[GitHub] [spark] viirya commented on a change in pull request #25925: [SPARK-29239][SPARK-29221][SQL] Subquery should not cause NPE when eliminating subexpression
viirya commented on a change in pull request #25925:
[SPARK-29239][SPARK-29221][SQL] Subquery should not cause NPE when eliminating
subexpression
URL: https://github.com/apache/spark/pull/25925#discussion_r328445546
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/EquivalentExpressions.scala
##
@@ -72,7 +73,10 @@ class EquivalentExpressions {
val skip = expr.isInstanceOf[LeafExpression] ||
// `LambdaVariable` is usually used as a loop variable, which can't be
evaluated ahead of the
// loop. So we can't evaluate sub-expressions containing
`LambdaVariable` at the beginning.
- expr.find(_.isInstanceOf[LambdaVariable]).isDefined
+ expr.find(_.isInstanceOf[LambdaVariable]).isDefined ||
+ // `PlanExpression` wraps query plan. To compare query plans of
`PlanExpression` on executor,
+ // can cause error like NPE.
+ (expr.isInstanceOf[PlanExpression[_]] && TaskContext.get != null)
Review comment:
Ok. Please let me know if you have some ideas later.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25863: [SPARK-28945][SPARK-29037][CORE][SQL] Fix the issue that spark gives duplicate result and support concurrent file source write operati
AmplabJenkins removed a comment on issue #25863: [SPARK-28945][SPARK-29037][CORE][SQL] Fix the issue that spark gives duplicate result and support concurrent file source write operations write to different partitions in the same table. URL: https://github.com/apache/spark/pull/25863#issuecomment-535349163 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16433/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25863: [SPARK-28945][SPARK-29037][CORE][SQL] Fix the issue that spark gives duplicate result and support concurrent file source write operati
AmplabJenkins removed a comment on issue #25863: [SPARK-28945][SPARK-29037][CORE][SQL] Fix the issue that spark gives duplicate result and support concurrent file source write operations write to different partitions in the same table. URL: https://github.com/apache/spark/pull/25863#issuecomment-535349156 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #25925: [SPARK-29239][SPARK-29221][SQL] Subquery should not cause NPE when eliminating subexpression
cloud-fan closed pull request #25925: [SPARK-29239][SPARK-29221][SQL] Subquery should not cause NPE when eliminating subexpression URL: https://github.com/apache/spark/pull/25925 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25863: [SPARK-28945][SPARK-29037][CORE][SQL] Fix the issue that spark gives duplicate result and support concurrent file source write operations writ
AmplabJenkins commented on issue #25863: [SPARK-28945][SPARK-29037][CORE][SQL] Fix the issue that spark gives duplicate result and support concurrent file source write operations write to different partitions in the same table. URL: https://github.com/apache/spark/pull/25863#issuecomment-535349156 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25863: [SPARK-28945][SPARK-29037][CORE][SQL] Fix the issue that spark gives duplicate result and support concurrent file source write operations writ
AmplabJenkins commented on issue #25863: [SPARK-28945][SPARK-29037][CORE][SQL] Fix the issue that spark gives duplicate result and support concurrent file source write operations write to different partitions in the same table. URL: https://github.com/apache/spark/pull/25863#issuecomment-535349163 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16433/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25863: [SPARK-28945][SPARK-29037][CORE][SQL] Fix the issue that spark gives duplicate result and support concurrent file source write operations write to d
SparkQA commented on issue #25863: [SPARK-28945][SPARK-29037][CORE][SQL] Fix the issue that spark gives duplicate result and support concurrent file source write operations write to different partitions in the same table. URL: https://github.com/apache/spark/pull/25863#issuecomment-535348734 **[Test build #111392 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/111392/testReport)** for PR 25863 at commit [`dacd0f8`](https://github.com/apache/spark/commit/dacd0f8de28bd7face688cbfa23cc0dde065bc14). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on a change in pull request #25775: [SPARK-29015][SQL][test-hadoop3.2]Reset class loader after initializing SessionState for built-in Hive 2.3
wangyum commented on a change in pull request #25775:
[SPARK-29015][SQL][test-hadoop3.2]Reset class loader after initializing
SessionState for built-in Hive 2.3
URL: https://github.com/apache/spark/pull/25775#discussion_r328444154
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala
##
@@ -190,6 +190,13 @@ private[hive] class HiveClientImpl(
if (clientLoader.cachedHive != null) {
Hive.set(clientLoader.cachedHive.asInstanceOf[Hive])
}
+// Hive 2.3 will set UDFClassLoader to hiveConf when initializing
SessionState
+// since HIVE-11878, and ADDJarCommand will add jars to
clientLoader.classLoader.
+// For this reason we cannot load the jars added by ADDJarCommand because
of class loader
+// got changed. We reset it to clientLoader.ClassLoader here.
+if (HiveUtils.isHive23) {
+ state.getConf.setClassLoader(clientLoader.classLoader)
+}
Review comment:
@gatorsmile @srowen @HyukjinKwon @dongjoon-hyun @juliuszsompolski Do you
have more comments?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25925: [SPARK-29239][SPARK-29221][SQL] Subquery should not cause NPE when eliminating subexpression
cloud-fan commented on a change in pull request #25925:
[SPARK-29239][SPARK-29221][SQL] Subquery should not cause NPE when eliminating
subexpression
URL: https://github.com/apache/spark/pull/25925#discussion_r328443645
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/EquivalentExpressions.scala
##
@@ -72,7 +73,10 @@ class EquivalentExpressions {
val skip = expr.isInstanceOf[LeafExpression] ||
// `LambdaVariable` is usually used as a loop variable, which can't be
evaluated ahead of the
// loop. So we can't evaluate sub-expressions containing
`LambdaVariable` at the beginning.
- expr.find(_.isInstanceOf[LambdaVariable]).isDefined
+ expr.find(_.isInstanceOf[LambdaVariable]).isDefined ||
+ // `PlanExpression` wraps query plan. To compare query plans of
`PlanExpression` on executor,
+ // can cause error like NPE.
+ (expr.isInstanceOf[PlanExpression[_]] && TaskContext.get != null)
Review comment:
This issue also reminds me that it's better to always do codegen at driver
side, even if whole-stage-codegen is false. We can investigate it later.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25925: [SPARK-29239][SPARK-29221][SQL] Subquery should not cause NPE when eliminating subexpression
cloud-fan commented on a change in pull request #25925:
[SPARK-29239][SPARK-29221][SQL] Subquery should not cause NPE when eliminating
subexpression
URL: https://github.com/apache/spark/pull/25925#discussion_r328443315
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/EquivalentExpressions.scala
##
@@ -72,7 +73,10 @@ class EquivalentExpressions {
val skip = expr.isInstanceOf[LeafExpression] ||
// `LambdaVariable` is usually used as a loop variable, which can't be
evaluated ahead of the
// loop. So we can't evaluate sub-expressions containing
`LambdaVariable` at the beginning.
