[GitHub] [spark] beliefer commented on a diff in pull request #39660: [SPARK-42128][SQL] Support TOP (N) for MS SQL Server dialect as an alternative to Limit pushdown
beliefer commented on code in PR #39660:
URL: https://github.com/apache/spark/pull/39660#discussion_r1083729512
##
sql/core/src/main/scala/org/apache/spark/sql/jdbc/JdbcDialects.scala:
##
@@ -544,6 +544,14 @@ abstract class JdbcDialect extends Serializable with
Logging {
if (limit > 0 ) s"LIMIT $limit" else ""
}
+ /**
+ * MS SQL Server version of `getLimitClause`.
+ * This is only supported by SQL Server as it uses TOP (N) instead.
+ */
+ def getTopExpression(limit: Integer): String = {
Review Comment:
I think we should define the different syntax by dialect themself. I exact
the API getSQLText so as some dialect could implement it in special way.
##
sql/core/src/main/scala/org/apache/spark/sql/jdbc/JdbcDialects.scala:
##
@@ -544,6 +544,14 @@ abstract class JdbcDialect extends Serializable with
Logging {
if (limit > 0 ) s"LIMIT $limit" else ""
}
+ /**
+ * MS SQL Server version of `getLimitClause`.
+ * This is only supported by SQL Server as it uses TOP (N) instead.
+ */
+ def getTopExpression(limit: Integer): String = {
Review Comment:
I think we should define the different syntax by dialect themself. I exact
the API `getSQLText` so as some dialect could implement it in special way.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic opened a new pull request, #39706: [SPARK-42158][SQL] Integrate `_LEGACY_ERROR_TEMP_1003` into `FIELD_NOT_FOUND`
itholic opened a new pull request, #39706: URL: https://github.com/apache/spark/pull/39706 ### What changes were proposed in this pull request? This PR proposes to integrate `_LEGACY_ERROR_TEMP_1003` into `FIELD_NOT_FOUND` ### Why are the changes needed? We should deduplicate the similar error classes into single error class by merging them. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Fixed exiting UTs. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on a diff in pull request #39508: [SPARK-41985][SQL] Centralize more column resolution rules
viirya commented on code in PR #39508: URL: https://github.com/apache/spark/pull/39508#discussion_r1083698974 ## sql/core/src/test/resources/sql-tests/inputs/group-by.sql: ## @@ -45,6 +45,15 @@ SELECT COUNT(DISTINCT b), COUNT(DISTINCT b, c) FROM (SELECT 1 AS a, 2 AS b, 3 AS SELECT a AS k, COUNT(b) FROM testData GROUP BY k; SELECT a AS k, COUNT(b) FROM testData GROUP BY k HAVING k > 1; +-- GROUP BY alias is not triggered if SELECT list has lateral column alias. +SELECT 1 AS x, x + 1 AS k FROM testData GROUP BY k; + +-- GROUP BY alias is not triggered if SELECT list has outer reference. +SELECT * FROM testData WHERE a = 1 AND EXISTS (SELECT a AS k GROUP BY k); + +-- GROUP BY alias inside subquery expression with conflicting outer reference +SELECT * FROM testData WHERE a = 1 AND EXISTS (SELECT 1 AS a GROUP BY a); + Review Comment: GROUP BY alias takes precedence than outer reference? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39703: [SPARK-42157][CORE] `spark.scheduler.mode=FAIR` should provide FAIR scheduler
dongjoon-hyun commented on PR #39703: URL: https://github.com/apache/spark/pull/39703#issuecomment-1399888545 No problem. I totally understand your concern on the usage of template file. I'll also think about a new way. Thank you for your thoughtful review, @mridulm . -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] mridulm commented on pull request #39703: [SPARK-42157][CORE] `spark.scheduler.mode=FAIR` should provide FAIR scheduler
mridulm commented on PR #39703: URL: https://github.com/apache/spark/pull/39703#issuecomment-1399887383 Looks like I misunderstood the PR, I see what you mean @dongjoon-hyun. I am not sure what is a good way to make progress here ... let me think about it more. +CC @tgravescs, @Ngone51 in case you have thoughts. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on a diff in pull request #39508: [SPARK-41985][SQL] Centralize more column resolution rules
viirya commented on code in PR #39508: URL: https://github.com/apache/spark/pull/39508#discussion_r1083695957 ## sql/core/src/test/resources/sql-tests/inputs/group-by.sql: ## @@ -45,6 +45,15 @@ SELECT COUNT(DISTINCT b), COUNT(DISTINCT b, c) FROM (SELECT 1 AS a, 2 AS b, 3 AS SELECT a AS k, COUNT(b) FROM testData GROUP BY k; SELECT a AS k, COUNT(b) FROM testData GROUP BY k HAVING k > 1; +-- GROUP BY alias is not triggered if SELECT list has lateral column alias. +SELECT 1 AS x, x + 1 AS k FROM testData GROUP BY k; + +-- GROUP BY alias is not triggered if SELECT list has outer reference. +SELECT * FROM testData WHERE a = 1 AND EXISTS (SELECT a AS k GROUP BY k); Review Comment: If it is not group by alias but group by outer reference, it works? From `ResolveReferencesInAggregate` seems so, just want to confirm. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #39703: [SPARK-42157][CORE] `spark.scheduler.mode=FAIR` should provide FAIR scheduler
dongjoon-hyun commented on code in PR #39703:
URL: https://github.com/apache/spark/pull/39703#discussion_r1083692686
##
core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala:
##
@@ -86,10 +87,17 @@ private[spark] class FairSchedulableBuilder(val rootPool:
Pool, sc: SparkContext
logInfo(s"Creating Fair Scheduler pools from default file:
$DEFAULT_SCHEDULER_FILE")
Some((is, DEFAULT_SCHEDULER_FILE))
} else {
- logWarning("Fair Scheduler configuration file not found so jobs will
be scheduled in " +
-s"FIFO order. To use fair scheduling, configure pools in
$DEFAULT_SCHEDULER_FILE or " +
-s"set ${SCHEDULER_ALLOCATION_FILE.key} to a file that contains the
configuration.")
- None
+ val is =
Utils.getSparkClassLoader.getResourceAsStream(DEFAULT_SCHEDULER_TEMPLATE_FILE)
+ if (is != null) {
+logInfo("Creating Fair Scheduler pools from default template file:
" +
+ s"$DEFAULT_SCHEDULER_TEMPLATE_FILE.")
+Some((is, DEFAULT_SCHEDULER_TEMPLATE_FILE))
+ } else {
+logWarning("Fair Scheduler configuration file not found so jobs
will be scheduled in " +
+ s"FIFO order. To use fair scheduling, configure pools in
$DEFAULT_SCHEDULER_FILE " +
+ s"or set ${SCHEDULER_ALLOCATION_FILE.key} to a file that
contains the configuration.")
+None
+ }
Review Comment:
First of all, this is not a testing issue. As I wrote in the PR description,
our documentation is wrong. It says `spark.scheduler.mode=FAIR` will return a
FAIR scheduler. However, we are getting `FIFO` scheduler now.
> Note - if this is only for testing, we can special case it that way via
spark.testing
`None` is the previous behavior which ends up with `FIFO` scheduler with the
WARNING message, `23/01/22 14:47:38 WARN FairSchedulableBuilder: Fair Scheduler
configuration file not found so jobs will be scheduled in FIFO order. To use
fair scheduling, configure pools in fairscheduler.xml or set
spark.scheduler.allocation.file to a file that contains the configuration.`
> Instead, why not simply rely on returning None here ?
Got it. I understand your point about the `template` file. The reason why I
tried to use template file is that I cannot put the real `fairscheduler.xml`
file because it can be used already in the production.
> We should not be relying on template file - in deployments, template file
can be invalid - admin's are not expecting it to be read by spark.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #39555: [SPARK-42051][SQL] Codegen Support for HiveGenericUDF
LuciferYang commented on code in PR #39555:
URL: https://github.com/apache/spark/pull/39555#discussion_r1083687701
##
sql/hive/src/main/scala/org/apache/spark/sql/hive/hiveUDFs.scala:
##
@@ -192,6 +194,48 @@ private[hive] case class HiveGenericUDF(
override protected def withNewChildrenInternal(newChildren:
IndexedSeq[Expression]): Expression =
copy(children = newChildren)
+ override protected def doGenCode(ctx: CodegenContext, ev: ExprCode):
ExprCode = {
+val refTerm = ctx.addReferenceObj("this", this)
+val childrenEvals = children.map(_.genCode(ctx))
+
+val setDeferredObjects = childrenEvals.zipWithIndex.map {
+ case (eval, i) =>
+val deferredObjectAdapterClz =
classOf[DeferredObjectAdapter].getCanonicalName
+s"""
+ |if (${eval.isNull}) {
+ | (($deferredObjectAdapterClz)
$refTerm.deferredObjects()[$i]).set(null);
+ |} else {
+ | (($deferredObjectAdapterClz)
$refTerm.deferredObjects()[$i]).set(${eval.value});
+ |}
+ |""".stripMargin
+}
+
+val resultType = CodeGenerator.boxedType(dataType)
+val resultTerm = ctx.freshName("result")
+ev.copy(code =
+ code"""
+ |${childrenEvals.map(_.code).mkString("\n")}
+ |${setDeferredObjects.mkString("\n")}
+ |$resultType $resultTerm = null;
+ |boolean ${ev.isNull} = false;
+ |try {
+ | $resultTerm = ($resultType) $refTerm.unwrapper().apply(
+ |$refTerm.function().evaluate($refTerm.deferredObjects()));
+ | ${ev.isNull} = $resultTerm == null;
+ |} catch (Throwable e) {
+ | throw QueryExecutionErrors.failedExecuteUserDefinedFunctionError(
Review Comment:
For safety, better to add a case check the exception scenario
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #39555: [SPARK-42051][SQL] Codegen Support for HiveGenericUDF
LuciferYang commented on code in PR #39555:
URL: https://github.com/apache/spark/pull/39555#discussion_r1083674070
##
sql/hive/src/main/scala/org/apache/spark/sql/hive/hiveUDFs.scala:
##
@@ -154,17 +154,19 @@ private[hive] case class HiveGenericUDF(
function.initializeAndFoldConstants(argumentInspectors.toArray)
}
+ // Visible for codegen
@transient
- private lazy val unwrapper = unwrapperFor(returnInspector)
+ lazy val unwrapper = unwrapperFor(returnInspector)
@transient
private lazy val isUDFDeterministic = {
val udfType = function.getClass.getAnnotation(classOf[HiveUDFType])
udfType != null && udfType.deterministic() && !udfType.stateful()
}
+ // Visible for codegen
@transient
- private lazy val deferredObjects = argumentInspectors.zip(children).map {
case (inspect, child) =>
+ lazy val deferredObjects = argumentInspectors.zip(children).map { case
(inspect, child) =>
Review Comment:
ditto
##
sql/hive/src/main/scala/org/apache/spark/sql/hive/hiveUDFs.scala:
##
@@ -192,6 +194,48 @@ private[hive] case class HiveGenericUDF(
override protected def withNewChildrenInternal(newChildren:
IndexedSeq[Expression]): Expression =
copy(children = newChildren)
+ override protected def doGenCode(ctx: CodegenContext, ev: ExprCode):
ExprCode = {
+val refTerm = ctx.addReferenceObj("this", this)
+val childrenEvals = children.map(_.genCode(ctx))
+
+val setDeferredObjects = childrenEvals.zipWithIndex.map {
+ case (eval, i) =>
+val deferredObjectAdapterClz =
classOf[DeferredObjectAdapter].getCanonicalName
+s"""
+ |if (${eval.isNull}) {
+ | (($deferredObjectAdapterClz)
$refTerm.deferredObjects()[$i]).set(null);
Review Comment:
The initial value of `func` is null.
