[GitHub] [spark] dilipbiswal commented on a change in pull request #26042: [SPARK-29092][SQL] Report additional information about DataSourceScanExec in EXPLAIN FORMATTED
dilipbiswal commented on a change in pull request #26042: [SPARK-29092][SQL]
Report additional information about DataSourceScanExec in EXPLAIN FORMATTED
URL: https://github.com/apache/spark/pull/26042#discussion_r333671047
##
File path:
sql/hive-thriftserver/src/test/scala/org/apache/spark/sql/hive/thriftserver/ThriftServerQueryTestSuite.scala
##
@@ -100,7 +100,8 @@ class ThriftServerQueryTestSuite extends SQLQueryTestSuite
{
"subquery/in-subquery/in-group-by.sql",
"subquery/in-subquery/simple-in.sql",
"subquery/in-subquery/in-order-by.sql",
-"subquery/in-subquery/in-set-operations.sql"
+"subquery/in-subquery/in-set-operations.sql",
+"explain.sql"
Review comment:
@cloud-fan Let me enable it and see.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dilipbiswal commented on a change in pull request #26042: [SPARK-29092][SQL] Report additional information about DataSourceScanExec in EXPLAIN FORMATTED
dilipbiswal commented on a change in pull request #26042: [SPARK-29092][SQL] Report additional information about DataSourceScanExec in EXPLAIN FORMATTED URL: https://github.com/apache/spark/pull/26042#discussion_r333670345 ## File path: sql/core/src/test/resources/sql-tests/results/explain.sql.out ## @@ -58,6 +58,11 @@ struct (1) Scan parquet default.explain_temp1 Output: [key#x, val#x] +Batched: true +Format: Parquet Review comment: @cloud-fan I can filter it. But wanted to double check first. The one we print in the node name is `relation.toString` and the one printed here is `relation.format.toString`. Are they going to be same always ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] brkyvz commented on issue #26071: [SPARK-29412][SQL] refine the document of v2 session catalog config
brkyvz commented on issue #26071: [SPARK-29412][SQL] refine the document of v2 session catalog config URL: https://github.com/apache/spark/pull/26071#issuecomment-540707191 LGTM as well This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] rdblue commented on issue #26071: [SPARK-29412][SQL] refine the document of v2 session catalog config
rdblue commented on issue #26071: [SPARK-29412][SQL] refine the document of v2 session catalog config URL: https://github.com/apache/spark/pull/26071#issuecomment-540704376 +1 Unless there are other comments, I'll merge this later today. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on issue #25994: [SPARK-29323][WEBUI] Add tooltip for The Executors Tab's column names in the Spark history server Page
srowen commented on issue #25994: [SPARK-29323][WEBUI] Add tooltip for The Executors Tab's column names in the Spark history server Page URL: https://github.com/apache/spark/pull/25994#issuecomment-540700641 We'll have to wait for Jenkins to come back, to evaluate this with tests, but I'm sure it will be OK. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen closed pull request #25994: [SPARK-29323][WEBUI] Add tooltip for The Executors Tab's column names in the Spark history server Page
srowen closed pull request #25994: [SPARK-29323][WEBUI] Add tooltip for The Executors Tab's column names in the Spark history server Page URL: https://github.com/apache/spark/pull/25994 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] liucht-inspur opened a new pull request #25994: [SPARK-29323][WEBUI] Add tooltip for The Executors Tab's column names in the Spark history server Page
liucht-inspur opened a new pull request #25994: [SPARK-29323][WEBUI] Add tooltip for The Executors Tab's column names in the Spark history server Page URL: https://github.com/apache/spark/pull/25994 ### What changes were proposed in this pull request? This PR is Adding tooltip for The Executors Tab's column names include RDD Blocks, Disk Used,Cores, Activity Tasks, Failed Tasks , Complete Tasks, Total Tasks in the history server Page. https://issues.apache.org/jira/browse/SPARK-29323  I have modify the following code in executorspage-template.html Before: RDD Blocks Disk Used Cores Active Tasks Failed Tasks Complete Tasks Total Tasks  After: RDD Blocks Disk Used Cores Active Tasks Failed Tasks Complete Tasks Total Tasks  ### Why are the changes needed? the spark Executors of history Tab page, the Summary part shows the line in the list of title, but format is irregular. Some column names have tooltip, such as Storage Memory, Task Time(GC Time), Input, Shuffle Read, Shuffle Write and Blacklisted, but there are still some list names that have not tooltip. They are RDD Blocks, Disk Used,Cores, Activity Tasks, Failed Tasks , Complete Tasks and Total Tasks. oddly, Executors section below,All the column names Contains the column names above have tooltip . It's important for open source projects to have consistent style and user-friendly UI, and I'm working on keeping it consistent And more user-friendly. ### Does this PR introduce any user-facing change? No. ### How was this patch tested? Manual tests for Chrome, Firefox and Safari Authored-by: liucht-inspur Signed-off-by: liucht-inspur This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] rafaelkyrdan commented on issue #19424: [SPARK-22197][SQL] push down operators to data source before planning
rafaelkyrdan commented on issue #19424: [SPARK-22197][SQL] push down operators
to data source before planning
URL: https://github.com/apache/spark/pull/19424#issuecomment-540687736
I think I found what I have to implement:
`
trait TableScan {
def buildScan(): RDD[Row]
}
`
am I right?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] tgravescs commented on issue #26083: [SPARK-29417][CORE] Resource Scheduling - add TaskContext.resource java api
tgravescs commented on issue #26083: [SPARK-29417][CORE] Resource Scheduling - add TaskContext.resource java api URL: https://github.com/apache/spark/pull/26083#issuecomment-540684613 @mengxr @jiangxb1987 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] tgravescs opened a new pull request #26083: [SPARK-29417][CORE] Resource Scheduling - add TaskContext.resource java api
tgravescs opened a new pull request #26083: [SPARK-29417][CORE] Resource Scheduling - add TaskContext.resource java api URL: https://github.com/apache/spark/pull/26083 ### What changes were proposed in this pull request? We added a TaskContext.resources() api, but I realized this is returning a scala Map which is not ideal for access from Java. Here I add a resourcesJMap function which returns a java.util.Map to make it easily accessible from Java. ### Why are the changes needed? Java API access ### Does this PR introduce any user-facing change? Yes, new TaskContext function to access from Java ### How was this patch tested? new unit test This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #24851: [SPARK-27303][GRAPH] Add Spark Graph API
dongjoon-hyun commented on issue #24851: [SPARK-27303][GRAPH] Add Spark Graph API URL: https://github.com/apache/spark/pull/24851#issuecomment-540683239 Thank you for the swift updates. I'll review this afternoon again. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24851: [SPARK-27303][GRAPH] Add Spark Graph API
dongjoon-hyun commented on a change in pull request #24851:
[SPARK-27303][GRAPH] Add Spark Graph API
URL: https://github.com/apache/spark/pull/24851#discussion_r42983
##
File path:
graph/api/src/main/scala/org/apache/spark/graph/api/PropertyGraphWriter.scala
##
@@ -0,0 +1,92 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.graph.api
+
+import java.util.Locale
+
+import org.apache.spark.sql.SaveMode
+
+abstract class PropertyGraphWriter(val graph: PropertyGraph) {
+
+ protected var saveMode: SaveMode = SaveMode.ErrorIfExists
+ protected var format: String =
+graph.cypherSession.sparkSession.sessionState.conf.defaultDataSourceName
+
+ /**
+ * Specifies the behavior when the graph already exists. Options include:
+ *
+ * `SaveMode.Overwrite`: overwrite the existing data.
+ * `SaveMode.Ignore`: ignore the operation (i.e. no-op).
+ * `SaveMode.ErrorIfExists`: throw an exception at runtime.
+ *
+ *
+ * When writing the default option is `ErrorIfExists`.
+ *
+ * @since 3.0.0
+ */
+ def mode(mode: SaveMode): PropertyGraphWriter = {
+mode match {
+ case SaveMode.Append =>
+throw new IllegalArgumentException(s"Unsupported save mode: $mode. " +
+ "Accepted save modes are 'overwrite', 'ignore', 'error',
'errorifexists'.")
+ case _ =>
+this.saveMode = mode
+}
+this
+ }
+
+ /**
+ * Specifies the behavior when the graph already exists. Options include:
+ *
+ * `overwrite`: overwrite the existing graph.
+ * `ignore`: ignore the operation (i.e. no-op).
+ * `error` or `errorifexists`: default option, throw an exception at
runtime.
+ *
+ *
+ * @since 3.0.0
+ */
+ def mode(saveMode: String): PropertyGraphWriter = {
+saveMode.toLowerCase(Locale.ROOT) match {
+ case "overwrite" => mode(SaveMode.Overwrite)
+ case "ignore" => mode(SaveMode.Ignore)
+ case "error" | "errorifexists" => mode(SaveMode.ErrorIfExists)
+ case "default" => this
Review comment:
Ur, this can be wrong in case of `mode("overwrite").mode("default")`. Please
merge `default` to the line 67. Please add a test case for this, too.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 commented on a change in pull request #25943: [WIP][SPARK-29261][SQL][CORE] Support recover live entities from KVStore for (SQL)AppStatusListener
Ngone51 commented on a change in pull request #25943:
[WIP][SPARK-29261][SQL][CORE] Support recover live entities from KVStore for
(SQL)AppStatusListener
URL: https://github.com/apache/spark/pull/25943#discussion_r333634637
##
File path: core/src/main/scala/org/apache/spark/status/storeTypes.scala
##
@@ -76,6 +109,29 @@ private[spark] class JobDataWrapper(
@JsonIgnore @KVIndex("completionTime")
private def completionTime: Long =
info.completionTime.map(_.getTime).getOrElse(-1L)
+
+ def toLiveJob: LiveJob = {
Review comment:
While converting `LiveJob` to `JobDataWrapper`, only
`completedIndices.size`/`completedStages.size` are written into KVStore. So,
it's impossible to recover the detail `completedIndices`/`completedStages`. So,
as a compromises, we only recover the number in this case.
And this brings a problem that the recovered live job wouldn't be 100% the
same as the previous one. But, this can be acceptable when you look at
their(`completedIndices`, `completedStages`) usages in `AppStatusListener`, as
it does not mistake the final result(that is number).
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #26028: [SPARK-29359][SQL][TESTS] Better exception handling in (SQL|ThriftServer)QueryTestSuite
dongjoon-hyun commented on issue #26028: [SPARK-29359][SQL][TESTS] Better exception handling in (SQL|ThriftServer)QueryTestSuite URL: https://github.com/apache/spark/pull/26028#issuecomment-540667842 Hi, @wangyum . You can merge this after manual testing. Or, we can wait until our Jenkins is back again. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] planga82 opened a new pull request #26082: [SPARK-29431][WebUI] Improve Web UI / Sql tab visualization with cached dataframes.
planga82 opened a new pull request #26082: [SPARK-29431][WebUI] Improve Web UI / Sql tab visualization with cached dataframes. URL: https://github.com/apache/spark/pull/26082 ### What changes were proposed in this pull request? With this pull request I want to improve the Web UI / SQL tab visualization. The principal problem that I find is when you have a cache in your plan, the SQL visualization don’t show any information about the part of the plan that has been cached. Before the change 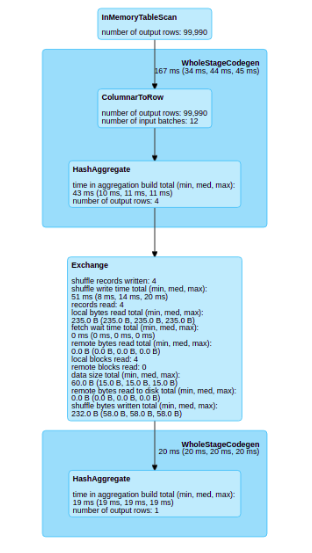 After the change  ### Why are the changes needed? When we have a SQL plan with cached dataframes we lose the graphical information of this dataframe in the sql tab ### Does this PR introduce any user-facing change? Yes, in the sql tab ### How was this patch tested? Unit testing and manual tests throught spark shell This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] rafaelkyrdan commented on issue #19424: [SPARK-22197][SQL] push down operators to data source before planning
rafaelkyrdan commented on issue #19424: [SPARK-22197][SQL] push down operators to data source before planning URL: https://github.com/apache/spark/pull/19424#issuecomment-540666492 @cloud-fan I'm wondering whether it is not a priority or it wasn't easy to implement? If I want to implement it what class/interface should I extend? Is it possible to do it in a custom `JDBC` source? Do you have any suggestions? The use case looks like this: there are 50M records in the DB I wanna select only 1M why I should read all of them? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on a change in pull request #26065: [SPARK-29404][DOCS] Add an explanation about the executor color changed in WebUI documentation
srowen commented on a change in pull request #26065: [SPARK-29404][DOCS] Add an explanation about the executor color changed in WebUI documentation URL: https://github.com/apache/spark/pull/26065#discussion_r333611603 ## File path: docs/web-ui.md ## @@ -51,12 +51,17 @@ The information that is displayed in this section is -* Details of jobs grouped by status: Displays detailed information of the jobs including Job ID, description (with a link to detailed job page), submitted time, duration, stages summary and tasks progress bar +When you click on a executor, you can make the color darker to point it at. Review comment: No, I just don't think it's meaningful enough to try to explain, and the new text above is incorrect too. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 commented on a change in pull request #25943: [WIP][SPARK-29261][SQL][CORE] Support recover live entities from KVStore for (SQL)AppStatusListener
Ngone51 commented on a change in pull request #25943:
[WIP][SPARK-29261][SQL][CORE] Support recover live entities from KVStore for
(SQL)AppStatusListener
URL: https://github.com/apache/spark/pull/25943#discussion_r333611704
##
File path: core/src/main/scala/org/apache/spark/status/AppStatusListener.scala
##
@@ -103,6 +104,81 @@ private[spark] class AppStatusListener(
}
}
+ // visible for tests
+ private[spark] def recoverLiveEntities(): Unit = {
+if (!live) {
+ kvstore.view(classOf[JobDataWrapper])
+.asScala.filter(_.info.status == JobExecutionStatus.RUNNING)
Review comment:
Yeah. I didn't see any place we set Job status to `UNKNOWN`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 commented on a change in pull request #25943: [WIP][SPARK-29261][SQL][CORE] Support recover live entities from KVStore for (SQL)AppStatusListener
Ngone51 commented on a change in pull request #25943:
[WIP][SPARK-29261][SQL][CORE] Support recover live entities from KVStore for
(SQL)AppStatusListener
URL: https://github.com/apache/spark/pull/25943#discussion_r333610531
##
File path: core/src/main/scala/org/apache/spark/status/AppStatusListener.scala
##
@@ -103,6 +104,81 @@ private[spark] class AppStatusListener(
}
}
+ // visible for tests
+ private[spark] def recoverLiveEntities(): Unit = {
+if (!live) {
+ kvstore.view(classOf[JobDataWrapper])
+.asScala.filter(_.info.status == JobExecutionStatus.RUNNING)
+.map(_.toLiveJob).foreach(job => liveJobs.put(job.jobId, job))
+
+ kvstore.view(classOf[StageDataWrapper]).asScala
+.filter { stageData =>
+ stageData.info.status == v1.StageStatus.PENDING ||
+stageData.info.status == v1.StageStatus.ACTIVE
+}
+.map { stageData =>
+ val stageId = stageData.info.stageId
+ val jobs = liveJobs.values.filter(_.stageIds.contains(stageId)).toSeq
+ stageData.toLiveStage(jobs)
+}.foreach { stage =>
+val stageId = stage.info.stageId
+val stageAttempt = stage.info.attemptNumber()
+liveStages.put((stageId, stageAttempt), stage)
+
+kvstore.view(classOf[ExecutorStageSummaryWrapper])
+ .index("stage")
+ .first(Array(stageId, stageAttempt))
+ .last(Array(stageId, stageAttempt))
+ .asScala
+ .map(_.toLiveExecutorStageSummary)
+ .foreach { esummary =>
+stage.executorSummaries.put(esummary.executorId, esummary)
+if (esummary.isBlacklisted) {
+ stage.blackListedExecutors += esummary.executorId
+ liveExecutors(esummary.executorId).isBlacklisted = true
+ liveExecutors(esummary.executorId).blacklistedInStages += stageId
+}
+ }
+
+
+kvstore.view(classOf[TaskDataWrapper])
+ .parent(Array(stageId, stageAttempt))
+ .index(TaskIndexNames.STATUS)
+ .first(TaskState.RUNNING.toString)
Review comment:
Ignore `LAUNCHING` is safe, because `status` in `TaskDataWrapper` is
actually from `LiveTask.TaskInfo.status`:
https://github.com/apache/spark/blob/e1ea806b3075d279b5f08a29fe4c1ad6d3c4191a/core/src/main/scala/org/apache/spark/scheduler/TaskInfo.scala#L96-L112
And there's no `LAUNCHING`.
