[GitHub] [spark] imback82 commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
imback82 commented on a change in pull request #25771: [SPARK-28970][SQL]
Implement USE CATALOG/NAMESPACE for Data Source V2
URL: https://github.com/apache/spark/pull/25771#discussion_r325509207
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##
@@ -60,7 +60,7 @@ object SimpleAnalyzer extends Analyzer(
},
new SQLConf().copy(SQLConf.CASE_SENSITIVE -> true))
-object FakeV2SessionCatalog extends TableCatalog {
+object FakeV2SessionCatalog extends BaseSessionCatalog {
Review comment:
Sure. I got rid of everything except for `initialize()` and `name()`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] imback82 commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
imback82 commented on a change in pull request #25771: [SPARK-28970][SQL]
Implement USE CATALOG/NAMESPACE for Data Source V2
URL: https://github.com/apache/spark/pull/25771#discussion_r325505891
##
File path:
sql/catalyst/src/main/java/org/apache/spark/sql/connector/catalog/BaseSessionCatalog.java
##
@@ -0,0 +1,28 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.connector.catalog;
+
+import org.apache.spark.annotation.Experimental;
+
+/**
+ * An interface that aggregates different catalog interfaces that can be
supported
+ * by a session catalog.
+ */
+@Experimental
+public interface BaseSessionCatalog extends TableCatalog, SupportsNamespaces {
Review comment:
OK. I removed `BaseSessionCatalog` and modified `DelegatingCatalogExtension`
to do downcasting delegate for each function.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries
AmplabJenkins removed a comment on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries URL: https://github.com/apache/spark/pull/25464#issuecomment-532540704 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110864/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries
AmplabJenkins commented on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries URL: https://github.com/apache/spark/pull/25464#issuecomment-532540704 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110864/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries
AmplabJenkins removed a comment on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries URL: https://github.com/apache/spark/pull/25464#issuecomment-532540699 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries
AmplabJenkins commented on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries URL: https://github.com/apache/spark/pull/25464#issuecomment-532540699 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries
SparkQA removed a comment on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries URL: https://github.com/apache/spark/pull/25464#issuecomment-532515150 **[Test build #110864 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110864/testReport)** for PR 25464 at commit [`8af48d3`](https://github.com/apache/spark/commit/8af48d34ce7494cd3f687486710503d6c777fd7d). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries
SparkQA commented on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries URL: https://github.com/apache/spark/pull/25464#issuecomment-532540557 **[Test build #110864 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110864/testReport)** for PR 25464 at commit [`8af48d3`](https://github.com/apache/spark/commit/8af48d34ce7494cd3f687486710503d6c777fd7d). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * ` class ResolveCoalesceHints(conf: SQLConf) extends Rule[LogicalPlan] ` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu edited a comment on issue #25729: [SPARK-29022][SQL][test-hadoop3.2][test-java11] Fix spark 'add jar', CliSessionState's hiveConf 's classLoader ClassNotFound
AngersZh edited a comment on issue #25729: [SPARK-29022][SQL][test-hadoop3.2][test-java11] Fix spark 'add jar', CliSessionState's hiveConf 's classLoader ClassNotFound URL: https://github.com/apache/spark/pull/25729#issuecomment-532480148 > The last python two failures look consistent. Could you take a look if it's relevant? Look the test of python, it won't use code I have changed., it just start SparkContext and SparkStreamingContext, won't start SparkSession. And you can see the third build from last [BUILD](https://github.com/apache/spark/pull/25729#issuecomment-532043555) and my latest two commit, I just modify UT and add some comment. Two test result success now. ``` pyspark.mllib.tests.test_streaming_algorithms.StreamingLinearRegressionWithTests.test_parameter_convergence pyspark.mllib.tests.test_streaming_algorithms.StreamingLinearRegressionWithTests.test_train_prediction ``` Build and use jdk11 run pyspark mllib test: 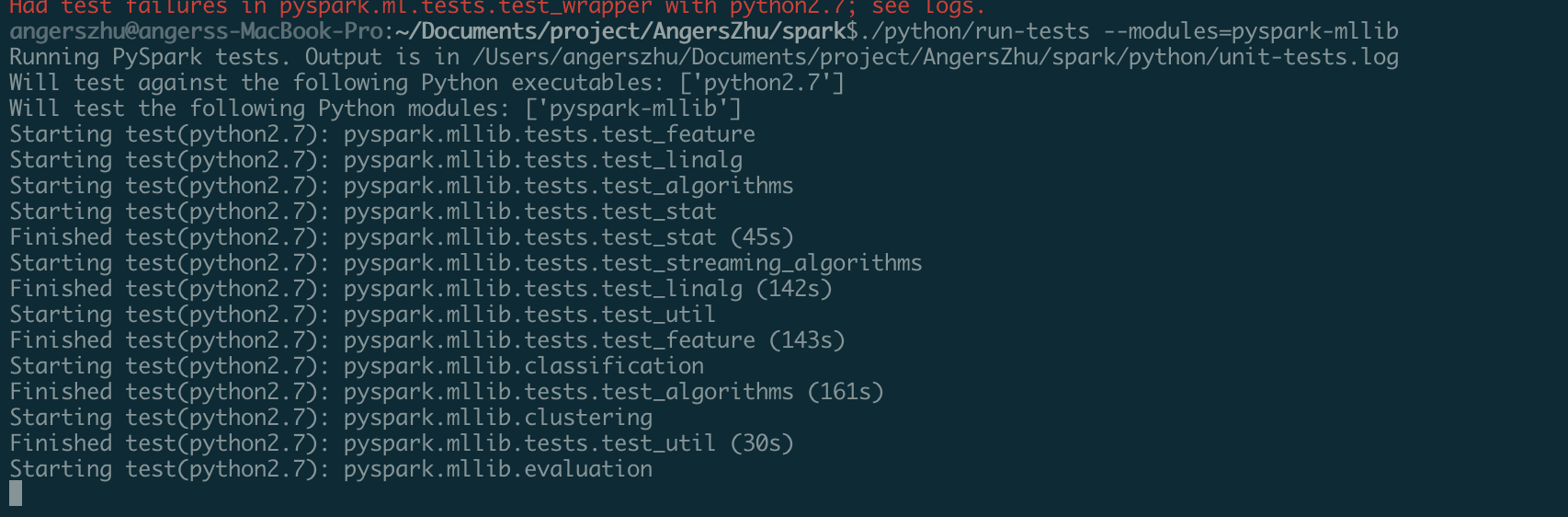 It can pass test will argument **PARALLELISM** `-p 1`, `-p 4`, `-p 6` , always failed with parameter `-p 8` with the some relevant error. ``` FAIL: test_parameter_accuracy (pyspark.mllib.tests.test_streaming_algorithms.StreamingLogisticRegressionWithSGDTests) -- Traceback (most recent call last): File "/Users/angerszhu/Documents/project/AngersZhu/spark/python/pyspark/mllib/tests/test_streaming_algorithms.py", line 266, in test_parameter_accuracy self._eventually(condition, catch_assertions=True) File "/Users/angerszhu/Documents/project/AngersZhu/spark/python/pyspark/mllib/tests/test_streaming_algorithms.py", line 74, in _eventually raise lastValue AssertionError: 0.24354595657120295 != 0.1 within 1 places ``` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected
AmplabJenkins removed a comment on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25820#issuecomment-532538308 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected
AmplabJenkins removed a comment on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25820#issuecomment-532538312 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/15997/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected
AmplabJenkins commented on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25820#issuecomment-532538308 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected
AmplabJenkins commented on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25820#issuecomment-532538312 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/15997/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25670: [SPARK-28869][CORE] Roll over event log files
AmplabJenkins removed a comment on issue #25670: [SPARK-28869][CORE] Roll over event log files URL: https://github.com/apache/spark/pull/25670#issuecomment-532537884 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110862/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected
SparkQA commented on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25820#issuecomment-532537887 **[Test build #110871 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110871/testReport)** for PR 25820 at commit [`1078e8a`](https://github.com/apache/spark/commit/1078e8af01b2467196ca19eff1b67517b425bcc4). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25670: [SPARK-28869][CORE] Roll over event log files
