[GitHub] spark issue #20601: [SPARK-23413][UI] Fix sorting tasks by Host / Executor I...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20601 **[Test build #87487 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87487/testReport)** for PR 20601 at commit [`22179e8`](https://github.com/apache/spark/commit/22179e84f6cf601be18e9b060246c54bd0cede8d). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20511: [SPARK-23340][SQL] Upgrade Apache ORC to 1.4.3
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20511 **[Test build #87483 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87483/testReport)** for PR 20511 at commit [`b42fd4d`](https://github.com/apache/spark/commit/b42fd4d4584277aaab925e3d6ed1125f474439e7). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20623: [SPARK-23413][UI] Fix sorting tasks by Host / Executor I...
Github user zsxwing commented on the issue: https://github.com/apache/spark/pull/20623 @squito The k8s test passed message is misleading :( The test is still running. Hope we don't break 2.3 build :) --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20623: [SPARK-23413][UI] Fix sorting tasks by Host / Exe...
Github user squito closed the pull request at: https://github.com/apache/spark/pull/20623 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20620: [SPARK-23438][DSTREAMS] Fix DStreams data loss with WAL ...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20620 **[Test build #87494 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87494/testReport)** for PR 20620 at commit [`bd46d1c`](https://github.com/apache/spark/commit/bd46d1cb63e7a04e0236f7b1bf70b46fb55f3ea4). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20619: [SPARK-23390][SQL] Register task completion listerners f...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20619 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20619: [SPARK-23390][SQL] Register task completion listerners f...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20619 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/87482/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20619: [SPARK-23390][SQL] Register task completion listerners f...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20619 **[Test build #87482 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87482/testReport)** for PR 20619 at commit [`43f809f`](https://github.com/apache/spark/commit/43f809fd2ff619c901e05bc062ab70aa65371a46). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20057: [SPARK-22880][SQL] Add cascadeTruncate option to JDBC da...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20057 **[Test build #87493 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87493/testReport)** for PR 20057 at commit [`6c0d3df`](https://github.com/apache/spark/commit/6c0d3dfd415e5630dbb02ce65c6adf3db419bdec). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20623: [SPARK-23413][UI] Fix sorting tasks by Host / Executor I...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20623 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/925/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20623: [SPARK-23413][UI] Fix sorting tasks by Host / Executor I...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20623 **[Test build #87492 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87492/testReport)** for PR 20623 at commit [`f7a2282`](https://github.com/apache/spark/commit/f7a22827694a3aa92e8a7dd20195e2895e86880a). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20623: [SPARK-23413][UI] Fix sorting tasks by Host / Executor I...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20623 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20057: [SPARK-22880][SQL] Add cascadeTruncate option to JDBC da...
Github user danielvdende commented on the issue: https://github.com/apache/spark/pull/20057 Tests are failing on a spark streaming test. I think it's probably because of the age of this PR, will rebase to get the changes into the PR that were merged into master since I opened the PR --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20601: [SPARK-23413][UI] Fix sorting tasks by Host / Executor I...
