[jira] [Updated] (COLLECTIONS-714) PatriciaTrie ignores trailing null characters in keys
[
https://issues.apache.org/jira/browse/COLLECTIONS-714?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Rohan Padhye updated COLLECTIONS-714:
-
Description:
In Java, strings are not null terminated. The string "x" (of length = 1 char)
is different from the string "x\u" (of length = 2 chars). However,
PatriciaTrie does not seem to distinguish between these strings.
To reproduce:
{code:java}
public void testNullTerminatedKey1() {
Map map = new HashMap<>();
map.put("x", 0); // key of length 1
map.put("x\u", 1); // key of length 2
map.put("x\uy", 2); // key of length 3
Assert.assertEquals(3, map.size()); // ok, 3 distinct keys
PatriciaTrie trie = new PatriciaTrie<>(map);
Assert.assertEquals(3, trie.size()); // fail; actual=2
}{code}
In the above example, the resulting trie has only two keys: "x\u" and
"x\uy". The key "x" gets overwritten. Here is another way to repro the bug:
{code:java}
public void testNullTerminatedKey2() {
PatriciaTrie trie = new PatriciaTrie<>();
trie.put("x", 0);
Assert.assertTrue(trie.containsKey("x")); // ok
trie.put("x\u", 1);
Assert.assertTrue(trie.containsKey("x")); // fail
}
{code}
In the above example, the key "x" suddenly disappears when an entry with key
"x\u" is inserted.
The PatriciaTrie docs do not mention anything about null-terminated strings. In
general, I believe this also breaks the JDK Map contract since the keys
"x".equals("x\u") is false.
This bug was found automatically using JQF:
[https://github.com/rohanpadhye/jqf].
was:
In Java, strings are not null terminated. The string "x" (of length = 1 char)
is different from the string "x\u" (of length = 2 chars). However,
PatriciaTrie does not seem to distinguish between these strings.
To reproduce:
{code:java}
public void testNullTerminatedKey1() {
Map map = new HashMap<>();
map.put("x", 0); // key of length 1
map.put("x\u", 1); // key of length 2
map.put("x\uy", 2); // key of length 3
Assert.assertEquals(3, map.size()); // ok, 3 distinct keys
PatriciaTrie trie = new PatriciaTrie<>(map);
Assert.assertEquals(3, trie.size()); // fail; actual=2
}{code}
In the above example, the resulting trie has only two keys: "x\u" and
"x\uy". The key "x" gets overwritten. Here is another way to repro the bug:
{code:java}
public void testNullTerminatedKey2() {
PatriciaTrie trie = new PatriciaTrie<>();
trie.put("x", 0);
Assert.assertTrue(trie.containsKey("x")); // ok
trie.put("x\u", 1);
Assert.assertTrue(trie.containsKey("x")); // fail
}
{code}
In the above example, the key "x" suddenly disappears when an entry with key
"x\u" is inserted.
The PatriciaKey docs do not mention anything about null terminated strings. In
general, I believe this also breaks the JDK Map contract since the keys
"x".equals("x\u") is false.
This bug was found automatically using JQF:
[https://github.com/rohanpadhye/jqf].
> PatriciaTrie ignores trailing null characters in keys
> -
>
> Key: COLLECTIONS-714
> URL: https://issues.apache.org/jira/browse/COLLECTIONS-714
> Project: Commons Collections
> Issue Type: Bug
> Components: Collection, Map
>Affects Versions: 4.3
>Reporter: Rohan Padhye
>Priority: Critical
>
> In Java, strings are not null terminated. The string "x" (of length = 1 char)
> is different from the string "x\u" (of length = 2 chars). However,
> PatriciaTrie does not seem to distinguish between these strings.
> To reproduce:
> {code:java}
> public void testNullTerminatedKey1() {
> Map map = new HashMap<>();
> map.put("x", 0); // key of length 1
> map.put("x\u", 1); // key of length 2
> map.put("x\uy", 2); // key of length 3
> Assert.assertEquals(3, map.size()); // ok, 3 distinct keys
> PatriciaTrie trie = new PatriciaTrie<>(map);
> Assert.assertEquals(3, trie.size()); // fail; actual=2
> }{code}
> In the above example, the resulting trie has only two keys: "x\u" and
> "x\uy". The key "x" gets overwritten. Here is another way to repro the
> bug:
> {code:java}
> public void testNullTerminatedKey2() {
> PatriciaTrie trie = new PatriciaTrie<>();
> trie.put("x", 0);
> Assert.assertTrue(trie.containsKey("x")); // ok
> trie.put("x\u", 1);
> Assert.assertTrue(trie.containsKey("x")); // fail
> }
> {code}
> In the above example, the key "x" suddenly disappears when an entry with key
> "x\u" is inserted.
> The PatriciaTrie docs do not mention anything about null-terminated strings.
> In general, I believe this also breaks the JDK Map contract since the keys
> "x".equals("x\u") is false.
> This bug was found automatically using JQF:
>
[jira] [Updated] (COLLECTIONS-714) PatriciaTrie ignores trailing null characters in keys
[
https://issues.apache.org/jira/browse/COLLECTIONS-714?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Rohan Padhye updated COLLECTIONS-714:
-
Description:
In Java, strings are not null terminated. The string "x" (of length = 1 char)
is different from the string "x\u" (of length = 2 chars). However,
PatriciaTrie does not seem to distinguish between these strings.
To reproduce:
{code:java}
@Test
public void testNullTerminatedKey1() {
Map map = new HashMap<>();
map.put("x", 0); // key of length 1
map.put("x\u", 1); // key of length 2
map.put("x\uy", 2); // key of length 3
Assert.assertEquals(3, map.size()); // ok, 3 distinct keys
PatriciaTrie trie = new PatriciaTrie<>(map);
Assert.assertEquals(3, trie.size()); // fail; actual=2
}{code}
In the above example, the resulting trie has only two keys: "x\u" and
"x\uy". The key "x" gets overwritten. Here is another way to repro the bug:
{code:java}
@Test
public void testNullTerminatedKey2() {
PatriciaTrie trie = new PatriciaTrie<>();
trie.put("x", 0);
Assert.assertTrue(trie.containsKey("x")); // ok
trie.put("x\u", 1);
Assert.assertTrue(trie.containsKey("x")); // fail
}
{code}
In the above example, the key "x" suddenly disappears when an entry with key
"x\u" is inserted.
The PatriciaKey docs do not mention anything about null terminated strings. In
general, I believe this also breaks the JDK Map contract since the keys
"x".equals("x\u") is false.
This bug was found automatically using JQF:
[https://github.com/rohanpadhye/jqf].
was:
In Java, strings are not null terminated. The string "x" (of length = 1 char)
is different from the string "x\u" (of length = 2 chars). However,
PatriciaTrie does not seem to distinguish between these strings.
To reproduce:
{code:java}
@Test
public void testNullTerminatedKey1() {
Map map = new HashMap<>();
map.put("x", 0); // key of length 1
map.put("x\u", 1); // key of length 2
map.put("x\uy", 2); // key of length 3
Assert.assertEquals(3, map.size()); // ok, 3 distinct keys
PatriciaTrie trie = new PatriciaTrie<>(map);
Assert.assertEquals(3, trie.size()); // fail; actual=2
}{code}
In the above example, the resulting trie has only two keys: "x\u" and
"x\uy". The key "x" gets overwritten. Here is another way to repro the bug:
{code:java}
@Test
public void testNullTerminatedKey2() {
PatriciaTrie trie = new PatriciaTrie<>();
trie.put("x", 0);
Assert.assertTrue(trie.containsKey("x")); // ok
trie.put("x\u", 1);
Assert.assertTrue(trie.containsKey("x")); // fail
}
{code}
In the above example, the key "x" suddenly disappears when an entry with key
"x\u" is inserted.
The PatriciaKey docs do not mention anything about null terminated strings. In
general, I believe this also breaks the JDK Map contract since the keys
"x".equals("x\u") is false.
This bug was found automatically using
[JQF|[https://github.com/rohanpadhye/jqf]].