`set(null)` seem to be a protective operation
##
sql/hive/src/main/scala/org/apache/spark/sql/hive/hiveUDFs.scala:
##
@@ -154,17 +154,19 @@ private[hive] case class HiveGenericUDF(
function.initializeAndFoldConstants(argumentInspectors.toArray)
}
+ // Visible for codegen
@transient
- private lazy val unwrapper = unwrapperFor(returnInspector)
+ lazy val unwrapper = unwrapperFor(returnInspector)
Review Comment:
change to public should add type annotation
##
sql/hive/src/main/scala/org/apache/spark/sql/hive/hiveUDFs.scala:
##
@@ -192,6 +194,48 @@ private[hive] case class HiveGenericUDF(
override protected def withNewChildrenInternal(newChildren:
IndexedSeq[Expression]): Expression =
copy(children = newChildren)
+ override protected def doGenCode(ctx: CodegenContext, ev: ExprCode):
ExprCode = {
+val refTerm = ctx.addReferenceObj("this", this)
+val childrenEvals = children.map(_.genCode(ctx))
+
+val setDeferredObjects = childrenEvals.zipWithIndex.map {
+ case (eval, i) =>
+val deferredObjectAdapterClz =
classOf[DeferredObjectAdapter].getCanonicalName
+s"""
+ |if (${eval.isNull}) {
+ | (($deferredObjectAdapterClz)
$refTerm.deferredObjects()[$i]).set(null);
+ |} else {
+ | (($deferredObjectAdapterClz)
$refTerm.deferredObjects()[$i]).set(${eval.value});
+ |}
+ |""".stripMargin
+}
+
+val resultType = CodeGenerator.boxedType(dataType)
+val resultTerm = ctx.freshName("result")
+ev.copy(code =
+ code"""
+ |${childrenEvals.map(_.code).mkString("\n")}
+ |${setDeferredObjects.mkString("\n")}
+ |$resultType $resultTerm = null;
+ |boolean ${ev.isNull} = false;
+ |try {
+ | $resultTerm = ($resultType) $refTerm.unwrapper().apply(
+ |$refTerm.function().evaluate($refTerm.deferredObjects()));
+ | ${ev.isNull} = $resultTerm == null;
+ |} catch (Throwable e) {
+ | throw QueryExecutionErrors.failedExecuteUserDefinedFunctionError(
Review Comment:
For safety, better to add a case check to exception scenario
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] purple-dude commented on pull request #30889: [SPARK-33398] Fix loading tree models prior to Spark 3.0
purple-dude commented on PR #30889: URL: https://github.com/apache/spark/pull/30889#issuecomment-1399881202 Hi All, I have trained a random forest model in pyspark version 2.4 but I am unable to reload it in pyspark version 3.0.3 but it gives below error : 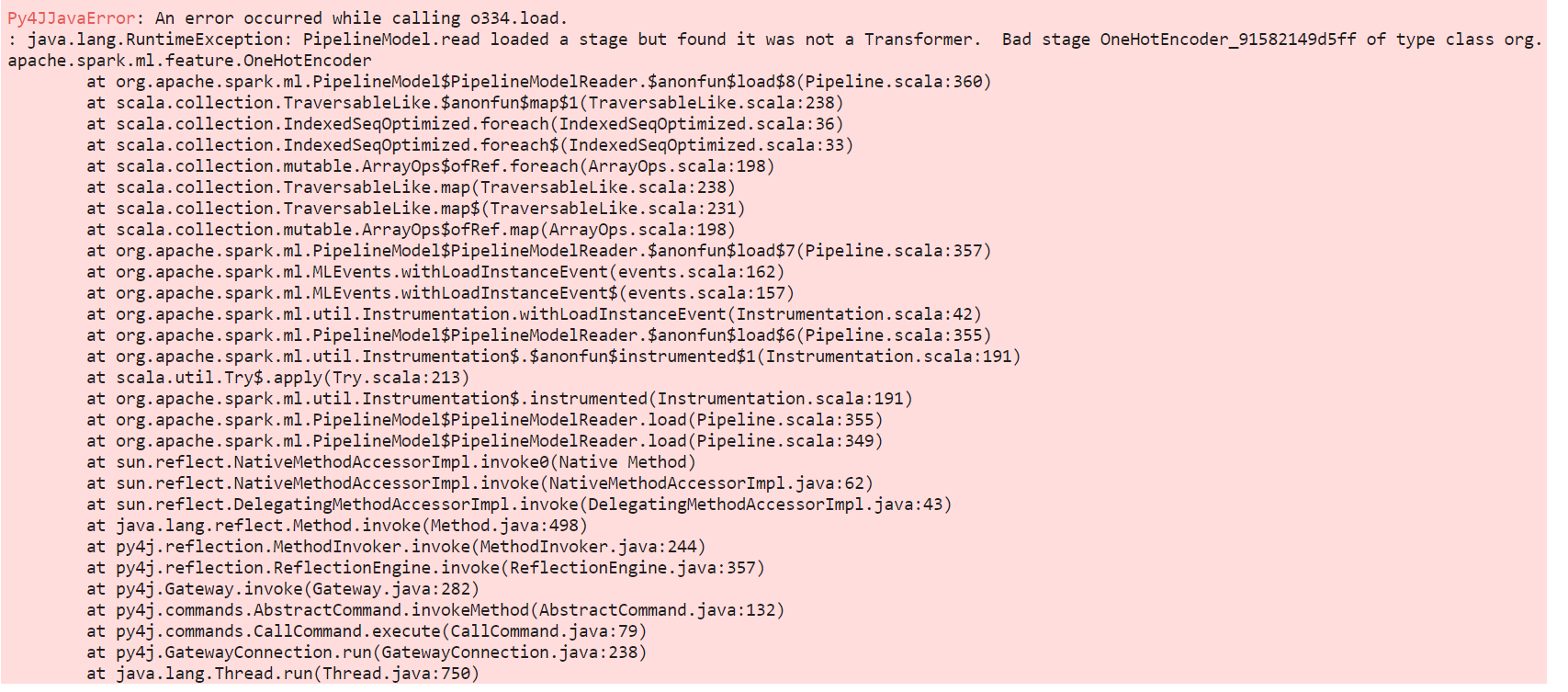 Please suggest how should I proceed ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #39703: [SPARK-42157][CORE] `spark.scheduler.mode=FAIR` should provide FAIR scheduler
dongjoon-hyun commented on code in PR #39703: URL: https://github.com/apache/spark/pull/39703#discussion_r1083690034 ## conf/fairscheduler-default.xml.template: ## @@ -0,0 +1,26 @@ + + + + + + +FAIR +1 +0 + + Review Comment: This is not for testing, @mridulm . As mentioned in https://github.com/apache/spark/pull/39703#pullrequestreview-1264907510, we already have a testing resource, `fairscheduler.xml`, not a template. In addition, the content of `conf/fairscheduler.xml.template` is not matched with the expected default behavior. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #39705: [SPARK-41488][SQL] Assign name to _LEGACY_ERROR_TEMP_1176 (and 1177)
itholic commented on PR #39705: URL: https://github.com/apache/spark/pull/39705#issuecomment-1399864027 I referred to code path in `sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/unresolved.scala` below: ```scala case class GetViewColumnByNameAndOrdinal( viewName: String, colName: String, ordinal: Int, expectedNumCandidates: Int, // viewDDL is used to help user fix incompatible schema issue for permanent views // it will be None for temp views. viewDDL: Option[String]) ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] imhunterand commented on pull request #39566: Patched()Fix Protobuf Java vulnerable to Uncontrolled Resource Consumption
imhunterand commented on PR #39566: URL: https://github.com/apache/spark/pull/39566#issuecomment-1399849534 **Hi!** @everyone @apache any update is last week's ago for waited fixed. could you `merged` this pull-request as fixed/patched. Kind regards, -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #39705: [SPARK-41488][SQL] Assign name to _LEGACY_ERROR_TEMP_1176
itholic commented on PR #39705: URL: https://github.com/apache/spark/pull/39705#issuecomment-1399837315 cc @srielau @MaxGekk @cloud-fan -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #39501: [SPARK-41295][SPARK-41296][SQL] Rename the error classes
itholic commented on PR #39501: URL: https://github.com/apache/spark/pull/39501#issuecomment-1399836266 @srowen Could you happen to help creating JIRA account for @NarekDW when you find some time?? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #39501: [SPARK-41295][SPARK-41296][SQL] Rename the error classes
itholic commented on PR #39501: URL: https://github.com/apache/spark/pull/39501#issuecomment-1399836177 Oh, I just submit a PR for SPARK-41488, so please take a look SPARK-41302 when you have some time. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on a diff in pull request #39691: [SPARK-31561][SQL] Add QUALIFY clause
itholic commented on code in PR #39691:
URL: https://github.com/apache/spark/pull/39691#discussion_r1083665941
##
sql/core/src/test/resources/sql-tests/results/window.sql.out:
##
@@ -1342,3 +1342,139 @@ org.apache.spark.sql.AnalysisException
"windowName" : "w"
}
}
+
+
+-- !query
+SELECT val_long,
+ val_date,
+ max(val) OVER (partition BY val_date) AS m
+FROM testdata
+WHERE val_long > 2
+QUALIFY m > 2 AND m < 10
+-- !query schema
+struct
+-- !query output
+2147483650 2020-12-31 3
+2147483650 2020-12-31 3
+
+
+-- !query
+SELECT val_long,
+ val_date,
+ val
+FROM testdata QUALIFY max(val) OVER (partition BY val_date) >= 3
+-- !query schema
+struct
+-- !query output
+1 2017-08-01 1
+1 2017-08-01 3
+1 2017-08-01 NULL
+2147483650 2020-12-31 2
+2147483650 2020-12-31 3
+NULL 2017-08-01 1
+
+
+-- !query
+SELECT val_date,
+ val * sum(val) OVER (partition BY val_date) AS w
+FROM testdata
+QUALIFY w > 10
+-- !query schema
+struct
+-- !query output
+2017-08-01 15
+2020-12-31 15
+
+
+-- !query
+SELECT w.val_date
+FROM testdata w
+JOIN testdata w2 ON w.val_date=w2.val_date
+QUALIFY row_number() OVER (partition BY w.val_date ORDER BY w.val) IN (2)
+-- !query schema
+struct
+-- !query output
+2017-08-01
+2020-12-31
+
+
+-- !query
+SELECT val_date,
+ count(val_long) OVER (partition BY val_date) AS w
+FROM testdata
+GROUP BY val_date,
+ val_long
+HAVING Sum(val) > 1
+QUALIFY w = 1
+-- !query schema
+struct
+-- !query output
+2017-08-01 1
+2017-08-03 1
+2020-12-31 1
+
+
+-- !query
+SELECT val_date,
+ val_long,
+ Sum(val)
+FROM testdata
+GROUP BY val_date,
+ val_long
+HAVING Sum(val) > 1
+QUALIFY count(val_long) OVER (partition BY val_date) IN(SELECT 1)
+-- !query schema
+struct
+-- !query output
+2017-08-01 1 4
+2017-08-03 3 2
+2020-12-31 2147483650 5
+
+
+-- !query
+SELECT val_date,
+ val_long
+FROM testdata
+QUALIFY count(val_long) OVER (partition BY val_date) > 1 AND val > 1
+-- !query schema
+struct
+-- !query output
+2017-08-01 1
+2020-12-31 2147483650
+2020-12-31 2147483650
+
+
+-- !query
+SELECT val_date,
+ val_long
+FROM testdata
+QUALIFY val > 1
+-- !query schema
+struct<>
+-- !query output
+org.apache.spark.sql.AnalysisException
+{
+ "errorClass" : "_LEGACY_ERROR_TEMP_1032",
Review Comment:
Sure! Will follow-up after merging this PR jus in case to avoid unexpected
conflicts.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic opened a new pull request, #39705: [SPARK-41488][SQL] Assign name to _LEGACY_ERROR_TEMP_1176
itholic opened a new pull request, #39705: URL: https://github.com/apache/spark/pull/39705 ### What changes were proposed in this pull request? This PR proposes to assign name to _LEGACY_ERROR_TEMP_1176, "INCOMPATIBLE_VIEW_SCHEMA_CHANGE". ### Why are the changes needed? We should assign proper name to _LEGACY_ERROR_TEMP_* ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? `./build/sbt "sql/testOnly org.apache.spark.sql.SQLQueryTestSuite*` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] mridulm commented on a diff in pull request #39703: [SPARK-42157][CORE] `spark.scheduler.mode=FAIR` should provide FAIR scheduler
mridulm commented on code in PR #39703:
URL: https://github.com/apache/spark/pull/39703#discussion_r1083660245
##
conf/fairscheduler-default.xml.template:
##
@@ -0,0 +1,26 @@
+
+
+
+
+
+
+FAIR
+1
+0
+
+
Review Comment:
There is a `conf/fairscheduler.xml.template` - why do we need this ?
If it is for testing, move it as a resource there instead of in conf ?
##
core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala:
##
@@ -86,10 +87,17 @@ private[spark] class FairSchedulableBuilder(val rootPool:
Pool, sc: SparkContext
logInfo(s"Creating Fair Scheduler pools from default file:
$DEFAULT_SCHEDULER_FILE")
Some((is, DEFAULT_SCHEDULER_FILE))
} else {
- logWarning("Fair Scheduler configuration file not found so jobs will
be scheduled in " +
-s"FIFO order. To use fair scheduling, configure pools in
$DEFAULT_SCHEDULER_FILE or " +
-s"set ${SCHEDULER_ALLOCATION_FILE.key} to a file that contains the
configuration.")
- None
+ val is =
Utils.getSparkClassLoader.getResourceAsStream(DEFAULT_SCHEDULER_TEMPLATE_FILE)
+ if (is != null) {
+logInfo("Creating Fair Scheduler pools from default template file:
" +
+ s"$DEFAULT_SCHEDULER_TEMPLATE_FILE.")
+Some((is, DEFAULT_SCHEDULER_TEMPLATE_FILE))
+ } else {
+logWarning("Fair Scheduler configuration file not found so jobs
will be scheduled in " +
+ s"FIFO order. To use fair scheduling, configure pools in
$DEFAULT_SCHEDULER_FILE " +
+ s"or set ${SCHEDULER_ALLOCATION_FILE.key} to a file that
contains the configuration.")
