[GitHub] [kafka] dajac merged pull request #9602: MINOR: Use string interpolation in FinalizedFeatureCache
dajac merged pull request #9602: URL: https://github.com/apache/kafka/pull/9602 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] dajac commented on pull request #9602: MINOR: Use string interpolation in FinalizedFeatureCache
dajac commented on pull request #9602: URL: https://github.com/apache/kafka/pull/9602#issuecomment-728753741 Failed test is unrelated. Merging to trunk. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (KAFKA-10730) KafkaApis#handleProduceRequest should use auto-generated protocol
[ https://issues.apache.org/jira/browse/KAFKA-10730?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Chia-Ping Tsai updated KAFKA-10730: --- Description: This is follow-up of KAFKA-9628 the construction of ProduceResponse is able to accept auto-generated protocol data so KafkaApis#handleProduceRequest should apply auto-generated protocol to avoid extra conversion. was:the construction of ProduceResponse is able to accept auto-generated protocol data so KafkaApis#handleProduceRequest should apply auto-generated protocol to avoid extra conversion. > KafkaApis#handleProduceRequest should use auto-generated protocol > - > > Key: KAFKA-10730 > URL: https://issues.apache.org/jira/browse/KAFKA-10730 > Project: Kafka > Issue Type: Improvement >Reporter: Chia-Ping Tsai >Assignee: Chia-Ping Tsai >Priority: Major > > This is follow-up of KAFKA-9628 > the construction of ProduceResponse is able to accept auto-generated protocol > data so KafkaApis#handleProduceRequest should apply auto-generated protocol > to avoid extra conversion. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (KAFKA-10730) KafkaApis#handleProduceRequest should use auto-generated protocol
Chia-Ping Tsai created KAFKA-10730: -- Summary: KafkaApis#handleProduceRequest should use auto-generated protocol Key: KAFKA-10730 URL: https://issues.apache.org/jira/browse/KAFKA-10730 Project: Kafka Issue Type: Improvement Reporter: Chia-Ping Tsai Assignee: Chia-Ping Tsai the construction of ProduceResponse is able to accept auto-generated protocol data so KafkaApis#handleProduceRequest should apply auto-generated protocol to avoid extra conversion. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-10726) How to detect heartbeat failure between broker/zookeeper leader
[ https://issues.apache.org/jira/browse/KAFKA-10726?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17233304#comment-17233304 ] Keiichiro Wakasa commented on KAFKA-10726: -- [~Jack-Lee] Hello Jack, thank you so much for your comment and so sorry for the confusion. The issue of heartbeat timeout has already been solved. (it's actually due to heavy logrotate on zk nodes.) *So we are just looking for the way to detect the timeout issue for the future occurance* > How to detect heartbeat failure between broker/zookeeper leader > --- > > Key: KAFKA-10726 > URL: https://issues.apache.org/jira/browse/KAFKA-10726 > Project: Kafka > Issue Type: Bug > Components: controller, logging >Affects Versions: 2.1.1 >Reporter: Keiichiro Wakasa >Priority: Critical > > Hello experts, > I'm not sure this is proper place to ask but I'd appreciate if you could help > us with the following question... > > We've continuously suffered from broker exclusion caused by heartbeat timeout > between broker and zookeeper leader. > This issue can be easily detected by checking ephemeral nodes via zkcli.sh > but we'd like to detect this with logs like server.log/controller.log since > we have an existing system to forward these logs to our system. > Looking at server.log/controller.log, we couldn't find any logs that > indicates the heartbeat timeout. Is there any other logs to check for > heartbeat health? -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-10726) How to detect heartbeat failure between broker/zookeeper leader
[ https://issues.apache.org/jira/browse/KAFKA-10726?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17233300#comment-17233300 ] lqjacklee commented on KAFKA-10726: --- If you are seeing excessive pauses during garbage collection, you can consider upgrading your JDK version or garbage collector (or extend your timeout value for zookeeper.session.timeout.ms). Additionally, you can tune your Java runtime to minimize garbage collection. The engineers at LinkedIn have written about optimizing JVM garbage collection in depth. Of course, you can also check the Kafka documentation for some recommendations. some metrics which provide more information can help you : ||Name|| Description || Metric type|| Availability|| |outstanding_requests |Number of requests queued| Resource: Saturation | Four-letter words, AdminServer, JMX| |avg_latency|Amount of time it takes to respond to a client request (in ms)|Work: Throughput|Four-letter words, AdminServer, JMX| |num_alive_connections|Number of clients connected to ZooKeeper|Resource: Availability|Four-letter words, AdminServer, JMX| |followers|Number of active followers|Resource: Availability|Four-letter words, AdminServer |pending_syncs|Number of pending syncs from followers|Other|Four-letter words, AdminServer, JMX| |open_file_descriptor_count|Number of file descriptors in use|Resource: Utilization|Four-letter words, AdminServer| > How to detect heartbeat failure between broker/zookeeper leader > --- > > Key: KAFKA-10726 > URL: https://issues.apache.org/jira/browse/KAFKA-10726 > Project: Kafka > Issue Type: Bug > Components: controller, logging >Affects Versions: 2.1.1 >Reporter: Keiichiro Wakasa >Priority: Critical > > Hello experts, > I'm not sure this is proper place to ask but I'd appreciate if you could help > us with the following question... > > We've continuously suffered from broker exclusion caused by heartbeat timeout > between broker and zookeeper leader. > This issue can be easily detected by checking ephemeral nodes via zkcli.sh > but we'd like to detect this with logs like server.log/controller.log since > we have an existing system to forward these logs to our system. > Looking at server.log/controller.log, we couldn't find any logs that > indicates the heartbeat timeout. Is there any other logs to check for > heartbeat health? -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Resolved] (KAFKA-10709) Sender#sendProduceRequest should use auto-generated protocol directly
[ https://issues.apache.org/jira/browse/KAFKA-10709?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Chia-Ping Tsai resolved KAFKA-10709. Resolution: Won't Fix This fix will be included by https://github.com/apache/kafka/pull/9401 > Sender#sendProduceRequest should use auto-generated protocol directly > - > > Key: KAFKA-10709 > URL: https://issues.apache.org/jira/browse/KAFKA-10709 > Project: Kafka > Issue Type: Improvement >Reporter: Chia-Ping Tsai >Assignee: Chia-Ping Tsai >Priority: Minor > > That can avoid extra conversion to improve the performance. > related discussion: > https://github.com/apache/kafka/pull/9401#discussion_r521902936 -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] lqjack commented on a change in pull request #9596: KAFKA-10723: Fix LogManager shutdown error handling
lqjack commented on a change in pull request #9596:
URL: https://github.com/apache/kafka/pull/9596#discussion_r524907470
##
File path: core/src/test/scala/unit/kafka/log/LogManagerTest.scala
##
@@ -83,6 +87,51 @@ class LogManagerTest {
log.appendAsLeader(TestUtils.singletonRecords("test".getBytes()),
leaderEpoch = 0)
}
+ /**
+ * Tests that all internal futures are completed before
LogManager.shutdown() returns to the
+ * caller during error situations.
+ */
+ @Test
+ def testHandlingExceptionsDuringShutdown(): Unit = {
+logManager.shutdown()
+
+// We create two directories logDir1 and logDir2 to help effectively test
error handling
+// during LogManager.shutdown().
+val logDir1 = TestUtils.tempDir()
+val logDir2 = TestUtils.tempDir()
+logManager = createLogManager(Seq(logDir1, logDir2))
+assertEquals(2, logManager.liveLogDirs.size)
+logManager.startup()
+
+val log1 = logManager.getOrCreateLog(new TopicPartition(name, 0), () =>
logConfig)
+val log2 = logManager.getOrCreateLog(new TopicPartition(name, 1), () =>
logConfig)
+
+val logFile1 = new File(logDir1, name + "-0")
+assertTrue(logFile1.exists)
+val logFile2 = new File(logDir2, name + "-1")
+assertTrue(logFile2.exists)
+
+log1.appendAsLeader(TestUtils.singletonRecords("test1".getBytes()),
leaderEpoch = 0)
+log1.takeProducerSnapshot()
+log1.appendAsLeader(TestUtils.singletonRecords("test1".getBytes()),
leaderEpoch = 0)
+
+log2.appendAsLeader(TestUtils.singletonRecords("test2".getBytes()),
leaderEpoch = 0)
+log2.takeProducerSnapshot()
+log2.appendAsLeader(TestUtils.singletonRecords("test2".getBytes()),
leaderEpoch = 0)
+
+// This should cause log1.close() to fail during LogManger shutdown
sequence.
+FileUtils.deleteDirectory(logFile1)
Review comment:
What if error occur during the shutdown of the broker ? should we log
the error info to the log or just throw the exception ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (KAFKA-10666) Kafka doesn't use keystore / key / truststore passwords for named SSL connections
[ https://issues.apache.org/jira/browse/KAFKA-10666?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17233277#comment-17233277 ] lqjacklee commented on KAFKA-10666: --- [~pfjason] Does https://issues.apache.org/jira/browse/KAFKA-10700 can resolve the issue you provided ? > Kafka doesn't use keystore / key / truststore passwords for named SSL > connections > - > > Key: KAFKA-10666 > URL: https://issues.apache.org/jira/browse/KAFKA-10666 > Project: Kafka > Issue Type: Bug > Components: admin >Affects Versions: 2.5.0, 2.6.0 > Environment: kafka in an openjdk-11 docker container, the client java > application is in an alpine container. zookeeper in a separate container. >Reporter: Jason >Priority: Minor > > When configuring named listener SSL connections with ssl key and keystore > with passwords including listener.name.ourname.ssl.key.password, > listener.name.ourname.ssl.keystore.password, and > listener.name.ourname.ssl.truststore.password via via the AdminClient the > settings are not used and the setting is not accepted if the default > ssl.key.password or ssl.keystore.password are not set. We configure all > keystore and truststore values for the named listener in a single batch using > incrementalAlterConfigs. Additionally, when ssl.keystore.password is set to > the value of our keystore password the keystore is loaded for SSL > communication without issue, however if ssl.keystore.password is incorrect > and listener.name.ourname.keystore.password is correct, we are unable to load > the keystore with bad password errors. It appears that only the default > ssl.xxx.password settings are used. This setting is immutable as when we > attempt to set it we get an error indicating that the listener.name. setting > can be set. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] quanuw commented on pull request #9598: KAFKA-10701 : First line of detailed stats from consumer-perf-test.sh incorrect
quanuw commented on pull request #9598: URL: https://github.com/apache/kafka/pull/9598#issuecomment-728698903 Hi @lijubjohn, can you explain how having joinStart initialized to 0L led to a negative fetchTimeMs? I'm new to the project and not sure how having joinStart initialized as 0L could have been the problem. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] kowshik opened a new pull request #9602: MINOR: Use string interpolation in FinalizedFeatureCache
kowshik opened a new pull request #9602: URL: https://github.com/apache/kafka/pull/9602 This is a small change. In this PR, I'm using string interpolation in `FinalizedFeatureCache` at places where string format was otherwise used. This just ensures uniformity, with this change we ensure that throughout the file we just use string interpolation. **Test plan:** Rely on existing tests since this PR is not changing behavior. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
hachikuji commented on pull request #9401: URL: https://github.com/apache/kafka/pull/9401#issuecomment-728669194 @chia7712 It might be worth checking the fancy new `toSend` implementation. I did a quick test and found that gc overhead actually increased with this change even though the new implementation seemed much better for cpu. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
chia7712 commented on pull request #9401: URL: https://github.com/apache/kafka/pull/9401#issuecomment-728664200 @hachikuji @ijuma Thanks for all feedback. I'm going to do more tests :) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] kowshik commented on pull request #9596: KAFKA-10723: Fix LogManager shutdown error handling
kowshik commented on pull request #9596: URL: https://github.com/apache/kafka/pull/9596#issuecomment-728654950 Thanks for the review @junrao! I have addressed the comments in f917f0c24cebbb0fb5eb7029ccb6676734b60b3e. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] kowshik commented on a change in pull request #9596: KAFKA-10723: Fix LogManager shutdown error handling
kowshik commented on a change in pull request #9596:
URL: https://github.com/apache/kafka/pull/9596#discussion_r524853231
##
File path: core/src/test/scala/unit/kafka/log/LogManagerTest.scala
##
@@ -83,6 +87,51 @@ class LogManagerTest {
log.appendAsLeader(TestUtils.singletonRecords("test".getBytes()),
leaderEpoch = 0)
}
+ /**
+ * Tests that all internal futures are completed before
LogManager.shutdown() returns to the
+ * caller during error situations.
+ */
+ @Test
+ def testHandlingExceptionsDuringShutdown(): Unit = {
+logManager.shutdown()
Review comment:
Thinking about it again, you are right. I have eliminated the need for
the `shutdown()` now by using a `LogManager` instance specific to the test.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Commented] (KAFKA-10062) Add a method to retrieve the current timestamp as known by the Streams app
[ https://issues.apache.org/jira/browse/KAFKA-10062?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17233230#comment-17233230 ] Rohit Deshpande commented on KAFKA-10062: - Thank you [~wbottrell] > Add a method to retrieve the current timestamp as known by the Streams app > -- > > Key: KAFKA-10062 > URL: https://issues.apache.org/jira/browse/KAFKA-10062 > Project: Kafka > Issue Type: Improvement > Components: streams >Reporter: Piotr Smolinski >Assignee: William Bottrell >Priority: Major > Labels: needs-kip, newbie > > Please add to the ProcessorContext a method to retrieve current timestamp > compatible with Punctuator#punctate(long) method. > Proposal in ProcessorContext: > long getTimestamp(PunctuationType type); > The method should return time value as known by the Punctuator scheduler with > the respective PunctuationType. > The use-case is tracking of a process with timeout-based escalation. > A transformer receives process events and in case of missing an event execute > an action (emit message) after given escalation timeout (several stages). The > initial message may already arrive with reference timestamp in the past and > may trigger different action upon arrival depending on how far in the past it > is. > If the timeout should be computed against some further time only, Punctuator > is perfectly sufficient. The problem is that I have to evaluate the current > time-related state once the message arrives. > I am using wall-clock time. Normally accessing System.currentTimeMillis() is > sufficient, but it breaks in unit testing with TopologyTestDriver, where the > app wall clock time is different from the system-wide one. > To access the mentioned clock I am using reflection to access > ProcessorContextImpl#task and then StreamTask#time. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Assigned] (KAFKA-10062) Add a method to retrieve the current timestamp as known by the Streams app
[ https://issues.apache.org/jira/browse/KAFKA-10062?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Rohit Deshpande reassigned KAFKA-10062: --- Assignee: Rohit Deshpande (was: William Bottrell) > Add a method to retrieve the current timestamp as known by the Streams app > -- > > Key: KAFKA-10062 > URL: https://issues.apache.org/jira/browse/KAFKA-10062 > Project: Kafka > Issue Type: Improvement > Components: streams >Reporter: Piotr Smolinski >Assignee: Rohit Deshpande >Priority: Major > Labels: needs-kip, newbie > > Please add to the ProcessorContext a method to retrieve current timestamp > compatible with Punctuator#punctate(long) method. > Proposal in ProcessorContext: > long getTimestamp(PunctuationType type); > The method should return time value as known by the Punctuator scheduler with > the respective PunctuationType. > The use-case is tracking of a process with timeout-based escalation. > A transformer receives process events and in case of missing an event execute > an action (emit message) after given escalation timeout (several stages). The > initial message may already arrive with reference timestamp in the past and > may trigger different action upon arrival depending on how far in the past it > is. > If the timeout should be computed against some further time only, Punctuator > is perfectly sufficient. The problem is that I have to evaluate the current > time-related state once the message arrives. > I am using wall-clock time. Normally accessing System.currentTimeMillis() is > sufficient, but it breaks in unit testing with TopologyTestDriver, where the > app wall clock time is different from the system-wide one. > To access the mentioned clock I am using reflection to access > ProcessorContextImpl#task and then StreamTask#time. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] kowshik commented on a change in pull request #9596: KAFKA-10723: Fix LogManager shutdown error handling
kowshik commented on a change in pull request #9596:
URL: https://github.com/apache/kafka/pull/9596#discussion_r524848584
##
File path: core/src/test/scala/unit/kafka/log/LogManagerTest.scala
##
@@ -83,6 +87,51 @@ class LogManagerTest {
log.appendAsLeader(TestUtils.singletonRecords("test".getBytes()),
leaderEpoch = 0)
}
+ /**
+ * Tests that all internal futures are completed before
LogManager.shutdown() returns to the
+ * caller during error situations.
+ */
+ @Test
+ def testHandlingExceptionsDuringShutdown(): Unit = {
+logManager.shutdown()
Review comment:
Yeah this explicit shutdown is needed to:
1) Re-create a new `LogManager` instance with multiple `logDirs` for this
test. This is different from the default one provided in `setUp()`.
2) Help do some additional checks post shutdown (towards the end of this
test).
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] kowshik commented on a change in pull request #9596: KAFKA-10723: Fix LogManager shutdown error handling
kowshik commented on a change in pull request #9596:
URL: https://github.com/apache/kafka/pull/9596#discussion_r524847888
##
File path: core/src/main/scala/kafka/log/LogManager.scala
##
@@ -477,27 +477,41 @@ class LogManager(logDirs: Seq[File],
jobs(dir) = jobsForDir.map(pool.submit).toSeq
}
+var firstExceptionOpt: Option[Throwable] = Option.empty
try {
for ((dir, dirJobs) <- jobs) {
-dirJobs.foreach(_.get)
+val errorsForDirJobs = dirJobs.map {
+ future =>
+try {
+ future.get
+ Option.empty
+} catch {
+ case e: ExecutionException =>
+error(s"There was an error in one of the threads during
LogManager shutdown: ${e.getCause}")
+Some(e.getCause)
+}
+}.filter{ e => e.isDefined }.map{ e => e.get }
+
+if (firstExceptionOpt.isEmpty) {
+ firstExceptionOpt = errorsForDirJobs.headOption
+}
-val logs = logsInDir(localLogsByDir, dir)
+if (errorsForDirJobs.isEmpty) {
+ val logs = logsInDir(localLogsByDir, dir)
-// update the last flush point
-debug(s"Updating recovery points at $dir")
-checkpointRecoveryOffsetsInDir(dir, logs)
+ // update the last flush point
+ debug(s"Updating recovery points at $dir")
+ checkpointRecoveryOffsetsInDir(dir, logs)
-debug(s"Updating log start offsets at $dir")
-checkpointLogStartOffsetsInDir(dir, logs)
+ debug(s"Updating log start offsets at $dir")
+ checkpointLogStartOffsetsInDir(dir, logs)
-// mark that the shutdown was clean by creating marker file
-debug(s"Writing clean shutdown marker at $dir")
-CoreUtils.swallow(Files.createFile(new File(dir,
Log.CleanShutdownFile).toPath), this)
+ // mark that the shutdown was clean by creating marker file
+ debug(s"Writing clean shutdown marker at $dir")
+ CoreUtils.swallow(Files.createFile(new File(dir,
Log.CleanShutdownFile).toPath), this)
+}
}
-} catch {
- case e: ExecutionException =>
-error(s"There was an error in one of the threads during LogManager
shutdown: ${e.getCause}")
-throw e.getCause
+ firstExceptionOpt.foreach{ e => throw e}
Review comment:
Great point. I've changed the code to do the same.