> PatriciaTrie ignores trailing null characters in keys
> -
>
> Key: COLLECTIONS-714
> URL: https://issues.apache.org/jira/browse/COLLECTIONS-714
> Project: Commons Collections
> Issue Type: Bug
> Components: Collection, Map
>Affects Versions: 4.3
>Reporter: Rohan Padhye
>Priority: Critical
>
> In Java, strings are not null terminated. The string "x" (of length = 1 char)
> is different from the string "x\u" (of length = 2 chars). However,
> PatriciaTrie does not seem to distinguish between these strings.
> To reproduce:
> {code:java}
> @Test
> public void testNullTerminatedKey1() {
> Map map = new HashMap<>();
> map.put("x", 0); // key of length 1
> map.put("x\u", 1); // key of length 2
> map.put("x\uy", 2); // key of length 3
> Assert.assertEquals(3, map.size()); // ok, 3 distinct keys
> PatriciaTrie trie = new PatriciaTrie<>(map);
> Assert.assertEquals(3, trie.size()); // fail; actual=2
> }{code}
> In the above example, the resulting trie has only two keys: "x\u" and
> "x\uy". The key "x" gets overwritten. Here is another way to repro the
> bug:
> {code:java}
> @Test
> public void testNullTerminatedKey2() {
> PatriciaTrie trie = new PatriciaTrie<>();
> trie.put("x", 0);
> Assert.assertTrue(trie.containsKey("x")); // ok
> trie.put("x\u", 1);
> Assert.assertTrue(trie.containsKey("x")); // fail
> }
> {code}
> In the above example, the key "x" suddenly disappears when an entry with key
> "x\u" is inserted.
> The PatriciaKey docs do not mention anything about null terminated strings.
> In general, I believe this also breaks the JDK Map contract since the keys
> "x".equals("x\u") is false.
> This bug
[jira] [Updated] (COLLECTIONS-714) PatriciaTrie ignores trailing null characters in keys
[
https://issues.apache.org/jira/browse/COLLECTIONS-714?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Rohan Padhye updated COLLECTIONS-714:
-
Description:
In Java, strings are not null terminated. The string "x" (of length = 1 char)
is different from the string "x\u" (of length = 2 chars). However,
PatriciaTrie does not seem to distinguish between these strings.
To reproduce:
{code:java}
public void testNullTerminatedKey1() {
Map map = new HashMap<>();
map.put("x", 0); // key of length 1
map.put("x\u", 1); // key of length 2
map.put("x\uy", 2); // key of length 3
Assert.assertEquals(3, map.size()); // ok, 3 distinct keys
PatriciaTrie trie = new PatriciaTrie<>(map);
Assert.assertEquals(3, trie.size()); // fail; actual=2
}{code}
In the above example, the resulting trie has only two keys: "x\u" and
"x\uy". The key "x" gets overwritten. Here is another way to repro the bug:
{code:java}
public void testNullTerminatedKey2() {
PatriciaTrie trie = new PatriciaTrie<>();
trie.put("x", 0);
Assert.assertTrue(trie.containsKey("x")); // ok
trie.put("x\u", 1);
Assert.assertTrue(trie.containsKey("x")); // fail
}
{code}
In the above example, the key "x" suddenly disappears when an entry with key
"x\u" is inserted.
The PatriciaKey docs do not mention anything about null terminated strings. In
general, I believe this also breaks the JDK Map contract since the keys
"x".equals("x\u") is false.
This bug was found automatically using JQF:
[https://github.com/rohanpadhye/jqf].
was:
In Java, strings are not null terminated. The string "x" (of length = 1 char)
is different from the string "x\u" (of length = 2 chars). However,
PatriciaTrie does not seem to distinguish between these strings.
To reproduce:
{code:java}
@Test
public void testNullTerminatedKey1() {
Map map = new HashMap<>();
map.put("x", 0); // key of length 1
map.put("x\u", 1); // key of length 2
map.put("x\uy", 2); // key of length 3
Assert.assertEquals(3, map.size()); // ok, 3 distinct keys
PatriciaTrie trie = new PatriciaTrie<>(map);
Assert.assertEquals(3, trie.size()); // fail; actual=2
}{code}
In the above example, the resulting trie has only two keys: "x\u" and
"x\uy". The key "x" gets overwritten. Here is another way to repro the bug:
{code:java}
@Test
public void testNullTerminatedKey2() {
PatriciaTrie trie = new PatriciaTrie<>();
trie.put("x", 0);
Assert.assertTrue(trie.containsKey("x")); // ok
trie.put("x\u", 1);
Assert.assertTrue(trie.containsKey("x")); // fail
}
{code}
In the above example, the key "x" suddenly disappears when an entry with key
"x\u" is inserted.
The PatriciaKey docs do not mention anything about null terminated strings. In
general, I believe this also breaks the JDK Map contract since the keys
"x".equals("x\u") is false.
This bug was found automatically using JQF:
[https://github.com/rohanpadhye/jqf].
> PatriciaTrie ignores trailing null characters in keys
> -
>
> Key: COLLECTIONS-714
> URL: https://issues.apache.org/jira/browse/COLLECTIONS-714
> Project: Commons Collections
> Issue Type: Bug
> Components: Collection, Map
>Affects Versions: 4.3
>Reporter: Rohan Padhye
>Priority: Critical
>
> In Java, strings are not null terminated. The string "x" (of length = 1 char)
> is different from the string "x\u" (of length = 2 chars). However,
> PatriciaTrie does not seem to distinguish between these strings.
> To reproduce:
> {code:java}
> public void testNullTerminatedKey1() {
> Map map = new HashMap<>();
> map.put("x", 0); // key of length 1
> map.put("x\u", 1); // key of length 2
> map.put("x\uy", 2); // key of length 3
> Assert.assertEquals(3, map.size()); // ok, 3 distinct keys
> PatriciaTrie trie = new PatriciaTrie<>(map);
> Assert.assertEquals(3, trie.size()); // fail; actual=2
> }{code}
> In the above example, the resulting trie has only two keys: "x\u" and
> "x\uy". The key "x" gets overwritten. Here is another way to repro the
> bug:
> {code:java}
> public void testNullTerminatedKey2() {
> PatriciaTrie trie = new PatriciaTrie<>();
> trie.put("x", 0);
> Assert.assertTrue(trie.containsKey("x")); // ok
> trie.put("x\u", 1);
> Assert.assertTrue(trie.containsKey("x")); // fail
> }
> {code}
> In the above example, the key "x" suddenly disappears when an entry with key
> "x\u" is inserted.
> The PatriciaKey docs do not mention anything about null terminated strings.
> In general, I believe this also breaks the JDK Map contract since the keys
> "x".equals("x\u") is false.
> This bug was found automatically using
[jira] [Created] (COLLECTIONS-714) PatriciaTrie ignores trailing null characters in keys
Rohan Padhye created COLLECTIONS-714:
Summary: PatriciaTrie ignores trailing null characters in keys
Key: COLLECTIONS-714
URL: https://issues.apache.org/jira/browse/COLLECTIONS-714
Project: Commons Collections
Issue Type: Bug
Components: Collection, Map
Affects Versions: 4.3
Reporter: Rohan Padhye
In Java, strings are not null terminated. The string "x" (of length = 1 char)
is different from the string "x\u" (of length = 2 chars). However,
PatriciaTrie does not seem to distinguish between these strings.
To reproduce:
{code:java}
@Test
public void testNullTerminatedKey1() {
Map map = new HashMap<>();
map.put("x", 0); // key of length 1
map.put("x\u", 1); // key of length 2
map.put("x\uy", 2); // key of length 3
Assert.assertEquals(3, map.size()); // ok, 3 distinct keys
PatriciaTrie trie = new PatriciaTrie<>(map);
Assert.assertEquals(3, trie.size()); // fail; actual=2
}{code}
In the above example, the resulting trie has only two keys: "x\u" and
"x\uy". The key "x" gets overwritten. Here is another way to repro the bug:
{code:java}
@Test
public void testNullTerminatedKey2() {
PatriciaTrie trie = new PatriciaTrie<>();
trie.put("x", 0);
Assert.assertTrue(trie.containsKey("x")); // ok
trie.put("x\u", 1);
Assert.assertTrue(trie.containsKey("x")); // fail
}
{code}
In the above example, the key "x" suddenly disappears when an entry with key
"x\u" is inserted.
