[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r551850022
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/KubernetesClientUtils.scala
##
@@ -156,11 +162,8 @@ private[spark] object KubernetesClientUtils extends
Logging {
}
val confFiles: Seq[File] = {
val dir = new File(confDir)
- if (dir.isDirectory) {
-dir.listFiles.filter(x => fileFilter(x)).toSeq
- } else {
-Nil
- }
+ assert(dir.isDirectory, "Spark conf should be a directory.")
Review comment:
In terms of execution, both have similar effect. Still if others also
feel - that this should be moved, I can do so.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r550406649
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/KubernetesClientUtils.scala
##
@@ -90,29 +92,67 @@ private[spark] object KubernetesClientUtils extends Logging
{
.build()
}
- private def loadSparkConfDirFiles(conf: SparkConf): Map[String, String] = {
+ private def orderFilesBySize(confFiles: Seq[File]): Seq[File] = {
+val fileToFileSizePairs = confFiles.map(f => (f, f.getName.length +
f.length()))
+// sort first by name and then by length, so that during tests we have
consistent results.
+fileToFileSizePairs.sortBy(f => f._1).sortBy(f => f._2).map(_._1)
Review comment:
Values are actually sum total of the size of filename and it's content.
Two items with same size (i.e. `"b" ->10 and "abcdef" ->10` ) would mean, that
if first one did not fit, next one won't fit either. Anyway, I have addressed
it, by -- update the `truncateMapSize` iff `truncateMap` is updated.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r550406649
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/KubernetesClientUtils.scala
##
@@ -90,29 +92,67 @@ private[spark] object KubernetesClientUtils extends Logging
{
.build()
}
- private def loadSparkConfDirFiles(conf: SparkConf): Map[String, String] = {
+ private def orderFilesBySize(confFiles: Seq[File]): Seq[File] = {
+val fileToFileSizePairs = confFiles.map(f => (f, f.getName.length +
f.length()))
+// sort first by name and then by length, so that during tests we have
consistent results.
+fileToFileSizePairs.sortBy(f => f._1).sortBy(f => f._2).map(_._1)
Review comment:
Values are actually sum total of the size of filename and it's content.
Two items with same size (i.e. `"b" ->10 and "abcdef" ->10` ) would mean, that
if first one did not fit, next one won't fit either. Anyway, I have addressed
it, by -- update the `truncateMapSize` iff it `truncateMap` updated.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r550406649
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/KubernetesClientUtils.scala
##
@@ -90,29 +92,67 @@ private[spark] object KubernetesClientUtils extends Logging
{
.build()
}
- private def loadSparkConfDirFiles(conf: SparkConf): Map[String, String] = {
+ private def orderFilesBySize(confFiles: Seq[File]): Seq[File] = {
+val fileToFileSizePairs = confFiles.map(f => (f, f.getName.length +
f.length()))
+// sort first by name and then by length, so that during tests we have
consistent results.
+fileToFileSizePairs.sortBy(f => f._1).sortBy(f => f._2).map(_._1)
Review comment:
Values are actually sum total of the size of filename and it's content.
Two items with same size (i.e. `"b" ->10 and "abcdef" ->10` ) would mean, that
if first one did not fit, next one won't fit either. Anyway, I have addressed
it, by - update the `truncateMapSize` iff it is updated.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r550408715
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/KubernetesClientUtils.scala
##
@@ -90,29 +92,67 @@ private[spark] object KubernetesClientUtils extends Logging
{
.build()
}
- private def loadSparkConfDirFiles(conf: SparkConf): Map[String, String] = {
+ private def orderFilesBySize(confFiles: Seq[File]): Seq[File] = {
+val fileToFileSizePairs = confFiles.map(f => (f, f.getName.length +
f.length()))
+// sort first by name and then by length, so that during tests we have
consistent results.