My understanding is that the exception swallow safety net exists inside
`KafkaServer.shutdown()` today, but it makes sense to also just log a warning
here instead instead of relying on the safety net:
https://github.com/apache/kafka/blob/bb34c5c8cc32d1b769a34329e34b83cda040aafc/core/src/main/scala/kafka/server/KafkaServer.scala#L732.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
hachikuji commented on pull request #9401: URL: https://github.com/apache/kafka/pull/9401#issuecomment-728643380 I think the large difference in latency in my test is due to the producer's buffer pool getting exhausted. I was looking at the "bufferpool-wait-ratio" metric exposed in the producer. With this patch, it was hovering around 0.6 while on trunk it remained around 0.01. I'll need to lower the throughput a little bit in order to get a better estimate of the regression. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] hachikuji edited a comment on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
hachikuji edited a comment on pull request #9401: URL: https://github.com/apache/kafka/pull/9401#issuecomment-728383115 Posting allocation flame graphs from the producer before and after this patch: 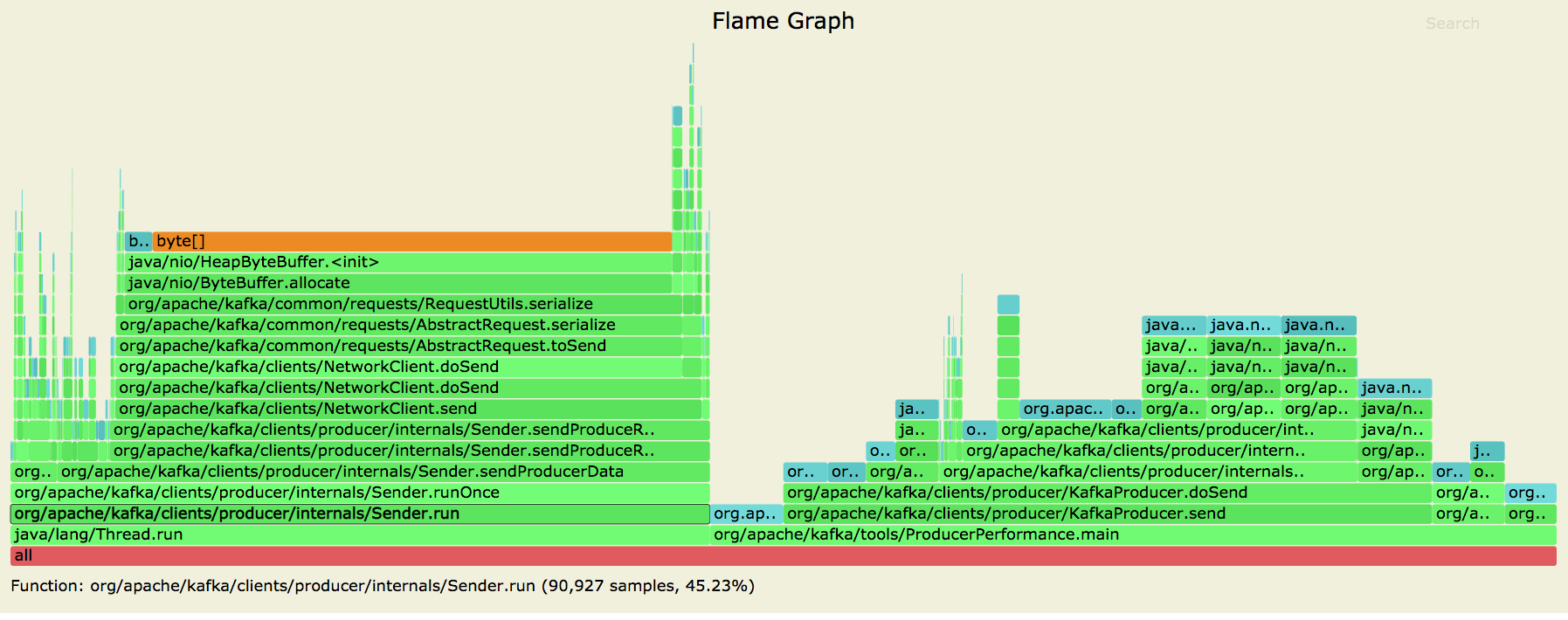 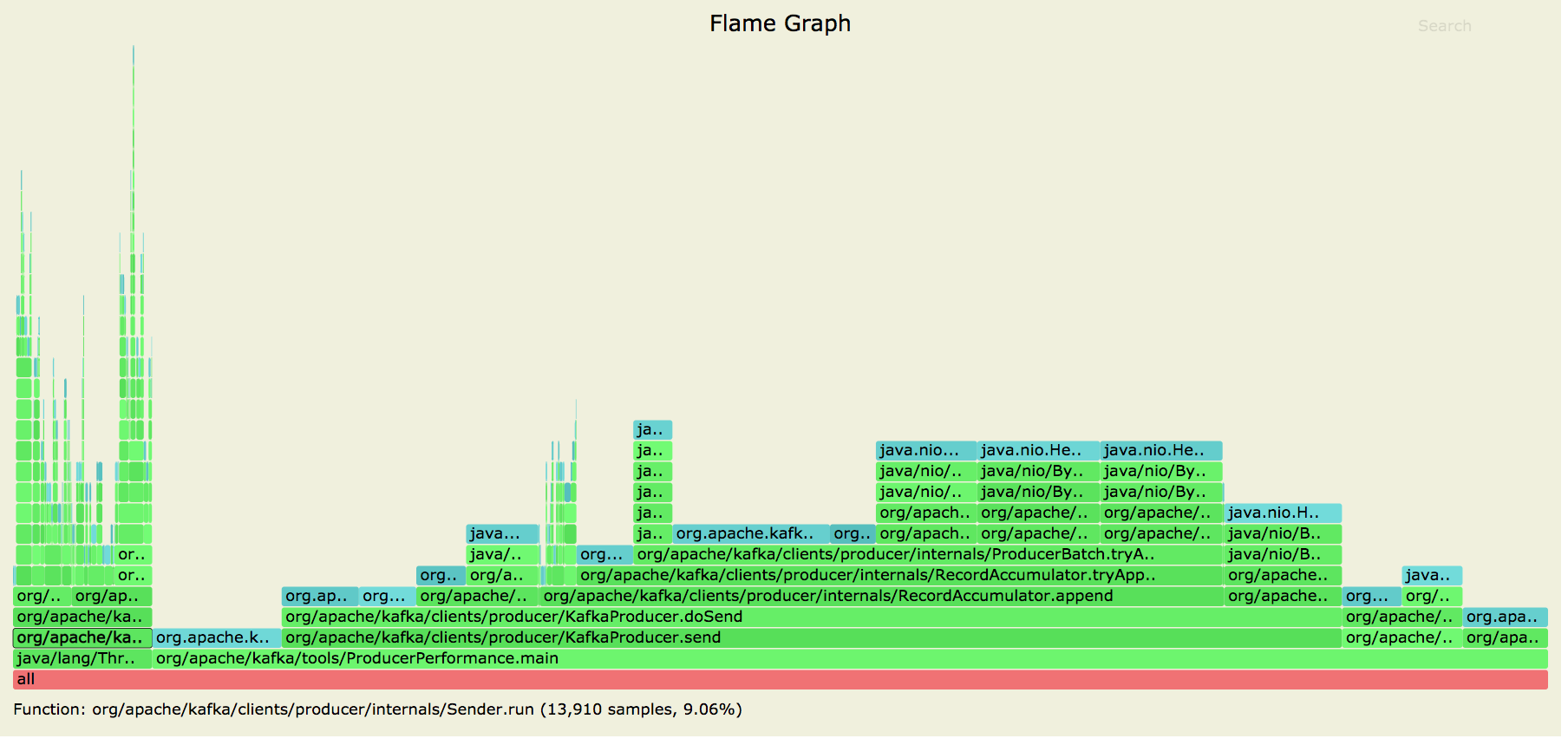 So we succeeded in getting rid of the extra allocations in the network layer! I generated these graphs using the producer performance test writing to a topic with 10 partitions on a cluster with a single broker. ``` > bin/kafka-producer-perf-test.sh --topic foo --num-records 25000 --throughput -1 --record-size 256 --producer-props bootstrap.servers=localhost:9092 ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #9487: KAFKA-9331: Add a streams specific uncaught exception handler
ableegoldman commented on a change in pull request #9487:
URL: https://github.com/apache/kafka/pull/9487#discussion_r524824649
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamThread.java
##
@@ -559,18 +552,52 @@ void runLoop() {
}
} catch (final TaskCorruptedException e) {
log.warn("Detected the states of tasks " +
e.corruptedTaskWithChangelogs() + " are corrupted. " +
- "Will close the task as dirty and re-create and
bootstrap from scratch.", e);
+"Will close the task as dirty and re-create and
bootstrap from scratch.", e);
try {
taskManager.handleCorruption(e.corruptedTaskWithChangelogs());
} catch (final TaskMigratedException taskMigrated) {
handleTaskMigrated(taskMigrated);
}
} catch (final TaskMigratedException e) {
handleTaskMigrated(e);
+} catch (final UnsupportedVersionException e) {
Review comment:
Mm ok actually I think this should be fine. I was thinking of the
handler as just "swallowing" the exception, but in reality the user would still
let the current thread die and just spin up a new one in its place. And then
the new one would hit this UnsupportedVersionException and so on, until the
brokers are upgraded. So there shouldn't be any way to get into a bad state
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] twobeeb edited a comment on pull request #9589: KAFKA-10710 - Mirror Maker 2 - Create herders only if source->target.enabled=true
twobeeb edited a comment on pull request #9589: URL: https://github.com/apache/kafka/pull/9589#issuecomment-728593310 @ryannedolan @hachikuji If I understand correctly, when setting up a link A->B.enabled=true (with defaults settings regarding heartbeat), it creates a topic heartbeat which produces beats on B I figured it was the other way around, so that the topic could be picked up by replication process, leading to a replicated topic B.heartbeat (which we monitor actually). Looking into my configuration, I now understand that I was lucky because I have one link going up back up ``replica_OLS->replica_CENTRAL`` which is now the single emitter of beats (which are then replicated in every other cluster) Reading the KIP led me to interpret that the production of heartbeat would be done within the same herder (the source one) : > Internal Topics > MM2 emits a heartbeat topic in each source cluster, which is replicated to demonstrate connectivity through the connectors. Wouldn't it make more sense to produce the beats into the source side of the replication ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] gardnervickers commented on a change in pull request #9601: MINOR: Enable flexible versioning for ListOffsetRequest/ListOffsetResponse.
gardnervickers commented on a change in pull request #9601:
URL: https://github.com/apache/kafka/pull/9601#discussion_r524820388
##
File path: core/src/main/scala/kafka/api/ApiVersion.scala
##
@@ -424,6 +426,13 @@ case object KAFKA_2_7_IV2 extends DefaultApiVersion {
val id: Int = 30
}
+case object KAFKA_2_7_IV3 extends DefaultApiVersion {
Review comment:
Thanks, that makes more sense.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] twobeeb edited a comment on pull request #9589: KAFKA-10710 - Mirror Maker 2 - Create herders only if source->target.enabled=true
twobeeb edited a comment on pull request #9589: URL: https://github.com/apache/kafka/pull/9589#issuecomment-728593310 @ryannedolan @hachikuji If I understand correctly, when setting up a link A->B.enabled=true (with defaults settings regarding heartbeat), it creates a topic heartbeat which produces beats on B I figured it was the other way around, so that the topic could be picked up by replication process, leading to a replicated topic B.heartbeat (which we monitor actually). Looking into my configuration, I now understand that I was lucky because I have one link going up back up ``replica_OLS->replica_CENTRAL`` which is now the single emitter of beats (which are then replicated in every other cluster) Reading the KIP led me to interpret that the production of heartbeat would be done within the same herder (the source one) : > Internal Topics > MM2 emits a heartbeat topic in each source cluster, which is replicated to demonstrate connectivity through the connectors. Wouldn't it make more sense to produce the beats from the same "side" of the replication ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] twobeeb commented on pull request #9589: KAFKA-10710 - Mirror Maker 2 - Create herders only if source->target.enabled=true
twobeeb commented on pull request #9589: URL: https://github.com/apache/kafka/pull/9589#issuecomment-728593310 @ryannedolan @hachikuji If I understand correctly, when setting up a link A->B.enabled=true (with defaults settings regarding heartbeat), it creates a topic heartbeat which produces beats on B I figured it was the other way around, so that the topic could be picked up by replication process, leading to a replicated topic B.heartbeat (which we monitor actually). Looking into my configuration, I now understand that I was lucky because I have one link going up back up ``replica_OLS->replica_CENTRAL`` which is now the single emitter of beats (which are then replicated in every other cluster) Reading the KIP lead me to interpret that the production of heartbeat would be done within the same herder (the source one) : > Internal Topics > MM2 emits a heartbeat topic in each source cluster, which is replicated to demonstrate connectivity through the connectors. Wouldn't it make more sense to produce the beats from the same "side" of the replication ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #9487: KAFKA-9331: Add a streams specific uncaught exception handler
ableegoldman commented on a change in pull request #9487:
URL: https://github.com/apache/kafka/pull/9487#discussion_r524819063
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamThread.java
##
@@ -559,18 +552,52 @@ void runLoop() {
}
} catch (final TaskCorruptedException e) {
log.warn("Detected the states of tasks " +
e.corruptedTaskWithChangelogs() + " are corrupted. " +
- "Will close the task as dirty and re-create and
bootstrap from scratch.", e);
+"Will close the task as dirty and re-create and
bootstrap from scratch.", e);
try {
taskManager.handleCorruption(e.corruptedTaskWithChangelogs());
} catch (final TaskMigratedException taskMigrated) {
handleTaskMigrated(taskMigrated);
}
} catch (final TaskMigratedException e) {
handleTaskMigrated(e);
+} catch (final UnsupportedVersionException e) {
Review comment:
Just to clarify I think it's ok to leave this as-is for now, since as
Walker said all handler options are fatal at this point
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #9487: KAFKA-9331: Add a streams specific uncaught exception handler
ableegoldman commented on a change in pull request #9487:
URL: https://github.com/apache/kafka/pull/9487#discussion_r524817135
##
File path: streams/src/main/java/org/apache/kafka/streams/KafkaStreams.java
##
@@ -366,6 +374,63 @@ public void setUncaughtExceptionHandler(final
Thread.UncaughtExceptionHandler eh
}
}
+/**
+ * Set the handler invoked when an {@link
StreamsConfig#NUM_STREAM_THREADS_CONFIG internal thread}
+ * throws an unexpected exception.
+ * These might be exceptions indicating rare bugs in Kafka Streams, or they
+ * might be exceptions thrown by your code, for example a
NullPointerException thrown from your processor
+ * logic.
+ *
+ * Note, this handler must be threadsafe, since it will be shared among
all threads, and invoked from any
+ * thread that encounters such an exception.
+ *
+ * @param streamsUncaughtExceptionHandler the uncaught exception handler
of type {@link StreamsUncaughtExceptionHandler} for all internal threads
+ * @throws IllegalStateException if this {@code KafkaStreams} instance is
not in state {@link State#CREATED CREATED}.
+ * @throws NullPointerException if streamsUncaughtExceptionHandler is null.
+ */
+public void setUncaughtExceptionHandler(final
StreamsUncaughtExceptionHandler streamsUncaughtExceptionHandler) {
+final StreamsUncaughtExceptionHandler handler = exception ->
handleStreamsUncaughtException(exception, streamsUncaughtExceptionHandler);
+synchronized (stateLock) {
+if (state == State.CREATED) {
+Objects.requireNonNull(streamsUncaughtExceptionHandler);
+for (final StreamThread thread : threads) {
+thread.setStreamsUncaughtExceptionHandler(handler);
+}
+if (globalStreamThread != null) {
+globalStreamThread.setUncaughtExceptionHandler(handler);
+}
+} else {
+throw new IllegalStateException("Can only set
UncaughtExceptionHandler in CREATED state. " +
+"Current state is: " + state);
+}
+}
+}
+
+private StreamsUncaughtExceptionHandler.StreamThreadExceptionResponse
handleStreamsUncaughtException(final Throwable e,
+
final StreamsUncaughtExceptionHandler
streamsUncaughtExceptionHandler) {
+final StreamsUncaughtExceptionHandler.StreamThreadExceptionResponse
action = streamsUncaughtExceptionHandler.handle(e);
+switch (action) {
+case SHUTDOWN_CLIENT:
+log.error("Encountered the following exception during
processing " +
+"and the registered exception handler opted to \" +
action + \"." +
+" The streams client is going to shut down now. ", e);
+close(Duration.ZERO);
Review comment:
> Since the stream thread is alive when it calls close() there will not
be a deadlock anymore. So, why do we call close() with duration zero
@cadonna can you clarify? I thought we would still be in danger of deadlock
if we use the blocking `close()`, since `close()` will not return until every
thread has joined but the StreamThread that called `close()` would be stuck in
this blocking call and thus never stop/join
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on a change in pull request #9487: KAFKA-9331: Add a streams specific uncaught exception handler
ableegoldman commented on a change in pull request #9487:
URL: https://github.com/apache/kafka/pull/9487#discussion_r524814932
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamThread.java
##
@@ -559,18 +552,52 @@ void runLoop() {
}
} catch (final TaskCorruptedException e) {
log.warn("Detected the states of tasks " +
e.corruptedTaskWithChangelogs() + " are corrupted. " +
- "Will close the task as dirty and re-create and
bootstrap from scratch.", e);
+"Will close the task as dirty and re-create and
bootstrap from scratch.", e);
try {
taskManager.handleCorruption(e.corruptedTaskWithChangelogs());
} catch (final TaskMigratedException taskMigrated) {
handleTaskMigrated(taskMigrated);
}
} catch (final TaskMigratedException e) {
handleTaskMigrated(e);
+} catch (final UnsupportedVersionException e) {
Review comment:
That's a fair point about broker upgrades, but don't we require the
brokers to be upgraded to a version that supports EOS _before_ turning on
eos-beta?