The PatriciaKey docs do not mention anything about null terminated strings. In
general, I believe this also breaks the JDK Map contract since the keys
"x".equals("x\u") is false.
This bug was found automatically using
[JQF|[https://github.com/rohanpadhye/jqf]].
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [commons-vfs] woonsan commented on issue #52: VFS-686: webdav4 provider based on the latest Jackrabbit 2.x
woonsan commented on issue #52: VFS-686: webdav4 provider based on the latest Jackrabbit 2.x URL: https://github.com/apache/commons-vfs/pull/52#issuecomment-488129264 Hi @garydgregory , I don't know, but the patch file downloaded from GitHub seems to make problems. I found an alternative by creating and uploading the patch file to the JIRA ticket: https://issues.apache.org/jira/browse/VFS-686. Could you try with that alternative instead? Thanks, Woonsan This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Comment Edited] (VFS-686) Upgrade Jackrabbit dependency to the latest 2.x
[
https://issues.apache.org/jira/browse/VFS-686?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16830723#comment-16830723
]
Woonsan Ko edited comment on VFS-686 at 4/30/19 9:53 PM:
-
Hi [~garydgregory],
For some reason, the patch file downloaded from GitHub makes problems when
applying it to master branch.
So, I created the patch file ( [^feature-VFS-686.patch] ) locally:
{code}
$ git diff master feature/VFS-686 --binary > feature-VFS-686.patch
{code}
And this seems working with this command:
{code}
$ git apply --whitespace=fix /tmp/feature-VFS-686.patch
{code}
Could you try with this instead?
Thanks,
Woonsan
was (Author: woon_san):
Hi [~garydgregory],
For some reason, the patch file downloaded from GitHub makes problems when
applying it to master branch.
So, I created the patch file ( [^feature-VFS-686.patch] ) locally:
{code:title}
$ git diff master feature/VFS-686 --binary > feature-VFS-686.patch
{code}
And this seems working with this command:
{code}
$ git apply --whitespace=fix /tmp/feature-VFS-686.patch
{code}
Could you try with this instead?
Thanks,
Woonsan
> Upgrade Jackrabbit dependency to the latest 2.x
> ---
>
> Key: VFS-686
> URL: https://issues.apache.org/jira/browse/VFS-686
> Project: Commons VFS
> Issue Type: Improvement
>Affects Versions: 2.2
>Reporter: Woonsan Ko
>Priority: Major
> Labels: pull-request-available
> Attachments: feature-VFS-686.patch
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> The current dependency, Jackrabbit 1.6.5, still depends on HttpClient 3.x,
> while Jackrabbit 2.x depends on HttpClient 4.x.
> So, WebDAV file system provider should use the latest stable version of
> Jackrabbit 2.x.
> As of VFS-360, it is possible to let the WebDAV file system use
> HttpComponents 4.x.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (VFS-686) Upgrade Jackrabbit dependency to the latest 2.x
[
https://issues.apache.org/jira/browse/VFS-686?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16830723#comment-16830723
]
Woonsan Ko commented on VFS-686:
Hi [~garydgregory],
For some reason, the patch file downloaded from GitHub makes problems when
applying it to master branch.
So, I created the patch file ( [^feature-VFS-686.patch] ) locally:
{code:title}
$ git diff master feature/VFS-686 --binary > feature-VFS-686.patch
{code}
And this seems working with this command:
{code}
$ git apply --whitespace=fix /tmp/feature-VFS-686.patch
{code}
Could you try with this instead?
Thanks,
Woonsan
> Upgrade Jackrabbit dependency to the latest 2.x
> ---
>
> Key: VFS-686
> URL: https://issues.apache.org/jira/browse/VFS-686
> Project: Commons VFS
> Issue Type: Improvement
>Affects Versions: 2.2
>Reporter: Woonsan Ko
>Priority: Major
> Labels: pull-request-available
> Attachments: feature-VFS-686.patch
>
> Time Spent: 10m
> Remaining Estimate: 0h
>
> The current dependency, Jackrabbit 1.6.5, still depends on HttpClient 3.x,
> while Jackrabbit 2.x depends on HttpClient 4.x.
> So, WebDAV file system provider should use the latest stable version of
> Jackrabbit 2.x.
> As of VFS-360, it is possible to let the WebDAV file system use
> HttpComponents 4.x.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (VFS-686) Upgrade Jackrabbit dependency to the latest 2.x
[ https://issues.apache.org/jira/browse/VFS-686?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Woonsan Ko updated VFS-686: --- Attachment: feature-VFS-686.patch > Upgrade Jackrabbit dependency to the latest 2.x > --- > > Key: VFS-686 > URL: https://issues.apache.org/jira/browse/VFS-686 > Project: Commons VFS > Issue Type: Improvement >Affects Versions: 2.2 >Reporter: Woonsan Ko >Priority: Major > Labels: pull-request-available > Attachments: feature-VFS-686.patch > > Time Spent: 10m > Remaining Estimate: 0h > > The current dependency, Jackrabbit 1.6.5, still depends on HttpClient 3.x, > while Jackrabbit 2.x depends on HttpClient 4.x. > So, WebDAV file system provider should use the latest stable version of > Jackrabbit 2.x. > As of VFS-360, it is possible to let the WebDAV file system use > HttpComponents 4.x. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (COMPRESS-484) Update optional library zstd-jni from 1.3.3-3 to 1.4.0-1
Gary Gregory created COMPRESS-484: - Summary: Update optional library zstd-jni from 1.3.3-3 to 1.4.0-1 Key: COMPRESS-484 URL: https://issues.apache.org/jira/browse/COMPRESS-484 Project: Commons Compress Issue Type: Improvement Components: Compressors Reporter: Gary Gregory Update optional library zstd-jni from 1.3.3-3 to 1.4.0-1. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Closed] (COMPRESS-484) Update optional library zstd-jni from 1.3.3-3 to 1.4.0-1
[ https://issues.apache.org/jira/browse/COMPRESS-484?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Gary Gregory closed COMPRESS-484. - Resolution: Fixed Fix Version/s: 1.19 In git master. > Update optional library zstd-jni from 1.3.3-3 to 1.4.0-1 > > > Key: COMPRESS-484 > URL: https://issues.apache.org/jira/browse/COMPRESS-484 > Project: Commons Compress > Issue Type: Improvement > Components: Compressors >Reporter: Gary Gregory >Priority: Major > Fix For: 1.19 > > > Update optional library zstd-jni from 1.3.3-3 to 1.4.0-1. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] [commons-vfs] garydgregory commented on issue #52: VFS-686: webdav4 provider based on the latest Jackrabbit 2.x
garydgregory commented on issue #52: VFS-686: webdav4 provider based on the latest Jackrabbit 2.x URL: https://github.com/apache/commons-vfs/pull/52#issuecomment-488096381 @woonsan Thank you. WRT the patch. could there might still be conflicts: ``` C:\git\commons-vfs>git apply \temp\52.patch.txt /temp/52.patch.txt:1685: trailing whitespace. /* /temp/52.patch.txt:1686: trailing whitespace. * Licensed to the Apache Software Foundation (ASF) under one or more /temp/52.patch.txt:1687: trailing whitespace. * contributor license agreements. See the NOTICE file distributed with /temp/52.patch.txt:1688: trailing whitespace. * this work for additional information regarding copyright ownership. /temp/52.patch.txt:1689: trailing whitespace. * The ASF licenses this file to You under the Apache License, Version 2.0 error: patch failed: pom.xml:179 error: pom.xml: patch does not apply error: patch failed: pom.xml:554 error: pom.xml: patch does not apply error: patch failed: pom.xml:36 error: pom.xml: patch does not apply error: patch failed: pom.xml:194 error: pom.xml: patch does not apply error: patch failed: pom.xml:194 error: pom.xml: patch does not apply error: patch failed: pom.xml:194 error: pom.xml: patch does not apply ``` Can you try to apply the patch locally to your master to see what happens? I wanted to review it in Eclipse instead of here... Thank you! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [commons-vfs] woonsan commented on issue #52: VFS-686: webdav4 provider based on the latest Jackrabbit 2.x
woonsan commented on issue #52: VFS-686: webdav4 provider based on the latest Jackrabbit 2.x URL: https://github.com/apache/commons-vfs/pull/52#issuecomment-487989859 Hi @garydgregory , I've just merged mater. It's great to see greens even for JVM11! Great work! Woonsan This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [commons-dbutils] garydgregory commented on issue #8: Added jdk versions in travis
garydgregory commented on issue #8: Added jdk versions in travis URL: https://github.com/apache/commons-dbutils/pull/8#issuecomment-487980176 -1: Since Java 9 and 10 are not supported long term, I think we test on Java 8, 11 and up. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [commons-dbutils] visruth opened a new pull request #8: Added jdk versions in travis
visruth opened a new pull request #8: Added jdk versions in travis URL: https://github.com/apache/commons-dbutils/pull/8 openjdk9, openjdk10 and oraclejdk9 are added This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Closed] (POOL-366) Update optional library cglib from 3.2.10 to 3.2.11
[ https://issues.apache.org/jira/browse/POOL-366?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Gary Gregory closed POOL-366. - Resolution: Fixed Fix Version/s: 2.7.0 In git master. > Update optional library cglib from 3.2.10 to 3.2.11 > --- > > Key: POOL-366 > URL: https://issues.apache.org/jira/browse/POOL-366 > Project: Commons Pool > Issue Type: Improvement >Reporter: Gary Gregory >Priority: Major > Fix For: 2.7.0 > > > Update optional library cglib from 3.2.10 to 3.2.11 -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (POOL-366) Update optional library cglib from 3.2.10 to 3.2.11
Gary Gregory created POOL-366: - Summary: Update optional library cglib from 3.2.10 to 3.2.11 Key: POOL-366 URL: https://issues.apache.org/jira/browse/POOL-366 Project: Commons Pool Issue Type: Improvement Reporter: Gary Gregory Update optional library cglib from 3.2.10 to 3.2.11 -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (LANG-1451) Should there be a better implementation of substring that deals with Unicode surrogate pairs correctly?
