[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24631: [MINOR][CORE][DOC]Avoid hardcoded configs and fix kafka sink write semantics in document
dongjoon-hyun commented on a change in pull request #24631: [MINOR][CORE][DOC]Avoid hardcoded configs and fix kafka sink write semantics in document URL: https://github.com/apache/spark/pull/24631#discussion_r284981733 ## File path: docs/structured-streaming-kafka-integration.md ## @@ -441,7 +441,7 @@ Apache Kafka only supports at least once write semantics. Consequently, when wri or Batch Queries---to Kafka, some records may be duplicated; this can happen, for example, if Kafka needs to retry a message that was not acknowledged by a Broker, even though that Broker received and wrote the message record. Structured Streaming cannot prevent such duplicates from occurring due to these Kafka write semantics. However, -if writing the query is successful, then you can assume that the query output was written at least once. A possible +if writing the query is successful, then you can assume that the query output was written exactly once. A possible Review comment: The existing one looks okay to me. Let's remove this doc change from this PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wenxuanguan commented on a change in pull request #24631: [MINOR][CORE][DOC]Avoid hardcoded configs and fix kafka sink write semantics in document
wenxuanguan commented on a change in pull request #24631: [MINOR][CORE][DOC]Avoid hardcoded configs and fix kafka sink write semantics in document URL: https://github.com/apache/spark/pull/24631#discussion_r284976140 ## File path: docs/structured-streaming-kafka-integration.md ## @@ -441,7 +441,7 @@ Apache Kafka only supports at least once write semantics. Consequently, when wri or Batch Queries---to Kafka, some records may be duplicated; this can happen, for example, if Kafka needs to retry a message that was not acknowledged by a Broker, even though that Broker received and wrote the message record. Structured Streaming cannot prevent such duplicates from occurring due to these Kafka write semantics. However, -if writing the query is successful, then you can assume that the query output was written at least once. A possible +if writing the query is successful, then you can assume that the query output was written exactly once. A possible Review comment: Thanks for your reply. @dongjoon-hyun I thought this describes the situation that query writes to kafka successfully and no records are duplicated. How about change to `So if writing the query is successful, then you can assume that the query output was written at least once`, which will not be confused by `However` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] shahidki31 commented on a change in pull request #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format.
shahidki31 commented on a change in pull request #24609: [SPARK-27715][SQL] SQL
query details in UI dose not show in correct format.
URL: https://github.com/apache/spark/pull/24609#discussion_r284978946
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/ui/AllExecutionsPage.scala
##
@@ -382,13 +382,14 @@ private[ui] class ExecutionPagedTable(
}
private def descriptionCell(execution: SQLExecutionUIData): Seq[Node] = {
+val jobDescription = UIUtils.makeDescription(execution.description,
basePath, plainText = false)
val details = if (execution.details != null && execution.details.nonEmpty)
{
+details
++
-{execution.description}{execution.details}
+{jobDescription}{execution.details}
Review comment:
In the `details`, before this change it used to show entire query if the
query is large. But after the change, it seems not showing the entire sql query.
**After change:**
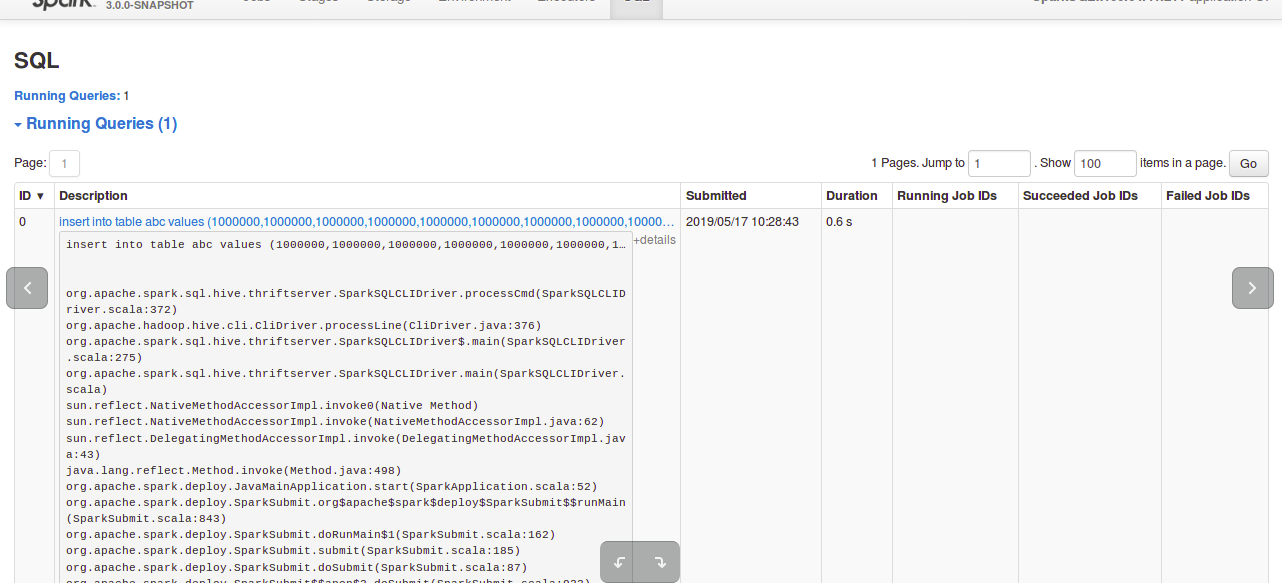
**Before change:**
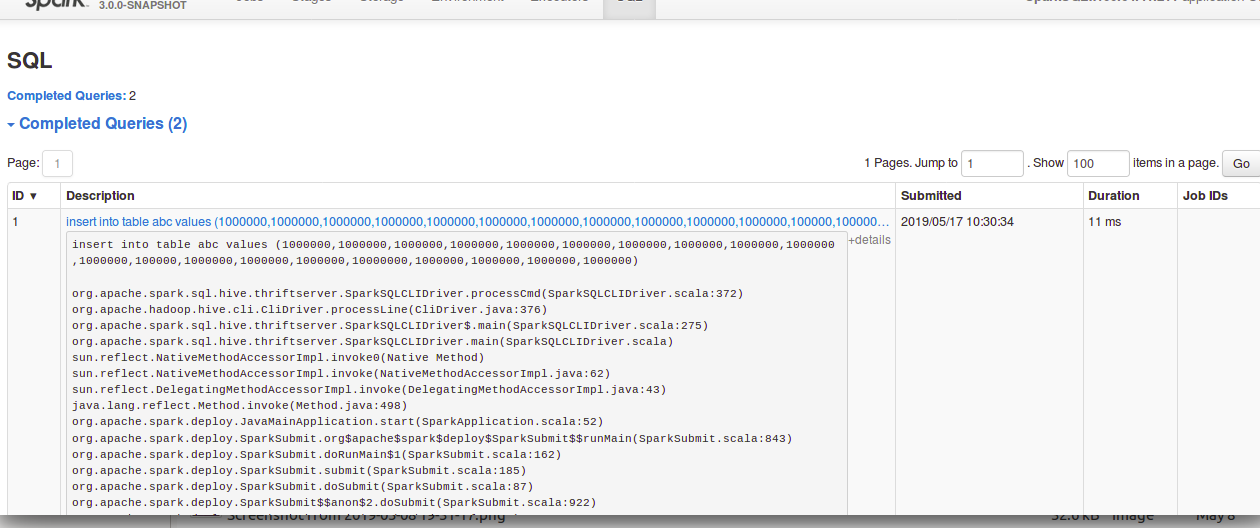
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks
AmplabJenkins removed a comment on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks URL: https://github.com/apache/spark/pull/24565#issuecomment-493321249 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks
AmplabJenkins removed a comment on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks URL: https://github.com/apache/spark/pull/24565#issuecomment-493321253 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/105480/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks
AmplabJenkins commented on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks URL: https://github.com/apache/spark/pull/24565#issuecomment-493321249 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks
AmplabJenkins commented on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks URL: https://github.com/apache/spark/pull/24565#issuecomment-493321253 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/105480/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] shahidki31 commented on a change in pull request #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format.
shahidki31 commented on a change in pull request #24609: [SPARK-27715][SQL] SQL
query details in UI dose not show in correct format.
