[GitHub] [spark] gaborgsomogyi commented on a change in pull request #29729: [SPARK-32032][SS] Avoid infinite wait in driver because of KafkaConsumer.poll(long) API
gaborgsomogyi commented on a change in pull request #29729:
URL: https://github.com/apache/spark/pull/29729#discussion_r533134611
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/internal/SQLConf.scala
##
@@ -1415,6 +1415,15 @@ object SQLConf {
.booleanConf
.createWithDefault(true)
+ val USE_DEPRECATED_KAFKA_OFFSET_FETCHING =
+buildConf("spark.sql.streaming.kafka.useDeprecatedOffsetFetching")
+ .internal()
+ .doc("When true, the deprecated Consumer based offset fetching used
which could cause " +
Review comment:
Fixed. Updating the description because I've double checked the
generated HTML files too.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 opened a new pull request #30488: [SPARK-33071][SPARK-33536][SQL] Avoid changing dataset_id of LogicalPlan in join() to not break DetectAmbiguousSelfJoin
Ngone51 opened a new pull request #30488:
URL: https://github.com/apache/spark/pull/30488
### What changes were proposed in this pull request?
Currently, `join()` uses `withPlan(logicalPlan)` for convenient to call some
Dataset functions. But it leads to the `dataset_id` inconsistent between the
`logicalPlan` and the original `Dataset`(because `withPlan(logicalPlan)` will
create a new Dataset with the new id and reset the `dataset_id` with the new id
of the `logicalPlan`). As a result, it breaks the rule
`DetectAmbiguousSelfJoin`.
In this PR, we propose to drop the usage of `withPlan` but use the
`logicalPlan` directly so its `dataset_id` doesn't change.
Besides, this PR also removes related metadata (`DATASET_ID_KEY`,
`COL_POS_KEY`) when an `Alias` tries to construct its own metadata. Because the
`Alias` is no longer a reference column after converting to an `Attribute`. To
achieve that, we add a new field, `deniedMetadataKeys`, to indicate the
metadata that needs to be removed.
### Why are the changes needed?
For the query below, it returns the wrong result while it should throws
ambiguous self join exception instead:
```scala
val emp1 = Seq[TestData](
TestData(1, "sales"),
TestData(2, "personnel"),
TestData(3, "develop"),
TestData(4, "IT")).toDS()
val emp2 = Seq[TestData](
TestData(1, "sales"),
TestData(2, "personnel"),
TestData(3, "develop")).toDS()
val emp3 = emp1.join(emp2, emp1("key") === emp2("key")).select(emp1("*"))
emp1.join(emp3, emp1.col("key") === emp3.col("key"), "left_outer")
.select(emp1.col("*"), emp3.col("key").as("e2")).show()
// wrong result
+---+-+---+
|key|value| e2|
+---+-+---+
| 1|sales| 1|
| 2|personnel| 2|
| 3| develop| 3|
| 4| IT| 4|
+---+-+---+
```
This PR fixes the wrong behaviour.
### Does this PR introduce _any_ user-facing change?
Yes, users hit the exception instead of the wrong result after this PR.
### How was this patch tested?
Added a new unit test.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 closed pull request #30488: [SPARK-33071][SPARK-33536][SQL] Avoid changing dataset_id of LogicalPlan in join() to not break DetectAmbiguousSelfJoin
Ngone51 closed pull request #30488: URL: https://github.com/apache/spark/pull/30488 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #30395: [SPARK-32863][SS] Full outer stream-stream join
HeartSaVioR commented on pull request #30395: URL: https://github.com/apache/spark/pull/30395#issuecomment-736282615 All current reviewers are OK with this, so I'm kicking the Github Action build again. Once the test passes I'll merge this. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AngersZh commented on a change in pull request #29966:
URL: https://github.com/apache/spark/pull/29966#discussion_r533123647
##
File path: core/src/main/scala/org/apache/spark/SparkContext.scala
##
@@ -1919,18 +1919,24 @@ class SparkContext(config: SparkConf) extends Logging {
// A JAR file which exists only on the driver node
case "file" => addLocalJarFile(new File(uri.getPath))
// A JAR file which exists locally on every worker node
- case "local" => "file:" + uri.getPath
+ case "local" => Array("file:" + uri.getPath)
+ case "ivy" =>
+// Since `new Path(path).toUri` will lose query information,
+// so here we use `URI.create(path)`
+
DependencyUtils.resolveMavenDependencies(URI.create(path)).split(",")
case _ => checkRemoteJarFile(path)
}
}
- if (key != null) {
+ if (keys.nonEmpty) {
val timestamp = if (addedOnSubmit) startTime else
System.currentTimeMillis
-if (addedJars.putIfAbsent(key, timestamp).isEmpty) {
- logInfo(s"Added JAR $path at $key with timestamp $timestamp")
- postEnvironmentUpdate()
-} else {
- logWarning(s"The jar $path has been added already. Overwriting of
added jars " +
-"is not supported in the current version.")
+keys.foreach { key =>
+ if (addedJars.putIfAbsent(key, timestamp).isEmpty) {
+logInfo(s"Added JAR $path at $key with timestamp $timestamp")
+postEnvironmentUpdate()
+ } else {
+logWarning(s"The jar $path has been added already. Overwriting of
added jars " +
Review comment:
> If `transitive=true` and there are too many dependencies, users
possibly see a lot of warning messages?
Also `logInfo(s"Added JAR $path at $key with timestamp $timestamp")`
How about like
```
val (added, existed) = keys.partition(addedJars.putIfAbsent(_,
timestamp).isEmpty)
if (added.nonEmpty) {
logInfo(s"Added JAR $path at ${added.mkString(",")} with timestamp
$timestamp")
postEnvironmentUpdate()
}
if(existed.nonEmpty) {
logWarning(s"The dependencies jars ${existed.mkString(",")} of
$path has been added" +
s" already. Overwriting of added jars is not supported in the
current version.")
}
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] aokolnychyi commented on a change in pull request #30558: [SPARK-33612][SQL] Add v2SourceRewriteRules batch to Optimizer
aokolnychyi commented on a change in pull request #30558:
URL: https://github.com/apache/spark/pull/30558#discussion_r533123744
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
##
@@ -189,6 +189,9 @@ abstract class Optimizer(catalogManager: CatalogManager)
// plan may contain nodes that do not report stats. Anything that uses
stats must run after
// this batch.
Batch("Early Filter and Projection Push-Down", Once,
earlyScanPushDownRules: _*) :+
+// This batch rewrites plans for v2 tables. It should be run after the
operator
+// optimization batch and before any batches that depend on stats.
+Batch("V2 Source Rewrite Rules", Once, v2SourceRewriteRules: _*) :+
Review comment:
Right now, scan construction and pushdown happens in the same method. We
could split that later so I agree with moving this batch before early filter
and projection pushdown.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AngersZh commented on a change in pull request #29966:
URL: https://github.com/apache/spark/pull/29966#discussion_r533123647
##
File path: core/src/main/scala/org/apache/spark/SparkContext.scala
##
@@ -1919,18 +1919,24 @@ class SparkContext(config: SparkConf) extends Logging {
// A JAR file which exists only on the driver node
case "file" => addLocalJarFile(new File(uri.getPath))
// A JAR file which exists locally on every worker node
- case "local" => "file:" + uri.getPath
+ case "local" => Array("file:" + uri.getPath)
+ case "ivy" =>
+// Since `new Path(path).toUri` will lose query information,
+// so here we use `URI.create(path)`
+
DependencyUtils.resolveMavenDependencies(URI.create(path)).split(",")
case _ => checkRemoteJarFile(path)
}
}
- if (key != null) {
+ if (keys.nonEmpty) {
val timestamp = if (addedOnSubmit) startTime else
System.currentTimeMillis
-if (addedJars.putIfAbsent(key, timestamp).isEmpty) {
- logInfo(s"Added JAR $path at $key with timestamp $timestamp")
- postEnvironmentUpdate()
-} else {
- logWarning(s"The jar $path has been added already. Overwriting of
added jars " +
-"is not supported in the current version.")
+keys.foreach { key =>
+ if (addedJars.putIfAbsent(key, timestamp).isEmpty) {
+logInfo(s"Added JAR $path at $key with timestamp $timestamp")
+postEnvironmentUpdate()
+ } else {
+logWarning(s"The jar $path has been added already. Overwriting of
added jars " +
Review comment:
> If `transitive=true` and there are too many dependencies, users
possibly see a lot of warning messages?
Also `logInfo(s"Added JAR $path at $key with timestamp $timestamp")`
How about like
```
val (added, existed) = keys.partition(addedJars.putIfAbsent(_,
timestamp).isEmpty)
if (added.nonEmpty) {
logInfo(s"Added JAR $path at ${added.mkString(",")} with timestamp
$timestamp")
postEnvironmentUpdate()
}
if(existed.nonEmpty) {
logWarning(s"The dependencies jars ${existed.mkString(",")} of
$path has been added" +
s" already. Overwriting of added jars is not supported in the
current version.")
}
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AngersZh commented on a change in pull request #29966:
URL: https://github.com/apache/spark/pull/29966#discussion_r533123647
##
File path: core/src/main/scala/org/apache/spark/SparkContext.scala
##
@@ -1919,18 +1919,24 @@ class SparkContext(config: SparkConf) extends Logging {
// A JAR file which exists only on the driver node
case "file" => addLocalJarFile(new File(uri.getPath))
// A JAR file which exists locally on every worker node
- case "local" => "file:" + uri.getPath
+ case "local" => Array("file:" + uri.getPath)
+ case "ivy" =>
+// Since `new Path(path).toUri` will lose query information,
+// so here we use `URI.create(path)`
+
DependencyUtils.resolveMavenDependencies(URI.create(path)).split(",")
case _ => checkRemoteJarFile(path)
}
}
- if (key != null) {
+ if (keys.nonEmpty) {
val timestamp = if (addedOnSubmit) startTime else
System.currentTimeMillis
-if (addedJars.putIfAbsent(key, timestamp).isEmpty) {
- logInfo(s"Added JAR $path at $key with timestamp $timestamp")
- postEnvironmentUpdate()
-} else {
- logWarning(s"The jar $path has been added already. Overwriting of
added jars " +
-"is not supported in the current version.")
+keys.foreach { key =>
+ if (addedJars.putIfAbsent(key, timestamp).isEmpty) {
+logInfo(s"Added JAR $path at $key with timestamp $timestamp")
+postEnvironmentUpdate()
+ } else {
+logWarning(s"The jar $path has been added already. Overwriting of
added jars " +
Review comment:
> If `transitive=true` and there are too many dependencies, users
possibly see a lot of warning messages?
Also `logInfo(s"Added JAR $path at $key with timestamp $timestamp")`
How about like
```
val (added, existed) = keys.partition(addedJars.putIfAbsent(_,
timestamp).isEmpty)
if (added.nonEmpty) {
logInfo(s"Added JAR $path at ${added.mkString(",")} with timestamp
$timestamp")
postEnvironmentUpdate()
}
if(existed.nonEmpty) {
logWarning(s"The dependencies jars ${existed.mkString(",")} of
$path has been added" +
s" already. Overwriting of added jars is not supported in the
current version.")
}
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #30504: [SPARK-33544][SQL] Optimizer should not insert filter when explode with CreateArray/CreateMap
HyukjinKwon commented on a change in pull request #30504:
URL: https://github.com/apache/spark/pull/30504#discussion_r533123592
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/expressions.scala
##
@@ -48,6 +48,9 @@ object ConstantFolding extends Rule[LogicalPlan] {
// object and running eval unnecessarily.
case l: Literal => l
+ case Size(c: CreateArray, _) => Literal(c.children.length)
+ case Size(c: CreateMap, _) => Literal(c.children.length / 2)
Review comment:
Hm .. one case I can imagine is the case when the children of
`CreateArray` or `CreateMap` throw an exception e.g.) from a UDF or when ANSI
mode is enabled. After this change, looks it's going to suppress such
exceptions. For example:
```scala
spark.range(1).selectExpr("size(array(assert_true(false)))").show()
```
As an alternative, we could maybe only allow this when the children of
`CreateArray` or `CreateMap` are safe and don't throw an exception? e.g.) only
when they are `AttributeReference`s?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] otterc commented on a change in pull request #30312: [SPARK-32917][SHUFFLE][CORE] Adds support for executors to push shuffle blocks after successful map task completion
otterc commented on a change in pull request #30312:
URL: https://github.com/apache/spark/pull/30312#discussion_r533121614
##
File path:
core/src/test/scala/org/apache/spark/shuffle/ShuffleBlockPusherSuite.scala
##
@@ -0,0 +1,248 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.shuffle
+
+import java.io.File
+import java.net.ConnectException
+import java.nio.ByteBuffer
+
+import scala.collection.mutable.ArrayBuffer
+
+import org.mockito.{Mock, MockitoAnnotations}
+import org.mockito.Answers.RETURNS_SMART_NULLS
+import org.mockito.ArgumentMatchers.any
+import org.mockito.Mockito._
+import org.mockito.invocation.InvocationOnMock
+import org.scalatest.BeforeAndAfterEach
+
+import org.apache.spark._
+import org.apache.spark.network.buffer.ManagedBuffer
+import org.apache.spark.network.shuffle.{BlockFetchingListener,
BlockStoreClient}
+import org.apache.spark.network.shuffle.ErrorHandler.BlockPushErrorHandler
+import org.apache.spark.network.util.TransportConf
+import org.apache.spark.serializer.JavaSerializer
+import org.apache.spark.storage._
+
+class ShuffleBlockPusherSuite extends SparkFunSuite with BeforeAndAfterEach {
+
+ @Mock(answer = RETURNS_SMART_NULLS) private var blockManager: BlockManager =
_
+ @Mock(answer = RETURNS_SMART_NULLS) private var dependency:
ShuffleDependency[Int, Int, Int] = _
+ @Mock(answer = RETURNS_SMART_NULLS) private var shuffleClient:
BlockStoreClient = _
+
+ private var conf: SparkConf = _
+ private var pushedBlocks = new ArrayBuffer[String]
+
+ override def beforeEach(): Unit = {
+super.beforeEach()
+conf = new SparkConf(loadDefaults = false)
+MockitoAnnotations.initMocks(this)
+when(dependency.partitioner).thenReturn(new HashPartitioner(8))
+when(dependency.serializer).thenReturn(new JavaSerializer(conf))
+
when(dependency.getMergerLocs).thenReturn(Seq(BlockManagerId("test-client",
"test-client", 1)))
+conf.set("spark.shuffle.push.based.enabled", "true")
+conf.set("spark.shuffle.service.enabled", "true")
+// Set the env because the shuffler writer gets the shuffle client
instance from the env.
