AngersZhuuuu commented on a change in pull request #31402:
URL: https://github.com/apache/spark/pull/31402#discussion_r568500664
##########
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##########
@@ -3170,7 +3170,9 @@ class Analyzer(override val catalogManager:
CatalogManager)
WindowExpression(wf, s.copy(frameSpecification = wf.frame))
case we @ WindowExpression(e, s @ WindowSpecDefinition(_, o,
UnspecifiedFrame))
if e.resolved =>
- val frame = if (o.nonEmpty) {
+ val frame = if (e.isInstanceOf[RankLike]) {
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow)
Review comment:
Hive 2.3.7 don't allow to specify frame.
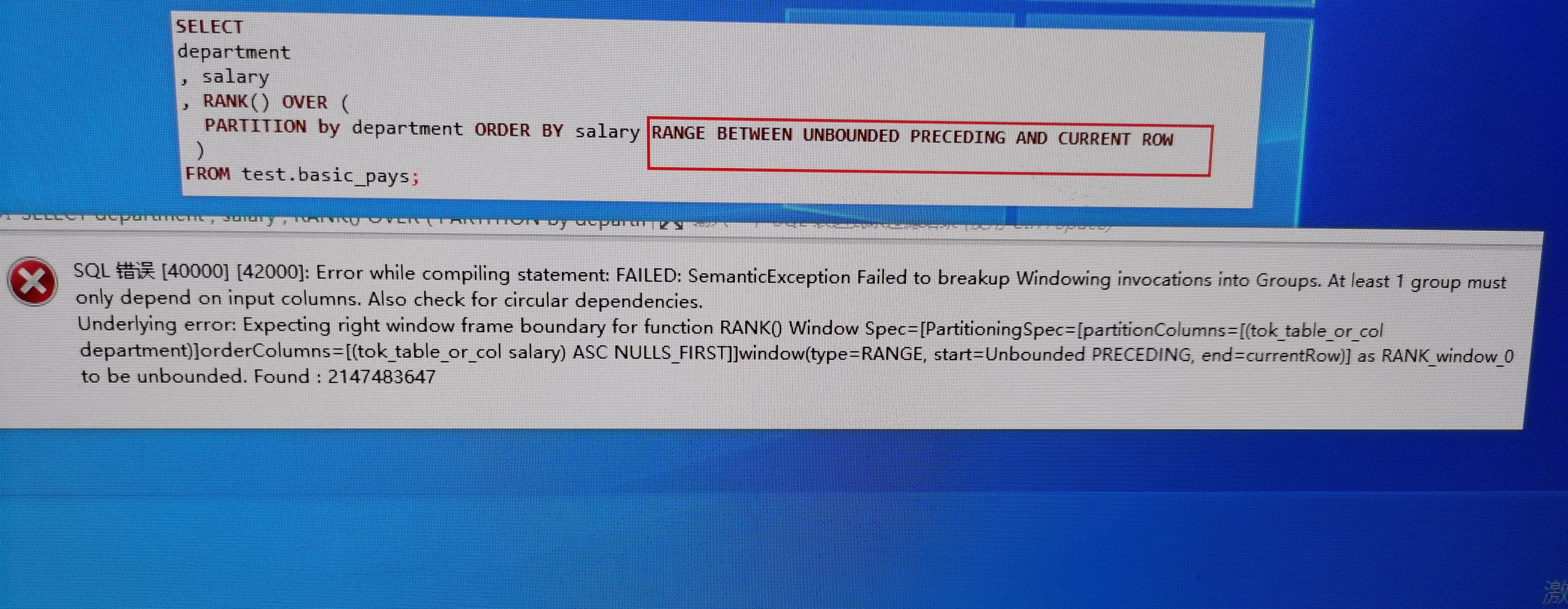
But this two sql can run:
```
SELECT department, salary, RANK() OVER (
PARTITION by department ORDER BY salary ROWS BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING
)
FROM basic_pays;
SELECT department, salary, RANK() OVER (
PARTITION by department ORDER BY salary RANGE BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING
)
FROM basic_pays;
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}