AmplabJenkins removed a comment on issue #25670: [SPARK-28869][CORE] Roll over event log files URL: https://github.com/apache/spark/pull/25670#issuecomment-532537877 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25670: [SPARK-28869][CORE] Roll over event log files
AmplabJenkins commented on issue #25670: [SPARK-28869][CORE] Roll over event log files URL: https://github.com/apache/spark/pull/25670#issuecomment-532537884 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110862/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25670: [SPARK-28869][CORE] Roll over event log files
AmplabJenkins commented on issue #25670: [SPARK-28869][CORE] Roll over event log files URL: https://github.com/apache/spark/pull/25670#issuecomment-532537877 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25670: [SPARK-28869][CORE] Roll over event log files
SparkQA removed a comment on issue #25670: [SPARK-28869][CORE] Roll over event log files URL: https://github.com/apache/spark/pull/25670#issuecomment-532513877 **[Test build #110862 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110862/testReport)** for PR 25670 at commit [`5e8dde2`](https://github.com/apache/spark/commit/5e8dde2b62a921319cb6caa12a9221737867647c). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25670: [SPARK-28869][CORE] Roll over event log files
SparkQA commented on issue #25670: [SPARK-28869][CORE] Roll over event log files URL: https://github.com/apache/spark/pull/25670#issuecomment-532537596 **[Test build #110862 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110862/testReport)** for PR 25670 at commit [`5e8dde2`](https://github.com/apache/spark/commit/5e8dde2b62a921319cb6caa12a9221737867647c). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] imback82 commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
imback82 commented on a change in pull request #25771: [SPARK-28970][SQL]
Implement USE CATALOG/NAMESPACE for Data Source V2
URL: https://github.com/apache/spark/pull/25771#discussion_r325497926
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/connector/DataSourceV2SQLSuite.scala
##
@@ -780,11 +794,8 @@ class DataSourceV2SQLSuite
test("ShowNamespaces: default v2 catalog is not set") {
spark.sql("CREATE TABLE testcat.ns.table (id bigint) USING foo")
-val exception = intercept[AnalysisException] {
- sql("SHOW NAMESPACES")
-}
-
-assert(exception.getMessage.contains("No default v2 catalog is set"))
+// The current catalog is resolved to a v2 session catalog.
+testShowNamespaces("SHOW NAMESPACES", Seq())
Review comment:
@cloud-fan you are right. I am fixing this. Thanks for catching this.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected
AmplabJenkins removed a comment on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25820#issuecomment-532536110 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected
AmplabJenkins removed a comment on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25820#issuecomment-532536122 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/15996/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected
AmplabJenkins commented on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25820#issuecomment-532536122 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/15996/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected
AmplabJenkins commented on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25820#issuecomment-532536110 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected
SparkQA commented on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25820#issuecomment-532535805 **[Test build #110870 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110870/testReport)** for PR 25820 at commit [`05786cb`](https://github.com/apache/spark/commit/05786cb06ca350ce1842194e941542c4eca7d122). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jerryshao closed pull request #25810: [SPARK-29112][YARN] Expose more details when ApplicationMaster reporter faces a fatal exception
jerryshao closed pull request #25810: [SPARK-29112][YARN] Expose more details when ApplicationMaster reporter faces a fatal exception URL: https://github.com/apache/spark/pull/25810 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #17254: [SPARK-19917][SQL]qualified partition path stored in catalog
AmplabJenkins removed a comment on issue #17254: [SPARK-19917][SQL]qualified partition path stored in catalog URL: https://github.com/apache/spark/pull/17254#issuecomment-532534502 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110847/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #17254: [SPARK-19917][SQL]qualified partition path stored in catalog
AmplabJenkins removed a comment on issue #17254: [SPARK-19917][SQL]qualified partition path stored in catalog URL: https://github.com/apache/spark/pull/17254#issuecomment-532534496 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #17254: [SPARK-19917][SQL]qualified partition path stored in catalog
AmplabJenkins commented on issue #17254: [SPARK-19917][SQL]qualified partition path stored in catalog URL: https://github.com/apache/spark/pull/17254#issuecomment-532534496 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #17254: [SPARK-19917][SQL]qualified partition path stored in catalog
AmplabJenkins commented on issue #17254: [SPARK-19917][SQL]qualified partition path stored in catalog URL: https://github.com/apache/spark/pull/17254#issuecomment-532534502 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110847/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #17254: [SPARK-19917][SQL]qualified partition path stored in catalog
SparkQA removed a comment on issue #17254: [SPARK-19917][SQL]qualified partition path stored in catalog URL: https://github.com/apache/spark/pull/17254#issuecomment-532481043 **[Test build #110847 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110847/testReport)** for PR 17254 at commit [`fadc15c`](https://github.com/apache/spark/commit/fadc15c7dfb8115a4df14a7e9fb50372d7b355ea). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2 URL: https://github.com/apache/spark/pull/25771#discussion_r325495823 ## File path: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 ## @@ -1399,6 +1401,7 @@ CACHE: 'CACHE'; CASCADE: 'CASCADE'; CASE: 'CASE'; CAST: 'CAST'; +CATALOG: 'CATALOG'; Review comment: this is a good question. `USE abc` has been supported for a long time and we can't drop it. I think the extended `USE ... IN ...` syntax is already very powerful, the only missing case is to switch to a catalog and its default namespace. Since we need a new syntax for it anyway, how about `SET CURRENT CATALOG ...`? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jerryshao commented on issue #25810: [SPARK-29112][YARN] Expose more details when ApplicationMaster reporter faces a fatal exception
jerryshao commented on issue #25810: [SPARK-29112][YARN] Expose more details when ApplicationMaster reporter faces a fatal exception URL: https://github.com/apache/spark/pull/25810#issuecomment-532534280 LGTM, merging to master branch. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25811: [SPARK-29111][CORE] Support snapshot/restore on KVStore
