[GitHub] spark pull request #20146: [SPARK-11215][ML] Add multiple columns support to...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/20146#discussion_r239889212
--- Diff:
mllib/src/main/scala/org/apache/spark/ml/feature/StringIndexer.scala ---
@@ -177,32 +245,47 @@ object StringIndexer extends
DefaultParamsReadable[StringIndexer] {
/**
* Model fitted by [[StringIndexer]].
*
- * @param labels Ordered list of labels, corresponding to indices to be
assigned.
+ * @param labelsArray Array of ordered list of labels, corresponding to
indices to be assigned
+ *for each input column.
*
- * @note During transformation, if the input column does not exist,
- * `StringIndexerModel.transform` would return the input dataset
unmodified.
+ * @note During transformation, if any input column does not exist,
+ * `StringIndexerModel.transform` would skip the input column.
+ * If all input columns do not exist, it returns the input dataset
unmodified.
* This is a temporary fix for the case when target labels do not exist
during prediction.
*/
@Since("1.4.0")
class StringIndexerModel (
@Since("1.4.0") override val uid: String,
-@Since("1.5.0") val labels: Array[String])
+@Since("2.4.0") val labelsArray: Array[Array[String]])
extends Model[StringIndexerModel] with StringIndexerBase with MLWritable
{
import StringIndexerModel._
@Since("1.5.0")
- def this(labels: Array[String]) = this(Identifiable.randomUID("strIdx"),
labels)
-
- private val labelToIndex: OpenHashMap[String, Double] = {
-val n = labels.length
-val map = new OpenHashMap[String, Double](n)
-var i = 0
-while (i < n) {
- map.update(labels(i), i)
- i += 1
+ def this(labels: Array[String]) = this(Identifiable.randomUID("strIdx"),
Array(labels))
+
+ @Since("2.4.0")
+ def this(labelsArray: Array[Array[String]]) =
this(Identifiable.randomUID("strIdx"), labelsArray)
+
+ @Since("1.5.0")
+ def labels: Array[String] = {
+require(labelsArray.length == 1, "This StringIndexerModel is fitted by
multi-columns, " +
+ "call for `labelsArray` instead.")
+labelsArray(0)
+ }
+
+ // Prepares the maps for string values to corresponding index values.
+ private val labelsToIndexArray: Array[OpenHashMap[String, Double]] = {
+for (labels <- labelsArray) yield {
+ val n = labels.length
+ val map = new OpenHashMap[String, Double](n)
+ var i = 0
--- End diff --
We could use a `foreach` here or similar to avoid the var + loop? (And or
put from seq logic in the openhashmap).
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20146: [SPARK-11215][ML] Add multiple columns support to...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/20146#discussion_r239887472
--- Diff:
mllib/src/main/scala/org/apache/spark/ml/feature/StringIndexer.scala ---
@@ -130,21 +159,60 @@ class StringIndexer @Since("1.4.0") (
@Since("1.4.0")
def setOutputCol(value: String): this.type = set(outputCol, value)
+ /** @group setParam */
+ @Since("2.4.0")
+ def setInputCols(value: Array[String]): this.type = set(inputCols, value)
+
+ /** @group setParam */
+ @Since("2.4.0")
+ def setOutputCols(value: Array[String]): this.type = set(outputCols,
value)
+
+ private def countByValue(
+ dataset: Dataset[_],
+ inputCols: Array[String]): Array[OpenHashMap[String, Long]] = {
+
+val aggregator = new StringIndexerAggregator(inputCols.length)
+implicit val encoder = Encoders.kryo[Array[OpenHashMap[String, Long]]]
+
+dataset.select(inputCols.map(col(_).cast(StringType)): _*)
+ .toDF
+ .groupBy().agg(aggregator.toColumn)
+ .as[Array[OpenHashMap[String, Long]]]
+ .collect()(0)
+ }
+
@Since("2.0.0")
override def fit(dataset: Dataset[_]): StringIndexerModel = {
transformSchema(dataset.schema, logging = true)
-val values = dataset.na.drop(Array($(inputCol)))
- .select(col($(inputCol)).cast(StringType))
- .rdd.map(_.getString(0))
-val labels = $(stringOrderType) match {
- case StringIndexer.frequencyDesc =>
values.countByValue().toSeq.sortBy(-_._2)
-.map(_._1).toArray
- case StringIndexer.frequencyAsc =>
values.countByValue().toSeq.sortBy(_._2)
-.map(_._1).toArray
- case StringIndexer.alphabetDesc =>
values.distinct.collect.sortWith(_ > _)
- case StringIndexer.alphabetAsc => values.distinct.collect.sortWith(_
< _)
-}
-copyValues(new StringIndexerModel(uid, labels).setParent(this))
+
+val (inputCols, _) = getInOutCols()
+
+val filteredDF = dataset.na.drop(inputCols)
+
+// In case of equal frequency when frequencyDesc/Asc, we further sort
the strings by alphabet.
--- End diff --
Is this a change of behaviour? If so we should document it in a visible
place.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20146: [SPARK-11215][ML] Add multiple columns support to...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/20146#discussion_r239889869
--- Diff:
mllib/src/main/scala/org/apache/spark/ml/feature/StringIndexer.scala ---
@@ -310,11 +439,23 @@ object StringIndexerModel extends
MLReadable[StringIndexerModel] {
override def load(path: String): StringIndexerModel = {
val metadata = DefaultParamsReader.loadMetadata(path, sc, className)
val dataPath = new Path(path, "data").toString
- val data = sparkSession.read.parquet(dataPath)
-.select("labels")
-.head()
- val labels = data.getAs[Seq[String]](0).toArray
- val model = new StringIndexerModel(metadata.uid, labels)
+
+ val (majorVersion, minorVersion) =
majorMinorVersion(metadata.sparkVersion)
+ val labelsArray = if (majorVersion < 2 || (majorVersion == 2 &&
minorVersion <= 3)) {
--- End diff --
I'm confused by this logic -- are we expecting people to use the MLlib code
with different version of Spark here?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20146: [SPARK-11215][ML] Add multiple columns support to...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/20146#discussion_r239885097
--- Diff:
mllib/src/main/scala/org/apache/spark/ml/feature/StringIndexer.scala ---
@@ -79,26 +81,53 @@ private[feature] trait StringIndexerBase extends Params
with HasHandleInvalid wi
@Since("2.3.0")
def getStringOrderType: String = $(stringOrderType)
- /** Validates and transforms the input schema. */
- protected def validateAndTransformSchema(schema: StructType): StructType
= {
-val inputColName = $(inputCol)
+ /** Returns the input and output column names corresponding in pair. */
+ private[feature] def getInOutCols(): (Array[String], Array[String]) = {
+ParamValidators.checkSingleVsMultiColumnParams(this, Seq(outputCol),
Seq(outputCols))
+
+if (isSet(inputCol)) {
+ (Array($(inputCol)), Array($(outputCol)))
+} else {
+ require($(inputCols).length == $(outputCols).length,
+"The number of input columns does not match output columns")
+ ($(inputCols), $(outputCols))
+}
+ }
+
+ private def validateAndTransformField(
+ schema: StructType,
+ inputColName: String,
+ outputColName: String): StructField = {
val inputDataType = schema(inputColName).dataType
require(inputDataType == StringType ||
inputDataType.isInstanceOf[NumericType],
s"The input column $inputColName must be either string type or
numeric type, " +
s"but got $inputDataType.")
-val inputFields = schema.fields
-val outputColName = $(outputCol)
-require(inputFields.forall(_.name != outputColName),
+require(schema.fields.forall(_.name != outputColName),
--- End diff --
minor: So this check seems good, should we add a check that there are not
any duplicate output fields?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20146: [SPARK-11215][ML] Add multiple columns support to...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/20146#discussion_r239888373
--- Diff:
mllib/src/main/scala/org/apache/spark/ml/feature/StringIndexer.scala ---
@@ -130,21 +159,60 @@ class StringIndexer @Since("1.4.0") (
@Since("1.4.0")
def setOutputCol(value: String): this.type = set(outputCol, value)
+ /** @group setParam */
+ @Since("2.4.0")
+ def setInputCols(value: Array[String]): this.type = set(inputCols, value)
+
+ /** @group setParam */
+ @Since("2.4.0")
+ def setOutputCols(value: Array[String]): this.type = set(outputCols,
value)
+
+ private def countByValue(
+ dataset: Dataset[_],
+ inputCols: Array[String]): Array[OpenHashMap[String, Long]] = {
+
+val aggregator = new StringIndexerAggregator(inputCols.length)
+implicit val encoder = Encoders.kryo[Array[OpenHashMap[String, Long]]]
+
+dataset.select(inputCols.map(col(_).cast(StringType)): _*)
+ .toDF
+ .groupBy().agg(aggregator.toColumn)
+ .as[Array[OpenHashMap[String, Long]]]
+ .collect()(0)
+ }
+
@Since("2.0.0")
override def fit(dataset: Dataset[_]): StringIndexerModel = {
transformSchema(dataset.schema, logging = true)
-val values = dataset.na.drop(Array($(inputCol)))
- .select(col($(inputCol)).cast(StringType))
- .rdd.map(_.getString(0))
-val labels = $(stringOrderType) match {
- case StringIndexer.frequencyDesc =>
values.countByValue().toSeq.sortBy(-_._2)
-.map(_._1).toArray
- case StringIndexer.frequencyAsc =>
values.countByValue().toSeq.sortBy(_._2)
-.map(_._1).toArray
- case StringIndexer.alphabetDesc =>
values.distinct.collect.sortWith(_ > _)
- case StringIndexer.alphabetAsc => values.distinct.collect.sortWith(_
< _)
-}
-copyValues(new StringIndexerModel(uid, labels).setParent(this))
+
+val (inputCols, _) = getInOutCols()
+
+val filteredDF = dataset.na.drop(inputCols)
+
+// In case of equal frequency when frequencyDesc/Asc, we further sort
the strings by alphabet.
