[jira] [Work logged] (HDFS-16624) Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR
[ https://issues.apache.org/jira/browse/HDFS-16624?focusedWorklogId=779318=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779318 ] ASF GitHub Bot logged work on HDFS-16624: - Author: ASF GitHub Bot Created on: 08/Jun/22 04:30 Start Date: 08/Jun/22 04:30 Worklog Time Spent: 10m Work Description: virajjasani commented on PR #4412: URL: https://github.com/apache/hadoop/pull/4412#issuecomment-1149447908 Thank you for the nice fix @slfan1989 and for the review @tomscut !! Issue Time Tracking --- Worklog Id: (was: 779318) Time Spent: 2.5h (was: 2h 20m) > Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR > > > Key: HDFS-16624 > URL: https://issues.apache.org/jira/browse/HDFS-16624 > Project: Hadoop HDFS > Issue Type: Bug >Affects Versions: 3.4.0 >Reporter: fanshilun >Assignee: fanshilun >Priority: Major > Labels: pull-request-available > Attachments: testAllDatanodesReconfig.png > > Time Spent: 2.5h > Remaining Estimate: 0h > > HDFS-16619 found an error message during Junit unit testing, as follows: > expected:<[SUCCESS: Changed property dfs.datanode.peer.stats.enabled]> but > was:<[ From: "false"]> > After code debugging, it was found that there was an error in the selection > outs.get(2) of the assertion(1208), index should be equal to 1. > Please refer to the attachment for debugging pictures > !testAllDatanodesReconfig.png! -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Comment Edited] (HDFS-16613) EC: Improve performance of decommissioning dn with many ec blocks
[
https://issues.apache.org/jira/browse/HDFS-16613?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17551381#comment-17551381
]
caozhiqiang edited comment on HDFS-16613 at 6/8/22 4:01 AM:
[~hadachi] , in my cluster,
dfs.namenode.replication.max-streams-hard-limit=512,
dfs.namenode.replication.work.multiplier.per.iteration=20.
The data process is below:
# Choose the blocks to be reconstructed from neededReconstruction. This
process use dfs.namenode.replication.work.multiplier.per.iteration to limit
process number.
# *Choose source datanode. This process use
dfs.namenode.replication.max-streams-hard-limit to limit process number.*
# Choose target datanode.
# Add task to datanode.
# The blocks to be replicated would put to pendingReconstruction. If blocks in
pendingReconstruction timeout, they will be put back to neededReconstruction
and continue process. *This process use
dfs.namenode.reconstruction.pending.timeout-sec to limit time interval.*
# *Send replication cmds to dn in heartbeat response. Use
dfs.namenode.decommission.max-streams to limit task number original.*
Firstly, the process 1 doesn't have performance bottleneck. And its process
interval is 3 seconds.
Performance bottleneck is in process 2, 5 and 6. So we should increase the
value of dfs.namenode.replication.max-streams-hard-limit and decrease the value
of dfs.namenode.reconstruction.pending.timeout-sec{*}.{*} With process 6, we
should change to use dfs.namenode.replication.max-streams-hard-limit to limit
the task number.
{code:java}
// DatanodeManager::handleHeartbeat
if (nodeinfo.isDecommissionInProgress()) {
maxTransfers = blockManager.getReplicationStreamsHardLimit()
- xmitsInProgress;
} else {
maxTransfers = blockManager.getMaxReplicationStreams()
- xmitsInProgress;
} {code}
*In other words, we should get blocks from pendingReconstruction to
neededReconstruction in shorter interval(process 5). And should seed more
replication tasks to datanode(process 2 and 6).*
The below graph with under_replicated_blocks and pending_replicated_blocks
metrics monitor in namenode, which can show the performance bottleneck. A lot
of blocks time out in pendingReconstruction and would be put back to
neededReconstruction repeatedly. The first graph is before optimization and the
second is after optimization.
Please help to check this process, thank you.
!image-2022-06-08-11-41-11-127.png|width=932,height=190!
!image-2022-06-08-11-38-29-664.png|width=931,height=175!
was (Author: caozhiqiang):
[~hadachi] , in my cluster,
dfs.namenode.replication.max-streams-hard-limit=512,
dfs.namenode.replication.work.multiplier.per.iteration=20.
The data process is below:
# Choose the blocks to be reconstructed from neededReconstruction. This
process use dfs.namenode.replication.work.multiplier.per.iteration to limit
process number.
# *Choose source datanode. This process use
dfs.namenode.replication.max-streams-hard-limit to limit process number.*
# Choose target datanode.
# Add task to datanode.
# The blocks to be replicated would put to pendingReconstruction. If blocks in
pendingReconstruction timeout, they will be put back to neededReconstruction
and continue process. *This process use
dfs.namenode.reconstruction.pending.timeout-sec to limit time interval.*
# *Send replication cmds to dn in heartbeat response. Use
dfs.namenode.decommission.max-streams to limit task number original.*
Firstly, the process 1 doesn't have performance bottleneck. And its process
interval is 3 seconds.
Performance bottleneck is in process 2, 5 and 6. So we should increase the
value of dfs.namenode.replication.max-streams-hard-limit and decrease the value
of dfs.namenode.reconstruction.pending.timeout-sec{*}.{*} With process 6, we
should change to use dfs.namenode.replication.max-streams-hard-limit to limit
the task number.
{code:java}
// DatanodeManager::handleHeartbeat
if (nodeinfo.isDecommissionInProgress()) {
maxTransfers = blockManager.getReplicationStreamsHardLimit()
- xmitsInProgress;
} else {
maxTransfers = blockManager.getMaxReplicationStreams()
- xmitsInProgress;
} {code}
*In other words, we should get blocks from pendingReconstruction to
neededReconstruction in shorter interval(process 5). And seed more replication
tasks to datanode(process 2 and 6).*
The below graph with under_replicated_blocks and pending_replicated_blocks
metrics monitor in namenode, which can show the performance bottleneck. A lot
of blocks time out in pendingReconstruction and would be put back to
neededReconstruction repeatedly. The first graph is before optimization and the
second is after optimization.
Please help to check this process, thank you.
!image-2022-06-08-11-41-11-127.png|width=932,height=190!
[jira] [Comment Edited] (HDFS-16613) EC: Improve performance of decommissioning dn with many ec blocks
[
https://issues.apache.org/jira/browse/HDFS-16613?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17551381#comment-17551381
]
caozhiqiang edited comment on HDFS-16613 at 6/8/22 3:58 AM:
[~hadachi] , in my cluster,
dfs.namenode.replication.max-streams-hard-limit=512,
dfs.namenode.replication.work.multiplier.per.iteration=20.
The data process is below:
# Choose the blocks to be reconstructed from neededReconstruction. This
process use dfs.namenode.replication.work.multiplier.per.iteration to limit
process number.
# *Choose source datanode. This process use
dfs.namenode.replication.max-streams-hard-limit to limit process number.*
# Choose target datanode.
# Add task to datanode.
# The blocks to be replicated would put to pendingReconstruction. If blocks in
pendingReconstruction timeout, they will be put back to neededReconstruction
and continue process. *This process use
dfs.namenode.reconstruction.pending.timeout-sec to limit time interval.*
# *Send replication cmds to dn in heartbeat response. Use
dfs.namenode.decommission.max-streams to limit task number original.*
Firstly, the process 1 doesn't have performance bottleneck. And its process
interval is 3 seconds.
Performance bottleneck is in process 2, 5 and 6. So we should increase the
value of dfs.namenode.replication.max-streams-hard-limit and decrease the value
of dfs.namenode.reconstruction.pending.timeout-sec{*}.{*} With process 6, we
should change to use dfs.namenode.replication.max-streams-hard-limit to limit
the task number.
{code:java}
// DatanodeManager::handleHeartbeat
if (nodeinfo.isDecommissionInProgress()) {
maxTransfers = blockManager.getReplicationStreamsHardLimit()
- xmitsInProgress;
} else {
maxTransfers = blockManager.getMaxReplicationStreams()
- xmitsInProgress;
} {code}
*In other words, we should get blocks from pendingReconstruction to
neededReconstruction in shorter interval(process 5). And seed more replication
tasks to datanode(process 2 and 6).*
The below graph with under_replicated_blocks and pending_replicated_blocks
metrics monitor in namenode, which can show the performance bottleneck. A lot
of blocks time out in pendingReconstruction and would be put back to
neededReconstruction repeatedly. The first graph is before optimization and the
second is after optimization.
Please help to check this process, thank you.
!image-2022-06-08-11-41-11-127.png|width=932,height=190!
!image-2022-06-08-11-38-29-664.png|width=931,height=175!
was (Author: caozhiqiang):
[~hadachi] , in my cluster,
dfs.namenode.replication.max-streams-hard-limit=512,
dfs.namenode.replication.work.multiplier.per.iteration=20.
The data process is below:
# Choose the blocks to be reconstructed from neededReconstruction. This
process use dfs.namenode.replication.work.multiplier.per.iteration to limit
process number.
# *Choose source datanode. This process use
dfs.namenode.replication.max-streams-hard-limit to limit process number.*
# Choose target datanode.
# Add task to datanode.
# The blocks to be replicated would put to pendingReconstruction. If blocks in
pendingReconstruction timeout, they will be put back to neededReconstruction
and continue process. *This process use
dfs.namenode.reconstruction.pending.timeout-sec to limit time interval.*
# *Send cmd to dn in heartbeat response. Use
dfs.namenode.decommission.max-streams to limit task number original.*
Firstly, the process 1 doesn't have performance bottleneck. And its process
interval is 3 seconds.
Performance bottleneck is in process 2, 5 and 6. So we should increase the
value of dfs.namenode.replication.max-streams-hard-limit and decrease the value
of dfs.namenode.reconstruction.pending.timeout-sec{*}.{*} With process 6, we
should use dfs.namenode.replication.max-streams-hard-limit to limit the task
number.
That mean we should take blocks from pendingReconstruction to
neededReconstruction in shorten interval(process 5). And seed more replication
tasks to datanode(process 2 and 6).
{code:java}
// DatanodeManager::handleHeartbeat
if (nodeinfo.isDecommissionInProgress()) {
maxTransfers = blockManager.getReplicationStreamsHardLimit()
- xmitsInProgress;
} else {
maxTransfers = blockManager.getMaxReplicationStreams()
- xmitsInProgress;
} {code}
The below graph with under replicated blocks and pending replicated blocks
metrics monitor, which can show the performance bottleneck. A lot of blocks
time out in pendingReconstruction and were put back to neededReconstruction
repeatedly. The first graph is before optimization and the second is after
optimization.
Please help to check this process, thank you.
!image-2022-06-08-11-41-11-127.png|width=932,height=190!
!image-2022-06-08-11-38-29-664.png|width=931,height=175!
> EC: Improve
[jira] [Comment Edited] (HDFS-16613) EC: Improve performance of decommissioning dn with many ec blocks
[
https://issues.apache.org/jira/browse/HDFS-16613?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17551381#comment-17551381
]
caozhiqiang edited comment on HDFS-16613 at 6/8/22 3:52 AM:
[~hadachi] , in my cluster,
dfs.namenode.replication.max-streams-hard-limit=512,
dfs.namenode.replication.work.multiplier.per.iteration=20.
The data process is below:
# Choose the blocks to be reconstructed from neededReconstruction. This
process use dfs.namenode.replication.work.multiplier.per.iteration to limit
process number.
# *Choose source datanode. This process use
dfs.namenode.replication.max-streams-hard-limit to limit process number.*
# Choose target datanode.
# Add task to datanode.
# The blocks to be replicated would put to pendingReconstruction. If blocks in
pendingReconstruction timeout, they will be put back to neededReconstruction
and continue process. *This process use
dfs.namenode.reconstruction.pending.timeout-sec to limit time interval.*
# *Send cmd to dn in heartbeat response. Use
dfs.namenode.decommission.max-streams to limit task number original.*
Firstly, the process 1 doesn't have performance bottleneck. And its process
interval is 3 seconds.
Performance bottleneck is in process 2, 5 and 6. So we should increase the
value of dfs.namenode.replication.max-streams-hard-limit and decrease the value
of dfs.namenode.reconstruction.pending.timeout-sec{*}.{*} With process 6, we
should use dfs.namenode.replication.max-streams-hard-limit to limit the task
number.
That mean we should take blocks from pendingReconstruction to
neededReconstruction in shorten interval(process 5). And seed more replication
tasks to datanode(process 2 and 6).
{code:java}
// DatanodeManager::handleHeartbeat
if (nodeinfo.isDecommissionInProgress()) {
maxTransfers = blockManager.getReplicationStreamsHardLimit()
- xmitsInProgress;
} else {
maxTransfers = blockManager.getMaxReplicationStreams()
- xmitsInProgress;
} {code}
The below graph with under replicated blocks and pending replicated blocks
metrics monitor, which can show the performance bottleneck. A lot of blocks
time out in pendingReconstruction and were put back to neededReconstruction
repeatedly. The first graph is before optimization and the second is after
optimization.
Please help to check this process, thank you.
!image-2022-06-08-11-41-11-127.png|width=932,height=190!
!image-2022-06-08-11-38-29-664.png|width=931,height=175!
was (Author: caozhiqiang):
[~hadachi] , in my cluster,
dfs.namenode.replication.max-streams-hard-limit=512,
dfs.namenode.replication.work.multiplier.per.iteration=20.
The data process is below:
# Choose the blocks to be reconstructed from neededReconstruction. This
process use dfs.namenode.replication.work.multiplier.per.iteration to limit
process number.
# *Choose source datanode. This process use
dfs.namenode.replication.max-streams-hard-limit to limit process number.*
# Choose target datanode.
# Add task to datanode.
# The blocks to be replicated would put to pendingReconstruction. If blocks in
pendingReconstruction timeout, they will be put back to neededReconstruction
and continue process. *This process use
dfs.namenode.reconstruction.pending.timeout-sec to limit time interval.*
# *Send cmd to dn in heartbeat response. Use
dfs.namenode.decommission.max-streams to limit task number original.*
Firstly, the process 1 doesn't have performance bottleneck.
Performance bottleneck is in process 2, 5 and 6. So we should increase the
value of dfs.namenode.replication.max-streams-hard-limit and decrease the value
of dfs.namenode.reconstruction.pending.timeout-sec{*}.{*} With process 6, we
should use dfs.namenode.replication.max-streams-hard-limit to limit the task
number.
{code:java}
// DatanodeManager::handleHeartbeat
if (nodeinfo.isDecommissionInProgress()) {
maxTransfers = blockManager.getReplicationStreamsHardLimit()
- xmitsInProgress;
} else {
maxTransfers = blockManager.getMaxReplicationStreams()
- xmitsInProgress;
} {code}
The below graph with under replicated blocks and pending replicated blocks
metrics monitor, which can show the performance bottleneck. A lot of blocks
time out in pendingReconstruction and were put back to neededReconstruction
repeatedly. The first graph is before optimization and the second is after
optimization.
Please help to check this process, thank you.
!image-2022-06-08-11-41-11-127.png|width=932,height=190!
!image-2022-06-08-11-38-29-664.png|width=931,height=175!
> EC: Improve performance of decommissioning dn with many ec blocks
> -
>
> Key: HDFS-16613
> URL: https://issues.apache.org/jira/browse/HDFS-16613
> Project: Hadoop HDFS
>
[jira] [Commented] (HDFS-16613) EC: Improve performance of decommissioning dn with many ec blocks
[
https://issues.apache.org/jira/browse/HDFS-16613?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17551381#comment-17551381
]
caozhiqiang commented on HDFS-16613:
[~hadachi] , in my cluster,
dfs.namenode.replication.max-streams-hard-limit=512,
dfs.namenode.replication.work.multiplier.per.iteration=20.
The data process is below:
# Choose the blocks to be reconstructed from neededReconstruction. This
process use dfs.namenode.replication.work.multiplier.per.iteration to limit
process number.
# *Choose source datanode. This process use
dfs.namenode.replication.max-streams-hard-limit to limit process number.*
# Choose target datanode.
# Add task to datanode.
# The blocks to be replicated would put to pendingReconstruction. If blocks in
pendingReconstruction timeout, they will be put back to neededReconstruction
and continue process. *This process use
dfs.namenode.reconstruction.pending.timeout-sec to limit time interval.*
# *Send cmd to dn in heartbeat response. Use
dfs.namenode.decommission.max-streams to limit task number original.*
Firstly, the process 1 doesn't have performance bottleneck.
Performance bottleneck is in process 2, 5 and 6. So we should increase the
value of dfs.namenode.replication.max-streams-hard-limit and decrease the value
of dfs.namenode.reconstruction.pending.timeout-sec{*}.{*} With process 6, we
should use dfs.namenode.replication.max-streams-hard-limit to limit the task
number.
{code:java}
// DatanodeManager::handleHeartbeat
if (nodeinfo.isDecommissionInProgress()) {
maxTransfers = blockManager.getReplicationStreamsHardLimit()
- xmitsInProgress;
} else {
maxTransfers = blockManager.getMaxReplicationStreams()
- xmitsInProgress;
} {code}
The below graph with under replicated blocks and pending replicated blocks
metrics monitor, which can show the performance bottleneck. A lot of blocks
time out in pendingReconstruction and were put back to neededReconstruction
repeatedly. The first graph is before optimization and the second is after
optimization.
Please help to check this process, thank you.
!image-2022-06-08-11-41-11-127.png|width=932,height=190!
!image-2022-06-08-11-38-29-664.png|width=931,height=175!
> EC: Improve performance of decommissioning dn with many ec blocks
> -
>
> Key: HDFS-16613
> URL: https://issues.apache.org/jira/browse/HDFS-16613
> Project: Hadoop HDFS
> Issue Type: Improvement
> Components: ec, erasure-coding, namenode
>Affects Versions: 3.4.0
>Reporter: caozhiqiang
>Assignee: caozhiqiang
>Priority: Major
> Labels: pull-request-available
> Attachments: image-2022-06-07-11-46-42-389.png,
> image-2022-06-07-17-42-16-075.png, image-2022-06-07-17-45-45-316.png,
> image-2022-06-07-17-51-04-876.png, image-2022-06-07-17-55-40-203.png,
> image-2022-06-08-11-38-29-664.png, image-2022-06-08-11-41-11-127.png
>
> Time Spent: 0.5h
> Remaining Estimate: 0h
>
> In a hdfs cluster with a lot of EC blocks, decommission a dn is very slow.
> The reason is unlike replication blocks can be replicated from any dn which
> has the same block replication, the ec block have to be replicated from the
> decommissioning dn.
> The configurations dfs.namenode.replication.max-streams and
> dfs.namenode.replication.max-streams-hard-limit will limit the replication
> speed, but increase these configurations will create risk to the whole
> cluster's network. So it should add a new configuration to limit the
> decommissioning dn, distinguished from the cluster wide max-streams limit.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16613) EC: Improve performance of decommissioning dn with many ec blocks
[ https://issues.apache.org/jira/browse/HDFS-16613?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] caozhiqiang updated HDFS-16613: --- Attachment: image-2022-06-08-11-41-11-127.png > EC: Improve performance of decommissioning dn with many ec blocks > - > > Key: HDFS-16613 > URL: https://issues.apache.org/jira/browse/HDFS-16613 > Project: Hadoop HDFS > Issue Type: Improvement > Components: ec, erasure-coding, namenode >Affects Versions: 3.4.0 >Reporter: caozhiqiang >Assignee: caozhiqiang >Priority: Major > Labels: pull-request-available > Attachments: image-2022-06-07-11-46-42-389.png, > image-2022-06-07-17-42-16-075.png, image-2022-06-07-17-45-45-316.png, > image-2022-06-07-17-51-04-876.png, image-2022-06-07-17-55-40-203.png, > image-2022-06-08-11-38-29-664.png, image-2022-06-08-11-41-11-127.png > > Time Spent: 0.5h > Remaining Estimate: 0h > > In a hdfs cluster with a lot of EC blocks, decommission a dn is very slow. > The reason is unlike replication blocks can be replicated from any dn which > has the same block replication, the ec block have to be replicated from the > decommissioning dn. > The configurations dfs.namenode.replication.max-streams and > dfs.namenode.replication.max-streams-hard-limit will limit the replication > speed, but increase these configurations will create risk to the whole > cluster's network. So it should add a new configuration to limit the > decommissioning dn, distinguished from the cluster wide max-streams limit. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16613) EC: Improve performance of decommissioning dn with many ec blocks
[ https://issues.apache.org/jira/browse/HDFS-16613?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] caozhiqiang updated HDFS-16613: --- Attachment: image-2022-06-08-11-38-29-664.png > EC: Improve performance of decommissioning dn with many ec blocks > - > > Key: HDFS-16613 > URL: https://issues.apache.org/jira/browse/HDFS-16613 > Project: Hadoop HDFS > Issue Type: Improvement > Components: ec, erasure-coding, namenode >Affects Versions: 3.4.0 >Reporter: caozhiqiang >Assignee: caozhiqiang >Priority: Major > Labels: pull-request-available > Attachments: image-2022-06-07-11-46-42-389.png, > image-2022-06-07-17-42-16-075.png, image-2022-06-07-17-45-45-316.png, > image-2022-06-07-17-51-04-876.png, image-2022-06-07-17-55-40-203.png, > image-2022-06-08-11-38-29-664.png > > Time Spent: 0.5h > Remaining Estimate: 0h > > In a hdfs cluster with a lot of EC blocks, decommission a dn is very slow. > The reason is unlike replication blocks can be replicated from any dn which > has the same block replication, the ec block have to be replicated from the > decommissioning dn. > The configurations dfs.namenode.replication.max-streams and > dfs.namenode.replication.max-streams-hard-limit will limit the replication > speed, but increase these configurations will create risk to the whole > cluster's network. So it should add a new configuration to limit the > decommissioning dn, distinguished from the cluster wide max-streams limit. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16557) BootstrapStandby failed because of checking gap for inprogress EditLogInputStream
[
https://issues.apache.org/jira/browse/HDFS-16557?focusedWorklogId=779311=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779311
]
ASF GitHub Bot logged work on HDFS-16557:
-
Author: ASF GitHub Bot
Created on: 08/Jun/22 03:34
Start Date: 08/Jun/22 03:34
Worklog Time Spent: 10m
Work Description: tomscut commented on PR #4219:
URL: https://github.com/apache/hadoop/pull/4219#issuecomment-1149418728
Hi @xkrogen , if you have enough bandwidth, please take a look. Thank you.