+None
+ }
Review Comment:
We should not be relying on template file - in deployments, template file
can be invalid - admin's are not expecting it to be read by spark.
Instead, why not simply rely on returning `None` here ?
Note - if this is only for testing, we can special case it that way via
`spark.testing`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on a diff in pull request #39695: [SPARK-42156] SparkConnectClient supports RetryPolicies now
itholic commented on code in PR #39695:
URL: https://github.com/apache/spark/pull/39695#discussion_r1083661917
##
python/pyspark/sql/connect/client.py:
##
@@ -365,6 +385,15 @@ def __init__(
# Parse the connection string.
self._builder = ChannelBuilder(connectionString, channelOptions)
self._user_id = None
+self._retry_policy = {
+"max_retries": 15,
+"backoff_multiplier": 4,
+"initial_backoff": 50,
+"max_backoff": 6,
+}
Review Comment:
Thanks for the context
Looks good if it's enough to test!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #39701: [SPARK-41489][SQL] Assign name to _LEGACY_ERROR_TEMP_2415
itholic commented on PR #39701: URL: https://github.com/apache/spark/pull/39701#issuecomment-1399797647 cc @MaxGekk @srielau @cloud-fan -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #39702: [SPARK-41487][SQL] Assign name to _LEGACY_ERROR_TEMP_1020
itholic commented on PR #39702: URL: https://github.com/apache/spark/pull/39702#issuecomment-1399797614 cc @MaxGekk @srielau @cloud-fan -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #39700: [SPARK-41490][SQL] Assign name to _LEGACY_ERROR_TEMP_2441
itholic commented on PR #39700: URL: https://github.com/apache/spark/pull/39700#issuecomment-1399797488 cc @MaxGekk @srielau @cloud-fan -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] grundprinzip commented on a diff in pull request #39695: [SPARK-42156] SparkConnectClient supports RetryPolicies now
grundprinzip commented on code in PR #39695:
URL: https://github.com/apache/spark/pull/39695#discussion_r1083643562
##
python/pyspark/sql/connect/client.py:
##
@@ -365,6 +385,15 @@ def __init__(
# Parse the connection string.
self._builder = ChannelBuilder(connectionString, channelOptions)
self._user_id = None
+self._retry_policy = {
+"max_retries": 15,
+"backoff_multiplier": 4,
+"initial_backoff": 50,
+"max_backoff": 6,
+}
Review Comment:
These values modeled roughly after the GRPC retry policies. In this case
this gives us enough time for the system to be ready.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #39642: [SPARK-41677][CORE][SQL][SS][UI] Add Protobuf serializer for `StreamingQueryProgressWrapper`
LuciferYang commented on code in PR #39642:
URL: https://github.com/apache/spark/pull/39642#discussion_r1083643178
##
core/src/main/protobuf/org/apache/spark/status/protobuf/store_types.proto:
##
@@ -765,3 +765,54 @@ message PoolData {
optional string name = 1;
repeated int64 stage_ids = 2;
}
+
+message StateOperatorProgress {
+ optional string operator_name = 1;
+ int64 num_rows_total = 2;
+ int64 num_rows_updated = 3;
+ int64 all_updates_time_ms = 4;
+ int64 num_rows_removed = 5;
+ int64 all_removals_time_ms = 6;
+ int64 commit_time_ms = 7;
+ int64 memory_used_bytes = 8;
+ int64 num_rows_dropped_by_watermark = 9;
+ int64 num_shuffle_partitions = 10;
+ int64 num_state_store_instances = 11;
+ map custom_metrics = 12;
Review Comment:
[a904a27](https://github.com/apache/spark/pull/39642/commits/a904a27919a47cebf3784a8756f46b3237b4be46)
check/test all map
[699ebd1](https://github.com/apache/spark/pull/39642/commits/699ebd1e6c3905722d0b09ff11e5dccc31813d3c)
add `setJMapField` function to `Utils`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] grundprinzip commented on a diff in pull request #39695: [SPARK-42156] SparkConnectClient supports RetryPolicies now
grundprinzip commented on code in PR #39695:
URL: https://github.com/apache/spark/pull/39695#discussion_r1083643160
##
python/pyspark/sql/connect/client.py:
##
@@ -531,12 +560,16 @@ def _analyze(self, plan: pb2.Plan, explain_mode: str =
"extended") -> AnalyzeRes
req.explain.explain_mode = pb2.Explain.ExplainMode.CODEGEN
else: # formatted
req.explain.explain_mode = pb2.Explain.ExplainMode.FORMATTED
-
try:
-resp = self._stub.AnalyzePlan(req,
metadata=self._builder.metadata())
-if resp.client_id != self._session_id:
-raise SparkConnectException("Received incorrect session
identifier for request.")
-return AnalyzeResult.fromProto(resp)
+for attempt in Retrying(SparkConnectClient.retry_exception,
**self._retry_policy):
+with attempt:
+resp = self._stub.AnalyzePlan(req,
metadata=self._builder.metadata())
+if resp.client_id != self._session_id:
+raise SparkConnectException(
+"Received incorrect session identifier for
request."
Review Comment:
Done.
##
python/pyspark/sql/connect/client.py:
##
@@ -567,54 +602,48 @@ def _execute_and_fetch(
logger.info("ExecuteAndFetch")
m: Optional[pb2.ExecutePlanResponse.Metrics] = None
-
batches: List[pa.RecordBatch] = []
try:
-for b in self._stub.ExecutePlan(req,
metadata=self._builder.metadata()):
-if b.client_id != self._session_id:
-raise SparkConnectException(
-"Received incorrect session identifier for request."
-)
-if b.metrics is not None:
-logger.debug("Received metric batch.")
-m = b.metrics
-if b.HasField("arrow_batch"):
-logger.debug(
-f"Received arrow batch rows={b.arrow_batch.row_count} "
-f"size={len(b.arrow_batch.data)}"
-)
-
-with pa.ipc.open_stream(b.arrow_batch.data) as reader:
-for batch in reader:
-assert isinstance(batch, pa.RecordBatch)
-batches.append(batch)
+for attempt in Retrying(SparkConnectClient.retry_exception,
**self._retry_policy):
+with attempt:
+for b in self._stub.ExecutePlan(req,
metadata=self._builder.metadata()):
+if b.client_id != self._session_id:
+raise SparkConnectException(
+"Received incorrect session identifier for
request."
Review Comment:
Done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] grundprinzip commented on a diff in pull request #39695: [SPARK-42156] SparkConnectClient supports RetryPolicies now
grundprinzip commented on code in PR #39695: URL: https://github.com/apache/spark/pull/39695#discussion_r1083642374 ## python/pyspark/sql/tests/connect/test_connect_basic.py: ## @@ -2591,6 +2591,73 @@ def test_unsupported_io_functions(self): getattr(df.write, f)() +@unittest.skipIf(not should_test_connect, connect_requirement_message) +class ClientTests(unittest.TestCase): +def test_retry_error_handling(self): +# Helper class for wrapping the test. +class TestError(grpc.RpcError, Exception): +def __init__(self, code: grpc.StatusCode): +self._code = code + +def code(self): +return self._code + +def stub(retries, w, code): +w["counter"] += 1 +if w["counter"] < retries: +raise TestError(code) + +from pyspark.sql.connect.client import Retrying Review Comment: Done -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] grundprinzip commented on a diff in pull request #39695: [SPARK-42156] SparkConnectClient supports RetryPolicies now
grundprinzip commented on code in PR #39695: URL: https://github.com/apache/spark/pull/39695#discussion_r1083642191 ## python/pyspark/sql/connect/client.py: ## @@ -640,6 +669,136 @@ def _handle_error(self, rpc_error: grpc.RpcError) -> NoReturn: raise SparkConnectException(str(rpc_error)) from None +class RetryState: +""" +Simple state helper that captures the state between retries of the exceptions. It +keeps track of the last exception thrown and how many in total. when the task +finishes successfully done() returns True. +""" + +def __init__(self) -> None: +self._exception: Optional[BaseException] = None +self._done = False +self._count = 0 + +def set_exception(self, exc: Optional[BaseException]) -> None: +self._exception = exc +self._count += 1 + +def exception(self) -> Optional[BaseException]: +return self._exception + +def set_done(self) -> None: +self._done = True + +def count(self) -> int: +return self._count + +def done(self) -> bool: +return self._done + + +class AttemptManager: +""" +Simple ContextManager that is used to capture the exception thrown inside the context. +""" + +def __init__(self, check: Callable[..., bool], retry_state: RetryState) -> None: +self._retry_state = retry_state +self._can_retry = check + +def __enter__(self) -> None: +pass + +def __exit__( +self, +exc_type: Optional[Type[BaseException]], +exc_val: Optional[BaseException], +exc_tb: Optional[TracebackType], +) -> Optional[bool]: +if isinstance(exc_val, BaseException): +# Swallow the exception. +if self._can_retry(exc_val): +self._retry_state.set_exception(exc_val) +return True +# Bubble up the exception. +return False +else: +self._retry_state.set_done() +return None + + +class Retrying: +""" +This helper class is used as a generator together with a context manager to +allow retrying exceptions in particular code blocks. The Retrying can be configured +with a lambda function that is can be filtered what kind of exceptions should be +retried. + +In addition, there are several parameters that are used to configure the exponential +backoff behavior. + +An example to use this class looks like this: + +for attempt in Retrying(lambda x: isinstance(x, TransientError)): +with attempt: +# do the work. + +""" + +def __init__( +self, +can_retry: Callable[..., bool] = lambda x: True, +max_retries: int = 15, +initial_backoff: int = 50, +max_backoff: int = 6, +backoff_multiplier: float = 4.0, +) -> None: +self._can_retry = can_retry +self._max_retries = max_retries +self._initial_backoff = initial_backoff +self._max_backoff = max_backoff +self._backoff_multiplier = backoff_multiplier + +def __iter__(self) -> Generator[AttemptManager, None, None]: +""" +Generator function to wrap the exception producing code block. +Returns +--- + Review Comment: Done -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] grundprinzip commented on a diff in pull request #39695: [SPARK-42156] SparkConnectClient supports RetryPolicies now
grundprinzip commented on code in PR #39695: URL: https://github.com/apache/spark/pull/39695#discussion_r1083641679 ## python/pyspark/sql/connect/client.py: ## @@ -640,6 +669,136 @@ def _handle_error(self, rpc_error: grpc.RpcError) -> NoReturn: raise SparkConnectException(str(rpc_error)) from None +class RetryState: +""" +Simple state helper that captures the state between retries of the exceptions. It +keeps track of the last exception thrown and how many in total. when the task +finishes successfully done() returns True. +""" + +def __init__(self) -> None: +self._exception: Optional[BaseException] = None +self._done = False +self._count = 0 + +def set_exception(self, exc: Optional[BaseException]) -> None: +self._exception = exc +self._count += 1 + +def exception(self) -> Optional[BaseException]: +return self._exception + +def set_done(self) -> None: +self._done = True + +def count(self) -> int: +return self._count + +def done(self) -> bool: +return self._done + + +class AttemptManager: +""" +Simple ContextManager that is used to capture the exception thrown inside the context. +""" + +def __init__(self, check: Callable[..., bool], retry_state: RetryState) -> None: +self._retry_state = retry_state +self._can_retry = check + +def __enter__(self) -> None: +pass + +def __exit__( +self, +exc_type: Optional[Type[BaseException]], +exc_val: Optional[BaseException], +exc_tb: Optional[TracebackType], +) -> Optional[bool]: +if isinstance(exc_val, BaseException): +# Swallow the exception. +if self._can_retry(exc_val): +self._retry_state.set_exception(exc_val) +return True +# Bubble up the exception. +return False +else: +self._retry_state.set_done() +return None + + +class Retrying: +""" +This helper class is used as a generator together with a context manager to +allow retrying exceptions in particular code blocks. The Retrying can be configured +with a lambda function that is can be filtered what kind of exceptions should be +retried. + +In addition, there are several parameters that are used to configure the exponential +backoff behavior. + +An example to use this class looks like this: + +for attempt in Retrying(lambda x: isinstance(x, TransientError)): +with attempt: +# do the work. + Review Comment: Done -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] grundprinzip commented on a diff in pull request #39695: [SPARK-42156] SparkConnectClient supports RetryPolicies now
grundprinzip commented on code in PR #39695:
URL: https://github.com/apache/spark/pull/39695#discussion_r1083641393
##
python/pyspark/sql/connect/client.py:
##
@@ -567,54 +602,48 @@ def _execute_and_fetch(
logger.info("ExecuteAndFetch")
m: Optional[pb2.ExecutePlanResponse.Metrics] = None
-
batches: List[pa.RecordBatch] = []
try:
-for b in self._stub.ExecutePlan(req,
metadata=self._builder.metadata()):
-if b.client_id != self._session_id:
-raise SparkConnectException(
-"Received incorrect session identifier for request."