Another available running status is `GET RESULT`. But this also seems
impossible. `TaskInfo` in `LiveTask` is only updated when
`SparkListenerTaskStart` and `SparkListenerTaskEnd` events comes. And these two
events don't change task's status to `GET RESULT`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #26081: [SPARK-29032][FOLLOWUP][DOCS] Add PrometheusServlet in the monitoring documentation
dongjoon-hyun closed pull request #26081: [SPARK-29032][FOLLOWUP][DOCS] Add PrometheusServlet in the monitoring documentation URL: https://github.com/apache/spark/pull/26081 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #26081: [SPARK-29032][FOLLOWUP][DOC] Document PrometheusServlet in the monitoring documentation
dongjoon-hyun commented on issue #26081: [SPARK-29032][FOLLOWUP][DOC] Document PrometheusServlet in the monitoring documentation URL: https://github.com/apache/spark/pull/26081#issuecomment-540653620 +1, LGTM. Thanks for the interest. Merged to master. Actually, I'm working on the full document, too. Please wait for one day~ :) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #26060: [SPARK-29400][CORE] Improve PrometheusResource to use labels
dongjoon-hyun closed pull request #26060: [SPARK-29400][CORE] Improve PrometheusResource to use labels URL: https://github.com/apache/spark/pull/26060 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 commented on a change in pull request #25943: [WIP][SPARK-29261][SQL][CORE] Support recover live entities from KVStore for (SQL)AppStatusListener
Ngone51 commented on a change in pull request #25943:
[WIP][SPARK-29261][SQL][CORE] Support recover live entities from KVStore for
(SQL)AppStatusListener
URL: https://github.com/apache/spark/pull/25943#discussion_r333598202
##
File path: core/src/main/scala/org/apache/spark/status/AppStatusListener.scala
##
@@ -103,6 +104,81 @@ private[spark] class AppStatusListener(
}
}
+ // visible for tests
+ private[spark] def recoverLiveEntities(): Unit = {
+if (!live) {
+ kvstore.view(classOf[JobDataWrapper])
+.asScala.filter(_.info.status == JobExecutionStatus.RUNNING)
+.map(_.toLiveJob).foreach(job => liveJobs.put(job.jobId, job))
+
+ kvstore.view(classOf[StageDataWrapper]).asScala
+.filter { stageData =>
+ stageData.info.status == v1.StageStatus.PENDING ||
+stageData.info.status == v1.StageStatus.ACTIVE
+}
+.map { stageData =>
+ val stageId = stageData.info.stageId
+ val jobs = liveJobs.values.filter(_.stageIds.contains(stageId)).toSeq
+ stageData.toLiveStage(jobs)
+}.foreach { stage =>
+val stageId = stage.info.stageId
+val stageAttempt = stage.info.attemptNumber()
+liveStages.put((stageId, stageAttempt), stage)
Review comment:
Yeah. But for now, I'd prefer to use Tuple2 (stageId, stageAttempt) as
`AppStatusListener` already do. And we could leave such optimization in a
separate PR later.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #26060: [SPARK-29400][CORE] Improve PrometheusResource to use labels
dongjoon-hyun commented on issue #26060: [SPARK-29400][CORE] Improve PrometheusResource to use labels URL: https://github.com/apache/spark/pull/26060#issuecomment-540649306 Thank you all, @yuecong , @viirya , @srowen , @HyukjinKwon . Merged to master. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 commented on a change in pull request #25943: [WIP][SPARK-29261][SQL][CORE] Support recover live entities from KVStore for (SQL)AppStatusListener
Ngone51 commented on a change in pull request #25943: [WIP][SPARK-29261][SQL][CORE] Support recover live entities from KVStore for (SQL)AppStatusListener URL: https://github.com/apache/spark/pull/25943#discussion_r333596849 ## File path: core/src/main/scala/org/apache/spark/status/api/v1/api.scala ## @@ -181,6 +182,7 @@ class RDDStorageInfo private[spark]( val partitions: Option[Seq[RDDPartitionInfo]]) class RDDDataDistribution private[spark]( +val executorId: String, Review comment: Hi @squito, thanks for providing the api versioning requirements. That's really helpful. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 commented on a change in pull request #25943: [WIP][SPARK-29261][SQL][CORE] Support recover live entities from KVStore for (SQL)AppStatusListener
Ngone51 commented on a change in pull request #25943:
[WIP][SPARK-29261][SQL][CORE] Support recover live entities from KVStore for
(SQL)AppStatusListener
URL: https://github.com/apache/spark/pull/25943#discussion_r333596371
##
File path: core/src/main/scala/org/apache/spark/storage/StorageLevel.scala
##
@@ -163,6 +163,20 @@ object StorageLevel {
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
+ /**
+ * :: DeveloperApi ::
+ * Return the StorageLevel object with the specified description.
+ */
+ @DeveloperApi
+ def fromDescription(desc: String): StorageLevel = {
Review comment:
Good suggestion, I'll add a unit test for it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 commented on issue #25943: [WIP][SPARK-29261][SQL][CORE] Support recover live entities from KVStore for (SQL)AppStatusListener
Ngone51 commented on issue #25943: [WIP][SPARK-29261][SQL][CORE] Support recover live entities from KVStore for (SQL)AppStatusListener URL: https://github.com/apache/spark/pull/25943#issuecomment-540647353 @squito > Sorry I am getting caught up on a lot of stuff here -- how is this related to #25577 ? This PR just extracts recovering live entities functionality from #25577. > Just for storing live entities, this approach seems more promising to me -- using Java serialization is really bad for compatibility, any changes to classes will break deserialization. If we want the snapshot / checkpoint files to be able to entirely replace the event log files, we'll need the compatibility. Hmm...This PR doesn't store live entities, instead, it recovers (or say, restore) live entities from a KVStore. For snapshot / checkpoint files, I think @HeartSaVioR has already posted a good solution in #25811, which has good compatibility for serialization/de-serialization. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] nonsleepr commented on a change in pull request #26000: [SPARK-29330][CORE][YARN] Allow users to chose the name of Spark Shuffle service
nonsleepr commented on a change in pull request #26000: [SPARK-29330][CORE][YARN] Allow users to chose the name of Spark Shuffle service URL: https://github.com/apache/spark/pull/26000#discussion_r333594674 ## File path: docs/running-on-yarn.md ## @@ -492,6 +492,13 @@ To use a custom metrics.properties for the application master and executors, upd If it is not set then the YARN application ID is used. + + spark.yarn.shuffle.service.name + spark_shuffle + +Name of the external shuffle service. Review comment: That's what "external" word is for, isn't it? Should I reword it as follows? > Name of the external shuffle service used by executors. *The external service is configured and started by YARN (see [Configuring the External Shuffle Service](#configuring-the-external-shuffle-service) for details). Apache Spark distribution uses name `spark_shuffle`, but other distributions (e.g. HDP) might use other names.* This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] tgravescs commented on a change in pull request #26078: [SPARK-29151][CORE] Support fractional resources for task resource scheduling
tgravescs commented on a change in pull request #26078: [SPARK-29151][CORE]
Support fractional resources for task resource scheduling
URL: https://github.com/apache/spark/pull/26078#discussion_r333581119
##
File path: core/src/main/scala/org/apache/spark/SparkContext.scala
##
@@ -2775,7 +2775,10 @@ object SparkContext extends Logging {
s" = ${taskReq.amount}")
}
// Compare and update the max slots each executor can provide.
-val resourceNumSlots = execAmount / taskReq.amount
+// If the configured amount per task was < 1.0, a task is subdividing
+// executor resources. If the amount per task was > 1.0, the task wants
+// multiple executor resources.
+val resourceNumSlots = Math.floor(execAmount *
taskReq.numParts/taskReq.amount).toInt
Review comment:
add spaces around the "/"
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] tgravescs commented on a change in pull request #26078: [SPARK-29151][CORE] Support fractional resources for task resource scheduling
tgravescs commented on a change in pull request #26078: [SPARK-29151][CORE]
Support fractional resources for task resource scheduling
URL: https://github.com/apache/spark/pull/26078#discussion_r333539938
##
File path: docs/configuration.md
##
@@ -1982,9 +1982,13 @@ Apart from these, the following properties are also
available, and may be useful
spark.task.resource.{resourceName}.amount
1
-Amount of a particular resource type to allocate for each task. If this is
specified
-you must also provide the executor config
spark.executor.resource.{resourceName}.amount
-and any corresponding discovery configs so that your executors are created
with that resource type.
+Amount of a particular resource type to allocate for each task, note that
this can be a double.
+If this is specified you must also provide the executor config
+spark.executor.resource.{resourceName}.amount and any
corresponding discovery configs
+so that your executors are created with that resource type. In addition to
whole amounts,
+a fractional amount (for example, 0.25, or 1/4th of a resource) may be
specified.
Review comment:
change "or 1/4th" to something like "which means 1/4th". They way I read
the or makes me question is I can pass in "1/4" to the config, just want it to
be clear.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] tgravescs commented on a change in pull request #26078: [SPARK-29151][CORE] Support fractional resources for task resource scheduling
tgravescs commented on a change in pull request #26078: [SPARK-29151][CORE]
Support fractional resources for task resource scheduling
URL: https://github.com/apache/spark/pull/26078#discussion_r333571682
##
File path:
core/src/main/scala/org/apache/spark/scheduler/ExecutorResourceInfo.scala
##
@@ -25,10 +25,13 @@ import org.apache.spark.resource.{ResourceAllocator,
ResourceInformation}
* information.
* @param name Resource name
* @param addresses Resource addresses provided by the executor
+ * @param numParts Number of ways each resource is subdivided when scheduling
tasks
*/
-private[spark] class ExecutorResourceInfo(name: String, addresses: Seq[String])
+private[spark] class ExecutorResourceInfo(name: String, addresses: Seq[String],
+ numParts: Int)
Review comment:
fix formatting, should be 4 spaces idented from left
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] tgravescs commented on a change in pull request #26078: [SPARK-29151][CORE] Support fractional resources for task resource scheduling
tgravescs commented on a change in pull request #26078: [SPARK-29151][CORE]
Support fractional resources for task resource scheduling
URL: https://github.com/apache/spark/pull/26078#discussion_r333586973
##
File path:
core/src/main/scala/org/apache/spark/scheduler/cluster/CoarseGrainedSchedulerBackend.scala
##
@@ -215,7 +217,14 @@ class CoarseGrainedSchedulerBackend(scheduler:
TaskSchedulerImpl, val rpcEnv: Rp
totalCoreCount.addAndGet(cores)
totalRegisteredExecutors.addAndGet(1)
val resourcesInfo = resources.map{ case (k, v) =>
-(v.name, new ExecutorResourceInfo(v.name, v.addresses))}
+(v.name,
+ new ExecutorResourceInfo(v.name, v.addresses,
+ taskResources
Review comment:
instead of doing this filter each time how about we convert taskResources
into a Map (and rename it) one time at the top when its declared and then just
lookup in the map here.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] tgravescs commented on a change in pull request #26078: [SPARK-29151][CORE] Support fractional resources for task resource scheduling
tgravescs commented on a change in pull request #26078: [SPARK-29151][CORE] Support fractional resources for task resource scheduling URL: https://github.com/apache/spark/pull/26078#discussion_r333538698 ## File path: core/src/main/scala/org/apache/spark/resource/ResourceUtils.scala ## @@ -47,7 +48,9 @@ private[spark] case class ResourceRequest( discoveryScript: Option[String], vendor: Option[String]) -private[spark] case class ResourceRequirement(resourceName: String, amount: Int) +private[spark] case class ResourceRequirement(resourceName: String, amount: Int, Review comment: lets add description, especially explaining numParts and amount. Mention fractional use case where amount is user specified get changed to 1 and numParts is the number per resource equivalent. Also need to fix formatting. Please use formatting like ResourceRequest above This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] tgravescs commented on a change in pull request #26078: [SPARK-29151][CORE] Support fractional resources for task resource scheduling
tgravescs commented on a change in pull request #26078: [SPARK-29151][CORE]
Support fractional resources for task resource scheduling
URL: https://github.com/apache/spark/pull/26078#discussion_r333564756
##
File path: docs/configuration.md
##
@@ -1982,9 +1982,13 @@ Apart from these, the following properties are also
available, and may be useful
spark.task.resource.{resourceName}.amount
1
-Amount of a particular resource type to allocate for each task. If this is
specified
-you must also provide the executor config
spark.executor.resource.{resourceName}.amount
-and any corresponding discovery configs so that your executors are created
with that resource type.
+Amount of a particular resource type to allocate for each task, note that
this can be a double.
+If this is specified you must also provide the executor config
+spark.executor.resource.{resourceName}.amount and any
corresponding discovery configs
+so that your executors are created with that resource type. In addition to
whole amounts,
+a fractional amount (for example, 0.25, or 1/4th of a resource) may be
specified.
+Fractional amounts must be less than or equal to 0.5, or in other words,
the minimum amount of
Review comment:
we should also add that any fractional value specified gets rounded to have
an even number of tasks per resource. ie 0. end up with 4 tasks per
resource
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] tgravescs commented on a change in pull request #26078: [SPARK-29151][CORE] Support fractional resources for task resource scheduling
tgravescs commented on a change in pull request #26078: [SPARK-29151][CORE]
Support fractional resources for task resource scheduling
URL: https://github.com/apache/spark/pull/26078#discussion_r333582986
##
File path:
core/src/main/scala/org/apache/spark/resource/ResourceAllocator.scala
##
@@ -30,27 +30,35 @@ trait ResourceAllocator {
protected def resourceName: String
protected def resourceAddresses: Seq[String]
+ protected def resourcesPerAddress: Int
/**
- * Map from an address to its availability, the value `true` means the
address is available,
- * while value `false` means the address is assigned.
+ * Map from an address to its availability, a value > 0 means the address is
available,
+ * while value of 0 means the address is fully assigned.
+ *
+ * For task resources ([[org.apache.spark.scheduler.ExecutorResourceInfo]]),
this value
+ * can be fractional.
Review comment:
I think we should clarify, here its actually not fractional its a multiple.
I think if its called tasksPerAddress that will help
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] tgravescs commented on a change in pull request #26078: [SPARK-29151][CORE] Support fractional resources for task resource scheduling
tgravescs commented on a change in pull request #26078: [SPARK-29151][CORE]
Support fractional resources for task resource scheduling
URL: https://github.com/apache/spark/pull/26078#discussion_r333574367
##
File path:
core/src/main/scala/org/apache/spark/scheduler/ExecutorResourceInfo.scala
##
@@ -25,10 +25,13 @@ import org.apache.spark.resource.{ResourceAllocator,
ResourceInformation}
* information.
* @param name Resource name
* @param addresses Resource addresses provided by the executor
+ * @param numParts Number of ways each resource is subdivided when scheduling
tasks
*/
-private[spark] class ExecutorResourceInfo(name: String, addresses: Seq[String])
+private[spark] class ExecutorResourceInfo(name: String, addresses: Seq[String],
+ numParts: Int)
extends ResourceInformation(name, addresses.toArray) with ResourceAllocator {
override protected def resourceName = this.name
override protected def resourceAddresses = this.addresses
+ override protected def resourcesPerAddress = numParts
Review comment:
I think we should rename. resourcesPerAddress could be confusing since an
address is a single resource.
I'm thinking we just call this tasksPerAddress and perhaps update this to be
consistent everywhere - ie rename numParts as well.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] viirya commented on issue #25979: [SPARK-29295][SQL] Insert overwrite to Hive external table partition should delete old data
viirya commented on issue #25979: [SPARK-29295][SQL] Insert overwrite to Hive external table partition should delete old data URL: https://github.com/apache/spark/pull/25979#issuecomment-540638149 @cloud-fan @felixcheung Do you have more comments on this? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL] Support string intervals without the `interval` prefix
MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL]
Support string intervals without the `interval` prefix
URL: https://github.com/apache/spark/pull/26079#discussion_r333579599
##
File path:
common/unsafe/src/main/java/org/apache/spark/unsafe/types/CalendarInterval.java
##
@@ -73,45 +72,53 @@ private static long toLong(String s) {
* This method is case-insensitive.
*/
public static CalendarInterval fromString(String s) {
-if (s == null) {
- return null;
-}
-s = s.trim();
-Matcher m = p.matcher(s);
-if (!m.matches() || s.compareToIgnoreCase("interval") == 0) {
+try {
+ return fromCaseInsensitiveString(s);
+} catch (IllegalArgumentException e) {
return null;
-} else {
- long months = toLong(m.group(1)) * 12 + toLong(m.group(2));
- long microseconds = toLong(m.group(3)) * MICROS_PER_WEEK;
- microseconds += toLong(m.group(4)) * MICROS_PER_DAY;
- microseconds += toLong(m.group(5)) * MICROS_PER_HOUR;
- microseconds += toLong(m.group(6)) * MICROS_PER_MINUTE;
- microseconds += toLong(m.group(7)) * MICROS_PER_SECOND;
- microseconds += toLong(m.group(8)) * MICROS_PER_MILLI;
- microseconds += toLong(m.group(9));
- return new CalendarInterval((int) months, microseconds);
}
}
/**
- * Convert a string to CalendarInterval. Unlike fromString, this method can
handle
+ * Convert a string to CalendarInterval. This method can handle
* strings without the `interval` prefix and throws IllegalArgumentException
* when the input string is not a valid interval.
