Github user yucai commented on the issue:
https://github.com/apache/spark/pull/22197
@dongjoon-hyun In the **schema matched case** as you listed, it is expected
behavior in current master.
```
spark.sparkContext.hadoopConfiguration.setInt("parquet.block.size", 8 *
1024 * 1024)
spark.range(1, 40 * 1024 * 1024, 1,
1).sortWithinPartitions("id").write.mode("overwrite").parquet("/tmp/t")
sql("CREATE TABLE t (id LONG) USING parquet LOCATION '/tmp/t'")
// master and 2.3 have different plan for top limit (see below), that's why
28.4 MB are read in master
sql("select * from t where id < 100L").show()
```
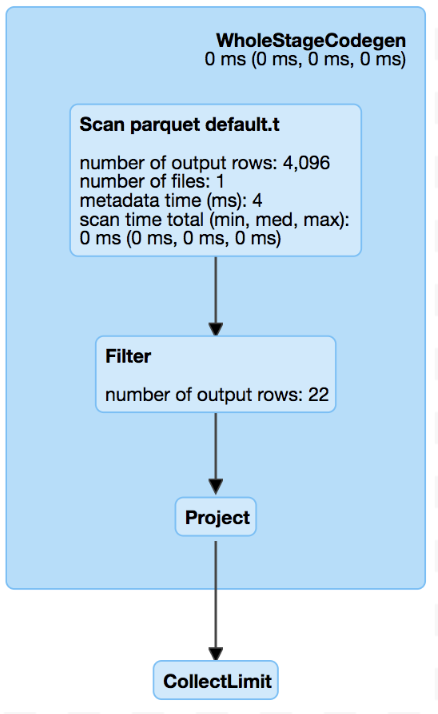
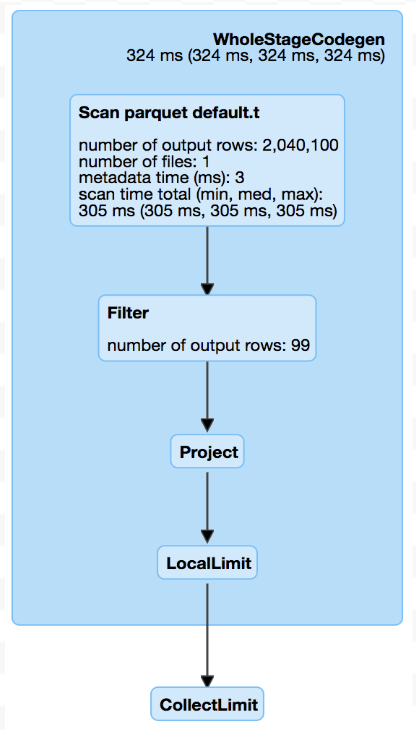
This difference is probably introduced by #21573, @cloud-fan, current
master read more data than 2.3 for top limit like in
https://github.com/apache/spark/pull/22197#issuecomment-416085556 , is it a
regression or not?
Master:
2.3 branch:
---
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}
{kind=link}