark Job which is increase explain query time even though isQueryStatisticsEnabled is false ## What changes were proposed in this pull request? Even though isQueryStatisticsEnabled is false which means user doesnt wants to see statistics for explain command, still the engine tries to fetch the paritions information which causes a job execution in case of order by query, this is mainly because spark engine does sampling for defifning certain range within paritions for sorting process. As part of solution the explain command process shall fetch the parition info only if isQueryStatisticsEnabled true. ## How was this patch tested? Manual testing. Before fix 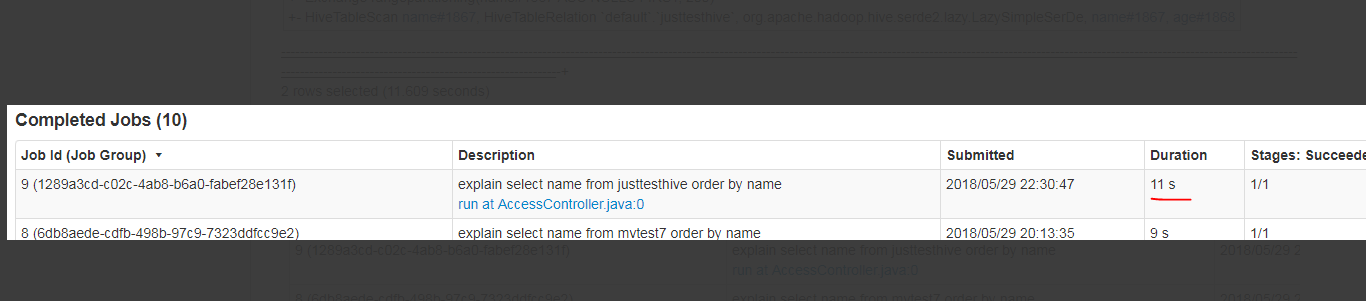 After fix 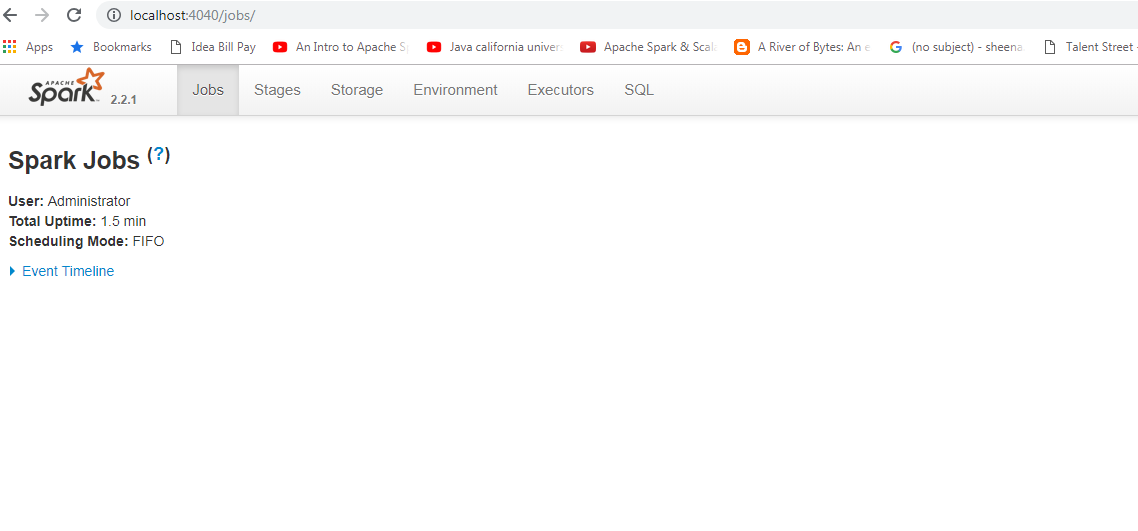 You can merge this pull request into a Git repository by running: $ git pull https://github.com/sujith71955/incubator-carbondata master_explin Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2974.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2974 commit b20005d3cfbfbadd316ef9d8f7749c9236fe8bc8 Author: s71955 Date: 2018-12-04T15:18:55Z [CARBONDATA-2563][CATALYST] Explain query with Order by operator is fired Spark Job which is increase explain query time even though isQueryStatisticsEnabled is false ## What changes were proposed in this pull request? Even though isQueryStatisticsEnabled is false which means user doesnt wants to see statistics for explain command, still the engine tries to fetch the paritions information which causes a job execution in case of order by query, this is mainly because spark engine does sampling for defifning certain range within paritions for sorting process. As part of solution the explain command process shall fetch the parition info only if isQueryStatisticsEnabled true. ## How was this patch tested? Manual testing. ---
[GitHub] carbondata issue #2913: [CARBONDATA-3090][Integration][Perf] optimizing the ...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2913 cc @jackylk @kumarvishal09 ---
[GitHub] carbondata pull request #2913: [CARBONDATA-3090][Integration] optimizing the...