*
* @throws IllegalArgumentException if the string is not a valid internal.
*/
public static CalendarInterval fromCaseInsensitiveString(String s) {
-if (s == null || s.trim().isEmpty()) {
- throw new IllegalArgumentException("Interval cannot be null or blank.");
+if (s == null) {
+ throw new IllegalArgumentException("Interval cannot be null");
}
-String sInLowerCase = s.trim().toLowerCase(Locale.ROOT);
-String interval =
- sInLowerCase.startsWith("interval ") ? sInLowerCase : "interval " +
sInLowerCase;
-CalendarInterval cal = fromString(interval);
-if (cal == null) {
+String trimmed = s.trim();
+if (trimmed.isEmpty()) {
+ throw new IllegalArgumentException("Interval cannot be blank");
+}
+String prefix = "interval";
+String intervalStr = trimmed;
+// Checks the given interval string does not start with the `interval`
prefix
+if (!intervalStr.regionMatches(true, 0, prefix, 0, prefix.length())) {
+ // Prepend `interval` if it does not present because
+ // the regular expression strictly require it.
Review comment:
> String intervalStr = trimmed.toLowerCase();
Your code is more expensive because you lower case whole input string.
> // parse the interval string assuming there is no leading "interval"
Here there is a problem with current regexp when you delete the anchor
`"interval"`. Without this anchor, it cannot match to valid inputs:
```scala
scala> import java.util.regex._
import java.util.regex._
scala> def unitRegex(unit: String) = "(?:\\s+(-?\\d+)\\s+" + unit + "s?)?"
unitRegex: (unit: String)String
scala> val p = Pattern.compile(unitRegex("year") + unitRegex("month") +
| unitRegex("week") + unitRegex("day") + unitRegex("hour") +
unitRegex("minute") +
| unitRegex("second") + unitRegex("millisecond") +
unitRegex("microsecond"),
| Pattern.CASE_INSENSITIVE)
p: java.util.regex.Pattern =
(?:\s+(-?\d+)\s+years?)?(?:\s+(-?\d+)\s+months?)?(?:\s+(-?\d+)\s+weeks?)?(?:\s+(-?\d+)\s+days?)?(?:\s+(-?\d+)\s+hours?)?(?:\s+(-?\d+)\s+minutes?)?(?:\s+(-?\d+)\s+seconds?)?(?:\s+(-?\d+)\s+milliseconds?)?(?:\s+(-?\d+)\s+microseconds?)?
scala> val m = p.matcher("1 month 1 second")
m: java.util.regex.Matcher =
java.util.regex.Matcher[pattern=(?:\s+(-?\d+)\s+years?)?(?:\s+(-?\d+)\s+months?)?(?:\s+(-?\d+)\s+weeks?)?(?:\s+(-?\d+)\s+days?)?(?:\s+(-?\d+)\s+hours?)?(?:\s+(-?\d+)\s+minutes?)?(?:\s+(-?\d+)\s+seconds?)?(?:\s+(-?\d+)\s+milliseconds?)?(?:\s+(-?\d+)\s+microseconds?)?
region=0,16 lastmatch=]
scala> m.matches()
res7: Boolean = false
```
If we added it back:
```scala
scala> val p = Pattern.compile("interval" + unitRegex("year") +
unitRegex("month") +
| unitRegex("week") + unitRegex("day") + unitRegex("hour") +
unitRegex("minute") +
| unitRegex("second") + unitRegex("millisecond") +
unitRegex("microsecond"),
| Pattern.CASE_INSENSITIVE)
p: java.util.regex.Pattern =
interval(?:\s+(-?\d+)\s+years?)?(?:\s+(-?\d+)\s+months?)?(?:\s+(-?\d+)\s+weeks?)?(?:\s+(-?\d+)\s+days?)?(?:\s+(-?\d+)\s+hours?)?(?:\s+(-?\d+)\s+minutes?)?(?:\s+(-?\d+)\s+seconds?)?(?:\s+(-?\d+)\s+milliseconds?)?(?:\s+(-?\d+)\s+microseconds?)?
scala> val m = p.matcher("interval 1
[GitHub] [spark] cloud-fan commented on a change in pull request #26079: [SPARK-29369][SQL] Support string intervals without the `interval` prefix
cloud-fan commented on a change in pull request #26079: [SPARK-29369][SQL]
Support string intervals without the `interval` prefix
URL: https://github.com/apache/spark/pull/26079#discussion_r333562923
##
File path:
common/unsafe/src/main/java/org/apache/spark/unsafe/types/CalendarInterval.java
##
@@ -73,45 +72,53 @@ private static long toLong(String s) {
* This method is case-insensitive.
*/
public static CalendarInterval fromString(String s) {
-if (s == null) {
- return null;
-}
-s = s.trim();
-Matcher m = p.matcher(s);
-if (!m.matches() || s.compareToIgnoreCase("interval") == 0) {
+try {
+ return fromCaseInsensitiveString(s);
+} catch (IllegalArgumentException e) {
return null;
-} else {
- long months = toLong(m.group(1)) * 12 + toLong(m.group(2));
- long microseconds = toLong(m.group(3)) * MICROS_PER_WEEK;
- microseconds += toLong(m.group(4)) * MICROS_PER_DAY;
- microseconds += toLong(m.group(5)) * MICROS_PER_HOUR;
- microseconds += toLong(m.group(6)) * MICROS_PER_MINUTE;
- microseconds += toLong(m.group(7)) * MICROS_PER_SECOND;
- microseconds += toLong(m.group(8)) * MICROS_PER_MILLI;
- microseconds += toLong(m.group(9));
- return new CalendarInterval((int) months, microseconds);
}
}
/**
- * Convert a string to CalendarInterval. Unlike fromString, this method can
handle
+ * Convert a string to CalendarInterval. This method can handle
* strings without the `interval` prefix and throws IllegalArgumentException
* when the input string is not a valid interval.
*
* @throws IllegalArgumentException if the string is not a valid internal.
*/
public static CalendarInterval fromCaseInsensitiveString(String s) {
-if (s == null || s.trim().isEmpty()) {
- throw new IllegalArgumentException("Interval cannot be null or blank.");
+if (s == null) {
+ throw new IllegalArgumentException("Interval cannot be null");
}
-String sInLowerCase = s.trim().toLowerCase(Locale.ROOT);
-String interval =
- sInLowerCase.startsWith("interval ") ? sInLowerCase : "interval " +
sInLowerCase;
-CalendarInterval cal = fromString(interval);
-if (cal == null) {
+String trimmed = s.trim();
+if (trimmed.isEmpty()) {
+ throw new IllegalArgumentException("Interval cannot be blank");
+}
+String prefix = "interval";
+String intervalStr = trimmed;
+// Checks the given interval string does not start with the `interval`
prefix
+if (!intervalStr.regionMatches(true, 0, prefix, 0, prefix.length())) {
+ // Prepend `interval` if it does not present because
+ // the regular expression strictly require it.
Review comment:
How about something like
```
String intervalStr = trimmed.toLowerCase();
if (intervalStr.startsWith("interval")) {
intervalStr = intervalStr.drop(8)
}
// parse the interval string assuming there is no leading "interval"
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #26079: [SPARK-29369][SQL] Support string intervals without the `interval` prefix
cloud-fan commented on a change in pull request #26079: [SPARK-29369][SQL]
Support string intervals without the `interval` prefix
URL: https://github.com/apache/spark/pull/26079#discussion_r333562923
##
File path:
common/unsafe/src/main/java/org/apache/spark/unsafe/types/CalendarInterval.java
##
@@ -73,45 +72,53 @@ private static long toLong(String s) {
* This method is case-insensitive.
*/
public static CalendarInterval fromString(String s) {
-if (s == null) {
- return null;
-}
-s = s.trim();
-Matcher m = p.matcher(s);
-if (!m.matches() || s.compareToIgnoreCase("interval") == 0) {
+try {
+ return fromCaseInsensitiveString(s);
+} catch (IllegalArgumentException e) {
return null;
-} else {
- long months = toLong(m.group(1)) * 12 + toLong(m.group(2));
- long microseconds = toLong(m.group(3)) * MICROS_PER_WEEK;
- microseconds += toLong(m.group(4)) * MICROS_PER_DAY;
- microseconds += toLong(m.group(5)) * MICROS_PER_HOUR;
- microseconds += toLong(m.group(6)) * MICROS_PER_MINUTE;
- microseconds += toLong(m.group(7)) * MICROS_PER_SECOND;
- microseconds += toLong(m.group(8)) * MICROS_PER_MILLI;
- microseconds += toLong(m.group(9));
- return new CalendarInterval((int) months, microseconds);
}
}
/**
- * Convert a string to CalendarInterval. Unlike fromString, this method can
handle
+ * Convert a string to CalendarInterval. This method can handle
* strings without the `interval` prefix and throws IllegalArgumentException
* when the input string is not a valid interval.
*
* @throws IllegalArgumentException if the string is not a valid internal.
*/
public static CalendarInterval fromCaseInsensitiveString(String s) {
-if (s == null || s.trim().isEmpty()) {
- throw new IllegalArgumentException("Interval cannot be null or blank.");
+if (s == null) {
+ throw new IllegalArgumentException("Interval cannot be null");
}
-String sInLowerCase = s.trim().toLowerCase(Locale.ROOT);
-String interval =
- sInLowerCase.startsWith("interval ") ? sInLowerCase : "interval " +
sInLowerCase;
-CalendarInterval cal = fromString(interval);
-if (cal == null) {
+String trimmed = s.trim();
+if (trimmed.isEmpty()) {
+ throw new IllegalArgumentException("Interval cannot be blank");
+}
+String prefix = "interval";
+String intervalStr = trimmed;
+// Checks the given interval string does not start with the `interval`
prefix
+if (!intervalStr.regionMatches(true, 0, prefix, 0, prefix.length())) {
+ // Prepend `interval` if it does not present because
+ // the regular expression strictly require it.
Review comment:
How about something like
```
String intervalStr = trimmed.toLowerCase();
if (intervalStr.startsWith("interval")) {
intervalStr = intervalStr.drop(8)
}
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jkremser edited a comment on issue #26075: [WIP][K8S] Spark operator
jkremser edited a comment on issue #26075: [WIP][K8S] Spark operator URL: https://github.com/apache/spark/pull/26075#issuecomment-540605666 Thanks for looking into this. Ok, I will open the discussion on the dev list. I wanted to have the PR open before the summit and put the link on the slides. And yes, it's basically dump of that repo (radanalyticsio/spark-operator) with couple of modifications. I for instance aligned the versions of the libraries to be the same as those that are used by Spark. > Is this the following? Please give a clear explanation if this is your own contribution. https://github.com/GoogleCloudPlatform/spark-on-k8s-operator No, it's different operator written in Java (GCP's one is in Go) and it supports three different custom resources, `SparkCluster` (spark running in standalone mode in the pods), `SparkApplication` (this has the same API as the operator from GCP, so it's using spark-on-k8s scheduling) and `SparkHistoryServer`. So there is some overlap, but it's a different thing. This operator is also available on [operatorhub.io](operatorhub.io) ([link](https://operatorhub.io/operator/radanalytics-spark)) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] jkremser commented on issue #26075: [WIP][K8S] Spark operator
jkremser commented on issue #26075: [WIP][K8S] Spark operator URL: https://github.com/apache/spark/pull/26075#issuecomment-540605666 Thanks for looking into this. Ok, I will open the discussion on the dev list. I wanted to have the PR open before the summit and put the link on the slides. And yes, it's basically dump of that repo (radanalyticsio/spark-operator) with couple of modifications. I for instance aligned the versions of the libraries to be the same as those that are used by Spark. > Is this the following? Please give a clear explanation if this is your own contribution. https://github.com/GoogleCloudPlatform/spark-on-k8s-operator No, it's different operator written in Java and it supports three different custom resources, `SparkCluster` (spark running in standalone mode in the pods), `SparkApplication` (this has the same API as the operator from GCP, so it's using spark-on-k8s scheduling) and `SparkHistoryServer`. So there is some overlap, but it's a different thing. This operator is also available on [operatorhub.io](operatorhub.io) ([link](https://operatorhub.io/operator/radanalytics-spark)) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] tgravescs commented on issue #26078: [SPARK-29151][CORE] Support fractional resources for task resource scheduling
tgravescs commented on issue #26078: [SPARK-29151][CORE] Support fractional resources for task resource scheduling URL: https://github.com/apache/spark/pull/26078#issuecomment-540591922 ok to test This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on a change in pull request #26014: [SPARK-29349][SQL] Support FETCH_PRIOR in Thriftserver fetch request
wangyum commented on a change in pull request #26014: [SPARK-29349][SQL]
Support FETCH_PRIOR in Thriftserver fetch request
URL: https://github.com/apache/spark/pull/26014#discussion_r333516458
##
File path:
sql/hive-thriftserver/src/test/scala/org/apache/spark/sql/hive/thriftserver/HiveThriftServer2Suites.scala
##
@@ -684,6 +685,92 @@ class HiveThriftBinaryServerSuite extends
HiveThriftJdbcTest {
assert(e.getMessage.contains("org.apache.spark.sql.catalyst.parser.ParseException"))
}
}
+
+ test("ThriftCLIService FetchResults FETCH_FIRST, FETCH_NEXT, FETCH_PRIOR") {
+def checkResult(rows: RowSet, start: Long, end: Long): Unit = {
+ assert(rows.getStartOffset() == start)
+ assert(rows.numRows() == end - start)
+ rows.iterator.asScala.zip((start until end).iterator).foreach { case
(row, v) =>
+assert(row(0).asInstanceOf[Long] === v)
+ }
+}
+
+withCLIServiceClient { client =>
+ val user = System.getProperty("user.name")
+ val sessionHandle = client.openSession(user, "")
+
+ val confOverlay = new java.util.HashMap[java.lang.String,
java.lang.String]
+ val operationHandle = client.executeStatement(
+sessionHandle,
+"SELECT * FROM range(10)",
+confOverlay) // 10 rows result with sequence 0, 1, 2, ..., 9
+ var rows: RowSet = null
+
+ // Fetch 5 rows with FETCH_NEXT
+ rows = client.fetchResults(
+operationHandle, FetchOrientation.FETCH_NEXT, 5,
FetchType.QUERY_OUTPUT)
+ checkResult(rows, 0, 5) // fetched [0, 5)
+
+ // Fetch another 2 rows with FETCH_NEXT
+ rows = client.fetchResults(
+operationHandle, FetchOrientation.FETCH_NEXT, 2,
FetchType.QUERY_OUTPUT)
+ checkResult(rows, 5, 7) // fetched [5, 7)
+
+ // FETCH_PRIOR 3 rows
Review comment:
Thank you @juliuszsompolski
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on a change in pull request #26014: [SPARK-29349][SQL] Support FETCH_PRIOR in Thriftserver fetch request
wangyum commented on a change in pull request #26014: [SPARK-29349][SQL]
Support FETCH_PRIOR in Thriftserver fetch request
URL: https://github.com/apache/spark/pull/26014#discussion_r333516458
##
File path:
sql/hive-thriftserver/src/test/scala/org/apache/spark/sql/hive/thriftserver/HiveThriftServer2Suites.scala
##
@@ -684,6 +685,92 @@ class HiveThriftBinaryServerSuite extends
HiveThriftJdbcTest {
assert(e.getMessage.contains("org.apache.spark.sql.catalyst.parser.ParseException"))
}
}
+
+ test("ThriftCLIService FetchResults FETCH_FIRST, FETCH_NEXT, FETCH_PRIOR") {
+def checkResult(rows: RowSet, start: Long, end: Long): Unit = {
+ assert(rows.getStartOffset() == start)
+ assert(rows.numRows() == end - start)
+ rows.iterator.asScala.zip((start until end).iterator).foreach { case
(row, v) =>
+assert(row(0).asInstanceOf[Long] === v)
+ }
+}
+
+withCLIServiceClient { client =>
+ val user = System.getProperty("user.name")
+ val sessionHandle = client.openSession(user, "")
+
+ val confOverlay = new java.util.HashMap[java.lang.String,
java.lang.String]
+ val operationHandle = client.executeStatement(
+sessionHandle,
+"SELECT * FROM range(10)",
+confOverlay) // 10 rows result with sequence 0, 1, 2, ..., 9
+ var rows: RowSet = null
+
+ // Fetch 5 rows with FETCH_NEXT
+ rows = client.fetchResults(
+operationHandle, FetchOrientation.FETCH_NEXT, 5,
FetchType.QUERY_OUTPUT)
+ checkResult(rows, 0, 5) // fetched [0, 5)
+
+ // Fetch another 2 rows with FETCH_NEXT
+ rows = client.fetchResults(
+operationHandle, FetchOrientation.FETCH_NEXT, 2,
FetchType.QUERY_OUTPUT)
+ checkResult(rows, 5, 7) // fetched [5, 7)
+
+ // FETCH_PRIOR 3 rows
Review comment:
Thank you @juliuszsompolski?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL] Support string intervals without the `interval` prefix
MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL]
Support string intervals without the `interval` prefix
URL: https://github.com/apache/spark/pull/26079#discussion_r333516377
##
File path:
common/unsafe/src/main/java/org/apache/spark/unsafe/types/CalendarInterval.java
##
@@ -73,45 +72,53 @@ private static long toLong(String s) {
* This method is case-insensitive.
