TyrantLucifer edited a comment on pull request #1188: URL: https://github.com/apache/incubator-seatunnel/pull/1188#issuecomment-1030797538
> @TyrantLucifer It seems that you omitted some scala files, like SparkStreamingExecution, SparkStreamingSink, SparkStreamingSource. Well, I found a compilation error when I tried to convert the stream-related API, as shown below 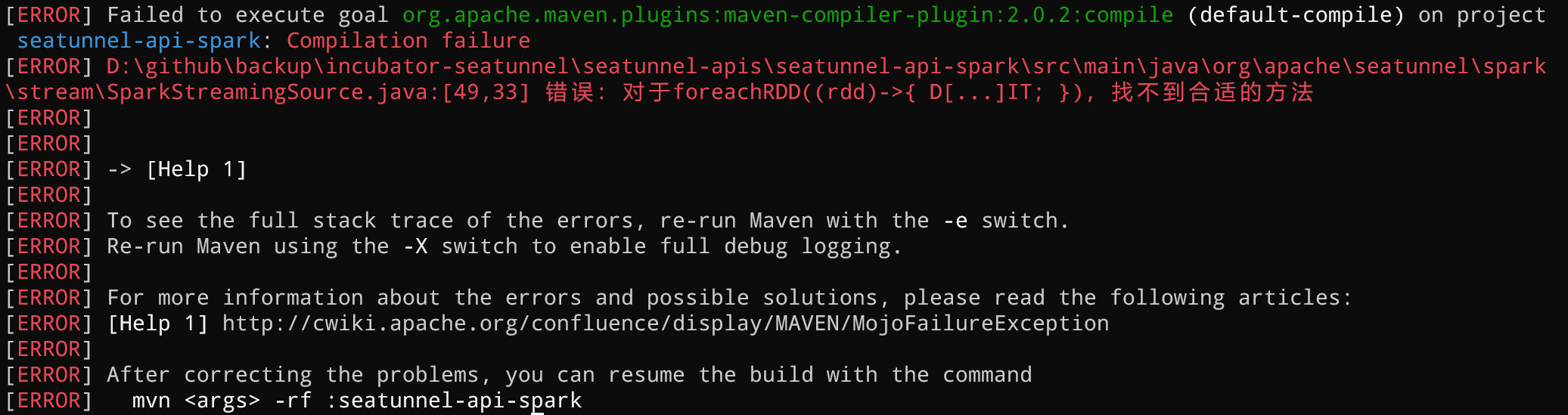 The specific code is as follows: `SparkStreamingSource.java` ```java /* * Licensed to the Apache Software Foundation (ASF) under one or more * contributor license agreements. See the NOTICE file distributed with * this work for additional information regarding copyright ownership. * The ASF licenses this file to You under the Apache License, Version 2.0 * (the "License"); you may not use this file except in compliance with * the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ package org.apache.seatunnel.spark.stream; import org.apache.seatunnel.spark.BaseSparkSource; import org.apache.seatunnel.spark.SparkEnvironment; import org.apache.spark.rdd.RDD; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; import org.apache.spark.sql.SparkSession; import org.apache.spark.streaming.dstream.DStream; import java.util.function.Consumer; import scala.runtime.BoxedUnit; /** * a SparkStreamingSource plugin will read data from other system * using Spark Streaming API. */ @SuppressWarnings("PMD.AbstractClassShouldStartWithAbstractNamingRule") public abstract class SparkStreamingSource<T> extends BaseSparkSource<DStream<T>> { public void beforeOutput() { } public void afterOutput() { } public abstract Dataset<Row> rdd2dataset(SparkSession sparkSession, RDD<T> rdd); public void start(SparkEnvironment sparkEnvironment, Consumer<Dataset<Row>> handler) { getData(sparkEnvironment).foreachRDD(rdd -> { Dataset<Row> dataset = rdd2dataset(sparkEnvironment.getSparkSession(), rdd); handler.accept(dataset); return BoxedUnit.UNIT; }); } } ``` `SparkStreamingSink.java` ```java /* * Licensed to the Apache Software Foundation (ASF) under one or more * contributor license agreements. See the NOTICE file distributed with * this work for additional information regarding copyright ownership. * The ASF licenses this file to You under the Apache License, Version 2.0 * (the "License"); you may not use this file except in compliance with * the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ package org.apache.seatunnel.spark.stream; import org.apache.seatunnel.spark.BaseSparkSink; /** * a SparkStreamingSink plugin will write data to other system * using Spark Streaming API. */ @SuppressWarnings("PMD.AbstractClassShouldStartWithAbstractNamingRule") public abstract class SparkStreamingSink extends BaseSparkSink<Void> { } ``` `SparkStreamingExecution.java` ```java /* * Licensed to the Apache Software Foundation (ASF) under one or more * contributor license agreements. See the NOTICE file distributed with * this work for additional information regarding copyright ownership. * The ASF licenses this file to You under the Apache License, Version 2.0 * (the "License"); you may not use this file except in compliance