- expr.find(_.isInstanceOf[LambdaVariable]).isDefined
+ expr.find(_.isInstanceOf[LambdaVariable]).isDefined ||
+ // `PlanExpression` wraps query plan. To compare query plans of
`PlanExpression` on executor,
+ // can cause error like NPE.
+ (expr.isInstanceOf[PlanExpression[_]] && TaskContext.get != null)
Review comment:
ah got it, so the kept value is serialized and sent to executor side in
interpreted code path.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec
AmplabJenkins removed a comment on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec URL: https://github.com/apache/spark/pull/25902#issuecomment-535346984 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/111378/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec
AmplabJenkins removed a comment on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec URL: https://github.com/apache/spark/pull/25902#issuecomment-535346980 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type
SparkQA commented on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type URL: https://github.com/apache/spark/pull/25085#issuecomment-535347065 **[Test build #111391 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/111391/testReport)** for PR 25085 at commit [`9997ac1`](https://github.com/apache/spark/commit/9997ac17362fa456d2206f5c7553b29c0c665c29). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec
AmplabJenkins commented on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec URL: https://github.com/apache/spark/pull/25902#issuecomment-535346980 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec
AmplabJenkins commented on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec URL: https://github.com/apache/spark/pull/25902#issuecomment-535346984 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/111378/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec
SparkQA removed a comment on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec URL: https://github.com/apache/spark/pull/25902#issuecomment-535298797 **[Test build #111378 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/111378/testReport)** for PR 25902 at commit [`fcada1c`](https://github.com/apache/spark/commit/fcada1cd65260601d6b3ef951359dd3ed6b0003d). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25651: [SPARK-28948][SQL] Support passing all Table metadata in TableProvider
cloud-fan commented on a change in pull request #25651: [SPARK-28948][SQL]
Support passing all Table metadata in TableProvider
URL: https://github.com/apache/spark/pull/25651#discussion_r328442663
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/CatalogExtensionForTableProvider.scala
##
@@ -0,0 +1,98 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources.v2
+
+import java.util
+
+import scala.util.control.NonFatal
+
+import org.apache.spark.sql.AnalysisException
+import org.apache.spark.sql.connector.catalog.{DelegatingCatalogExtension,
Identifier, SupportsSpecifiedSchemaPartitioning, Table}
+import org.apache.spark.sql.connector.expressions.Transform
+import org.apache.spark.sql.execution.datasources.DataSource
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.types.StructType
+import org.apache.spark.sql.util.CaseInsensitiveStringMap
+
+class CatalogExtensionForTableProvider extends DelegatingCatalogExtension {
+
+ private val conf = SQLConf.get
+
+ override def loadTable(ident: Identifier): Table = {
+val table = super.loadTable(ident)
+tryResolveTableProvider(table)
+ }
+
+ override def createTable(
+ ident: Identifier,
+ schema: StructType,
+ partitions: Array[Transform],
+ properties: util.Map[String, String]): Table = {
+val provider = properties.getOrDefault("provider",
conf.defaultDataSourceName)
+val maybeProvider = DataSource.lookupDataSourceV2(provider, conf)
+val (actualSchema, actualPartitioning) = if (maybeProvider.isDefined &&
schema.isEmpty) {
+ // A sanity check. The parser should guarantee it.
+ assert(partitions.isEmpty)
+ // If `CREATE TABLE ... USING` does not specify table metadata, get the
table metadata from
+ // data source first.
+ val table = maybeProvider.get.getTable(new
CaseInsensitiveStringMap(properties))
+ table.schema() -> table.partitioning()
+} else {
+ schema -> partitions
+}
+super.createTable(ident, actualSchema, actualPartitioning, properties)
+// call `loadTable` to make sure the schema/partitioning specified in
`CREATE TABLE ... USING`
+// matches the actual data schema/partitioning. If error happens during
table loading, drop
+// the table.
+try {
+ loadTable(ident)
+} catch {
+ case NonFatal(e) =>
+dropTable(ident)
+throw e
+}
+ }
+
+ private def tryResolveTableProvider(table: Table): Table = {
+val providerName = table.properties().get("provider")
+assert(providerName != null)
+DataSource.lookupDataSourceV2(providerName, conf).map {
+ // TODO: support file source v2 in CREATE TABLE USING.
+ case _: FileDataSourceV2 => table
Review comment:
As you already found out in
https://github.com/apache/spark/pull/25651#discussion_r328336988
File source v2 can't take the partitioning from metastore because the
`TableProvider` API was incompleted before. I don't want to fix file source v2
in this PR, so I simply ignore it here.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on a change in pull request #25925: [SPARK-29239][SPARK-29221][SQL] Subquery should not cause NPE when eliminating subexpression
viirya commented on a change in pull request #25925:
[SPARK-29239][SPARK-29221][SQL] Subquery should not cause NPE when eliminating
subexpression
URL: https://github.com/apache/spark/pull/25925#discussion_r328442649
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/EquivalentExpressions.scala
##
@@ -72,7 +73,10 @@ class EquivalentExpressions {
val skip = expr.isInstanceOf[LeafExpression] ||
// `LambdaVariable` is usually used as a loop variable, which can't be
evaluated ahead of the
// loop. So we can't evaluate sub-expressions containing
`LambdaVariable` at the beginning.
- expr.find(_.isInstanceOf[LambdaVariable]).isDefined
+ expr.find(_.isInstanceOf[LambdaVariable]).isDefined ||
+ // `PlanExpression` wraps query plan. To compare query plans of
`PlanExpression` on executor,
+ // can cause error like NPE.
+ (expr.isInstanceOf[PlanExpression[_]] && TaskContext.get != null)
Review comment:
Not sure I understand your question correctly. But PlanExpressions of a
SparkPlan are evaluated and updated (e.g., ExecSubqueryExpression.updateResult)
with values before a query begins to run. The values are kept in
PlanExpression, and on executor side when to call eval of PlanExpression, it
simply returns the kept value. I think we do not really evaluate a
PlanExpression at executor side.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec
SparkQA commented on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec URL: https://github.com/apache/spark/pull/25902#issuecomment-535346536 **[Test build #111378 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/111378/testReport)** for PR 25902 at commit [`fcada1c`](https://github.com/apache/spark/commit/fcada1cd65260601d6b3ef951359dd3ed6b0003d). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on a change in pull request #25775: [SPARK-29015][SQL][test-hadoop3.2]Reset class loader after initializing SessionState for built-in Hive 2.3
wangyum commented on a change in pull request #25775:
[SPARK-29015][SQL][test-hadoop3.2]Reset class loader after initializing
SessionState for built-in Hive 2.3
URL: https://github.com/apache/spark/pull/25775#discussion_r328442568
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/client/HiveClientImpl.scala
##
@@ -190,6 +190,13 @@ private[hive] class HiveClientImpl(
if (clientLoader.cachedHive != null) {
Hive.set(clientLoader.cachedHive.asInstanceOf[Hive])
}
+// Hive 2.3 will set UDFClassLoader to hiveConf when initializing
SessionState
+// since HIVE-11878, and ADDJarCommand will add jars to
clientLoader.classLoader.