URL: https://github.com/apache/spark/pull/24609#discussion_r284978946
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/ui/AllExecutionsPage.scala
##
@@ -382,13 +382,14 @@ private[ui] class ExecutionPagedTable(
}
private def descriptionCell(execution: SQLExecutionUIData): Seq[Node] = {
+val jobDescription = UIUtils.makeDescription(execution.description,
basePath, plainText = false)
val details = if (execution.details != null && execution.details.nonEmpty)
{
+details
++
-{execution.description}{execution.details}
+{jobDescription}{execution.details}
Review comment:
In the `details`, before this change it used to show entire query if the
query is large. But after the change, it seems not showing the entire sql query.
**Before change:**
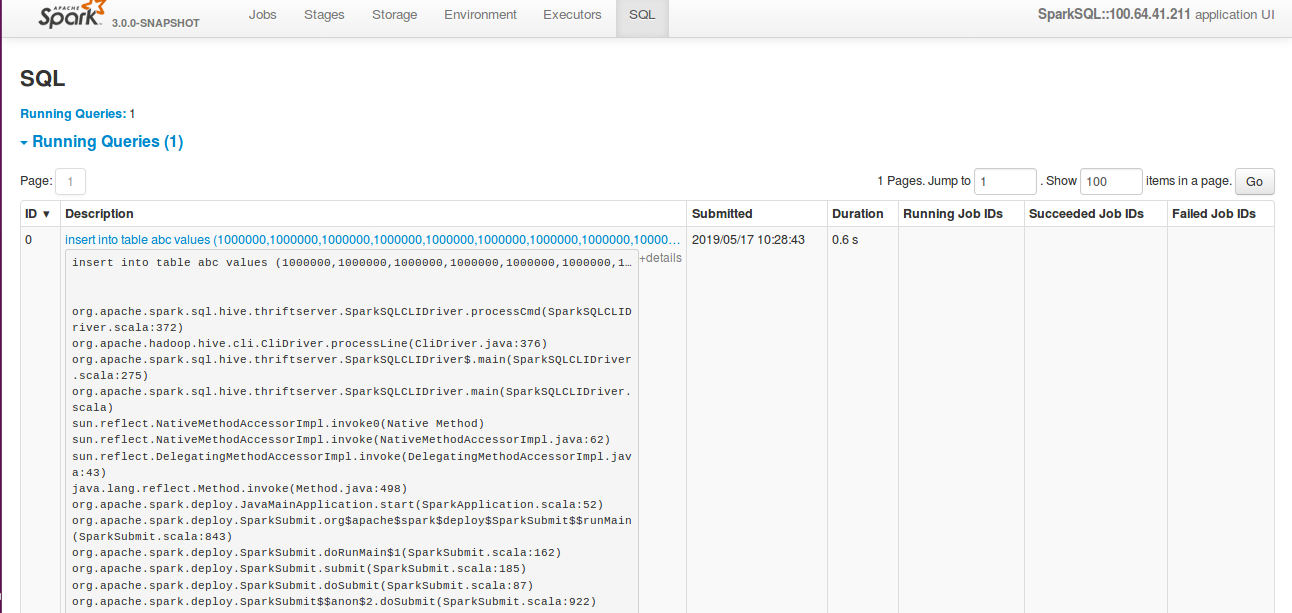
**After change:**
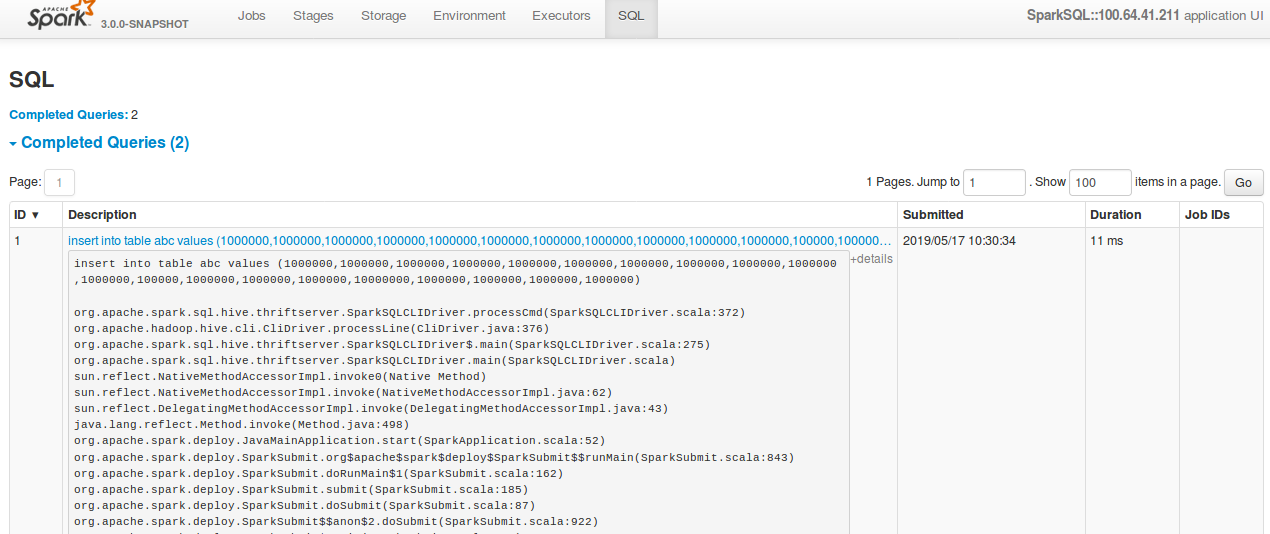
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] shahidki31 commented on a change in pull request #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format.
shahidki31 commented on a change in pull request #24609: [SPARK-27715][SQL] SQL
query details in UI dose not show in correct format.
URL: https://github.com/apache/spark/pull/24609#discussion_r284978946
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/ui/AllExecutionsPage.scala
##
@@ -382,13 +382,14 @@ private[ui] class ExecutionPagedTable(
}
private def descriptionCell(execution: SQLExecutionUIData): Seq[Node] = {
+val jobDescription = UIUtils.makeDescription(execution.description,
basePath, plainText = false)
val details = if (execution.details != null && execution.details.nonEmpty)
{
+details
++
-{execution.description}{execution.details}
+{jobDescription}{execution.details}
Review comment:
In the `details`, before this change it used to show entire query if the
query is large. But after the change, it seems not showing the entire sql query.
**After change:**

**Before change:**

This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] shahidki31 commented on a change in pull request #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format.
shahidki31 commented on a change in pull request #24609: [SPARK-27715][SQL] SQL
query details in UI dose not show in correct format.