GitHub user sujith71955 opened a pull request: https://github.com/apache/carbondata/pull/2913 [CARBONDATA-3090][Integration] optimizing the columnar vector filling flow by removing unwanted filter check. ## What changes were proposed in this pull request? optimizing the columnar vector filling flow by removing unwanted filter check, currently while filling column vectors as part of vector reading flow in the carbon query, while processing the batch of rows there is a filter condition check which will validate each row whether its part of filter, since the batch already has filtered rows r , the filter check is not useful while forming the ColunVector, in the current flow the boolean filteredRows[] is never been set once its initialized so always the values will be false. As part of the optimization this redundant validation of filter check is been removed. This optimization can also improve the performance of queries which undergoes vectorized reading since this check for each row processing will add overhead while query processing. ## How was this patch tested? Existing Unit test. Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? None - [ ] Any backward compatibility impacted? None - [ ] Document update required? None - [ ] Testing done Please provide details on Existing testcases can verify the impact. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/sujith71955/incubator-carbondata master_perf_vector Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2913.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2913 commit 62ade40f8fd3cfeda65678828ff18a7ad64f8c3c Author: s71955 Date: 2018-11-10T19:12:13Z [CARBONDATA-3090][Integration] optimizing the columnar vector filling flow by removing unwanted filter check. ## What changes were proposed in this pull request? optimizing the columnar vector filling flow by removing unwanted filter check, currently while filling the column vectors as part of vector reading flow in the carbon query, while processing the batch of rows there is a filter condition check which will validate each row whether its part of filter, since the batch already has filtered rows while filling the columnvector , the filter check is not useful, and even in the current flow the boolean filteredRows[] is never been set, always the values will be false. As part of the optimization this redundant validation of filter check is been removed. ## How was this patch tested? Existing Unit test. ---
[GitHub] carbondata pull request #2729: [WIP]Store optimization
Github user sujith71955 commented on a diff in the pull request: https://github.com/apache/carbondata/pull/2729#discussion_r224988369 --- Diff: core/src/main/java/org/apache/carbondata/core/datastore/chunk/DimensionColumnPage.java --- @@ -97,21 +96,19 @@ * @param compareValue value to compare * @return compare result */ - int compareTo(int rowId, byte[] compareValue); + int compareTo(int rowId, Object compareValue); /** * below method will be used to free the allocated memory */ void freeMemory(); - /** - * to check whether the page is adaptive encoded - */ boolean isAdaptiveEncoded(); /** - * to get the null bit sets in case of adaptive encoded page + * method return presence meta which represents + * rowid for which values are null or not null + * @return */ - BitSet getNullBits(); - + PresenceMeta getPresentMeta(); --- End diff -- This method purpose is not clear, seems to be PresenceMeta is not very informative as per the comment which you provided on the method ---
[GitHub] carbondata pull request #2729: [WIP]Store optimization
Github user sujith71955 commented on a diff in the pull request: https://github.com/apache/carbondata/pull/2729#discussion_r224988211 --- Diff: core/src/main/java/org/apache/carbondata/core/datastore/chunk/AbstractRawColumnChunk.java --- @@ -47,6 +48,14 @@ private DataChunk3 dataChunkV3; + private PresenceMeta[] presenceMeta; + + private boolean isLVSeperated; + + private boolean isAdaptiveForDictionary; --- End diff -- is it required for both dictionary and nodictionary? since its an abstract class we can just add a property to know whether its adaptive or not in base class ? the child is anyways DimensionRawColumnChunk ---
[GitHub] carbondata pull request #2729: [WIP]Store optimization
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2729#discussion_r224987956
--- Diff:
core/src/main/java/org/apache/carbondata/core/datastore/chunk/impl/AbstractPrimitiveDimColumnPage.java
---
@@ -0,0 +1,84 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.carbondata.core.datastore.chunk.impl;
+
+import org.apache.carbondata.core.datastore.chunk.DimensionColumnPage;
+import org.apache.carbondata.core.datastore.page.ColumnPage;
+import org.apache.carbondata.core.metadata.blocklet.PresenceMeta;
+
+public abstract class AbstractPrimitiveDimColumnPage implements
DimensionColumnPage {
--- End diff --
please add comments class level and public method level
---
[GitHub] carbondata pull request #2729: [WIP]Store optimization
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2729#discussion_r224987867
--- Diff:
core/src/main/java/org/apache/carbondata/core/datastore/chunk/AbstractRawColumnChunk.java
---
@@ -129,4 +138,35 @@ public void setDataChunkV3(DataChunk3 dataChunkV3) {
public void setMinMaxFlagArray(boolean[] minMaxFlagArray) {
this.minMaxFlagArray = minMaxFlagArray;
}
+ public boolean isAdaptiveForDictionary() {
--- End diff --
please add comments for public methods for better maintainability
---
[GitHub] carbondata pull request #2729: [WIP]Store optimization
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2729#discussion_r224987420
--- Diff:
core/src/main/java/org/apache/carbondata/core/datastore/TableSpec.java ---
@@ -280,12 +288,16 @@ public void readFields(DataInput in) throws
IOException {
}
}
- public class MeasureSpec extends ColumnSpec implements Writable {
+ public static class MeasureSpec extends ColumnSpec implements Writable {
MeasureSpec(String fieldName, DataType dataType) {
super(fieldName, dataType, ColumnType.MEASURE);
}
+public static MeasureSpec newInstance(String fieldName, DataType
dataType) {
--- End diff --
can we keep columnName similar to DimensionSpec , basically make it
consistent. if fieldName is columnName then better we can use columnName
everywhere as its more readable. whats your suggestion?
---
[GitHub] carbondata issue #2729: [WIP]Store optimization
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2729 Please add a description for the PR so that the intention of the PR will be clear to understand ---
[GitHub] carbondata issue #2796: [CARBONDATA-2991]NegativeArraySizeException during q...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2796 @BJangir @jackylk @chenliang613 @ravipesala I think UUID.randomUUID().toString() has some performance bottle necks even though its negligible, as it internally uses SecureRandom API which is a synchronized method. if possible explore more on this as our system is more performance driven. What about using JUG? There is also a time bound uuid generation which seems to work lot faster compare to normal UUID generation supported by java. Following link will give you a fair idea regarding implementation and performance comparison. http://www.dcalabresi.com/blog/java/generate-java-uuid-performance/ ---
[GitHub] carbondata pull request #2791: [HOTFIX]correct the exception handling in loo...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2791#discussion_r222416107
--- Diff:
integration/spark2/src/main/scala/org/apache/spark/sql/hive/CarbonFileMetastore.scala
---
@@ -23,6 +23,7 @@ import java.net.URI
import scala.collection.mutable.ArrayBuffer
import org.apache.hadoop.fs.permission.{FsAction, FsPermission}
+import org.apache.hadoop.hive.ql.metadata.HiveException
--- End diff --
nit: space is required, please check the rule
---
[GitHub] carbondata pull request #2791: [HOTFIX]correct the exception handling in loo...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2791#discussion_r222415572
--- Diff:
integration/spark2/src/main/scala/org/apache/spark/sql/hive/CarbonFileMetastore.scala
---
@@ -208,7 +209,10 @@ class CarbonFileMetastore extends CarbonMetaStore {
try {
lookupRelation(tableIdentifier)(sparkSession)
} catch {
- case _: Exception =>
+ case ex: Exception =>
+if (ex.getCause.isInstanceOf[HiveException]) {
+ throw ex
+}
--- End diff --
Didn't got your context of explanation is for which review comment?