+val labelsArray = $(stringOrderType) match {
+ case StringIndexer.frequencyDesc =>
+countByValue(filteredDF, inputCols).map { counts =>
+ counts.toSeq.sortBy(_._1).sortBy(-_._2).map(_._1).toArray
+}
+ case StringIndexer.frequencyAsc =>
+countByValue(filteredDF, inputCols).map { counts =>
+ counts.toSeq.sortBy(_._1).sortBy(_._2).map(_._1).toArray
+}
+ case StringIndexer.alphabetDesc =>
+import dataset.sparkSession.implicits._
+inputCols.map { inputCol =>
+
filteredDF.select(inputCol).distinct().sort(dataset(s"$inputCol").desc)
--- End diff --
This could trigger many actions and if the input is not cached that's not
great. We could cache the filteredDF (and explicitily uncache later) as one
solution, what do you think?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20146: [SPARK-11215][ML] Add multiple columns support to...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/20146#discussion_r239887259
--- Diff:
mllib/src/main/scala/org/apache/spark/ml/feature/StringIndexer.scala ---
@@ -130,21 +159,60 @@ class StringIndexer @Since("1.4.0") (
@Since("1.4.0")
def setOutputCol(value: String): this.type = set(outputCol, value)
+ /** @group setParam */
+ @Since("2.4.0")
+ def setInputCols(value: Array[String]): this.type = set(inputCols, value)
+
+ /** @group setParam */
+ @Since("2.4.0")
+ def setOutputCols(value: Array[String]): this.type = set(outputCols,
value)
+
+ private def countByValue(
+ dataset: Dataset[_],
+ inputCols: Array[String]): Array[OpenHashMap[String, Long]] = {
+
+val aggregator = new StringIndexerAggregator(inputCols.length)
+implicit val encoder = Encoders.kryo[Array[OpenHashMap[String, Long]]]
+
+dataset.select(inputCols.map(col(_).cast(StringType)): _*)
+ .toDF
+ .groupBy().agg(aggregator.toColumn)
+ .as[Array[OpenHashMap[String, Long]]]
+ .collect()(0)
+ }
+
@Since("2.0.0")
override def fit(dataset: Dataset[_]): StringIndexerModel = {
transformSchema(dataset.schema, logging = true)
-val values = dataset.na.drop(Array($(inputCol)))
- .select(col($(inputCol)).cast(StringType))
- .rdd.map(_.getString(0))
-val labels = $(stringOrderType) match {
- case StringIndexer.frequencyDesc =>
values.countByValue().toSeq.sortBy(-_._2)
-.map(_._1).toArray
- case StringIndexer.frequencyAsc =>
values.countByValue().toSeq.sortBy(_._2)
-.map(_._1).toArray
- case StringIndexer.alphabetDesc =>
values.distinct.collect.sortWith(_ > _)
- case StringIndexer.alphabetAsc => values.distinct.collect.sortWith(_
< _)
-}
-copyValues(new StringIndexerModel(uid, labels).setParent(this))
+
+val (inputCols, _) = getInOutCols()
+
+val filteredDF = dataset.na.drop(inputCols)
+
+// In case of equal frequency when frequencyDesc/Asc, we further sort
the strings by alphabet.
+val labelsArray = $(stringOrderType) match {
+ case StringIndexer.frequencyDesc =>
+countByValue(filteredDF, inputCols).map { counts =>
+ counts.toSeq.sortBy(_._1).sortBy(-_._2).map(_._1).toArray
--- End diff --
So would it make sense to do a single sortBy with a compound expression
instead of 2 sorts (and same bellow)?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20146: [SPARK-11215][ML] Add multiple columns support to...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/20146#discussion_r239888591
--- Diff:
mllib/src/main/scala/org/apache/spark/ml/feature/StringIndexer.scala ---
@@ -130,21 +159,60 @@ class StringIndexer @Since("1.4.0") (
@Since("1.4.0")
def setOutputCol(value: String): this.type = set(outputCol, value)
+ /** @group setParam */
+ @Since("2.4.0")
+ def setInputCols(value: Array[String]): this.type = set(inputCols, value)
+
+ /** @group setParam */
+ @Since("2.4.0")
+ def setOutputCols(value: Array[String]): this.type = set(outputCols,
value)
+
+ private def countByValue(
+ dataset: Dataset[_],
+ inputCols: Array[String]): Array[OpenHashMap[String, Long]] = {
+
+val aggregator = new StringIndexerAggregator(inputCols.length)
+implicit val encoder = Encoders.kryo[Array[OpenHashMap[String, Long]]]
+
+dataset.select(inputCols.map(col(_).cast(StringType)): _*)
+ .toDF
+ .groupBy().agg(aggregator.toColumn)
+ .as[Array[OpenHashMap[String, Long]]]
+ .collect()(0)
+ }
+
@Since("2.0.0")
override def fit(dataset: Dataset[_]): StringIndexerModel = {
transformSchema(dataset.schema, logging = true)
-val values = dataset.na.drop(Array($(inputCol)))
- .select(col($(inputCol)).cast(StringType))
- .rdd.map(_.getString(0))
-val labels = $(stringOrderType) match {
- case StringIndexer.frequencyDesc =>
values.countByValue().toSeq.sortBy(-_._2)
-.map(_._1).toArray
- case StringIndexer.frequencyAsc =>
values.countByValue().toSeq.sortBy(_._2)
-.map(_._1).toArray
- case StringIndexer.alphabetDesc =>
values.distinct.collect.sortWith(_ > _)
- case StringIndexer.alphabetAsc => values.distinct.collect.sortWith(_
< _)
-}
-copyValues(new StringIndexerModel(uid, labels).setParent(this))
+
+val (inputCols, _) = getInOutCols()
+
+val filteredDF = dataset.na.drop(inputCols)
+
+// In case of equal frequency when frequencyDesc/Asc, we further sort
the strings by alphabet.
+val labelsArray = $(stringOrderType) match {
+ case StringIndexer.frequencyDesc =>
+countByValue(filteredDF, inputCols).map { counts =>
+ counts.toSeq.sortBy(_._1).sortBy(-_._2).map(_._1).toArray
+}
+ case StringIndexer.frequencyAsc =>
+countByValue(filteredDF, inputCols).map { counts =>
+ counts.toSeq.sortBy(_._1).sortBy(_._2).map(_._1).toArray
+}
+ case StringIndexer.alphabetDesc =>
+import dataset.sparkSession.implicits._
+inputCols.map { inputCol =>
+
filteredDF.select(inputCol).distinct().sort(dataset(s"$inputCol").desc)
+.as[String].collect()
+}
+ case StringIndexer.alphabetAsc =>
+import dataset.sparkSession.implicits._
+inputCols.map { inputCol =>
+
filteredDF.select(inputCol).distinct().sort(dataset(s"$inputCol").asc)
--- End diff --
Same comment as the Desc case.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20146: [SPARK-11215][ML] Add multiple columns support to...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/20146#discussion_r239885459
--- Diff:
mllib/src/main/scala/org/apache/spark/ml/feature/StringIndexer.scala ---
@@ -130,21 +159,60 @@ class StringIndexer @Since("1.4.0") (
@Since("1.4.0")
def setOutputCol(value: String): this.type = set(outputCol, value)
+ /** @group setParam */
+ @Since("2.4.0")
--- End diff --
Going to want to update these to 3.0
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17654: [SPARK-20351] [ML] Add trait hasTrainingSummary to repla...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/17654 Gentle ping here, it's out of sync with master if you've got the time to bring it up to date that would be great. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22273: [SPARK-25272][PYTHON][TEST] Add test to better indicate ...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22273 How about if we checked an env variable like EXPECT_ARROW (and set it when tests are running in Jenkins) and if it's set but we don't have the required versions installed fail? That way we know if our code is being tested in CI? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19045: [WIP][SPARK-20628][CORE][K8S] Keep track of nodes (/ spo...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/19045 Jenkins retest this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22996: [SPARK-25997][ML]add Python example code for Power Itera...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22996 Thanks for working on this! I noticed you have the example on / off tags, normally those correspond with it being included in documentation somewhere the those tags are used -- is that the plan for this PR? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22275: [SPARK-25274][PYTHON][SQL] In toPandas with Arrow...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22275#discussion_r232420076
--- Diff: python/pyspark/sql/tests.py ---
@@ -4923,6 +4923,28 @@ def test_timestamp_dst(self):
self.assertPandasEqual(pdf, df_from_python.toPandas())
self.assertPandasEqual(pdf, df_from_pandas.toPandas())
+def test_toPandas_batch_order(self):
+
+# Collects Arrow RecordBatches out of order in driver JVM then
re-orders in Python
+def run_test(num_records, num_parts, max_records):
+df = self.spark.range(num_records,
numPartitions=num_parts).toDF("a")
+with
self.sql_conf({"spark.sql.execution.arrow.maxRecordsPerBatch": max_records}):
+pdf, pdf_arrow = self._toPandas_arrow_toggle(df)
+self.assertPandasEqual(pdf, pdf_arrow)
+
+cases = [
+(1024, 512, 2), # Try large num partitions for good chance of
not collecting in order
+(512, 64, 2),# Try medium num partitions to test out of
order collection
+(64, 8, 2), # Try small number of partitions to test out
of order collection
+(64, 64, 1), # Test single batch per partition
+(64, 1, 64), # Test single partition, single batch
+(64, 1, 8), # Test single partition, multiple batches
+(30, 7, 2), # Test different sized partitions
+]
--- End diff --
I like the new tests, I think 0.1 on one of partitions is enough.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22275: [SPARK-25274][PYTHON][SQL] In toPandas with Arrow...
