achimbab opened a new pull request #11467:
URL: https://github.com/apache/druid/pull/11467
This PR implements functions that extract a value from a JSON-encoded string.
### New functions
| function | description |
| --- | --- |
| json_extract_string(expr,string...) | Extracts the String value from expr
based on string arguments. |
| json_extract_long(expr,string...) | Extracts the Long value from expr
based on string arguments. |
| json_extract_double(expr,string...) | Extracts the Double value from expr
based on string arguments. |
| jsonpath_extract_string(expr,json-path) | Extracts the String value from
expr based on json-path. |
| jsonpath_extract_long(expr,json-path) | Extracts the Long value from expr
based on json-path. |
| jsonpath_extract_double(expr,json-path) | Extracts the Double value from
expr based on json-path. |
### Examples
The `json_extract_*` family of functions extract a value from a JSON-encoded
string.
```SQL
SELECT json_extract_string('{"key1":"val1"}', 'key1')
-- Extract a value from a nested object
SELECT json_extract_string('{"key1":{"key2":"val2"}}', 'key1', 'key2')
```
The `jsonpath_extract_*` family of functions support JSONPath expressions
referring to a JSON structure in the same way as XPath expression.
```SQL
SELECT jsonpath_extract_string('{"key":[{"k":"v1"},{"k":"v2"}]}',
'$.key[0].k')
```
### FastJsonReader
The `json_extract_*` family of functions use FastJsonReader.
In order to improve extraction performance, I implemented light and fast
parser called FastJsonReader.
In my environment, it is faster than Jsonpath in the case of extracting a
scalar value. However, Jsonpath offers lots of functionalities.
### Benchmark
I did benchmark test with the query below.
```SQL
select v, count(*)
from (
select json_extract_string(json_column, 'key') as v
from test
)
group by v
order by count(*) desc
```
#### Benchmark 1 - Single Node, Small dataset
1 node / 6 core, 32G RAM, SSD
Sample rows: 445,283
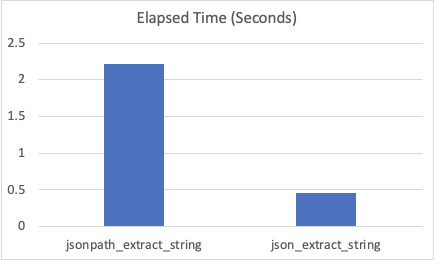
#### Benchmark 2 - Cluster, Medium dataset
15 Historical nodes / 32 core, 256G RAM, NVME
Sample rows: 3247568
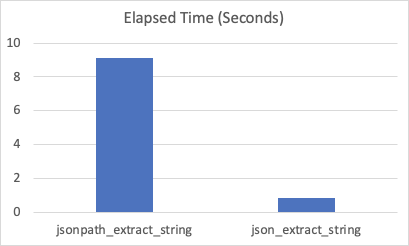
#### Benchmark 3 - Cluster, Large dataset
15 Historical nodes / 32 core, 256G RAM, NVME
Sample rows: 9614347
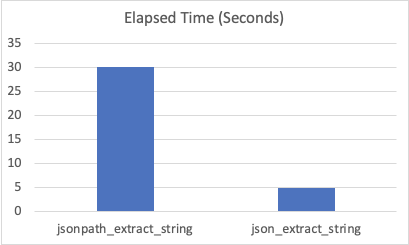
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: [email protected]
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}