+// For this reason we cannot load the jars added by ADDJarCommand because
of class loader
+// got changed. We reset it to clientLoader.ClassLoader here.
+if (HiveUtils.isHive23) {
+ state.getConf.setClassLoader(clientLoader.classLoader)
+}
SessionState.start(state)
Review comment:
Sorry. It's another bug: https://issues.apache.org/jira/browse/SPARK-29254
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #25925: [SPARK-29239][SPARK-29221][SQL] Subquery should not cause NPE when eliminating subexpression
maropu commented on a change in pull request #25925:
[SPARK-29239][SPARK-29221][SQL] Subquery should not cause NPE when eliminating
subexpression
URL: https://github.com/apache/spark/pull/25925#discussion_r328442132
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/EquivalentExpressions.scala
##
@@ -72,7 +73,10 @@ class EquivalentExpressions {
val skip = expr.isInstanceOf[LeafExpression] ||
// `LambdaVariable` is usually used as a loop variable, which can't be
evaluated ahead of the
// loop. So we can't evaluate sub-expressions containing
`LambdaVariable` at the beginning.
- expr.find(_.isInstanceOf[LambdaVariable]).isDefined
+ expr.find(_.isInstanceOf[LambdaVariable]).isDefined ||
+ // `PlanExpression` wraps query plan. To compare query plans of
`PlanExpression` on executor,
+ // can cause error like NPE.
+ (expr.isInstanceOf[PlanExpression[_]] && TaskContext.get != null)
Review comment:
IIUC,`EquivalentExpressions` is only used in the codegen mode now, e.g.,
`GenerateUnsafeProjection` uses this class in common subexpr elimination, but
`InterpretedUnsafeProject does not elimnate common subexprs.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type
AmplabJenkins removed a comment on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type URL: https://github.com/apache/spark/pull/25085#issuecomment-535345630 Build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type
AmplabJenkins commented on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type URL: https://github.com/apache/spark/pull/25085#issuecomment-535345633 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16432/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25933: [SPARK-29252][BUILD] Upgrade zookeeper to 3.4.14 and fix vulnerabilities.
AmplabJenkins removed a comment on issue #25933: [SPARK-29252][BUILD] Upgrade zookeeper to 3.4.14 and fix vulnerabilities. URL: https://github.com/apache/spark/pull/25933#issuecomment-535345533 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/111383/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type
AmplabJenkins commented on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type URL: https://github.com/apache/spark/pull/25085#issuecomment-535345630 Build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type
AmplabJenkins removed a comment on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type URL: https://github.com/apache/spark/pull/25085#issuecomment-535345633 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16432/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25933: [SPARK-29252][BUILD] Upgrade zookeeper to 3.4.14 and fix vulnerabilities.
AmplabJenkins commented on issue #25933: [SPARK-29252][BUILD] Upgrade zookeeper to 3.4.14 and fix vulnerabilities. URL: https://github.com/apache/spark/pull/25933#issuecomment-535345528 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25651: [SPARK-28948][SQL] Support passing all Table metadata in TableProvider
cloud-fan commented on a change in pull request #25651: [SPARK-28948][SQL]
Support passing all Table metadata in TableProvider
URL: https://github.com/apache/spark/pull/25651#discussion_r328441721
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/CatalogExtensionForTableProvider.scala
##
@@ -0,0 +1,98 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources.v2
+
+import java.util
+
+import scala.util.control.NonFatal
+
+import org.apache.spark.sql.AnalysisException
+import org.apache.spark.sql.connector.catalog.{DelegatingCatalogExtension,
Identifier, SupportsSpecifiedSchemaPartitioning, Table}
+import org.apache.spark.sql.connector.expressions.Transform
+import org.apache.spark.sql.execution.datasources.DataSource
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.types.StructType
+import org.apache.spark.sql.util.CaseInsensitiveStringMap
+
+class CatalogExtensionForTableProvider extends DelegatingCatalogExtension {
+
+ private val conf = SQLConf.get
+
+ override def loadTable(ident: Identifier): Table = {
+val table = super.loadTable(ident)
+tryResolveTableProvider(table)
+ }
+
+ override def createTable(
+ ident: Identifier,
+ schema: StructType,
+ partitions: Array[Transform],
+ properties: util.Map[String, String]): Table = {
+val provider = properties.getOrDefault("provider",
conf.defaultDataSourceName)
+val maybeProvider = DataSource.lookupDataSourceV2(provider, conf)
+val (actualSchema, actualPartitioning) = if (maybeProvider.isDefined &&
schema.isEmpty) {
+ // A sanity check. The parser should guarantee it.
+ assert(partitions.isEmpty)
+ // If `CREATE TABLE ... USING` does not specify table metadata, get the
table metadata from
+ // data source first.
+ val table = maybeProvider.get.getTable(new
CaseInsensitiveStringMap(properties))
+ table.schema() -> table.partitioning()
+} else {
+ schema -> partitions
+}
+super.createTable(ident, actualSchema, actualPartitioning, properties)
+// call `loadTable` to make sure the schema/partitioning specified in
`CREATE TABLE ... USING`
+// matches the actual data schema/partitioning. If error happens during
table loading, drop
+// the table.
Review comment:
e.g. `CREATE TABLE t(i int) USING jdbc OPTIONS (table=t2)`. It's possible
that the JDBC table `t2` has a different schema.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25933: [SPARK-29252][BUILD] Upgrade zookeeper to 3.4.14 and fix vulnerabilities.
AmplabJenkins removed a comment on issue #25933: [SPARK-29252][BUILD] Upgrade zookeeper to 3.4.14 and fix vulnerabilities. URL: https://github.com/apache/spark/pull/25933#issuecomment-535345528 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25933: [SPARK-29252][BUILD] Upgrade zookeeper to 3.4.14 and fix vulnerabilities.
SparkQA removed a comment on issue #25933: [SPARK-29252][BUILD] Upgrade zookeeper to 3.4.14 and fix vulnerabilities. URL: https://github.com/apache/spark/pull/25933#issuecomment-535320442 **[Test build #111383 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/111383/testReport)** for PR 25933 at commit [`39ea96d`](https://github.com/apache/spark/commit/39ea96d105c98a2d405f683619f150d564f24800). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25933: [SPARK-29252][BUILD] Upgrade zookeeper to 3.4.14 and fix vulnerabilities.
AmplabJenkins commented on issue #25933: [SPARK-29252][BUILD] Upgrade zookeeper to 3.4.14 and fix vulnerabilities. URL: https://github.com/apache/spark/pull/25933#issuecomment-535345533 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/111383/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25933: [SPARK-29252][BUILD] Upgrade zookeeper to 3.4.14 and fix vulnerabilities.