---
[GitHub] carbondata issue #2779: [CARBONDATA-2989] Upgrade spark integration version ...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2779 Right, independently run this case and check once. Also retrigger the build. Thanks On Sun, 30 Sep 2018 at 12:44 PM, Zhichao Zhang wrote: > ok, but it doesn't add lazy for spak 2.2. > > â > You are receiving this because you were mentioned. > Reply to this email directly, view it on GitHub > <https://github.com/apache/carbondata/pull/2779#issuecomment-425700192>, > or mute the thread > <https://github.com/notifications/unsubscribe-auth/AMZZ-TP2bfR9iJTUhBM1yDJDUusA5VcDks5ugG9HgaJpZM4W9IBA> > . > ---
[GitHub] carbondata issue #2779: [CARBONDATA-2989] Upgrade spark integration version ...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2779 Seems to be impact of this PR , please recheck once ---
[GitHub] carbondata issue #2779: [CARBONDATA-2989] Upgrade spark integration version ...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2779 retest this please ---
[GitHub] carbondata issue #2779: [CARBONDATA-2989] Upgrade spark integration version ...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2779 I think better to re-trigger once ---
[GitHub] carbondata pull request #2791: [HOTFIX]correct the exception handling in loo...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2791#discussion_r221449294
--- Diff:
integration/spark2/src/main/scala/org/apache/spark/sql/hive/CarbonFileMetastore.scala
---
@@ -208,7 +209,10 @@ class CarbonFileMetastore extends CarbonMetaStore {
try {
lookupRelation(tableIdentifier)(sparkSession)
} catch {
- case _: Exception =>
+ case ex: Exception =>
+if (ex.getCause.isInstanceOf[HiveException]) {
+ throw ex
+}
--- End diff --
I think it will better to have a testcases here? i can see from your code
in CarbonFileMetastore.scala that you are only expecting a HiveException type
to be thrown out, other exceptions you are ignoring.
---
[GitHub] carbondata issue #2779: [CARBONDATA-2989] Upgrade spark integration version ...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2779 LGTM ---
[GitHub] carbondata pull request #2791: [HOTFIX]correct the exception handling in loo...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2791#discussion_r221449108
--- Diff:
integration/spark2/src/main/scala/org/apache/spark/sql/hive/CarbonFileMetastore.scala
---
@@ -208,7 +209,10 @@ class CarbonFileMetastore extends CarbonMetaStore {
try {
lookupRelation(tableIdentifier)(sparkSession)
} catch {
- case _: Exception =>
+ case ex: Exception =>
+if (ex.getCause.isInstanceOf[HiveException]) {
+ throw ex
+}
--- End diff --
i suggest if you are skipping the exception propagation, better you log
the reason why you are returning false.
this will be better for a secondary developer to locate the exact problem
from a log in some unwanted failure scenarios.
---
[GitHub] carbondata pull request #2791: [HOTFIX]correct the exception handling in loo...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2791#discussion_r221449001
--- Diff:
integration/spark2/src/main/commonTo2.2And2.3/org/apache/spark/sql/hive/CarbonInMemorySessionState.scala
---
@@ -157,7 +158,13 @@ class InMemorySessionCatalog(
}
override def lookupRelation(name: TableIdentifier): LogicalPlan = {
-val rtnRelation = super.lookupRelation(name)
+val rtnRelation: LogicalPlan =
+ try {
+super.lookupRelation(name)
+ } catch {
+case ex: Exception =>
+ throw ex
--- End diff --
but here you are returning same type of exception object right? or am i
missing anything?what about wraping this exception object with custom exception
object ? or else i cannot see anything in this statement you are doing different
---
[GitHub] carbondata pull request #2791: [HOTFIX]correct the exception handling in loo...
Github user sujith71955 commented on a diff in the pull request: https://github.com/apache/carbondata/pull/2791#discussion_r221448768 --- Diff: integration/spark2/src/main/commonTo2.2And2.3/org/apache/spark/sql/hive/CarbonInMemorySessionState.scala --- @@ -18,6 +18,7 @@ package org.apache.spark.sql.hive import org.apache.hadoop.conf.Configuration import org.apache.hadoop.fs.Path +import org.apache.hadoop.hive.ql.metadata.HiveException --- End diff -- I think there should be space between different system imports, like there shall be space between carbon and spark system, same shall be followed in case of hadoop also, spark is following the same styling format. please have a look, i think you can revisit the scala style guideline once again and update if required.  ---
[GitHub] carbondata pull request #2791: [HOTFIX]correct the exception handling in loo...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2791#discussion_r221447314
--- Diff:
integration/spark2/src/main/commonTo2.2And2.3/org/apache/spark/sql/hive/CarbonInMemorySessionState.scala
---
@@ -157,7 +158,13 @@ class InMemorySessionCatalog(
}
override def lookupRelation(name: TableIdentifier): LogicalPlan = {
-val rtnRelation = super.lookupRelation(name)
+val rtnRelation: LogicalPlan =
+ try {
--- End diff --
why we need this try/catch, its super class doesn't throw any exception
right, moreover we are throwing out the same exception object, can you please
define the intention of this statement?
---
[GitHub] carbondata issue #2791: [HOTFIX]correct the exception handling in lookup rel...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2791 @akashrn5 It will be very helpful if you can provide proper descriptions for the PR. ---
[GitHub] carbondata pull request #2791: [HOTFIX]correct the exception handling in loo...
Github user sujith71955 commented on a diff in the pull request: https://github.com/apache/carbondata/pull/2791#discussion_r221447092 --- Diff: integration/spark2/src/main/commonTo2.2And2.3/org/apache/spark/sql/hive/CarbonInMemorySessionState.scala --- @@ -18,6 +18,7 @@ package org.apache.spark.sql.hive import org.apache.hadoop.conf.Configuration import org.apache.hadoop.fs.Path +import org.apache.hadoop.hive.ql.metadata.HiveException --- End diff -- there shall be a space after hadoop module imports right? how this is passing scala checkstyle? we dont have such rule? can you please check once ---
[GitHub] carbondata issue #2779: [CARBONDATA-2989] Upgrade spark integration version ...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2779 LGTM ---
[GitHub] carbondata pull request #2779: [CARBONDATA-2989] Upgrade spark integration v...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2779#discussion_r221445524
--- Diff:
integration/spark2/src/main/spark2.3/org/apache/spark/sql/execution/strategy/CarbonDataSourceScan.scala
---
@@ -0,0 +1,55 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.execution.strategy
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.catalyst.{InternalRow, TableIdentifier}
+import org.apache.spark.sql.catalyst.expressions.{Attribute, SortOrder}
+import org.apache.spark.sql.catalyst.plans.physical.Partitioning
+import org.apache.spark.sql.execution.FileSourceScanExec
+import org.apache.spark.sql.execution.datasources.{HadoopFsRelation,
LogicalRelation}
+
+/**
+ * Physical plan node for scanning data. It is applied for both tables
+ * USING carbondata and STORED AS CARBONDATA.