SparkQA commented on issue #25811: [SPARK-29111][CORE] Support snapshot/restore on KVStore URL: https://github.com/apache/spark/pull/25811#issuecomment-532533912 **[Test build #110869 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110869/testReport)** for PR 25811 at commit [`9b63b05`](https://github.com/apache/spark/commit/9b63b054d7a5d49f635c28c55f4d7da97c8bffba). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #17254: [SPARK-19917][SQL]qualified partition path stored in catalog
SparkQA commented on issue #17254: [SPARK-19917][SQL]qualified partition path stored in catalog URL: https://github.com/apache/spark/pull/17254#issuecomment-532533951 **[Test build #110847 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110847/testReport)** for PR 17254 at commit [`fadc15c`](https://github.com/apache/spark/commit/fadc15c7dfb8115a4df14a7e9fb50372d7b355ea). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on issue #25811: [SPARK-29111][CORE] Support snapshot/restore on KVStore
HeartSaVioR commented on issue #25811: [SPARK-29111][CORE] Support snapshot/restore on KVStore URL: https://github.com/apache/spark/pull/25811#issuecomment-532533101 retest this, please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25404: [SPARK-28683][BUILD][test-hadoop3.2][test-java11] Upgrade Scala to 2.12.10
AmplabJenkins removed a comment on issue #25404: [SPARK-28683][BUILD][test-hadoop3.2][test-java11] Upgrade Scala to 2.12.10 URL: https://github.com/apache/spark/pull/25404#issuecomment-532530468 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/15995/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25404: [SPARK-28683][BUILD][test-hadoop3.2][test-java11] Upgrade Scala to 2.12.10
AmplabJenkins removed a comment on issue #25404: [SPARK-28683][BUILD][test-hadoop3.2][test-java11] Upgrade Scala to 2.12.10 URL: https://github.com/apache/spark/pull/25404#issuecomment-532530465 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25404: [SPARK-28683][BUILD][test-hadoop3.2][test-java11] Upgrade Scala to 2.12.10
AmplabJenkins commented on issue #25404: [SPARK-28683][BUILD][test-hadoop3.2][test-java11] Upgrade Scala to 2.12.10 URL: https://github.com/apache/spark/pull/25404#issuecomment-532530468 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/15995/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25404: [SPARK-28683][BUILD][test-hadoop3.2][test-java11] Upgrade Scala to 2.12.10
AmplabJenkins commented on issue #25404: [SPARK-28683][BUILD][test-hadoop3.2][test-java11] Upgrade Scala to 2.12.10 URL: https://github.com/apache/spark/pull/25404#issuecomment-532530465 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25404: [SPARK-28683][BUILD][test-hadoop3.2][test-java11] Upgrade Scala to 2.12.10
SparkQA commented on issue #25404: [SPARK-28683][BUILD][test-hadoop3.2][test-java11] Upgrade Scala to 2.12.10 URL: https://github.com/apache/spark/pull/25404#issuecomment-532530096 **[Test build #110868 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110868/testReport)** for PR 25404 at commit [`da7b223`](https://github.com/apache/spark/commit/da7b2235eae45fd1406b9164ab9d0f3d67a6d6e6). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25404: [SPARK-28683][BUILD][test-hadoop3.2][test-java11] Upgrade Scala to 2.12.10
AmplabJenkins commented on issue #25404: [SPARK-28683][BUILD][test-hadoop3.2][test-java11] Upgrade Scala to 2.12.10 URL: https://github.com/apache/spark/pull/25404#issuecomment-532529136 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110854/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25404: [SPARK-28683][BUILD][test-hadoop3.2][test-java11] Upgrade Scala to 2.12.10
AmplabJenkins removed a comment on issue #25404: [SPARK-28683][BUILD][test-hadoop3.2][test-java11] Upgrade Scala to 2.12.10 URL: https://github.com/apache/spark/pull/25404#issuecomment-532529132 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25404: [SPARK-28683][BUILD][test-hadoop3.2][test-java11] Upgrade Scala to 2.12.10
AmplabJenkins removed a comment on issue #25404: [SPARK-28683][BUILD][test-hadoop3.2][test-java11] Upgrade Scala to 2.12.10 URL: https://github.com/apache/spark/pull/25404#issuecomment-532529136 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110854/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25404: [SPARK-28683][BUILD][test-hadoop3.2][test-java11] Upgrade Scala to 2.12.10
AmplabJenkins commented on issue #25404: [SPARK-28683][BUILD][test-hadoop3.2][test-java11] Upgrade Scala to 2.12.10 URL: https://github.com/apache/spark/pull/25404#issuecomment-532529132 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] imback82 commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
imback82 commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2 URL: https://github.com/apache/spark/pull/25771#discussion_r325491005 ## File path: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 ## @@ -1399,6 +1401,7 @@ CACHE: 'CACHE'; CASCADE: 'CASCADE'; CASE: 'CASE'; CAST: 'CAST'; +CATALOG: 'CATALOG'; Review comment: If we put it in `nonReserved`, `USE CATALOG` is parsed as `USE namespace=multipartIdentifier`. Any trick to go around this? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25735: [SPARK-29030][SQL] Simplify lookupV2Relation
AmplabJenkins removed a comment on issue #25735: [SPARK-29030][SQL] Simplify lookupV2Relation URL: https://github.com/apache/spark/pull/25735#issuecomment-532528669 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25404: [SPARK-28683][BUILD] Upgrade Scala to 2.12.10
SparkQA removed a comment on issue #25404: [SPARK-28683][BUILD] Upgrade Scala to 2.12.10 URL: https://github.com/apache/spark/pull/25404#issuecomment-532500078 **[Test build #110854 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110854/testReport)** for PR 25404 at commit [`57de6c4`](https://github.com/apache/spark/commit/57de6c4f8f6401c3643847288072ab028d603103). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25735: [SPARK-29030][SQL] Simplify lookupV2Relation
AmplabJenkins removed a comment on issue #25735: [SPARK-29030][SQL] Simplify lookupV2Relation URL: https://github.com/apache/spark/pull/25735#issuecomment-532528673 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110846/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25735: [SPARK-29030][SQL] Simplify lookupV2Relation
AmplabJenkins commented on issue #25735: [SPARK-29030][SQL] Simplify lookupV2Relation URL: https://github.com/apache/spark/pull/25735#issuecomment-532528673 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110846/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25735: [SPARK-29030][SQL] Simplify lookupV2Relation
AmplabJenkins commented on issue #25735: [SPARK-29030][SQL] Simplify lookupV2Relation URL: https://github.com/apache/spark/pull/25735#issuecomment-532528669 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25404: [SPARK-28683][BUILD] Upgrade Scala to 2.12.10