Github user holdenk commented on a diff in the pull request: https://github.com/apache/spark/pull/22275#discussion_r232420015 --- Diff: python/pyspark/sql/tests.py --- @@ -4923,6 +4923,34 @@ def test_timestamp_dst(self): self.assertPandasEqual(pdf, df_from_python.toPandas()) self.assertPandasEqual(pdf, df_from_pandas.toPandas()) +def test_toPandas_batch_order(self): + +def delay_first_part(partition_index, iterator): +if partition_index == 0: +time.sleep(0.1) --- End diff -- I like this :) --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18610: [SPARK-21386] ML LinearRegression supports warm start fr...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/18610 @JohnHBrock this PR is pretty old so the biggest challenge is going to be updating it to the current master branch. There's some discussion around the types needing to be changed as well. If this is a thing you want to work on I'd love to do what I can to help with the review process. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22921: [SPARK-25908][CORE][SQL] Remove old deprecated it...
Github user holdenk commented on a diff in the pull request: https://github.com/apache/spark/pull/22921#discussion_r230428697 --- Diff: python/pyspark/sql/functions.py --- @@ -275,15 +273,6 @@ def _(): del _name, _doc -@since(1.3) -def approxCountDistinct(col, rsd=None): --- End diff -- Looks like the removal of this is causing the test failure, maybe do a grep for `approxCountDistinct` in the tests? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22921: [SPARK-25908][CORE][SQL] Remove old deprecated it...
Github user holdenk commented on a diff in the pull request: https://github.com/apache/spark/pull/22921#discussion_r230429014 --- Diff: python/pyspark/storagelevel.py --- @@ -56,16 +56,3 @@ def __str__(self): StorageLevel.MEMORY_AND_DISK = StorageLevel(True, True, False, False) StorageLevel.MEMORY_AND_DISK_2 = StorageLevel(True, True, False, False, 2) StorageLevel.OFF_HEAP = StorageLevel(True, True, True, False, 1) - -""" -.. note:: The following four storage level constants are deprecated in 2.0, since the records --- End diff -- cc @MLnick I know this was a thing on your radar in some way for dataframe caching maybe? Do we actually want to remove this for 3+? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22921: [SPARK-25908][CORE][SQL] Remove old deprecated it...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22921#discussion_r230427671
--- Diff: R/pkg/R/functions.R ---
@@ -1641,30 +1641,30 @@ setMethod("tanh",
})
#' @details
-#' \code{toDegrees}: Converts an angle measured in radians to an
approximately equivalent angle
+#' \code{degrees}: Converts an angle measured in radians to an
approximately equivalent angle
#' measured in degrees.
#'
#' @rdname column_math_functions
-#' @aliases toDegrees toDegrees,Column-method
-#' @note toDegrees since 1.4.0
-setMethod("toDegrees",
+#' @aliases degrees degrees,Column-method
+#' @note degrees since 2.1.0
--- End diff --
I'm confused about the since annotation here, where was the degrees
implementation in 2.1.0? When I look at
https://spark.apache.org/docs/latest/api/R/index.html I don't see the `degrees`
function just `toDegrees`>=?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22921: [SPARK-25908][CORE][SQL] Remove old deprecated it...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22921#discussion_r230427828
--- Diff: R/pkg/R/functions.R ---
@@ -1641,30 +1641,30 @@ setMethod("tanh",
})
#' @details
-#' \code{toDegrees}: Converts an angle measured in radians to an
approximately equivalent angle
+#' \code{degrees}: Converts an angle measured in radians to an
approximately equivalent angle
#' measured in degrees.
#'
#' @rdname column_math_functions
-#' @aliases toDegrees toDegrees,Column-method
-#' @note toDegrees since 1.4.0
-setMethod("toDegrees",
+#' @aliases degrees degrees,Column-method
+#' @note degrees since 2.1.0
+setMethod("degrees",
signature(x = "Column"),
function(x) {
-jc <- callJStatic("org.apache.spark.sql.functions",
"toDegrees", x@jc)
+jc <- callJStatic("org.apache.spark.sql.functions", "degrees",
x@jc)
column(jc)
})
#' @details
-#' \code{toRadians}: Converts an angle measured in degrees to an
approximately equivalent angle
+#' \code{radians}: Converts an angle measured in degrees to an
approximately equivalent angle
#' measured in radians.
#'
#' @rdname column_math_functions
-#' @aliases toRadians toRadians,Column-method
-#' @note toRadians since 1.4.0
-setMethod("toRadians",
+#' @aliases radians radians,Column-method
+#' @note radians since 2.1.0
--- End diff --
Similar comment with degrees
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #7842: [SPARK-8542][MLlib]PMML export for Decision Trees
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/7842 Jenkins OK to test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #15496: [SPARK-17950] [Python] Match SparseVector behavior with ...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/15496 Gentle ping, are you still interested in this? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20503: [SPARK-23299][SQL][PYSPARK] Fix __repr__ behaviour for R...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/20503 Awesome, thanks. Let me know if I can help :) --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22275: [SPARK-25274][PYTHON][SQL] In toPandas with Arrow...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22275#discussion_r230423471
--- Diff: python/pyspark/sql/tests.py ---
@@ -4923,6 +4923,28 @@ def test_timestamp_dst(self):
self.assertPandasEqual(pdf, df_from_python.toPandas())
self.assertPandasEqual(pdf, df_from_pandas.toPandas())
+def test_toPandas_batch_order(self):
+
+# Collects Arrow RecordBatches out of order in driver JVM then
re-orders in Python
+def run_test(num_records, num_parts, max_records):
+df = self.spark.range(num_records,
numPartitions=num_parts).toDF("a")
+with
self.sql_conf({"spark.sql.execution.arrow.maxRecordsPerBatch": max_records}):
+pdf, pdf_arrow = self._toPandas_arrow_toggle(df)
+self.assertPandasEqual(pdf, pdf_arrow)
+
+cases = [
+(1024, 512, 2), # Try large num partitions for good chance of
not collecting in order
+(512, 64, 2),# Try medium num partitions to test out of
order collection
+(64, 8, 2), # Try small number of partitions to test out
of order collection
+(64, 64, 1), # Test single batch per partition
+(64, 1, 64), # Test single partition, single batch
+(64, 1, 8), # Test single partition, multiple batches
+(30, 7, 2), # Test different sized partitions
+]
--- End diff --
I don't see how we're guaranteeing out-of-order from the JVM. Could we
delay on one of the early partitions to guarantee out of order?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #12066: [SPARK-7424] [ML] ML ClassificationModel should add meta...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/12066 I still this is important, but if you're not working on it @yanboliang would you be OK closing it so someone else can take this over? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19045: [WIP][SPARK-20628][CORE][K8S] Keep track of nodes...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/19045#discussion_r229788821
--- Diff:
resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/KubernetesSuite.scala
---
@@ -242,12 +243,19 @@ private[spark] class KubernetesSuite extends
SparkFunSuite
action match {
case Action.ADDED | Action.MODIFIED =>
execPods(name) = resource
+ // If testing decomissioning delete the node 10 seconds after
+ if (decomissioningTest) {
+Thread.sleep(1000)
--- End diff --
We probably want to wait some fudge factor above running to ensure it has a
chance to properly register and everything but yeah we can decrease the fudge
factor and check the pod status to be more reliable.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19045: [WIP][SPARK-20628][CORE][K8S] Keep track of nodes (/ spo...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/19045 Hey @ifilonenko I'd appreciate your thoughts on the testing approach I took here and if matches your suggestions. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22295: [SPARK-25255][PYTHON]Add getActiveSession to SparkSessio...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22295 Merged to master for 3.0. Thanks for fixing this @huaxingao :) --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18339: [SPARK-21094][PYTHON] Add popen_kwargs to launch_gateway
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/18339 Since @HyukjinKwon's concerns for this PR have been addressed if @parente can update this to master would be lovely to get this in for 3+ since I'm working on some multi-language pipeline stuff which could benefit. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #15670: [SPARK-18161] [Python] Allow pickle to serialize >4 GB o...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/15670 Jenkins ok to test. @inpefess if you can update this PR to master now is a great time to get this in since the next release after 2.4 is going to be 3 so it's easier to change formats and stuff. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20503: [SPARK-23299][SQL][PYSPARK] Fix __repr__ behaviour for R...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/20503 Jenkins ok to test. Gentle ping again to @ashashwat - are you still interested in this PR? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22425: [SPARK-23367][Build] Include python document style check...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22425 I think the scaladoc error is unrelated, jenkins retest this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #15496: [SPARK-17950] [Python] Match SparseVector behavior with ...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/15496 While you update to master i might include in the docstring that the similar funcitonality in densevector is done with manual delegation in `_delegate`. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #15496: [SPARK-17950] [Python] Match SparseVector behavior with ...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/15496 Jenkins Ok to test --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #15496: [SPARK-17950] [Python] Match SparseVector behavior with ...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/15496 Sorry for letting this slide for so long. This looks really close, I think now that we don't have append I don't have the concerns with the copy any more. Can you update this to master and we can make sure it passes the new style guides? Would be nice to get for Spark 3 for sure :) And really sorry this slipped my plate. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21654: [SPARK-24671][PySpark] DataFrame length using a dunder/m...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/21654 hey @kokes this is out of sync with master, can you merge in the latest master? I'm going to follow up on the dev@ list for the plan which @HyukjinKwon wants to see (please feel free to join in that discussion). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21654: [SPARK-24671][PySpark] DataFrame length using a dunder/m...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/21654 Jenkins, ok to test. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22810: [SPARK-24516][K8S] Change Python default to Python3