+ */
+class CarbonDataSourceScan(
+override val output: Seq[Attribute],
+val rdd: RDD[InternalRow],
+@transient override val relation: HadoopFsRelation,
+val partitioning: Partitioning,
+val md: Map[String, String],
+identifier: Option[TableIdentifier],
+@transient private val logicalRelation: LogicalRelation)
+ extends FileSourceScanExec(
+relation,
+output,
+relation.dataSchema,
+Seq.empty,
+Seq.empty,
+identifier) {
+
+ override lazy val supportsBatch: Boolean = true
+
+ override lazy val (outputPartitioning, outputOrdering): (Partitioning,
Seq[SortOrder]) =
+(partitioning, Nil)
+
+ override lazy val metadata: Map[String, String] = md
--- End diff --
nit: made lazy since spark 2.3.2 version (SPARK-PR#21815)
---
[GitHub] carbondata issue #2779: [CARBONDATA-2989] Upgrade spark integration version ...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2779 LGTM Even though SPARK-PR#21815 changes is a workaround solution and in future its subjected to change. Need a caution here. Can you please add this PR reference in the modified code of the carbon for future reference. Thanks for your effort. ---
[GitHub] carbondata issue #2779: [WIP] Upgrade spark integration version to 2.3.2
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2779 Thanks for raising the PR, It will better if you can add the description about the changes in this PR. ---
[GitHub] carbondata issue #2642: [CARBONDATA-2532][Integration] Carbon to support spa...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2642 @jackylk , We need to rebase once again with 2.3.2, but rebasing effort shall be less compare to 2.3.1 since the major changes related to interfaces has been taken care as part of current PR. ---
[GitHub] carbondata issue #2642: [CARBONDATA-2532][Integration] Carbon to support spa...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2642 @ravipesala Please retrigger spark 2.3 release build. Thanks ---
[GitHub] carbondata issue #2642: [CARBONDATA-2532][Integration] Carbon to support spa...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2642 @ravipesala Please re-verify and merge the PR. Thanks ---
[GitHub] carbondata issue #2642: [CARBONDATA-2532][Integration] Carbon to support spa...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2642 @ravipesala seems to CI environment issue, please re-trigger the build. Thanks ---
[GitHub] carbondata pull request #2642: [CARBONDATA-2532][Integration] Carbon to supp...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2642#discussion_r213905161
--- Diff:
integration/spark-datasource/src/main/spark2.3/org/apache/spark/sql/CarbonVectorProxy.java
---
@@ -0,0 +1,276 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql;
+
+import java.math.BigInteger;
+
+import org.apache.spark.memory.MemoryMode;
+import org.apache.spark.sql.catalyst.InternalRow;
+import org.apache.spark.sql.execution.vectorized.Dictionary;
+import org.apache.spark.sql.execution.vectorized.WritableColumnVector;
+import org.apache.spark.sql.types.*;
+import org.apache.spark.sql.vectorized.ColumnarBatch;
+import org.apache.spark.unsafe.types.CalendarInterval;
+import org.apache.spark.unsafe.types.UTF8String;
+
+/**
+ * Adapter class which handles the columnar vector reading of the
carbondata
+ * based on the spark ColumnVector and ColumnarBatch API. This proxy class
+ * handles the complexity of spark 2.3 version related api changes since
+ * spark ColumnVector and ColumnarBatch interfaces are still evolving.
+ */
+public class CarbonVectorProxy {
+
+private ColumnarBatch columnarBatch;
+private WritableColumnVector[] columnVectors;
+
+/**
+ * Adapter class which handles the columnar vector reading of the
carbondata
+ * based on the spark ColumnVector and ColumnarBatch API. This proxy
class
+ * handles the complexity of spark 2.3 version related api changes
since
+ * spark ColumnVector and ColumnarBatch interfaces are still evolving.
+ *
+ * @param memMode which represent the type onheap or offheap
vector.
+ * @param rowNumrows number for vector reading
+ * @param structFileds, metadata related to current schema of table.
+ */
+public CarbonVectorProxy(MemoryMode memMode, int rowNum, StructField[]
structFileds) {
+columnVectors = ColumnVectorFactory
+.getColumnVector(memMode, new StructType(structFileds),
rowNum);
+columnarBatch = new ColumnarBatch(columnVectors);
+columnarBatch.setNumRows(rowNum);
+}
+
+public CarbonVectorProxy(MemoryMode memMode, StructType outputSchema,
int rowNum) {
+columnVectors = ColumnVectorFactory
+.getColumnVector(memMode, outputSchema, rowNum);
+columnarBatch = new ColumnarBatch(columnVectors);
+columnarBatch.setNumRows(rowNum);
+}
+
+/**
+ * Returns the number of rows for read, including filtered rows.
+ */
+public int numRows() {
+return columnarBatch.numRows();
+}
+
+public Object reserveDictionaryIds(int capacity, int ordinal) {
+return columnVectors[ordinal].reserveDictionaryIds(capacity);
+}
+
+/**
+ * This API will return a columnvector from a batch of column vector
rows
+ * based on the ordinal
+ *
+ * @param ordinal
+ * @return
+ */
+public WritableColumnVector column(int ordinal) {
+return (WritableColumnVector) columnarBatch.column(ordinal);
+}
+
+public WritableColumnVector getColumnVector(int ordinal) {
+return columnVectors[ordinal];
+}
+
+/**
+ * Resets this column for writing. The currently stored values are no
longer accessible.
+ */
+public void reset() {
+for (WritableColumnVector col : columnVectors) {
+col.reset();
+}
+}
+
+public void resetDictionaryIds(int ordinal) {
+columnVectors[ordinal].getDictionaryIds().reset();
+}
+
+/**
+ * Returns the row in this batch at `rowId`. Returned row is reused
across calls.
+ */
+public InternalRow getRow(int rowId) {
+return column
[GitHub] carbondata issue #2642: [CARBONDATA-2532][Integration] Carbon to support spa...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2642 @jackylk Now spark 2.3.2 is about to release, can this PR works with all spark 2.3 branch including 2.3.2? As i told before there should not be much problem while rebasing with spark 2.3.2 version also, since its a minor versions the interfaces are intact till now. Rebasing effort with spark 2.3.2 should be very minimal ---
[GitHub] carbondata issue #2642: [CARBONDATA-2532][Integration] Carbon to support spa...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2642 SDV Build Fail , Please check CI http://144.76.159.231:8080/job/ApacheSDVTests/6461/ Already failing in other builds also, seems to build environment issue ---
[GitHub] carbondata issue #2642: [CARBONDATA-2532][Integration] Carbon to support spa...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2642 @aaron-aa @zzcclp Re-base work is pending which i will finish might be in a day or couple. Will check with committers regarding the merge plan of this feature. As @zzcclp told it will be better to use spark 2.3.2 version because of some major defect fixes, but currently the release date for spark 2.3.2 is unclear. anyways once this feature will be merged it will take very less effort for rebasing with spark 2.3.2 version. ---
[GitHub] carbondata issue #2642: [CARBONDATA-2532][Integration] Carbon to support spa...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2642 @sandeep-katta @gvramana ---
[GitHub] carbondata issue #2524: [CARBONDATA-2532][Integration] Carbon to support spa...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2524 Closing the PR, Raised new PR in master branch https://github.com/apache/carbondata/pull/2642 ---
[GitHub] carbondata pull request #2524: [CARBONDATA-2532][Integration] Carbon to supp...