+fileToFileSizePairs.sortBy(f => f._1).sortBy(f => f._2).map(_._1)
+ }
+
+ // exposed for testing
+ private[submit] def loadSparkConfDirFiles(conf: SparkConf): Map[String,
String] = {
val confDir = Option(conf.getenv(ENV_SPARK_CONF_DIR)).orElse(
conf.getOption("spark.home").map(dir => s"$dir/conf"))
+val maxSize = conf.get(Config.CONFIG_MAP_MAXSIZE)
if (confDir.isDefined) {
- val confFiles = listConfFiles(confDir.get)
- logInfo(s"Spark configuration files loaded from $confDir :
${confFiles.mkString(",")}")
- confFiles.map { file =>
-val source = Source.fromFile(file)(Codec.UTF8)
-val mapping = (file.getName -> source.mkString)
-source.close()
-mapping
- }.toMap
+ val confFiles: Seq[File] = listConfFiles(confDir.get, maxSize)
+ val orderedConfFiles = orderFilesBySize(confFiles)
+ var truncatedMapSize: Long = 0
+ val truncatedMap = mutable.HashMap[String, String]()
+ var source: Source = Source.fromString("") // init with empty source.
+ for (file <- orderedConfFiles) {
+try {
+ source = Source.fromFile(file)(Codec.UTF8)
+ val (fileName, fileContent) = file.getName -> source.mkString
+ truncatedMapSize = truncatedMapSize + (fileName.length +
fileContent.length)
+ if (truncatedMapSize < maxSize) {
+truncatedMap.put(fileName, fileContent)
+ } else {
Review comment:
Now, we increment the size, only when the map is updated.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r550406649
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/KubernetesClientUtils.scala
##
@@ -90,29 +92,67 @@ private[spark] object KubernetesClientUtils extends Logging
{
.build()
}
- private def loadSparkConfDirFiles(conf: SparkConf): Map[String, String] = {
+ private def orderFilesBySize(confFiles: Seq[File]): Seq[File] = {
+val fileToFileSizePairs = confFiles.map(f => (f, f.getName.length +
f.length()))
+// sort first by name and then by length, so that during tests we have
consistent results.
+fileToFileSizePairs.sortBy(f => f._1).sortBy(f => f._2).map(_._1)
Review comment:
Values are actually sum total of the size of filename and it's content.
Two items with same size (i.e. `"b" ->10 and "abcdef" ->10` ) would mean, that
if first one did not fit, next one won't fit either. Anyway, I have addressed
it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r550406649
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/KubernetesClientUtils.scala
##
@@ -90,29 +92,67 @@ private[spark] object KubernetesClientUtils extends Logging
{
.build()
}
- private def loadSparkConfDirFiles(conf: SparkConf): Map[String, String] = {
+ private def orderFilesBySize(confFiles: Seq[File]): Seq[File] = {
+val fileToFileSizePairs = confFiles.map(f => (f, f.getName.length +
f.length()))
+// sort first by name and then by length, so that during tests we have
consistent results.
+fileToFileSizePairs.sortBy(f => f._1).sortBy(f => f._2).map(_._1)
Review comment:
Values are actually sum total of the size of filename and it's content.
Two items with same size would mean, that if first one did not fit, next one
won't fit either. Anyway, I have addressed it.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r550402095
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/Config.scala
##
@@ -99,6 +99,14 @@ private[spark] object Config extends Logging {
.toSequence
.createWithDefault(Nil)
+ val CONFIG_MAP_MAXSIZE =
+ConfigBuilder("spark.kubernetes.configMap.maxSize")
+ .doc("Max size limit for a config map. This is configurable as per" +
+" https://etcd.io/docs/v3.4.0/dev-guide/limit/ on k8s server end.")