SparkQA commented on issue #25933: [SPARK-29252][BUILD] Upgrade zookeeper to 3.4.14 and fix vulnerabilities. URL: https://github.com/apache/spark/pull/25933#issuecomment-535345380 **[Test build #111383 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/111383/testReport)** for PR 25933 at commit [`39ea96d`](https://github.com/apache/spark/commit/39ea96d105c98a2d405f683619f150d564f24800). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25651: [SPARK-28948][SQL] Support passing all Table metadata in TableProvider
cloud-fan commented on a change in pull request #25651: [SPARK-28948][SQL]
Support passing all Table metadata in TableProvider
URL: https://github.com/apache/spark/pull/25651#discussion_r328441296
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/DataSourceV2Utils.scala
##
@@ -57,4 +60,21 @@ private[sql] object DataSourceV2Utils extends Logging {
case _ => Map.empty
}
}
+
+ def loadTableWithUserSpecifiedSchema(
+ provider: TableProvider,
+ schema: StructType,
+ options: CaseInsensitiveStringMap): Table = {
+provider match {
+ case s: SupportsSpecifiedSchemaPartitioning =>
+// TODO: `DataFrameReader`/`DataStreamReader` should have an API to
set user-specified
+// partitioning.
Review comment:
But there is no API to specify the partitioning here, neither
`DataFrameReader` or `DataStreamReader`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25651: [SPARK-28948][SQL] Support passing all Table metadata in TableProvider
cloud-fan commented on a change in pull request #25651: [SPARK-28948][SQL]
Support passing all Table metadata in TableProvider
URL: https://github.com/apache/spark/pull/25651#discussion_r328440980
##
File path:
sql/catalyst/src/main/java/org/apache/spark/sql/connector/catalog/TableProvider.java
##
@@ -36,26 +35,12 @@
public interface TableProvider {
/**
- * Return a {@link Table} instance to do read/write with user-specified
options.
+ * Return a {@link Table} instance with the given table options to do
read/write.
+ * Implementations should infer the table schema and partitioning.
*
* @param options the user-specified options that can identify a table, e.g.
file path, Kafka
*topic name, etc. It's an immutable case-insensitive
string-to-string map.
*/
+ // TODO: this should take a Map as table properties.
Review comment:
SGTM. Shall we do it in this PR? We need to update all the `TableProvider`
implementations, i.e. file source v2, streaming source v2, testing v2 sources.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25651: [SPARK-28948][SQL] Support passing all Table metadata in TableProvider
cloud-fan commented on a change in pull request #25651: [SPARK-28948][SQL]
Support passing all Table metadata in TableProvider
URL: https://github.com/apache/spark/pull/25651#discussion_r328440703
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/csv/CSVDataSourceV2.scala
##
@@ -35,9 +38,12 @@ class CSVDataSourceV2 extends FileDataSourceV2 {
CSVTable(tableName, sparkSession, options, paths, None, fallbackFileFormat)
}
- override def getTable(options: CaseInsensitiveStringMap, schema:
StructType): Table = {
-val paths = getPaths(options)
+ override def getTable(
+ schema: StructType,
+ partitions: Array[Transform],
Review comment:
shall we also update `TableCatalog.createTable`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec
AmplabJenkins removed a comment on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec URL: https://github.com/apache/spark/pull/25902#issuecomment-535344093 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/111377/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec
AmplabJenkins commented on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec URL: https://github.com/apache/spark/pull/25902#issuecomment-535344093 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/111377/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec
AmplabJenkins removed a comment on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec URL: https://github.com/apache/spark/pull/25902#issuecomment-535344092 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec
AmplabJenkins commented on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec URL: https://github.com/apache/spark/pull/25902#issuecomment-535344092 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25932: [SPARK-29250][BUILD][test-hadoop3.2][test-java11] Upgrade to Hadoop 3.2.1
AmplabJenkins removed a comment on issue #25932: [SPARK-29250][BUILD][test-hadoop3.2][test-java11] Upgrade to Hadoop 3.2.1 URL: https://github.com/apache/spark/pull/25932#issuecomment-535343835 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25932: [SPARK-29250][BUILD][test-hadoop3.2][test-java11] Upgrade to Hadoop 3.2.1
AmplabJenkins removed a comment on issue #25932: [SPARK-29250][BUILD][test-hadoop3.2][test-java11] Upgrade to Hadoop 3.2.1 URL: https://github.com/apache/spark/pull/25932#issuecomment-535343842 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16431/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25932: [SPARK-29250][BUILD][test-hadoop3.2][test-java11] Upgrade to Hadoop 3.2.1
AmplabJenkins commented on issue #25932: [SPARK-29250][BUILD][test-hadoop3.2][test-java11] Upgrade to Hadoop 3.2.1 URL: https://github.com/apache/spark/pull/25932#issuecomment-535343842 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16431/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25932: [SPARK-29250][BUILD][test-hadoop3.2][test-java11] Upgrade to Hadoop 3.2.1
AmplabJenkins commented on issue #25932: [SPARK-29250][BUILD][test-hadoop3.2][test-java11] Upgrade to Hadoop 3.2.1 URL: https://github.com/apache/spark/pull/25932#issuecomment-535343835 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec
SparkQA removed a comment on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec URL: https://github.com/apache/spark/pull/25902#issuecomment-535297109 **[Test build #111377 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/111377/testReport)** for PR 25902 at commit [`5272097`](https://github.com/apache/spark/commit/52720971986285a40e83ecdd50c16528db38df65). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec
SparkQA commented on issue #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec URL: https://github.com/apache/spark/pull/25902#issuecomment-535343588 **[Test build #111377 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/111377/testReport)** for PR 25902 at commit [`5272097`](https://github.com/apache/spark/commit/52720971986285a40e83ecdd50c16528db38df65). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25932: [SPARK-29250][BUILD][test-hadoop3.2][test-java11] Upgrade to Hadoop 3.2.1
SparkQA commented on issue #25932: [SPARK-29250][BUILD][test-hadoop3.2][test-java11] Upgrade to Hadoop 3.2.1 URL: https://github.com/apache/spark/pull/25932#issuecomment-535343523 **[Test build #111390 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/111390/testReport)** for PR 25932 at commit [`a417073`](https://github.com/apache/spark/commit/a417073f11f2a188e36644e0509ac44f745a7142). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25925: [SPARK-29239][SPARK-29221][SQL] Subquery should not cause NPE when eliminating subexpression
cloud-fan commented on a change in pull request #25925:
[SPARK-29239][SPARK-29221][SQL] Subquery should not cause NPE when eliminating
subexpression
URL: https://github.com/apache/spark/pull/25925#discussion_r328439691
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/EquivalentExpressions.scala
##
@@ -72,7 +73,10 @@ class EquivalentExpressions {
val skip = expr.isInstanceOf[LeafExpression] ||
// `LambdaVariable` is usually used as a loop variable, which can't be
evaluated ahead of the
// loop. So we can't evaluate sub-expressions containing
`LambdaVariable` at the beginning.