Github user sujith71955 closed the pull request at: https://github.com/apache/carbondata/pull/2524 ---
[GitHub] carbondata pull request #2642: [CARBONDATA-2532][Integration] Carbon to supp...
GitHub user sujith71955 opened a pull request: https://github.com/apache/carbondata/pull/2642 [CARBONDATA-2532][Integration] Carbon to support spark 2.3.1 version In this PR inorder to hide the compatibility issues of columnar vector API's from the existing common classes, i introduced an interface of the proxy vector readers, this proxy vector readers will take care the compatibility issues with respect to spark different versions. Column vector and Columnar Batch interface compatibility issues has been addressed in this PR, The changes were related to below modifications done in spark interface. Highlights: a) This is a refactoring of ColumnVector hierarchy and related classes. By Sujith b) make ColumnVector read-only. By Sujith c) introduce WritableColumnVector with write interface. By Sujith d) remove ReadOnlyColumnVector. By Sujith e) Fixed spark-carbon integration API compatibility issues - By sandeep katta f) Corrected the testcases based on spark 2.3.0 behaviour change - By sandeep katta g) Excluded following dependency from pom.xml files net.jpountzlz4 as spark 2.3.0 changed it to org.lz4, so removed from the test class path of spark2,spark-common-test,spark2-examples You can merge this pull request into a Git repository by running: $ git pull https://github.com/sujith71955/incubator-carbondata mas_mig_spark2.3_carbon_latest Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2642.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2642 commit 7359151b612d3403e53c4759c853e1ab681fae7f Author: sujith71955 Date: 2018-05-24T05:51:50Z [CARBONDATA-2532][Integration] Carbon to support spark 2.3 version, ColumnVector Interface Column vector and Columnar Batch interface compatibility issues has been addressed in this PR, The changes were related to below modifications done in spark interface a) This is a refactoring of ColumnVector hierarchy and related classes. b) make ColumnVector read-only c) introduce WritableColumnVector with write interface d) remove ReadOnlyColumnVector In this PR inorder to hide the compatibility issues of columnar vector API's from the existing common classes, i introduced an interface of the proxy vector readers, this proxy vector readers will take care the compatibility issues with respect to spark different versions. commit 5934d975b53276b2490c6c178ae5b71f539dac60 Author: sandeep-katta Date: 2018-07-06T04:31:29Z [CARBONDATA-2532][Integration] Carbon to support spark 2.3 version, compatability issues All compatability issues when supporting 2.3 addressed Supported pom profile -P"spark-2.3" ---
[GitHub] carbondata issue #2524: [CARBONDATA-2532][Integration] Carbon to support spa...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2524 @sandeep-katta please check the below issue. thanks  ---
[GitHub] carbondata pull request #2366: [CARBONDATA-2532][Integration] Carbon to supp...
Github user sujith71955 closed the pull request at: https://github.com/apache/carbondata/pull/2366 ---
[GitHub] carbondata issue #2366: [CARBONDATA-2532][Integration] Carbon to support spa...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2366 New PR has been raised https://github.com/apache/carbondata/pull/2524 ---
[GitHub] carbondata pull request #2524: Carbonstore migration spark2.3
GitHub user sujith71955 opened a pull request: https://github.com/apache/carbondata/pull/2524 Carbonstore migration spark2.3 ## What changes were proposed in this pull request? In this PR inorder to hide the compatibility issues of columnar vector API's from the existing common classes, i introduced an interface of the proxy vector readers, this proxy vector readers will take care the compatibility issues with respect to spark different versions. Column vector and Columnar Batch interface compatibility issues has been addressed in this PR, The changes were related to below modifications done in spark interface. Highlights: a) This is a refactoring of ColumnVector hierarchy and related classes. b) make ColumnVector read-only c) introduce WritableColumnVector with write interface d) remove ReadOnlyColumnVector e) Fixed spark-carbon integration API compatibility issues - By sandeep katta f) Corrected the testcases based on spark 2.3.0 behaviour change - By sandeep katta g) Excluded following dependency from pom.xml files net.jpountzlz4 as spark 2.3.0 changed it to org.lz4, so removed from the test class path of spark2,spark-common-test,spark2-examples - By sandeep katta ## How was this patch tested? Manual testing, and existing test-case execution You can merge this pull request into a Git repository by running: $ git pull https://github.com/sujith71955/incubator-carbondata carbonstore_migration_spark2.3 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2524.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2524 commit 088612753c8587c941d37a624b83decca447989d Author: sujith71955 Date: 2018-05-24T05:51:50Z [CARBONDATA-2532][Integration] Carbon to support spark 2.3 version, ColumnVector Interface Column vector and Columnar Batch interface compatibility issues has been addressed in this PR, The changes were related to below modifications done in spark interface a) This is a refactoring of ColumnVector hierarchy and related classes. b) make ColumnVector read-only c) introduce WritableColumnVector with write interface d) remove ReadOnlyColumnVector In this PR inorder to hide the compatibility issues of columnar vector API's from the existing common classes, i introduced an interface of the proxy vector readers, this proxy vector readers will take care the compatibility issues with respect to spark different versions. # Conflicts: # integration/spark2/src/main/java/org/apache/carbondata/spark/vectorreader/ColumnarVectorWrapper.java # integration/spark2/src/main/java/org/apache/carbondata/spark/vectorreader/VectorizedCarbonRecordReader.java commit b667e8d5613a23e50a39e918664a60624c646954 Author: sandeep-katta Date: 2018-07-06T04:31:29Z [CARBONDATA-2532][Integration] Carbon to support spark 2.3 version, compatability issues Changes continued.. All compatability issues when supporting 2.3 addressed Supported pom profile -P"spark-2.3" ---
[GitHub] carbondata pull request #2366: [CARBONDATA-2532][Integration] Carbon to supp...