+ .version("3.1.0")
+ .longConf
+ .createWithDefault(1573000) // 1.5 MiB
Review comment:
@dongjoon-hyun I think you are correct about this (though it is 1.5MiB
not 1.5Mib Mebibyte v/s Mebibit). I was deceived by google:
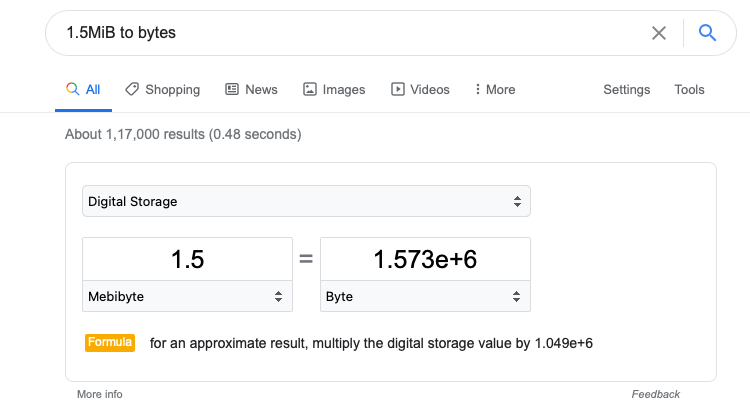
Correct value is : 1.5MiB= 1572864 bytes
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r546383494
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/KubernetesClientUtils.scala
##
@@ -90,29 +92,66 @@ private[spark] object KubernetesClientUtils extends Logging
{
.build()
}
- private def loadSparkConfDirFiles(conf: SparkConf): Map[String, String] = {
+ private def orderFilesBySize(confFiles: Seq[File]): Seq[File] = {
+val fileToFileSizePairs = confFiles.map(f => (f, f.getName.length +
f.length()))
+// sort first by name and then by length, so that during tests we have
consistent results.
+fileToFileSizePairs.sortBy(f => f._1).sortBy(f => f._2).map(_._1)
+ }
+
+ // exposed for testing
+ private[submit] def loadSparkConfDirFiles(conf: SparkConf): Map[String,
String] = {
val confDir = Option(conf.getenv(ENV_SPARK_CONF_DIR)).orElse(
conf.getOption("spark.home").map(dir => s"$dir/conf"))
+val maxSize = conf.get(Config.CONFIG_MAP_MAXSIZE)
if (confDir.isDefined) {
- val confFiles = listConfFiles(confDir.get)
- logInfo(s"Spark configuration files loaded from $confDir :
${confFiles.mkString(",")}")
- confFiles.map { file =>
-val source = Source.fromFile(file)(Codec.UTF8)
-val mapping = (file.getName -> source.mkString)
-source.close()
-mapping
- }.toMap
+ val confFiles: Seq[File] = listConfFiles(confDir.get, maxSize)
+ val orderedConfFiles = orderFilesBySize(confFiles)
+ var i: Long = 0
+ val truncatedMap = mutable.HashMap[String, String]()
+ for (file <- orderedConfFiles) {
+var source: Source = Source.fromString("") // init with empty source.
+try {
+ source = Source.fromFile(file)(Codec.UTF8)
+ val (fileName, fileContent) = file.getName -> source.mkString
+ if (fileContent.length > 0) {
Review comment:
reverted this change.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r540706293
##
File path:
resource-managers/kubernetes/core/src/test/scala/org/apache/spark/deploy/k8s/submit/ClientSuite.scala
##
@@ -191,25 +191,32 @@ class ClientSuite extends SparkFunSuite with
BeforeAndAfter {
assert(configMap.getData.get(SPARK_CONF_FILE_NAME).contains("conf2key=conf2value"))
}
- test("All files from SPARK_CONF_DIR, except templates and spark config " +
+ test("All files from SPARK_CONF_DIR, " +
+"except templates, spark config, binary files and are within size limit, "
+
"should be populated to pod's configMap.") {
def testSetup: (SparkConf, Seq[String]) = {
val tempDir = Utils.createTempDir()
- val sparkConf = new SparkConf(loadDefaults =
false).setSparkHome(tempDir.getAbsolutePath)
+ val sparkConf = new SparkConf(loadDefaults = false)
+.setSparkHome(tempDir.getAbsolutePath)
val tempConfDir = new File(s"${tempDir.getAbsolutePath}/conf")
tempConfDir.mkdir()
// File names - which should not get mounted on the resultant config map.