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22810 Let me look on Friday during weekly review time. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22756: [SPARK-25758][ML] Deprecate computeCost on BisectingKMea...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22756 I'm seeing this linked from https://github.com/apache/spark/pull/22764 and I'm wondering if we need to revert this. If the information is not actually available where we tell folks it is I think we need to revert this especially since we are in the middle of the release process. Or raise SPARK-25765 to blocker release blocker. Have I misunderstood the situation here? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #12066: [SPARK-7424] [ML] ML ClassificationModel should add meta...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/12066 Hey @yanboliang I think improved metadata on the pipeline would be great, but if this abonded I get it if so do you want to close this PR and switch the JIRA back to open so someone else can take a crack at it? If you're still working on it that's cool too. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21522: [SPARK-24467][ML] VectorAssemblerEstimator
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/21522 cc @jkbradley again --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22729: [SPARK-25737][CORE] Remove JavaSparkContextVarargsWorkar...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22729 Jenkins, retest this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22425: [SPARK-23367][Build] Include python document style check...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22425 Gentle ping, whats up? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18457: [SPARK-21241][MLlib]- Add setIntercept to StreamingLinea...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/18457 Would you be OK closing this PR @SoulGuedria --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22533: [SPARK-18818][PYTHON] Add 'ascending' parameter to Windo...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22533 Jenkins OK to test. @annamolchanova if you want help making the Scala version of this PR first I'd be happy to lend what help I can. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21157: [SPARK-22674][PYTHON] Removed the namedtuple pickling pa...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/21157 If removing the hack entirely is going to brake named tuples defined in the repl I'm a -1 on that change. While we certainly are more free to make breaking API changes in a majour version release we still have to think through the scope of the change we're going to be pushing onto users and that's pretty large. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22295: [SPARK-25255][PYTHON]Add getActiveSession to SparkSessio...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22295 I'll leave this for if @HyukjinKwon has any final comments, otherwise I'm happy to merge. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19045: [WIP][SPARK-20628][CORE][K8S] Keep track of nodes (/ spo...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/19045 Thanks @ifilonenko added :) --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21157: [SPARK-22674][PYTHON] Removed the namedtuple pickling pa...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/21157 I mean, we could warn if we are doing the hijacking and not break peoples pipelines? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20503: [SPARK-23299][SQL][PYSPARK] Fix __repr__ behaviour for R...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/20503 Gentle ping again to @ashashwat . Also @HyukjinKwon what are your opinions on the test coverage? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21157: [SPARK-22674][PYTHON] Removed the namedtuple pickling pa...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/21157 Do you have the code for demonstrating the 2x speed up @superbobry ? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21157: [SPARK-22674][PYTHON] Removed the namedtuple pickling pa...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/21157 Ok it looks like it was @HyukjinKwon who suggested that we remove this hack in general rather than the partial work around can I get your thoughts on why? It seems like the partial work around would give us the best of both worlds (e.g. we don't break peoples existing Spark code and we handle Python tuples better). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #18457: [SPARK-21241][MLlib]- Add setIntercept to StreamingLinea...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/18457 Sounds like we're not going to change this @SoulGuedria but we'd love your contributions in Spark ML where things are actively being developed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22295: [SPARK-25255][PYTHON]Add getActiveSession to Spar...
Github user holdenk commented on a diff in the pull request: https://github.com/apache/spark/pull/22295#discussion_r224860828 --- Diff: python/pyspark/sql/session.py --- @@ -231,6 +231,7 @@ def __init__(self, sparkContext, jsparkSession=None): or SparkSession._instantiatedSession._sc._jsc is None: SparkSession._instantiatedSession = self self._jvm.SparkSession.setDefaultSession(self._jsparkSession) +self._jvm.SparkSession.setActiveSession(self._jsparkSession) --- End diff -- If we're going to support this we should have test for it, or if we aren't going to support this right now we should document the behaviour. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22295: [SPARK-25255][PYTHON]Add getActiveSession to Spar...
Github user holdenk commented on a diff in the pull request: https://github.com/apache/spark/pull/22295#discussion_r224858616 --- Diff: python/pyspark/sql/session.py --- @@ -252,6 +253,22 @@ def newSession(self): """ return self.__class__(self._sc, self._jsparkSession.newSession()) +@since(3.0) --- End diff -- @HyukjinKwon are you OK to mark this comment as resolved since we're now targeting `3.0`? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22295: [SPARK-25255][PYTHON]Add getActiveSession to Spar...
Github user holdenk commented on a diff in the pull request: https://github.com/apache/spark/pull/22295#discussion_r224858233 --- Diff: python/pyspark/sql/functions.py --- @@ -2633,6 +2633,23 @@ def sequence(start, stop, step=None): _to_java_column(start), _to_java_column(stop), _to_java_column(step))) +@since(3.0) +def getActiveSession(): +""" +Returns the active SparkSession for the current thread +""" +from pyspark.sql import SparkSession +sc = SparkContext._active_spark_context --- End diff -- If this is being done to simplify implementation and we don't expect people to call it directly here we should mention that in the docstring and also use an _ prefix. I disagree with @HyukjinKwon about this behaviour being what people would expect -- it doesn't match the Scala behaviour and one of the reasons to have something like `getActiveSession()` instead of `getOrCreate()` is to allow folks to do something if we have an active session or do something else if we don't. What about if `sc` is`None` we just return `None `since we can't have an `activeSession` without an active `SparkContext` -- does that sound reasonable? That being said if folks feel strongly about this I'm _ok_ with us setting up a SparkContext but we need to document that if that's the path we go. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22295: [SPARK-25255][PYTHON]Add getActiveSession to Spar...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22295#discussion_r224860350
--- Diff: python/pyspark/sql/tests.py ---
@@ -3654,6 +3654,109 @@ def test_jvm_default_session_already_set(self):
spark.stop()
+class SparkSessionTests2(unittest.TestCase):
+
+def test_active_session(self):
+spark = SparkSession.builder \
+.master("local") \
+.getOrCreate()
+try:
+activeSession = SparkSession.getActiveSession()
+df = activeSession.createDataFrame([(1, 'Alice')], ['age',
'name'])
+self.assertEqual(df.collect(), [Row(age=1, name=u'Alice')])
+finally:
+spark.stop()
+
+def test_get_active_session_when_no_active_session(self):
+active = SparkSession.getActiveSession()
+self.assertEqual(active, None)
+spark = SparkSession.builder \
+.master("local") \
+.getOrCreate()
+active = SparkSession.getActiveSession()
+self.assertEqual(active, spark)
+spark.stop()
+active = SparkSession.getActiveSession()
+self.assertEqual(active, None)
--- End diff --
Given the change for how we construct the SparkSession can we add a test
that makes sure we do whatever we decide to with the SparkContext?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22010 Open question: is this suitable for branch-2.4 since it predates the branch cut or not? (I know we've gone back and forth on how we do that). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22627: [SPARK-25639] [DOCS] Added docs for foreachBatch, python...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22627 I think we should consider this for backport to 2.4 given that it documents new behaviour in 2.4 unless folks object. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21157: [SPARK-22674][PYTHON] Removed the namedtuple pickling pa...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/21157 Is it possible to keep the current hack for things which can't be pickled, but remove the hack in the situation where the namedtuple is well behaved and it could be pickled directly by cloudpickle? That way we don't have a functionality regression but we also improve handling of named tuples more generally. Even if so, it would probably be best to wait for 3.0 since this is a pretty core change in terms of PySpark. Before you put in the work though let's see if that the consensus approach (if possible). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22295: [SPARK-25255][PYTHON]Add getActiveSession to Spar...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22295#discussion_r222700425
--- Diff: python/pyspark/sql/session.py ---
@@ -252,6 +255,20 @@ def newSession(self):
"""
return self.__class__(self._sc, self._jsparkSession.newSession())
+@classmethod
+@since(2.5)
+def getActiveSession(cls):
+"""
+Returns the active SparkSession for the current thread, returned
by the builder.