*/
public static CalendarInterval fromString(String s) {
-if (s == null) {
- return null;
-}
-s = s.trim();
-Matcher m = p.matcher(s);
-if (!m.matches() || s.compareToIgnoreCase("interval") == 0) {
+try {
+ return fromCaseInsensitiveString(s);
+} catch (IllegalArgumentException e) {
return null;
-} else {
- long months = toLong(m.group(1)) * 12 + toLong(m.group(2));
- long microseconds = toLong(m.group(3)) * MICROS_PER_WEEK;
- microseconds += toLong(m.group(4)) * MICROS_PER_DAY;
- microseconds += toLong(m.group(5)) * MICROS_PER_HOUR;
- microseconds += toLong(m.group(6)) * MICROS_PER_MINUTE;
- microseconds += toLong(m.group(7)) * MICROS_PER_SECOND;
- microseconds += toLong(m.group(8)) * MICROS_PER_MILLI;
- microseconds += toLong(m.group(9));
- return new CalendarInterval((int) months, microseconds);
}
}
/**
- * Convert a string to CalendarInterval. Unlike fromString, this method can
handle
+ * Convert a string to CalendarInterval. This method can handle
* strings without the `interval` prefix and throws IllegalArgumentException
* when the input string is not a valid interval.
*
* @throws IllegalArgumentException if the string is not a valid internal.
*/
public static CalendarInterval fromCaseInsensitiveString(String s) {
-if (s == null || s.trim().isEmpty()) {
- throw new IllegalArgumentException("Interval cannot be null or blank.");
+if (s == null) {
+ throw new IllegalArgumentException("Interval cannot be null");
}
-String sInLowerCase = s.trim().toLowerCase(Locale.ROOT);
-String interval =
- sInLowerCase.startsWith("interval ") ? sInLowerCase : "interval " +
sInLowerCase;
-CalendarInterval cal = fromString(interval);
-if (cal == null) {
+String trimmed = s.trim();
+if (trimmed.isEmpty()) {
+ throw new IllegalArgumentException("Interval cannot be blank");
+}
+String prefix = "interval";
+String intervalStr = trimmed;
+// Checks the given interval string does not start with the `interval`
prefix
+if (!intervalStr.regionMatches(true, 0, prefix, 0, prefix.length())) {
+ // Prepend `interval` if it does not present because
+ // the regular expression strictly require it.
Review comment:
Probably, this needs this feature
https://www.regular-expressions.info/branchreset.html which Java's regexps
doesn't have.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL] Support string intervals without the `interval` prefix
MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL]
Support string intervals without the `interval` prefix
URL: https://github.com/apache/spark/pull/26079#discussion_r333514414
##
File path:
common/unsafe/src/main/java/org/apache/spark/unsafe/types/CalendarInterval.java
##
@@ -73,45 +72,53 @@ private static long toLong(String s) {
* This method is case-insensitive.
*/
public static CalendarInterval fromString(String s) {
-if (s == null) {
- return null;
-}
-s = s.trim();
-Matcher m = p.matcher(s);
-if (!m.matches() || s.compareToIgnoreCase("interval") == 0) {
+try {
+ return fromCaseInsensitiveString(s);
+} catch (IllegalArgumentException e) {
return null;
-} else {
- long months = toLong(m.group(1)) * 12 + toLong(m.group(2));
- long microseconds = toLong(m.group(3)) * MICROS_PER_WEEK;
- microseconds += toLong(m.group(4)) * MICROS_PER_DAY;
- microseconds += toLong(m.group(5)) * MICROS_PER_HOUR;
- microseconds += toLong(m.group(6)) * MICROS_PER_MINUTE;
- microseconds += toLong(m.group(7)) * MICROS_PER_SECOND;
- microseconds += toLong(m.group(8)) * MICROS_PER_MILLI;
- microseconds += toLong(m.group(9));
- return new CalendarInterval((int) months, microseconds);
}
}
/**
- * Convert a string to CalendarInterval. Unlike fromString, this method can
handle
+ * Convert a string to CalendarInterval. This method can handle
* strings without the `interval` prefix and throws IllegalArgumentException
* when the input string is not a valid interval.
*
* @throws IllegalArgumentException if the string is not a valid internal.
*/
public static CalendarInterval fromCaseInsensitiveString(String s) {
-if (s == null || s.trim().isEmpty()) {
- throw new IllegalArgumentException("Interval cannot be null or blank.");
+if (s == null) {
+ throw new IllegalArgumentException("Interval cannot be null");
}
-String sInLowerCase = s.trim().toLowerCase(Locale.ROOT);
-String interval =
- sInLowerCase.startsWith("interval ") ? sInLowerCase : "interval " +
sInLowerCase;
-CalendarInterval cal = fromString(interval);
-if (cal == null) {
+String trimmed = s.trim();
+if (trimmed.isEmpty()) {
+ throw new IllegalArgumentException("Interval cannot be blank");
+}
+String prefix = "interval";
+String intervalStr = trimmed;
+// Checks the given interval string does not start with the `interval`
prefix
+if (!intervalStr.regionMatches(true, 0, prefix, 0, prefix.length())) {
+ // Prepend `interval` if it does not present because
+ // the regular expression strictly require it.
Review comment:
I have not figured out how to modify the regular expression to make the
`interval` prefix optional.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL] Support string intervals without the `interval` prefix
MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL]
Support string intervals without the `interval` prefix
URL: https://github.com/apache/spark/pull/26079#discussion_r333514414
##
File path:
common/unsafe/src/main/java/org/apache/spark/unsafe/types/CalendarInterval.java
##
@@ -73,45 +72,53 @@ private static long toLong(String s) {
* This method is case-insensitive.
*/
public static CalendarInterval fromString(String s) {
-if (s == null) {
- return null;
-}
-s = s.trim();
-Matcher m = p.matcher(s);
-if (!m.matches() || s.compareToIgnoreCase("interval") == 0) {
+try {
+ return fromCaseInsensitiveString(s);
+} catch (IllegalArgumentException e) {
return null;
-} else {
- long months = toLong(m.group(1)) * 12 + toLong(m.group(2));
- long microseconds = toLong(m.group(3)) * MICROS_PER_WEEK;
- microseconds += toLong(m.group(4)) * MICROS_PER_DAY;
- microseconds += toLong(m.group(5)) * MICROS_PER_HOUR;
- microseconds += toLong(m.group(6)) * MICROS_PER_MINUTE;
- microseconds += toLong(m.group(7)) * MICROS_PER_SECOND;
- microseconds += toLong(m.group(8)) * MICROS_PER_MILLI;
- microseconds += toLong(m.group(9));
- return new CalendarInterval((int) months, microseconds);
}
}
/**
- * Convert a string to CalendarInterval. Unlike fromString, this method can
handle
+ * Convert a string to CalendarInterval. This method can handle
* strings without the `interval` prefix and throws IllegalArgumentException
* when the input string is not a valid interval.
*
* @throws IllegalArgumentException if the string is not a valid internal.
*/
public static CalendarInterval fromCaseInsensitiveString(String s) {
-if (s == null || s.trim().isEmpty()) {
- throw new IllegalArgumentException("Interval cannot be null or blank.");
+if (s == null) {
+ throw new IllegalArgumentException("Interval cannot be null");
}
-String sInLowerCase = s.trim().toLowerCase(Locale.ROOT);
-String interval =
- sInLowerCase.startsWith("interval ") ? sInLowerCase : "interval " +
sInLowerCase;
-CalendarInterval cal = fromString(interval);
-if (cal == null) {
+String trimmed = s.trim();
+if (trimmed.isEmpty()) {
+ throw new IllegalArgumentException("Interval cannot be blank");
+}
+String prefix = "interval";
+String intervalStr = trimmed;
+// Checks the given interval string does not start with the `interval`
prefix
+if (!intervalStr.regionMatches(true, 0, prefix, 0, prefix.length())) {
+ // Prepend `interval` if it does not present because
+ // the regular expression strictly require it.
Review comment:
I have not figure out how to modify the regular expression to make the
`interval` prefix optional.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL] Support string intervals without the `interval` prefix
MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL]
Support string intervals without the `interval` prefix
URL: https://github.com/apache/spark/pull/26079#discussion_r333513598
##
File path:
common/unsafe/src/main/java/org/apache/spark/unsafe/types/CalendarInterval.java
##
@@ -73,45 +72,50 @@ private static long toLong(String s) {
* This method is case-insensitive.
*/
public static CalendarInterval fromString(String s) {
-if (s == null) {
- return null;
-}
-s = s.trim();
-Matcher m = p.matcher(s);
-if (!m.matches() || s.compareToIgnoreCase("interval") == 0) {
+try {
+ return fromCaseInsensitiveString(s);
+} catch (IllegalArgumentException e) {
return null;
-} else {
- long months = toLong(m.group(1)) * 12 + toLong(m.group(2));
- long microseconds = toLong(m.group(3)) * MICROS_PER_WEEK;
- microseconds += toLong(m.group(4)) * MICROS_PER_DAY;
- microseconds += toLong(m.group(5)) * MICROS_PER_HOUR;
- microseconds += toLong(m.group(6)) * MICROS_PER_MINUTE;
- microseconds += toLong(m.group(7)) * MICROS_PER_SECOND;
- microseconds += toLong(m.group(8)) * MICROS_PER_MILLI;
- microseconds += toLong(m.group(9));
- return new CalendarInterval((int) months, microseconds);
}
}
/**
- * Convert a string to CalendarInterval. Unlike fromString, this method can
handle
+ * Convert a string to CalendarInterval. This method can handle
* strings without the `interval` prefix and throws IllegalArgumentException
* when the input string is not a valid interval.
*
* @throws IllegalArgumentException if the string is not a valid internal.
*/
public static CalendarInterval fromCaseInsensitiveString(String s) {
-if (s == null || s.trim().isEmpty()) {
- throw new IllegalArgumentException("Interval cannot be null or blank.");
+if (s == null) {
+ throw new IllegalArgumentException("Interval cannot be null");
}
-String sInLowerCase = s.trim().toLowerCase(Locale.ROOT);
-String interval =
- sInLowerCase.startsWith("interval ") ? sInLowerCase : "interval " +
sInLowerCase;
-CalendarInterval cal = fromString(interval);
-if (cal == null) {
+String trimmed = s.trim();
+if (trimmed.isEmpty()) {
+ throw new IllegalArgumentException("Interval cannot be blank");
+}
+String prefix = "interval";
+String intervalStr = trimmed;
+if (!intervalStr.regionMatches(true, 0, prefix, 0, prefix.length())) {
Review comment:
I added comments about this.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #26079: [SPARK-29369][SQL] Support string intervals without the `interval` prefix
cloud-fan commented on a change in pull request #26079: [SPARK-29369][SQL]
Support string intervals without the `interval` prefix
URL: https://github.com/apache/spark/pull/26079#discussion_r333504359
##
File path:
common/unsafe/src/main/java/org/apache/spark/unsafe/types/CalendarInterval.java
##
@@ -73,45 +72,50 @@ private static long toLong(String s) {
* This method is case-insensitive.
*/
public static CalendarInterval fromString(String s) {
-if (s == null) {
- return null;
-}
-s = s.trim();
-Matcher m = p.matcher(s);
-if (!m.matches() || s.compareToIgnoreCase("interval") == 0) {
+try {
+ return fromCaseInsensitiveString(s);
+} catch (IllegalArgumentException e) {
return null;
-} else {
- long months = toLong(m.group(1)) * 12 + toLong(m.group(2));
- long microseconds = toLong(m.group(3)) * MICROS_PER_WEEK;
- microseconds += toLong(m.group(4)) * MICROS_PER_DAY;
- microseconds += toLong(m.group(5)) * MICROS_PER_HOUR;
- microseconds += toLong(m.group(6)) * MICROS_PER_MINUTE;
- microseconds += toLong(m.group(7)) * MICROS_PER_SECOND;
- microseconds += toLong(m.group(8)) * MICROS_PER_MILLI;
- microseconds += toLong(m.group(9));
- return new CalendarInterval((int) months, microseconds);
}
}
/**
- * Convert a string to CalendarInterval. Unlike fromString, this method can
handle
+ * Convert a string to CalendarInterval. This method can handle
* strings without the `interval` prefix and throws IllegalArgumentException
* when the input string is not a valid interval.
*
* @throws IllegalArgumentException if the string is not a valid internal.
*/
public static CalendarInterval fromCaseInsensitiveString(String s) {
-if (s == null || s.trim().isEmpty()) {
- throw new IllegalArgumentException("Interval cannot be null or blank.");
+if (s == null) {
+ throw new IllegalArgumentException("Interval cannot be null");
}
-String sInLowerCase = s.trim().toLowerCase(Locale.ROOT);
-String interval =
- sInLowerCase.startsWith("interval ") ? sInLowerCase : "interval " +
sInLowerCase;
-CalendarInterval cal = fromString(interval);
-if (cal == null) {
+String trimmed = s.trim();
+if (trimmed.isEmpty()) {
+ throw new IllegalArgumentException("Interval cannot be blank");
+}
+String prefix = "interval";
+String intervalStr = trimmed;
+if (!intervalStr.regionMatches(true, 0, prefix, 0, prefix.length())) {
Review comment:
what does this condition mean?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #26079: [SPARK-29369][SQL] Support string intervals without the `interval` prefix
cloud-fan commented on a change in pull request #26079: [SPARK-29369][SQL]
Support string intervals without the `interval` prefix
URL: https://github.com/apache/spark/pull/26079#discussion_r333503281
##
File path:
common/unsafe/src/main/java/org/apache/spark/unsafe/types/CalendarInterval.java
##
@@ -73,45 +72,50 @@ private static long toLong(String s) {
* This method is case-insensitive.
*/
public static CalendarInterval fromString(String s) {
-if (s == null) {
- return null;
-}
-s = s.trim();
-Matcher m = p.matcher(s);
-if (!m.matches() || s.compareToIgnoreCase("interval") == 0) {
+try {
+ return fromCaseInsensitiveString(s);
+} catch (IllegalArgumentException e) {
return null;
-} else {
- long months = toLong(m.group(1)) * 12 + toLong(m.group(2));
- long microseconds = toLong(m.group(3)) * MICROS_PER_WEEK;
- microseconds += toLong(m.group(4)) * MICROS_PER_DAY;
- microseconds += toLong(m.group(5)) * MICROS_PER_HOUR;
- microseconds += toLong(m.group(6)) * MICROS_PER_MINUTE;
- microseconds += toLong(m.group(7)) * MICROS_PER_SECOND;
- microseconds += toLong(m.group(8)) * MICROS_PER_MILLI;
- microseconds += toLong(m.group(9));
- return new CalendarInterval((int) months, microseconds);
}
}
/**
- * Convert a string to CalendarInterval. Unlike fromString, this method can
handle
+ * Convert a string to CalendarInterval. This method can handle
* strings without the `interval` prefix and throws IllegalArgumentException
* when the input string is not a valid interval.
*
* @throws IllegalArgumentException if the string is not a valid internal.
*/
public static CalendarInterval fromCaseInsensitiveString(String s) {
Review comment:
SGTM
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL] Support string intervals without the `interval` prefix
MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL]
Support string intervals without the `interval` prefix
URL: https://github.com/apache/spark/pull/26079#discussion_r333485581
##
File path:
common/unsafe/src/main/java/org/apache/spark/unsafe/types/CalendarInterval.java
##
@@ -73,45 +72,50 @@ private static long toLong(String s) {
* This method is case-insensitive.
*/
public static CalendarInterval fromString(String s) {
-if (s == null) {
- return null;
-}
-s = s.trim();
-Matcher m = p.matcher(s);
-if (!m.matches() || s.compareToIgnoreCase("interval") == 0) {
+try {
+ return fromCaseInsensitiveString(s);
+} catch (IllegalArgumentException e) {
return null;
-} else {
- long months = toLong(m.group(1)) * 12 + toLong(m.group(2));
- long microseconds = toLong(m.group(3)) * MICROS_PER_WEEK;
- microseconds += toLong(m.group(4)) * MICROS_PER_DAY;
- microseconds += toLong(m.group(5)) * MICROS_PER_HOUR;
- microseconds += toLong(m.group(6)) * MICROS_PER_MINUTE;
- microseconds += toLong(m.group(7)) * MICROS_PER_SECOND;
- microseconds += toLong(m.group(8)) * MICROS_PER_MILLI;
- microseconds += toLong(m.group(9));
- return new CalendarInterval((int) months, microseconds);
}
}
/**
- * Convert a string to CalendarInterval. Unlike fromString, this method can
handle
+ * Convert a string to CalendarInterval. This method can handle
* strings without the `interval` prefix and throws IllegalArgumentException
* when the input string is not a valid interval.
