[GitHub] gaodayue opened a new pull request #6242: fix incorrect check of maxSemiJoinRowsInMemory
gaodayue opened a new pull request #6242: fix incorrect check of maxSemiJoinRowsInMemory URL: https://github.com/apache/incubator-druid/pull/6242 We should check maxSemiJoinRowsInMemory on right table's output rows count instead of number of values inside one row. Added a test case for that. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gaodayue opened a new issue #6243: semi join query throws AssertionError
gaodayue opened a new issue #6243: semi join query throws AssertionError URL: https://github.com/apache/incubator-druid/issues/6243 Example query: ```sql SELECT COUNT(*) FROM ( SELECT DISTINCT dim2 FROM druid.foo WHERE SUBSTRING(dim2, 1, 1) IN ( SELECT SUBSTRING(dim1, 1, 1) FROM druid.foo WHERE dim1 <> '' ) AND __time >= '2000-01-01' AND __time < '2002-01-01' ) ``` When outer query contains AND filters like above, druid throws AssertionError when constructing Filter. ``` java.lang.AssertionError: AND(AND(>=($0, 2000-01-01 00:00:00), <($0, 2002-01-01 00:00:00)), OR(=(SUBSTRING($3, 1, 1), '1'), =(SUBSTRING($3, 1, 1), '2'), =(SUBSTRING($3, 1, 1), 'a'), =(SUBSTRING($3, 1, 1), 'd'))) at org.apache.calcite.rel.core.Filter.(Filter.java:74) at org.apache.calcite.rel.logical.LogicalFilter.(LogicalFilter.java:71) at org.apache.calcite.rel.logical.LogicalFilter.copy(LogicalFilter.java:136) at org.apache.calcite.rel.logical.LogicalFilter.copy(LogicalFilter.java:48) at io.druid.sql.calcite.rel.DruidSemiJoin.getLeftRelWithFilter(DruidSemiJoin.java:345) ``` The reason is calcite requires filter condition to be flattened, while DruidSemiJoin#getLeftRelWithFilter may construct unflatten filter. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gaodayue opened a new pull request #6244: fix AssertionError of semi join query
gaodayue opened a new pull request #6244: fix AssertionError of semi join query URL: https://github.com/apache/incubator-druid/pull/6244 Fixed #6243 This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] fjy closed pull request #6191: SQL: Support more result formats, add columns header.
fjy closed pull request #6191: SQL: Support more result formats, add columns
header.
URL: https://github.com/apache/incubator-druid/pull/6191
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/docs/content/ingestion/index.md b/docs/content/ingestion/index.md
index 02fa1cc548e..378b308d9e9 100644
--- a/docs/content/ingestion/index.md
+++ b/docs/content/ingestion/index.md
@@ -147,7 +147,7 @@ This is a special variation of the JSON ParseSpec that
lower cases all the colum
CSV ParseSpec
-Use this with the String Parser to load CSV. Strings are parsed using the
net.sf.opencsv library.
+Use this with the String Parser to load CSV. Strings are parsed using the
com.opencsv library.
| Field | Type | Description | Required |
|---|--|-|--|
diff --git a/docs/content/querying/sql.md b/docs/content/querying/sql.md
index ffd655a76f6..0f15b936129 100644
--- a/docs/content/querying/sql.md
+++ b/docs/content/querying/sql.md
@@ -339,10 +339,6 @@ of configuration.
You can make Druid SQL queries using JSON over HTTP by posting to the endpoint
`/druid/v2/sql/`. The request should
be a JSON object with a "query" field, like `{"query" : "SELECT COUNT(*) FROM
data_source WHERE foo = 'bar'"}`.
-Results are available in two formats: "object" (the default; a JSON array of
JSON objects), and "array" (a JSON array
-of JSON arrays). In "object" form, each row's field names will match the
column names from your SQL query. In "array"
-form, each row's values are returned in the order specified in your SQL query.
-
You can use _curl_ to send SQL queries from the command-line:
```bash
@@ -353,9 +349,8 @@ $ curl -XPOST -H'Content-Type: application/json'
http://BROKER:8082/druid/v2/sql
[{"TheCount":24433}]
```
-Metadata is available over the HTTP API by querying the ["INFORMATION_SCHEMA"
tables](#retrieving-metadata).
-
-Finally, you can also provide [connection context
parameters](#connection-context) by adding a "context" map, like:
+There are a variety of [connection context parameters](#connection-context)
you can provide by adding a "context" map,
+like:
```json
{
@@ -366,6 +361,45 @@ Finally, you can also provide [connection context
parameters](#connection-contex
}
```
+Metadata is available over the HTTP API by querying [system
tables](#retrieving-metadata).
+
+ Responses
+
+All Druid SQL HTTP responses include a "X-Druid-Column-Names" header with a
JSON-encoded array of columns that
+will appear in the result rows and an "X-Druid-Column-Types" header with a
JSON-encoded array of
+[types](#data-types-and-casts).
+
+For the result rows themselves, Druid SQL supports a variety of result
formats. You can
+specify these by adding a "resultFormat" parameter, like:
+
+```json
+{
+ "query" : "SELECT COUNT(*) FROM data_source WHERE foo = 'bar' AND __time >
TIMESTAMP '2000-01-01 00:00:00'",
+ "resultFormat" : "object"
+}
+```
+
+The supported result formats are:
+
+|Format|Description|Content-Type|
+|--|---||
+|`object`|The default, a JSON array of JSON objects. Each object's field names
match the columns returned by the SQL query, and are provided in the same order
as the SQL query.|application/json|
+|`array`|JSON array of JSON arrays. Each inner array has elements matching the
columns returned by the SQL query, in order.|application/json|
+|`objectLines`|Like "object", but the JSON objects are separated by newlines
instead of being wrapped in a JSON array. This can make it easier to parse the
entire response set as a stream, if you do not have ready access to a streaming
JSON parser. To make it possible to detect a truncated response, this format
includes a trailer of one blank line.|text/plain|
+|`arrayLines`|Like "array", but the JSON arrays are separated by newlines
instead of being wrapped in a JSON array. This can make it easier to parse the
entire response set as a stream, if you do not have ready access to a streaming
JSON parser. To make it possible to detect a truncated response, this format
includes a trailer of one blank line.|text/plain|
+|`csv`|Comma-separated values, with one row per line. Individual field values
may be escaped by being surrounded in double quotes. If double quotes appear in
a field value, they will be escaped by replacing them with double-double-quotes
like `""this""`. To make it possible to detect a truncated response, this
format includes a trailer of one blank line.|text/csv|
+
+Errors that occur before the response body is sent will be reported in JSON,
with an HTTP 500 status code, in the
+same format as [native Druid query errors](../querying#query-errors). If an
error occurs while the response body is
+being sent, at that point it is too late
[GitHub] fjy closed pull request #6240: [Backport] SQL: Fix precision of TIMESTAMP types.
fjy closed pull request #6240: [Backport] SQL: Fix precision of TIMESTAMP types.
URL: https://github.com/apache/incubator-druid/pull/6240
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git
a/sql/src/main/java/io/druid/sql/calcite/expression/OperatorConversions.java
b/sql/src/main/java/io/druid/sql/calcite/expression/OperatorConversions.java
index c129388d2a8..f75186d4ab5 100644
--- a/sql/src/main/java/io/druid/sql/calcite/expression/OperatorConversions.java
+++ b/sql/src/main/java/io/druid/sql/calcite/expression/OperatorConversions.java
@@ -20,6 +20,7 @@
package io.druid.sql.calcite.expression;
import com.google.common.base.Preconditions;
+import io.druid.sql.calcite.planner.Calcites;
import io.druid.sql.calcite.planner.PlannerContext;
import io.druid.sql.calcite.table.RowSignature;
import org.apache.calcite.rex.RexCall;
@@ -131,18 +132,16 @@ public OperatorBuilder kind(final SqlKind kind)
public OperatorBuilder returnType(final SqlTypeName typeName)
{
- this.returnTypeInference = ReturnTypes.explicit(typeName);
+ this.returnTypeInference = ReturnTypes.explicit(
+ factory -> Calcites.createSqlType(factory, typeName)
+ );
return this;
}
public OperatorBuilder nullableReturnType(final SqlTypeName typeName)
{
this.returnTypeInference = ReturnTypes.explicit(
- factory ->
- factory.createTypeWithNullability(
- factory.createSqlType(typeName),
- true
- )
+ factory -> Calcites.createSqlTypeWithNullability(factory, typeName,
true)
);
return this;
}
diff --git a/sql/src/main/java/io/druid/sql/calcite/planner/Calcites.java
b/sql/src/main/java/io/druid/sql/calcite/planner/Calcites.java
index bf39def562b..dfcfad96868 100644
--- a/sql/src/main/java/io/druid/sql/calcite/planner/Calcites.java
+++ b/sql/src/main/java/io/druid/sql/calcite/planner/Calcites.java
@@ -32,10 +32,13 @@
import io.druid.sql.calcite.schema.DruidSchema;
import io.druid.sql.calcite.schema.InformationSchema;
import org.apache.calcite.jdbc.CalciteSchema;
+import org.apache.calcite.rel.type.RelDataType;
+import org.apache.calcite.rel.type.RelDataTypeFactory;
import org.apache.calcite.rex.RexLiteral;
import org.apache.calcite.rex.RexNode;
import org.apache.calcite.schema.Schema;
import org.apache.calcite.schema.SchemaPlus;
+import org.apache.calcite.sql.SqlCollation;
import org.apache.calcite.sql.SqlKind;
import org.apache.calcite.sql.type.SqlTypeName;
import org.apache.calcite.util.ConversionUtil;
@@ -163,6 +166,46 @@ public static StringComparator
getStringComparatorForValueType(ValueType valueTy
}
}
+ /**
+ * Like RelDataTypeFactory.createSqlType, but creates types that align best
with how Druid represents them.
+ */
+ public static RelDataType createSqlType(final RelDataTypeFactory
typeFactory, final SqlTypeName typeName)
+ {
+return createSqlTypeWithNullability(typeFactory, typeName, false);
+ }
+
+ /**
+ * Like RelDataTypeFactory.createSqlTypeWithNullability, but creates types
that align best with how Druid
+ * represents them.
+ */
+ public static RelDataType createSqlTypeWithNullability(
+ final RelDataTypeFactory typeFactory,
+ final SqlTypeName typeName,
+ final boolean nullable
+ )
+ {
+final RelDataType dataType;
+
+switch (typeName) {
+ case TIMESTAMP:
+// Our timestamps are down to the millisecond (precision = 3).
+dataType = typeFactory.createSqlType(typeName, 3);
+break;
+ case CHAR:
+ case VARCHAR:
+dataType = typeFactory.createTypeWithCharsetAndCollation(
+typeFactory.createSqlType(typeName),
+Calcites.defaultCharset(),
+SqlCollation.IMPLICIT
+);
+break;
+ default:
+dataType = typeFactory.createSqlType(typeName);
+}
+
+return typeFactory.createTypeWithNullability(dataType, nullable);
+ }
+
/**
* Calcite expects "TIMESTAMP" types to be an instant that has the expected
local time fields if printed as UTC.
*
diff --git a/sql/src/main/java/io/druid/sql/calcite/planner/DruidPlanner.java
b/sql/src/main/java/io/druid/sql/calcite/planner/DruidPlanner.java
index 8779d793e06..4a9feae0cd2 100644
--- a/sql/src/main/java/io/druid/sql/calcite/planner/DruidPlanner.java
+++ b/sql/src/main/java/io/druid/sql/calcite/planner/DruidPlanner.java
@@ -321,7 +321,7 @@ private PlannerResult planExplanation(
return new PlannerResult(
resultsSupplier,
typeFactory.createStructType(
-ImmutableList.of(typeFactory.createSqlType(SqlTypeName.VARCHAR)),
+ImmutableList.of(Calcites.createSqlType(typeFactory,
[GitHub] gianm commented on issue #6206: Fix NPE in KafkaSupervisor.checkpointTaskGroup
gianm commented on issue #6206: Fix NPE in KafkaSupervisor.checkpointTaskGroup URL: https://github.com/apache/incubator-druid/pull/6206#issuecomment-416115263 @jihoonson Got it, could you please merge master into this branch in order to get that? This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gianm closed issue #6021: NPE in KafkaSupervisor.checkpointTaskGroup
gianm closed issue #6021: NPE in KafkaSupervisor.checkpointTaskGroup URL: https://github.com/apache/incubator-druid/issues/6021 This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gianm closed pull request #6206: Fix NPE in KafkaSupervisor.checkpointTaskGroup
gianm closed pull request #6206: Fix NPE in KafkaSupervisor.checkpointTaskGroup
URL: https://github.com/apache/incubator-druid/pull/6206
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git
a/extensions-core/kafka-indexing-service/src/main/java/io/druid/indexing/kafka/supervisor/KafkaSupervisor.java
b/extensions-core/kafka-indexing-service/src/main/java/io/druid/indexing/kafka/supervisor/KafkaSupervisor.java
index 8c9bb599ada..8e12f591461 100644
---
a/extensions-core/kafka-indexing-service/src/main/java/io/druid/indexing/kafka/supervisor/KafkaSupervisor.java
+++
b/extensions-core/kafka-indexing-service/src/main/java/io/druid/indexing/kafka/supervisor/KafkaSupervisor.java
@@ -146,6 +146,8 @@
*/
private class TaskGroup
{
+final int groupId;
+
// This specifies the partitions and starting offsets for this task group.
It is set on group creation from the data
// in [partitionGroups] and never changes during the lifetime of this task
group, which will live until a task in
// this task group has completed successfully, at which point this will be
destroyed and a new task group will be
@@ -161,11 +163,13 @@
final String baseSequenceName;
TaskGroup(
+int groupId,
ImmutableMap partitionOffsets,
Optional minimumMessageTime,
Optional maximumMessageTime
)
{
+ this.groupId = groupId;
this.partitionOffsets = partitionOffsets;
this.minimumMessageTime = minimumMessageTime;
this.maximumMessageTime = maximumMessageTime;
@@ -187,9 +191,21 @@ int addNewCheckpoint(Map checkpoint)
private static class TaskData
{
+@Nullable
volatile TaskStatus status;
+@Nullable
volatile DateTime startTime;
volatile Map currentOffsets = new HashMap<>();
+
+@Override
+public String toString()
+{
+ return "TaskData{" +
+ "status=" + status +
+ ", startTime=" + startTime +
+ ", currentOffsets=" + currentOffsets +
+ '}';
+}
}
// Map<{group ID}, {actively reading task group}>; see documentation for
TaskGroup class
@@ -718,8 +734,8 @@ public void handle() throws ExecutionException,
InterruptedException
log.info("Already checkpointed with offsets [%s]",
checkpoints.lastEntry().getValue());
return;
}
-final Map newCheckpoint =
checkpointTaskGroup(taskGroupId, false).get();
-taskGroups.get(taskGroupId).addNewCheckpoint(newCheckpoint);
+final Map newCheckpoint =
checkpointTaskGroup(taskGroup, false).get();
+taskGroup.addNewCheckpoint(newCheckpoint);
log.info("Handled checkpoint notice, new checkpoint is [%s] for
taskGroup [%s]", newCheckpoint, taskGroupId);
}
}
@@ -785,10 +801,13 @@ void resetInternal(DataSourceMetadata dataSourceMetadata)
:
currentMetadata.getKafkaPartitions()
.getPartitionOffsetMap()
.get(resetPartitionOffset.getKey());
- final TaskGroup partitionTaskGroup =
taskGroups.get(getTaskGroupIdForPartition(resetPartitionOffset.getKey()));
- if (partitionOffsetInMetadataStore != null ||
- (partitionTaskGroup != null &&
partitionTaskGroup.partitionOffsets.get(resetPartitionOffset.getKey())
-
.equals(resetPartitionOffset.getValue( {
+ final TaskGroup partitionTaskGroup = taskGroups.get(
+ getTaskGroupIdForPartition(resetPartitionOffset.getKey())
+ );
+ final boolean isSameOffset = partitionTaskGroup != null
+ &&
partitionTaskGroup.partitionOffsets.get(resetPartitionOffset.getKey())
+
.equals(resetPartitionOffset.getValue());
+ if (partitionOffsetInMetadataStore != null || isSameOffset) {
doReset = true;
break;
}
@@ -1012,7 +1031,7 @@ private void discoverTasks() throws ExecutionException,
InterruptedException, Ti
List futureTaskIds = Lists.newArrayList();
List> futures = Lists.newArrayList();
List tasks = taskStorage.getActiveTasks();
-final Set taskGroupsToVerify = new HashSet<>();
+final Map taskGroupsToVerify = new HashMap<>();
for (Task task : tasks) {
if (!(task instanceof KafkaIndexTask) ||
!dataSource.equals(task.getDataSource())) {
@@ -1119,6 +1138,7 @@ public Boolean apply(KafkaIndexTask.Status status)
k -> {
[GitHub] gianm opened a new pull request #6245: [Backport] Fix NPE in KafkaSupervisor.checkpointTaskGroup
gianm opened a new pull request #6245: [Backport] Fix NPE in KafkaSupervisor.checkpointTaskGroup URL: https://github.com/apache/incubator-druid/pull/6245 Backport of #6206 to 0.12.3. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] fjy closed pull request #6229: [Backport] SQL: Finalize aggregations for inner queries when necessary.
fjy closed pull request #6229: [Backport] SQL: Finalize aggregations for inner
queries when necessary.