Issue Time Tracking
---
Worklog Id: (was: 779311)
Time Spent: 2h 50m (was: 2h 40m)
> BootstrapStandby failed because of checking gap for inprogress
> EditLogInputStream
> -
>
> Key: HDFS-16557
> URL: https://issues.apache.org/jira/browse/HDFS-16557
> Project: Hadoop HDFS
> Issue Type: Bug
>Reporter: Tao Li
>Assignee: Tao Li
>Priority: Major
> Labels: pull-request-available
> Attachments: image-2022-04-22-17-17-14-577.png,
> image-2022-04-22-17-17-14-618.png, image-2022-04-22-17-17-23-113.png,
> image-2022-04-22-17-17-32-487.png
>
> Time Spent: 2h 50m
> Remaining Estimate: 0h
>
> The lastTxId of an inprogress EditLogInputStream lastTxId isn't necessarily
> HdfsServerConstants.INVALID_TXID. We can determine its status directly by
> EditLogInputStream#isInProgress.
> We introduced [SBN READ], and set
> {color:#ff}{{dfs.ha.tail-edits.in-progress=true}}{color}. Then
> bootstrapStandby, the EditLogInputStream of inProgress is misjudged,
> resulting in a gap check failure, which causes bootstrapStandby to fail.
> hdfs namenode -bootstrapStandby
> !image-2022-04-22-17-17-32-487.png|width=766,height=161!
> !image-2022-04-22-17-17-14-577.png|width=598,height=187!
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Commented] (HDFS-16624) Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR
[ https://issues.apache.org/jira/browse/HDFS-16624?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17551360#comment-17551360 ] fanshilun commented on HDFS-16624: -- Thanks for the suggestion, I have linked jira. > Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR > > > Key: HDFS-16624 > URL: https://issues.apache.org/jira/browse/HDFS-16624 > Project: Hadoop HDFS > Issue Type: Bug >Affects Versions: 3.4.0 >Reporter: fanshilun >Assignee: fanshilun >Priority: Major > Labels: pull-request-available > Attachments: testAllDatanodesReconfig.png > > Time Spent: 2h 20m > Remaining Estimate: 0h > > HDFS-16619 found an error message during Junit unit testing, as follows: > expected:<[SUCCESS: Changed property dfs.datanode.peer.stats.enabled]> but > was:<[ From: "false"]> > After code debugging, it was found that there was an error in the selection > outs.get(2) of the assertion(1208), index should be equal to 1. > Please refer to the attachment for debugging pictures > !testAllDatanodesReconfig.png! -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work started] (HDFS-16624) Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR
[ https://issues.apache.org/jira/browse/HDFS-16624?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Work on HDFS-16624 started by fanshilun. > Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR > > > Key: HDFS-16624 > URL: https://issues.apache.org/jira/browse/HDFS-16624 > Project: Hadoop HDFS > Issue Type: Bug >Affects Versions: 3.4.0 >Reporter: fanshilun >Assignee: fanshilun >Priority: Major > Labels: pull-request-available > Attachments: testAllDatanodesReconfig.png > > Time Spent: 2h 20m > Remaining Estimate: 0h > > HDFS-16619 found an error message during Junit unit testing, as follows: > expected:<[SUCCESS: Changed property dfs.datanode.peer.stats.enabled]> but > was:<[ From: "false"]> > After code debugging, it was found that there was an error in the selection > outs.get(2) of the assertion(1208), index should be equal to 1. > Please refer to the attachment for debugging pictures > !testAllDatanodesReconfig.png! -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work started] (HDFS-16605) Improve Code With Lambda in hadoop-hdfs-rbf moudle
[ https://issues.apache.org/jira/browse/HDFS-16605?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Work on HDFS-16605 started by fanshilun. > Improve Code With Lambda in hadoop-hdfs-rbf moudle > -- > > Key: HDFS-16605 > URL: https://issues.apache.org/jira/browse/HDFS-16605 > Project: Hadoop HDFS > Issue Type: Improvement > Components: rbf >Affects Versions: 3.4.0 >Reporter: fanshilun >Assignee: fanshilun >Priority: Minor > Labels: pull-request-available > Time Spent: 1.5h > Remaining Estimate: 0h > -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work started] (HDFS-16590) Fix Junit Test Deprecated assertThat
[ https://issues.apache.org/jira/browse/HDFS-16590?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Work on HDFS-16590 started by fanshilun. > Fix Junit Test Deprecated assertThat > > > Key: HDFS-16590 > URL: https://issues.apache.org/jira/browse/HDFS-16590 > Project: Hadoop HDFS > Issue Type: Improvement >Reporter: fanshilun >Assignee: fanshilun >Priority: Major > Labels: pull-request-available > Time Spent: 2h 10m > Remaining Estimate: 0h > -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work started] (HDFS-16619) impove HttpHeaders.Values And HttpHeaders.Names With recommended Class
[ https://issues.apache.org/jira/browse/HDFS-16619?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Work on HDFS-16619 started by fanshilun. > impove HttpHeaders.Values And HttpHeaders.Names With recommended Class > -- > > Key: HDFS-16619 > URL: https://issues.apache.org/jira/browse/HDFS-16619 > Project: Hadoop HDFS > Issue Type: Improvement >Affects Versions: 3.4.0 >Reporter: fanshilun >Assignee: fanshilun >Priority: Major > Labels: pull-request-available > Fix For: 3.4.0 > > Time Spent: 40m > Remaining Estimate: 0h > > HttpHeaders.Values and HttpHeaders.Names are deprecated, use > HttpHeaderValues and HttpHeaderNames instead. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16621) Remove unused JNStorage#getCurrentDir()
[ https://issues.apache.org/jira/browse/HDFS-16621?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] JiangHua Zhu updated HDFS-16621: Description: There is no use of getCurrentDir() anywhere in JNStorage, we should remove it. (was: In JNStorage, sd.getCurrentDir() is used in 5~6 places, It can be replaced with JNStorage#getCurrentDir(), which will be more concise.) > Remove unused JNStorage#getCurrentDir() > --- > > Key: HDFS-16621 > URL: https://issues.apache.org/jira/browse/HDFS-16621 > Project: Hadoop HDFS > Issue Type: Improvement > Components: journal-node, qjm >Affects Versions: 3.3.0 >Reporter: JiangHua Zhu >Assignee: JiangHua Zhu >Priority: Minor > Labels: pull-request-available > Time Spent: 1h > Remaining Estimate: 0h > > There is no use of getCurrentDir() anywhere in JNStorage, we should remove it. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16621) Remove unused JNStorage#getCurrentDir()
[ https://issues.apache.org/jira/browse/HDFS-16621?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] JiangHua Zhu updated HDFS-16621: Summary: Remove unused JNStorage#getCurrentDir() (was: Replace sd.getCurrentDir() with JNStorage#getCurrentDir()) > Remove unused JNStorage#getCurrentDir() > --- > > Key: HDFS-16621 > URL: https://issues.apache.org/jira/browse/HDFS-16621 > Project: Hadoop HDFS > Issue Type: Improvement > Components: journal-node, qjm >Affects Versions: 3.3.0 >Reporter: JiangHua Zhu >Assignee: JiangHua Zhu >Priority: Minor > Labels: pull-request-available > Time Spent: 1h > Remaining Estimate: 0h > > In JNStorage, sd.getCurrentDir() is used in 5~6 places, > It can be replaced with JNStorage#getCurrentDir(), which will be more concise. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16621) Replace sd.getCurrentDir() with JNStorage#getCurrentDir()
[ https://issues.apache.org/jira/browse/HDFS-16621?focusedWorklogId=779307=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779307 ] ASF GitHub Bot logged work on HDFS-16621: - Author: ASF GitHub Bot Created on: 08/Jun/22 02:05 Start Date: 08/Jun/22 02:05 Worklog Time Spent: 10m Work Description: jianghuazhu commented on PR #4404: URL: https://github.com/apache/hadoop/pull/4404#issuecomment-1149370199 Thanks @ayushtkn for the comment and reply. I initially thought that the previous author created JNStorage#getCurrentDir() to replace sd.getCurrentDir(), so I made this suggestion. I will remove JNStorage#getCurrentDir() and resubmit. Issue Time Tracking --- Worklog Id: (was: 779307) Time Spent: 1h (was: 50m) > Replace sd.getCurrentDir() with JNStorage#getCurrentDir() > - > > Key: HDFS-16621 > URL: https://issues.apache.org/jira/browse/HDFS-16621 > Project: Hadoop HDFS > Issue Type: Improvement > Components: journal-node, qjm >Affects Versions: 3.3.0 >Reporter: JiangHua Zhu >Assignee: JiangHua Zhu >Priority: Minor > Labels: pull-request-available > Time Spent: 1h > Remaining Estimate: 0h > > In JNStorage, sd.getCurrentDir() is used in 5~6 places, > It can be replaced with JNStorage#getCurrentDir(), which will be more concise. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Commented] (HDFS-16563) Namenode WebUI prints sensitive information on Token Expiry
[ https://issues.apache.org/jira/browse/HDFS-16563?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17551345#comment-17551345 ] fanshilun commented on HDFS-16563: -- [~ste...@apache.org] Sorry, I saw this pr was merged in the git log, I thought this was forgotten to close, so I closed it. > Namenode WebUI prints sensitive information on Token Expiry > --- > > Key: HDFS-16563 > URL: https://issues.apache.org/jira/browse/HDFS-16563 > Project: Hadoop HDFS > Issue Type: Bug > Components: namanode, security, webhdfs >Affects Versions: 3.3.3 >Reporter: Renukaprasad C >Assignee: Renukaprasad C >Priority: Major > Labels: pull-request-available > Fix For: 3.4.0, 3.3.4 > > Attachments: image-2022-04-27-23-01-16-033.png, > image-2022-04-27-23-28-40-568.png > > Time Spent: 3h > Remaining Estimate: 0h > > Login to Namenode WebUI. > Wait for token to expire. (Or modify the Token refresh time > dfs.namenode.delegation.token.renew/update-interval to lower value) > Refresh the WebUI after the Token expiry. > Full token information gets printed in WebUI. > > !image-2022-04-27-23-01-16-033.png! -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16625) Unit tests aren't checking for PMDK availability
[
https://issues.apache.org/jira/browse/HDFS-16625?focusedWorklogId=779284=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779284
]
ASF GitHub Bot logged work on HDFS-16625:
-
Author: ASF GitHub Bot
Created on: 08/Jun/22 00:15
Start Date: 08/Jun/22 00:15
Worklog Time Spent: 10m
Work Description: ashutoshcipher commented on PR #4414:
URL: https://github.com/apache/hadoop/pull/4414#issuecomment-1149301940
LGTM
Issue Time Tracking
---
Worklog Id: (was: 779284)
Time Spent: 20m (was: 10m)
> Unit tests aren't checking for PMDK availability
>
>
> Key: HDFS-16625
> URL: https://issues.apache.org/jira/browse/HDFS-16625
> Project: Hadoop HDFS
> Issue Type: Test
> Components: test
>Affects Versions: 3.4.0, 3.3.4
>Reporter: Steve Vaughan
>Priority: Blocker
> Labels: pull-request-available
> Time Spent: 20m
> Remaining Estimate: 0h
>
> There are unit tests that require native PMDK libraries which aren't checking
> if the library is available, resulting in unsuccessful test. Adding the
> following in the test setup addresses the problem.
> {code:java}
> assumeTrue ("Requires PMDK", NativeIO.POSIX.isPmdkAvailable()); {code}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16624) Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR
[ https://issues.apache.org/jira/browse/HDFS-16624?focusedWorklogId=779280=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779280 ] ASF GitHub Bot logged work on HDFS-16624: - Author: ASF GitHub Bot Created on: 08/Jun/22 00:09 Start Date: 08/Jun/22 00:09 Worklog Time Spent: 10m Work Description: slfan1989 commented on PR #4412: URL: https://github.com/apache/hadoop/pull/4412#issuecomment-1149298084 > Good find btw @slfan1989 The code you contributed is very useful, I have learned a lot from you, thank you again! Issue Time Tracking --- Worklog Id: (was: 779280) Time Spent: 2h 20m (was: 2h 10m) > Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR > > > Key: HDFS-16624 > URL: https://issues.apache.org/jira/browse/HDFS-16624 > Project: Hadoop HDFS > Issue Type: Bug >Affects Versions: 3.4.0 >Reporter: fanshilun >Assignee: fanshilun >Priority: Major > Labels: pull-request-available > Attachments: testAllDatanodesReconfig.png > > Time Spent: 2h 20m > Remaining Estimate: 0h > > HDFS-16619 found an error message during Junit unit testing, as follows: > expected:<[SUCCESS: Changed property dfs.datanode.peer.stats.enabled]> but > was:<[ From: "false"]> > After code debugging, it was found that there was an error in the selection > outs.get(2) of the assertion(1208), index should be equal to 1. > Please refer to the attachment for debugging pictures > !testAllDatanodesReconfig.png! -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16624) Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR
[ https://issues.apache.org/jira/browse/HDFS-16624?focusedWorklogId=779279=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779279 ] ASF GitHub Bot logged work on HDFS-16624: - Author: ASF GitHub Bot Created on: 08/Jun/22 00:08 Start Date: 08/Jun/22 00:08 Worklog Time Spent: 10m Work Description: slfan1989 commented on PR #4412: URL: https://github.com/apache/hadoop/pull/4412#issuecomment-1149297182 @virajjasani @tomscut please help me review the code again. Issue Time Tracking --- Worklog Id: (was: 779279) Time Spent: 2h 10m (was: 2h) > Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR > > > Key: HDFS-16624 > URL: https://issues.apache.org/jira/browse/HDFS-16624 > Project: Hadoop HDFS > Issue Type: Bug >Affects Versions: 3.4.0 >Reporter: fanshilun >Assignee: fanshilun >Priority: Major > Labels: pull-request-available > Attachments: testAllDatanodesReconfig.png > > Time Spent: 2h 10m > Remaining Estimate: 0h > > HDFS-16619 found an error message during Junit unit testing, as follows: > expected:<[SUCCESS: Changed property dfs.datanode.peer.stats.enabled]> but > was:<[ From: "false"]> > After code debugging, it was found that there was an error in the selection > outs.get(2) of the assertion(1208), index should be equal to 1. > Please refer to the attachment for debugging pictures > !testAllDatanodesReconfig.png! -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16605) Improve Code With Lambda in hadoop-hdfs-rbf moudle
[ https://issues.apache.org/jira/browse/HDFS-16605?focusedWorklogId=779277=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779277 ] ASF GitHub Bot logged work on HDFS-16605: - Author: ASF GitHub Bot Created on: 07/Jun/22 23:48 Start Date: 07/Jun/22 23:48 Worklog Time Spent: 10m Work Description: slfan1989 commented on PR #4375: URL: https://github.com/apache/hadoop/pull/4375#issuecomment-1149281613 @ayushtkn Please help me review the code. Issue Time Tracking --- Worklog Id: (was: 779277) Time Spent: 1.5h (was: 1h 20m) > Improve Code With Lambda in hadoop-hdfs-rbf moudle > -- > > Key: HDFS-16605 > URL: https://issues.apache.org/jira/browse/HDFS-16605 > Project: Hadoop HDFS > Issue Type: Improvement > Components: rbf >Affects Versions: 3.4.0 >Reporter: fanshilun >Assignee: fanshilun >Priority: Minor > Labels: pull-request-available > Time Spent: 1.5h > Remaining Estimate: 0h > -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16624) Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR
[
https://issues.apache.org/jira/browse/HDFS-16624?focusedWorklogId=779274=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779274
]
ASF GitHub Bot logged work on HDFS-16624:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 23:18
Start Date: 07/Jun/22 23:18
Worklog Time Spent: 10m
Work Description: slfan1989 commented on code in PR #4412:
URL: https://github.com/apache/hadoop/pull/4412#discussion_r891781997
##
hadoop-hdfs-project/hadoop-hdfs/src/test/java/org/apache/hadoop/hdfs/tools/TestDFSAdmin.java:
##
@@ -1205,9 +1205,9 @@ public void testAllDatanodesReconfig()
LOG.info("dfsadmin -status -livenodes output:");
outs.forEach(s -> LOG.info("{}", s));
assertTrue(outs.get(0).startsWith("Reconfiguring status for node"));
-assertEquals("SUCCESS: Changed property dfs.datanode.peer.stats.enabled",
outs.get(2));
-assertEquals("\tFrom: \"false\"", outs.get(3));
-assertEquals("\tTo: \"true\"", outs.get(4));
+assertEquals("SUCCESS: Changed property dfs.datanode.peer.stats.enabled",
outs.get(1));
+assertEquals("\tFrom: \"false\"", outs.get(2));
+assertEquals("\tTo: \"true\"", outs.get(3));
Review Comment:
I will modify the code.
Issue Time Tracking
---
Worklog Id: (was: 779274)
Time Spent: 2h (was: 1h 50m)
> Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR
>
>
> Key: HDFS-16624
> URL: https://issues.apache.org/jira/browse/HDFS-16624
> Project: Hadoop HDFS
> Issue Type: Bug
>Affects Versions: 3.4.0
>Reporter: fanshilun
>Assignee: fanshilun
>Priority: Major
> Labels: pull-request-available
> Attachments: testAllDatanodesReconfig.png
>
> Time Spent: 2h
> Remaining Estimate: 0h
>
> HDFS-16619 found an error message during Junit unit testing, as follows:
> expected:<[SUCCESS: Changed property dfs.datanode.peer.stats.enabled]> but
> was:<[ From: "false"]>
> After code debugging, it was found that there was an error in the selection
> outs.get(2) of the assertion(1208), index should be equal to 1.
> Please refer to the attachment for debugging pictures
> !testAllDatanodesReconfig.png!
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16624) Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR
[
https://issues.apache.org/jira/browse/HDFS-16624?focusedWorklogId=779273=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779273
]
ASF GitHub Bot logged work on HDFS-16624:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 23:16
Start Date: 07/Jun/22 23:16
Worklog Time Spent: 10m
Work Description: slfan1989 commented on code in PR #4412:
URL: https://github.com/apache/hadoop/pull/4412#discussion_r891780928
##
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/tools/DFSAdmin.java:
##
@@ -2068,51 +2068,51 @@ int getReconfigurationStatus(final String nodeType,
final String address, final
errMsg = String.format("Node [%s] reloading configuration: %s.", address,
e.toString());
}
-
-if (errMsg != null) {
- err.println(errMsg);
- return 1;
-} else {
- out.print(outMsg);
-}
-
-if (status != null) {
- if (!status.hasTask()) {
-out.println("no task was found.");
-return 0;
- }
- out.print("started at " + new Date(status.getStartTime()));
- if (!status.stopped()) {
-out.println(" and is still running.");
-return 0;
+synchronized (this) {
Review Comment:
thanks for your suggestion, I will modify the junit test.
