[GitHub] [incubator-druid] vogievetsky commented on issue #8823: Add InputSource and InputFormat interfaces
vogievetsky commented on issue #8823: Add InputSource and InputFormat interfaces URL: https://github.com/apache/incubator-druid/pull/8823#issuecomment-549699847 This is amazing. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] jihoonson opened a new pull request #8823: Add InputSource and InputFormat interfaces
jihoonson opened a new pull request #8823: Add InputSource and InputFormat interfaces URL: https://github.com/apache/incubator-druid/pull/8823 ### Description This is the First PR for https://github.com/apache/incubator-druid/issues/8812 which includes the new interfaces proposed in #8812. A couple of implementations are also included such as `LocalInputSource` and `HttpInputSource` for `InputSource`, and `CsvInputFormat` and `JsonInputFormat` for `InputFormat`. The old `firehose` and `parser` parameters should still work, but you cannot mix them. Only the combinations of `firehose` + `parser` or `inputSource` + `inputFormat` are allowed. Documents will be added after more inputSources and inputFormats are implemented in follow-up PRs. This PR has: - [x] been self-reviewed. - [ ] using the [concurrency checklist](https://github.com/apache/incubator-druid/blob/master/dev/code-review/concurrency.md) (Remove this item if the PR doesn't have any relation to concurrency.) - [ ] added documentation for new or modified features or behaviors. - [x] added Javadocs for most classes and all non-trivial methods. Linked related entities via Javadoc links. - [ ] added or updated version, license, or notice information in [licenses.yaml](https://github.com/apache/incubator-druid/blob/master/licenses.yaml) - [ ] added comments explaining the "why" and the intent of the code wherever would not be obvious for an unfamiliar reader. - [x] added unit tests or modified existing tests to cover new code paths. - [ ] added integration tests. - [x] been tested in a test Druid cluster. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] stale[bot] commented on issue #6922: Authorizer is never executed after passing from Authenticator
stale[bot] commented on issue #6922: Authorizer is never executed after passing from Authenticator URL: https://github.com/apache/incubator-druid/issues/6922#issuecomment-549661674 This issue has been marked as stale due to 280 days of inactivity. It will be closed in 4 weeks if no further activity occurs. If this issue is still relevant, please simply write any comment. Even if closed, you can still revive the issue at any time or discuss it on the d...@druid.apache.org list. Thank you for your contributions. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] suneet-amp commented on issue #8822: optimize numeric column null value checking for low filter selectivity (more rows)
suneet-amp commented on issue #8822: optimize numeric column null value checking for low filter selectivity (more rows) URL: https://github.com/apache/incubator-druid/pull/8822#issuecomment-549657961 The heatmaps look super cool! (although I don't think I fully understand them yet :| ) What did you use to build them? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis commented on issue #6823: Use an enum for aggregator cache key byte identifiers instead of static values
clintropolis commented on issue #6823: Use an enum for aggregator cache key byte identifiers instead of static values URL: https://github.com/apache/incubator-druid/issues/6823#issuecomment-549650904 Still relevant This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] stale[bot] commented on issue #6823: Use an enum for aggregator cache key byte identifiers instead of static values
stale[bot] commented on issue #6823: Use an enum for aggregator cache key byte identifiers instead of static values URL: https://github.com/apache/incubator-druid/issues/6823#issuecomment-549650919 This issue is no longer marked as stale. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] stale[bot] commented on issue #6823: Use an enum for aggregator cache key byte identifiers instead of static values
stale[bot] commented on issue #6823: Use an enum for aggregator cache key byte identifiers instead of static values URL: https://github.com/apache/incubator-druid/issues/6823#issuecomment-549640247 This issue has been marked as stale due to 280 days of inactivity. It will be closed in 4 weeks if no further activity occurs. If this issue is still relevant, please simply write any comment. Even if closed, you can still revive the issue at any time or discuss it on the d...@druid.apache.org list. Thank you for your contributions. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis opened a new pull request #8822: optimize numeric column null value checking for low filter selectivity (more rows)
clintropolis opened a new pull request #8822: optimize numeric column null value checking for low filter selectivity (more rows) URL: https://github.com/apache/incubator-druid/pull/8822 ### Description I would like to add documentation for Druid SQL compatible null handling added in #4349 to the website, in part because it has been merged for quite a while now, but also so that we can feel better about the changes #8566 causes in SQL behavior in Druids native mode (tl;dr some calcite optimizations lead to some query incompatibilities specifically around our treatment of `''` and `null` as equivalent). Part of like.. being responsible and stuff, before adding this documentation I first wanted to collect some data to determine if it _was a good idea to in fact document it at this time_. The place I was specifically worried about was the `isNull` check, so I added a benchmark, `NullHandlingBitmapGetVsIteratorBenchmark`, and ran some experiments to see what to expect as well as if we could do better. The