URL: https://github.com/apache/incubator-druid/pull/6229
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git
a/extensions-core/histogram/src/main/java/io/druid/query/aggregation/histogram/sql/QuantileSqlAggregator.java
b/extensions-core/histogram/src/main/java/io/druid/query/aggregation/histogram/sql/QuantileSqlAggregator.java
index b9c8d3d3d46..28c0d65b10d 100644
---
a/extensions-core/histogram/src/main/java/io/druid/query/aggregation/histogram/sql/QuantileSqlAggregator.java
+++
b/extensions-core/histogram/src/main/java/io/druid/query/aggregation/histogram/sql/QuantileSqlAggregator.java
@@ -48,6 +48,7 @@
import org.apache.calcite.sql.type.SqlTypeFamily;
import org.apache.calcite.sql.type.SqlTypeName;
+import javax.annotation.Nullable;
import java.util.ArrayList;
import java.util.List;
@@ -62,6 +63,7 @@ public SqlAggFunction calciteFunction()
return FUNCTION_INSTANCE;
}
+ @Nullable
@Override
public Aggregation toDruidAggregation(
final PlannerContext plannerContext,
@@ -70,7 +72,8 @@ public Aggregation toDruidAggregation(
final String name,
final AggregateCall aggregateCall,
final Project project,
- final List existingAggregations
+ final List existingAggregations,
+ final boolean finalizeAggregations
)
{
final DruidExpression input = Expressions.toDruidExpression(
diff --git
a/sql/src/main/java/io/druid/sql/calcite/aggregation/DimensionExpression.java
b/sql/src/main/java/io/druid/sql/calcite/aggregation/DimensionExpression.java
index d5da02d37b7..abc697c59e7 100644
---
a/sql/src/main/java/io/druid/sql/calcite/aggregation/DimensionExpression.java
+++
b/sql/src/main/java/io/druid/sql/calcite/aggregation/DimensionExpression.java
@@ -20,13 +20,13 @@
package io.druid.sql.calcite.aggregation;
import com.google.common.collect.ImmutableList;
-import io.druid.java.util.common.StringUtils;
import io.druid.math.expr.ExprMacroTable;
import io.druid.query.dimension.DefaultDimensionSpec;
import io.druid.query.dimension.DimensionSpec;
import io.druid.segment.VirtualColumn;
import io.druid.segment.column.ValueType;
import io.druid.sql.calcite.expression.DruidExpression;
+import io.druid.sql.calcite.planner.Calcites;
import javax.annotation.Nullable;
import java.util.List;
@@ -85,7 +85,7 @@ public DimensionSpec toDimensionSpec()
@Nullable
public String getVirtualColumnName()
{
-return expression.isSimpleExtraction() ? null : StringUtils.format("%s:v",
outputName);
+return expression.isSimpleExtraction() ? null :
Calcites.makePrefixedName(outputName, "v");
}
@Override
diff --git
a/sql/src/main/java/io/druid/sql/calcite/aggregation/SqlAggregator.java
b/sql/src/main/java/io/druid/sql/calcite/aggregation/SqlAggregator.java
index e6983ffb87a..dcf2c4e8d20 100644
--- a/sql/src/main/java/io/druid/sql/calcite/aggregation/SqlAggregator.java
+++ b/sql/src/main/java/io/druid/sql/calcite/aggregation/SqlAggregator.java
@@ -53,6 +53,9 @@
* @param project project that should be applied before
aggregation; may be null
* @param existingAggregations existing aggregations for this query; useful
for re-using aggregations. May be safely
* ignored if you do not want to re-use existing
aggregations.
+ * @param finalizeAggregations true if this query should include explicit
finalization for all of its
+ * aggregators, where required. This is set for
subqueries where Druid's native query
+ * layer does not do this automatically.
*
* @return aggregation, or null if the call cannot be translated
*/
@@ -64,6 +67,7 @@ Aggregation toDruidAggregation(
String name,
AggregateCall aggregateCall,
Project project,
- List existingAggregations
+ List existingAggregations,
+ boolean finalizeAggregations
);
}
diff --git
a/sql/src/main/java/io/druid/sql/calcite/aggregation/builtin/ApproxCountDistinctSqlAggregator.java
b/sql/src/main/java/io/druid/sql/calcite/aggregation/builtin/ApproxCountDistinctSqlAggregator.java
index 161c3ef9c31..0abdb8a7206 100644
---
a/sql/src/main/java/io/druid/sql/calcite/aggregation/builtin/ApproxCountDistinctSqlAggregator.java
+++
b/sql/src/main/java/io/druid/sql/calcite/aggregation/builtin/ApproxCountDistinctSqlAggregator.java
@@ -22,9 +22,9 @@
import com.google.common.collect.ImmutableList;
import com.google.common.collect.Iterables;
import io.druid.java.util.common.ISE;
-import io.druid.java.util.common.StringUtils;
import io.druid.query.aggregation.AggregatorFactory;
import
[GitHub] fjy closed pull request #6236: Fix all inspection errors currently reported.
fjy closed pull request #6236: Fix all inspection errors currently reported.
URL: https://github.com/apache/incubator-druid/pull/6236
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/api/src/test/java/io/druid/timeline/DataSegmentTest.java
b/api/src/test/java/io/druid/timeline/DataSegmentTest.java
index fc5bd282d8e..43b95598c25 100644
--- a/api/src/test/java/io/druid/timeline/DataSegmentTest.java
+++ b/api/src/test/java/io/druid/timeline/DataSegmentTest.java
@@ -23,7 +23,6 @@
import com.fasterxml.jackson.databind.ObjectMapper;
import com.google.common.collect.ImmutableList;
import com.google.common.collect.ImmutableMap;
-import com.google.common.collect.Lists;
import com.google.common.collect.RangeSet;
import com.google.common.collect.Sets;
import io.druid.TestObjectMapper;
@@ -40,6 +39,7 @@
import org.junit.Before;
import org.junit.Test;
+import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
@@ -238,7 +238,7 @@ public void testBucketMonthComparator()
makeDataSegment("test2", "2011-02-02/2011-02-03", "a"),
};
-List shuffled = Lists.newArrayList(sortedOrder);
+List shuffled = new ArrayList<>(Arrays.asList(sortedOrder));
Collections.shuffle(shuffled);
Set theSet =
Sets.newTreeSet(DataSegment.bucketMonthComparator());
diff --git
a/benchmarks/src/main/java/io/druid/benchmark/query/timecompare/TimeCompareBenchmark.java
b/benchmarks/src/main/java/io/druid/benchmark/query/timecompare/TimeCompareBenchmark.java
index 97522d5d921..ccf8e3f6fc0 100644
---
a/benchmarks/src/main/java/io/druid/benchmark/query/timecompare/TimeCompareBenchmark.java
+++
b/benchmarks/src/main/java/io/druid/benchmark/query/timecompare/TimeCompareBenchmark.java
@@ -22,7 +22,6 @@
import com.fasterxml.jackson.databind.InjectableValues;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.google.common.collect.Lists;
-import com.google.common.collect.Maps;
import com.google.common.io.Files;
import io.druid.benchmark.datagen.BenchmarkDataGenerator;
import io.druid.benchmark.datagen.BenchmarkSchemaInfo;
@@ -96,6 +95,7 @@
import java.io.IOException;
import java.util.ArrayList;
import java.util.Collections;
+import java.util.HashMap;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
@@ -117,7 +117,7 @@
@Param({"100"})
private int threshold;
- protected static final Map scriptDoubleSum =
Maps.newHashMap();
+ protected static final Map scriptDoubleSum = new HashMap<>();
static {
scriptDoubleSum.put("fnAggregate", "function aggregate(current, a) {
return current + a }");
scriptDoubleSum.put("fnReset", "function reset() { return 0 }");
@@ -427,10 +427,7 @@ private IncrementalIndex makeIncIndex()
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public void queryMultiQueryableIndexTopN(Blackhole blackhole)
{
-Sequence> queryResult = topNRunner.run(
-QueryPlus.wrap(topNQuery),
-Maps.newHashMap()
-);
+Sequence> queryResult =
topNRunner.run(QueryPlus.wrap(topNQuery), new HashMap<>());
List> results = queryResult.toList();
for (Result result : results) {
@@ -446,7 +443,7 @@ public void queryMultiQueryableIndexTimeseries(Blackhole
blackhole)
{
Sequence> queryResult = timeseriesRunner.run(
QueryPlus.wrap(timeseriesQuery),
-Maps.newHashMap()
+new HashMap<>()
);
List> results = queryResult.toList();
diff --git
a/indexing-service/src/main/java/io/druid/indexing/common/task/batch/parallel/ParallelIndexSupervisorTask.java
b/indexing-service/src/main/java/io/druid/indexing/common/task/batch/parallel/ParallelIndexSupervisorTask.java
index 438e0f1d81f..b0e0ed24714 100644
---
a/indexing-service/src/main/java/io/druid/indexing/common/task/batch/parallel/ParallelIndexSupervisorTask.java
+++
b/indexing-service/src/main/java/io/druid/indexing/common/task/batch/parallel/ParallelIndexSupervisorTask.java
@@ -268,7 +268,7 @@ private TaskStatus runParallel(TaskToolbox toolbox) throws
Exception
return TaskStatus.fromCode(getId(), runner.run());
}
- private TaskStatus runSequential(TaskToolbox toolbox) throws Exception
+ private TaskStatus runSequential(TaskToolbox toolbox)
{
return new IndexTask(
getId(),
diff --git
a/indexing-service/src/test/java/io/druid/indexing/overlord/autoscaling/EC2AutoScalerTest.java
b/indexing-service/src/test/java/io/druid/indexing/overlord/autoscaling/EC2AutoScalerTest.java
index d34c9660632..68daf7f762b 100644
---
a/indexing-service/src/test/java/io/druid/indexing/overlord/autoscaling/EC2AutoScalerTest.java
+++
b/indexing-service/src/test/java/io/druid/indexing/overlord/autoscaling/EC2AutoScalerTest.java
@@
[GitHub] gianm commented on issue #6206: Fix NPE in KafkaSupervisor.checkpointTaskGroup
gianm commented on issue #6206: Fix NPE in KafkaSupervisor.checkpointTaskGroup URL: https://github.com/apache/incubator-druid/pull/6206#issuecomment-416085168 Merged master into this branch to get the fixes from #6236. Let's see how this goes. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] fjy closed pull request #6228: [Backport] Support projection after sorting in SQL
fjy closed pull request #6228: [Backport] Support projection after sorting in
SQL
URL: https://github.com/apache/incubator-druid/pull/6228
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git
a/sql/src/main/java/io/druid/sql/calcite/aggregation/Aggregation.java
b/sql/src/main/java/io/druid/sql/calcite/aggregation/Aggregation.java
index 2532c8d7f82..09436b96e9d 100644
--- a/sql/src/main/java/io/druid/sql/calcite/aggregation/Aggregation.java
+++ b/sql/src/main/java/io/druid/sql/calcite/aggregation/Aggregation.java
@@ -36,6 +36,7 @@
import io.druid.sql.calcite.table.RowSignature;
import javax.annotation.Nullable;
+import java.util.Collections;
import java.util.List;
import java.util.Objects;
import java.util.Set;
@@ -112,7 +113,7 @@ public static Aggregation create(final AggregatorFactory
aggregatorFactory)
public static Aggregation create(final PostAggregator postAggregator)
{
-return new Aggregation(ImmutableList.of(), ImmutableList.of(),
postAggregator);
+return new Aggregation(Collections.emptyList(), Collections.emptyList(),
postAggregator);
}
public static Aggregation create(
diff --git a/sql/src/main/java/io/druid/sql/calcite/rel/DruidQuery.java
b/sql/src/main/java/io/druid/sql/calcite/rel/DruidQuery.java
index bca4481992f..5503f50adf9 100644
--- a/sql/src/main/java/io/druid/sql/calcite/rel/DruidQuery.java
+++ b/sql/src/main/java/io/druid/sql/calcite/rel/DruidQuery.java
@@ -89,6 +89,7 @@
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
+import java.util.OptionalInt;
import java.util.TreeSet;
import java.util.stream.Collectors;
@@ -105,9 +106,11 @@
private final DimFilter filter;
private final SelectProjection selectProjection;
private final Grouping grouping;
+ private final SortProject sortProject;
+ private final DefaultLimitSpec limitSpec;
private final RowSignature outputRowSignature;
private final RelDataType outputRowType;
- private final DefaultLimitSpec limitSpec;
+
private final Query query;
public DruidQuery(
@@ -128,15 +131,22 @@ public DruidQuery(
this.selectProjection = computeSelectProjection(partialQuery,
plannerContext, sourceRowSignature);
this.grouping = computeGrouping(partialQuery, plannerContext,
sourceRowSignature, rexBuilder);
+final RowSignature sortingInputRowSignature;
+
if (this.selectProjection != null) {
- this.outputRowSignature = this.selectProjection.getOutputRowSignature();
+ sortingInputRowSignature = this.selectProjection.getOutputRowSignature();
} else if (this.grouping != null) {
- this.outputRowSignature = this.grouping.getOutputRowSignature();
+ sortingInputRowSignature = this.grouping.getOutputRowSignature();
} else {
- this.outputRowSignature = sourceRowSignature;
+ sortingInputRowSignature = sourceRowSignature;
}
-this.limitSpec = computeLimitSpec(partialQuery, this.outputRowSignature);
+this.sortProject = computeSortProject(partialQuery, plannerContext,
sortingInputRowSignature, grouping);
+
+// outputRowSignature is used only for scan and select query, and thus
sort and grouping must be null
+this.outputRowSignature = sortProject == null ? sortingInputRowSignature :
sortProject.getOutputRowSignature();
+
+this.limitSpec = computeLimitSpec(partialQuery, sortingInputRowSignature);
this.query = computeQuery();
}
@@ -235,7 +245,7 @@ private static Grouping computeGrouping(
)
{
final Aggregate aggregate = partialQuery.getAggregate();
-final Project postProject = partialQuery.getPostProject();
+final Project aggregateProject = partialQuery.getAggregateProject();
if (aggregate == null) {
return null;
@@ -265,49 +275,27 @@ private static Grouping computeGrouping(
plannerContext
);
-if (postProject == null) {
+if (aggregateProject == null) {
return Grouping.create(dimensions, aggregations, havingFilter,
aggregateRowSignature);
} else {
- final List rowOrder = new ArrayList<>();
-
- int outputNameCounter = 0;
- for (final RexNode postAggregatorRexNode : postProject.getChildExps()) {
-// Attempt to convert to PostAggregator.
-final DruidExpression postAggregatorExpression =
Expressions.toDruidExpression(
-plannerContext,
-aggregateRowSignature,
-postAggregatorRexNode
-);
-
-if (postAggregatorExpression == null) {
- throw new CannotBuildQueryException(postProject,
postAggregatorRexNode);
-}
-
-if (postAggregatorDirectColumnIsOk(aggregateRowSignature,
postAggregatorExpression, postAggregatorRexNode)) {
- // Direct column access, without any type cast as far as
[GitHub] fjy closed pull request #6230: [Backport] Fix four bugs with numeric dimension output types.
fjy closed pull request #6230: [Backport] Fix four bugs with numeric dimension
output types.