URL: https://github.com/apache/spark/pull/24609#discussion_r284978946
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/ui/AllExecutionsPage.scala
##
@@ -382,13 +382,14 @@ private[ui] class ExecutionPagedTable(
}
private def descriptionCell(execution: SQLExecutionUIData): Seq[Node] = {
+val jobDescription = UIUtils.makeDescription(execution.description,
basePath, plainText = false)
val details = if (execution.details != null && execution.details.nonEmpty)
{
+details
++
-{execution.description}{execution.details}
+{jobDescription}{execution.details}
Review comment:
In the `details`, before this change it used to show entire query if the
query is large. But after the change it seems, it seems not showing the entire
sql query.
**Before change:**

**After change:**

This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks
SparkQA removed a comment on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks URL: https://github.com/apache/spark/pull/24565#issuecomment-493301810 **[Test build #105480 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/105480/testReport)** for PR 24565 at commit [`fddcd6c`](https://github.com/apache/spark/commit/fddcd6ce7a6a01c497a0f750c43fd4357fb1a2fd). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] shahidki31 commented on a change in pull request #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format.
shahidki31 commented on a change in pull request #24609: [SPARK-27715][SQL] SQL
query details in UI dose not show in correct format.
URL: https://github.com/apache/spark/pull/24609#discussion_r284978946
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/ui/AllExecutionsPage.scala
##
@@ -382,13 +382,14 @@ private[ui] class ExecutionPagedTable(
}
private def descriptionCell(execution: SQLExecutionUIData): Seq[Node] = {
+val jobDescription = UIUtils.makeDescription(execution.description,
basePath, plainText = false)
val details = if (execution.details != null && execution.details.nonEmpty)
{
+details
++
-{execution.description}{execution.details}
+{jobDescription}{execution.details}
Review comment:
In the `details`, before this change it used to show entire query if the
query is large. But after the change it seems, it seems not showing the entire
sql query
Before change:

After change:

This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks
SparkQA commented on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks URL: https://github.com/apache/spark/pull/24565#issuecomment-493320966 **[Test build #105480 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/105480/testReport)** for PR 24565 at commit [`fddcd6c`](https://github.com/apache/spark/commit/fddcd6ce7a6a01c497a0f750c43fd4357fb1a2fd). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] shahidki31 commented on a change in pull request #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format.
shahidki31 commented on a change in pull request #24609: [SPARK-27715][SQL] SQL
query details in UI dose not show in correct format.
URL: https://github.com/apache/spark/pull/24609#discussion_r284978946
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/ui/AllExecutionsPage.scala
##
@@ -382,13 +382,14 @@ private[ui] class ExecutionPagedTable(
}
private def descriptionCell(execution: SQLExecutionUIData): Seq[Node] = {
+val jobDescription = UIUtils.makeDescription(execution.description,
basePath, plainText = false)
val details = if (execution.details != null && execution.details.nonEmpty)
{
+details
++
-{execution.description}{execution.details}
+{jobDescription}{execution.details}
Review comment:
It the `details`, before this change it used to show entire query if the
query is large. But after the change it seems, it seems not showing the entire
sql query
Before change:

After change:

This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format.
AmplabJenkins removed a comment on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format. URL: https://github.com/apache/spark/pull/24609#issuecomment-493319728 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/105479/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format.
AmplabJenkins removed a comment on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format. URL: https://github.com/apache/spark/pull/24609#issuecomment-493319721 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format.
AmplabJenkins commented on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format. URL: https://github.com/apache/spark/pull/24609#issuecomment-493319728 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/105479/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format.
AmplabJenkins commented on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format. URL: https://github.com/apache/spark/pull/24609#issuecomment-493319721 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format.
SparkQA removed a comment on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format. URL: https://github.com/apache/spark/pull/24609#issuecomment-493291753 **[Test build #105479 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/105479/testReport)** for PR 24609 at commit [`ca1a1f7`](https://github.com/apache/spark/commit/ca1a1f787ea17aebeb0910e39c24b44268126bb7). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format.
SparkQA commented on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format. URL: https://github.com/apache/spark/pull/24609#issuecomment-493319411 **[Test build #105479 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/105479/testReport)** for PR 24609 at commit [`ca1a1f7`](https://github.com/apache/spark/commit/ca1a1f787ea17aebeb0910e39c24b44268126bb7). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wenxuanguan commented on a change in pull request #24631: [MINOR][CORE][DOC]Avoid hardcoded configs and fix kafka sink write semantics in document
wenxuanguan commented on a change in pull request #24631: [MINOR][CORE][DOC]Avoid hardcoded configs and fix kafka sink write semantics in document URL: https://github.com/apache/spark/pull/24631#discussion_r284976140 ## File path: docs/structured-streaming-kafka-integration.md ## @@ -441,7 +441,7 @@ Apache Kafka only supports at least once write semantics. Consequently, when wri or Batch Queries---to Kafka, some records may be duplicated; this can happen, for example, if Kafka needs to retry a message that was not acknowledged by a Broker, even though that Broker received and wrote the message record. Structured Streaming cannot prevent such duplicates from occurring due to these Kafka write semantics. However, -if writing the query is successful, then you can assume that the query output was written at least once. A possible +if writing the query is successful, then you can assume that the query output was written exactly once. A possible Review comment: Thanks for your reply. I thought this describes the situation that query writes to kafka successfully and no records are duplicated. How about change to `So if writing the query is successful, then you can assume that the query output was written at least once`, which will not be confused by `However` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24631: [MINOR][CORE][DOC]Avoid hardcoded configs and fix kafka sink write semantics in document
dongjoon-hyun commented on a change in pull request #24631: [MINOR][CORE][DOC]Avoid hardcoded configs and fix kafka sink write semantics in document URL: https://github.com/apache/spark/pull/24631#discussion_r284972996 ## File path: docs/structured-streaming-kafka-integration.md ## @@ -441,7 +441,7 @@ Apache Kafka only supports at least once write semantics. Consequently, when wri or Batch Queries---to Kafka, some records may be duplicated; this can happen, for example, if Kafka needs to retry a message that was not acknowledged by a Broker, even though that Broker received and wrote the message record. Structured Streaming cannot prevent such duplicates from occurring due to these Kafka write semantics. However, -if writing the query is successful, then you can assume that the query output was written at least once. A possible +if writing the query is successful, then you can assume that the query output was written exactly once. A possible Review comment: Hi, @wenxuanguan . This looks wrong in this context. Could you explain your thought? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a change in pull request #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC
gengliangwang commented on a change in pull request #24598: [SPARK-27699][SQL]
Partially push down disjunctive predicated in Parquet/ORC
URL: https://github.com/apache/spark/pull/24598#discussion_r284972693
##
File path:
sql/core/v1.2.1/src/main/scala/org/apache/spark/sql/execution/datasources/orc/OrcFilters.scala
##
@@ -75,10 +75,42 @@ private[sql] object OrcFilters extends OrcFiltersBase {
schema: StructType,
dataTypeMap: Map[String, DataType],
filters: Seq[Filter]): Seq[Filter] = {
-for {
- filter <- filters
- _ <- buildSearchArgument(dataTypeMap, filter, newBuilder())
-} yield filter
+import org.apache.spark.sql.sources._
+
+def convertibleFiltersHelper(
Review comment:
This is a helper method for converting Filter to Expression recursively. It
can also be `_convertibleFilters` or `convertibleFilters0`...