+>>> s = SparkSession.getActiveSession()
+>>> l = [('Alice', 1)]
+>>> rdd = s.sparkContext.parallelize(l)
+>>> df = s.createDataFrame(rdd, ['name', 'age'])
+>>> df.select("age").collect()
+[Row(age=1)]
+"""
+return cls._activeSession
--- End diff --
Do you mean in a multi-language notebook environment?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20503: [SPARK-23299][SQL][PYSPARK] Fix __repr__ behaviour for R...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/20503 Gentle ping --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22295: [SPARK-25255][PYTHON]Add getActiveSession to Spar...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22295#discussion_r222699236
--- Diff: python/pyspark/sql/session.py ---
@@ -231,6 +231,7 @@ def __init__(self, sparkContext, jsparkSession=None):
or SparkSession._instantiatedSession._sc._jsc is None:
SparkSession._instantiatedSession = self
self._jvm.SparkSession.setDefaultSession(self._jsparkSession)
+self._jvm.SparkSession.setActiveSession(self._jsparkSession)
--- End diff --
So @HyukjinKwon in this code session1 and session2 are already equal:
> Welcome to
> __
> / __/__ ___ _/ /__
> _\ \/ _ \/ _ `/ __/ '_/
>/__ / .__/\_,_/_/ /_/\_\ version 2.3.1
> /_/
>
> Using Python version 3.6.5 (default, Apr 29 2018 16:14:56)
> SparkSession available as 'spark'.
> >>> session1 = SparkSession.builder.config("key1", "value1").getOrCreate()
> >>> session2 = SparkSession.builder.config("key2", "value2").getOrCreate()
> >>> session1
>
> >>> session2
>
> >>> session1 == session2
> True
> >>>
>
>
>
>
>
That being said the possibility of having multiple Spark session in Python
is doable you manually have to call the init e.g.:
> >>> session3 = SparkSession(sc)
> >>> session3
>
> >>>
>
And supporting that is reasonable.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21990: [SPARK-25003][PYSPARK] Use SessionExtensions in Pyspark
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/21990 I'm +1 on switching to the builder and not using the private interface. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20503: [SPARK-23299][SQL][PYSPARK] Fix __repr__ behaviour for R...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/20503 I _think_ this could be good to backport into 2.4 assuming the current RC fails if @ashashwat has the chance to update it and no one sees any issues with including this in a backport to that branch. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20503: [SPARK-23299][SQL][PYSPARK] Fix __repr__ behaviour for R...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/20503 Sure let's add a test with a unicode string to it if there's concern about that and make sure the existing repr with named fields is covered the same test case since I don't see an existing explicit test for that (although it's probably covered implicitly elsewhere). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22425: [SPARK-23367][Build] Include python document styl...
Github user holdenk commented on a diff in the pull request: https://github.com/apache/spark/pull/22425#discussion_r220950524 --- Diff: dev/tox.ini --- @@ -14,6 +14,8 @@ # limitations under the License. [pycodestyle] -ignore=E226,E241,E305,E402,E722,E731,E741,W503,W504 +ignore=E226,E241,E305,E402,E722,E731,E741,W503,W504,W605 max-line-length=100 exclude=cloudpickle.py,heapq3.py,shared.py,python/docs/conf.py,work/*/*.py,python/.eggs/*,dist/* +[pydocstyle] +ignore=D100,D101,D102,D103,D104,D105,D106,D107,D200,D201,D202,D203,D204,D205,D206,D207,D208,D209,D210,D211,D212,D213,D214,D215,D300,D301,D302,D400,D401,D402,D403,D404,D405,D406,D407,D408,D409,D410,D411,D412,D413,D414 --- End diff -- I don't think that's what @ueshin was asking for, I think it was a blank line after the `ignore=...`, but if @ueshin is around we can see what @ueshin says. It's also relatively minor provided everything functions. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22425: [SPARK-23367][Build] Include python document styl...
Github user holdenk commented on a diff in the pull request: https://github.com/apache/spark/pull/22425#discussion_r220950740 --- Diff: dev/tox.ini --- @@ -14,6 +14,8 @@ # limitations under the License. [pycodestyle] -ignore=E226,E241,E305,E402,E722,E731,E741,W503,W504 +ignore=E226,E241,E305,E402,E722,E731,E741,W503,W504,W605 --- End diff -- I'm just confused why this would need to be changed in this PR -- hopefully just a hold over from the previous PR? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22295: [SPARK-25255][PYTHON]Add getActiveSession to SparkSessio...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22295 nvm, the merge script only triggers the edits if we have conflicts. If you can update 3.0 to 2.5 I'd be happy to merge. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22295: [SPARK-25255][PYTHON]Add getActiveSession to SparkSessio...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22295 LGTM except the 3.0 to 2.5 I'll change that during the merge. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #17654: [SPARK-20351] [ML] Add trait hasTrainingSummary to repla...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/17654 Thanks for working on this, remove duplicated code is great. I'm curious as to why we couldn't remove some of the function calls to super and instead depend on inheritance? If it's the types on the setters could we add another type parameter of the model? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21522: [SPARK-24467][ML] VectorAssemblerEstimator
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/21522 cc @jkbradley as the reporter of this issue you might want to take a look. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21522: [SPARK-24467][ML] VectorAssemblerEstimator