Github user sujith71955 commented on a diff in the pull request: https://github.com/apache/carbondata/pull/2366#discussion_r196715002 --- Diff: integration/spark-common/src/main/java/org/apache/carbondata/streaming/CarbonStreamRecordReader.java --- @@ -71,15 +72,10 @@ import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import org.apache.spark.memory.MemoryMode; +import org.apache.carbondata.spark.vectorreader.CarbonSparkVectorReader; import org.apache.spark.sql.catalyst.InternalRow; import org.apache.spark.sql.catalyst.expressions.GenericInternalRow; -import org.apache.spark.sql.execution.vectorized.ColumnVector; -import org.apache.spark.sql.execution.vectorized.ColumnarBatch; -import org.apache.spark.sql.types.CalendarIntervalType; -import org.apache.spark.sql.types.Decimal; -import org.apache.spark.sql.types.DecimalType; -import org.apache.spark.sql.types.StructField; -import org.apache.spark.sql.types.StructType; +import org.apache.spark.sql.types.*; --- End diff -- Please find the task jira id https://issues.apache.org/jira/browse/CARBONDATA-2619 ---
[GitHub] carbondata pull request #2366: [CARBONDATA-2532][Integration] Carbon to supp...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2366#discussion_r196650804
--- Diff: integration/spark-common/pom.xml ---
@@ -65,6 +65,11 @@
scalatest_${scala.binary.version}
provided
+
+ org.apache.zookeeper
--- End diff --
Not intentional change i guess :)
---
[GitHub] carbondata pull request #2366: [CARBONDATA-2532][Integration] Carbon to supp...
Github user sujith71955 commented on a diff in the pull request: https://github.com/apache/carbondata/pull/2366#discussion_r196310355 --- Diff: integration/spark-common/src/main/java/org/apache/carbondata/streaming/CarbonStreamRecordReader.java --- @@ -71,15 +72,10 @@ import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.input.FileSplit; import org.apache.spark.memory.MemoryMode; +import org.apache.carbondata.spark.vectorreader.CarbonSparkVectorReader; import org.apache.spark.sql.catalyst.InternalRow; import org.apache.spark.sql.catalyst.expressions.GenericInternalRow; -import org.apache.spark.sql.execution.vectorized.ColumnVector; -import org.apache.spark.sql.execution.vectorized.ColumnarBatch; -import org.apache.spark.sql.types.CalendarIntervalType; -import org.apache.spark.sql.types.Decimal; -import org.apache.spark.sql.types.DecimalType; -import org.apache.spark.sql.types.StructField; -import org.apache.spark.sql.types.StructType; +import org.apache.spark.sql.types.*; --- End diff -- Handled ---
[GitHub] carbondata pull request #2366: [CARBONDATA-2532][Integration] Carbon to supp...
Github user sujith71955 commented on a diff in the pull request: https://github.com/apache/carbondata/pull/2366#discussion_r196309854 --- Diff: integration/spark-common/src/main/java/org/apache/carbondata/streaming/CarbonStreamRecordReader.java --- @@ -115,7 +109,7 @@ // vectorized reader private StructType outputSchema; - private ColumnarBatch columnarBatch; + private CarbonSparkVectorReader vectorProxy; --- End diff -- Mainly because we cannot have any common api's as columnvector and columnarbatch package itself is changed, so we will not be able to extract it. ---
[GitHub] carbondata pull request #2366: [CARBONDATA-2532][Integration] Carbon to supp...
Github user sujith71955 commented on a diff in the pull request: https://github.com/apache/carbondata/pull/2366#discussion_r196309518 --- Diff: integration/spark-common/src/main/java/org/apache/carbondata/streaming/CarbonStreamRecordReader.java --- @@ -115,7 +109,7 @@ // vectorized reader private StructType outputSchema; - private ColumnarBatch columnarBatch; + private CarbonSparkVectorReader vectorProxy; --- End diff -- I will remove this interface, as we are moving CarbonstreamRecordReader to spark2 this interface will not be required ---
[GitHub] carbondata issue #2366: [CARBONDATA-2532][Integration] Carbon to support spa...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2366 @sandeep-katta Please handle the comments if its applicable to your commit. Thanks. ---
[GitHub] carbondata issue #2366: [CARBONDATA-2532][Integration] Carbon to support spa...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2366 @ravipesala @gvramana @chenliang613 . Please review and merge as the builds are already passed. ---
[GitHub] carbondata issue #2364: [CARBONDATA-2592][Integration] Getting NoSuchMethod ...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2364 @ravipesala @gvramana @chenliang613 Please review and merge as the builds are already passed. ---
[GitHub] carbondata issue #2366: [CARBONDATA-2532][Integration] Carbon to support spa...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2366 Please review and let us know for any suggestions. While squashing please squash the commits independently of mine and sandeep as both of us has commits related to this upgrade activity. ---
[GitHub] carbondata issue #2366: [CARBONDATA-2532][Integration] Carbon to support spa...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2366 @gvramana ---
[GitHub] carbondata issue #2365: [CARBONDATA-2532][Integration] Carbon to support spa...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2365 closing this PR as new PR is been raised in spark 2.3 branch https://github.com/apache/carbondata/pull/2366 ---
[GitHub] carbondata pull request #2365: [CARBONDATA-2532][Integration] Carbon to supp...
Github user sujith71955 closed the pull request at: https://github.com/apache/carbondata/pull/2365 ---
[GitHub] carbondata pull request #2366: [CARBONDATA-2532][Integration] Carbon to supp...