val filteredConfFileNames =
-Set("spark-env.sh.template", "spark.properties", "spark-defaults.conf")
- val confFileNames = for (i <- 1 to 5) yield s"testConf.$i" ++
+Set("spark-env.sh.template", "spark.properties", "spark-defaults.conf",
+ "test.gz", "test2.jar", "non_utf8.txt")
Review comment:
For example, if a user needs to pass his hadoop's core-site.xml. or some
other framework he is trying to use, has a configuration file and for that
matter, he has a custom application which can be configured.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r540704406
##
File path:
resource-managers/kubernetes/core/src/test/scala/org/apache/spark/deploy/k8s/submit/ClientSuite.scala
##
@@ -191,25 +191,32 @@ class ClientSuite extends SparkFunSuite with
BeforeAndAfter {
assert(configMap.getData.get(SPARK_CONF_FILE_NAME).contains("conf2key=conf2value"))
}
- test("All files from SPARK_CONF_DIR, except templates and spark config " +
+ test("All files from SPARK_CONF_DIR, " +
+"except templates, spark config, binary files and are within size limit, "
+
"should be populated to pod's configMap.") {
def testSetup: (SparkConf, Seq[String]) = {
val tempDir = Utils.createTempDir()
- val sparkConf = new SparkConf(loadDefaults =
false).setSparkHome(tempDir.getAbsolutePath)
+ val sparkConf = new SparkConf(loadDefaults = false)
+.setSparkHome(tempDir.getAbsolutePath)
val tempConfDir = new File(s"${tempDir.getAbsolutePath}/conf")
tempConfDir.mkdir()
// File names - which should not get mounted on the resultant config map.
val filteredConfFileNames =
-Set("spark-env.sh.template", "spark.properties", "spark-defaults.conf")
- val confFileNames = for (i <- 1 to 5) yield s"testConf.$i" ++
+Set("spark-env.sh.template", "spark.properties", "spark-defaults.conf",
+ "test.gz", "test2.jar", "non_utf8.txt")
Review comment:
Hi @HyukjinKwon, thanks for taking a look. That would disallow a user
from supplying his library/framework specific configuration.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r540704406
##
File path:
resource-managers/kubernetes/core/src/test/scala/org/apache/spark/deploy/k8s/submit/ClientSuite.scala
##
@@ -191,25 +191,32 @@ class ClientSuite extends SparkFunSuite with
BeforeAndAfter {
assert(configMap.getData.get(SPARK_CONF_FILE_NAME).contains("conf2key=conf2value"))
}
- test("All files from SPARK_CONF_DIR, except templates and spark config " +
+ test("All files from SPARK_CONF_DIR, " +
+"except templates, spark config, binary files and are within size limit, "
+
"should be populated to pod's configMap.") {
def testSetup: (SparkConf, Seq[String]) = {
val tempDir = Utils.createTempDir()
- val sparkConf = new SparkConf(loadDefaults =
false).setSparkHome(tempDir.getAbsolutePath)
+ val sparkConf = new SparkConf(loadDefaults = false)
+.setSparkHome(tempDir.getAbsolutePath)
val tempConfDir = new File(s"${tempDir.getAbsolutePath}/conf")
tempConfDir.mkdir()
// File names - which should not get mounted on the resultant config map.
val filteredConfFileNames =
-Set("spark-env.sh.template", "spark.properties", "spark-defaults.conf")
- val confFileNames = for (i <- 1 to 5) yield s"testConf.$i" ++
+Set("spark-env.sh.template", "spark.properties", "spark-defaults.conf",
+ "test.gz", "test2.jar", "non_utf8.txt")
Review comment:
That would disallow a user from supplying his library/framework specific
configuration.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r540084075
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/Config.scala
##
@@ -90,6 +90,14 @@ private[spark] object Config extends Logging {
.toSequence
.createWithDefault(Nil)
+ val CONFIG_MAP_MAXSIZE =
+ConfigBuilder("spark.kubernetes.configMap.maxSize")
+ .doc("Max size limit for a config map. This is configurable as per" +
+" https://etcd.io/docs/v3.4.0/dev-guide/limit/ on k8s server end.")