URL: https://github.com/apache/incubator-druid/pull/6230
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/processing/src/main/java/io/druid/query/groupby/GroupByQuery.java
b/processing/src/main/java/io/druid/query/groupby/GroupByQuery.java
index 1f9b45e62eb..7d3dbc0844b 100644
--- a/processing/src/main/java/io/druid/query/groupby/GroupByQuery.java
+++ b/processing/src/main/java/io/druid/query/groupby/GroupByQuery.java
@@ -58,6 +58,7 @@
import io.druid.query.ordering.StringComparators;
import io.druid.query.spec.LegacySegmentSpec;
import io.druid.query.spec.QuerySegmentSpec;
+import io.druid.segment.DimensionHandlerUtils;
import io.druid.segment.VirtualColumn;
import io.druid.segment.VirtualColumns;
import io.druid.segment.column.Column;
@@ -377,7 +378,7 @@ public boolean determineApplyLimitPushDown()
final List orderedFieldNames = new ArrayList<>();
final Set dimsInOrderBy = new HashSet<>();
final List needsReverseList = new ArrayList<>();
-final List isNumericField = new ArrayList<>();
+final List dimensionTypes = new ArrayList<>();
final List comparators = new ArrayList<>();
for (OrderByColumnSpec orderSpec : limitSpec.getColumns()) {
@@ -389,7 +390,7 @@ public boolean determineApplyLimitPushDown()
dimsInOrderBy.add(dimIndex);
needsReverseList.add(needsReverse);
final ValueType type = dimensions.get(dimIndex).getOutputType();
-isNumericField.add(ValueType.isNumeric(type));
+dimensionTypes.add(type);
comparators.add(orderSpec.getDimensionComparator());
}
}
@@ -399,7 +400,7 @@ public boolean determineApplyLimitPushDown()
orderedFieldNames.add(dimensions.get(i).getOutputName());
needsReverseList.add(false);
final ValueType type = dimensions.get(i).getOutputType();
-isNumericField.add(ValueType.isNumeric(type));
+dimensionTypes.add(type);
comparators.add(StringComparators.LEXICOGRAPHIC);
}
}
@@ -416,7 +417,7 @@ public int compare(Row lhs, Row rhs)
return compareDimsForLimitPushDown(
orderedFieldNames,
needsReverseList,
- isNumericField,
+ dimensionTypes,
comparators,
lhs,
rhs
@@ -434,7 +435,7 @@ public int compare(Row lhs, Row rhs)
final int cmp = compareDimsForLimitPushDown(
orderedFieldNames,
needsReverseList,
- isNumericField,
+ dimensionTypes,
comparators,
lhs,
rhs
@@ -463,7 +464,7 @@ public int compare(Row lhs, Row rhs)
return compareDimsForLimitPushDown(
orderedFieldNames,
needsReverseList,
- isNumericField,
+ dimensionTypes,
comparators,
lhs,
rhs
@@ -530,28 +531,12 @@ public int compare(Row lhs, Row rhs)
private static int compareDims(List dimensions, Row lhs, Row
rhs)
{
for (DimensionSpec dimension : dimensions) {
- final int dimCompare;
- if (dimension.getOutputType() == ValueType.LONG) {
-dimCompare = Long.compare(
-((Number) lhs.getRaw(dimension.getOutputName())).longValue(),
-((Number) rhs.getRaw(dimension.getOutputName())).longValue()
-);
- } else if (dimension.getOutputType() == ValueType.FLOAT) {
-dimCompare = Float.compare(
-((Number) lhs.getRaw(dimension.getOutputName())).floatValue(),
-((Number) rhs.getRaw(dimension.getOutputName())).floatValue()
-);
- } else if (dimension.getOutputType() == ValueType.DOUBLE) {
-dimCompare = Double.compare(
-((Number) lhs.getRaw(dimension.getOutputName())).doubleValue(),
-((Number) rhs.getRaw(dimension.getOutputName())).doubleValue()
-);
- } else {
-dimCompare = ((Ordering) Comparators.naturalNullsFirst()).compare(
-lhs.getRaw(dimension.getOutputName()),
-rhs.getRaw(dimension.getOutputName())
-);
- }
+ //noinspection unchecked
+ final int dimCompare = DimensionHandlerUtils.compareObjectsAsType(
+ lhs.getRaw(dimension.getOutputName()),
+ rhs.getRaw(dimension.getOutputName()),
+ dimension.getOutputType()
+ );
if (dimCompare != 0) {
return dimCompare;
}
@@ -563,7 +548,7 @@ private static int compareDims(List
dimensions, Row lhs, Row rhs)
private static int
[GitHub] gianm commented on issue #6255: Heavy GC activities after upgrading to 0.12
gianm commented on issue #6255: Heavy GC activities after upgrading to 0.12 URL: https://github.com/apache/incubator-druid/issues/6255#issuecomment-416616545 Great catch! Btw, I think you meant to link to #4704 instead of #4707. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gianm commented on a change in pull request #6254: fix opentsdb emitter occupy 100%(#6247)
gianm commented on a change in pull request #6254: fix opentsdb emitter occupy
100%(#6247)
URL: https://github.com/apache/incubator-druid/pull/6254#discussion_r213366682
##
File path:
extensions-contrib/opentsdb-emitter/src/main/java/io/druid/emitter/opentsdb/OpentsdbSender.java
##
@@ -110,12 +119,15 @@ private void sendEvents()
public void run()
{
while (running) {
-if (!eventQueue.isEmpty()) {
- OpentsdbEvent event = eventQueue.poll();
+try {
+ OpentsdbEvent event = eventQueue.take();
events.add(event);
- if (events.size() >= flushThreshold) {
-sendEvents();
- }
+}
+catch (InterruptedException e) {
+ log.error(e, "consumer take event failed!");
+}
+if (events.size() >= flushThreshold) {
+ sendEvents();
Review comment:
`take` will block until an item becomes available, so I think it is okay.
This function will spend most of its time waiting on `take` rather than in a
spin loop.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gaodayue commented on issue #6255: Heavy GC activities after upgrading to 0.12
gaodayue commented on issue #6255: Heavy GC activities after upgrading to 0.12 URL: https://github.com/apache/incubator-druid/issues/6255#issuecomment-416583814 In order to find out which class puts too much pressure on garbage collector, I captured flight record (60s) before and after upgrade and compare them. In our cluster, each node is constantly serving ~30 queries per second, so the workload should be the same before and after. Here are the clues I found from the record. First, TLAB and non-TLAB allocation rate are 64MB/s and 284KB/s before upgrade, but 107MB/s and 100MB/s after upgrade. That is non-TLAB allocated memory is 362 times more. https://user-images.githubusercontent.com/1198446/44724021-31e35100-ab04-11e8-81d8-04057c744e5f.png;> https://user-images.githubusercontent.com/1198446/44724030-37d93200-ab04-11e8-9f3f-cdc6a0ada1eb.png;> Second, nearly 99% of the memory is allocated inside `RowBasedKeySerde`'s constructor. It's initializing forward and reverse dictionary. https://user-images.githubusercontent.com/1198446/44724736-2f81f680-ab06-11e8-898f-2d58848a0111.png;> From [the code](https://github.com/apache/incubator-druid/blob/0.12.0/processing/src/main/java/io/druid/query/groupby/epinephelinae/RowBasedGrouperHelper.java#L993) we can see, the initial dictionary capacity is 1. So every SpillGrouper needs to allocate at least two 1-sized dictionary. We have `processing.numThreads` set to 31 and QPS around 30, therefore each second we're creating 1860's 1-sized dictionary. Most of our groupby queries returns just a few rows, set initial dictionary size to 1 is too big. This bug was introduced by #4707. Before 0.12, [initial dictionary is empty](https://github.com/apache/incubator-druid/blob/0.11.0/processing/src/main/java/io/druid/query/groupby/epinephelinae/RowBasedGrouperHelper.java#L907). #4707 changes it to 1. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gaodayue opened a new pull request #6256: RowBasedKeySerde should use empty dictionary in constructor
gaodayue opened a new pull request #6256: RowBasedKeySerde should use empty dictionary in constructor URL: https://github.com/apache/incubator-druid/pull/6256 Fixes #6255 This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gianm commented on issue #6253: Multiple datasources with multiple topic in one spec file
gianm commented on issue #6253: Multiple datasources with multiple topic in one spec file URL: https://github.com/apache/incubator-druid/issues/6253#issuecomment-416635332 Hi @Harish346, currently the model is 1 supervisor and 1 set of tasks per datasource. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] QiuMM commented on a change in pull request #6254: fix opentsdb emitter occupy 100%(#6247)
QiuMM commented on a change in pull request #6254: fix opentsdb emitter occupy
100%(#6247)
URL: https://github.com/apache/incubator-druid/pull/6254#discussion_r213365894
##
File path:
extensions-contrib/opentsdb-emitter/src/main/java/io/druid/emitter/opentsdb/OpentsdbSender.java
##
@@ -110,12 +119,15 @@ private void sendEvents()
public void run()
{
while (running) {
-if (!eventQueue.isEmpty()) {
- OpentsdbEvent event = eventQueue.poll();
+try {
+ OpentsdbEvent event = eventQueue.take();
events.add(event);
- if (events.size() >= flushThreshold) {
-sendEvents();
- }
+}
+catch (InterruptedException e) {
+ log.error(e, "consumer take event failed!");
+}
+if (events.size() >= flushThreshold) {
+ sendEvents();
Review comment:
The while loop still always be running! Problem have not been solved.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] QiuMM commented on issue #6254: fix opentsdb emitter occupy 100%(#6247)
QiuMM commented on issue #6254: fix opentsdb emitter occupy 100%(#6247) URL: https://github.com/apache/incubator-druid/pull/6254#issuecomment-416634103 It have been solved in #6251 . This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] QiuMM commented on a change in pull request #6254: fix opentsdb emitter occupy 100%(#6247)
QiuMM commented on a change in pull request #6254: fix opentsdb emitter occupy
100%(#6247)
URL: https://github.com/apache/incubator-druid/pull/6254#discussion_r213372654
##
File path:
extensions-contrib/opentsdb-emitter/src/main/java/io/druid/emitter/opentsdb/OpentsdbSender.java
##
@@ -110,12 +119,15 @@ private void sendEvents()
public void run()
{
while (running) {
-if (!eventQueue.isEmpty()) {
- OpentsdbEvent event = eventQueue.poll();
+try {
+ OpentsdbEvent event = eventQueue.take();
events.add(event);
- if (events.size() >= flushThreshold) {
-sendEvents();
- }
+}
+catch (InterruptedException e) {
+ log.error(e, "consumer take event failed!");
+}
+if (events.size() >= flushThreshold) {
+ sendEvents();
Review comment:
Sorry, you are right, but I do not think this is a elegant solution.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] himanshug commented on issue #6219: Add optional `name` to top level of FilteredAggregatorFactory
himanshug commented on issue #6219: Add optional `name` to top level of FilteredAggregatorFactory URL: https://github.com/apache/incubator-druid/pull/6219#issuecomment-416659072 @drcrallen I added the `compatibility` label to this PR for the catch that you [mentioned](https://github.com/apache/incubator-druid/pull/6219#discussion_r212738542). It should be covered in the release notes. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jihoonson commented on issue #6124: KafkaIndexTask can delete published segments on restart
jihoonson commented on issue #6124: KafkaIndexTask can delete published segments on restart URL: https://github.com/apache/incubator-druid/issues/6124#issuecomment-416669984 @gianm I think it makes sense to close this issue since the title is about kafka tasks deleting pushed segments. However, the tasks would still fail in the same scenario which can make users confused. Do you think we need to file this in another issue? This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] himanshug commented on issue #6212: fix TaskQueue-HRTR deadlock
himanshug commented on issue #6212: fix TaskQueue-HRTR deadlock URL: https://github.com/apache/incubator-druid/pull/6212#issuecomment-416659850 @gianm sure, thanks. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] himanshug closed issue #2406: [proposal]datasketches lib based quantiles/histogram support in druid
himanshug closed issue #2406: [proposal]datasketches lib based quantiles/histogram support in druid URL: https://github.com/apache/incubator-druid/issues/2406 This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gianm commented on issue #6124: KafkaIndexTask can delete published segments on restart
gianm commented on issue #6124: KafkaIndexTask can delete published segments on restart URL: https://github.com/apache/incubator-druid/issues/6124#issuecomment-416667501 Got it, I think we can close this then. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] himanshug commented on a change in pull request #5280: add "subtotalsSpec" attribute to groupBy query
himanshug commented on a change in pull request #5280: add "subtotalsSpec"
attribute to groupBy query
URL: https://github.com/apache/incubator-druid/pull/5280#discussion_r213413936
##
File path: docs/content/querying/groupbyquery.md
##
@@ -113,6 +114,94 @@ improve performance.
See [Multi-value dimensions](multi-value-dimensions.html) for more details.
+### More on subtotalsSpec
+you can have a groupBy query that looks something like below...
+
+```json
+{
+"type": "groupBy",
+ ...
+ ...
+"dimenstions": [
+ {
+ "type" : "default",
+ "dimension" : "d1col",
+ "outputName": "D1"
+ },
+ {
+ "type" : "extraction",
+ "dimension" : "d2col",
+ "outputName" : "D2",
+ "extractionFn" : extraction_func
+ },
+ {
+ "type":"lookup",
+ "dimension":"d3col",
+ "outputName":"D3",
+ "name":"my_lookup"
+ }
+],
+...
+...
+"subtotalsSpec":[ ["D1", "D2", D3"], ["D1", "D3"], ["D3"]],
+..
+
+}
+```
+
+Response returned would be equivalent to concatenating result of 3 groupBy
queries with "dimensions" field being ["D1", "D2", D3"], ["D1", "D3"] and
["D3"] with appropriate `DimensionSpec` json blob as used in above query.
+Response for above query would look something like below...
+
+```json
+[
+ {
+"version" : "v1",
+"timestamp" : "t1",
+"event" : { "D1": "..", "D2": "..", "D3": ".." }
+}
+ },
+{
+"version" : "v1",
+"timestamp" : "t2",
+"event" : { "D1": "..", "D2": "..", "D3": ".." }
+}
+ },
+ ...
+ ...
+
+ {
+"version" : "v1",
+"timestamp" : "t1",
+"event" : { "D1": "..", "D3": ".." }
+}
+ },
+{
+"version" : "v1",
+"timestamp" : "t2",
+"event" : { "D1": "..", "D3": ".." }
+}
+ },
+ ...
+ ...
+
+ {
+"version" : "v1",
+"timestamp" : "t1",
+"event" : { "D3": ".." }
+}
+ },
+{
+"version" : "v1",
+"timestamp" : "t2",
+"event" : { "D3": ".." }
+}
+ },
+...
+]
+```
+
+Note that "subtotalsSpec" must contain subsets of "outputName" from various
`DimensionSpec` json blobs in `dimensions` attribute and also ordering of
dimensions inside subtotal spec must be same as that inside top level
"dimensions" attribute e.g. ["D2", "D1"] subtotal spec is not valid as it is
not in same order.
Review comment:
deleted
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] himanshug commented on a change in pull request #5280: add "subtotalsSpec" attribute to groupBy query
himanshug commented on a change in pull request #5280: add "subtotalsSpec" attribute to groupBy query URL: https://github.com/apache/incubator-druid/pull/5280#discussion_r213413907 ## File path: docs/content/querying/groupbyquery.md ## @@ -113,6 +114,94 @@ improve performance. See [Multi-value dimensions](multi-value-dimensions.html) for more details. +### More on subtotalsSpec +you can have a groupBy query that looks something like below... Review comment: thanks for writing above, added/replaced. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gianm closed issue #6124: KafkaIndexTask can delete published segments on restart
gianm closed issue #6124: KafkaIndexTask can delete published segments on restart URL: https://github.com/apache/incubator-druid/issues/6124 This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jihoonson commented on issue #6256: RowBasedKeySerde should use empty dictionary in constructor
jihoonson commented on issue #6256: RowBasedKeySerde should use empty dictionary in constructor URL: https://github.com/apache/incubator-druid/pull/6256#issuecomment-416668830 Hi @gaodayue, I left a comment on https://github.com/apache/incubator-druid/issues/6255. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jihoonson commented on issue #6255: Heavy GC activities after upgrading to 0.12
jihoonson commented on issue #6255: Heavy GC activities after upgrading to 0.12 URL: https://github.com/apache/incubator-druid/issues/6255#issuecomment-416668676 @gaodayue thank you for catching this. Could you share some more details of your use case? I wonder especially how large the dictionary was. I set the initial size of dictionary map to 1 because I thought `SpillingGrouper` isn't supposed to be used for small dictionary. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] himanshug commented on issue #6255: Heavy GC activities after upgrading to 0.12
himanshug commented on issue #6255: Heavy GC activities after upgrading to 0.12 URL: https://github.com/apache/incubator-druid/issues/6255#issuecomment-416662430 #4704 did run the benchmarks for performance, unfortunately benchmarks don't report memory allocation or else it would be noticed while #4704 was under development. it would be nice if benchmarks could report some stats on memory as well. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] QiuMM edited a comment on issue #6254: fix opentsdb emitter occupy 100%(#6247)
QiuMM edited a comment on issue #6254: fix opentsdb emitter occupy 100%(#6247) URL: https://github.com/apache/incubator-druid/pull/6254#issuecomment-416634103 I have opened #6251 to solve same issue. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] himanshug commented on a change in pull request #5280: add "subtotalsSpec" attribute to groupBy query
himanshug commented on a change in pull request #5280: add "subtotalsSpec"
attribute to groupBy query
URL: https://github.com/apache/incubator-druid/pull/5280#discussion_r213413800
##
File path: docs/content/querying/groupbyquery.md
##
@@ -113,6 +114,94 @@ improve performance.
See [Multi-value dimensions](multi-value-dimensions.html) for more details.
+### More on subtotalsSpec
+you can have a groupBy query that looks something like below...
+
+```json
+{
+"type": "groupBy",
+ ...
+ ...