nature of selectors lends itself to using a bitmap iterator as an alternative to calling bitmap.get for every `isNull` check, so I first tested `get` vs `iterator` with various null bitmap densities and filter selectivities to simulate the overhead of having null value handling selector with each approach. I have so far only collected information on roaring, because with `concise` the `get` method would not complete at low selectivity, so I'm assuming it's numbers are quite bad (and more on this later). To help make sense of the numbers collected from this, I created heatmaps to compare the differences between the approaches. With the raw output, these looked something like this which isn't so telling:  Interpolating the data to fill in the gaps yields something a bit prettier, but still not incredibly telling on it's own:  But does start to offer that the iterator is better at dealing with a larger number of rows, diminishing as the density of the bitmap increases. Scaling the data points to estimate the _cost per row_ in nanoseconds provides a much more useful picture, and shows the abysmal performance of using the iterator at super high selectivity (e.g. 0.1% of rows match and are selected) with really dense bitmaps:  However if we truncate the results and compare areas where the `iterator` is better:  to where `get` is better  it does look like the iterator does perform up to 15 `ns per row` better than using `get` when processing a lot of rows. Searching for a way around the limitation, I was unaware that the `IntIterator` for roaring was actually a `PeekableIntIterator` which is an iterator that offers an `advanceIfNeeded` method that allows skipping the iterator ahead to an index. `ConciseSet` actually has a similar method on it's iterator, `skipAllBefore`, which _is used by_ the `contains` method that the `get` of concise uses! This is likely why concise just flat out wouldn't complete the benchmarks when processing a higher number of rows, because every `get` is creating an iterator, skipping to the position, loop checking to see if the iterator contains the index or passes it, and then throwing it away. Adding the 'peekable' iterator to the benchmark had a similar outcome to using the plain iterator,  but without nearly the overhead at high selectivity on dense bitmaps.  It's still worse, but not nearly as bad, no more than 60ns slower per row when processing a small number of rows than get, compared to over 2 microseconds for using the plain iterator. Peekable iterator better:  Get better than peekable iterator:  F
[GitHub] [incubator-druid] ccaominh commented on a change in pull request #8748: Use earliest offset on kafka newly discovered partitions
ccaominh commented on a change in pull request #8748: Use earliest offset on
kafka newly discovered partitions
URL: https://github.com/apache/incubator-druid/pull/8748#discussion_r342339664
##
File path:
extensions-core/kafka-indexing-service/src/test/java/org/apache/druid/indexing/kafka/supervisor/KafkaSupervisorTest.java
##
@@ -585,6 +589,108 @@ public void testLatestOffset() throws Exception
);
}
+ /**
+ * Test if partitionIds get updated
+ */
+ @Test
+ public void testPartitionIdsUpdates() throws Exception
+ {
+supervisor = getTestableSupervisor(1, 1, false, "PT1H", null, null);
+addSomeEvents(1100);
+
+Capture captured = Capture.newInstance();
+
EasyMock.expect(taskMaster.getTaskQueue()).andReturn(Optional.of(taskQueue)).anyTimes();
+
EasyMock.expect(taskMaster.getTaskRunner()).andReturn(Optional.absent()).anyTimes();
+
EasyMock.expect(taskStorage.getActiveTasksByDatasource(DATASOURCE)).andReturn(ImmutableList.of()).anyTimes();
+
EasyMock.expect(indexerMetadataStorageCoordinator.getDataSourceMetadata(DATASOURCE)).andReturn(
+new KafkaDataSourceMetadata(
+null
+)
+).anyTimes();
+EasyMock.expect(taskQueue.add(EasyMock.capture(captured))).andReturn(true);
+replayAll();
+
+supervisor.start();
+supervisor.runInternal();
+verifyAll();
+
+Assert.assertFalse(supervisor.isPartitionIdsEmpty());
+ }
+
+
+ /**
+ * Test For if always use earliest offset on newly discovered partitions
+ */
+ @Ignore("This is a regression test that needs to wait 10s+, ignore for now")
+ @Test
+ public void testLatestOffsetOnDiscovery() throws Exception
+ {
+supervisor = getTestableSupervisor(1, 1, false, "PT1H", null, null);
+addSomeEvents(9);
+
+Capture captured = Capture.newInstance();
+
EasyMock.expect(taskMaster.getTaskQueue()).andReturn(Optional.of(taskQueue)).anyTimes();
+
EasyMock.expect(taskMaster.getTaskRunner()).andReturn(Optional.absent()).anyTimes();
+
EasyMock.expect(taskStorage.getActiveTasksByDatasource(DATASOURCE)).andReturn(ImmutableList.of()).anyTimes();
+
EasyMock.expect(indexerMetadataStorageCoordinator.getDataSourceMetadata(DATASOURCE)).andReturn(
+new KafkaDataSourceMetadata(
+null
+)
+).anyTimes();
+EasyMock.expect(taskQueue.add(EasyMock.capture(captured))).andReturn(true);
+replayAll();
+supervisor.start();
+supervisor.runInternal();
+verifyAll();
+
+KafkaIndexTask task = captured.getValue();
+Assert.assertEquals(
+10,
+
task.getIOConfig().getStartSequenceNumbers().getPartitionSequenceNumberMap().get(0).longValue()
+);
+Assert.assertEquals(
+10,
+
task.getIOConfig().getStartSequenceNumbers().getPartitionSequenceNumberMap().get(1).longValue()
+);
+Assert.assertEquals(
+10,
+
task.getIOConfig().getStartSequenceNumbers().getPartitionSequenceNumberMap().get(2).longValue()
+);
+
+addMoreEvents(9, 6);
+Thread.sleep(1);
Review comment:
The GitHub comment is useful, but having it in the source code is what I had
in mind.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] SEKIRO-J commented on a change in pull request #8748: Use earliest offset on kafka newly discovered partitions
SEKIRO-J commented on a change in pull request #8748: Use earliest offset on
kafka newly discovered partitions
