AngersZhuuuu commented on a change in pull request #31402:
URL: https://github.com/apache/spark/pull/31402#discussion_r568298627
##########
File path: sql/core/src/test/resources/sql-functions/sql-expression-schema.md
##########
@@ -205,7 +205,7 @@
| org.apache.spark.sql.catalyst.expressions.ParseToDate | to_date | SELECT
to_date('2009-07-30 04:17:52') | struct<to_date(2009-07-30 04:17:52):date> |
| org.apache.spark.sql.catalyst.expressions.ParseToTimestamp | to_timestamp |
SELECT to_timestamp('2016-12-31 00:12:00') | struct<to_timestamp(2016-12-31
00:12:00):timestamp> |
| org.apache.spark.sql.catalyst.expressions.ParseUrl | parse_url | SELECT
parse_url('http://spark.apache.org/path?query=1', 'HOST') |
struct<parse_url(http://spark.apache.org/path?query=1, HOST):string> |
-| org.apache.spark.sql.catalyst.expressions.PercentRank | percent_rank |
SELECT a, b, percent_rank(b) OVER (PARTITION BY a ORDER BY b) FROM VALUES
('A1', 2), ('A1', 1), ('A2', 3), ('A1', 1) tab(a, b) |
struct<a:string,b:int,PERCENT_RANK() OVER (PARTITION BY a ORDER BY b ASC NULLS
FIRST ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW):double> |
+| org.apache.spark.sql.catalyst.expressions.PercentRank | percent_rank |
SELECT a, b, percent_rank(b) OVER (PARTITION BY a ORDER BY b) FROM VALUES
('A1', 2), ('A1', 1), ('A2', 3), ('A1', 1) tab(a, b) |
struct<a:string,b:int,PERCENT_RANK() OVER (PARTITION BY a ORDER BY b ASC NULLS
FIRST RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW):double> |
Review comment:
> Why we change `ROWS` -> `RANGE` ?
Since we remove `AggregationWindowFunction`'s default. then will add a
default frame in `ResolveWindowFrame`
##########
File path: sql/core/src/test/resources/sql-functions/sql-expression-schema.md
##########
@@ -205,7 +205,7 @@
| org.apache.spark.sql.catalyst.expressions.ParseToDate | to_date | SELECT
to_date('2009-07-30 04:17:52') | struct<to_date(2009-07-30 04:17:52):date> |
| org.apache.spark.sql.catalyst.expressions.ParseToTimestamp | to_timestamp |
SELECT to_timestamp('2016-12-31 00:12:00') | struct<to_timestamp(2016-12-31
00:12:00):timestamp> |
| org.apache.spark.sql.catalyst.expressions.ParseUrl | parse_url | SELECT
parse_url('http://spark.apache.org/path?query=1', 'HOST') |
struct<parse_url(http://spark.apache.org/path?query=1, HOST):string> |
-| org.apache.spark.sql.catalyst.expressions.PercentRank | percent_rank |
SELECT a, b, percent_rank(b) OVER (PARTITION BY a ORDER BY b) FROM VALUES
('A1', 2), ('A1', 1), ('A2', 3), ('A1', 1) tab(a, b) |
struct<a:string,b:int,PERCENT_RANK() OVER (PARTITION BY a ORDER BY b ASC NULLS
FIRST ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW):double> |
+| org.apache.spark.sql.catalyst.expressions.PercentRank | percent_rank |
SELECT a, b, percent_rank(b) OVER (PARTITION BY a ORDER BY b) FROM VALUES
('A1', 2), ('A1', 1), ('A2', 3), ('A1', 1) tab(a, b) |
struct<a:string,b:int,PERCENT_RANK() OVER (PARTITION BY a ORDER BY b ASC NULLS
FIRST RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW):double> |
Review comment:
> Why we change `ROWS` -> `RANGE` ?
Since we remove `AggregationWindowFunction`'s default. then will add a
default frame in `ResolveWindowFrame`
##########
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/windowExpressions.scala
##########
@@ -633,7 +633,9 @@ case class CumeDist() extends RowNumberLike with
SizeBasedWindowFunction {
group = "window_funcs")
// scalastyle:on line.size.limit line.contains.tab
case class NthValue(input: Expression, offset: Expression, ignoreNulls:
Boolean)
- extends AggregateWindowFunction with OffsetWindowFunction with
ImplicitCastInputTypes {
+ extends AggregateWindowFunction
+ with OffsetWindowFunction
+ with ImplicitCastInputTypes {
Review comment:
> unnecessary change.