Here it is following `createFilterHelper` in `ParquetFilters`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #24529: [SPARK-27634][Structured Streaming] deleteCheckpointOnStop should be configurable
dongjoon-hyun closed pull request #24529: [SPARK-27634][Structured Streaming] deleteCheckpointOnStop should be configurable URL: https://github.com/apache/spark/pull/24529 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #24529: [SPARK-27634][Structured Streaming] deleteCheckpointOnStop should be configurable
dongjoon-hyun commented on issue #24529: [SPARK-27634][Structured Streaming] deleteCheckpointOnStop should be configurable URL: https://github.com/apache/spark/pull/24529#issuecomment-493312396 Hi, @gentlewangyu . Thank you for making a PR. But it seems that Apache Spark already implemented the required option. I'll close this PR and Apache JIRA issue as a duplicate of SPARK-26389 . Sorry for closing your PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24605: [SPARK-27711][CORE] Unset InputFileBlockHolder at the end of tasks
dongjoon-hyun commented on a change in pull request #24605: [SPARK-27711][CORE]
Unset InputFileBlockHolder at the end of tasks
URL: https://github.com/apache/spark/pull/24605#discussion_r284970207
##
File path: python/pyspark/sql/tests/test_functions.py
##
@@ -278,6 +279,22 @@ def test_sort_with_nulls_order(self):
df.select(df.name).orderBy(functions.desc_nulls_last('name')).collect(),
[Row(name=u'Tom'), Row(name=u'Alice'), Row(name=None)])
+def test_input_file_name_reset_for_rdd(self):
+from pyspark.sql.functions import udf, input_file_name
+rdd =
self.sc.textFile('python/test_support/hello/hello.txt').map(lambda x: {'data':
x})
+df = self.spark.createDataFrame(rdd, StructType([StructField('data',
StringType(), True)]))
+df.select(input_file_name().alias('file')).collect()
+
+non_file_df = self.spark.range(0, 100, 1,
100).select(input_file_name().alias('file'))
+
+results = non_file_df.collect()
+self.assertTrue(len(results) == 100)
+
+# [SC-12160]: if everything was properly reset after the last job,
this should return
Review comment:
+1 for @HyukjinKwon 's comment. Is this the internal issue tracker ID?
Could you update the PR, @jose-torres ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #24629: [SPARK-27752][Core] Upgrade lz4-java from 1.5.1 to 1.6.0
dongjoon-hyun closed pull request #24629: [SPARK-27752][Core] Upgrade lz4-java from 1.5.1 to 1.6.0 URL: https://github.com/apache/spark/pull/24629 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC
cloud-fan commented on a change in pull request #24598: [SPARK-27699][SQL]
Partially push down disjunctive predicated in Parquet/ORC
URL: https://github.com/apache/spark/pull/24598#discussion_r284969751
##
File path:
sql/core/v1.2.1/src/main/scala/org/apache/spark/sql/execution/datasources/orc/OrcFilters.scala
##
@@ -75,10 +75,42 @@ private[sql] object OrcFilters extends OrcFiltersBase {
schema: StructType,
dataTypeMap: Map[String, DataType],
filters: Seq[Filter]): Seq[Filter] = {
-for {
- filter <- filters
- _ <- buildSearchArgument(dataTypeMap, filter, newBuilder())
-} yield filter
+import org.apache.spark.sql.sources._
+
+def convertibleFiltersHelper(
Review comment:
it's weird to call a method "helper", what does it do?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC
AmplabJenkins removed a comment on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC URL: https://github.com/apache/spark/pull/24598#issuecomment-493308277 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC
AmplabJenkins removed a comment on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC URL: https://github.com/apache/spark/pull/24598#issuecomment-493308285 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/105477/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC
SparkQA commented on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC URL: https://github.com/apache/spark/pull/24598#issuecomment-493308028 **[Test build #105477 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/105477/testReport)** for PR 24598 at commit [`90b0b69`](https://github.com/apache/spark/commit/90b0b697246251b1e0b8acfe07f53f1153aefe45). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC
AmplabJenkins commented on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC URL: https://github.com/apache/spark/pull/24598#issuecomment-493308285 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/105477/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC
AmplabJenkins commented on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC URL: https://github.com/apache/spark/pull/24598#issuecomment-493308277 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC
SparkQA removed a comment on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC URL: https://github.com/apache/spark/pull/24598#issuecomment-493278220 **[Test build #105477 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/105477/testReport)** for PR 24598 at commit [`90b0b69`](https://github.com/apache/spark/commit/90b0b697246251b1e0b8acfe07f53f1153aefe45). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #24630: [SPARK-27754][K8S] Introduce config for driver request cores
dongjoon-hyun commented on issue #24630: [SPARK-27754][K8S] Introduce config for driver request cores URL: https://github.com/apache/spark/pull/24630#issuecomment-493307559 BTW, @arunmahadevan . The PR title, `Introduce config for driver request cores`, seems to claim too much. We already have a configuration, `spark.driver.cores`. And, it's intentionally designed like that. This PR should focus on the new benefits. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24630: [SPARK-27754][K8S] Introduce config for driver request cores
dongjoon-hyun commented on a change in pull request #24630: [SPARK-27754][K8S]
Introduce config for driver request cores
URL: https://github.com/apache/spark/pull/24630#discussion_r284967932
##
File path:
resource-managers/kubernetes/core/src/test/scala/org/apache/spark/deploy/k8s/features/BasicDriverFeatureStepSuite.scala
##
@@ -117,6 +117,33 @@ class BasicDriverFeatureStepSuite extends SparkFunSuite {
assert(featureStep.getAdditionalPodSystemProperties() ===
expectedSparkConf)
}
+ test("Check driver pod respects kubernetes driver request cores") {
+val sparkConf = new SparkConf()
+ .set(KUBERNETES_DRIVER_POD_NAME, "spark-driver-pod")
+ .set(CONTAINER_IMAGE, "spark-driver:latest")
+
+val basePod = SparkPod.initialPod()
+val requests1 = new
BasicDriverFeatureStep(KubernetesTestConf.createDriverConf(sparkConf))
+ .configurePod(basePod)
+ .container.getResources
+ .getRequests.asScala
+assert(requests1("cpu").getAmount === "1")
Review comment:
Can we avoid this assumption? You had better get the default value of
`DRIVER_CORES` and compare with that.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24630: [SPARK-27754][K8S] Introduce config for driver request cores
dongjoon-hyun commented on a change in pull request #24630: [SPARK-27754][K8S]
Introduce config for driver request cores
URL: https://github.com/apache/spark/pull/24630#discussion_r284968318
##
File path:
resource-managers/kubernetes/core/src/test/scala/org/apache/spark/deploy/k8s/features/BasicDriverFeatureStepSuite.scala
##
@@ -117,6 +117,33 @@ class BasicDriverFeatureStepSuite extends SparkFunSuite {
assert(featureStep.getAdditionalPodSystemProperties() ===
expectedSparkConf)
}
+ test("Check driver pod respects kubernetes driver request cores") {
+val sparkConf = new SparkConf()
+ .set(KUBERNETES_DRIVER_POD_NAME, "spark-driver-pod")
+ .set(CONTAINER_IMAGE, "spark-driver:latest")
+
+val basePod = SparkPod.initialPod()
+val requests1 = new
BasicDriverFeatureStep(KubernetesTestConf.createDriverConf(sparkConf))
+ .configurePod(basePod)
+ .container.getResources
+ .getRequests.asScala
+assert(requests1("cpu").getAmount === "1")
+
+sparkConf.set(KUBERNETES_DRIVER_REQUEST_CORES, "0.1")
+val requests2 = new
BasicDriverFeatureStep(KubernetesTestConf.createDriverConf(sparkConf))
+ .configurePod(basePod)
+ .container.getResources
+ .getRequests.asScala
+assert(requests2("cpu").getAmount === "0.1")
+
+sparkConf.set(KUBERNETES_DRIVER_REQUEST_CORES, "100m")
+val requests3 = new
BasicDriverFeatureStep(KubernetesTestConf.createDriverConf(sparkConf))
+ .configurePod(basePod)
+ .container.getResources
+ .getRequests.asScala
+assert(requests3("cpu").getAmount === "100m")
Review comment:
If you don't mind, could you avoid repetitions like the following?