URL: https://github.com/apache/incubator-druid/pull/8748#discussion_r342334184
##
File path:
extensions-core/kafka-indexing-service/src/test/java/org/apache/druid/indexing/kafka/supervisor/KafkaSupervisorTest.java
##
@@ -585,6 +589,108 @@ public void testLatestOffset() throws Exception
);
}
+ /**
+ * Test if partitionIds get updated
+ */
+ @Test
+ public void testPartitionIdsUpdates() throws Exception
+ {
+supervisor = getTestableSupervisor(1, 1, false, "PT1H", null, null);
+addSomeEvents(1100);
+
+Capture captured = Capture.newInstance();
+
EasyMock.expect(taskMaster.getTaskQueue()).andReturn(Optional.of(taskQueue)).anyTimes();
+
EasyMock.expect(taskMaster.getTaskRunner()).andReturn(Optional.absent()).anyTimes();
+
EasyMock.expect(taskStorage.getActiveTasksByDatasource(DATASOURCE)).andReturn(ImmutableList.of()).anyTimes();
+
EasyMock.expect(indexerMetadataStorageCoordinator.getDataSourceMetadata(DATASOURCE)).andReturn(
+new KafkaDataSourceMetadata(
+null
+)
+).anyTimes();
+EasyMock.expect(taskQueue.add(EasyMock.capture(captured))).andReturn(true);
+replayAll();
+
+supervisor.start();
+supervisor.runInternal();
+verifyAll();
+
+Assert.assertFalse(supervisor.isPartitionIdsEmpty());
+ }
+
+
+ /**
+ * Test For if always use earliest offset on newly discovered partitions
+ */
+ @Ignore("This is a regression test that needs to wait 10s+, ignore for now")
+ @Test
+ public void testLatestOffsetOnDiscovery() throws Exception
+ {
+supervisor = getTestableSupervisor(1, 1, false, "PT1H", null, null);
+addSomeEvents(9);
+
+Capture captured = Capture.newInstance();
+
EasyMock.expect(taskMaster.getTaskQueue()).andReturn(Optional.of(taskQueue)).anyTimes();
+
EasyMock.expect(taskMaster.getTaskRunner()).andReturn(Optional.absent()).anyTimes();
+
EasyMock.expect(taskStorage.getActiveTasksByDatasource(DATASOURCE)).andReturn(ImmutableList.of()).anyTimes();
+
EasyMock.expect(indexerMetadataStorageCoordinator.getDataSourceMetadata(DATASOURCE)).andReturn(
+new KafkaDataSourceMetadata(
+null
+)
+).anyTimes();
+EasyMock.expect(taskQueue.add(EasyMock.capture(captured))).andReturn(true);
+replayAll();
+supervisor.start();
+supervisor.runInternal();
+verifyAll();
+
+KafkaIndexTask task = captured.getValue();
+Assert.assertEquals(
+10,
+
task.getIOConfig().getStartSequenceNumbers().getPartitionSequenceNumberMap().get(0).longValue()
+);
+Assert.assertEquals(
+10,
+
task.getIOConfig().getStartSequenceNumbers().getPartitionSequenceNumberMap().get(1).longValue()
+);
+Assert.assertEquals(
+10,
+
task.getIOConfig().getStartSequenceNumbers().getPartitionSequenceNumberMap().get(2).longValue()
+);
+
+addMoreEvents(9, 6);
+Thread.sleep(1);
Review comment:
https://github.com/apache/incubator-druid/pull/8748#issuecomment-548955564
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] SEKIRO-J commented on a change in pull request #8748: Use earliest offset on kafka newly discovered partitions
SEKIRO-J commented on a change in pull request #8748: Use earliest offset on
kafka newly discovered partitions
URL: https://github.com/apache/incubator-druid/pull/8748#discussion_r342334184
##
File path:
extensions-core/kafka-indexing-service/src/test/java/org/apache/druid/indexing/kafka/supervisor/KafkaSupervisorTest.java
##
@@ -585,6 +589,108 @@ public void testLatestOffset() throws Exception
);
}
+ /**
+ * Test if partitionIds get updated
+ */
+ @Test
+ public void testPartitionIdsUpdates() throws Exception
+ {
+supervisor = getTestableSupervisor(1, 1, false, "PT1H", null, null);
+addSomeEvents(1100);
+
+Capture captured = Capture.newInstance();
+
EasyMock.expect(taskMaster.getTaskQueue()).andReturn(Optional.of(taskQueue)).anyTimes();
+
EasyMock.expect(taskMaster.getTaskRunner()).andReturn(Optional.absent()).anyTimes();
+
EasyMock.expect(taskStorage.getActiveTasksByDatasource(DATASOURCE)).andReturn(ImmutableList.of()).anyTimes();
+
EasyMock.expect(indexerMetadataStorageCoordinator.getDataSourceMetadata(DATASOURCE)).andReturn(
+new KafkaDataSourceMetadata(
+null
+)
+).anyTimes();
+EasyMock.expect(taskQueue.add(EasyMock.capture(captured))).andReturn(true);
+replayAll();
+
+supervisor.start();
+supervisor.runInternal();
+verifyAll();
+
+Assert.assertFalse(supervisor.isPartitionIdsEmpty());
+ }
+
+
+ /**
+ * Test For if always use earliest offset on newly discovered partitions
+ */
+ @Ignore("This is a regression test that needs to wait 10s+, ignore for now")
+ @Test
+ public void testLatestOffsetOnDiscovery() throws Exception
+ {
+supervisor = getTestableSupervisor(1, 1, false, "PT1H", null, null);
+addSomeEvents(9);
+
+Capture captured = Capture.newInstance();
+
EasyMock.expect(taskMaster.getTaskQueue()).andReturn(Optional.of(taskQueue)).anyTimes();
+
EasyMock.expect(taskMaster.getTaskRunner()).andReturn(Optional.absent()).anyTimes();
+
EasyMock.expect(taskStorage.getActiveTasksByDatasource(DATASOURCE)).andReturn(ImmutableList.of()).anyTimes();
+
EasyMock.expect(indexerMetadataStorageCoordinator.getDataSourceMetadata(DATASOURCE)).andReturn(
+new KafkaDataSourceMetadata(
+null
+)
+).anyTimes();
+EasyMock.expect(taskQueue.add(EasyMock.capture(captured))).andReturn(true);
+replayAll();
+supervisor.start();
+supervisor.runInternal();
+verifyAll();
+
+KafkaIndexTask task = captured.getValue();
+Assert.assertEquals(
+10,
+
task.getIOConfig().getStartSequenceNumbers().getPartitionSequenceNumberMap().get(0).longValue()
+);
+Assert.assertEquals(
+10,
+
task.getIOConfig().getStartSequenceNumbers().getPartitionSequenceNumberMap().get(1).longValue()
+);
+Assert.assertEquals(
+10,
+
task.getIOConfig().getStartSequenceNumbers().getPartitionSequenceNumberMap().get(2).longValue()
+);
+
+addMoreEvents(9, 6);
+Thread.sleep(1);
Review comment:
https://github.com/apache/incubator-druid/pull/8748#discussion_r342276353
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] ccaominh commented on a change in pull request #8748: Use earliest offset on kafka newly discovered partitions
