[jira] [Commented] (FLINK-8230) NPE in OrcRowInputFormat on nested structs
[
https://issues.apache.org/jira/browse/FLINK-8230?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16348140#comment-16348140
]
ASF GitHub Bot commented on FLINK-8230:
---
Github user packet23 commented on the issue:
https://github.com/apache/flink/pull/5145
@twalthr Sure. And thanks to @fhueske for fixing the existing IF.
> NPE in OrcRowInputFormat on nested structs
> --
>
> Key: FLINK-8230
> URL: https://issues.apache.org/jira/browse/FLINK-8230
> Project: Flink
> Issue Type: Bug
> Components: Batch Connectors and Input/Output Formats
>Affects Versions: 1.4.0
>Reporter: Sebastian Klemke
>Assignee: Fabian Hueske
>Priority: Blocker
> Fix For: 1.5.0, 1.4.1
>
>
> OrcRowInputFormat ignores isNull and isRepeating on nested struct columns. If
> a struct column contains nulls, it tries to read struct fields, leading to
> NPE in case of string fields:
> {code}
> java.lang.NullPointerException
> at java.lang.String.checkBounds(String.java:384)
> at java.lang.String.(String.java:462)
> at
> org.apache.flink.orc.OrcUtils.readNonNullBytesColumnAsString(OrcUtils.java:392)
> at org.apache.flink.orc.OrcUtils.readField(OrcUtils.java:215)
> at org.apache.flink.orc.OrcUtils.readStructColumn(OrcUtils.java:1203)
> at org.apache.flink.orc.OrcUtils.readField(OrcUtils.java:252)
> at
> org.apache.flink.orc.OrcUtils.readNonNullStructColumn(OrcUtils.java:677)
> at org.apache.flink.orc.OrcUtils.readField(OrcUtils.java:250)
> at org.apache.flink.orc.OrcUtils.fillRows(OrcUtils.java:142)
> at
> org.apache.flink.orc.OrcRowInputFormat.ensureBatch(OrcRowInputFormat.java:334)
> at
> org.apache.flink.orc.OrcRowInputFormat.reachedEnd(OrcRowInputFormat.java:314)
> at
> org.apache.flink.runtime.operators.DataSourceTask.invoke(DataSourceTask.java:165)
> at org.apache.flink.runtime.taskmanager.Task.run(Task.java:718)
> at java.lang.Thread.run(Thread.java:748)
> {code}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-8230) NPE in OrcRowInputFormat on nested structs
[
https://issues.apache.org/jira/browse/FLINK-8230?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16348141#comment-16348141
]
ASF GitHub Bot commented on FLINK-8230:
---
Github user packet23 closed the pull request at:
https://github.com/apache/flink/pull/5145
> NPE in OrcRowInputFormat on nested structs
> --
>
> Key: FLINK-8230
> URL: https://issues.apache.org/jira/browse/FLINK-8230
> Project: Flink
> Issue Type: Bug
> Components: Batch Connectors and Input/Output Formats
>Affects Versions: 1.4.0
>Reporter: Sebastian Klemke
>Assignee: Fabian Hueske
>Priority: Blocker
> Fix For: 1.5.0, 1.4.1
>
>
> OrcRowInputFormat ignores isNull and isRepeating on nested struct columns. If
> a struct column contains nulls, it tries to read struct fields, leading to
> NPE in case of string fields:
> {code}
> java.lang.NullPointerException
> at java.lang.String.checkBounds(String.java:384)
> at java.lang.String.(String.java:462)
> at
> org.apache.flink.orc.OrcUtils.readNonNullBytesColumnAsString(OrcUtils.java:392)
> at org.apache.flink.orc.OrcUtils.readField(OrcUtils.java:215)
> at org.apache.flink.orc.OrcUtils.readStructColumn(OrcUtils.java:1203)
> at org.apache.flink.orc.OrcUtils.readField(OrcUtils.java:252)
> at
> org.apache.flink.orc.OrcUtils.readNonNullStructColumn(OrcUtils.java:677)
> at org.apache.flink.orc.OrcUtils.readField(OrcUtils.java:250)
> at org.apache.flink.orc.OrcUtils.fillRows(OrcUtils.java:142)
> at
> org.apache.flink.orc.OrcRowInputFormat.ensureBatch(OrcRowInputFormat.java:334)
> at
> org.apache.flink.orc.OrcRowInputFormat.reachedEnd(OrcRowInputFormat.java:314)
> at
> org.apache.flink.runtime.operators.DataSourceTask.invoke(DataSourceTask.java:165)
> at org.apache.flink.runtime.taskmanager.Task.run(Task.java:718)
> at java.lang.Thread.run(Thread.java:748)
> {code}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink issue #5145: [FLINK-8230] [ORC] Improved mapping of Orc records to Fli...
Github user packet23 commented on the issue: https://github.com/apache/flink/pull/5145 @twalthr Sure. And thanks to @fhueske for fixing the existing IF. ---
[GitHub] flink pull request #5145: [FLINK-8230] [ORC] Improved mapping of Orc records...