Anyways I was wondering if there was something special about this exception
such that ignoring it could violate eos or corrupt the state of the program.
I'll ping the eos experts to assuage my concerns
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
hachikuji commented on pull request #9401: URL: https://github.com/apache/kafka/pull/9401#issuecomment-728545356 It would be helpful if someone can reproduce the tests I did to make sure it is not something funky in my environment. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ijuma commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
ijuma commented on pull request #9401: URL: https://github.com/apache/kafka/pull/9401#issuecomment-728531187 That is really weird. The difference seems significant enough that we need to understand it better before we can merge IMO. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ableegoldman commented on pull request #9583: [KAFKA-10705]: Make state stores not readable by others
ableegoldman commented on pull request #9583: URL: https://github.com/apache/kafka/pull/9583#issuecomment-728523131 I don't think so. It would be nice to have if you happen to end up cutting a new RC, but I wouldn't delay the ongoing release over this This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] jolshan commented on pull request #9590: KAFKA-7556: KafkaConsumer.beginningOffsets does not return actual first offsets
jolshan commented on pull request #9590: URL: https://github.com/apache/kafka/pull/9590#issuecomment-728513284 Also looks like the test I added may be flaky, so I'll take a look at that. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
hachikuji commented on pull request #9401: URL: https://github.com/apache/kafka/pull/9401#issuecomment-728486374 Yeah, there is something strange going on, especially in regard to latency. Running the same producer performance test, I saw the following: ``` Patch: 25000 records sent, 1347222.297068 records/sec (328.91 MB/sec), 91.98 ms avg latency, 1490.00 ms max latency, 71 ms 50th, 242 ms 95th, 320 ms 99th, 728 ms 99.9th. Trunk: 25000 records sent, 1426264.954388 records/sec (348.21 MB/sec), 15.11 ms avg latency, 348.00 ms max latency, 3 ms 50th, 94 ms 95th, 179 ms 99th, 265 ms 99.9th. ``` I was able to reproduce similar results several times. Take this with a grain of salt, but from the flame graphs, I see the following differences: `RequestContext.parseRequest`: 1% -> 0.45% `RequestUtils.hasTransactionalRecords`: 0% -> 0.59% `RequestUtils.hasIdempotentRecords`: 0% -> 0.14% `KafkaApis.sendResponseCallback`: 3.20% -> 2.33% `KafkaApis.clearPartitionRecords`: 0% -> 0.16% I think `hasTransactionalRecords` and `hasIdempotentRecords` are the most obvious optimization targets (they also show up in allocations), but I do not think they explain the increase in latency. Just to be sure, I commented out these lines and I got similar results. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-10062) Add a method to retrieve the current timestamp as known by the Streams app
[ https://issues.apache.org/jira/browse/KAFKA-10062?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17233170#comment-17233170 ] William Bottrell commented on KAFKA-10062: -- Go ahead and take over. I had left off at the KIP approval step. > Add a method to retrieve the current timestamp as known by the Streams app > -- > > Key: KAFKA-10062 > URL: https://issues.apache.org/jira/browse/KAFKA-10062 > Project: Kafka > Issue Type: Improvement > Components: streams >Reporter: Piotr Smolinski >Assignee: William Bottrell >Priority: Major > Labels: needs-kip, newbie > > Please add to the ProcessorContext a method to retrieve current timestamp > compatible with Punctuator#punctate(long) method. > Proposal in ProcessorContext: > long getTimestamp(PunctuationType type); > The method should return time value as known by the Punctuator scheduler with > the respective PunctuationType. > The use-case is tracking of a process with timeout-based escalation. > A transformer receives process events and in case of missing an event execute > an action (emit message) after given escalation timeout (several stages). The > initial message may already arrive with reference timestamp in the past and > may trigger different action upon arrival depending on how far in the past it > is. > If the timeout should be computed against some further time only, Punctuator > is perfectly sufficient. The problem is that I have to evaluate the current > time-related state once the message arrives. > I am using wall-clock time. Normally accessing System.currentTimeMillis() is > sufficient, but it breaks in unit testing with TopologyTestDriver, where the > app wall clock time is different from the system-wide one. > To access the mentioned clock I am using reflection to access > ProcessorContextImpl#task and then StreamTask#time. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-10062) Add a method to retrieve the current timestamp as known by the Streams app
[ https://issues.apache.org/jira/browse/KAFKA-10062?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17233158#comment-17233158 ] Rohit Deshpande commented on KAFKA-10062: - Thanks [~cadonna] I will wait for the response. > Add a method to retrieve the current timestamp as known by the Streams app > -- > > Key: KAFKA-10062 > URL: https://issues.apache.org/jira/browse/KAFKA-10062 > Project: Kafka > Issue Type: Improvement > Components: streams >Reporter: Piotr Smolinski >Assignee: William Bottrell >Priority: Major > Labels: needs-kip, newbie > > Please add to the ProcessorContext a method to retrieve current timestamp > compatible with Punctuator#punctate(long) method. > Proposal in ProcessorContext: > long getTimestamp(PunctuationType type); > The method should return time value as known by the Punctuator scheduler with > the respective PunctuationType. > The use-case is tracking of a process with timeout-based escalation. > A transformer receives process events and in case of missing an event execute > an action (emit message) after given escalation timeout (several stages). The > initial message may already arrive with reference timestamp in the past and > may trigger different action upon arrival depending on how far in the past it > is. > If the timeout should be computed against some further time only, Punctuator > is perfectly sufficient. The problem is that I have to evaluate the current > time-related state once the message arrives. > I am using wall-clock time. Normally accessing System.currentTimeMillis() is > sufficient, but it breaks in unit testing with TopologyTestDriver, where the > app wall clock time is different from the system-wide one. > To access the mentioned clock I am using reflection to access > ProcessorContextImpl#task and then StreamTask#time. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] ijuma commented on a change in pull request #9566: KAFKA-10618: Update to Uuid class
ijuma commented on a change in pull request #9566:
URL: https://github.com/apache/kafka/pull/9566#discussion_r524738967
##
File path: clients/src/test/java/org/apache/kafka/common/UuidTest.java
##
@@ -21,50 +21,50 @@
import static org.junit.Assert.assertEquals;
import static org.junit.Assert.assertNotEquals;
-public class UUIDTest {
+public class UuidTest {
@Test
public void testSignificantBits() {
-UUID id = new UUID(34L, 98L);
+Uuid id = new Uuid(34L, 98L);
assertEquals(id.getMostSignificantBits(), 34L);
assertEquals(id.getLeastSignificantBits(), 98L);
}
@Test
-public void testUUIDEquality() {
-UUID id1 = new UUID(12L, 13L);
-UUID id2 = new UUID(12L, 13L);
-UUID id3 = new UUID(24L, 38L);
+public void testUuidEquality() {
Review comment:
We don't have to specify it, but it would be good to ensure we have a
test for the actual hashCode we're implementing. At the moment, we are only
verifying that the hashCode is the same for two equal UUIDs and different for
two unequal UUIDs. One option would be to have a few tests where we verify that
the result is what we expect it to be.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] vvcephei commented on a change in pull request #9570: KAFKA-9274: Handle TimeoutException on commit
vvcephei commented on a change in pull request #9570:
URL: https://github.com/apache/kafka/pull/9570#discussion_r524564694
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamTask.java
##
@@ -817,13 +817,15 @@ private void initializeMetadata() {
.filter(e -> e.getValue() != null)
.collect(Collectors.toMap(Map.Entry::getKey,
Map.Entry::getValue));
initializeTaskTime(offsetsAndMetadata);
-} catch (final TimeoutException e) {
-log.warn("Encountered {} while trying to fetch committed offsets,
will retry initializing the metadata in the next loop." +
-"\nConsider overwriting consumer config {} to a
larger value to avoid timeout errors",
-e.toString(),
-ConsumerConfig.DEFAULT_API_TIMEOUT_MS_CONFIG);
-
-throw e;
+} catch (final TimeoutException timeoutException) {
+log.warn(
+"Encountered {} while trying to fetch committed offsets, will
retry initializing the metadata in the next loop." +
+"\nConsider overwriting consumer config {} to a larger
value to avoid timeout errors",
+time.toString(),
+ConsumerConfig.DEFAULT_API_TIMEOUT_MS_CONFIG);
Review comment:
It might still be nice to see the stacktrace here (even if it also gets
logged elsewhere). If you want to do it, don't forget you have to change to
using `String.format` for the variable substitution.
I don't feel strongly in this case, so I'll defer to you whether you want to
do this or not.
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/TaskManager.java
##
@@ -1029,20 +1048,40 @@ int commit(final Collection tasksToCommit) {
return -1;
} else {
int committed = 0;
-final Map>
consumedOffsetsAndMetadataPerTask = new HashMap<>();
-for (final Task task : tasksToCommit) {
+final Map>
consumedOffsetsAndMetadataPerTask = new HashMap<>();
+final Iterator it = tasksToCommit.iterator();
+while (it.hasNext()) {
+final Task task = it.next();
if (task.commitNeeded()) {
final Map
offsetAndMetadata = task.prepareCommit();
if (task.isActive()) {
-consumedOffsetsAndMetadataPerTask.put(task.id(),
offsetAndMetadata);
+consumedOffsetsAndMetadataPerTask.put(task,
offsetAndMetadata);
}
+} else {
+it.remove();
}
}
-commitOffsetsOrTransaction(consumedOffsetsAndMetadataPerTask);
+final Set uncommittedTasks = new HashSet<>();
+try {
+commitOffsetsOrTransaction(consumedOffsetsAndMetadataPerTask);
+tasksToCommit.forEach(Task::clearTaskTimeout);
+} catch (final TaskTimeoutExceptions taskTimeoutExceptions) {
+final TimeoutException timeoutException =
taskTimeoutExceptions.timeoutException();
+if (timeoutException != null) {
+tasksToCommit.forEach(t ->
t.maybeInitTaskTimeoutOrThrow(time.milliseconds(), timeoutException));
+uncommittedTasks.addAll(tasksToCommit);
+} else {
+for (final Map.Entry
timeoutExceptions : taskTimeoutExceptions.exceptions().entrySet()) {
+final Task task = timeoutExceptions.getKey();
+task.maybeInitTaskTimeoutOrThrow(time.milliseconds(),
timeoutExceptions.getValue());
+uncommittedTasks.add(task);
+}
+}
+}
for (final Task task : tasksToCommit) {
-if (task.commitNeeded()) {
+if (!uncommittedTasks.contains(task)) {
++committed;
task.postCommit(false);
Review comment:
maybe we should move `clearTaskTimeout` here, in case some of the tasks
timed out, but not all?
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/TaskManager.java
##
@@ -1029,20 +1048,40 @@ int commit(final Collection tasksToCommit) {
return -1;
} else {
int committed = 0;
-final Map>
consumedOffsetsAndMetadataPerTask = new HashMap<>();
-for (final Task task : tasksToCommit) {
+final Map>
consumedOffsetsAndMetadataPerTask = new HashMap<>();
+final Iterator it = tasksToCommit.iterator();
Review comment:
I was initially worried about potential side-effects of removing from
the input collection, but on second thought, maybe it's reasonable (considering
the usage of this method) to assume that
[GitHub] [kafka] jolshan commented on a change in pull request #9566: KAFKA-10618: Update to Uuid class
jolshan commented on a change in pull request #9566:
URL: https://github.com/apache/kafka/pull/9566#discussion_r524727151
##
File path: clients/src/test/java/org/apache/kafka/common/UuidTest.java
##
@@ -21,50 +21,50 @@
import static org.junit.Assert.assertEquals;
import static org.junit.Assert.assertNotEquals;
-public class UUIDTest {
+public class UuidTest {
@Test
public void testSignificantBits() {
-UUID id = new UUID(34L, 98L);
+Uuid id = new Uuid(34L, 98L);
assertEquals(id.getMostSignificantBits(), 34L);
assertEquals(id.getLeastSignificantBits(), 98L);
}
@Test
-public void testUUIDEquality() {
-UUID id1 = new UUID(12L, 13L);
-UUID id2 = new UUID(12L, 13L);
-UUID id3 = new UUID(24L, 38L);
+public void testUuidEquality() {
Review comment:
We don't have that yet. I also didn't specify this behavior. Should I?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] ijuma commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
ijuma commented on pull request #9401: URL: https://github.com/apache/kafka/pull/9401#issuecomment-728385188 Nice! So what's the reason for the small regression in the PR description? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] hachikuji edited a comment on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
hachikuji edited a comment on pull request #9401: URL: https://github.com/apache/kafka/pull/9401#issuecomment-728383115 Posting allocation flame graphs from the producer before and after this patch:  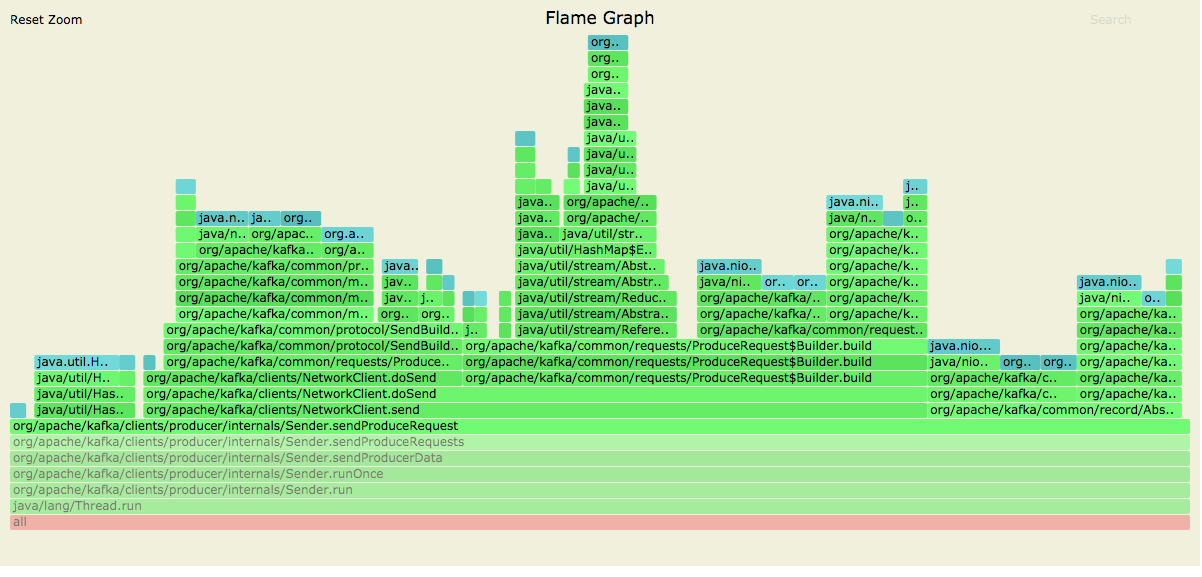 So we succeeded in getting rid of the extra allocations in the network layer! I generated these graphs using the producer performance test writing to a topic with 10 partitions on a cluster with a single broker. ``` > bin/kafka-producer-perf-test.sh --topic foo --num-records 25000 --throughput -1 --record-size 256 --producer-props bootstrap.servers=localhost:9092 ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ijuma commented on a change in pull request #9566: KAFKA-10618: Update to Uuid class
ijuma commented on a change in pull request #9566:
URL: https://github.com/apache/kafka/pull/9566#discussion_r524722302
##
File path: clients/src/test/java/org/apache/kafka/common/UuidTest.java
##
@@ -21,50 +21,50 @@
import static org.junit.Assert.assertEquals;
import static org.junit.Assert.assertNotEquals;
-public class UUIDTest {
+public class UuidTest {
@Test
public void testSignificantBits() {
-UUID id = new UUID(34L, 98L);
+Uuid id = new Uuid(34L, 98L);
assertEquals(id.getMostSignificantBits(), 34L);
assertEquals(id.getLeastSignificantBits(), 98L);
}
@Test
-public void testUUIDEquality() {
-UUID id1 = new UUID(12L, 13L);
-UUID id2 = new UUID(12L, 13L);
-UUID id3 = new UUID(24L, 38L);
+public void testUuidEquality() {
Review comment:
Can we add a test that verifies that the `hashCode` is the same for our
`Uuid` and Java's `UUID`? Or do we have that already?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
hachikuji commented on pull request #9401: URL: https://github.com/apache/kafka/pull/9401#issuecomment-728383115 Posting allocation flame graphs from the producer before and after this patch:   So we succeeded in getting rid of the extra allocations in the network layer! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (KAFKA-10729) KIP-482: Bump remaining RPC's to use tagged fields
[
https://issues.apache.org/jira/browse/KAFKA-10729?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Gardner Vickers updated KAFKA-10729:
Summary: KIP-482: Bump remaining RPC's to use tagged fields (was: KIP-482:
Bump remaining RPC's to use flexible versions)
> KIP-482: Bump remaining RPC's to use tagged fields
> --
>
> Key: KAFKA-10729
> URL: https://issues.apache.org/jira/browse/KAFKA-10729
> Project: Kafka
> Issue Type: Improvement
>Reporter: Gardner Vickers
>Assignee: Gardner Vickers
>Priority: Major
>
> With
> [KIP-482|https://cwiki.apache.org/confluence/display/KAFKA/KIP-482%3A+The+Kafka+Protocol+should+Support+Optional+Tagged+Fields],
> the Kafka protocol gained support for tagged fields.
> Not all RPC's were bumped to use flexible versioning and tagged fields. We
> should bump the remaining RPC's and provide a new IBP to take advantage of
> tagged fields via the flexible versioning mechanism.
>
> The RPC's which need to be bumped are:
>
> {code:java}
> AddOffsetsToTxnRequest
> AddOffsetsToTxnResponse
> AddPartitionsToTxnRequest
> AddPartitionsToTxnResponse
> AlterClientQuotasRequest
> AlterClientQuotasResponse
> AlterConfigsRequest
> AlterConfigsResponse
> AlterReplicaLogDirsRequest
> AlterReplicaLogDirsResponse
> DescribeClientQuotasRequest
> DescribeClientQuotasResponse
> DescribeConfigsRequest
> DescribeConfigsResponse
> EndTxnRequest
> EndTxnResponse
> ListOffsetRequest
> ListOffsetResponse
> OffsetForLeaderEpochRequest
> OffsetForLeaderEpochResponse
> ProduceRequest
> ProduceResponse
> WriteTxnMarkersRequest
> WriteTxnMarkersResponse
> {code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Created] (KAFKA-10729) KIP-482: Bump remaining RPC's to use flexible versions
Gardner Vickers created KAFKA-10729:
---
Summary: KIP-482: Bump remaining RPC's to use flexible versions
Key: KAFKA-10729
URL: https://issues.apache.org/jira/browse/KAFKA-10729
Project: Kafka
Issue Type: Improvement
Reporter: Gardner Vickers
Assignee: Gardner Vickers
With
[KIP-482|https://cwiki.apache.org/confluence/display/KAFKA/KIP-482%3A+The+Kafka+Protocol+should+Support+Optional+Tagged+Fields],
the Kafka protocol gained support for tagged fields.