ccaominh commented on a change in pull request #8748: Use earliest offset on
kafka newly discovered partitions
URL: https://github.com/apache/incubator-druid/pull/8748#discussion_r342276331
##
File path:
extensions-core/kafka-indexing-service/src/test/java/org/apache/druid/indexing/kafka/supervisor/KafkaSupervisorTest.java
##
@@ -585,6 +589,108 @@ public void testLatestOffset() throws Exception
);
}
+ /**
+ * Test if partitionIds get updated
+ */
+ @Test
+ public void testPartitionIdsUpdates() throws Exception
+ {
+supervisor = getTestableSupervisor(1, 1, false, "PT1H", null, null);
+addSomeEvents(1100);
+
+Capture captured = Capture.newInstance();
+
EasyMock.expect(taskMaster.getTaskQueue()).andReturn(Optional.of(taskQueue)).anyTimes();
+
EasyMock.expect(taskMaster.getTaskRunner()).andReturn(Optional.absent()).anyTimes();
+
EasyMock.expect(taskStorage.getActiveTasksByDatasource(DATASOURCE)).andReturn(ImmutableList.of()).anyTimes();
+
EasyMock.expect(indexerMetadataStorageCoordinator.getDataSourceMetadata(DATASOURCE)).andReturn(
+new KafkaDataSourceMetadata(
+null
+)
+).anyTimes();
+EasyMock.expect(taskQueue.add(EasyMock.capture(captured))).andReturn(true);
+replayAll();
+
+supervisor.start();
+supervisor.runInternal();
+verifyAll();
+
+Assert.assertFalse(supervisor.isPartitionIdsEmpty());
+ }
+
+
+ /**
+ * Test For if always use earliest offset on newly discovered partitions
+ */
+ @Ignore("This is a regression test that needs to wait 10s+, ignore for now")
+ @Test
+ public void testLatestOffsetOnDiscovery() throws Exception
Review comment:
Suggestion: Rename test method to something like
`testAlwaysUsesEarliestOffsetForNewlyDiscoveredPartitions` and get rid of the
method javadoc.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] ccaominh commented on a change in pull request #8748: Use earliest offset on kafka newly discovered partitions
ccaominh commented on a change in pull request #8748: Use earliest offset on
kafka newly discovered partitions
URL: https://github.com/apache/incubator-druid/pull/8748#discussion_r342281423
##
File path:
extensions-core/kafka-indexing-service/src/test/java/org/apache/druid/indexing/kafka/supervisor/KafkaSupervisorTest.java
##
@@ -585,6 +589,108 @@ public void testLatestOffset() throws Exception
);
}
+ /**
+ * Test if partitionIds get updated
+ */
+ @Test
+ public void testPartitionIdsUpdates() throws Exception
+ {
+supervisor = getTestableSupervisor(1, 1, false, "PT1H", null, null);
+addSomeEvents(1100);
+
+Capture captured = Capture.newInstance();
+
EasyMock.expect(taskMaster.getTaskQueue()).andReturn(Optional.of(taskQueue)).anyTimes();
+
EasyMock.expect(taskMaster.getTaskRunner()).andReturn(Optional.absent()).anyTimes();
+
EasyMock.expect(taskStorage.getActiveTasksByDatasource(DATASOURCE)).andReturn(ImmutableList.of()).anyTimes();
+
EasyMock.expect(indexerMetadataStorageCoordinator.getDataSourceMetadata(DATASOURCE)).andReturn(
+new KafkaDataSourceMetadata(
+null
+)
+).anyTimes();
+EasyMock.expect(taskQueue.add(EasyMock.capture(captured))).andReturn(true);
+replayAll();
+
+supervisor.start();
+supervisor.runInternal();
+verifyAll();
+
+Assert.assertFalse(supervisor.isPartitionIdsEmpty());
+ }
+
+
+ /**
+ * Test For if always use earliest offset on newly discovered partitions
+ */
+ @Ignore("This is a regression test that needs to wait 10s+, ignore for now")
+ @Test
+ public void testLatestOffsetOnDiscovery() throws Exception
+ {
+supervisor = getTestableSupervisor(1, 1, false, "PT1H", null, null);
+addSomeEvents(9);
+
+Capture captured = Capture.newInstance();
+
EasyMock.expect(taskMaster.getTaskQueue()).andReturn(Optional.of(taskQueue)).anyTimes();
Review comment:
FYI, for this use case, using `andStubReturn()` may be simpler than doing
`andReturn().anyTimes()`:
https://stackoverflow.com/questions/34233447/is-there-any-difference-between-andreturn-anytimes-and-andstubreturn/34477207
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] ccaominh commented on a change in pull request #8748: Use earliest offset on kafka newly discovered partitions
ccaominh commented on a change in pull request #8748: Use earliest offset on
kafka newly discovered partitions
URL: https://github.com/apache/incubator-druid/pull/8748#discussion_r342276659
##
File path:
extensions-core/kafka-indexing-service/src/test/java/org/apache/druid/indexing/kafka/supervisor/KafkaSupervisorTest.java
##
@@ -585,6 +589,108 @@ public void testLatestOffset() throws Exception
);
}
+ /**
+ * Test if partitionIds get updated
+ */
+ @Test
+ public void testPartitionIdsUpdates() throws Exception
+ {
+supervisor = getTestableSupervisor(1, 1, false, "PT1H", null, null);
+addSomeEvents(1100);
+
+Capture captured = Capture.newInstance();
+
EasyMock.expect(taskMaster.getTaskQueue()).andReturn(Optional.of(taskQueue)).anyTimes();
+
EasyMock.expect(taskMaster.getTaskRunner()).andReturn(Optional.absent()).anyTimes();
+
EasyMock.expect(taskStorage.getActiveTasksByDatasource(DATASOURCE)).andReturn(ImmutableList.of()).anyTimes();
+
EasyMock.expect(indexerMetadataStorageCoordinator.getDataSourceMetadata(DATASOURCE)).andReturn(
+new KafkaDataSourceMetadata(
+null
+)
+).anyTimes();
+EasyMock.expect(taskQueue.add(EasyMock.capture(captured))).andReturn(true);
+replayAll();
+
+supervisor.start();
+supervisor.runInternal();
+verifyAll();
+
+Assert.assertFalse(supervisor.isPartitionIdsEmpty());
+ }
+
+
+ /**
+ * Test For if always use earliest offset on newly discovered partitions
+ */
+ @Ignore("This is a regression test that needs to wait 10s+, ignore for now")
+ @Test
+ public void testLatestOffsetOnDiscovery() throws Exception
+ {
+supervisor = getTestableSupervisor(1, 1, false, "PT1H", null, null);
+addSomeEvents(9);
+
+Capture captured = Capture.newInstance();
+