Github user squito commented on the issue: https://github.com/apache/spark/pull/20601 ack I merged to master but screwed up on 2.3 -- fixing that here: https://github.com/apache/spark/pull/20623 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20623: [SPARK-23413][UI] Fix sorting tasks by Host / Exe...
GitHub user squito opened a pull request: https://github.com/apache/spark/pull/20623 [SPARK-23413][UI] Fix sorting tasks by Host / Executor ID at the Stag⦠â¦e page ## What changes were proposed in this pull request? Fixing exception got at sorting tasks by Host / Executor ID: ``` java.lang.IllegalArgumentException: Invalid sort column: Host at org.apache.spark.ui.jobs.ApiHelper$.indexName(StagePage.scala:1017) at org.apache.spark.ui.jobs.TaskDataSource.sliceData(StagePage.scala:694) at org.apache.spark.ui.PagedDataSource.pageData(PagedTable.scala:61) at org.apache.spark.ui.PagedTable$class.table(PagedTable.scala:96) at org.apache.spark.ui.jobs.TaskPagedTable.table(StagePage.scala:708) at org.apache.spark.ui.jobs.StagePage.liftedTree1$1(StagePage.scala:293) at org.apache.spark.ui.jobs.StagePage.render(StagePage.scala:282) at org.apache.spark.ui.WebUI$$anonfun$2.apply(WebUI.scala:82) at org.apache.spark.ui.WebUI$$anonfun$2.apply(WebUI.scala:82) at org.apache.spark.ui.JettyUtils$$anon$3.doGet(JettyUtils.scala:90) at javax.servlet.http.HttpServlet.service(HttpServlet.java:687) at javax.servlet.http.HttpServlet.service(HttpServlet.java:790) at org.spark_project.jetty.servlet.ServletHolder.handle(ServletHolder.java:848) at org.spark_project.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:584) ``` Moreover some refactoring to avoid similar problems by introducing constants for each header name and reusing them at the identification of the corresponding sorting index. ## How was this patch tested? Manually: 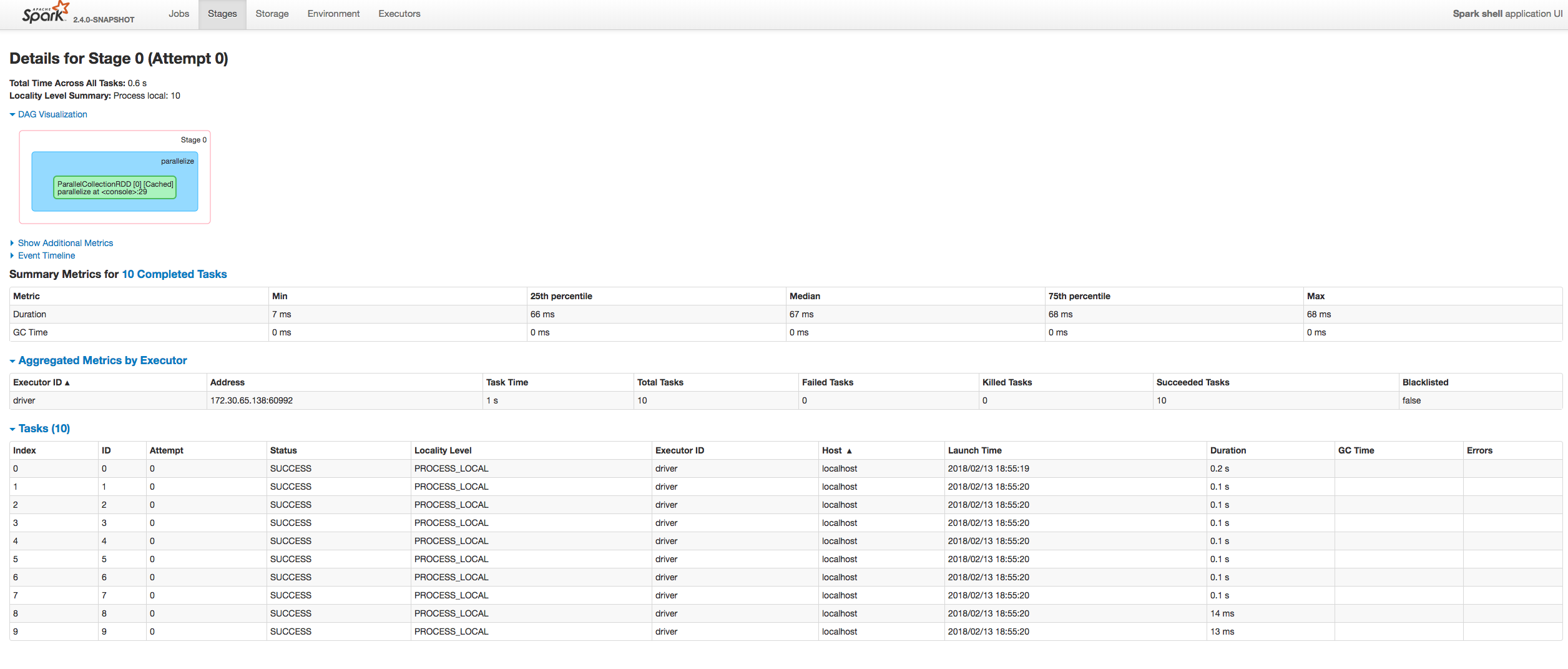 Author: âattilapirosâ Closes #20601 from attilapiros/SPARK-23413. (cherry picked from commit 1dc2c1d5e85c5f404f470aeb44c1f3c22786bdea) You can merge this pull request into a Git repository by running: $ git pull https://github.com/squito/spark fix_backport Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20623.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20623 commit f7a22827694a3aa92e8a7dd20195e2895e86880a Author: âattilapirosâ Date: 2018-02-15T19:51:24Z [SPARK-23413][UI] Fix sorting tasks by Host / Executor ID at the Stage page ## What changes were proposed in this pull request? Fixing exception got at sorting tasks by Host / Executor ID: ``` java.lang.IllegalArgumentException: Invalid sort column: Host at org.apache.spark.ui.jobs.ApiHelper$.indexName(StagePage.scala:1017) at org.apache.spark.ui.jobs.TaskDataSource.sliceData(StagePage.scala:694) at org.apache.spark.ui.PagedDataSource.pageData(PagedTable.scala:61) at org.apache.spark.ui.PagedTable$class.table(PagedTable.scala:96) at org.apache.spark.ui.jobs.TaskPagedTable.table(StagePage.scala:708) at org.apache.spark.ui.jobs.StagePage.liftedTree1$1(StagePage.scala:293) at org.apache.spark.ui.jobs.StagePage.render(StagePage.scala:282) at org.apache.spark.ui.WebUI$$anonfun$2.apply(WebUI.scala:82) at org.apache.spark.ui.WebUI$$anonfun$2.apply(WebUI.scala:82) at org.apache.spark.ui.JettyUtils$$anon$3.doGet(JettyUtils.scala:90) at javax.servlet.http.HttpServlet.service(HttpServlet.java:687) at javax.servlet.http.HttpServlet.service(HttpServlet.java:790) at org.spark_project.jetty.servlet.ServletHolder.handle(ServletHolder.java:848) at org.spark_project.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:584) ``` Moreover some refactoring to avoid similar problems by introducing constants for each header name and reusing them at the identification of the corresponding sorting index. ## How was this patch tested? Manually:  Author: âattilapirosâ Closes #20601 from attilapiros/SPARK-23413. (cherry picked from commit 1dc2c1d5e85c5f404f470aeb44c1f3c22786bdea) --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20554: [SPARK-23362][SS] Migrate Kafka Microbatch source...