Not all RPC's were bumped to use flexible versioning and tagged fields. We
should bump the remaining RPC's and provide a new IBP to take advantage of
tagged fields via the flexible versioning mechanism.
The RPC's which need to be bumped are:
{code:java}
AddOffsetsToTxnRequest
AddOffsetsToTxnResponse
AddPartitionsToTxnRequest
AddPartitionsToTxnResponse
AlterClientQuotasRequest
AlterClientQuotasResponse
AlterConfigsRequest
AlterConfigsResponse
AlterReplicaLogDirsRequest
AlterReplicaLogDirsResponse
DescribeClientQuotasRequest
DescribeClientQuotasResponse
DescribeConfigsRequest
DescribeConfigsResponse
EndTxnRequest
EndTxnResponse
ListOffsetRequest
ListOffsetResponse
OffsetForLeaderEpochRequest
OffsetForLeaderEpochResponse
ProduceRequest
ProduceResponse
WriteTxnMarkersRequest
WriteTxnMarkersResponse
{code}
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] junrao commented on a change in pull request #9596: KAFKA-10723: Fix LogManager shutdown error handling
junrao commented on a change in pull request #9596:
URL: https://github.com/apache/kafka/pull/9596#discussion_r524673732
##
File path: core/src/main/scala/kafka/log/LogManager.scala
##
@@ -477,27 +477,41 @@ class LogManager(logDirs: Seq[File],
jobs(dir) = jobsForDir.map(pool.submit).toSeq
}
+var firstExceptionOpt: Option[Throwable] = Option.empty
try {
for ((dir, dirJobs) <- jobs) {
-dirJobs.foreach(_.get)
+val errorsForDirJobs = dirJobs.map {
+ future =>
+try {
+ future.get
+ Option.empty
+} catch {
+ case e: ExecutionException =>
+error(s"There was an error in one of the threads during
LogManager shutdown: ${e.getCause}")
+Some(e.getCause)
+}
+}.filter{ e => e.isDefined }.map{ e => e.get }
+
+if (firstExceptionOpt.isEmpty) {
+ firstExceptionOpt = errorsForDirJobs.headOption
+}
-val logs = logsInDir(localLogsByDir, dir)
+if (errorsForDirJobs.isEmpty) {
+ val logs = logsInDir(localLogsByDir, dir)
-// update the last flush point
-debug(s"Updating recovery points at $dir")
-checkpointRecoveryOffsetsInDir(dir, logs)
+ // update the last flush point
+ debug(s"Updating recovery points at $dir")
+ checkpointRecoveryOffsetsInDir(dir, logs)
-debug(s"Updating log start offsets at $dir")
-checkpointLogStartOffsetsInDir(dir, logs)
+ debug(s"Updating log start offsets at $dir")
+ checkpointLogStartOffsetsInDir(dir, logs)
-// mark that the shutdown was clean by creating marker file
-debug(s"Writing clean shutdown marker at $dir")
-CoreUtils.swallow(Files.createFile(new File(dir,
Log.CleanShutdownFile).toPath), this)
+ // mark that the shutdown was clean by creating marker file
+ debug(s"Writing clean shutdown marker at $dir")
+ CoreUtils.swallow(Files.createFile(new File(dir,
Log.CleanShutdownFile).toPath), this)
+}
}
-} catch {
- case e: ExecutionException =>
-error(s"There was an error in one of the threads during LogManager
shutdown: ${e.getCause}")
-throw e.getCause
+ firstExceptionOpt.foreach{ e => throw e}
Review comment:
Hmm, since we are about to shut down the JVM, should we just log a WARN
here instead of throwing the exception?
##
File path: core/src/test/scala/unit/kafka/log/LogManagerTest.scala
##
@@ -83,6 +87,51 @@ class LogManagerTest {
log.appendAsLeader(TestUtils.singletonRecords("test".getBytes()),
leaderEpoch = 0)
}
+ /**
+ * Tests that all internal futures are completed before
LogManager.shutdown() returns to the
+ * caller during error situations.
+ */
+ @Test
+ def testHandlingExceptionsDuringShutdown(): Unit = {
+logManager.shutdown()
Review comment:
Hmm, do we need this given that we do this in tearDown() already?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] jolshan commented on pull request #9590: KAFKA-7556: KafkaConsumer.beginningOffsets does not return actual first offsets
jolshan commented on pull request #9590: URL: https://github.com/apache/kafka/pull/9590#issuecomment-728360755 I've updated the code to delay creating a new segment until there is a non-compacted record. If a segment is never created in cleanSegments, the old segments are simply deleted rather than replaced. I had to change some code surrounding the transactionMetadata that allows a delay before updating the transactionIndex of a segment until the segment is actually created. Any aborted transactions will be added once the segment is created. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] jolshan commented on a change in pull request #9590: KAFKA-7556: KafkaConsumer.beginningOffsets does not return actual first offsets
jolshan commented on a change in pull request #9590: URL: https://github.com/apache/kafka/pull/9590#discussion_r524659149 ## File path: core/src/main/scala/kafka/log/LogCleaner.scala ## @@ -711,6 +723,9 @@ private[log] class Cleaner(val id: Int, shallowOffsetOfMaxTimestamp = result.shallowOffsetOfMaxTimestamp, records = retained) throttler.maybeThrottle(outputBuffer.limit()) +if (newCanUpdateBaseOffset) + dest.updateBaseOffset(result.minOffset()) +newCanUpdateBaseOffset = false Review comment: I've updated to delete segments that end up being empty. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] ryannedolan commented on pull request #9589: KAFKA-10710 - Mirror Maker 2 - Create herders only if source->target.enabled=true
ryannedolan commented on pull request #9589: URL: https://github.com/apache/kafka/pull/9589#issuecomment-728354718 > The code seems to explicitly allow the connector to be created even when the link is disabled. > @ryannedolan maybe you could clarify? My intention was to ensure that MirrorHeartbeatConnector always runs, even when a link/flow is not otherwise needed. This is because MirrorHeartbeatConnector is most useful when it emits to all clusters, not just those clusters targeted by some flow. For example, in a two-cluster environment with only A->B replicated, it is nice to have heartbeats emitted to A s.t. they get replicated to B. Without a Herder targeting A, there can be no MirrorHeartbeatConnector emitting heartbeats there, and B will see no heartbeats from A. I know that some vendors/providers use heartbeats in this way, e.g. for discovering which flows are active and healthy. And I know that some vendors/providers don't use heartbeats at all, or use something else to send them (instead of MirrorHeartbeatConnector). Hard to say whether anything would break if we nixed these extra herders without addressing the heartbeats that would go missing. IMO, we'd ideally skip creating the A->B herder whenever A->B.emit.heartbeats.enabled=false (defaults to true) and A->B.enabled=false (defaults to false). A top-level emit.heartbeats.enabled=false would then disable heartbeats altogether, which would trivially eliminate the extra herders. N.B. this would just be an optimization and wouldn't required a KIP, IMO. Ryanne This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Commented] (KAFKA-10722) Timestamped store is used even if not desired
[
https://issues.apache.org/jira/browse/KAFKA-10722?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17233116#comment-17233116
]
fml2 commented on KAFKA-10722:
--
OK, I accept that Kafka Streams needs timestamps for the internal processing.
But I still fail to see why all the users (clients) are imposed to use it. It
adds an additional (I assume, rarely needed) wrapping layer
(`ValueAndTimestamp` with the value within in being a `KeyValues` vs. just
`KeyValue`). But OK, I accepti it.
I can't see why a method can't be deprecated. Deprecation does not change the
API, the code will still work. Just the IDE will issue a warning alert if the
method is used.
And you are of course right that I can just use `Materialized.as("MyStore")`.
Actually this is what I did first. And got a `ClassCastException`. And started
to investigate the case. And wanted to guarantee that I get a non-timestamped
store – but could not get it. And hence this ticket :).
I also saw the upgrade note for 2.3.0. I understood the words "Some DSL
operators (for example KTables) are using those new stores." as "they can use
them" or "they use them internally" – but not as "you will always get the new
store type and should unwrap timestamped values". And "you might need to update
your code to cast to the correct type" did not sound very obligatory too.
Would it make sense to introduce the method "value()" (or similar) that would
return the real data – both for a `KeyValue` and a `ValueAndTimestamp`? This
would be confusing for `ValueAndTimestamp` though since `value` (the field)
would return a `KeyValue` but `value()` (the method) would return the value
part of the KeyValue.
Another note is that I could not find the explanation of the values of
timestamps used in Kafka Streams. I found out this is a millis epoch. But,
judging just by the type, it could have been the nano epoch. Using e.g.
`Instance` would eliminate the question. But this is spread over so many places
that I assume a change is not possible. Besides, this is another topic.
Thank you for your replies!
> Timestamped store is used even if not desired
> -
>
> Key: KAFKA-10722
> URL: https://issues.apache.org/jira/browse/KAFKA-10722
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Affects Versions: 2.4.1, 2.6.0
>Reporter: fml2
>Priority: Major
>
> I have a stream which I then group and aggregate (this results in a KTable).
> When aggregating, I explicitly tell to materialize the result table using a
> usual (not timestamped) store.
> After that, the KTable is filtered and streamed. This stream is processed by
> a processor that accesses the store.
> The problem/bug is that even if I tell to use a non-timestamped store, a
> timestamped one is used, which leads to a ClassCastException in the processor
> (it iterates over the store and expects the items to be of type "KeyValue"
> but they are of type "ValueAndTimestamp").
> Here is the code (schematically).
> First, I define the topology:
> {code:java}
> KTable table = ...aggregate(
> initializer, // initializer for the KTable row
> aggregator, // aggregator
> Materialized.as(Stores.persistentKeyValueStore("MyStore")) // <--
> Non-Timestamped!
> .withKeySerde(...).withValueSerde(...));
> table.toStream().process(theProcessor);
> {code}
> In the class for the processor:
> {code:java}
> public void init(ProcessorContext context) {
>var store = context.getStateStore("MyStore"); // Returns a
> TimestampedKeyValueStore!
> }
> {code}
> A timestamped store is returned even if I explicitly told to use a
> non-timestamped one!
>
> I tried to find the cause for this behaviour and think that I've found it. It
> lies in this line:
> [https://github.com/apache/kafka/blob/cfc813537e955c267106eea989f6aec4879e14d7/streams/src/main/java/org/apache/kafka/streams/kstream/internals/KGroupedStreamImpl.java#L241]
> There, TimestampedKeyValueStoreMaterializer is used regardless of whether
> materialization supplier is a timestamped one or not.
> I think this is a bug.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] ijuma commented on a change in pull request #9601: MINOR: Enable flexible versioning for ListOffsetRequest/ListOffsetResponse.
ijuma commented on a change in pull request #9601:
URL: https://github.com/apache/kafka/pull/9601#discussion_r524636462
##
File path: core/src/main/scala/kafka/api/ApiVersion.scala
##
@@ -424,6 +426,13 @@ case object KAFKA_2_7_IV2 extends DefaultApiVersion {
val id: Int = 30
}
+case object KAFKA_2_7_IV3 extends DefaultApiVersion {
Review comment:
2.7 has been branched. It should be 2.8, right?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] twobeeb commented on pull request #9589: KAFKA-10710 - Mirror Maker 2 - Create herders only if source->target.enabled=true
twobeeb commented on pull request #9589: URL: https://github.com/apache/kafka/pull/9589#issuecomment-728339571 Thank you for your help @hachikuji. I agree with your analysis and it kind of makes sense for most use-cases with 2-3 clusters as described in the original KIP. I also understand that the original intent was that the ``clusterPairs`` variable would not grow exponential thanks to the command line parameter ``--clusters`` which is target-based (not source-based). But this parameter doesn't help the business case we are implementing which can be better viewed as one "central cluster" and multiple "local clusters": - Some topics (_schema is a perfect example) must be replicated down to every local cluster, - and some "local" topics will be replicated up to the central cluster. As stated in the KAFKA-10710, I cherry picked this commit in 2.5.2 and we are now running this build of MirrorMaker in production, because we can't ramp up deployment with current code as it stands. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] wcarlson5 commented on a change in pull request #9487: KAFKA-9331: Add a streams specific uncaught exception handler
wcarlson5 commented on a change in pull request #9487:
URL: https://github.com/apache/kafka/pull/9487#discussion_r524540416
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamsPartitionAssignor.java
##
@@ -255,8 +255,9 @@ public ByteBuffer subscriptionUserData(final Set
topics) {
taskManager.processId(),
userEndPoint,
taskManager.getTaskOffsetSums(),
-uniqueField)
-.encode();
+uniqueField,
+(byte) assignmentErrorCode.get()
Review comment:
I guess I must have misunderstood your earlier comment. I thought you
wanted it to stay a byte so that is why I pushed back. But if you have no
objections I will just change it
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] hachikuji commented on pull request #9589: KAFKA-10710 - Mirror Maker 2 - Create herders only if source->target.enabled=true
hachikuji commented on pull request #9589: URL: https://github.com/apache/kafka/pull/9589#issuecomment-728294205 Thanks for the patch. The proposed fix makes sense. I am only trying to confirm that this is a defect and not intended. The code seems to explicitly allow the connector to be created even when the link is disabled. Perhaps the cost of a disabled herder was not understood. @ryannedolan maybe you could clarify? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] gardnervickers opened a new pull request #9601: MINOR: Enable flexible versioning for ListOffsetRequest/ListOffsetResponse.
gardnervickers opened a new pull request #9601: URL: https://github.com/apache/kafka/pull/9601 This patch enables flexible versioning for ListOffsets req/response, as well as introducing a new IBP version allowing the replica fetchers to use this new ListOffsets version. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] abbccdda opened a new pull request #9600: KAFKA-10674: Controller API version bond with forwardable APIs
abbccdda opened a new pull request #9600: URL: https://github.com/apache/kafka/pull/9600 To make sure the forwarded request could be properly handled by the controller, when forwarding is enabled, we should acquire the controller API versions to enforce as joint constraints back to the client. ### Committer Checklist (excluded from commit message) - [ ] Verify design and implementation - [ ] Verify test coverage and CI build status - [ ] Verify documentation (including upgrade notes) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] lijubjohn edited a comment on pull request #9598: KAFKA-10701 : First line of detailed stats from consumer-perf-test.sh incorrect
lijubjohn edited a comment on pull request #9598: URL: https://github.com/apache/kafka/pull/9598#issuecomment-728277968 @mumrah Thanks for reviewing the pr. The return type of the method which is modified is void and the purpose of the method is to print the performance stats to console , so there isn't any direct hook to test this method This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] lijubjohn commented on pull request #9598: KAFKA-10701 : First line of detailed stats from consumer-perf-test.sh incorrect
lijubjohn commented on pull request #9598: URL: https://github.com/apache/kafka/pull/9598#issuecomment-728277968 @mumrah the return type of the method which is modified is void and the purpose of the method is to print the performance stats to console , so there isn't any direct hook to test this method This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] splett2 commented on a change in pull request #9386: KAFKA-10024: Add dynamic configuration and enforce quota for per-IP connection rate limits (KIP-612, part 2)
splett2 commented on a change in pull request #9386:
URL: https://github.com/apache/kafka/pull/9386#discussion_r521856417
##
File path: core/src/main/scala/kafka/network/SocketServer.scala
##
@@ -1324,7 +1401,59 @@ class ConnectionQuotas(config: KafkaConfig, time: Time,
metrics: Metrics) extend
private[network] def updateBrokerMaxConnectionRate(maxConnectionRate: Int):
Unit = {
// if there is a connection waiting on the rate throttle delay, we will
let it wait the original delay even if
// the rate limit increases, because it is just one connection per
listener and the code is simpler that way
-updateConnectionRateQuota(maxConnectionRate)
+updateConnectionRateQuota(maxConnectionRate, BrokerQuotaEntity)
+ }
+
+ /**
+ * Update the connection rate quota for a given IP and updates quota configs
for updated IPs.
+ * If an IP is given, metric config will be updated only for the given IP,
otherwise
+ * all metric configs will be checked and updated if required.
+ *
+ * @param ip ip to update or default if None
+ * @param maxConnectionRate new connection rate, or resets entity to default
if None
+ */
+ def updateIpConnectionRateQuota(ip: Option[String], maxConnectionRate:
Option[Int]): Unit = {
+def isIpConnectionRateMetric(metricName: MetricName) = {
+ metricName.name == ConnectionRateMetricName &&
+ metricName.group == MetricsGroup &&
+ metricName.tags.containsKey(IpMetricTag)
+}
+
+def shouldUpdateQuota(metric: KafkaMetric, quotaLimit: Int) = {
+ quotaLimit != metric.config.quota.bound
+}
+counts.synchronized {
Review comment:
After thinking on this a bit more, I think that only locking on updates
to `defaultConnectionRatePerIp` should be sufficient for correctness.
ZK dynamic config changes are processed within one thread, so we will only
have one thread executing in `updateIpConnectionRateQuota`. If we want to be
really careful about this, we can have `updateIpConnectionRateQuota`
synchronized on `ConnectionQuotas`.
The case we want to avoid by synchronizing on `counts` is that thread 1
reads `defaultConnectionRatePerIp` as connection rate limit `A` while calling
`inc()`, then thread 2 updates connection rate and quota metric config to `B`,
then thread 1 resumes execution and creates a sensor/metric with quota limit
`A` => inconsistency.
If we synchronize on `counts` for only updates to
`connectionRateForIp/defaultConnectionRate`, we know that thread 1 that has
read a connection rate quota as `A` will finish creating quota metrics with
limit `A` before thread 2 acquires the `counts` lock and updates
`connectionRateForIp/defaultConnectionRate` to `B`.
After thread 2 releases the `counts` lock, subsequent threads calling
`inc()` will read the quota as `B` and create a metric as `B`. Thread 2 can
then be able to update any quota metrics from `A` to `B`, without holding the
`counts` lock knowing that there are no operations that could have read the
default connection rate limit as `A` without already having finished created
the sensor with quota as `A`, and that all subsequent quotas will be read and
created as `B`.
The only issue remaining is that we can get concurrent reads of
`connectionRatePerIp` while updating quota metrics, but we can just replace
`mutable.Map` with `ConcurrentHashMap` which is preferable to coarsely locking
on `counts`.