- expr.find(_.isInstanceOf[LambdaVariable]).isDefined
+ expr.find(_.isInstanceOf[LambdaVariable]).isDefined ||
+ // `PlanExpression` wraps query plan. To compare query plans of
`PlanExpression` on executor,
+ // can cause error like NPE.
+ (expr.isInstanceOf[PlanExpression[_]] && TaskContext.get != null)
Review comment:
Just for curiosity, does this issue happen in interpreted code path as well?
e.g. we send `PlanExpression` to executor side and eval it, and hit NPE.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #25932: [SPARK-29250][BUILD][test-hadoop3.2][test-java11] Upgrade to Hadoop 3.2.1
dongjoon-hyun commented on issue #25932: [SPARK-29250][BUILD][test-hadoop3.2][test-java11] Upgrade to Hadoop 3.2.1 URL: https://github.com/apache/spark/pull/25932#issuecomment-535342915 Retest this please. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec
maropu commented on a change in pull request #25902: [SPARK-29213][SQL] Make it
consistent when get notnull output and generate null checks in FilterExec
URL: https://github.com/apache/spark/pull/25902#discussion_r328439412
##
File path: sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
##
@@ -3192,6 +3192,32 @@ class SQLQuerySuite extends QueryTest with
SharedSparkSession {
checkAnswer(df3, Array(Row(new
java.math.BigDecimal("0.1000100"
}
}
+
+ test("SPARK-29213: FilterExec should not throw NPE") {
+withView("t1", "t2", "t3") {
+ sql("select
''").as[String].map(identity).toDF("x").createOrReplaceTempView("t1")
+ sql("select * from values 0, cast(null as bigint)")
+.as[java.lang.Long]
+.map(identity)
+.toDF("x")
+.createOrReplaceTempView("t2")
+ sql("select
''").as[String].map(identity).toDF("x").createOrReplaceTempView("t3")
+ sql(
+"""
+ |select t1.x
Review comment:
nit: No strict rule though, I like capitalized words for SQL keywords: e.g.,
select -> SELECT,
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #25932: [SPARK-29250][BUILD] Upgrade to Hadoop 3.2.1
dongjoon-hyun commented on a change in pull request #25932: [SPARK-29250][BUILD] Upgrade to Hadoop 3.2.1 URL: https://github.com/apache/spark/pull/25932#discussion_r328439235 ## File path: dev/deps/spark-deps-hadoop-3.2 ## @@ -22,6 +22,8 @@ automaton-1.11-8.jar avro-1.8.2.jar avro-ipc-1.8.2.jar avro-mapred-1.8.2-hadoop2.jar +bcpkix-jdk15on-1.60.jar +bcprov-jdk15on-1.60.jar Review comment: Oops. It sounds too much for me. Please help me after I merge this. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #25932: [SPARK-29250][BUILD] Upgrade to Hadoop 3.2.1
dongjoon-hyun commented on a change in pull request #25932: [SPARK-29250][BUILD] Upgrade to Hadoop 3.2.1 URL: https://github.com/apache/spark/pull/25932#discussion_r328439235 ## File path: dev/deps/spark-deps-hadoop-3.2 ## @@ -22,6 +22,8 @@ automaton-1.11-8.jar avro-1.8.2.jar avro-ipc-1.8.2.jar avro-mapred-1.8.2-hadoop2.jar +bcpkix-jdk15on-1.60.jar +bcprov-jdk15on-1.60.jar Review comment: Oops. It sounds too much for me. Please help me after I merge this. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] kiszk commented on issue #25797: [SPARK-29043][Core] Improve the concurrent performance of History Server
kiszk commented on issue #25797: [SPARK-29043][Core] Improve the concurrent performance of History Server URL: https://github.com/apache/spark/pull/25797#issuecomment-535342437 ping @vanzin @wangyum This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #25933: [SPARK-29252][BUILD] Upgrade zookeeper to 3.4.14 and fix vulnerabilities.
dongjoon-hyun commented on a change in pull request #25933: [SPARK-29252][BUILD] Upgrade zookeeper to 3.4.14 and fix vulnerabilities. URL: https://github.com/apache/spark/pull/25933#discussion_r328438514 ## File path: pom.xml ## @@ -2979,7 +2979,7 @@ 3.2.0 2.13.0 -3.4.13 Review comment: Thank you, @beliefer . This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] merrily01 edited a comment on issue #25920: [SPARK-29233][KUBERNETES] Add regex expression checks for executorEnv…
merrily01 edited a comment on issue #25920: [SPARK-29233][KUBERNETES] Add regex expression checks for executorEnv… URL: https://github.com/apache/spark/pull/25920#issuecomment-535341503 Hey~ @srowen I was so sleepy last night that my mind was a little unclear. After my careful consideration, I have something to tell you: 1. This validation is necessary, otherwise an executor environment variable name that does not conform to the specification will lead to pod creation errors. 2. As you know, this check rule is different in high and low versions of k8s.(The low version is stricter than the high version) That means there will be no problem for low to high versions of k8s, but in the case of high to low versions,k8s itself may also have this problem. 3. Compatibility can be achieved with lower version regex (Stricter), but this is contrary to the original intention of the high version of k8s to make this change. 4. I prefer the validation here to be consistent with the high version behavior of k8s, rather than considering this as a compatibility issue. 5. What do you think if I declare it in the notes and log message?For example, as follows: 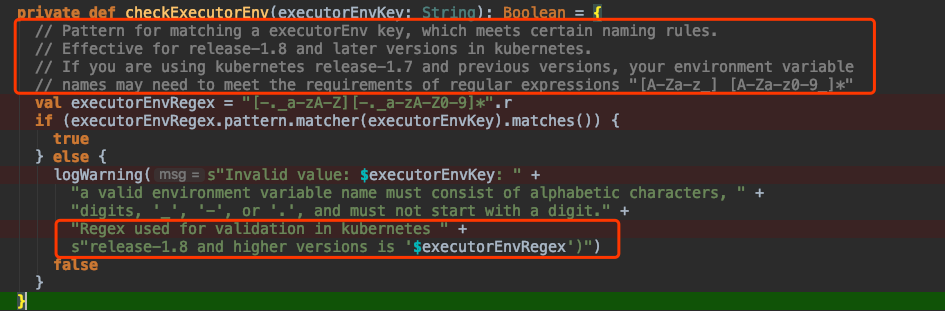 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #25933: [SPARK-29252][BUILD] Upgrade zookeeper to 3.4.14 and fix vulnerabilities.
