LuciferYang edited a comment on pull request #30663: URL: https://github.com/apache/spark/pull/30663#issuecomment-748988593
I'm sorry, I've been busy with internal meetings of the company in recent days :( One of the cases being tried is as follows: 1. create a temp table use parquet or orc table with 150 files and each file has 1000 columns 2. SQL with count on one column like `select count(columnX) FROM parquetTable` However, there was no significant performance difference when tested locally. 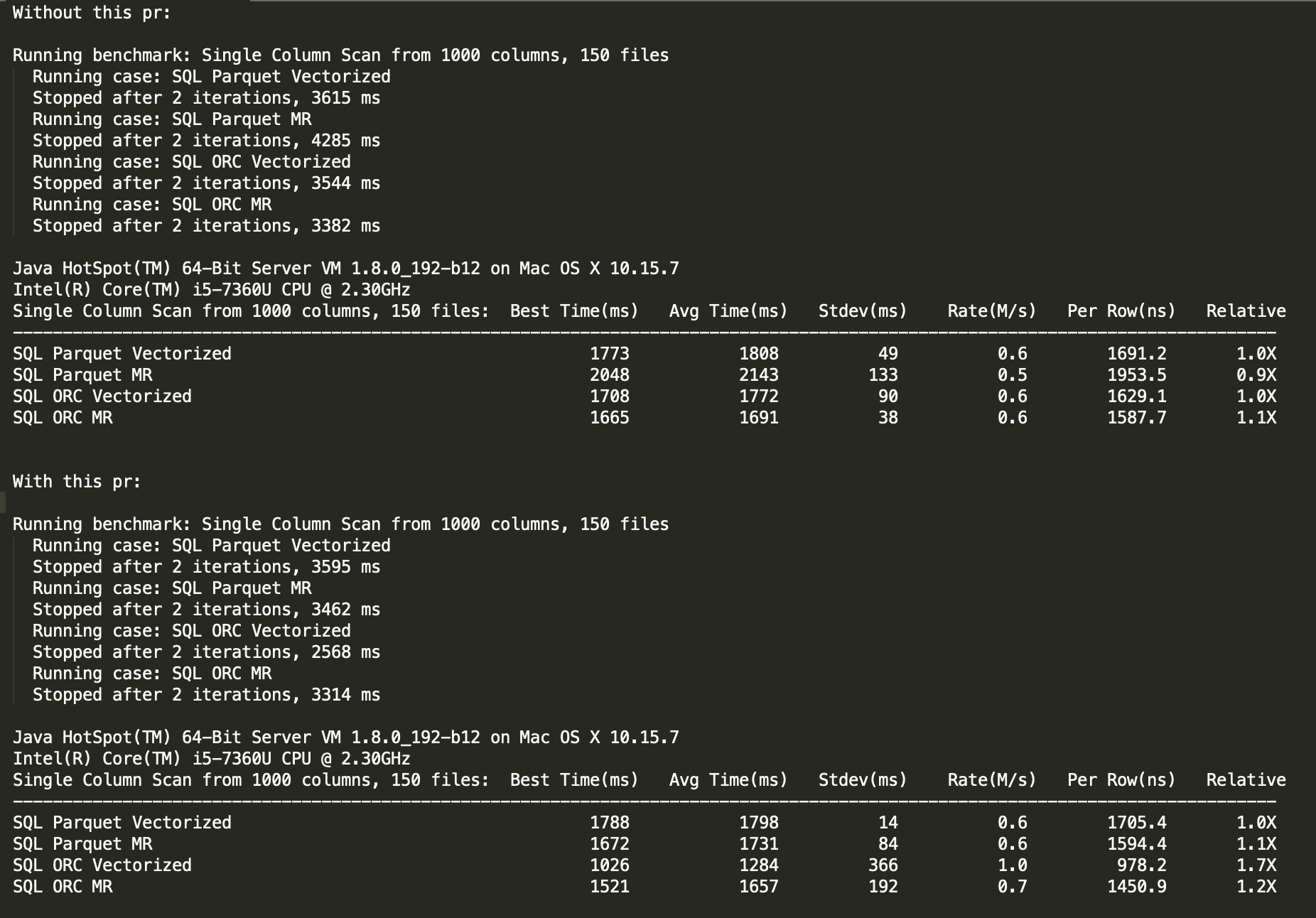 ---------------------------------------------------------------- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}