Issue Time Tracking
---
Worklog Id: (was: 779273)
Time Spent: 1h 50m (was: 1h 40m)
> Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR
>
>
> Key: HDFS-16624
> URL: https://issues.apache.org/jira/browse/HDFS-16624
> Project: Hadoop HDFS
> Issue Type: Bug
>Affects Versions: 3.4.0
>Reporter: fanshilun
>Assignee: fanshilun
>Priority: Major
> Labels: pull-request-available
> Attachments: testAllDatanodesReconfig.png
>
> Time Spent: 1h 50m
> Remaining Estimate: 0h
>
> HDFS-16619 found an error message during Junit unit testing, as follows:
> expected:<[SUCCESS: Changed property dfs.datanode.peer.stats.enabled]> but
> was:<[ From: "false"]>
> After code debugging, it was found that there was an error in the selection
> outs.get(2) of the assertion(1208), index should be equal to 1.
> Please refer to the attachment for debugging pictures
> !testAllDatanodesReconfig.png!
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Commented] (HDFS-16624) Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR
[ https://issues.apache.org/jira/browse/HDFS-16624?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17551305#comment-17551305 ] Ayush Saxena commented on HDFS-16624: - Can you link the Jira which broke this, add the root cause and loop in the folks involved in that Jira. > Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR > > > Key: HDFS-16624 > URL: https://issues.apache.org/jira/browse/HDFS-16624 > Project: Hadoop HDFS > Issue Type: Bug >Affects Versions: 3.4.0 >Reporter: fanshilun >Assignee: fanshilun >Priority: Major > Labels: pull-request-available > Attachments: testAllDatanodesReconfig.png > > Time Spent: 1h 40m > Remaining Estimate: 0h > > HDFS-16619 found an error message during Junit unit testing, as follows: > expected:<[SUCCESS: Changed property dfs.datanode.peer.stats.enabled]> but > was:<[ From: "false"]> > After code debugging, it was found that there was an error in the selection > outs.get(2) of the assertion(1208), index should be equal to 1. > Please refer to the attachment for debugging pictures > !testAllDatanodesReconfig.png! -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16624) Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR
[ https://issues.apache.org/jira/browse/HDFS-16624?focusedWorklogId=779266=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779266 ] ASF GitHub Bot logged work on HDFS-16624: - Author: ASF GitHub Bot Created on: 07/Jun/22 22:05 Start Date: 07/Jun/22 22:05 Worklog Time Spent: 10m Work Description: virajjasani commented on PR #4412: URL: https://github.com/apache/hadoop/pull/4412#issuecomment-1149219846 Good find btw @slfan1989 Issue Time Tracking --- Worklog Id: (was: 779266) Time Spent: 1h 40m (was: 1.5h) > Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR > > > Key: HDFS-16624 > URL: https://issues.apache.org/jira/browse/HDFS-16624 > Project: Hadoop HDFS > Issue Type: Bug >Affects Versions: 3.4.0 >Reporter: fanshilun >Assignee: fanshilun >Priority: Major > Labels: pull-request-available > Attachments: testAllDatanodesReconfig.png > > Time Spent: 1h 40m > Remaining Estimate: 0h > > HDFS-16619 found an error message during Junit unit testing, as follows: > expected:<[SUCCESS: Changed property dfs.datanode.peer.stats.enabled]> but > was:<[ From: "false"]> > After code debugging, it was found that there was an error in the selection > outs.get(2) of the assertion(1208), index should be equal to 1. > Please refer to the attachment for debugging pictures > !testAllDatanodesReconfig.png! -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16624) Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR
[
https://issues.apache.org/jira/browse/HDFS-16624?focusedWorklogId=779265=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779265
]
ASF GitHub Bot logged work on HDFS-16624:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 22:04
Start Date: 07/Jun/22 22:04
Worklog Time Spent: 10m
Work Description: virajjasani commented on code in PR #4412:
URL: https://github.com/apache/hadoop/pull/4412#discussion_r891747569
##
hadoop-hdfs-project/hadoop-hdfs/src/test/java/org/apache/hadoop/hdfs/tools/TestDFSAdmin.java:
##
@@ -1205,9 +1205,9 @@ public void testAllDatanodesReconfig()
LOG.info("dfsadmin -status -livenodes output:");
outs.forEach(s -> LOG.info("{}", s));
assertTrue(outs.get(0).startsWith("Reconfiguring status for node"));
-assertEquals("SUCCESS: Changed property dfs.datanode.peer.stats.enabled",
outs.get(2));
-assertEquals("\tFrom: \"false\"", outs.get(3));
-assertEquals("\tTo: \"true\"", outs.get(4));
+assertEquals("SUCCESS: Changed property dfs.datanode.peer.stats.enabled",
outs.get(1));
+assertEquals("\tFrom: \"false\"", outs.get(2));
+assertEquals("\tTo: \"true\"", outs.get(3));
Review Comment:
Given that concurrency is at play here, we can do something like this:
```
assertTrue("SUCCESS: Changed property
dfs.datanode.peer.stats.enabled".equals(outs.get(2))
|| "SUCCESS: Changed property
dfs.datanode.peer.stats.enabled".equals(outs.get(1)));
```
##
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/tools/DFSAdmin.java:
##
@@ -2068,51 +2068,51 @@ int getReconfigurationStatus(final String nodeType,
final String address, final
errMsg = String.format("Node [%s] reloading configuration: %s.", address,
e.toString());
}
-
-if (errMsg != null) {
- err.println(errMsg);
- return 1;
-} else {
- out.print(outMsg);
-}
-
-if (status != null) {
- if (!status.hasTask()) {
-out.println("no task was found.");
-return 0;
- }
- out.print("started at " + new Date(status.getStartTime()));
- if (!status.stopped()) {
-out.println(" and is still running.");
-return 0;
+synchronized (this) {
Review Comment:
@slfan1989 This is good for concurrency control but we should avoid this for
performance issues. Rather, we can update test.
Issue Time Tracking
---
Worklog Id: (was: 779265)
Time Spent: 1.5h (was: 1h 20m)
> Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR
>
>
> Key: HDFS-16624
> URL: https://issues.apache.org/jira/browse/HDFS-16624
> Project: Hadoop HDFS
> Issue Type: Bug
>Affects Versions: 3.4.0
>Reporter: fanshilun
>Assignee: fanshilun
>Priority: Major
> Labels: pull-request-available
> Attachments: testAllDatanodesReconfig.png
>
> Time Spent: 1.5h
> Remaining Estimate: 0h
>
> HDFS-16619 found an error message during Junit unit testing, as follows:
> expected:<[SUCCESS: Changed property dfs.datanode.peer.stats.enabled]> but
> was:<[ From: "false"]>
> After code debugging, it was found that there was an error in the selection
> outs.get(2) of the assertion(1208), index should be equal to 1.
> Please refer to the attachment for debugging pictures
> !testAllDatanodesReconfig.png!
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16623) IllegalArgumentException in LifelineSender
[
https://issues.apache.org/jira/browse/HDFS-16623?focusedWorklogId=779260=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779260
]
ASF GitHub Bot logged work on HDFS-16623:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 20:58
Start Date: 07/Jun/22 20:58
Worklog Time Spent: 10m
Work Description: cnauroth commented on PR #4409:
URL: https://github.com/apache/hadoop/pull/4409#issuecomment-1149161121
@ZanderXu , yes, I was thinking of just testing that `getLifelineWaitTime()`
only returns non-negative numbers. There is a similar kind of test in
`TestBpServiceActorScheduler#testScheduleLifeline`, but it doesn't yet cover
the case that would lead to a negative value.
I think testing for LifelineSender thread exit would be more complete, but
also a lot more complex. Testing directly against the `getLifelineWaitTime()`
return values is a good compromise.
Thanks!
Issue Time Tracking
---
Worklog Id: (was: 779260)
Time Spent: 40m (was: 0.5h)
> IllegalArgumentException in LifelineSender
> --
>
> Key: HDFS-16623
> URL: https://issues.apache.org/jira/browse/HDFS-16623
> Project: Hadoop HDFS
> Issue Type: Bug
>Reporter: ZanderXu
>Assignee: ZanderXu
>Priority: Major
> Labels: pull-request-available
> Time Spent: 40m
> Remaining Estimate: 0h
>
> In our production environment, an IllegalArgumentException occurred in the
> LifelineSender at one DataNode which was undergoing GC at that time.
> And the bug code is at line 1060 in BPServiceActor.java, because the sleep
> time is negative.
> {code:java}
> while (shouldRun()) {
> try {
> if (lifelineNamenode == null) {
> lifelineNamenode = dn.connectToLifelineNN(lifelineNnAddr);
> }
> sendLifelineIfDue();
> Thread.sleep(scheduler.getLifelineWaitTime());
> } catch (InterruptedException e) {
> Thread.currentThread().interrupt();
> } catch (IOException e) {
> LOG.warn("IOException in LifelineSender for " + BPServiceActor.this,
> e);
> }
> }
> {code}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16463) Make dirent cross platform compatible
[
https://issues.apache.org/jira/browse/HDFS-16463?focusedWorklogId=779185=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779185
]
ASF GitHub Bot logged work on HDFS-16463:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 16:39
Start Date: 07/Jun/22 16:39
Worklog Time Spent: 10m
Work Description: goiri commented on code in PR #4370:
URL: https://github.com/apache/hadoop/pull/4370#discussion_r891470689
##
hadoop-hdfs-project/hadoop-hdfs-native-client/src/main/native/libhdfspp/lib/x-platform/c-api/dirent.h:
##
@@ -0,0 +1,92 @@
+/**
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+#ifndef NATIVE_LIBHDFSPP_LIB_CROSS_PLATFORM_C_API_DIRENT_H
+#define NATIVE_LIBHDFSPP_LIB_CROSS_PLATFORM_C_API_DIRENT_H
+
+#if !(defined(WIN32) || defined(USE_X_PLATFORM_DIRENT))
+/*
+ * For non-Windows environments, we use the dirent.h header itself.
+ */
+#include
+#else
+/*
+ * If it's a Windows environment or if the macro USE_X_PLATFORM_DIRENT is
+ * defined, we switch to using dirent from the XPlatform library.
+ */
+
+/*
+ * We will use extern "C" only on Windows.
+ */
+#if defined(WIN32) && defined(__cplusplus)
+extern "C" {
+#endif
+
+/**
Review Comment:
Line 40 to 84 could be in its own .h file.
Then you can have another .h which does the adding of the extern.
Finally, you would have this one that includes accordingly.
The issue I try to avoid is having nested preprocessor ifs which are not
easy to read.
Issue Time Tracking
---
Worklog Id: (was: 779185)
Time Spent: 5h 10m (was: 5h)
> Make dirent cross platform compatible
> -
>
> Key: HDFS-16463
> URL: https://issues.apache.org/jira/browse/HDFS-16463
> Project: Hadoop HDFS
> Issue Type: Improvement
> Components: libhdfs++
>Affects Versions: 3.4.0
> Environment: Windows 10
>Reporter: Gautham Banasandra
>Assignee: Gautham Banasandra
>Priority: Major
> Labels: libhdfscpp, pull-request-available
> Time Spent: 5h 10m
> Remaining Estimate: 0h
>
> [jnihelper.c|https://github.com/apache/hadoop/blob/1fed18bb2d8ac3dbaecc3feddded30bed918d556/hadoop-hdfs-project/hadoop-hdfs-native-client/src/main/native/libhdfs/jni_helper.c#L28]
> in HDFS native client uses *dirent.h*. This header file isn't available on
> Windows. Thus, we need to replace this with a cross platform compatible
> implementation for dirent.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16625) Unit tests aren't checking for PMDK availability
[
https://issues.apache.org/jira/browse/HDFS-16625?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
ASF GitHub Bot updated HDFS-16625:
--
Labels: pull-request-available (was: )
> Unit tests aren't checking for PMDK availability
>
>
> Key: HDFS-16625
> URL: https://issues.apache.org/jira/browse/HDFS-16625
> Project: Hadoop HDFS
> Issue Type: Test
> Components: test
>Affects Versions: 3.4.0, 3.3.4
>Reporter: Steve Vaughan
>Priority: Blocker
> Labels: pull-request-available
> Time Spent: 10m
> Remaining Estimate: 0h
>
> There are unit tests that require native PMDK libraries which aren't checking
> if the library is available, resulting in unsuccessful test. Adding the
> following in the test setup addresses the problem.
> {code:java}
> assumeTrue ("Requires PMDK", NativeIO.POSIX.isPmdkAvailable()); {code}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16625) Unit tests aren't checking for PMDK availability
[
https://issues.apache.org/jira/browse/HDFS-16625?focusedWorklogId=779145=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779145
]
ASF GitHub Bot logged work on HDFS-16625:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 15:11
Start Date: 07/Jun/22 15:11
Worklog Time Spent: 10m
Work Description: snmvaughan opened a new pull request, #4414:
URL: https://github.com/apache/hadoop/pull/4414
### Description of PR
There are unit tests that require native PMDK libraries which aren't
checking if the library is available, resulting in unsuccessful test. This
patch checks the assumption about PMDK availability. The same changes have
been applied and tested against trunk (3.4.0-SNAPSHOT), branch-3.3
(3.3.4-SNAPSHOT), and branch-3.3.3.
### How was this patch tested?
This patch has been applied to a local build that runs in the Hadoop
development environment, which doesn't include the PMDK shared libraries.
### For code changes:
- [X] Does the title or this PR starts with the corresponding JIRA issue id
(e.g. 'HADOOP-17799. Your PR title ...')?
- [ ] Object storage: have the integration tests been executed and the
endpoint declared according to the connector-specific documentation?
- [ ] If adding new dependencies to the code, are these dependencies
licensed in a way that is compatible for inclusion under [ASF
2.0](http://www.apache.org/legal/resolved.html#category-a)?
- [ ] If applicable, have you updated the `LICENSE`, `LICENSE-binary`,
`NOTICE-binary` files?
Issue Time Tracking
---
Worklog Id: (was: 779145)
Remaining Estimate: 0h
Time Spent: 10m
> Unit tests aren't checking for PMDK availability
>
>
> Key: HDFS-16625
> URL: https://issues.apache.org/jira/browse/HDFS-16625
> Project: Hadoop HDFS
> Issue Type: Test
> Components: test
>Affects Versions: 3.4.0, 3.3.4
>Reporter: Steve Vaughan
>Priority: Blocker
> Time Spent: 10m
> Remaining Estimate: 0h
>
> There are unit tests that require native PMDK libraries which aren't checking
> if the library is available, resulting in unsuccessful test. Adding the
> following in the test setup addresses the problem.
> {code:java}
> assumeTrue ("Requires PMDK", NativeIO.POSIX.isPmdkAvailable()); {code}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16596) Improve the processing capability of FsDatasetAsyncDiskService
[ https://issues.apache.org/jira/browse/HDFS-16596?focusedWorklogId=779141=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779141 ] ASF GitHub Bot logged work on HDFS-16596: - Author: ASF GitHub Bot Created on: 07/Jun/22 15:00 Start Date: 07/Jun/22 15:00 Worklog Time Spent: 10m Work Description: ZanderXu commented on PR #4360: URL: https://github.com/apache/hadoop/pull/4360#issuecomment-1148793254 Thanks @saintstack for you suggestion. I have updated the patch according your suggestion, and help me review it again, thanks~ Issue Time Tracking --- Worklog Id: (was: 779141) Time Spent: 50m (was: 40m) > Improve the processing capability of FsDatasetAsyncDiskService > -- > > Key: HDFS-16596 > URL: https://issues.apache.org/jira/browse/HDFS-16596 > Project: Hadoop HDFS > Issue Type: Improvement >Reporter: ZanderXu >Assignee: ZanderXu >Priority: Major > Labels: pull-request-available > Time Spent: 50m > Remaining Estimate: 0h > > In our production environment, when DN needs to delete a large number blocks, > we find that many deletion tasks are backlogged in the queue of > threadPoolExecutor in FsDatasetAsyncDiskService. We can't improve its > throughput because the number of core threads is hard coded. > So DN needs to support the number of core threads of > FsDatasetAsyncDiskService can be configured. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16600) Deadlock on DataNode
[
https://issues.apache.org/jira/browse/HDFS-16600?focusedWorklogId=779134=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779134
]
ASF GitHub Bot logged work on HDFS-16600:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 14:39
Start Date: 07/Jun/22 14:39
Worklog Time Spent: 10m
Work Description: ZanderXu commented on PR #4367:
URL: https://github.com/apache/hadoop/pull/4367#issuecomment-1148766297
> Another suggestion, can you write the junit test?
you can see the UT
org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.testSynchronousEviction.
Issue Time Tracking
---
Worklog Id: (was: 779134)
Time Spent: 2h 40m (was: 2.5h)
> Deadlock on DataNode
>
>
> Key: HDFS-16600
> URL: https://issues.apache.org/jira/browse/HDFS-16600
> Project: Hadoop HDFS
> Issue Type: Bug
>Reporter: ZanderXu
>Assignee: ZanderXu
>Priority: Major
> Labels: pull-request-available
> Time Spent: 2h 40m
> Remaining Estimate: 0h
>
> The UT
> org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.testSynchronousEviction
> failed, because happened deadlock, which is introduced by
> [HDFS-16534|https://issues.apache.org/jira/browse/HDFS-16534].
> DeadLock:
> {code:java}
> // org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.createRbw line 1588
> need a read lock
> try (AutoCloseableLock lock = lockManager.readLock(LockLevel.BLOCK_POOl,
> b.getBlockPoolId()))
> // org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.evictBlocks line
> 3526 need a write lock
> try (AutoCloseableLock lock = lockManager.writeLock(LockLevel.BLOCK_POOl,
> bpid))
> {code}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16533) COMPOSITE_CRC failed between replicated file and striped file.
[
https://issues.apache.org/jira/browse/HDFS-16533?focusedWorklogId=779133=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779133
]
ASF GitHub Bot logged work on HDFS-16533:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 14:36
Start Date: 07/Jun/22 14:36
Worklog Time Spent: 10m
Work Description: ZanderXu commented on PR #4155:
URL: https://github.com/apache/hadoop/pull/4155#issuecomment-1148763022
@Hexiaoqiao @jojochuang Could you help me review this patch? The failed UTs
not caused by this modification, and has been solved in other jira.
Issue Time Tracking
---
Worklog Id: (was: 779133)
Time Spent: 3h 20m (was: 3h 10m)
> COMPOSITE_CRC failed between replicated file and striped file.
> --
>
> Key: HDFS-16533
> URL: https://issues.apache.org/jira/browse/HDFS-16533
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: hdfs, hdfs-client
>Reporter: ZanderXu
>Assignee: ZanderXu
>Priority: Major
> Labels: pull-request-available
> Time Spent: 3h 20m
> Remaining Estimate: 0h
>
> After testing the COMPOSITE_CRC with some random length between replicated
> file and striped file which has same data with replicated file, it failed.
> Reproduce step like this:
> {code:java}
> @Test(timeout = 9)
> public void testStripedAndReplicatedFileChecksum2() throws Exception {
> int abnormalSize = (dataBlocks * 2 - 2) * blockSize +
> (int) (blockSize * 0.5);
> prepareTestFiles(abnormalSize, new String[] {stripedFile1, replicatedFile});
> int loopNumber = 100;
> while (loopNumber-- > 0) {
> int verifyLength = ThreadLocalRandom.current()
> .nextInt(10, abnormalSize);
> FileChecksum stripedFileChecksum1 = getFileChecksum(stripedFile1,
> verifyLength, false);
> FileChecksum replicatedFileChecksum = getFileChecksum(replicatedFile,
> verifyLength, false);
> if (checksumCombineMode.equals(ChecksumCombineMode.COMPOSITE_CRC.name()))
> {
> Assert.assertEquals(stripedFileChecksum1, replicatedFileChecksum);
> } else {
> Assert.assertNotEquals(stripedFileChecksum1, replicatedFileChecksum);
> }
> }
> } {code}
> And after tracing the root cause, `FileChecksumHelper#makeCompositeCrcResult`
> maybe compute an error `consumedLastBlockLength` when updating checksum for
> the last block of the fixed length which maybe not the last block in the file.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16593) Correct inaccurate BlocksRemoved metric on DataNode side
[
https://issues.apache.org/jira/browse/HDFS-16593?focusedWorklogId=779132=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779132
]
ASF GitHub Bot logged work on HDFS-16593:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 14:35
Start Date: 07/Jun/22 14:35
Worklog Time Spent: 10m
Work Description: ZanderXu commented on PR #4353:
URL: https://github.com/apache/hadoop/pull/4353#issuecomment-1148761554
@Hexiaoqiao Could you help me review this patch? The failed UTs not caused
by this modification, and has been solved in other jira.
Issue Time Tracking
---
Worklog Id: (was: 779132)
Time Spent: 0.5h (was: 20m)
> Correct inaccurate BlocksRemoved metric on DataNode side
>
>
> Key: HDFS-16593
> URL: https://issues.apache.org/jira/browse/HDFS-16593
> Project: Hadoop HDFS
> Issue Type: Bug
>Reporter: ZanderXu
>Assignee: ZanderXu
>Priority: Minor
> Labels: pull-request-available
> Time Spent: 0.5h
> Remaining Estimate: 0h
>
> When tracing the root cause of production issue, I found that the
> BlocksRemoved metric on Datanode size was inaccurate.