Github user packet23 closed the pull request at: https://github.com/apache/flink/pull/5145 ---
[jira] [Commented] (FLINK-8360) Implement task-local state recovery
[
https://issues.apache.org/jira/browse/FLINK-8360?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16348132#comment-16348132
]
ASF GitHub Bot commented on FLINK-8360:
---
Github user tillrohrmann commented on a diff in the pull request:
https://github.com/apache/flink/pull/5239#discussion_r165275719
--- Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/state/StateSnapshotContextSynchronousImpl.java
---
@@ -109,14 +109,20 @@ public OperatorStateCheckpointOutputStream
getRawOperatorStateOutput() throws Ex
return operatorStateCheckpointOutputStream;
}
- public RunnableFuture getKeyedStateStreamFuture()
throws IOException {
- KeyGroupsStateHandle keyGroupsStateHandle =
closeAndUnregisterStreamToObtainStateHandle(keyedStateCheckpointOutputStream);
- return new DoneFuture(keyGroupsStateHandle);
+ public RunnableFuture>
getKeyedStateStreamFuture() throws IOException {
+ return
getGenericStateStreamFuture(keyedStateCheckpointOutputStream);
}
- public RunnableFuture
getOperatorStateStreamFuture() throws IOException {
- OperatorStateHandle operatorStateHandle =
closeAndUnregisterStreamToObtainStateHandle(operatorStateCheckpointOutputStream);
- return new DoneFuture<>(operatorStateHandle);
+ public RunnableFuture>
getOperatorStateStreamFuture() throws IOException {
+ return
getGenericStateStreamFuture(operatorStateCheckpointOutputStream);
+ }
+
+ private RunnableFuture>
getGenericStateStreamFuture(
+ NonClosingCheckpointOutputStream stream) throws
IOException {
+ T operatorStateHandle = (T)
closeAndUnregisterStreamToObtainStateHandle(stream);
--- End diff --
This cast seems a bit fishy to me. I think it should not be necessary if
the generics are applied correctly. A way to solve it would be `T extends
StreamStateHandle` and `RunnableFuture> getKeyedStateStreamFuture()`
> Implement task-local state recovery
> ---
>
> Key: FLINK-8360
> URL: https://issues.apache.org/jira/browse/FLINK-8360
> Project: Flink
> Issue Type: New Feature
> Components: State Backends, Checkpointing
>Reporter: Stefan Richter
>Assignee: Stefan Richter
>Priority: Major
> Fix For: 1.5.0
>
>
> This issue tracks the development of recovery from task-local state. The main
> idea is to have a secondary, local copy of the checkpointed state, while
> there is still a primary copy in DFS that we report to the checkpoint
> coordinator.
> Recovery can attempt to restore from the secondary local copy, if available,
> to save network bandwidth. This requires that the assignment from tasks to
> slots is as sticky is possible.
> For starters, we will implement this feature for all managed keyed states and
> can easily enhance it to all other state types (e.g. operator state) later.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #5239: [FLINK-8360] Implement task-local state recovery
Github user tillrohrmann commented on a diff in the pull request:
https://github.com/apache/flink/pull/5239#discussion_r165275719
--- Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/state/StateSnapshotContextSynchronousImpl.java
---
@@ -109,14 +109,20 @@ public OperatorStateCheckpointOutputStream
getRawOperatorStateOutput() throws Ex
return operatorStateCheckpointOutputStream;
}
- public RunnableFuture getKeyedStateStreamFuture()
throws IOException {
- KeyGroupsStateHandle keyGroupsStateHandle =
closeAndUnregisterStreamToObtainStateHandle(keyedStateCheckpointOutputStream);
- return new DoneFuture(keyGroupsStateHandle);
+ public RunnableFuture>
getKeyedStateStreamFuture() throws IOException {
+ return
getGenericStateStreamFuture(keyedStateCheckpointOutputStream);
}
- public RunnableFuture
getOperatorStateStreamFuture() throws IOException {
- OperatorStateHandle operatorStateHandle =
closeAndUnregisterStreamToObtainStateHandle(operatorStateCheckpointOutputStream);
- return new DoneFuture<>(operatorStateHandle);
+ public RunnableFuture>
getOperatorStateStreamFuture() throws IOException {
+ return
getGenericStateStreamFuture(operatorStateCheckpointOutputStream);
+ }
+
+ private RunnableFuture>
getGenericStateStreamFuture(
+ NonClosingCheckpointOutputStream stream) throws
IOException {
+ T operatorStateHandle = (T)
closeAndUnregisterStreamToObtainStateHandle(stream);
--- End diff --
This cast seems a bit fishy to me. I think it should not be necessary if
the generics are applied correctly. A way to solve it would be `T extends
StreamStateHandle` and `RunnableFuture> getKeyedStateStreamFuture()`
---
[jira] [Commented] (FLINK-8533) Support MasterTriggerRestoreHook state reinitialization
[
https://issues.apache.org/jira/browse/FLINK-8533?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16348017#comment-16348017
]
Eron Wright commented on FLINK-8533:
-
Incidentally, a variation on this problem would (I believe) occur when using
the Kafka consumer and {{setStartFromGroupOffsets}} is enabled. That's
because the Kafka connector uses external storage to initialize its state (i.e.
the starting position) in the non-restore case.
> Support MasterTriggerRestoreHook state reinitialization
> ---
>
> Key: FLINK-8533
> URL: https://issues.apache.org/jira/browse/FLINK-8533
> Project: Flink
> Issue Type: Bug
> Components: State Backends, Checkpointing
>Affects Versions: 1.3.0
>Reporter: Eron Wright
>Assignee: Eron Wright
>Priority: Major
>
> {{MasterTriggerRestoreHook}} enables coordination with an external system for
> taking or restoring checkpoints. When execution is restarted from a
> checkpoint, {{restoreCheckpoint}} is called to restore or reinitialize the
> external system state. There's an edge case where the external state is not
> adequately reinitialized, that is when execution fails _before the first
> checkpoint_. In that case, the hook is not invoked and has no opportunity to
> restore the external state to initial conditions.
> The impact is a loss of exactly-once semantics in this case. For example, in
> the Pravega source function, the reader group state (e.g. stream position
> data) is stored externally. In the normal restore case, the reader group
> state is forcibly rewound to the checkpointed position. In the edge case
> where no checkpoint has yet been successful, the reader group state is not
> rewound and consequently some amount of stream data is not reprocessed.