dongjoon-hyun commented on a change in pull request #25933: [SPARK-29252][BUILD] Upgrade zookeeper to 3.4.14 and fix vulnerabilities. URL: https://github.com/apache/spark/pull/25933#discussion_r328438514 ## File path: pom.xml ## @@ -2979,7 +2979,7 @@ 3.2.0 2.13.0 -3.4.13 Review comment: Thank you, @beliefer . For this line, I'll include my Hadoop 3.2.1 PR, too. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] merrily01 commented on issue #25920: [SPARK-29233][KUBERNETES] Add regex expression checks for executorEnv…
merrily01 commented on issue #25920: [SPARK-29233][KUBERNETES] Add regex expression checks for executorEnv… URL: https://github.com/apache/spark/pull/25920#issuecomment-535341503 Hey~ @srowen I was so sleepy last night that my mind was a little unclear. After my careful consideration, I have something to tell you: 1. This validation is necessary, otherwise an executor environment variable name that does not conform to the specification will lead to pod creation errors. 2. As you know, this check rule is different in high and low versions of k8s.(The low version is stricter than the high version) That means there will be no problem for low to high versions of k8s, but in the case of high to low versions,k8s itself may also have this problem. 3. Compatibility can be achieved with lower version (Stricter), but this is contrary to the original intention of the high version of k8s to make this change. 4. I prefer the validation here to be consistent with the high version behavior of k8s, rather than considering this as a compatibility issue. 5. What do you think if I declare it in the notes and log message?For example, as follows:  This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #25902: [SPARK-29213][SQL] Make it consistent when get notnull output and generate null checks in FilterExec
maropu commented on a change in pull request #25902: [SPARK-29213][SQL] Make it
consistent when get notnull output and generate null checks in FilterExec
URL: https://github.com/apache/spark/pull/25902#discussion_r328438434
##
File path: sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala
##
@@ -3192,6 +3192,32 @@ class SQLQuerySuite extends QueryTest with
SharedSparkSession {
checkAnswer(df3, Array(Row(new
java.math.BigDecimal("0.1000100"
}
}
+
+ test("SPARK-29213: FilterExec should not throw NPE") {
+withView("t1", "t2", "t3") {
Review comment:
nit: `withView` -> `withTempView`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL]
Implement USE CATALOG/NAMESPACE for Data Source V2
URL: https://github.com/apache/spark/pull/25771#discussion_r328437962
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSourceResolution.scala
##
@@ -170,48 +170,34 @@ case class DataSourceResolution(
DeleteFromTable(aliased, delete.condition)
case ShowNamespacesStatement(None, pattern) =>
- defaultCatalog match {
-case Some(catalog) =>
- ShowNamespaces(catalog.asNamespaceCatalog, None, pattern)
-case None =>
- throw new AnalysisException("No default v2 catalog is set.")
- }
+ ShowNamespaces(currentCatalog.asNamespaceCatalog, None, pattern)
case ShowNamespacesStatement(Some(namespace), pattern) =>
- val CatalogNamespace(maybeCatalog, ns) = namespace
- maybeCatalog match {
-case Some(catalog) =>
- ShowNamespaces(catalog.asNamespaceCatalog, Some(ns), pattern)
-case None =>
- throw new AnalysisException(
-s"No v2 catalog is available for ${namespace.quoted}")
- }
+ val CurrentCatalogAndNamespace(catalog, ns) = namespace
Review comment:
seems like this is to fix SPARK-29014. Can we do it in another PR? Let's
focus on the new command to set current catalog/namespace in this PR.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type
AmplabJenkins removed a comment on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type URL: https://github.com/apache/spark/pull/25085#issuecomment-535340594 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/111382/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type
AmplabJenkins commented on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type URL: https://github.com/apache/spark/pull/25085#issuecomment-535340589 Build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type
AmplabJenkins commented on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type URL: https://github.com/apache/spark/pull/25085#issuecomment-535340594 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/111382/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type
AmplabJenkins removed a comment on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type URL: https://github.com/apache/spark/pull/25085#issuecomment-535340589 Build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type
SparkQA removed a comment on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type URL: https://github.com/apache/spark/pull/25085#issuecomment-535316444 **[Test build #111382 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/111382/testReport)** for PR 25085 at commit [`b4cc595`](https://github.com/apache/spark/commit/b4cc595c138aacaaad16191519bda14f8478aeda). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25934: [SPARK-29253][SQL] Add agg(String, String*) to Dataset
AmplabJenkins removed a comment on issue #25934: [SPARK-29253][SQL] Add agg(String, String*) to Dataset URL: https://github.com/apache/spark/pull/25934#issuecomment-535340069 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type
SparkQA commented on issue #25085: [SPARK-28313][SQL] Spark sql null type incompatible with hive void type URL: https://github.com/apache/spark/pull/25085#issuecomment-535340385 **[Test build #111382 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/111382/testReport)** for PR 25085 at commit [`b4cc595`](https://github.com/apache/spark/commit/b4cc595c138aacaaad16191519bda14f8478aeda). * This patch **fails Spark unit tests**. * This patch **does not merge cleanly**. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25934: [SPARK-29253][SQL] Add agg(String, String*) to Dataset
AmplabJenkins commented on issue #25934: [SPARK-29253][SQL] Add agg(String, String*) to Dataset URL: https://github.com/apache/spark/pull/25934#issuecomment-535340298 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25934: [SPARK-29253][SQL] Add agg(String, String*) to Dataset
AmplabJenkins commented on issue #25934: [SPARK-29253][SQL] Add agg(String, String*) to Dataset URL: https://github.com/apache/spark/pull/25934#issuecomment-535340069 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL]
Implement USE CATALOG/NAMESPACE for Data Source V2
URL: https://github.com/apache/spark/pull/25771#discussion_r328437225
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/internal/BaseSessionStateBuilder.scala
##
@@ -224,8 +225,8 @@ abstract class BaseSessionStateBuilder(
*
* Note: this depends on `catalog` and `experimentalMethods` fields.
*/
- protected def optimizer: Optimizer = {
-new SparkOptimizer(catalog, experimentalMethods) {
+ protected def optimizer(catalogManager: CatalogManager): Optimizer = {
Review comment:
We can create the `CatalogManager` in `BaseSessionStateBuilder` and pass it
to analyzer/optimizer.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] TomokoKomiyama opened a new pull request #25934: [SPARK-29253][SQL] Add agg(String, String*) to Dataset
TomokoKomiyama opened a new pull request #25934: [SPARK-29253][SQL] Add agg(String, String*) to Dataset URL: https://github.com/apache/spark/pull/25934 ### What changes were proposed in this pull request? Add agg(String, String*) and its test. ### Why are the changes needed? agg() was able to use use when we use String on argument. ### Does this PR introduce any user-facing change? Yes. Users can use agg(String, String*). ### How was this patch tested? Added test case to DataFrameAggregateSuite.scala . This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL]
Implement USE CATALOG/NAMESPACE for Data Source V2
URL: https://github.com/apache/spark/pull/25771#discussion_r328436300
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/basicLogicalOperators.scala
##
@@ -659,6 +659,14 @@ case class ShowTables(
AttributeReference("tableName", StringType, nullable = false)())
}
+/**
+ * The logical plan of the USE/USE CATALOG command that works for v2 catalogs.