+val mockEnv = mock(classOf[SparkEnv])
+when(mockEnv.conf).thenReturn(conf)
+when(mockEnv.blockManager).thenReturn(blockManager)
+SparkEnv.set(mockEnv)
+when(blockManager.blockStoreClient).thenReturn(shuffleClient)
+ }
+
+ override def afterEach(): Unit = {
+pushedBlocks.clear()
+super.afterEach()
+ }
+
+ private def interceptPushedBlocksForSuccess(): Unit = {
+when(shuffleClient.pushBlocks(any(), any(), any(), any(), any()))
+ .thenAnswer((invocation: InvocationOnMock) => {
+val blocks = invocation.getArguments()(2).asInstanceOf[Array[String]]
+pushedBlocks ++= blocks
+val managedBuffers =
invocation.getArguments()(3).asInstanceOf[Array[ManagedBuffer]]
+val blockFetchListener =
invocation.getArguments()(4).asInstanceOf[BlockFetchingListener]
+(blocks, managedBuffers).zipped.foreach((blockId, buffer) => {
+ blockFetchListener.onBlockFetchSuccess(blockId, buffer)
+})
+ })
+ }
+
+ test("Basic block push") {
+interceptPushedBlocksForSuccess()
+new TestShuffleBlockPusher(mock(classOf[File]),
+ Array.fill(dependency.partitioner.numPartitions) { 2 }, dependency, 0,
conf)
+.initiateBlockPush()
+verify(shuffleClient, times(1))
+ .pushBlocks(any(), any(), any(), any(), any())
+assert(pushedBlocks.length == dependency.partitioner.numPartitions)
+ShuffleBlockPusher.stop()
+ }
+
+ test("Large blocks are skipped for push") {
+conf.set("spark.shuffle.push.maxBlockSizeToPush", "1k")
+interceptPushedBlocksForSuccess()
+new TestShuffleBlockPusher(mock(classOf[File]), Array(2, 2, 2, 2, 2, 2, 2,
1100),
+ dependency, 0, conf).initiateBlockPush()
+verify(shuffleClient, times(1))
+ .pushBlocks(any(), any(), any(), any(), any())
+assert(pushedBlocks.length == dependency.partitioner.numPartitions - 1)
+ShuffleBlockPusher.stop()
+ }
+
+ test("Number of blocks in flight per address are limited by
maxBlocksInFlightPerAddress") {
+
[GitHub] [spark] otterc commented on a change in pull request #30312: [SPARK-32917][SHUFFLE][CORE] Adds support for executors to push shuffle blocks after successful map task completion
otterc commented on a change in pull request #30312:
URL: https://github.com/apache/spark/pull/30312#discussion_r533120860
##
File path:
core/src/test/scala/org/apache/spark/shuffle/ShuffleBlockPusherSuite.scala
##
@@ -0,0 +1,248 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.shuffle
+
+import java.io.File
+import java.net.ConnectException
+import java.nio.ByteBuffer
+
+import scala.collection.mutable.ArrayBuffer
+
+import org.mockito.{Mock, MockitoAnnotations}
+import org.mockito.Answers.RETURNS_SMART_NULLS
+import org.mockito.ArgumentMatchers.any
+import org.mockito.Mockito._
+import org.mockito.invocation.InvocationOnMock
+import org.scalatest.BeforeAndAfterEach
+
+import org.apache.spark._
+import org.apache.spark.network.buffer.ManagedBuffer
+import org.apache.spark.network.shuffle.{BlockFetchingListener,
BlockStoreClient}
+import org.apache.spark.network.shuffle.ErrorHandler.BlockPushErrorHandler
+import org.apache.spark.network.util.TransportConf
+import org.apache.spark.serializer.JavaSerializer
+import org.apache.spark.storage._
+
+class ShuffleBlockPusherSuite extends SparkFunSuite with BeforeAndAfterEach {
+
+ @Mock(answer = RETURNS_SMART_NULLS) private var blockManager: BlockManager =
_
+ @Mock(answer = RETURNS_SMART_NULLS) private var dependency:
ShuffleDependency[Int, Int, Int] = _
+ @Mock(answer = RETURNS_SMART_NULLS) private var shuffleClient:
BlockStoreClient = _
+
+ private var conf: SparkConf = _
+ private var pushedBlocks = new ArrayBuffer[String]
+
+ override def beforeEach(): Unit = {
+super.beforeEach()
+conf = new SparkConf(loadDefaults = false)
+MockitoAnnotations.initMocks(this)
+when(dependency.partitioner).thenReturn(new HashPartitioner(8))
+when(dependency.serializer).thenReturn(new JavaSerializer(conf))
+
when(dependency.getMergerLocs).thenReturn(Seq(BlockManagerId("test-client",
"test-client", 1)))
+conf.set("spark.shuffle.push.based.enabled", "true")
+conf.set("spark.shuffle.service.enabled", "true")
+// Set the env because the shuffler writer gets the shuffle client
instance from the env.
+val mockEnv = mock(classOf[SparkEnv])
+when(mockEnv.conf).thenReturn(conf)
+when(mockEnv.blockManager).thenReturn(blockManager)
+SparkEnv.set(mockEnv)
+when(blockManager.blockStoreClient).thenReturn(shuffleClient)
+ }
+
+ override def afterEach(): Unit = {
+pushedBlocks.clear()
+super.afterEach()
+ }
+
+ private def interceptPushedBlocksForSuccess(): Unit = {
+when(shuffleClient.pushBlocks(any(), any(), any(), any(), any()))
+ .thenAnswer((invocation: InvocationOnMock) => {
+val blocks = invocation.getArguments()(2).asInstanceOf[Array[String]]
+pushedBlocks ++= blocks
+val managedBuffers =
invocation.getArguments()(3).asInstanceOf[Array[ManagedBuffer]]
+val blockFetchListener =
invocation.getArguments()(4).asInstanceOf[BlockFetchingListener]
+(blocks, managedBuffers).zipped.foreach((blockId, buffer) => {
+ blockFetchListener.onBlockFetchSuccess(blockId, buffer)
+})
+ })
+ }
+
+ test("Basic block push") {
+interceptPushedBlocksForSuccess()
+new TestShuffleBlockPusher(mock(classOf[File]),
+ Array.fill(dependency.partitioner.numPartitions) { 2 }, dependency, 0,
conf)
+.initiateBlockPush()
+verify(shuffleClient, times(1))
+ .pushBlocks(any(), any(), any(), any(), any())
Review comment:
done
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] otterc commented on a change in pull request #30312: [SPARK-32917][SHUFFLE][CORE] Adds support for executors to push shuffle blocks after successful map task completion
otterc commented on a change in pull request #30312:
URL: https://github.com/apache/spark/pull/30312#discussion_r533120443
##
File path: core/src/main/scala/org/apache/spark/shuffle/ShuffleBlockPusher.scala
##
@@ -0,0 +1,462 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.shuffle
+
+import java.io.File
+import java.net.ConnectException
+import java.nio.ByteBuffer
+import java.util.concurrent.ExecutorService
+
+import scala.collection.mutable.{ArrayBuffer, HashMap, HashSet, Queue}
+
+import com.google.common.base.Throwables
+
+import org.apache.spark.{ShuffleDependency, SparkConf, SparkEnv}
+import org.apache.spark.annotation.Since
+import org.apache.spark.internal.Logging
+import org.apache.spark.internal.config._
+import org.apache.spark.launcher.SparkLauncher
+import org.apache.spark.network.buffer.{FileSegmentManagedBuffer,
ManagedBuffer, NioManagedBuffer}
+import org.apache.spark.network.netty.SparkTransportConf
+import org.apache.spark.network.shuffle.BlockFetchingListener
+import org.apache.spark.network.shuffle.ErrorHandler.BlockPushErrorHandler
+import org.apache.spark.network.util.TransportConf
+import org.apache.spark.shuffle.ShuffleBlockPusher._
+import org.apache.spark.storage.{BlockId, BlockManagerId, ShufflePushBlockId}
+import org.apache.spark.util.{ThreadUtils, Utils}
+
+/**
+ * Used for pushing shuffle blocks to remote shuffle services when push
shuffle is enabled.
+ * When push shuffle is enabled, it is created after the shuffle writer
finishes writing the shuffle
+ * file and initiates the block push process.
+ *
+ * @param dataFile mapper generated shuffle data file
+ * @param partitionLengths array of shuffle block size so we can tell shuffle
block
+ * boundaries within the shuffle file
+ * @param dep shuffle dependency to get shuffle ID and the
location of remote shuffle
+ * services to push local shuffle blocks
+ * @param partitionId map index of the shuffle map task
+ * @param conf spark configuration
+ */
+@Since("3.1.0")
+private[spark] class ShuffleBlockPusher(
+dataFile: File,
+partitionLengths: Array[Long],
+dep: ShuffleDependency[_, _, _],
+partitionId: Int,
+conf: SparkConf) extends Logging {
Review comment:
I have made the change. Please take a look.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AngersZh commented on a change in pull request #29966:
URL: https://github.com/apache/spark/pull/29966#discussion_r533117100
##
File path: core/src/main/scala/org/apache/spark/util/DependencyUtils.scala
##
@@ -15,22 +15,122 @@
* limitations under the License.
*/
-package org.apache.spark.deploy
+package org.apache.spark.util
import java.io.File
-import java.net.URI
+import java.net.{URI, URISyntaxException}
import org.apache.commons.lang3.StringUtils
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.{SecurityManager, SparkConf, SparkException}
+import org.apache.spark.deploy.SparkSubmitUtils
import org.apache.spark.internal.Logging
-import org.apache.spark.util.{MutableURLClassLoader, Utils}
-private[deploy] object DependencyUtils extends Logging {
+private[spark] object DependencyUtils extends Logging {
+
+ def getIvyProperties(): Seq[String] = {
+Seq(
+ "spark.jars.excludes",
+ "spark.jars.packages",
+ "spark.jars.repositories",
+ "spark.jars.ivy",
+ "spark.jars.ivySettings"
+).map(sys.props.get(_).orNull)
+ }
+
+ /**
+ * Parse excluded list in ivy URL. When download ivy URL jar, Spark won't
download transitive jar
+ * in excluded list.
+ *
+ * @param queryString Ivy URI query part string.
+ * @return Exclude list which contains grape parameters of exclude.
+ * Example: Input:
exclude=org.mortbay.jetty:jetty,org.eclipse.jetty:jetty-http
+ * Output: [org.mortbay.jetty:jetty, org.eclipse.jetty:jetty-http]
+ */
+ private def parseExcludeList(excludes: Array[String]): String = {
+excludes.flatMap { excludeString =>
+ val excludes: Array[String] = excludeString.split(",")
+ if (excludes.exists(_.split(":").length != 2)) {
+throw new URISyntaxException(excludeString,
+ "Invalid exclude string: expected 'org:module,org:module,..', found
" + excludeString)
+ }
+ excludes
+}.mkString(":")
+ }
+
+ /**
+ * Parse transitive parameter in ivy URL, default value is false.
+ *
+ * @param queryString Ivy URI query part string.
+ * @return Exclude list which contains grape parameters of transitive.
+ * Example: Input: exclude=org.mortbay.jetty:jetty=true
+ * Output: true
+ */
+ private def parseTransitive(transitives: Array[String]): Boolean = {
+if (transitives.isEmpty) {
+ false
+} else {
+ if (transitives.length > 1) {
+logWarning("It's best to specify `transitive` parameter in ivy URL
query only once." +
+ " If there are multiple `transitive` parameter, we will select the
last one")
+ }
+ transitives.last.toBoolean
Review comment:
> What if `transitive=invalidStr` in hive? Could you add tests?
I change the logical, make it like hive. avoid convert error in `toBoolean`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AngersZh commented on a change in pull request #29966:
URL: https://github.com/apache/spark/pull/29966#discussion_r533116569
##
File path: core/src/main/scala/org/apache/spark/util/DependencyUtils.scala
##
@@ -15,22 +15,122 @@
* limitations under the License.
*/
-package org.apache.spark.deploy
+package org.apache.spark.util
import java.io.File
-import java.net.URI
+import java.net.{URI, URISyntaxException}
import org.apache.commons.lang3.StringUtils
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.{SecurityManager, SparkConf, SparkException}
+import org.apache.spark.deploy.SparkSubmitUtils
import org.apache.spark.internal.Logging
-import org.apache.spark.util.{MutableURLClassLoader, Utils}
-private[deploy] object DependencyUtils extends Logging {
+private[spark] object DependencyUtils extends Logging {
+
+ def getIvyProperties(): Seq[String] = {
+Seq(
+ "spark.jars.excludes",
+ "spark.jars.packages",
+ "spark.jars.repositories",
+ "spark.jars.ivy",
+ "spark.jars.ivySettings"
+).map(sys.props.get(_).orNull)
+ }
+
+ /**
+ * Parse excluded list in ivy URL. When download ivy URL jar, Spark won't
download transitive jar
+ * in excluded list.
+ *
+ * @param queryString Ivy URI query part string.
+ * @return Exclude list which contains grape parameters of exclude.
+ * Example: Input:
exclude=org.mortbay.jetty:jetty,org.eclipse.jetty:jetty-http
+ * Output: [org.mortbay.jetty:jetty, org.eclipse.jetty:jetty-http]
+ */
+ private def parseExcludeList(excludes: Array[String]): String = {
+excludes.flatMap { excludeString =>
+ val excludes: Array[String] = excludeString.split(",")
+ if (excludes.exists(_.split(":").length != 2)) {
+throw new URISyntaxException(excludeString,
+ "Invalid exclude string: expected 'org:module,org:module,..', found
" + excludeString)
+ }
+ excludes
+}.mkString(":")
+ }
+
+ /**
+ * Parse transitive parameter in ivy URL, default value is false.
+ *
+ * @param queryString Ivy URI query part string.
+ * @return Exclude list which contains grape parameters of transitive.
+ * Example: Input: exclude=org.mortbay.jetty:jetty=true
+ * Output: true
+ */
+ private def parseTransitive(transitives: Array[String]): Boolean = {
+if (transitives.isEmpty) {
+ false
+} else {
+ if (transitives.length > 1) {
+logWarning("It's best to specify `transitive` parameter in ivy URL
query only once." +
+ " If there are multiple `transitive` parameter, we will select the
last one")
+ }
+ transitives.last.toBoolean
Review comment:
Added in `test("SPARK-33084: Add jar support ivy url")`
```
// Invalid transitive value, will use default value `false`
sc.addJar("ivy://org.scala-js:scalajs-test-interface_2.12:1.2.0?transitive=foo")
assert(!sc.listJars().exists(_.contains("scalajs-library_2.12")))
assert(sc.listJars().exists(_.contains("scalajs-test-interface_2.12")))
```
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AngersZh commented on a change in pull request #29966:
URL: https://github.com/apache/spark/pull/29966#discussion_r533115969
##
File path: core/src/test/scala/org/apache/spark/SparkContextSuite.scala
##
@@ -366,6 +366,12 @@ class SparkContextSuite extends SparkFunSuite with
LocalSparkContext with Eventu
}
}
+ test("add jar local path with comma") {
+sc = new SparkContext(new
SparkConf().setAppName("test").setMaster("local"))
+sc.addJar("file://Test,UDTF.jar")
+assert(!sc.listJars().exists(_.contains("UDTF.jar")))
Review comment:
> What does this test mean? Why didn't you write it like `
assert(sc.listJars().exists(_.contains("Test,UDTF.jar")))`?
Mess in brain...
##
File path: core/src/test/scala/org/apache/spark/SparkContextSuite.scala
##
@@ -366,6 +366,12 @@ class SparkContextSuite extends SparkFunSuite with
LocalSparkContext with Eventu
}
}
+ test("add jar local path with comma") {
+sc = new SparkContext(new
SparkConf().setAppName("test").setMaster("local"))
Review comment:
> Cold you add tests for other other schemas?
Updated
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #30544: [SPARK-32405][SQL][FOLLOWUP] Throw Exception if provider is specified in JDBCTableCatalog create table
cloud-fan commented on a change in pull request #30544:
URL: https://github.com/apache/spark/pull/30544#discussion_r533110907
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/v2/jdbc/JDBCTableCatalog.scala
##
@@ -128,6 +128,8 @@ class JDBCTableCatalog extends TableCatalog with Logging {
case "comment" => tableComment = v
// ToDo: have a follow up to fail provider once unify create table
syntax PR is merged
Review comment:
nit: remove TODO
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] waitinfuture commented on pull request #30516: [SPARK-33572][SQL] Datetime building should fail if the year, month, ..., second combination is invalid
waitinfuture commented on pull request #30516: URL: https://github.com/apache/spark/pull/30516#issuecomment-736253437 @cloud-fan test passed, ready for merge This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AngersZh commented on a change in pull request #29966:
URL: https://github.com/apache/spark/pull/29966#discussion_r533099833
##
File path: core/src/main/scala/org/apache/spark/util/DependencyUtils.scala
##
@@ -15,22 +15,122 @@
* limitations under the License.