-)
-if b.metrics is not None:
-logger.debug("Received metric batch.")
-m = b.metrics
-if b.HasField("arrow_batch"):
-logger.debug(
-f"Received arrow batch rows={b.arrow_batch.row_count} "
-f"size={len(b.arrow_batch.data)}"
-)
-
-with pa.ipc.open_stream(b.arrow_batch.data) as reader:
-for batch in reader:
-assert isinstance(batch, pa.RecordBatch)
-batches.append(batch)
+for attempt in Retrying(SparkConnectClient.retry_exception,
**self._retry_policy):
+with attempt:
+for b in self._stub.ExecutePlan(req,
metadata=self._builder.metadata()):
+if b.client_id != self._session_id:
+raise SparkConnectException(
+"Received incorrect session identifier for
request."
+)
+if b.metrics is not None:
+logger.debug("Received metric batch.")
+m = b.metrics
+if b.HasField("arrow_batch"):
+logger.debug(
+f"Received arrow batch
rows={b.arrow_batch.row_count} "
+f"size={len(b.arrow_batch.data)}"
+)
+
+with pa.ipc.open_stream(b.arrow_batch.data) as
reader:
+for batch in reader:
+assert isinstance(batch, pa.RecordBatch)
+batches.append(batch)
except grpc.RpcError as rpc_error:
self._handle_error(rpc_error)
-
assert len(batches) > 0
-
table = pa.Table.from_batches(batches=batches)
-
metrics: List[PlanMetrics] = self._build_metrics(m) if m is not None
else []
-
return table, metrics
def _handle_error(self, rpc_error: grpc.RpcError) -> NoReturn:
"""
Error handling helper for dealing with GRPC Errors. On the server
side, certain
exceptions are enriched with additional RPC Status information. These
are
unpacked in this function and put into the exception.
-
To avoid overloading the user with GRPC errors, this message explicitly
swallows the error context from the call. This GRPC Error is logged
however,
and can be enabled.
-
Review Comment:
done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] grundprinzip commented on a diff in pull request #39695: [SPARK-42156] SparkConnectClient supports RetryPolicies now
grundprinzip commented on code in PR #39695:
URL: https://github.com/apache/spark/pull/39695#discussion_r1083641323
##
python/pyspark/sql/connect/client.py:
##
@@ -567,54 +602,48 @@ def _execute_and_fetch(
logger.info("ExecuteAndFetch")
m: Optional[pb2.ExecutePlanResponse.Metrics] = None
-
batches: List[pa.RecordBatch] = []
try:
-for b in self._stub.ExecutePlan(req,
metadata=self._builder.metadata()):
-if b.client_id != self._session_id:
-raise SparkConnectException(
-"Received incorrect session identifier for request."
-)
-if b.metrics is not None:
-logger.debug("Received metric batch.")
-m = b.metrics
-if b.HasField("arrow_batch"):
-logger.debug(
-f"Received arrow batch rows={b.arrow_batch.row_count} "
-f"size={len(b.arrow_batch.data)}"
-)
-
-with pa.ipc.open_stream(b.arrow_batch.data) as reader:
-for batch in reader:
-assert isinstance(batch, pa.RecordBatch)
-batches.append(batch)
+for attempt in Retrying(SparkConnectClient.retry_exception,
**self._retry_policy):
+with attempt:
+for b in self._stub.ExecutePlan(req,
metadata=self._builder.metadata()):
+if b.client_id != self._session_id:
+raise SparkConnectException(
+"Received incorrect session identifier for
request."
+)
+if b.metrics is not None:
+logger.debug("Received metric batch.")
+m = b.metrics
+if b.HasField("arrow_batch"):
+logger.debug(
+f"Received arrow batch
rows={b.arrow_batch.row_count} "
+f"size={len(b.arrow_batch.data)}"
+)
+
+with pa.ipc.open_stream(b.arrow_batch.data) as
reader:
+for batch in reader:
+assert isinstance(batch, pa.RecordBatch)
+batches.append(batch)
except grpc.RpcError as rpc_error:
self._handle_error(rpc_error)
-
assert len(batches) > 0
-
table = pa.Table.from_batches(batches=batches)
-
metrics: List[PlanMetrics] = self._build_metrics(m) if m is not None
else []
-
return table, metrics
def _handle_error(self, rpc_error: grpc.RpcError) -> NoReturn:
"""
Error handling helper for dealing with GRPC Errors. On the server
side, certain
exceptions are enriched with additional RPC Status information. These
are
unpacked in this function and put into the exception.
-
To avoid overloading the user with GRPC errors, this message explicitly
swallows the error context from the call. This GRPC Error is logged
however,
and can be enabled.
-
Parameters
--
rpc_error : grpc.RpcError
RPC Error containing the details of the exception.
-
Review Comment:
Done
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] grundprinzip commented on a diff in pull request #39695: [SPARK-42156] SparkConnectClient supports RetryPolicies now
grundprinzip commented on code in PR #39695:
URL: https://github.com/apache/spark/pull/39695#discussion_r1083641243
##
python/pyspark/sql/connect/client.py:
##
@@ -567,54 +602,48 @@ def _execute_and_fetch(
logger.info("ExecuteAndFetch")
m: Optional[pb2.ExecutePlanResponse.Metrics] = None
-
batches: List[pa.RecordBatch] = []
try:
-for b in self._stub.ExecutePlan(req,
metadata=self._builder.metadata()):
-if b.client_id != self._session_id:
-raise SparkConnectException(
-"Received incorrect session identifier for request."
-)
-if b.metrics is not None:
-logger.debug("Received metric batch.")
-m = b.metrics
-if b.HasField("arrow_batch"):
-logger.debug(
-f"Received arrow batch rows={b.arrow_batch.row_count} "
-f"size={len(b.arrow_batch.data)}"
-)
-
-with pa.ipc.open_stream(b.arrow_batch.data) as reader:
-for batch in reader:
-assert isinstance(batch, pa.RecordBatch)
-batches.append(batch)
+for attempt in Retrying(SparkConnectClient.retry_exception,
**self._retry_policy):
+with attempt:
+for b in self._stub.ExecutePlan(req,
metadata=self._builder.metadata()):
+if b.client_id != self._session_id:
+raise SparkConnectException(
+"Received incorrect session identifier for
request."
+)
+if b.metrics is not None:
+logger.debug("Received metric batch.")
+m = b.metrics
+if b.HasField("arrow_batch"):
+logger.debug(
+f"Received arrow batch
rows={b.arrow_batch.row_count} "
+f"size={len(b.arrow_batch.data)}"
+)
+
+with pa.ipc.open_stream(b.arrow_batch.data) as
reader:
+for batch in reader:
+assert isinstance(batch, pa.RecordBatch)
+batches.append(batch)
except grpc.RpcError as rpc_error:
self._handle_error(rpc_error)
-
assert len(batches) > 0
-
table = pa.Table.from_batches(batches=batches)
-
metrics: List[PlanMetrics] = self._build_metrics(m) if m is not None
else []
-
return table, metrics
def _handle_error(self, rpc_error: grpc.RpcError) -> NoReturn:
"""
Error handling helper for dealing with GRPC Errors. On the server
side, certain
exceptions are enriched with additional RPC Status information. These
are
unpacked in this function and put into the exception.
-
Review Comment:
Done.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] grundprinzip commented on a diff in pull request #39695: [SPARK-42156] SparkConnectClient supports RetryPolicies now
grundprinzip commented on code in PR #39695:
URL: https://github.com/apache/spark/pull/39695#discussion_r1083640867
##
python/pyspark/sql/connect/client.py:
##
@@ -531,12 +560,16 @@ def _analyze(self, plan: pb2.Plan, explain_mode: str =
"extended") -> AnalyzeRes
req.explain.explain_mode = pb2.Explain.ExplainMode.CODEGEN
else: # formatted
req.explain.explain_mode = pb2.Explain.ExplainMode.FORMATTED
-
try:
-resp = self._stub.AnalyzePlan(req,
metadata=self._builder.metadata())
-if resp.client_id != self._session_id:
-raise SparkConnectException("Received incorrect session
identifier for request.")
-return AnalyzeResult.fromProto(resp)
+for attempt in Retrying(SparkConnectClient.retry_exception,
**self._retry_policy):
+with attempt:
+resp = self._stub.AnalyzePlan(req,
metadata=self._builder.metadata())
+if resp.client_id != self._session_id:
+raise SparkConnectException(
+"Received incorrect session identifier for
request."
Review Comment:
This is unchanged code from the old handling, but I can add the two IDs
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #39642: [SPARK-41677][CORE][SQL][SS][UI] Add Protobuf serializer for `StreamingQueryProgressWrapper`
LuciferYang commented on code in PR #39642:
URL: https://github.com/apache/spark/pull/39642#discussion_r1083634888
##
sql/core/src/test/scala/org/apache/spark/status/protobuf/sql/KVStoreProtobufSerializerSuite.scala:
##
@@ -271,4 +278,254 @@ class KVStoreProtobufSerializerSuite extends
SparkFunSuite {
assert(result.endTimestamp == input.endTimestamp)
}
}
+
+ test("StreamingQueryProgressWrapper") {
+val normalInput = {
+ val stateOperatorProgress0 = new StateOperatorProgress(
+operatorName = "op-0",
+numRowsTotal = 1L,
+numRowsUpdated = 2L,
+allUpdatesTimeMs = 3L,
+numRowsRemoved = 4L,
+allRemovalsTimeMs = 5L,
+commitTimeMs = 6L,
+memoryUsedBytes = 7L,
+numRowsDroppedByWatermark = 8L,
+numShufflePartitions = 9L,
+numStateStoreInstances = 10L,
+customMetrics = Map(
+ "custom-metrics-00" -> JLong.valueOf("10"),
+ "custom-metrics-01" -> JLong.valueOf("11")).asJava
+ )
+ val stateOperatorProgress1 = new StateOperatorProgress(
+operatorName = null,
+numRowsTotal = 11L,
+numRowsUpdated = 12L,
+allUpdatesTimeMs = 13L,
+numRowsRemoved = 14L,
+allRemovalsTimeMs = 15L,
+commitTimeMs = 16L,
+memoryUsedBytes = 17L,
+numRowsDroppedByWatermark = 18L,
+numShufflePartitions = 19L,
+numStateStoreInstances = 20L,
+customMetrics = Map(
+ "custom-metrics-10" -> JLong.valueOf("20"),
+ "custom-metrics-11" -> JLong.valueOf("21")).asJava
+ )
+ val source0 = new SourceProgress(
+description = "description-0",
+startOffset = "startOffset-0",
+endOffset = "endOffset-0",
+latestOffset = "latestOffset-0",
+numInputRows = 10L,
+inputRowsPerSecond = 11.0,
+processedRowsPerSecond = 12.0,
+metrics = Map(
+ "metrics-00" -> "10",
+ "metrics-01" -> "11").asJava
+ )
+ val source1 = new SourceProgress(
+description = "description-1",
+startOffset = "startOffset-1",
+endOffset = "endOffset-1",
+latestOffset = "latestOffset-1",
+numInputRows = 20L,
+inputRowsPerSecond = 21.0,
+processedRowsPerSecond = 22.0,
+metrics = Map(
+ "metrics-10" -> "20",
+ "metrics-11" -> "21").asJava
+ )
+ val sink = new SinkProgress(
+description = "sink-0",
+numOutputRows = 30,
+metrics = Map(
+ "metrics-20" -> "30",
+ "metrics-21" -> "31").asJava
+ )
+ val schema1 = new StructType()
+.add("c1", "long")
+.add("c2", "double")
+ val schema2 = new StructType()
+.add("rc", "long")
+.add("min_q", "string")
+.add("max_q", "string")
+ val observedMetrics = Map[String, Row](
+"event1" -> new GenericRowWithSchema(Array(1L, 3.0d), schema1),
+"event2" -> new GenericRowWithSchema(Array(1L, "hello", "world"),
schema2)
+ ).asJava
+ val progress = new StreamingQueryProgress(
+id = UUID.randomUUID(),
+runId = UUID.randomUUID(),
+name = "name-1",
+timestamp = "2023-01-03T09:14:04.175Z",
+batchId = 1L,
+batchDuration = 2L,
+durationMs = Map(
+ "duration-0" -> JLong.valueOf("10"),
+ "duration-1" -> JLong.valueOf("11")).asJava,
+eventTime = Map(
+ "eventTime-0" -> "20",
+ "eventTime-1" -> "21").asJava,
+stateOperators = Array(stateOperatorProgress0, stateOperatorProgress1),
+sources = Array(source0, source1),
+sink = sink,
+observedMetrics = observedMetrics
+ )
+ new StreamingQueryProgressWrapper(progress)
+}
+
+val withNullInput = {
+ val stateOperatorProgress0 = new StateOperatorProgress(
+operatorName = null,
+numRowsTotal = 1L,
+numRowsUpdated = 2L,
+allUpdatesTimeMs = 3L,
+numRowsRemoved = 4L,
+allRemovalsTimeMs = 5L,
+commitTimeMs = 6L,
+memoryUsedBytes = 7L,
+numRowsDroppedByWatermark = 8L,
+numShufflePartitions = 9L,
+numStateStoreInstances = 10L,
+customMetrics = null
+ )
+ val stateOperatorProgress1 = new StateOperatorProgress(
+operatorName = null,
+numRowsTotal = 11L,
+numRowsUpdated = 12L,
+allUpdatesTimeMs = 13L,
+numRowsRemoved = 14L,
+allRemovalsTimeMs = 15L,
+commitTimeMs = 16L,
+memoryUsedBytes = 17L,
+numRowsDroppedByWatermark = 18L,
+numShufflePartitions = 19L,
+numStateStoreInstances = 20L,
+customMetrics = null
+ )
+ val source0 = new SourceProgress(
+description = null,
+startOffset = null,
+endOffset = null,
+latestOffset = null,
+numInputRows = 10L,
+
[GitHub] [spark] LuciferYang commented on a diff in pull request #39642: [SPARK-41677][CORE][SQL][SS][UI] Add Protobuf serializer for `StreamingQueryProgressWrapper`