SparkQA commented on issue #25404: [SPARK-28683][BUILD] Upgrade Scala to 2.12.10 URL: https://github.com/apache/spark/pull/25404#issuecomment-532528611 **[Test build #110854 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110854/testReport)** for PR 25404 at commit [`57de6c4`](https://github.com/apache/spark/commit/57de6c4f8f6401c3643847288072ab028d603103). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Udbhav30 commented on issue #25398: [SPARK-28659][SQL] Use data source if convertible in insert overwrite directory
Udbhav30 commented on issue #25398: [SPARK-28659][SQL] Use data source if convertible in insert overwrite directory URL: https://github.com/apache/spark/pull/25398#issuecomment-532528460 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25735: [SPARK-29030][SQL] Simplify lookupV2Relation
SparkQA removed a comment on issue #25735: [SPARK-29030][SQL] Simplify lookupV2Relation URL: https://github.com/apache/spark/pull/25735#issuecomment-532476735 **[Test build #110846 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110846/testReport)** for PR 25735 at commit [`eb14b7f`](https://github.com/apache/spark/commit/eb14b7f99352a5881653d12e736bf85365afc7c4). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25735: [SPARK-29030][SQL] Simplify lookupV2Relation
SparkQA commented on issue #25735: [SPARK-29030][SQL] Simplify lookupV2Relation URL: https://github.com/apache/spark/pull/25735#issuecomment-532528201 **[Test build #110846 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110846/testReport)** for PR 25735 at commit [`eb14b7f`](https://github.com/apache/spark/commit/eb14b7f99352a5881653d12e736bf85365afc7c4). * This patch passes all tests. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * ` implicit class MultipartIdentifierHelper(parts: Seq[String]) ` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25398: [SPARK-28659][SQL] Use data source if convertible in insert overwrite directory
AmplabJenkins removed a comment on issue #25398: [SPARK-28659][SQL] Use data source if convertible in insert overwrite directory URL: https://github.com/apache/spark/pull/25398#issuecomment-532526847 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110857/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected
AmplabJenkins removed a comment on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25820#issuecomment-532526914 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25398: [SPARK-28659][SQL] Use data source if convertible in insert overwrite directory
AmplabJenkins removed a comment on issue #25398: [SPARK-28659][SQL] Use data source if convertible in insert overwrite directory URL: https://github.com/apache/spark/pull/25398#issuecomment-532526842 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected
AmplabJenkins commented on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25820#issuecomment-532526922 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/15994/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25398: [SPARK-28659][SQL] Use data source if convertible in insert overwrite directory
SparkQA removed a comment on issue #25398: [SPARK-28659][SQL] Use data source if convertible in insert overwrite directory URL: https://github.com/apache/spark/pull/25398#issuecomment-532504075 **[Test build #110857 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110857/testReport)** for PR 25398 at commit [`72d6dd4`](https://github.com/apache/spark/commit/72d6dd4082cdc8d45204af8aabfecf78288c6eed). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected
AmplabJenkins removed a comment on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25820#issuecomment-532526922 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/15994/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected
AmplabJenkins commented on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25820#issuecomment-532526914 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25398: [SPARK-28659][SQL] Use data source if convertible in insert overwrite directory
AmplabJenkins commented on issue #25398: [SPARK-28659][SQL] Use data source if convertible in insert overwrite directory URL: https://github.com/apache/spark/pull/25398#issuecomment-532526847 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/110857/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25398: [SPARK-28659][SQL] Use data source if convertible in insert overwrite directory
AmplabJenkins commented on issue #25398: [SPARK-28659][SQL] Use data source if convertible in insert overwrite directory URL: https://github.com/apache/spark/pull/25398#issuecomment-532526842 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected
SparkQA commented on issue #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected URL: https://github.com/apache/spark/pull/25820#issuecomment-532526615 **[Test build #110867 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110867/testReport)** for PR 25820 at commit [`ab0c5a9`](https://github.com/apache/spark/commit/ab0c5a9b1292b9a49fa029cf6d2e84aedb3d171f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25398: [SPARK-28659][SQL] Use data source if convertible in insert overwrite directory
SparkQA commented on issue #25398: [SPARK-28659][SQL] Use data source if convertible in insert overwrite directory URL: https://github.com/apache/spark/pull/25398#issuecomment-532526717 **[Test build #110857 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110857/testReport)** for PR 25398 at commit [`72d6dd4`](https://github.com/apache/spark/commit/72d6dd4082cdc8d45204af8aabfecf78288c6eed). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] tooptoop4 commented on issue #25214: [SPARK-28461][SQL] Pad Decimal numbers with trailing zeros to the scale of the column
tooptoop4 commented on issue #25214: [SPARK-28461][SQL] Pad Decimal numbers with trailing zeros to the scale of the column URL: https://github.com/apache/spark/pull/25214#issuecomment-532526523 does this fix https://issues.apache.org/jira/browse/SPARK-23576 ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sandeep-katta commented on a change in pull request #25820: [SPARK-29101][SQL] Fix count API for csv file when DROPMALFORMED mode is selected
sandeep-katta commented on a change in pull request #25820: [SPARK-29101][SQL]
Fix count API for csv file when DROPMALFORMED mode is selected
URL: https://github.com/apache/spark/pull/25820#discussion_r325488782
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/csv/UnivocityParser.scala
##
@@ -188,19 +188,11 @@ class UnivocityParser(
}
}
- private val doParse = if (requiredSchema.nonEmpty) {
-(input: String) => convert(tokenizer.parseLine(input))
- } else {
-// If `columnPruning` enabled and partition attributes scanned only,
-// `schema` gets empty.
-(_: String) => InternalRow.empty
Review comment:
ahh!!!, you are correct, we should only parse when
`spark.sql.csv.parser.columnPruning.enabled` disabled or
`requiredSchema.nonEmpty`.