*/
-package org.apache.spark.deploy
+package org.apache.spark.util
import java.io.File
-import java.net.URI
+import java.net.{URI, URISyntaxException}
import org.apache.commons.lang3.StringUtils
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.{SecurityManager, SparkConf, SparkException}
+import org.apache.spark.deploy.SparkSubmitUtils
import org.apache.spark.internal.Logging
-import org.apache.spark.util.{MutableURLClassLoader, Utils}
-private[deploy] object DependencyUtils extends Logging {
+private[spark] object DependencyUtils extends Logging {
+
+ def getIvyProperties(): Seq[String] = {
+Seq(
+ "spark.jars.excludes",
+ "spark.jars.packages",
+ "spark.jars.repositories",
+ "spark.jars.ivy",
+ "spark.jars.ivySettings"
+).map(sys.props.get(_).orNull)
+ }
+
+ /**
+ * Parse excluded list in ivy URL. When download ivy URL jar, Spark won't
download transitive jar
+ * in excluded list.
+ *
+ * @param queryString Ivy URI query part string.
+ * @return Exclude list which contains grape parameters of exclude.
+ * Example: Input:
exclude=org.mortbay.jetty:jetty,org.eclipse.jetty:jetty-http
+ * Output: [org.mortbay.jetty:jetty, org.eclipse.jetty:jetty-http]
+ */
+ private def parseExcludeList(excludes: Array[String]): String = {
+excludes.flatMap { excludeString =>
+ val excludes: Array[String] = excludeString.split(",")
+ if (excludes.exists(_.split(":").length != 2)) {
+throw new URISyntaxException(excludeString,
+ "Invalid exclude string: expected 'org:module,org:module,..', found
" + excludeString)
+ }
+ excludes
+}.mkString(":")
+ }
+
+ /**
+ * Parse transitive parameter in ivy URL, default value is false.
+ *
+ * @param queryString Ivy URI query part string.
+ * @return Exclude list which contains grape parameters of transitive.
+ * Example: Input: exclude=org.mortbay.jetty:jetty=true
+ * Output: true
+ */
+ private def parseTransitive(transitives: Array[String]): Boolean = {
+if (transitives.isEmpty) {
+ false
+} else {
+ if (transitives.length > 1) {
+logWarning("It's best to specify `transitive` parameter in ivy URL
query only once." +
+ " If there are multiple `transitive` parameter, we will select the
last one")
+ }
+ transitives.last.toBoolean
+}
+ }
+
+ /**
+ * Download Ivy URIs dependency jars.
+ *
+ * @param uri Ivy uri need to be downloaded. The URI format should be:
+ * `ivy://group:module:version[?query]`
+ *Ivy URI query part format should be:
+ * `parameter=value=value...`
+ *Note that currently ivy URI query part support two parameters:
+ * 1. transitive: whether to download dependent jars related to
your ivy URL.
+ *transitive=false or `transitive=true`, if not set, the
default value is false.
+ * 2. exclude: exclusion list when download ivy URL jar and
dependency jars.
+ *The `exclude` parameter content is a ',' separated
`group:module` pair string :
+ *`exclude=group:module,group:module...`
+ * @return Comma separated string list of URIs of downloaded jars
+ */
+ def resolveMavenDependencies(uri: URI): String = {
+val Seq(_, _, repositories, ivyRepoPath, ivySettingsPath) =
+ DependencyUtils.getIvyProperties()
+val authority = uri.getAuthority
+if (authority == null) {
+ throw new URISyntaxException(
+authority, "Invalid url: Expected 'org:module:version', found null")
+}
+if (authority.split(":").length != 3) {
+ throw new URISyntaxException(
+authority, "Invalid url: Expected 'org:module:version', found " +
authority)
+}
+
+val uriQuery = uri.getQuery
+val queryParams: Array[(String, String)] = if (uriQuery == null) {
+ Array.empty[(String, String)]
+} else {
+ val mapTokens = uriQuery.split("&").map(_.split("="))
+ if (mapTokens.exists(_.length != 2)) {
+throw new URISyntaxException(uriQuery, s"Invalid query string:
$uriQuery")
+ }
+ mapTokens.map(kv => (kv(0), kv(1)))
+}
+
+resolveMavenDependencies(
+ parseTransitive(queryParams.filter(_._1.equals("transitive")).map(_._2)),
+ parseExcludeList(queryParams.filter(_._1.equals("exclude")).map(_._2)),
Review comment:
Yea.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AngersZh commented on a change in pull request #29966:
URL: https://github.com/apache/spark/pull/29966#discussion_r533099768
##
File path: core/src/main/scala/org/apache/spark/util/DependencyUtils.scala
##
@@ -15,22 +15,122 @@
* limitations under the License.
*/
-package org.apache.spark.deploy
+package org.apache.spark.util
import java.io.File
-import java.net.URI
+import java.net.{URI, URISyntaxException}
import org.apache.commons.lang3.StringUtils
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.{SecurityManager, SparkConf, SparkException}
+import org.apache.spark.deploy.SparkSubmitUtils
import org.apache.spark.internal.Logging
-import org.apache.spark.util.{MutableURLClassLoader, Utils}
-private[deploy] object DependencyUtils extends Logging {
+private[spark] object DependencyUtils extends Logging {
+
+ def getIvyProperties(): Seq[String] = {
+Seq(
+ "spark.jars.excludes",
+ "spark.jars.packages",
+ "spark.jars.repositories",
+ "spark.jars.ivy",
+ "spark.jars.ivySettings"
+).map(sys.props.get(_).orNull)
+ }
+
+ /**
+ * Parse excluded list in ivy URL. When download ivy URL jar, Spark won't
download transitive jar
+ * in excluded list.
+ *
+ * @param queryString Ivy URI query part string.
+ * @return Exclude list which contains grape parameters of exclude.
+ * Example: Input:
exclude=org.mortbay.jetty:jetty,org.eclipse.jetty:jetty-http
+ * Output: [org.mortbay.jetty:jetty, org.eclipse.jetty:jetty-http]
+ */
+ private def parseExcludeList(excludes: Array[String]): String = {
Review comment:
Yea, thank s for your advise
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on pull request #30532: [MINOR] Spelling sql not core
maropu commented on pull request #30532: URL: https://github.com/apache/spark/pull/30532#issuecomment-736249327 Jenkins is down now, so could you re-invoke the GA tests? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AngersZh commented on a change in pull request #29966: URL: https://github.com/apache/spark/pull/29966#discussion_r533095376 ## File path: docs/sql-ref-syntax-aux-resource-mgmt-add-jar.md ## @@ -33,15 +33,30 @@ ADD JAR file_name * **file_name** -The name of the JAR file to be added. It could be either on a local file system or a distributed file system. +The name of the JAR file to be added. It could be either on a local file system or a distributed file system or an ivy URL. +Apache Ivy is a popular dependency manager focusing on flexibility and simplicity. Now we support two parameter in URL query string: + * transitive: whether to download dependent jars related to your ivy URL. + * exclude: exclusion list when download ivy URL jar and dependent jars. + +User can write ivy URL such as: + + ivy://group:module:version + ivy://group:module:version?transitive=true Review comment: Done This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AngersZh commented on a change in pull request #29966:
URL: https://github.com/apache/spark/pull/29966#discussion_r533095212
##
File path: core/src/main/scala/org/apache/spark/util/DependencyUtils.scala
##
@@ -15,22 +15,122 @@
* limitations under the License.
*/
-package org.apache.spark.deploy
+package org.apache.spark.util
import java.io.File
-import java.net.URI
+import java.net.{URI, URISyntaxException}
import org.apache.commons.lang3.StringUtils
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.{SecurityManager, SparkConf, SparkException}
+import org.apache.spark.deploy.SparkSubmitUtils
import org.apache.spark.internal.Logging
-import org.apache.spark.util.{MutableURLClassLoader, Utils}
-private[deploy] object DependencyUtils extends Logging {
+private[spark] object DependencyUtils extends Logging {
+
+ def getIvyProperties(): Seq[String] = {
+Seq(
+ "spark.jars.excludes",
+ "spark.jars.packages",
+ "spark.jars.repositories",
+ "spark.jars.ivy",
+ "spark.jars.ivySettings"
+).map(sys.props.get(_).orNull)
+ }
+
+ /**
+ * Parse excluded list in ivy URL. When download ivy URL jar, Spark won't
download transitive jar
+ * in excluded list.
+ *
+ * @param queryString Ivy URI query part string.
+ * @return Exclude list which contains grape parameters of exclude.
+ * Example: Input:
exclude=org.mortbay.jetty:jetty,org.eclipse.jetty:jetty-http
+ * Output: [org.mortbay.jetty:jetty, org.eclipse.jetty:jetty-http]
+ */
+ private def parseExcludeList(excludes: Array[String]): String = {
+excludes.flatMap { excludeString =>
+ val excludes: Array[String] = excludeString.split(",")
+ if (excludes.exists(_.split(":").length != 2)) {
+throw new URISyntaxException(excludeString,
+ "Invalid exclude string: expected 'org:module,org:module,..', found
" + excludeString)
+ }
+ excludes
+}.mkString(":")
+ }
+
+ /**
+ * Parse transitive parameter in ivy URL, default value is false.
+ *
+ * @param queryString Ivy URI query part string.
+ * @return Exclude list which contains grape parameters of transitive.
+ * Example: Input: exclude=org.mortbay.jetty:jetty=true
+ * Output: true
+ */
+ private def parseTransitive(transitives: Array[String]): Boolean = {
+if (transitives.isEmpty) {
+ false
+} else {
+ if (transitives.length > 1) {
+logWarning("It's best to specify `transitive` parameter in ivy URL
query only once." +
+ " If there are multiple `transitive` parameter, we will select the
last one")
+ }
+ transitives.last.toBoolean
+}
+ }
+
+ /**
+ * Download Ivy URIs dependency jars.
+ *
+ * @param uri Ivy uri need to be downloaded. The URI format should be:
+ * `ivy://group:module:version[?query]`
+ *Ivy URI query part format should be:
+ * `parameter=value=value...`
+ *Note that currently ivy URI query part support two parameters:
+ * 1. transitive: whether to download dependent jars related to
your ivy URL.
+ *transitive=false or `transitive=true`, if not set, the
default value is false.
+ * 2. exclude: exclusion list when download ivy URL jar and
dependency jars.
+ *The `exclude` parameter content is a ',' separated
`group:module` pair string :
+ *`exclude=group:module,group:module...`
+ * @return Comma separated string list of URIs of downloaded jars
+ */
+ def resolveMavenDependencies(uri: URI): String = {
Review comment:
Change this
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30547: [SPARK-33557][CORE][MESOS][TEST] Ensure the relationship between STORAGE_BLOCKMANAGER_HEARTBEAT_TIMEOUT and NETWORK_TIMEOUT
LuciferYang commented on a change in pull request #30547: URL: https://github.com/apache/spark/pull/30547#discussion_r533094765 ## File path: core/src/main/scala/org/apache/spark/HeartbeatReceiver.scala ## @@ -80,7 +80,7 @@ private[spark] class HeartbeatReceiver(sc: SparkContext, clock: Clock) // executor ID -> timestamp of when the last heartbeat from this executor was received private val executorLastSeen = new HashMap[String, Long] - private val executorTimeoutMs = sc.conf.get(config.STORAGE_BLOCKMANAGER_HEARTBEAT_TIMEOUT) + private val executorTimeoutMs = Utils.blockManagerHeartbeatTimeoutAsMs(sc.conf) Review comment: So if use `fallbackConf `, we need to change the name of `spark.storage.blockManagerHeartbeatTimeoutMs` to remove the suffix `Ms`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30547: [SPARK-33557][CORE][MESOS][TEST] Ensure the relationship between STORAGE_BLOCKMANAGER_HEARTBEAT_TIMEOUT and NETWORK_TIMEOUT
LuciferYang commented on a change in pull request #30547: URL: https://github.com/apache/spark/pull/30547#discussion_r533094765 ## File path: core/src/main/scala/org/apache/spark/HeartbeatReceiver.scala ## @@ -80,7 +80,7 @@ private[spark] class HeartbeatReceiver(sc: SparkContext, clock: Clock) // executor ID -> timestamp of when the last heartbeat from this executor was received private val executorLastSeen = new HashMap[String, Long] - private val executorTimeoutMs = sc.conf.get(config.STORAGE_BLOCKMANAGER_HEARTBEAT_TIMEOUT) + private val executorTimeoutMs = Utils.blockManagerHeartbeatTimeoutAsMs(sc.conf) Review comment: So if use `fallbackConf `, we need to change the name of `spark.storage.blockManagerHeartbeatTimeoutMs` to remove the suffix "Ms". This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a change in pull request #30547: [SPARK-33557][CORE][MESOS][TEST] Ensure the relationship between STORAGE_BLOCKMANAGER_HEARTBEAT_TIMEOUT and NETWORK_TIMEOUT
LuciferYang commented on a change in pull request #30547:
URL: https://github.com/apache/spark/pull/30547#discussion_r533093278
##
File path: core/src/main/scala/org/apache/spark/HeartbeatReceiver.scala
##
@@ -80,7 +80,7 @@ private[spark] class HeartbeatReceiver(sc: SparkContext,
clock: Clock)
// executor ID -> timestamp of when the last heartbeat from this executor
was received
private val executorLastSeen = new HashMap[String, Long]
- private val executorTimeoutMs =
sc.conf.get(config.STORAGE_BLOCKMANAGER_HEARTBEAT_TIMEOUT)
+ private val executorTimeoutMs =
Utils.blockManagerHeartbeatTimeoutAsMs(sc.conf)
Review comment:
definition `STORAGE_BLOCKMANAGER_HEARTBEAT_TIMEOUT` from
```
private[spark] val STORAGE_BLOCKMANAGER_HEARTBEAT_TIMEOUT =
ConfigBuilder("spark.storage.blockManagerHeartbeatTimeoutMs")
.version("0.7.0")
.withAlternative("spark.storage.blockManagerSlaveTimeoutMs")
.timeConf(TimeUnit.MILLISECONDS)
.createWithDefaultString(Network.NETWORK_TIMEOUT.defaultValueString)
```
to
```
private[spark] val STORAGE_BLOCKMANAGER_HEARTBEAT_TIMEOUT =
ConfigBuilder("spark.storage.blockManagerHeartbeatTimeoutMs")
.version("0.7.0")
.withAlternative("spark.storage.blockManagerSlaveTimeoutMs")
.fallbackConf(Network.NETWORK_TIMEOUT)
```
?
If so, the TimeUnit of `STORAGE_BLOCKMANAGER_HEARTBEAT_TIMEOUT` will change
from `TimeUnit.MILLISECONDS` to `TimeUnit.SECONDS`, and the default value will
change from `12` to `120`,
This does not match the "Ms" unit described in
`spark.storage.blockManagerHeartbeatTimeoutMs`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AngersZh commented on a change in pull request #29966:
URL: https://github.com/apache/spark/pull/29966#discussion_r533091418
##
File path: core/src/main/scala/org/apache/spark/SparkContext.scala
##
@@ -1869,15 +1869,15 @@ class SparkContext(config: SparkConf) extends Logging {
throw new IllegalArgumentException(
s"Directory ${file.getAbsoluteFile} is not allowed for addJar")
}
-env.rpcEnv.fileServer.addJar(file)
+Array(env.rpcEnv.fileServer.addJar(file))
} catch {
case NonFatal(e) =>
logError(s"Failed to add $path to Spark environment", e)
- null
+ Array.empty
Review comment:
Yea
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #30212: [SPARK-33308][SQL] Refactor current grouping analytics
maropu commented on a change in pull request #30212:
URL: https://github.com/apache/spark/pull/30212#discussion_r533090836
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##
@@ -2027,65 +1952,76 @@ class Analyzer(override val catalogManager:
CatalogManager)
*/
object ResolveFunctions extends Rule[LogicalPlan] {
val trimWarningEnabled = new AtomicBoolean(true)
+
+def resolveFunction(): PartialFunction[Expression, Expression] = {
+ case u if !u.childrenResolved => u // Skip until children are resolved.