+ .version("3.2.0")
Review comment:
It would be good, if this could make it into 3.1.0 ? @dongjoon-hyun and
@srowen WDYT?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r537298366
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/KubernetesClientUtils.scala
##
@@ -94,25 +120,41 @@ private[spark] object KubernetesClientUtils extends
Logging {
val confDir = Option(conf.getenv(ENV_SPARK_CONF_DIR)).orElse(
conf.getOption("spark.home").map(dir => s"$dir/conf"))
if (confDir.isDefined) {
- val confFiles = listConfFiles(confDir.get)
- logInfo(s"Spark configuration files loaded from $confDir :
${confFiles.mkString(",")}")
- confFiles.map { file =>
-val source = Source.fromFile(file)(Codec.UTF8)
-val mapping = (file.getName -> source.mkString)
-source.close()
-mapping
- }.toMap
+ val confFiles = listConfFiles(confDir.get,
conf.get(Config.CONFIG_MAP_MAXSIZE))
+ val filesSeq: Seq[Option[(String, String)]] = confFiles.map { file =>
+try {
+ val source = Source.fromFile(file)(Codec.UTF8)
+ val mapping = Some(file.getName -> source.mkString)
+ source.close()
+ mapping
+} catch {
+ case e: MalformedInputException =>
+logWarning(s"skipped a non UTF-8 encoded file
${file.getAbsolutePath}.", e)
+None
+}
+ }
+ val truncatedMap = truncateToSize(filesSeq.flatten,
conf.get(Config.CONFIG_MAP_MAXSIZE))
+ logInfo(s"Spark configuration files loaded from $confDir :" +
Review comment:
~~Challenge with trying to truncate before reading is, we do not know
which files will have `MalformedInputException` i.e. they are not encoded with
UTF-8.~~
Yeah, there is one corner case, that if a user places a really large number
of small files (<1.5MiB) in the SPARK_CONF_DIR then, we may run into SPARK OOM.
The way to avoid is to not read everything in the memory.
So now, we read only as much required in the memory and not everything.
Thanks @srowen for correcting me on this.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r537291078
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/KubernetesClientUtils.scala
##
@@ -51,6 +54,29 @@ private[spark] object KubernetesClientUtils extends Logging {
propertiesWriter.toString
}
+ object StringLengthOrdering extends Ordering[(String, String)] {
+override def compare(x: (String, String), y: (String, String)): Int = {
+ // compare based on file length and break the tie with string comparison
of keys.
+ (x._1.length + x._2.length).compare(y._1.length + y._2.length) * 10 +
+x._1.compareTo(y._1)
+}
Review comment:
Good questions, and hoping that I have understood correctly, attempting
to answer.
1) We need to compare the file sizes _including their names_, because that
is how they will occupy space in a config map.
2) We would like to give priority to as many config files as possible we can
mount (or store in the configMap), so we would like to sort them by size.
3) If the two files are equal in lengths, then we do not want to declare
them equal, so in the compare equation, if two files are equal in length - we
check their string compare results as well. This is done to break the tie.
When two files have equal lengths, we check if the two files have same name as
well ? Then we say they are truly equal - in principle this should not happen,
because they are files in the same directory i.e. `SPARK_CONF_DIR`. So, each
file will get some ordering value as a result of computing comparison equation,
and no data will be lost.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r537291078
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/KubernetesClientUtils.scala
##
@@ -51,6 +54,29 @@ private[spark] object KubernetesClientUtils extends Logging {
propertiesWriter.toString
}
+ object StringLengthOrdering extends Ordering[(String, String)] {
+override def compare(x: (String, String), y: (String, String)): Int = {
+ // compare based on file length and break the tie with string comparison
of keys.