+ */
+case class UseCatalogAndNamespace(
Review comment:
let's make the name clearer: `SetCurrentCatalogAndNamespace`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2 URL: https://github.com/apache/spark/pull/25771#discussion_r328436344 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/plans/logical/sql/UseCatalogAndNamespaceStatement.scala ## @@ -0,0 +1,28 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one or more + * contributor license agreements. See the NOTICE file distributed with + * this work for additional information regarding copyright ownership. + * The ASF licenses this file to You under the Apache License, Version 2.0 + * (the "License"); you may not use this file except in compliance with + * the License. You may obtain a copy of the License at + * + *http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.spark.sql.catalyst.plans.logical.sql + +/** + * A USE/USE CATALOG statement, as parsed from SQL. + */ +case class UseCatalogAndNamespaceStatement( Review comment: ditto This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25670: [SPARK-28869][CORE] Roll over event log files
SparkQA commented on issue #25670: [SPARK-28869][CORE] Roll over event log files URL: https://github.com/apache/spark/pull/25670#issuecomment-535338400 **[Test build #111389 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/111389/testReport)** for PR 25670 at commit [`0531578`](https://github.com/apache/spark/commit/053157865562fdbca0271cf5918468b6055c5796). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
cloud-fan commented on a change in pull request #25771: [SPARK-28970][SQL]
Implement USE CATALOG/NAMESPACE for Data Source V2
URL: https://github.com/apache/spark/pull/25771#discussion_r328436187
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/finishAnalysis.scala
##
@@ -78,11 +78,13 @@ object ComputeCurrentTime extends Rule[LogicalPlan] {
/** Replaces the expression of CurrentDatabase with the current database name.
*/
-case class GetCurrentDatabase(sessionCatalog: SessionCatalog) extends
Rule[LogicalPlan] {
+case class GetCurrentDatabase(catalogManager: CatalogManager) extends
Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = {
+import org.apache.spark.sql.connector.catalog.CatalogV2Implicits._
+
plan transformAllExpressions {
case CurrentDatabase() =>
-Literal.create(sessionCatalog.getCurrentDatabase, StringType)
+Literal.create(catalogManager.currentNamespace.quoted, StringType)
Review comment:
super nit: shall we keep the `catalogManager.currentNamespace.quoted` in a
variable and use it here? Then we can avoid calling
`catalogManager.currentNamespace.quoted` many times.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
AmplabJenkins commented on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2 URL: https://github.com/apache/spark/pull/25771#issuecomment-535333411 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
AmplabJenkins removed a comment on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2 URL: https://github.com/apache/spark/pull/25771#issuecomment-535333411 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25697: [SPARK-28997][SQL] Add `spark.sql.dialect`
AmplabJenkins commented on issue #25697: [SPARK-28997][SQL] Add `spark.sql.dialect` URL: https://github.com/apache/spark/pull/25697#issuecomment-535333461 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25697: [SPARK-28997][SQL] Add `spark.sql.dialect`
AmplabJenkins commented on issue #25697: [SPARK-28997][SQL] Add `spark.sql.dialect` URL: https://github.com/apache/spark/pull/25697#issuecomment-535333462 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16430/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25697: [SPARK-28997][SQL] Add `spark.sql.dialect`
AmplabJenkins removed a comment on issue #25697: [SPARK-28997][SQL] Add `spark.sql.dialect` URL: https://github.com/apache/spark/pull/25697#issuecomment-535333462 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16430/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25697: [SPARK-28997][SQL] Add `spark.sql.dialect`
AmplabJenkins removed a comment on issue #25697: [SPARK-28997][SQL] Add `spark.sql.dialect` URL: https://github.com/apache/spark/pull/25697#issuecomment-535333461 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
AmplabJenkins removed a comment on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2 URL: https://github.com/apache/spark/pull/25771#issuecomment-535333418 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16429/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
AmplabJenkins commented on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2 URL: https://github.com/apache/spark/pull/25771#issuecomment-535333418 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16429/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25697: [SPARK-28997][SQL] Add `spark.sql.dialect`
SparkQA commented on issue #25697: [SPARK-28997][SQL] Add `spark.sql.dialect` URL: https://github.com/apache/spark/pull/25697#issuecomment-535333103 **[Test build #111388 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/111388/testReport)** for PR 25697 at commit [`b518114`](https://github.com/apache/spark/commit/b5181145f157b1d874cde3acfad9e20efb0c2bf0). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
SparkQA commented on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2 URL: https://github.com/apache/spark/pull/25771#issuecomment-535333098 **[Test build #111387 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/111387/testReport)** for PR 25771 at commit [`110f6bf`](https://github.com/apache/spark/commit/110f6bf26dbbbc0b64ce13bef503b7609f5757b5). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #25697: [SPARK-28997][SQL] Add `spark.sql.dialect`
maropu commented on a change in pull request #25697: [SPARK-28997][SQL] Add `spark.sql.dialect` URL: https://github.com/apache/spark/pull/25697#discussion_r328432255 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/postgreSQL/StringUtils.scala ## @@ -0,0 +1,33 @@ +/* Review comment: Yea, ok to me. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on issue #25931: [SPARK-29249][SQL] V2 writer: Don't allow tableProperty for existing tables
cloud-fan commented on issue #25931: [SPARK-29249][SQL] V2 writer: Don't allow tableProperty for existing tables URL: https://github.com/apache/spark/pull/25931#issuecomment-535331906 thanks, merging to master! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #25697: [SPARK-28997][SQL] Add `spark.sql.dialect`
maropu commented on a change in pull request #25697: [SPARK-28997][SQL] Add
`spark.sql.dialect`
URL: https://github.com/apache/spark/pull/25697#discussion_r328432357
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/PostgreSQLDialectQuerySuite.scala
##
@@ -0,0 +1,43 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql
+
+import org.apache.spark.SparkConf
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.test.SharedSparkSession
+
+class PostgreSQLDialectQuerySuite extends QueryTest with SharedSparkSession {
+
+ override def sparkConf: SparkConf =
+super.sparkConf
+ .set(SQLConf.DIALECT.key, SQLConf.Dialect.POSTGRESQL.toString)
+
+ test("cast string to boolean") {
+ Seq("true", "tru", "tr", "t", "tRue ", "tRu ", "yes", "ye",
Review comment:
Need a single space before `Seq(`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #25931: [SPARK-29249][SQL] V2 writer: Don't allow tableProperty for existing tables
cloud-fan closed pull request #25931: [SPARK-29249][SQL] V2 writer: Don't allow tableProperty for existing tables URL: https://github.com/apache/spark/pull/25931 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
