[
https://issues.apache.org/jira/browse/DRILL-5975?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16258372#comment-16258372
]
Paul Rogers commented on DRILL-5975:
------------------------------------
As it turns out, Drill provides a very rudimentary scheduler in the form of
ZK-based queues. You can turn them on by changing the `exec.queue.enable`
system option.
Drill 1.12 will build on the queue mechanism to allocate memory to queries
based on the configured queue sizes and a few other parameters. See DRILL-5716
and the documentation in the PR.
As noted, the ZK-based scheme is very simple. The work done in DRILL-5716
should help you think about a better scheduler. The Foreman has been modified
to accept a variety of queueing mechanisms. The three currently available are
1) do-nothing, 2) in-memory (for testing), and 3) ZK-based.
You can easily defined a new queueing mechanism as part of your scheduler
project. The interface allows you to set the memory to be used for each query.
(For example, if your scheduler limits loads to, say, 10 queries, and you have
60 GB per node, then the implementation can assign each query 6 GB.)
The API lets you hold a query to delay execution until an execution slot
becomes available in your scheduler.
There are improvements to be made. For example, there is no reason to hold a
thread while a query is queued. [~arina] is looking at some improvements in
this area.
A while back we did a sketch for an admission control mechanism that would
delegate one Drillbit as the scheduler. The scheduler would provide a set of
prioritized queues. The scheduler would assign resources as queries come in,
holding queries until resources are available. A scheduler introduces a single
point of failure, but there is a fairly easy scheme to allow rapid failover to
a new scheduler.
If this material is of interest, I can dig up the old design doc and post it
here for reference.
Also consider looking into the schedulers provided by Presto and Impala for
good ideas. Impala, for example, adopted a YARN-like model, presumably because
most people understand that model. Presto, as I recall, has a simpler model.
> Resource utilization
> --------------------
>
> Key: DRILL-5975
> URL: https://issues.apache.org/jira/browse/DRILL-5975
> Project: Apache Drill
> Issue Type: New Feature
> Affects Versions: 2.0.0
> Reporter: weijie.tong
> Assignee: weijie.tong
>
> h1. Motivation
> Now the resource utilization radio of Drill's cluster is not too good. Most
> of the cluster resource is wasted. We can not afford too much concurrent
> queries. Once the system accepted more queries with a not high cpu load, the
> query which originally is very quick will become slower and slower.
> The reason is Drill does not supply a scheduler . It just assume all the
> nodes have enough calculation resource. Once a query comes, it will schedule
> the related fragments to random nodes not caring about the node's load. Some
> nodes will suffer more cpu context switch to satisfy the coming query. The
> profound causes to this is that the runtime minor fragments construct a
> runtime tree whose nodes spread different drillbits. The runtime tree is a
> memory pipeline that is all the nodes will stay alone the whole lifecycle of
> a query by sending out data to upper nodes successively, even though some
> node could run quickly and quit immediately.What's more the runtime tree is
> constructed before actual running. The schedule target to Drill will become
> the whole runtime tree nodes.
> h1. Design
> It will be hard to schedule the runtime tree nodes as a whole. So I try to
> solve this by breaking the runtime cascade nodes. The graph below describes
> the initial design.
> !https://raw.githubusercontent.com/wiki/weijietong/drill/images/design.png!
> [graph
> link|https://raw.githubusercontent.com/wiki/weijietong/drill/images/design.png]
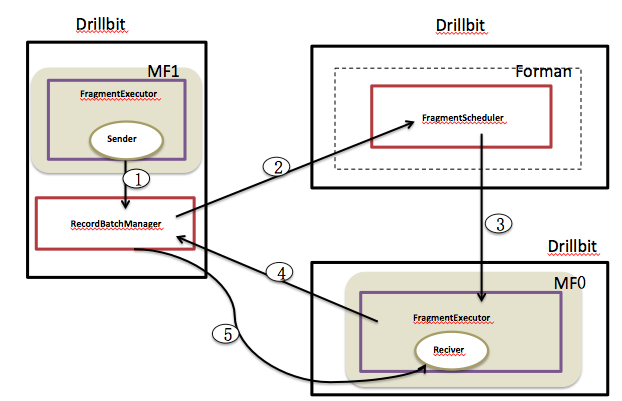
> Every Drillbit instance will have a RecordBatchManager which will accept all
> the RecordBatchs written by the senders of local different MinorFragments.
> The RecordBatchManager will hold the RecordBatchs in memory firstly then disk
> storage . Once the first RecordBatch of a MinorFragment sender of one query
> occurs , it will notice the FragmentScheduler. The FragmentScheduler is
> instanced by the Foreman.It holds the whole PlanFragment execution graph.It
> will allocate a new corresponding FragmentExecutor to run the generated
> RecordBatch. The allocated FragmentExecutor will then notify the
> corresponding FragmentManager to indicate that I am ready to receive the
> data. Then the FragmentManger will send out the RecordBatch one by one to the
> corresponding FragmentExecutor's receiver like what the current Sender does
> by throttling the data stream.
> What we can gain from this design is :
> a. The computation leaf node does not to wait for the consumer's speed to end
> its life to release the resource.
> b. The sending data logic will be isolated from the computation nodes and
> shared by different FragmentManagers.
> c. We can schedule the MajorFragments according to Drillbit's actual resource
> capacity at runtime.
> d. Drill's pipeline data processing characteristic is also retained.
> h1. Plan
> This will be a large PR ,so I plan to divide it into some small ones.
> a. to implement the RecordManager.
> b. to implement a simple random FragmentScheduler and the whole event flow.
> c. to implement a primitive FragmentScheduler which may reference the Sparrow
> project.
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
{kind=link}