+ (x._1.length + x._2.length).compare(y._1.length + y._2.length) * 10 +
+x._1.compareTo(y._1)
+}
Review comment:
Good questions, and hoping that I have understood correctly, attempting
to answer.
1) We need to compare the file sizes _including their names_, because that
is how they will occupy space in a config map.
2) We would like to give priority to as many config files as possible we can
mount (or store in the configMap), so we would like to sort them by size.
3) If the two files are equal in lengths, then we do not want to declare
them equal, so in the compare equation we add their string compare results as
well. This is done to break the tie. When two files have equal lengths, we
check if the two files have same name as well ? Then we say they are truly
equal - in principle this should not happen, because they are files in the same
directory i.e. `SPARK_CONF_DIR`. So, each file will get some ordering value as
a result of computing comparison equation, and no data will be lost.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r537298366
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/KubernetesClientUtils.scala
##
@@ -94,25 +120,41 @@ private[spark] object KubernetesClientUtils extends
Logging {
val confDir = Option(conf.getenv(ENV_SPARK_CONF_DIR)).orElse(
conf.getOption("spark.home").map(dir => s"$dir/conf"))
if (confDir.isDefined) {
- val confFiles = listConfFiles(confDir.get)
- logInfo(s"Spark configuration files loaded from $confDir :
${confFiles.mkString(",")}")
- confFiles.map { file =>
-val source = Source.fromFile(file)(Codec.UTF8)
-val mapping = (file.getName -> source.mkString)
-source.close()
-mapping
- }.toMap
+ val confFiles = listConfFiles(confDir.get,
conf.get(Config.CONFIG_MAP_MAXSIZE))
+ val filesSeq: Seq[Option[(String, String)]] = confFiles.map { file =>
+try {
+ val source = Source.fromFile(file)(Codec.UTF8)
+ val mapping = Some(file.getName -> source.mkString)
+ source.close()
+ mapping
+} catch {
+ case e: MalformedInputException =>
+logWarning(s"skipped a non UTF-8 encoded file
${file.getAbsolutePath}.", e)
+None
+}
+ }
+ val truncatedMap = truncateToSize(filesSeq.flatten,
conf.get(Config.CONFIG_MAP_MAXSIZE))
+ logInfo(s"Spark configuration files loaded from $confDir :" +
Review comment:
Challenge with trying to truncate before reading is, we do not know
which files will have `MalformedInputException` i.e. they are not encoded with
UTF-8.
Yeah, there is one corner case, that if a user places a really large number
of small files (<1.5MiB) in the SPARK_CONF_DIR then, we may run into SPARK OOM.
The way to avoid is to not read everything in the memory.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r537297478
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/KubernetesClientUtils.scala
##
@@ -51,6 +54,29 @@ private[spark] object KubernetesClientUtils extends Logging {
propertiesWriter.toString
}
+ object StringLengthOrdering extends Ordering[(String, String)] {
+override def compare(x: (String, String), y: (String, String)): Int = {
+ // compare based on file length and break the tie with string comparison
of keys.
+ (x._1.length + x._2.length).compare(y._1.length + y._2.length) * 10 +
+x._1.compareTo(y._1)
+}
+ }
+
+ def truncateToSize(seq: Seq[(String, String)], maxSize: Long): Map[String,
String] = {
+// First order the entries in order of their size.
+// Skip entries if the resulting Map size exceeds maxSize.
+val ordering: Ordering[(String, String)] = StringLengthOrdering
+val sortedSet = SortedSet[(String, String)](seq : _*)(ordering)
+var i: Int = 0
+val map = mutable.HashMap[String, String]()
+for (item <- sortedSet) {
+ i += item._1.length + item._2.length
+ if ( i < maxSize) {
Review comment:
P.S. I have evaluated the approach of trying to extend SortedSet, and some
how make it size limited i.e. items cannot be added beyond a size is reached.