LuciferYang commented on code in PR #39642:
URL: https://github.com/apache/spark/pull/39642#discussion_r1083634709
##
sql/core/src/test/scala/org/apache/spark/status/protobuf/sql/KVStoreProtobufSerializerSuite.scala:
##
@@ -271,4 +278,254 @@ class KVStoreProtobufSerializerSuite extends
SparkFunSuite {
assert(result.endTimestamp == input.endTimestamp)
}
}
+
+ test("StreamingQueryProgressWrapper") {
+val normalInput = {
Review Comment:
Two objects are manually created due to many fields can be null
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on a diff in pull request #39691: [SPARK-31561][SQL] Add QUALIFY clause
wangyum commented on code in PR #39691:
URL: https://github.com/apache/spark/pull/39691#discussion_r1083632796
##
sql/core/src/test/resources/sql-tests/results/window.sql.out:
##
@@ -1342,3 +1342,139 @@ org.apache.spark.sql.AnalysisException
"windowName" : "w"
}
}
+
+
+-- !query
+SELECT val_long,
+ val_date,
+ max(val) OVER (partition BY val_date) AS m
+FROM testdata
+WHERE val_long > 2
+QUALIFY m > 2 AND m < 10
+-- !query schema
+struct
+-- !query output
+2147483650 2020-12-31 3
+2147483650 2020-12-31 3
+
+
+-- !query
+SELECT val_long,
+ val_date,
+ val
+FROM testdata QUALIFY max(val) OVER (partition BY val_date) >= 3
+-- !query schema
+struct
+-- !query output
+1 2017-08-01 1
+1 2017-08-01 3
+1 2017-08-01 NULL
+2147483650 2020-12-31 2
+2147483650 2020-12-31 3
+NULL 2017-08-01 1
+
+
+-- !query
+SELECT val_date,
+ val * sum(val) OVER (partition BY val_date) AS w
+FROM testdata
+QUALIFY w > 10
+-- !query schema
+struct
+-- !query output
+2017-08-01 15
+2020-12-31 15
+
+
+-- !query
+SELECT w.val_date
+FROM testdata w
+JOIN testdata w2 ON w.val_date=w2.val_date
+QUALIFY row_number() OVER (partition BY w.val_date ORDER BY w.val) IN (2)
+-- !query schema
+struct
+-- !query output
+2017-08-01
+2020-12-31
+
+
+-- !query
+SELECT val_date,
+ count(val_long) OVER (partition BY val_date) AS w
+FROM testdata
+GROUP BY val_date,
+ val_long
+HAVING Sum(val) > 1
+QUALIFY w = 1
+-- !query schema
+struct
+-- !query output
+2017-08-01 1
+2017-08-03 1
+2020-12-31 1
+
+
+-- !query
+SELECT val_date,
+ val_long,
+ Sum(val)
+FROM testdata
+GROUP BY val_date,
+ val_long
+HAVING Sum(val) > 1
+QUALIFY count(val_long) OVER (partition BY val_date) IN(SELECT 1)
+-- !query schema
+struct
+-- !query output
+2017-08-01 1 4
+2017-08-03 3 2
+2020-12-31 2147483650 5
+
+
+-- !query
+SELECT val_date,
+ val_long
+FROM testdata
+QUALIFY count(val_long) OVER (partition BY val_date) > 1 AND val > 1
+-- !query schema
+struct
+-- !query output
+2017-08-01 1
+2020-12-31 2147483650
+2020-12-31 2147483650
+
+
+-- !query
+SELECT val_date,
+ val_long
+FROM testdata
+QUALIFY val > 1
+-- !query schema
+struct<>
+-- !query output
+org.apache.spark.sql.AnalysisException
+{
+ "errorClass" : "_LEGACY_ERROR_TEMP_1032",
Review Comment:
+1 for follow-up.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on a diff in pull request #39691: [SPARK-31561][SQL] Add QUALIFY clause
wangyum commented on code in PR #39691: URL: https://github.com/apache/spark/pull/39691#discussion_r1083632654 ## docs/sql-ref-syntax-qry-select-qualify.md: ## @@ -0,0 +1,98 @@ +--- +layout: global +title: QUALIFY Clause +displayTitle: QUALIFY Clause +license: | + Licensed to the Apache Software Foundation (ASF) under one or more + contributor license agreements. See the NOTICE file distributed with + this work for additional information regarding copyright ownership. + The ASF licenses this file to You under the Apache License, Version 2.0 + (the "License"); you may not use this file except in compliance with + the License. You may obtain a copy of the License at + + http://www.apache.org/licenses/LICENSE-2.0 + + Unless required by applicable law or agreed to in writing, software + distributed under the License is distributed on an "AS IS" BASIS, + WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + See the License for the specific language governing permissions and + limitations under the License. +--- + +### Description + +The `QUALIFY` clause is used to filter the results of +[window functions](sql-ref-syntax-qry-select-window.md). To use QUALIFY, +at least one window function is required to be present in the SELECT list or the QUALIFY clause. Review Comment: OK. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #39694: [SPARK-42152][BUILD][CORE][SQL][PYTHON][PROTOBUF] Use `_` instead of `-` for relocation package name
LuciferYang commented on PR #39694: URL: https://github.com/apache/spark/pull/39694#issuecomment-1399724538 also cc @srowen @dongjoon-hyun @HyukjinKwon -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #39694: [SPARK-42152][BUILD][CORE][SQL][PYTHON][PROTOBUF] Use `_` instead of `-` for relocation package name
LuciferYang commented on PR #39694: URL: https://github.com/apache/spark/pull/39694#issuecomment-1399724327 @itholic Thanks for your suggestion, pr description has been updated -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #39684: [SPARK-42140][CORE] Handle null string values in ApplicationEnvironmentInfoWrapper/ApplicationInfoWrapper
LuciferYang commented on PR #39684: URL: https://github.com/apache/spark/pull/39684#issuecomment-1399721398 thanks @gengliangwang -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #39683: [SPARK-42144][CORE][SQL] Handle null string values in StageDataWrapper/StreamBlockData/StreamingQueryData
LuciferYang commented on PR #39683: URL: https://github.com/apache/spark/pull/39683#issuecomment-1399721161 thanks @gengliangwang -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun opened a new pull request, #39704: [MINOR][DOCS] Add all supported resource managers in `Scheduling Within an Application` section
dongjoon-hyun opened a new pull request, #39704: URL: https://github.com/apache/spark/pull/39704 … ### What changes were proposed in this pull request? ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #39657: [SPARK-42123][SQL] Include column default values in DESCRIBE and SHOW CREATE TABLE output
AmplabJenkins commented on PR #39657: URL: https://github.com/apache/spark/pull/39657#issuecomment-1399670640 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #39660: [SPARK-42128][SQL] Support TOP (N) for MS SQL Server dialect as an alternative to Limit pushdown
AmplabJenkins commented on PR #39660: URL: https://github.com/apache/spark/pull/39660#issuecomment-1399670621 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on a diff in pull request #39660: [SPARK-42128][SQL] Support TOP (N) for MS SQL Server dialect as an alternative to Limit pushdown
srowen commented on code in PR #39660: URL: https://github.com/apache/spark/pull/39660#discussion_r1083570242 ## sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/jdbc/JDBCRDD.scala: ## @@ -307,11 +307,12 @@ private[jdbc] class JDBCRDD( "" } +val myTopExpression: String = dialect.getTopExpression(limit) // SQL Server Limit alternative Review Comment: Oops yes I'm talking about what you're talking about, typo - MS SQL Server I'm OK with it; the alternative is to somehow edit the SQL query down in the MS SQL dialect maybe, I haven't thought about it. It'd be nicer but not sure it's cleaner. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #39697: [SPARK-42154][K8S][TESTS] Enable `Volcano` unit and integration tests in GitHub Action
dongjoon-hyun closed pull request #39697: [SPARK-42154][K8S][TESTS] Enable `Volcano` unit and integration tests in GitHub Action URL: https://github.com/apache/spark/pull/39697 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39697: [SPARK-42154][K8S][TESTS] Enable `Volcano` unit and integration tests in GitHub Action
dongjoon-hyun commented on PR #39697: URL: https://github.com/apache/spark/pull/39697#issuecomment-1399640431 Thank you, @gengliangwang and @viirya . Merged to master. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #39697: [SPARK-42154][K8S][TESTS] Enable `Volcano` unit and integration tests in GitHub Action
dongjoon-hyun commented on code in PR #39697:
URL: https://github.com/apache/spark/pull/39697#discussion_r1083565704
##
.github/workflows/build_and_test.yml:
##
@@ -952,9 +952,9 @@ jobs:
export PVC_TESTS_VM_PATH=$PVC_TMP_DIR
minikube mount ${PVC_TESTS_HOST_PATH}:${PVC_TESTS_VM_PATH} --gid=0
--uid=185 &
kubectl create clusterrolebinding serviceaccounts-cluster-admin
--clusterrole=cluster-admin --group=system:serviceaccounts || true
+ kubectl apply -f
https://raw.githubusercontent.com/volcano-sh/volcano/v1.7.0/installer/volcano-development.yaml
|| true
eval $(minikube docker-env)
- # - Exclude Volcano test (-Pvolcano), batch jobs need more CPU
resource
Review Comment:
Yes, SPARK-41253 fixed it~
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on a diff in pull request #39697: [SPARK-42154][K8S][TESTS] Enable `Volcano` unit and integration tests in GitHub Action
viirya commented on code in PR #39697:
URL: https://github.com/apache/spark/pull/39697#discussion_r1083562995
##
.github/workflows/build_and_test.yml:
##
@@ -952,9 +952,9 @@ jobs:
export PVC_TESTS_VM_PATH=$PVC_TMP_DIR
minikube mount ${PVC_TESTS_HOST_PATH}:${PVC_TESTS_VM_PATH} --gid=0
--uid=185 &
kubectl create clusterrolebinding serviceaccounts-cluster-admin
--clusterrole=cluster-admin --group=system:serviceaccounts || true
+ kubectl apply -f
https://raw.githubusercontent.com/volcano-sh/volcano/v1.7.0/installer/volcano-development.yaml
|| true
eval $(minikube docker-env)
- # - Exclude Volcano test (-Pvolcano), batch jobs need more CPU
resource
Review Comment:
The reason to exclude them is not anymore now?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sadikovi commented on a diff in pull request #39660: [SPARK-42128][SQL] Support TOP (N) for MS SQL Server dialect as an alternative to Limit pushdown
sadikovi commented on code in PR #39660: URL: https://github.com/apache/spark/pull/39660#discussion_r1083562843 ## sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/jdbc/JDBCRDD.scala: ## @@ -307,11 +307,12 @@ private[jdbc] class JDBCRDD( "" } +val myTopExpression: String = dialect.getTopExpression(limit) // SQL Server Limit alternative Review Comment: MySQL supports LIMIT clause, I assume you meant MSSQL/SQL Server. Yes, you are right. Although TOP N has similar semantics as LIMIT, it is more of an expression (?) rather than a clause, sort of like DISTINCT. We need to insert TOP N before the list of columns in select, unfortunately, this is the syntax for it. I came up with this approach of introducing another `getTopExpression` because I thought it would be the least intrusive one but I am open to alternative approaches, please let me know if you have any suggestions as to how I can refactor the code to support this. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on a diff in pull request #39660: [SPARK-42128][SQL] Support TOP (N) for MS SQL Server dialect as an alternative to Limit pushdown
srowen commented on code in PR #39660: URL: https://github.com/apache/spark/pull/39660#discussion_r1083561744 ## sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/jdbc/JDBCRDD.scala: ## @@ -307,11 +307,12 @@ private[jdbc] class JDBCRDD( "" } +val myTopExpression: String = dialect.getTopExpression(limit) // SQL Server Limit alternative Review Comment: Of course, what i mean is, is "TOP n" just the 'limit' clause you need to generate for MySQL? then it doesn't need different handling, just needs to generate a different clause. But looks like it goes into the SELECT part, not at the end, OK -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #39672: [SPARK-42133] Add basic Dataset API methods to Spark Connect Scala Client
AmplabJenkins commented on PR #39672: URL: https://github.com/apache/spark/pull/39672#issuecomment-1399633308 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #39673: [SPARK-42132][SQL] Deduplicate attributes in groupByKey.cogroup