> A possible fix would be to introduce an {{initializeState}} method on the
> hook interface. Similar to {{CheckpointedFunction::initializeState}}, this
> method would be invoked unconditionally upon hook initialization. The Pravega
> hook would, for example, initialize or forcibly reinitialize the reader group
> state.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Comment Edited] (FLINK-8500) Get the timestamp of the Kafka message from kafka consumer(Kafka010Fetcher)
[ https://issues.apache.org/jira/browse/FLINK-8500?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347951#comment-16347951 ] yanxiaobin edited comment on FLINK-8500 at 2/1/18 3:28 AM: --- Greate!I think it's reasonable that the method deserialize of KeyedDeserializationSchema needs a parameter 'kafka message timestamp' (from ConsumerRecord) .In some business scenarios, this is useful . And I think it's best to optimize it. The user interface is as unified as possible! thanks , [~aljoscha] . was (Author: backlight): Greate!I think it's reasonable.But I think it's best to optimize it. The user interface is as unified as possible! thanks , [~aljoscha] . > Get the timestamp of the Kafka message from kafka consumer(Kafka010Fetcher) > --- > > Key: FLINK-8500 > URL: https://issues.apache.org/jira/browse/FLINK-8500 > Project: Flink > Issue Type: Improvement > Components: Kafka Connector >Affects Versions: 1.4.0 >Reporter: yanxiaobin >Priority: Blocker > Fix For: 1.5.0, 1.4.1 > > Attachments: image-2018-01-30-14-58-58-167.png, > image-2018-01-31-10-48-59-633.png > > > The method deserialize of KeyedDeserializationSchema needs a parameter > 'kafka message timestamp' (from ConsumerRecord) .In some business scenarios, > this is useful! > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-8534) if insert too much BucketEntry into one bucket in join of iteration will cause a error (Caused : java.io.FileNotFoundException release file error)
[ https://issues.apache.org/jira/browse/FLINK-8534?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347953#comment-16347953 ] zhu.qing commented on FLINK-8534: - Just set Xms to 1g will reproduce the bug > if insert too much BucketEntry into one bucket in join of iteration will > cause a error (Caused : java.io.FileNotFoundException release file error) > -- > > Key: FLINK-8534 > URL: https://issues.apache.org/jira/browse/FLINK-8534 > Project: Flink > Issue Type: Bug > Components: Local Runtime > Environment: windows, intellij idea, 8g ram, 4core i5 cpu, Flink > 1.4.0, and parallelism = 2 will cause problem and others will not. >Reporter: zhu.qing >Priority: Major > Attachments: T2AdjSetBfs.java > > > When insert too much entry into bucket (MutableHashTable insertBucketEntry() > line 1054 more than 255) will cause spillPartition() (HashPartition line > 317). So > this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, > bufferReturnQueue); > And in > prepareNextPartition() of ReOpenableMutableHashTable (line 156) > furtherPartitioning = true; > so in > finalizeProbePhase() in HashPartition (line 367) > this.probeSideChannel.close(); > //the file will be delete > this.buildSideChannel.deleteChannel(); > this.probeSideChannel.deleteChannel(); > after deleteChannel the next iteartion will fail. > > And I use web-google(SNAP) as dataset. > > Exception in thread "main" > org.apache.flink.runtime.client.JobExecutionException: Job execution failed. > at > org.apache.flink.runtime.jobmanager.JobManager$$anonfun$handleMessage$1$$anonfun$applyOrElse$6.apply$mcV$sp(JobManager.scala:897) > at > org.apache.flink.runtime.jobmanager.JobManager$$anonfun$handleMessage$1$$anonfun$applyOrElse$6.apply(JobManager.scala:840) > at > org.apache.flink.runtime.jobmanager.JobManager$$anonfun$handleMessage$1$$anonfun$applyOrElse$6.apply(JobManager.scala:840) > at > scala.concurrent.impl.Future$PromiseCompletingRunnable.liftedTree1$1(Future.scala:24) > at > scala.concurrent.impl.Future$PromiseCompletingRunnable.run(Future.scala:24) > at akka.dispatch.TaskInvocation.run(AbstractDispatcher.scala:39) > at > akka.dispatch.ForkJoinExecutorConfigurator$AkkaForkJoinTask.exec(AbstractDispatcher.scala:415) > at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260) > at > scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339) > at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979) > at > scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107) > Caused by: java.io.IOException: Channel to path > 'C:\Users\sanquan.qz\AppData\Local\Temp\flink-io-5af23edc-1ec0-4718-87a5-916ee022a8be\fc08af25b6f879b8e7bb24291c47ea1d.18.channel' > could not be opened. > at > org.apache.flink.runtime.io.disk.iomanager.AbstractFileIOChannel.(AbstractFileIOChannel.java:61) > at > org.apache.flink.runtime.io.disk.iomanager.AsynchronousFileIOChannel.(AsynchronousFileIOChannel.java:86) > at > org.apache.flink.runtime.io.disk.iomanager.AsynchronousBulkBlockReader.(AsynchronousBulkBlockReader.java:46) > at > org.apache.flink.runtime.io.disk.iomanager.AsynchronousBulkBlockReader.(AsynchronousBulkBlockReader.java:39) > at > org.apache.flink.runtime.io.disk.iomanager.IOManagerAsync.createBulkBlockChannelReader(IOManagerAsync.java:294) > at > org.apache.flink.runtime.operators.hash.MutableHashTable.buildTableFromSpilledPartition(MutableHashTable.java:880) > at > org.apache.flink.runtime.operators.hash.MutableHashTable.prepareNextPartition(MutableHashTable.java:637) > at > org.apache.flink.runtime.operators.hash.ReOpenableMutableHashTable.prepareNextPartition(ReOpenableMutableHashTable.java:170) > at > org.apache.flink.runtime.operators.hash.MutableHashTable.nextRecord(MutableHashTable.java:675) > at > org.apache.flink.runtime.operators.hash.NonReusingBuildFirstHashJoinIterator.callWithNextKey(NonReusingBuildFirstHashJoinIterator.java:117) > at > org.apache.flink.runtime.operators.AbstractCachedBuildSideJoinDriver.run(AbstractCachedBuildSideJoinDriver.java:176) > at org.apache.flink.runtime.operators.BatchTask.run(BatchTask.java:490) > at > org.apache.flink.runtime.iterative.task.AbstractIterativeTask.run(AbstractIterativeTask.java:145) > at > org.apache.flink.runtime.iterative.task.IterationIntermediateTask.run(IterationIntermediateTask.java:93) > at org.apache.flink.runtime.operators.BatchTask.invoke(BatchTask.java:355) > at org.apache.flink.runtime.taskmanager.Task.run(Task.java:718) > at java.lang.Thread.run(Thread.java:745) > Caused by: java.io.FileNotFoundException: > C:\Us
[jira] [Commented] (FLINK-8500) Get the timestamp of the Kafka message from kafka consumer(Kafka010Fetcher)
[ https://issues.apache.org/jira/browse/FLINK-8500?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347951#comment-16347951 ] yanxiaobin commented on FLINK-8500: --- Greate!I think it's reasonable.But I think it's best to optimize it. The user interface is as unified as possible! thanks , [~aljoscha] . > Get the timestamp of the Kafka message from kafka consumer(Kafka010Fetcher) > --- > > Key: FLINK-8500 > URL: https://issues.apache.org/jira/browse/FLINK-8500 > Project: Flink > Issue Type: Improvement > Components: Kafka Connector >Affects Versions: 1.4.0 >Reporter: yanxiaobin >Priority: Blocker > Fix For: 1.5.0, 1.4.1 > > Attachments: image-2018-01-30-14-58-58-167.png, > image-2018-01-31-10-48-59-633.png > > > The method deserialize of KeyedDeserializationSchema needs a parameter > 'kafka message timestamp' (from ConsumerRecord) .In some business scenarios, > this is useful! > -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-6160) Retry JobManager/ResourceManager connection in case of timeout
[
https://issues.apache.org/jira/browse/FLINK-6160?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347928#comment-16347928
]
mingleizhang commented on FLINK-6160:
-
Thanks [~till.rohrmann] I will take a look on what you said.