This seemed to be simpler to maintain.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r537298366
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/KubernetesClientUtils.scala
##
@@ -94,25 +120,41 @@ private[spark] object KubernetesClientUtils extends
Logging {
val confDir = Option(conf.getenv(ENV_SPARK_CONF_DIR)).orElse(
conf.getOption("spark.home").map(dir => s"$dir/conf"))
if (confDir.isDefined) {
- val confFiles = listConfFiles(confDir.get)
- logInfo(s"Spark configuration files loaded from $confDir :
${confFiles.mkString(",")}")
- confFiles.map { file =>
-val source = Source.fromFile(file)(Codec.UTF8)
-val mapping = (file.getName -> source.mkString)
-source.close()
-mapping
- }.toMap
+ val confFiles = listConfFiles(confDir.get,
conf.get(Config.CONFIG_MAP_MAXSIZE))
+ val filesSeq: Seq[Option[(String, String)]] = confFiles.map { file =>
+try {
+ val source = Source.fromFile(file)(Codec.UTF8)
+ val mapping = Some(file.getName -> source.mkString)
+ source.close()
+ mapping
+} catch {
+ case e: MalformedInputException =>
+logWarning(s"skipped a non UTF-8 encoded file
${file.getAbsolutePath}.", e)
+None
+}
+ }
+ val truncatedMap = truncateToSize(filesSeq.flatten,
conf.get(Config.CONFIG_MAP_MAXSIZE))
+ logInfo(s"Spark configuration files loaded from $confDir :" +
Review comment:
Challenge with trying to truncate before reading is, we do not know
which files will have `MalformedInputException` i.e. they are not encoded with
UTF-8.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r537297478
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/KubernetesClientUtils.scala
##
@@ -51,6 +54,29 @@ private[spark] object KubernetesClientUtils extends Logging {
propertiesWriter.toString
}
+ object StringLengthOrdering extends Ordering[(String, String)] {
+override def compare(x: (String, String), y: (String, String)): Int = {
+ // compare based on file length and break the tie with string comparison
of keys.
+ (x._1.length + x._2.length).compare(y._1.length + y._2.length) * 10 +
+x._1.compareTo(y._1)
+}
+ }
+
+ def truncateToSize(seq: Seq[(String, String)], maxSize: Long): Map[String,
String] = {
+// First order the entries in order of their size.
+// Skip entries if the resulting Map size exceeds maxSize.
+val ordering: Ordering[(String, String)] = StringLengthOrdering
+val sortedSet = SortedSet[(String, String)](seq : _*)(ordering)
+var i: Int = 0
+val map = mutable.HashMap[String, String]()
+for (item <- sortedSet) {
+ i += item._1.length + item._2.length
+ if ( i < maxSize) {
Review comment:
P.S. I have evaluated the approach of trying to extend SortedSet, and
some how make it size limited i.e. items cannot be added beyond a size is
reached. But that was more complex in terms of code, so here I have chosen a
piece of code that is more simpler to maintain and does not need an overhauling
every time we upgrade scala major version.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r537291078
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/KubernetesClientUtils.scala
##
@@ -51,6 +54,29 @@ private[spark] object KubernetesClientUtils extends Logging {
propertiesWriter.toString
}
+ object StringLengthOrdering extends Ordering[(String, String)] {
+override def compare(x: (String, String), y: (String, String)): Int = {
+ // compare based on file length and break the tie with string comparison
of keys.
+ (x._1.length + x._2.length).compare(y._1.length + y._2.length) * 10 +
+x._1.compareTo(y._1)
+}
Review comment:
Good questions, and hoping that I have understood correctly, attempting
to answer.
1) We need to compare the file sizes _including their names_, because that
is how they will occupy space in a config map.
2) We would like to give priority to as many config files as possible we can
mount (or store in the configMap), so we would like to sort them by size.