```scala
Seq("0.1", "100m").foreach { value =>
sparkConf.set(KUBERNETES_DRIVER_REQUEST_CORES, value)
val requests = new
BasicDriverFeatureStep(KubernetesTestConf.createDriverConf(sparkConf))
.configurePod(basePod)
.container.getResources
.getRequests.asScala
assert(requests("cpu").getAmount === value)
}
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24630: [SPARK-27754][K8S] Introduce config for driver request cores
dongjoon-hyun commented on a change in pull request #24630: [SPARK-27754][K8S]
Introduce config for driver request cores
URL: https://github.com/apache/spark/pull/24630#discussion_r284968318
##
File path:
resource-managers/kubernetes/core/src/test/scala/org/apache/spark/deploy/k8s/features/BasicDriverFeatureStepSuite.scala
##
@@ -117,6 +117,33 @@ class BasicDriverFeatureStepSuite extends SparkFunSuite {
assert(featureStep.getAdditionalPodSystemProperties() ===
expectedSparkConf)
}
+ test("Check driver pod respects kubernetes driver request cores") {
+val sparkConf = new SparkConf()
+ .set(KUBERNETES_DRIVER_POD_NAME, "spark-driver-pod")
+ .set(CONTAINER_IMAGE, "spark-driver:latest")
+
+val basePod = SparkPod.initialPod()
+val requests1 = new
BasicDriverFeatureStep(KubernetesTestConf.createDriverConf(sparkConf))
+ .configurePod(basePod)
+ .container.getResources
+ .getRequests.asScala
+assert(requests1("cpu").getAmount === "1")
+
+sparkConf.set(KUBERNETES_DRIVER_REQUEST_CORES, "0.1")
+val requests2 = new
BasicDriverFeatureStep(KubernetesTestConf.createDriverConf(sparkConf))
+ .configurePod(basePod)
+ .container.getResources
+ .getRequests.asScala
+assert(requests2("cpu").getAmount === "0.1")
+
+sparkConf.set(KUBERNETES_DRIVER_REQUEST_CORES, "100m")
+val requests3 = new
BasicDriverFeatureStep(KubernetesTestConf.createDriverConf(sparkConf))
+ .configurePod(basePod)
+ .container.getResources
+ .getRequests.asScala
+assert(requests3("cpu").getAmount === "100m")
Review comment:
If you don't mind, could you avoid repetitions like the following?
```
Seq("0.1", "100m").foreach { value =>
sparkConf.set(KUBERNETES_DRIVER_REQUEST_CORES, value)
val requests = new
BasicDriverFeatureStep(KubernetesTestConf.createDriverConf(sparkConf))
.configurePod(basePod)
.container.getResources
.getRequests.asScala
assert(requests("cpu").getAmount === value)
}
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24630: [SPARK-27754][K8S] Introduce config for driver request cores
dongjoon-hyun commented on a change in pull request #24630: [SPARK-27754][K8S]
Introduce config for driver request cores
URL: https://github.com/apache/spark/pull/24630#discussion_r284966698
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/features/BasicDriverFeatureStep.scala
##
@@ -44,6 +44,11 @@ private[spark] class BasicDriverFeatureStep(conf:
KubernetesDriverConf)
// CPU settings
private val driverCpuCores = conf.get(DRIVER_CORES.key, "1")
+ private val driverCoresRequest = if
(conf.contains(KUBERNETES_DRIVER_REQUEST_CORES)) {
+conf.get(KUBERNETES_DRIVER_REQUEST_CORES).get
+ } else {
+driverCpuCores
+ }
Review comment:
Thank you for making a PR, @arunmahadevan . Could you rewrite like the
following one-liner?
```scala
- private val driverCoresRequest = if
(conf.contains(KUBERNETES_DRIVER_REQUEST_CORES)) {
-conf.get(KUBERNETES_DRIVER_REQUEST_CORES).get
- } else {
-driverCpuCores
- }
+ private val driverCoresRequest =
conf.get(KUBERNETES_DRIVER_REQUEST_CORES.key, driverCpuCores)
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24630: [SPARK-27754][K8S] Introduce config for driver request cores
dongjoon-hyun commented on a change in pull request #24630: [SPARK-27754][K8S] Introduce config for driver request cores URL: https://github.com/apache/spark/pull/24630#discussion_r284967598 ## File path: docs/running-on-kubernetes.md ## @@ -793,6 +793,15 @@ See the [configuration page](configuration.html) for information on Spark config Interval between reports of the current Spark job status in cluster mode. + + spark.kubernetes.driver.request.cores + (none) + +Specify the cpu request for the driver pod. Values conform to the Kubernetes https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/#meaning-of-cpu;>convention. +Example values include 0.1, 500m, 1.5, 5, etc., with the definition of cpu units documented in https://kubernetes.io/docs/tasks/configure-pod-container/assign-cpu-resource/#cpu-units;>CPU units. +This takes precedence over spark.driver.cores for specifying the driver pod cpu request if set. Review comment: So, is the goal of this PR to support fractional cpu requests (like `0.5`) and the unit (like `500m`) because `spark.driver.cores` is an integral configuration? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24630: [SPARK-27754][K8S] Introduce config for driver request cores
dongjoon-hyun commented on a change in pull request #24630: [SPARK-27754][K8S] Introduce config for driver request cores URL: https://github.com/apache/spark/pull/24630#discussion_r284967598 ## File path: docs/running-on-kubernetes.md ## @@ -793,6 +793,15 @@ See the [configuration page](configuration.html) for information on Spark config Interval between reports of the current Spark job status in cluster mode. + + spark.kubernetes.driver.request.cores + (none) + +Specify the cpu request for the driver pod. Values conform to the Kubernetes https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/#meaning-of-cpu;>convention. +Example values include 0.1, 500m, 1.5, 5, etc., with the definition of cpu units documented in https://kubernetes.io/docs/tasks/configure-pod-container/assign-cpu-resource/#cpu-units;>CPU units. +This takes precedence over spark.driver.cores for specifying the driver pod cpu request if set. Review comment: So, is the goal of this PR to support fractional cpu requests (like `0.5`) because `spark.driver.cores` is an integral configuration? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC
AmplabJenkins removed a comment on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC URL: https://github.com/apache/spark/pull/24598#issuecomment-493303740 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC
AmplabJenkins removed a comment on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC URL: https://github.com/apache/spark/pull/24598#issuecomment-493303746 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/105476/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC
AmplabJenkins commented on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC URL: https://github.com/apache/spark/pull/24598#issuecomment-493303740 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC
AmplabJenkins commented on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC URL: https://github.com/apache/spark/pull/24598#issuecomment-493303746 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/105476/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #24621: [WIP][SPARK-27738][BUILD][test-hadoop3.2] Upgrade the built-in Hive to 2.3.5 for hadoop-3.2
dongjoon-hyun closed pull request #24621: [WIP][SPARK-27738][BUILD][test-hadoop3.2] Upgrade the built-in Hive to 2.3.5 for hadoop-3.2 URL: https://github.com/apache/spark/pull/24621 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #24621: [WIP][SPARK-27738][BUILD][test-hadoop3.2] Upgrade the built-in Hive to 2.3.5 for hadoop-3.2