I have updated the code
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL]
Implement USE CATALOG/NAMESPACE for Data Source V2
URL: https://github.com/apache/spark/pull/25771#discussion_r325488148
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/connector/DataSourceV2SQLSuite.scala
##
@@ -780,11 +794,8 @@ class DataSourceV2SQLSuite
test("ShowNamespaces: default v2 catalog is not set") {
spark.sql("CREATE TABLE testcat.ns.table (id bigint) USING foo")
-val exception = intercept[AnalysisException] {
- sql("SHOW NAMESPACES")
-}
-
-assert(exception.getMessage.contains("No default v2 catalog is set"))
+// The current catalog is resolved to a v2 session catalog.
+testShowNamespaces("SHOW NAMESPACES", Seq())
Review comment:
wait, I think the previous conclusion was to ignore current name space and
always list the root namespaces for `SHOW NAMESPACES`. cc @rdblue
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL]
Implement USE CATALOG/NAMESPACE for Data Source V2
URL: https://github.com/apache/spark/pull/25771#discussion_r325487772
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSourceResolution.scala
##
@@ -188,18 +186,10 @@ case class DataSourceResolution(
}
case ShowTablesStatement(None, pattern) =>
- defaultCatalog match {
-case Some(catalog) =>
- ShowTables(
-catalog.asTableCatalog,
-catalogManager.currentNamespace,
-pattern)
-case None =>
- ShowTablesCommand(None, pattern)
- }
+ ShowTables(currentCatalog.asTableCatalog,
catalogManager.currentNamespace, pattern)
Review comment:
I think so
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL]
Implement USE CATALOG/NAMESPACE for Data Source V2
URL: https://github.com/apache/spark/pull/25771#discussion_r325487596
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##
@@ -60,7 +60,7 @@ object SimpleAnalyzer extends Analyzer(
},
new SQLConf().copy(SQLConf.CASE_SENSITIVE -> true))
-object FakeV2SessionCatalog extends TableCatalog {
+object FakeV2SessionCatalog extends BaseSessionCatalog {
Review comment:
if we use `CatalogPlugin`, this class can be simplified a lot.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL]
Implement USE CATALOG/NAMESPACE for Data Source V2
URL: https://github.com/apache/spark/pull/25771#discussion_r325487453
##
File path:
sql/catalyst/src/main/java/org/apache/spark/sql/connector/catalog/BaseSessionCatalog.java
##
@@ -0,0 +1,28 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.connector.catalog;
+
+import org.apache.spark.annotation.Experimental;
+
+/**
+ * An interface that aggregates different catalog interfaces that can be
supported
+ * by a session catalog.
+ */
+@Experimental
+public interface BaseSessionCatalog extends TableCatalog, SupportsNamespaces {
Review comment:
I'd like to avoid a new interface.
We can do `CatalogExtension extends TableCatalog, SupportsNamespaces`, and
change the method to
```
void setDelegateCatalog(CatalogPlguin delegate);
```
`CatalogManager.defaultSessionCatalog` can also be `CatalogPlugin`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #25827: [SPARK-29128][SQL] Split predicate code in OR expressions
maropu commented on a change in pull request #25827: [SPARK-29128][SQL] Split
predicate code in OR expressions
URL: https://github.com/apache/spark/pull/25827#discussion_r325487146
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Expression.scala
##
@@ -156,6 +156,12 @@ abstract class Expression extends TreeNode[Expression] {
private def reduceCodeSize(ctx: CodegenContext, eval: ExprCode): Unit = {
// TODO: support whole stage codegen too
+//
+// NOTE: We could use `CodeGenerator.defineIndependentFunction` here for
the code path
+// of the whole stage codegen. But, we don't do so now because the
performance changes that
+// we don't expect might occur in many queries. Therefore, we currently
apply
+// this split function to specific performance-sensitive places only,
+// e.g., common subexpression elimination for the whole stage codegen and
OR expressions.
Review comment:
Aha, I see.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2 URL: https://github.com/apache/spark/pull/25771#discussion_r325487069 ## File path: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 ## @@ -1399,6 +1401,7 @@ CACHE: 'CACHE'; CASCADE: 'CASCADE'; CASE: 'CASE'; CAST: 'CAST'; +CATALOG: 'CATALOG'; Review comment: We also need to put it in `ansiNonReserved` and `nonReserved` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2 URL: https://github.com/apache/spark/pull/25771#discussion_r325486651 ## File path: docs/sql-keywords.md ## @@ -57,6 +57,7 @@ Below is a list of all the keywords in Spark SQL. CASCADEnon-reservednon-reservedreserved CASEreservednon-reservedreserved CASTreservednon-reservedreserved + CATALOGreservedreservednon-reserved Review comment: This is non-reserved in pgsql and sql 2011, please see https://www.postgresql.org/docs/current/sql-keywords-appendix.html This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on a change in pull request #25827: [SPARK-29128][SQL] Split predicate code in OR expressions
viirya commented on a change in pull request #25827: [SPARK-29128][SQL] Split
predicate code in OR expressions
URL: https://github.com/apache/spark/pull/25827#discussion_r325486404
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Expression.scala
##
@@ -156,6 +156,12 @@ abstract class Expression extends TreeNode[Expression] {
private def reduceCodeSize(ctx: CodegenContext, eval: ExprCode): Unit = {
// TODO: support whole stage codegen too
+//
+// NOTE: We could use `CodeGenerator.defineIndependentFunction` here for
the code path
+// of the whole stage codegen. But, we don't do so now because the
performance changes that
+// we don't expect might occur in many queries. Therefore, we currently
apply
+// this split function to specific performance-sensitive places only,
+// e.g., common subexpression elimination for the whole stage codegen and
OR expressions.