+ case u: UnresolvedAttribute if resolver(u.name,
VirtualColumn.hiveGroupingIdName) =>
+withPosition(u) {
+ Alias(GroupingID(Nil), VirtualColumn.hiveGroupingIdName)()
+}
+ case u @ UnresolvedGenerator(name, children) =>
+withPosition(u) {
+ v1SessionCatalog.lookupFunction(name, children) match {
+case generator: Generator => generator
+case other =>
+ failAnalysis(s"$name is expected to be a generator. However, " +
+s"its class is ${other.getClass.getCanonicalName}, which is
not a generator.")
+ }
+}
+ case u @ UnresolvedFunction(funcId, arguments, isDistinct, filter) =>
+withPosition(u) {
+ v1SessionCatalog.lookupFunction(funcId, arguments) match {
+// AggregateWindowFunctions are AggregateFunctions that can only
be evaluated within
+// the context of a Window clause. They do not need to be wrapped
in an
+// AggregateExpression.
+case wf: AggregateWindowFunction =>
+ if (isDistinct || filter.isDefined) {
+failAnalysis("DISTINCT or FILTER specified, " +
+ s"but ${wf.prettyName} is not an aggregate function")
+ } else {
+wf
+ }
+// We get an aggregate function, we need to wrap it in an
AggregateExpression.
+case agg: AggregateFunction =>
+ if (filter.isDefined && !filter.get.deterministic) {
+failAnalysis("FILTER expression is non-deterministic, " +
+ "it cannot be used in aggregate functions")
+ }
+ AggregateExpression(agg, Complete, isDistinct, filter)
+// This function is not an aggregate function, just return the
resolved one.
+case other if (isDistinct || filter.isDefined) =>
+ failAnalysis("DISTINCT or FILTER specified, " +
+s"but ${other.prettyName} is not an aggregate function")
+case e: String2TrimExpression if arguments.size == 2 =>
+ if (trimWarningEnabled.get) {
+logWarning("Two-parameter TRIM/LTRIM/RTRIM function signatures
are deprecated." +
+ " Use SQL syntax `TRIM((BOTH | LEADING | TRAILING)? trimStr
FROM str)`" +
+ " instead.")
+trimWarningEnabled.set(false)
+ }
+ e
+case other =>
+ other
+ }
+}
+}
+
def apply(plan: LogicalPlan): LogicalPlan = plan.resolveOperatorsUp {
// Resolve functions with concrete relations from v2 catalog.
case UnresolvedFunc(multipartIdent) =>
val funcIdent = parseSessionCatalogFunctionIdentifier(multipartIdent)
ResolvedFunc(Identifier.of(funcIdent.database.toArray,
funcIdent.funcName))
- case q: LogicalPlan =>
-q transformExpressions {
- case u if !u.childrenResolved => u // Skip until children are
resolved.
- case u: UnresolvedAttribute if resolver(u.name,
VirtualColumn.hiveGroupingIdName) =>
-withPosition(u) {
- Alias(GroupingID(Nil), VirtualColumn.hiveGroupingIdName)()
-}
- case u @ UnresolvedGenerator(name, children) =>
-withPosition(u) {
- v1SessionCatalog.lookupFunction(name, children) match {
-case generator: Generator => generator
-case other =>
- failAnalysis(s"$name is expected to be a generator. However,
" +
-s"its class is ${other.getClass.getCanonicalName}, which
is not a generator.")
- }
-}
- case u @ UnresolvedFunction(funcId, arguments, isDistinct, filter) =>
-withPosition(u) {
- v1SessionCatalog.lookupFunction(funcId, arguments) match {
-// AggregateWindowFunctions are AggregateFunctions that can
only be evaluated within
-// the context of a Window clause. They do not need to be
wrapped in an
-// AggregateExpression.
-case wf: AggregateWindowFunction =>
- if (isDistinct || filter.isDefined) {
-failAnalysis("DISTINCT or FILTER specified, " +
- s"but ${wf.prettyName} is not an
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AngersZh commented on a change in pull request #29966:
URL: https://github.com/apache/spark/pull/29966#discussion_r533090454
##
File path: core/src/main/scala/org/apache/spark/SparkContext.scala
##
@@ -1860,7 +1860,7 @@ class SparkContext(config: SparkConf) extends Logging {
}
private def addJar(path: String, addedOnSubmit: Boolean): Unit = {
-def addLocalJarFile(file: File): String = {
+def addLocalJarFile(file: File): Array[String] = {
Review comment:
Yea
##
File path: core/src/main/scala/org/apache/spark/SparkContext.scala
##
@@ -1869,15 +1869,15 @@ class SparkContext(config: SparkConf) extends Logging {
throw new IllegalArgumentException(
s"Directory ${file.getAbsoluteFile} is not allowed for addJar")
}
-env.rpcEnv.fileServer.addJar(file)
+Array(env.rpcEnv.fileServer.addJar(file))
} catch {
case NonFatal(e) =>
logError(s"Failed to add $path to Spark environment", e)
- null
+ Array.empty
}
}
-def checkRemoteJarFile(path: String): String = {
+def checkRemoteJarFile(path: String): Array[String] = {
Review comment:
Yea
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AngersZh commented on pull request #29966: URL: https://github.com/apache/spark/pull/29966#issuecomment-736240432 > For other reviewers, could you put the screenshot of the updated doc in the PR description? 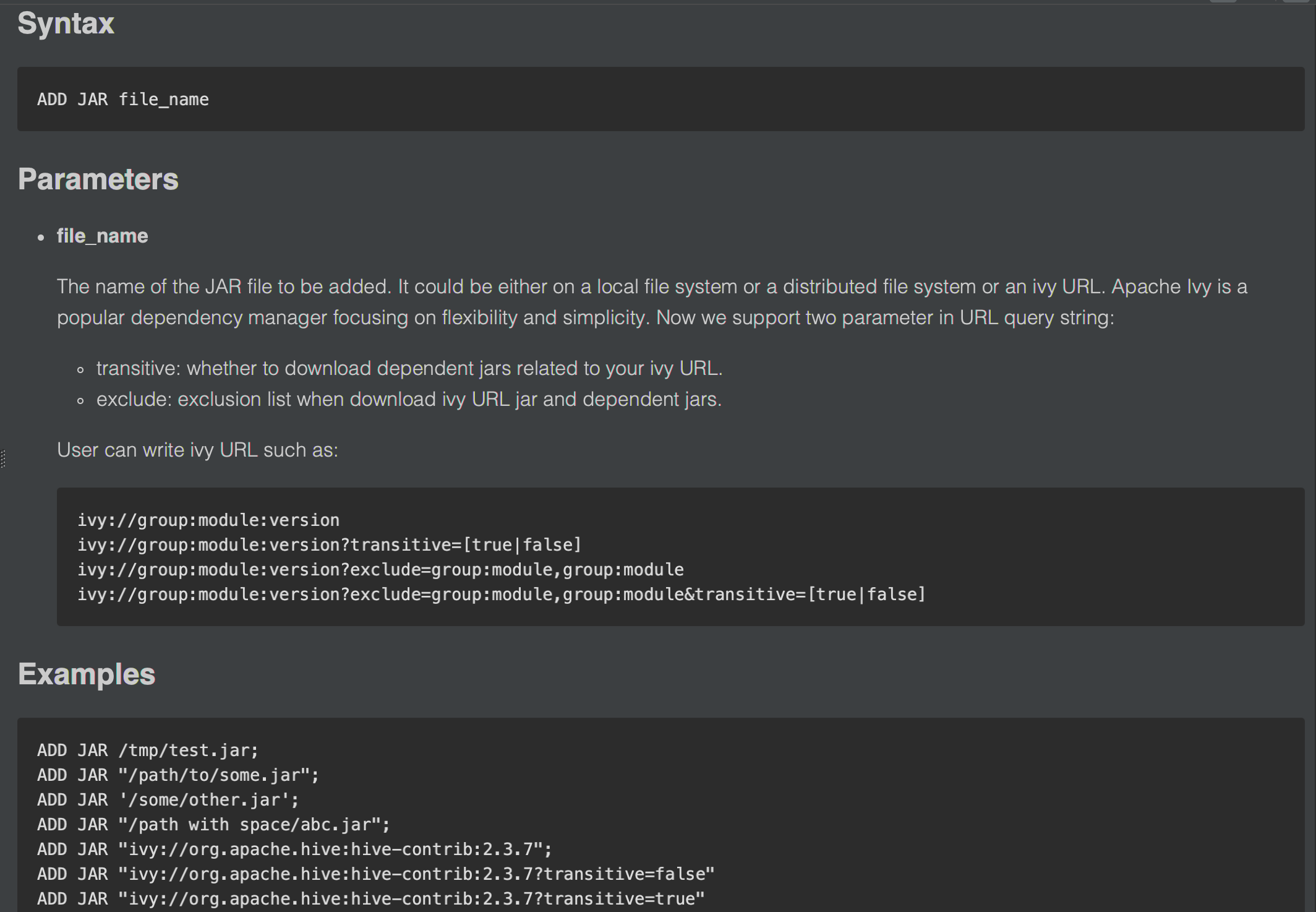 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
AngersZh commented on a change in pull request #29966:
URL: https://github.com/apache/spark/pull/29966#discussion_r533088945
##
File path: core/src/main/scala/org/apache/spark/util/DependencyUtils.scala
##
@@ -15,22 +15,122 @@
* limitations under the License.
*/
-package org.apache.spark.deploy
+package org.apache.spark.util
import java.io.File
-import java.net.URI
+import java.net.{URI, URISyntaxException}
import org.apache.commons.lang3.StringUtils
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.{SecurityManager, SparkConf, SparkException}
+import org.apache.spark.deploy.SparkSubmitUtils
import org.apache.spark.internal.Logging
-import org.apache.spark.util.{MutableURLClassLoader, Utils}
-private[deploy] object DependencyUtils extends Logging {
+private[spark] object DependencyUtils extends Logging {
+
+ def getIvyProperties(): Seq[String] = {
+Seq(
+ "spark.jars.excludes",
+ "spark.jars.packages",
+ "spark.jars.repositories",
+ "spark.jars.ivy",
+ "spark.jars.ivySettings"
+).map(sys.props.get(_).orNull)
+ }
+
+ /**
+ * Parse excluded list in ivy URL. When download ivy URL jar, Spark won't
download transitive jar
+ * in excluded list.
+ *
+ * @param queryString Ivy URI query part string.
+ * @return Exclude list which contains grape parameters of exclude.
+ * Example: Input:
exclude=org.mortbay.jetty:jetty,org.eclipse.jetty:jetty-http
+ * Output: [org.mortbay.jetty:jetty, org.eclipse.jetty:jetty-http]
+ */
+ private def parseExcludeList(excludes: Array[String]): String = {
+excludes.flatMap { excludeString =>
+ val excludes: Array[String] = excludeString.split(",")
+ if (excludes.exists(_.split(":").length != 2)) {
+throw new URISyntaxException(excludeString,
+ "Invalid exclude string: expected 'org:module,org:module,..', found
" + excludeString)
+ }
+ excludes
+}.mkString(":")
+ }
+
+ /**
+ * Parse transitive parameter in ivy URL, default value is false.
+ *
+ * @param queryString Ivy URI query part string.
+ * @return Exclude list which contains grape parameters of transitive.
+ * Example: Input: exclude=org.mortbay.jetty:jetty=true
+ * Output: true
+ */
+ private def parseTransitive(transitives: Array[String]): Boolean = {
+if (transitives.isEmpty) {
+ false
+} else {
+ if (transitives.length > 1) {
+logWarning("It's best to specify `transitive` parameter in ivy URL
query only once." +
+ " If there are multiple `transitive` parameter, we will select the
last one")
+ }
+ transitives.last.toBoolean
+}
+ }
+
+ /**
+ * Download Ivy URIs dependency jars.
+ *
+ * @param uri Ivy uri need to be downloaded. The URI format should be:
+ * `ivy://group:module:version[?query]`
+ *Ivy URI query part format should be:
+ * `parameter=value=value...`
+ *Note that currently ivy URI query part support two parameters:
+ * 1. transitive: whether to download dependent jars related to
your ivy URL.
+ *transitive=false or `transitive=true`, if not set, the
default value is false.
+ * 2. exclude: exclusion list when download ivy URL jar and
dependency jars.
+ *The `exclude` parameter content is a ',' separated
`group:module` pair string :
+ *`exclude=group:module,group:module...`
+ * @return Comma separated string list of URIs of downloaded jars
+ */
+ def resolveMavenDependencies(uri: URI): String = {
+val Seq(_, _, repositories, ivyRepoPath, ivySettingsPath) =
+ DependencyUtils.getIvyProperties()
+val authority = uri.getAuthority
+if (authority == null) {
+ throw new URISyntaxException(
+authority, "Invalid url: Expected 'org:module:version', found null")
+}
+if (authority.split(":").length != 3) {
+ throw new URISyntaxException(
+authority, "Invalid url: Expected 'org:module:version', found " +
authority)
+}
+
+val uriQuery = uri.getQuery
+val queryParams: Array[(String, String)] = if (uriQuery == null) {
+ Array.empty[(String, String)]
+} else {
+ val mapTokens = uriQuery.split("&").map(_.split("="))
+ if (mapTokens.exists(_.length != 2)) {
+throw new URISyntaxException(uriQuery, s"Invalid query string:
$uriQuery")
+ }
+ mapTokens.map(kv => (kv(0), kv(1)))
+}
+
+resolveMavenDependencies(
+ parseTransitive(queryParams.filter(_._1.equals("transitive")).map(_._2)),
Review comment:
> We need to respect case-sensitivity for params?
Normally we use lowercase, respect may be good, and hive respect too.
This is an automated message from the Apache Git Service.
To
[GitHub] [spark] otterc commented on a change in pull request #30312: [SPARK-32917][SHUFFLE][CORE] Adds support for executors to push shuffle blocks after successful map task completion
otterc commented on a change in pull request #30312:
URL: https://github.com/apache/spark/pull/30312#discussion_r533088124
##
File path:
core/src/test/scala/org/apache/spark/shuffle/ShuffleBlockPusherSuite.scala
##
@@ -0,0 +1,248 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.shuffle
+
+import java.io.File
+import java.net.ConnectException
+import java.nio.ByteBuffer
+
+import scala.collection.mutable.ArrayBuffer
+
+import org.mockito.{Mock, MockitoAnnotations}
+import org.mockito.Answers.RETURNS_SMART_NULLS
+import org.mockito.ArgumentMatchers.any
+import org.mockito.Mockito._
+import org.mockito.invocation.InvocationOnMock
+import org.scalatest.BeforeAndAfterEach
+
+import org.apache.spark._
+import org.apache.spark.network.buffer.ManagedBuffer
+import org.apache.spark.network.shuffle.{BlockFetchingListener,
BlockStoreClient}
+import org.apache.spark.network.shuffle.ErrorHandler.BlockPushErrorHandler
+import org.apache.spark.network.util.TransportConf
+import org.apache.spark.serializer.JavaSerializer
+import org.apache.spark.storage._
+
+class ShuffleBlockPusherSuite extends SparkFunSuite with BeforeAndAfterEach {
+
+ @Mock(answer = RETURNS_SMART_NULLS) private var blockManager: BlockManager =
_
+ @Mock(answer = RETURNS_SMART_NULLS) private var dependency:
ShuffleDependency[Int, Int, Int] = _
+ @Mock(answer = RETURNS_SMART_NULLS) private var shuffleClient:
BlockStoreClient = _
+
+ private var conf: SparkConf = _
+ private var pushedBlocks = new ArrayBuffer[String]
+
+ override def beforeEach(): Unit = {
+super.beforeEach()
+conf = new SparkConf(loadDefaults = false)
+MockitoAnnotations.initMocks(this)
+when(dependency.partitioner).thenReturn(new HashPartitioner(8))
+when(dependency.serializer).thenReturn(new JavaSerializer(conf))
+
when(dependency.getMergerLocs).thenReturn(Seq(BlockManagerId("test-client",
"test-client", 1)))
+conf.set("spark.shuffle.push.based.enabled", "true")
+conf.set("spark.shuffle.service.enabled", "true")
+// Set the env because the shuffler writer gets the shuffle client
instance from the env.