> {code:java}
> case DatanodeProtocol.DNA_INVALIDATE:
> //
> // Some local block(s) are obsolete and can be
> // safely garbage-collected.
> //
> Block toDelete[] = bcmd.getBlocks();
> try {
> // using global fsdataset
> dn.getFSDataset().invalidate(bcmd.getBlockPoolId(), toDelete);
> } catch(IOException e) {
> // Exceptions caught here are not expected to be disk-related.
> throw e;
> }
> dn.metrics.incrBlocksRemoved(toDelete.length);
> break;
> {code}
> Because even if the invalidate method throws an exception, some blocks may
> have been successfully deleted internally.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16600) Deadlock on DataNode
[
https://issues.apache.org/jira/browse/HDFS-16600?focusedWorklogId=779130=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779130
]
ASF GitHub Bot logged work on HDFS-16600:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 14:31
Start Date: 07/Jun/22 14:31
Worklog Time Spent: 10m
Work Description: slfan1989 commented on PR #4367:
URL: https://github.com/apache/hadoop/pull/4367#issuecomment-1148756359
@ZanderXu @Hexiaoqiao Thank you very much everyone, I learned a lot from the
discussion, I didn't pay attention to this pr, because the description
information is too short, especially for me who just started reading hdfs code.
I will summarize the calling process in the comment area of HDFS-16600 Leave
a message (ASAP), and I hope @ZanderXu @Hexiaoqiao you can help me check it too.
Issue Time Tracking
---
Worklog Id: (was: 779130)
Time Spent: 2.5h (was: 2h 20m)
> Deadlock on DataNode
>
>
> Key: HDFS-16600
> URL: https://issues.apache.org/jira/browse/HDFS-16600
> Project: Hadoop HDFS
> Issue Type: Bug
>Reporter: ZanderXu
>Assignee: ZanderXu
>Priority: Major
> Labels: pull-request-available
> Time Spent: 2.5h
> Remaining Estimate: 0h
>
> The UT
> org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.testSynchronousEviction
> failed, because happened deadlock, which is introduced by
> [HDFS-16534|https://issues.apache.org/jira/browse/HDFS-16534].
> DeadLock:
> {code:java}
> // org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.createRbw line 1588
> need a read lock
> try (AutoCloseableLock lock = lockManager.readLock(LockLevel.BLOCK_POOl,
> b.getBlockPoolId()))
> // org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.evictBlocks line
> 3526 need a write lock
> try (AutoCloseableLock lock = lockManager.writeLock(LockLevel.BLOCK_POOl,
> bpid))
> {code}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16622) addRDBI in IncrementalBlockReportManager may remove the block with bigger GS.
[
https://issues.apache.org/jira/browse/HDFS-16622?focusedWorklogId=779121=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779121
]
ASF GitHub Bot logged work on HDFS-16622:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 14:24
Start Date: 07/Jun/22 14:24
Worklog Time Spent: 10m
Work Description: ZanderXu commented on code in PR #4407:
URL: https://github.com/apache/hadoop/pull/4407#discussion_r891298950
##
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/IncrementalBlockReportManager.java:
##
@@ -251,12 +251,20 @@ synchronized void addRDBI(ReceivedDeletedBlockInfo rdbi,
DatanodeStorage storage) {
// Make sure another entry for the same block is first removed.
// There may only be one such entry.
+ReceivedDeletedBlockInfo removedInfo = null;
for (PerStorageIBR perStorage : pendingIBRs.values()) {
- if (perStorage.remove(rdbi.getBlock()) != null) {
+ removedInfo = perStorage.remove(rdbi.getBlock());
+ if (removedInfo != null) {
break;
}
}
-getPerStorageIBR(storage).put(rdbi);
+if (removedInfo != null &&
Review Comment:
We encountered the case of concurrent CloseRecovery. The CloseRecovery with
small GS early process block on Storage but later being added into pendingIBRs,
and CloseRecovery with bigger GS later process block on Storage but early being
added into pendingIBRs. As a result, the large GS block is stored on the disk,
but small GS block being reported to Namenode. And very unfortunately, the
block has one this valid replica, and leads to the block missing.
Issue Time Tracking
---
Worklog Id: (was: 779121)
Time Spent: 50m (was: 40m)
> addRDBI in IncrementalBlockReportManager may remove the block with bigger GS.
> -
>
> Key: HDFS-16622
> URL: https://issues.apache.org/jira/browse/HDFS-16622
> Project: Hadoop HDFS
> Issue Type: Bug
>Reporter: ZanderXu
>Assignee: ZanderXu
>Priority: Major
> Labels: pull-request-available
> Time Spent: 50m
> Remaining Estimate: 0h
>
> In our production environment, there is a strange missing block, according
> to the log, I suspect there is a bug in function
> addRDBI(ReceivedDeletedBlockInfo rdbi,DatanodeStorage storage)(line 250).
> Bug code in the for loop:
> {code:java}
> synchronized void addRDBI(ReceivedDeletedBlockInfo rdbi,
> DatanodeStorage storage) {
> // Make sure another entry for the same block is first removed.
> // There may only be one such entry.
> for (PerStorageIBR perStorage : pendingIBRs.values()) {
> if (perStorage.remove(rdbi.getBlock()) != null) {
> break;
> }
> }
> getPerStorageIBR(storage).put(rdbi);
> }
> {code}
> Removed the GS of the Block in ReceivedDeletedBlockInfo may be greater than
> the GS of the Block in rdbi. And NN will invalidate the Replicate will small
> GS when complete one block.
> So If there is only one replicate for one block, there is a possibility of
> missingblock because of this wrong logic.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16622) addRDBI in IncrementalBlockReportManager may remove the block with bigger GS.
[
https://issues.apache.org/jira/browse/HDFS-16622?focusedWorklogId=779118=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779118
]
ASF GitHub Bot logged work on HDFS-16622:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 14:21
Start Date: 07/Jun/22 14:21
Worklog Time Spent: 10m
Work Description: ZanderXu commented on code in PR #4407:
URL: https://github.com/apache/hadoop/pull/4407#discussion_r891298950
##
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/IncrementalBlockReportManager.java:
##
@@ -251,12 +251,20 @@ synchronized void addRDBI(ReceivedDeletedBlockInfo rdbi,
DatanodeStorage storage) {
// Make sure another entry for the same block is first removed.
// There may only be one such entry.
+ReceivedDeletedBlockInfo removedInfo = null;
for (PerStorageIBR perStorage : pendingIBRs.values()) {
- if (perStorage.remove(rdbi.getBlock()) != null) {
+ removedInfo = perStorage.remove(rdbi.getBlock());
+ if (removedInfo != null) {
break;
}
}
-getPerStorageIBR(storage).put(rdbi);
+if (removedInfo != null &&
Review Comment:
We encountered the case of concurrent CloseRecovery. The CloseRecovery with
small GS early process block on Storage but later being added into pendingIBRs,
and CloseRecovery with bigger GS later process block on Storage but early being
added into pendingIBRs. As a result, the large GS block is stored on the disk,
but small GS block being reported to Namenode.
Issue Time Tracking
---
Worklog Id: (was: 779118)
Time Spent: 40m (was: 0.5h)
> addRDBI in IncrementalBlockReportManager may remove the block with bigger GS.
> -
>
> Key: HDFS-16622
> URL: https://issues.apache.org/jira/browse/HDFS-16622
> Project: Hadoop HDFS
> Issue Type: Bug
>Reporter: ZanderXu
>Assignee: ZanderXu
>Priority: Major
> Labels: pull-request-available
> Time Spent: 40m
> Remaining Estimate: 0h
>
> In our production environment, there is a strange missing block, according
> to the log, I suspect there is a bug in function
> addRDBI(ReceivedDeletedBlockInfo rdbi,DatanodeStorage storage)(line 250).
> Bug code in the for loop:
> {code:java}
> synchronized void addRDBI(ReceivedDeletedBlockInfo rdbi,
> DatanodeStorage storage) {
> // Make sure another entry for the same block is first removed.
> // There may only be one such entry.
> for (PerStorageIBR perStorage : pendingIBRs.values()) {
> if (perStorage.remove(rdbi.getBlock()) != null) {
> break;
> }
> }
> getPerStorageIBR(storage).put(rdbi);
> }
> {code}
> Removed the GS of the Block in ReceivedDeletedBlockInfo may be greater than
> the GS of the Block in rdbi. And NN will invalidate the Replicate will small
> GS when complete one block.
> So If there is only one replicate for one block, there is a possibility of
> missingblock because of this wrong logic.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16601) Failed to replace a bad datanode on the existing pipeline due to no more good datanodes being available to try
[
https://issues.apache.org/jira/browse/HDFS-16601?focusedWorklogId=779109=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779109
]
ASF GitHub Bot logged work on HDFS-16601:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 14:09
Start Date: 07/Jun/22 14:09
Worklog Time Spent: 10m
Work Description: ZanderXu commented on PR #4369:
URL: https://github.com/apache/hadoop/pull/4369#issuecomment-1148728940
Thanks @Hexiaoqiao .
When client is recovering pipeline, the source dn of selected to transfer
block to new DN may be abnormal, so that the source dn cannot transfer the
block to the new node normally, but the failed exception not returned to the
client, caused the client to think that the transfer is completed
successfully. Because new DN not contains the block, so client will fail to
build the pipeline and mark the new DN is bad. And then Client will add the new
DN into exclude list to get a new DN for the new loop pipeline recovery.
The new pipeline recovery will still choose the abnormal dn as source dn to
transfer block, and will failed again..
So Dn should return the failed transfer exception to client, so that client
can choose anther existed dn as source dn to transfer the block to new DN.
Issue Time Tracking
---
Worklog Id: (was: 779109)
Time Spent: 50m (was: 40m)
> Failed to replace a bad datanode on the existing pipeline due to no more good
> datanodes being available to try
> --
>
> Key: HDFS-16601
> URL: https://issues.apache.org/jira/browse/HDFS-16601
> Project: Hadoop HDFS
> Issue Type: Bug
>Reporter: ZanderXu
>Assignee: ZanderXu
>Priority: Major
> Labels: pull-request-available
> Time Spent: 50m
> Remaining Estimate: 0h
>
> In our production environment, we found a bug and stack like:
> {code:java}
> java.io.IOException: Failed to replace a bad datanode on the existing
> pipeline due to no more good datanodes being available to try. (Nodes:
> current=[DatanodeInfoWithStorage[127.0.0.1:59687,DS-b803febc-7b22-4144-9b39-7bf521cdaa8d,DISK],
>
> DatanodeInfoWithStorage[127.0.0.1:59670,DS-0d652bc2-1784-430d-961f-750f80a290f1,DISK]],
>
> original=[DatanodeInfoWithStorage[127.0.0.1:59670,DS-0d652bc2-1784-430d-961f-750f80a290f1,DISK],
>
> DatanodeInfoWithStorage[127.0.0.1:59687,DS-b803febc-7b22-4144-9b39-7bf521cdaa8d,DISK]]).
> The current failed datanode replacement policy is DEFAULT, and a client may
> configure this via
> 'dfs.client.block.write.replace-datanode-on-failure.policy' in its
> configuration.
> at
> org.apache.hadoop.hdfs.DataStreamer.findNewDatanode(DataStreamer.java:1418)
> at
> org.apache.hadoop.hdfs.DataStreamer.addDatanode2ExistingPipeline(DataStreamer.java:1478)
> at
> org.apache.hadoop.hdfs.DataStreamer.handleDatanodeReplacement(DataStreamer.java:1704)
> at
> org.apache.hadoop.hdfs.DataStreamer.setupPipelineInternal(DataStreamer.java:1605)
> at
> org.apache.hadoop.hdfs.DataStreamer.setupPipelineForAppendOrRecovery(DataStreamer.java:1587)
> at
> org.apache.hadoop.hdfs.DataStreamer.processDatanodeOrExternalError(DataStreamer.java:1371)
> at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:674)
> {code}
> And the root cause is that DFSClient cannot perceive the exception of
> TransferBlock during PipelineRecovery. If failed during TransferBlock, the
> DFSClient will retry all datanodes in the cluster and then failed.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Resolved] (HDFS-16610) Make fsck read timeout configurable
[ https://issues.apache.org/jira/browse/HDFS-16610?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Stephen O'Donnell resolved HDFS-16610. -- Resolution: Fixed > Make fsck read timeout configurable > --- > > Key: HDFS-16610 > URL: https://issues.apache.org/jira/browse/HDFS-16610 > Project: Hadoop HDFS > Issue Type: Improvement > Components: hdfs-client >Reporter: Stephen O'Donnell >Assignee: Stephen O'Donnell >Priority: Major > Labels: pull-request-available > Fix For: 3.4.0, 3.2.4, 3.3.4 > > Time Spent: 1h 50m > Remaining Estimate: 0h > > In a cluster with a lot of small files, we encountered a case where fsck was > very slow. I believe it is due to contention with many other threads reading > / writing data on the cluster. > Sometimes fsck does not report any progress for more than 60 seconds and the > client times out. Currently the connect and read timeout are hardcoded to 60 > seconds. This change is to make them configurable. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16610) Make fsck read timeout configurable
[ https://issues.apache.org/jira/browse/HDFS-16610?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Stephen O'Donnell updated HDFS-16610: - Fix Version/s: 3.4.0 3.2.4 3.3.4 > Make fsck read timeout configurable > --- > > Key: HDFS-16610 > URL: https://issues.apache.org/jira/browse/HDFS-16610 > Project: Hadoop HDFS > Issue Type: Improvement > Components: hdfs-client >Reporter: Stephen O'Donnell >Assignee: Stephen O'Donnell >Priority: Major > Labels: pull-request-available > Fix For: 3.4.0, 3.2.4, 3.3.4 > > Time Spent: 1h 50m > Remaining Estimate: 0h > > In a cluster with a lot of small files, we encountered a case where fsck was > very slow. I believe it is due to contention with many other threads reading > / writing data on the cluster. > Sometimes fsck does not report any progress for more than 60 seconds and the > client times out. Currently the connect and read timeout are hardcoded to 60 > seconds. This change is to make them configurable. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16624) Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR
[ https://issues.apache.org/jira/browse/HDFS-16624?focusedWorklogId=779102=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779102 ] ASF GitHub Bot logged work on HDFS-16624: - Author: ASF GitHub Bot Created on: 07/Jun/22 13:51 Start Date: 07/Jun/22 13:51 Worklog Time Spent: 10m Work Description: slfan1989 commented on PR #4412: URL: https://github.com/apache/hadoop/pull/4412#issuecomment-1148706563 I already know the cause of the problem, because the log is out of order due to multi-threading. Issue Time Tracking --- Worklog Id: (was: 779102) Time Spent: 1h 20m (was: 1h 10m) > Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR > > > Key: HDFS-16624 > URL: https://issues.apache.org/jira/browse/HDFS-16624 > Project: Hadoop HDFS > Issue Type: Bug >Affects Versions: 3.4.0 >Reporter: fanshilun >Assignee: fanshilun >Priority: Major > Labels: pull-request-available > Attachments: testAllDatanodesReconfig.png > > Time Spent: 1h 20m > Remaining Estimate: 0h > > HDFS-16619 found an error message during Junit unit testing, as follows: > expected:<[SUCCESS: Changed property dfs.datanode.peer.stats.enabled]> but > was:<[ From: "false"]> > After code debugging, it was found that there was an error in the selection > outs.get(2) of the assertion(1208), index should be equal to 1. > Please refer to the attachment for debugging pictures > !testAllDatanodesReconfig.png! -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Commented] (HDFS-16625) Unit tests aren't checking for PMDK availability
[
https://issues.apache.org/jira/browse/HDFS-16625?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17551095#comment-17551095
]
Steve Vaughan commented on HDFS-16625:
--
I'll be submitting a tested patch this morning.
> Unit tests aren't checking for PMDK availability
>
>
> Key: HDFS-16625
> URL: https://issues.apache.org/jira/browse/HDFS-16625
> Project: Hadoop HDFS
> Issue Type: Test
> Components: test
>Affects Versions: 3.4.0, 3.3.4
>Reporter: Steve Vaughan
>Priority: Blocker
>
> There are unit tests that require native PMDK libraries which aren't checking
> if the library is available, resulting in unsuccessful test. Adding the
> following in the test setup addresses the problem.
> {code:java}
> assumeTrue ("Requires PMDK", NativeIO.POSIX.isPmdkAvailable()); {code}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16622) addRDBI in IncrementalBlockReportManager may remove the block with bigger GS.
[
https://issues.apache.org/jira/browse/HDFS-16622?focusedWorklogId=779101=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779101
]
ASF GitHub Bot logged work on HDFS-16622:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 13:41
Start Date: 07/Jun/22 13:41
Worklog Time Spent: 10m
Work Description: Hexiaoqiao commented on code in PR #4407:
URL: https://github.com/apache/hadoop/pull/4407#discussion_r891245808
##
hadoop-hdfs-project/hadoop-hdfs/src/main/java/org/apache/hadoop/hdfs/server/datanode/IncrementalBlockReportManager.java:
##
@@ -251,12 +251,20 @@ synchronized void addRDBI(ReceivedDeletedBlockInfo rdbi,
DatanodeStorage storage) {
// Make sure another entry for the same block is first removed.
// There may only be one such entry.
+ReceivedDeletedBlockInfo removedInfo = null;
for (PerStorageIBR perStorage : pendingIBRs.values()) {
- if (perStorage.remove(rdbi.getBlock()) != null) {
+ removedInfo = perStorage.remove(rdbi.getBlock());
+ if (removedInfo != null) {
break;
}
}
-getPerStorageIBR(storage).put(rdbi);
+if (removedInfo != null &&
Review Comment:
My first feeling is `pendingIBRs` should keep the freshest `rdbis` set to
report NameNode. But after changes, it will be not the fresh data and also
inconsistence with block data on Storage, right?
Issue Time Tracking
---
Worklog Id: (was: 779101)
Time Spent: 0.5h (was: 20m)
> addRDBI in IncrementalBlockReportManager may remove the block with bigger GS.
> -
>
> Key: HDFS-16622
> URL: https://issues.apache.org/jira/browse/HDFS-16622
> Project: Hadoop HDFS
> Issue Type: Bug
>Reporter: ZanderXu
>Assignee: ZanderXu
>Priority: Major
> Labels: pull-request-available
> Time Spent: 0.5h
> Remaining Estimate: 0h
>
> In our production environment, there is a strange missing block, according
> to the log, I suspect there is a bug in function
> addRDBI(ReceivedDeletedBlockInfo rdbi,DatanodeStorage storage)(line 250).
> Bug code in the for loop:
> {code:java}
> synchronized void addRDBI(ReceivedDeletedBlockInfo rdbi,
> DatanodeStorage storage) {
> // Make sure another entry for the same block is first removed.
> // There may only be one such entry.
> for (PerStorageIBR perStorage : pendingIBRs.values()) {
> if (perStorage.remove(rdbi.getBlock()) != null) {
> break;
> }
> }
> getPerStorageIBR(storage).put(rdbi);
> }
> {code}
> Removed the GS of the Block in ReceivedDeletedBlockInfo may be greater than
> the GS of the Block in rdbi. And NN will invalidate the Replicate will small
> GS when complete one block.