> Retry JobManager/ResourceManager connection in case of timeout
> ---
>
> Key: FLINK-6160
> URL: https://issues.apache.org/jira/browse/FLINK-6160
> Project: Flink
> Issue Type: Sub-task
> Components: Distributed Coordination
>Affects Versions: 1.3.0
>Reporter: Till Rohrmann
>Priority: Major
> Labels: flip-6
>
> In case of a heartbeat timeout, the {{TaskExecutor}} closes the connection to
> the remote component. Furthermore, it assumes that the component has actually
> failed and, thus, it will only start trying to connect to the component if it
> is notified about a new leader address and leader session id. This is
> brittle, because the heartbeat could also time out without the component
> having crashed. Thus, we should add an automatic retry to the latest known
> leader address information in case of a timeout.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-8534) if insert too much BucketEntry into one bucket in join of iteration will cause a error (Caused : java.io.FileNotFoundException release file error)
[ https://issues.apache.org/jira/browse/FLINK-8534?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] zhu.qing updated FLINK-8534: Description: When insert too much entry into bucket (MutableHashTable insertBucketEntry() line 1054 more than 255) will cause spillPartition() (HashPartition line 317). So this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, bufferReturnQueue); And in prepareNextPartition() of ReOpenableMutableHashTable (line 156) furtherPartitioning = true; so in finalizeProbePhase() in HashPartition (line 367) this.probeSideChannel.close(); //the file will be delete this.buildSideChannel.deleteChannel(); this.probeSideChannel.deleteChannel(); after deleteChannel the next iteartion will fail. And I use web-google(SNAP) as dataset. Exception in thread "main" org.apache.flink.runtime.client.JobExecutionException: Job execution failed. at org.apache.flink.runtime.jobmanager.JobManager$$anonfun$handleMessage$1$$anonfun$applyOrElse$6.apply$mcV$sp(JobManager.scala:897) at org.apache.flink.runtime.jobmanager.JobManager$$anonfun$handleMessage$1$$anonfun$applyOrElse$6.apply(JobManager.scala:840) at org.apache.flink.runtime.jobmanager.JobManager$$anonfun$handleMessage$1$$anonfun$applyOrElse$6.apply(JobManager.scala:840) at scala.concurrent.impl.Future$PromiseCompletingRunnable.liftedTree1$1(Future.scala:24) at scala.concurrent.impl.Future$PromiseCompletingRunnable.run(Future.scala:24) at akka.dispatch.TaskInvocation.run(AbstractDispatcher.scala:39) at akka.dispatch.ForkJoinExecutorConfigurator$AkkaForkJoinTask.exec(AbstractDispatcher.scala:415) at scala.concurrent.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260) at scala.concurrent.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339) at scala.concurrent.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979) at scala.concurrent.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107) Caused by: java.io.IOException: Channel to path 'C:\Users\sanquan.qz\AppData\Local\Temp\flink-io-5af23edc-1ec0-4718-87a5-916ee022a8be\fc08af25b6f879b8e7bb24291c47ea1d.18.channel' could not be opened. at org.apache.flink.runtime.io.disk.iomanager.AbstractFileIOChannel.(AbstractFileIOChannel.java:61) at org.apache.flink.runtime.io.disk.iomanager.AsynchronousFileIOChannel.(AsynchronousFileIOChannel.java:86) at org.apache.flink.runtime.io.disk.iomanager.AsynchronousBulkBlockReader.(AsynchronousBulkBlockReader.java:46) at org.apache.flink.runtime.io.disk.iomanager.AsynchronousBulkBlockReader.(AsynchronousBulkBlockReader.java:39) at org.apache.flink.runtime.io.disk.iomanager.IOManagerAsync.createBulkBlockChannelReader(IOManagerAsync.java:294) at org.apache.flink.runtime.operators.hash.MutableHashTable.buildTableFromSpilledPartition(MutableHashTable.java:880) at org.apache.flink.runtime.operators.hash.MutableHashTable.prepareNextPartition(MutableHashTable.java:637) at org.apache.flink.runtime.operators.hash.ReOpenableMutableHashTable.prepareNextPartition(ReOpenableMutableHashTable.java:170) at org.apache.flink.runtime.operators.hash.MutableHashTable.nextRecord(MutableHashTable.java:675) at org.apache.flink.runtime.operators.hash.NonReusingBuildFirstHashJoinIterator.callWithNextKey(NonReusingBuildFirstHashJoinIterator.java:117) at org.apache.flink.runtime.operators.AbstractCachedBuildSideJoinDriver.run(AbstractCachedBuildSideJoinDriver.java:176) at org.apache.flink.runtime.operators.BatchTask.run(BatchTask.java:490) at org.apache.flink.runtime.iterative.task.AbstractIterativeTask.run(AbstractIterativeTask.java:145) at org.apache.flink.runtime.iterative.task.IterationIntermediateTask.run(IterationIntermediateTask.java:93) at org.apache.flink.runtime.operators.BatchTask.invoke(BatchTask.java:355) at org.apache.flink.runtime.taskmanager.Task.run(Task.java:718) at java.lang.Thread.run(Thread.java:745) Caused by: java.io.FileNotFoundException: C:\Users\sanquan.qz\AppData\Local\Temp\flink-io-5af23edc-1ec0-4718-87a5-916ee022a8be\fc08af25b6f879b8e7bb24291c47ea1d.18.channel (系统找不到指定的文件。) at java.io.RandomAccessFile.open0(Native Method) at java.io.RandomAccessFile.open(RandomAccessFile.java:316) at java.io.RandomAccessFile.(RandomAccessFile.java:243) at java.io.RandomAccessFile.(RandomAccessFile.java:124) at org.apache.flink.runtime.io.disk.iomanager.AbstractFileIOChannel.(AbstractFileIOChannel.java:57) ... 16 more Process finished with exit code 1 here is the full stack of exception was: When insert too much entry into bucket (MutableHashTable insertBucketEntry() line 1054 more than 255) will cause spillPartition() (HashPartition line 317). So this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, bufferReturnQueue); And in prepareNextPartition() of ReOpenableMutableHashTable (line 156) furtherPartitioning = true; so in finalizeProbePhase() in HashPartition
[jira] [Commented] (FLINK-8357) enable rolling in default log settings
[
https://issues.apache.org/jira/browse/FLINK-8357?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347921#comment-16347921
]
ASF GitHub Bot commented on FLINK-8357:
---
Github user zhangminglei commented on the issue:
https://github.com/apache/flink/pull/5371
Changed!