+val mockEnv = mock(classOf[SparkEnv])
+when(mockEnv.conf).thenReturn(conf)
+when(mockEnv.blockManager).thenReturn(blockManager)
+SparkEnv.set(mockEnv)
+when(blockManager.blockStoreClient).thenReturn(shuffleClient)
+ }
+
+ override def afterEach(): Unit = {
+pushedBlocks.clear()
+super.afterEach()
+ }
+
+ private def interceptPushedBlocksForSuccess(): Unit = {
+when(shuffleClient.pushBlocks(any(), any(), any(), any(), any()))
+ .thenAnswer((invocation: InvocationOnMock) => {
+val blocks = invocation.getArguments()(2).asInstanceOf[Array[String]]
+pushedBlocks ++= blocks
+val managedBuffers =
invocation.getArguments()(3).asInstanceOf[Array[ManagedBuffer]]
+val blockFetchListener =
invocation.getArguments()(4).asInstanceOf[BlockFetchingListener]
+(blocks, managedBuffers).zipped.foreach((blockId, buffer) => {
+ blockFetchListener.onBlockFetchSuccess(blockId, buffer)
+})
+ })
+ }
+
+ test("Basic block push") {
+interceptPushedBlocksForSuccess()
+new TestShuffleBlockPusher(mock(classOf[File]),
+ Array.fill(dependency.partitioner.numPartitions) { 2 }, dependency, 0,
conf)
+.initiateBlockPush()
+verify(shuffleClient, times(1))
+ .pushBlocks(any(), any(), any(), any(), any())
+assert(pushedBlocks.length == dependency.partitioner.numPartitions)
+ShuffleBlockPusher.stop()
+ }
+
+ test("Large blocks are skipped for push") {
+conf.set("spark.shuffle.push.maxBlockSizeToPush", "1k")
+interceptPushedBlocksForSuccess()
+new TestShuffleBlockPusher(mock(classOf[File]), Array(2, 2, 2, 2, 2, 2, 2,
1100),
+ dependency, 0, conf).initiateBlockPush()
+verify(shuffleClient, times(1))
+ .pushBlocks(any(), any(), any(), any(), any())
+assert(pushedBlocks.length == dependency.partitioner.numPartitions - 1)
+ShuffleBlockPusher.stop()
+ }
+
+ test("Number of blocks in flight per address are limited by
maxBlocksInFlightPerAddress") {
+
[GitHub] [spark] AngersZhuuuu commented on a change in pull request #30212: [SPARK-33308][SQL] Refactor current grouping analytics
AngersZh commented on a change in pull request #30212:
URL: https://github.com/apache/spark/pull/30212#discussion_r533087740
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##
@@ -2027,65 +1952,76 @@ class Analyzer(override val catalogManager:
CatalogManager)
*/
object ResolveFunctions extends Rule[LogicalPlan] {
val trimWarningEnabled = new AtomicBoolean(true)
+
+def resolveFunction(): PartialFunction[Expression, Expression] = {
+ case u if !u.childrenResolved => u // Skip until children are resolved.
+ case u: UnresolvedAttribute if resolver(u.name,
VirtualColumn.hiveGroupingIdName) =>
+withPosition(u) {
+ Alias(GroupingID(Nil), VirtualColumn.hiveGroupingIdName)()
+}
+ case u @ UnresolvedGenerator(name, children) =>
+withPosition(u) {
+ v1SessionCatalog.lookupFunction(name, children) match {
+case generator: Generator => generator
+case other =>
+ failAnalysis(s"$name is expected to be a generator. However, " +
+s"its class is ${other.getClass.getCanonicalName}, which is
not a generator.")
+ }
+}
+ case u @ UnresolvedFunction(funcId, arguments, isDistinct, filter) =>
+withPosition(u) {
+ v1SessionCatalog.lookupFunction(funcId, arguments) match {
+// AggregateWindowFunctions are AggregateFunctions that can only
be evaluated within
+// the context of a Window clause. They do not need to be wrapped
in an
+// AggregateExpression.
+case wf: AggregateWindowFunction =>
+ if (isDistinct || filter.isDefined) {
+failAnalysis("DISTINCT or FILTER specified, " +
+ s"but ${wf.prettyName} is not an aggregate function")
+ } else {
+wf
+ }
+// We get an aggregate function, we need to wrap it in an
AggregateExpression.
+case agg: AggregateFunction =>
+ if (filter.isDefined && !filter.get.deterministic) {
+failAnalysis("FILTER expression is non-deterministic, " +
+ "it cannot be used in aggregate functions")
+ }
+ AggregateExpression(agg, Complete, isDistinct, filter)
+// This function is not an aggregate function, just return the
resolved one.
+case other if (isDistinct || filter.isDefined) =>
+ failAnalysis("DISTINCT or FILTER specified, " +
+s"but ${other.prettyName} is not an aggregate function")
+case e: String2TrimExpression if arguments.size == 2 =>
+ if (trimWarningEnabled.get) {
+logWarning("Two-parameter TRIM/LTRIM/RTRIM function signatures
are deprecated." +
+ " Use SQL syntax `TRIM((BOTH | LEADING | TRAILING)? trimStr
FROM str)`" +
+ " instead.")
+trimWarningEnabled.set(false)
+ }
+ e
+case other =>
+ other
+ }
+}
+}
+
def apply(plan: LogicalPlan): LogicalPlan = plan.resolveOperatorsUp {
// Resolve functions with concrete relations from v2 catalog.
case UnresolvedFunc(multipartIdent) =>
val funcIdent = parseSessionCatalogFunctionIdentifier(multipartIdent)
ResolvedFunc(Identifier.of(funcIdent.database.toArray,
funcIdent.funcName))
- case q: LogicalPlan =>
-q transformExpressions {
- case u if !u.childrenResolved => u // Skip until children are
resolved.
- case u: UnresolvedAttribute if resolver(u.name,
VirtualColumn.hiveGroupingIdName) =>
-withPosition(u) {
- Alias(GroupingID(Nil), VirtualColumn.hiveGroupingIdName)()
-}
- case u @ UnresolvedGenerator(name, children) =>
-withPosition(u) {
- v1SessionCatalog.lookupFunction(name, children) match {
-case generator: Generator => generator
-case other =>
- failAnalysis(s"$name is expected to be a generator. However,
" +
-s"its class is ${other.getClass.getCanonicalName}, which
is not a generator.")
- }
-}
- case u @ UnresolvedFunction(funcId, arguments, isDistinct, filter) =>
-withPosition(u) {
- v1SessionCatalog.lookupFunction(funcId, arguments) match {
-// AggregateWindowFunctions are AggregateFunctions that can
only be evaluated within
-// the context of a Window clause. They do not need to be
wrapped in an
-// AggregateExpression.
-case wf: AggregateWindowFunction =>
- if (isDistinct || filter.isDefined) {
-failAnalysis("DISTINCT or FILTER specified, " +
- s"but ${wf.prettyName} is not an
[GitHub] [spark] maropu commented on a change in pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
maropu commented on a change in pull request #29966:
URL: https://github.com/apache/spark/pull/29966#discussion_r533087617
##
File path: core/src/main/scala/org/apache/spark/util/DependencyUtils.scala
##
@@ -15,22 +15,122 @@
* limitations under the License.
*/
-package org.apache.spark.deploy
+package org.apache.spark.util
import java.io.File
-import java.net.URI
+import java.net.{URI, URISyntaxException}
import org.apache.commons.lang3.StringUtils
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.{SecurityManager, SparkConf, SparkException}
+import org.apache.spark.deploy.SparkSubmitUtils
import org.apache.spark.internal.Logging
-import org.apache.spark.util.{MutableURLClassLoader, Utils}
-private[deploy] object DependencyUtils extends Logging {
+private[spark] object DependencyUtils extends Logging {
+
+ def getIvyProperties(): Seq[String] = {
+Seq(
+ "spark.jars.excludes",
+ "spark.jars.packages",
+ "spark.jars.repositories",
+ "spark.jars.ivy",
+ "spark.jars.ivySettings"
+).map(sys.props.get(_).orNull)
+ }
+
+ /**
+ * Parse excluded list in ivy URL. When download ivy URL jar, Spark won't
download transitive jar
+ * in excluded list.
+ *
+ * @param queryString Ivy URI query part string.
+ * @return Exclude list which contains grape parameters of exclude.
+ * Example: Input:
exclude=org.mortbay.jetty:jetty,org.eclipse.jetty:jetty-http
+ * Output: [org.mortbay.jetty:jetty, org.eclipse.jetty:jetty-http]
+ */
+ private def parseExcludeList(excludes: Array[String]): String = {
+excludes.flatMap { excludeString =>
+ val excludes: Array[String] = excludeString.split(",")
+ if (excludes.exists(_.split(":").length != 2)) {
+throw new URISyntaxException(excludeString,
+ "Invalid exclude string: expected 'org:module,org:module,..', found
" + excludeString)
+ }
+ excludes
+}.mkString(":")
+ }
+
+ /**
+ * Parse transitive parameter in ivy URL, default value is false.
+ *
+ * @param queryString Ivy URI query part string.
+ * @return Exclude list which contains grape parameters of transitive.
+ * Example: Input: exclude=org.mortbay.jetty:jetty=true
+ * Output: true
+ */
+ private def parseTransitive(transitives: Array[String]): Boolean = {
+if (transitives.isEmpty) {
+ false
+} else {
+ if (transitives.length > 1) {
+logWarning("It's best to specify `transitive` parameter in ivy URL
query only once." +
+ " If there are multiple `transitive` parameter, we will select the
last one")
+ }
+ transitives.last.toBoolean
+}
+ }
+
+ /**
+ * Download Ivy URIs dependency jars.
+ *
+ * @param uri Ivy uri need to be downloaded. The URI format should be:
+ * `ivy://group:module:version[?query]`
+ *Ivy URI query part format should be:
+ * `parameter=value=value...`
+ *Note that currently ivy URI query part support two parameters:
+ * 1. transitive: whether to download dependent jars related to
your ivy URL.
+ *transitive=false or `transitive=true`, if not set, the
default value is false.
+ * 2. exclude: exclusion list when download ivy URL jar and
dependency jars.
+ *The `exclude` parameter content is a ',' separated
`group:module` pair string :
+ *`exclude=group:module,group:module...`
+ * @return Comma separated string list of URIs of downloaded jars
+ */
+ def resolveMavenDependencies(uri: URI): String = {
+val Seq(_, _, repositories, ivyRepoPath, ivySettingsPath) =
+ DependencyUtils.getIvyProperties()
+val authority = uri.getAuthority
+if (authority == null) {
+ throw new URISyntaxException(
+authority, "Invalid url: Expected 'org:module:version', found null")
+}
+if (authority.split(":").length != 3) {
+ throw new URISyntaxException(
+authority, "Invalid url: Expected 'org:module:version', found " +
authority)
+}
+
+val uriQuery = uri.getQuery
+val queryParams: Array[(String, String)] = if (uriQuery == null) {
+ Array.empty[(String, String)]
+} else {
+ val mapTokens = uriQuery.split("&").map(_.split("="))
+ if (mapTokens.exists(_.length != 2)) {
+throw new URISyntaxException(uriQuery, s"Invalid query string:
$uriQuery")
+ }
+ mapTokens.map(kv => (kv(0), kv(1)))
+}
+
+resolveMavenDependencies(
+ parseTransitive(queryParams.filter(_._1.equals("transitive")).map(_._2)),
Review comment:
We need to respect case-sensitivity for params?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the
[GitHub] [spark] maropu commented on pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
maropu commented on pull request #29966: URL: https://github.com/apache/spark/pull/29966#issuecomment-736236902 For other reviewers, could you put the screenshot of the updated doc in the PR description? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
maropu commented on a change in pull request #29966: URL: https://github.com/apache/spark/pull/29966#discussion_r533086750 ## File path: docs/sql-ref-syntax-aux-resource-mgmt-add-jar.md ## @@ -33,15 +33,30 @@ ADD JAR file_name * **file_name** -The name of the JAR file to be added. It could be either on a local file system or a distributed file system. +The name of the JAR file to be added. It could be either on a local file system or a distributed file system or an ivy URL. +Apache Ivy is a popular dependency manager focusing on flexibility and simplicity. Now we support two parameter in URL query string: + * transitive: whether to download dependent jars related to your ivy URL. + * exclude: exclusion list when download ivy URL jar and dependent jars. + +User can write ivy URL such as: + + ivy://group:module:version + ivy://group:module:version?transitive=true Review comment: `transitive=true` -> `transitive=[true|false]`? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR closed pull request #28363: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
HeartSaVioR closed pull request #28363: URL: https://github.com/apache/spark/pull/28363 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #28363: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
HeartSaVioR commented on pull request #28363: URL: https://github.com/apache/spark/pull/28363#issuecomment-736234860 Thanks all for the thoughtful reviews! Merging to master. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
maropu commented on a change in pull request #29966:
URL: https://github.com/apache/spark/pull/29966#discussion_r533081191
##
File path: core/src/test/scala/org/apache/spark/SparkContextSuite.scala
##
@@ -366,6 +366,12 @@ class SparkContextSuite extends SparkFunSuite with
LocalSparkContext with Eventu
}
}
+ test("add jar local path with comma") {
+sc = new SparkContext(new
SparkConf().setAppName("test").setMaster("local"))
+sc.addJar("file://Test,UDTF.jar")
+assert(!sc.listJars().exists(_.contains("UDTF.jar")))
Review comment:
What does this test mean? Why didn't you write it like `
assert(sc.listJars().exists(_.contains("Test,UDTF.jar")))`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
maropu commented on a change in pull request #29966:
URL: https://github.com/apache/spark/pull/29966#discussion_r533081191
##
File path: core/src/test/scala/org/apache/spark/SparkContextSuite.scala
##
@@ -366,6 +366,12 @@ class SparkContextSuite extends SparkFunSuite with
LocalSparkContext with Eventu
}
}
+ test("add jar local path with comma") {
+sc = new SparkContext(new
SparkConf().setAppName("test").setMaster("local"))
+sc.addJar("file://Test,UDTF.jar")
+assert(!sc.listJars().exists(_.contains("UDTF.jar")))
Review comment:
What does this test mean? Why didn't you do `
assert(sc.listJars().exists(_.contains("Test,UDTF.jar")))`?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #29966: [SPARK-33084][CORE][SQL] Add jar support ivy path
maropu commented on a change in pull request #29966:
URL: https://github.com/apache/spark/pull/29966#discussion_r533076491
##
File path: core/src/main/scala/org/apache/spark/SparkContext.scala
##
@@ -1860,7 +1860,7 @@ class SparkContext(config: SparkConf) extends Logging {
}
private def addJar(path: String, addedOnSubmit: Boolean): Unit = {
-def addLocalJarFile(file: File): String = {
+def addLocalJarFile(file: File): Array[String] = {
Review comment:
`Array` -> `Seq`
##
File path: core/src/test/scala/org/apache/spark/SparkContextSuite.scala
##
@@ -366,6 +366,12 @@ class SparkContextSuite extends SparkFunSuite with
LocalSparkContext with Eventu
}
}
+ test("add jar local path with comma") {
+sc = new SparkContext(new
SparkConf().setAppName("test").setMaster("local"))
Review comment:
Cold you add tests for other other schemas?