+"dimenstions": [
Review comment:
:)
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] himanshug commented on a change in pull request #5280: add "subtotalsSpec" attribute to groupBy query
himanshug commented on a change in pull request #5280: add "subtotalsSpec" attribute to groupBy query URL: https://github.com/apache/incubator-druid/pull/5280#discussion_r213413760 ## File path: docs/content/querying/groupbyquery.md ## @@ -70,6 +70,7 @@ There are 11 main parts to a groupBy query: |aggregations|See [Aggregations](../querying/aggregations.html)|no| |postAggregations|See [Post Aggregations](../querying/post-aggregations.html)|no| |intervals|A JSON Object representing ISO-8601 Intervals. This defines the time ranges to run the query over.|yes| +|subtotalsSpec| A JSON array of arrays to return additional result sets for groupings of subsets of top level `dimensions`. It is described later in more detail.|no| Review comment: sure This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] b-slim commented on a change in pull request #6251: fix opentsdb emitter always be running
b-slim commented on a change in pull request #6251: fix opentsdb emitter always be running URL: https://github.com/apache/incubator-druid/pull/6251#discussion_r213459729 ## File path: docs/content/development/extensions-contrib/opentsdb-emitter.md ## @@ -18,10 +18,11 @@ All the configuration parameters for the opentsdb emitter are under `druid.emitt ||---|-|---| |`druid.emitter.opentsdb.host`|The host of the OpenTSDB server.|yes|none| |`druid.emitter.opentsdb.port`|The port of the OpenTSDB server.|yes|none| -|`druid.emitter.opentsdb.connectionTimeout`|Connection timeout(in milliseconds).|no|2000| -|`druid.emitter.opentsdb.readTimeout`|Read timeout(in milliseconds).|no|2000| +|`druid.emitter.opentsdb.connectionTimeout`|`Jersey client` connection timeout(in milliseconds).|no|2000| +|`druid.emitter.opentsdb.readTimeout`|`Jersey client` read timeout(in milliseconds).|no|2000| |`druid.emitter.opentsdb.flushThreshold`|Queue flushing threshold.(Events will be sent as one batch)|no|100| |`druid.emitter.opentsdb.maxQueueSize`|Maximum size of the queue used to buffer events.|no|1000| +|`druid.emitter.opentsdb.consumeDelay`|Queue consuming delay(in milliseconds).|no|1| Review comment: can we add a short description about what this means like what happen if increased or decreased ? and maybe why 10second is a good default? This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gianm opened a new pull request #6257: SQL: Fix post-aggregator naming logic for sort-project. (#6250)
gianm opened a new pull request #6257: SQL: Fix post-aggregator naming logic
for sort-project. (#6250)
URL: https://github.com/apache/incubator-druid/pull/6257
The old code assumes that post-aggregator prefixes are one character
long followed by numbers. This isn't always true (we may pad with
underscores to avoid conflicts). Instead, the new code uses a different
base prefix for sort-project postaggregators ("s" instead of "p") and
uses the usual Calcites.findUnusedPrefix function to avoid conflicts.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jon-wei commented on a change in pull request #6258: Don't let catch/finally suppress main exception in IncrementalPublishingKafkaIndexTaskRunner
jon-wei commented on a change in pull request #6258: Don't let catch/finally
suppress main exception in IncrementalPublishingKafkaIndexTaskRunner
URL: https://github.com/apache/incubator-druid/pull/6258#discussion_r213468683
##
File path:
extensions-core/kafka-indexing-service/src/main/java/io/druid/indexing/kafka/IncrementalPublishingKafkaIndexTaskRunner.java
##
@@ -706,21 +727,38 @@ public void onFailure(Throwable t)
}
catch (Exception e) {
// (3) catch all other exceptions thrown for the whole ingestion steps
including the final publishing.
- Futures.allAsList(publishWaitList).cancel(true);
- Futures.allAsList(handOffWaitList).cancel(true);
- appenderator.closeNow();
+ caughtExceptionOuter = e;
+ try {
+Futures.allAsList(publishWaitList).cancel(true);
+Futures.allAsList(handOffWaitList).cancel(true);
+if (appenderator != null) {
+ appenderator.closeNow();
+}
+ }
+ catch (Exception e2) {
+e.addSuppressed(e2);
+ }
throw e;
}
finally {
- if (driver != null) {
-driver.close();
+ try {
+if (driver != null) {
+ driver.close();
+}
+if (chatHandlerProvider.isPresent()) {
+ chatHandlerProvider.get().unregister(task.getId());
+}
+
+toolbox.getDruidNodeAnnouncer().unannounce(discoveryDruidNode);
+toolbox.getDataSegmentServerAnnouncer().unannounce();
}
- if (chatHandlerProvider.isPresent()) {
-chatHandlerProvider.get().unregister(task.getId());
+ catch (Exception e) {
+if (caughtExceptionOuter != null) {
+ caughtExceptionOuter.addSuppressed(e);
Review comment:
it's in the finally block, so if caughtExceptionOuter is not null it was
already thrown earlier
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jihoonson commented on a change in pull request #6258: Don't let catch/finally suppress main exception in IncrementalPublishingKafkaIndexTaskRunner
jihoonson commented on a change in pull request #6258: Don't let catch/finally
suppress main exception in IncrementalPublishingKafkaIndexTaskRunner
URL: https://github.com/apache/incubator-druid/pull/6258#discussion_r213467270
##
File path:
extensions-core/kafka-indexing-service/src/main/java/io/druid/indexing/kafka/IncrementalPublishingKafkaIndexTaskRunner.java
##
@@ -706,21 +727,38 @@ public void onFailure(Throwable t)
}
catch (Exception e) {
// (3) catch all other exceptions thrown for the whole ingestion steps
including the final publishing.
- Futures.allAsList(publishWaitList).cancel(true);
- Futures.allAsList(handOffWaitList).cancel(true);
- appenderator.closeNow();
+ caughtExceptionOuter = e;
+ try {
+Futures.allAsList(publishWaitList).cancel(true);
+Futures.allAsList(handOffWaitList).cancel(true);
+if (appenderator != null) {
+ appenderator.closeNow();
+}
+ }
+ catch (Exception e2) {
+e.addSuppressed(e2);
+ }
throw e;
}
finally {
- if (driver != null) {
-driver.close();
+ try {
+if (driver != null) {
+ driver.close();
+}
+if (chatHandlerProvider.isPresent()) {
+ chatHandlerProvider.get().unregister(task.getId());
+}
+
+toolbox.getDruidNodeAnnouncer().unannounce(discoveryDruidNode);
+toolbox.getDataSegmentServerAnnouncer().unannounce();
}
- if (chatHandlerProvider.isPresent()) {
-chatHandlerProvider.get().unregister(task.getId());
+ catch (Exception e) {
+if (caughtExceptionOuter != null) {
+ caughtExceptionOuter.addSuppressed(e);
Review comment:
`throw caughtExceptionOuter`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jihoonson commented on a change in pull request #6258: Don't let catch/finally suppress main exception in IncrementalPublishingKafkaIndexTaskRunner
jihoonson commented on a change in pull request #6258: Don't let catch/finally
suppress main exception in IncrementalPublishingKafkaIndexTaskRunner
URL: https://github.com/apache/incubator-druid/pull/6258#discussion_r213467072
##
File path:
extensions-core/kafka-indexing-service/src/main/java/io/druid/indexing/kafka/IncrementalPublishingKafkaIndexTaskRunner.java
##
@@ -616,12 +618,22 @@ public void onFailure(Throwable t)
}
catch (Exception e) {
// (1) catch all exceptions while reading from kafka
+caughtExceptionInner = e;
log.error(e, "Encountered exception in run() before persisting.");
throw e;
}
finally {
log.info("Persisting all pending data");
-driver.persist(committerSupplier.get()); // persist pending data
+try {
+ driver.persist(committerSupplier.get()); // persist pending data
+}
+catch (Exception e) {
+ if (caughtExceptionInner != null) {
+caughtExceptionInner.addSuppressed(e);
Review comment:
`throw caughtExceptionInner`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] himanshug commented on a change in pull request #5872: add method getRequiredColumns for DimFilter
himanshug commented on a change in pull request #5872: add method getRequiredColumns for DimFilter URL: https://github.com/apache/incubator-druid/pull/5872#discussion_r213452493 ## File path: processing/src/main/java/io/druid/query/filter/DimFilter.java ## @@ -75,4 +77,9 @@ * determine for this DimFilter. */ RangeSet getDimensionRangeSet(String dimension); + + /** + * @return a HashSet that represents all columns' name which the DimFilter required to do filter. + */ + HashSet getRequiredColumns(); Review comment: Can we have the return type be `Set` instead so that single column cases can just return `ImmutableSet.of(col)` ? This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gianm commented on issue #6254: fix opentsdb emitter occupy 100%(#6247)
gianm commented on issue #6254: fix opentsdb emitter occupy 100%(#6247) URL: https://github.com/apache/incubator-druid/pull/6254#issuecomment-416729102 What are the pros and cons of this approach vs. the approach in #6251? (Sorry, I haven't had a chance to study how the OpenTSDB emitter works.) This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jon-wei opened a new pull request #6258: Don't let catch/finally suppress main exception in IncrementalPublishingKafkaIndexTaskRunner
jon-wei opened a new pull request #6258: Don't let catch/finally suppress main exception in IncrementalPublishingKafkaIndexTaskRunner URL: https://github.com/apache/incubator-druid/pull/6258 This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] himanshug commented on issue #5280: add "subtotalsSpec" attribute to groupBy query
himanshug commented on issue #5280: add "subtotalsSpec" attribute to groupBy query URL: https://github.com/apache/incubator-druid/pull/5280#issuecomment-416745224 @gianm updated the docs. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] amalakar commented on issue #5150: Druid-parquet-extensions fails on timestamps (stored as INT96) in parquet files
amalakar commented on issue #5150: Druid-parquet-extensions fails on timestamps (stored as INT96) in parquet files URL: https://github.com/apache/incubator-druid/issues/5150#issuecomment-416762573 @shaharck in our case we ended up converting to csv and then importing into druid, which is less than ideal but unblocked us for now. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] b-slim commented on a change in pull request #6251: fix opentsdb emitter always be running
b-slim commented on a change in pull request #6251: fix opentsdb emitter always be running URL: https://github.com/apache/incubator-druid/pull/6251#discussion_r213460483 ## File path: extensions-contrib/opentsdb-emitter/src/main/java/io/druid/emitter/opentsdb/OpentsdbSender.java ## @@ -40,28 +43,40 @@ */ private static final String PATH = "/api/put"; private static final Logger log = new Logger(OpentsdbSender.class); + private static final long FLUSH_TIMEOUT = 6; // default flush wait 1 min Review comment: does this means the emitter will block 1 min waiting for the flush to finish? This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] shaharck commented on issue #5150: Druid-parquet-extensions fails on timestamps (stored as INT96) in parquet files
shaharck commented on issue #5150: Druid-parquet-extensions fails on timestamps (stored as INT96) in parquet files URL: https://github.com/apache/incubator-druid/issues/5150#issuecomment-416733014 is there an existing work around if you do not need that column? doesn't seem like excluding the dimension helps This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jihoonson commented on a change in pull request #6258: Don't let catch/finally suppress main exception in IncrementalPublishingKafkaIndexTaskRunner
jihoonson commented on a change in pull request #6258: Don't let catch/finally
suppress main exception in IncrementalPublishingKafkaIndexTaskRunner
URL: https://github.com/apache/incubator-druid/pull/6258#discussion_r213473735
##
File path:
extensions-core/kafka-indexing-service/src/main/java/io/druid/indexing/kafka/IncrementalPublishingKafkaIndexTaskRunner.java
##
@@ -706,21 +727,38 @@ public void onFailure(Throwable t)
}
catch (Exception e) {
// (3) catch all other exceptions thrown for the whole ingestion steps
including the final publishing.
- Futures.allAsList(publishWaitList).cancel(true);
- Futures.allAsList(handOffWaitList).cancel(true);
- appenderator.closeNow();
+ caughtExceptionOuter = e;
+ try {
+Futures.allAsList(publishWaitList).cancel(true);
+Futures.allAsList(handOffWaitList).cancel(true);
+if (appenderator != null) {
+ appenderator.closeNow();
+}
+ }
+ catch (Exception e2) {
+e.addSuppressed(e2);
+ }
throw e;
}
finally {
- if (driver != null) {
-driver.close();
+ try {
+if (driver != null) {
+ driver.close();
+}
+if (chatHandlerProvider.isPresent()) {
+ chatHandlerProvider.get().unregister(task.getId());
+}
+
+toolbox.getDruidNodeAnnouncer().unannounce(discoveryDruidNode);
+toolbox.getDataSegmentServerAnnouncer().unannounce();
}
- if (chatHandlerProvider.isPresent()) {
-chatHandlerProvider.get().unregister(task.getId());
+ catch (Exception e) {
+if (caughtExceptionOuter != null) {
+ caughtExceptionOuter.addSuppressed(e);
Review comment:
Correct. Thanks.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] himanshug commented on issue #6252: Deadlock may be in TaskMaster when stopping
himanshug commented on issue #6252: Deadlock may be in TaskMaster when stopping URL: https://github.com/apache/incubator-druid/issues/6252#issuecomment-416743373 did you shutdown zookeeper processes along with druid or did Overlord somehow lost connection to zookeeper ? from a quick look at code, `LeaderSelector[/druid/overlord/_OVERLORD]` thread should've eventually finished unless it stopped receiving notifications from curator/zookeeper . This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jon-wei closed pull request #6258: Don't let catch/finally suppress main exception in IncrementalPublishingKafkaIndexTaskRunner
jon-wei closed pull request #6258: Don't let catch/finally suppress main
exception in IncrementalPublishingKafkaIndexTaskRunner
URL: https://github.com/apache/incubator-druid/pull/6258
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git
a/extensions-core/kafka-indexing-service/src/main/java/io/druid/indexing/kafka/IncrementalPublishingKafkaIndexTaskRunner.java
b/extensions-core/kafka-indexing-service/src/main/java/io/druid/indexing/kafka/IncrementalPublishingKafkaIndexTaskRunner.java
index 434e16eda4b..660ee016edb 100644
---
a/extensions-core/kafka-indexing-service/src/main/java/io/druid/indexing/kafka/IncrementalPublishingKafkaIndexTaskRunner.java
+++
b/extensions-core/kafka-indexing-service/src/main/java/io/druid/indexing/kafka/IncrementalPublishingKafkaIndexTaskRunner.java
@@ -317,6 +317,7 @@ private TaskStatus runInternal(TaskToolbox toolbox) throws
Exception
)
);
+Throwable caughtExceptionOuter = null;
try (final KafkaConsumer consumer = task.newConsumer()) {
toolbox.getDataSegmentServerAnnouncer().announce();
toolbox.getDruidNodeAnnouncer().announce(discoveryDruidNode);
@@ -412,6 +413,7 @@ public void run()
// Could eventually support leader/follower mode (for keeping replicas
more in sync)
boolean stillReading = !assignment.isEmpty();
status = Status.READING;
+ Throwable caughtExceptionInner = null;
try {
while (stillReading) {
if (possiblyPause()) {
@@ -616,12 +618,22 @@ public void onFailure(Throwable t)
}
catch (Exception e) {
// (1) catch all exceptions while reading from kafka
+caughtExceptionInner = e;
log.error(e, "Encountered exception in run() before persisting.");
throw e;
}
finally {
log.info("Persisting all pending data");
-driver.persist(committerSupplier.get()); // persist pending data
+try {
+ driver.persist(committerSupplier.get()); // persist pending data
+}
+catch (Exception e) {
+ if (caughtExceptionInner != null) {
+caughtExceptionInner.addSuppressed(e);
+ } else {
+throw e;
+ }
+}
}
synchronized (statusLock) {
@@ -687,9 +699,18 @@ public void onFailure(Throwable t)
catch (InterruptedException | RejectedExecutionException e) {
// (2) catch InterruptedException and RejectedExecutionException thrown
for the whole ingestion steps including
// the final publishing.
- Futures.allAsList(publishWaitList).cancel(true);
- Futures.allAsList(handOffWaitList).cancel(true);
- appenderator.closeNow();
+ caughtExceptionOuter = e;
+ try {
+Futures.allAsList(publishWaitList).cancel(true);
+Futures.allAsList(handOffWaitList).cancel(true);
+if (appenderator != null) {
+ appenderator.closeNow();
+}
+ }
+ catch (Exception e2) {
+e.addSuppressed(e2);
+ }
+
// handle the InterruptedException that gets wrapped in a
RejectedExecutionException
if (e instanceof RejectedExecutionException
&& (e.getCause() == null || !(e.getCause() instanceof
InterruptedException))) {
@@ -706,21 +727,38 @@ public void onFailure(Throwable t)
}
catch (Exception e) {
// (3) catch all other exceptions thrown for the whole ingestion steps
including the final publishing.
- Futures.allAsList(publishWaitList).cancel(true);
- Futures.allAsList(handOffWaitList).cancel(true);
- appenderator.closeNow();
+ caughtExceptionOuter = e;
+ try {
+Futures.allAsList(publishWaitList).cancel(true);
+Futures.allAsList(handOffWaitList).cancel(true);
+if (appenderator != null) {
+ appenderator.closeNow();
+}
+ }
+ catch (Exception e2) {
+e.addSuppressed(e2);
+ }
throw e;
}
finally {
- if (driver != null) {
-driver.close();
+ try {
+if (driver != null) {
+ driver.close();
+}
+if (chatHandlerProvider.isPresent()) {
+ chatHandlerProvider.get().unregister(task.getId());
+}
+
+toolbox.getDruidNodeAnnouncer().unannounce(discoveryDruidNode);
+toolbox.getDataSegmentServerAnnouncer().unannounce();
}
- if (chatHandlerProvider.isPresent()) {
-chatHandlerProvider.get().unregister(task.getId());
+ catch (Exception e) {
+if (caughtExceptionOuter != null) {
+ caughtExceptionOuter.addSuppressed(e);
+} else {
+ throw e;
+}
}
-
- toolbox.getDruidNodeAnnouncer().unannounce(discoveryDruidNode);
-
[GitHub] jihoonson commented on a change in pull request #5913: Move Caching Cluster Client to java streams and allow parallel intermediate merges
jihoonson commented on a change in pull request #5913: Move Caching Cluster
Client to java streams and allow parallel intermediate merges
URL: https://github.com/apache/incubator-druid/pull/5913#discussion_r213460949
##
File path:
java-util/src/main/java/io/druid/java/util/common/guava/MergeWorkTask.java
##
@@ -0,0 +1,194 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package io.druid.java.util.common.guava;
+
+import com.google.common.annotations.VisibleForTesting;
+import io.druid.java.util.common.Pair;
+
+import java.util.ArrayList;
+import java.util.Deque;
+import java.util.Iterator;
+import java.util.LinkedList;
+import java.util.List;
+import java.util.NoSuchElementException;
+import java.util.Spliterator;
+import java.util.Spliterators;
+import java.util.concurrent.ArrayBlockingQueue;
+import java.util.concurrent.BlockingQueue;
+import java.util.concurrent.ForkJoinPool;
+import java.util.concurrent.ForkJoinTask;
+import java.util.function.Function;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+public class MergeWorkTask extends ForkJoinTask>
+{
+
+ /**
+ * Take a stream of sequences, split them as possible, and do intermediate
merges. If the input stream is not
+ * a parallel stream, do a traditional merge. The stream attempts to use
groups of {@code batchSize} to do its work, but this
+ * goal is on a best effort basis. Input streams that cannot be split or are
not sized or not subsized might not be
+ * elligable for this parallelization. The intermediate merges are done in
the passed in ForkJoinPool, but the final
+ * merge is still done when the returned sequence accumulated. The
intermediate merges are yielded in the order
+ * in which they are ready.
