Stephen-Robin commented on issue #2195: URL: https://github.com/apache/iceberg/issues/2195#issuecomment-771708362
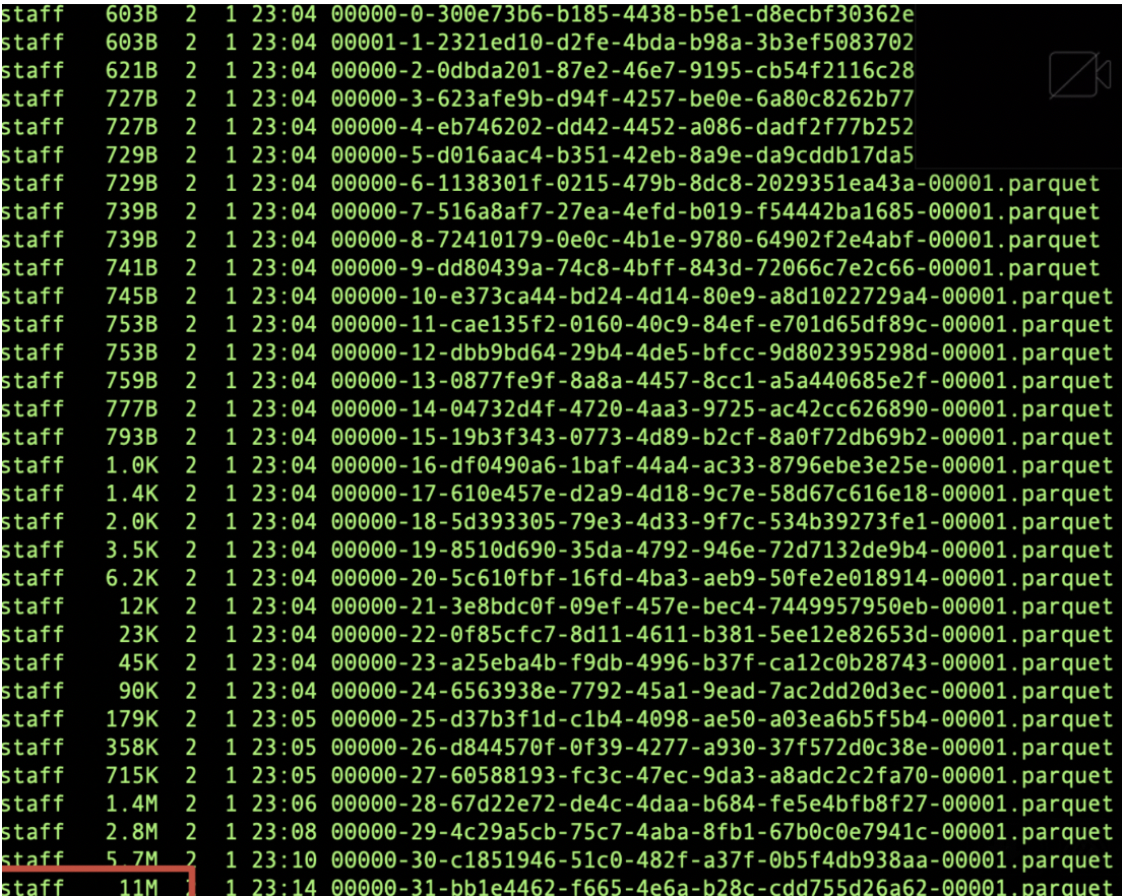
> That does seem pretty dangerous although I haven't seen this happen before. Do you have the snapshot summary for the compaction operation? It should hopefully also provide some hints as to what is going on It would also be great if you had a programmatic reproduction of the issue. > […](#) > On Tue, Feb 2, 2021 at 12:38 AM Stephen-Robin ***@***.***> wrote: There is a high probability of data loss after compaction through some rewrite data files test. After compacting a table ,some rows will be lost. The reproduction process is as follows: 1. create a new iceberg table create table test (id int, age int) using iceberg; 2. Write initial data, Keep writing data until the generated file size is more than 10M(splitTargetSize), Which is 11M in this example insert into test values (1,2),(3,4); insert into test select * from test; [image: image] <https://user-images.githubusercontent.com/77377842/106560840-a424af00-6562-11eb-840e-321d8e926396.png> 3. count the number of rows in the table: select count(*) from table [image: image] <https://user-images.githubusercontent.com/77377842/106560909-c74f5e80-6562-11eb-8d84-9346864aa9d4.png> 4. execute compaction The compaction params like splitTargetSize are 10M and other parameters such as splitOpenFileCost(4M) are default values. Actions.forTable(table).rewriteDataFiles.targetSizeInBytes(10 * 10 * 1024).execute() 5. count the number of rows in the table: select count(*) from table [image: image] <https://user-images.githubusercontent.com/77377842/106560966-dcc48880-6562-11eb-8135-09d5b74a2483.png> Actually, The origin 11M file has been split into a 10M file A and a 1M file B after bin pack. However the CombinedScanTask with only one FileScanTask will be filtered out. When RewriteFiles.commit() is executed finally, because the 1M file B exists, the 11M manifest corresponding files will be deleted (status set 2). Regardless of whether the remaining 1M file B was successfully written, we lost the 10M file A. The result shows that the number of rows