[
https://issues.apache.org/jira/browse/LANG-1451?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16830303#comment-16830303
]
Rob Tompkins commented on LANG-1451:
If so, then we'd clearly want separate methods I would think
> Should there be a better implementation of substring that deals with Unicode
> surrogate pairs correctly?
> ---
>
> Key: LANG-1451
> URL: https://issues.apache.org/jira/browse/LANG-1451
> Project: Commons Lang
> Issue Type: New Feature
>Affects Versions: 3.9
> Environment: Any
>Reporter: Sebastiaan
>Assignee: Rob Tompkins
>Priority: Minor
> Labels: features
>
> There are some major problems with Java's substring implementation which
> works using chars. For a brief overview read this blog post:
> [https://codeahoy.com/2016/05/08/the-char-type-in-java-is-broken/]
>
> I have some demo code showing the issues and a possible solution here:
> {code:java}
> public class SubstringTest {
> public static void main(String[] args) {
> String stringWithPlus2ByteCodePoints = "";
> String substring1 = stringWithPlus2ByteCodePoints.substring(0, 1);
> String substring2 = stringWithPlus2ByteCodePoints.substring(0, 2);
> String substring3 = stringWithPlus2ByteCodePoints.substring(1, 3);
> System.out.println(stringWithPlus2ByteCodePoints);
> System.out.println("invalid sub: " + substring1);
> System.out.println("invalid sub: " + substring2);
> System.out.println("invalid sub: " + substring3);
> String realSub1 = getRealSubstring(stringWithPlus2ByteCodePoints, 0,
> 1);
> String realSub2 = getRealSubstring(stringWithPlus2ByteCodePoints, 0,
> 2);
> String realSub3 = getRealSubstring(stringWithPlus2ByteCodePoints, 1,
> 3);
> System.out.println("real sub: " + realSub1);
> System.out.println("real sub: " + realSub2);
> System.out.println("real sub: " + realSub3);
> }
> private static String getRealSubstring(String string, int beginIndex, int
> endIndex) {
> if (string == null)
> throw new IllegalArgumentException("String should not be null");
> int length = string.length();
> if (endIndex < 0 || beginIndex > endIndex || beginIndex > length ||
> endIndex > length)
> throw new IllegalArgumentException("Invalid indices");
> int realBeginIndex = string.offsetByCodePoints(0, beginIndex);
> int realEndIndex = string.offsetByCodePoints(0, endIndex);
> return string.substring(realBeginIndex, realEndIndex);
> }
> }{code}
> The output is:
> {noformat}
>
> invalid sub: ?
> invalid sub:
> invalid sub: ??
> real sub:
> real sub:
> real sub: {noformat}
>
> The same issues appear in Apache Commons Text's substring method.
> Should Apache Commons Text use this code or something similar in the
> substring implementation, rather than the flawed Java substring method? Or at
> least offer an additional utility method that does take a string with unicode
> codepoints that require surrogate pairs and substrings it correctly?
> I also posted my implementation at
> [https://stackoverflow.com/questions/55663213/java-substring-by-code-point-indices-treating-pairs-of-surrogate-code-units-as/]
> asking for advice and there is a more robust version as an answer.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [commons-vfs] abashev commented on issue #62: Don’t fail on openjdk-ea builds
abashev commented on issue #62: Don’t fail on openjdk-ea builds URL: https://github.com/apache/commons-vfs/pull/62#issuecomment-487948405 Because of this one https://github.com/apache/commons-vfs/pull/62/commits/44700e19bdb03e3d38c43f2b361fdb9661ccfc9a This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (LANG-1451) Should there be a better implementation of substring that deals with Unicode surrogate pairs correctly?
[
https://issues.apache.org/jira/browse/LANG-1451?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16830278#comment-16830278
]
Gary Gregory commented on LANG-1451:
Would there be negative performance consequences worth documenting, either in
the code or in the Javadoc?
> Should there be a better implementation of substring that deals with Unicode
> surrogate pairs correctly?
> ---
>
> Key: LANG-1451
> URL: https://issues.apache.org/jira/browse/LANG-1451
> Project: Commons Lang
> Issue Type: New Feature
>Affects Versions: 3.9
> Environment: Any
>Reporter: Sebastiaan
>Assignee: Rob Tompkins
>Priority: Minor
> Labels: features
>
> There are some major problems with Java's substring implementation which
> works using chars. For a brief overview read this blog post:
> [https://codeahoy.com/2016/05/08/the-char-type-in-java-is-broken/]
>
> I have some demo code showing the issues and a possible solution here:
> {code:java}
> public class SubstringTest {
> public static void main(String[] args) {
> String stringWithPlus2ByteCodePoints = "";
> String substring1 = stringWithPlus2ByteCodePoints.substring(0, 1);
> String substring2 = stringWithPlus2ByteCodePoints.substring(0, 2);
> String substring3 = stringWithPlus2ByteCodePoints.substring(1, 3);
> System.out.println(stringWithPlus2ByteCodePoints);
> System.out.println("invalid sub: " + substring1);
> System.out.println("invalid sub: " + substring2);
> System.out.println("invalid sub: " + substring3);
> String realSub1 = getRealSubstring(stringWithPlus2ByteCodePoints, 0,
> 1);
> String realSub2 = getRealSubstring(stringWithPlus2ByteCodePoints, 0,
> 2);
> String realSub3 = getRealSubstring(stringWithPlus2ByteCodePoints, 1,
> 3);
> System.out.println("real sub: " + realSub1);
> System.out.println("real sub: " + realSub2);
> System.out.println("real sub: " + realSub3);
> }
> private static String getRealSubstring(String string, int beginIndex, int
> endIndex) {
> if (string == null)
> throw new IllegalArgumentException("String should not be null");
> int length = string.length();
> if (endIndex < 0 || beginIndex > endIndex || beginIndex > length ||
> endIndex > length)
> throw new IllegalArgumentException("Invalid indices");
> int realBeginIndex = string.offsetByCodePoints(0, beginIndex);
> int realEndIndex = string.offsetByCodePoints(0, endIndex);
> return string.substring(realBeginIndex, realEndIndex);
> }
> }{code}
> The output is:
> {noformat}
>
> invalid sub: ?