> So If there is only one replicate for one block, there is a possibility of
> missingblock because of this wrong logic.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16563) Namenode WebUI prints sensitive information on Token Expiry
[ https://issues.apache.org/jira/browse/HDFS-16563?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Steve Loughran updated HDFS-16563: -- Affects Version/s: 3.3.3 > Namenode WebUI prints sensitive information on Token Expiry > --- > > Key: HDFS-16563 > URL: https://issues.apache.org/jira/browse/HDFS-16563 > Project: Hadoop HDFS > Issue Type: Bug > Components: namanode, security, webhdfs >Affects Versions: 3.3.3 >Reporter: Renukaprasad C >Assignee: Renukaprasad C >Priority: Major > Labels: pull-request-available > Fix For: 3.4.0, 3.3.4 > > Attachments: image-2022-04-27-23-01-16-033.png, > image-2022-04-27-23-28-40-568.png > > Time Spent: 3h > Remaining Estimate: 0h > > Login to Namenode WebUI. > Wait for token to expire. (Or modify the Token refresh time > dfs.namenode.delegation.token.renew/update-interval to lower value) > Refresh the WebUI after the Token expiry. > Full token information gets printed in WebUI. > > !image-2022-04-27-23-01-16-033.png! -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16563) Namenode WebUI prints sensitive information on Token Expiry
[ https://issues.apache.org/jira/browse/HDFS-16563?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Steve Loughran updated HDFS-16563: -- Fix Version/s: 3.4.0 > Namenode WebUI prints sensitive information on Token Expiry > --- > > Key: HDFS-16563 > URL: https://issues.apache.org/jira/browse/HDFS-16563 > Project: Hadoop HDFS > Issue Type: Bug > Components: namanode, security, webhdfs >Reporter: Renukaprasad C >Assignee: Renukaprasad C >Priority: Major > Labels: pull-request-available > Fix For: 3.4.0, 3.3.4 > > Attachments: image-2022-04-27-23-01-16-033.png, > image-2022-04-27-23-28-40-568.png > > Time Spent: 3h > Remaining Estimate: 0h > > Login to Namenode WebUI. > Wait for token to expire. (Or modify the Token refresh time > dfs.namenode.delegation.token.renew/update-interval to lower value) > Refresh the WebUI after the Token expiry. > Full token information gets printed in WebUI. > > !image-2022-04-27-23-01-16-033.png! -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Commented] (HDFS-16563) Namenode WebUI prints sensitive information on Token Expiry
[ https://issues.apache.org/jira/browse/HDFS-16563?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17551088#comment-17551088 ] Steve Loughran commented on HDFS-16563: --- [~slfan1989] please let whoever is doing the merging close the issue. in this instance i was actually doing the backport to branch-3.3, which is why it was still open also, all issues for which there is a change committed *MUST* have the fix version. it is how we create the release notes > Namenode WebUI prints sensitive information on Token Expiry > --- > > Key: HDFS-16563 > URL: https://issues.apache.org/jira/browse/HDFS-16563 > Project: Hadoop HDFS > Issue Type: Bug > Components: namanode, security, webhdfs >Reporter: Renukaprasad C >Assignee: Renukaprasad C >Priority: Major > Labels: pull-request-available > Fix For: 3.3.4 > > Attachments: image-2022-04-27-23-01-16-033.png, > image-2022-04-27-23-28-40-568.png > > Time Spent: 3h > Remaining Estimate: 0h > > Login to Namenode WebUI. > Wait for token to expire. (Or modify the Token refresh time > dfs.namenode.delegation.token.renew/update-interval to lower value) > Refresh the WebUI after the Token expiry. > Full token information gets printed in WebUI. > > !image-2022-04-27-23-01-16-033.png! -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Resolved] (HDFS-16563) Namenode WebUI prints sensitive information on Token Expiry
[ https://issues.apache.org/jira/browse/HDFS-16563?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Steve Loughran resolved HDFS-16563. --- Resolution: Fixed > Namenode WebUI prints sensitive information on Token Expiry > --- > > Key: HDFS-16563 > URL: https://issues.apache.org/jira/browse/HDFS-16563 > Project: Hadoop HDFS > Issue Type: Bug > Components: namanode, security, webhdfs >Reporter: Renukaprasad C >Assignee: Renukaprasad C >Priority: Major > Labels: pull-request-available > Fix For: 3.3.4 > > Attachments: image-2022-04-27-23-01-16-033.png, > image-2022-04-27-23-28-40-568.png > > Time Spent: 3h > Remaining Estimate: 0h > > Login to Namenode WebUI. > Wait for token to expire. (Or modify the Token refresh time > dfs.namenode.delegation.token.renew/update-interval to lower value) > Refresh the WebUI after the Token expiry. > Full token information gets printed in WebUI. > > !image-2022-04-27-23-01-16-033.png! -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Reopened] (HDFS-16563) Namenode WebUI prints sensitive information on Token Expiry
[ https://issues.apache.org/jira/browse/HDFS-16563?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Steve Loughran reopened HDFS-16563: --- > Namenode WebUI prints sensitive information on Token Expiry > --- > > Key: HDFS-16563 > URL: https://issues.apache.org/jira/browse/HDFS-16563 > Project: Hadoop HDFS > Issue Type: Bug > Components: namanode, security, webhdfs >Reporter: Renukaprasad C >Assignee: Renukaprasad C >Priority: Major > Labels: pull-request-available > Fix For: 3.3.4 > > Attachments: image-2022-04-27-23-01-16-033.png, > image-2022-04-27-23-28-40-568.png > > Time Spent: 3h > Remaining Estimate: 0h > > Login to Namenode WebUI. > Wait for token to expire. (Or modify the Token refresh time > dfs.namenode.delegation.token.renew/update-interval to lower value) > Refresh the WebUI after the Token expiry. > Full token information gets printed in WebUI. > > !image-2022-04-27-23-01-16-033.png! -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16601) Failed to replace a bad datanode on the existing pipeline due to no more good datanodes being available to try
[
https://issues.apache.org/jira/browse/HDFS-16601?focusedWorklogId=779091=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779091
]
ASF GitHub Bot logged work on HDFS-16601:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 13:27
Start Date: 07/Jun/22 13:27
Worklog Time Spent: 10m
Work Description: Hexiaoqiao commented on PR #4369:
URL: https://github.com/apache/hadoop/pull/4369#issuecomment-1148675874
@ZanderXu Thanks for report and contribution. Sorry I don't get what
scenario lead this issue. Would you like to offer more information. Thanks.
Issue Time Tracking
---
Worklog Id: (was: 779091)
Time Spent: 40m (was: 0.5h)
> Failed to replace a bad datanode on the existing pipeline due to no more good
> datanodes being available to try
> --
>
> Key: HDFS-16601
> URL: https://issues.apache.org/jira/browse/HDFS-16601
> Project: Hadoop HDFS
> Issue Type: Bug
>Reporter: ZanderXu
>Assignee: ZanderXu
>Priority: Major
> Labels: pull-request-available
> Time Spent: 40m
> Remaining Estimate: 0h
>
> In our production environment, we found a bug and stack like:
> {code:java}
> java.io.IOException: Failed to replace a bad datanode on the existing
> pipeline due to no more good datanodes being available to try. (Nodes:
> current=[DatanodeInfoWithStorage[127.0.0.1:59687,DS-b803febc-7b22-4144-9b39-7bf521cdaa8d,DISK],
>
> DatanodeInfoWithStorage[127.0.0.1:59670,DS-0d652bc2-1784-430d-961f-750f80a290f1,DISK]],
>
> original=[DatanodeInfoWithStorage[127.0.0.1:59670,DS-0d652bc2-1784-430d-961f-750f80a290f1,DISK],
>
> DatanodeInfoWithStorage[127.0.0.1:59687,DS-b803febc-7b22-4144-9b39-7bf521cdaa8d,DISK]]).
> The current failed datanode replacement policy is DEFAULT, and a client may
> configure this via
> 'dfs.client.block.write.replace-datanode-on-failure.policy' in its
> configuration.
> at
> org.apache.hadoop.hdfs.DataStreamer.findNewDatanode(DataStreamer.java:1418)
> at
> org.apache.hadoop.hdfs.DataStreamer.addDatanode2ExistingPipeline(DataStreamer.java:1478)
> at
> org.apache.hadoop.hdfs.DataStreamer.handleDatanodeReplacement(DataStreamer.java:1704)
> at
> org.apache.hadoop.hdfs.DataStreamer.setupPipelineInternal(DataStreamer.java:1605)
> at
> org.apache.hadoop.hdfs.DataStreamer.setupPipelineForAppendOrRecovery(DataStreamer.java:1587)
> at
> org.apache.hadoop.hdfs.DataStreamer.processDatanodeOrExternalError(DataStreamer.java:1371)
> at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:674)
> {code}
> And the root cause is that DFSClient cannot perceive the exception of
> TransferBlock during PipelineRecovery. If failed during TransferBlock, the
> DFSClient will retry all datanodes in the cluster and then failed.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16600) Deadlock on DataNode
[
https://issues.apache.org/jira/browse/HDFS-16600?focusedWorklogId=779080=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779080
]
ASF GitHub Bot logged work on HDFS-16600:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 13:14
Start Date: 07/Jun/22 13:14
Worklog Time Spent: 10m
Work Description: ZanderXu commented on PR #4367:
URL: https://github.com/apache/hadoop/pull/4367#issuecomment-1148657754
Thanks @Hexiaoqiao for your review, and I will check other methods.
Issue Time Tracking
---
Worklog Id: (was: 779080)
Time Spent: 2h 20m (was: 2h 10m)
> Deadlock on DataNode
>
>
> Key: HDFS-16600
> URL: https://issues.apache.org/jira/browse/HDFS-16600
> Project: Hadoop HDFS
> Issue Type: Bug
>Reporter: ZanderXu
>Assignee: ZanderXu
>Priority: Major
> Labels: pull-request-available
> Time Spent: 2h 20m
> Remaining Estimate: 0h
>
> The UT
> org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.testSynchronousEviction
> failed, because happened deadlock, which is introduced by
> [HDFS-16534|https://issues.apache.org/jira/browse/HDFS-16534].
> DeadLock:
> {code:java}
> // org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.createRbw line 1588
> need a read lock
> try (AutoCloseableLock lock = lockManager.readLock(LockLevel.BLOCK_POOl,
> b.getBlockPoolId()))
> // org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.evictBlocks line
> 3526 need a write lock
> try (AutoCloseableLock lock = lockManager.writeLock(LockLevel.BLOCK_POOl,
> bpid))
> {code}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16600) Deadlock on DataNode
[
https://issues.apache.org/jira/browse/HDFS-16600?focusedWorklogId=779077=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779077
]
ASF GitHub Bot logged work on HDFS-16600:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 13:06
Start Date: 07/Jun/22 13:06
Worklog Time Spent: 10m
Work Description: Hexiaoqiao commented on PR #4367:
URL: https://github.com/apache/hadoop/pull/4367#issuecomment-1148648304
@ZanderXu Thanks for the great catch here.
It is indeed missed method which need to improve. cc @MingXiangLi @ZanderXu
would you mind to check if other methods also leave this issues?
> Thank you for your contribution, but I still have some concerns about
[HDFS-16534](https://issues.apache.org/jira/browse/HDFS-16534). I feel that for
a new feature, multiple prs should not be used to fix the problem separately,
which makes the code very difficult to read. I recommend creating it under
[HDFS-15382](https://issues.apache.org/jira/browse/HDFS-15382) A subtask to fix
[HDFS-16598](https://issues.apache.org/jira/browse/HDFS-16598) and
[HDFS-16600](https://issues.apache.org/jira/browse/HDFS-16600) together.
@slfan1989 Thansk for your suggestions. IMO, this is not the blocker issue.
Any tickets will be collected to subtask of HDFS-16534 before checkin for
committers. -1 to combine HDFS-16598 and HDFS-16600 together. IIUC, it is
recommended to add/fix one issue for one ticket. Welcome to any more
discussions.
@ZanderXu @slfan1989 Thanks again.
Issue Time Tracking
---
Worklog Id: (was: 779077)
Time Spent: 2h 10m (was: 2h)
> Deadlock on DataNode
>
>
> Key: HDFS-16600
> URL: https://issues.apache.org/jira/browse/HDFS-16600
> Project: Hadoop HDFS
> Issue Type: Bug
>Reporter: ZanderXu
>Assignee: ZanderXu
>Priority: Major
> Labels: pull-request-available
> Time Spent: 2h 10m
> Remaining Estimate: 0h
>
> The UT
> org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.testSynchronousEviction
> failed, because happened deadlock, which is introduced by
> [HDFS-16534|https://issues.apache.org/jira/browse/HDFS-16534].
> DeadLock:
> {code:java}
> // org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.createRbw line 1588
> need a read lock
> try (AutoCloseableLock lock = lockManager.readLock(LockLevel.BLOCK_POOl,
> b.getBlockPoolId()))
> // org.apache.hadoop.hdfs.server.datanode.fsdataset.impl.evictBlocks line
> 3526 need a write lock
> try (AutoCloseableLock lock = lockManager.writeLock(LockLevel.BLOCK_POOl,
> bpid))
> {code}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16623) IllegalArgumentException in LifelineSender
[
https://issues.apache.org/jira/browse/HDFS-16623?focusedWorklogId=779075=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779075
]
ASF GitHub Bot logged work on HDFS-16623:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 12:55
Start Date: 07/Jun/22 12:55
Worklog Time Spent: 10m
Work Description: ZanderXu commented on PR #4409:
URL: https://github.com/apache/hadoop/pull/4409#issuecomment-1148630372
Thanks @cnauroth for your comment. Do you mean to add a UT to test that
`getLifelineWaitTime()` can only return non-negative numbers?
I think if we need a UT, we should test the LifelineSender thread exit, but
it is difficult to judge whether the thread exits or not. Do you have some good
ideas? Thanks
Issue Time Tracking
---
Worklog Id: (was: 779075)
Time Spent: 0.5h (was: 20m)
> IllegalArgumentException in LifelineSender
> --
>
> Key: HDFS-16623
> URL: https://issues.apache.org/jira/browse/HDFS-16623
> Project: Hadoop HDFS
> Issue Type: Bug
>Reporter: ZanderXu
>Assignee: ZanderXu
>Priority: Major
> Labels: pull-request-available
> Time Spent: 0.5h
> Remaining Estimate: 0h
>
> In our production environment, an IllegalArgumentException occurred in the
> LifelineSender at one DataNode which was undergoing GC at that time.
> And the bug code is at line 1060 in BPServiceActor.java, because the sleep
> time is negative.
> {code:java}
> while (shouldRun()) {
> try {
> if (lifelineNamenode == null) {
> lifelineNamenode = dn.connectToLifelineNN(lifelineNnAddr);
> }
> sendLifelineIfDue();
> Thread.sleep(scheduler.getLifelineWaitTime());
> } catch (InterruptedException e) {
> Thread.currentThread().interrupt();
> } catch (IOException e) {
> LOG.warn("IOException in LifelineSender for " + BPServiceActor.this,
> e);
> }
> }
> {code}
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16598) All datanodes [DatanodeInfoWithStorage[127.0.0.1:57448,DS-1b5f7e33-a2bf-4edc-9122-a74c995a99f5,DISK]] are bad. Aborting...
[
https://issues.apache.org/jira/browse/HDFS-16598?focusedWorklogId=779073=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779073
]
ASF GitHub Bot logged work on HDFS-16598:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 12:53
Start Date: 07/Jun/22 12:53
Worklog Time Spent: 10m
Work Description: Hexiaoqiao commented on PR #4366:
URL: https://github.com/apache/hadoop/pull/4366#issuecomment-1148627690
> getReplicaInfo(ExtendedBlock b) will check gs, and getReplicaInfo(String
bpid, long blkid) will not check the gs.
@ZanderXu Thanks for the great catch here.
> I would like to ask a question, after reading your discussion, is it
possible that block GS of client may be smaller than DN appears in all places
where getReplicaInfo(String bpid, long blkid) is called?
It is good question.
IMO, it is not necessary to compare GS for any cases when get fine-grained
lock for BLOCK_POOl or VOLUME, because both of them are not depended on block.
Just suggest to improve them together in one PR.
Thanks again.
Issue Time Tracking
---
Worklog Id: (was: 779073)
Time Spent: 2h (was: 1h 50m)
> All datanodes
> [DatanodeInfoWithStorage[127.0.0.1:57448,DS-1b5f7e33-a2bf-4edc-9122-a74c995a99f5,DISK]]
> are bad. Aborting...
> --
>
> Key: HDFS-16598
> URL: https://issues.apache.org/jira/browse/HDFS-16598
> Project: Hadoop HDFS
> Issue Type: Bug
>Reporter: ZanderXu
>Assignee: ZanderXu
>Priority: Major
> Labels: pull-request-available
> Time Spent: 2h
> Remaining Estimate: 0h
>
> org.apache.hadoop.hdfs.testPipelineRecoveryOnRestartFailure failed with the
> stack like:
> {code:java}
> java.io.IOException: All datanodes
> [DatanodeInfoWithStorage[127.0.0.1:57448,DS-1b5f7e33-a2bf-4edc-9122-a74c995a99f5,DISK]]
> are bad. Aborting...
> at
> org.apache.hadoop.hdfs.DataStreamer.handleBadDatanode(DataStreamer.java:1667)
> at
> org.apache.hadoop.hdfs.DataStreamer.setupPipelineInternal(DataStreamer.java:1601)
> at
> org.apache.hadoop.hdfs.DataStreamer.setupPipelineForAppendOrRecovery(DataStreamer.java:1587)
> at
> org.apache.hadoop.hdfs.DataStreamer.processDatanodeOrExternalError(DataStreamer.java:1371)
> at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:674)
> {code}
> After tracing the root cause, this bug was introduced by
> [HDFS-16534|https://issues.apache.org/jira/browse/HDFS-16534]. Because the
> block GS of client may be smaller than DN when pipeline recovery failed.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Comment Edited] (HDFS-16064) HDFS-721 causes DataNode decommissioning to get stuck indefinitely
[
https://issues.apache.org/jira/browse/HDFS-16064?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17550619#comment-17550619
]
Kevin Wikant edited comment on HDFS-16064 at 6/7/22 12:29 PM:
--
Thanks [~it_singer] , you are correct in that my initial root cause was
incomplete
In the past few months I have seen this issue re-occur multiple times, I
decided to do a deeper dive & I identified the bug described here:
[https://github.com/apache/hadoop/pull/4410]
I think the issue described in this ticket is occurring because the corrupt
replica on DN3 will not be invalidated until DN3 either:
* restarts & sends a block report
* sends its next periodic block report (default interval is 6 hours)
So in the worst case the decommissioning in the aforementioned scenario will
take up to 6 hours to complete because DN3 may take up to 6 hours to send its
next block report & have the corrupt replica invalidated. I have not targeted
fixing this decommissioning blocker scenario because it is arguably expected
behavior & will resolve in at most "dfs.blockreport.intervalMsec". Instead the
fix [[https://github.com/apache/hadoop/pull/4410]] is targeting a more severe
bug where decommissioning gets blocked indefinitely
was (Author: kevinwikant):
Thanks [~it_singer] , you are correct in that my initial root cause was very
much incorrect
In the past few months I have seen this issue re-occur multiple times, I
decided to do a deeper dive & I identified the bug described here:
[https://github.com/apache/hadoop/pull/4410]
I think the issue described in this ticket is occurring because the corrupt
replica on DN3 will not be invalidated until DN3 either:
* restarts & sends a block report
* sends its next periodic block report (default interval is 6 hours)
So in the worst case the decommissioning in the aforementioned scenario will
take up to 6 hours to complete because DN3 may take up to 6 hours to send its
next block report & have the corrupt replica invalidated. I have not targeted
fixing this decommissioning blocker scenario because it is arguably expected
behavior & will resolve in at most "dfs.blockreport.intervalMsec". Instead the
fix [[https://github.com/apache/hadoop/pull/4410]] is targeting a more severe
bug where decommissioning gets blocked indefinitely
> HDFS-721 causes DataNode decommissioning to get stuck indefinitely
> --
>
> Key: HDFS-16064
> URL: https://issues.apache.org/jira/browse/HDFS-16064
> Project: Hadoop HDFS
> Issue Type: Bug
> Components: datanode, namenode
>Affects Versions: 3.2.1
>Reporter: Kevin Wikant
>Priority: Major
> Labels: pull-request-available
> Time Spent: 0.5h
> Remaining Estimate: 0h
>
> Seems that https://issues.apache.org/jira/browse/HDFS-721 was resolved as a
> non-issue under the assumption that if the namenode & a datanode get into an
> inconsistent state for a given block pipeline, there should be another
> datanode available to replicate the block to
> While testing datanode decommissioning using "dfs.exclude.hosts", I have
> encountered a scenario where the decommissioning gets stuck indefinitely
> Below is the progression of events:
> * there are initially 4 datanodes DN1, DN2, DN3, DN4
> * scale-down is started by adding DN1 & DN2 to "dfs.exclude.hosts"
> * HDFS block pipelines on DN1 & DN2 must now be replicated to DN3 & DN4 in
> order to satisfy their minimum replication factor of 2
> * during this replication process
> https://issues.apache.org/jira/browse/HDFS-721 is encountered which causes
> the following inconsistent state:
> ** DN3 thinks it has the block pipeline in FINALIZED state
> ** the namenode does not think DN3 has the block pipeline
> {code:java}
> 2021-06-06 10:38:23,604 INFO org.apache.hadoop.hdfs.server.datanode.DataNode
> (DataXceiver for client at /DN2:45654 [Receiving block BP-YYY:blk_XXX]):
> DN3:9866:DataXceiver error processing WRITE_BLOCK operation src: /DN2:45654
> dst: /DN3:9866;
> org.apache.hadoop.hdfs.server.datanode.ReplicaAlreadyExistsException: Block
> BP-YYY:blk_XXX already exists in state FINALIZED and thus cannot be created.