Review comment:
I recall that is because string-based manipulation was thought too buggy? I
didn't remember it is because of performance issue.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #17254: [SPARK-19917][SQL]qualified partition path stored in catalog
cloud-fan commented on a change in pull request #17254: [SPARK-19917][SQL]qualified partition path stored in catalog URL: https://github.com/apache/spark/pull/17254#discussion_r325486439 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/catalog/SessionCatalog.scala ## @@ -1064,6 +1076,23 @@ class SessionCatalog( } } + /** + * Make the partition path qualified. + * If the partition path is relative, e.g. 'paris', it will be qualified with + * parent path using table location, e.g. 'file:/warehouse/table/paris' + */ + private def partitionWithQualifiedPath( Review comment: > Currently only ALTER TABLE t ADD PARTITION(b=1) LOCATION for hive serde table has the expected qualified path. we should make other scenes to be consist with it. If this is true, can we reuse the related code that is used to qualify paths? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25626: [SPARK-28892][SQL] Add UPDATE support for DataSource V2
cloud-fan commented on a change in pull request #25626: [SPARK-28892][SQL] Add UPDATE support for DataSource V2 URL: https://github.com/apache/spark/pull/25626#discussion_r325485701 ## File path: docs/sql-keywords.md ## @@ -280,6 +280,7 @@ Below is a list of all the keywords in Spark SQL. UNKNOWNreservednon-reservedreserved UNLOCKnon-reservednon-reservednon-reserved UNSETnon-reservednon-reservednon-reserved + UPDATEnon-reservednon-reservedreserved Review comment: I checked other keywords and seems like the general rule here is to follow Postgres, we can revisit it later. cc @gengliangwang This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25747: [SPARK-29039][SQL] centralize the catalog and table lookup logic
cloud-fan commented on a change in pull request #25747: [SPARK-29039][SQL]
centralize the catalog and table lookup logic
URL: https://github.com/apache/spark/pull/25747#discussion_r325485311
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/execution/command/PlanResolutionSuite.scala
##
@@ -26,31 +26,49 @@ import org.mockito.invocation.InvocationOnMock
import org.apache.spark.sql.{AnalysisException, SaveMode}
import org.apache.spark.sql.catalyst.TableIdentifier
-import org.apache.spark.sql.catalyst.analysis.AnalysisTest
+import org.apache.spark.sql.catalyst.analysis.{AnalysisTest,
NoSuchTableException, ResolveCatalogs, ResolveTables}
import org.apache.spark.sql.catalyst.catalog.{BucketSpec,
CatalogStorageFormat, CatalogTable, CatalogTableType}
import org.apache.spark.sql.catalyst.parser.CatalystSqlParser
-import org.apache.spark.sql.catalyst.plans.logical.{CreateTableAsSelect,
CreateV2Table, DropTable, LogicalPlan}
-import org.apache.spark.sql.connector.{InMemoryTableCatalog,
InMemoryTableProvider}
-import org.apache.spark.sql.connector.catalog.{CatalogManager,
CatalogNotFoundException, Identifier, TableCatalog}
-import org.apache.spark.sql.execution.datasources.{CreateTable,
DataSourceResolution}
+import org.apache.spark.sql.catalyst.plans.logical.{AlterTable,
CreateTableAsSelect, CreateV2Table, DropTable, LogicalPlan}
+import
org.apache.spark.sql.catalyst.plans.logical.sql.{AlterTableSetPropertiesStatement,
AlterTableUnsetPropertiesStatement}
+import org.apache.spark.sql.connector.InMemoryTableProvider
+import org.apache.spark.sql.connector.catalog.{CatalogManager,
CatalogNotFoundException, Identifier, Table, TableCatalog, TableChange, V1Table}
+import org.apache.spark.sql.execution.datasources.CreateTable
import org.apache.spark.sql.internal.SQLConf.DEFAULT_V2_CATALOG
import org.apache.spark.sql.types.{DoubleType, IntegerType, LongType,
StringType, StructType}
-import org.apache.spark.sql.util.CaseInsensitiveStringMap
class PlanResolutionSuite extends AnalysisTest {
Review comment:
improve the test coverage of this test suite, to covert all the cases:
1. statement is converted to v1 command.
2. statement is converted to v2 command.
3. statement is left unchanged because table not found.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25747: [SPARK-29039][SQL] centralize the catalog and table lookup logic
AmplabJenkins commented on issue #25747: [SPARK-29039][SQL] centralize the catalog and table lookup logic URL: https://github.com/apache/spark/pull/25747#issuecomment-532522162 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] xianyinxin commented on a change in pull request #25601: [SPARK-28856][SQL] Implement SHOW DATABASES for Data Source V2 Tables
xianyinxin commented on a change in pull request #25601: [SPARK-28856][SQL] Implement SHOW DATABASES for Data Source V2 Tables URL: https://github.com/apache/spark/pull/25601#discussion_r325485223 ## File path: docs/sql-keywords.md ## @@ -179,6 +179,7 @@ Below is a list of all the keywords in Spark SQL. MONTHreservednon-reservedreserved MONTHSnon-reservednon-reservednon-reserved MSCKnon-reservednon-reservednon-reserved + NAMESPACESnon-reservednon-reservednon-reserved Review comment: DELETE is already there. UPDATE is included in https://github.com/apache/spark/pull/25626 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25747: [SPARK-29039][SQL] centralize the catalog and table lookup logic
AmplabJenkins removed a comment on issue #25747: [SPARK-29039][SQL] centralize the catalog and table lookup logic URL: https://github.com/apache/spark/pull/25747#issuecomment-532522162 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25747: [SPARK-29039][SQL] centralize the catalog and table lookup logic
AmplabJenkins commented on issue #25747: [SPARK-29039][SQL] centralize the catalog and table lookup logic URL: https://github.com/apache/spark/pull/25747#issuecomment-532522168 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/15993/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25747: [SPARK-29039][SQL] centralize the catalog and table lookup logic
AmplabJenkins removed a comment on issue #25747: [SPARK-29039][SQL] centralize the catalog and table lookup logic URL: https://github.com/apache/spark/pull/25747#issuecomment-532522168 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/15993/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25747: [SPARK-29039][SQL] centralize the catalog and table lookup logic
SparkQA commented on issue #25747: [SPARK-29039][SQL] centralize the catalog and table lookup logic URL: https://github.com/apache/spark/pull/25747#issuecomment-532521965 **[Test build #110866 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110866/testReport)** for PR 25747 at commit [`8524b46`](https://github.com/apache/spark/commit/8524b46538967e5df28d8bb2b9a7db3647dd3c61). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25747: [SPARK-29039][SQL] centralize the catalog and table lookup logic
cloud-fan commented on a change in pull request #25747: [SPARK-29039][SQL]
centralize the catalog and table lookup logic
URL: https://github.com/apache/spark/pull/25747#discussion_r325216854
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/catalyst/analysis/ResolveTables.scala
##
@@ -0,0 +1,190 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.analysis
+
+import org.apache.spark.sql.AnalysisException
+import org.apache.spark.sql.catalyst.plans.logical.{AlterTable,
DeleteFromTable, DescribeTable, LogicalPlan, SubqueryAlias}
+import
org.apache.spark.sql.catalyst.plans.logical.sql.{AlterTableAddColumnsStatement,
AlterTableAlterColumnStatement, AlterTableDropColumnsStatement,
AlterTableRenameColumnStatement, AlterTableSetLocationStatement,
AlterTableSetPropertiesStatement, AlterTableUnsetPropertiesStatement,
AlterViewSetPropertiesStatement, AlterViewUnsetPropertiesStatement,
DeleteFromStatement, DescribeTableStatement, QualifiedColType}
+import org.apache.spark.sql.catalyst.rules.Rule
+import org.apache.spark.sql.connector.catalog.{CatalogManager, LookupCatalog,
TableChange}
+import org.apache.spark.sql.execution.command.{AlterTableAddColumnsCommand,
AlterTableSetLocationCommand, AlterTableSetPropertiesCommand,
AlterTableUnsetPropertiesCommand, DescribeTableCommand}
+import org.apache.spark.sql.execution.datasources.v2.DataSourceV2Relation
+import org.apache.spark.sql.types.{HIVE_TYPE_STRING, HiveStringType,
MetadataBuilder, StructField}
+
+/**
+ * Resolves tables from the multi-part identifiers in DDL/DML commands.