> invalid sub:
> invalid sub: ??
> real sub:
> real sub:
> real sub: {noformat}
>
> The same issues appear in Apache Commons Text's substring method.
> Should Apache Commons Text use this code or something similar in the
> substring implementation, rather than the flawed Java substring method? Or at
> least offer an additional utility method that does take a string with unicode
> codepoints that require surrogate pairs and substrings it correctly?
> I also posted my implementation at
> [https://stackoverflow.com/questions/55663213/java-substring-by-code-point-indices-treating-pairs-of-surrogate-code-units-as/]
> asking for advice and there is a more robust version as an answer.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [commons-vfs] garydgregory edited a comment on issue #62: Don’t fail on openjdk-ea builds
garydgregory edited a comment on issue #62: Don’t fail on openjdk-ea builds URL: https://github.com/apache/commons-vfs/pull/62#issuecomment-487944561 I'd like to understand why the PR build passes: https://travis-ci.org/apache/commons-vfs/builds/526143774 AND that EA build actually ran. While the master build failed, _not even having started the EA build_: https://travis-ci.org/apache/commons-vfs/jobs/526040009 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [commons-vfs] garydgregory commented on issue #62: Don’t fail on openjdk-ea builds
garydgregory commented on issue #62: Don’t fail on openjdk-ea builds URL: https://github.com/apache/commons-vfs/pull/62#issuecomment-487944561 I'd like to understand why the PR build passes: https://travis-ci.org/apache/commons-vfs/builds/526143774 AND that build actually ran. While the master build failed, _not even having started the build_: https://travis-ci.org/apache/commons-vfs/jobs/526040009 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Comment Edited] (LANG-1451) Should there be a better implementation of substring that deals with Unicode surrogate pairs correctly?
[
https://issues.apache.org/jira/browse/LANG-1451?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16830275#comment-16830275
]
Rob Tompkins edited comment on LANG-1451 at 4/30/19 1:02 PM:
-
maybe rename the variables to analogs of {{startOffsetByCodePoints}}
was (Author: chtompki):
maybe rename the variables to {{startOffsetByCodePoints}}
> Should there be a better implementation of substring that deals with Unicode
> surrogate pairs correctly?
> ---
>
> Key: LANG-1451
> URL: https://issues.apache.org/jira/browse/LANG-1451
> Project: Commons Lang
> Issue Type: New Feature
>Affects Versions: 3.9
> Environment: Any
>Reporter: Sebastiaan
>Assignee: Rob Tompkins
>Priority: Minor
> Labels: features
>
> There are some major problems with Java's substring implementation which
> works using chars. For a brief overview read this blog post:
> [https://codeahoy.com/2016/05/08/the-char-type-in-java-is-broken/]
>
> I have some demo code showing the issues and a possible solution here:
> {code:java}
> public class SubstringTest {
> public static void main(String[] args) {
> String stringWithPlus2ByteCodePoints = "";
> String substring1 = stringWithPlus2ByteCodePoints.substring(0, 1);
> String substring2 = stringWithPlus2ByteCodePoints.substring(0, 2);
> String substring3 = stringWithPlus2ByteCodePoints.substring(1, 3);
> System.out.println(stringWithPlus2ByteCodePoints);
> System.out.println("invalid sub: " + substring1);
> System.out.println("invalid sub: " + substring2);
> System.out.println("invalid sub: " + substring3);
> String realSub1 = getRealSubstring(stringWithPlus2ByteCodePoints, 0,
> 1);
> String realSub2 = getRealSubstring(stringWithPlus2ByteCodePoints, 0,
> 2);
> String realSub3 = getRealSubstring(stringWithPlus2ByteCodePoints, 1,
> 3);
> System.out.println("real sub: " + realSub1);
> System.out.println("real sub: " + realSub2);
> System.out.println("real sub: " + realSub3);
> }
> private static String getRealSubstring(String string, int beginIndex, int
> endIndex) {
> if (string == null)
> throw new IllegalArgumentException("String should not be null");
> int length = string.length();
> if (endIndex < 0 || beginIndex > endIndex || beginIndex > length ||
> endIndex > length)
> throw new IllegalArgumentException("Invalid indices");
> int realBeginIndex = string.offsetByCodePoints(0, beginIndex);
> int realEndIndex = string.offsetByCodePoints(0, endIndex);
> return string.substring(realBeginIndex, realEndIndex);
> }
> }{code}
> The output is:
> {noformat}
>
> invalid sub: ?
> invalid sub:
> invalid sub: ??
> real sub:
> real sub:
> real sub: {noformat}
>
> The same issues appear in Apache Commons Text's substring method.
> Should Apache Commons Text use this code or something similar in the
> substring implementation, rather than the flawed Java substring method? Or at
> least offer an additional utility method that does take a string with unicode
> codepoints that require surrogate pairs and substrings it correctly?
> I also posted my implementation at
> [https://stackoverflow.com/questions/55663213/java-substring-by-code-point-indices-treating-pairs-of-surrogate-code-units-as/]
> asking for advice and there is a more robust version as an answer.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [commons-vfs] abashev commented on issue #62: Don’t fail on openjdk-ea builds
abashev commented on issue #62: Don’t fail on openjdk-ea builds URL: https://github.com/apache/commons-vfs/pull/62#issuecomment-487943312 @garydgregory I'm not sure how do you mean. 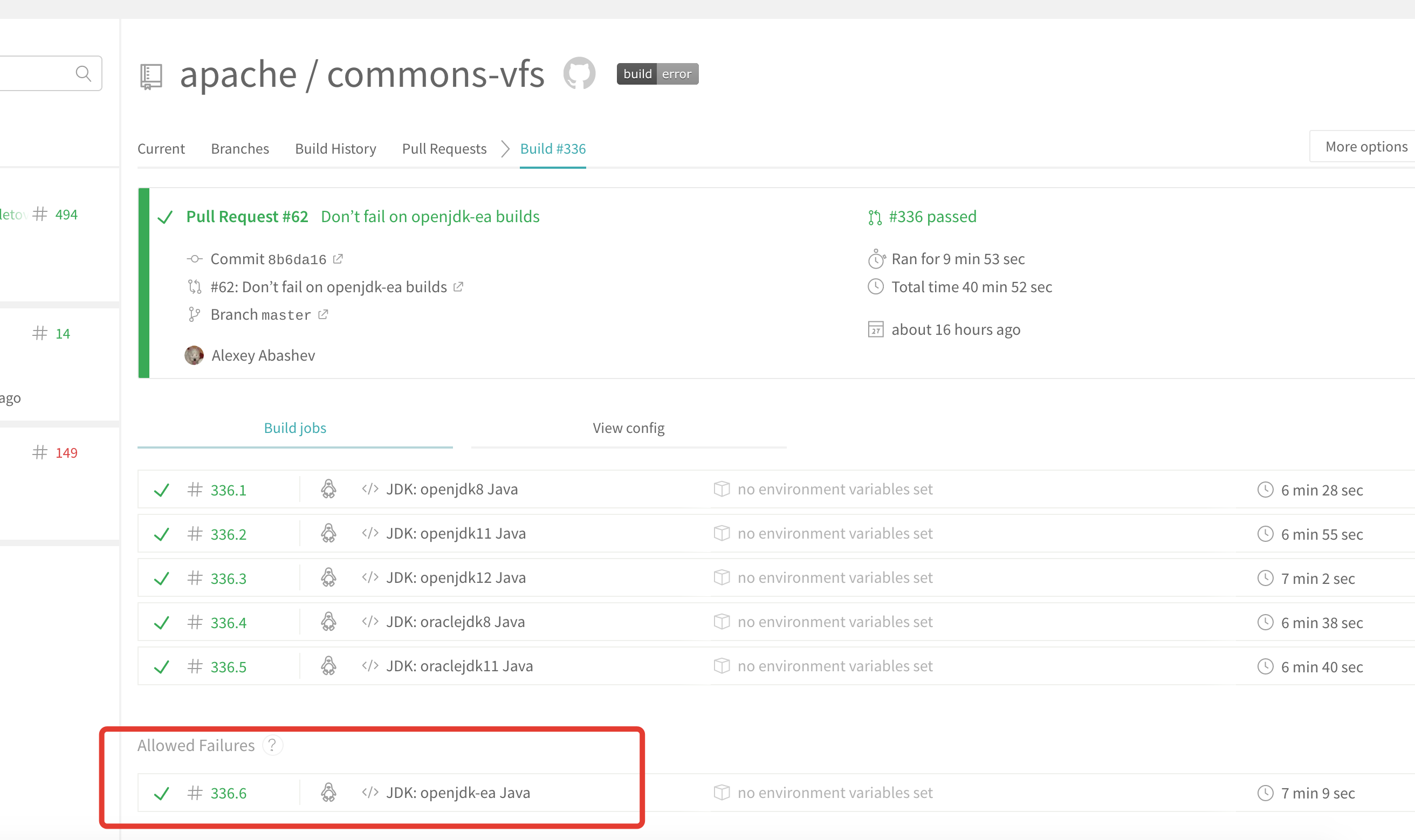 EA build is up and running, I left it inside failed just in case. Is it not enough? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (LANG-1451) Should there be a better implementation of substring that deals with Unicode surrogate pairs correctly?
