[
https://issues.apache.org/jira/browse/DRILL-5975?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16266114#comment-16266114
]
Paul Rogers commented on DRILL-5975:
------------------------------------
Thanks [~weijie] for the description of the workload. I wonder if yours is a
special case? You mentioned the use of Druid, which, as I recall, does its own
aggregation across the multi-dimensional records stored in each of its data
chunks. That is unlike the usual Drill use case in which Drill does the work of
reading from disk, decoding data, and performing aggregation.
It may be worth exploring the differences that Druid introduces.
First, what is the architecture between Drill and Druid? Does Drill send
queries to Druid brokers for distribution, or does Drill connect directly to
historical or real-time nodes?
Second, does Druid run on the same cluster as Drill? If so, how do you ensure
that each Drillbit reads only from the historical or real-time node on that
same node (for data locality?)
Or, is Druid on a separate cluster? How, then, do you coordinate between the,
say, 120 Drill nodes and the however many Druid nodes?
Third, how many queries can Druid effectively run per node? When running a
Drill query, what is the CPU load on the Druid cluster?
Fourth, left to its own, Drill will try to run 16 * 70% = 11 Druid readers per
major fragment per node. Given your knowledge of Drill internals, you may have
adjusted that number. If left unchanged, each Drill query will fire off 120
nodes * 11 readers/node = 1320 Druid queries.
The above suggests that this particular configuration may be limited by Druid,
not by Drill itself.
As mentioned earlier, most (non-Druid) Drill clusters are CPU-bound because the
do the grunt-work of reading data, decoding, filtering and so on. In the Druid
use case, Druid does all that work; Drill may just be sitting around waiting
for the work to be done by Druid.
This is easy to test, just look at the CPU usage on the Druid cluster when
running Drill queries.
If Druid turns out to be the bottleneck, you may want to determine the best
throughput for Druid nodes: how man queries, with which distribution, maximizes
the Druid hardware?
Then, work out the size of the Drill cluster needed to drive Druid fully. It
may be that you simply have to large a Drill cluster for the available Druid
throughput, most Drill tasks just wait for data. Fewer Drill resources may
better utilize the Drill cluster.
Said yet another way, you have two distributed systems, each trying to spread
work: Drill and Druid. They may be working at cross purposes. Certainly their
sizing needs to be coordinated for even workload.
On the other hand, if neither Drill nor Druid are near 100% CPU, then there is
an even more complex interaction happening between the two systems. As hinted
above, perhaps Drill and Druid should exist on the same cluster, with Drill
taking the place of the Druid coordinator: Drill ships queries directly to the
historical or real-time nodes on the same node as the Drillbit.
Under this revised architecture, the goal is to drive each Drill/Druid node to
full CPU usage.
Perhaps the scheduler design is intended to address this use case. If so, then
perhaps you could add a bit more explanation about how that will work.
> Resource utilization
> --------------------
>
> Key: DRILL-5975
> URL: https://issues.apache.org/jira/browse/DRILL-5975
> Project: Apache Drill
> Issue Type: New Feature
> Affects Versions: 2.0.0
> Reporter: weijie.tong
> Assignee: weijie.tong
>
> h1. Motivation
> Now the resource utilization radio of Drill's cluster is not too good. Most
> of the cluster resource is wasted. We can not afford too much concurrent
> queries. Once the system accepted more queries with a not high cpu load, the
> query which originally is very quick will become slower and slower.
> The reason is Drill does not supply a scheduler . It just assume all the
> nodes have enough calculation resource. Once a query comes, it will schedule
> the related fragments to random nodes not caring about the node's load. Some
> nodes will suffer more cpu context switch to satisfy the coming query. The
> profound causes to this is that the runtime minor fragments construct a
> runtime tree whose nodes spread different drillbits. The runtime tree is a
> memory pipeline that is all the nodes will stay alone the whole lifecycle of
> a query by sending out data to upper nodes successively, even though some
> node could run quickly and quit immediately.What's more the runtime tree is
> constructed before actual running. The schedule target to Drill will become
> the whole runtime tree nodes.
> h1. Design
> It will be hard to schedule the runtime tree nodes as a whole. So I try to
> solve this by breaking the runtime cascade nodes. The graph below describes
> the initial design.
> !https://raw.githubusercontent.com/wiki/weijietong/drill/images/design.png!
> [graph
> link|https://raw.githubusercontent.com/wiki/weijietong/drill/images/design.png]
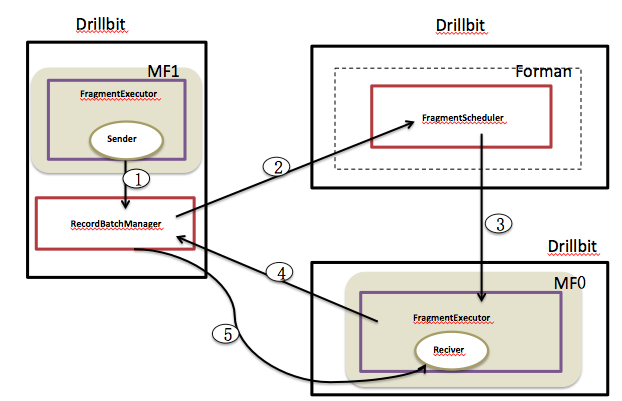
> Every Drillbit instance will have a RecordBatchManager which will accept all
> the RecordBatchs written by the senders of local different MinorFragments.
> The RecordBatchManager will hold the RecordBatchs in memory firstly then disk
> storage . Once the first RecordBatch of a MinorFragment sender of one query
> occurs , it will notice the FragmentScheduler. The FragmentScheduler is
> instanced by the Foreman.It holds the whole PlanFragment execution graph.It
> will allocate a new corresponding FragmentExecutor to run the generated
> RecordBatch. The allocated FragmentExecutor will then notify the
> corresponding FragmentManager to indicate that I am ready to receive the
> data. Then the FragmentManger will send out the RecordBatch one by one to the
> corresponding FragmentExecutor's receiver like what the current Sender does
> by throttling the data stream.
> What we can gain from this design is :
> a. The computation leaf node does not to wait for the consumer's speed to end
> its life to release the resource.
> b. The sending data logic will be isolated from the computation nodes and
> shared by different FragmentManagers.
> c. We can schedule the MajorFragments according to Drillbit's actual resource
> capacity at runtime.
> d. Drill's pipeline data processing characteristic is also retained.
> h1. Plan
> This will be a large PR ,so I plan to divide it into some small ones.
> a. to implement the RecordManager.
> b. to implement a simple random FragmentScheduler and the whole event flow.
> c. to implement a primitive FragmentScheduler which may reference the Sparrow
> project.
--
This message was sent by Atlassian JIRA
(v6.4.14#64029)
{kind=link}