+ *
+ * For each SQL statement, this rule has 2 different code paths for v1 and v2
tables.
+ */
+class ResolveTables(val catalogManager: CatalogManager)
+ extends Rule[LogicalPlan] with LookupCatalog {
+ import org.apache.spark.sql.connector.catalog.CatalogV2Implicits._
+
+ override def apply(plan: LogicalPlan): LogicalPlan = plan.resolveOperatorsUp
{
+case AlterTableAddColumnsStatement(
+ CatalogAndTable(catalog, tblName, Left(v1Table)), cols) =>
+ cols.foreach(c => assertTopLeveColumn(c.name,
"AlterTableAddColumnsCommand"))
+ AlterTableAddColumnsCommand(tblName.toV1Identifier,
cols.map(convertToStructField))
+
+case AlterTableAddColumnsStatement(
+ CatalogAndTable(catalog, tblName, Right(table)), cols) =>
+ val changes = cols.map { col =>
+TableChange.addColumn(col.name.toArray, col.dataType, true,
col.comment.orNull)
+ }
+ AlterTable(catalog, tblName.toIdentifier, table, changes)
+
+// The v1 `AlterTableAddColumnsCommand` will check temp view and provide
better error message.
+// Here we convert the statement to the v1 command to get the better error
message.
+// TODO: apply the temp view check for all ALTER TABLE statements.
+case AlterTableAddColumnsStatement(tblName, cols) =>
+ cols.foreach(c => assertTopLeveColumn(c.name,
"AlterTableAddColumnsCommand"))
+ AlterTableAddColumnsCommand(tblName.toV1Identifier,
cols.map(convertToStructField))
+
+// TODO: we should fallback to the v1 `AlterTableChangeColumnCommand`.
+case AlterTableAlterColumnStatement(
+ CatalogAndTable(catalog, tblName, Left(v1Table)), colName, dataType,
comment) =>
+ throw new AnalysisException("ALTER COLUMN is not supported with v1
table.")
+
+case AlterTableAlterColumnStatement(
+ CatalogAndTable(catalog, tblName, Right(table)), colName, dataType,
comment) =>
+ val typeChange = dataType.map { newDataType =>
+TableChange.updateColumnType(colName.toArray, newDataType, true)
+ }
+ val commentChange = comment.map { newComment =>
+TableChange.updateColumnComment(colName.toArray, newComment)
+ }
+ AlterTable(catalog, tblName.toIdentifier, table, typeChange.toSeq ++
commentChange)
+
+case AlterTableRenameColumnStatement(
+ CatalogAndTable(catalog, tblName, Left(v1Table)), col, newName) =>
+ throw new AnalysisException("RENAME COLUMN is not supported with v1
table.")
+
+case AlterTableRenameColumnStatement(
+ CatalogAndTable(catalog, tblName, Right(table)), col, newName) =>
+ val changes
[GitHub] [spark] cloud-fan commented on a change in pull request #25747: [SPARK-29039][SQL] centralize the catalog and table lookup logic
cloud-fan commented on a change in pull request #25747: [SPARK-29039][SQL]
centralize the catalog and table lookup logic
URL: https://github.com/apache/spark/pull/25747#discussion_r325484422
##
File path:
sql/catalyst/src/main/java/org/apache/spark/sql/connector/catalog/TableChange.java
##
@@ -210,6 +213,20 @@ public String property() {
public String value() {
return value;
}
+
+@Override
+public boolean equals(Object o) {
Review comment:
these `equal/hashCode` are useful in general and we need them in tests.
These are generated by IDE, we can also implement these classes in Scala case
class to get `equal/hashCode` for free.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25827: [SPARK-29128][SQL] Split predicate code in OR expressions
AmplabJenkins removed a comment on issue #25827: [SPARK-29128][SQL] Split predicate code in OR expressions URL: https://github.com/apache/spark/pull/25827#issuecomment-532520777 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/15992/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25827: [SPARK-29128][SQL] Split predicate code in OR expressions
AmplabJenkins removed a comment on issue #25827: [SPARK-29128][SQL] Split predicate code in OR expressions URL: https://github.com/apache/spark/pull/25827#issuecomment-532520771 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25827: [SPARK-29128][SQL] Split predicate code in OR expressions
AmplabJenkins commented on issue #25827: [SPARK-29128][SQL] Split predicate code in OR expressions URL: https://github.com/apache/spark/pull/25827#issuecomment-532520771 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25827: [SPARK-29128][SQL] Split predicate code in OR expressions
AmplabJenkins commented on issue #25827: [SPARK-29128][SQL] Split predicate code in OR expressions URL: https://github.com/apache/spark/pull/25827#issuecomment-532520777 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/15992/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #25827: [SPARK-29128][SQL] Split predicate code in OR expressions
maropu commented on a change in pull request #25827: [SPARK-29128][SQL] Split
predicate code in OR expressions
URL: https://github.com/apache/spark/pull/25827#discussion_r325483953
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/Expression.scala
##
@@ -156,6 +156,12 @@ abstract class Expression extends TreeNode[Expression] {
private def reduceCodeSize(ctx: CodegenContext, eval: ExprCode): Unit = {
// TODO: support whole stage codegen too
+//
+// NOTE: We could use `CodeGenerator.defineIndependentFunction` here for
the code path
+// of the whole stage codegen. But, we don't do so now because the
performance changes that
+// we don't expect might occur in many queries. Therefore, we currently
apply
+// this split function to specific performance-sensitive places only,
+// e.g., common subexpression elimination for the whole stage codegen and
OR expressions.