##
File path: core/src/main/scala/org/apache/spark/SparkContext.scala
##
@@ -1869,15 +1869,15 @@ class SparkContext(config: SparkConf) extends Logging {
throw new IllegalArgumentException(
s"Directory ${file.getAbsoluteFile} is not allowed for addJar")
}
-env.rpcEnv.fileServer.addJar(file)
+Array(env.rpcEnv.fileServer.addJar(file))
} catch {
case NonFatal(e) =>
logError(s"Failed to add $path to Spark environment", e)
- null
+ Array.empty
}
}
-def checkRemoteJarFile(path: String): String = {
+def checkRemoteJarFile(path: String): Array[String] = {
Review comment:
ditto
##
File path: core/src/main/scala/org/apache/spark/util/DependencyUtils.scala
##
@@ -15,22 +15,122 @@
* limitations under the License.
*/
-package org.apache.spark.deploy
+package org.apache.spark.util
import java.io.File
-import java.net.URI
+import java.net.{URI, URISyntaxException}
import org.apache.commons.lang3.StringUtils
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.{SecurityManager, SparkConf, SparkException}
+import org.apache.spark.deploy.SparkSubmitUtils
import org.apache.spark.internal.Logging
-import org.apache.spark.util.{MutableURLClassLoader, Utils}
-private[deploy] object DependencyUtils extends Logging {
+private[spark] object DependencyUtils extends Logging {
+
+ def getIvyProperties(): Seq[String] = {
+Seq(
+ "spark.jars.excludes",
+ "spark.jars.packages",
+ "spark.jars.repositories",
+ "spark.jars.ivy",
+ "spark.jars.ivySettings"
+).map(sys.props.get(_).orNull)
+ }
+
+ /**
+ * Parse excluded list in ivy URL. When download ivy URL jar, Spark won't
download transitive jar
+ * in excluded list.
+ *
+ * @param queryString Ivy URI query part string.
+ * @return Exclude list which contains grape parameters of exclude.
+ * Example: Input:
exclude=org.mortbay.jetty:jetty,org.eclipse.jetty:jetty-http
+ * Output: [org.mortbay.jetty:jetty, org.eclipse.jetty:jetty-http]
+ */
+ private def parseExcludeList(excludes: Array[String]): String = {
+excludes.flatMap { excludeString =>
+ val excludes: Array[String] = excludeString.split(",")
+ if (excludes.exists(_.split(":").length != 2)) {
+throw new URISyntaxException(excludeString,
+ "Invalid exclude string: expected 'org:module,org:module,..', found
" + excludeString)
+ }
+ excludes
+}.mkString(":")
+ }
+
+ /**
+ * Parse transitive parameter in ivy URL, default value is false.
+ *
+ * @param queryString Ivy URI query part string.
+ * @return Exclude list which contains grape parameters of transitive.
+ * Example: Input: exclude=org.mortbay.jetty:jetty=true
+ * Output: true
+ */
+ private def parseTransitive(transitives: Array[String]): Boolean = {
+if (transitives.isEmpty) {
+ false
+} else {
+ if (transitives.length > 1) {
+logWarning("It's best to specify `transitive` parameter in ivy URL
query only once." +
+ " If there are multiple `transitive` parameter, we will select the
last one")
+ }
+ transitives.last.toBoolean
Review comment:
What if `transitive=invalidStr` in hive? Could you add tests?
##
File path: core/src/main/scala/org/apache/spark/SparkContext.scala
##
@@ -1869,15 +1869,15 @@ class SparkContext(config: SparkConf) extends Logging {
throw new IllegalArgumentException(
s"Directory ${file.getAbsoluteFile} is not allowed for addJar")
}
-env.rpcEnv.fileServer.addJar(file)
+Array(env.rpcEnv.fileServer.addJar(file))
} catch {
case NonFatal(e) =>
logError(s"Failed to add $path to Spark environment", e)
- null
+ Array.empty
Review comment:
Then, `Nil`
##
File path:
[GitHub] [spark] zsxwing commented on pull request #28363: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
zsxwing commented on pull request #28363: URL: https://github.com/apache/spark/pull/28363#issuecomment-736230794 LGTM. Thanks for your patience. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #30547: [SPARK-33557][CORE][MESOS][TEST] Ensure the relationship between STORAGE_BLOCKMANAGER_HEARTBEAT_TIMEOUT and NETWORK_TIMEOUT
HyukjinKwon commented on a change in pull request #30547: URL: https://github.com/apache/spark/pull/30547#discussion_r533081349 ## File path: core/src/main/scala/org/apache/spark/HeartbeatReceiver.scala ## @@ -80,7 +80,7 @@ private[spark] class HeartbeatReceiver(sc: SparkContext, clock: Clock) // executor ID -> timestamp of when the last heartbeat from this executor was received private val executorLastSeen = new HashMap[String, Long] - private val executorTimeoutMs = sc.conf.get(config.STORAGE_BLOCKMANAGER_HEARTBEAT_TIMEOUT) + private val executorTimeoutMs = Utils.blockManagerHeartbeatTimeoutAsMs(sc.conf) Review comment: Can you use `fallbackConf` at the definition of this configuration at `config/package.scala`? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #30547: [SPARK-33557][CORE][MESOS][TEST] Ensure the relationship between STORAGE_BLOCKMANAGER_HEARTBEAT_TIMEOUT and NETWORK_TIMEOUT
HyukjinKwon commented on pull request #30547: URL: https://github.com/apache/spark/pull/30547#issuecomment-736225520 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon edited a comment on pull request #30486: [SPARK-33530][CORE] Support --archives and spark.archives option natively
HyukjinKwon edited a comment on pull request #30486: URL: https://github.com/apache/spark/pull/30486#issuecomment-736214769 Oh, maybe I will use tar.gz and tgz in the integration test. That will address https://github.com/apache/spark/pull/30486#discussion_r532678330 together. I filed a JIRA at SPARK-33615 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #30486: [SPARK-33530][CORE] Support --archives and spark.archives option natively
HyukjinKwon commented on pull request #30486: URL: https://github.com/apache/spark/pull/30486#issuecomment-736214769 Oh, maybe I will use tar.gz and tgz in the integration test. That will address https://github.com/apache/spark/pull/30486#discussion_r532678330 togeter. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #30486: [SPARK-33530][CORE] Support --archives and spark.archives option natively
HyukjinKwon closed pull request #30486: URL: https://github.com/apache/spark/pull/30486 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #30486: [SPARK-33530][CORE] Support --archives and spark.archives option natively
HyukjinKwon commented on pull request #30486: URL: https://github.com/apache/spark/pull/30486#issuecomment-736213589 Thanks all @dongjoon-hyun @maropu @Ngone51 @mridulm and @tgravescs. Let me merge this in. I will try to have some time to prepare an IT test with K8S which hopefully will be added before Spark 3.1.0 release. Merged to master. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] mridulm commented on a change in pull request #30433: [SPARK-32916][SHUFFLE][test-maven][test-hadoop2.7] Ensure the number of chunks in meta file and index file are equal
mridulm commented on a change in pull request #30433:
URL: https://github.com/apache/spark/pull/30433#discussion_r533068912
##
File path:
common/network-shuffle/src/main/java/org/apache/spark/network/shuffle/RemoteBlockPushResolver.java
##
@@ -827,13 +833,16 @@ void resetChunkTracker() {
void updateChunkInfo(long chunkOffset, int mapIndex) throws IOException {
long idxStartPos = -1;
try {
-// update the chunk tracker to meta file before index file
-writeChunkTracker(mapIndex);
idxStartPos = indexFile.getFilePointer();
logger.trace("{} shuffleId {} reduceId {} updated index current {}
updated {}",
appShuffleId.appId, appShuffleId.shuffleId, reduceId,
this.lastChunkOffset,
chunkOffset);
-indexFile.writeLong(chunkOffset);
+indexFile.write(Longs.toByteArray(chunkOffset));
+// Chunk bitmap should be written to the meta file after the index
file because if there are
+// any exceptions during writing the offset to the index file, meta
file should not be
+// updated. If the update to the index file is successful but the
update to meta file isn't
+// then the index file position is reset in the catch clause.
+writeChunkTracker(mapIndex);
Review comment:
Thanks for confirming @otterc, this means we should not have seek
throwing exception in almost all cases for us.
We have two paths here:
a) Ignore seek exception as unexpected.
b) Abort merge, assuming EBADF/etc - as it is unrecoverable error.
I am partial towards (b) as we cannot recover with seek exception. Thoughts ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] mridulm commented on a change in pull request #30433: [SPARK-32916][SHUFFLE][test-maven][test-hadoop2.7] Ensure the number of chunks in meta file and index file are equal
mridulm commented on a change in pull request #30433:
URL: https://github.com/apache/spark/pull/30433#discussion_r533068912
##
File path:
common/network-shuffle/src/main/java/org/apache/spark/network/shuffle/RemoteBlockPushResolver.java
##
@@ -827,13 +833,16 @@ void resetChunkTracker() {
void updateChunkInfo(long chunkOffset, int mapIndex) throws IOException {
long idxStartPos = -1;
try {
-// update the chunk tracker to meta file before index file
-writeChunkTracker(mapIndex);
idxStartPos = indexFile.getFilePointer();
logger.trace("{} shuffleId {} reduceId {} updated index current {}
updated {}",
appShuffleId.appId, appShuffleId.shuffleId, reduceId,
this.lastChunkOffset,
chunkOffset);
-indexFile.writeLong(chunkOffset);
+indexFile.write(Longs.toByteArray(chunkOffset));
+// Chunk bitmap should be written to the meta file after the index
file because if there are
+// any exceptions during writing the offset to the index file, meta
file should not be
+// updated. If the update to the index file is successful but the
update to meta file isn't
+// then the index file position is reset in the catch clause.
+writeChunkTracker(mapIndex);
Review comment:
Thanks for confirming @otterc.
We have two paths here:
a) Ignore seek exception as unexpected.
b) Abort merge, assuming EBADF/etc - as it is unrecoverable error.
I am partial towards (b) as we cannot recover with seek exception. Thoughts ?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #30533: [SPARK-33380] [EXAMPLES] New python example (series-pi.py) to calculate pi via series
HyukjinKwon closed pull request #30533: URL: https://github.com/apache/spark/pull/30533 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon edited a comment on pull request #30554: [SPARK-30098][SQL] Use default datasource as provider for CREATE TABLE command
HyukjinKwon edited a comment on pull request #30554: URL: https://github.com/apache/spark/pull/30554#issuecomment-736208612 I agree with the point of describing the things and explaining rationalization. I would have imagined to have a detailed PR description as well. Enough discussion should better be made for a significant change of course. I don't believe this PR targeted to push without it. Also, I don't believe such discussions should happen in a specific place like mailing list. They can happen in JIRA, PR, etc. One alternative is just to turn this switch off by default, issue warnings and turn it on later in another release in the future. Just to make it extra clear, what this PR changes looks correct and straightforward to me. Spark should create a Spark table when users `CREATE TABLE`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #30556: [WIP][SPARK-33212][BUILD] Provide hadoop-aws-shaded jar in hadoop-cloud module
AngersZh commented on pull request #30556: URL: https://github.com/apache/spark/pull/30556#issuecomment-736210125 All right, there is still a lot of work to be done to integrate these engine with hadoop. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #30554: [SPARK-30098][SQL] Use default datasource as provider for CREATE TABLE command
HyukjinKwon commented on pull request #30554: URL: https://github.com/apache/spark/pull/30554#issuecomment-736208612 I agree with the point of describing the things and explaining rationalization. I would have imagined to have a detailed PR description as well. Enough discussion should better be made for a significant change of course. I don't believe this PR targeted to push without it - I don't believe such discussions should happen in a specific place like mailing list. They can happen in JIRA, PR, etc. One alternative is just to turn this switch off by default, issue warnings and turn it on later in another release in the future. Just to make it extra clear, what this PR changes looks correct and straightforward to me. Spark should create a Spark table when users `CREATE TABLE`. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR closed pull request #27649: [SPARK-30900][SS] FileStreamSource: Avoid reading compact metadata log twice if the query restarts from compact batch
HeartSaVioR closed pull request #27649: URL: https://github.com/apache/spark/pull/27649 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #27649: [SPARK-30900][SS] FileStreamSource: Avoid reading compact metadata log twice if the query restarts from compact batch
HeartSaVioR commented on pull request #27649: URL: https://github.com/apache/spark/pull/27649#issuecomment-736205169 GA passed. Merging to master. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] luluorta commented on a change in pull request #29882: [SPARK-33008][SQL] Division by zero on divide-like operations returns incorrect result
luluorta commented on a change in pull request #29882: URL: https://github.com/apache/spark/pull/29882#discussion_r533058089 ## File path: sql/core/src/test/resources/sql-tests/inputs/postgreSQL/select_having.sql ## @@ -49,6 +49,7 @@ SELECT 1 AS one FROM test_having HAVING a > 1; SELECT 1 AS one FROM test_having HAVING 1 > 2; SELECT 1 AS one FROM test_having HAVING 1 < 2; +-- [SPARK-33008] Spark SQL throws an exception Review comment: I found that postgres returns correct results without errors for both `1 < 2` and `1 > 2`. While Spark SQL always scans the table and throws exceptions cause its optimizer does not take this case into account. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #30421: [SPARK-33474][SQL] Support TypeConstructed partition spec value
AngersZh commented on pull request #30421: URL: https://github.com/apache/spark/pull/30421#issuecomment-736198521 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #30374: [WIP][SPARK-33444][ML] Added support for Initial model in Gaussian Mixture Model in ML
zhengruifeng commented on pull request #30374: URL: https://github.com/apache/spark/pull/30374#issuecomment-736196878 in the .ml side, models do not support initialization for now. I think we need more discussion and design a general method to support them. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sunchao commented on pull request #30556: [WIP][SPARK-33212][BUILD] Provide hadoop-aws-shaded jar in hadoop-cloud module
sunchao commented on pull request #30556: URL: https://github.com/apache/spark/pull/30556#issuecomment-736196419 Ah ok. That part, as far as I know, is stuck because Hive has dependency on a old version of Spark which blocks it from upgrading Guava. Hopefully that should be unblocked after [HADOOP-17288](https://issues.apache.org/jira/browse/HADOOP-17288) is shipped in the upcoming release (whether that be 3.3.1 or 3.4.0). I'm not sure whether the change will go to Hive 2.3 branch though. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #28363: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
HeartSaVioR commented on pull request #28363: URL: https://github.com/apache/spark/pull/28363#issuecomment-736195621 Thanks for the detailed review. Just applied both. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #30556: [WIP][SPARK-33212][BUILD] Provide hadoop-aws-shaded jar in hadoop-cloud module
AngersZh commented on pull request #30556: URL: https://github.com/apache/spark/pull/30556#issuecomment-736194591 > @AngersZh you mean for Spark to work with Hive and Hadoop 3.3.0, right? the major issue is around resolving potential Guava conflicts between these components. Hadoop 3.2.1+/3.3.0+ has moved to Guava 27 while Hive/Spark are still on Guava 14. One of the motivations to move to the shaded client in Spark is to isolate the Guava dependencies on the Hadoop side. Similarly, @viirya is working on the above PR to shade Guava from Hive side. Not only spark, we need hive can support running with hadoop-3.3.0 too. Seems doesn't look finished yet. https://issues.apache.org/jira/browse/HIVE-21569 https://issues.apache.org/jira/browse/HIVE-22916 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zsxwing commented on pull request #28363: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
zsxwing commented on pull request #28363: URL: https://github.com/apache/spark/pull/28363#issuecomment-736193634 > TTL is defined via current timestamp - commit time (the time `ManifestFileCommitProtocol.commitJob` is called to write streaming file sink metadata log). Could you update this in the PR description? We are using the file modification time now. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sunchao commented on pull request #30556: [WIP][SPARK-33212][BUILD] Provide hadoop-aws-shaded jar in hadoop-cloud module
sunchao commented on pull request #30556: URL: https://github.com/apache/spark/pull/30556#issuecomment-736193307 @AngersZh you mean for Spark to work with Hive and Hadoop 3.3.0, right? the major issue is around resolving potential Guava conflicts between these components. Hadoop 3.2.1+/3.3.0+ has moved to Guava 27 while Hive/Spark are still on Guava 14. One of the motivations to move to the shaded client in Spark is to isolate the Guava dependencies on the Hadoop side. Similarly, @viirya is working on the above PR to shade Guava from Hive side. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zsxwing commented on a change in pull request #28363: [SPARK-27188][SS] FileStreamSink: provide a new option to have retention on output files
zsxwing commented on a change in pull request #28363:
URL: https://github.com/apache/spark/pull/28363#discussion_r533048816
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/streaming/CompactibleFileStreamLog.scala
##
@@ -258,7 +259,8 @@ abstract class CompactibleFileStreamLog[T <: AnyRef :
ClassTag](
try {
val logs =
getAllValidBatches(latestId, compactInterval).flatMap { id =>
- filterInBatch(id)(shouldRetain).getOrElse {
+ val curTime = System.currentTimeMillis()
Review comment:
nit: we can move this out of the `flatMap` function.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] huaxingao closed pull request #29581: [SPARK-32523][SQL] Override alter table in JDBC dialects
huaxingao closed pull request #29581: URL: https://github.com/apache/spark/pull/29581 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #30212: [SPARK-33308][SQL] Refactor current grouping analytics
maropu commented on a change in pull request #30212:
URL: https://github.com/apache/spark/pull/30212#discussion_r533046341
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/Analyzer.scala
##
@@ -2027,65 +1952,76 @@ class Analyzer(override val catalogManager:
CatalogManager)
*/
object ResolveFunctions extends Rule[LogicalPlan] {
val trimWarningEnabled = new AtomicBoolean(true)
+
+def resolveFunction(): PartialFunction[Expression, Expression] = {
+ case u if !u.childrenResolved => u // Skip until children are resolved.