GitHub user sujith71955 opened a pull request: https://github.com/apache/carbondata/pull/2366 [CARBONDATA-2532][Integration] Carbon to support spark 2.3 version ``` ## What changes were proposed in this pull request? In this PR inorder to hide the compatibility issues of columnar vector API's from the existing common classes, i introduced an interface of the proxy vector readers, this proxy vector readers will take care the compatibility issues with respect to spark different versions. Column vector and Columnar Batch interface compatibility issues has been addressed in this PR, The changes were related to below modifications done in spark interface. Highlights: a) This is a refactoring of ColumnVector hierarchy and related classes. b) make ColumnVector read-only c) introduce WritableColumnVector with write interface d) remove ReadOnlyColumnVector e) Fixed spark-carbon integration API compatibility issues - By Sandi f) Corrected the testcases based on spark 2.3.0 behaviour change g) Excluded following dependency from pom.xml files net.jpountzlz4 as spark 2.3.0 changed it to org.lz4, so removed from the test class path of spark2,spark-common-test,spark2-examples ## How was this patch tested? Manual testing, and existing test-case execution ``` You can merge this pull request into a Git repository by running: $ git pull https://github.com/sujith71955/incubator-carbondata spark-2.3_carbon_spark_2.3 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2366.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2366 commit 9d68b4270c46b99d8d7985069ce633a60c04ba87 Author: sujith71955 Date: 2018-05-24T05:51:50Z [CARBONDATA-2532][Integration] Carbon to support spark 2.3 version ## What changes were proposed in this pull request? Column vector and Columnar Batch interface compatibility issues has been addressed in this PR, The changes were related to below modifications done in spark interface a) This is a refactoring of ColumnVector hierarchy and related classes. b) make ColumnVector read-only c) introduce WritableColumnVector with write interface d) remove ReadOnlyColumnVector In this PR inorder to hide the compatibility issues of columnar vector API's from the existing common classes, i introduced an interface of the proxy vector readers, this proxy vector readers will take care the compatibility issues with respect to spark different versions. ## How was this patch tested? Manual testing, and existing test-case execution [CARBONDATA-2532][Integration] Carbon to support spark 2.3 version ## What changes were proposed in this pull request? Column vector and Columnar Batch interface compatibility issues has been addressed in this PR, The changes were related to below modifications done in spark interface a) This is a refactoring of ColumnVector hierarchy and related classes. b) make ColumnVector read-only c) introduce WritableColumnVector with write interface d) remove ReadOnlyColumnVector In this PR inorder to hide the compatibility issues of columnar vector API's from the existing common classes, i introduced an interface of the proxy vector readers, this proxy vector readers will take care the compatibility issues with respect to spark different versions. ## How was this patch tested? Manual testing, and existing test-case execution commit 8e62ac800c39ee308466f70d574ce1892dde9436 Author: sujith71955 Date: 2018-06-08T07:27:39Z ``` ## What changes were proposed in this pull request? In this PR inorder to hide the compatibility issues of columnar vector API's from the existing common classes, i introduced an interface of the proxy vector readers, this proxy vector readers will take care the compatibility issues with respect to spark different versions. Column vector and Columnar Batch interface compatibility issues has been addressed in this PR, The changes were related to below modifications done in spark interface. Highlights: a) This is a refactoring of ColumnVector hierarchy and related classes. b) make ColumnVector read-only c) introduce WritableColumnVector with write interface d) remove ReadOnlyColumnVector e) Fixed spark-carbon integration API compatibility issues - By Sandi f) Corrected the testcases based on spark 2.3.0 behaviour change g) Excluded following dependency from pom.xml files net.jpountzlz4 as spark 2.3.0 changed it to org.lz4, so removed from the test class path of spark2,spark-common-test,spark2-examples ## How was this patch tested? Manual testing, and existing test-case execution
[GitHub] carbondata issue #2342: [WIP][CARBONDATA-2532][Integration] Carbon to suppor...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2342 Raised new PR https://github.com/apache/carbondata/pull/2365 ---
[GitHub] carbondata pull request #2342: [WIP][CARBONDATA-2532][Integration] Carbon to...
Github user sujith71955 closed the pull request at: https://github.com/apache/carbondata/pull/2342 ---
[GitHub] carbondata pull request #2365: [CARBONDATA-2532][Integration] Carbon to supp...
GitHub user sujith71955 opened a pull request: https://github.com/apache/carbondata/pull/2365 [CARBONDATA-2532][Integration] Carbon to support spark 2.3 version ``` ## What changes were proposed in this pull request? In this PR inorder to hide the compatibility issues of columnar vector API's from the existing common classes, i introduced an interface of the proxy vector readers, this proxy vector readers will take care the compatibility issues with respect to spark different versions. Column vector and Columnar Batch interface compatibility issues has been addressed in this PR, The changes were related to below modifications done in spark interface. Highlights: a) This is a refactoring of ColumnVector hierarchy and related classes. b) make ColumnVector read-only c) introduce WritableColumnVector with write interface d) remove ReadOnlyColumnVector e) Fixed spark-carbon integration API compatibility issues - By Sandi f) Corrected the testcases based on spark 2.3.0 behaviour change g) Excluded following dependency from pom.xml files net.jpountzlz4 as spark 2.3.0 changed it to org.lz4, so removed from the test class path of spark2,spark-common-test,spark2-examples ## How was this patch tested? Manual testing, and existing test-case execution ``` You can merge this pull request into a Git repository by running: $ git pull https://github.com/sujith71955/incubator-carbondata master_spark_carbon_upgradation Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2365.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2365 commit 7b0f6a6c68170501368446111c386469d76fa414 Author: sujith71955 Date: 2018-05-24T05:51:50Z [CARBONDATA-2532][Integration] Carbon to support spark 2.3 version ## What changes were proposed in this pull request? Column vector and Columnar Batch interface compatibility issues has been addressed in this PR, The changes were related to below modifications done in spark interface a) This is a refactoring of ColumnVector hierarchy and related classes. b) make ColumnVector read-only c) introduce WritableColumnVector with write interface d) remove ReadOnlyColumnVector In this PR inorder to hide the compatibility issues of columnar vector API's from the existing common classes, i introduced an interface of the proxy vector readers, this proxy vector readers will take care the compatibility issues with respect to spark different versions. ## How was this patch tested? Manual testing, and existing test-case execution [CARBONDATA-2532][Integration] Carbon to support spark 2.3 version ## What changes were proposed in this pull request? Column vector and Columnar Batch interface compatibility issues has been addressed in this PR, The changes were related to below modifications done in spark interface a) This is a refactoring of ColumnVector hierarchy and related classes. b) make ColumnVector read-only c) introduce WritableColumnVector with write interface d) remove ReadOnlyColumnVector In this PR inorder to hide the compatibility issues of columnar vector API's from the existing common classes, i introduced an interface of the proxy vector readers, this proxy vector readers will take care the compatibility issues with respect to spark different versions. ## How was this patch tested? Manual testing, and existing test-case execution commit 5b0005a9f241b5406fcf621c9f8e107dda83a1b8 Author: sandeep-katta Date: 2018-05-25T10:17:48Z WIP changed to completed.Only 1 testcase related to projection is failing. Carbon support for 2.3.1 ---
[GitHub] carbondata issue #2364: [CARBONDATA-2592][Integration] Getting NoSuchMethod ...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2364 @ravipesala Build is failing due to timeouts, i could see same issue is happening for other builds also as its skipping few test projects, no errors are present in the test execution logs ---
[GitHub] carbondata pull request #2362: [CARBONDATA-2578] fixed memory leak inside Ca...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2362#discussion_r193714989
--- Diff:
integration/spark-common-test/src/test/scala/org/apache/carbondata/spark/testsuite/createTable/TestNonTransactionalCarbonTable.scala
---
@@ -401,7 +402,7 @@ class TestNonTransactionalCarbonTable extends QueryTest
with BeforeAndAfterAll {
intercept[RuntimeException] {
buildTestDataWithSortColumns(List(""))
}
-
+
--- End diff --
do we require this extra space?