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/21522 Jenkins ok to test. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22010 I'll leave this until Friday morning (pacific) in case anyone has last minute comments. cc @rxin / @HyukjinKwon / @mgaido91 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22010 So by running `sc.parallelize(1.to(1000)).map(x => (x % 10, x)).sortByKey().distinct().count()` in 2.3.0 and my PR we can see the difference: 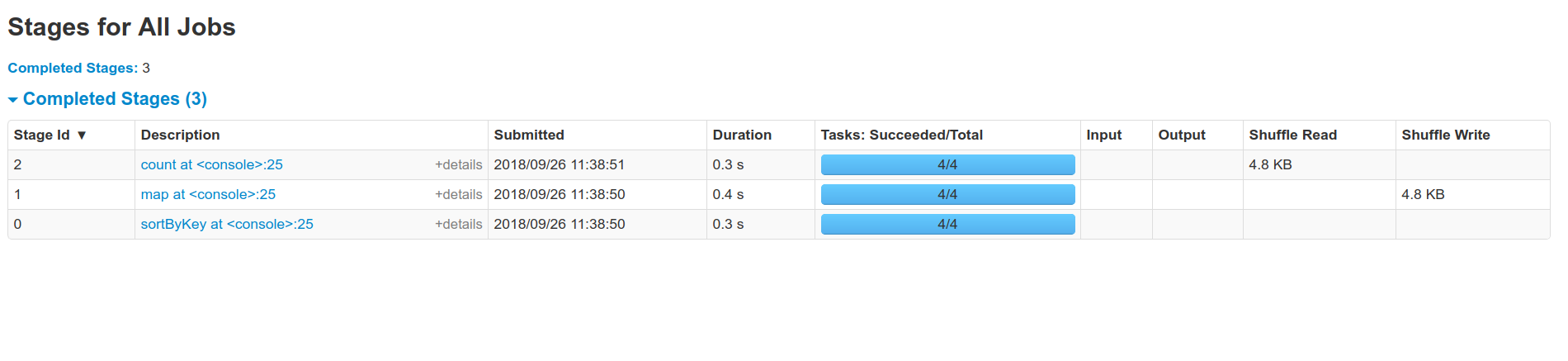 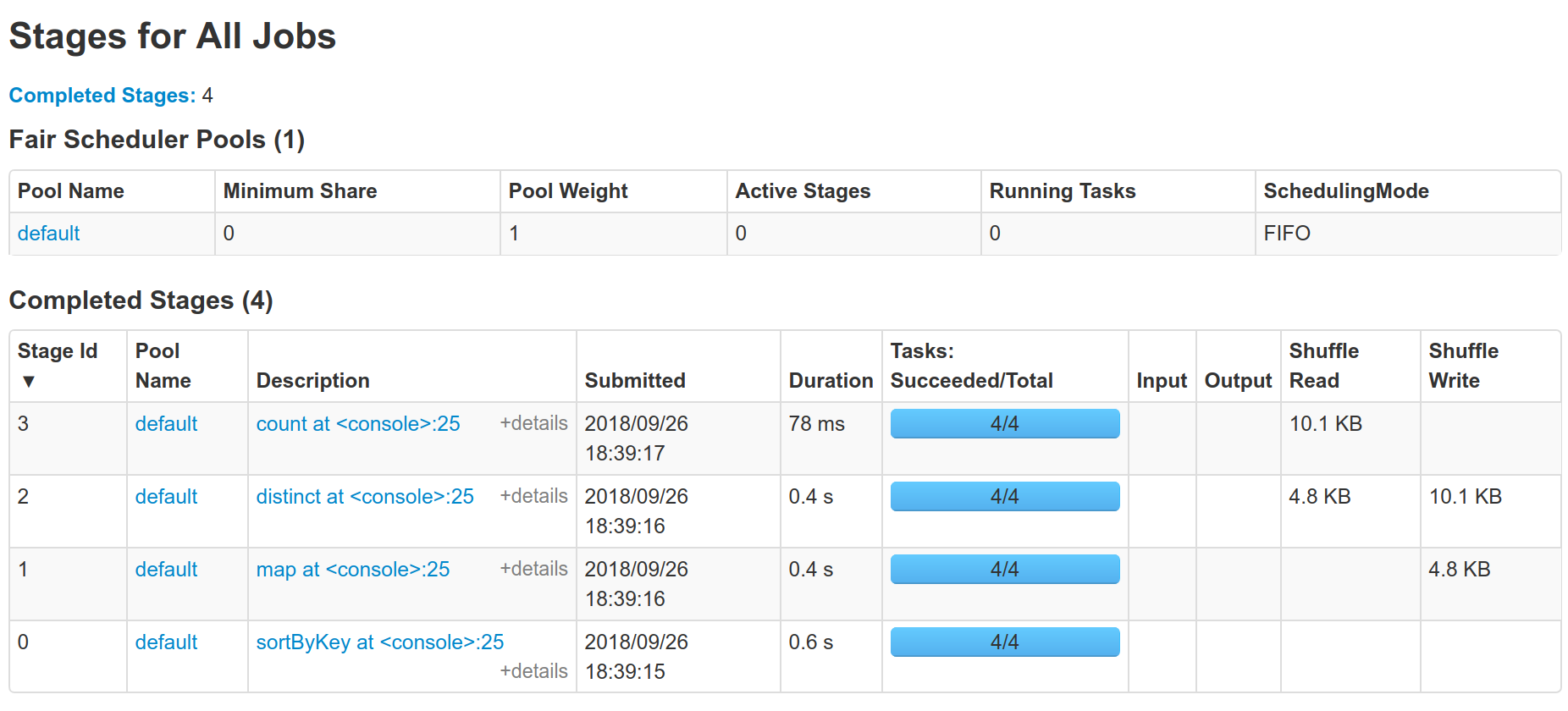 And see one less shuffle. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r220674969
--- Diff: core/src/main/scala/org/apache/spark/rdd/MapPartitionsRDD.scala
---
@@ -19,7 +19,7 @@ package org.apache.spark.rdd
import scala.reflect.ClassTag
-import org.apache.spark.{Partition, TaskContext}
+import org.apache.spark.{Partition, Partitioner, TaskContext}
--- End diff --
Thanks! I'll fix that.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r220674846
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -42,7 +42,8 @@ import org.apache.spark.partial.GroupedCountEvaluator
import org.apache.spark.partial.PartialResult
import org.apache.spark.storage.{RDDBlockId, StorageLevel}
import org.apache.spark.util.{BoundedPriorityQueue, Utils}
-import org.apache.spark.util.collection.{OpenHashMap, Utils =>
collectionUtils}
+import org.apache.spark.util.collection.{ExternalAppendOnlyMap,
OpenHashMap,
+ Utils => collectionUtils}
--- End diff --
yeah but we generally break anyways based on the rest of the code base.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r220674552
--- Diff: core/src/test/scala/org/apache/spark/rdd/RDDSuite.scala ---
@@ -95,6 +95,18 @@ class RDDSuite extends SparkFunSuite with
SharedSparkContext {
assert(!deserial.toString().isEmpty())
}
+ test("distinct with known partitioner preserves partitioning") {
+val rdd = sc.parallelize(1.to(100), 10).map(x => (x % 10, x %
10)).sortByKey()
+val initialPartitioner = rdd.partitioner
+val distinctRdd = rdd.distinct()
+val resultingPartitioner = distinctRdd.partitioner
+assert(initialPartitioner === resultingPartitioner)
+val distinctRddDifferent = rdd.distinct(5)
+val distinctRddDifferentPartitioner = distinctRddDifferent.partitioner
+assert(initialPartitioner != distinctRddDifferentPartitioner)
+assert(distinctRdd.collect().sorted ===
distinctRddDifferent.collect().sorted)
--- End diff --
We could, but we don't need to.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22010: [SPARK-21436][CORE] Take advantage of known partitioner ...
Github user holdenk commented on the issue:
https://github.com/apache/spark/pull/22010
Did another quick micro benchmark on a small cluster:
```scala
import org.apache.spark.util.collection.ExternalAppendOnlyMap
def removeDuplicatesInPartition(partition: Iterator[(Int, Int)]):
Iterator[(Int, Int)] = {
// Create an instance of external append only map which ignores values.
val map = new ExternalAppendOnlyMap[(Int, Int), Null, Null](
createCombiner = value => null,
mergeValue = (a, b) => a,
mergeCombiners = (a, b) => a)
map.insertAll(partition.map(_ -> null))
map.iterator.map(_._1)
}
def time[R](block: => R): (Long, R) = {
val t0 = System.nanoTime()
val result = block // call-by-name
val t1 = System.nanoTime()
println("Elapsed time: " + (t1 - t0) + "ns")
(t1, result)
}
val count = 1000
val inputData = sc.parallelize(1.to(count))
val keyed = inputData.map(x => (x % 100, x))
val shuffled = keyed.repartition(50).cache()
shuffled.count()
val o1 = time(shuffled.distinct().count())
val n1 = time(shuffled.mapPartitions(removeDuplicatesInPartition).count())
val n2 = time(shuffled.mapPartitions(removeDuplicatesInPartition).count())
val o2 = time(shuffled.distinct().count())
val n3 = time(shuffled.mapPartitions(removeDuplicatesInPartition).count())
```
And the result is:
> Elapsed time: 1790932239ns
> Elapsed time: 381450402ns
> Elapsed time: 340449179ns
> Elapsed time: 1524955492ns
> Elapsed time: 291948041ns
> import org.apache.spark.util.collection.ExternalAppendOnlyMap
> removeDuplicatesInPartition: (partition: Iterator[(Int,
Int)])Iterator[(Int, Int)]
> time: [R](block: => R)(Long, R)
> count: Int = 1000
> inputData: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[10] at
parallelize at :52
> keyed: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[11] at map
at :53
> shuffled: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[15] at
repartition at :54
> o1: (Long, Long) = (2943493642271881,1000)
> n1: (Long, Long) = (2943494027399482,1000)
> n2: (Long, Long) = (2943494371228656,1000)
> o2: (Long, Long) = (2943495899580372,1000)
> n3: (Long, Long) = (2943496195569891,1000)
>
Increasing count by a factor of 10 we get:
> Elapsed time: 21679193176ns
> Elapsed time: 3114223737ns
> Elapsed time: 3348141004ns
> Elapsed time: 51267597984ns
> Elapsed time: 3931899963ns
> import org.apache.spark.util.collection.ExternalAppendOnlyMap
> removeDuplicatesInPartition: (partition: Iterator[(Int,
Int)])Iterator[(Int, Int)]
> time: [R](block: => R)(Long, R)
> count: Int = 1
> inputData: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[25] at
parallelize at :56
> keyed: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[26] at map
at :57
> shuffled: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[30] at
repartition at :58
> o1: (Long, Long) = (2943648438919959,1)
> n1: (Long, Long) = (2943651557292201,1)
> n2: (Long, Long) = (2943654909392808,1)
> o2: (Long, Long) = (2943706180722021,1)
> n3: (Long, Long) = (2943710116461734,1)
>
>
So that looks like close to an order of magnitude improvement.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22480: [SPARK-25473][PYTHON][SS][TEST] ForeachWriter tests fail...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22480 So my one concern is the comment "I am pretty sure there are some guys already debugging this." - do we actually know who, do we have a place to track this? Do we have a blocker filed to verify this before release or how are we going to ensure it's fixed? I don't have MacOs personally so I just want make sure we don't have this issue fall through the cracks. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22275: [SPARK-25274][PYTHON][SQL] In toPandas with Arrow...