AmplabJenkins commented on PR #39673: URL: https://github.com/apache/spark/pull/39673#issuecomment-1399633297 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #39678: [SPARK-16484][SQL] Add HyperLogLogPlusPlus sketch generator/evaluator/aggregator
AmplabJenkins commented on PR #39678: URL: https://github.com/apache/spark/pull/39678#issuecomment-1399633285 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #39681: [SPARK-18011] Fix SparkR NA date serialization
AmplabJenkins commented on PR #39681: URL: https://github.com/apache/spark/pull/39681#issuecomment-1399633268 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #39703: [SPARK-42157][CORE] `spark.scheduler.mode=FAIR` should provide FAIR scheduler
dongjoon-hyun commented on code in PR #39703: URL: https://github.com/apache/spark/pull/39703#discussion_r1083560527 ## core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala: ## @@ -61,6 +61,7 @@ private[spark] class FairSchedulableBuilder(val rootPool: Pool, sc: SparkContext val schedulerAllocFile = sc.conf.get(SCHEDULER_ALLOCATION_FILE) val DEFAULT_SCHEDULER_FILE = "fairscheduler.xml" + val DEFAULT_SCHEDULER_TEMPLATE_FILE = "fairscheduler-default.xml.template" Review Comment: To avoid any conflicts in the existing production jobs, this PR provide and use new file as `.xml.template`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #39703: [SPARK-42157][CORE] `spark.scheduler.mode=FAIR` should provide FAIR scheduler
dongjoon-hyun commented on code in PR #39703: URL: https://github.com/apache/spark/pull/39703#discussion_r1083560421 ## conf/fairscheduler-default.xml.template: ## @@ -0,0 +1,26 @@ + + + + + + +FAIR +1 +0 Review Comment: https://github.com/apache/spark/blob/0c3f4cf1632e48e52351d1b0664bbe6d0ae4e882/core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala#L72 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #39703: [SPARK-42157][CORE] `spark.scheduler.mode=FAIR` should provide FAIR scheduler
dongjoon-hyun commented on code in PR #39703: URL: https://github.com/apache/spark/pull/39703#discussion_r1083560381 ## conf/fairscheduler-default.xml.template: ## @@ -0,0 +1,26 @@ + + + + + + +FAIR +1 Review Comment: https://github.com/apache/spark/blob/0c3f4cf1632e48e52351d1b0664bbe6d0ae4e882/core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala#L73 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #39703: [SPARK-42157][CORE] `spark.scheduler.mode=FAIR` should provide FAIR scheduler
dongjoon-hyun commented on code in PR #39703: URL: https://github.com/apache/spark/pull/39703#discussion_r1083560182 ## conf/fairscheduler-default.xml.template: ## @@ -0,0 +1,26 @@ + + + + + + Review Comment: https://github.com/apache/spark/blob/0c3f4cf1632e48e52351d1b0664bbe6d0ae4e882/core/src/main/scala/org/apache/spark/scheduler/SchedulableBuilder.scala#L65 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun opened a new pull request, #39703: [SPARK-42157][CORE] spark.scheduler.mode=FAIR should provide FAIR scheduler
dongjoon-hyun opened a new pull request, #39703: URL: https://github.com/apache/spark/pull/39703 … ### What changes were proposed in this pull request? ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xinrong-meng commented on a diff in pull request #39585: [SPARK-42124][PYTHON][CONNECT] Scalar Inline Python UDF in Spark Connect
xinrong-meng commented on code in PR #39585:
URL: https://github.com/apache/spark/pull/39585#discussion_r1083556210
##
python/pyspark/sql/connect/udf.py:
##
@@ -0,0 +1,165 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+#http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+"""
+User-defined function related classes and functions
+"""
+import functools
+from typing import Callable, Any, TYPE_CHECKING, Optional
+
+from pyspark.serializers import CloudPickleSerializer
+from pyspark.sql.connect.expressions import (
+ColumnReference,
+PythonUDF,
+ScalarInlineUserDefinedFunction,
+)
+from pyspark.sql.connect.column import Column
+from pyspark.sql.types import DataType, StringType
+
+
+if TYPE_CHECKING:
+from pyspark.sql.connect._typing import (
+ColumnOrName,
+DataTypeOrString,
+UserDefinedFunctionLike,
+)
+from pyspark.sql.types import StringType
+
+
+def _create_udf(
+f: Callable[..., Any],
+returnType: "DataTypeOrString",
+evalType: int,
+name: Optional[str] = None,
+deterministic: bool = True,
+) -> "UserDefinedFunctionLike":
+# Set the name of the UserDefinedFunction object to be the name of
function f
+udf_obj = UserDefinedFunction(
+f, returnType=returnType, name=name, evalType=evalType,
deterministic=deterministic
+)
+return udf_obj._wrapped()
+
+
+class UserDefinedFunction:
+"""
+User defined function in Python
+
+Notes
+-
+The constructor of this class is not supposed to be directly called.
+Use :meth:`pyspark.sql.functions.udf` or
:meth:`pyspark.sql.functions.pandas_udf`
+to create this instance.
+"""
+
+def __init__(
+self,
+func: Callable[..., Any],
+returnType: "DataTypeOrString" = StringType(),
+name: Optional[str] = None,
+evalType: int = 100,
+deterministic: bool = True,
+):
+if not callable(func):
+raise TypeError(
+"Invalid function: not a function or callable (__call__ is not
defined): "
+"{0}".format(type(func))
+)
+
+if not isinstance(returnType, (DataType, str)):
+raise TypeError(
+"Invalid return type: returnType should be DataType or str "
+"but is {}".format(returnType)
+)
+
+if not isinstance(evalType, int):
+raise TypeError(
+"Invalid evaluation type: evalType should be an int but is
{}".format(evalType)
+)
+
+self.func = func
+self._returnType = returnType
Review Comment:
Great! I'll do it in a separate PR. Thanks!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sadikovi commented on a diff in pull request #39660: [SPARK-42128][SQL] Support TOP (N) for MS SQL Server dialect as an alternative to Limit pushdown
sadikovi commented on code in PR #39660:
URL: https://github.com/apache/spark/pull/39660#discussion_r1083555135
##
sql/core/src/main/scala/org/apache/spark/sql/jdbc/JdbcDialects.scala:
##
@@ -544,6 +544,14 @@ abstract class JdbcDialect extends Serializable with
Logging {
if (limit > 0 ) s"LIMIT $limit" else ""
}
+ /**
+ * MS SQL Server version of `getLimitClause`.
+ * This is only supported by SQL Server as it uses TOP (N) instead.
+ */
+ def getTopExpression(limit: Integer): String = {
Review Comment:
What exactly is hacky in this API? As far as I can see, it just follows the
existing JDBC code. If you are referring to an alternative implementation, then
I am happy to consider it, otherwise please elaborate.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sadikovi commented on a diff in pull request #39660: [SPARK-42128][SQL] Support TOP (N) for MS SQL Server dialect as an alternative to Limit pushdown
sadikovi commented on code in PR #39660:
URL: https://github.com/apache/spark/pull/39660#discussion_r1083555750
##
sql/core/src/main/scala/org/apache/spark/sql/jdbc/JdbcDialects.scala:
##
@@ -544,6 +544,14 @@ abstract class JdbcDialect extends Serializable with
Logging {
if (limit > 0 ) s"LIMIT $limit" else ""
}
+ /**
+ * MS SQL Server version of `getLimitClause`.
+ * This is only supported by SQL Server as it uses TOP (N) instead.
+ */
+ def getTopExpression(limit: Integer): String = {
Review Comment:
I also don't see how the PR you linked solves this problem. Yes, there is no
top reference in the general JdbcDialects but now MSSQL dialect needs to
reimplement `getSQLText` method which is suboptimal IMHO.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sadikovi commented on a diff in pull request #39660: [SPARK-42128][SQL] Support TOP (N) for MS SQL Server dialect as an alternative to Limit pushdown
sadikovi commented on code in PR #39660: URL: https://github.com/apache/spark/pull/39660#discussion_r1083555430 ## sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/jdbc/JDBCRDD.scala: ## @@ -307,11 +307,12 @@ private[jdbc] class JDBCRDD( "" } +val myTopExpression: String = dialect.getTopExpression(limit) // SQL Server Limit alternative Review Comment: As I mentioned in the PR description, SQL Server does not support LIMIT clause. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sadikovi commented on a diff in pull request #39667: [SPARK-42131][SQL] Extract the function that construct the select statement for JDBC dialect.
sadikovi commented on code in PR #39667:
URL: https://github.com/apache/spark/pull/39667#discussion_r1083555237
##
sql/core/src/main/scala/org/apache/spark/sql/jdbc/JdbcDialects.scala:
##
@@ -551,6 +552,63 @@ abstract class JdbcDialect extends Serializable with
Logging {
if (offset > 0 ) s"OFFSET $offset" else ""
}
+ /**
+ * returns the SQL text for the SELECT statement.
+ *
+ * @param options - JDBC options that contains url, table and other
information.
+ * @param columnList - The names of the columns or aggregate columns to
SELECT.
+ * @param sample - The pushed down tableSample.
+ * @param predicates - The predicates to include in all WHERE clauses.
+ * @param part - The JDBCPartition specifying partition id and WHERE clause.
+ * @param groupByClause - The group by clause for the SELECT statement.
+ * @param orderByClause - The order by clause for the SELECT statement.
+ * @param limit - The pushed down limit. If the value is 0, it means no
limit or limit
+ *is not pushed down.
+ * @param offset - The pushed down offset. If the value is 0, it means no
offset or offset
+ * is not pushed down.
+ * @return
+ */
+ def getSQLText(
Review Comment:
Do we have unit tests that cover it? If not, maybe it is a good time to add
them to make sure the string is generated correctly.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sadikovi commented on a diff in pull request #39660: [SPARK-42128][SQL] Support TOP (N) for MS SQL Server dialect as an alternative to Limit pushdown
sadikovi commented on code in PR #39660:
URL: https://github.com/apache/spark/pull/39660#discussion_r1083555135
##
sql/core/src/main/scala/org/apache/spark/sql/jdbc/JdbcDialects.scala:
##
@@ -544,6 +544,14 @@ abstract class JdbcDialect extends Serializable with
Logging {
if (limit > 0 ) s"LIMIT $limit" else ""
}
+ /**
+ * MS SQL Server version of `getLimitClause`.
+ * This is only supported by SQL Server as it uses TOP (N) instead.
+ */
+ def getTopExpression(limit: Integer): String = {
Review Comment:
What exactly is hacky in this API? As far as I can see, it is just follows
the existing JDBC code. If you are referring to an alternative implementation,
then I am happy to consider it, otherwise please be elaborate.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sadikovi commented on a diff in pull request #39660: [SPARK-42128][SQL] Support TOP (N) for MS SQL Server dialect as an alternative to Limit pushdown
sadikovi commented on code in PR #39660:
URL: https://github.com/apache/spark/pull/39660#discussion_r1083554734
##
sql/core/src/test/scala/org/apache/spark/sql/jdbc/JDBCSuite.scala:
##
@@ -1001,6 +1001,35 @@ class JDBCSuite extends QueryTest with
SharedSparkSession {
}
}
+ test("Dialect Limit and Top implementation") {
Review Comment:
Done!
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sadikovi commented on a diff in pull request #39660: [SPARK-42128][SQL] Support TOP (N) for MS SQL Server dialect as an alternative to Limit pushdown
sadikovi commented on code in PR #39660:
URL: https://github.com/apache/spark/pull/39660#discussion_r1083554624
##
sql/core/src/main/scala/org/apache/spark/sql/jdbc/MsSqlServerDialect.scala:
##
@@ -167,10 +167,15 @@ private object MsSqlServerDialect extends JdbcDialect {
throw QueryExecutionErrors.commentOnTableUnsupportedError()
}
+ // SQL Server does not support, it uses `getTopExpression` instead.
override def getLimitClause(limit: Integer): String = {
""
}
+ override def getTopExpression(limit: Integer): String = {
+if (limit > 0) s"TOP ($limit)" else ""
Review Comment:
TOP 0 is supported but 0 is used as a sentinel value to disable the
pushdown, it is similar to how LIMIT works currently. I tested
`df.select("a").limit(0)` query and it is optimised to ignore the query (?).