*
* @throws IllegalArgumentException if the string is not a valid internal.
*/
public static CalendarInterval fromCaseInsensitiveString(String s) {
Review comment:
Let's keep them separate so far. And I will try to write flexible and common
code in the near future for parsing string intervals that could handle other
features found in https://github.com/apache/spark/pull/26055
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL] Support string intervals without the `interval` prefix
MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL]
Support string intervals without the `interval` prefix
URL: https://github.com/apache/spark/pull/26079#discussion_r333485581
##
File path:
common/unsafe/src/main/java/org/apache/spark/unsafe/types/CalendarInterval.java
##
@@ -73,45 +72,50 @@ private static long toLong(String s) {
* This method is case-insensitive.
*/
public static CalendarInterval fromString(String s) {
-if (s == null) {
- return null;
-}
-s = s.trim();
-Matcher m = p.matcher(s);
-if (!m.matches() || s.compareToIgnoreCase("interval") == 0) {
+try {
+ return fromCaseInsensitiveString(s);
+} catch (IllegalArgumentException e) {
return null;
-} else {
- long months = toLong(m.group(1)) * 12 + toLong(m.group(2));
- long microseconds = toLong(m.group(3)) * MICROS_PER_WEEK;
- microseconds += toLong(m.group(4)) * MICROS_PER_DAY;
- microseconds += toLong(m.group(5)) * MICROS_PER_HOUR;
- microseconds += toLong(m.group(6)) * MICROS_PER_MINUTE;
- microseconds += toLong(m.group(7)) * MICROS_PER_SECOND;
- microseconds += toLong(m.group(8)) * MICROS_PER_MILLI;
- microseconds += toLong(m.group(9));
- return new CalendarInterval((int) months, microseconds);
}
}
/**
- * Convert a string to CalendarInterval. Unlike fromString, this method can
handle
+ * Convert a string to CalendarInterval. This method can handle
* strings without the `interval` prefix and throws IllegalArgumentException
* when the input string is not a valid interval.
*
* @throws IllegalArgumentException if the string is not a valid internal.
*/
public static CalendarInterval fromCaseInsensitiveString(String s) {
Review comment:
Let's keep them separate so far. And I will try to write flexible and common
code for parsing string interval that could handle other features found in
https://github.com/apache/spark/pull/26055
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL] Support string intervals without the `interval` prefix
MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL]
Support string intervals without the `interval` prefix
URL: https://github.com/apache/spark/pull/26079#discussion_r333484672
##
File path:
common/unsafe/src/main/java/org/apache/spark/unsafe/types/CalendarInterval.java
##
@@ -73,45 +72,50 @@ private static long toLong(String s) {
* This method is case-insensitive.
*/
public static CalendarInterval fromString(String s) {
-if (s == null) {
- return null;
-}
-s = s.trim();
-Matcher m = p.matcher(s);
-if (!m.matches() || s.compareToIgnoreCase("interval") == 0) {
+try {
+ return fromCaseInsensitiveString(s);
+} catch (IllegalArgumentException e) {
return null;
-} else {
- long months = toLong(m.group(1)) * 12 + toLong(m.group(2));
- long microseconds = toLong(m.group(3)) * MICROS_PER_WEEK;
- microseconds += toLong(m.group(4)) * MICROS_PER_DAY;
- microseconds += toLong(m.group(5)) * MICROS_PER_HOUR;
- microseconds += toLong(m.group(6)) * MICROS_PER_MINUTE;
- microseconds += toLong(m.group(7)) * MICROS_PER_SECOND;
- microseconds += toLong(m.group(8)) * MICROS_PER_MILLI;
- microseconds += toLong(m.group(9));
- return new CalendarInterval((int) months, microseconds);
}
}
/**
- * Convert a string to CalendarInterval. Unlike fromString, this method can
handle
+ * Convert a string to CalendarInterval. This method can handle
* strings without the `interval` prefix and throws IllegalArgumentException
* when the input string is not a valid interval.
*
* @throws IllegalArgumentException if the string is not a valid internal.
*/
public static CalendarInterval fromCaseInsensitiveString(String s) {
Review comment:
And your regexp is not tolerant to the order of interval units, see:
```sql
spark-sql> select interval 'interval 1 microsecond 2 months';
NULL
spark-sql> select interval 1 microsecond 2 months;
interval 2 months 1 microseconds
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL] Support string intervals without the `interval` prefix
MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL]
Support string intervals without the `interval` prefix
URL: https://github.com/apache/spark/pull/26079#discussion_r333483069
##
File path:
common/unsafe/src/main/java/org/apache/spark/unsafe/types/CalendarInterval.java
##
@@ -73,45 +72,50 @@ private static long toLong(String s) {
* This method is case-insensitive.
*/
public static CalendarInterval fromString(String s) {
-if (s == null) {
- return null;
-}
-s = s.trim();
-Matcher m = p.matcher(s);
-if (!m.matches() || s.compareToIgnoreCase("interval") == 0) {
+try {
+ return fromCaseInsensitiveString(s);
+} catch (IllegalArgumentException e) {
return null;
-} else {
- long months = toLong(m.group(1)) * 12 + toLong(m.group(2));
- long microseconds = toLong(m.group(3)) * MICROS_PER_WEEK;
- microseconds += toLong(m.group(4)) * MICROS_PER_DAY;
- microseconds += toLong(m.group(5)) * MICROS_PER_HOUR;
- microseconds += toLong(m.group(6)) * MICROS_PER_MINUTE;
- microseconds += toLong(m.group(7)) * MICROS_PER_SECOND;
- microseconds += toLong(m.group(8)) * MICROS_PER_MILLI;
- microseconds += toLong(m.group(9));
- return new CalendarInterval((int) months, microseconds);
}
}
/**
- * Convert a string to CalendarInterval. Unlike fromString, this method can
handle
+ * Convert a string to CalendarInterval. This method can handle
* strings without the `interval` prefix and throws IllegalArgumentException
* when the input string is not a valid interval.
*
* @throws IllegalArgumentException if the string is not a valid internal.
*/
public static CalendarInterval fromCaseInsensitiveString(String s) {
Review comment:
This PR introduced code duplication
https://github.com/apache/spark/pull/8034 for your code
https://github.com/apache/spark/pull/7355 5 years ago.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL] Support string intervals without the `interval` prefix
MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL]
Support string intervals without the `interval` prefix
URL: https://github.com/apache/spark/pull/26079#discussion_r333480766
##
File path:
common/unsafe/src/main/java/org/apache/spark/unsafe/types/CalendarInterval.java
##
@@ -73,45 +72,50 @@ private static long toLong(String s) {
* This method is case-insensitive.
*/
public static CalendarInterval fromString(String s) {
-if (s == null) {
- return null;
-}
-s = s.trim();
-Matcher m = p.matcher(s);
-if (!m.matches() || s.compareToIgnoreCase("interval") == 0) {
+try {
+ return fromCaseInsensitiveString(s);
+} catch (IllegalArgumentException e) {
return null;
-} else {
- long months = toLong(m.group(1)) * 12 + toLong(m.group(2));
- long microseconds = toLong(m.group(3)) * MICROS_PER_WEEK;
- microseconds += toLong(m.group(4)) * MICROS_PER_DAY;
- microseconds += toLong(m.group(5)) * MICROS_PER_HOUR;
- microseconds += toLong(m.group(6)) * MICROS_PER_MINUTE;
- microseconds += toLong(m.group(7)) * MICROS_PER_SECOND;
- microseconds += toLong(m.group(8)) * MICROS_PER_MILLI;
- microseconds += toLong(m.group(9));
- return new CalendarInterval((int) months, microseconds);
}
}
/**
- * Convert a string to CalendarInterval. Unlike fromString, this method can
handle
+ * Convert a string to CalendarInterval. This method can handle
* strings without the `interval` prefix and throws IllegalArgumentException
* when the input string is not a valid interval.
*
* @throws IllegalArgumentException if the string is not a valid internal.
*/
public static CalendarInterval fromCaseInsensitiveString(String s) {
Review comment:
Maybe something has been duplicated, and can be reused but this is heavy
refactoring for this PR.
For instance, `AstBuilder.visitInterval` gets already split interval units
but `CalendarInterval.fromString()` uses regular expression to parse & split:
https://github.com/apache/spark/blob/b10344956d672fca495d0684b351ab5cf9f210d8/common/unsafe/src/main/java/org/apache/spark/unsafe/types/CalendarInterval.java#L50-L53
If you don't mind, I would try to do that in a separate PR.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LucaCanali opened a new pull request #26081: [SPARK-29032][FOLLOWUP][DOC] Document PrometheusServlet in the monitoring documentation
LucaCanali opened a new pull request #26081: [SPARK-29032][FOLLOWUP][DOC] Document PrometheusServlet in the monitoring documentation URL: https://github.com/apache/spark/pull/26081 This adds an entry about PrometheusServlet to the documentation, following SPARK-29032 ### Why are the changes needed? The monitoring documentation lists all the available metrics sinks, this should be added to the list for completeness. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #26079: [SPARK-29369][SQL] Support string intervals without the `interval` prefix
cloud-fan commented on a change in pull request #26079: [SPARK-29369][SQL]
Support string intervals without the `interval` prefix
URL: https://github.com/apache/spark/pull/26079#discussion_r333472752
##
File path:
common/unsafe/src/main/java/org/apache/spark/unsafe/types/CalendarInterval.java
##
@@ -73,45 +72,50 @@ private static long toLong(String s) {
* This method is case-insensitive.
*/
public static CalendarInterval fromString(String s) {
-if (s == null) {
- return null;
-}
-s = s.trim();
-Matcher m = p.matcher(s);
-if (!m.matches() || s.compareToIgnoreCase("interval") == 0) {
+try {
+ return fromCaseInsensitiveString(s);
+} catch (IllegalArgumentException e) {
return null;
-} else {
- long months = toLong(m.group(1)) * 12 + toLong(m.group(2));
- long microseconds = toLong(m.group(3)) * MICROS_PER_WEEK;
- microseconds += toLong(m.group(4)) * MICROS_PER_DAY;
- microseconds += toLong(m.group(5)) * MICROS_PER_HOUR;
- microseconds += toLong(m.group(6)) * MICROS_PER_MINUTE;
- microseconds += toLong(m.group(7)) * MICROS_PER_SECOND;
- microseconds += toLong(m.group(8)) * MICROS_PER_MILLI;
- microseconds += toLong(m.group(9));
- return new CalendarInterval((int) months, microseconds);
}
}
/**
- * Convert a string to CalendarInterval. Unlike fromString, this method can
handle
+ * Convert a string to CalendarInterval. This method can handle
* strings without the `interval` prefix and throws IllegalArgumentException
* when the input string is not a valid interval.
*
* @throws IllegalArgumentException if the string is not a valid internal.
*/
public static CalendarInterval fromCaseInsensitiveString(String s) {
Review comment:
This looks duplicated. Shall we add a `parseInterval` method to the
`ParserInterface` interface and call the parser here?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL] Support string intervals without the `interval` prefix
MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL]
Support string intervals without the `interval` prefix
URL: https://github.com/apache/spark/pull/26079#discussion_r333469680
##
File path:
common/unsafe/src/main/java/org/apache/spark/unsafe/types/CalendarInterval.java
##
@@ -73,45 +72,50 @@ private static long toLong(String s) {
* This method is case-insensitive.
*/
public static CalendarInterval fromString(String s) {
-if (s == null) {
- return null;
-}
-s = s.trim();
-Matcher m = p.matcher(s);
-if (!m.matches() || s.compareToIgnoreCase("interval") == 0) {
+try {
+ return fromCaseInsensitiveString(s);
+} catch (IllegalArgumentException e) {
return null;
-} else {
- long months = toLong(m.group(1)) * 12 + toLong(m.group(2));
- long microseconds = toLong(m.group(3)) * MICROS_PER_WEEK;
- microseconds += toLong(m.group(4)) * MICROS_PER_DAY;
- microseconds += toLong(m.group(5)) * MICROS_PER_HOUR;
- microseconds += toLong(m.group(6)) * MICROS_PER_MINUTE;
- microseconds += toLong(m.group(7)) * MICROS_PER_SECOND;
- microseconds += toLong(m.group(8)) * MICROS_PER_MILLI;
- microseconds += toLong(m.group(9));
- return new CalendarInterval((int) months, microseconds);
}
}
/**
- * Convert a string to CalendarInterval. Unlike fromString, this method can
handle
+ * Convert a string to CalendarInterval. This method can handle
* strings without the `interval` prefix and throws IllegalArgumentException
* when the input string is not a valid interval.
*
* @throws IllegalArgumentException if the string is not a valid internal.
*/
public static CalendarInterval fromCaseInsensitiveString(String s) {
Review comment:
antlr parser does this as well but [it parses sql
elements](https://github.com/apache/spark/blob/f2ead4d0b50715e3dec79ce762c31f145d46a5b5/sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/parser/AstBuilder.scala#L1907-L1961)
like
```sql
spark-sql> select interval 10 days 1 second;
interval 1 weeks 3 days 1 seconds
```
here is only the place where we parse string values:
```sql
spark-sql> select interval 'interval 10 days 1 second';
interval 1 weeks 3 days 1 seconds
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL] Support string intervals without the `interval` prefix
MaxGekk commented on a change in pull request #26079: [SPARK-29369][SQL]
Support string intervals without the `interval` prefix
URL: https://github.com/apache/spark/pull/26079#discussion_r333469680
##
File path:
common/unsafe/src/main/java/org/apache/spark/unsafe/types/CalendarInterval.java
##
@@ -73,45 +72,50 @@ private static long toLong(String s) {
* This method is case-insensitive.
*/
public static CalendarInterval fromString(String s) {
-if (s == null) {
- return null;
-}
-s = s.trim();
-Matcher m = p.matcher(s);
-if (!m.matches() || s.compareToIgnoreCase("interval") == 0) {
+try {
+ return fromCaseInsensitiveString(s);
+} catch (IllegalArgumentException e) {
return null;
-} else {
- long months = toLong(m.group(1)) * 12 + toLong(m.group(2));
- long microseconds = toLong(m.group(3)) * MICROS_PER_WEEK;
- microseconds += toLong(m.group(4)) * MICROS_PER_DAY;
- microseconds += toLong(m.group(5)) * MICROS_PER_HOUR;
- microseconds += toLong(m.group(6)) * MICROS_PER_MINUTE;
- microseconds += toLong(m.group(7)) * MICROS_PER_SECOND;
- microseconds += toLong(m.group(8)) * MICROS_PER_MILLI;
- microseconds += toLong(m.group(9));
- return new CalendarInterval((int) months, microseconds);
}
}
/**
- * Convert a string to CalendarInterval. Unlike fromString, this method can
handle
+ * Convert a string to CalendarInterval. This method can handle
* strings without the `interval` prefix and throws IllegalArgumentException
* when the input string is not a valid interval.
*
* @throws IllegalArgumentException if the string is not a valid internal.
*/
public static CalendarInterval fromCaseInsensitiveString(String s) {
Review comment:
antlr parser does this as well but it parses sql elements like
```sql
spark-sql> select interval 10 days 1 second;
interval 1 weeks 3 days 1 seconds
```
here is only the place where we parse string values:
```sql
spark-sql> select interval 'interval 10 days 1 second';
interval 1 weeks 3 days 1 seconds
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #26079: [SPARK-29369][SQL] Support string intervals without the `interval` prefix
cloud-fan commented on a change in pull request #26079: [SPARK-29369][SQL]
Support string intervals without the `interval` prefix
URL: https://github.com/apache/spark/pull/26079#discussion_r333465668
##
File path:
common/unsafe/src/main/java/org/apache/spark/unsafe/types/CalendarInterval.java
##
@@ -73,45 +72,50 @@ private static long toLong(String s) {
* This method is case-insensitive.