+ *
+ * Exceptions that happen during execution of the merge are passed through
and bubbled up during the resulting sequence
+ * iteration
+ *
+ * @param mergerFn The function that will merge a stream of sequences
into a single sequence. If the baseSequences stream is parallel, this work will
be done in the FJP, otherwise it will be called directly.
+ * @param baseSequences The sequences that need merged
+ * @param batchSize The input stream should be split down to this number
if possible. This sets the target number of segments per merge thread work
+ * @param fjp The ForkJoinPool to do the intermediate merges in.
+ * @paramThe result type
+ *
+ * @return A Sequence that will be the merged results of the sub-sequences
+ *
+ * @throws RuntimeException Will throw a RuntimeException in during
iterating through the returned Sequence if a Throwable
+ * was encountered in an intermediate merge
+ */
+ public static Sequence parallelMerge(
Review comment:
@drcrallen would you check Roman's comment?
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jihoonson commented on a change in pull request #5913: Move Caching Cluster Client to java streams and allow parallel intermediate merges
jihoonson commented on a change in pull request #5913: Move Caching Cluster
Client to java streams and allow parallel intermediate merges
URL: https://github.com/apache/incubator-druid/pull/5913#discussion_r213503720
##
File path: server/src/main/java/io/druid/client/CachingClusteredClient.java
##
@@ -162,34 +184,75 @@ public CachingClusteredClient(
return new SpecificQueryRunnable<>(queryPlus,
responseContext).run(timelineConverter);
}
- @Override
- public QueryRunner getQueryRunnerForSegments(final Query query,
final Iterable specs)
+ private QueryRunner runAndMergeWithTimelineChange(
+ final Query query,
+ final UnaryOperator>
timelineConverter
+ )
{
-return new QueryRunner()
-{
- @Override
- public Sequence run(final QueryPlus queryPlus, final Map responseContext)
- {
-return CachingClusteredClient.this.run(
+final OptionalLong mergeBatch =
QueryContexts.getIntermediateMergeBatchThreshold(query);
+
+if (mergeBatch.isPresent()) {
+ final QueryRunnerFactory> queryRunnerFactory =
conglomerate.findFactory(query);
+ final QueryToolChest> toolChest =
queryRunnerFactory.getToolchest();
+ return (queryPlus, responseContext) -> {
+final Stream> sequences = run(
queryPlus,
responseContext,
-timeline -> {
- final VersionedIntervalTimeline
timeline2 =
- new VersionedIntervalTimeline<>(Ordering.natural());
- for (SegmentDescriptor spec : specs) {
-final PartitionHolder entry =
timeline.findEntry(spec.getInterval(), spec.getVersion());
-if (entry != null) {
- final PartitionChunk chunk =
entry.getChunk(spec.getPartitionNumber());
- if (chunk != null) {
-timeline2.add(spec.getInterval(), spec.getVersion(),
chunk);
- }
-}
- }
- return timeline2;
-}
+timelineConverter
+);
+return MergeWorkTask.parallelMerge(
+sequences.parallel(),
+sequenceStream ->
+new FluentQueryRunnerBuilder<>(toolChest)
+.create(
+queryRunnerFactory.mergeRunners(
Review comment:
This requires to use `ForkJoinPool.managedBlock()` in
`SegmentMetadataQueryRunnerFactory.mergeRunners()`,
`GroupByMergedQueryRunner.run()`, and `GroupByMergingQueryRunnerV2.run()`.
It would be great if there is a util method to create
`ForkJoinPool.managedBlock()` for futures to make the code clearer.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jihoonson commented on a change in pull request #5913: Move Caching Cluster Client to java streams and allow parallel intermediate merges
jihoonson commented on a change in pull request #5913: Move Caching Cluster
Client to java streams and allow parallel intermediate merges
URL: https://github.com/apache/incubator-druid/pull/5913#discussion_r213495920
##
File path: server/src/main/java/io/druid/client/CachingClusteredClient.java
##
@@ -389,169 +471,249 @@ private String computeCurrentEtag(final
Set segments, @Nullable
}
}
-private List> pruneSegmentsWithCachedResults(
+private Pair> lookupInCache(
+Pair key,
+Map> cache
+)
+{
+ final ServerToSegment segment = key.getLhs();
+ final Cache.NamedKey segmentCacheKey = key.getRhs();
+ final Interval segmentQueryInterval =
segment.getSegmentDescriptor().getInterval();
+ final Optional cachedValue = Optional
+ .ofNullable(cache.get(segmentCacheKey))
+ // Shouldn't happen in practice, but can screw up unit tests where
cache state is mutated in crazy
+ // ways when the cache returns null instead of an optional.
+ .orElse(Optional.empty());
+ if (!cachedValue.isPresent()) {
+// if populating cache, add segment to list of segments to cache if it
is not cached
+final String segmentIdentifier =
segment.getServer().getSegment().getIdentifier();
+addCachePopulatorKey(segmentCacheKey, segmentIdentifier,
segmentQueryInterval);
+ }
+ return Pair.of(segment, cachedValue);
+}
+
+/**
+ * This materializes the input segment stream in order to let the BulkGet
stuff in the cache system work
+ *
+ * @param queryCacheKey The cache key that is for the query (not-segment)
portion
+ * @param segments The segments to check if they are in cache
+ *
+ * @return A stream of the server and segment combinations as well as an
optional that is present
+ * if a cached value was found
+ */
+private Stream>>
maybeFetchCacheResults(
final byte[] queryCacheKey,
-final Set segments
+final Stream segments
)
{
if (queryCacheKey == null) {
-return Collections.emptyList();
+return segments.map(s -> Pair.of(s, Optional.empty()));
}
- final List> alreadyCachedResults =
Lists.newArrayList();
- Map perSegmentCacheKeys =
computePerSegmentCacheKeys(segments, queryCacheKey);
- // Pull cached segments from cache and remove from set of segments to
query
- final Map cachedValues =
computeCachedValues(perSegmentCacheKeys);
-
- perSegmentCacheKeys.forEach((segment, segmentCacheKey) -> {
-final Interval segmentQueryInterval =
segment.getSegmentDescriptor().getInterval();
-
-final byte[] cachedValue = cachedValues.get(segmentCacheKey);
-if (cachedValue != null) {
- // remove cached segment from set of segments to query
- segments.remove(segment);
- alreadyCachedResults.add(Pair.of(segmentQueryInterval, cachedValue));
-} else if (populateCache) {
- // otherwise, if populating cache, add segment to list of segments
to cache
- final String segmentIdentifier =
segment.getServer().getSegment().getIdentifier();
- addCachePopulatorKey(segmentCacheKey, segmentIdentifier,
segmentQueryInterval);
-}
- });
- return alreadyCachedResults;
+ // We materialize the stream here in order to have the bulk cache
fetching work as expected
+ final List> materializedKeyList =
computePerSegmentCacheKeys(
+ segments,
+ queryCacheKey
+ ).collect(Collectors.toList());
+
+ // Do bulk fetch
+ final Map> cachedValues =
computeCachedValues(materializedKeyList.stream())
+ .collect(Pair.mapCollector());
+
+ // A limitation of the cache system is that the cached values are
returned without passing through the original
+ // objects. This hash join is a way to get the ServerToSegment and
Optional matched up again
+ return materializedKeyList
+ .stream()
+ .map(serializedPairSegmentAndKey ->
lookupInCache(serializedPairSegmentAndKey, cachedValues));
}
-private Map computePerSegmentCacheKeys(
-Set segments,
+private Stream>
computePerSegmentCacheKeys(
+Stream segments,
byte[] queryCacheKey
)
{
- // cacheKeys map must preserve segment ordering, in order for shards to
always be combined in the same order
- Map cacheKeys = Maps.newLinkedHashMap();
- for (ServerToSegment serverToSegment : segments) {
-final Cache.NamedKey segmentCacheKey =
CacheUtil.computeSegmentCacheKey(
-serverToSegment.getServer().getSegment().getIdentifier(),
-serverToSegment.getSegmentDescriptor(),
-queryCacheKey
-);
-cacheKeys.put(serverToSegment, segmentCacheKey);
- }
- return cacheKeys;
+ return segments
+ .map(serverToSegment -> {
+// cacheKeys
[GitHub] jihoonson commented on a change in pull request #5913: Move Caching Cluster Client to java streams and allow parallel intermediate merges
jihoonson commented on a change in pull request #5913: Move Caching Cluster
Client to java streams and allow parallel intermediate merges
URL: https://github.com/apache/incubator-druid/pull/5913#discussion_r213461237
##
File path:
java-util/src/main/java/io/druid/java/util/common/guava/MergeWorkTask.java
##
@@ -0,0 +1,194 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package io.druid.java.util.common.guava;
+
+import com.google.common.annotations.VisibleForTesting;
+import io.druid.java.util.common.Pair;
+
+import java.util.ArrayList;
+import java.util.Deque;
+import java.util.Iterator;
+import java.util.LinkedList;
+import java.util.List;
+import java.util.NoSuchElementException;
+import java.util.Spliterator;
+import java.util.Spliterators;
+import java.util.concurrent.ArrayBlockingQueue;
+import java.util.concurrent.BlockingQueue;
+import java.util.concurrent.ForkJoinPool;
+import java.util.concurrent.ForkJoinTask;
+import java.util.function.Function;
+import java.util.stream.Stream;
+import java.util.stream.StreamSupport;
+
+public class MergeWorkTask extends ForkJoinTask>
+{
+
+ /**
+ * Take a stream of sequences, split them as possible, and do intermediate
merges. If the input stream is not
+ * a parallel stream, do a traditional merge. The stream attempts to use
groups of {@code batchSize} to do its work, but this
+ * goal is on a best effort basis. Input streams that cannot be split or are
not sized or not subsized might not be
+ * elligable for this parallelization. The intermediate merges are done in
the passed in ForkJoinPool, but the final
+ * merge is still done when the returned sequence accumulated. The
intermediate merges are yielded in the order
+ * in which they are ready.
+ *
+ * Exceptions that happen during execution of the merge are passed through
and bubbled up during the resulting sequence
+ * iteration
+ *
+ * @param mergerFn The function that will merge a stream of sequences
into a single sequence. If the baseSequences stream is parallel, this work will
be done in the FJP, otherwise it will be called directly.
Review comment:
Format: this line exceeds 120 characters. Also there are more places like
this. Please check them.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jihoonson commented on a change in pull request #5913: Move Caching Cluster Client to java streams and allow parallel intermediate merges
jihoonson commented on a change in pull request #5913: Move Caching Cluster Client to java streams and allow parallel intermediate merges URL: https://github.com/apache/incubator-druid/pull/5913#discussion_r213156930 ## File path: common/src/test/java/io/druid/concurrent/ExecsTest.java ## @@ -55,6 +54,20 @@ public void testBlockingExecutorServiceThreeCapacity() throws Exception runTest(3); } + @Test + public void testNameFormatGood() throws Exception Review comment: Unnecessary `throws` clause This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jihoonson commented on a change in pull request #5913: Move Caching Cluster Client to java streams and allow parallel intermediate merges
jihoonson commented on a change in pull request #5913: Move Caching Cluster
Client to java streams and allow parallel intermediate merges
URL: https://github.com/apache/incubator-druid/pull/5913#discussion_r213502966
##
File path:
processing/src/main/java/io/druid/query/ChainedExecutionQueryRunner.java
##
@@ -70,87 +74,115 @@ public ChainedExecutionQueryRunner(
QueryRunner... queryables
)
{
-this(exec, queryWatcher, Arrays.asList(queryables));
+this(exec, queryWatcher, Arrays.stream(queryables));
}
public ChainedExecutionQueryRunner(
ExecutorService exec,
QueryWatcher queryWatcher,
Iterable> queryables
)
+ {
+this(exec, queryWatcher, StreamSupport.stream(queryables.spliterator(),
false));
+ }
+
+ public ChainedExecutionQueryRunner(
+ ExecutorService exec,
+ QueryWatcher queryWatcher,
+ Stream> queryables
+ )
{
// listeningDecorator will leave PrioritizedExecutorService unchanged,
// since it already implements ListeningExecutorService
this.exec = MoreExecutors.listeningDecorator(exec);
-this.queryables = Iterables.unmodifiableIterable(queryables);
this.queryWatcher = queryWatcher;
+this.queryables = queryables;
}
@Override
public Sequence run(final QueryPlus queryPlus, final Map responseContext)
{
-Query query = queryPlus.getQuery();
+final Query query = queryPlus.getQuery();
final int priority = QueryContexts.getPriority(query);
-final Ordering ordering = query.getResultOrdering();
+final Ordering ordering = query.getResultOrdering();
final QueryPlus threadSafeQueryPlus =
queryPlus.withoutThreadUnsafeState();
-return new BaseSequence>(
+return new BaseSequence<>(
new BaseSequence.IteratorMaker>()
{
@Override
public Iterator make()
{
// Make it a List<> to materialize all of the values (so that it
will submit everything to the executor)
-ListenableFuture>> futures = Futures.allAsList(
-Lists.newArrayList(
-Iterables.transform(
-queryables,
-input -> {
- if (input == null) {
-throw new ISE("Null queryRunner! Looks to be some
segment unmapping action happening");
+final ListenableFuture>> futures =
GuavaUtils.allFuturesAsList(
+queryables.peek(
+queryRunner -> {
+ if (queryRunner == null) {
+throw new ISE("Null queryRunner! Looks to be some
segment unmapping action happening");
+ }
+}
+).map(
+queryRunner -> new
AbstractPrioritizedCallable>(priority)
+{
+ @Override
+ public Iterable call()
+ {
+try {
+ Sequence result =
queryRunner.run(threadSafeQueryPlus, responseContext);
+ if (result == null) {
+throw new ISE("Got a null result! Segments are
missing!");
+ }
+
+ List retVal = result.toList();
+ if (retVal == null) {
+throw new ISE("Got a null list of results! WTF?!");
}
- return exec.submit(
- new
AbstractPrioritizedCallable>(priority)
- {
-@Override
-public Iterable call()
-{
- try {
-Sequence result =
input.run(threadSafeQueryPlus, responseContext);
-if (result == null) {
- throw new ISE("Got a null result!
Segments are missing!");
-}
-
-List retVal = result.toList();
-if (retVal == null) {
- throw new ISE("Got a null list of
results! WTF?!");
-}
-
-return retVal;
- }
- catch (QueryInterruptedException e) {
-throw Throwables.propagate(e);
- }
- catch (Exception e) {
-log.error(e, "Exception with one of the
sequences!");
-throw Throwables.propagate(e);
- }
-}
- }
-
[GitHub] jihoonson commented on a change in pull request #5913: Move Caching Cluster Client to java streams and allow parallel intermediate merges
jihoonson commented on a change in pull request #5913: Move Caching Cluster
Client to java streams and allow parallel intermediate merges
URL: https://github.com/apache/incubator-druid/pull/5913#discussion_r213499301
##
File path: server/src/main/java/io/druid/client/CachingClusteredClient.java
##
@@ -242,74 +305,93 @@ public CachingClusteredClient(
contextBuilder.put(CacheConfig.POPULATE_CACHE, false);
contextBuilder.put("bySegment", true);
}
- return contextBuilder.build();
+ return Collections.unmodifiableMap(contextBuilder);
}
-Sequence run(final UnaryOperator> timelineConverter)
+Stream> run(final UnaryOperator> timelineConverter)
{
@Nullable
TimelineLookup timeline =
serverView.getTimeline(query.getDataSource());
if (timeline == null) {
-return Sequences.empty();
+return Stream.empty();
}
timeline = timelineConverter.apply(timeline);
if (uncoveredIntervalsLimit > 0) {
computeUncoveredIntervals(timeline);
}
- final Set segments = computeSegmentsToQuery(timeline);
+ Stream segments = computeSegmentsToQuery(timeline);
@Nullable
final byte[] queryCacheKey = computeQueryCacheKey();
if (query.getContext().get(QueryResource.HEADER_IF_NONE_MATCH) != null) {
+// Materialize then re-stream
+final List materializedSegments =
segments.collect(Collectors.toList());
+segments = materializedSegments.stream();
+
@Nullable
final String prevEtag = (String)
query.getContext().get(QueryResource.HEADER_IF_NONE_MATCH);
@Nullable
-final String currentEtag = computeCurrentEtag(segments, queryCacheKey);
+final String currentEtag = computeCurrentEtag(materializedSegments,
queryCacheKey);
if (currentEtag != null && currentEtag.equals(prevEtag)) {
- return Sequences.empty();
+ return Stream.empty();
}
}
- final List> alreadyCachedResults =
pruneSegmentsWithCachedResults(queryCacheKey, segments);
- final SortedMap> segmentsByServer =
groupSegmentsByServer(segments);
- return new LazySequence<>(() -> {
-List> sequencesByInterval = new
ArrayList<>(alreadyCachedResults.size() + segmentsByServer.size());
-addSequencesFromCache(sequencesByInterval, alreadyCachedResults);
-addSequencesFromServer(sequencesByInterval, segmentsByServer);
-return Sequences
-.simple(sequencesByInterval)
-.flatMerge(seq -> seq, query.getResultOrdering());
- });
+ // This pipeline follows a few general steps:
+ // 1. Fetch cache results - Unfortunately this is an eager operation so
that the non cached items can
Review comment:
I wonder if the below is feasible.