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39555: [SPARK-42051][SQL] Codegen Support for HiveGenericUDF
dongjoon-hyun commented on PR #39555: URL: https://github.com/apache/spark/pull/39555#issuecomment-1399620284 Also cc @LuciferYang , too -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39697: [SPARK-42154][K8S][TESTS] Enable `Volcano` unit and integration tests in GitHub Action
dongjoon-hyun commented on PR #39697: URL: https://github.com/apache/spark/pull/39697#issuecomment-1399619557 Could you review this please, @viirya ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39697: [SPARK-42154][K8S][TESTS] Enable `Volcano` unit and integration tests in GitHub Action
dongjoon-hyun commented on PR #39697: URL: https://github.com/apache/spark/pull/39697#issuecomment-1399619465 All tests passed.  -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on a diff in pull request #39691: [SPARK-31561][SQL] Add QUALIFY clause
itholic commented on code in PR #39691:
URL: https://github.com/apache/spark/pull/39691#discussion_r1083550178
##
sql/core/src/test/resources/sql-tests/results/window.sql.out:
##
@@ -1342,3 +1342,139 @@ org.apache.spark.sql.AnalysisException
"windowName" : "w"
}
}
+
+
+-- !query
+SELECT val_long,
+ val_date,
+ max(val) OVER (partition BY val_date) AS m
+FROM testdata
+WHERE val_long > 2
+QUALIFY m > 2 AND m < 10
+-- !query schema
+struct
+-- !query output
+2147483650 2020-12-31 3
+2147483650 2020-12-31 3
+
+
+-- !query
+SELECT val_long,
+ val_date,
+ val
+FROM testdata QUALIFY max(val) OVER (partition BY val_date) >= 3
+-- !query schema
+struct
+-- !query output
+1 2017-08-01 1
+1 2017-08-01 3
+1 2017-08-01 NULL
+2147483650 2020-12-31 2
+2147483650 2020-12-31 3
+NULL 2017-08-01 1
+
+
+-- !query
+SELECT val_date,
+ val * sum(val) OVER (partition BY val_date) AS w
+FROM testdata
+QUALIFY w > 10
+-- !query schema
+struct
+-- !query output
+2017-08-01 15
+2020-12-31 15
+
+
+-- !query
+SELECT w.val_date
+FROM testdata w
+JOIN testdata w2 ON w.val_date=w2.val_date
+QUALIFY row_number() OVER (partition BY w.val_date ORDER BY w.val) IN (2)
+-- !query schema
+struct
+-- !query output
+2017-08-01
+2020-12-31
+
+
+-- !query
+SELECT val_date,
+ count(val_long) OVER (partition BY val_date) AS w
+FROM testdata
+GROUP BY val_date,
+ val_long
+HAVING Sum(val) > 1
+QUALIFY w = 1
+-- !query schema
+struct
+-- !query output
+2017-08-01 1
+2017-08-03 1
+2020-12-31 1
+
+
+-- !query
+SELECT val_date,
+ val_long,
+ Sum(val)
+FROM testdata
+GROUP BY val_date,
+ val_long
+HAVING Sum(val) > 1
+QUALIFY count(val_long) OVER (partition BY val_date) IN(SELECT 1)
+-- !query schema
+struct
+-- !query output
+2017-08-01 1 4
+2017-08-03 3 2
+2020-12-31 2147483650 5
+
+
+-- !query
+SELECT val_date,
+ val_long
+FROM testdata
+QUALIFY count(val_long) OVER (partition BY val_date) > 1 AND val > 1
+-- !query schema
+struct
+-- !query output
+2017-08-01 1
+2020-12-31 2147483650
+2020-12-31 2147483650
+
+
+-- !query
+SELECT val_date,
+ val_long
+FROM testdata
+QUALIFY val > 1
+-- !query schema
+struct<>
+-- !query output
+org.apache.spark.sql.AnalysisException
+{
+ "errorClass" : "_LEGACY_ERROR_TEMP_1032",
Review Comment:
nit: Can we assign the name for `_LEGACY_ERROR_TEMP_1032` to
`MISSING_WINDOW_EXPR` or something while we here ?
But it's not a necessary, and I can help it as follow-up, tho.
##
docs/sql-ref-syntax-qry-select-qualify.md:
##
@@ -0,0 +1,98 @@
+---
+layout: global
+title: QUALIFY Clause
+displayTitle: QUALIFY Clause
+license: |
+ Licensed to the Apache Software Foundation (ASF) under one or more
+ contributor license agreements. See the NOTICE file distributed with
+ this work for additional information regarding copyright ownership.
+ The ASF licenses this file to You under the Apache License, Version 2.0
+ (the "License"); you may not use this file except in compliance with
+ the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
+---
+
+### Description
+
+The `QUALIFY` clause is used to filter the results of
+[window functions](sql-ref-syntax-qry-select-window.md). To use QUALIFY,
+at least one window function is required to be present in the SELECT list or
the QUALIFY clause.
Review Comment:
`SELECT` -> `[SELECT](sql-ref-syntax-qry-select.html)` ?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a diff in pull request #39642: [SPARK-41677][CORE][SQL][SS][UI] Add Protobuf serializer for `StreamingQueryProgressWrapper`
gengliangwang commented on code in PR #39642:
URL: https://github.com/apache/spark/pull/39642#discussion_r1083550779
##
core/src/main/protobuf/org/apache/spark/status/protobuf/store_types.proto:
##
@@ -765,3 +765,54 @@ message PoolData {
optional string name = 1;
repeated int64 stage_ids = 2;
}
+
+message StateOperatorProgress {
+ optional string operator_name = 1;
+ int64 num_rows_total = 2;
+ int64 num_rows_updated = 3;
+ int64 all_updates_time_ms = 4;
+ int64 num_rows_removed = 5;
+ int64 all_removals_time_ms = 6;
+ int64 commit_time_ms = 7;
+ int64 memory_used_bytes = 8;
+ int64 num_rows_dropped_by_watermark = 9;
+ int64 num_shuffle_partitions = 10;
+ int64 num_state_store_instances = 11;
+ map custom_metrics = 12;
Review Comment:
I am concerned about the nullability of all these maps. Shall we check/test
all of them?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang closed pull request #39683: [SPARK-42144][CORE][SQL] Handle null string values in StageDataWrapper/StreamBlockData/StreamingQueryData
gengliangwang closed pull request #39683: [SPARK-42144][CORE][SQL] Handle null string values in StageDataWrapper/StreamBlockData/StreamingQueryData URL: https://github.com/apache/spark/pull/39683 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on pull request #39683: [SPARK-42144][CORE][SQL] Handle null string values in StageDataWrapper/StreamBlockData/StreamingQueryData
gengliangwang commented on PR #39683: URL: https://github.com/apache/spark/pull/39683#issuecomment-1399617671 Thanks, merging to master -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang closed pull request #39682: [SPARK-42139][CORE][SQL] Handle null string values in SQLExecutionUIData/SparkPlanGraphWrapper/SQLPlanMetric
gengliangwang closed pull request #39682: [SPARK-42139][CORE][SQL] Handle null string values in SQLExecutionUIData/SparkPlanGraphWrapper/SQLPlanMetric URL: https://github.com/apache/spark/pull/39682 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on pull request #39682: [SPARK-42139][CORE][SQL] Handle null string values in SQLExecutionUIData/SparkPlanGraphWrapper/SQLPlanMetric
gengliangwang commented on PR #39682: URL: https://github.com/apache/spark/pull/39682#issuecomment-1399617495 Thanks, merging to master -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on a diff in pull request #39695: [SPARK-42156] SparkConnectClient supports RetryPolicies now
itholic commented on code in PR #39695:
URL: https://github.com/apache/spark/pull/39695#discussion_r1083547431
##
python/pyspark/sql/connect/client.py:
##
@@ -567,54 +602,48 @@ def _execute_and_fetch(
logger.info("ExecuteAndFetch")
m: Optional[pb2.ExecutePlanResponse.Metrics] = None
-
batches: List[pa.RecordBatch] = []
try:
-for b in self._stub.ExecutePlan(req,
metadata=self._builder.metadata()):
-if b.client_id != self._session_id:
-raise SparkConnectException(
-"Received incorrect session identifier for request."
-)
-if b.metrics is not None:
-logger.debug("Received metric batch.")
-m = b.metrics
-if b.HasField("arrow_batch"):
-logger.debug(
-f"Received arrow batch rows={b.arrow_batch.row_count} "
-f"size={len(b.arrow_batch.data)}"
-)
-
-with pa.ipc.open_stream(b.arrow_batch.data) as reader:
-for batch in reader:
-assert isinstance(batch, pa.RecordBatch)
-batches.append(batch)
+for attempt in Retrying(SparkConnectClient.retry_exception,
**self._retry_policy):
+with attempt:
+for b in self._stub.ExecutePlan(req,
metadata=self._builder.metadata()):
+if b.client_id != self._session_id:
+raise SparkConnectException(
+"Received incorrect session identifier for
request."
Review Comment:
ditto ?
##
python/pyspark/sql/connect/client.py:
##
@@ -640,6 +669,136 @@ def _handle_error(self, rpc_error: grpc.RpcError) ->
NoReturn:
raise SparkConnectException(str(rpc_error)) from None
+class RetryState:
+"""
+Simple state helper that captures the state between retries of the
exceptions. It
+keeps track of the last exception thrown and how many in total. when the
task
+finishes successfully done() returns True.
+"""
+
+def __init__(self) -> None:
+self._exception: Optional[BaseException] = None
+self._done = False
+self._count = 0
+
+def set_exception(self, exc: Optional[BaseException]) -> None:
+self._exception = exc
+self._count += 1
+
+def exception(self) -> Optional[BaseException]:
+return self._exception
+
+def set_done(self) -> None:
+self._done = True
+
+def count(self) -> int:
+return self._count
+
+def done(self) -> bool:
+return self._done
+
+
+class AttemptManager:
+"""
+Simple ContextManager that is used to capture the exception thrown inside
the context.
+"""
+
+def __init__(self, check: Callable[..., bool], retry_state: RetryState) ->
None:
+self._retry_state = retry_state
+self._can_retry = check
+
+def __enter__(self) -> None:
+pass
+
+def __exit__(
+self,
+exc_type: Optional[Type[BaseException]],
+exc_val: Optional[BaseException],
+exc_tb: Optional[TracebackType],
+) -> Optional[bool]:
+if isinstance(exc_val, BaseException):
+# Swallow the exception.
+if self._can_retry(exc_val):
+self._retry_state.set_exception(exc_val)
+return True
+# Bubble up the exception.
+return False
+else:
+self._retry_state.set_done()
+return None
+
+
+class Retrying:
+"""
+This helper class is used as a generator together with a context manager to
+allow retrying exceptions in particular code blocks. The Retrying can be
configured
+with a lambda function that is can be filtered what kind of exceptions
should be
+retried.
+
+In addition, there are several parameters that are used to configure the
exponential
+backoff behavior.
+
+An example to use this class looks like this:
+
+for attempt in Retrying(lambda x: isinstance(x, TransientError)):
+with attempt:
+# do the work.
+
Review Comment:
I think we can use `.. code-block:: python` here in docstring for the better
example as below:
```
An example to use this class looks like this:
.. code-block:: python
for attempt in Retrying(lambda x: isinstance(x, TransientError)):
with attempt:
# do the work.
```
##
python/pyspark/sql/tests/connect/test_connect_basic.py:
##
@@ -2591,6 +2591,73 @@ def test_unsupported_io_functions(self):
getattr(df.write, f)()
+@unittest.skipIf(not should_test_connect, connect_requirement_message)
+class ClientTests(unittest.TestCase):
+def test_retry_error_handling(self):
+
[GitHub] [spark] NarekDW commented on pull request #39501: [SPARK-41295][SPARK-41296][SQL] Rename the error classes
NarekDW commented on PR #39501: URL: https://github.com/apache/spark/pull/39501#issuecomment-1399605596 > Cool, thanks!! > > BTW, if you happen to interested in more contribution to rename error class, could you try resolving [SPARK-41302](https://issues.apache.org/jira/browse/SPARK-41302) and [SPARK-41488](https://issues.apache.org/jira/browse/SPARK-41488) ?? > > I believe these are pretty common errors, but haven't been assigned a proper name yet. (Please no pressure, I'm just recommending a good item to contribute if you're interested. ) Yep, I will take a look, no problem, thanks for suggestion :) Also I have an off topic question, is it possible to get a JIRA account to be created for me? (I'd like to create couple of tickets there, I wrote a mail to priv...@spark.apache.org about 2-3 weeks ago, but still didn't get any response...) -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #39501: [SPARK-41295][SPARK-41296][SQL] Rename the error classes
itholic commented on PR #39501: URL: https://github.com/apache/spark/pull/39501#issuecomment-1399602887 Cool, thanks!! BTW, if you happen to interested in more contribution to rename error class, could you try resolving SPARK-41302 and SPARK-41488 ?? I believe these are pretty common errors, but haven't been assigned a proper name yet. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic opened a new pull request, #39702: [SPARK-41487][SQL] Assign name to _LEGACY_ERROR_TEMP_1020
itholic opened a new pull request, #39702: URL: https://github.com/apache/spark/pull/39702 ### What changes were proposed in this pull request? This PR proposes to assign name to _LEGACY_ERROR_TEMP_1020, "INVALID_USAGE_OF_STAR". ### Why are the changes needed? We should assign proper name to _LEGACY_ERROR_TEMP_* ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? `./build/sbt "sql/testOnly org.apache.spark.sql.SQLQueryTestSuite*` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #38428: [SPARK-40912][CORE]Overhead of Exceptions in KryoDeserializationStream
dongjoon-hyun commented on code in PR #38428:
URL: https://github.com/apache/spark/pull/38428#discussion_r1083538101
##
core/src/test/scala/org/apache/spark/serializer/KryoIteratorBenchmark.scala:
##
@@ -0,0 +1,117 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.serializer
+
+import java.io.{ByteArrayInputStream, ByteArrayOutputStream}
+
+import scala.reflect.ClassTag
+import scala.util.Random
+
+import org.apache.spark.SparkConf
+import org.apache.spark.benchmark.{Benchmark, BenchmarkBase}
+import org.apache.spark.internal.config._
+import org.apache.spark.internal.config.Kryo._
+import org.apache.spark.serializer.KryoTest._
+
+/**
+ * Benchmark for kryo asIterator on a deserialization stream". To run this
benchmark:
+ * {{{
+ * 1. without sbt:
+ * bin/spark-submit --class
+ * 2. build/sbt "core/Test/runMain "
+ * 3. generate result:
+ * SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt "core/Test/runMain "
+ * Results will be written to
"benchmarks/KryoSerializerBenchmark-results.txt".