*/
public static CalendarInterval fromString(String s) {
-if (s == null) {
- return null;
-}
-s = s.trim();
-Matcher m = p.matcher(s);
-if (!m.matches() || s.compareToIgnoreCase("interval") == 0) {
+try {
+ return fromCaseInsensitiveString(s);
+} catch (IllegalArgumentException e) {
return null;
-} else {
- long months = toLong(m.group(1)) * 12 + toLong(m.group(2));
- long microseconds = toLong(m.group(3)) * MICROS_PER_WEEK;
- microseconds += toLong(m.group(4)) * MICROS_PER_DAY;
- microseconds += toLong(m.group(5)) * MICROS_PER_HOUR;
- microseconds += toLong(m.group(6)) * MICROS_PER_MINUTE;
- microseconds += toLong(m.group(7)) * MICROS_PER_SECOND;
- microseconds += toLong(m.group(8)) * MICROS_PER_MILLI;
- microseconds += toLong(m.group(9));
- return new CalendarInterval((int) months, microseconds);
}
}
/**
- * Convert a string to CalendarInterval. Unlike fromString, this method can
handle
+ * Convert a string to CalendarInterval. This method can handle
* strings without the `interval` prefix and throws IllegalArgumentException
* when the input string is not a valid interval.
*
* @throws IllegalArgumentException if the string is not a valid internal.
*/
public static CalendarInterval fromCaseInsensitiveString(String s) {
Review comment:
Is it the only place we parse interval string? I thought we parse it with
antlr parser.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn commented on issue #26068: [SPARK-29405][SQL] Alter table / Insert statements should not change a table's ownership
yaooqinn commented on issue #26068: [SPARK-29405][SQL] Alter table / Insert statements should not change a table's ownership URL: https://github.com/apache/spark/pull/26068#issuecomment-540521129 cc @wangyum This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn removed a comment on issue #26068: [SPARK-29405][SQL] Alter table / Insert statements should not change a table's ownership
yaooqinn removed a comment on issue #26068: [SPARK-29405][SQL] Alter table / Insert statements should not change a table's ownership URL: https://github.com/apache/spark/pull/26068#issuecomment-540413720 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn opened a new pull request #26080: [SPARK-29425][SQL] The ownership of a database should be respected
yaooqinn opened a new pull request #26080: [SPARK-29425][SQL] The ownership of a database should be respected URL: https://github.com/apache/spark/pull/26080 ### What changes were proposed in this pull request? Keep the owner of a database when executing alter database commands ### Why are the changes needed? Spark will inadvertently delete the owner of a database for executing databases ddls ### Does this PR introduce any user-facing change? NO ### How was this patch tested? add and modify uts This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] mob-ai edited a comment on issue #25909: [SPARK-29224]Implement Factorization Machines as a ml-pipeline component
mob-ai edited a comment on issue #25909: [SPARK-29224]Implement Factorization Machines as a ml-pipeline component URL: https://github.com/apache/spark/pull/25909#issuecomment-540466862 > @mob-ai Thanks for this work! > But before you continue, I guess you can refer to previous dicsussion [SPARK-7008](https://issues.apache.org/jira/browse/SPARK-7008). I think you should provide some information like convergence curves on common datasets, and proof that mini-batch SGD is a good choice as an efficient solver. > As to the PR itself, besides owen's comments, I think there should be `FMClassifier` & `FMRegressor` respectively. Thank you for your suggestion. I will test FM on public datasets. Actually, this PR also implements AdamW solver to optimize FM. AdamW is more efficient than normal SGD, so default solver is AdamW. I will compare normal SGD and AdamW on public datasets. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu edited a comment on issue #25984: [SPARK-29308][BUILD] Update deps in dev/deps/spark-deps-hadoop-3.2 for hadoop-3.2
AngersZh edited a comment on issue #25984: [SPARK-29308][BUILD] Update deps in dev/deps/spark-deps-hadoop-3.2 for hadoop-3.2 URL: https://github.com/apache/spark/pull/25984#issuecomment-540485456 > Unfortunately, Jenkins is down. Let's wait until Jenkins is back. Bad news, wait for Jenkins back. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on issue #25984: [SPARK-29308][BUILD] Update deps in dev/deps/spark-deps-hadoop-3.2 for hadoop-3.2
AngersZh commented on issue #25984: [SPARK-29308][BUILD] Update deps in dev/deps/spark-deps-hadoop-3.2 for hadoop-3.2 URL: https://github.com/apache/spark/pull/25984#issuecomment-540485456 > Unfortunately, Jenkins is down. Let's wait until Jenkins is back. > Unfortunately, Jenkins is down. Let's wait until Jenkins is back. Bad news, wait for Jenkins back. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] juliuszsompolski commented on a change in pull request #26014: [SPARK-29349][SQL] Support FETCH_PRIOR in Thriftserver fetch request
juliuszsompolski commented on a change in pull request #26014:
[SPARK-29349][SQL] Support FETCH_PRIOR in Thriftserver fetch request
URL: https://github.com/apache/spark/pull/26014#discussion_r333412752
##
File path:
sql/hive-thriftserver/src/test/scala/org/apache/spark/sql/hive/thriftserver/HiveThriftServer2Suites.scala
##
@@ -684,6 +685,92 @@ class HiveThriftBinaryServerSuite extends
HiveThriftJdbcTest {
assert(e.getMessage.contains("org.apache.spark.sql.catalyst.parser.ParseException"))
}
}
+
+ test("ThriftCLIService FetchResults FETCH_FIRST, FETCH_NEXT, FETCH_PRIOR") {
+def checkResult(rows: RowSet, start: Long, end: Long): Unit = {
+ assert(rows.getStartOffset() == start)
+ assert(rows.numRows() == end - start)
+ rows.iterator.asScala.zip((start until end).iterator).foreach { case
(row, v) =>
+assert(row(0).asInstanceOf[Long] === v)
+ }
+}
+
+withCLIServiceClient { client =>
+ val user = System.getProperty("user.name")
+ val sessionHandle = client.openSession(user, "")
+
+ val confOverlay = new java.util.HashMap[java.lang.String,
java.lang.String]
+ val operationHandle = client.executeStatement(
+sessionHandle,
+"SELECT * FROM range(10)",
+confOverlay) // 10 rows result with sequence 0, 1, 2, ..., 9
+ var rows: RowSet = null
+
+ // Fetch 5 rows with FETCH_NEXT
+ rows = client.fetchResults(
+operationHandle, FetchOrientation.FETCH_NEXT, 5,
FetchType.QUERY_OUTPUT)
+ checkResult(rows, 0, 5) // fetched [0, 5)
+
+ // Fetch another 2 rows with FETCH_NEXT
+ rows = client.fetchResults(
+operationHandle, FetchOrientation.FETCH_NEXT, 2,
FetchType.QUERY_OUTPUT)
+ checkResult(rows, 5, 7) // fetched [5, 7)
+
+ // FETCH_PRIOR 3 rows
Review comment:
@wangyum this is expected.
`FETCH_PRIOR` of the Thriftserver is not the same as FETCH PRIOR in the
cursor of the client.
Fetch in Thriftserver operates in batches of rows, and the cursor in the
client caches these batches and returns results row by row. Let's say it's
batching by maxRows=100, and we returned row 99. The client has rows [0, 100)
from the first batch and is at row 99. The next FETCH NEXT on the cursor will
have to call FETCH_NEXT to the Thriftserver to get a batch of rows [100, 200)
and return row 100 to the client. Another FETCH NEXT will return row 101 from
the batch without having to call FETCH_NEXT on the Thriftserver. Another FETCH
NEXT on the cursor will return row 102. Then FETCH PRIOR will return row 101
again. Then FETCH PRIOR will return row 100. Only then, another FETCH PRIOR
should return row 99, but the cursor doesn't have its current batch. Then it
has to call FETCH_PRIOR on Thriftserver to get rows [0, 99) again.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on a change in pull request #25416: [SPARK-28330][SQL] Support ANSI SQL: result offset clause in query expression
beliefer commented on a change in pull request #25416: [SPARK-28330][SQL]
Support ANSI SQL: result offset clause in query expression
URL: https://github.com/apache/spark/pull/25416#discussion_r333403518
##
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/offset.scala
##
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.serializer.Serializer
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Attribute, SortOrder}
+import org.apache.spark.sql.catalyst.plans.physical.{Partitioning,
SinglePartition}
+
+
+/**
+ * Skip the first `offset` elements and collect them to a single partition.
+ * This operator will be used when a logical `Offset` operation is the final
operator in an
+ * logical plan, which happens when the user is collecting results back to the
driver.
+ */
+case class CollectOffsetExec(offset: Int, child: SparkPlan) extends
UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def outputPartitioning: Partitioning = SinglePartition
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def executeCollect(): Array[InternalRow] =
child.executeCollect.drop(offset)
+
+ private val serializer: Serializer = new
UnsafeRowSerializer(child.output.size)
+
+ protected override def doExecute(): RDD[InternalRow] = {
+sparkContext.parallelize(executeCollect(), 1)
+ }
+
+}
+
+/**
+ * Skip the first `offset` elements and collect them to a single partition.
+ */
+case class OffsetExec(offset: Int, child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ protected override def doExecute(): RDD[InternalRow] = {
+val rdd = child.execute()
+val arr = rdd.take(offset)
+rdd.filter(!arr.contains(_))
Review comment:
So, I want know how to assurance the order?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on a change in pull request #25416: [SPARK-28330][SQL] Support ANSI SQL: result offset clause in query expression
beliefer commented on a change in pull request #25416: [SPARK-28330][SQL]
Support ANSI SQL: result offset clause in query expression
URL: https://github.com/apache/spark/pull/25416#discussion_r333402192
##
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/offset.scala
##
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.serializer.Serializer
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Attribute, SortOrder}
+import org.apache.spark.sql.catalyst.plans.physical.{Partitioning,
SinglePartition}
+
+
+/**
+ * Skip the first `offset` elements and collect them to a single partition.
+ * This operator will be used when a logical `Offset` operation is the final
operator in an
+ * logical plan, which happens when the user is collecting results back to the
driver.
+ */
+case class CollectOffsetExec(offset: Int, child: SparkPlan) extends
UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def outputPartitioning: Partitioning = SinglePartition
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def executeCollect(): Array[InternalRow] =
child.executeCollect.drop(offset)
+
+ private val serializer: Serializer = new
UnsafeRowSerializer(child.output.size)
+
+ protected override def doExecute(): RDD[InternalRow] = {
+sparkContext.parallelize(executeCollect(), 1)
+ }
+
+}
+
+/**
+ * Skip the first `offset` elements and collect them to a single partition.
+ */
+case class OffsetExec(offset: Int, child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ protected override def doExecute(): RDD[InternalRow] = {
+val rdd = child.execute()
+val arr = rdd.take(offset)
+rdd.filter(!arr.contains(_))
Review comment:
@cloud-fan There are exists a problem the index of partition and the order
of data are inconsistent.
I have a new implement but not works file as I can't assurance the order of
output produced by child plans.
```
protected override def doExecute(): RDD[InternalRow] = {
val rdd = child.execute()
val partIdxToCountItr = rdd.mapPartitionsWithIndex{(partIdx, iter) => {
val partIdxToRowCount = scala.collection.mutable.Map[Int,Int]()
var rowCount = 0
while(iter.hasNext){
rowCount += 1
iter.next()
}
partIdxToRowCount.put(partIdx, rowCount)
partIdxToRowCount.iterator
}}.collect().iterator
var remainder = offset
val partIdxToSkipCount = scala.collection.mutable.Map[Int,Int]()
while (partIdxToCountItr.hasNext && remainder > 0) {
val kv = partIdxToCountItr.next()
val partIdx = kv._1
val count = kv._2
if (count > remainder) {
partIdxToSkipCount(partIdx) = remainder
remainder = 0
} else {
partIdxToSkipCount(partIdx) = count
remainder -= count
}
}
val broadcastPartIdxToSkipCount =
sparkContext.broadcast(partIdxToSkipCount)
rdd.mapPartitionsWithIndex{(partIdx, iter) => {
val skipCount = broadcastPartIdxToSkipCount.value.getOrElse(partIdx, 0)
iter.drop(skipCount)
}}
}
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] peter-toth edited a comment on issue #26028: [SPARK-29359][SQL][TESTS] Better exception handling in (SQL|ThriftServer)QueryTestSuite
peter-toth edited a comment on issue #26028: [SPARK-29359][SQL][TESTS] Better exception handling in (SQL|ThriftServer)QueryTestSuite URL: https://github.com/apache/spark/pull/26028#issuecomment-540414457 @dongjoon-hyun @wangyum do you think this PR is ok now? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on a change in pull request #25416: [SPARK-28330][SQL] Support ANSI SQL: result offset clause in query expression
beliefer commented on a change in pull request #25416: [SPARK-28330][SQL]
Support ANSI SQL: result offset clause in query expression
URL: https://github.com/apache/spark/pull/25416#discussion_r333402192
##
File path: sql/core/src/main/scala/org/apache/spark/sql/execution/offset.scala
##
@@ -0,0 +1,66 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.execution
+
+import org.apache.spark.rdd.RDD
+import org.apache.spark.serializer.Serializer
+import org.apache.spark.sql.catalyst.InternalRow
+import org.apache.spark.sql.catalyst.expressions.{Attribute, SortOrder}
+import org.apache.spark.sql.catalyst.plans.physical.{Partitioning,
SinglePartition}
+
+
+/**
+ * Skip the first `offset` elements and collect them to a single partition.
+ * This operator will be used when a logical `Offset` operation is the final
operator in an
+ * logical plan, which happens when the user is collecting results back to the
driver.
+ */
+case class CollectOffsetExec(offset: Int, child: SparkPlan) extends
UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def outputPartitioning: Partitioning = SinglePartition
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ override def executeCollect(): Array[InternalRow] =
child.executeCollect.drop(offset)
+
+ private val serializer: Serializer = new
UnsafeRowSerializer(child.output.size)
+
+ protected override def doExecute(): RDD[InternalRow] = {
+sparkContext.parallelize(executeCollect(), 1)
+ }
+
+}
+
+/**
+ * Skip the first `offset` elements and collect them to a single partition.
+ */
+case class OffsetExec(offset: Int, child: SparkPlan) extends UnaryExecNode {
+
+ override def output: Seq[Attribute] = child.output
+
+ override def outputOrdering: Seq[SortOrder] = child.outputOrdering
+
+ protected override def doExecute(): RDD[InternalRow] = {
+val rdd = child.execute()
+val arr = rdd.take(offset)
+rdd.filter(!arr.contains(_))
Review comment:
@cloud-fan There are exists a problem the index of partition and the order
of data are inconsistent.