dongjoon-hyun commented on issue #24621: [WIP][SPARK-27738][BUILD][test-hadoop3.2] Upgrade the built-in Hive to 2.3.5 for hadoop-3.2 URL: https://github.com/apache/spark/pull/24621#issuecomment-493303507 We should show the correct value if you don't have any reason to disguise this. And let's discuss on #24620 together. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC
SparkQA removed a comment on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC URL: https://github.com/apache/spark/pull/24598#issuecomment-493271725 **[Test build #105476 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/105476/testReport)** for PR 24598 at commit [`4d84060`](https://github.com/apache/spark/commit/4d840607490b52ebdf65a103a3502a1442fc2198). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC
SparkQA commented on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC URL: https://github.com/apache/spark/pull/24598#issuecomment-493303438 **[Test build #105476 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/105476/testReport)** for PR 24598 at commit [`4d84060`](https://github.com/apache/spark/commit/4d840607490b52ebdf65a103a3502a1442fc2198). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24631: [MINOR][CORE][DOC]Avoid hardcoded configs and fix kafka sink write semantics in document
AmplabJenkins removed a comment on issue #24631: [MINOR][CORE][DOC]Avoid hardcoded configs and fix kafka sink write semantics in document URL: https://github.com/apache/spark/pull/24631#issuecomment-493302595 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24631: [MINOR][CORE][DOC]Avoid hardcoded configs and fix kafka sink write semantics in document
AmplabJenkins commented on issue #24631: [MINOR][CORE][DOC]Avoid hardcoded configs and fix kafka sink write semantics in document URL: https://github.com/apache/spark/pull/24631#issuecomment-493302940 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24631: [MINOR][CORE][DOC]Avoid hardcoded configs and fix kafka sink write semantics in document
AmplabJenkins removed a comment on issue #24631: [MINOR][CORE][DOC]Avoid hardcoded configs and fix kafka sink write semantics in document URL: https://github.com/apache/spark/pull/24631#issuecomment-493302509 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24631: [MINOR][CORE][DOC]Avoid hardcoded configs and fix kafka sink write semantics in document
AmplabJenkins commented on issue #24631: [MINOR][CORE][DOC]Avoid hardcoded configs and fix kafka sink write semantics in document URL: https://github.com/apache/spark/pull/24631#issuecomment-493302595 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24631: [MINOR][CORE][DOC]Avoid hardcoded configs and fix kafka sink write semantics in document
AmplabJenkins commented on issue #24631: [MINOR][CORE][DOC]Avoid hardcoded configs and fix kafka sink write semantics in document URL: https://github.com/apache/spark/pull/24631#issuecomment-493302509 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wenxuanguan opened a new pull request #24631: [MINOR][CORE][DOC]Avoid hardcoded configs and fix kafka sink write semantics in document
wenxuanguan opened a new pull request #24631: [MINOR][CORE][DOC]Avoid hardcoded configs and fix kafka sink write semantics in document URL: https://github.com/apache/spark/pull/24631 ## What changes were proposed in this pull request? some minor updates: 1. avoid hardcoded configs in SparkConf 2. fix kafka sink write semantics in SS-kafka document ## How was this patch tested? N/A This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xuanyuanking commented on a change in pull request #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks
xuanyuanking commented on a change in pull request #24565: [SPARK-27665][Core]
Split fetch shuffle blocks protocol from OpenBlocks
URL: https://github.com/apache/spark/pull/24565#discussion_r284964236
##
File path:
common/network-shuffle/src/main/java/org/apache/spark/network/shuffle/OneForOneBlockFetcher.java
##
@@ -76,12 +80,73 @@ public OneForOneBlockFetcher(
TransportConf transportConf,
DownloadFileManager downloadFileManager) {
this.client = client;
-this.openMessage = new OpenBlocks(appId, execId, blockIds);
this.blockIds = blockIds;
this.listener = listener;
this.chunkCallback = new ChunkCallback();
this.transportConf = transportConf;
this.downloadFileManager = downloadFileManager;
+if (blockIds.length == 0) {
+ throw new IllegalArgumentException("Zero-sized blockIds array");
+}
+if (isShuffleBlocks(blockIds)) {
+ this.message = createFetchShuffleBlocksMsg(appId, execId, blockIds);
+} else {
+ this.message = new OpenBlocks(appId, execId, blockIds);
+}
+ }
+
+ private boolean isShuffleBlocks(String[] blockIds) {
+for (String blockId : blockIds) {
+ if (!blockId.startsWith("shuffle_")) {
+return false;
+ }
+}
+return true;
+ }
+
+ /**
+ * Analyze the pass in blockIds and create FetchShuffleBlocks message.
+ * The blockIds has been sorted by mapId and reduceId. It's produced in
+ * org.apache.spark.MapOutputTracker.convertMapStatuses.
+ */
+ private FetchShuffleBlocks createFetchShuffleBlocksMsg(
+ String appId, String execId, String[] blockIds) {
+int shuffleId;
+shuffleId = splitBlockId(blockIds[0])[0];
+HashMap> mapIdToReduceIds = new HashMap<>();
+for (String blockId : blockIds) {
+ int[] blockIdParts = splitBlockId(blockId);
+ if (blockIdParts[0] != shuffleId) {
+throw new IllegalArgumentException("Expected shuffleId=" + shuffleId +
+ ", got:" + blockId);
+ }
+ int mapId = blockIdParts[1];
+ if (!mapIdToReduceIds.containsKey(mapId)) {
+mapIdToReduceIds.put(mapId, new ArrayList<>());
+ }
+ mapIdToReduceIds.get(mapId).add(blockIdParts[2]);
+}
+int[] mapIds;
+mapIds = Ints.toArray(mapIdToReduceIds.keySet());
Review comment:
fddcd6c.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks
SparkQA commented on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks URL: https://github.com/apache/spark/pull/24565#issuecomment-493301810 **[Test build #105480 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/105480/testReport)** for PR 24565 at commit [`fddcd6c`](https://github.com/apache/spark/commit/fddcd6ce7a6a01c497a0f750c43fd4357fb1a2fd). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xuanyuanking commented on a change in pull request #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks
xuanyuanking commented on a change in pull request #24565: [SPARK-27665][Core]
Split fetch shuffle blocks protocol from OpenBlocks
URL: https://github.com/apache/spark/pull/24565#discussion_r284964210
##
File path:
common/network-shuffle/src/main/java/org/apache/spark/network/shuffle/OneForOneBlockFetcher.java
##
@@ -76,12 +80,73 @@ public OneForOneBlockFetcher(
TransportConf transportConf,
DownloadFileManager downloadFileManager) {
this.client = client;
-this.openMessage = new OpenBlocks(appId, execId, blockIds);
this.blockIds = blockIds;
this.listener = listener;
this.chunkCallback = new ChunkCallback();
this.transportConf = transportConf;
this.downloadFileManager = downloadFileManager;
+if (blockIds.length == 0) {
+ throw new IllegalArgumentException("Zero-sized blockIds array");
+}
+if (isShuffleBlocks(blockIds)) {
+ this.message = createFetchShuffleBlocksMsg(appId, execId, blockIds);
+} else {
+ this.message = new OpenBlocks(appId, execId, blockIds);
+}
+ }
+
+ private boolean isShuffleBlocks(String[] blockIds) {
+for (String blockId : blockIds) {
+ if (!blockId.startsWith("shuffle_")) {
+return false;
+ }
+}
+return true;
+ }
+
+ /**
+ * Analyze the pass in blockIds and create FetchShuffleBlocks message.
