Stephen-Robin edited a comment on issue #2195:
URL: https://github.com/apache/iceberg/issues/2195#issuecomment-771712074
> That does seem pretty dangerous although I haven't seen this happen
before. Do you have the snapshot summary for the compaction operation? It
should hopefully also provide some hints as to what is going on It would also
be great if you had a programmatic reproduction of the issue.
> […](#)
@RussellSpitzer Thanks for your reply.I have described how to reproduce in
the issue.
First create a new iceberg table, and insert initial values. The compaction
params like splitTargetSize are 10M and other parameters such as
splitOpenFileCost(4M) are default values.
Then insert data continuously through `insert into table select * from
table`, until the size of the most recently generated parquet file is more than
10M, which is 11M in this example.
Finally, call the BaseRewriteDataFilesAction rewriteDataFiles interface to
execute compaction.
The main problem is the code marked in this red box
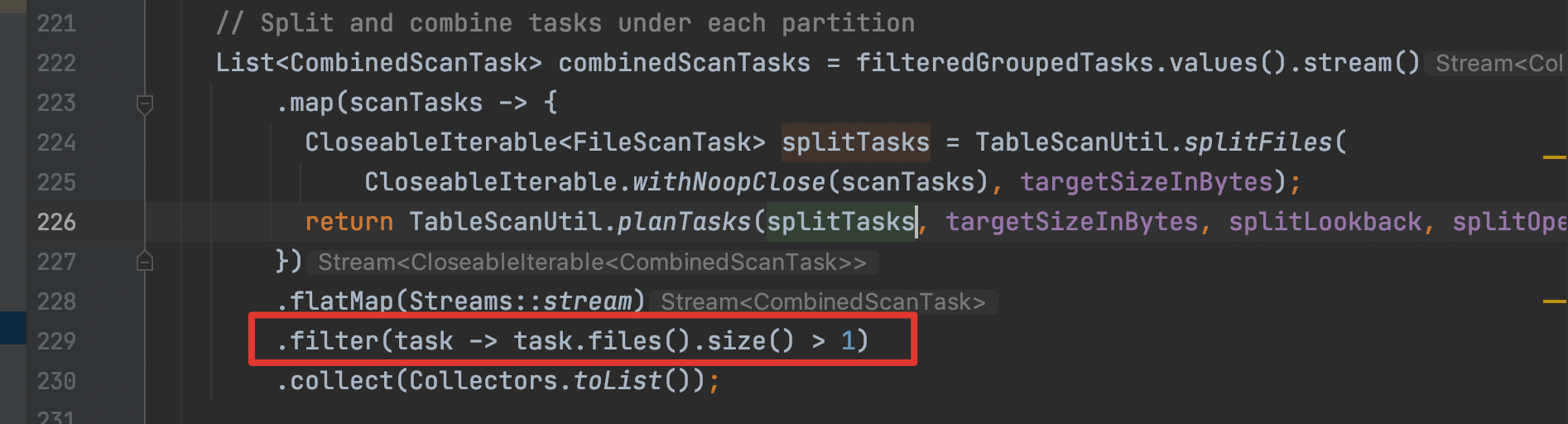
The main purpose is to filter out the CombinedScanTask that only has one
scanTask. For example, a file size is 8M, and the default value of the open
file cost is 4M. After bin pack, the 8M files are in a package. The line code
is to filter out. In this case, redundant writing is avoided, but files that
exceed the split target size will have problems in the issue.
I have tried to fix the problem and can view it
https://github.com/apache/iceberg/pull/2196/commits.
If you need some data during my test, I will provide it at any time
Thanks
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}