---
[GitHub] carbondata pull request #2362: [CARBONDATA-2578] fixed memory leak inside Ca...
Github user sujith71955 commented on a diff in the pull request:
https://github.com/apache/carbondata/pull/2362#discussion_r193714706
--- Diff:
store/sdk/src/main/java/org/apache/carbondata/sdk/file/CarbonReader.java ---
@@ -74,6 +74,8 @@ public boolean hasNext() throws IOException,
InterruptedException {
return false;
} else {
index++;
+// current reader is closed
+currentReader.close();
--- End diff --
Shall we close this in a finally block? else still there will be a chance
of memory leak.
---
[GitHub] carbondata pull request #2364: [CARBONDATA-2592][Integration] Getting NoSuch...
GitHub user sujith71955 opened a pull request: https://github.com/apache/carbondata/pull/2364 [CARBONDATA-2592][Integration] Getting NoSuchMethod error due to aws sdk multple version jar conflicts ``` ## What changes were proposed in this pull request? Currently in Carbon Spark2 project multiple dependency for the aws-sdk jar has been defined,this will create issue when we build carbon-assembly jars with latest versions of hadoop/spark project. As part of hadoop-aws project, already aws-sdk 1.10.6 version jar will be fetched, since in the carbon-spark2 pom.xml there is an explicit dependency defined/hardcoded for aws-sdk 1.7.4(old version) this can lead to conflicts while loading the class files. because of this problem when we run any carbon examples passing carbon-assembly jars as the argument using spark-submit none of the testcases will work. As a solution we can remove this dependency(aws-sdk 1.7.4) as already hadoop-aws dependency defined in the pom.xml of carbon-spark2 project will fetch the latest aws-sdk jars. ## How was this patch tested? After updating the pom, manually projects has been build and the use-case mentioned above is manually tested.``` You can merge this pull request into a Git repository by running: $ git pull https://github.com/sujith71955/incubator-carbondata master_pom Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2364.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2364 commit 6fe46836fd72e2efa5e1b24742601439f6d71fb0 Author: sujith71955 Date: 2018-06-07T07:08:56Z [CARBONDATA-2592][Integration] Getting NoSuchMethod error due to aws-sdk multple version jar conflicts ## What changes were proposed in this pull request? Currently in Carbon Spark2 project multiple dependency for the aws-sdk jar has been defined,this will create issue when we build carbon-assembly jars with latest versions of hadoop/spark project. As part of hadoop-aws project, already aws-sdk 1.10.6 version jar will be fetched, since in the carbon-spark2 pom.xml there is an explicit dependency defined/hardcoded for aws-sdk 1.7.4(old version) this can lead to conflicts while loading the class files. because of this problem when we run any carbon examples passing carbon-assembly jars as the argument using spark-submit none of the testcases will work. As a solution we can remove this dependency(aws-sdk 1.7.4) as already hadoop-aws dependency defined in the pom.xml of carbon-spark2 project will fetch the latest aws-sdk jars. ## How was this patch tested? After updating the pom, manually projects has been build and the use-case mentioned above is manually tested. ## How was this patch tested? ---
[GitHub] carbondata issue #2342: [WIP][CARBONDATA-2532][Integration] Carbon to suppor...
Github user sujith71955 commented on the issue: https://github.com/apache/carbondata/pull/2342 Please review and provide me valuable feedback, This PR is dependent on another PR which is yet to be raised , this is intial draft, any comments are welcome ---
[GitHub] carbondata pull request #2342: [CARBONDATA-2532][Integration] Carbon to supp...
GitHub user sujith71955 opened a pull request: https://github.com/apache/carbondata/pull/2342 [CARBONDATA-2532][Integration] Carbon to support spark 2.3 version ## What changes were proposed in this pull request? Column vector and Columnar Batch interface compatibility issues has been addressed in this PR, The changes were related to below modifications done in spark interface a) This is a refactoring of ColumnVector hierarchy and related classes. b) make ColumnVector read-only c) introduce WritableColumnVector with write interface d) remove ReadOnlyColumnVector In this PR inorder to hide the compatibility issues of columnar vector API's from the existing common classes, i introduced an interface of the proxy vector readers, this proxy vector readers will take care the compatibility issues with respect to spark different versions. ## How was this patch tested? Manual testing, and existing test-case execution Be sure to do all of the following checklist to help us incorporate your contribution quickly and easily: - [ ] Any interfaces changed? - [ ] Any backward compatibility impacted? - [ ] Document update required? - [ ] Testing done Please provide details on - Whether new unit test cases have been added or why no new tests are required? - How it is tested? Please attach test report. - Is it a performance related change? Please attach the performance test report. - Any additional information to help reviewers in testing this change. - [ ] For large changes, please consider breaking it into sub-tasks under an umbrella JIRA. You can merge this pull request into a Git repository by running: $ git pull https://github.com/sujith71955/incubator-carbondata spark-2.3_vectorchange Alternatively you can review and apply these changes as the patch at: https://github.com/apache/carbondata/pull/2342.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #2342 commit daa6475bf180208859d4db54e5145738aee08b3c Author: sujith71955 <sujithchacko.2010@...> Date: 2018-05-24T05:51:50Z [CARBONDATA-2532][Integration] Carbon to support spark 2.3 version ## What changes were proposed in this pull request? Column vector and Columnar Batch interface compatibility issues has been addressed in this PR, The changes were related to below modifications done in spark interface a) This is a refactoring of ColumnVector hierarchy and related classes. b) make ColumnVector read-only c) introduce WritableColumnVector with write interface d) remove ReadOnlyColumnVector In this PR inorder to hide the compatibility issues of columnar vector API's from the existing common classes, i introduced an interface of the proxy vector readers, this proxy vector readers will take care the compatibility issues with respect to spark different versions. ## How was this patch tested? Manual testing, and existing test-case execution ---
[GitHub] carbondata pull request #296: [WIP-CARBONDATA-382]Like Filter Query Optimiza...
Github user sujith71955 closed the pull request at: https://github.com/apache/carbondata/pull/296 ---
[GitHub] carbondata pull request #423: [CARBONDATA-527] Greater than/less-than/Like f...
Github user sujith71955 closed the pull request at: https://github.com/apache/carbondata/pull/423 ---