Github user jose-torres commented on a diff in the pull request:
https://github.com/apache/spark/pull/20554#discussion_r168558972
--- Diff:
external/kafka-0-10-sql/src/test/scala/org/apache/spark/sql/kafka010/KafkaMicroBatchSourceSuite.scala
---
@@ -112,14 +112,18 @@ abstract class KafkaSourceTest extends StreamTest
with SharedSQLContext {
query.nonEmpty,
"Cannot add data when there is no query for finding the active
kafka source")
- val sources = query.get.logicalPlan.collect {
-case StreamingExecutionRelation(source: KafkaSource, _) => source
- } ++ (query.get.lastExecution match {
-case null => Seq()
-case e => e.logical.collect {
- case DataSourceV2Relation(_, reader: KafkaContinuousReader) =>
reader
-}
- })
+ val sources = {
+query.get.logicalPlan.collect {
+ case StreamingExecutionRelation(source: KafkaSource, _) => source
+ case StreamingExecutionRelation(source: KafkaMicroBatchReader,
_) => source
+} ++ (query.get.lastExecution match {
+ case null => Seq()
+ case e => e.logical.collect {
+case DataSourceV2Relation(_, reader: KafkaContinuousReader) =>
reader
+ }
+})
+ }.distinct
--- End diff --
Is the distinct for the self join test?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20554: [SPARK-23362][SS] Migrate Kafka Microbatch source...
Github user jose-torres commented on a diff in the pull request:
https://github.com/apache/spark/pull/20554#discussion_r168559060
--- Diff:
external/kafka-0-10-sql/src/test/scala/org/apache/spark/sql/kafka010/KafkaSourceSuite.scala
---
@@ -303,94 +302,75 @@ class KafkaMicroBatchSourceSuite extends
KafkaSourceSuiteBase {
)
}
- testWithUninterruptibleThread(
--- End diff --
+1
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20554: [SPARK-23362][SS] Migrate Kafka Microbatch source...
Github user jose-torres commented on a diff in the pull request:
https://github.com/apache/spark/pull/20554#discussion_r168591005
--- Diff:
external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaMicroBatchReader.scala
---
@@ -0,0 +1,410 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.kafka010
+
+import java.{util => ju}
+import java.io._
+import java.nio.charset.StandardCharsets
+
+import scala.collection.JavaConverters._
+
+import org.apache.commons.io.IOUtils
+import org.apache.kafka.common.TopicPartition
+
+import org.apache.spark.SparkEnv
+import org.apache.spark.internal.Logging
+import org.apache.spark.scheduler.ExecutorCacheTaskLocation
+import org.apache.spark.sql.{Row, SparkSession}
+import org.apache.spark.sql.execution.streaming.{HDFSMetadataLog,
SerializedOffset}
+import
org.apache.spark.sql.kafka010.KafkaSourceProvider.{INSTRUCTION_FOR_FAIL_ON_DATA_LOSS_FALSE,
INSTRUCTION_FOR_FAIL_ON_DATA_LOSS_TRUE}
+import org.apache.spark.sql.sources.v2.DataSourceOptions
+import org.apache.spark.sql.sources.v2.reader.{DataReader,
DataReaderFactory}
+import org.apache.spark.sql.sources.v2.reader.streaming.{MicroBatchReader,
Offset}
+import org.apache.spark.sql.types.StructType
+import org.apache.spark.util.UninterruptibleThread
+
+/**
+ * A [[MicroBatchReader]] that reads data from Kafka.
+ *
+ * The [[KafkaSourceOffset]] is the custom [[Offset]] defined for this
source that contains
+ * a map of TopicPartition -> offset. Note that this offset is 1 +
(available offset). For
+ * example if the last record in a Kafka topic "t", partition 2 is offset
5, then
+ * KafkaSourceOffset will contain TopicPartition("t", 2) -> 6. This is
done keep it consistent
+ * with the semantics of `KafkaConsumer.position()`.
+ *
+ * Zero data lost is not guaranteed when topics are deleted. If zero data
lost is critical, the user
+ * must make sure all messages in a topic have been processed when
deleting a topic.