was exactly half missing, because the 11M parquet file was missing in this example, and the remaining 1M file B did not rewrite the new data file because the origin Parquet row group split point was not found. In my opinion, the Iceberg RewriteFile operation not only combines small files, but also needs to split large files. Flink may need to deal with more small file merging cases, in addition to small file merging, Spark also need to consider as much as possible the reasonable segmentation of large files. In either case, it is necessary to ensure the reliability of the data Please anyone confirm if this is a problem, If there is a problem, I have tried to fix and submit a pr right away. Thanks — You are receiving this because you are subscribed to this thread. Reply to this email directly, view it on GitHub <#2195>, or unsubscribe <https://github.com/notifications/unsubscribe-auth/AADE2YIJBMUL45MCVHPGZQLS46MVBANCNFSM4W6CJNSA> . Thank you for your reply.I have described how to reproduce in the issue. First create a new iceberg table, and insert initial values. The compaction params like splitTargetSize are 10M and other parameters such as splitOpenFileCost(4M) are default values. Then insert data continuously through `insert into table select * from table`, until the size of the most recently generated parquet file is more than 10M, which is 11M in this example. Finally, call the BaseRewriteDataFilesAction rewriteDataFiles interface to execute compaction. The main problem is the code marked in this red box 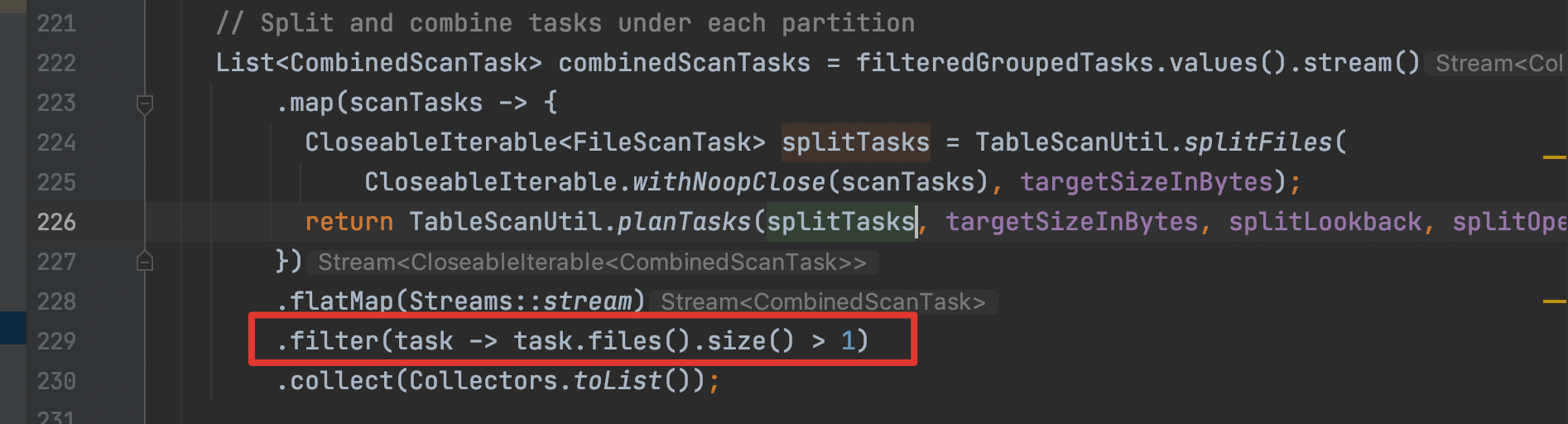 The main purpose is to filter out the CombinedScanTask that only has one scanTask. For example, a file size is 8M, and the default value of the open file cost is 4M. After bin pack, the 8M files are in a package. The line code is to filter out. In this case, redundant writing is avoided, but files that exceed the split target size will have problems in the issue. I have tried to fix the problem and can view it https://github.com/apache/iceberg/pull/2196/commits. If you need some data during my test, I will provide it at any time Thanks ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}