3) If the two files are equal in lengths, then we do not want to declare
them equal, so in the compare equation we add their string compare results as
well. This is done to break the tie. So `*10` is done to give more priority to
compare by their length but if the comparison result is equal, i.e. two files
are exactly equal in length then we get zero as the comparison result. By
adding string comparison result of their names, i.e. when two files have equal
lengths, we check if the two files have same name as well ? Then we say they
are truly equal - in principle this should not happen, because they are files
in the same directory i.e. `SPARK_CONF_DIR`. So, each file will get some
ordering value as a result of computing comparison equation, and no data will
be lost.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r535900210
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/submit/KubernetesClientUtils.scala
##
@@ -94,25 +120,41 @@ private[spark] object KubernetesClientUtils extends
Logging {
val confDir = Option(conf.getenv(ENV_SPARK_CONF_DIR)).orElse(
conf.getOption("spark.home").map(dir => s"$dir/conf"))
if (confDir.isDefined) {
- val confFiles = listConfFiles(confDir.get)
- logInfo(s"Spark configuration files loaded from $confDir :
${confFiles.mkString(",")}")
- confFiles.map { file =>
-val source = Source.fromFile(file)(Codec.UTF8)
-val mapping = (file.getName -> source.mkString)
-source.close()
-mapping
- }.toMap
+ val confFiles = listConfFiles(confDir.get,
conf.get(Config.CONFIG_MAP_MAXSIZE))
+ val filesSeq: Seq[Option[(String, String)]] = confFiles.map { file =>
+try {
+ val source = Source.fromFile(file)(Codec.UTF8)
+ val mapping = Some(file.getName -> source.mkString)
+ source.close()
+ mapping
+} catch {
+ case e: MalformedInputException =>
+logWarning(s"skipped a non UTF-8 encoded file
${file.getAbsolutePath}.", e)
+None
+}
+ }
+ val truncatedMap = truncateToSize(filesSeq.flatten,
conf.get(Config.CONFIG_MAP_MAXSIZE))
+ logInfo(s"Spark configuration files loaded from $confDir :" +
+s" ${truncatedMap.keys.mkString(",")}")
+ truncatedMap
} else {
Map.empty[String, String]
}
}
- private def listConfFiles(confDir: String): Seq[File] = {
-// We exclude all the template files and user provided spark conf or
properties.
-// As spark properties are resolved in a different step.
+ private def listConfFiles(confDir: String, maxSize: Long): Seq[File] = {
+// At the moment configmaps does not support storing binary content.
+// configMaps do not allow for size greater than 1.5 MiB(configurable).
+// https://etcd.io/docs/v3.4.0/dev-guide/limit/
+// We exclude all the template files and user provided spark conf or
properties,
+// and binary files (e.g. jars and zip). Spark properties are resolved in
a different step.
+def test(f: File): Boolean = (f.length() + f.getName.length > maxSize) ||
Review comment:
> BTW, why f.length() + f.getName.length > 0 is here?
Ensures a single file which is larger than the total capacity for the config
map is skipped. As we cannot accommodate it anyway.
An alternative is to fail here with proper exception, what do you think?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ScrapCodes commented on a change in pull request #30472: [SPARK-32221][k8s] Avoid possible errors due to incorrect file size or type supplied in spark conf.
ScrapCodes commented on a change in pull request #30472:
URL: https://github.com/apache/spark/pull/30472#discussion_r530893082
##
File path:
resource-managers/kubernetes/core/src/main/scala/org/apache/spark/deploy/k8s/Config.scala
##
@@ -90,6 +90,14 @@ private[spark] object Config extends Logging {
.toSequence
.createWithDefault(Nil)
+ val CONFIG_MAP_MAXSIZE =
+ConfigBuilder("spark.kubernetes.configMap.maxsize")
+.doc("Max size limit for a config map. This may be configurable as per" +
+ " https://etcd.io/docs/v3.4.0/dev-guide/limit/ in the future.")
+.version("3.1.0")
Review comment:
"Max size limit for a config map. This is configurable as per
https://etcd.io/docs/v3.4.0/dev-guide/limit/ on k8s server end."
So may be we should keep it configurable too.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org