+ *
+ * There is a known issue caused by KAFKA-1894: the query using Kafka
maybe cannot be stopped.
+ * To avoid this issue, you should make sure stopping the query before
stopping the Kafka brokers
+ * and not use wrong broker addresses.
+ */
+private[kafka010] class KafkaMicroBatchReader(
+kafkaOffsetReader: KafkaOffsetReader,
+executorKafkaParams: ju.Map[String, Object],
+options: DataSourceOptions,
+metadataPath: String,
+startingOffsets: KafkaOffsetRangeLimit,
+failOnDataLoss: Boolean)
+ extends MicroBatchReader with Logging {
+
+ type PartitionOffsetMap = Map[TopicPartition, Long]
+
+ private var startPartitionOffsets: PartitionOffsetMap = _
+ private var endPartitionOffsets: PartitionOffsetMap = _
+
+ private val pollTimeoutMs = options.getLong(
+"kafkaConsumer.pollTimeoutMs",
+SparkEnv.get.conf.getTimeAsMs("spark.network.timeout", "120s"))
+
+ private val maxOffsetsPerTrigger =
+Option(options.get("maxOffsetsPerTrigger").orElse(null)).map(_.toLong)
+
+ /**
+ * Lazily initialize `initialPartitionOffsets` to make sure that
`KafkaConsumer.poll` is only
+ * called in StreamExecutionThread. Otherwise, interrupting a thread
while running
+ * `KafkaConsumer.poll` may hang forever (KAFKA-1894).
+ */
+ private lazy val initialPartitionOffsets =
getOrCreateInitialPartitionOffsets()
+
+ override def setOffsetRange(start: ju.Optional[Offset], end:
ju.Optional[Offset]): Unit = {
+// Make sure initialPartitionOffsets is initialized
+initialPartitionOffsets
+
+startPartitionOffsets = Option(start.orElse(null))
+.map(_.asInstanceOf[KafkaSourceOffset].partitionToOffsets)
+.getOrElse(initialPartitionOffsets)
+
+endPartitionOffsets = Option(end.orElse(null))
+.map(_.asInstanceOf[KafkaSourceOffset].partitionToOffsets)
+.g
[GitHub] spark pull request #20554: [SPARK-23362][SS] Migrate Kafka Microbatch source...
Github user jose-torres commented on a diff in the pull request: https://github.com/apache/spark/pull/20554#discussion_r168558562 --- Diff: external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaSource.scala --- @@ -306,7 +307,7 @@ private[kafka010] class KafkaSource( kafkaReader.close() } - override def toString(): String = s"KafkaSource[$kafkaReader]" + override def toString(): String = s"KafkaSourceV1[$kafkaReader]" --- End diff -- good catch --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20554: [SPARK-23362][SS] Migrate Kafka Microbatch source...
Github user jose-torres commented on a diff in the pull request:
https://github.com/apache/spark/pull/20554#discussion_r167127585
--- Diff:
external/kafka-0-10-sql/src/test/resources/kafka-source-initial-offset-version-2.1.0.bin
---
@@ -1 +1 @@
-2{"kafka-initial-offset-2-1-0":{"2":0,"1":0,"0":0}}
\ No newline at end of file
+2{"kafka-initial-offset-2-1-0":{"2":2,"1":1,"0":0}}
--- End diff --
Why does this need to be modified? The point of this file IIUC is to ensure
that compatibility is maintained with offsets logged in old versions, so I
worry something's wrong if we need to update it.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20601: [SPARK-23413][UI] Fix sorting tasks by Host / Exe...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/20601 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20622: [SPARK-23441][SS] Remove queryExecutionThread.interrupt(...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20622 **[Test build #87491 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87491/testReport)** for PR 20622 at commit [`3d8acd2`](https://github.com/apache/spark/commit/3d8acd2974d11a790ab9cd9338673bba18d683ac). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20601: [SPARK-23413][UI] Fix sorting tasks by Host / Executor I...
Github user squito commented on the issue: https://github.com/apache/spark/pull/20601 Everything that might have changed from this has passed, the failures are known flaky tests: https://issues.apache.org/jira/browse/SPARK-23369 https://issues.apache.org/jira/browse/SPARK-23390 merging to master / 2.3 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20622: [SPARK-23441][SS] Remove queryExecutionThread.interrupt(...
Github user jose-torres commented on the issue: https://github.com/apache/spark/pull/20622 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20622: [SPARK-23441][SS] Remove queryExecutionThread.interrupt(...
