AngersZhuuuu opened a new pull request #30958: URL: https://github.com/apache/spark/pull/30958
### What changes were proposed in this pull request? For same SQL ``` SELECT TRANSFORM(a, b, c, null) ROW FORMAT DELIMITED USING 'cat' ROW FORMAT DELIMITED FIELDS TERMINATED BY '&' FROM (select 1 as a, 2 as b, 3 as c) t ``` In hive: 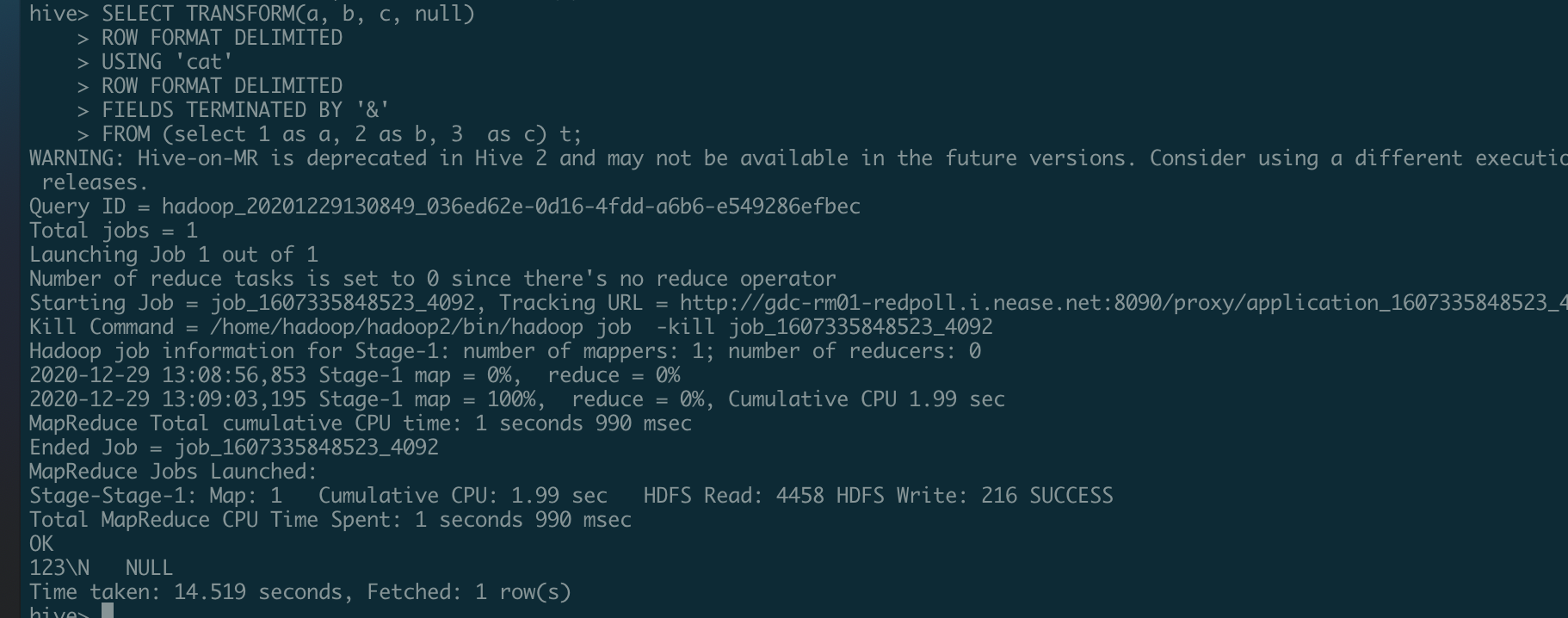 In Spark 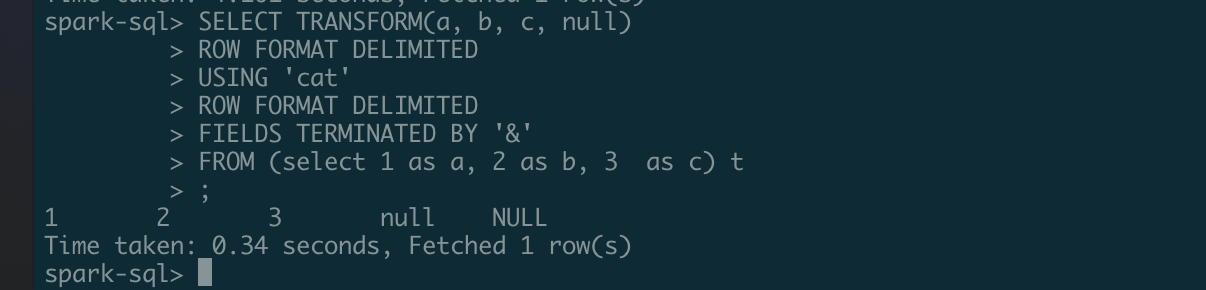 We should keep same. Change default ROW FORMAT FIELD DELIMIT to `\u0001` ### Why are the changes needed? Keep same behavior with hive ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Added UT ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org --------------------------------------------------------------------- To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
{kind=link}
{kind=link}