+ * }}}
+ */
+object KryoIteratorBenchmark extends BenchmarkBase {
+ val N = 1
+ override def runBenchmarkSuite(mainArgs: Array[String]): Unit = {
+val name = "Benchmark of kryo asIterator on deserialization stream"
+runBenchmark(name) {
+ val benchmark = new Benchmark(name, N, 10, output = output)
+ Seq(true, false).map(useIterator => run(useIterator, benchmark))
+ benchmark.run()
+}
+ }
+
+ private def run(useIterator: Boolean, benchmark: Benchmark): Unit = {
+val ser = createSerializer()
+
+def roundTrip[T: ClassTag](
+elements: Array[T],
+useIterator: Boolean,
+ser: SerializerInstance): Int = {
+ val serialized: Array[Byte] = {
+val baos = new ByteArrayOutputStream()
+val serStream = ser.serializeStream(baos)
+var i = 0
+while (i < elements.length) {
+ serStream.writeObject(elements(i))
+ i += 1
+}
+serStream.close()
+baos.toByteArray
+ }
+
+ val deserStream = ser.deserializeStream(new
ByteArrayInputStream(serialized))
+ if (useIterator) {
+if (deserStream.asIterator.toArray.length == elements.length) 1 else 0
+ } else {
+val res = new Array[T](elements.length)
+var i = 0
+while (i < elements.length) {
+ res(i) = deserStream.readValue()
+ i += 1
+}
+deserStream.close()
+if (res.length == elements.length) 1 else 0
+ }
+}
+
+def createCase[T: ClassTag](name: String, elementCount: Int,
createElement: => T): Unit = {
+ val elements = Array.fill[T](elementCount)(createElement)
+
+ benchmark.addCase(
+s"Colletion of $name with $elementCount elements, useIterator:
$useIterator") { _ =>
+var sum = 0L
+var i = 0
+while (i < N) {
+ sum += roundTrip(elements, useIterator, ser)
+ i += 1
+}
+sum
+ }
+}
+
+createCase("int", 1, Random.nextInt)
+createCase("int", 10, Random.nextInt)
+createCase("int", 100, Random.nextInt)
+createCase("string", 1, Random.nextString(5))
+createCase("string", 10, Random.nextString(5))
+createCase("string", 100, Random.nextString(5))
Review Comment:
Could you add more complex data structure like Array?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Kimahriman commented on pull request #37616: [SPARK-40178][PYTHON][SQL] Fix partitioning hint parameters in PySpark
Kimahriman commented on PR #37616: URL: https://github.com/apache/spark/pull/37616#issuecomment-1399596763 Came across this wanting to test out the `rebalance` hint in pyspark (since it looks like rebalance can only be used as a hint right now). Does it make more sense to support strings directly in the `ResolveHints`? It is pretty awkward that SQL hints get interpreted as expressions, but DataFrame hints don't. It's definitely awkward having to use `$"col".expr` even on the Scala side. And in `ResolveHints` it already supports the number of partitions either being an Literal or an integer -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #38428: [SPARK-40912][CORE]Overhead of Exceptions in KryoDeserializationStream
dongjoon-hyun commented on PR #38428: URL: https://github.com/apache/spark/pull/38428#issuecomment-1399596628 Got it, @mridulm . Could you rebase this once more, @eejbyfeldt ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39697: [SPARK-42154][K8S][TESTS] Enable `Volcano` unit and integration tests in GitHub Action
dongjoon-hyun commented on PR #39697: URL: https://github.com/apache/spark/pull/39697#issuecomment-1399595199 Could you review this, @Yikun ? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] NarekDW commented on pull request #39501: [SPARK-41295][SPARK-41296][SQL] Rename the error classes
NarekDW commented on PR #39501: URL: https://github.com/apache/spark/pull/39501#issuecomment-1399593726 > Sure, done -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #39501: [SPARK-41295][SQL] Rename the error classes
itholic commented on PR #39501: URL: https://github.com/apache/spark/pull/39501#issuecomment-1399591723 @NarekDW Can you add `[SPARK-41296]` to PR title instead explaining in PR description ? `[SPARK-41295][SPARK-41296][SQL] Rename the error classes` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #39501: [SPARK-41295][SQL] Rename the error classes
itholic commented on PR #39501: URL: https://github.com/apache/spark/pull/39501#issuecomment-1399590022 It looks good to me. Also cc @cloud-fan -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on a diff in pull request #39693: [SPARK-41712][PYTHON][CONNECT] Migrate the Spark Connect errors into PySpark error framework.
itholic commented on code in PR #39693: URL: https://github.com/apache/spark/pull/39693#discussion_r1083528302 ## python/pyspark/errors/exceptions.py: ## @@ -288,7 +291,57 @@ class UnknownException(CapturedException): class SparkUpgradeException(CapturedException): """ -Exception thrown because of Spark upgrade +Exception thrown because of Spark upgrade. +""" + + +class SparkConnectException(PySparkException): +""" +Exception thrown from Spark Connect. +""" + + +class SparkConnectGrpcException(SparkConnectException): +""" +Base class to handle the errors from GRPC. +""" + +def __init__( +self, +message: Optional[str] = None, +error_class: Optional[str] = None, +message_parameters: Optional[Dict[str, str]] = None, +plan: Optional[str] = None, +reason: Optional[str] = None, Review Comment: Thanks for the detail! Just moved `plan` into `SparkConnectAnalysisException`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #39687: [SPARK-41470][SQL] Relax constraints on Storage-Partitioned-Join should assume InternalRow implements equals and hashCode
AmplabJenkins commented on PR #39687: URL: https://github.com/apache/spark/pull/39687#issuecomment-1399572509 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on a diff in pull request #39701: [SPARK-41489][SQL] Assign name to _LEGACY_ERROR_TEMP_2415
itholic commented on code in PR #39701:
URL: https://github.com/apache/spark/pull/39701#discussion_r1083521103
##
core/src/main/resources/error/error-classes.json:
##
@@ -933,6 +933,12 @@
],
"sqlState" : "42604"
},
+ "INVALID_TYPE_FOR_FILTER_EXPR" : {
+"message" : [
+ "Filter expression '' of type is not a boolean."
+],
+"sqlState" : "428H2"
Review Comment:
FYI: referred to
https://github.com/apache/spark/tree/master/core/src/main/resources/error
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic opened a new pull request, #39701: [SPARK-41489][SQL] Assign name to _LEGACY_ERROR_TEMP_2415
itholic opened a new pull request, #39701: URL: https://github.com/apache/spark/pull/39701 ### What changes were proposed in this pull request? This PR proposes to assign name to _LEGACY_ERROR_TEMP_2415, "INVALID_TYPE_FOR_FILTER_EXPR". ### Why are the changes needed? We should assign proper name to _LEGACY_ERROR_TEMP_* ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? `./build/sbt "sql/testOnly org.apache.spark.sql.SQLQueryTestSuite*` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] grundprinzip commented on a diff in pull request #39693: [SPARK-41712][PYTHON][CONNECT] Migrate the Spark Connect errors into PySpark error framework.
grundprinzip commented on code in PR #39693: URL: https://github.com/apache/spark/pull/39693#discussion_r1083516891 ## python/pyspark/errors/exceptions.py: ## @@ -288,7 +291,57 @@ class UnknownException(CapturedException): class SparkUpgradeException(CapturedException): """ -Exception thrown because of Spark upgrade +Exception thrown because of Spark upgrade. +""" + + +class SparkConnectException(PySparkException): +""" +Exception thrown from Spark Connect. +""" + + +class SparkConnectGrpcException(SparkConnectException): +""" +Base class to handle the errors from GRPC. +""" + +def __init__( +self, +message: Optional[str] = None, +error_class: Optional[str] = None, +message_parameters: Optional[Dict[str, str]] = None, +plan: Optional[str] = None, +reason: Optional[str] = None, Review Comment: plan is actually only present in `SparkConnectAnalysisException` because it's a special property submitted as part of the error details. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] grundprinzip commented on a diff in pull request #39585: [SPARK-42124][PYTHON][CONNECT] Scalar Inline Python UDF in Spark Connect
grundprinzip commented on code in PR #39585:
URL: https://github.com/apache/spark/pull/39585#discussion_r1083516677
##
connector/connect/common/src/main/protobuf/spark/connect/expressions.proto:
##
@@ -217,6 +218,28 @@ message Expression {
bool is_user_defined_function = 4;
}
+ message ScalarInlineUserDefinedFunction {
Review Comment:
Right now the message is nested inside expression.
```
message Expression {
oneof type {
ScalarInlineUserDefinedFunction function = 1;
}
message ScalarInlineUserDefinedFunction {
}
}
```
Just move it outside, the nesting is really just for convenience and intend
and that is why it makes sense to move it outside of expression because it can
be used in both variants.
```
message Expression {
oneof type {
ScalarInlineUserDefinedFunction function = 1;
}
}
message ScalarInlineUserDefinedFunction {
}
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] grundprinzip commented on pull request #39695: [SPARK-42156] SparkConnectClient supports RetryPolicies now
grundprinzip commented on PR #39695: URL: https://github.com/apache/spark/pull/39695#issuecomment-1399563679 R: @HyukjinKwon @zhengruifeng -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic opened a new pull request, #39700: [SPARK-41490][SQL] Assign name to _LEGACY_ERROR_TEMP_2441
itholic opened a new pull request, #39700: URL: https://github.com/apache/spark/pull/39700 ### What changes were proposed in this pull request? This PR proposes to assign name to _LEGACY_ERROR_TEMP_2441, "UNSUPPORTED_EXPR_FOR_OPERATOR". ### Why are the changes needed? We should assign proper name to _LEGACY_ERROR_TEMP_* ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? `./build/sbt "sql/testOnly org.apache.spark.sql.SQLQueryTestSuite*` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on pull request #39695: [SPARK-XXXX] SparkConnectClient supports RetryPolicies now
AmplabJenkins commented on PR #39695: URL: https://github.com/apache/spark/pull/39695#issuecomment-1399473053 Can one of the admins verify this patch? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Yikun commented on pull request #39690: [SPARK-42150][K8S][DOCS] Upgrade `Volcano` to 1.7.0
Yikun commented on PR #39690: URL: https://github.com/apache/spark/pull/39690#issuecomment-1399462666 @dongjoon-hyun Thanks! Late LGTM. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #39693: [SPARK-41712][PYTHON][CONNECT] Migrate the Spark Connect errors into PySpark error framework.
itholic commented on PR #39693: URL: https://github.com/apache/spark/pull/39693#issuecomment-1399452695 > not related to this PR, but we may also need to add tests to check the messages in these exceptions. For sure! I'm planning to improve the tests for new error framework as follow up tasks. I think that's going to be quite a big task, I plan to create JIRA sub-tasks a per-file basis. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on a diff in pull request #39693: [SPARK-41712][PYTHON][CONNECT] Migrate the Spark Connect errors into PySpark error framework.
itholic commented on code in PR #39693: URL: https://github.com/apache/spark/pull/39693#discussion_r1083429604 ## python/pyspark/errors/__init__.py: ## @@ -45,4 +50,11 @@ "SparkUpgradeException", "PySparkTypeError", "PySparkValueError", +"SparkConnectException", +"SparkConnectGrpcException", +"SparkConnectAnalysisException", +"SparkConnectParseException", +"SparkConnectTempTableAlreadyExistsException", +"PySparkTypeError", +"PySparkValueError", Review Comment: Oops. Thanks for the correction! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org