> {code}
> * the replication is attempted again, but:
> ** DN4 has the block
> ** DN1 and/or DN2 have the block, but don't count towards the minimum
> replication factor because they are being decommissioned
> ** DN3 does not have the block & cannot have the block replicated to it
> because of HDFS-721
> * the namenode repeatedly tries to replicate the block to DN3 & repeatedly
> fails, this continues indefinitely
> * therefore DN4 is the only live datanode with the block & the minimum
> replication factor of 2 cannot be satisfied
> * because the minimum replication factor cannot be satisfied for the
[jira] [Updated] (HDFS-16563) Namenode WebUI prints sensitive information on Token Expiry
[ https://issues.apache.org/jira/browse/HDFS-16563?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Steve Loughran updated HDFS-16563: -- Summary: Namenode WebUI prints sensitive information on Token Expiry (was: Namenode WebUI prints sensitve information on Token Expiry) > Namenode WebUI prints sensitive information on Token Expiry > --- > > Key: HDFS-16563 > URL: https://issues.apache.org/jira/browse/HDFS-16563 > Project: Hadoop HDFS > Issue Type: Bug > Components: namanode, security, webhdfs >Reporter: Renukaprasad C >Assignee: Renukaprasad C >Priority: Major > Labels: pull-request-available > Fix For: 3.3.4 > > Attachments: image-2022-04-27-23-01-16-033.png, > image-2022-04-27-23-28-40-568.png > > Time Spent: 3h > Remaining Estimate: 0h > > Login to Namenode WebUI. > Wait for token to expire. (Or modify the Token refresh time > dfs.namenode.delegation.token.renew/update-interval to lower value) > Refresh the WebUI after the Token expiry. > Full token information gets printed in WebUI. > > !image-2022-04-27-23-01-16-033.png! -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16563) Namenode WebUI prints sensitve information on Token Expiry
[ https://issues.apache.org/jira/browse/HDFS-16563?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Steve Loughran updated HDFS-16563: -- Fix Version/s: 3.3.4 > Namenode WebUI prints sensitve information on Token Expiry > -- > > Key: HDFS-16563 > URL: https://issues.apache.org/jira/browse/HDFS-16563 > Project: Hadoop HDFS > Issue Type: Bug > Components: namanode, security, webhdfs >Reporter: Renukaprasad C >Assignee: Renukaprasad C >Priority: Major > Labels: pull-request-available > Fix For: 3.3.4 > > Attachments: image-2022-04-27-23-01-16-033.png, > image-2022-04-27-23-28-40-568.png > > Time Spent: 3h > Remaining Estimate: 0h > > Login to Namenode WebUI. > Wait for token to expire. (Or modify the Token refresh time > dfs.namenode.delegation.token.renew/update-interval to lower value) > Refresh the WebUI after the Token expiry. > Full token information gets printed in WebUI. > > !image-2022-04-27-23-01-16-033.png! -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16621) Replace sd.getCurrentDir() with JNStorage#getCurrentDir()
[ https://issues.apache.org/jira/browse/HDFS-16621?focusedWorklogId=779008=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779008 ] ASF GitHub Bot logged work on HDFS-16621: - Author: ASF GitHub Bot Created on: 07/Jun/22 11:42 Start Date: 07/Jun/22 11:42 Worklog Time Spent: 10m Work Description: jianghuazhu commented on PR #4404: URL: https://github.com/apache/hadoop/pull/4404#issuecomment-1148553695 Hi @jojochuang @aajisaka , can you help review this pr? If improvements are needed here, I'll work hard. Thank you very much. Issue Time Tracking --- Worklog Id: (was: 779008) Time Spent: 50m (was: 40m) > Replace sd.getCurrentDir() with JNStorage#getCurrentDir() > - > > Key: HDFS-16621 > URL: https://issues.apache.org/jira/browse/HDFS-16621 > Project: Hadoop HDFS > Issue Type: Improvement > Components: journal-node, qjm >Affects Versions: 3.3.0 >Reporter: JiangHua Zhu >Assignee: JiangHua Zhu >Priority: Minor > Labels: pull-request-available > Time Spent: 50m > Remaining Estimate: 0h > > In JNStorage, sd.getCurrentDir() is used in 5~6 places, > It can be replaced with JNStorage#getCurrentDir(), which will be more concise. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16621) Replace sd.getCurrentDir() with JNStorage#getCurrentDir()
[ https://issues.apache.org/jira/browse/HDFS-16621?focusedWorklogId=779007=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779007 ] ASF GitHub Bot logged work on HDFS-16621: - Author: ASF GitHub Bot Created on: 07/Jun/22 11:42 Start Date: 07/Jun/22 11:42 Worklog Time Spent: 10m Work Description: jianghuazhu commented on PR #4404: URL: https://github.com/apache/hadoop/pull/4404#issuecomment-1148553693 Hi @jojochuang @aajisaka , can you help review this pr? If improvements are needed here, I'll work hard. Thank you very much. Issue Time Tracking --- Worklog Id: (was: 779007) Time Spent: 40m (was: 0.5h) > Replace sd.getCurrentDir() with JNStorage#getCurrentDir() > - > > Key: HDFS-16621 > URL: https://issues.apache.org/jira/browse/HDFS-16621 > Project: Hadoop HDFS > Issue Type: Improvement > Components: journal-node, qjm >Affects Versions: 3.3.0 >Reporter: JiangHua Zhu >Assignee: JiangHua Zhu >Priority: Minor > Labels: pull-request-available > Time Spent: 40m > Remaining Estimate: 0h > > In JNStorage, sd.getCurrentDir() is used in 5~6 places, > It can be replaced with JNStorage#getCurrentDir(), which will be more concise. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16581) Print node status when executing printTopology
[ https://issues.apache.org/jira/browse/HDFS-16581?focusedWorklogId=779003=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-779003 ] ASF GitHub Bot logged work on HDFS-16581: - Author: ASF GitHub Bot Created on: 07/Jun/22 11:38 Start Date: 07/Jun/22 11:38 Worklog Time Spent: 10m Work Description: jianghuazhu commented on PR #4321: URL: https://github.com/apache/hadoop/pull/4321#issuecomment-1148550038 Thanks @tomscut . Hi @jojochuang @aajisaka , can you help review this pr? Thank you very much. Issue Time Tracking --- Worklog Id: (was: 779003) Time Spent: 1h 20m (was: 1h 10m) > Print node status when executing printTopology > -- > > Key: HDFS-16581 > URL: https://issues.apache.org/jira/browse/HDFS-16581 > Project: Hadoop HDFS > Issue Type: Improvement > Components: dfsadmin, namenode >Affects Versions: 3.3.0 >Reporter: JiangHua Zhu >Assignee: JiangHua Zhu >Priority: Major > Labels: pull-request-available > Time Spent: 1h 20m > Remaining Estimate: 0h > > We can use the dfsadmin tool to see which DataNodes the cluster has, and some > of these nodes are alive, DECOMMISSIONED, or DECOMMISSION_INPROGRESS. It > would be helpful if we could get this information in a timely manner, such as > troubleshooting cluster failures, tracking node status, etc. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Commented] (HDFS-16613) EC: Improve performance of decommissioning dn with many ec blocks
[
https://issues.apache.org/jira/browse/HDFS-16613?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17550940#comment-17550940
]
Hiroyuki Adachi commented on HDFS-16613:
[~caozhiqiang] , thank you for your explanation. It looks good.
Now I understand that the blocksToProcess controls the number of replication
works, so if it is less than dfs.namenode.replication.max-streams-hard-limit,
all blocks use replication on decommissioning node but not reconstruction.
Could you please tell me the value of
dfs.namenode.replication.max-streams-hard-limit and
dfs.namenode.replication.work.multiplier.per.iteration?
{code:java}
// BlockManager#computeDatanodeWork
final int blocksToProcess = numlive
* this.blocksReplWorkMultiplier;
final int nodesToProcess = (int) Math.ceil(numlive
* this.blocksInvalidateWorkPct);
int workFound = this.computeBlockReconstructionWork(blocksToProcess); {code}
> EC: Improve performance of decommissioning dn with many ec blocks
> -
>
> Key: HDFS-16613
> URL: https://issues.apache.org/jira/browse/HDFS-16613
> Project: Hadoop HDFS
> Issue Type: Improvement
> Components: ec, erasure-coding, namenode
>Affects Versions: 3.4.0
>Reporter: caozhiqiang
>Assignee: caozhiqiang
>Priority: Major
> Labels: pull-request-available
> Attachments: image-2022-06-07-11-46-42-389.png,
> image-2022-06-07-17-42-16-075.png, image-2022-06-07-17-45-45-316.png,
> image-2022-06-07-17-51-04-876.png, image-2022-06-07-17-55-40-203.png
>
> Time Spent: 0.5h
> Remaining Estimate: 0h
>
> In a hdfs cluster with a lot of EC blocks, decommission a dn is very slow.
> The reason is unlike replication blocks can be replicated from any dn which
> has the same block replication, the ec block have to be replicated from the
> decommissioning dn.
> The configurations dfs.namenode.replication.max-streams and
> dfs.namenode.replication.max-streams-hard-limit will limit the replication
> speed, but increase these configurations will create risk to the whole
> cluster's network. So it should add a new configuration to limit the
> decommissioning dn, distinguished from the cluster wide max-streams limit.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org
For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16463) Make dirent cross platform compatible
[ https://issues.apache.org/jira/browse/HDFS-16463?focusedWorklogId=778995=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-778995 ] ASF GitHub Bot logged work on HDFS-16463: - Author: ASF GitHub Bot Created on: 07/Jun/22 11:13 Start Date: 07/Jun/22 11:13 Worklog Time Spent: 10m Work Description: GauthamBanasandra commented on code in PR #4370: URL: https://github.com/apache/hadoop/pull/4370#discussion_r891085844 ## hadoop-hdfs-project/hadoop-hdfs-native-client/src/main/native/libhdfspp/lib/x-platform/c-api/dirent.cc: ## @@ -0,0 +1,100 @@ +/** + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +#include +#include +#include +#include +#include +#include + +#include "x-platform/c-api/dirent.h" +#include "x-platform/dirent.h" + +#if defined(WIN32) && defined(__cplusplus) Review Comment: I've put the `extern "C"` in the `c-api/dirent.h` header file. I thought that I had to enclose the implementation as well. I just removed the `extern "C"` enclosure in the implementation and I was able to build fine on both Windows and Ubuntu. I ran the tests on both the platforms and they're working fine as well - ## Windows 10 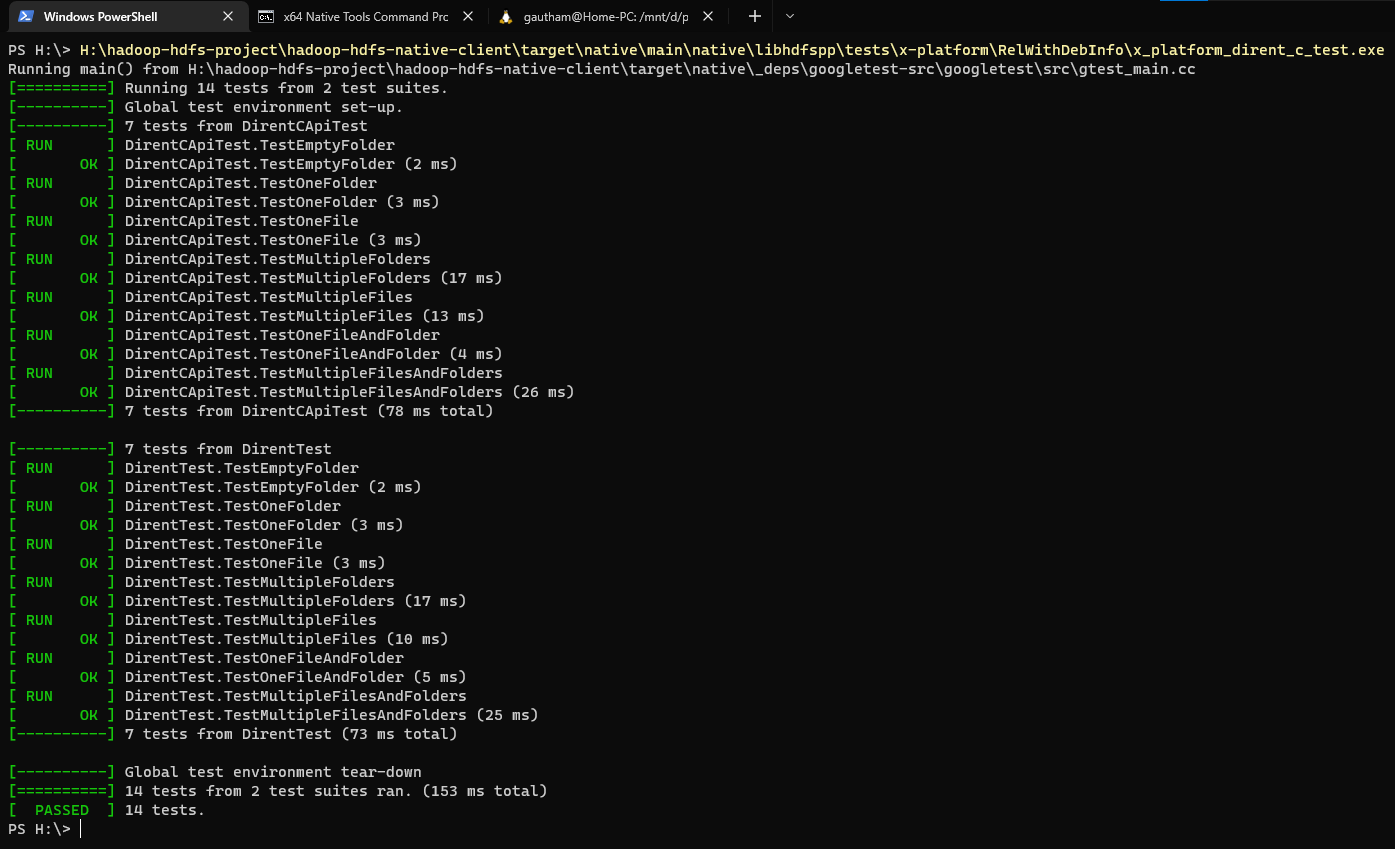 ## Ubuntu Focal  I've removed the `extern "C"` enclosure from the implementation now, since it's redundant. Issue Time Tracking --- Worklog Id: (was: 778995) Time Spent: 5h (was: 4h 50m) > Make dirent cross platform compatible > - > > Key: HDFS-16463 > URL: https://issues.apache.org/jira/browse/HDFS-16463 > Project: Hadoop HDFS > Issue Type: Improvement > Components: libhdfs++ >Affects Versions: 3.4.0 > Environment: Windows 10 >Reporter: Gautham Banasandra >Assignee: Gautham Banasandra >Priority: Major > Labels: libhdfscpp, pull-request-available > Time Spent: 5h > Remaining Estimate: 0h > > [jnihelper.c|https://github.com/apache/hadoop/blob/1fed18bb2d8ac3dbaecc3feddded30bed918d556/hadoop-hdfs-project/hadoop-hdfs-native-client/src/main/native/libhdfs/jni_helper.c#L28] > in HDFS native client uses *dirent.h*. This header file isn't available on > Windows. Thus, we need to replace this with a cross platform compatible > implementation for dirent. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16463) Make dirent cross platform compatible
[ https://issues.apache.org/jira/browse/HDFS-16463?focusedWorklogId=778992=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-778992 ] ASF GitHub Bot logged work on HDFS-16463: - Author: ASF GitHub Bot Created on: 07/Jun/22 11:12 Start Date: 07/Jun/22 11:12 Worklog Time Spent: 10m Work Description: GauthamBanasandra commented on code in PR #4370: URL: https://github.com/apache/hadoop/pull/4370#discussion_r891085844 ## hadoop-hdfs-project/hadoop-hdfs-native-client/src/main/native/libhdfspp/lib/x-platform/c-api/dirent.cc: ## @@ -0,0 +1,100 @@ +/** + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +#include +#include +#include +#include +#include +#include + +#include "x-platform/c-api/dirent.h" +#include "x-platform/dirent.h" + +#if defined(WIN32) && defined(__cplusplus) Review Comment: I've put the `extern "C"` in the `c-api/dirent.h`. I thought that I had to enclose the implementation as well. I just removed the `extern "C"` enclosure in the implementation and I was able to build fine on both Windows and Ubuntu. I ran the tests on both the platforms and they're working fine - ## Windows 10  ## Ubuntu Focal  I've removed the `extern "C"` enclosure from the implementation now, since it's redundant. Issue Time Tracking --- Worklog Id: (was: 778992) Time Spent: 4h 40m (was: 4.5h) > Make dirent cross platform compatible > - > > Key: HDFS-16463 > URL: https://issues.apache.org/jira/browse/HDFS-16463 > Project: Hadoop HDFS > Issue Type: Improvement > Components: libhdfs++ >Affects Versions: 3.4.0 > Environment: Windows 10 >Reporter: Gautham Banasandra >Assignee: Gautham Banasandra >Priority: Major > Labels: libhdfscpp, pull-request-available > Time Spent: 4h 40m > Remaining Estimate: 0h > > [jnihelper.c|https://github.com/apache/hadoop/blob/1fed18bb2d8ac3dbaecc3feddded30bed918d556/hadoop-hdfs-project/hadoop-hdfs-native-client/src/main/native/libhdfs/jni_helper.c#L28] > in HDFS native client uses *dirent.h*. This header file isn't available on > Windows. Thus, we need to replace this with a cross platform compatible > implementation for dirent. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16463) Make dirent cross platform compatible
[ https://issues.apache.org/jira/browse/HDFS-16463?focusedWorklogId=778994=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-778994 ] ASF GitHub Bot logged work on HDFS-16463: - Author: ASF GitHub Bot Created on: 07/Jun/22 11:12 Start Date: 07/Jun/22 11:12 Worklog Time Spent: 10m Work Description: GauthamBanasandra commented on code in PR #4370: URL: https://github.com/apache/hadoop/pull/4370#discussion_r891085844 ## hadoop-hdfs-project/hadoop-hdfs-native-client/src/main/native/libhdfspp/lib/x-platform/c-api/dirent.cc: ## @@ -0,0 +1,100 @@ +/** + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +#include +#include +#include +#include +#include +#include + +#include "x-platform/c-api/dirent.h" +#include "x-platform/dirent.h" + +#if defined(WIN32) && defined(__cplusplus) Review Comment: I've put the `extern "C"` in the `c-api/dirent.h` header file. I thought that I had to enclose the implementation as well. I just removed the `extern "C"` enclosure in the implementation and I was able to build fine on both Windows and Ubuntu. I ran the tests on both the platforms and they're working fine - ## Windows 10  ## Ubuntu Focal  I've removed the `extern "C"` enclosure from the implementation now, since it's redundant. Issue Time Tracking --- Worklog Id: (was: 778994) Time Spent: 4h 50m (was: 4h 40m) > Make dirent cross platform compatible > - > > Key: HDFS-16463 > URL: https://issues.apache.org/jira/browse/HDFS-16463 > Project: Hadoop HDFS > Issue Type: Improvement > Components: libhdfs++ >Affects Versions: 3.4.0 > Environment: Windows 10 >Reporter: Gautham Banasandra >Assignee: Gautham Banasandra >Priority: Major > Labels: libhdfscpp, pull-request-available > Time Spent: 4h 50m > Remaining Estimate: 0h > > [jnihelper.c|https://github.com/apache/hadoop/blob/1fed18bb2d8ac3dbaecc3feddded30bed918d556/hadoop-hdfs-project/hadoop-hdfs-native-client/src/main/native/libhdfs/jni_helper.c#L28] > in HDFS native client uses *dirent.h*. This header file isn't available on > Windows. Thus, we need to replace this with a cross platform compatible > implementation for dirent. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Comment Edited] (HDFS-16613) EC: Improve performance of decommissioning dn with many ec blocks
[ https://issues.apache.org/jira/browse/HDFS-16613?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17550907#comment-17550907 ] caozhiqiang edited comment on HDFS-16613 at 6/7/22 10:52 AM: - [~hadachi] , thank you for your review. Firstly, my hadoop branch has included HDFS-14768. In my test, even the decommissioning node is made busy, ec blocks will not be reconstructed. It would not send ec task to datanode this time and only be reserved in BlockManager::pendingReconstruction. After timeout, these blocks will be put back to BlockManager::neededReconstruction and be rescheduled next time. So all blocks use replication on decommissioning node but not reconstruction. By the way, I decommission only one dn at a time. Secondly, there are 12 datanodes in my cluster, and each dn has 12 disks. There are 27217 ec block groups in my cluster and about 2 blocks in each datanode. Other nodes' load are very low beside the decommissioning node, include load average, cpu iowait and network. These can also illustrate that the blocks are replicated from the decommissioning node to other nodes. !image-2022-06-07-17-55-40-203.png|width=772,height=192! !image-2022-06-07-17-45-45-316.png|width=772,height=198! !image-2022-06-07-17-51-04-876.png|width=769,height=256! was (Author: caozhiqiang): [~hadachi] , thank you for your review. Firstly, my hadoop branch has included HDFS-14768. In my test, even the decommissioning node is made busy, ec blocks will not be reconstructed. It would not send ec task to datanode this time and only be reserved in BlockManager::pendingReconstruction. After timeout, these blocks will be put back to BlockManager::neededReconstruction and be rescheduled next time. So all blocks use replication on decommissioning node but not reconstruction. By the way, I decommission only one dn at a time. Secondly, there are 12 datanodes in my cluster, and each dn has 12 disks. There are 27217 ec block groups in my cluster and about 2 blocks in each datanode. Other nodes' load are very low beside the decommissioning node, include load average, cpu iowait and network. These also illustrate the blocks are replicated from the decommissioning node to other nodes. !image-2022-06-07-17-55-40-203.png|width=772,height=192! !image-2022-06-07-17-45-45-316.png|width=772,height=198! !image-2022-06-07-17-51-04-876.png|width=769,height=256! > EC: Improve performance of decommissioning dn with many ec blocks > - > > Key: HDFS-16613 > URL: https://issues.apache.org/jira/browse/HDFS-16613 > Project: Hadoop HDFS > Issue Type: Improvement > Components: ec, erasure-coding, namenode >Affects Versions: 3.4.0 >Reporter: caozhiqiang >Assignee: caozhiqiang >Priority: Major > Labels: pull-request-available > Attachments: image-2022-06-07-11-46-42-389.png, > image-2022-06-07-17-42-16-075.png, image-2022-06-07-17-45-45-316.png, > image-2022-06-07-17-51-04-876.png, image-2022-06-07-17-55-40-203.png > > Time Spent: 0.5h > Remaining Estimate: 0h > > In a hdfs cluster with a lot of EC blocks, decommission a dn is very slow. > The reason is unlike replication blocks can be replicated from any dn which > has the same block replication, the ec block have to be replicated from the > decommissioning dn. > The configurations dfs.namenode.replication.max-streams and > dfs.namenode.replication.max-streams-hard-limit will limit the replication > speed, but increase these configurations will create risk to the whole > cluster's network. So it should add a new configuration to limit the > decommissioning dn, distinguished from the cluster wide max-streams limit. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Comment Edited] (HDFS-16613) EC: Improve performance of decommissioning dn with many ec blocks