+ * The blockIds has been sorted by mapId and reduceId. It's produced in
+ * org.apache.spark.MapOutputTracker.convertMapStatuses.
+ */
+ private FetchShuffleBlocks createFetchShuffleBlocksMsg(
+ String appId, String execId, String[] blockIds) {
+int shuffleId;
+shuffleId = splitBlockId(blockIds[0])[0];
Review comment:
Ah yes, quick fix in fddcd6c.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks
AmplabJenkins removed a comment on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks URL: https://github.com/apache/spark/pull/24565#issuecomment-493301530 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks
AmplabJenkins removed a comment on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks URL: https://github.com/apache/spark/pull/24565#issuecomment-493301534 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/10741/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks
AmplabJenkins commented on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks URL: https://github.com/apache/spark/pull/24565#issuecomment-493301530 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks
AmplabJenkins commented on issue #24565: [SPARK-27665][Core] Split fetch shuffle blocks protocol from OpenBlocks URL: https://github.com/apache/spark/pull/24565#issuecomment-493301534 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/10741/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3
AmplabJenkins removed a comment on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3 URL: https://github.com/apache/spark/pull/24620#issuecomment-493299099 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3
AmplabJenkins commented on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3 URL: https://github.com/apache/spark/pull/24620#issuecomment-493299106 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/105478/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3
AmplabJenkins commented on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3 URL: https://github.com/apache/spark/pull/24620#issuecomment-493299099 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3
AmplabJenkins removed a comment on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3 URL: https://github.com/apache/spark/pull/24620#issuecomment-493299106 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/105478/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3
SparkQA commented on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3 URL: https://github.com/apache/spark/pull/24620#issuecomment-493298869 **[Test build #105478 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/105478/testReport)** for PR 24620 at commit [`34e4817`](https://github.com/apache/spark/commit/34e481751312ef54bbaac908151aee828822e01c). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3
SparkQA removed a comment on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3 URL: https://github.com/apache/spark/pull/24620#issuecomment-493281916 **[Test build #105478 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/105478/testReport)** for PR 24620 at commit [`34e4817`](https://github.com/apache/spark/commit/34e481751312ef54bbaac908151aee828822e01c). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer edited a comment on issue #24535: [SPARK-27640][SQL|SS]Avoid duplicate lookups for datasource through provider
beliefer edited a comment on issue #24535: [SPARK-27640][SQL|SS]Avoid duplicate lookups for datasource through provider URL: https://github.com/apache/spark/pull/24535#issuecomment-489587785 cc @cloud-fan This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] racc commented on issue #18127: [SPARK-6628][SQL][Branch-2.1] Fix ClassCastException when executing sql statement 'insert into' on hbase table
racc commented on issue #18127: [SPARK-6628][SQL][Branch-2.1] Fix ClassCastException when executing sql statement 'insert into' on hbase table URL: https://github.com/apache/spark/pull/18127#issuecomment-493292931 @lhsvobodaj ok so that issue is fixed in Hive 4.0.0, but the problem is that we run on Cloudera's Distribution of Hadoop which uses an older version of Hive and there's no way around it then :( This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format.
AmplabJenkins removed a comment on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format. URL: https://github.com/apache/spark/pull/24609#issuecomment-493292789 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format.
AmplabJenkins removed a comment on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format. URL: https://github.com/apache/spark/pull/24609#issuecomment-493292793 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/10740/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format.
AmplabJenkins commented on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format. URL: https://github.com/apache/spark/pull/24609#issuecomment-493292793 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/10740/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format.
AmplabJenkins commented on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format. URL: https://github.com/apache/spark/pull/24609#issuecomment-493292789 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format.
SparkQA commented on issue #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format. URL: https://github.com/apache/spark/pull/24609#issuecomment-493291753 **[Test build #105479 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/105479/testReport)** for PR 24609 at commit [`ca1a1f7`](https://github.com/apache/spark/commit/ca1a1f787ea17aebeb0910e39c24b44268126bb7). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] uncleGen commented on a change in pull request #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format.
uncleGen commented on a change in pull request #24609: [SPARK-27715][SQL] SQL
query details in UI dose not show in correct format.
URL: https://github.com/apache/spark/pull/24609#discussion_r284956262
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/ui/AllExecutionsPage.scala
##
@@ -382,13 +382,14 @@ private[ui] class ExecutionPagedTable(
}
private def descriptionCell(execution: SQLExecutionUIData): Seq[Node] = {
+val jobDescription = UIUtils.makeDescription(execution.description,
basePath, plainText = false)
val details = if (execution.details != null && execution.details.nonEmpty)
{
+details
++
-{execution.description}{execution.details}
+{jobDescription}{execution.details}
Review comment:
Sorry, do not understand what you mean. `makeDescription` returns HTML
rendering of a job or stage description. It will try to parse the string as
HTML and make sure that it only contains anchors with root-relative links.
Otherwise, the whole string will rendered as a simple escaped text.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] uncleGen commented on a change in pull request #24609: [SPARK-27715][SQL] SQL query details in UI dose not show in correct format.
uncleGen commented on a change in pull request #24609: [SPARK-27715][SQL] SQL
query details in UI dose not show in correct format.