Let me know if I'm missing something here with respect to thread safety.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] splett2 commented on a change in pull request #9386: KAFKA-10024: Add dynamic configuration and enforce quota for per-IP connection rate limits (KIP-612, part 2)
splett2 commented on a change in pull request #9386:
URL: https://github.com/apache/kafka/pull/9386#discussion_r521856417
##
File path: core/src/main/scala/kafka/network/SocketServer.scala
##
@@ -1324,7 +1401,59 @@ class ConnectionQuotas(config: KafkaConfig, time: Time,
metrics: Metrics) extend
private[network] def updateBrokerMaxConnectionRate(maxConnectionRate: Int):
Unit = {
// if there is a connection waiting on the rate throttle delay, we will
let it wait the original delay even if
// the rate limit increases, because it is just one connection per
listener and the code is simpler that way
-updateConnectionRateQuota(maxConnectionRate)
+updateConnectionRateQuota(maxConnectionRate, BrokerQuotaEntity)
+ }
+
+ /**
+ * Update the connection rate quota for a given IP and updates quota configs
for updated IPs.
+ * If an IP is given, metric config will be updated only for the given IP,
otherwise
+ * all metric configs will be checked and updated if required.
+ *
+ * @param ip ip to update or default if None
+ * @param maxConnectionRate new connection rate, or resets entity to default
if None
+ */
+ def updateIpConnectionRateQuota(ip: Option[String], maxConnectionRate:
Option[Int]): Unit = {
+def isIpConnectionRateMetric(metricName: MetricName) = {
+ metricName.name == ConnectionRateMetricName &&
+ metricName.group == MetricsGroup &&
+ metricName.tags.containsKey(IpMetricTag)
+}
+
+def shouldUpdateQuota(metric: KafkaMetric, quotaLimit: Int) = {
+ quotaLimit != metric.config.quota.bound
+}
+counts.synchronized {
Review comment:
After thinking on this a bit more, I think that only locking on updates
to `defaultConnectionRatePerIp` should be sufficient for correctness.
ZK dynamic config changes are processed within one thread, so we will only
have one thread executing in `updateIpConnectionRateQuota`. If we want to be
really careful about this, we can have `updateIpConnectionRateQuota`
synchronized on `ConnectionQuotas`.
The case we want to avoid by synchronizing on `counts` is that thread 1
reads `defaultConnectionRatePerIp` as connection rate limit `A` while calling
`inc()`, then thread 2 updates connection rate and quota metric config to `B`,
then thread 1 resumes execution and creates a sensor/metric with quota limit
`A` => inconsistency.
If we synchronize on `counts` for only updates to
`connectionRateForIp/defaultConnectionRate`, we know that thread 1 that has
read a connection rate quota as `A` will finish creating quota metrics with
quota metric config `A` before thread 2 acquires the `counts` lock and updates
`connectionRateForIp/defaultConnectionRate` to `B`.
After thread 2 releases the `counts` lock, subsequent threads calling
`inc()` will read the quota as `B` and create a metric as `B`. Thread 2 can
then be able to update any quota metrics from `A` to `B`, without holding the
`counts` lock knowing that there are no operations that could have read the
default connection rate limit as `A` without already having finished created
the sensor with quota as `A`, and that all subsequent quotas will be read and
created as `B`.
The only issue remaining is that we can get concurrent reads of
`connectionRatePerIp` while updating quota metrics, but we can just replace
`mutable.Map` with `ConcurrentHashMap` which is preferable to coarsely locking
on `counts`.
Let me know if I'm missing something here with respect to thread safety.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[jira] [Comment Edited] (KAFKA-10722) Timestamped store is used even if not desired
[
https://issues.apache.org/jira/browse/KAFKA-10722?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17232993#comment-17232993
]
Matthias J. Sax edited comment on KAFKA-10722 at 11/16/20, 6:59 PM:
Every record in Kafka Streams has a timestamp, and aggregate() needs to set a
timestamp for its output records. It computes the output record timestamps as
"max" over all input records. That is why it needs a timestamped key-value
store to track the maximum timestamp.
Unfortunately, we cannot deprecate the API easily because of Java type
erasure... I guess we could log a warn message thought... Feel free to do a PR
for it. We could log when we create the
`KeyValueToTimestampedKeyValueByteStoreAdapter`.
And yes, you always get a timestamped key-value store and you can simplify your
code accordingly. (Note thought, that if you provide a non-timestamped store,
the timestamp won't really be stored, because the above mentioned adapter will
just drop the timestamp before storing the data in the provided store – on
read, the adapter will just set `-1`, ie, unknown, as timestamp.)
Thus, I would actually recommend to pass in a timestamped key-value store to
begin with. On the other hand, why do you pass in a store at all? I seem you
actually only want to set a name (to be able to access the store from the other
`Processor`) what you can do via `Materialized.as("MyStore")` – passing in a
`StoreSupplier` should be used if you want to pass in your own custom store
implementation. As you create the store using `Stores` anyway, you can just let
KS DSL create the store for you.
I am also open to improve our docs, to point out this issue better. Atm, it
seem we only documented in the upgrade guide when the feature was added:
[https://kafka.apache.org/26/documentation/streams/upgrade-guide#streams_api_changes_230]
was (Author: mjsax):
Every record in Kafka Streams has a timestamp, and aggregate() needs to set a
timestamp for its output records. It computes the output record timestamps as
"max" over all input records. That is why it needs a timestamped key-value
store to track the maximum timestamp.
Unfortunately, we cannot deprecate the API easily because of Java type
erasure... I guess we could log a warn message thought... Feel free to do a PR
for it. We could log when we create the
`KeyValueToTimestampedKeyValueByteStoreAdapter`.
And yes, you always get a timestamped key-value store and you can simplify your
code accordingly. (Note thought, that if you provide a non-timestamped store,
the timestamp won't really be stored, because the above mentioned adapter will
just drop the timestamp before storing the data in the provided store – on
read, the adapter will just set `-1`, ie, unknown, as timestamp.)
Thus, I would actually recommend to pass in a timestamped key-value store to
begin with.
I am also open to improve our docs, to point out this issue better. Atm, it
seem we only documented in the upgrade guide when the feature was added:
https://kafka.apache.org/26/documentation/streams/upgrade-guide#streams_api_changes_230
> Timestamped store is used even if not desired
> -
>
> Key: KAFKA-10722
> URL: https://issues.apache.org/jira/browse/KAFKA-10722
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Affects Versions: 2.4.1, 2.6.0
>Reporter: fml2
>Priority: Major
>
> I have a stream which I then group and aggregate (this results in a KTable).
> When aggregating, I explicitly tell to materialize the result table using a
> usual (not timestamped) store.
> After that, the KTable is filtered and streamed. This stream is processed by
> a processor that accesses the store.
> The problem/bug is that even if I tell to use a non-timestamped store, a
> timestamped one is used, which leads to a ClassCastException in the processor
> (it iterates over the store and expects the items to be of type "KeyValue"
> but they are of type "ValueAndTimestamp").
> Here is the code (schematically).
> First, I define the topology:
> {code:java}
> KTable table = ...aggregate(
> initializer, // initializer for the KTable row
> aggregator, // aggregator
> Materialized.as(Stores.persistentKeyValueStore("MyStore")) // <--
> Non-Timestamped!
> .withKeySerde(...).withValueSerde(...));
> table.toStream().process(theProcessor);
> {code}
> In the class for the processor:
> {code:java}
> public void init(ProcessorContext context) {
>var store = context.getStateStore("MyStore"); // Returns a
> TimestampedKeyValueStore!
> }
> {code}
> A timestamped store is returned even if I explicitly told to use a
> non-timestamped one!
>
> I tried to find the cause for this behaviour and think that I've found it. It
> lies in this line:
>
[jira] [Comment Edited] (KAFKA-10722) Timestamped store is used even if not desired
[
https://issues.apache.org/jira/browse/KAFKA-10722?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17232993#comment-17232993
]
Matthias J. Sax edited comment on KAFKA-10722 at 11/16/20, 6:55 PM:
Every record in Kafka Streams has a timestamp, and aggregate() needs to set a
timestamp for its output records. It computes the output record timestamps as
"max" over all input records. That is why it needs a timestamped key-value
store to track the maximum timestamp.
Unfortunately, we cannot deprecate the API easily because of Java type
erasure... I guess we could log a warn message thought... Feel free to do a PR
for it. We could log when we create the
`KeyValueToTimestampedKeyValueByteStoreAdapter`.
And yes, you always get a timestamped key-value store and you can simplify your
code accordingly. (Note thought, that if you provide a non-timestamped store,
the timestamp won't really be stored, because the above mentioned adapter will
just drop the timestamp before storing the data in the provided store – on
read, the adapter will just set `-1`, ie, unknown, as timestamp.)
Thus, I would actually recommend to pass in a timestamped key-value store to
begin with.
I am also open to improve our docs, to point out this issue better. Atm, it
seem we only documented in the upgrade guide when the feature was added:
https://kafka.apache.org/26/documentation/streams/upgrade-guide#streams_api_changes_230
was (Author: mjsax):
Every record in Kafka Streams has a timestamp, and aggregate() needs to set a
timestamp for its output records. It computes the output record timestamps as
"max" over all input records. That is why it needs a timestamped key-value
store to track the maximum timestamp.
Unfortunately, we cannot deprecate the API easily because of Java type
erasure... I guess we could log a warn message thought... Feel free to do a PR
for it. We could log when we create the
`KeyValueToTimestampedKeyValueByteStoreAdapter`.
And yes, you always get a timestamped key-value store and you can simplify your
code accordingly. (Note thought, that if you provide a non-timestamped store,
the timestamp won't really be stored, because the above mentioned adapter will
just drop the timestamp before storing the data in the provided store – on
read, the adapter will just set `-1`, ie, unknown, as timestamp.)
Thus, I would actually recommend to pass in a timestamped key-value store to
begin with.
> Timestamped store is used even if not desired
> -
>
> Key: KAFKA-10722
> URL: https://issues.apache.org/jira/browse/KAFKA-10722
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Affects Versions: 2.4.1, 2.6.0
>Reporter: fml2
>Priority: Major
>
> I have a stream which I then group and aggregate (this results in a KTable).
> When aggregating, I explicitly tell to materialize the result table using a
> usual (not timestamped) store.
> After that, the KTable is filtered and streamed. This stream is processed by
> a processor that accesses the store.
> The problem/bug is that even if I tell to use a non-timestamped store, a
> timestamped one is used, which leads to a ClassCastException in the processor
> (it iterates over the store and expects the items to be of type "KeyValue"
> but they are of type "ValueAndTimestamp").
> Here is the code (schematically).
> First, I define the topology:
> {code:java}
> KTable table = ...aggregate(
> initializer, // initializer for the KTable row
> aggregator, // aggregator
> Materialized.as(Stores.persistentKeyValueStore("MyStore")) // <--
> Non-Timestamped!
> .withKeySerde(...).withValueSerde(...));
> table.toStream().process(theProcessor);
> {code}
> In the class for the processor:
> {code:java}
> public void init(ProcessorContext context) {
>var store = context.getStateStore("MyStore"); // Returns a
> TimestampedKeyValueStore!
> }
> {code}
> A timestamped store is returned even if I explicitly told to use a
> non-timestamped one!
>
> I tried to find the cause for this behaviour and think that I've found it. It
> lies in this line:
> [https://github.com/apache/kafka/blob/cfc813537e955c267106eea989f6aec4879e14d7/streams/src/main/java/org/apache/kafka/streams/kstream/internals/KGroupedStreamImpl.java#L241]
> There, TimestampedKeyValueStoreMaterializer is used regardless of whether
> materialization supplier is a timestamped one or not.
> I think this is a bug.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Comment Edited] (KAFKA-10722) Timestamped store is used even if not desired
[
https://issues.apache.org/jira/browse/KAFKA-10722?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17232993#comment-17232993
]
Matthias J. Sax edited comment on KAFKA-10722 at 11/16/20, 6:50 PM:
Every record in Kafka Streams has a timestamp, and aggregate() needs to set a
timestamp for its output records. It computes the output record timestamps as
"max" over all input records. That is why it needs a timestamped key-value
store to track the maximum timestamp.
Unfortunately, we cannot deprecate the API easily because of Java type
erasure... I guess we could log a warn message thought... Feel free to do a PR
for it. We could log when we create the
`KeyValueToTimestampedKeyValueByteStoreAdapter`.
And yes, you always get a timestamped key-value store and you can simplify your
code accordingly. (Note thought, that if you provide a non-timestamped store,
the timestamp won't really be stored, because the above mentioned adapter will
just drop the timestamp before storing the data in the provided store – on
read, the adapter will just set `-1`, ie, unknown, as timestamp.)
Thus, I would actually recommend to pass in a timestamped key-value store to
begin with.
was (Author: mjsax):
Every record in Kafka Streams has a timestamp, and aggregate() needs to set a
timestamp for its output records. It computes the output record timestamps as
"max" over all input records. That is why it needs a timestamped key-value
store to track the maximum timestamp.
Unfortunately, we cannot deprecate the API easily because of Java type
erasure... I guess we could log a warn message thought... Feel free to do a PR
for it. We could log when we create the
`KeyValueToTimestampedKeyValueByteStoreAdapter`.
And yes, you always get a timestamped key-value store and you can simplify your
code accordingly. (Note thought, that if you provide a non-timestamped store,
the timestamp won't really be stored, because the above mentioned adapter will
just drop the timestamp before storing the data in the provided store – on
read, the adapter will just set `-1`, ie, unknown, as timestamp.)
> Timestamped store is used even if not desired
> -
>
> Key: KAFKA-10722
> URL: https://issues.apache.org/jira/browse/KAFKA-10722
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Affects Versions: 2.4.1, 2.6.0
>Reporter: fml2
>Priority: Major
>
> I have a stream which I then group and aggregate (this results in a KTable).
> When aggregating, I explicitly tell to materialize the result table using a
> usual (not timestamped) store.
> After that, the KTable is filtered and streamed. This stream is processed by
> a processor that accesses the store.
> The problem/bug is that even if I tell to use a non-timestamped store, a
> timestamped one is used, which leads to a ClassCastException in the processor
> (it iterates over the store and expects the items to be of type "KeyValue"
> but they are of type "ValueAndTimestamp").
> Here is the code (schematically).
> First, I define the topology:
> {code:java}
> KTable table = ...aggregate(
> initializer, // initializer for the KTable row
> aggregator, // aggregator
> Materialized.as(Stores.persistentKeyValueStore("MyStore")) // <--
> Non-Timestamped!
> .withKeySerde(...).withValueSerde(...));
> table.toStream().process(theProcessor);
> {code}
> In the class for the processor:
> {code:java}
> public void init(ProcessorContext context) {
>var store = context.getStateStore("MyStore"); // Returns a
> TimestampedKeyValueStore!
> }
> {code}
> A timestamped store is returned even if I explicitly told to use a
> non-timestamped one!
>
> I tried to find the cause for this behaviour and think that I've found it. It
> lies in this line:
> [https://github.com/apache/kafka/blob/cfc813537e955c267106eea989f6aec4879e14d7/streams/src/main/java/org/apache/kafka/streams/kstream/internals/KGroupedStreamImpl.java#L241]
> There, TimestampedKeyValueStoreMaterializer is used regardless of whether
> materialization supplier is a timestamped one or not.
> I think this is a bug.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Updated] (KAFKA-10721) Rewrite topology to allow for overlapping unequal topic subscriptions
[
https://issues.apache.org/jira/browse/KAFKA-10721?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Guozhang Wang updated KAFKA-10721:
--
Labels: newbie++ (was: )
> Rewrite topology to allow for overlapping unequal topic subscriptions
> -
>
> Key: KAFKA-10721
> URL: https://issues.apache.org/jira/browse/KAFKA-10721
> Project: Kafka
> Issue Type: Improvement
> Components: streams
>Reporter: A. Sophie Blee-Goldman
>Priority: Minor
> Labels: newbie++
>
> Minor followup improvement to KAFKA-6687 in which we rewrite the topology to
> make it possible for a user to subscribe multiple KStream/KTables to the same
> topic or identical set of topics. We could further extend this to make it
> possible for multiple KStream/KTables to be subscribed to overlapping but not
> identical sets of topics, ie
> {code:java}
> KStream streamA = builder.stream("topic");
> KStream streamB = builder.stream("topic, "other-topic"); {code}
> One way to do this would be to break up multiple-topic source nodes into
> multiple single-topic sources that get merged together in the child node.
> See
> https://github.com/apache/kafka/pull/9582/files#diff-ac1bf2b23b80784dec20b00fdc42f2df7e5a5133d6c68978fa44aea11e950c3aR347-R349
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Commented] (KAFKA-10722) Timestamped store is used even if not desired
[
https://issues.apache.org/jira/browse/KAFKA-10722?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17232993#comment-17232993
]
Matthias J. Sax commented on KAFKA-10722:
-
Every record in Kafka Streams has a timestamp, and aggregate() needs to set a
timestamp for its output records. It computes the output record timestamps as
"max" over all input records. That is why it needs a timestamped key-value
store to track the maximum timestamp.
Unfortunately, we cannot deprecate the API easily because of Java type
erasure... I guess we could log a warn message thought... Feel free to do a PR
for it. We could log when we create the
`KeyValueToTimestampedKeyValueByteStoreAdapter`.
And yes, you always get a timestamped key-value store and you can simplify your
code accordingly. (Note thought, that if you provide a non-timestamped store,
the timestamp won't really be stored, because the above mentioned adapter will
just drop the timestamp before storing the data in the provided store – on
read, the adapter will just set `-1`, ie, unknown, as timestamp.)
> Timestamped store is used even if not desired
> -
>
> Key: KAFKA-10722
> URL: https://issues.apache.org/jira/browse/KAFKA-10722
> Project: Kafka
> Issue Type: Bug
> Components: streams
>Affects Versions: 2.4.1, 2.6.0
>Reporter: fml2
>Priority: Major
>
> I have a stream which I then group and aggregate (this results in a KTable).
> When aggregating, I explicitly tell to materialize the result table using a
> usual (not timestamped) store.
> After that, the KTable is filtered and streamed. This stream is processed by
> a processor that accesses the store.
> The problem/bug is that even if I tell to use a non-timestamped store, a
> timestamped one is used, which leads to a ClassCastException in the processor
> (it iterates over the store and expects the items to be of type "KeyValue"
> but they are of type "ValueAndTimestamp").
> Here is the code (schematically).
> First, I define the topology:
> {code:java}
> KTable table = ...aggregate(
> initializer, // initializer for the KTable row
> aggregator, // aggregator
> Materialized.as(Stores.persistentKeyValueStore("MyStore")) // <--
> Non-Timestamped!