[ https://issues.apache.org/jira/browse/HDFS-16613?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17550907#comment-17550907 ] caozhiqiang edited comment on HDFS-16613 at 6/7/22 10:45 AM: - [~hadachi] , thank you for your review. Firstly, my hadoop branch has included HDFS-14768. In my test, even the decommissioning node is made busy, ec blocks will not be reconstructed. It would not send ec task to datanode this time and only be reserved in BlockManager::pendingReconstruction. After timeout, these blocks will be put back to BlockManager::neededReconstruction and be rescheduled next time. So all blocks use replication on decommissioning node but not reconstruction. By the way, I decommission only one dn at a time. Secondly, there are 12 datanodes in my cluster, and each dn has 12 disks. There are 27217 ec block groups in my cluster and about 2 blocks in each datanode. Other nodes' load are very low beside the decommissioning node, include load average, cpu iowait and network. These also illustrate the blocks are replicated from the decommissioning node to other nodes. !image-2022-06-07-17-55-40-203.png|width=772,height=192! !image-2022-06-07-17-45-45-316.png|width=772,height=198! !image-2022-06-07-17-51-04-876.png|width=769,height=256! was (Author: caozhiqiang): [~hadachi] , thank you for your review. Firstly, my hadoop branch has included HDFS-14768. In my test, even the decommissioning node is made busy, ec blocks will not be reconstructed. It would not send ec task to datanode and only be reserved in BlockManager::pendingReconstruction. After timeout, these blocks will be put back to BlockManager::neededReconstruction and be rescheduled next time. So all blocks use replication on decommissioning node but not reconstruction. By the way, I decommission only one dn at a time. Secondly, there are 12 datanodes in my cluster, and each dn has 12 disks. There are 27217 ec block groups in my cluster and about 2 blocks in one datanode. Other nodes' load are very low beside the decommissioning node, include load average, cpu iowait and network. !image-2022-06-07-17-55-40-203.png|width=772,height=192! !image-2022-06-07-17-45-45-316.png|width=772,height=198! !image-2022-06-07-17-51-04-876.png|width=769,height=256! > EC: Improve performance of decommissioning dn with many ec blocks > - > > Key: HDFS-16613 > URL: https://issues.apache.org/jira/browse/HDFS-16613 > Project: Hadoop HDFS > Issue Type: Improvement > Components: ec, erasure-coding, namenode >Affects Versions: 3.4.0 >Reporter: caozhiqiang >Assignee: caozhiqiang >Priority: Major > Labels: pull-request-available > Attachments: image-2022-06-07-11-46-42-389.png, > image-2022-06-07-17-42-16-075.png, image-2022-06-07-17-45-45-316.png, > image-2022-06-07-17-51-04-876.png, image-2022-06-07-17-55-40-203.png > > Time Spent: 0.5h > Remaining Estimate: 0h > > In a hdfs cluster with a lot of EC blocks, decommission a dn is very slow. > The reason is unlike replication blocks can be replicated from any dn which > has the same block replication, the ec block have to be replicated from the > decommissioning dn. > The configurations dfs.namenode.replication.max-streams and > dfs.namenode.replication.max-streams-hard-limit will limit the replication > speed, but increase these configurations will create risk to the whole > cluster's network. So it should add a new configuration to limit the > decommissioning dn, distinguished from the cluster wide max-streams limit. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16463) Make dirent cross platform compatible
[
https://issues.apache.org/jira/browse/HDFS-16463?focusedWorklogId=778977=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-778977
]
ASF GitHub Bot logged work on HDFS-16463:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 10:36
Start Date: 07/Jun/22 10:36
Worklog Time Spent: 10m
Work Description: hadoop-yetus commented on PR #4370:
URL: https://github.com/apache/hadoop/pull/4370#issuecomment-1148493377
:confetti_ball: **+1 overall**
| Vote | Subsystem | Runtime | Logfile | Comment |
|::|--:|:|::|:---:|
| +0 :ok: | reexec | 0m 41s | | Docker mode activated. |
_ Prechecks _ |
| +1 :green_heart: | dupname | 0m 0s | | No case conflicting files
found. |
| +0 :ok: | codespell | 0m 0s | | codespell was not available. |
| +0 :ok: | detsecrets | 0m 0s | | detect-secrets was not available.
|
| +1 :green_heart: | @author | 0m 0s | | The patch does not contain
any @author tags. |
| +1 :green_heart: | test4tests | 0m 0s | | The patch appears to
include 5 new or modified test files. |
_ trunk Compile Tests _ |
| +1 :green_heart: | mvninstall | 38m 33s | | trunk passed |
| +1 :green_heart: | compile | 3m 58s | | trunk passed |
| +1 :green_heart: | mvnsite | 0m 48s | | trunk passed |
| +1 :green_heart: | shadedclient | 62m 16s | | branch has no errors
when building and testing our client artifacts. |
_ Patch Compile Tests _ |
| +1 :green_heart: | mvninstall | 0m 24s | | the patch passed |
| +1 :green_heart: | compile | 3m 47s | | the patch passed |
| +1 :green_heart: | cc | 3m 47s | | the patch passed |
| +1 :green_heart: | golang | 3m 47s | | the patch passed |
| +1 :green_heart: | javac | 3m 47s | | the patch passed |
| +1 :green_heart: | blanks | 0m 0s | | The patch has no blanks
issues. |
| +1 :green_heart: | mvnsite | 0m 27s | | the patch passed |
| +1 :green_heart: | shadedclient | 19m 2s | | patch has no errors
when building and testing our client artifacts. |
_ Other Tests _ |
| +1 :green_heart: | unit | 32m 45s | | hadoop-hdfs-native-client in
the patch passed. |
| +1 :green_heart: | asflicense | 0m 55s | | The patch does not
generate ASF License warnings. |
| | | 122m 59s | | |
| Subsystem | Report/Notes |
|--:|:-|
| Docker | ClientAPI=1.41 ServerAPI=1.41 base:
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4370/12/artifact/out/Dockerfile
|
| GITHUB PR | https://github.com/apache/hadoop/pull/4370 |
| Optional Tests | dupname asflicense compile cc mvnsite javac unit
codespell detsecrets golang |
| uname | Linux 4a5684be8a65 4.15.0-112-generic #113-Ubuntu SMP Thu Jul 9
23:41:39 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux |
| Build tool | maven |
| Personality | dev-support/bin/hadoop.sh |
| git revision | trunk / 8cc389d66a7609a3fe8a4d4b50f6e30aaf6cb77d |
| Default Java | Red Hat, Inc.-1.8.0_332-b09 |
| Test Results |
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4370/12/testReport/ |
| Max. process+thread count | 543 (vs. ulimit of 5500) |
| modules | C: hadoop-hdfs-project/hadoop-hdfs-native-client U:
hadoop-hdfs-project/hadoop-hdfs-native-client |
| Console output |
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4370/12/console |
| versions | git=2.9.5 maven=3.6.3 |
| Powered by | Apache Yetus 0.14.0 https://yetus.apache.org |
This message was automatically generated.
Issue Time Tracking
---
Worklog Id: (was: 778977)
Time Spent: 4.5h (was: 4h 20m)
> Make dirent cross platform compatible
> -
>
> Key: HDFS-16463
> URL: https://issues.apache.org/jira/browse/HDFS-16463
> Project: Hadoop HDFS
> Issue Type: Improvement
> Components: libhdfs++
>Affects Versions: 3.4.0
> Environment: Windows 10
>Reporter: Gautham Banasandra
>Assignee: Gautham Banasandra
>Priority: Major
> Labels: libhdfscpp, pull-request-available
> Time Spent: 4.5h
> Remaining Estimate: 0h
>
> [jnihelper.c|https://github.com/apache/hadoop/blob/1fed18bb2d8ac3dbaecc3feddded30bed918d556/hadoop-hdfs-project/hadoop-hdfs-native-client/src/main/native/libhdfs/jni_helper.c#L28]
> in HDFS native client uses *dirent.h*. This header file isn't available on
> Windows. Thus, we need to replace this with a cross platform compatible
> implementation for dirent.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
-
[jira] [Work logged] (HDFS-16609) Fix Flakes Junit Tests that often report timeouts
[
https://issues.apache.org/jira/browse/HDFS-16609?focusedWorklogId=778975=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-778975
]
ASF GitHub Bot logged work on HDFS-16609:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 10:30
Start Date: 07/Jun/22 10:30
Worklog Time Spent: 10m
Work Description: hadoop-yetus commented on PR #4382:
URL: https://github.com/apache/hadoop/pull/4382#issuecomment-1148487464
:broken_heart: **-1 overall**
| Vote | Subsystem | Runtime | Logfile | Comment |
|::|--:|:|::|:---:|
| +0 :ok: | reexec | 18m 3s | | Docker mode activated. |
_ Prechecks _ |
| +1 :green_heart: | dupname | 0m 0s | | No case conflicting files
found. |
| +0 :ok: | codespell | 0m 1s | | codespell was not available. |
| +0 :ok: | detsecrets | 0m 1s | | detect-secrets was not available.
|
| +1 :green_heart: | @author | 0m 0s | | The patch does not contain
any @author tags. |
| +1 :green_heart: | test4tests | 0m 0s | | The patch appears to
include 3 new or modified test files. |
_ trunk Compile Tests _ |
| +1 :green_heart: | mvninstall | 40m 7s | | trunk passed |
| +1 :green_heart: | compile | 1m 40s | | trunk passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | compile | 1m 33s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | checkstyle | 1m 20s | | trunk passed |
| +1 :green_heart: | mvnsite | 1m 40s | | trunk passed |
| +1 :green_heart: | javadoc | 1m 20s | | trunk passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | javadoc | 1m 40s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 3m 46s | | trunk passed |
| +1 :green_heart: | shadedclient | 25m 44s | | branch has no errors
when building and testing our client artifacts. |
_ Patch Compile Tests _ |
| +1 :green_heart: | mvninstall | 1m 20s | | the patch passed |
| +1 :green_heart: | compile | 1m 30s | | the patch passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | javac | 1m 30s | | the patch passed |
| +1 :green_heart: | compile | 1m 20s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | javac | 1m 20s | | the patch passed |
| +1 :green_heart: | blanks | 0m 0s | | The patch has no blanks
issues. |
| +1 :green_heart: | checkstyle | 1m 1s | | the patch passed |
| +1 :green_heart: | mvnsite | 1m 26s | | the patch passed |
| +1 :green_heart: | javadoc | 0m 59s | | the patch passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | javadoc | 1m 27s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 3m 31s | | the patch passed |
| +1 :green_heart: | shadedclient | 25m 22s | | patch has no errors
when building and testing our client artifacts. |
_ Other Tests _ |
| -1 :x: | unit | 338m 51s |
[/patch-unit-hadoop-hdfs-project_hadoop-hdfs.txt](https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4382/2/artifact/out/patch-unit-hadoop-hdfs-project_hadoop-hdfs.txt)
| hadoop-hdfs in the patch passed. |
| +1 :green_heart: | asflicense | 1m 10s | | The patch does not
generate ASF License warnings. |
| | | 472m 32s | | |
| Reason | Tests |
|---:|:--|
| Failed junit tests | hadoop.hdfs.server.mover.TestMover |
| Subsystem | Report/Notes |
|--:|:-|
| Docker | ClientAPI=1.41 ServerAPI=1.41 base:
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4382/2/artifact/out/Dockerfile
|
| GITHUB PR | https://github.com/apache/hadoop/pull/4382 |
| Optional Tests | dupname asflicense compile javac javadoc mvninstall
mvnsite unit shadedclient spotbugs checkstyle codespell detsecrets |
| uname | Linux d513d8b00c5f 4.15.0-175-generic #184-Ubuntu SMP Thu Mar 24
17:48:36 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux |
| Build tool | maven |
| Personality | dev-support/bin/hadoop.sh |
| git revision | trunk / 2d1142032f73858476e189ff66522751ce722b05 |
| Default Java | Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Multi-JDK versions | /usr/lib/jvm/java-11-openjdk-amd64:Private
Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1
/usr/lib/jvm/java-8-openjdk-amd64:Private
Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Test Results |
[jira] [Commented] (HDFS-16613) EC: Improve performance of decommissioning dn with many ec blocks
[ https://issues.apache.org/jira/browse/HDFS-16613?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17550907#comment-17550907 ] caozhiqiang commented on HDFS-16613: [~hadachi] , thank you for your review. Firstly, my hadoop branch has included HDFS-14768. In my test, even the decommissioning node is made busy, ec blocks will not be reconstructed. It would not send ec task to datanode and only be reserved in BlockManager::pendingReconstruction. After timeout, these blocks will be put back to BlockManager::neededReconstruction and be rescheduled next time. So all blocks use replication on decommissioning node but not reconstruction. By the way, I decommission only one dn at a time. Secondly, there are 12 datanodes in my cluster, and each dn has 12 disks. There are 27217 ec block groups in my cluster and about 2 blocks in one datanode. Other nodes' load are very low beside the decommissioning node, include load average, cpu iowait and network. !image-2022-06-07-17-55-40-203.png|width=772,height=192! !image-2022-06-07-17-45-45-316.png|width=772,height=198! !image-2022-06-07-17-51-04-876.png|width=769,height=256! > EC: Improve performance of decommissioning dn with many ec blocks > - > > Key: HDFS-16613 > URL: https://issues.apache.org/jira/browse/HDFS-16613 > Project: Hadoop HDFS > Issue Type: Improvement > Components: ec, erasure-coding, namenode >Affects Versions: 3.4.0 >Reporter: caozhiqiang >Assignee: caozhiqiang >Priority: Major > Labels: pull-request-available > Attachments: image-2022-06-07-11-46-42-389.png, > image-2022-06-07-17-42-16-075.png, image-2022-06-07-17-45-45-316.png, > image-2022-06-07-17-51-04-876.png, image-2022-06-07-17-55-40-203.png > > Time Spent: 0.5h > Remaining Estimate: 0h > > In a hdfs cluster with a lot of EC blocks, decommission a dn is very slow. > The reason is unlike replication blocks can be replicated from any dn which > has the same block replication, the ec block have to be replicated from the > decommissioning dn. > The configurations dfs.namenode.replication.max-streams and > dfs.namenode.replication.max-streams-hard-limit will limit the replication > speed, but increase these configurations will create risk to the whole > cluster's network. So it should add a new configuration to limit the > decommissioning dn, distinguished from the cluster wide max-streams limit. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Resolved] (HDFS-16618) sync_file_range error should include more volume and file info
[ https://issues.apache.org/jira/browse/HDFS-16618?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Tao Li resolved HDFS-16618. --- Fix Version/s: 3.4.0 3.2.4 3.3.4 Resolution: Fixed > sync_file_range error should include more volume and file info > -- > > Key: HDFS-16618 > URL: https://issues.apache.org/jira/browse/HDFS-16618 > Project: Hadoop HDFS > Issue Type: Task >Reporter: Viraj Jasani >Assignee: Viraj Jasani >Priority: Minor > Labels: pull-request-available > Fix For: 3.4.0, 3.2.4, 3.3.4 > > Time Spent: 1h 10m > Remaining Estimate: 0h > > Having seen multiple sync_file_range errors recently with Bad file > descriptor, it would be good to include more volume stats as well as file > offset/length info with the error log to get some more insights. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Commented] (HDFS-16618) sync_file_range error should include more volume and file info
[ https://issues.apache.org/jira/browse/HDFS-16618?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17550906#comment-17550906 ] Tao Li commented on HDFS-16618: --- Cherry-picked to branch-3.3 and branch-3.2. > sync_file_range error should include more volume and file info > -- > > Key: HDFS-16618 > URL: https://issues.apache.org/jira/browse/HDFS-16618 > Project: Hadoop HDFS > Issue Type: Task >Reporter: Viraj Jasani >Assignee: Viraj Jasani >Priority: Minor > Labels: pull-request-available > Time Spent: 1h 10m > Remaining Estimate: 0h > > Having seen multiple sync_file_range errors recently with Bad file > descriptor, it would be good to include more volume stats as well as file > offset/length info with the error log to get some more insights. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16613) EC: Improve performance of decommissioning dn with many ec blocks
[ https://issues.apache.org/jira/browse/HDFS-16613?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] caozhiqiang updated HDFS-16613: --- Attachment: image-2022-06-07-17-55-40-203.png > EC: Improve performance of decommissioning dn with many ec blocks > - > > Key: HDFS-16613 > URL: https://issues.apache.org/jira/browse/HDFS-16613 > Project: Hadoop HDFS > Issue Type: Improvement > Components: ec, erasure-coding, namenode >Affects Versions: 3.4.0 >Reporter: caozhiqiang >Assignee: caozhiqiang >Priority: Major > Labels: pull-request-available > Attachments: image-2022-06-07-11-46-42-389.png, > image-2022-06-07-17-42-16-075.png, image-2022-06-07-17-45-45-316.png, > image-2022-06-07-17-51-04-876.png, image-2022-06-07-17-55-40-203.png > > Time Spent: 0.5h > Remaining Estimate: 0h > > In a hdfs cluster with a lot of EC blocks, decommission a dn is very slow. > The reason is unlike replication blocks can be replicated from any dn which > has the same block replication, the ec block have to be replicated from the > decommissioning dn. > The configurations dfs.namenode.replication.max-streams and > dfs.namenode.replication.max-streams-hard-limit will limit the replication > speed, but increase these configurations will create risk to the whole > cluster's network. So it should add a new configuration to limit the > decommissioning dn, distinguished from the cluster wide max-streams limit. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16613) EC: Improve performance of decommissioning dn with many ec blocks
[ https://issues.apache.org/jira/browse/HDFS-16613?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] caozhiqiang updated HDFS-16613: --- Attachment: image-2022-06-07-17-51-04-876.png > EC: Improve performance of decommissioning dn with many ec blocks > - > > Key: HDFS-16613 > URL: https://issues.apache.org/jira/browse/HDFS-16613 > Project: Hadoop HDFS > Issue Type: Improvement > Components: ec, erasure-coding, namenode >Affects Versions: 3.4.0 >Reporter: caozhiqiang >Assignee: caozhiqiang >Priority: Major > Labels: pull-request-available > Attachments: image-2022-06-07-11-46-42-389.png, > image-2022-06-07-17-42-16-075.png, image-2022-06-07-17-45-45-316.png, > image-2022-06-07-17-51-04-876.png > > Time Spent: 0.5h > Remaining Estimate: 0h > > In a hdfs cluster with a lot of EC blocks, decommission a dn is very slow. > The reason is unlike replication blocks can be replicated from any dn which > has the same block replication, the ec block have to be replicated from the > decommissioning dn. > The configurations dfs.namenode.replication.max-streams and > dfs.namenode.replication.max-streams-hard-limit will limit the replication > speed, but increase these configurations will create risk to the whole > cluster's network. So it should add a new configuration to limit the > decommissioning dn, distinguished from the cluster wide max-streams limit. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16613) EC: Improve performance of decommissioning dn with many ec blocks