Github user jose-torres commented on the issue: https://github.com/apache/spark/pull/20622 StreamingOuterJoinSuite failure is a known flakiness issue. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20622: [SPARK-23441][SS] Remove queryExecutionThread.interrupt(...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20622 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/87486/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20622: [SPARK-23441][SS] Remove queryExecutionThread.interrupt(...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20622 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20622: [SPARK-23441][SS] Remove queryExecutionThread.interrupt(...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20622 **[Test build #87486 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87486/testReport)** for PR 20622 at commit [`3d8acd2`](https://github.com/apache/spark/commit/3d8acd2974d11a790ab9cd9338673bba18d683ac). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20057: [SPARK-22880][SQL] Add cascadeTruncate option to JDBC da...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20057 **[Test build #87484 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87484/testReport)** for PR 20057 at commit [`3a7dda4`](https://github.com/apache/spark/commit/3a7dda4a0df8ef684d8fb803a98434c170953f4c). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20620: [SPARK-23438][DSTREAMS] Fix DStreams data loss with WAL ...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20620 **[Test build #87489 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87489/testReport)** for PR 20620 at commit [`152fec4`](https://github.com/apache/spark/commit/152fec431218161e538c377a6cb82753100dc70b). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20620: [SPARK-23438][DSTREAMS] Fix DStreams data loss with WAL ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20620 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/87489/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20620: [SPARK-23438][DSTREAMS] Fix DStreams data loss with WAL ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20620 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20057: [SPARK-22880][SQL] Add cascadeTruncate option to JDBC da...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20057 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20057: [SPARK-22880][SQL] Add cascadeTruncate option to JDBC da...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20057 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/87484/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20601: [SPARK-23413][UI] Fix sorting tasks by Host / Executor I...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20601 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20601: [SPARK-23413][UI] Fix sorting tasks by Host / Executor I...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20601 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/87481/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20601: [SPARK-23413][UI] Fix sorting tasks by Host / Executor I...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20601 **[Test build #87481 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87481/testReport)** for PR 20601 at commit [`22179e8`](https://github.com/apache/spark/commit/22179e84f6cf601be18e9b060246c54bd0cede8d). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20594: [SPARK-23377][ML] Fixes Bucketizer with multiple columns...
Github user jkbradley commented on the issue: https://github.com/apache/spark/pull/20594 Success! Merged to branch-2.3 too. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20295: [SPARK-23011] Support alternative function form with gro...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20295 **[Test build #87490 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87490/testReport)** for PR 20295 at commit [`9ed3779`](https://github.com/apache/spark/commit/9ed3779b665c90e5bb25bc6636997a4b080c3d34). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20567: [SPARK-23380][PYTHON] Make toPandas fallback to n...
Github user icexelloss commented on a diff in the pull request:
https://github.com/apache/spark/pull/20567#discussion_r168579785
--- Diff: python/pyspark/sql/dataframe.py ---
@@ -1941,12 +1941,24 @@ def toPandas(self):
timezone = None
if self.sql_ctx.getConf("spark.sql.execution.arrow.enabled",
"false").lower() == "true":
+should_fallback = False
try:
-from pyspark.sql.types import
_check_dataframe_convert_date, \
-_check_dataframe_localize_timestamps
+from pyspark.sql.types import to_arrow_schema
from pyspark.sql.utils import
require_minimum_pyarrow_version
-import pyarrow
require_minimum_pyarrow_version()
+# Check if its schema is convertible in Arrow format.
+to_arrow_schema(self.schema)
+except Exception as e:
--- End diff --
Do we want to catch more specific exceptions here? i.e. `TypeError` and
`ImportError`?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20295: [SPARK-23011] Support alternative function form with gro...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20295 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20295: [SPARK-23011] Support alternative function form with gro...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20295 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/924/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20295: [SPARK-23011] Support alternative function form with gro...
Github user icexelloss commented on the issue: https://github.com/apache/spark/pull/20295 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20622: [SPARK-23441][SS] Remove queryExecutionThread.interrupt(...
Github user mgaido91 commented on the issue: https://github.com/apache/spark/pull/20622 thanks for pinging me @jose-torres! Unfortunately I don't know yet structured streaming codebase well enough to give a feedback. Thanks anyway for looking at it! --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20618: [SPARK-23329][SQL] Fix documentation of trigonome...
Github user misutoth commented on a diff in the pull request:
https://github.com/apache/spark/pull/20618#discussion_r168578156
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/functions.scala ---
@@ -1313,131 +1313,178 @@ object functions {
//
/**
- * Computes the cosine inverse of the given value; the returned angle is
in the range
- * 0.0 through pi.
+ * @param e the value whose arc cosine is to be returned
+ * @return cosine inverse of the given value in the range of 0.0
through pi,
--- End diff --
I am not sure what you mean on _above_. Do you mean reverting this part of
the change?
How about simply `@return the angle whose cosine is 'e'` and refer to
java.lang.Math for further details?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20601: [SPARK-23413][UI] Fix sorting tasks by Host / Executor I...
Github user zsxwing commented on the issue: https://github.com/apache/spark/pull/20601 LGTM --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20615: [SPARK-23430][WebUI]ApiHelper.COLUMN_TO_INDEX should mat...
Github user zsxwing commented on the issue: https://github.com/apache/spark/pull/20615 Great! Closing my PR. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20615: [SPARK-23430][WebUI]ApiHelper.COLUMN_TO_INDEX sho...