> .withKeySerde(...).withValueSerde(...));
> table.toStream().process(theProcessor);
> {code}
> In the class for the processor:
> {code:java}
> public void init(ProcessorContext context) {
>var store = context.getStateStore("MyStore"); // Returns a
> TimestampedKeyValueStore!
> }
> {code}
> A timestamped store is returned even if I explicitly told to use a
> non-timestamped one!
>
> I tried to find the cause for this behaviour and think that I've found it. It
> lies in this line:
> [https://github.com/apache/kafka/blob/cfc813537e955c267106eea989f6aec4879e14d7/streams/src/main/java/org/apache/kafka/streams/kstream/internals/KGroupedStreamImpl.java#L241]
> There, TimestampedKeyValueStoreMaterializer is used regardless of whether
> materialization supplier is a timestamped one or not.
> I think this is a bug.
>
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] wcarlson5 commented on a change in pull request #9487: KAFKA-9331: Add a streams specific uncaught exception handler
wcarlson5 commented on a change in pull request #9487:
URL: https://github.com/apache/kafka/pull/9487#discussion_r524490211
##
File path: streams/src/main/java/org/apache/kafka/streams/KafkaStreams.java
##
@@ -366,6 +377,90 @@ public void setUncaughtExceptionHandler(final
Thread.UncaughtExceptionHandler eh
}
}
+/**
+ * Set the handler invoked when an {@link
StreamsConfig#NUM_STREAM_THREADS_CONFIG internal thread}
+ * throws an unexpected exception.
+ * These might be exceptions indicating rare bugs in Kafka Streams, or they
+ * might be exceptions thrown by your code, for example a
NullPointerException thrown from your processor
+ * logic.
+ * The handler will execute on the thread that produced the exception.
+ * In order to get the thread use Thread.currentThread()
+ *
+ * Note, this handler must be threadsafe, since it will be shared among
all threads, and invoked from any
+ * thread that encounters such an exception.
+ *
+ * @param streamsUncaughtExceptionHandler the uncaught exception handler
of type {@link StreamsUncaughtExceptionHandler} for all internal threads
+ * @throws IllegalStateException if this {@code KafkaStreams} instance is
not in state {@link State#CREATED CREATED}.
+ * @throws NullPointerException if streamsUncaughtExceptionHandler is null.
+ */
+public void setUncaughtExceptionHandler(final
StreamsUncaughtExceptionHandler streamsUncaughtExceptionHandler) {
+final Consumer handler = exception ->
handleStreamsUncaughtException(exception, streamsUncaughtExceptionHandler);
+synchronized (stateLock) {
+if (state == State.CREATED) {
+Objects.requireNonNull(streamsUncaughtExceptionHandler);
+for (final StreamThread thread : threads) {
+thread.setStreamsUncaughtExceptionHandler(handler);
+}
+if (globalStreamThread != null) {
+globalStreamThread.setUncaughtExceptionHandler(handler);
+}
+} else {
+throw new IllegalStateException("Can only set
UncaughtExceptionHandler in CREATED state. " +
+"Current state is: " + state);
+}
+}
+}
+
+private void defaultStreamsUncaughtExceptionHandler(final Throwable
throwable) {
+if (oldHanlder) {
+if (throwable instanceof RuntimeException) {
+throw (RuntimeException) throwable;
+} else if (throwable instanceof Error) {
+throw (Error) throwable;
+} else {
+throw new RuntimeException("Unexpected checked exception
caught in the uncaught exception handler", throwable);
+}
+} else {
+handleStreamsUncaughtException(throwable, t -> SHUTDOWN_CLIENT);
+}
+}
+
+private void handleStreamsUncaughtException(final Throwable throwable,
+final
StreamsUncaughtExceptionHandler streamsUncaughtExceptionHandler) {
+final StreamsUncaughtExceptionHandler.StreamThreadExceptionResponse
action = streamsUncaughtExceptionHandler.handle(throwable);
+if (oldHanlder) {
+log.warn("Stream's new uncaught exception handler is set as well
as the deprecated old handler." +
+"The old handler will be ignored as long as a new handler
is set.");
+}
+switch (action) {
+case SHUTDOWN_CLIENT:
+log.error("Encountered the following exception during
processing " +
+"and the registered exception handler opted to " +
action + "." +
+" The streams client is going to shut down now. ",
throwable);
+close(Duration.ZERO);
+break;
+case SHUTDOWN_APPLICATION:
+if (throwable instanceof Error) {
+log.error("This option requires running threads to shut
down the application." +
+"but the uncaught exception was an Error, which
means this runtime is no " +
+"longer in a well-defined state. Attempting to
send the shutdown command anyway.", throwable);
+}
+if (Thread.currentThread().equals(globalStreamThread) &&
threads.stream().noneMatch(StreamThread::isRunning)) {
+log.error("Exception in global thread caused the
application to attempt to shutdown." +
+" This action will succeed only if there is at
least one StreamThread running on this client." +
+" Currently there are no running threads so will
now close the client.");
+close();
Review comment:
It doesn't really matter to me, though I think that non blocking is
probably preferable.
[GitHub] [kafka] wcarlson5 commented on a change in pull request #9487: KAFKA-9331: Add a streams specific uncaught exception handler
wcarlson5 commented on a change in pull request #9487:
URL: https://github.com/apache/kafka/pull/9487#discussion_r524487609
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/StreamThread.java
##
@@ -559,18 +552,52 @@ void runLoop() {
}
} catch (final TaskCorruptedException e) {
log.warn("Detected the states of tasks " +
e.corruptedTaskWithChangelogs() + " are corrupted. " +
- "Will close the task as dirty and re-create and
bootstrap from scratch.", e);
+"Will close the task as dirty and re-create and
bootstrap from scratch.", e);
try {
taskManager.handleCorruption(e.corruptedTaskWithChangelogs());
} catch (final TaskMigratedException taskMigrated) {
handleTaskMigrated(taskMigrated);
}
} catch (final TaskMigratedException e) {
handleTaskMigrated(e);
+} catch (final UnsupportedVersionException e) {
Review comment:
That is probably fine. We can really get into it when we add the replace
option, as now all calls to the handler are fatal.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] vvcephei commented on a change in pull request #9487: KAFKA-9331: Add a streams specific uncaught exception handler
vvcephei commented on a change in pull request #9487:
URL: https://github.com/apache/kafka/pull/9487#discussion_r524448160
##
File path: streams/src/main/java/org/apache/kafka/streams/KafkaStreams.java
##
@@ -366,6 +377,90 @@ public void setUncaughtExceptionHandler(final
Thread.UncaughtExceptionHandler eh
}
}
+/**
+ * Set the handler invoked when an {@link
StreamsConfig#NUM_STREAM_THREADS_CONFIG internal thread}
+ * throws an unexpected exception.
+ * These might be exceptions indicating rare bugs in Kafka Streams, or they
+ * might be exceptions thrown by your code, for example a
NullPointerException thrown from your processor
+ * logic.
+ * The handler will execute on the thread that produced the exception.
+ * In order to get the thread use Thread.currentThread()
+ *
+ * Note, this handler must be threadsafe, since it will be shared among
all threads, and invoked from any
+ * thread that encounters such an exception.
+ *
+ * @param streamsUncaughtExceptionHandler the uncaught exception handler
of type {@link StreamsUncaughtExceptionHandler} for all internal threads
+ * @throws IllegalStateException if this {@code KafkaStreams} instance is
not in state {@link State#CREATED CREATED}.
+ * @throws NullPointerException if streamsUncaughtExceptionHandler is null.
+ */
+public void setUncaughtExceptionHandler(final
StreamsUncaughtExceptionHandler streamsUncaughtExceptionHandler) {
+final Consumer handler = exception ->
handleStreamsUncaughtException(exception, streamsUncaughtExceptionHandler);
+synchronized (stateLock) {
+if (state == State.CREATED) {
+Objects.requireNonNull(streamsUncaughtExceptionHandler);
+for (final StreamThread thread : threads) {
+thread.setStreamsUncaughtExceptionHandler(handler);
+}
+if (globalStreamThread != null) {
+globalStreamThread.setUncaughtExceptionHandler(handler);
+}
+} else {
+throw new IllegalStateException("Can only set
UncaughtExceptionHandler in CREATED state. " +
+"Current state is: " + state);
+}
+}
+}
+
+private void defaultStreamsUncaughtExceptionHandler(final Throwable
throwable) {
+if (oldHanlder) {
+if (throwable instanceof RuntimeException) {
+throw (RuntimeException) throwable;
+} else if (throwable instanceof Error) {
+throw (Error) throwable;
+} else {
+throw new RuntimeException("Unexpected checked exception
caught in the uncaught exception handler", throwable);
+}
+} else {
+handleStreamsUncaughtException(throwable, t -> SHUTDOWN_CLIENT);
+}
+}
+
+private void handleStreamsUncaughtException(final Throwable throwable,
+final
StreamsUncaughtExceptionHandler streamsUncaughtExceptionHandler) {
+final StreamsUncaughtExceptionHandler.StreamThreadExceptionResponse
action = streamsUncaughtExceptionHandler.handle(throwable);
+if (oldHanlder) {
+log.warn("Stream's new uncaught exception handler is set as well
as the deprecated old handler." +
+"The old handler will be ignored as long as a new handler
is set.");
+}
+switch (action) {
+case SHUTDOWN_CLIENT:
+log.error("Encountered the following exception during
processing " +
+"and the registered exception handler opted to " +
action + "." +
+" The streams client is going to shut down now. ",
throwable);
+close(Duration.ZERO);
+break;
+case SHUTDOWN_APPLICATION:
+if (throwable instanceof Error) {
+log.error("This option requires running threads to shut
down the application." +
+"but the uncaught exception was an Error, which
means this runtime is no " +
+"longer in a well-defined state. Attempting to
send the shutdown command anyway.", throwable);
+}
+if (Thread.currentThread().equals(globalStreamThread) &&
threads.stream().noneMatch(StreamThread::isRunning)) {
+log.error("Exception in global thread caused the
application to attempt to shutdown." +
+" This action will succeed only if there is at
least one StreamThread running on this client." +
+" Currently there are no running threads so will
now close the client.");
+close();
Review comment:
Likewise, here, it seems better to do a non-blocking close.
##
File path:
[jira] [Resolved] (KAFKA-10704) Mirror maker with TLS at target
[
https://issues.apache.org/jira/browse/KAFKA-10704?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Tushar Bhasme resolved KAFKA-10704.
---
Resolution: Not A Problem
> Mirror maker with TLS at target
> ---
>
> Key: KAFKA-10704
> URL: https://issues.apache.org/jira/browse/KAFKA-10704
> Project: Kafka
> Issue Type: Bug
> Components: mirrormaker
>Affects Versions: 2.6.0
>Reporter: Tushar Bhasme
>Priority: Critical
> Fix For: 2.7.0
>
>
> We need to setup mirror maker from a single node kafka cluster to a three
> node Strimzi cluster. There is no SSL setup at source, however the target
> cluster is configured with MTLS.
> With below config, commands from source like listing topics etc are working:
> {code:java}
> cat client-ssl.properties
> security.protocol=SSL
> ssl.truststore.location=my.truststore
> ssl.truststore.password=123456
> ssl.keystore.location=my.keystore
> ssl.keystore.password=123456
> ssl.key.password=password{code}
> However, we are not able to get mirror maker working with the similar configs:
> {code:java}
> source.security.protocol=PLAINTEXT
> target.security.protocol=SSL
> target.ssl.truststore.location=my.truststore
> target.ssl.truststore.password=123456
> target.ssl.keystore.location=my.keystore
> target.ssl.keystore.password=123456
> target.ssl.key.password=password{code}
> Errors while running mirror maker:
> {code:java}
> org.apache.kafka.common.errors.TimeoutException: Call(callName=fetchMetadata,
> deadlineMs=1605011994642, tries=1, nextAllowedTryMs=1605011994743) timed out
> at 1605011994643 after 1 attempt(s)
> Caused by: org.apache.kafka.common.errors.TimeoutException: Timed out waiting
> for a node assignment. Call: fetchMetadata
> [2020-11-10 12:40:24,642] INFO App info kafka.admin.client for adminclient-8
> unregistered (org.apache.kafka.common.utils.AppInfoParser:83)
> [2020-11-10 12:40:24,643] INFO [AdminClient clientId=adminclient-8] Metadata
> update failed
> (org.apache.kafka.clients.admin.internals.AdminMetadataManager:235)
> org.apache.kafka.common.errors.TimeoutException: Call(callName=fetchMetadata,
> deadlineMs=1605012024643, tries=1, nextAllowedTryMs=-9223372036854775709)
> timed out at 9223372036854775807 after 1attempt(s)
> Caused by: org.apache.kafka.common.errors.TimeoutException: The AdminClient
> thread has exited. Call: fetchMetadata
> [2020-11-10 12:40:24,644] INFO Metrics scheduler closed
> (org.apache.kafka.common.metrics.Metrics:668)
> [2020-11-10 12:40:24,644] INFO Closing reporter
> org.apache.kafka.common.metrics.JmxReporter
> (org.apache.kafka.common.metrics.Metrics:672)
> [2020-11-10 12:40:24,644] INFO Metrics reporters closed
> (org.apache.kafka.common.metrics.Metrics:678)
> [2020-11-10 12:40:24,645] ERROR Stopping due to error
> (org.apache.kafka.connect.mirror.MirrorMaker:304)
> org.apache.kafka.connect.errors.ConnectException: Failed to connect to and
> describe Kafka cluster. Check worker's broker connection and security
> properties.
> at
> org.apache.kafka.connect.util.ConnectUtils.lookupKafkaClusterId(ConnectUtils.java:70)
> at
> org.apache.kafka.connect.util.ConnectUtils.lookupKafkaClusterId(ConnectUtils.java:51)
> at
> org.apache.kafka.connect.mirror.MirrorMaker.addHerder(MirrorMaker.java:235)
> at
> org.apache.kafka.connect.mirror.MirrorMaker.lambda$new$1(MirrorMaker.java:136)
> at java.lang.Iterable.forEach(Iterable.java:75)
> at
> org.apache.kafka.connect.mirror.MirrorMaker.(MirrorMaker.java:136)
> at
> org.apache.kafka.connect.mirror.MirrorMaker.(MirrorMaker.java:148)
> at
> org.apache.kafka.connect.mirror.MirrorMaker.main(MirrorMaker.java:291)
> Caused by: java.util.concurrent.ExecutionException:
> org.apache.kafka.common.errors.TimeoutException: Call(callName=listNodes,
> deadlineMs=1605012024641, tries=1, nextAllowedTryMs=1605012024742)timed out
> at 1605012024642 after 1 attempt(s)
> at
> org.apache.kafka.common.internals.KafkaFutureImpl.wrapAndThrow(KafkaFutureImpl.java:45)
> at
> org.apache.kafka.common.internals.KafkaFutureImpl.access$000(KafkaFutureImpl.java:32)
> at
> org.apache.kafka.common.internals.KafkaFutureImpl$SingleWaiter.await(KafkaFutureImpl.java:89)
> at
> org.apache.kafka.common.internals.KafkaFutureImpl.get(KafkaFutureImpl.java:260)
> at
> org.apache.kafka.connect.util.ConnectUtils.lookupKafkaClusterId(ConnectUtils.java:64)
> ... 7 more
> Caused by: org.apache.kafka.common.errors.TimeoutException:
> Call(callName=listNodes, deadlineMs=1605012024641, tries=1,
> nextAllowedTryMs=1605012024742) timed out at 1605012024642 after 1 attempt(s)
> Caused by: org.apache.kafka.common.errors.TimeoutException: Timed out waiting
> for a node assignment. Call: listNodes
> {code}
--
This
[jira] [Commented] (KAFKA-10704) Mirror maker with TLS at target
[
https://issues.apache.org/jira/browse/KAFKA-10704?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17232972#comment-17232972
]
Tushar Bhasme commented on KAFKA-10704:
---
Sorry, I forgot to update this bug. We were able to find the correct
configuration to make it work. It would have been great if all the
configurations for mm2 were well documented, maybe it is but I don't know
where. I had to debug through the code to get the correct nomenclature. Correct
configuration that worked for us was:
{code:java}
clusters = A, B
B.security.protocol=SSL
B.ssl.truststore.location=client.truststore
B.ssl.truststore.password=123456
B.ssl.keystore.location=client.keystore
B.ssl.keystore.password=123456
B.ssl.key.password=123456 {code}
> Mirror maker with TLS at target
> ---
>
> Key: KAFKA-10704
> URL: https://issues.apache.org/jira/browse/KAFKA-10704
> Project: Kafka
> Issue Type: Bug
> Components: mirrormaker
>Affects Versions: 2.6.0
>Reporter: Tushar Bhasme
>Priority: Critical
> Fix For: 2.7.0
>
>
> We need to setup mirror maker from a single node kafka cluster to a three
> node Strimzi cluster. There is no SSL setup at source, however the target
> cluster is configured with MTLS.
> With below config, commands from source like listing topics etc are working:
> {code:java}
> cat client-ssl.properties
> security.protocol=SSL
> ssl.truststore.location=my.truststore
> ssl.truststore.password=123456
> ssl.keystore.location=my.keystore
> ssl.keystore.password=123456
> ssl.key.password=password{code}
> However, we are not able to get mirror maker working with the similar configs:
> {code:java}
> source.security.protocol=PLAINTEXT
> target.security.protocol=SSL
> target.ssl.truststore.location=my.truststore
> target.ssl.truststore.password=123456
> target.ssl.keystore.location=my.keystore
> target.ssl.keystore.password=123456
> target.ssl.key.password=password{code}
> Errors while running mirror maker:
> {code:java}
> org.apache.kafka.common.errors.TimeoutException: Call(callName=fetchMetadata,
> deadlineMs=1605011994642, tries=1, nextAllowedTryMs=1605011994743) timed out
> at 1605011994643 after 1 attempt(s)
> Caused by: org.apache.kafka.common.errors.TimeoutException: Timed out waiting
> for a node assignment. Call: fetchMetadata
> [2020-11-10 12:40:24,642] INFO App info kafka.admin.client for adminclient-8
> unregistered (org.apache.kafka.common.utils.AppInfoParser:83)
> [2020-11-10 12:40:24,643] INFO [AdminClient clientId=adminclient-8] Metadata
> update failed
> (org.apache.kafka.clients.admin.internals.AdminMetadataManager:235)
> org.apache.kafka.common.errors.TimeoutException: Call(callName=fetchMetadata,
> deadlineMs=1605012024643, tries=1, nextAllowedTryMs=-9223372036854775709)
> timed out at 9223372036854775807 after 1attempt(s)
> Caused by: org.apache.kafka.common.errors.TimeoutException: The AdminClient
> thread has exited. Call: fetchMetadata
> [2020-11-10 12:40:24,644] INFO Metrics scheduler closed
> (org.apache.kafka.common.metrics.Metrics:668)
> [2020-11-10 12:40:24,644] INFO Closing reporter
> org.apache.kafka.common.metrics.JmxReporter
> (org.apache.kafka.common.metrics.Metrics:672)
> [2020-11-10 12:40:24,644] INFO Metrics reporters closed
> (org.apache.kafka.common.metrics.Metrics:678)
> [2020-11-10 12:40:24,645] ERROR Stopping due to error
> (org.apache.kafka.connect.mirror.MirrorMaker:304)
> org.apache.kafka.connect.errors.ConnectException: Failed to connect to and
> describe Kafka cluster. Check worker's broker connection and security
> properties.
