zhengruifeng commented on pull request #28458:
URL: https://github.com/apache/spark/pull/28458#issuecomment-624427337
performace test on the first 10,000 instances of
`webspam_wc_normalized_trigram`
code:
```scala
val df = spark.read.option("numFeatures",
"8289919").format("libsvm").load("/data1/Datasets/webspam/webspam_wc_normalized_trigram.svm.10k").withColumn("label",
(col("label")+1)/2)
df.persist(StorageLevel.MEMORY_AND_DISK)
df.count
val lr = new LogisticRegression().setBlockSize(1).setMaxIter(10)
lr.fit(df)
val results = Seq(1, 4, 16, 64, 256, 1024, 4096).map { size => val start =
System.currentTimeMillis; val model = lr.setBlockSize(size).fit(df); val end =
System.currentTimeMillis; (size, model.coefficients, end - start) }
```
results:
```
scala> results.map(_._3)
res17: Seq[Long] = List(33948, 425923, 129811, 56288, 47587, 42816, 39809)
scala> results.map(_._2).foreach(coef => println(coef.toString.take(100)))
(8289919,[549219,551719,592137,592138,592141,592154,592160,592162,592163,592164,592166,592167,592168
(8289919,[549219,551719,592137,592138,592141,592154,592160,592162,592163,592164,592166,592167,592168
(8289919,[549219,551719,592137,592138,592141,592154,592160,592162,592163,592164,592166,592167,592168
(8289919,[549219,551719,592137,592138,592141,592154,592160,592162,592163,592164,592166,592167,592168
(8289919,[549219,551719,592137,592138,592141,592154,592160,592162,592163,592164,592166,592167,592168
(8289919,[549219,551719,592137,592138,592141,592154,592160,592162,592163,592164,592166,592167,592168
(8289919,[549219,551719,592137,592138,592141,592154,592160,592162,592163,592164,592166,592167,592168
scala> results.map(_._2).foreach(coef =>
println(coef.toString.takeRight(100)))
87,-1188.1053920127556,335.5565308836645,-135.79302172669907,849.0515530033497,-27.040836637047736])