Github user holdenk commented on a diff in the pull request: https://github.com/apache/spark/pull/22275#discussion_r219556033 --- Diff: python/pyspark/serializers.py --- @@ -208,8 +214,26 @@ def load_stream(self, stream): for batch in reader: yield batch +if self.load_batch_order: +num = read_int(stream) +self.batch_order = [] +for i in xrange(num): +index = read_int(stream) +self.batch_order.append(index) + +def get_batch_order_and_reset(self): --- End diff -- Looking at `_load_from_socket` I think I understand why this was done as a separate function here, but what about if the serializer its self returned either a tuple or re-ordered the batches its self? I'm just trying to get a better understanding, not saying those are better designs. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22275: [SPARK-25274][PYTHON][SQL] In toPandas with Arrow...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22275#discussion_r219558311
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -3279,34 +3280,33 @@ class Dataset[T] private[sql](
val timeZoneId = sparkSession.sessionState.conf.sessionLocalTimeZone
withAction("collectAsArrowToPython", queryExecution) { plan =>
- PythonRDD.serveToStream("serve-Arrow") { out =>
+ PythonRDD.serveToStream("serve-Arrow") { outputStream =>
+val out = new DataOutputStream(outputStream)
val batchWriter = new ArrowBatchStreamWriter(schema, out,
timeZoneId)
val arrowBatchRdd = toArrowBatchRdd(plan)
val numPartitions = arrowBatchRdd.partitions.length
-// Store collection results for worst case of 1 to N-1 partitions
-val results = new Array[Array[Array[Byte]]](numPartitions - 1)
-var lastIndex = -1 // index of last partition written
+// Batches ordered by (index of partition, batch # in partition)
tuple
+val batchOrder = new ArrayBuffer[(Int, Int)]()
+var partitionCount = 0
-// Handler to eagerly write partitions to Python in order
+// Handler to eagerly write batches to Python out of order
def handlePartitionBatches(index: Int, arrowBatches:
Array[Array[Byte]]): Unit = {
- // If result is from next partition in order
- if (index - 1 == lastIndex) {
+ if (arrowBatches.nonEmpty) {
batchWriter.writeBatches(arrowBatches.iterator)
-lastIndex += 1
-// Write stored partitions that come next in order
-while (lastIndex < results.length && results(lastIndex) !=
null) {
- batchWriter.writeBatches(results(lastIndex).iterator)
- results(lastIndex) = null
- lastIndex += 1
-}
-// After last batch, end the stream
-if (lastIndex == results.length) {
- batchWriter.end()
+arrowBatches.indices.foreach { i => batchOrder.append((index,
i)) }
+ }
+ partitionCount += 1
+
+ // After last batch, end the stream and write batch order
+ if (partitionCount == numPartitions) {
+batchWriter.end()
+out.writeInt(batchOrder.length)
+// Batch order indices are from 0 to N-1 batches, sorted by
order they arrived
--- End diff --
How about something like `// Sort by the output global batch indexes
partition index, partition batch index tuple`?
When I was first read this code path I got confused my self so I think we
should spend a bit of time on the comment here.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22275: [SPARK-25274][PYTHON][SQL] In toPandas with Arrow...
Github user holdenk commented on a diff in the pull request: https://github.com/apache/spark/pull/22275#discussion_r219556534 --- Diff: python/pyspark/serializers.py --- @@ -208,8 +214,26 @@ def load_stream(self, stream): for batch in reader: yield batch +if self.load_batch_order: +num = read_int(stream) +self.batch_order = [] --- End diff -- If we're going to have get_batch_order_and_reset as a separate function, could we verify batch_order is None before we reset and throw here if it's not? Just thinking of future folks who might have to debug something here. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22275: [SPARK-25274][PYTHON][SQL] In toPandas with Arrow...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22275#discussion_r219561178
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/Dataset.scala ---
@@ -3279,34 +3280,33 @@ class Dataset[T] private[sql](
val timeZoneId = sparkSession.sessionState.conf.sessionLocalTimeZone
withAction("collectAsArrowToPython", queryExecution) { plan =>
- PythonRDD.serveToStream("serve-Arrow") { out =>
+ PythonRDD.serveToStream("serve-Arrow") { outputStream =>
+val out = new DataOutputStream(outputStream)
val batchWriter = new ArrowBatchStreamWriter(schema, out,
timeZoneId)
val arrowBatchRdd = toArrowBatchRdd(plan)
val numPartitions = arrowBatchRdd.partitions.length
-// Store collection results for worst case of 1 to N-1 partitions
-val results = new Array[Array[Array[Byte]]](numPartitions - 1)
-var lastIndex = -1 // index of last partition written
+// Batches ordered by (index of partition, batch # in partition)
tuple
+val batchOrder = new ArrayBuffer[(Int, Int)]()
+var partitionCount = 0
-// Handler to eagerly write partitions to Python in order
+// Handler to eagerly write batches to Python out of order
def handlePartitionBatches(index: Int, arrowBatches:
Array[Array[Byte]]): Unit = {
- // If result is from next partition in order
- if (index - 1 == lastIndex) {
+ if (arrowBatches.nonEmpty) {
batchWriter.writeBatches(arrowBatches.iterator)
-lastIndex += 1
-// Write stored partitions that come next in order
-while (lastIndex < results.length && results(lastIndex) !=
null) {
- batchWriter.writeBatches(results(lastIndex).iterator)
- results(lastIndex) = null
- lastIndex += 1
-}
-// After last batch, end the stream
-if (lastIndex == results.length) {
- batchWriter.end()
+arrowBatches.indices.foreach { i => batchOrder.append((index,
i)) }
--- End diff --
Could we call `i` something more descriptive like partition_batch_num or
similar?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22275: [SPARK-25274][PYTHON][SQL] In toPandas with Arrow...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22275#discussion_r219557215
--- Diff: python/pyspark/sql/tests.py ---
@@ -4434,6 +4434,12 @@ def test_timestamp_dst(self):
self.assertPandasEqual(pdf, df_from_python.toPandas())
self.assertPandasEqual(pdf, df_from_pandas.toPandas())
+def test_toPandas_batch_order(self):
+df = self.spark.range(64, numPartitions=8).toDF("a")
+with
self.sql_conf({"spark.sql.execution.arrow.maxRecordsPerBatch": 4}):
+pdf, pdf_arrow = self._toPandas_arrow_toggle(df)
+self.assertPandasEqual(pdf, pdf_arrow)
--- End diff --
This looks pretty similar to the kind of test case we could verify with
something like hypothesis. Integrating hypothesis is probably too much work,
but we could at least explore num partitions space in a loop quickly here.
Would that help do you think @felixcheung ?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22295: [SPARK-25255][PYTHON]Add getActiveSession to Spar...
Github user holdenk commented on a diff in the pull request: https://github.com/apache/spark/pull/22295#discussion_r219551669 --- Diff: python/pyspark/sql/tests.py --- @@ -3654,6 +3654,107 @@ def test_jvm_default_session_already_set(self): spark.stop() +class SparkSessionTests2(ReusedSQLTestCase): --- End diff -- @HyukjinKwon there's no strong need for it, however it does mean that the first `getOrCreate` will already have a session it can use, but given that we set up and tear down the session this may be less than ideal. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22295: [SPARK-25255][PYTHON]Add getActiveSession to Spar...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22295#discussion_r219552522
--- Diff: python/pyspark/sql/tests.py ---
@@ -3654,6 +3654,107 @@ def test_jvm_default_session_already_set(self):
spark.stop()
+class SparkSessionTests2(ReusedSQLTestCase):
+
+def test_active_session(self):
+spark = SparkSession.builder \
+.master("local") \
+.getOrCreate()
+try:
+activeSession = spark.getActiveSession()
+df = activeSession.createDataFrame([(1, 'Alice')], ['age',
'name'])
+self.assertEqual(df.collect(), [Row(age=1, name=u'Alice')])
+finally:
+spark.stop()
+
+def test_SparkSession(self):
+spark = SparkSession.builder \
+.master("local") \
+.config("some-config", "v2") \
+.getOrCreate()
+try:
+self.assertEqual(spark.conf.get("some-config"), "v2")
+self.assertEqual(spark.sparkContext._conf.get("some-config"),
"v2")
+self.assertEqual(spark.version, spark.sparkContext.version)
+spark.sql("CREATE DATABASE test_db")
+spark.catalog.setCurrentDatabase("test_db")
+self.assertEqual(spark.catalog.currentDatabase(), "test_db")
+spark.sql("CREATE TABLE table1 (name STRING, age INT) USING
parquet")
+self.assertEqual(spark.table("table1").columns, ['name',
'age'])
+self.assertEqual(spark.range(3).count(), 3)
+finally:
+spark.stop()
+
+def test_global_default_session(self):
+spark = SparkSession.builder \
+.master("local") \
+.getOrCreate()
+try:
+self.assertEqual(SparkSession.builder.getOrCreate(), spark)
+finally:
+spark.stop()
+
+def test_default_and_active_session(self):
+spark = SparkSession.builder \
+.master("local") \
+.getOrCreate()
+activeSession = spark._jvm.SparkSession.getActiveSession()
+defaultSession = spark._jvm.SparkSession.getDefaultSession()
+try:
+self.assertEqual(activeSession, defaultSession)
+finally:
+spark.stop()
+
+def test_config_option_propagated_to_existing_SparkSession(self):
+session1 = SparkSession.builder \
+.master("local") \
+.config("spark-config1", "a") \
+.getOrCreate()
+self.assertEqual(session1.conf.get("spark-config1"), "a")
+session2 = SparkSession.builder \
+.config("spark-config1", "b") \
+.getOrCreate()
+try:
+self.assertEqual(session1, session2)
+self.assertEqual(session1.conf.get("spark-config1"), "b")
+finally:
+session1.stop()
+
+def test_newSession(self):
+session = SparkSession.builder \
+.master("local") \
+.getOrCreate()
+newSession = session.newSession()
+try:
+self.assertNotEqual(session, newSession)
+finally:
+session.stop()
+newSession.stop()
+
+def test_create_new_session_if_old_session_stopped(self):
+session = SparkSession.builder \
+.master("local") \
+.getOrCreate()
+session.stop()
+newSession = SparkSession.builder \
+.master("local") \
+.getOrCreate()
+try:
+self.assertNotEqual(session, newSession)
+finally:
+newSession.stop()
+
+def test_create_SparkContext_then_SparkSession(self):
--- End diff --
I don't strongly agree here. I think given that the method names are camel
case in the `SparkSession` & `SparkContext` in Python this naming is perfectly
reasonable.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22295: [SPARK-25255][PYTHON]Add getActiveSession to Spar...