> at
> org.apache.kafka.connect.util.ConnectUtils.lookupKafkaClusterId(ConnectUtils.java:70)
> at
> org.apache.kafka.connect.util.ConnectUtils.lookupKafkaClusterId(ConnectUtils.java:51)
> at
> org.apache.kafka.connect.mirror.MirrorMaker.addHerder(MirrorMaker.java:235)
> at
> org.apache.kafka.connect.mirror.MirrorMaker.lambda$new$1(MirrorMaker.java:136)
> at java.lang.Iterable.forEach(Iterable.java:75)
> at
> org.apache.kafka.connect.mirror.MirrorMaker.(MirrorMaker.java:136)
> at
> org.apache.kafka.connect.mirror.MirrorMaker.(MirrorMaker.java:148)
> at
> org.apache.kafka.connect.mirror.MirrorMaker.main(MirrorMaker.java:291)
> Caused by: java.util.concurrent.ExecutionException:
> org.apache.kafka.common.errors.TimeoutException: Call(callName=listNodes,
> deadlineMs=1605012024641, tries=1, nextAllowedTryMs=1605012024742)timed out
> at 1605012024642 after 1 attempt(s)
> at
> org.apache.kafka.common.internals.KafkaFutureImpl.wrapAndThrow(KafkaFutureImpl.java:45)
> at
> org.apache.kafka.common.internals.KafkaFutureImpl.access$000(KafkaFutureImpl.java:32)
> at
>
[GitHub] [kafka] vvcephei commented on a change in pull request #9414: KAFKA-10585: Kafka Streams should clean up the state store directory from cleanup
vvcephei commented on a change in pull request #9414:
URL: https://github.com/apache/kafka/pull/9414#discussion_r524437121
##
File path:
streams/src/test/java/org/apache/kafka/streams/processor/internals/StateDirectoryTest.java
##
@@ -186,19 +186,29 @@ public void shouldReportDirectoryEmpty() throws
IOException {
@Test
public void shouldThrowProcessorStateException() throws IOException {
Review comment:
Since you have modified the purpose of this test, maybe we can go ahead
and give the test a more specific name as well.
```suggestion
public void
shouldThrowProcessorStateExceptionIfTaskDirectoryIsOccupiedByFile() throws
IOException {
```
Also, I won't dispute the value of checking this condition, but would like
to point out that this test was previously verifying a specific error on
failure to create the task directory, and now we are no longer checking that
failure. In other words, we were previously verifying "task directory [%s]
doesn't exist and couldn't be created", but now we are only verifying the
separate and specific failure reason "task directory path [%s] is already
occupied".
It actually seems like maybe we don't need to check that specific
`!taskDir.isDirectory()` case, since it seems like having this file sitting
there should cause a failure to create the task directory, right?
##
File path:
streams/src/test/java/org/apache/kafka/streams/integration/EOSUncleanShutdownIntegrationTest.java
##
@@ -140,9 +140,6 @@ public void
shouldWorkWithUncleanShutdownWipeOutStateStore() throws InterruptedE
IntegrationTestUtils.produceSynchronously(producerConfig, false,
input, Optional.empty(),
singletonList(new KeyValueTimestamp<>("k1", "v1", 0L)));
-TestUtils.waitForCondition(stateDir::exists,
-"Failed awaiting CreateTopics first request failure");
Review comment:
Can you explain why we need to remove this? It seems like the
application must have created the state directory by this point, right?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] wcarlson5 commented on a change in pull request #9487: KAFKA-9331: Add a streams specific uncaught exception handler
wcarlson5 commented on a change in pull request #9487:
URL: https://github.com/apache/kafka/pull/9487#discussion_r524437940
##
File path:
streams/src/main/java/org/apache/kafka/streams/processor/internals/GlobalStreamThread.java
##
@@ -311,6 +314,8 @@ public void run() {
"Updating global state failed. You can restart KafkaStreams to
recover from this error.",
recoverableException
);
+} catch (final Exception e) {
+this.streamsUncaughtExceptionHandler.accept(e);
Review comment:
+1 to sorting out FSM before next release, I have a ticket to track the
work. I started to change it and it ballooned out to be much more expansive
than I thought. This PR is already complicated enough, so we can add is later.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] wcarlson5 commented on a change in pull request #9487: KAFKA-9331: Add a streams specific uncaught exception handler
wcarlson5 commented on a change in pull request #9487:
URL: https://github.com/apache/kafka/pull/9487#discussion_r524435241
##
File path:
streams/src/test/java/org/apache/kafka/streams/processor/internals/StreamThreadTest.java
##
@@ -1000,7 +1012,17 @@ public void restore(final Map tasks) {
CLIENT_ID,
new LogContext(""),
new AtomicInteger(),
-new AtomicLong(Long.MAX_VALUE)
+new AtomicLong(Long.MAX_VALUE),
+null,
+e -> {
+if (e instanceof RuntimeException) {
+throw (RuntimeException) e;
+} else if (e instanceof Error) {
+throw (Error) e;
+} else {
+throw new RuntimeException("Unexpected checked exception
caught in the uncaught exception handler", e);
+}
Review comment:
The default is in KafkaStreams, but I see your point. We can make all of
them rethrow then we will not have to worry about swallowing
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] wcarlson5 commented on a change in pull request #9487: KAFKA-9331: Add a streams specific uncaught exception handler
wcarlson5 commented on a change in pull request #9487:
URL: https://github.com/apache/kafka/pull/9487#discussion_r524433881
##
File path: streams/src/main/java/org/apache/kafka/streams/KafkaStreams.java
##
@@ -366,6 +375,93 @@ public void setUncaughtExceptionHandler(final
Thread.UncaughtExceptionHandler eh
}
}
+/**
+ * Set the handler invoked when an {@link
StreamsConfig#NUM_STREAM_THREADS_CONFIG internal thread}
+ * throws an unexpected exception.
+ * These might be exceptions indicating rare bugs in Kafka Streams, or they
+ * might be exceptions thrown by your code, for example a
NullPointerException thrown from your processor
+ * logic.
+ * The handler will execute on the thread that produced the exception.
+ * So inorder to get the thread as the java handler type uses use
Thread.currentThread()
+ *
+ * Note, this handler must be threadsafe, since it will be shared among
all threads, and invoked from any
+ * thread that encounters such an exception.
+ *
+ * @param streamsUncaughtExceptionHandler the uncaught exception handler
of type {@link StreamsUncaughtExceptionHandler} for all internal threads
+ * @throws IllegalStateException if this {@code KafkaStreams} instance is
not in state {@link State#CREATED CREATED}.
+ * @throws NullPointerException if streamsUncaughtExceptionHandler is null.
+ */
+public void setUncaughtExceptionHandler(final
StreamsUncaughtExceptionHandler streamsUncaughtExceptionHandler) {
+final Consumer handler = exception ->
handleStreamsUncaughtException(exception, streamsUncaughtExceptionHandler);
+synchronized (stateLock) {
+if (state == State.CREATED) {
+Objects.requireNonNull(streamsUncaughtExceptionHandler);
+for (final StreamThread thread : threads) {
+thread.setStreamsUncaughtExceptionHandler(handler);
+}
+if (globalStreamThread != null) {
+globalStreamThread.setUncaughtExceptionHandler(handler);
+}
+} else {
+throw new IllegalStateException("Can only set
UncaughtExceptionHandler in CREATED state. " +
+"Current state is: " + state);
+}
+}
+}
+
+private void handleStreamsUncaughtExceptionDefaultWrapper(final Throwable
throwable) {
Review comment:
It's actually not always used. It is only used until a new handler is
set in which it is over written. Once that happens we don't want the old
handler to be set so we do not wrap a user provided handler with this method
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] kowshik commented on a change in pull request #9596: KAFKA-10723: Fix LogManager shutdown error handling
kowshik commented on a change in pull request #9596:
URL: https://github.com/apache/kafka/pull/9596#discussion_r524345459
##
File path: core/src/test/scala/unit/kafka/log/LogManagerTest.scala
##
@@ -83,6 +87,51 @@ class LogManagerTest {
log.appendAsLeader(TestUtils.singletonRecords("test".getBytes()),
leaderEpoch = 0)
}
+ /**
+ * Tests that all internal futures are completed before
LogManager.shutdown() returns to the
+ * caller during error situations.
+ */
+ @Test
+ def testHandlingExceptionsDuringShutdown(): Unit = {
+logManager.shutdown()
+
+// We create two directories logDir1 and logDir2 to help effectively test
error handling
+// during LogManager.shutdown().
+val logDir1 = TestUtils.tempDir()
+val logDir2 = TestUtils.tempDir()
+logManager = createLogManager(Seq(logDir1, logDir2))
+assertEquals(2, logManager.liveLogDirs.size)
+logManager.startup()
+
+val log1 = logManager.getOrCreateLog(new TopicPartition(name, 0), () =>
logConfig)
+val log2 = logManager.getOrCreateLog(new TopicPartition(name, 1), () =>
logConfig)
+
+val logFile1 = new File(logDir1, name + "-0")
+assertTrue(logFile1.exists)
+val logFile2 = new File(logDir2, name + "-1")
+assertTrue(logFile2.exists)
+
+log1.appendAsLeader(TestUtils.singletonRecords("test1".getBytes()),
leaderEpoch = 0)
+log1.takeProducerSnapshot()
+log1.appendAsLeader(TestUtils.singletonRecords("test1".getBytes()),
leaderEpoch = 0)
+
+log2.appendAsLeader(TestUtils.singletonRecords("test2".getBytes()),
leaderEpoch = 0)
+log2.takeProducerSnapshot()
+log2.appendAsLeader(TestUtils.singletonRecords("test2".getBytes()),
leaderEpoch = 0)
+
+// This should cause log1.close() to fail during LogManger shutdown
sequence.
+FileUtils.deleteDirectory(logFile1)
Review comment:
Sorry I do not understand the question.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] C0urante opened a new pull request #9599: MINOR: Include connector name in error message
C0urante opened a new pull request #9599: URL: https://github.com/apache/kafka/pull/9599 These log messages aren't triggered very frequently, but when they are it can indicate a serious problem with the connector, and it'd be nice to know exactly which connector is having that problem without having to dig through other log messages and try to correlate the stack trace here with existing connector configs. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Created] (KAFKA-10728) Mirroring data without decompressing with MirrorMaker 2.0
Eazhilan Nagarajan created KAFKA-10728:
--
Summary: Mirroring data without decompressing with MirrorMaker 2.0
Key: KAFKA-10728
URL: https://issues.apache.org/jira/browse/KAFKA-10728
Project: Kafka
Issue Type: Improvement
Components: mirrormaker
Reporter: Eazhilan Nagarajan
Hello,
I use MirrorMaker 2.0 to copy data across two Kafka clusters and it's all
working fine. Recently we enabled compressing while producing data into any
topic which had a very positive impact on the storage and other resources but
while mirroring, the data seems to be decompressed at the target Kafka cluster.
I tried enabling compression using the below config in MM2, the data at the
target cluster is compressed now, the decompress and re-compress continues to
happen and it eats up a lot of resources unnecessarily.
{noformat}
- alias: my-passive-cluster
authentication:
passwordSecret:
password: password
secretName: passive-cluster-secret
type: scram-sha-512
username: user-1
bootstrapServers: my-passive-cluster.com:443
config:
config.storage.replication.factor: 3
offset.storage.replication.factor: 3
status.storage.replication.factor: 3
producer.compression.type: gzip{noformat}
I found couple of Jira issues talking about it but I don't know if the shallow
iterator option is available now.
https://issues.apache.org/jira/browse/KAFKA-732,
https://issues.apache.org/jira/browse/KAFKA-845
Kindly let me if this is currently available or if it'll be available in the
future.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Created] (KAFKA-10727) Kafka clients throw AuthenticationException during Kerberos re-login
Rajini Sivaram created KAFKA-10727: -- Summary: Kafka clients throw AuthenticationException during Kerberos re-login Key: KAFKA-10727 URL: https://issues.apache.org/jira/browse/KAFKA-10727 Project: Kafka Issue Type: Bug Reporter: Rajini Sivaram Assignee: Rajini Sivaram During Kerberos re-login, we log out and login again. There is a timing issue where the principal in the Subject has been cleared, but a new one hasn't been populated yet. We need to ensure that we don't throw AuthenticationException in this case to avoid Kafka clients (consumer/producer etc.) failing instead of retrying. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-10652) Raft leader should flush accumulated writes after a min size is reached
[ https://issues.apache.org/jira/browse/KAFKA-10652?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17232720#comment-17232720 ] Sagar Rao commented on KAFKA-10652: --- hi [~hachikuji], wanted to know if the approach made sense to you or not. > Raft leader should flush accumulated writes after a min size is reached > --- > > Key: KAFKA-10652 > URL: https://issues.apache.org/jira/browse/KAFKA-10652 > Project: Kafka > Issue Type: Sub-task >Reporter: Jason Gustafson >Assignee: Sagar Rao >Priority: Major > > In KAFKA-10601, we implemented linger semantics similar to the producer to > let the leader accumulate a batch of writes before fsyncing them to disk. > Currently the fsync is only based on the linger time, but it would be helpful > to make it size-based as well. In other words, if we accumulate a > configurable N bytes, then we should not wait for linger expiration and > should just fsync immediately. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-10701) First line of detailed stats from consumer-perf-test.sh incorrect
[
https://issues.apache.org/jira/browse/KAFKA-10701?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17232698#comment-17232698
]
Liju commented on KAFKA-10701:
--
Opened below pr for the fix
https://github.com/apache/kafka/pull/9598
> First line of detailed stats from consumer-perf-test.sh incorrect
> -
>
> Key: KAFKA-10701
> URL: https://issues.apache.org/jira/browse/KAFKA-10701
> Project: Kafka
> Issue Type: Bug
> Components: tools
>Reporter: David Arthur
>Assignee: Liju
>Priority: Minor
> Labels: newbie
>
> When running the console perf test with {{--show-detailed-stats}}, the first
> line out of output has incorrect results
> {code}
> $ ./bin/kafka-consumer-perf-test.sh --bootstrap-server localhost:9092 --topic
> test --messages 1000 --reporting-interval 1000 --show-detailed-stats
> time, threadId, data.consumed.in.MB, MB.sec, data.consumed.in.nMsg, nMsg.sec,
> rebalance.time.ms, fetch.time.ms, fetch.MB.sec, fetch.nMsg.sec
> 2020-11-06 11:57:01:420, 0, 275.3878, 275.3878, 288765, 288765.,
> 1604681820723, -1604681819723, 0., 0.
> 2020-11-06 11:57:02:420, 0, 952.1456, 676.7578, 998397, 709632., 0, 1000,
> 676.7578, 709632.
> 2020-11-06 11:57:03:420, 0, 1654.2940, 702.1484, 1734653, 736256., 0,
> 1000, 702.1484, 736256.
> 2020-11-06 11:57:04:420, 0, 2492.1389, 837.8448, 2613197, 878544., 0,
> 1000, 837.8448, 878544.
> 2020-11-06 11:57:05:420, 0, 3403.2993, 911.1605, 3568618, 955421., 0,
> 1000, 911.1605, 955421.
> 2020-11-06 11:57:06:420, 0, 4204.1540, 800.8547, 4408375, 839757., 0,
> 1000, 800.8547, 839757.
> 2020-11-06 11:57:07:420, 0, 4747.1275, 542.9735, 4977724, 569349., 0,
> 1000, 542.9735, 569349.
> 2020-11-06 11:57:08:420, 0, 5282.2266, 535.0990, 5538816, 561092., 0,
> 1000, 535.0990, 561092.
> 2020-11-06 11:57:09:420, 0, 5824.3732, 542.1467, 6107298, 568482., 0,
> 1000, 542.1467, 568482.
> {code}
> This seems to be due to incorrect initialization of the {{joinStart}}
> variable in the consumer perf test code.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] C0urante commented on a change in pull request #9597: KAFKA-10720: Document prohibition on header mutation by SMTs
C0urante commented on a change in pull request #9597:
URL: https://github.com/apache/kafka/pull/9597#discussion_r524160693
##
File path:
connect/api/src/main/java/org/apache/kafka/connect/transforms/Transformation.java
##
@@ -33,6 +33,9 @@
* Apply transformation to the {@code record} and return another record
object (which may be {@code record} itself) or {@code null},
* corresponding to a map or filter operation respectively.
*
+ * A transformation must not mutate the headers of a given {@code record}.
If the headers need to be changed
+ * a new record with different headers should be created and returned.
+ *
Review comment:
Should we also make a note about mutating the key/value of the record,
which is possible for `Struct`, `Map`, and `Array` instances?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] C0urante commented on a change in pull request #9597: KAFKA-10720: Document prohibition on header mutation by SMTs
C0urante commented on a change in pull request #9597:
URL: https://github.com/apache/kafka/pull/9597#discussion_r524160693
##
File path:
connect/api/src/main/java/org/apache/kafka/connect/transforms/Transformation.java
##
@@ -33,6 +33,9 @@
* Apply transformation to the {@code record} and return another record
object (which may be {@code record} itself) or {@code null},
* corresponding to a map or filter operation respectively.
*
+ * A transformation must not mutate the headers of a given {@code record}.
If the headers need to be changed
+ * a new record with different headers should be created and returned.