1. Group the segment information by server
2. Per server, check the cache and fetch the results if they are cached.
3. Call `runOnServer()` on cache misses.
I would say the benefit of this is we probably do everything lazily until
the query results are fetched either from the cache or servers.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jihoonson commented on a change in pull request #5913: Move Caching Cluster Client to java streams and allow parallel intermediate merges
jihoonson commented on a change in pull request #5913: Move Caching Cluster
Client to java streams and allow parallel intermediate merges
URL: https://github.com/apache/incubator-druid/pull/5913#discussion_r213502018
##
File path: server/src/main/java/io/druid/client/DirectDruidClient.java
##
@@ -590,6 +591,27 @@ private void init()
{
if (jp == null) {
try {
+ // Safety for if we are in a FJP
+ ForkJoinPool.managedBlock(new ForkJoinPool.ManagedBlocker()
Review comment:
I wonder how this affects to the query performance. It looks like directly
calling `future.get()` is more efficient than wrapping it with this Blocker. Is
there any available document about this?
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jihoonson commented on a change in pull request #5913: Move Caching Cluster Client to java streams and allow parallel intermediate merges
jihoonson commented on a change in pull request #5913: Move Caching Cluster
Client to java streams and allow parallel intermediate merges
URL: https://github.com/apache/incubator-druid/pull/5913#discussion_r213484372
##
File path: server/src/main/java/io/druid/client/CachingClusteredClient.java
##
@@ -242,74 +305,93 @@ public CachingClusteredClient(
contextBuilder.put(CacheConfig.POPULATE_CACHE, false);
contextBuilder.put("bySegment", true);
}
- return contextBuilder.build();
+ return Collections.unmodifiableMap(contextBuilder);
}
-Sequence run(final UnaryOperator> timelineConverter)
+Stream> run(final UnaryOperator> timelineConverter)
{
@Nullable
TimelineLookup timeline =
serverView.getTimeline(query.getDataSource());
if (timeline == null) {
-return Sequences.empty();
+return Stream.empty();
}
timeline = timelineConverter.apply(timeline);
if (uncoveredIntervalsLimit > 0) {
computeUncoveredIntervals(timeline);
}
- final Set segments = computeSegmentsToQuery(timeline);
+ Stream segments = computeSegmentsToQuery(timeline);
@Nullable
final byte[] queryCacheKey = computeQueryCacheKey();
if (query.getContext().get(QueryResource.HEADER_IF_NONE_MATCH) != null) {
+// Materialize then re-stream
Review comment:
What's the purpose of this?
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jihoonson commented on a change in pull request #5913: Move Caching Cluster Client to java streams and allow parallel intermediate merges
jihoonson commented on a change in pull request #5913: Move Caching Cluster
Client to java streams and allow parallel intermediate merges
URL: https://github.com/apache/incubator-druid/pull/5913#discussion_r213490673
##
File path: processing/src/main/java/io/druid/guice/LifecycleForkJoinPool.java
##
@@ -0,0 +1,58 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package io.druid.guice;
+
+import io.druid.java.util.common.lifecycle.LifecycleStop;
+import io.druid.java.util.common.logger.Logger;
+
+import java.util.concurrent.ForkJoinPool;
+import java.util.concurrent.TimeUnit;
+
+public class LifecycleForkJoinPool extends ForkJoinPool
+{
+ private static final Logger LOG = new Logger(LifecycleForkJoinPool.class);
+
+ public LifecycleForkJoinPool(
+ int parallelism,
+ ForkJoinWorkerThreadFactory factory,
+ Thread.UncaughtExceptionHandler handler,
+ boolean asyncMode
+ )
+ {
+super(parallelism, factory, handler, asyncMode);
+ }
+
+ @LifecycleStop
+ public void stop()
+ {
+LOG.info("Shutting down ForkJoinPool [%s]", this);
+shutdown();
+try {
+ // Should this be configurable?
Review comment:
I think it makes sense to do this. Please raise an issue for it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jihoonson commented on a change in pull request #5913: Move Caching Cluster Client to java streams and allow parallel intermediate merges
jihoonson commented on a change in pull request #5913: Move Caching Cluster
Client to java streams and allow parallel intermediate merges
URL: https://github.com/apache/incubator-druid/pull/5913#discussion_r213496363
##
File path: server/src/main/java/io/druid/client/CachingClusteredClient.java
##
@@ -389,169 +471,249 @@ private String computeCurrentEtag(final
Set segments, @Nullable
}
}
-private List> pruneSegmentsWithCachedResults(
+private Pair> lookupInCache(
+Pair key,
+Map> cache
+)
+{
+ final ServerToSegment segment = key.getLhs();
+ final Cache.NamedKey segmentCacheKey = key.getRhs();
+ final Interval segmentQueryInterval =
segment.getSegmentDescriptor().getInterval();
+ final Optional cachedValue = Optional
+ .ofNullable(cache.get(segmentCacheKey))
+ // Shouldn't happen in practice, but can screw up unit tests where
cache state is mutated in crazy
+ // ways when the cache returns null instead of an optional.
+ .orElse(Optional.empty());
+ if (!cachedValue.isPresent()) {
+// if populating cache, add segment to list of segments to cache if it
is not cached
+final String segmentIdentifier =
segment.getServer().getSegment().getIdentifier();
+addCachePopulatorKey(segmentCacheKey, segmentIdentifier,
segmentQueryInterval);
+ }
+ return Pair.of(segment, cachedValue);
+}
+
+/**
+ * This materializes the input segment stream in order to let the BulkGet
stuff in the cache system work
+ *
+ * @param queryCacheKey The cache key that is for the query (not-segment)
portion
+ * @param segments The segments to check if they are in cache
+ *
+ * @return A stream of the server and segment combinations as well as an
optional that is present
+ * if a cached value was found
+ */
+private Stream>>
maybeFetchCacheResults(
final byte[] queryCacheKey,
-final Set segments
+final Stream segments
)
{
if (queryCacheKey == null) {
-return Collections.emptyList();
+return segments.map(s -> Pair.of(s, Optional.empty()));
}
- final List> alreadyCachedResults =
Lists.newArrayList();
- Map perSegmentCacheKeys =
computePerSegmentCacheKeys(segments, queryCacheKey);
- // Pull cached segments from cache and remove from set of segments to
query
- final Map cachedValues =
computeCachedValues(perSegmentCacheKeys);
-
- perSegmentCacheKeys.forEach((segment, segmentCacheKey) -> {
-final Interval segmentQueryInterval =
segment.getSegmentDescriptor().getInterval();
-
-final byte[] cachedValue = cachedValues.get(segmentCacheKey);
-if (cachedValue != null) {
- // remove cached segment from set of segments to query
- segments.remove(segment);
- alreadyCachedResults.add(Pair.of(segmentQueryInterval, cachedValue));
-} else if (populateCache) {
- // otherwise, if populating cache, add segment to list of segments
to cache
- final String segmentIdentifier =
segment.getServer().getSegment().getIdentifier();
- addCachePopulatorKey(segmentCacheKey, segmentIdentifier,
segmentQueryInterval);
-}
- });
- return alreadyCachedResults;
+ // We materialize the stream here in order to have the bulk cache
fetching work as expected
+ final List> materializedKeyList =
computePerSegmentCacheKeys(
+ segments,
+ queryCacheKey
+ ).collect(Collectors.toList());
+
+ // Do bulk fetch
+ final Map> cachedValues =
computeCachedValues(materializedKeyList.stream())
+ .collect(Pair.mapCollector());
+
+ // A limitation of the cache system is that the cached values are
returned without passing through the original
+ // objects. This hash join is a way to get the ServerToSegment and
Optional matched up again
+ return materializedKeyList
+ .stream()
+ .map(serializedPairSegmentAndKey ->
lookupInCache(serializedPairSegmentAndKey, cachedValues));
}
-private Map computePerSegmentCacheKeys(
-Set segments,
+private Stream>
computePerSegmentCacheKeys(
+Stream segments,
byte[] queryCacheKey
)
{
- // cacheKeys map must preserve segment ordering, in order for shards to
always be combined in the same order
- Map cacheKeys = Maps.newLinkedHashMap();
- for (ServerToSegment serverToSegment : segments) {
-final Cache.NamedKey segmentCacheKey =
CacheUtil.computeSegmentCacheKey(
-serverToSegment.getServer().getSegment().getIdentifier(),
-serverToSegment.getSegmentDescriptor(),
-queryCacheKey
-);
-cacheKeys.put(serverToSegment, segmentCacheKey);
- }
- return cacheKeys;
+ return segments
+ .map(serverToSegment -> {
+// cacheKeys
[GitHub] jon-wei opened a new pull request #6260: [Backport] Don't let catch/finally suppress main exception in IncrementalPublishingKafkaIndexTaskRunner
jon-wei opened a new pull request #6260: [Backport] Don't let catch/finally suppress main exception in IncrementalPublishingKafkaIndexTaskRunner URL: https://github.com/apache/incubator-druid/pull/6260 Backport of #6258 to 0.12.3 This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gianm closed pull request #5280: add "subtotalsSpec" attribute to groupBy query
gianm closed pull request #5280: add "subtotalsSpec" attribute to groupBy query
URL: https://github.com/apache/incubator-druid/pull/5280
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/docs/content/querying/groupbyquery.md
b/docs/content/querying/groupbyquery.md
index 4048551f84f..337415512c8 100644
--- a/docs/content/querying/groupbyquery.md
+++ b/docs/content/querying/groupbyquery.md
@@ -56,7 +56,7 @@ An example groupBy query object is shown below:
}
```
-There are 11 main parts to a groupBy query:
+Following are main parts to a groupBy query:
|property|description|required?|
||---|-|
@@ -70,6 +70,7 @@ There are 11 main parts to a groupBy query:
|aggregations|See [Aggregations](../querying/aggregations.html)|no|
|postAggregations|See [Post
Aggregations](../querying/post-aggregations.html)|no|
|intervals|A JSON Object representing ISO-8601 Intervals. This defines the
time ranges to run the query over.|yes|
+|subtotalsSpec| A JSON array of arrays to return additional result sets for
groupings of subsets of top level `dimensions`. It is [described
later](groupbyquery.html#more-on-subtotalsspec) in more detail.|no|
|context|An additional JSON Object which can be used to specify certain
flags.|no|
To pull it all together, the above query would return *n\*m* data points, up
to a maximum of 5000 points, where n is the cardinality of the `country`
dimension, m is the cardinality of the `device` dimension, each day between
2012-01-01 and 2012-01-03, from the `sample_datasource` table. Each data point
contains the (long) sum of `total_usage` if the value of the data point is
greater than 100, the (double) sum of `data_transfer` and the (double) result
of `total_usage` divided by `data_transfer` for the filter set for a particular
grouping of `country` and `device`. The output looks like this:
@@ -113,6 +114,92 @@ improve performance.
See [Multi-value dimensions](multi-value-dimensions.html) for more details.
+### More on subtotalsSpec
+The subtotals feature allows computation of multiple sub-groupings in a single
query. To use this feature, add a "subtotalsSpec" to your query, which should
be a list of subgroup dimension sets. It should contain the "outputName" from
dimensions in your "dimensions" attribute, in the same order as they appear in
the "dimensions" attribute (although, of course, you may skip some). For
example, consider a groupBy query like this one:
+
+```json
+{
+"type": "groupBy",
+ ...
+ ...
+"dimensions": [
+ {
+ "type" : "default",
+ "dimension" : "d1col",
+ "outputName": "D1"
+ },
+ {
+ "type" : "extraction",
+ "dimension" : "d2col",
+ "outputName" : "D2",
+ "extractionFn" : extraction_func
+ },
+ {
+ "type":"lookup",
+ "dimension":"d3col",
+ "outputName":"D3",
+ "name":"my_lookup"
+ }
+],
+...
+...
+"subtotalsSpec":[ ["D1", "D2", D3"], ["D1", "D3"], ["D3"]],
+..
+
+}
+```
+
+Response returned would be equivalent to concatenating result of 3 groupBy
queries with "dimensions" field being ["D1", "D2", D3"], ["D1", "D3"] and
["D3"] with appropriate `DimensionSpec` json blob as used in above query.
+Response for above query would look something like below...
+
+```json
+[
+ {
+"version" : "v1",
+"timestamp" : "t1",
+"event" : { "D1": "..", "D2": "..", "D3": ".." }
+}
+ },
+{
+"version" : "v1",
+"timestamp" : "t2",
+"event" : { "D1": "..", "D2": "..", "D3": ".." }
+}
+ },
+ ...
+ ...
+
+ {
+"version" : "v1",
+"timestamp" : "t1",
+"event" : { "D1": "..", "D3": ".." }
+}
+ },
+{
+"version" : "v1",
+"timestamp" : "t2",
+"event" : { "D1": "..", "D3": ".." }
+}
+ },
+ ...
+ ...
+
+ {
+"version" : "v1",
+"timestamp" : "t1",
+"event" : { "D3": ".." }
+}
+ },
+{
+"version" : "v1",
+"timestamp" : "t2",
+"event" : { "D3": ".." }
+}
+ },
+...
+]
+```
+
### Implementation details
Strategies
@@ -182,6 +269,10 @@ With groupBy v2, cluster operators should make sure that
the off-heap hash table
will not exceed available memory for the maximum possible concurrent query
load (given by
druid.processing.numMergeBuffers). See [How much direct memory does Druid
use?](../operations/performance-faq.html) for more details.
+Brokers do not need merge buffers for basic groupBy queries. Queries with
subqueries (using a "query" [dataSource](datasource.html#query-data-source))
require one merge buffer if there is a single subquery, or two merge buffers if
there is more than one layer of nested subqueries. Queries with
[subtotals](groupbyquery.html#more-on-subtotalsspec) need one merge buffer.
These can stack on top of each other: a groupBy query with multiple layers of
[GitHub] gianm closed issue #5179: [Proposal] Add support for multiple grouping specs in groupBy query
gianm closed issue #5179: [Proposal] Add support for multiple grouping specs in groupBy query URL: https://github.com/apache/incubator-druid/issues/5179 This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jihoonson closed pull request #6261: [Backport] RowBasedKeySerde should use empty dictionary in constructor
jihoonson closed pull request #6261: [Backport] RowBasedKeySerde should use
empty dictionary in constructor
URL: https://github.com/apache/incubator-druid/pull/6261
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git
a/processing/src/main/java/io/druid/query/groupby/epinephelinae/RowBasedGrouperHelper.java
b/processing/src/main/java/io/druid/query/groupby/epinephelinae/RowBasedGrouperHelper.java
index fa4f2a95aea..aec0676e2a0 100644
---
a/processing/src/main/java/io/druid/query/groupby/epinephelinae/RowBasedGrouperHelper.java
+++
b/processing/src/main/java/io/druid/query/groupby/epinephelinae/RowBasedGrouperHelper.java
@@ -916,7 +916,6 @@ static long estimateStringKeySize(String key)
private static class RowBasedKeySerde implements
Grouper.KeySerde
{
-private static final int DICTIONARY_INITIAL_CAPACITY = 1;
private static final int UNKNOWN_DICTIONARY_ID = -1;
private final boolean includeTimestamp;
@@ -962,9 +961,9 @@ static long estimateStringKeySize(String key)
this.valueTypes = valueTypes;
this.limitSpec = limitSpec;
this.enableRuntimeDictionaryGeneration = dictionary == null;
- this.dictionary = enableRuntimeDictionaryGeneration ? new
ArrayList<>(DICTIONARY_INITIAL_CAPACITY) : dictionary;
+ this.dictionary = enableRuntimeDictionaryGeneration ? new ArrayList<>()
: dictionary;
this.reverseDictionary = enableRuntimeDictionaryGeneration ?