+ case u: UnresolvedAttribute if resolver(u.name,
VirtualColumn.hiveGroupingIdName) =>
+withPosition(u) {
+ Alias(GroupingID(Nil), VirtualColumn.hiveGroupingIdName)()
+}
+ case u @ UnresolvedGenerator(name, children) =>
+withPosition(u) {
+ v1SessionCatalog.lookupFunction(name, children) match {
+case generator: Generator => generator
+case other =>
+ failAnalysis(s"$name is expected to be a generator. However, " +
+s"its class is ${other.getClass.getCanonicalName}, which is
not a generator.")
+ }
+}
+ case u @ UnresolvedFunction(funcId, arguments, isDistinct, filter) =>
+withPosition(u) {
+ v1SessionCatalog.lookupFunction(funcId, arguments) match {
+// AggregateWindowFunctions are AggregateFunctions that can only
be evaluated within
+// the context of a Window clause. They do not need to be wrapped
in an
+// AggregateExpression.
+case wf: AggregateWindowFunction =>
+ if (isDistinct || filter.isDefined) {
+failAnalysis("DISTINCT or FILTER specified, " +
+ s"but ${wf.prettyName} is not an aggregate function")
+ } else {
+wf
+ }
+// We get an aggregate function, we need to wrap it in an
AggregateExpression.
+case agg: AggregateFunction =>
+ if (filter.isDefined && !filter.get.deterministic) {
+failAnalysis("FILTER expression is non-deterministic, " +
+ "it cannot be used in aggregate functions")
+ }
+ AggregateExpression(agg, Complete, isDistinct, filter)
+// This function is not an aggregate function, just return the
resolved one.
+case other if (isDistinct || filter.isDefined) =>
+ failAnalysis("DISTINCT or FILTER specified, " +
+s"but ${other.prettyName} is not an aggregate function")
+case e: String2TrimExpression if arguments.size == 2 =>
+ if (trimWarningEnabled.get) {
+logWarning("Two-parameter TRIM/LTRIM/RTRIM function signatures
are deprecated." +
+ " Use SQL syntax `TRIM((BOTH | LEADING | TRAILING)? trimStr
FROM str)`" +
+ " instead.")
+trimWarningEnabled.set(false)
+ }
+ e
+case other =>
+ other
+ }
+}
+}
+
def apply(plan: LogicalPlan): LogicalPlan = plan.resolveOperatorsUp {
// Resolve functions with concrete relations from v2 catalog.
case UnresolvedFunc(multipartIdent) =>
val funcIdent = parseSessionCatalogFunctionIdentifier(multipartIdent)
ResolvedFunc(Identifier.of(funcIdent.database.toArray,
funcIdent.funcName))
- case q: LogicalPlan =>
-q transformExpressions {
- case u if !u.childrenResolved => u // Skip until children are
resolved.
- case u: UnresolvedAttribute if resolver(u.name,
VirtualColumn.hiveGroupingIdName) =>
-withPosition(u) {
- Alias(GroupingID(Nil), VirtualColumn.hiveGroupingIdName)()
-}
- case u @ UnresolvedGenerator(name, children) =>
-withPosition(u) {
- v1SessionCatalog.lookupFunction(name, children) match {
-case generator: Generator => generator
-case other =>
- failAnalysis(s"$name is expected to be a generator. However,
" +
-s"its class is ${other.getClass.getCanonicalName}, which
is not a generator.")
- }
-}
- case u @ UnresolvedFunction(funcId, arguments, isDistinct, filter) =>
-withPosition(u) {
- v1SessionCatalog.lookupFunction(funcId, arguments) match {
-// AggregateWindowFunctions are AggregateFunctions that can
only be evaluated within
-// the context of a Window clause. They do not need to be
wrapped in an
-// AggregateExpression.
-case wf: AggregateWindowFunction =>
- if (isDistinct || filter.isDefined) {
-failAnalysis("DISTINCT or FILTER specified, " +
- s"but ${wf.prettyName} is not an
[GitHub] [spark] AngersZhuuuu commented on pull request #30556: [WIP][SPARK-33212][BUILD] Provide hadoop-aws-shaded jar in hadoop-cloud module
AngersZh commented on pull request #30556: URL: https://github.com/apache/spark/pull/30556#issuecomment-736189690 > @AngersZh yes that should work. On the other hand, if you are building Spark with `hadoop-provided` option on, you can also build your own shaded `hadoop-aws` jar and put it in the classpath. Thanks for your suggestion. Is there any new developments in Hive 2.3 support for Hadoop-3.3.0? I saw this pr https://github.com/apache/hive/pull/1356 but I am not sure it will make hive run well with hadoop-3.3.0 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sunchao commented on pull request #30556: [WIP][SPARK-33212][BUILD] Provide hadoop-aws-shaded jar in hadoop-cloud module
sunchao commented on pull request #30556: URL: https://github.com/apache/spark/pull/30556#issuecomment-736188374 @AngersZh yes that should work. On the other hand, if you are building Spark with `hadoop-provided` option on, you can also build your own shaded `hadoop-aws` jar and put it in the classpath. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #30521: [SPARK-33577][SS] Add support for V1Table in stream writer table API
HeartSaVioR commented on a change in pull request #30521:
URL: https://github.com/apache/spark/pull/30521#discussion_r533043551
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/streaming/DataStreamWriter.scala
##
@@ -304,46 +308,68 @@ final class DataStreamWriter[T] private[sql](ds:
Dataset[T]) {
* @since 3.1.0
*/
@throws[TimeoutException]
- def saveAsTable(tableName: String): StreamingQuery = {
-this.source = SOURCE_NAME_TABLE
+ def table(tableName: String): StreamingQuery = {
Review comment:
Again I don't just say about the name. I say about the usage pattern -
at least for DataStreamWriter, for years `start()` is the only trigger entry
starting the query. Isn't it enough reason to have DataStreamWriterV2 instead
of breaking the pattern? Once we have `df.writeStreamTo("table")` everything is
in sync with DataFrameWriterV2 (`df.writeTo("table")`) and no confusion.
If we really insist to have two different trigger entries I'm OK to go with
`toTable` but not just simply `table`, because it doesn't say intuitively that
the method is a terminal operation. We'll have to rely on return type to see
whether it's returning StreamingQuery instance - JVM languages will get blessed
by IDE, but I'm not quite sure IDE will guide for all supported non-JVM
languages.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #30521: [SPARK-33577][SS] Add support for V1Table in stream writer table API
HeartSaVioR commented on a change in pull request #30521:
URL: https://github.com/apache/spark/pull/30521#discussion_r533043551
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/streaming/DataStreamWriter.scala
##
@@ -304,46 +308,68 @@ final class DataStreamWriter[T] private[sql](ds:
Dataset[T]) {
* @since 3.1.0
*/
@throws[TimeoutException]
- def saveAsTable(tableName: String): StreamingQuery = {
-this.source = SOURCE_NAME_TABLE
+ def table(tableName: String): StreamingQuery = {
Review comment:
Again I don't just say about the name. I say about the usage pattern -
at least for DataStreamWriter, for years `start()` is the only trigger entry
starting the query. Isn't it enough reason to have DataStreamWriterV2 instead
of breaking the pattern? Once we have `df.writeStreamTo("table")` everything is
in sync with DataFrameWriterV2 (`df.writeTo("table")`) and no confusion.
If we really insist to have two different trigger entries I'm OK to go with
`toTable` but not just simply `table`, because it doesn't say intuitively that
the method is a terminal operation. We'll have to rely on return type to see
whether it's returning StreamingQuery instance - JVM languages will get blessed
by IDE, but I'm not quite sure IDE won't guide for all supported non-JVM
languages.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on a change in pull request #30521: [SPARK-33577][SS] Add support for V1Table in stream writer table API
HeartSaVioR commented on a change in pull request #30521:
URL: https://github.com/apache/spark/pull/30521#discussion_r533043551
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/streaming/DataStreamWriter.scala
##
@@ -304,46 +308,68 @@ final class DataStreamWriter[T] private[sql](ds:
Dataset[T]) {
* @since 3.1.0
*/
@throws[TimeoutException]
- def saveAsTable(tableName: String): StreamingQuery = {
-this.source = SOURCE_NAME_TABLE
+ def table(tableName: String): StreamingQuery = {
Review comment:
Again I don't just say about the name. I say about the usage pattern -
at least for DataStreamWriter, for years `start()` is the only trigger entry
starting the query. Isn't it enough reason to have DataStreamWriterV2 for
breaking the pattern? Once we have `df.writeStreamTo("table")` everything is in
sync with DataFrameWriterV2 (`df.writeTo("table")`) and no confusion.
If we really insist to have two different trigger entries I'm OK to go with
`toTable` but not just simply `table`, because it doesn't say intuitively that
the method is a terminal operation. We'll have to rely on return type to see
whether it's returning StreamingQuery instance - JVM languages will get blessed
by IDE, but I'm not quite sure IDE won't guide for all supported non-JVM
languages.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR closed pull request #30546: [SPARK-33607][SS][WEBUI] Input Rate timeline/histogram aren't rendered if built with Scala 2.13
HeartSaVioR closed pull request #30546: URL: https://github.com/apache/spark/pull/30546 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR edited a comment on pull request #30546: [SPARK-33607][SS][WEBUI] Input Rate timeline/histogram aren't rendered if built with Scala 2.13
HeartSaVioR edited a comment on pull request #30546: URL: https://github.com/apache/spark/pull/30546#issuecomment-736180446 This is a single line change, and both Jenkins and GA passed. Merging to master. (I'll skip porting back as Scala 2.13 compatible doesn't look to be a target for 3.0.x.) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #30546: [SPARK-33607][SS][WEBUI] Input Rate timeline/histogram aren't rendered if built with Scala 2.13
HeartSaVioR commented on pull request #30546: URL: https://github.com/apache/spark/pull/30546#issuecomment-736180446 This is a single line change, and both Jenkins and GA passed. Merging to master (as Scala 2.13 compatible doesn't look to be a target for 3.0.x) This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] luluorta commented on a change in pull request #29882: [SPARK-33008][SQL] Division by zero on divide-like operations returns incorrect result
luluorta commented on a change in pull request #29882: URL: https://github.com/apache/spark/pull/29882#discussion_r533036738 ## File path: sql/core/src/test/resources/sql-tests/inputs/postgreSQL/select_having.sql ## @@ -49,6 +49,7 @@ SELECT 1 AS one FROM test_having HAVING a > 1; SELECT 1 AS one FROM test_having HAVING 1 > 2; SELECT 1 AS one FROM test_having HAVING 1 < 2; +-- [SPARK-33008] Spark SQL throws an exception Review comment: IIUC, the `HAVING` condition here is performed on the globally grouped result set. I think this query is to prove the row count of the global group does not affect the output of an always-true `HAVING` clause. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] brkyvz commented on a change in pull request #30521: [SPARK-33577][SS] Add support for V1Table in stream writer table API
brkyvz commented on a change in pull request #30521:
URL: https://github.com/apache/spark/pull/30521#discussion_r533036448
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/streaming/DataStreamWriter.scala
##
@@ -304,46 +308,68 @@ final class DataStreamWriter[T] private[sql](ds:
Dataset[T]) {
* @since 3.1.0
*/
@throws[TimeoutException]
- def saveAsTable(tableName: String): StreamingQuery = {
-this.source = SOURCE_NAME_TABLE
+ def table(tableName: String): StreamingQuery = {
Review comment:
I prefer something like `table`, because:
```
df.writeStream.table("table_name")
```
seems natural to me (though it is missing a `to` to make total sense.