> enable rolling in default log settings
> --
>
> Key: FLINK-8357
> URL: https://issues.apache.org/jira/browse/FLINK-8357
> Project: Flink
> Issue Type: Improvement
> Components: Logging
>Reporter: Xu Mingmin
>Assignee: mingleizhang
>Priority: Major
> Fix For: 1.5.0
>
>
> The release packages uses {{org.apache.log4j.FileAppender}} for log4j and
> {{ch.qos.logback.core.FileAppender}} for logback, which could results in very
> large log files.
> For most cases, if not all, we need to enable rotation in a production
> cluster, and I suppose it's a good idea to make rotation as default.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink issue #5371: [FLINK-8357] [conf] Enable rolling in default log setting...
Github user zhangminglei commented on the issue: https://github.com/apache/flink/pull/5371 Changed! ---
[jira] [Commented] (FLINK-8357) enable rolling in default log settings
[
https://issues.apache.org/jira/browse/FLINK-8357?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347909#comment-16347909
]
ASF GitHub Bot commented on FLINK-8357:
---
Github user zhangminglei commented on a diff in the pull request:
https://github.com/apache/flink/pull/5371#discussion_r165244013
--- Diff: flink-dist/src/main/flink-bin/conf/logback-yarn.xml ---
@@ -17,8 +17,14 @@
-->
-
+
${log.file}
+
+
+
logFile.%d{-MM-dd}.log
--- End diff --
Yea. It should be.
> enable rolling in default log settings
> --
>
> Key: FLINK-8357
> URL: https://issues.apache.org/jira/browse/FLINK-8357
> Project: Flink
> Issue Type: Improvement
> Components: Logging
>Reporter: Xu Mingmin
>Assignee: mingleizhang
>Priority: Major
> Fix For: 1.5.0
>
>
> The release packages uses {{org.apache.log4j.FileAppender}} for log4j and
> {{ch.qos.logback.core.FileAppender}} for logback, which could results in very
> large log files.
> For most cases, if not all, we need to enable rotation in a production
> cluster, and I suppose it's a good idea to make rotation as default.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-8357) enable rolling in default log settings
[
https://issues.apache.org/jira/browse/FLINK-8357?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347910#comment-16347910
]
ASF GitHub Bot commented on FLINK-8357:
---
Github user zhangminglei commented on a diff in the pull request:
https://github.com/apache/flink/pull/5371#discussion_r165244025
--- Diff: flink-dist/src/main/flink-bin/conf/logback.xml ---
@@ -17,8 +17,14 @@
-->
-
+
${log.file}
+
+
+
logFile.%d{-MM-dd}.log
--- End diff --
Same as above.
> enable rolling in default log settings
> --
>
> Key: FLINK-8357
> URL: https://issues.apache.org/jira/browse/FLINK-8357
> Project: Flink
> Issue Type: Improvement
> Components: Logging
>Reporter: Xu Mingmin
>Assignee: mingleizhang
>Priority: Major
> Fix For: 1.5.0
>
>
> The release packages uses {{org.apache.log4j.FileAppender}} for log4j and
> {{ch.qos.logback.core.FileAppender}} for logback, which could results in very
> large log files.
> For most cases, if not all, we need to enable rotation in a production
> cluster, and I suppose it's a good idea to make rotation as default.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #5371: [FLINK-8357] [conf] Enable rolling in default log ...
Github user zhangminglei commented on a diff in the pull request:
https://github.com/apache/flink/pull/5371#discussion_r165244013
--- Diff: flink-dist/src/main/flink-bin/conf/logback-yarn.xml ---
@@ -17,8 +17,14 @@
-->
-
+
${log.file}
+
+
+
logFile.%d{-MM-dd}.log
--- End diff --
Yea. It should be.
---
[GitHub] flink pull request #5371: [FLINK-8357] [conf] Enable rolling in default log ...
Github user zhangminglei commented on a diff in the pull request:
https://github.com/apache/flink/pull/5371#discussion_r165244025
--- Diff: flink-dist/src/main/flink-bin/conf/logback.xml ---
@@ -17,8 +17,14 @@
-->
-
+
${log.file}
+
+
+
logFile.%d{-MM-dd}.log
--- End diff --
Same as above.