- new
Object2IntOpenHashMap<>(DICTIONARY_INITIAL_CAPACITY) :
+ new Object2IntOpenHashMap<>() :
new Object2IntOpenHashMap<>(dictionary.size());
this.reverseDictionary.defaultReturnValue(UNKNOWN_DICTIONARY_ID);
this.maxDictionarySize = maxDictionarySize;
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jihoonson commented on a change in pull request #5913: Move Caching Cluster Client to java streams and allow parallel intermediate merges
jihoonson commented on a change in pull request #5913: Move Caching Cluster
Client to java streams and allow parallel intermediate merges
URL: https://github.com/apache/incubator-druid/pull/5913#discussion_r213502827
##
File path:
processing/src/main/java/io/druid/query/ChainedExecutionQueryRunner.java
##
@@ -70,87 +74,115 @@ public ChainedExecutionQueryRunner(
QueryRunner... queryables
)
{
-this(exec, queryWatcher, Arrays.asList(queryables));
+this(exec, queryWatcher, Arrays.stream(queryables));
}
public ChainedExecutionQueryRunner(
ExecutorService exec,
QueryWatcher queryWatcher,
Iterable> queryables
)
+ {
+this(exec, queryWatcher, StreamSupport.stream(queryables.spliterator(),
false));
+ }
+
+ public ChainedExecutionQueryRunner(
+ ExecutorService exec,
+ QueryWatcher queryWatcher,
+ Stream> queryables
+ )
{
// listeningDecorator will leave PrioritizedExecutorService unchanged,
// since it already implements ListeningExecutorService
this.exec = MoreExecutors.listeningDecorator(exec);
-this.queryables = Iterables.unmodifiableIterable(queryables);
this.queryWatcher = queryWatcher;
+this.queryables = queryables;
}
@Override
public Sequence run(final QueryPlus queryPlus, final Map responseContext)
{
-Query query = queryPlus.getQuery();
+final Query query = queryPlus.getQuery();
final int priority = QueryContexts.getPriority(query);
-final Ordering ordering = query.getResultOrdering();
+final Ordering ordering = query.getResultOrdering();
final QueryPlus threadSafeQueryPlus =
queryPlus.withoutThreadUnsafeState();
-return new BaseSequence>(
+return new BaseSequence<>(
new BaseSequence.IteratorMaker>()
{
@Override
public Iterator make()
{
// Make it a List<> to materialize all of the values (so that it
will submit everything to the executor)
-ListenableFuture>> futures = Futures.allAsList(
-Lists.newArrayList(
-Iterables.transform(
-queryables,
-input -> {
- if (input == null) {
-throw new ISE("Null queryRunner! Looks to be some
segment unmapping action happening");
+final ListenableFuture>> futures =
GuavaUtils.allFuturesAsList(
+queryables.peek(
+queryRunner -> {
+ if (queryRunner == null) {
+throw new ISE("Null queryRunner! Looks to be some
segment unmapping action happening");
+ }
+}
+).map(
+queryRunner -> new
AbstractPrioritizedCallable>(priority)
+{
+ @Override
+ public Iterable call()
+ {
+try {
+ Sequence result =
queryRunner.run(threadSafeQueryPlus, responseContext);
+ if (result == null) {
+throw new ISE("Got a null result! Segments are
missing!");
+ }
+
+ List retVal = result.toList();
+ if (retVal == null) {
+throw new ISE("Got a null list of results! WTF?!");
}
- return exec.submit(
- new
AbstractPrioritizedCallable>(priority)
- {
-@Override
-public Iterable call()
-{
- try {
-Sequence result =
input.run(threadSafeQueryPlus, responseContext);
-if (result == null) {
- throw new ISE("Got a null result!
Segments are missing!");
-}
-
-List retVal = result.toList();
-if (retVal == null) {
- throw new ISE("Got a null list of
results! WTF?!");
-}
-
-return retVal;
- }
- catch (QueryInterruptedException e) {
-throw Throwables.propagate(e);
- }
- catch (Exception e) {
-log.error(e, "Exception with one of the
sequences!");
-throw Throwables.propagate(e);
- }
-}
- }
-
[GitHub] jihoonson commented on a change in pull request #5913: Move Caching Cluster Client to java streams and allow parallel intermediate merges
jihoonson commented on a change in pull request #5913: Move Caching Cluster Client to java streams and allow parallel intermediate merges URL: https://github.com/apache/incubator-druid/pull/5913#discussion_r213474326 ## File path: processing/src/main/java/io/druid/query/QueryContexts.java ## @@ -218,6 +239,12 @@ return val == null ? defaultValue : Numbers.parseLong(val); } + static OptionalLong parseLong(Query query, String key) Review comment: All other similar methods return a primitive, so please make this consistent. Maybe it can return a default value if it's not in the context. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jihoonson commented on a change in pull request #5913: Move Caching Cluster Client to java streams and allow parallel intermediate merges
jihoonson commented on a change in pull request #5913: Move Caching Cluster
Client to java streams and allow parallel intermediate merges
URL: https://github.com/apache/incubator-druid/pull/5913#discussion_r213156952
##
File path: common/src/test/java/io/druid/concurrent/ExecsTest.java
##
@@ -55,6 +54,20 @@ public void testBlockingExecutorServiceThreeCapacity()
throws Exception
runTest(3);
}
+ @Test
+ public void testNameFormatGood() throws Exception
+ {
+Execs.checkThreadNameFormat("good-%s");
+Execs.checkThreadNameFormat("good-%d");
+Execs.checkThreadNameFormat("whoops");
+ }
+
+ @Test(expected = IllegalFormatException.class)
+ public void testNameForamtBad() throws Exception
Review comment:
Unnecessary `throws` clause
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gianm commented on issue #6257: [Backport] SQL: Fix post-aggregator naming logic for sort-project.
gianm commented on issue #6257: [Backport] SQL: Fix post-aggregator naming logic for sort-project. URL: https://github.com/apache/incubator-druid/pull/6257#issuecomment-416780459 Had to fix a test-- repushed. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gianm opened a new pull request #6261: [Backport] RowBasedKeySerde should use empty dictionary in constructor
gianm opened a new pull request #6261: [Backport] RowBasedKeySerde should use empty dictionary in constructor URL: https://github.com/apache/incubator-druid/pull/6261 Backport of #6256 to 0.12.3. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jihoonson commented on issue #6255: Heavy GC activities after upgrading to 0.12
jihoonson commented on issue #6255: Heavy GC activities after upgrading to 0.12 URL: https://github.com/apache/incubator-druid/issues/6255#issuecomment-416798810 @gaodayue thank you for the details! Probably we can optimize the initial dictionary size based on 1) spilling is enabled, 2) the column is dictionary encoded, 3) the cardinality of the column, and 4) the filter selectivity. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] fjy closed pull request #6260: [Backport] Don't let catch/finally suppress main exception in IncrementalPublishingKafkaIndexTaskRunner
fjy closed pull request #6260: [Backport] Don't let catch/finally suppress main
exception in IncrementalPublishingKafkaIndexTaskRunner
URL: https://github.com/apache/incubator-druid/pull/6260
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git
a/extensions-core/kafka-indexing-service/src/main/java/io/druid/indexing/kafka/KafkaIndexTask.java
b/extensions-core/kafka-indexing-service/src/main/java/io/druid/indexing/kafka/KafkaIndexTask.java
index d0590dcc4c6..6ace1352fef 100644
---
a/extensions-core/kafka-indexing-service/src/main/java/io/druid/indexing/kafka/KafkaIndexTask.java
+++
b/extensions-core/kafka-indexing-service/src/main/java/io/druid/indexing/kafka/KafkaIndexTask.java
@@ -419,6 +419,7 @@ public TaskStatus run(final TaskToolbox toolbox) throws
Exception
)
);
+Throwable caughtExceptionOuter = null;
try (final KafkaConsumer consumer = newConsumer()) {
toolbox.getDataSegmentServerAnnouncer().announce();
toolbox.getDruidNodeAnnouncer().announce(discoveryDruidNode);
@@ -512,6 +513,7 @@ public void run()
// Could eventually support leader/follower mode (for keeping replicas
more in sync)
boolean stillReading = !assignment.isEmpty();
status = Status.READING;
+ Throwable caughtExceptionInner = null;
try {
while (stillReading) {
if (possiblyPause()) {
@@ -717,12 +719,22 @@ public void onFailure(Throwable t)
}
catch (Exception e) {
// (1) catch all exceptions while reading from kafka
+caughtExceptionInner = e;
log.error(e, "Encountered exception in run() before persisting.");
throw e;
}
finally {
log.info("Persisting all pending data");
-driver.persist(committerSupplier.get()); // persist pending data
+try {
+ driver.persist(committerSupplier.get()); // persist pending data
+}
+catch (Exception e) {
+ if (caughtExceptionInner != null) {
+caughtExceptionInner.addSuppressed(e);
+ } else {
+throw e;
+ }
+}
}
synchronized (statusLock) {
@@ -792,9 +804,17 @@ public void onFailure(Throwable t)
catch (InterruptedException | RejectedExecutionException e) {
// (2) catch InterruptedException and RejectedExecutionException thrown
for the whole ingestion steps including
// the final publishing.
- Futures.allAsList(publishWaitList).cancel(true);
- Futures.allAsList(handOffWaitList).cancel(true);
- appenderator.closeNow();
+ caughtExceptionOuter = e;
+ try {
+Futures.allAsList(publishWaitList).cancel(true);
+Futures.allAsList(handOffWaitList).cancel(true);
+if (appenderator != null) {
+ appenderator.closeNow();
+}
+ }
+ catch (Exception e2) {
+e.addSuppressed(e2);
+ }
// handle the InterruptedException that gets wrapped in a
RejectedExecutionException
if (e instanceof RejectedExecutionException
&& (e.getCause() == null || !(e.getCause() instanceof
InterruptedException))) {
@@ -811,21 +831,38 @@ public void onFailure(Throwable t)
}
catch (Exception e) {
// (3) catch all other exceptions thrown for the whole ingestion steps
including the final publishing.
- Futures.allAsList(publishWaitList).cancel(true);
- Futures.allAsList(handOffWaitList).cancel(true);
- appenderator.closeNow();
+ caughtExceptionOuter = e;
+ try {
+Futures.allAsList(publishWaitList).cancel(true);
+Futures.allAsList(handOffWaitList).cancel(true);
+if (appenderator != null) {
+ appenderator.closeNow();
+}
+ }
+ catch (Exception e2) {
+e.addSuppressed(e2);
+ }
throw e;
}
finally {
- if (driver != null) {
-driver.close();
+ try {
+if (driver != null) {
+ driver.close();
+}
+if (chatHandlerProvider.isPresent()) {
+ chatHandlerProvider.get().unregister(getId());
+}
+
+toolbox.getDruidNodeAnnouncer().unannounce(discoveryDruidNode);
+toolbox.getDataSegmentServerAnnouncer().unannounce();
}
- if (chatHandlerProvider.isPresent()) {
-chatHandlerProvider.get().unregister(getId());
+ catch (Exception e) {
+if (caughtExceptionOuter != null) {
+ caughtExceptionOuter.addSuppressed(e);
+} else {
+ throw e;
+}
}
-
- toolbox.getDruidNodeAnnouncer().unannounce(discoveryDruidNode);
- toolbox.getDataSegmentServerAnnouncer().unannounce();
}
return success();
This
[GitHub] gaodayue commented on issue #6255: Heavy GC activities after upgrading to 0.12
gaodayue commented on issue #6255: Heavy GC activities after upgrading to 0.12 URL: https://github.com/apache/incubator-druid/issues/6255#issuecomment-416797137 > @gaodayue thank you for catching this. Could you share some more details of your use case? I wonder especially how large the dictionary was. I set the initial size of dictionary map to 1 because I thought SpillingGrouper isn't supposed to be used for small dictionary. Hi @jihoonson , as you commented in #6256 , ConcurrentGrouper always uses SpillingGrouper as sub-groupers no matter whether spilling is enabled or not. So dictionary is initialized for all groupby queries even when it's not used (not grouping by string columns). One of our use cases is providing realtime KPI monitoring for BD (business developer). The query for each BD is something like `where bd=xx and dim1=yy group by bd, dim1`. As a result, the size of dictionary used in merging is always 2. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gaodayue commented on issue #6256: RowBasedKeySerde should use empty dictionary in constructor
gaodayue commented on issue #6256: RowBasedKeySerde should use empty dictionary in constructor URL: https://github.com/apache/incubator-druid/pull/6256#issuecomment-416799333 > Could you please add a comment about why the map is starting out empty (avoiding allocating too much when it's not needed)? Otherwise, a future contributor might not realize it. Thank you @gianm . It's a good advice, but the PR is merged. Maybe we can add it in future optimization. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gaodayue commented on issue #6246: add a sql option to force user to specify time condition
gaodayue commented on issue #6246: add a sql option to force user to specify time condition URL: https://github.com/apache/incubator-druid/pull/6246#issuecomment-416800294 Hi @gianm , could you take a look at this? This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gaodayue commented on issue #6255: Heavy GC activities after upgrading to 0.12
gaodayue commented on issue #6255: Heavy GC activities after upgrading to 0.12 URL: https://github.com/apache/incubator-druid/issues/6255#issuecomment-416798257 As I mentioned above, the creation rate of merging dictionary is roughly `2 (forward and reverse dict) x processing.numThreads (ConcurrentGrouper's concurrency) x QPS`. The higher processing.numThreads and qps, the greater the probability to encounter the problem. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] QiuMM commented on a change in pull request #6251: fix opentsdb emitter always be running
QiuMM commented on a change in pull request #6251: fix opentsdb emitter always be running URL: https://github.com/apache/incubator-druid/pull/6251#discussion_r213537407 ## File path: extensions-contrib/opentsdb-emitter/src/main/java/io/druid/emitter/opentsdb/OpentsdbSender.java ## @@ -40,28 +43,40 @@ */ private static final String PATH = "/api/put"; private static final Logger log = new Logger(OpentsdbSender.class); + private static final long FLUSH_TIMEOUT = 6; // default flush wait 1 min Review comment: Yes it is. This is learned from other emitter extensions, e.g graphite-emitter. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] QiuMM commented on issue #6254: fix opentsdb emitter occupy 100%(#6247)
QiuMM commented on issue #6254: fix opentsdb emitter occupy 100%(#6247) URL: https://github.com/apache/incubator-druid/pull/6254#issuecomment-416835680 I have fixed what you mentioned @zhaojiandong. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] waixiaoyu commented on issue #6252: Deadlock may be in TaskMaster when stopping
waixiaoyu commented on issue #6252: Deadlock may be in TaskMaster when stopping URL: https://github.com/apache/incubator-druid/issues/6252#issuecomment-416838393 @himanshug No, my zookeeper is used by other programs. So I just wanna shutdown Druid cluster, except Zookeeper. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] QiuMM commented on a change in pull request #6251: fix opentsdb emitter always be running
QiuMM commented on a change in pull request #6251: fix opentsdb emitter always
be running
URL: https://github.com/apache/incubator-druid/pull/6251#discussion_r213552927
##
File path:
extensions-contrib/opentsdb-emitter/src/main/java/io/druid/emitter/opentsdb/OpentsdbSender.java
##
@@ -109,13 +141,11 @@ private void sendEvents()
@Override
public void run()
{
- while (running) {
-if (!eventQueue.isEmpty()) {
- OpentsdbEvent event = eventQueue.poll();
- events.add(event);
- if (events.size() >= flushThreshold) {
-sendEvents();
- }
+ while (!eventQueue.isEmpty() && !scheduler.isShutdown()) {
+OpentsdbEvent event = eventQueue.poll();
+events.add(event);
+if (events.size() >= flushThreshold) {
+ sendEvents();
Review comment:
Actually, I used `scheduleWithFixedDelay` not `scheduleAtFixedRate` in my
code. There may be two EventConsumer tasks at the same time only in the case of
`flush` method being called. And I fixed it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] QiuMM commented on a change in pull request #6251: fix opentsdb emitter always be running
QiuMM commented on a change in pull request #6251: fix opentsdb emitter always
be running
URL: https://github.com/apache/incubator-druid/pull/6251#discussion_r213552927
##
File path:
extensions-contrib/opentsdb-emitter/src/main/java/io/druid/emitter/opentsdb/OpentsdbSender.java
##
@@ -109,13 +141,11 @@ private void sendEvents()
@Override
public void run()
{
- while (running) {
-if (!eventQueue.isEmpty()) {
- OpentsdbEvent event = eventQueue.poll();
- events.add(event);
- if (events.size() >= flushThreshold) {
-sendEvents();
- }
+ while (!eventQueue.isEmpty() && !scheduler.isShutdown()) {
+OpentsdbEvent event = eventQueue.poll();
+events.add(event);
+if (events.size() >= flushThreshold) {
+ sendEvents();
Review comment:
Actually, I used `scheduleWithFixedDelay` not `scheduleAtFixedRate` in my
code. There may be two EventConsumer tasks at the same time only in the case of