[
https://issues.apache.org/jira/browse/LANG-1451?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16830275#comment-16830275
]
Rob Tompkins commented on LANG-1451:
maybe rename the variables to {{startOffsetByCodePoints}}
> Should there be a better implementation of substring that deals with Unicode
> surrogate pairs correctly?
> ---
>
> Key: LANG-1451
> URL: https://issues.apache.org/jira/browse/LANG-1451
> Project: Commons Lang
> Issue Type: New Feature
>Affects Versions: 3.9
> Environment: Any
>Reporter: Sebastiaan
>Assignee: Rob Tompkins
>Priority: Minor
> Labels: features
>
> There are some major problems with Java's substring implementation which
> works using chars. For a brief overview read this blog post:
> [https://codeahoy.com/2016/05/08/the-char-type-in-java-is-broken/]
>
> I have some demo code showing the issues and a possible solution here:
> {code:java}
> public class SubstringTest {
> public static void main(String[] args) {
> String stringWithPlus2ByteCodePoints = "";
> String substring1 = stringWithPlus2ByteCodePoints.substring(0, 1);
> String substring2 = stringWithPlus2ByteCodePoints.substring(0, 2);
> String substring3 = stringWithPlus2ByteCodePoints.substring(1, 3);
> System.out.println(stringWithPlus2ByteCodePoints);
> System.out.println("invalid sub: " + substring1);
> System.out.println("invalid sub: " + substring2);
> System.out.println("invalid sub: " + substring3);
> String realSub1 = getRealSubstring(stringWithPlus2ByteCodePoints, 0,
> 1);
> String realSub2 = getRealSubstring(stringWithPlus2ByteCodePoints, 0,
> 2);
> String realSub3 = getRealSubstring(stringWithPlus2ByteCodePoints, 1,
> 3);
> System.out.println("real sub: " + realSub1);
> System.out.println("real sub: " + realSub2);
> System.out.println("real sub: " + realSub3);
> }
> private static String getRealSubstring(String string, int beginIndex, int
> endIndex) {
> if (string == null)
> throw new IllegalArgumentException("String should not be null");
> int length = string.length();
> if (endIndex < 0 || beginIndex > endIndex || beginIndex > length ||
> endIndex > length)
> throw new IllegalArgumentException("Invalid indices");
> int realBeginIndex = string.offsetByCodePoints(0, beginIndex);
> int realEndIndex = string.offsetByCodePoints(0, endIndex);
> return string.substring(realBeginIndex, realEndIndex);
> }
> }{code}
> The output is:
> {noformat}
>
> invalid sub: ?
> invalid sub:
> invalid sub: ??
> real sub:
> real sub:
> real sub: {noformat}
>
> The same issues appear in Apache Commons Text's substring method.
> Should Apache Commons Text use this code or something similar in the
> substring implementation, rather than the flawed Java substring method? Or at
> least offer an additional utility method that does take a string with unicode
> codepoints that require surrogate pairs and substrings it correctly?
> I also posted my implementation at
> [https://stackoverflow.com/questions/55663213/java-substring-by-code-point-indices-treating-pairs-of-surrogate-code-units-as/]
> asking for advice and there is a more robust version as an answer.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (LANG-1451) Should there be a better implementation of substring that deals with Unicode surrogate pairs correctly?
[
https://issues.apache.org/jira/browse/LANG-1451?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16830274#comment-16830274
]
Rob Tompkins commented on LANG-1451:
Actuallyif we make our {{substring}} method the following:
{code:java}
public static String substring(final String str, int start, int end) {
if (str == null) {
return null;
}
// handle negatives
if (end < 0) {
end = str.length() + end; // remember end is negative
}
if (start < 0) {
start = str.length() + start; // remember start is negative
}
// check length next
if (end > str.length()) {
end = str.length();
}
// if start is greater than end, return ""
if (start > end) {
return EMPTY;
}
if (start < 0) {
start = 0;
}
if (end < 0) {
end = 0;
}
int realUtf16Start = str.offsetByCodePoints(0, start);
int realUtf16End = str.offsetByCodePoints(0, end);
return str.substring(realUtf16Start, realUtf16End);
}
{code}
we're just good. I think this is likely the best path.
> Should there be a better implementation of substring that deals with Unicode
> surrogate pairs correctly?
> ---
>
> Key: LANG-1451
> URL: https://issues.apache.org/jira/browse/LANG-1451
> Project: Commons Lang
> Issue Type: New Feature
>Affects Versions: 3.9
> Environment: Any
>Reporter: Sebastiaan
>Assignee: Rob Tompkins
>Priority: Minor
> Labels: features
>
> There are some major problems with Java's substring implementation which
> works using chars. For a brief overview read this blog post:
> [https://codeahoy.com/2016/05/08/the-char-type-in-java-is-broken/]
>
> I have some demo code showing the issues and a possible solution here:
> {code:java}
> public class SubstringTest {
> public static void main(String[] args) {
> String stringWithPlus2ByteCodePoints = "";
> String substring1 = stringWithPlus2ByteCodePoints.substring(0, 1);
> String substring2 = stringWithPlus2ByteCodePoints.substring(0, 2);
> String substring3 = stringWithPlus2ByteCodePoints.substring(1, 3);
> System.out.println(stringWithPlus2ByteCodePoints);
> System.out.println("invalid sub: " + substring1);
> System.out.println("invalid sub: " + substring2);
> System.out.println("invalid sub: " + substring3);
> String realSub1 = getRealSubstring(stringWithPlus2ByteCodePoints, 0,
> 1);
> String realSub2 = getRealSubstring(stringWithPlus2ByteCodePoints, 0,
> 2);
> String realSub3 = getRealSubstring(stringWithPlus2ByteCodePoints, 1,
> 3);
> System.out.println("real sub: " + realSub1);
> System.out.println("real sub: " + realSub2);
> System.out.println("real sub: " + realSub3);
> }
> private static String getRealSubstring(String string, int beginIndex, int
> endIndex) {
> if (string == null)
> throw new IllegalArgumentException("String should not be null");
> int length = string.length();
> if (endIndex < 0 || beginIndex > endIndex || beginIndex > length ||
> endIndex > length)
> throw new IllegalArgumentException("Invalid indices");
> int realBeginIndex = string.offsetByCodePoints(0, beginIndex);
> int realEndIndex = string.offsetByCodePoints(0, endIndex);
> return string.substring(realBeginIndex, realEndIndex);
> }
> }{code}
> The output is:
> {noformat}
>
> invalid sub: ?
> invalid sub:
> invalid sub: ??
> real sub:
> real sub:
> real sub: {noformat}
>
> The same issues appear in Apache Commons Text's substring method.
> Should Apache Commons Text use this code or something similar in the
> substring implementation, rather than the flawed Java substring method? Or at
> least offer an additional utility method that does take a string with unicode
> codepoints that require surrogate pairs and substrings it correctly?