EasyMock.expect(taskMaster.getTaskQueue()).andReturn(Optional.of(taskQueue)).anyTimes();
+
EasyMock.expect(taskMaster.getTaskRunner()).andReturn(Optional.absent()).anyTimes();
+
EasyMock.expect(taskStorage.getActiveTasksByDatasource(DATASOURCE)).andReturn(ImmutableList.of()).anyTimes();
+
EasyMock.expect(indexerMetadataStorageCoordinator.getDataSourceMetadata(DATASOURCE)).andReturn(
+new KafkaDataSourceMetadata(
+null
+)
+).anyTimes();
+EasyMock.expect(taskQueue.add(EasyMock.capture(captured))).andReturn(true);
+replayAll();
+supervisor.start();
+supervisor.runInternal();
+verifyAll();
+
+KafkaIndexTask task = captured.getValue();
+Assert.assertEquals(
+10,
+
task.getIOConfig().getStartSequenceNumbers().getPartitionSequenceNumberMap().get(0).longValue()
+);
+Assert.assertEquals(
+10,
+
task.getIOConfig().getStartSequenceNumbers().getPartitionSequenceNumberMap().get(1).longValue()
+);
+Assert.assertEquals(
+10,
+
task.getIOConfig().getStartSequenceNumbers().getPartitionSequenceNumberMap().get(2).longValue()
+);
+
+addMoreEvents(9, 6);
+Thread.sleep(1);
Review comment:
Adding a comment explaining why you need the 10 second sleep here is helpful
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] ccaominh commented on a change in pull request #8748: Use earliest offset on kafka newly discovered partitions
ccaominh commented on a change in pull request #8748: Use earliest offset on
kafka newly discovered partitions
URL: https://github.com/apache/incubator-druid/pull/8748#discussion_r342276353
##
File path:
extensions-core/kafka-indexing-service/src/main/java/org/apache/druid/indexing/kafka/supervisor/KafkaSupervisor.java
##
@@ -156,9 +156,12 @@ protected void scheduleReporting(ScheduledExecutorService
reportingExec)
@Override
- protected int getTaskGroupIdForPartition(Integer partition)
+ protected int getTaskGroupIdForPartition(Integer partitionId)
{
-return partition % spec.getIoConfig().getTaskCount();
+if (!partitionIds.contains(partitionId)) {
Review comment:
Can you add a comment explaining how this change prevents the original bug?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] vogievetsky commented on issue #8777: Web console: Interval input component
vogievetsky commented on issue #8777: Web console: Interval input component URL: https://github.com/apache/incubator-druid/pull/8777#issuecomment-549519351 Could you restrict the input to only accept chars that are valid for intervals to have so so not allow this: 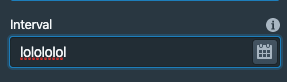 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] suneet-amp commented on a change in pull request #8815: SQL: EARLIEST, LATEST aggregators.
suneet-amp commented on a change in pull request #8815: SQL: EARLIEST, LATEST
aggregators.
URL: https://github.com/apache/incubator-druid/pull/8815#discussion_r342236463
##
File path:
sql/src/main/java/org/apache/druid/sql/calcite/aggregation/builtin/EarliestLatestSqlAggregator.java
##
@@ -0,0 +1,221 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.druid.sql.calcite.aggregation.builtin;
+
+import org.apache.calcite.rel.core.AggregateCall;
+import org.apache.calcite.rel.core.Project;
+import org.apache.calcite.rex.RexBuilder;
+import org.apache.calcite.rex.RexLiteral;
+import org.apache.calcite.rex.RexNode;
+import org.apache.calcite.sql.SqlAggFunction;
+import org.apache.calcite.sql.SqlFunctionCategory;
+import org.apache.calcite.sql.SqlKind;
+import org.apache.calcite.sql.type.InferTypes;
+import org.apache.calcite.sql.type.OperandTypes;
+import org.apache.calcite.sql.type.ReturnTypes;
+import org.apache.calcite.sql.type.SqlTypeName;
+import org.apache.druid.java.util.common.ISE;
+import org.apache.druid.query.aggregation.AggregatorFactory;
+import org.apache.druid.query.aggregation.first.DoubleFirstAggregatorFactory;
+import org.apache.druid.query.aggregation.first.FloatFirstAggregatorFactory;
+import org.apache.druid.query.aggregation.first.LongFirstAggregatorFactory;
+import org.apache.druid.query.aggregation.first.StringFirstAggregatorFactory;
+import org.apache.druid.query.aggregation.last.DoubleLastAggregatorFactory;
+import org.apache.druid.query.aggregation.last.FloatLastAggregatorFactory;
+import org.apache.druid.query.aggregation.last.LongLastAggregatorFactory;
+import org.apache.druid.query.aggregation.last.StringLastAggregatorFactory;
+import
org.apache.druid.query.aggregation.post.FinalizingFieldAccessPostAggregator;
+import org.apache.druid.segment.VirtualColumn;
+import org.apache.druid.segment.column.ValueType;
+import org.apache.druid.sql.calcite.aggregation.Aggregation;
+import org.apache.druid.sql.calcite.aggregation.SqlAggregator;
+import org.apache.druid.sql.calcite.expression.DruidExpression;
+import org.apache.druid.sql.calcite.expression.Expressions;
+import org.apache.druid.sql.calcite.planner.Calcites;
+import org.apache.druid.sql.calcite.planner.PlannerContext;
+import org.apache.druid.sql.calcite.rel.VirtualColumnRegistry;
+import org.apache.druid.sql.calcite.table.RowSignature;
+
+import javax.annotation.Nullable;
+import java.util.Collections;
+import java.util.List;
+import java.util.Objects;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+public class EarliestLatestSqlAggregator implements SqlAggregator
+{
+ public static final SqlAggregator EARLIEST = new
EarliestLatestSqlAggregator(EarliestOrLatest.EARLIEST);
+ public static final SqlAggregator LATEST = new
EarliestLatestSqlAggregator(EarliestOrLatest.LATEST);
+
+ enum EarliestOrLatest
+ {
+EARLIEST {
Review comment:
nit: leave a comment here reminding people not to rename the enum since the
name() is used in the AggFunction below
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] suneet-amp commented on a change in pull request #8815: SQL: EARLIEST, LATEST aggregators.
suneet-amp commented on a change in pull request #8815: SQL: EARLIEST, LATEST
aggregators.