---
[jira] [Assigned] (FLINK-8247) Support Hadoop-free variant of Flink on Mesos
[ https://issues.apache.org/jira/browse/FLINK-8247?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] Eron Wright reassigned FLINK-8247: --- Assignee: Eron Wright > Support Hadoop-free variant of Flink on Mesos > - > > Key: FLINK-8247 > URL: https://issues.apache.org/jira/browse/FLINK-8247 > Project: Flink > Issue Type: Bug > Components: Mesos >Affects Versions: 1.4.0 >Reporter: Eron Wright >Assignee: Eron Wright >Priority: Major > Fix For: 1.5.0, 1.4.1 > > > In Hadoop-free mode, Hadoop isn't on the classpath. The Mesos job manager > normally uses the Hadoop UserGroupInformation class to overlay a user context > (`HADOOP_USER_NAME`) for the task managers. > Detect the absence of Hadoop and skip over the `HadoopUserOverlay`, similar > to the logic in `HadoopModuleFactory`.This may require the introduction > of an overlay factory. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (FLINK-8541) Mesos RM should recover from failover timeout
Eron Wright created FLINK-8541: --- Summary: Mesos RM should recover from failover timeout Key: FLINK-8541 URL: https://issues.apache.org/jira/browse/FLINK-8541 Project: Flink Issue Type: Bug Components: Cluster Management, Mesos Affects Versions: 1.3.0 Reporter: Eron Wright Assignee: Eron Wright When a framework disconnects unexpectedly from Mesos, the framework's Mesos tasks continue to run for a configurable period of time known as the failover timeout. If the framework reconnects to Mesos after the timeout has expired, Mesos rejects the connection attempt. It is expected that the framework discard the previous framework ID and then connect as a new framework. When Flink is in this situation, the only recourse is to manually delete the ZK state where the framework ID kept. Let's improve the logic of the Mesos RM to automate that. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-8308) Update yajl-ruby dependency to 1.3.1 or higher
[ https://issues.apache.org/jira/browse/FLINK-8308?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347693#comment-16347693 ] ASF GitHub Bot commented on FLINK-8308: --- Github user uce commented on the issue: https://github.com/apache/flink/pull/5395 https://ci.apache.org/builders/flink-docs-master/builds/977/steps/Flink%20docs/logs/stdio says ``` Ruby version: ruby 2.0.0p384 (2014-01-12) [x86_64-linux-gnu] ``` I can ask INFRA whether it is possible to run a more recent Ruby version. > Update yajl-ruby dependency to 1.3.1 or higher > -- > > Key: FLINK-8308 > URL: https://issues.apache.org/jira/browse/FLINK-8308 > Project: Flink > Issue Type: Task > Components: Project Website >Reporter: Fabian Hueske >Assignee: Steven Langbroek >Priority: Critical > Fix For: 1.5.0, 1.4.1 > > > We got notified that yajl-ruby < 1.3.1, a dependency which is used to build > the Flink website, has a security vulnerability of high severity. > We should update yajl-ruby to 1.3.1 or higher. > Since the website is built offline and served as static HTML, I don't think > this is a super critical issue (please correct me if I'm wrong), but we > should resolve this soon. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink issue #5395: [FLINK-8308] Remove explicit yajl-ruby dependency, update...
Github user uce commented on the issue: https://github.com/apache/flink/pull/5395 https://ci.apache.org/builders/flink-docs-master/builds/977/steps/Flink%20docs/logs/stdio says ``` Ruby version: ruby 2.0.0p384 (2014-01-12) [x86_64-linux-gnu] ``` I can ask INFRA whether it is possible to run a more recent Ruby version. ---
[jira] [Commented] (FLINK-7477) Use "hadoop classpath" to augment classpath when available
[
https://issues.apache.org/jira/browse/FLINK-7477?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347685#comment-16347685
]
Ken Krugler commented on FLINK-7477:
I posted to the mailing list about an issue that this change seemed to create
for me, but didn't hear back.
{quote}With Flink 1.4 and FLINK-7477, I ran into a problem with jar versions
for HttpCore, when using the AWS SDK to read from S3.
I believe the issue is that even when setting classloader.resolve-order to
child-first in flink-conf.yaml, the change to put all jars returned by “hadoop
classpath” on the classpath means that classes in these jars are found before
the classes in my shaded Flink uber jar.
If I ensure that I don’t have the “hadoop” command set up on my Bash path, then
I don’t run into this issue.
Does this make sense, or is there something else going on that I can fix to
avoid this situation?{quote}
Any input? Thanks...Ken
> Use "hadoop classpath" to augment classpath when available
> --
>
> Key: FLINK-7477
> URL: https://issues.apache.org/jira/browse/FLINK-7477
> Project: Flink
> Issue Type: Bug
> Components: Startup Shell Scripts
>Reporter: Aljoscha Krettek
>Assignee: Aljoscha Krettek
>Priority: Major
> Fix For: 1.4.0
>
>
> Currently, some cloud environments don't properly put the Hadoop jars into
> {{HADOOP_CLASSPATH}} (or don't set {{HADOOP_CLASSPATH}}) at all. We should
> check in {{config.sh}} if the {{hadoop}} binary is on the path and augment
> our {{INTERNAL_HADOOP_CLASSPATHS}} with the result of {{hadoop classpath}} in
> our scripts.
> This will improve the out-of-box experience of users that otherwise have to
> manually set {{HADOOP_CLASSPATH}}.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-8101) Elasticsearch 6.x support
[
https://issues.apache.org/jira/browse/FLINK-8101?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347610#comment-16347610
]
ASF GitHub Bot commented on FLINK-8101:
---
Github user cjolif commented on a diff in the pull request:
https://github.com/apache/flink/pull/5374#discussion_r165186422
--- Diff:
flink-connectors/flink-connector-elasticsearch5.3/src/main/java/org/apache/flink/streaming/connectors/elasticsearch53/BulkProcessorIndexer.java
---
@@ -0,0 +1,57 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.streaming.connectors.elasticsearch53;
+
+import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
+
+import org.elasticsearch.action.ActionRequest;
+import org.elasticsearch.action.DocWriteRequest;
+import org.elasticsearch.action.bulk.BulkProcessor;
+
+import java.util.concurrent.atomic.AtomicLong;
+
+/**
+ * Implementation of a {@link RequestIndexer}, using a {@link
BulkProcessor}.