Done
##########
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##########
@@ -3170,7 +3170,9 @@ class Analyzer(override val catalogManager:
CatalogManager)
WindowExpression(wf, s.copy(frameSpecification = wf.frame))
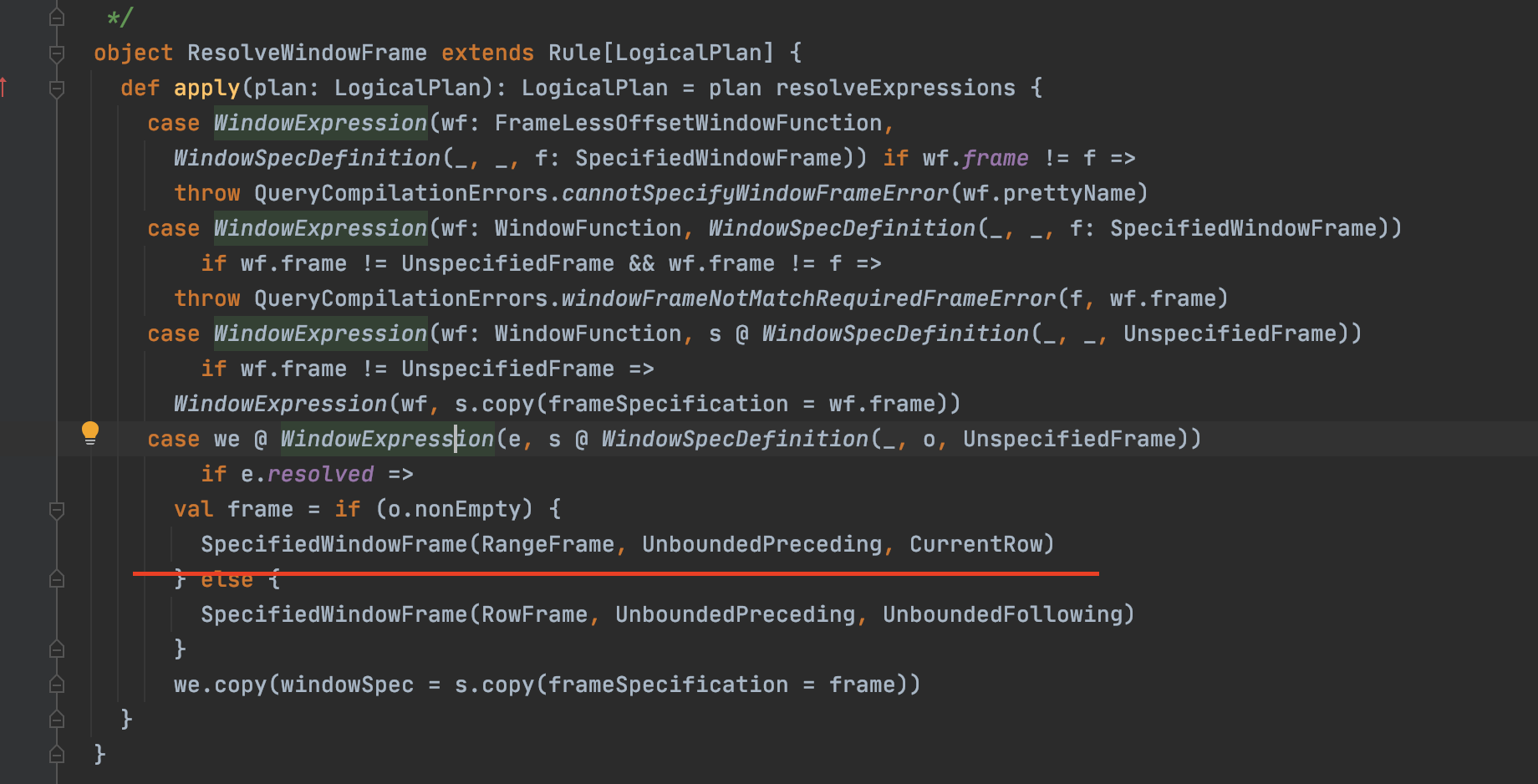
case we @ WindowExpression(e, s @ WindowSpecDefinition(_, o,
UnspecifiedFrame))
if e.resolved =>
- val frame = if (o.nonEmpty) {
+ val frame = if (e.isInstanceOf[RankLike]) {
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow)
Review comment:
> what happens if order spec is present? do we force to use row frame?
In PostgresSQL, for all AggregationWindowFunction, it has a default frame,
but user can write all kind of frame and finally it just use default frame. So
in current PR, We can replace user-defined frame to default frame in
`ResolveWindowFrame`, how about current change.
##########
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##########
@@ -3162,6 +3162,9 @@ class Analyzer(override val catalogManager:
CatalogManager)
case WindowExpression(wf: FrameLessOffsetWindowFunction,
WindowSpecDefinition(_, _, f: SpecifiedWindowFrame)) if wf.frame != f
=>
throw
QueryCompilationErrors.cannotSpecifyWindowFrameError(wf.prettyName)
+ case WindowExpression(wf: AggregateWindowFunction, s:
WindowSpecDefinition)
+ if wf.frame != UnspecifiedFrame =>
+ WindowExpression(wf, s.copy(frameSpecification = wf.frame))
Review comment:
> It seems duplicate with
>
>
https://github.com/apache/spark/blob/a5af58bde544985d152bd974aa18cf0bdbfad2d5/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala#L3171
Yea, but logically they are not same.
This behavior should be earlier before throw exception.