Github user zsxwing closed the pull request at: https://github.com/apache/spark/pull/20615 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20424: [Spark-23240][python] Better error message when extraneo...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20424 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/87479/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20424: [Spark-23240][python] Better error message when extraneo...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20424 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20424: [Spark-23240][python] Better error message when extraneo...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20424 **[Test build #87479 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87479/testReport)** for PR 20424 at commit [`eceb24e`](https://github.com/apache/spark/commit/eceb24e61798f9e5da0ed3c4dfb94d677d08b10e). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20620: [SPARK-23438][DSTREAMS] Fix DStreams data loss with WAL ...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20620 **[Test build #87489 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87489/testReport)** for PR 20620 at commit [`152fec4`](https://github.com/apache/spark/commit/152fec431218161e538c377a6cb82753100dc70b). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20621: [SPARK-23436][SQL] Infer partition as Date only if it ca...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20621 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/923/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20621: [SPARK-23436][SQL] Infer partition as Date only if it ca...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20621 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20621: [SPARK-23436][SQL] Infer partition as Date only if it ca...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20621 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/922/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20621: [SPARK-23436][SQL] Infer partition as Date only if it ca...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20621 **[Test build #87488 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87488/testReport)** for PR 20621 at commit [`6b56408`](https://github.com/apache/spark/commit/6b5640833a2d45986a0cf6074d7211a8ba9d2b3e). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20620: [SPARK-23438][DSTREAMS] Fix DStreams data loss with WAL ...
Github user vanzin commented on the issue: https://github.com/apache/spark/pull/20620 ok to test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20621: [SPARK-23436][SQL] Infer partition as Date only if it ca...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20621 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20612: [SPARK-23424][SQL]Add codegenStageId in comment
Github user rednaxelafx commented on the issue: https://github.com/apache/spark/pull/20612 LGTM. Let's wait for one more LGTM from @gatorsmile / @cloud-fan . --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18672: [kafka010] Fix: On first run DirectKafkaInputDStream was...
Github user oliviertoupin commented on the issue: https://github.com/apache/spark/pull/18672 My PR predate #19431, but essentially fix the same issue. Since #19431 have more traction and is more thorough, I'll close this one, and comment on the new one if necessary. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #18672: [kafka010] Fix: On first run DirectKafkaInputDStr...
Github user oliviertoupin closed the pull request at: https://github.com/apache/spark/pull/18672 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20295: [SPARK-23011] Support alternative function form with gro...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20295 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20295: [SPARK-23011] Support alternative function form with gro...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20295 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/87480/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20295: [SPARK-23011] Support alternative function form with gro...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20295 **[Test build #87480 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87480/testReport)** for PR 20295 at commit [`9ed3779`](https://github.com/apache/spark/commit/9ed3779b665c90e5bb25bc6636997a4b080c3d34). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20594: [SPARK-23377][ML] Fixes Bucketizer with multiple columns...
Github user jkbradley commented on the issue: https://github.com/apache/spark/pull/20594 Well I succeeded in merging this with master, but the merge script isn't working for branch-2.3. I wait to see if the read-only repo syncs and fixes the issue. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20601: [SPARK-23413][UI] Fix sorting tasks by Host / Executor I...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20601 **[Test build #87487 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87487/testReport)** for PR 20601 at commit [`22179e8`](https://github.com/apache/spark/commit/22179e84f6cf601be18e9b060246c54bd0cede8d). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20594: [SPARK-23377][ML] Fixes Bucketizer with multiple ...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/20594 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20617: [MINOR][SQL] Fix an error message about inserting into b...
Github user dongjoon-hyun commented on the issue: https://github.com/apache/spark/pull/20617 Thank you always guys, @gatorsmile , @HyukjinKwon , and @mgaido91 . --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20619: [SPARK-23390][SQL] Register task completion liste...
Github user dongjoon-hyun commented on a diff in the pull request:
https://github.com/apache/spark/pull/20619#discussion_r168557092
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFileFormat.scala
---
@@ -414,16 +417,16 @@ class ParquetFileFormat
} else {
new ParquetRecordReader[UnsafeRow](new
ParquetReadSupport(convertTz))
}
+val recordReaderIterator = new RecordReaderIterator(reader)
+// Register a task completion lister before `initalization`.
+taskContext.foreach(_.addTaskCompletionListener(_ =>
recordReaderIterator.close()))
reader.initialize(split, hadoopAttemptContext)
-reader
+recordReaderIterator
}
- val iter = new RecordReaderIterator(parquetReader)
- taskContext.foreach(_.addTaskCompletionListener(_ => iter.close()))
--- End diff --
According to the reported leakage, this is too late.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20620: [SPARK-23438][DSTREAMS] Fix DStreams data loss with WAL ...
Github user gaborgsomogyi commented on the issue: https://github.com/apache/spark/pull/20620 @jose-torres @tdas @zsxwing could you take a look at this please? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20619: [SPARK-23390][SQL] Register task completion liste...