with * the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ package org.apache.seatunnel.spark.stream; import org.apache.seatunnel.common.config.CheckResult; import org.apache.seatunnel.env.Execution; import org.apache.seatunnel.spark.BaseSparkSink; import org.apache.seatunnel.spark.BaseSparkSource; import org.apache.seatunnel.spark.BaseSparkTransform; import org.apache.seatunnel.spark.SparkEnvironment; import org.apache.seatunnel.spark.batch.SparkBatchExecution; import org.apache.seatunnel.shade.com.typesafe.config.Config; import org.apache.seatunnel.shade.com.typesafe.config.ConfigFactory; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; import org.apache.spark.streaming.StreamingContext; import java.util.List; public class SparkStreamingExecution implements Execution<BaseSparkSource<?>, BaseSparkTransform, BaseSparkSink<?>> { private final SparkEnvironment sparkEnvironment; private Config config = ConfigFactory.empty(); public SparkStreamingExecution(SparkEnvironment sparkEnvironment) { this.sparkEnvironment = sparkEnvironment; } @Override public void start(List<BaseSparkSource<?>> sources, List<BaseSparkTransform> transforms, List<BaseSparkSink<?>> sinks) { SparkStreamingSource<?> source = (SparkStreamingSource<?>) sources.get(0); List<BaseSparkSource<?>> subSources = sources.subList(1, sources.size()); sources.subList(1, sources.size()).forEach(s -> { SparkBatchExecution.registerInputTempView((BaseSparkSource<Dataset<Row>>) s, sparkEnvironment); }); source.start(sparkEnvironment, dataset -> { Config config = source.getConfig(); if (config.hasPath(SparkBatchExecution.RESULT_TABLE_NAME)) { SparkBatchExecution.registerTempView(config.getString(SparkBatchExecution.RESULT_TABLE_NAME), dataset); } Dataset<Row> ds = dataset; for (BaseSparkTransform transform : transforms) { if (ds.head().size() > 0) { ds = SparkBatchExecution.transformProcess(sparkEnvironment, transform, ds); SparkBatchExecution.registerTransformTempView(transform, ds); } } source.beforeOutput(); if (ds.head().length() > 0) { for (BaseSparkSink<?> sink : sinks) { SparkBatchExecution.sinkProcess(sparkEnvironment, sink, ds); } } source.afterOutput(); StreamingContext streamingContext = sparkEnvironment.getStreamingContext(); streamingContext.start(); streamingContext.awaitTermination(); }); } @Override public void setConfig(Config config) { this.config = config; } @Override public Config getConfig() { return this.config; } @Override public CheckResult checkConfig() { return CheckResult.success(); } @Override public void prepare(Void prepareEnv) { } } ``` I think it should be compilation error caused by using spark-streaming API of Scala version in Java. I have tried to modify RDD and DStream to Java version, but the subsequent data sources connected in stream form are all developed in Scala. I don't know how to solve this problem. In order not to affect other functions, I did not submit this part of the code. Do you have any other good solutions? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: [email protected] For queries about this service, please contact Infrastructure at: [email protected]
{kind=link}