Github user cloud-fan commented on the issue:
https://github.com/apache/spark/pull/22112
Sorry to be late, as this bug is really hard to reproduce. We need fetch
failure to happen after an indeterminate map stage, we also need a large
cluster, so that a fetch failure doesn't lose all the executors and retry the
entire job.
I created 2 test cases to verify the fix: one is having fetch failure
happen in the result stage, so with this fix the job should fail. one is having
fetch failure happen in a map stage, so this fix can properly retry the stages
and get the correct result.
The tests are run in Databricks cloud with a 20-nodes Spark cluster. The
following is the result for the master branch without this PR:


In the tests, we first do a shuffle to produce unordered data, then do a
repartition to trigger the bug, finally collect the result and distinct it to
see if it's corrected, or call `RDD#distinct` to add another shuffle.
The result for the master branch with this PR:
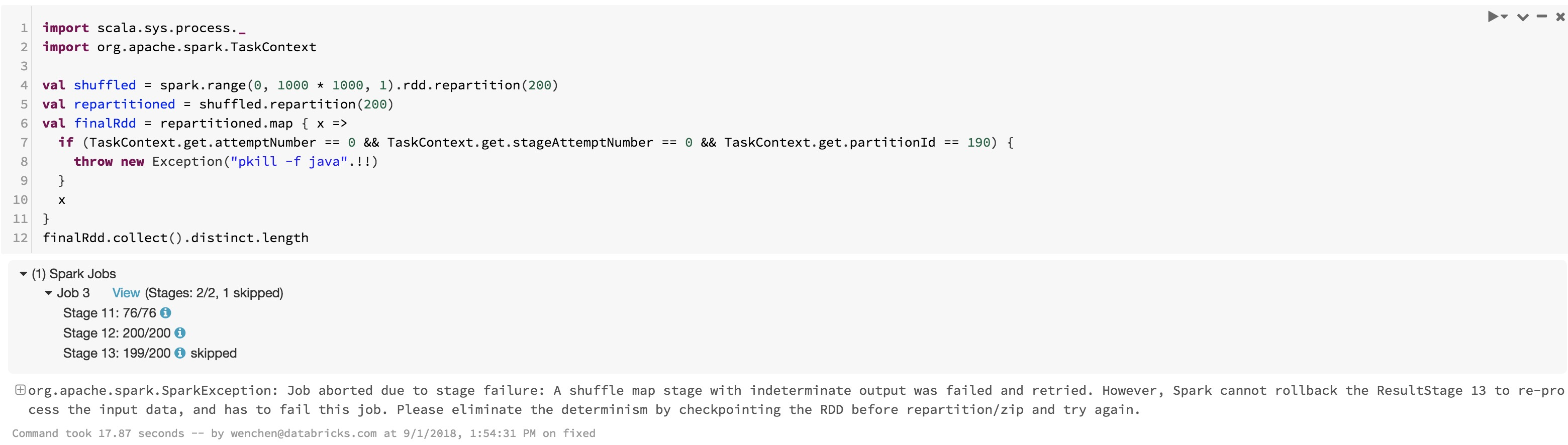

The first job fails, because we detect this bug but are not able to
rollback the result stage currently. The second job finishes with corrected
result.
If you look into the number of tasks of the stages, you can see that with
this fix, the stage hitting fetch failure is entirely retried(200 tasks), while
without this fix, only the failed tasks are retried and produce wrong answer.
The last thing: I have to revert https://github.com/apache/spark/pull/20422
to make this fix work. It seems like a dangerous optimization to me: we skip
the shuffle writing if the size of the existing shuffle file is same with the
size of data we are writing. Same size doesn't mean same data, and my tests
exposed it.
---
---------------------------------------------------------------------
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
{kind=link}
{kind=link}
{kind=link}
{kind=link}