Github user dongjoon-hyun commented on a diff in the pull request:
https://github.com/apache/spark/pull/20619#discussion_r168556797
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFileFormat.scala
---
@@ -414,16 +417,16 @@ class ParquetFileFormat
} else {
new ParquetRecordReader[UnsafeRow](new
ParquetReadSupport(convertTz))
}
+val recordReaderIterator = new RecordReaderIterator(reader)
+// Register a task completion lister before `initalization`.
+taskContext.foreach(_.addTaskCompletionListener(_ =>
recordReaderIterator.close()))
reader.initialize(split, hadoopAttemptContext)
-reader
+recordReaderIterator
}
- val iter = new RecordReaderIterator(parquetReader)
- taskContext.foreach(_.addTaskCompletionListener(_ => iter.close()))
// UnsafeRowParquetRecordReader appends the columns internally to
avoid another copy.
- if (parquetReader.isInstanceOf[VectorizedParquetRecordReader] &&
- enableVectorizedReader) {
+ if (enableVectorizedReader) {
--- End diff --
Yep. It looks possible. I'll update together after getting more reviews.
Thanks, @kiszk .
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20601: [SPARK-23413][UI] Fix sorting tasks by Host / Executor I...
Github user vanzin commented on the issue: https://github.com/apache/spark/pull/20601 ah, flaky tests. retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20601: [SPARK-23413][UI] Fix sorting tasks by Host / Executor I...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20601 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/87478/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20601: [SPARK-23413][UI] Fix sorting tasks by Host / Executor I...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20601 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20601: [SPARK-23413][UI] Fix sorting tasks by Host / Executor I...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20601 **[Test build #87478 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87478/testReport)** for PR 20601 at commit [`22179e8`](https://github.com/apache/spark/commit/22179e84f6cf601be18e9b060246c54bd0cede8d). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18672: [kafka010] Fix: On first run DirectKafkaInputDStream was...
Github user gaborgsomogyi commented on the issue: https://github.com/apache/spark/pull/18672 Looks like a shortcut to me as well. There is already a PR for backpressure: https://github.com/apache/spark/pull/19431 Could you explain what exactly would like to achieve here? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20396: [SPARK-23217][ML] Add cosine distance measure to Cluster...
Github user srowen commented on the issue: https://github.com/apache/spark/pull/20396 I think you can just add a follow-up --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20619: [SPARK-23390][SQL] Register task completion listerners f...
Github user gatorsmile commented on the issue: https://github.com/apache/spark/pull/20619 cc @ala @michal-databricks @cloud-fan --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20617: [MINOR][SQL] Fix an error message about inserting...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/20617 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20594: [SPARK-23377][ML] Fixes Bucketizer with multiple columns...
Github user jkbradley commented on the issue: https://github.com/apache/spark/pull/20594 Merging with master and branch-2.3 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20396: [SPARK-23217][ML] Add cosine distance measure to Cluster...
Github user mgaido91 commented on the issue: https://github.com/apache/spark/pull/20396 @srowen sorry, this needs also to add the parameter to the python API; given our discussion on JIRA, what should I do? Create a follow-up PR or a new ticket on JIRA? Thanks. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20617: [MINOR][SQL] Fix an error message about inserting into b...
Github user gatorsmile commented on the issue: https://github.com/apache/spark/pull/20617 Thanks! Merged to master/2.3 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20619: [SPARK-23390][SQL] Register task completion liste...
Github user kiszk commented on a diff in the pull request:
https://github.com/apache/spark/pull/20619#discussion_r168552292
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFileFormat.scala
---
@@ -414,16 +417,16 @@ class ParquetFileFormat
} else {
new ParquetRecordReader[UnsafeRow](new
ParquetReadSupport(convertTz))
}
+val recordReaderIterator = new RecordReaderIterator(reader)
+// Register a task completion lister before `initalization`.
+taskContext.foreach(_.addTaskCompletionListener(_ =>
recordReaderIterator.close()))
reader.initialize(split, hadoopAttemptContext)
-reader
+recordReaderIterator
}
- val iter = new RecordReaderIterator(parquetReader)
- taskContext.foreach(_.addTaskCompletionListener(_ => iter.close()))
// UnsafeRowParquetRecordReader appends the columns internally to
avoid another copy.
- if (parquetReader.isInstanceOf[VectorizedParquetRecordReader] &&
- enableVectorizedReader) {
+ if (enableVectorizedReader) {
--- End diff --
Would it be possible to merge this if-statement into the above if-statement?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20622: [SPARK-23441][SS] Remove queryExecutionThread.interrupt(...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20622 **[Test build #87486 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87486/testReport)** for PR 20622 at commit [`3d8acd2`](https://github.com/apache/spark/commit/3d8acd2974d11a790ab9cd9338673bba18d683ac). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20622: [SPARK-23441][SS] Remove queryExecutionThread.interrupt(...