URL: https://github.com/apache/incubator-druid/pull/8815#discussion_r342239233
##
File path:
sql/src/main/java/org/apache/druid/sql/calcite/aggregation/builtin/EarliestLatestSqlAggregator.java
##
@@ -0,0 +1,221 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.druid.sql.calcite.aggregation.builtin;
+
+import org.apache.calcite.rel.core.AggregateCall;
+import org.apache.calcite.rel.core.Project;
+import org.apache.calcite.rex.RexBuilder;
+import org.apache.calcite.rex.RexLiteral;
+import org.apache.calcite.rex.RexNode;
+import org.apache.calcite.sql.SqlAggFunction;
+import org.apache.calcite.sql.SqlFunctionCategory;
+import org.apache.calcite.sql.SqlKind;
+import org.apache.calcite.sql.type.InferTypes;
+import org.apache.calcite.sql.type.OperandTypes;
+import org.apache.calcite.sql.type.ReturnTypes;
+import org.apache.calcite.sql.type.SqlTypeName;
+import org.apache.druid.java.util.common.ISE;
+import org.apache.druid.query.aggregation.AggregatorFactory;
+import org.apache.druid.query.aggregation.first.DoubleFirstAggregatorFactory;
+import org.apache.druid.query.aggregation.first.FloatFirstAggregatorFactory;
+import org.apache.druid.query.aggregation.first.LongFirstAggregatorFactory;
+import org.apache.druid.query.aggregation.first.StringFirstAggregatorFactory;
+import org.apache.druid.query.aggregation.last.DoubleLastAggregatorFactory;
+import org.apache.druid.query.aggregation.last.FloatLastAggregatorFactory;
+import org.apache.druid.query.aggregation.last.LongLastAggregatorFactory;
+import org.apache.druid.query.aggregation.last.StringLastAggregatorFactory;
+import
org.apache.druid.query.aggregation.post.FinalizingFieldAccessPostAggregator;
+import org.apache.druid.segment.VirtualColumn;
+import org.apache.druid.segment.column.ValueType;
+import org.apache.druid.sql.calcite.aggregation.Aggregation;
+import org.apache.druid.sql.calcite.aggregation.SqlAggregator;
+import org.apache.druid.sql.calcite.expression.DruidExpression;
+import org.apache.druid.sql.calcite.expression.Expressions;
+import org.apache.druid.sql.calcite.planner.Calcites;
+import org.apache.druid.sql.calcite.planner.PlannerContext;
+import org.apache.druid.sql.calcite.rel.VirtualColumnRegistry;
+import org.apache.druid.sql.calcite.table.RowSignature;
+
+import javax.annotation.Nullable;
+import java.util.Collections;
+import java.util.List;
+import java.util.Objects;
+import java.util.stream.Collectors;
+import java.util.stream.Stream;
+
+public class EarliestLatestSqlAggregator implements SqlAggregator
+{
+ public static final SqlAggregator EARLIEST = new
EarliestLatestSqlAggregator(EarliestOrLatest.EARLIEST);
+ public static final SqlAggregator LATEST = new
EarliestLatestSqlAggregator(EarliestOrLatest.LATEST);
+
+ enum EarliestOrLatest
+ {
+EARLIEST {
+ @Override
+ AggregatorFactory createAggregatorFactory(String name, String fieldName,
ValueType type, int maxStringBytes)
+ {
+switch (type) {
+ case LONG:
+return new LongFirstAggregatorFactory(name, fieldName);
+ case FLOAT:
+return new FloatFirstAggregatorFactory(name, fieldName);
+ case DOUBLE:
+return new DoubleFirstAggregatorFactory(name, fieldName);
+ case STRING:
+return new StringFirstAggregatorFactory(name, fieldName,
maxStringBytes);
Review comment:
Do we want to validate that maxStringBytes >= 0 in both the aggregator
factories? I traced through the code and I think an exception will be thrown in
the String*BufferAggregator#aggregate because there will be an out of bounds
exception.
Also it's not clear to me what the expected result should be if
maxStringBytes is 0
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
--
[GitHub] [incubator-druid] suneet-amp commented on a change in pull request #8815: SQL: EARLIEST, LATEST aggregators.
suneet-amp commented on a change in pull request #8815: SQL: EARLIEST, LATEST
aggregators.
URL: https://github.com/apache/incubator-druid/pull/8815#discussion_r342235271
##
File path: sql/src/test/java/org/apache/druid/sql/calcite/CalciteQueryTest.java
##
@@ -889,6 +896,123 @@ public void testGroupBySingleColumnDescendingNoTopN()
throws Exception
);
}
+ @Test
+ public void testEarliestAggregators() throws Exception
+ {
+// Cannot vectorize EARLIEST aggregator.
+skipVectorize();
Review comment:
Does this need to be reset at the end of the test? Otherwise all the other
tests that run after this will run with vectorize disabled? Or is that being
handled by some rule that I'm not seeing in this delta
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] suneet-amp commented on a change in pull request #8814: SQL: Add RAND() function.
suneet-amp commented on a change in pull request #8814: SQL: Add RAND()
function.
URL: https://github.com/apache/incubator-druid/pull/8814#discussion_r342217314
##
File path:
processing/src/main/java/org/apache/druid/query/expression/RandExprMacro.java
##
@@ -0,0 +1,95 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.druid.query.expression;
+
+import com.google.common.collect.Iterables;
+import org.apache.druid.java.util.common.IAE;
+import org.apache.druid.math.expr.Expr;
+import org.apache.druid.math.expr.ExprEval;
+import org.apache.druid.math.expr.ExprMacroTable;
+import org.apache.druid.segment.DimensionHandlerUtils;
+
+import java.util.Collections;
+import java.util.List;
+import java.util.Random;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.function.DoubleSupplier;
+
+public class RandExprMacro implements ExprMacroTable.ExprMacro
+{
+ @Override
+ public String name()
+ {
+return "rand";
+ }
+
+ @Override
+ public Expr apply(List args)
+ {
+final DoubleSupplier randomGenerator;
+
+if (args.isEmpty()) {
+ randomGenerator = () -> ThreadLocalRandom.current().nextDouble();
Review comment:
If you wanted to make the test in ExpressionsTest.java easier, you could
inject an annotated `Supplier` into this class something like
```
@Inject
RandExprMacro(@ThreadRandom Supplier
localThreadRandomSupplier) {
...
}
```
As I'm typing this, it feels like overkill, so feel free to ignore
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] suneet-amp commented on a change in pull request #8814: SQL: Add RAND() function.
suneet-amp commented on a change in pull request #8814: SQL: Add RAND()
function.