I have a new implement but not works file as I can't assurance the order of
output produced by child plans.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] IgorBerman closed pull request #20640: [SPARK-19755][Mesos] Blacklist is always active for MesosCoarseGrainedSchedulerBackend
IgorBerman closed pull request #20640: [SPARK-19755][Mesos] Blacklist is always active for MesosCoarseGrainedSchedulerBackend URL: https://github.com/apache/spark/pull/20640 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] IgorBerman commented on issue #20640: [SPARK-19755][Mesos] Blacklist is always active for MesosCoarseGrainedSchedulerBackend
IgorBerman commented on issue #20640: [SPARK-19755][Mesos] Blacklist is always active for MesosCoarseGrainedSchedulerBackend URL: https://github.com/apache/spark/pull/20640#issuecomment-540468693 I'm closing this PR as it is long open one and there is no agreement that it's valuable. anyone who wants to pick it, are welcome to create some. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] mob-ai edited a comment on issue #25909: [SPARK-29224]Implement Factorization Machines as a ml-pipeline component
mob-ai edited a comment on issue #25909: [SPARK-29224]Implement Factorization Machines as a ml-pipeline component URL: https://github.com/apache/spark/pull/25909#issuecomment-540466862 > @mob-ai Thanks for this work! > But before you continue, I guess you can refer to previous dicsussion [SPARK-7008](https://issues.apache.org/jira/browse/SPARK-7008). I think you should provide some information like convergence curves on common datasets, and proof that mini-batch SGD is a good choice as an efficient solver. > As to the PR itself, besides owen's comments, I think there should be `FMClassifier` & `FMRegressor` respectively. Thank you for your suggestion. I will test FM on public datasets. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] mob-ai edited a comment on issue #25909: [SPARK-29224]Implement Factorization Machines as a ml-pipeline component
mob-ai edited a comment on issue #25909: [SPARK-29224]Implement Factorization Machines as a ml-pipeline component URL: https://github.com/apache/spark/pull/25909#issuecomment-540466862 > @mob-ai Thanks for this work! > But before you continue, I guess you can refer to previous dicsussion [SPARK-7008](https://issues.apache.org/jira/browse/SPARK-7008). I think you should provide some information like convergence curves on common datasets, and proof that mini-batch SGD is a good choice as an efficient solver. > As to the PR itself, besides owen's comments, I think there should be `FMClassifier` & `FMRegressor` respectively. Thank you for your suggestion. I will test FM use public datasets. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] mob-ai commented on issue #25909: [SPARK-29224]Implement Factorization Machines as a ml-pipeline component
mob-ai commented on issue #25909: [SPARK-29224]Implement Factorization Machines as a ml-pipeline component URL: https://github.com/apache/spark/pull/25909#issuecomment-540466862 > @mob-ai Thanks for this work! > But before you continue, I guess you can refer to previous dicsussion [SPARK-7008](https://issues.apache.org/jira/browse/SPARK-7008). I think you should provide some information like convergence curves on common datasets, and proof that mini-batch SGD is a good choice as an efficient solver. > As to the PR itself, besides owen's comments, I think there should be `FMClassifier` & `FMRegressor` respectively. Thank you for your suggests. I will test FM use public datasets. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] s1ck commented on issue #24851: [SPARK-27303][GRAPH] Add Spark Graph API
s1ck commented on issue #24851: [SPARK-27303][GRAPH] Add Spark Graph API URL: https://github.com/apache/spark/pull/24851#issuecomment-540456978 @dongjoon-hyun Thanks for the additional review. Your comments are addressed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] peter-toth commented on issue #26044: [SPARK-29375][SQL] Exchange reuse across all subquery levels
peter-toth commented on issue #26044: [SPARK-29375][SQL] Exchange reuse across all subquery levels URL: https://github.com/apache/spark/pull/26044#issuecomment-540445410 cc @gatorsmile @maryannxue @mgaido91 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] TomokoKomiyama commented on a change in pull request #26065: [SPARK-29404][DOCS] Add an explanation about the executor color changed in WebUI documentation
TomokoKomiyama commented on a change in pull request #26065: [SPARK-29404][DOCS] Add an explanation about the executor color changed in WebUI documentation URL: https://github.com/apache/spark/pull/26065#discussion_r74304 ## File path: docs/web-ui.md ## @@ -51,12 +51,17 @@ The information that is displayed in this section is -* Details of jobs grouped by status: Displays detailed information of the jobs including Job ID, description (with a link to detailed job page), submitted time, duration, stages summary and tasks progress bar +When you click on a executor, you can make the color darker to point it at. Review comment: Users may be confused because of the meaning of executor bar color changes with clicking is not obvious. I think this explanation works to show that the color changes is not bug, and to make user know the function which is just point up the bar. Do you have any better ideas to help users understand this non-obvious behavior? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] s1ck commented on a change in pull request #24851: [SPARK-27303][GRAPH] Add Spark Graph API
s1ck commented on a change in pull request #24851: [SPARK-27303][GRAPH] Add
Spark Graph API
URL: https://github.com/apache/spark/pull/24851#discussion_r74185
##
File path:
graph/api/src/main/scala/org/apache/spark/graph/api/PropertyGraphWriter.scala
##
@@ -0,0 +1,92 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.graph.api
+
+import java.util.Locale
+
+import org.apache.spark.sql.SaveMode
+
+abstract class PropertyGraphWriter(val graph: PropertyGraph) {
+
+ protected var saveMode: SaveMode = SaveMode.ErrorIfExists
+ protected var format: String =
+graph.cypherSession.sparkSession.sessionState.conf.defaultDataSourceName
+
+ /**
+ * Specifies the behavior when the graph already exists. Options include:
+ *
+ * `SaveMode.Overwrite`: overwrite the existing data.
+ * `SaveMode.Ignore`: ignore the operation (i.e. no-op).
+ * `SaveMode.ErrorIfExists`: throw an exception at runtime.
+ *
+ *
+ * When writing the default option is `ErrorIfExists`.
+ *
+ * @since 3.0.0
+ */
+ def mode(mode: SaveMode): PropertyGraphWriter = {
+mode match {
+ case SaveMode.Append =>
+throw new IllegalArgumentException(s"Unsupported save mode: $mode. " +
+ "Accepted save modes are 'overwrite', 'ignore', 'error',
'errorifexists'.")
+ case _ =>
+this.saveMode = mode
+}
+this
+ }
+
+ /**
+ * Specifies the behavior when the graph already exists. Options include:
+ *
+ * `overwrite`: overwrite the existing graph.
+ * `ignore`: ignore the operation (i.e. no-op).
+ * `error` or `errorifexists`: default option, throw an exception at
runtime.
+ *
+ *
+ * @since 3.0.0
+ */
+ def mode(saveMode: String): PropertyGraphWriter = {
+saveMode.toLowerCase(Locale.ROOT) match {
+ case "overwrite" => mode(SaveMode.Overwrite)
+ case "ignore" => mode(SaveMode.Ignore)
+ case "error" | "errorifexists" => mode(SaveMode.ErrorIfExists)
+ case "default" => this
Review comment:
Makes sense. It was a copy paste error from the `DataFrameWriter`:
https://github.com/apache/spark/blob/c8159c7941f51caf3d420c8ad8599b869fc56a08/sql/core/src/main/scala/org/apache/spark/sql/DataFrameWriter.scala#L91
Maybe somebody should fix that too ;)
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #26042: [SPARK-29092][SQL] Report additional information about DataSourceScanExec in EXPLAIN FORMATTED
cloud-fan commented on a change in pull request #26042: [SPARK-29092][SQL] Report additional information about DataSourceScanExec in EXPLAIN FORMATTED URL: https://github.com/apache/spark/pull/26042#discussion_r72836 ## File path: sql/core/src/test/resources/sql-tests/results/explain.sql.out ## @@ -654,6 +740,11 @@ struct (1) Scan parquet default.explain_temp1 Output: [key#x, val#x] +Batched: true +Format: Parquet +Location [not included in comparison]sql/core/spark-warehouse/[not included in comparison] +PushedFilters: [IsNotNull(key), GreaterThan(key,10)] +ReadSchema: struct Review comment: Can we have a test case to show the DPP filter? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #26042: [SPARK-29092][SQL] Report additional information about DataSourceScanExec in EXPLAIN FORMATTED
cloud-fan commented on a change in pull request #26042: [SPARK-29092][SQL]
Report additional information about DataSourceScanExec in EXPLAIN FORMATTED
URL: https://github.com/apache/spark/pull/26042#discussion_r72628
##
File path:
sql/hive-thriftserver/src/test/scala/org/apache/spark/sql/hive/thriftserver/ThriftServerQueryTestSuite.scala
##
@@ -100,7 +100,8 @@ class ThriftServerQueryTestSuite extends SQLQueryTestSuite
{
"subquery/in-subquery/in-group-by.sql",
"subquery/in-subquery/simple-in.sql",
"subquery/in-subquery/in-order-by.sql",
-"subquery/in-subquery/in-set-operations.sql"
+"subquery/in-subquery/in-set-operations.sql",
+"explain.sql"
Review comment:
why?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk commented on issue #26079: [SPARK-29369][SQL] Support string intervals without the `interval` prefix
MaxGekk commented on issue #26079: [SPARK-29369][SQL] Support string intervals without the `interval` prefix URL: https://github.com/apache/spark/pull/26079#issuecomment-540441798 @cloud-fan @dongjoon-hyun @zsxwing May I ask you to take a look at this PR. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #26042: [SPARK-29092][SQL] Report additional information about DataSourceScanExec in EXPLAIN FORMATTED
cloud-fan commented on a change in pull request #26042: [SPARK-29092][SQL] Report additional information about DataSourceScanExec in EXPLAIN FORMATTED URL: https://github.com/apache/spark/pull/26042#discussion_r71980 ## File path: sql/core/src/test/resources/sql-tests/results/explain.sql.out ## @@ -58,6 +58,11 @@ struct (1) Scan parquet default.explain_temp1 Output: [key#x, val#x] +Batched: true +Format: Parquet Review comment: This is already in the node name `Scan parquet default.explain_temp1` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] MaxGekk opened a new pull request #26079: [SPARK-29369][SQL] Support string intervals without the `interval` prefix
MaxGekk opened a new pull request #26079: [SPARK-29369][SQL] Support string
intervals without the `interval` prefix
URL: https://github.com/apache/spark/pull/26079
### What changes were proposed in this pull request?
In the PR, I propose to move interval parsing to
`CalendarInterval.fromCaseInsensitiveString()` which throws an
`IllegalArgumentException` for invalid strings, and reuse it from
`CalendarInterval.fromString()`. The former one handles
`IllegalArgumentException` only and returns `NULL` for invalid interval
strings. This will allow to support interval strings without the `interval`
prefix in casting strings to intervals and in interval type constructor.
For example:
```sql
spark-sql> select cast('1 year 10 days' as interval);
interval 1 years 1 weeks 3 days
spark-sql> SELECT INTERVAL '1 YEAR 10 DAYS';
interval 1 years 1 weeks 3 days
```
### Why are the changes needed?
To maintain feature parity with PostgreSQL which supports interval strings
without prefix:
```sql
# select interval '2 months 1 microsecond';
interval
2 mons 00:00:00.01
```
### Does this PR introduce any user-facing change?
Yes, previously parsing interval strings without `interval` gives `NULL`:
```sql
spark-sql> select interval '2 months 1 microsecond';
NULL
```
After:
```sql
spark-sql> select interval '2 months 1 microsecond';
interval 2 months 1 microseconds
```
### How was this patch tested?
- Added new tests to `CalendarIntervalSuite.java`
- A test for casting strings to intervals in `CastSuite`
- Test for interval type constructor from strings in `ExpressionParserSuite`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #26042: [SPARK-29092][SQL] Report additional information about DataSourceScanExec in EXPLAIN FORMATTED
cloud-fan commented on a change in pull request #26042: [SPARK-29092][SQL]
Report additional information about DataSourceScanExec in EXPLAIN FORMATTED
URL: https://github.com/apache/spark/pull/26042#discussion_r69937
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/DataSourceScanExec.scala
##
@@ -65,6 +65,23 @@ trait DataSourceScanExec extends LeafExecNode {
s"$nodeNamePrefix$nodeName${truncatedString(output, "[", ",", "]",
maxFields)}$metadataStr")
}
+ override def verboseStringWithOperatorId(): String = {
+ val metadataStr = metadata.toSeq.sorted.map {
Review comment:
nit: we can do `filter` fist then `map`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] rafaelkyrdan edited a comment on issue #19424: [SPARK-22197][SQL] push down operators to data source before planning
rafaelkyrdan edited a comment on issue #19424: [SPARK-22197][SQL] push down operators to data source before planning URL: https://github.com/apache/spark/pull/19424#issuecomment-540059983 Could you confirm that `limit` now optimized and pushed to PushedFilters? In the physical plan I see that it is not. I'm using spark 2.4.4 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] peter-toth commented on issue #26028: [SPARK-29359][SQL][TESTS] Better exception handling in (SQL|ThriftServer)QueryTestSuite
peter-toth commented on issue #26028: [SPARK-29359][SQL][TESTS] Better exception handling in (SQL|ThriftServer)QueryTestSuite URL: https://github.com/apache/spark/pull/26028#issuecomment-540414457 @dongjoon-hyun @wangyum do you this PR is ok now? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn commented on issue #26068: [SPARK-29405][SQL] Alter table / Insert statements should not change a table's ownership
yaooqinn commented on issue #26068: [SPARK-29405][SQL] Alter table / Insert statements should not change a table's ownership URL: https://github.com/apache/spark/pull/26068#issuecomment-540413720 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] yaooqinn removed a comment on issue #26068: [SPARK-29405][SQL] Alter table / Insert statements should not change a table's ownership
yaooqinn removed a comment on issue #26068: [SPARK-29405][SQL] Alter table / Insert statements should not change a table's ownership URL: https://github.com/apache/spark/pull/26068#issuecomment-540330063 test this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24851: [SPARK-27303][GRAPH] Add Spark Graph API
dongjoon-hyun commented on a change in pull request #24851:
[SPARK-27303][GRAPH] Add Spark Graph API
URL: https://github.com/apache/spark/pull/24851#discussion_r48648
##
File path:
graph/api/src/main/scala/org/apache/spark/graph/api/GraphElementFrame.scala
##
@@ -0,0 +1,264 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.graph.api
+
+import scala.collection.JavaConverters._
+
+import org.apache.spark.sql.DataFrame
+
+/**
+ * A [[PropertyGraph]] is created from GraphElementFrames.
+ *
+ * A graph element is either a node or a relationship.
+ * A GraphElementFrame wraps a DataFrame and describes how it maps to graph
elements.
+ *
+ * @since 3.0.0
+ */
+abstract class GraphElementFrame {
+
+ /**
+ * Initial DataFrame that can still contain unmapped, arbitrarily ordered
columns.
+ *
+ * @since 3.0.0
+ */
+ def df: DataFrame
+
+ /**
+ * Name of the column that contains the graph element identifier.
+ *
+ * @since 3.0.0
+ */
+ def idColumn: String
+
+ /**
+ * Name of all columns that contain graph element identifiers.
+ *
+ * @since 3.0.0
+ */
+ def idColumns: Seq[String] = Seq(idColumn)
+
+ /**
+ * Mapping from graph element property keys to the columns that contain the
corresponding property
+ * values.
+ *
+ * @since 3.0.0
+ */
+ def properties: Map[String, String]
+
+}
+
+/**
+ * Interface used to build a [[NodeFrame]].
+ *
+ * @param df DataFrame containing a single node in each row
+ * @since 3.0.0
+ */
+final class NodeFrameBuilder(var df: DataFrame) {
Review comment:
Although this is not a big file with 264 lines, let's split this single file
into multiple files.
- `GraphElementFrame.scala`
- `NodeFrameBuilder.scala`
- `NodeFrame.scala`
- `RelationshipFrameBuilder.scala`
- `RelationshipFrame.scala`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24851: [SPARK-27303][GRAPH] Add Spark Graph API
dongjoon-hyun commented on a change in pull request #24851:
[SPARK-27303][GRAPH] Add Spark Graph API
URL: https://github.com/apache/spark/pull/24851#discussion_r47342
##
File path:
graph/api/src/test/scala/org/apache/spark/graph/api/PropertyGraphSuite.scala
##
@@ -0,0 +1,309 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.graph.api
+
+import org.scalatest.Matchers
+
+import org.apache.spark.graph.api.CypherSession.{ID_COLUMN,
LABEL_COLUMN_PREFIX, SOURCE_ID_COLUMN, TARGET_ID_COLUMN}
+import org.apache.spark.sql.{DataFrame, QueryTest}
+import org.apache.spark.sql.test.SharedSparkSession
+
+abstract class PropertyGraphSuite extends QueryTest with SharedSparkSession
with Matchers {
+
+ // Override in spark-cypher
+ type IdType = Long
+ def convertId(inputId: Long): IdType
+
+ def cypherSession: CypherSession
+
+ test("create graph from NodeFrame") {
+val nodeData = spark.createDataFrame(Seq(0L -> "Alice", 1L ->
"Bob")).toDF("id", "name")
+val nodeFrame = cypherSession.buildNodeFrame(nodeData)
+ .idColumn("id")
+ .labelSet(Array("Person"))
+ .properties(Map("name" -> "name"))
+ .build()
+val graph = cypherSession.createGraph(Array(nodeFrame),
Array.empty[RelationshipFrame])
+
+val expectedDf = spark
+ .createDataFrame(Seq((convertId(0L), true, "Alice"), (convertId(1L),
true, "Bob")))
+ .toDF(ID_COLUMN, label("Person"), "name")
+
+checkAnswer(graph.nodes, expectedDf)
+ }
+
+ test("create graph from NodeFrame and RelationshipFrame") {
+val nodeData = spark.createDataFrame(Seq(0L -> "Alice", 1L ->
"Bob")).toDF("id", "name")
+val nodeFrame = cypherSession.buildNodeFrame(nodeData)
+ .idColumn("id")
+ .labelSet(Array("Person"))
+ .properties(Map("name" -> "name"))
+ .build()
+val relationshipData = spark
+ .createDataFrame(Seq((0L, 0L, 1L, 1984)))
+ .toDF("id", "source", "target", "since")
+val relationshipFrame =
cypherSession.buildRelationshipFrame(relationshipData)
+ .idColumn("id")
+ .sourceIdColumn("source")
+ .targetIdColumn("target")
+ .relationshipType("KNOWS")
+ .properties(Map("since" -> "since"))
+ .build()
+
+val graph = cypherSession.createGraph(Array(nodeFrame),
Array(relationshipFrame))
+
+val expectedNodeDf = spark
+ .createDataFrame(Seq((convertId(0L), true, "Alice"), (convertId(1L),
true, "Bob")))
+ .toDF(ID_COLUMN, label("Person"), "name")
+
+val expectedRelDf = spark
+ .createDataFrame(Seq((convertId(0L), convertId(0L), convertId(1L), true,
1984)))
+ .toDF(ID_COLUMN, SOURCE_ID_COLUMN, TARGET_ID_COLUMN, label("KNOWS"),
"since")
+
+checkAnswer(graph.nodes, expectedNodeDf)
+checkAnswer(graph.relationships, expectedRelDf)
+ }
+
+ test("create graph with multiple node and relationship types") {
+val studentDF = spark
+ .createDataFrame(Seq((0L, "Alice", 42), (1L, "Bob", 23)))
+ .toDF("id", "name", "age")
+val teacherDF = spark
+ .createDataFrame(Seq((2L, "Eve", "CS")))
+ .toDF("id", "name", "subject")
+
+val studentNF = cypherSession.buildNodeFrame(studentDF)
+.idColumn("id")
+.labelSet(Array("Person", "Student"))
+.properties(Map("name" -> "name", "age" -> "age"))
+.build()
+
+val teacherNF = cypherSession.buildNodeFrame(teacherDF)
+ .idColumn("id")
+ .labelSet(Array("Person", "Teacher"))
+ .properties(Map("name" -> "name", "subject" -> "subject"))
+ .build()
+
+val knowsDF = spark
+ .createDataFrame(Seq((0L, 0L, 1L, 1984)))
+ .toDF("id", "source", "target", "since")
+val teachesDF = spark
+ .createDataFrame(Seq((1L, 2L, 1L)))
+ .toDF("id", "source", "target")
+
+val knowsRF = cypherSession.buildRelationshipFrame(knowsDF)
+ .idColumn("id")
+ .sourceIdColumn("source")
+ .targetIdColumn("target")
+ .relationshipType("KNOWS")
+ .properties(Map("since" -> "since"))
+ .build()
+val teachesRF = cypherSession.buildRelationshipFrame(teachesDF)
+ .idColumn("id")
+ .sourceIdColumn("source")
+ .targetIdColumn("target")
+
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24851: [SPARK-27303][GRAPH] Add Spark Graph API
dongjoon-hyun commented on a change in pull request #24851:
[SPARK-27303][GRAPH] Add Spark Graph API
URL: https://github.com/apache/spark/pull/24851#discussion_r45707
##
File path:
graph/api/src/main/scala/org/apache/spark/graph/api/CypherSession.scala
##
@@ -0,0 +1,263 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.graph.api
+
+import scala.collection.JavaConverters._
+
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
+import org.apache.spark.sql.types.{BooleanType, StructType}
+
+/**
+ * Contains constants used for convention based column naming.