URL: https://github.com/apache/spark/pull/24609#discussion_r284956095
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/ui/AllExecutionsPage.scala
##
@@ -382,13 +382,14 @@ private[ui] class ExecutionPagedTable(
}
private def descriptionCell(execution: SQLExecutionUIData): Seq[Node] = {
+val jobDescription = UIUtils.makeDescription(execution.description,
basePath, plainText = false)
Review comment:
fixed
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum edited a comment on issue #24621: [WIP][SPARK-27738][BUILD][test-hadoop3.2] Upgrade the built-in Hive to 2.3.5 for hadoop-3.2
wangyum edited a comment on issue #24621: [WIP][SPARK-27738][BUILD][test-hadoop3.2] Upgrade the built-in Hive to 2.3.5 for hadoop-3.2 URL: https://github.com/apache/spark/pull/24621#issuecomment-493287308 Sorry @dongjoon-hyun The reason why I seperator it to 2 PRS is I'd like to discuss shoud we change the [`hive.version.short`](https://github.com/apache/spark/blob/8ef4da753d16b83aece8d5e164ab578398c0d83c/pom.xml#L2836) once we upgrade built-in Hive to 2.3.5 for hadoop-3.2. I have 3 options: 1. Do not change it, still use 2.3.4. 2. Update to 2.3.5. 3. Update to 2.3.0 because the shoutVersion is 2.3.0 for Hive branch-2.3: https://user-images.githubusercontent.com/5399861/57896922-aeca7c80-7885-11e9-859d-dfb8c151e21c.png; width="300"> https://user-images.githubusercontent.com/5399861/57896923-b12cd680-7885-11e9-8714-d513ebaa44fe.png; width="300"> cc @gatorsmile @srowen @HyukjinKwon @felixcheung This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on issue #24621: [WIP][SPARK-27738][BUILD][test-hadoop3.2] Upgrade the built-in Hive to 2.3.5 for hadoop-3.2
wangyum commented on issue #24621: [WIP][SPARK-27738][BUILD][test-hadoop3.2] Upgrade the built-in Hive to 2.3.5 for hadoop-3.2 URL: https://github.com/apache/spark/pull/24621#issuecomment-493287308 Sorry @dongjoon-hyun The reason why I seperator it to 2 PRS is I'd like to discuss shoud we change the [`hive.version.short`](https://github.com/apache/spark/blob/8ef4da753d16b83aece8d5e164ab578398c0d83c/pom.xml#L2836) once we upgrade built-in Hive to 2.3.5 for hadoop-3.2. I have 3 options: 1. Do not change it, still use 2.3.4. 2. Update to 2.3.5. 3. Update to 2.3.0 because the shoutVersion is 2.3.0 for Hive branch-2.3: https://user-images.githubusercontent.com/5399861/57896922-aeca7c80-7885-11e9-859d-dfb8c151e21c.png; width="320"> https://user-images.githubusercontent.com/5399861/57896923-b12cd680-7885-11e9-8714-d513ebaa44fe.png; width="320"> cc @gatorsmile @srowen @HyukjinKwon @felixcheung This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on a change in pull request #24626: [SPARK-27747][SQL] add a logical plan link in the physical plan
viirya commented on a change in pull request #24626: [SPARK-27747][SQL] add a
logical plan link in the physical plan
URL: https://github.com/apache/spark/pull/24626#discussion_r284952775
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/QueryPlan.scala
##
@@ -271,6 +271,8 @@ abstract class QueryPlan[PlanType <: QueryPlan[PlanType]]
extends TreeNode[PlanT
}
object QueryPlan extends PredicateHelper {
+ val LOGICAL_PLAN_TAG_NAME = TreeNodeTagName("logical_plan")
Review comment:
Can we add some comment? For example, `After query plans go through SQL
planner, the planner will attach the optimized logical plan to the generated
physical plan under this tag name.`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on a change in pull request #24626: [SPARK-27747][SQL] add a logical plan link in the physical plan
viirya commented on a change in pull request #24626: [SPARK-27747][SQL] add a
logical plan link in the physical plan
URL: https://github.com/apache/spark/pull/24626#discussion_r284951277
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala
##
@@ -280,9 +297,15 @@ abstract class TreeNode[BaseType <: TreeNode[BaseType]]
extends Product {
rule.applyOrElse(this, identity[BaseType])
Review comment:
Here after applying the `rule`, we need to carry over the tags, if needed,
too.
Since carrying the tags in both if and else branches, so maybe:
```scala
val newNode = if (this fastEquals afterRuleOnChildren) {
CurrentOrigin.withOrigin(origin) {
rule.applyOrElse(this, identity[BaseType])
}
} else {
CurrentOrigin.withOrigin(origin) {
rule.applyOrElse(afterRuleOnChildren, identity[BaseType])
}
}
// carrying over the tags to newNode...
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on a change in pull request #24626: [SPARK-27747][SQL] add a logical plan link in the physical plan
viirya commented on a change in pull request #24626: [SPARK-27747][SQL] add a
logical plan link in the physical plan
URL: https://github.com/apache/spark/pull/24626#discussion_r284951931
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees/TreeNode.scala
##
@@ -74,13 +74,24 @@ object CurrentOrigin {
}
}
+// The name of the tree node tag. This is preferred over using string
directly, as we can easily
+// find all the defined tags.
+case class TreeNodeTagName(name: String)
+
// scalastyle:off
abstract class TreeNode[BaseType <: TreeNode[BaseType]] extends Product {
// scalastyle:on
self: BaseType =>
val origin: Origin = CurrentOrigin.get
+ /**
+ * A mutable map for holding auxiliary information of this tree node. It
will be carried over
+ * when this node is copied via `makeCopy`. If a user copies the tree node
via other ways like the
+ * `copy` method, it's his responsibility to carry over the tags.
Review comment:
Maybe add something like `The tags will be kept after transforming, if
transformed to the same type, otherwise, will be dropped.`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] f422661 closed pull request #24612: [SPARK-27718][Examples] fixed the error of pagerank
f422661 closed pull request #24612: [SPARK-27718][Examples] fixed the error of pagerank URL: https://github.com/apache/spark/pull/24612 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] f422661 commented on issue #24612: [SPARK-27718][Examples] fixed the error of pagerank
f422661 commented on issue #24612: [SPARK-27718][Examples] fixed the error of pagerank URL: https://github.com/apache/spark/pull/24612#issuecomment-493286247 I got it. Thanks for your reply. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung commented on issue #24630: [SPARK-27754][K8S] Introduce config for driver request cores
felixcheung commented on issue #24630: [SPARK-27754][K8S] Introduce config for driver request cores URL: https://github.com/apache/spark/pull/24630#issuecomment-493284923 @mccheah ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3
SparkQA commented on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3 URL: https://github.com/apache/spark/pull/24620#issuecomment-493281916 **[Test build #105478 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/105478/testReport)** for PR 24620 at commit [`34e4817`](https://github.com/apache/spark/commit/34e481751312ef54bbaac908151aee828822e01c). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3
AmplabJenkins removed a comment on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3 URL: https://github.com/apache/spark/pull/24620#issuecomment-493281664 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/10739/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3
AmplabJenkins removed a comment on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3 URL: https://github.com/apache/spark/pull/24620#issuecomment-493281662 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3
AmplabJenkins commented on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3 URL: https://github.com/apache/spark/pull/24620#issuecomment-493281664 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/10739/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3
AmplabJenkins commented on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3 URL: https://github.com/apache/spark/pull/24620#issuecomment-493281662 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3
AmplabJenkins removed a comment on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3 URL: https://github.com/apache/spark/pull/24620#issuecomment-493007858 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/105451/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3
wangyum commented on issue #24620: [SPARK-27737][SQL] Upgrade to 2.3.5 for Hive Metastore Client 2.3 URL: https://github.com/apache/spark/pull/24620#issuecomment-493280860 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC
SparkQA commented on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC URL: https://github.com/apache/spark/pull/24598#issuecomment-493278220 **[Test build #105477 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/105477/testReport)** for PR 24598 at commit [`90b0b69`](https://github.com/apache/spark/commit/90b0b697246251b1e0b8acfe07f53f1153aefe45). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC
AmplabJenkins commented on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC URL: https://github.com/apache/spark/pull/24598#issuecomment-493277851 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC
AmplabJenkins removed a comment on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC URL: https://github.com/apache/spark/pull/24598#issuecomment-493277855 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/10738/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC
AmplabJenkins removed a comment on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC URL: https://github.com/apache/spark/pull/24598#issuecomment-493277851 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC
AmplabJenkins commented on issue #24598: [SPARK-27699][SQL] Partially push down disjunctive predicated in Parquet/ORC URL: https://github.com/apache/spark/pull/24598#issuecomment-493277855 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/10738/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #23767: [SPARK-26329][CORE] Faster polling of executor memory metrics.
AmplabJenkins removed a comment on issue #23767: [SPARK-26329][CORE] Faster polling of executor memory metrics. URL: https://github.com/apache/spark/pull/23767#issuecomment-493274586 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/105475/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #23767: [SPARK-26329][CORE] Faster polling of executor memory metrics.
AmplabJenkins removed a comment on issue #23767: [SPARK-26329][CORE] Faster polling of executor memory metrics. URL: https://github.com/apache/spark/pull/23767#issuecomment-493274574 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #23767: [SPARK-26329][CORE] Faster polling of executor memory metrics.
AmplabJenkins commented on issue #23767: [SPARK-26329][CORE] Faster polling of executor memory metrics. URL: https://github.com/apache/spark/pull/23767#issuecomment-493274586 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/105475/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org