AmplabJenkins removed a comment on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2 URL: https://github.com/apache/spark/pull/25771#issuecomment-535331558 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
AmplabJenkins removed a comment on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2 URL: https://github.com/apache/spark/pull/25771#issuecomment-535331564 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16428/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a change in pull request #25697: [SPARK-28997][SQL] Add `spark.sql.dialect`
gengliangwang commented on a change in pull request #25697: [SPARK-28997][SQL]
Add `spark.sql.dialect`
URL: https://github.com/apache/spark/pull/25697#discussion_r328432080
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/PostgreSQLDialectQuerySuite.scala
##
@@ -0,0 +1,43 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql
+
+import org.apache.spark.SparkConf
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.test.SharedSparkSession
+
+class PostgreSQLDialectQuerySuite extends QueryTest with SharedSparkSession {
+
+ override def sparkConf: SparkConf =
+super.sparkConf
+ .set(SQLConf.DIALECT.key, SQLConf.Dialect.POSTGRESQL.toString)
+
+ test("cast string to boolean") {
+ Seq("true", "tru", "tr", "t", "tRue ", "tRu ", "yes", "ye",
Review comment:
Sorry, but what is the issue here? The inputs contain spaces.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
AmplabJenkins commented on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2 URL: https://github.com/apache/spark/pull/25771#issuecomment-535331564 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder-K8s/16428/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
AmplabJenkins commented on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2 URL: https://github.com/apache/spark/pull/25771#issuecomment-535331558 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a change in pull request #25697: [SPARK-28997][SQL] Add `spark.sql.dialect`
gengliangwang commented on a change in pull request #25697: [SPARK-28997][SQL]
Add `spark.sql.dialect`
URL: https://github.com/apache/spark/pull/25697#discussion_r328432080
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/PostgreSQLDialectQuerySuite.scala
##
@@ -0,0 +1,43 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql
+
+import org.apache.spark.SparkConf
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.test.SharedSparkSession
+
+class PostgreSQLDialectQuerySuite extends QueryTest with SharedSparkSession {
+
+ override def sparkConf: SparkConf =
+super.sparkConf
+ .set(SQLConf.DIALECT.key, SQLConf.Dialect.POSTGRESQL.toString)
+
+ test("cast string to boolean") {
+ Seq("true", "tru", "tr", "t", "tRue ", "tRu ", "yes", "ye",
Review comment:
Sorry, but what is the issue here? The inputs contain spaces.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
SparkQA commented on issue #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2 URL: https://github.com/apache/spark/pull/25771#issuecomment-535331136 **[Test build #111386 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/111386/testReport)** for PR 25771 at commit [`30a0f7a`](https://github.com/apache/spark/commit/30a0f7a99155078a67edee2ec9210afdf12049ec). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a change in pull request #25697: [SPARK-28997][SQL] Add `spark.sql.dialect`
gengliangwang commented on a change in pull request #25697: [SPARK-28997][SQL] Add `spark.sql.dialect` URL: https://github.com/apache/spark/pull/25697#discussion_r328431617 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/postgreSQL/StringUtils.scala ## @@ -0,0 +1,33 @@ +/* Review comment: How about a follow-up to change `pgSQL` to `postgreSQL`. I prefer the official full name. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] imback82 commented on a change in pull request #25771: [SPARK-28970][SQL] Implement USE CATALOG/NAMESPACE for Data Source V2
imback82 commented on a change in pull request #25771: [SPARK-28970][SQL]
Implement USE CATALOG/NAMESPACE for Data Source V2
URL: https://github.com/apache/spark/pull/25771#discussion_r328431680
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/UseCatalogAndNamespaceExec.scala
##
@@ -0,0 +1,49 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution.datasources.v2
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.Attribute
+import org.apache.spark.sql.connector.catalog.CatalogManager
+import org.apache.spark.sql.execution.LeafExecNode
+
+/**
+ * Physical plan node for setting the current catalog and/or namespace.
+ */
+case class UseCatalogAndNamespaceExec(
+catalogManager: CatalogManager,
+catalogName: Option[String],
+namespace: Option[Seq[String]])
+extends LeafExecNode {
+ override protected def doExecute(): RDD[InternalRow] = {
+// The catalog is updated first because CatalogManager resets the current
namespace
+// when the current catalog is set.
+catalogName.map(catalogManager.setCurrentCatalog)
+
+namespace.map { ns =>
+ SparkSession.active.sessionState.catalog.setCurrentDatabase(ns.head)
Review comment:
This is resolved by #25903. Thanks @cloud-fan
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on issue #25697: [SPARK-28997][SQL] Add `spark.sql.dialect`
maropu commented on issue #25697: [SPARK-28997][SQL] Add `spark.sql.dialect` URL: https://github.com/apache/spark/pull/25697#issuecomment-535330675 LGTM except for minor comments. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #25697: [SPARK-28997][SQL] Add `spark.sql.dialect`
maropu commented on a change in pull request #25697: [SPARK-28997][SQL] Add `spark.sql.dialect` URL: https://github.com/apache/spark/pull/25697#discussion_r328431070 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/postgreSQL/StringUtils.scala ## @@ -0,0 +1,33 @@ +/* Review comment: nit: Since we already have the dir named `pgSQL` in `sql/core/src/test/resources/sql-tests/inputs/pgSQL`, `postgreSQL` -> `pgSQL`? Both names is ok, but I like a consistent name. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #25697: [SPARK-28997][SQL] Add `spark.sql.dialect`
maropu commented on a change in pull request #25697: [SPARK-28997][SQL] Add
`spark.sql.dialect`
URL: https://github.com/apache/spark/pull/25697#discussion_r328430438
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/PostgreSQLDialectQuerySuite.scala
##
@@ -0,0 +1,43 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql
+
+import org.apache.spark.SparkConf
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.test.SharedSparkSession
+
+class PostgreSQLDialectQuerySuite extends QueryTest with SharedSparkSession {
+
+ override def sparkConf: SparkConf =
+super.sparkConf
+ .set(SQLConf.DIALECT.key, SQLConf.Dialect.POSTGRESQL.toString)
Review comment:
nit: `super.sparkConf.set(SQLConf.DIALECT.key,
SQLConf.Dialect.POSTGRESQL.toString)`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #25697: [SPARK-28997][SQL] Add `spark.sql.dialect`
maropu commented on a change in pull request #25697: [SPARK-28997][SQL] Add
`spark.sql.dialect`
URL: https://github.com/apache/spark/pull/25697#discussion_r328430151
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/PostgreSQLDialectQuerySuite.scala
##
@@ -0,0 +1,43 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql
+
+import org.apache.spark.SparkConf
+import org.apache.spark.sql.internal.SQLConf
+import org.apache.spark.sql.test.SharedSparkSession
+
+class PostgreSQLDialectQuerySuite extends QueryTest with SharedSparkSession {
+
+ override def sparkConf: SparkConf =
+super.sparkConf
+ .set(SQLConf.DIALECT.key, SQLConf.Dialect.POSTGRESQL.toString)
+
+ test("cast string to boolean") {
+ Seq("true", "tru", "tr", "t", "tRue ", "tRu ", "yes", "ye",
Review comment:
nit: indent
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org