91,-1188.105392012755,335.55653088366444,-135.79302172669907,849.0515530033497,-27.040836637047736])
9,-1188.1053920127551,335.55653088366444,-135.79302172669904,849.0515530033495,-27.040836637047725])
94,-1188.1053920127556,335.55653088366444,-135.79302172669904,849.0515530033495,-27.04083663704773])
1,-1188.1053920127551,335.55653088366444,-135.79302172669904,849.0515530033493,-27.040836637047722])
5,-1188.1053920127556,335.55653088366444,-135.79302172669904,849.0515530033495,-27.040836637047736])
29,-1188.105392012756,335.55653088366444,-135.79302172669904,849.0515530033495,-27.040836637047736])
```
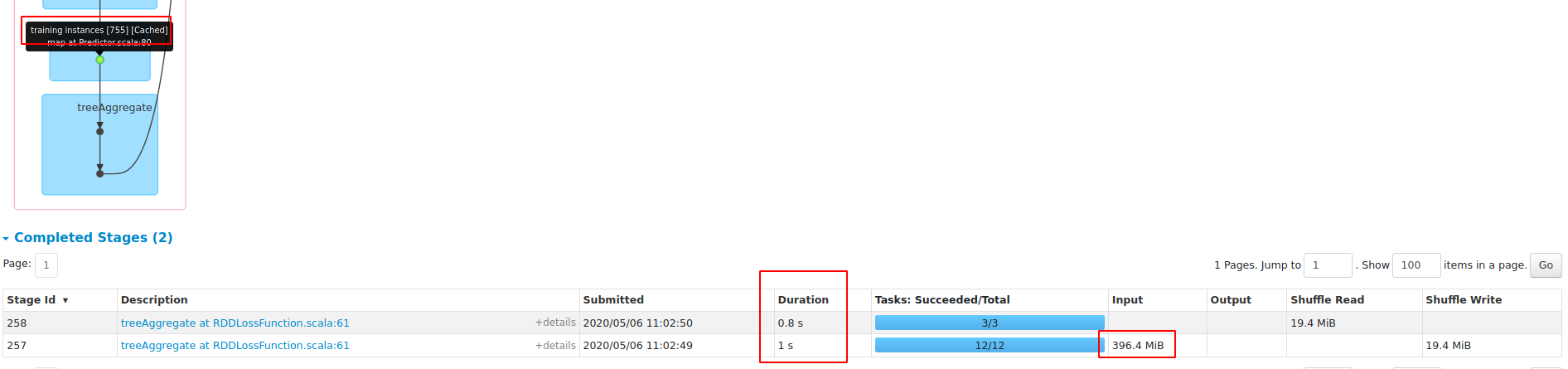
**blockSize==1**
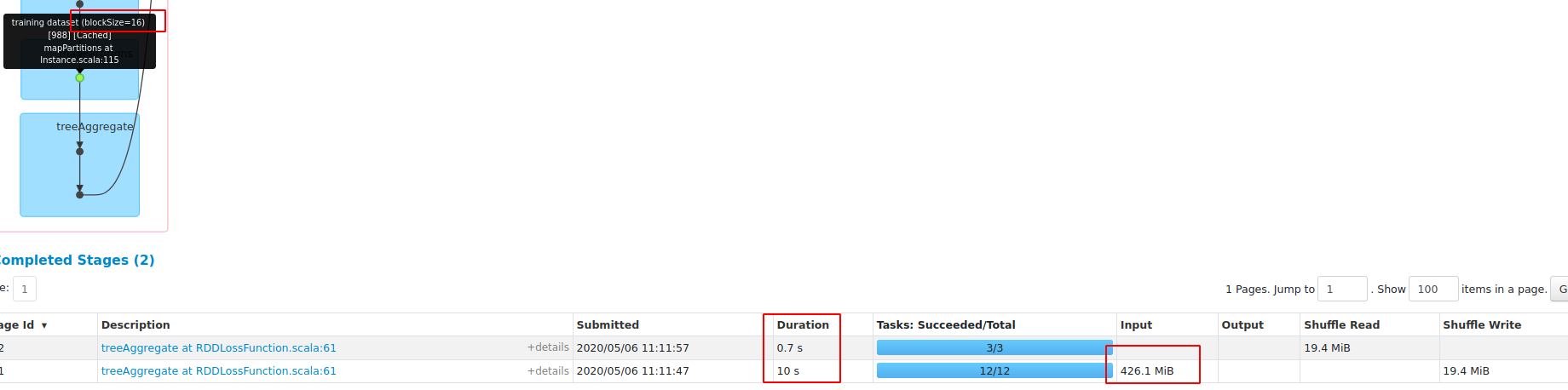
**blockSize=16**
test with **Master**:
```
import org.apache.spark.ml.classification._
import org.apache.spark.storage.StorageLevel
val df = spark.read.option("numFeatures",
"8289919").format("libsvm").load("/data1/Datasets/webspam/webspam_wc_normalized_trigram.svm.10k").withColumn("label",
(col("label")+1)/2)
df.persist(StorageLevel.MEMORY_AND_DISK)
df.count
val lr = new LogisticRegression().setMaxIter(10)
lr.fit(df)
val start = System.currentTimeMillis; val model = lr.setMaxIter(10).fit(df);
val end = System.currentTimeMillis; end - start
scala> val start = System.currentTimeMillis; val model =
lr.setMaxIter(10).fit(df); val end = System.currentTimeMillis; end - start
start: Long = 1588735447883
model: org.apache.spark.ml.classification.LogisticRegressionModel =
LogisticRegressionModel: uid=logreg_99d29a0ecc13, numClasses=2,
numFeatures=8289919
end: Long = 1588735483170
res3: Long = 35287
```
In this PR, when blockSize==1, the duration is 33948, so there will be no
performance regression on sparse datasets.
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}