URL: https://github.com/apache/incubator-druid/pull/8814#discussion_r342201369
##
File path:
processing/src/main/java/org/apache/druid/query/expression/RandExprMacro.java
##
@@ -0,0 +1,95 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.druid.query.expression;
+
+import com.google.common.collect.Iterables;
+import org.apache.druid.java.util.common.IAE;
+import org.apache.druid.math.expr.Expr;
+import org.apache.druid.math.expr.ExprEval;
+import org.apache.druid.math.expr.ExprMacroTable;
+import org.apache.druid.segment.DimensionHandlerUtils;
+
+import java.util.Collections;
+import java.util.List;
+import java.util.Random;
+import java.util.concurrent.ThreadLocalRandom;
+import java.util.function.DoubleSupplier;
+
+public class RandExprMacro implements ExprMacroTable.ExprMacro
+{
+ @Override
+ public String name()
+ {
+return "rand";
+ }
+
+ @Override
+ public Expr apply(List args)
+ {
+final DoubleSupplier randomGenerator;
+
+if (args.isEmpty()) {
+ randomGenerator = () -> ThreadLocalRandom.current().nextDouble();
+} else if (args.size() == 1) {
+ final Expr seedArg = Iterables.getOnlyElement(args);
+ if (seedArg.isLiteral()) {
+final Long seedValue =
DimensionHandlerUtils.convertObjectToLong(seedArg.getLiteralValue());
+if (seedValue != null) {
+ final Random random = new Random(seedValue);
+ randomGenerator = random::nextDouble;
+} else {
+ throw new IAE("Function[%s] first argument must be a number
literal");
+}
+ } else {
+throw new IAE("Function[%s] first argument must be a number literal");
+ }
+} else {
+ throw new IAE("Function[%s] needs zero or one arguments", name());
+}
+
+class RandExpr extends ExprMacroTable.BaseScalarMacroFunctionExpr
Review comment:
👀 I've never seen this pattern before.
dumb guy question: Is there any advantage of using this vs a private static
inner class. Do we do this just so we don't have to pass `randomGenerator` to
the constructor of this class?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] zhenxiao commented on a change in pull request #8808: use copy-on-write list in InMemoryAppender
zhenxiao commented on a change in pull request #8808: use copy-on-write list in
InMemoryAppender
URL: https://github.com/apache/incubator-druid/pull/8808#discussion_r342215463
##
File path:
core/src/test/java/org/apache/druid/testing/junit/LoggerCaptureRule.java
##
@@ -78,12 +77,13 @@ public void clearLogEvents()
{
static final String NAME = InMemoryAppender.class.getName();
-private final List logEvents;
+// need copy-on-write collection for thread safety of iteration and
modification concurrently outside of a critical section
Review comment:
how about:
logEvents has concurrent iteration and modification in
CuratorModuleTest::exitsJvmWhenMaxRetriesExceeded(), needs to be thread safe
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] jessp01 commented on issue #8305: Fix to always use end sequenceNumber for reset
jessp01 commented on issue #8305: Fix to always use end sequenceNumber for reset URL: https://github.com/apache/incubator-druid/pull/8305#issuecomment-549496846 Hello all, I'm hitting the exact same issue with 0.15.1. Since upgrading to 0.16.0 requires additional work, does anyone happen to have a built version of 0.15.1 with these changes I can obtain and test? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] leventov commented on a change in pull request #8808: use copy-on-write list in InMemoryAppender
leventov commented on a change in pull request #8808: use copy-on-write list in
InMemoryAppender
URL: https://github.com/apache/incubator-druid/pull/8808#discussion_r342202395
##
File path:
core/src/test/java/org/apache/druid/testing/junit/LoggerCaptureRule.java
##
@@ -78,12 +77,13 @@ public void clearLogEvents()
{
static final String NAME = InMemoryAppender.class.getName();
-private final List logEvents;
+// need copy-on-write collection for thread safety of iteration and
modification concurrently outside of a critical section
Review comment:
This comment doesn't achieve its goal: to help somebody to see why the
enclosing class needs to be thread-safe. With the current comment, in order to
do that, the reader (developer) should invoke "Find usages" IDE action and
analyze these usages carefully. This is time-consuming. In essence, there
should be concurrent access documentation, as described in
https://github.com/code-review-checklists/java-concurrency#justify-document.
This comment is also misleading because there are no critical sections in
this code.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] jihoonson commented on issue #8821: Upgrade joda-time to 2.10.5
jihoonson commented on issue #8821: Upgrade joda-time to 2.10.5 URL: https://github.com/apache/incubator-druid/pull/8821#issuecomment-549477950 Seems like there was an issue with thrift repo. Restarted failed ones. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] vogievetsky commented on issue #8820: groupBy() query is not working in Node Js
vogievetsky commented on issue #8820: groupBy() query is not working in Node Js URL: https://github.com/apache/incubator-druid/issues/8820#issuecomment-549462718 Could you post more details of the query and the error please? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm commented on issue #8814: SQL: Add RAND() function.
gianm commented on issue #8814: SQL: Add RAND() function. URL: https://github.com/apache/incubator-druid/pull/8814#issuecomment-549434724 > Does it fully fix #8661? I believe the other functions already exist (check the docs) so yes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[incubator-druid] branch master updated (49bd167 -> 511fa74)
This is an automated email from the ASF dual-hosted git repository.
gian pushed a change to branch master
in repository https://gitbox.apache.org/repos/asf/incubator-druid.git.
from 49bd167 serve web-console even if router management proxy is not
enabled (#8797)
add 511fa74 Move maxFetchRetry to FetchConfig; rename OpenObject (#8776)
No new revisions were added by this update.