`flush` method being called. And I fixed it. Thanks for your reminder.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] zhaojiandong commented on a change in pull request #6251: fix opentsdb emitter always be running
zhaojiandong commented on a change in pull request #6251: fix opentsdb emitter
always be running
URL: https://github.com/apache/incubator-druid/pull/6251#discussion_r213538511
##
File path:
extensions-contrib/opentsdb-emitter/src/main/java/io/druid/emitter/opentsdb/OpentsdbSender.java
##
@@ -109,13 +141,11 @@ private void sendEvents()
@Override
public void run()
{
- while (running) {
-if (!eventQueue.isEmpty()) {
- OpentsdbEvent event = eventQueue.poll();
- events.add(event);
- if (events.size() >= flushThreshold) {
-sendEvents();
- }
+ while (!eventQueue.isEmpty() && !scheduler.isShutdown()) {
+OpentsdbEvent event = eventQueue.poll();
+events.add(event);
+if (events.size() >= flushThreshold) {
+ sendEvents();
Review comment:
If emitter has large amounts data continuously, eventQueue always has
element, this will be multiple EventConsumer tasks at the same time. The object
events is a List, it's not safe when multiple tasks use it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] zhaojiandong commented on issue #6254: fix opentsdb emitter occupy 100%(#6247)
zhaojiandong commented on issue #6254: fix opentsdb emitter occupy 100%(#6247) URL: https://github.com/apache/incubator-druid/pull/6254#issuecomment-416825059 [#6251](https://github.com/apache/incubator-druid/pull/6251/files) uses ScheduledExecutorService to schedule. But if emitter has large amounts data continuously, eventQueue always has element, there will be multiple EventConsumer tasks at the same time. And the object "events" is a List, it's not safe when multiple tasks consumer it. @gianm 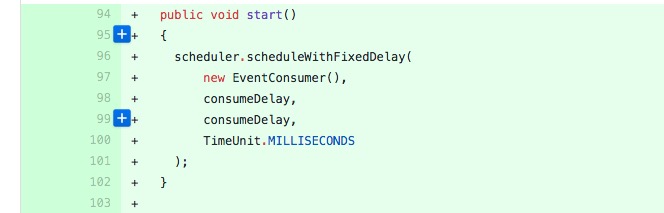 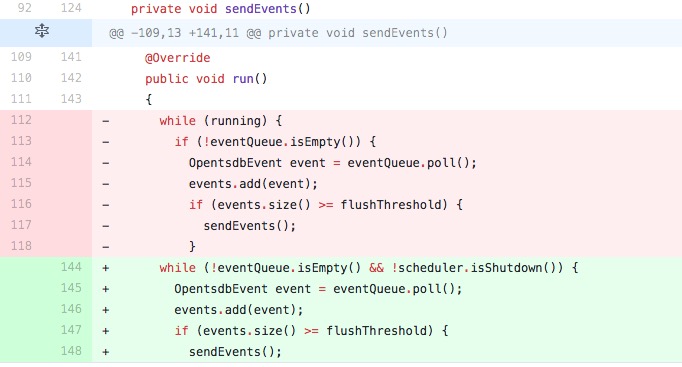 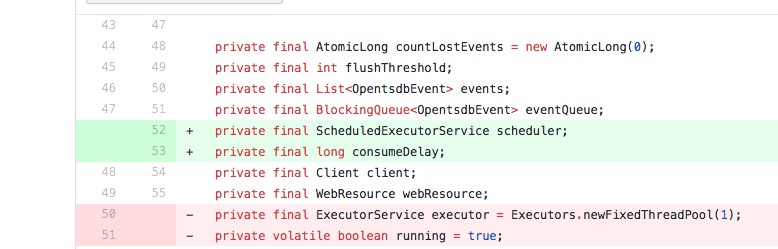 This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] QiuMM commented on a change in pull request #6251: fix opentsdb emitter always be running
QiuMM commented on a change in pull request #6251: fix opentsdb emitter always be running URL: https://github.com/apache/incubator-druid/pull/6251#discussion_r213553407 ## File path: docs/content/development/extensions-contrib/opentsdb-emitter.md ## @@ -18,10 +18,11 @@ All the configuration parameters for the opentsdb emitter are under `druid.emitt ||---|-|---| |`druid.emitter.opentsdb.host`|The host of the OpenTSDB server.|yes|none| |`druid.emitter.opentsdb.port`|The port of the OpenTSDB server.|yes|none| -|`druid.emitter.opentsdb.connectionTimeout`|Connection timeout(in milliseconds).|no|2000| -|`druid.emitter.opentsdb.readTimeout`|Read timeout(in milliseconds).|no|2000| +|`druid.emitter.opentsdb.connectionTimeout`|`Jersey client` connection timeout(in milliseconds).|no|2000| +|`druid.emitter.opentsdb.readTimeout`|`Jersey client` read timeout(in milliseconds).|no|2000| |`druid.emitter.opentsdb.flushThreshold`|Queue flushing threshold.(Events will be sent as one batch)|no|100| |`druid.emitter.opentsdb.maxQueueSize`|Maximum size of the queue used to buffer events.|no|1000| +|`druid.emitter.opentsdb.consumeDelay`|Queue consuming delay(in milliseconds).|no|1| Review comment: Done. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] ranjan321 commented on issue #6210: Csv with Header giving 'Success' but not loading any data
ranjan321 commented on issue #6210: Csv with Header giving 'Success' but not loading any data URL: https://github.com/apache/incubator-druid/issues/6210#issuecomment-416881656 Still i didn't get any response .please look into this issue as it an urgency This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gianm closed issue #6255: Heavy GC activities after upgrading to 0.12
gianm closed issue #6255: Heavy GC activities after upgrading to 0.12 URL: https://github.com/apache/incubator-druid/issues/6255 This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gianm closed pull request #6256: RowBasedKeySerde should use empty dictionary in constructor
gianm closed pull request #6256: RowBasedKeySerde should use empty dictionary
in constructor
URL: https://github.com/apache/incubator-druid/pull/6256
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git
a/processing/src/main/java/io/druid/query/groupby/epinephelinae/RowBasedGrouperHelper.java
b/processing/src/main/java/io/druid/query/groupby/epinephelinae/RowBasedGrouperHelper.java
index 2ae1dde0e97..3acd2fd705a 100644
---
a/processing/src/main/java/io/druid/query/groupby/epinephelinae/RowBasedGrouperHelper.java
+++
b/processing/src/main/java/io/druid/query/groupby/epinephelinae/RowBasedGrouperHelper.java
@@ -912,7 +912,6 @@ static long estimateStringKeySize(@Nullable String key)
private static class RowBasedKeySerde implements
Grouper.KeySerde
{
-private static final int DICTIONARY_INITIAL_CAPACITY = 1;
private static final int UNKNOWN_DICTIONARY_ID = -1;
private final boolean includeTimestamp;
@@ -958,9 +957,9 @@ static long estimateStringKeySize(@Nullable String key)
this.valueTypes = valueTypes;
this.limitSpec = limitSpec;
this.enableRuntimeDictionaryGeneration = dictionary == null;
- this.dictionary = enableRuntimeDictionaryGeneration ? new
ArrayList<>(DICTIONARY_INITIAL_CAPACITY) : dictionary;
+ this.dictionary = enableRuntimeDictionaryGeneration ? new ArrayList<>()
: dictionary;
this.reverseDictionary = enableRuntimeDictionaryGeneration ?
- new
Object2IntOpenHashMap<>(DICTIONARY_INITIAL_CAPACITY) :
+ new Object2IntOpenHashMap<>() :
new Object2IntOpenHashMap<>(dictionary.size());
this.reverseDictionary.defaultReturnValue(UNKNOWN_DICTIONARY_ID);
this.maxDictionarySize = maxDictionarySize;
This is an automated message from the Apache Git Service.
To respond to the message, please log on GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] fjy closed pull request #6257: [Backport] SQL: Fix post-aggregator naming logic for sort-project.
fjy closed pull request #6257: [Backport] SQL: Fix post-aggregator naming logic
for sort-project.
URL: https://github.com/apache/incubator-druid/pull/6257
This is a PR merged from a forked repository.
As GitHub hides the original diff on merge, it is displayed below for
the sake of provenance:
As this is a foreign pull request (from a fork), the diff is supplied
below (as it won't show otherwise due to GitHub magic):
diff --git a/sql/src/main/java/io/druid/sql/calcite/rel/DruidQuery.java
b/sql/src/main/java/io/druid/sql/calcite/rel/DruidQuery.java
index d10751010bd..5a3948e9e13 100644
--- a/sql/src/main/java/io/druid/sql/calcite/rel/DruidQuery.java
+++ b/sql/src/main/java/io/druid/sql/calcite/rel/DruidQuery.java
@@ -89,7 +89,6 @@
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
-import java.util.OptionalInt;
import java.util.TreeSet;
import java.util.stream.Collectors;
@@ -285,7 +284,7 @@ private static Grouping computeGrouping(
plannerContext,
aggregateRowSignature,
aggregateProject,
- 0
+ "p"
);
projectRowOrderAndPostAggregations.postAggregations.forEach(
postAggregator ->
aggregations.add(Aggregation.create(postAggregator))
@@ -324,17 +323,11 @@ private SortProject computeSortProject(
if (sortProject == null) {
return null;
} else {
- final List postAggregators =
grouping.getPostAggregators();
- final OptionalInt maybeMaxCounter = postAggregators
- .stream()
- .mapToInt(postAggregator ->
Integer.parseInt(postAggregator.getName().substring(1)))
- .max();
-
final ProjectRowOrderAndPostAggregations
projectRowOrderAndPostAggregations = computePostAggregations(
plannerContext,
sortingInputRowSignature,
sortProject,
- maybeMaxCounter.orElse(-1) + 1 // 0 if max doesn't exist
+ "s"
);
return new SortProject(
@@ -361,12 +354,17 @@ private static ProjectRowOrderAndPostAggregations
computePostAggregations(
PlannerContext plannerContext,
RowSignature inputRowSignature,
Project project,
- int outputNameCounter
+ String basePrefix
)
{
final List rowOrder = new ArrayList<>();
final List aggregations = new ArrayList<>();
+final String outputNamePrefix = Calcites.findUnusedPrefix(
+basePrefix,
+new TreeSet<>(inputRowSignature.getRowOrder())
+);
+int outputNameCounter = 0;
for (final RexNode postAggregatorRexNode : project.getChildExps()) {
// Attempt to convert to PostAggregator.
final DruidExpression postAggregatorExpression =
Expressions.toDruidExpression(
@@ -384,7 +382,7 @@ private static ProjectRowOrderAndPostAggregations
computePostAggregations(
// (There might be a SQL-level type cast that we don't care about)
rowOrder.add(postAggregatorExpression.getDirectColumn());
} else {
-final String postAggregatorName = "p" + outputNameCounter++;
+final String postAggregatorName = outputNamePrefix +
outputNameCounter++;
final PostAggregator postAggregator = new ExpressionPostAggregator(
postAggregatorName,
postAggregatorExpression.getExpression(),
diff --git a/sql/src/test/java/io/druid/sql/calcite/CalciteQueryTest.java
b/sql/src/test/java/io/druid/sql/calcite/CalciteQueryTest.java
index 842a76a8aa5..8683fe41589 100644
--- a/sql/src/test/java/io/druid/sql/calcite/CalciteQueryTest.java
+++ b/sql/src/test/java/io/druid/sql/calcite/CalciteQueryTest.java
@@ -4124,6 +4124,69 @@ public void testExactCountDistinctUsingSubquery() throws
Exception
);
}
+ @Test
+ public void testMinMaxAvgDailyCountWithLimit() throws Exception
+ {
+testQuery(
+"SELECT * FROM ("
++ " SELECT max(cnt), min(cnt), avg(cnt), TIME_EXTRACT(max(t),
'EPOCH') last_time, count(1) num_days FROM (\n"
++ " SELECT TIME_FLOOR(__time, 'P1D') AS t, count(1) cnt\n"
++ " FROM \"foo\"\n"
++ " GROUP BY 1\n"
++ " )"
++ ") LIMIT 1\n",
+ImmutableList.of(
+GroupByQuery.builder()
+.setDataSource(
+new QueryDataSource(
+GroupByQuery.builder()
+
.setDataSource(CalciteTests.DATASOURCE1)
+
.setInterval(QSS(Filtration.eternity()))
+.setGranularity(Granularities.ALL)
+.setVirtualColumns(
+EXPRESSION_VIRTUAL_COLUMN(
+"d0:v",
+
"timestamp_floor(\"__time\",'P1D','','UTC')",
+ValueType.LONG
+
[GitHub] fjy commented on issue #5938: URL encode datasources, task ids, authenticator names.
fjy commented on issue #5938: URL encode datasources, task ids, authenticator names. URL: https://github.com/apache/incubator-druid/pull/5938#issuecomment-414143789 @gianm this is having a hard time passing integration tests This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] KenjiTakahashi opened a new pull request #6195: Fix running Overlord inside Coordinator
KenjiTakahashi opened a new pull request #6195: Fix running Overlord inside Coordinator URL: https://github.com/apache/incubator-druid/pull/6195 Fixes #6133. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gianm edited a comment on issue #5709: Broker resiliency to misbehaving historical nodes
gianm edited a comment on issue #5709: Broker resiliency to misbehaving historical nodes URL: https://github.com/apache/incubator-druid/issues/5709#issuecomment-414175186 Hi @peferron, That scope sounds useful for an initial patch. I think the biggest risk is that queries that are doomed to failure, possibly because of resource limits being exceeded, will get retried too much and double/triple the load on the cluster (depending on how many retries are allowed). Some suggestions to mitigate that: - Check the error code (if there is one) and don't retry on codes like RESOURCE_LIMIT_EXCEEDED, UNAUTHORIZED, or QUERY_TIMEOUT. (The latter one because, probably, the overall timeout of the query has passed by then anyway.) - Don't retry more than X subqueries per query. Another thing to think about is that it is possible for results to be partially retrieved (and partially processed) and then for the subquery to fail midway through (before all results have come in). In this case, it's probably not possible for the broker to recover, since subquery results have already been mixed into the overall query results. The query may need to be retried from scratch. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gianm commented on issue #5709: Broker resiliency to misbehaving historical nodes
gianm commented on issue #5709: Broker resiliency to misbehaving historical nodes URL: https://github.com/apache/incubator-druid/issues/5709#issuecomment-414175186 Hi @peferron, That scope sounds useful for an initial patch. I think the biggest risk is that queries that are doomed to failure, possibly because of resource limits being exceeded, will get retried too much and double/triple the load on the cluster (depending on how many retries are allowed). Some suggestions to mitigate that: - Check the error code (if there is one) and don't retry on codes like RESOURCE_LIMIT_EXCEEDED, UNAUTHORIZED, or QUERY_TIMEOUT. (The latter one because, probably, the overall timeout of the query has passed by then anyway.) - Don't retry more than X subqueries per query. Another thing to think about is that it is possible for results to be partially retrieved (and partially processed) and then for the query to fail midway through. In this case, it's probably not possible to recover, since subquery results have already been mixed into the overall query results. The query may need to be retried from scratch. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gianm commented on issue #6189: Lucene indexing for free form text
gianm commented on issue #6189: Lucene indexing for free form text URL: https://github.com/apache/incubator-druid/issues/6189#issuecomment-414172408 Hi @RestfulBlue, it sounds like an interesting idea. Are you imagining adding a Lucene index as a companion to a Druid segment (i.e. adding one as a new column, maybe) or as an alternate format (a new type of StorageAdapter)? One other thing you could look at is using Druid's multivalue dimensions. The idea would be to support text search by tokenizing input fields into arrays and storing them as multivalue dimensions. Then, you can do a search by tokening the search string the same way and retrieving the relevant terms from the inverted index of the multivalue dimension. What do you think? This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gianm commented on issue #6088: Scan query: time-ordering
gianm commented on issue #6088: Scan query: time-ordering URL: https://github.com/apache/incubator-druid/issues/6088#issuecomment-414174269 > FYI: I'd just like to see this kept as option in the query, so ones that do no need sorting avoid the performance hit. Agreed, we should keep the default as unsorted. > Current implementation of select query is almost unusable. It cant be limited and can kill entire cluster. i hope this change will be implemented in near future. after that, i think current select query can be removed at all =) I'd definitely love to be able to remove the select query. I believe its design is not salvageable. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] gianm commented on issue #5938: URL encode datasources, task ids, authenticator names.
gianm commented on issue #5938: URL encode datasources, task ids, authenticator names. URL: https://github.com/apache/incubator-druid/pull/5938#issuecomment-414175659 I wasn't sure if it was timing out (we are pretty close to the timeout) or if there was something wrong with the patch that affects the integration tests. I'll take a closer look soon. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] leventov commented on issue #5737: Include hybrid and caffeine in cache docs and show caffeine as default
leventov commented on issue #5737: Include hybrid and caffeine in cache docs and show caffeine as default URL: https://github.com/apache/incubator-druid/pull/5737#issuecomment-414162618 Related: #6161 This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] QiuMM opened a new pull request #6193: remove duplicate link to operations/recommendations.html
QiuMM opened a new pull request #6193: remove duplicate link to operations/recommendations.html URL: https://github.com/apache/incubator-druid/pull/6193 There are two item links to the operations/recommendations.html, just remove one. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] QiuMM opened a new pull request #6194: remove unnecessary tlsPortFinder to avoid potential port conflicts
QiuMM opened a new pull request #6194: remove unnecessary tlsPortFinder to avoid potential port conflicts URL: https://github.com/apache/incubator-druid/pull/6194 Fix #6190. This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] jon-wei commented on issue #6187: [Backport] Fix three bugs with segment publishing. (#6155)
jon-wei commented on issue #6187: [Backport] Fix three bugs with segment publishing. (#6155) URL: https://github.com/apache/incubator-druid/pull/6187#issuecomment-414017677 @fjy The backport was incomplete, I fixed it now This is an automated message from the Apache Git Service. To respond to the message, please log on GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org