+ */
+object CypherSession {
+
+ /**
+ * Naming convention for identifier columns, both node and relationship
identifiers.
+ */
+ val ID_COLUMN = "$ID"
+
+ /**
+ * Naming convention for relationship source identifier.
+ */
+ val SOURCE_ID_COLUMN = "$SOURCE_ID"
+
+ /**
+ * Naming convention for relationship target identifier.
+ */
+ val TARGET_ID_COLUMN = "$TARGET_ID"
+
+ /**
+ * Naming convention both for node label and relationship type prefixes.
+ */
+ val LABEL_COLUMN_PREFIX = ":"
+}
+
+/**
+ * A CypherSession allows for creating, storing and loading [[PropertyGraph]]
instances as well as
+ * executing Cypher queries on them.
+ *
+ * Wraps a [[org.apache.spark.sql.SparkSession]].
+ *
+ * @since 3.0.0
+ */
+trait CypherSession extends Logging {
+
+ def sparkSession: SparkSession
+
+ /**
+ * Executes a Cypher query on the given input graph.
+ *
+ * @see https://neo4j.com/docs/cypher-manual/current/;>Cypher
Manual
+ * @param graph [[PropertyGraph]] on which the query is executed
+ * @param query Cypher query to execute
+ * @since 3.0.0
+ */
+ def cypher(graph: PropertyGraph, query: String): CypherResult
+
+ /**
+ * Executes a Cypher query on the given input graph.
+ *
+ * Note that queries can take optional parameters:
+ *
+ * {{{
+ * Parameters:
+ *
+ * {
+ *"name" : "Alice"
+ * }
+ *
+ * Query:
+ *
+ * MATCH (n:Person)
+ * WHERE n.name = $name
+ * RETURN n
+ * }}}
+ *
+ * @see https://neo4j.com/docs/cypher-manual/current/;>Cypher
Manual
+ * @see https://neo4j.com/docs/cypher-manual/current/syntax/parameters/;>Parameters
+ * @param graph [[PropertyGraph]] on which the query is executed
+ * @param query Cypher query to execute
+ * @param parameters parameters used by the Cypher query
+ * @since 3.0.0
+ */
+ def cypher(graph: PropertyGraph, query: String, parameters: Map[String,
Any]): CypherResult
+
+ /**
+ * Executes a Cypher query on the given input graph.
+ *
+ * Note that queries can take optional parameters:
+ *
+ * {{{
+ * Parameters:
+ *
+ * {
+ *"name" : "Alice"
+ * }
+ *
+ * Query:
+ *
+ * MATCH (n:Person)
+ * WHERE n.name = $name
+ * RETURN n
+ * }}}
+ *
+ * @see https://neo4j.com/docs/cypher-manual/current/;>Cypher
Manual
+ * @see https://neo4j.com/docs/cypher-manual/current/syntax/parameters/;>Parameters
Review comment:
Let's remove these two lines.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24851: [SPARK-27303][GRAPH] Add Spark Graph API
dongjoon-hyun commented on a change in pull request #24851:
[SPARK-27303][GRAPH] Add Spark Graph API
URL: https://github.com/apache/spark/pull/24851#discussion_r45612
##
File path:
graph/api/src/main/scala/org/apache/spark/graph/api/CypherSession.scala
##
@@ -0,0 +1,263 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.graph.api
+
+import scala.collection.JavaConverters._
+
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
+import org.apache.spark.sql.types.{BooleanType, StructType}
+
+/**
+ * Contains constants used for convention based column naming.
+ */
+object CypherSession {
+
+ /**
+ * Naming convention for identifier columns, both node and relationship
identifiers.
+ */
+ val ID_COLUMN = "$ID"
+
+ /**
+ * Naming convention for relationship source identifier.
+ */
+ val SOURCE_ID_COLUMN = "$SOURCE_ID"
+
+ /**
+ * Naming convention for relationship target identifier.
+ */
+ val TARGET_ID_COLUMN = "$TARGET_ID"
+
+ /**
+ * Naming convention both for node label and relationship type prefixes.
+ */
+ val LABEL_COLUMN_PREFIX = ":"
+}
+
+/**
+ * A CypherSession allows for creating, storing and loading [[PropertyGraph]]
instances as well as
+ * executing Cypher queries on them.
+ *
+ * Wraps a [[org.apache.spark.sql.SparkSession]].
+ *
+ * @since 3.0.0
+ */
+trait CypherSession extends Logging {
+
+ def sparkSession: SparkSession
+
+ /**
+ * Executes a Cypher query on the given input graph.
+ *
+ * @see https://neo4j.com/docs/cypher-manual/current/;>Cypher
Manual
+ * @param graph [[PropertyGraph]] on which the query is executed
+ * @param query Cypher query to execute
+ * @since 3.0.0
+ */
+ def cypher(graph: PropertyGraph, query: String): CypherResult
+
+ /**
+ * Executes a Cypher query on the given input graph.
+ *
+ * Note that queries can take optional parameters:
+ *
+ * {{{
+ * Parameters:
+ *
+ * {
+ *"name" : "Alice"
+ * }
+ *
+ * Query:
+ *
+ * MATCH (n:Person)
+ * WHERE n.name = $name
+ * RETURN n
+ * }}}
+ *
+ * @see https://neo4j.com/docs/cypher-manual/current/;>Cypher
Manual
+ * @see https://neo4j.com/docs/cypher-manual/current/syntax/parameters/;>Parameters
Review comment:
Let's remove these two lines.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24851: [SPARK-27303][GRAPH] Add Spark Graph API
dongjoon-hyun commented on a change in pull request #24851:
[SPARK-27303][GRAPH] Add Spark Graph API
URL: https://github.com/apache/spark/pull/24851#discussion_r45466
##
File path:
graph/api/src/main/scala/org/apache/spark/graph/api/CypherSession.scala
##
@@ -0,0 +1,263 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.graph.api
+
+import scala.collection.JavaConverters._
+
+import org.apache.spark.internal.Logging
+import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}
+import org.apache.spark.sql.types.{BooleanType, StructType}
+
+/**
+ * Contains constants used for convention based column naming.
+ */
+object CypherSession {
+
+ /**
+ * Naming convention for identifier columns, both node and relationship
identifiers.
+ */
+ val ID_COLUMN = "$ID"
+
+ /**
+ * Naming convention for relationship source identifier.
+ */
+ val SOURCE_ID_COLUMN = "$SOURCE_ID"
+
+ /**
+ * Naming convention for relationship target identifier.
+ */
+ val TARGET_ID_COLUMN = "$TARGET_ID"
+
+ /**
+ * Naming convention both for node label and relationship type prefixes.
+ */
+ val LABEL_COLUMN_PREFIX = ":"
+}
+
+/**
+ * A CypherSession allows for creating, storing and loading [[PropertyGraph]]
instances as well as
+ * executing Cypher queries on them.
+ *
+ * Wraps a [[org.apache.spark.sql.SparkSession]].
+ *
+ * @since 3.0.0
+ */
+trait CypherSession extends Logging {
+
+ def sparkSession: SparkSession
+
+ /**
+ * Executes a Cypher query on the given input graph.
+ *
+ * @see https://neo4j.com/docs/cypher-manual/current/;>Cypher
Manual
Review comment:
@s1ck . Please remove `neo4j.com` reference.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24851: [SPARK-27303][GRAPH] Add Spark Graph API
dongjoon-hyun commented on a change in pull request #24851:
[SPARK-27303][GRAPH] Add Spark Graph API
URL: https://github.com/apache/spark/pull/24851#discussion_r44565
##
File path:
graph/api/src/test/java/org/apache/spark/graph/api/JavaPropertyGraphSuite.java
##
@@ -74,9 +73,12 @@ public void testCreateFromNodeFrame() {
List knowsData = Collections.singletonList(RowFactory.create(0L, 0L,
1L, 1984));
-Dataset personDf = spark.createDataFrame(personData, personSchema);
-NodeFrame personNodeFrame = NodeFrame
-.create(personDf, "id", Sets.newHashSet("Person"));
+Dataset personDf = spark.createDataFrame(personData,
personSchema);
Review comment:
Indentation?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24851: [SPARK-27303][GRAPH] Add Spark Graph API
dongjoon-hyun commented on a change in pull request #24851:
[SPARK-27303][GRAPH] Add Spark Graph API
URL: https://github.com/apache/spark/pull/24851#discussion_r43840
##
File path:
graph/api/src/main/scala/org/apache/spark/graph/api/PropertyGraphWriter.scala
##
@@ -0,0 +1,92 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.graph.api
+
+import java.util.Locale
+
+import org.apache.spark.sql.SaveMode
+
+abstract class PropertyGraphWriter(val graph: PropertyGraph) {
+
+ protected var saveMode: SaveMode = SaveMode.ErrorIfExists
+ protected var format: String =
+graph.cypherSession.sparkSession.sessionState.conf.defaultDataSourceName
+
+ /**
+ * Specifies the behavior when the graph already exists. Options include:
+ *
+ * `SaveMode.Overwrite`: overwrite the existing data.
+ * `SaveMode.Ignore`: ignore the operation (i.e. no-op).
+ * `SaveMode.ErrorIfExists`: throw an exception at runtime.
+ *
+ *
+ * When writing the default option is `ErrorIfExists`.
+ *
+ * @since 3.0.0
+ */
+ def mode(mode: SaveMode): PropertyGraphWriter = {
+mode match {
+ case SaveMode.Append =>
+throw new IllegalArgumentException(s"Unsupported save mode: $mode. " +
+ "Accepted save modes are 'overwrite', 'ignore', 'error',
'errorifexists'.")
+ case _ =>
+this.saveMode = mode
+}
+this
+ }
+
+ /**
+ * Specifies the behavior when the graph already exists. Options include:
+ *
+ * `overwrite`: overwrite the existing graph.
+ * `ignore`: ignore the operation (i.e. no-op).
+ * `error` or `errorifexists`: default option, throw an exception at
runtime.
+ *
+ *
+ * @since 3.0.0
+ */
+ def mode(saveMode: String): PropertyGraphWriter = {
+saveMode.toLowerCase(Locale.ROOT) match {
+ case "overwrite" => mode(SaveMode.Overwrite)
+ case "ignore" => mode(SaveMode.Ignore)
+ case "error" | "errorifexists" => mode(SaveMode.ErrorIfExists)
+ case "default" => this
+ case "append" => mode(SaveMode.Append)
Review comment:
Although this will eventually raise exception, let's remove this to match
the line 70 and 71. That will improve the consistency in this function.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24851: [SPARK-27303][GRAPH] Add Spark Graph API
dongjoon-hyun commented on a change in pull request #24851:
[SPARK-27303][GRAPH] Add Spark Graph API
URL: https://github.com/apache/spark/pull/24851#discussion_r42983
##
File path:
graph/api/src/main/scala/org/apache/spark/graph/api/PropertyGraphWriter.scala
##
@@ -0,0 +1,92 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.graph.api
+
+import java.util.Locale
+
+import org.apache.spark.sql.SaveMode
+
+abstract class PropertyGraphWriter(val graph: PropertyGraph) {
+
+ protected var saveMode: SaveMode = SaveMode.ErrorIfExists
+ protected var format: String =
+graph.cypherSession.sparkSession.sessionState.conf.defaultDataSourceName
+
+ /**
+ * Specifies the behavior when the graph already exists. Options include:
+ *
+ * `SaveMode.Overwrite`: overwrite the existing data.
+ * `SaveMode.Ignore`: ignore the operation (i.e. no-op).
+ * `SaveMode.ErrorIfExists`: throw an exception at runtime.
+ *
+ *
+ * When writing the default option is `ErrorIfExists`.
+ *
+ * @since 3.0.0
+ */
+ def mode(mode: SaveMode): PropertyGraphWriter = {
+mode match {
+ case SaveMode.Append =>
+throw new IllegalArgumentException(s"Unsupported save mode: $mode. " +
+ "Accepted save modes are 'overwrite', 'ignore', 'error',
'errorifexists'.")
+ case _ =>
+this.saveMode = mode
+}
+this
+ }
+
+ /**
+ * Specifies the behavior when the graph already exists. Options include:
+ *
+ * `overwrite`: overwrite the existing graph.
+ * `ignore`: ignore the operation (i.e. no-op).
+ * `error` or `errorifexists`: default option, throw an exception at
runtime.
+ *
+ *
+ * @since 3.0.0
+ */
+ def mode(saveMode: String): PropertyGraphWriter = {
+saveMode.toLowerCase(Locale.ROOT) match {
+ case "overwrite" => mode(SaveMode.Overwrite)
+ case "ignore" => mode(SaveMode.Ignore)
+ case "error" | "errorifexists" => mode(SaveMode.ErrorIfExists)
+ case "default" => this
Review comment:
Ur, this can be wrong in case of `mode("overwrite").mode("default")``.
Please merge `default` to the line 67. Please add a test case for this, too.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24851: [SPARK-27303][GRAPH] Add Spark Graph API
dongjoon-hyun commented on a change in pull request #24851:
[SPARK-27303][GRAPH] Add Spark Graph API
URL: https://github.com/apache/spark/pull/24851#discussion_r42983
##
File path:
graph/api/src/main/scala/org/apache/spark/graph/api/PropertyGraphWriter.scala
##
@@ -0,0 +1,92 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.graph.api
+
+import java.util.Locale
+
+import org.apache.spark.sql.SaveMode
+
+abstract class PropertyGraphWriter(val graph: PropertyGraph) {
+
+ protected var saveMode: SaveMode = SaveMode.ErrorIfExists
+ protected var format: String =
+graph.cypherSession.sparkSession.sessionState.conf.defaultDataSourceName
+
+ /**
+ * Specifies the behavior when the graph already exists. Options include:
+ *
+ * `SaveMode.Overwrite`: overwrite the existing data.
+ * `SaveMode.Ignore`: ignore the operation (i.e. no-op).
+ * `SaveMode.ErrorIfExists`: throw an exception at runtime.
+ *
+ *
+ * When writing the default option is `ErrorIfExists`.
+ *
+ * @since 3.0.0
+ */
+ def mode(mode: SaveMode): PropertyGraphWriter = {
+mode match {
+ case SaveMode.Append =>
+throw new IllegalArgumentException(s"Unsupported save mode: $mode. " +
+ "Accepted save modes are 'overwrite', 'ignore', 'error',
'errorifexists'.")
+ case _ =>
+this.saveMode = mode
+}
+this
+ }
+
+ /**
+ * Specifies the behavior when the graph already exists. Options include:
+ *
+ * `overwrite`: overwrite the existing graph.
+ * `ignore`: ignore the operation (i.e. no-op).
+ * `error` or `errorifexists`: default option, throw an exception at
runtime.
+ *
+ *
+ * @since 3.0.0
+ */
+ def mode(saveMode: String): PropertyGraphWriter = {
+saveMode.toLowerCase(Locale.ROOT) match {
+ case "overwrite" => mode(SaveMode.Overwrite)
+ case "ignore" => mode(SaveMode.Ignore)
+ case "error" | "errorifexists" => mode(SaveMode.ErrorIfExists)
+ case "default" => this
Review comment:
Ur, this can be wrong in case of `mode("overwrite").mode("default")``.
Please merge `default` to the line 67.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org