Review comment:
@viirya @cloud-fan Is this correct? I remember @viirya worked on this in
#21140 long before, but the pr wasn't merged because of some reasons:
performance or design issues?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25827: [SPARK-29128][SQL] Split predicate code in OR expressions
SparkQA commented on issue #25827: [SPARK-29128][SQL] Split predicate code in OR expressions URL: https://github.com/apache/spark/pull/25827#issuecomment-532520533 **[Test build #110865 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/110865/testReport)** for PR 25827 at commit [`d116613`](https://github.com/apache/spark/commit/d1166139284146166849b1938ccdf71416d24465). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu opened a new pull request #25827: [SPARK-29128][SQL] Split predicate code in OR expressions
maropu opened a new pull request #25827: [SPARK-29128][SQL] Split predicate
code in OR expressions
URL: https://github.com/apache/spark/pull/25827
### What changes were proposed in this pull request?
This pr is to split predicate code in OR expressions. When I checked if
method bytecode size in `BenchmarkQueryTest` went over the OpenJDK default
limit (8000) or not in #25788, I found
[TPCDSQuerySuite.modified-q3](https://github.com/apache/spark/blob/master/sql/core/src/test/resources/tpcds-modifiedQueries/q3.sql)
had too big functions. That's because too long OR chains in the query generate
too long code in a single function;
`modified-q3` generates [the
code](https://gist.github.com/maropu/9bfdcf9f8b694ad68ad6b3dc67fddb7c#file-non-split-case-in-spark-x-tpcdsquerysuite-modified-q3)
below in the master
```
== Subtree 2 / 4 (maxMethodCodeSize:12497; maxConstantPoolSize:732(1.12%
used); numInnerClasses:1) ==
^^
*(3) HashAggregate(keys=[d_year#9, i_brand#62, i_brand_id#61],
functions=[partial_sum(UnscaledValue(ss_net_profit#53))], output=[d_year#9,
i_brand#62, i_brand_id#61, sum#85L])
+- *(3) Project [d_year#9, ss_net_profit#53, i_brand_id#61, i_brand#62]
/* 365 */ private void agg_doAggregateWithKeys_0() throws
java.io.IOException {
/* 366 */ if (columnartorow_mutableStateArray_1[0] == null) {
/* 367 */ columnartorow_nextBatch_0();
/* 368 */ }
/* 369 */ while ( columnartorow_mutableStateArray_1[0] != null) {
/* 370 */ int columnartorow_numRows_0 =
columnartorow_mutableStateArray_1[0].numRows();
/* 371 */ int columnartorow_localEnd_0 = columnartorow_numRows_0 -
columnartorow_batchIdx_0;
/* 372 */ for (int columnartorow_localIdx_0 = 0;
columnartorow_localIdx_0 < columnartorow_localEnd_0;
columnartorow_localIdx_0++) {
/* 373 */ int columnartorow_rowIdx_0 = columnartorow_batchIdx_0 +
columnartorow_localIdx_0;
/* 374 */ do {
/* 375 */ boolean columnartorow_isNull_0 =
columnartorow_mutableStateArray_2[0].isNullAt(columnartorow_rowIdx_0);
/* 376 */ int columnartorow_value_0 = columnartorow_isNull_0 ? -1
: (columnartorow_mutableStateArray_2[0].getInt(columnartorow_rowIdx_0));
/* 377 */
/* 378 */ boolean filter_value_2 = !columnartorow_isNull_0;
/* 379 */ if (!filter_value_2) continue;
/* 380 */
/* 381 */ boolean filter_value_12 = false;
/* 382 */ filter_value_12 = columnartorow_value_0 >= 2415355;
/* 383 */ boolean filter_value_11 = false;
/* 384 */
.
too long code
```
This pr split the predicate code into [small
functions](https://gist.github.com/maropu/f2f8dba8fe74b50fc0b8ba73ecfbb5d2)
below;
```
== Subtree 2 / 4 (maxMethodCodeSize:688; maxConstantPoolSize:949(1.45%
used); numInnerClasses:1) ==
*(3) HashAggregate(keys=[d_year#9, i_brand#62, i_brand_id#61],
functions=[partial_sum(UnscaledValue(ss_net_profit#53))], output=[d_year#9,
i_brand#62, i_brand_id#61, sum#85L])
+- *(3) Project [d_year#9, ss_net_profit#53, i_brand_id#61, i_brand#62]
...
/* 3285 */ private void agg_doAggregateWithKeys_0() throws
java.io.IOException {
/* 3286 */ if (columnartorow_mutableStateArray_1[0] == null) {
/* 3287 */ columnartorow_nextBatch_0();
/* 3288 */ }
/* 3289 */ while ( columnartorow_mutableStateArray_1[0] != null) {
/* 3290 */ int columnartorow_numRows_0 =
columnartorow_mutableStateArray_1[0].numRows();
/* 3291 */ int columnartorow_localEnd_0 = columnartorow_numRows_0 -
columnartorow_batchIdx_0;
/* 3292 */ for (int columnartorow_localIdx_0 = 0;
columnartorow_localIdx_0 < columnartorow_localEnd_0;
columnartorow_localIdx_0++) {
/* 3293 */ int columnartorow_rowIdx_0 = columnartorow_batchIdx_0 +
columnartorow_localIdx_0;
/* 3294 */ do {
/* 3295 */ boolean columnartorow_isNull_0 =
columnartorow_mutableStateArray_2[0].isNullAt(columnartorow_rowIdx_0);
/* 3296 */ int columnartorow_value_0 = columnartorow_isNull_0 ? -1
: (columnartorow_mutableStateArray_2[0].getInt(columnartorow_rowIdx_0));
/* 3297 */
/* 3298 */ boolean filter_value_2 = !columnartorow_isNull_0;
/* 3299 */ if (!filter_value_2) continue;
/* 3300 */
/* 3301 */ boolean filter_value_213 =
filter_or_8(columnartorow_value_0, columnartorow_isNull_0);
/* 3302 */ boolean filter_value_5 = true;
/* 3303 */
/* 3304 */ if (!filter_value_213) {
/* 3305 */ boolean filter_value_421 =
filter_or_17(columnartorow_value_0, columnartorow_isNull_0);
/* 3306 */ filter_value_5 = filter_value_421;
/* 3307 */ }
/* 3308 */ boolean filter_value_4 = true;
/* 3309 */
/* 3310
[GitHub] [spark] sujith71955 commented on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command
sujith71955 commented on issue #24903: [SPARK-28084][SQL] Resolving the partition column name based on the resolver in sql load command URL: https://github.com/apache/spark/pull/24903#issuecomment-532516781 gentle ping @dongjoon-hyun @maropu @HyukjinKwon This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries
AmplabJenkins commented on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries URL: https://github.com/apache/spark/pull/25464#issuecomment-532515380 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/15991/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries
AmplabJenkins commented on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries URL: https://github.com/apache/spark/pull/25464#issuecomment-532515378 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries
AmplabJenkins removed a comment on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries URL: https://github.com/apache/spark/pull/25464#issuecomment-532515380 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/15991/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries
AmplabJenkins removed a comment on issue #25464: [SPARK-28746][SQL] Add partitionby hint for sql queries URL: https://github.com/apache/spark/pull/25464#issuecomment-532515378 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org