> I also posted my implementation at
> [https://stackoverflow.com/questions/55663213/java-substring-by-code-point-indices-treating-pairs-of-surrogate-code-units-as/]
> asking for advice and there is a more robust version as an answer.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [commons-vfs] garydgregory commented on issue #52: VFS-686: webdav4 provider based on the latest Jackrabbit 2.x
garydgregory commented on issue #52: VFS-686: webdav4 provider based on the latest Jackrabbit 2.x URL: https://github.com/apache/commons-vfs/pull/52#issuecomment-487942620 Hi @woonsan, So sorry I got side tracked. May you please rebase on master so we can get a fresh set of Travis CI builds. Gary This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Closed] (VFS-705) Add ability to specify the buffer size of input/output streams
[ https://issues.apache.org/jira/browse/VFS-705?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Gary Gregory closed VFS-705. Resolution: Fixed Oops, I created [VFS-706] and committed with that ticket reference instead of this one. I marking this ticket as a duplicate of [VFS-706], sorry about that. > Add ability to specify the buffer size of input/output streams > -- > > Key: VFS-705 > URL: https://issues.apache.org/jira/browse/VFS-705 > Project: Commons VFS > Issue Type: Improvement >Affects Versions: 2.3 >Reporter: Boris Petrov >Priority: Major > > "FileContent.getInputStream"'s documentation specifies that "The input stream > is buffered" which is true (because the implementation in > "DefaultFileContent" wraps it in "FileContentInputStream" which inherits > "MonitorInputStream" which in turn "BufferedInputStream". However, there is > no way to configure the buffer size and sometimes the default one which is > just 8 KB might not be a good choice. Adding an ability to specify a > different buffer size will help greatly boost the performance when talking to > slow providers. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (VFS-706) Add ability to specify buffer sizes #59
[ https://issues.apache.org/jira/browse/VFS-706?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Gary Gregory updated VFS-706: - Description: Add ability to specify buffer sizes #59. "FileContent.getInputStream"'s documentation specifies that "The input stream is buffered" which is true (because the implementation in "DefaultFileContent" wraps it in "FileContentInputStream" which inherits "MonitorInputStream" which in turn "BufferedInputStream". However, there is no way to configure the buffer size and sometimes the default one which is just 8 KB might not be a good choice. Adding an ability to specify a different buffer size will help greatly boost the performance when talking to slow providers. was:Add ability to specify buffer sizes #59. > Add ability to specify buffer sizes #59 > --- > > Key: VFS-706 > URL: https://issues.apache.org/jira/browse/VFS-706 > Project: Commons VFS > Issue Type: New Feature >Reporter: Gary Gregory >Assignee: Gary Gregory >Priority: Major > Fix For: 2.4 > > > Add ability to specify buffer sizes #59. > "FileContent.getInputStream"'s documentation specifies that "The input stream > is buffered" which is true (because the implementation in > "DefaultFileContent" wraps it in "FileContentInputStream" which inherits > "MonitorInputStream" which in turn "BufferedInputStream". However, there is > no way to configure the buffer size and sometimes the default one which is > just 8 KB might not be a good choice. Adding an ability to specify a > different buffer size will help greatly boost the performance when talking to > slow providers. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Closed] (VFS-706) Add ability to specify buffer sizes #59
[ https://issues.apache.org/jira/browse/VFS-706?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Gary Gregory closed VFS-706. Resolution: Fixed > Add ability to specify buffer sizes #59 > --- > > Key: VFS-706 > URL: https://issues.apache.org/jira/browse/VFS-706 > Project: Commons VFS > Issue Type: New Feature >Reporter: Gary Gregory >Assignee: Gary Gregory >Priority: Major > Fix For: 2.4 > > > Add ability to specify buffer sizes #59. > "FileContent.getInputStream"'s documentation specifies that "The input stream > is buffered" which is true (because the implementation in > "DefaultFileContent" wraps it in "FileContentInputStream" which inherits > "MonitorInputStream" which in turn "BufferedInputStream". However, there is > no way to configure the buffer size and sometimes the default one which is > just 8 KB might not be a good choice. Adding an ability to specify a > different buffer size will help greatly boost the performance when talking to > slow providers. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Reopened] (VFS-706) Add ability to specify buffer sizes #59
[ https://issues.apache.org/jira/browse/VFS-706?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Gary Gregory reopened VFS-706: -- > Add ability to specify buffer sizes #59 > --- > > Key: VFS-706 > URL: https://issues.apache.org/jira/browse/VFS-706 > Project: Commons VFS > Issue Type: New Feature >Reporter: Gary Gregory >Assignee: Gary Gregory >Priority: Major > Fix For: 2.4 > > > Add ability to specify buffer sizes #59. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (LANG-1451) Should there be a better implementation of substring that deals with Unicode surrogate pairs correctly?
[
https://issues.apache.org/jira/browse/LANG-1451?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16830262#comment-16830262
]
Gary Gregory commented on LANG-1451:
Or we could have a new class {{CodePointStringUtils}} (or another name) to make
it clear that the domain of the functions are about different kinds of strings
than char[].
> Should there be a better implementation of substring that deals with Unicode
> surrogate pairs correctly?
> ---
>
> Key: LANG-1451
> URL: https://issues.apache.org/jira/browse/LANG-1451
> Project: Commons Lang
> Issue Type: New Feature
>Affects Versions: 3.9
> Environment: Any
>Reporter: Sebastiaan
>Assignee: Rob Tompkins
>Priority: Minor
> Labels: features
>
> There are some major problems with Java's substring implementation which
> works using chars. For a brief overview read this blog post:
> [https://codeahoy.com/2016/05/08/the-char-type-in-java-is-broken/]
>
> I have some demo code showing the issues and a possible solution here:
> {code:java}
> public class SubstringTest {
> public static void main(String[] args) {
> String stringWithPlus2ByteCodePoints = "";
> String substring1 = stringWithPlus2ByteCodePoints.substring(0, 1);
> String substring2 = stringWithPlus2ByteCodePoints.substring(0, 2);
> String substring3 = stringWithPlus2ByteCodePoints.substring(1, 3);
> System.out.println(stringWithPlus2ByteCodePoints);
> System.out.println("invalid sub: " + substring1);
> System.out.println("invalid sub: " + substring2);
> System.out.println("invalid sub: " + substring3);
> String realSub1 = getRealSubstring(stringWithPlus2ByteCodePoints, 0,
> 1);
> String realSub2 = getRealSubstring(stringWithPlus2ByteCodePoints, 0,
> 2);
> String realSub3 = getRealSubstring(stringWithPlus2ByteCodePoints, 1,
> 3);
> System.out.println("real sub: " + realSub1);
> System.out.println("real sub: " + realSub2);
> System.out.println("real sub: " + realSub3);
> }
> private static String getRealSubstring(String string, int beginIndex, int
> endIndex) {
> if (string == null)
> throw new IllegalArgumentException("String should not be null");
> int length = string.length();
> if (endIndex < 0 || beginIndex > endIndex || beginIndex > length ||
> endIndex > length)
> throw new IllegalArgumentException("Invalid indices");
> int realBeginIndex = string.offsetByCodePoints(0, beginIndex);
> int realEndIndex = string.offsetByCodePoints(0, endIndex);
> return string.substring(realBeginIndex, realEndIndex);
> }
> }{code}
> The output is:
> {noformat}
>
> invalid sub: ?
> invalid sub:
> invalid sub: ??
> real sub:
> real sub:
> real sub: {noformat}
>
> The same issues appear in Apache Commons Text's substring method.
> Should Apache Commons Text use this code or something similar in the
> substring implementation, rather than the flawed Java substring method? Or at
> least offer an additional utility method that does take a string with unicode
> codepoints that require surrogate pairs and substrings it correctly?
> I also posted my implementation at
> [https://stackoverflow.com/questions/55663213/java-substring-by-code-point-indices-treating-pairs-of-surrogate-code-units-as/]
> asking for advice and there is a more robust version as an answer.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (LANG-1451) Should there be a better implementation of substring that deals with Unicode surrogate pairs correctly?
[
https://issues.apache.org/jira/browse/LANG-1451?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16830256#comment-16830256
]
Rob Tompkins commented on LANG-1451:
Do we want to call these methods {{codePointSubstring}} and
{{codePointLastIndexOf}}? The accepted answer to the "question" in
stackoverflow would indicate that to be a good naming convention for such a
method.
