137alpha commented on pull request #32813: URL: https://github.com/apache/spark/pull/32813#issuecomment-857175746
@asolimando @srowen Here's a simple example that illustrates this. 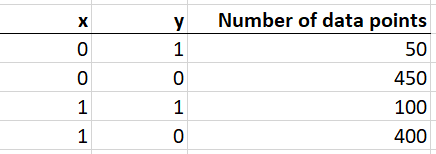 A decision tree which exactly fits this data is: * If x < 0.5, predict probability 0.1 (predict class 0) * If x >= 0.5, predict probability 0.2 (predict class 0) The pruning algorithm as currently implemented would prune this to: * Predict probability 0.15 (predict class 0) Whilst the class predictions are unchanged, the trees are not functionality identical. the first one exactly identifies the conditional relationship in the data. The pruned tree is totally useless for understanding the conditional probability relationship that exists. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: [email protected] --------------------------------------------------------------------- To unsubscribe, e-mail: [email protected] For additional commands, e-mail: [email protected]
{kind=link}