Summary of changes:
.../{PrefetchConfig.java => FetchConfig.java} | 29 +++
.../druid/data/input/impl/prefetch/Fetcher.java| 48 ++
.../data/input/impl/prefetch/FileFetcher.java | 27 --
.../{OpenedObject.java => OpenObject.java} | 6 +--
.../PrefetchableTextFilesFirehoseFactory.java | 58 ++
.../firehose/PrefetchSqlFirehoseFactory.java | 40 +++
.../segment/realtime/firehose/SqlFetcher.java | 14 +++---
7 files changed, 108 insertions(+), 114 deletions(-)
rename
core/src/main/java/org/apache/druid/data/input/impl/prefetch/{PrefetchConfig.java
=> FetchConfig.java} (75%)
rename
core/src/main/java/org/apache/druid/data/input/impl/prefetch/{OpenedObject.java
=> OpenObject.java} (92%)
-
To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org
For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] gianm merged pull request #8776: Move maxFetchRetry to FetchConfig; rename OpenObject
gianm merged pull request #8776: Move maxFetchRetry to FetchConfig; rename OpenObject URL: https://github.com/apache/incubator-druid/pull/8776 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] a2l007 opened a new pull request #8821: Upgrade joda-time to 2.10.5
a2l007 opened a new pull request #8821: Upgrade joda-time to 2.10.5 URL: https://github.com/apache/incubator-druid/pull/8821 Upgrading joda time to include the latest timezone data. An important timezone change is that Brazil recently scrapped Daylight savings (https://www.timeanddate.com/news/time/brazil-scraps-dst.html) and this version includes that change. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] Jaymin-adzmedia opened a new issue #8820: groupBy() query is not working in Node Js
Jaymin-adzmedia opened a new issue #8820: groupBy() query is not working in Node Js URL: https://github.com/apache/incubator-druid/issues/8820 Hello, I need to get records by time. For that, I have used groupBy() query. TopN() query is working fine but once i use groupBy(). It is showing nodejs error. Nodejs: Internal server error: 5000 code. Can you help me to solve this. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis edited a comment on issue #8578: parallel broker merges on fork join pool
clintropolis edited a comment on issue #8578: parallel broker merges on fork join pool URL: https://github.com/apache/incubator-druid/pull/8578#issuecomment-549253205 ### more realistic worst case I reworked the JMH thread based benchmark to use thread groups to examine what happens in a more realistic scenario, with the newly renamed `ParallelMergeCombiningSequenceThreadedBenchmark`. I find this benchmark to be a fair bit less scary than the previous 'worst case' benchmarks, which focused on an impossible scenario because I really wanted to dig in and see where and how the wheels fell off. This benchmark models a more 'typical' heavy load, where the majority of the queries are smaller result-sets with shorter blocking times and a smaller subset are larger result sets with longer initial blocking times. By using thread groups we can look at performance for these 'classes' of queries as load increases. This set was collected with a ratio of 1 'moderately large' query for every 8 'small' queries, where 'moderately large' is defined as input sequence row counts of 50k-75k rows and blocking for 1-2.5 seconds before yielding results, and 'small' is defined as input sequence row counts of 500-10k and blocking for 50-200ms. Keep in mind while reviewing the result that I collected data on a significantly higher level of parallelism than I would expect a 16 core machine to be realistically configured to handle. I would probably configure an m5.8xl with no more than 64 http threads, but collected data points up to 128 concurrent sequences being processed just to see where things went. The first plot shows the merge time (y axis) growth as concurrency (x axis) increases, animated to show the differences for a given number of input sequences (analagous to cluster size).  Note that the x axis is the _total_ concurrency count, not the number of threads of this particular group. Also worth pointing out is that the degradation of performance happens at a significantly higher level of concurrency than the previous (unrealistic) worse case performance, but in terms of characteristics, it does share some aspects with the previous plots, such as 8 input sequences being a lot more performant than say 64, and after a certain threshold, the performance of the parallel approach crosses the limit of the same threaded serial merge approach. The larger 'queries' tell a similar tale:  The differences here when the parallel merge sequence crosses the threshold look to me a fair bit less dramatic than the 'small' sequences, but keep in mind the 'big jump' in the small sequences only amount to a few hundred milliseconds, so it's not quite as dramatic as it appears. The final plot shows the overall average between both groups:  which I find a bit less useful than the other 2 plots, but included anyway for completeness. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] vogievetsky opened a new pull request #8819: Web console: show hollow circle when unavailable
vogievetsky opened a new pull request #8819: Web console: show hollow circle when unavailable URL: https://github.com/apache/incubator-druid/pull/8819 Show a hollow circle for the special state when a data source is totally unavailable 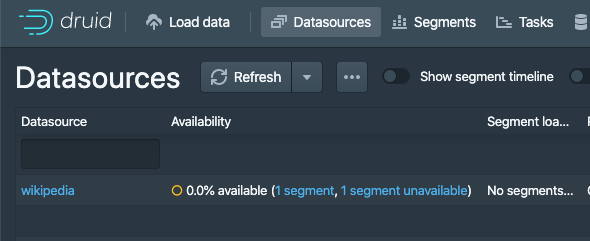 It makes sense for it to have a special state. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org
[GitHub] [incubator-druid] clintropolis commented on issue #8578: parallel broker merges on fork join pool
clintropolis commented on issue #8578: parallel broker merges on fork join pool URL: https://github.com/apache/incubator-druid/pull/8578#issuecomment-549253205 ### more realistic worst case I reworked the JMH thread based benchmark to use thread groups to examine what happens in a more realistic scenario, with the newly renamed `ParallelMergeCombiningSequenceThreadedBenchmark`. I find this benchmark to be a fair bit less scary than the previous 'worst case' benchmarks, which focused on an impossible scenario because I really wanted to dig in and see where and how the wheels fell off. This benchmark models a more 'typical' heavy load, where the majority of the queries are smaller result-sets with shorter blocking times and a smaller subset are larger result sets with longer initial blocking times. By using thread groups we can look at performance for these 'classes' of queries as load increases. This set was collected with a ratio of 1 'moderately large' query for every 8 'small' queries, where 'moderately large' is defined as input sequence row counts of 50k-75k rows and blocking for 1-2.5 seconds before yielding results, and 'small' is defined as input sequence row counts of 500-10k and blocking for 50-200ms. Keep in mind while reviewing the result that I collected data on a significantly higher level of parallelism than I would expect a 16 core machine to be realistically configured to handle. I would probably configure an m5.8xl with ~64 http threads, but collected data points up to 128 concurrent sequences being processed. The first plot shows the merge time (y axis) growth as concurrency (x axis) increases, animated to show the differences for a given number of input sequences (analagous to cluster size).  Note that the x axis is the _total_ concurrency count, not the number of threads of this particular group. Also worth pointing out is that the degradation of performance happens at a significantly higher level of concurrency than the previous (unrealistic) worse case performance, but in terms of characteristics, it does share some aspects with the previous plots, such as 8 input sequences being a lot more performant than say 64, and after a certain threshold, the performance of the parallel approach crosses the limit of the same threaded serial merge approach. The larger 'queries' tell a similar tale:  The differences here when the parallel merge sequence crosses the threshold look to me a fair bit less dramatic than the 'small' sequences, but keep in mind the 'big jump' in the small sequences only amount to a few hundred milliseconds, so it's not quite as dramatic as it appears. The final plot shows the overall average between both groups:  which I find a bit less useful than the other 2 plots, but included anyway for completeness. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: commits-unsubscr...@druid.apache.org For additional commands, e-mail: commits-h...@druid.apache.org