> Should there be a better implementation of substring that deals with Unicode
> surrogate pairs correctly?
> ---
>
> Key: LANG-1451
> URL: https://issues.apache.org/jira/browse/LANG-1451
> Project: Commons Lang
> Issue Type: New Feature
>Affects Versions: 3.9
> Environment: Any
>Reporter: Sebastiaan
>Assignee: Rob Tompkins
>Priority: Minor
> Labels: features
>
> There are some major problems with Java's substring implementation which
> works using chars. For a brief overview read this blog post:
> [https://codeahoy.com/2016/05/08/the-char-type-in-java-is-broken/]
>
> I have some demo code showing the issues and a possible solution here:
> {code:java}
> public class SubstringTest {
> public static void main(String[] args) {
> String stringWithPlus2ByteCodePoints = "";
> String substring1 = stringWithPlus2ByteCodePoints.substring(0, 1);
> String substring2 = stringWithPlus2ByteCodePoints.substring(0, 2);
> String substring3 = stringWithPlus2ByteCodePoints.substring(1, 3);
> System.out.println(stringWithPlus2ByteCodePoints);
> System.out.println("invalid sub: " + substring1);
> System.out.println("invalid sub: " + substring2);
> System.out.println("invalid sub: " + substring3);
> String realSub1 = getRealSubstring(stringWithPlus2ByteCodePoints, 0,
> 1);
> String realSub2 = getRealSubstring(stringWithPlus2ByteCodePoints, 0,
> 2);
> String realSub3 = getRealSubstring(stringWithPlus2ByteCodePoints, 1,
> 3);
> System.out.println("real sub: " + realSub1);
> System.out.println("real sub: " + realSub2);
> System.out.println("real sub: " + realSub3);
> }
> private static String getRealSubstring(String string, int beginIndex, int
> endIndex) {
> if (string == null)
> throw new IllegalArgumentException("String should not be null");
> int length = string.length();
> if (endIndex < 0 || beginIndex > endIndex || beginIndex > length ||
> endIndex > length)
> throw new IllegalArgumentException("Invalid indices");
> int realBeginIndex = string.offsetByCodePoints(0, beginIndex);
> int realEndIndex = string.offsetByCodePoints(0, endIndex);
> return string.substring(realBeginIndex, realEndIndex);
> }
> }{code}
> The output is:
> {noformat}
>
> invalid sub: ?
> invalid sub:
> invalid sub: ??
> real sub:
> real sub:
> real sub: {noformat}
>
> The same issues appear in Apache Commons Text's substring method.
> Should Apache Commons Text use this code or something similar in the
> substring implementation, rather than the flawed Java substring method? Or at
> least offer an additional utility method that does take a string with unicode
> codepoints that require surrogate pairs and substrings it correctly?
> I also posted my implementation at
> [https://stackoverflow.com/questions/55663213/java-substring-by-code-point-indices-treating-pairs-of-surrogate-code-units-as/]
> asking for advice and there is a more robust version as an answer.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] [commons-vfs] garydgregory edited a comment on issue #36: fix for VFS-662: SftpFileSystem has Thread-safe issue about idleChannel
garydgregory edited a comment on issue #36: fix for VFS-662: SftpFileSystem has Thread-safe issue about idleChannel URL: https://github.com/apache/commons-vfs/pull/36#issuecomment-487937541 @abashev BTW, welcome aboard the Apache Commons project :-) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [commons-vfs] garydgregory commented on issue #36: fix for VFS-662: SftpFileSystem has Thread-safe issue about idleChannel
garydgregory commented on issue #36: fix for VFS-662: SftpFileSystem has Thread-safe issue about idleChannel URL: https://github.com/apache/commons-vfs/pull/36#issuecomment-487937541 BTW, welcome aboard the Apache Commons project :-) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[GitHub] [commons-vfs] garydgregory commented on issue #62: Don’t fail on openjdk-ea builds
garydgregory commented on issue #62: Don’t fail on openjdk-ea builds URL: https://github.com/apache/commons-vfs/pull/62#issuecomment-487937038 Hi @abashev: I am kinda -1 on openjdk-ea as allowing to fail since we know it always fails. What I was trying to say, unsuccessfully ;-) is either: - Let's not even put openjdk-ea in the list of jdks if we then say it is allowed to fail, since it fails always - Make openjdk-ea work, are least work enough that the build starts. Thoughts? Gary This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services
[jira] [Commented] (LANG-1451) Should there be a better implementation of substring that deals with Unicode surrogate pairs correctly?
[
https://issues.apache.org/jira/browse/LANG-1451?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=16830242#comment-16830242
]
Rob Tompkins commented on LANG-1451:
[~Sebastiaan83] - when I try to even instantiate a string like one of those
above, I am unable to do so. Do you have some special settings such that you
can instantiate such strings? For example I get the followoing:
{code:java}
System.out.println(""); \\
{code}
The best thing that I could do to get the output was to do the following:
{code:java}
String PLUS_2_BYTE_CODE_POINTS =
"\uD83D\uDC66\uD83D\uDC69\uD83D\uDC6A\uD83D\uDC6B";
{code}
Does that work for you?
> Should there be a better implementation of substring that deals with Unicode
> surrogate pairs correctly?
> ---
>
> Key: LANG-1451
> URL: https://issues.apache.org/jira/browse/LANG-1451
> Project: Commons Lang
> Issue Type: New Feature
>Affects Versions: 3.9
> Environment: Any
>Reporter: Sebastiaan
>Assignee: Rob Tompkins
>Priority: Minor
> Labels: features
>
> There are some major problems with Java's substring implementation which
> works using chars. For a brief overview read this blog post:
> [https://codeahoy.com/2016/05/08/the-char-type-in-java-is-broken/]
>
> I have some demo code showing the issues and a possible solution here:
> {code:java}
> public class SubstringTest {
> public static void main(String[] args) {
> String stringWithPlus2ByteCodePoints = "";
> String substring1 = stringWithPlus2ByteCodePoints.substring(0, 1);
> String substring2 = stringWithPlus2ByteCodePoints.substring(0, 2);
> String substring3 = stringWithPlus2ByteCodePoints.substring(1, 3);
> System.out.println(stringWithPlus2ByteCodePoints);
> System.out.println("invalid sub: " + substring1);
> System.out.println("invalid sub: " + substring2);
> System.out.println("invalid sub: " + substring3);
> String realSub1 = getRealSubstring(stringWithPlus2ByteCodePoints, 0,
> 1);
> String realSub2 = getRealSubstring(stringWithPlus2ByteCodePoints, 0,
> 2);
> String realSub3 = getRealSubstring(stringWithPlus2ByteCodePoints, 1,
> 3);
> System.out.println("real sub: " + realSub1);
> System.out.println("real sub: " + realSub2);
> System.out.println("real sub: " + realSub3);
> }
> private static String getRealSubstring(String string, int beginIndex, int
> endIndex) {
> if (string == null)
> throw new IllegalArgumentException("String should not be null");
> int length = string.length();
> if (endIndex < 0 || beginIndex > endIndex || beginIndex > length ||
> endIndex > length)
> throw new IllegalArgumentException("Invalid indices");
> int realBeginIndex = string.offsetByCodePoints(0, beginIndex);
> int realEndIndex = string.offsetByCodePoints(0, endIndex);
> return string.substring(realBeginIndex, realEndIndex);
> }
> }{code}
> The output is:
> {noformat}
>
> invalid sub: ?
> invalid sub:
> invalid sub: ??
> real sub:
> real sub:
> real sub: {noformat}
>
> The same issues appear in Apache Commons Text's substring method.
> Should Apache Commons Text use this code or something similar in the
> substring implementation, rather than the flawed Java substring method? Or at
> least offer an additional utility method that does take a string with unicode
> codepoints that require surrogate pairs and substrings it correctly?
> I also posted my implementation at
> [https://stackoverflow.com/questions/55663213/java-substring-by-code-point-indices-treating-pairs-of-surrogate-code-units-as/]
> asking for advice and there is a more robust version as an answer.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)