+ * {@link ActionRequest ActionRequests} will be converted to {@link
DocWriteRequest}
+ * and will be buffered before sending a bulk request to the Elasticsearch
cluster.
+ */
+public class BulkProcessorIndexer implements RequestIndexer {
+
+ private final BulkProcessor bulkProcessor;
+ private final boolean flushOnCheckpoint;
+ private final AtomicLong numPendingRequestsRef;
+
+ public BulkProcessorIndexer(BulkProcessor bulkProcessor,
+ boolean
flushOnCheckpoint,
+ AtomicLong
numPendingRequests) {
+ this.bulkProcessor = bulkProcessor;
+ this.flushOnCheckpoint = flushOnCheckpoint;
+ this.numPendingRequestsRef = numPendingRequests;
+ }
+
+ @Override
+ public void add(ActionRequest... actionRequests) {
+ for (ActionRequest actionRequest : actionRequests) {
+ if (flushOnCheckpoint) {
+ numPendingRequestsRef.getAndIncrement();
+ }
+ this.bulkProcessor.add((DocWriteRequest) actionRequest);
--- End diff --
This is actually from the commit I brought into the PR from orignal
@zjureel's PR. That said I think the answer is definitely yes in the case that
matters for Flink. Indeed:
* The ActionRequest values here are actually coming from the implementation
of the `ElasticsearchSinkFunction.process` method which should create
`ActionRequest` and add them to the indexer.
* The idea here is not to create any sort of `ActionRequest` you would
possibly dream of but indexing requests?
* The way to create `ActionRequest` for indexing in Elasticsearch is to use
`org.elasticsearch.action.index.IndexRequest`
* starting with Elasticsearch 5.3 IndexRequest inherits from
`DocWriteRequest` while it was not before 5.3.
See:
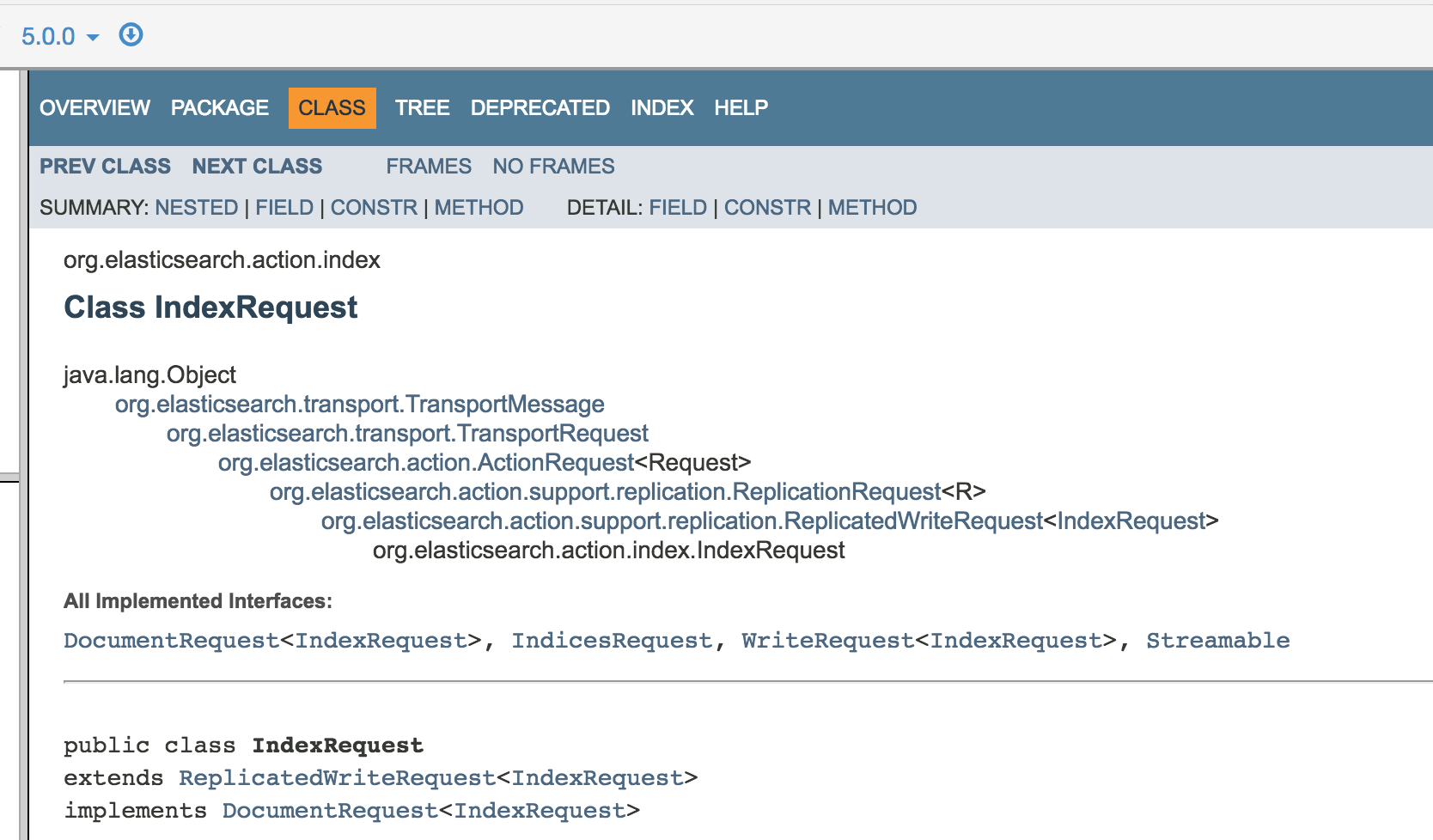
vs

So the only case I see where this could not be a `DocWriteRequest` would be
if someone in the `ElasticsearchSinkFunction` would create something else than
an index request. But I don't really see why?
That said this raises the question of why from the origin the API was not
typed against `IndexRequest` instead of `ActionRequest` as this would avoid
those questions and force the user to return a `IndexRequest`?
In every case there is little choice because starting with 5.3
Elasticsearch does not accept ActionRequest in BulkProcessor anymore but just
IndexRequest/DocWriteRequest.
