sandeep-katta commented on a change in pull request #25977:
[SPARK-29268][SQL]isolationOn value is wrong in case of
spark.sql.hive.metastore.jars != builtin
URL: https://github.com/apache/spark/pull/25977#discussion_r331858678
##########
File path: sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveUtils.scala
##########
@@ -414,7 +415,7 @@ private[spark] object HiveUtils extends Logging {
hadoopConf = hadoopConf,
execJars = jars.toSeq,
config = configurations,
- isolationOn = true,
+ isolationOn = !isCliSessionState(),
Review comment:
@wangyum if user is using !built-in hive then isolation should not be
turned off, so this issue has to solved in different ways .
1. Use in memory derby database. Configure hive-site.xml as below
```
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:memory:/opt/BigdataTools/spark-2.4.4-bin-hadoop2.7/metastore_db;create=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
```
2. Stop the derby instance started by
[SparkSQLCLIDriver](https://github.com/apache/spark/blob/master/sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLCLIDriver.scala#L136)
Something like below
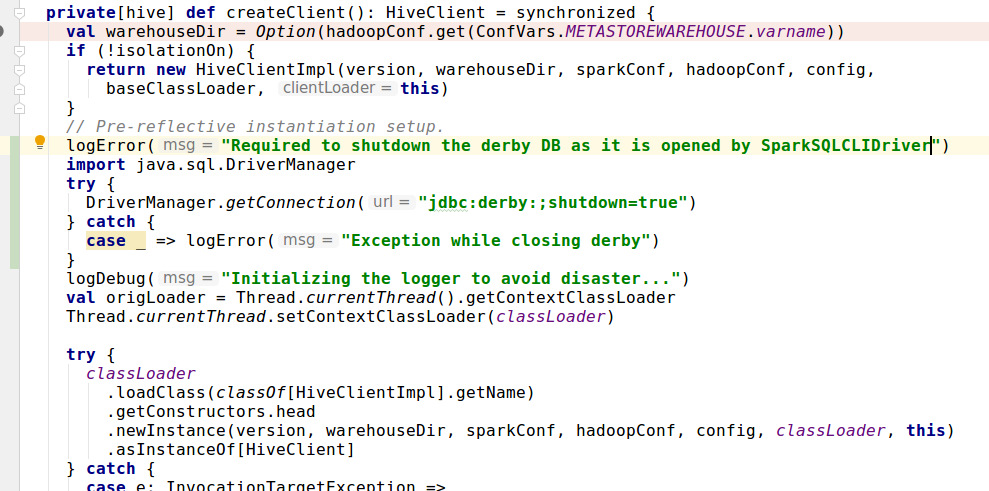
@yaooqinn what's your suggesstion
----------------------------------------------------------------
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
[email protected]
With regards,
Apache Git Services
---------------------------------------------------------------------
To unsubscribe, e-mail: [email protected]
For additional commands, e-mail: [email protected]
{kind=link}