+ *
Review comment:
Should we also make a note about mutating other things such as the
key/value of the record, which is possible for `Struct`, `Map`, and `Array`
instances?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] lijubjohn opened a new pull request #9598: fixes kafka-10701 : incorrect first line of detailed stats from consumer-perf-test.sh
lijubjohn opened a new pull request #9598: URL: https://github.com/apache/kafka/pull/9598 Corrected the initialization of joinStart variable to fix the first line of the consumer performance stats. Since the joinStart was initialized with 0 , so when the first time onPartitionAssigned method is called it makes the joinTime as System.currentTimeMillis which inturn made the fetchTimeMs incorrect (-ve) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Updated] (KAFKA-10726) How to detect heartbeat failure between broker/zookeeper leader
[ https://issues.apache.org/jira/browse/KAFKA-10726?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Keiichiro Wakasa updated KAFKA-10726: - Description: Hello experts, I'm not sure this is proper place to ask but I'd appreciate if you could help us with the following question... We've continuously suffered from broker exclusion caused by heartbeat timeout between broker and zookeeper leader. This issue can be easily detected by checking ephemeral nodes via zkcli.sh but we'd like to detect this with logs like server.log/controller.log since we have an existing system to forward these logs to our system. Looking at server.log/controller.log, we couldn't find any logs that indicates the heartbeat timeout. Is there any other logs to check for heartbeat health? was: Hello experts, I'm not sure this is proper place to ask but I'd appreciate if you could help us with the following question... We've continuously suffered from broker exclusion caused by heartbeat timeout between broker and zookeeper leader. This issue can easily detected by checking ephemeral nodes via zkcli.sh but we'd like to detect this with logs like server.log/controller.log since we have an existing system to forward these logs to our system. Looking at server.log/controller.log, we couldn't find any logs that indicates the heartbeat timeout. Is there any other logs to check for heartbeat health? > How to detect heartbeat failure between broker/zookeeper leader > --- > > Key: KAFKA-10726 > URL: https://issues.apache.org/jira/browse/KAFKA-10726 > Project: Kafka > Issue Type: Bug > Components: controller, logging >Affects Versions: 2.1.1 >Reporter: Keiichiro Wakasa >Priority: Critical > > Hello experts, > I'm not sure this is proper place to ask but I'd appreciate if you could help > us with the following question... > > We've continuously suffered from broker exclusion caused by heartbeat timeout > between broker and zookeeper leader. > This issue can be easily detected by checking ephemeral nodes via zkcli.sh > but we'd like to detect this with logs like server.log/controller.log since > we have an existing system to forward these logs to our system. > Looking at server.log/controller.log, we couldn't find any logs that > indicates the heartbeat timeout. Is there any other logs to check for > heartbeat health? -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Created] (KAFKA-10726) How to detect heartbeat failure between broker/zookeeper leader
Keiichiro Wakasa created KAFKA-10726: Summary: How to detect heartbeat failure between broker/zookeeper leader Key: KAFKA-10726 URL: https://issues.apache.org/jira/browse/KAFKA-10726 Project: Kafka Issue Type: Bug Components: controller, logging Affects Versions: 2.1.1 Reporter: Keiichiro Wakasa Hello experts, I'm not sure this is proper place to ask but I'd appreciate if you could help us with the following question... We've continuously suffered from broker exclusion caused by heartbeat timeout between broker and zookeeper leader. This issue can easily detected by checking ephemeral nodes via zkcli.sh but we'd like to detect this with logs like server.log/controller.log since we have an existing system to forward these logs to our system. Looking at server.log/controller.log, we couldn't find any logs that indicates the heartbeat timeout. Is there any other logs to check for heartbeat health? -- This message was sent by Atlassian Jira (v8.3.4#803005)
[GitHub] [kafka] lqjack commented on a change in pull request #9596: KAFKA-10723: Fix LogManager shutdown error handling
lqjack commented on a change in pull request #9596:
URL: https://github.com/apache/kafka/pull/9596#discussion_r524053292
##
File path: core/src/test/scala/unit/kafka/log/LogManagerTest.scala
##
@@ -83,6 +87,51 @@ class LogManagerTest {
log.appendAsLeader(TestUtils.singletonRecords("test".getBytes()),
leaderEpoch = 0)
}
+ /**
+ * Tests that all internal futures are completed before
LogManager.shutdown() returns to the
+ * caller during error situations.
+ */
+ @Test
+ def testHandlingExceptionsDuringShutdown(): Unit = {
+logManager.shutdown()
+
+// We create two directories logDir1 and logDir2 to help effectively test
error handling
+// during LogManager.shutdown().
+val logDir1 = TestUtils.tempDir()
+val logDir2 = TestUtils.tempDir()
+logManager = createLogManager(Seq(logDir1, logDir2))
+assertEquals(2, logManager.liveLogDirs.size)
+logManager.startup()
+
+val log1 = logManager.getOrCreateLog(new TopicPartition(name, 0), () =>
logConfig)
+val log2 = logManager.getOrCreateLog(new TopicPartition(name, 1), () =>
logConfig)
+
+val logFile1 = new File(logDir1, name + "-0")
+assertTrue(logFile1.exists)
+val logFile2 = new File(logDir2, name + "-1")
+assertTrue(logFile2.exists)
+
+log1.appendAsLeader(TestUtils.singletonRecords("test1".getBytes()),
leaderEpoch = 0)
+log1.takeProducerSnapshot()
+log1.appendAsLeader(TestUtils.singletonRecords("test1".getBytes()),
leaderEpoch = 0)
+
+log2.appendAsLeader(TestUtils.singletonRecords("test2".getBytes()),
leaderEpoch = 0)
+log2.takeProducerSnapshot()
+log2.appendAsLeader(TestUtils.singletonRecords("test2".getBytes()),
leaderEpoch = 0)
+
+// This should cause log1.close() to fail during LogManger shutdown
sequence.
+FileUtils.deleteDirectory(logFile1)
Review comment:
If the end user delete the log files Manually , the server cannot be
stopped. and The cannot startup it again? so in this case ,how do they resolve
it ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
[GitHub] [kafka] tombentley commented on pull request #9597: KAFKA-10720: Document prohibition on header mutation by SMTs
tombentley commented on pull request #9597: URL: https://github.com/apache/kafka/pull/9597#issuecomment-727858963 @kkonstantine @rhauch please could you take look at this trivial PR? cc @C0urante. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] tombentley opened a new pull request #9597: KAFKA-10720: Document prohibition on header mutation by SMTs
tombentley opened a new pull request #9597: URL: https://github.com/apache/kafka/pull/9597 Adds a sentence to the Javadoc for `Transformation` about not mutating headers. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
chia7712 commented on pull request #9401: URL: https://github.com/apache/kafka/pull/9401#issuecomment-727856785 @hachikuji @ijuma @lbradstreet @dajac I have updated the perf result. The regression is reduced by last commit. Please take a look. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] tombentley commented on pull request #9549: KIP-145: Add SMTs, HeaderFrom, DropHeaders and InsertHeader
tombentley commented on pull request #9549: URL: https://github.com/apache/kafka/pull/9549#issuecomment-727852419 @kkonstantine or perhaps @rhauch please could one of you take a look? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] tombentley commented on a change in pull request #9549: KIP-145: Add SMTs, HeaderFrom, DropHeaders and InsertHeader
tombentley commented on a change in pull request #9549:
URL: https://github.com/apache/kafka/pull/9549#discussion_r524016349
##
File path:
connect/transforms/src/test/java/org/apache/kafka/connect/transforms/HeaderFromTest.java
##
@@ -0,0 +1,357 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.kafka.connect.transforms;
+
+import org.apache.kafka.common.config.ConfigException;
+import org.apache.kafka.connect.data.Schema;
+import org.apache.kafka.connect.data.SchemaAndValue;
+import org.apache.kafka.connect.data.SchemaBuilder;
+import org.apache.kafka.connect.data.Struct;
+import org.apache.kafka.connect.header.ConnectHeaders;
+import org.apache.kafka.connect.header.Header;
+import org.apache.kafka.connect.header.Headers;
+import org.apache.kafka.connect.source.SourceRecord;
+import org.junit.Test;
+import org.junit.runner.RunWith;
+import org.junit.runners.Parameterized;
+
+import java.util.ArrayList;
+import java.util.Collection;
+import java.util.HashMap;
+import java.util.List;
+import java.util.Map;
+
+import static java.util.Arrays.asList;
+import static java.util.Collections.singletonList;
+import static java.util.Collections.singletonMap;
+import static org.apache.kafka.connect.data.Schema.STRING_SCHEMA;
+import static org.junit.Assert.assertEquals;
+
+@RunWith(Parameterized.class)
+public class HeaderFromTest {
+
+private final boolean keyTransform;
+
+static class RecordBuilder {
+private final List fields = new ArrayList<>(2);
+private final List fieldSchemas = new ArrayList<>(2);
+private final List fieldValues = new ArrayList<>(2);
+private final ConnectHeaders headers = new ConnectHeaders();
+
+public RecordBuilder() {
+}
+
+public RecordBuilder withField(String name, Schema schema, Object
value) {
+fields.add(name);
+fieldSchemas.add(schema);
+fieldValues.add(value);
+return this;
+}
+
+public RecordBuilder addHeader(String name, Schema schema, Object
value) {
+headers.add(name, new SchemaAndValue(schema, value));
+return this;
+}
+
+public SourceRecord schemaless(boolean keyTransform) {
+Map map = new HashMap<>();
+for (int i = 0; i < this.fields.size(); i++) {
+String fieldName = this.fields.get(i);
+map.put(fieldName, this.fieldValues.get(i));
+
+}
+return sourceRecord(keyTransform, null, map);
+}
+
+private Schema schema() {
+SchemaBuilder schemaBuilder = new
SchemaBuilder(Schema.Type.STRUCT);
+for (int i = 0; i < this.fields.size(); i++) {
+String fieldName = this.fields.get(i);
+schemaBuilder.field(fieldName, this.fieldSchemas.get(i));
+
+}
+return schemaBuilder.build();
+}
+
+private Struct struct(Schema schema) {
+Struct struct = new Struct(schema);
+for (int i = 0; i < this.fields.size(); i++) {
+String fieldName = this.fields.get(i);
+struct.put(fieldName, this.fieldValues.get(i));
+}
+return struct;
+}
+
+public SourceRecord withSchema(boolean keyTransform) {
+Schema schema = schema();
+Struct struct = struct(schema);
+return sourceRecord(keyTransform, schema, struct);
+}
+
+private SourceRecord sourceRecord(boolean keyTransform, Schema
keyOrValueSchema, Object keyOrValue) {
+Map sourcePartition = singletonMap("foo", "bar");
+Map sourceOffset = singletonMap("baz", "quxx");
+String topic = "topic";
+Integer partition = 0;
+Long timestamp = 0L;
+
+ConnectHeaders headers = this.headers;
+if (keyOrValueSchema == null) {
+// When doing a schemaless transformation we don't expect the
header to have a schema
+headers = new ConnectHeaders();
+for (Header header : this.headers) {
+headers.add(header.key(), new SchemaAndValue(null,
[jira] [Commented] (KAFKA-10062) Add a method to retrieve the current timestamp as known by the Streams app
[ https://issues.apache.org/jira/browse/KAFKA-10062?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17232638#comment-17232638 ] Bruno Cadonna commented on KAFKA-10062: --- [~rohitdeshaws] I think [~wbottrell] and [~psmolinski] have already worked on it. See the corresponding KIP here: [https://cwiki.apache.org/confluence/display/KAFKA/KIP-622%3A+Add+currentSystemTimeMs+and+currentStreamTimeMs+to+ProcessorContext] However, I do not know how much progress they have done on the implementation. [~wbottrell] and [~psmolinski] could you update the ticket, please? > Add a method to retrieve the current timestamp as known by the Streams app > -- > > Key: KAFKA-10062 > URL: https://issues.apache.org/jira/browse/KAFKA-10062 > Project: Kafka > Issue Type: Improvement > Components: streams >Reporter: Piotr Smolinski >Assignee: William Bottrell >Priority: Major > Labels: needs-kip, newbie > > Please add to the ProcessorContext a method to retrieve current timestamp > compatible with Punctuator#punctate(long) method. > Proposal in ProcessorContext: > long getTimestamp(PunctuationType type); > The method should return time value as known by the Punctuator scheduler with > the respective PunctuationType. > The use-case is tracking of a process with timeout-based escalation. > A transformer receives process events and in case of missing an event execute > an action (emit message) after given escalation timeout (several stages). The > initial message may already arrive with reference timestamp in the past and > may trigger different action upon arrival depending on how far in the past it > is. > If the timeout should be computed against some further time only, Punctuator > is perfectly sufficient. The problem is that I have to evaluate the current > time-related state once the message arrives. > I am using wall-clock time. Normally accessing System.currentTimeMillis() is > sufficient, but it breaks in unit testing with TopologyTestDriver, where the > app wall clock time is different from the system-wide one. > To access the mentioned clock I am using reflection to access > ProcessorContextImpl#task and then StreamTask#time. -- This message was sent by Atlassian Jira (v8.3.4#803005)
[jira] [Commented] (KAFKA-10683) Consumer.position() Ignores Transaction Marker with read_uncommitted
[
https://issues.apache.org/jira/browse/KAFKA-10683?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17232635#comment-17232635
]
Timur commented on KAFKA-10683:
---
[~grussell], absolutely - from the consumer side this marker is completely
hidden. This behavior looks like broker implementation details exposed to the
outside world IMHO.
> Consumer.position() Ignores Transaction Marker with read_uncommitted
>
>
> Key: KAFKA-10683
> URL: https://issues.apache.org/jira/browse/KAFKA-10683
> Project: Kafka
> Issue Type: Bug
> Components: clients, core
>Affects Versions: 2.6.0
>Reporter: Gary Russell
>Priority: Minor
>
> The workaround for https://issues.apache.org/jira/browse/KAFKA-6607# Says:
> {quote}
> or use `consumer.position()` that takes the commit marker into account and
> would "step over it")
> {quote}
> Note that this problem occurs with all consumers, not just Streams. We have
> implemented this solution in our project (as an option for those users
> concerned about the pseudo lag).
> We have discovered that this technique will only work with
> {code}isolation.level=read_committed{code} Otherwise, the
> {code}position(){code} call does not include the marker "record".
> https://github.com/spring-projects/spring-kafka/issues/1587#issuecomment-721899560
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] cadonna commented on pull request #9508: KAFKA-10648: Add Prefix Scan support to State Stores
cadonna commented on pull request #9508: URL: https://github.com/apache/kafka/pull/9508#issuecomment-727841634 @vamossagar12 I am really sorry. I haven't found the time yet, but it is on my ToDo list. I hope I will manage to make a pass this week. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[jira] [Assigned] (KAFKA-10720) Add note to Transformation docs to avoid mutating records or their members
[
https://issues.apache.org/jira/browse/KAFKA-10720?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Tom Bentley reassigned KAFKA-10720:
---
Assignee: Tom Bentley
> Add note to Transformation docs to avoid mutating records or their members
> --
>
> Key: KAFKA-10720
> URL: https://issues.apache.org/jira/browse/KAFKA-10720
> Project: Kafka
> Issue Type: Improvement
> Components: KafkaConnect
>Reporter: Chris Egerton
>Assignee: Tom Bentley
>Priority: Major
>
> The public documentation for the {{Transformation}} interface does not
> mention whether an SMT should or should not mutate records or their members
> (such as their values or headers), but there's some logic in the Connect
> framework that relies on SMTs not doing this, such as the invocation of
> `SourceTask::commitRecord` with a pre-transformation record in some cases.
> We should consider adding a note about not modifying records or their members
> to the public-facing documentation for the {{Transformation}} interface.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[jira] [Assigned] (KAFKA-10723) LogManager leaks internal thread pool activity during shutdown
[
https://issues.apache.org/jira/browse/KAFKA-10723?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Tom Bentley reassigned KAFKA-10723:
---
Assignee: Kowshik Prakasam
> LogManager leaks internal thread pool activity during shutdown
> --
>
> Key: KAFKA-10723
> URL: https://issues.apache.org/jira/browse/KAFKA-10723
> Project: Kafka
> Issue Type: Bug
>Reporter: Kowshik Prakasam
>Assignee: Kowshik Prakasam
>Priority: Major
>
> *TL;DR:*
> The asynchronous shutdown in {{LogManager}} has the shortcoming that if
> during shutdown any of the internal futures fail, then we do not always
> ensure that all futures are completed before {{LogManager.shutdown}} returns.
> As a result, despite the shut down completed message from KafkaServer is seen
> in the error logs, some futures continue to run from inside LogManager
> attempting to close the logs. This is misleading and it could possibly break
> the general rule of avoiding post-shutdown activity in the Broker.
> *Description:*
> When LogManager is shutting down, exceptions in log closure are handled
> [here|https://github.com/apache/kafka/blob/trunk/core/src/main/scala/kafka/log/LogManager.scala#L497-L501].
> However, this
> [line|https://github.com/apache/kafka/blob/trunk/core/src/main/scala/kafka/log/LogManager.scala#L502]
> in the finally clause shuts down the thread pools *asynchronously*. The
> code: _threadPools.foreach(.shutdown())_ initiates an orderly shutdown (for
> each thread pool) in which previously submitted tasks are executed, but no
> new tasks will be accepted (see javadoc link
> [here|https://docs.oracle.com/javase/7/docs/api/java/util/concurrent/ExecutorService.html#shutdown()])_._
> As a result, if there is an exception during log closure, some of the thread
> pools which are closing logs could be leaked and continue to run in the
> background, after the control returns to the caller (i.e. {{KafkaServer}}).
> As a result, even after the "shut down completed" message is seen in the
> error logs (originating from {{KafkaServer}} shutdown sequence), log closures
> continue to happen in the background, which is misleading.
>
> *Proposed options for fixes:*
> It seems useful that we maintain the contract with {{KafkaServer}} that after
> {{LogManager.shutdown}} is called once, all tasks that close the logs are
> guaranteed to have completed before the call returns. There are probably
> couple different ways to fix this:
> # Replace {{_threadPools.foreach(.shutdown())_ with
> _threadPools.foreach(.awaitTermination())_}}{{.}} This ensures that we wait
> for all threads to be shutdown before returning the {{_LogManager.shutdown_}}
> call.
> # Skip creating of checkpoint and clean shutdown file only for the affected
> directory if any of its futures throw an error. We continue to wait for all
> futures to complete for all directories. This can require some changes to
> [this for
> loop|https://github.com/apache/kafka/blob/trunk/core/src/main/scala/kafka/log/LogManager.scala#L481-L496],
> so that we wait for all futures to complete regardless of whether one of
> them threw an error.
--
This message was sent by Atlassian Jira
(v8.3.4#803005)
[GitHub] [kafka] chia7712 commented on pull request #9401: KAFKA-9628 Replace Produce request/response with automated protocol
chia7712 commented on pull request #9401: URL: https://github.com/apache/kafka/pull/9401#issuecomment-727825315 The last commit borrows some improvement from #9563. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org
[GitHub] [kafka] chia7712 commented on pull request #9204: KAFKA-6181 Examining log messages with {{--deep-iteration}} should show superset of fields
chia7712 commented on pull request #9204: URL: https://github.com/apache/kafka/pull/9204#issuecomment-727809410 @iprithv Could you rebase code (or add trivial change) to trigger QA again? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org