Github user jose-torres commented on the issue: https://github.com/apache/spark/pull/20622 cc @mgaido91 - this should completely resolve the other symptom you posted in SPARK-23416 cc @zsxwing @tdas --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20622: [SPARK-23441][SS] Remove queryExecutionThread.interrupt(...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20622 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20622: [SPARK-23441][SS] Remove queryExecutionThread.int...
GitHub user jose-torres opened a pull request: https://github.com/apache/spark/pull/20622 [SPARK-23441][SS] Remove queryExecutionThread.interrupt() from ContinuousExecution ## What changes were proposed in this pull request? Remove queryExecutionThread.interrupt() from ContinuousExecution. As detailed in the JIRA, interrupting the thread is only relevant in the microbatch case; for continuous processing the query execution can quickly clean itself up without. ## How was this patch tested? existing tests You can merge this pull request into a Git repository by running: $ git pull https://github.com/jose-torres/spark SPARK-23441 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20622.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20622 commit 3d8acd2974d11a790ab9cd9338673bba18d683ac Author: Jose Torres Date: 2018-02-15T17:27:09Z remove interrupt --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20617: [MINOR][SQL] Fix an error message about inserting into b...
Github user dongjoon-hyun commented on the issue: https://github.com/apache/spark/pull/20617 Thank you for review, @mgaido91 . --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20057: [SPARK-22880][SQL] Add cascadeTruncate option to JDBC da...
Github user gatorsmile commented on the issue: https://github.com/apache/spark/pull/20057 @danielvdende @Fokko We definitely want to help the community replace Sqoop by Spark SQL. However, `truncate` is only used when users use SaveMode.Overwrite to write the external JDBC tables. In this specific scenario, Spark will truncate an existing table instead of dropping and recreating it. Could you show me the key missing features that are available in Sqoop but not in Spark SQL JDBC connectors? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20621: [SPARK-23436][SQL] Infer partition as Date only if it ca...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20621 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/87485/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20621: [SPARK-23436][SQL] Infer partition as Date only if it ca...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20621 **[Test build #87485 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87485/testReport)** for PR 20621 at commit [`2f05ab8`](https://github.com/apache/spark/commit/2f05ab8e82b0940e84cbe407abe49f72cddeef11). * This patch **fails Scala style tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20621: [SPARK-23436][SQL] Infer partition as Date only if it ca...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20621 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20621: [SPARK-23436][SQL] Infer partition as Date only if it ca...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20621 **[Test build #87485 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87485/testReport)** for PR 20621 at commit [`2f05ab8`](https://github.com/apache/spark/commit/2f05ab8e82b0940e84cbe407abe49f72cddeef11). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20621: [SPARK-23436][SQL] Infer partition as Date only if it ca...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20621 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/921/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20621: [SPARK-23436][SQL] Infer partition as Date only if it ca...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20621 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20617: [MINOR][SQL] Fix an error message about inserting into b...
Github user mgaido91 commented on the issue: https://github.com/apache/spark/pull/20617 LGTM --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20621: [SPARK-23436][SQL] Infer partition as Date only if it ca...
Github user mgaido91 commented on the issue: https://github.com/apache/spark/pull/20621 cc @cloud-fan @HyukjinKwon @viirya --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20621: [SPARK-23436][SQL] Infer partition as Date only i...
GitHub user mgaido91 opened a pull request: https://github.com/apache/spark/pull/20621 [SPARK-23436][SQL] Infer partition as Date only if it can be casted to Date ## What changes were proposed in this pull request? Before the patch, Spark could infer as Date a partition value which cannot be casted to Date (this can happen when there are extra characters after a valid date, like `2018-02-15AAA`). When this happens and the input format has metadata which define the schema of the table, then `null` is returned as a value for the partition column, because the `cast` operator used in (`PartitioningAwareFileIndex.inferPartitioning`) is unable to convert the value. The PR checks in the partition inference that values can be casted to Date and Timestamp, in order to infer that datatype to them. ## How was this patch tested? added UT You can merge this pull request into a Git repository by running: $ git pull https://github.com/mgaido91/spark SPARK-23436 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/20621.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #20621 commit 2f05ab8e82b0940e84cbe407abe49f72cddeef11 Author: Marco Gaido Date: 2018-02-15T16:59:20Z [SPARK-23436][SQL] Infer partition as Date only if it can be casted to Date --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20057: [SPARK-22880][SQL] Add cascadeTruncate option to JDBC da...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20057 **[Test build #87484 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87484/testReport)** for PR 20057 at commit [`3a7dda4`](https://github.com/apache/spark/commit/3a7dda4a0df8ef684d8fb803a98434c170953f4c). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20511: [SPARK-23340][SQL] Upgrade Apache ORC to 1.4.3
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20511 **[Test build #87483 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/87483/testReport)** for PR 20511 at commit [`b42fd4d`](https://github.com/apache/spark/commit/b42fd4d4584277aaab925e3d6ed1125f474439e7). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org