[ https://issues.apache.org/jira/browse/HDFS-16613?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] caozhiqiang updated HDFS-16613: --- Attachment: image-2022-06-07-17-45-45-316.png > EC: Improve performance of decommissioning dn with many ec blocks > - > > Key: HDFS-16613 > URL: https://issues.apache.org/jira/browse/HDFS-16613 > Project: Hadoop HDFS > Issue Type: Improvement > Components: ec, erasure-coding, namenode >Affects Versions: 3.4.0 >Reporter: caozhiqiang >Assignee: caozhiqiang >Priority: Major > Labels: pull-request-available > Attachments: image-2022-06-07-11-46-42-389.png, > image-2022-06-07-17-42-16-075.png, image-2022-06-07-17-45-45-316.png > > Time Spent: 0.5h > Remaining Estimate: 0h > > In a hdfs cluster with a lot of EC blocks, decommission a dn is very slow. > The reason is unlike replication blocks can be replicated from any dn which > has the same block replication, the ec block have to be replicated from the > decommissioning dn. > The configurations dfs.namenode.replication.max-streams and > dfs.namenode.replication.max-streams-hard-limit will limit the replication > speed, but increase these configurations will create risk to the whole > cluster's network. So it should add a new configuration to limit the > decommissioning dn, distinguished from the cluster wide max-streams limit. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Updated] (HDFS-16613) EC: Improve performance of decommissioning dn with many ec blocks
[ https://issues.apache.org/jira/browse/HDFS-16613?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] caozhiqiang updated HDFS-16613: --- Attachment: image-2022-06-07-17-42-16-075.png > EC: Improve performance of decommissioning dn with many ec blocks > - > > Key: HDFS-16613 > URL: https://issues.apache.org/jira/browse/HDFS-16613 > Project: Hadoop HDFS > Issue Type: Improvement > Components: ec, erasure-coding, namenode >Affects Versions: 3.4.0 >Reporter: caozhiqiang >Assignee: caozhiqiang >Priority: Major > Labels: pull-request-available > Attachments: image-2022-06-07-11-46-42-389.png, > image-2022-06-07-17-42-16-075.png > > Time Spent: 0.5h > Remaining Estimate: 0h > > In a hdfs cluster with a lot of EC blocks, decommission a dn is very slow. > The reason is unlike replication blocks can be replicated from any dn which > has the same block replication, the ec block have to be replicated from the > decommissioning dn. > The configurations dfs.namenode.replication.max-streams and > dfs.namenode.replication.max-streams-hard-limit will limit the replication > speed, but increase these configurations will create risk to the whole > cluster's network. So it should add a new configuration to limit the > decommissioning dn, distinguished from the cluster wide max-streams limit. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16618) sync_file_range error should include more volume and file info
[ https://issues.apache.org/jira/browse/HDFS-16618?focusedWorklogId=778933=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-778933 ] ASF GitHub Bot logged work on HDFS-16618: - Author: ASF GitHub Bot Created on: 07/Jun/22 08:54 Start Date: 07/Jun/22 08:54 Worklog Time Spent: 10m Work Description: tomscut commented on PR #4402: URL: https://github.com/apache/hadoop/pull/4402#issuecomment-1148388828 Thanks @virajjasani for your contribution! Issue Time Tracking --- Worklog Id: (was: 778933) Time Spent: 1h 10m (was: 1h) > sync_file_range error should include more volume and file info > -- > > Key: HDFS-16618 > URL: https://issues.apache.org/jira/browse/HDFS-16618 > Project: Hadoop HDFS > Issue Type: Task >Reporter: Viraj Jasani >Assignee: Viraj Jasani >Priority: Minor > Labels: pull-request-available > Time Spent: 1h 10m > Remaining Estimate: 0h > > Having seen multiple sync_file_range errors recently with Bad file > descriptor, it would be good to include more volume stats as well as file > offset/length info with the error log to get some more insights. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16618) sync_file_range error should include more volume and file info
[ https://issues.apache.org/jira/browse/HDFS-16618?focusedWorklogId=778932=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-778932 ] ASF GitHub Bot logged work on HDFS-16618: - Author: ASF GitHub Bot Created on: 07/Jun/22 08:53 Start Date: 07/Jun/22 08:53 Worklog Time Spent: 10m Work Description: tomscut merged PR #4402: URL: https://github.com/apache/hadoop/pull/4402 Issue Time Tracking --- Worklog Id: (was: 778932) Time Spent: 1h (was: 50m) > sync_file_range error should include more volume and file info > -- > > Key: HDFS-16618 > URL: https://issues.apache.org/jira/browse/HDFS-16618 > Project: Hadoop HDFS > Issue Type: Task >Reporter: Viraj Jasani >Assignee: Viraj Jasani >Priority: Minor > Labels: pull-request-available > Time Spent: 1h > Remaining Estimate: 0h > > Having seen multiple sync_file_range errors recently with Bad file > descriptor, it would be good to include more volume stats as well as file > offset/length info with the error log to get some more insights. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16609) Fix Flakes Junit Tests that often report timeouts
[
https://issues.apache.org/jira/browse/HDFS-16609?focusedWorklogId=778928=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-778928
]
ASF GitHub Bot logged work on HDFS-16609:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 08:39
Start Date: 07/Jun/22 08:39
Worklog Time Spent: 10m
Work Description: hadoop-yetus commented on PR #4382:
URL: https://github.com/apache/hadoop/pull/4382#issuecomment-1148372876
:confetti_ball: **+1 overall**
| Vote | Subsystem | Runtime | Logfile | Comment |
|::|--:|:|::|:---:|
| +0 :ok: | reexec | 0m 44s | | Docker mode activated. |
_ Prechecks _ |
| +1 :green_heart: | dupname | 0m 0s | | No case conflicting files
found. |
| +0 :ok: | codespell | 0m 1s | | codespell was not available. |
| +0 :ok: | detsecrets | 0m 1s | | detect-secrets was not available.
|
| +1 :green_heart: | @author | 0m 0s | | The patch does not contain
any @author tags. |
| +1 :green_heart: | test4tests | 0m 0s | | The patch appears to
include 3 new or modified test files. |
_ trunk Compile Tests _ |
| +1 :green_heart: | mvninstall | 37m 19s | | trunk passed |
| +1 :green_heart: | compile | 1m 24s | | trunk passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | compile | 1m 23s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | checkstyle | 1m 8s | | trunk passed |
| +1 :green_heart: | mvnsite | 1m 30s | | trunk passed |
| +1 :green_heart: | javadoc | 1m 9s | | trunk passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | javadoc | 1m 30s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 3m 26s | | trunk passed |
| +1 :green_heart: | shadedclient | 21m 54s | | branch has no errors
when building and testing our client artifacts. |
_ Patch Compile Tests _ |
| +1 :green_heart: | mvninstall | 1m 17s | | the patch passed |
| +1 :green_heart: | compile | 1m 19s | | the patch passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | javac | 1m 19s | | the patch passed |
| +1 :green_heart: | compile | 1m 10s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | javac | 1m 10s | | the patch passed |
| +1 :green_heart: | blanks | 0m 0s | | The patch has no blanks
issues. |
| +1 :green_heart: | checkstyle | 0m 52s | | the patch passed |
| +1 :green_heart: | mvnsite | 1m 19s | | the patch passed |
| +1 :green_heart: | javadoc | 0m 49s | | the patch passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | javadoc | 1m 23s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 3m 14s | | the patch passed |
| +1 :green_heart: | shadedclient | 21m 41s | | patch has no errors
when building and testing our client artifacts. |
_ Other Tests _ |
| +1 :green_heart: | unit | 255m 36s | | hadoop-hdfs in the patch
passed. |
| +1 :green_heart: | asflicense | 0m 47s | | The patch does not
generate ASF License warnings. |
| | | 358m 40s | | |
| Subsystem | Report/Notes |
|--:|:-|
| Docker | ClientAPI=1.41 ServerAPI=1.41 base:
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4382/3/artifact/out/Dockerfile
|
| GITHUB PR | https://github.com/apache/hadoop/pull/4382 |
| Optional Tests | dupname asflicense compile javac javadoc mvninstall
mvnsite unit shadedclient spotbugs checkstyle codespell detsecrets |
| uname | Linux b039584d130e 4.15.0-169-generic #177-Ubuntu SMP Thu Feb 3
10:50:38 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux |
| Build tool | maven |
| Personality | dev-support/bin/hadoop.sh |
| git revision | trunk / 2d1142032f73858476e189ff66522751ce722b05 |
| Default Java | Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Multi-JDK versions | /usr/lib/jvm/java-11-openjdk-amd64:Private
Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1
/usr/lib/jvm/java-8-openjdk-amd64:Private
Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Test Results |
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4382/3/testReport/ |
| Max. process+thread count | 2968 (vs. ulimit of 5500) |
| modules | C: hadoop-hdfs-project/hadoop-hdfs U:
hadoop-hdfs-project/hadoop-hdfs |
| Console output |
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4382/3/console |
| versions |
[jira] [Commented] (HDFS-16613) EC: Improve performance of decommissioning dn with many ec blocks
[ https://issues.apache.org/jira/browse/HDFS-16613?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel=17550845#comment-17550845 ] Hiroyuki Adachi commented on HDFS-16613: Thank you for your share. How many EC blocks does the decommissioning datanode have and how many datanodes in your cluster? I'm also interested in the load (network traffic, disk I/O, etc.) of the other datanodes while decommissioning. As I mentioned above, I think the other datanodes' loads were higher due to the reconstruction tasks. Was there any impact? > EC: Improve performance of decommissioning dn with many ec blocks > - > > Key: HDFS-16613 > URL: https://issues.apache.org/jira/browse/HDFS-16613 > Project: Hadoop HDFS > Issue Type: Improvement > Components: ec, erasure-coding, namenode >Affects Versions: 3.4.0 >Reporter: caozhiqiang >Assignee: caozhiqiang >Priority: Major > Labels: pull-request-available > Attachments: image-2022-06-07-11-46-42-389.png > > Time Spent: 0.5h > Remaining Estimate: 0h > > In a hdfs cluster with a lot of EC blocks, decommission a dn is very slow. > The reason is unlike replication blocks can be replicated from any dn which > has the same block replication, the ec block have to be replicated from the > decommissioning dn. > The configurations dfs.namenode.replication.max-streams and > dfs.namenode.replication.max-streams-hard-limit will limit the replication > speed, but increase these configurations will create risk to the whole > cluster's network. So it should add a new configuration to limit the > decommissioning dn, distinguished from the cluster wide max-streams limit. -- This message was sent by Atlassian Jira (v8.20.7#820007) - To unsubscribe, e-mail: hdfs-issues-unsubscr...@hadoop.apache.org For additional commands, e-mail: hdfs-issues-h...@hadoop.apache.org
[jira] [Work logged] (HDFS-16463) Make dirent cross platform compatible
[
https://issues.apache.org/jira/browse/HDFS-16463?focusedWorklogId=778882=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-778882
]
ASF GitHub Bot logged work on HDFS-16463:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 07:00
Start Date: 07/Jun/22 07:00
Worklog Time Spent: 10m
Work Description: hadoop-yetus commented on PR #4370:
URL: https://github.com/apache/hadoop/pull/4370#issuecomment-1148272722
:confetti_ball: **+1 overall**
| Vote | Subsystem | Runtime | Logfile | Comment |
|::|--:|:|::|:---:|
| +0 :ok: | reexec | 0m 40s | | Docker mode activated. |
_ Prechecks _ |
| +1 :green_heart: | dupname | 0m 1s | | No case conflicting files
found. |
| +0 :ok: | codespell | 0m 0s | | codespell was not available. |
| +0 :ok: | detsecrets | 0m 0s | | detect-secrets was not available.
|
| +1 :green_heart: | @author | 0m 0s | | The patch does not contain
any @author tags. |
| +1 :green_heart: | test4tests | 0m 0s | | The patch appears to
include 5 new or modified test files. |
_ trunk Compile Tests _ |
| +1 :green_heart: | mvninstall | 38m 4s | | trunk passed |
| +1 :green_heart: | compile | 3m 52s | | trunk passed |
| +1 :green_heart: | mvnsite | 0m 48s | | trunk passed |
| +1 :green_heart: | shadedclient | 61m 51s | | branch has no errors
when building and testing our client artifacts. |
_ Patch Compile Tests _ |
| +1 :green_heart: | mvninstall | 0m 24s | | the patch passed |
| +1 :green_heart: | compile | 3m 42s | | the patch passed |
| +1 :green_heart: | cc | 3m 42s | | the patch passed |
| +1 :green_heart: | golang | 3m 42s | | the patch passed |
| +1 :green_heart: | javac | 3m 42s | | the patch passed |
| +1 :green_heart: | blanks | 0m 0s | | The patch has no blanks
issues. |
| +1 :green_heart: | mvnsite | 0m 28s | | the patch passed |
| +1 :green_heart: | shadedclient | 18m 59s | | patch has no errors
when building and testing our client artifacts. |
_ Other Tests _ |
| +1 :green_heart: | unit | 32m 51s | | hadoop-hdfs-native-client in
the patch passed. |
| +1 :green_heart: | asflicense | 0m 55s | | The patch does not
generate ASF License warnings. |
| | | 122m 29s | | |
| Subsystem | Report/Notes |
|--:|:-|
| Docker | ClientAPI=1.41 ServerAPI=1.41 base:
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4370/11/artifact/out/Dockerfile
|
| GITHUB PR | https://github.com/apache/hadoop/pull/4370 |
| Optional Tests | dupname asflicense compile cc mvnsite javac unit
codespell detsecrets golang |
| uname | Linux f480d307ee67 4.15.0-112-generic #113-Ubuntu SMP Thu Jul 9
23:41:39 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux |
| Build tool | maven |
| Personality | dev-support/bin/hadoop.sh |
| git revision | trunk / 33292facf5f8c7692e65bad6b4b65a7093c23fe7 |
| Default Java | Red Hat, Inc.-1.8.0_332-b09 |
| Test Results |
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4370/11/testReport/ |
| Max. process+thread count | 549 (vs. ulimit of 5500) |
| modules | C: hadoop-hdfs-project/hadoop-hdfs-native-client U:
hadoop-hdfs-project/hadoop-hdfs-native-client |
| Console output |
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4370/11/console |
| versions | git=2.9.5 maven=3.6.3 |
| Powered by | Apache Yetus 0.14.0 https://yetus.apache.org |
This message was automatically generated.
Issue Time Tracking
---
Worklog Id: (was: 778882)
Time Spent: 4h 20m (was: 4h 10m)
> Make dirent cross platform compatible
> -
>
> Key: HDFS-16463
> URL: https://issues.apache.org/jira/browse/HDFS-16463
> Project: Hadoop HDFS
> Issue Type: Improvement
> Components: libhdfs++
>Affects Versions: 3.4.0
> Environment: Windows 10
>Reporter: Gautham Banasandra
>Assignee: Gautham Banasandra
>Priority: Major
> Labels: libhdfscpp, pull-request-available
> Time Spent: 4h 20m
> Remaining Estimate: 0h
>
> [jnihelper.c|https://github.com/apache/hadoop/blob/1fed18bb2d8ac3dbaecc3feddded30bed918d556/hadoop-hdfs-project/hadoop-hdfs-native-client/src/main/native/libhdfs/jni_helper.c#L28]
> in HDFS native client uses *dirent.h*. This header file isn't available on
> Windows. Thus, we need to replace this with a cross platform compatible
> implementation for dirent.
--
This message was sent by Atlassian Jira
(v8.20.7#820007)
[jira] [Work logged] (HDFS-16624) Fix org.apache.hadoop.hdfs.tools.TestDFSAdmin#testAllDatanodesReconfig ERROR
[
https://issues.apache.org/jira/browse/HDFS-16624?focusedWorklogId=778864=com.atlassian.jira.plugin.system.issuetabpanels:worklog-tabpanel#worklog-778864
]
ASF GitHub Bot logged work on HDFS-16624:
-
Author: ASF GitHub Bot
Created on: 07/Jun/22 06:39
Start Date: 07/Jun/22 06:39
Worklog Time Spent: 10m
Work Description: hadoop-yetus commented on PR #4412:
URL: https://github.com/apache/hadoop/pull/4412#issuecomment-1148257091
:confetti_ball: **+1 overall**
| Vote | Subsystem | Runtime | Logfile | Comment |
|::|--:|:|::|:---:|
| +0 :ok: | reexec | 12m 54s | | Docker mode activated. |
_ Prechecks _ |
| +1 :green_heart: | dupname | 0m 0s | | No case conflicting files
found. |
| +0 :ok: | codespell | 0m 1s | | codespell was not available. |
| +0 :ok: | detsecrets | 0m 1s | | detect-secrets was not available.
|
| +1 :green_heart: | @author | 0m 0s | | The patch does not contain
any @author tags. |
| +1 :green_heart: | test4tests | 0m 0s | | The patch appears to
include 1 new or modified test files. |
_ trunk Compile Tests _ |
| +1 :green_heart: | mvninstall | 38m 44s | | trunk passed |
| +1 :green_heart: | compile | 1m 45s | | trunk passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | compile | 1m 34s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | checkstyle | 1m 19s | | trunk passed |
| +1 :green_heart: | mvnsite | 1m 36s | | trunk passed |
| +1 :green_heart: | javadoc | 1m 20s | | trunk passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | javadoc | 1m 51s | | trunk passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 3m 44s | | trunk passed |
| +1 :green_heart: | shadedclient | 23m 18s | | branch has no errors
when building and testing our client artifacts. |
_ Patch Compile Tests _ |
| +1 :green_heart: | mvninstall | 1m 26s | | the patch passed |
| +1 :green_heart: | compile | 1m 28s | | the patch passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | javac | 1m 28s | | the patch passed |
| +1 :green_heart: | compile | 1m 18s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | javac | 1m 18s | | the patch passed |
| +1 :green_heart: | blanks | 0m 0s | | The patch has no blanks
issues. |
| +1 :green_heart: | checkstyle | 1m 2s | | the patch passed |
| +1 :green_heart: | mvnsite | 1m 28s | | the patch passed |
| +1 :green_heart: | javadoc | 0m 57s | | the patch passed with JDK
Private Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1 |
| +1 :green_heart: | javadoc | 1m 31s | | the patch passed with JDK
Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| +1 :green_heart: | spotbugs | 3m 27s | | the patch passed |
| +1 :green_heart: | shadedclient | 23m 1s | | patch has no errors
when building and testing our client artifacts. |
_ Other Tests _ |
| +1 :green_heart: | unit | 252m 18s | | hadoop-hdfs in the patch
passed. |
| +1 :green_heart: | asflicense | 1m 13s | | The patch does not
generate ASF License warnings. |
| | | 375m 23s | | |
| Subsystem | Report/Notes |
|--:|:-|
| Docker | ClientAPI=1.41 ServerAPI=1.41 base:
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4412/1/artifact/out/Dockerfile
|
| GITHUB PR | https://github.com/apache/hadoop/pull/4412 |
| Optional Tests | dupname asflicense compile javac javadoc mvninstall
mvnsite unit shadedclient spotbugs checkstyle codespell detsecrets |
| uname | Linux 25c503b8420f 4.15.0-175-generic #184-Ubuntu SMP Thu Mar 24
17:48:36 UTC 2022 x86_64 x86_64 x86_64 GNU/Linux |
| Build tool | maven |
| Personality | dev-support/bin/hadoop.sh |
| git revision | trunk / 13422ba2a0310ad0a1545646c05f2a30fa27db4b |
| Default Java | Private Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Multi-JDK versions | /usr/lib/jvm/java-11-openjdk-amd64:Private
Build-11.0.15+10-Ubuntu-0ubuntu0.20.04.1
/usr/lib/jvm/java-8-openjdk-amd64:Private
Build-1.8.0_312-8u312-b07-0ubuntu1~20.04-b07 |
| Test Results |
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4412/1/testReport/ |
| Max. process+thread count | 3270 (vs. ulimit of 5500) |
| modules | C: hadoop-hdfs-project/hadoop-hdfs U:
hadoop-hdfs-project/hadoop-hdfs |
| Console output |
https://ci-hadoop.apache.org/job/hadoop-multibranch/job/PR-4412/1/console |
| versions |