`toTable` also makes sense, but then just `table` is shorter. I wouldn't want
to use `saveAsTable`, because it's not saving really, it's starting a stream
that's continuously saving/updating/overwriting - and the action depends on the
`outputMode`.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR edited a comment on pull request #30554: [SPARK-30098][SQL] Use default datasource as provider for CREATE TABLE command
HeartSaVioR edited a comment on pull request #30554: URL: https://github.com/apache/spark/pull/30554#issuecomment-736177445 I'd agree to change it even in minor release if we have discussed this for enough time in public, and put some efforts on figuring out impacts to the end users and guide in prior (like roadmap). I don't think we did anything I mentioned. The last discussion we did before Spark 3.0.0 was more likely concerning the change without proper discussion, and we reverted it. Unifying create table syntax fixes the long term issue along confused two create table syntaxes, but that's it and it's not a rationalization of changing the default provider. Changing the default provider for create table is totally different story. My experience of Spark community says that we're most likely reluctant to make a backward incompatible change (even we did for major release), and sometimes we set old behavior by default even the new functionality is available. I'm surprised PR description doesn't mention anything about impacts. I agree this requires enough discussion in public before going further. In discussion we should make clear the benefits of changing this, "AND" the all possible impacts of changing this. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gatorsmile commented on pull request #30555: [SPARK-33608][SQL] Handle DELETE/UPDATE/MERGE in PullupCorrelatedPredicates
gatorsmile commented on pull request #30555: URL: https://github.com/apache/spark/pull/30555#issuecomment-736178529 cc @dilipbiswal This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gatorsmile commented on a change in pull request #30555: [SPARK-33608][SQL] Handle DELETE/UPDATE/MERGE in PullupCorrelatedPredicates
gatorsmile commented on a change in pull request #30555: URL: https://github.com/apache/spark/pull/30555#discussion_r533034446 ## File path: sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/subquery.scala ## @@ -328,6 +328,8 @@ object PullupCorrelatedPredicates extends Rule[LogicalPlan] with PredicateHelper // Only a few unary nodes (Project/Filter/Aggregate) can contain subqueries. case q: UnaryNode => rewriteSubQueries(q, q.children) +case s: SupportsSubquery => Review comment: Add a comment above this line? To be honest, it is hard to tell that this trait means UPDATE/MERGE/DELETE. Also, I think this change is just part of the whole changes for supporting the subquery in UPDATE/MERGE/DELETE. We need the other changes in Analyzer and Optimizer rules. For example, CheckAnalysis. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HeartSaVioR commented on pull request #30554: [SPARK-30098][SQL] Use default datasource as provider for CREATE TABLE command
HeartSaVioR commented on pull request #30554: URL: https://github.com/apache/spark/pull/30554#issuecomment-736177445 I'd agree to change it even in minor release if we have discussed this for enough time in public, and put some efforts on figuring out impacts to the end users and guide in prior (like roadmap). I don't think we did anything I mentioned. The last discussion we did before Spark 3.0.0 was more likely concerning the change without proper discussion, and we reverted it. Unifying create table syntax fixes the long term issue along confused two create table syntaxes, but that's it and it's not a rationalization of changing the default provider. Changing the default provider for create table is totally different story. My experience of Spark community says that we're most likely reluctant to make a backward incompatible change (even we did for major release), and sometimes we set old behavior by default even the new functionality is available. I'm surprised PR description doesn't mention anything about impacts - do we really think this doesn't break anything? I agree this requires enough discussion in public before going further. In discussion we should make clear the benefits of changing this, "AND" the all possible impacts of changing this. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on pull request #30543: [SPARK-33597][SQL] Support REGEXP_LIKE for consistent with mainstream databases
beliefer commented on pull request #30543: URL: https://github.com/apache/spark/pull/30543#issuecomment-736176772 > You forget to update the golden file. Anyway, the alias looks fine to me. Thanks for your remind. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 commented on a change in pull request #30480: [SPARK-32921][SHUFFLE] MapOutputTracker extensions to support push-based shuffle
Ngone51 commented on a change in pull request #30480:
URL: https://github.com/apache/spark/pull/30480#discussion_r533032962
##
File path: core/src/main/scala/org/apache/spark/MapOutputTracker.scala
##
@@ -524,10 +669,37 @@ private[spark] class MapOutputTrackerMaster(
}
}
+ def registerMergeResult(shuffleId: Int, reduceId: Int, status: MergeStatus) {
+shuffleStatuses(shuffleId).addMergeResult(reduceId, status)
+ }
+
+ def registerMergeResults(shuffleId: Int, statuses: Seq[(Int, MergeStatus)]):
Unit = {
+statuses.foreach {
+ case (reduceId, status) => registerMergeResult(shuffleId, reduceId,
status)
+}
+ }
+
+ def unregisterMergeResult(shuffleId: Int, reduceId: Int, bmAddress:
BlockManagerId) {
Review comment:
Ok. We can leave it to the following PR since you already have a planned
ticket for it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] Ngone51 commented on a change in pull request #30312: [SPARK-32917][SHUFFLE][CORE] Adds support for executors to push shuffle blocks after successful map task completion
Ngone51 commented on a change in pull request #30312:
URL: https://github.com/apache/spark/pull/30312#discussion_r533031771
##
File path: core/src/main/scala/org/apache/spark/shuffle/ShuffleBlockPusher.scala
##
@@ -0,0 +1,462 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.shuffle
+
+import java.io.File
+import java.net.ConnectException
+import java.nio.ByteBuffer
+import java.util.concurrent.ExecutorService
+
+import scala.collection.mutable.{ArrayBuffer, HashMap, HashSet, Queue}
+
+import com.google.common.base.Throwables
+
+import org.apache.spark.{ShuffleDependency, SparkConf, SparkEnv}
+import org.apache.spark.annotation.Since
+import org.apache.spark.internal.Logging
+import org.apache.spark.internal.config._
+import org.apache.spark.launcher.SparkLauncher
+import org.apache.spark.network.buffer.{FileSegmentManagedBuffer,
ManagedBuffer, NioManagedBuffer}
+import org.apache.spark.network.netty.SparkTransportConf
+import org.apache.spark.network.shuffle.BlockFetchingListener
+import org.apache.spark.network.shuffle.ErrorHandler.BlockPushErrorHandler
+import org.apache.spark.network.util.TransportConf
+import org.apache.spark.shuffle.ShuffleBlockPusher._
+import org.apache.spark.storage.{BlockId, BlockManagerId, ShufflePushBlockId}
+import org.apache.spark.util.{ThreadUtils, Utils}
+
+/**
+ * Used for pushing shuffle blocks to remote shuffle services when push
shuffle is enabled.
+ * When push shuffle is enabled, it is created after the shuffle writer
finishes writing the shuffle
+ * file and initiates the block push process.
+ *
+ * @param dataFile mapper generated shuffle data file
+ * @param partitionLengths array of shuffle block size so we can tell shuffle
block
+ * boundaries within the shuffle file
+ * @param dep shuffle dependency to get shuffle ID and the
location of remote shuffle
+ * services to push local shuffle blocks
+ * @param partitionId map index of the shuffle map task
+ * @param conf spark configuration
+ */
+@Since("3.1.0")
+private[spark] class ShuffleBlockPusher(
+dataFile: File,
+partitionLengths: Array[Long],
+dep: ShuffleDependency[_, _, _],
+partitionId: Int,
+conf: SparkConf) extends Logging {
Review comment:
> For the constructor, I feel it's better to just pass in the spark conf
object and let the ShuffleBlockPusher read the values of the configuration from
it which it needs.
Sounds fine. I actually do not have a strong opinion on this.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #30421: [SPARK-33474][SQL] Support TypeConstructed partition spec value
AngersZh commented on pull request #30421: URL: https://github.com/apache/spark/pull/30421#issuecomment-736169410 Conflict resolved, any more update? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #30556: [WIP][SPARK-33212][BUILD] Provide hadoop-aws-shaded jar in hadoop-cloud module
AngersZh commented on pull request #30556: URL: https://github.com/apache/spark/pull/30556#issuecomment-736161647 For users of hadoop S3A using a custom version with custom code (such as me), they can change hadoop build info and deploy to their own maven repo and change spark dependencies to their own maven repo. In this way can solve problem of user who will use their own jar, right? But it seems like a lot of work. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #30539: [SPARK-33592] Fix: Pyspark ML Validator params in estimatorParamMaps may be lost after saving and reloading
zhengruifeng commented on pull request #30539: URL: https://github.com/apache/spark/pull/30539#issuecomment-736160622 Merged to master. It seem that this fix can not be directly backported to branch-3.0. @WeichenXu123 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng closed pull request #30539: [SPARK-33592] Fix: Pyspark ML Validator params in estimatorParamMaps may be lost after saving and reloading
zhengruifeng closed pull request #30539: URL: https://github.com/apache/spark/pull/30539 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #30557: [SPARK-33613][PYTHON][TESTS] Replace deprecated APIs in pyspark tests
HyukjinKwon closed pull request #30557: URL: https://github.com/apache/spark/pull/30557 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #30557: [SPARK-33613][PYTHON][TESTS] Replace deprecated APIs in pyspark tests
HyukjinKwon commented on pull request #30557: URL: https://github.com/apache/spark/pull/30557#issuecomment-736158773 Merged to master. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AngersZhuuuu commented on pull request #30243: [SPARK-33335][SQL] Support `array_contains_array` func
AngersZh commented on pull request #30243: URL: https://github.com/apache/spark/pull/30243#issuecomment-736156071 retest this please This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #30555: [SPARK-33608][SQL] Handle DELETE/UPDATE/MERGE in PullupCorrelatedPredicates
HyukjinKwon commented on pull request #30555: URL: https://github.com/apache/spark/pull/30555#issuecomment-736155845 cc @maryannxue as well. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sarutak commented on pull request #30546: [SPARK-33607][SS][WEBUI] Input Rate timeline/histogram aren't rendered if built with Scala 2.13
sarutak commented on pull request #30546: URL: https://github.com/apache/spark/pull/30546#issuecomment-736154866 @srowen > I only wonder if this value is used elsewhere where a big positive value is unexpected. `inputTimeSec` is a local val and it's used only for `numRecords / inputTimeSec` so I believe this change doesn't affect elsewhere. @HeartSaVioR > Is the calculation numRecords / inputTimeSec (= Double.PositiveInfinity) consistent between 2.12 and 2.13? I guess you've experimented for both versions, but just to confirm again. Yes, I have confirmed the result of `numRecords / Double.PositiveInfinity` is zero for both 2.12 and 2.13. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #30554: [SPARK-30098][SQL] Use default datasource as provider for CREATE TABLE command
HyukjinKwon commented on pull request #30554: URL: https://github.com/apache/spark/pull/30554#issuecomment-736153495 I don't think this is something banned as long as we have a way to restore the previous behaviour. More importantly, in Apache Spark, `CREATE TABLE` should create a Spark table, not Hive table. _All_ items in the migration guide are behaviour changes since we don't usually list bug fixes in the migration guide. I can provide a bunch of similar examples if you guys doubt. So I believe the point we should discuss/focus here is that this is a significant behaviour change since `CREATE TABLE` is the very entry point of users. Personally the vote sounds fine to me given that two committers think it might better need. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #30498: [SPARK-33556][ML] Add array_to_vector function for dataframe column
HyukjinKwon closed pull request #30498: URL: https://github.com/apache/spark/pull/30498 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #30498: [SPARK-33556][ML] Add array_to_vector function for dataframe column
HyukjinKwon commented on pull request #30498: URL: https://github.com/apache/spark/pull/30498#issuecomment-736145317 Merged to master. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] github-actions[bot] commented on pull request #29097: [SPARK-32299] [SQL] Decide SMJ Join Orientation adaptively
github-actions[bot] commented on pull request #29097: URL: https://github.com/apache/spark/pull/29097#issuecomment-736143670 We're closing this PR because it hasn't been updated in a while. This isn't a judgement on the merit of the PR in any way. It's just a way of keeping the PR queue manageable. If you'd like to revive this PR, please reopen it and ask a committer to remove the Stale tag! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] github-actions[bot] closed pull request #29511: [WIP][POC][SPARK-32642][K8S] Add an external shuffle service as a sidecar option for Kubernetes
github-actions[bot] closed pull request #29511: URL: https://github.com/apache/spark/pull/29511 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] WeichenXu123 commented on pull request #30539: [SPARK-33592] Fix: Pyspark ML Validator params in estimatorParamMaps may be lost after saving and reloading
WeichenXu123 commented on pull request #30539: URL: https://github.com/apache/spark/pull/30539#issuecomment-736142470 > Looks OK - test cleanup looks like a win too. Can the refactored logic be reused anywhere else? Yes. The MetaAlgorithmReadWrite code will be reused in the PR https://github.com/apache/spark/pull/30471 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] BryanCutler commented on a change in pull request #29818: [SPARK-32953][PYTHON] Add Arrow self_destruct support to toPandas
BryanCutler commented on a change in pull request #29818:
URL: https://github.com/apache/spark/pull/29818#discussion_r532996042
##
File path: python/pyspark/sql/tests/test_arrow.py
##
@@ -191,6 +191,32 @@ def test_pandas_round_trip(self):
pdf_arrow = df.toPandas()
assert_frame_equal(pdf_arrow, pdf)
+def test_pandas_self_destruct(self):
+import pyarrow as pa
+rows = 2 ** 16
+cols = 8
+df = self.spark.range(0, rows).select(*[rand() for _ in range(cols)])
+expected_bytes = rows * cols * 8
+with
self.sql_conf({"spark.sql.execution.arrow.pyspark.selfDestruct.enabled": True}):
+# We hold on to the table reference here, so if self destruct
didn't work, then
+# there would be 2 copies of the data (one in Arrow, one in
Pandas), both
+# tracked by the Arrow allocator
Review comment:
Oh, I missed this comment that you need the Table reference. Otherwise
it could be freed and then we lose track of memory allocated right? If that's
the case, what about just calling
`_collect_as_arrow(_force_split_batches=True)` here and perform batches ->
table -> pandas directly?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] BryanCutler commented on a change in pull request #29818: [SPARK-32953][PYTHON] Add Arrow self_destruct support to toPandas
BryanCutler commented on a change in pull request #29818:
URL: https://github.com/apache/spark/pull/29818#discussion_r532991912
##
File path: python/pyspark/sql/tests/test_arrow.py
##
@@ -191,6 +191,32 @@ def test_pandas_round_trip(self):
pdf_arrow = df.toPandas()
assert_frame_equal(pdf_arrow, pdf)
+def test_pandas_self_destruct(self):
+import pyarrow as pa
+rows = 2 ** 16
+cols = 8
+df = self.spark.range(0, rows).select(*[rand() for _ in range(cols)])
+expected_bytes = rows * cols * 8
+with
self.sql_conf({"spark.sql.execution.arrow.pyspark.selfDestruct.enabled": True}):
+# We hold on to the table reference here, so if self destruct
didn't work, then
+# there would be 2 copies of the data (one in Arrow, one in
Pandas), both
+# tracked by the Arrow allocator
+pdf, table = df._collect_as_arrow_table()
+self.assertEqual((rows, cols), pdf.shape)
+# If self destruct did work, then memory usage should be only a
little above
+# the minimum memory necessary for the dataframe
+self.assertLessEqual(pa.total_allocated_bytes(), 1.2 *
expected_bytes)
Review comment:
just to be safe, what do you think about getting allocated bytes before
and after, then comparing difference? It should probably be the same, but would
be a little more focused then in case something changes in the future
##
File path: python/pyspark/sql/tests/test_arrow.py
##
@@ -191,6 +191,32 @@ def test_pandas_round_trip(self):
pdf_arrow = df.toPandas()
assert_frame_equal(pdf_arrow, pdf)
+def test_pandas_self_destruct(self):
+import pyarrow as pa
+rows = 2 ** 16
+cols = 8
+df = self.spark.range(0, rows).select(*[rand() for _ in range(cols)])
+expected_bytes = rows * cols * 8
+with
self.sql_conf({"spark.sql.execution.arrow.pyspark.selfDestruct.enabled": True}):
+# We hold on to the table reference here, so if self destruct
didn't work, then
+# there would be 2 copies of the data (one in Arrow, one in
Pandas), both
+# tracked by the Arrow allocator
+pdf, table = df._collect_as_arrow_table()
+self.assertEqual((rows, cols), pdf.shape)
+# If self destruct did work, then memory usage should be only a
little above
+# the minimum memory necessary for the dataframe
+self.assertLessEqual(pa.total_allocated_bytes(), 1.2 *
expected_bytes)
+del pdf, table
+self.assertEqual(pa.total_allocated_bytes(), 0)
+with
self.sql_conf({"spark.sql.execution.arrow.pyspark.selfDestruct.enabled":
False}):
+# Force the internals to reallocate data via PyArrow's allocator
so that it
+# gets measured by total_allocated_bytes
+pdf, table = df._collect_as_arrow_table(_force_split_batches=True)
+total_allocated_bytes = pa.total_allocated_bytes()
Review comment:
looks to be unused?
##
File path: python/pyspark/sql/pandas/conversion.py
##
@@ -252,6 +242,74 @@ def _collect_as_arrow(self):
# Re-order the batch list using the correct order
return [batches[i] for i in batch_order]
+def _collect_as_arrow_table(self, _force_split_batches=False):
Review comment:
I don't think we really need to add this method, it just does the
conversion from batches to DataFrame. The unit test doesn't even use the
returned Table right?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org