Github user holdenk commented on a diff in the pull request: https://github.com/apache/spark/pull/22295#discussion_r219552270 --- Diff: python/pyspark/sql/session.py --- @@ -231,6 +231,7 @@ def __init__(self, sparkContext, jsparkSession=None): or SparkSession._instantiatedSession._sc._jsc is None: SparkSession._instantiatedSession = self self._jvm.SparkSession.setDefaultSession(self._jsparkSession) +self._jvm.SparkSession.setActiveSession(self._jsparkSession) --- End diff -- Yes this seems like the right path forward, thanks for figuring out that was missing as well. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22295: [SPARK-25255][PYTHON]Add getActiveSession to Spar...
Github user holdenk commented on a diff in the pull request: https://github.com/apache/spark/pull/22295#discussion_r219551059 --- Diff: python/pyspark/sql/session.py --- @@ -231,6 +231,7 @@ def __init__(self, sparkContext, jsparkSession=None): or SparkSession._instantiatedSession._sc._jsc is None: SparkSession._instantiatedSession = self self._jvm.SparkSession.setDefaultSession(self._jsparkSession) +self._jvm.SparkSession.setActiveSession(self._jsparkSession) --- End diff -- Yes, that sounds like the right approach and I think we need that. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22376: [SPARK-25021][K8S][BACKPORT] Add spark.executor.pyspark....
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22376 Merged with branch-2.4, feel free to close. Test failures are unrelated. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #19045: [WIP][SPARK-20628][CORE] Keep track of nodes (/ s...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/19045#discussion_r219000926
--- Diff:
core/src/main/scala/org/apache/spark/scheduler/ExecutorLossReason.scala ---
@@ -58,3 +58,11 @@ private [spark] object LossReasonPending extends
ExecutorLossReason("Pending los
private[spark]
case class SlaveLost(_message: String = "Slave lost", workerLost: Boolean
= false)
extends ExecutorLossReason(_message)
+
+/**
+ * A loss reason that means the worker is marked for decommissioning.
+ *
+ * This is used by the task scheduler to remove state associated with the
executor, but
+ * not yet fail any tasks that were running in the executor before the
executor is "fully" lost.
+ */
+private [spark] object WorkerDecommission extends
ExecutorLossReason("Worker Decommission.")
--- End diff --
Look at Master.scala (
https://github.com/apache/spark/pull/19045/files#diff-29dffdccd5a7f4c8b496c293e87c8668R243
)
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22376: [SPARK-25021][K8S][BACKPORT] Add spark.executor.pyspark....
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22376 Jenkins retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22376: [SPARK-25021][K8S][BACKPORT] Add spark.executor.pyspark....
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22376 That build failure _seems_ to be a host issue, but lets kick off a retest quickly anyways. Jenkins retest this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22376: [SPARK-25021][K8S][BACKPORT] Add spark.executor.pyspark....
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22376 For future reference the original PR is at https://github.com/apache/spark/pull/22298/files/fe8cc5aa6759cdf893e11c3d83814f8dffddce9c --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22376: [SPARK-25021][K8S][BACKPORT] Add spark.executor.pyspark....
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22376 The 3 failing tests reported in Jenkins were fixed in 76514a015168de8d8b54b3abf6b835050eefd8c2 and are unrelated to this change. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22376: [SPARK-25021][K8S][BACKPORT] Add spark.executor.pyspark....
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22376 Jenkins retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22376: [SPARK-25021][K8S][BACKPORT] Add spark.executor.pyspark....
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22376 Jenkins, ok to test. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r218918701
--- Diff: core/src/main/scala/org/apache/spark/rdd/RDD.scala ---
@@ -396,7 +396,26 @@ abstract class RDD[T: ClassTag](
* Return a new RDD containing the distinct elements in this RDD.
*/
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null):
RDD[T] = withScope {
-map(x => (x, null)).reduceByKey((x, y) => x, numPartitions).map(_._1)
+partitioner match {
+ case Some(p) if numPartitions == partitions.length =>
+def key(x: T): (T, Null) = (x, null)
+val cleanKey = sc.clean(key _)
+val keyed = new MapPartitionsRDD[(T, Null), T](
+ this,
+ (context, pid, iter) => iter.map(cleanKey),
+ knownPartitioner = Some(new WrappedPartitioner(p)))
+val duplicatesRemoved = keyed.reduceByKey((x, y) => x)
--- End diff --
So I _think_ it is partitioner of input RDD if known partitioner otherwise
hash partitioner of the default parallelism. Yes?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r218917483
--- Diff: core/src/main/scala/org/apache/spark/rdd/MapPartitionsRDD.scala
---
@@ -35,16 +35,24 @@ import org.apache.spark.{Partition, TaskContext}
* @param isOrderSensitive whether or not the function is order-sensitive.
If it's order
* sensitive, it may return totally different
result when the input order
* is changed. Mostly stateful functions are
order-sensitive.
+ * @param knownPartitioner If the result has a known partitioner.
*/
private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag](
var prev: RDD[T],
f: (TaskContext, Int, Iterator[T]) => Iterator[U], // (TaskContext,
partition index, iterator)
preservesPartitioning: Boolean = false,
isFromBarrier: Boolean = false,
-isOrderSensitive: Boolean = false)
+isOrderSensitive: Boolean = false,
+knownPartitioner: Option[Partitioner] = None)
extends RDD[U](prev) {
- override val partitioner = if (preservesPartitioning)
firstParent[T].partitioner else None
+ override val partitioner = {
+if (preservesPartitioning) {
+ firstParent[T].partitioner
+} else {
+ knownPartitioner
+}
+ }
--- End diff --
I mean yes we can sub-class just as easily -- is that what you mean?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #22275: [SPARK-25274][PYTHON][SQL] In toPandas with Arrow send o...
Github user holdenk commented on the issue: https://github.com/apache/spark/pull/22275 Sure, I'll take a look on Friday if it's not urgent --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22010: [SPARK-21436][CORE] Take advantage of known parti...
Github user holdenk commented on a diff in the pull request:
https://github.com/apache/spark/pull/22010#discussion_r217900574
--- Diff: core/src/main/scala/org/apache/spark/rdd/MapPartitionsRDD.scala
---
@@ -35,16 +35,24 @@ import org.apache.spark.{Partition, TaskContext}
* @param isOrderSensitive whether or not the function is order-sensitive.
If it's order
* sensitive, it may return totally different
result when the input order
* is changed. Mostly stateful functions are
order-sensitive.
+ * @param knownPartitioner If the result has a known partitioner.
*/
private[spark] class MapPartitionsRDD[U: ClassTag, T: ClassTag](
var prev: RDD[T],
f: (TaskContext, Int, Iterator[T]) => Iterator[U], // (TaskContext,
partition index, iterator)
preservesPartitioning: Boolean = false,
isFromBarrier: Boolean = false,
-isOrderSensitive: Boolean = false)
+isOrderSensitive: Boolean = false,
+knownPartitioner: Option[Partitioner] = None)
extends RDD[U](prev) {
- override val partitioner = if (preservesPartitioning)
firstParent[T].partitioner else None
+ override val partitioner = {
+if (preservesPartitioning) {
+ firstParent[T].partitioner
+} else {
+ knownPartitioner
+}
+ }
--- End diff --
`MapPartitionsRDD` is already private. But yes the other option is
sub-classing.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org