##########
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##########
@@ -3170,7 +3170,9 @@ class Analyzer(override val catalogManager:
CatalogManager)
WindowExpression(wf, s.copy(frameSpecification = wf.frame))
case we @ WindowExpression(e, s @ WindowSpecDefinition(_, o,
UnspecifiedFrame))
if e.resolved =>
- val frame = if (o.nonEmpty) {
+ val frame = if (e.isInstanceOf[RankLike]) {
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow)
Review comment:
Hive 2.3.7 don't allow to specify frame.
##########
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##########
@@ -3162,6 +3162,9 @@ class Analyzer(override val catalogManager:
CatalogManager)
case WindowExpression(wf: FrameLessOffsetWindowFunction,
WindowSpecDefinition(_, _, f: SpecifiedWindowFrame)) if wf.frame != f
=>
throw
QueryCompilationErrors.cannotSpecifyWindowFrameError(wf.prettyName)
+ case WindowExpression(wf: AggregateWindowFunction, s:
WindowSpecDefinition)
+ if wf.frame != UnspecifiedFrame =>
+ WindowExpression(wf, s.copy(frameSpecification = wf.frame))
Review comment:
> This block is to use the default frame regardless of the specified
frame ?
Yea..PG do like this ==
##########
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##########
@@ -3170,7 +3170,9 @@ class Analyzer(override val catalogManager:
CatalogManager)
WindowExpression(wf, s.copy(frameSpecification = wf.frame))
case we @ WindowExpression(e, s @ WindowSpecDefinition(_, o,
UnspecifiedFrame))
if e.resolved =>
- val frame = if (o.nonEmpty) {
+ val frame = if (e.isInstanceOf[RankLike]) {
+ SpecifiedWindowFrame(RowFrame, UnboundedPreceding, CurrentRow)
Review comment:
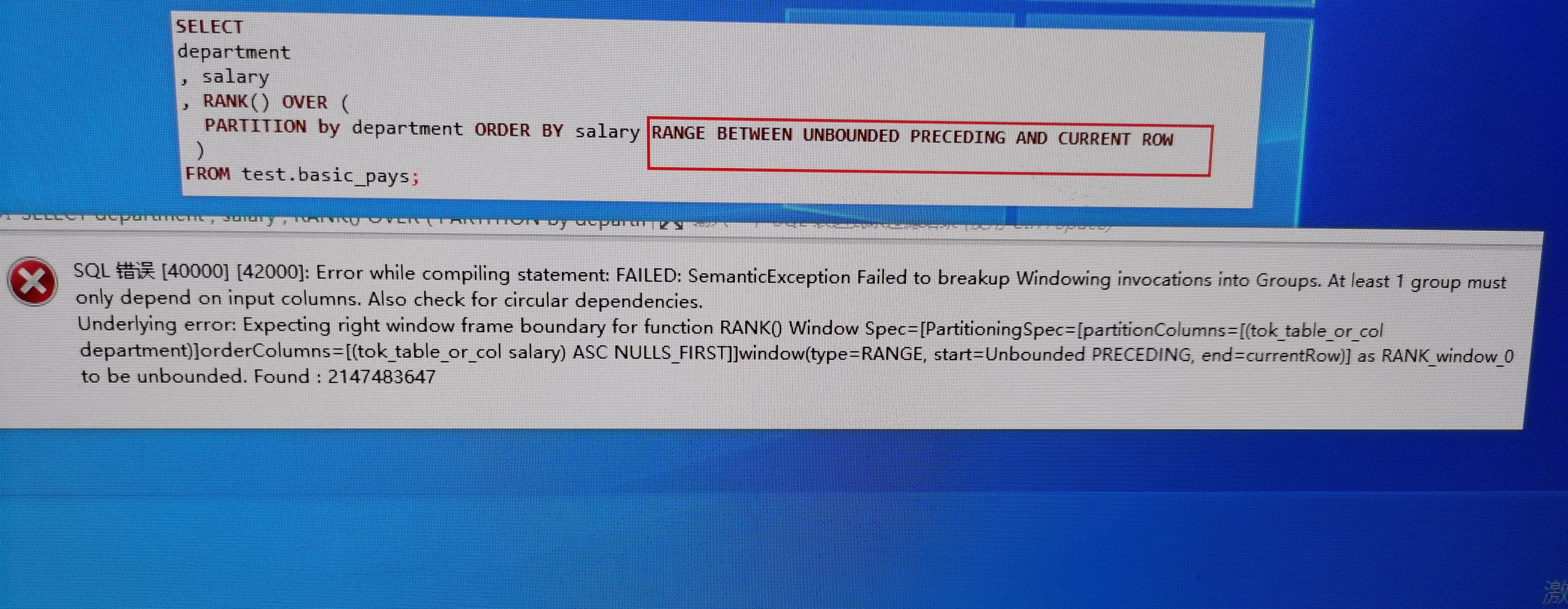
Hive 2.3.7 don't allow to specify frame.

But this two sql can run:
```
SELECT department, salary, RANK() OVER (
PARTITION by department ORDER BY salary ROWS BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING
)
FROM basic_pays;
SELECT department, salary, RANK() OVER (
PARTITION by department ORDER BY salary RANGE BETWEEN UNBOUNDED PRECEDING
AND UNBOUNDED FOLLOWING
)
FROM basic_pays;
```
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}