Do you have a suggestion on how to handle this better? Obviously I can add
documentation saying starting with 5.3 the sink function MUST return
[GitHub] flink pull request #5374: [FLINK-8101][flink-connectors] Elasticsearch 5.3+ ...
Github user cjolif commented on a diff in the pull request:
https://github.com/apache/flink/pull/5374#discussion_r165186422
--- Diff:
flink-connectors/flink-connector-elasticsearch5.3/src/main/java/org/apache/flink/streaming/connectors/elasticsearch53/BulkProcessorIndexer.java
---
@@ -0,0 +1,57 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.streaming.connectors.elasticsearch53;
+
+import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
+
+import org.elasticsearch.action.ActionRequest;
+import org.elasticsearch.action.DocWriteRequest;
+import org.elasticsearch.action.bulk.BulkProcessor;
+
+import java.util.concurrent.atomic.AtomicLong;
+
+/**
+ * Implementation of a {@link RequestIndexer}, using a {@link
BulkProcessor}.
+ * {@link ActionRequest ActionRequests} will be converted to {@link
DocWriteRequest}
+ * and will be buffered before sending a bulk request to the Elasticsearch
cluster.
+ */
+public class BulkProcessorIndexer implements RequestIndexer {
+
+ private final BulkProcessor bulkProcessor;
+ private final boolean flushOnCheckpoint;
+ private final AtomicLong numPendingRequestsRef;
+
+ public BulkProcessorIndexer(BulkProcessor bulkProcessor,
+ boolean
flushOnCheckpoint,
+ AtomicLong
numPendingRequests) {
+ this.bulkProcessor = bulkProcessor;
+ this.flushOnCheckpoint = flushOnCheckpoint;
+ this.numPendingRequestsRef = numPendingRequests;
+ }
+
+ @Override
+ public void add(ActionRequest... actionRequests) {
+ for (ActionRequest actionRequest : actionRequests) {
+ if (flushOnCheckpoint) {
+ numPendingRequestsRef.getAndIncrement();
+ }
+ this.bulkProcessor.add((DocWriteRequest) actionRequest);
--- End diff --
This is actually from the commit I brought into the PR from orignal
@zjureel's PR. That said I think the answer is definitely yes in the case that
matters for Flink. Indeed:
* The ActionRequest values here are actually coming from the implementation
of the `ElasticsearchSinkFunction.process` method which should create
`ActionRequest` and add them to the indexer.
* The idea here is not to create any sort of `ActionRequest` you would
possibly dream of but indexing requests?
* The way to create `ActionRequest` for indexing in Elasticsearch is to use
`org.elasticsearch.action.index.IndexRequest`
* starting with Elasticsearch 5.3 IndexRequest inherits from
`DocWriteRequest` while it was not before 5.3.
See:

vs

So the only case I see where this could not be a `DocWriteRequest` would be
if someone in the `ElasticsearchSinkFunction` would create something else than
an index request. But I don't really see why?
That said this raises the question of why from the origin the API was not
typed against `IndexRequest` instead of `ActionRequest` as this would avoid
those questions and force the user to return a `IndexRequest`?
In every case there is little choice because starting with 5.3
Elasticsearch does not accept ActionRequest in BulkProcessor anymore but just
IndexRequest/DocWriteRequest.
Do you have a suggestion on how to handle this better? Obviously I can add
documentation saying starting with 5.3 the sink function MUST return
DocWriteRequest? But is that enough for you?
---
[jira] [Commented] (FLINK-7608) LatencyGauge change to histogram metric
[
https://issues.apache.org/jira/browse/FLINK-7608?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347515#comment-16347515
]
ASF GitHub Bot commented on FLINK-7608:
---
Github user zentol commented on the issue:
https://github.com/apache/flink/pull/5161
Correction: We still can't display them in the UI since we have no tab for
job metrics.
> LatencyGauge change to histogram metric
>
>
> Key: FLINK-7608
> URL: https://issues.apache.org/jira/browse/FLINK-7608
> Project: Flink
> Issue Type: Bug
> Components: Metrics
>Reporter: Hai Zhou UTC+8
>Assignee: Hai Zhou UTC+8
>Priority: Major
> Fix For: 1.5.0
>
>
> I used slf4jReporter[https://issues.apache.org/jira/browse/FLINK-4831] to
> export metrics the log file.
> I found:
> {noformat}
> -- Gauges
> -
> ..
> zhouhai-mbp.taskmanager.f3fd3a269c8c3da4e8319c8f6a201a57.Flink Streaming
> Job.Map.0.latency:
> value={LatencySourceDescriptor{vertexID=1, subtaskIndex=-1}={p99=116.0,
> p50=59.5, min=11.0, max=116.0, p95=116.0, mean=61.836}}
> zhouhai-mbp.taskmanager.f3fd3a269c8c3da4e8319c8f6a201a57.Flink Streaming
> Job.Sink- Unnamed.0.latency:
> value={LatencySourceDescriptor{vertexID=1, subtaskIndex=0}={p99=195.0,
> p50=163.5, min=115.0, max=195.0, p95=195.0, mean=161.0}}
> ..
> {noformat}
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink issue #5161: [FLINK-7608][metric] Refactor latency statistics metric
Github user zentol commented on the issue: https://github.com/apache/flink/pull/5161 Correction: We still can't display them in the UI since we have no tab for job metrics. ---
[jira] [Commented] (FLINK-7856) Port JobVertexBackPressureHandler to REST endpoint
[ https://issues.apache.org/jira/browse/FLINK-7856?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347418#comment-16347418 ] ASF GitHub Bot commented on FLINK-7856: --- Github user GJL commented on a diff in the pull request: https://github.com/apache/flink/pull/5397#discussion_r165155912 --- Diff: flink-runtime/src/main/java/org/apache/flink/runtime/rest/handler/legacy/backpressure/BackPressureStatsTracker.java --- @@ -74,7 +74,7 @@ static final String EXPECTED_CLASS_NAME = "org.apache.flink.runtime.io.network.buffer.LocalBufferPool"; /** Expected method name for back pressure indicating stack trace element. */ - static final String EXPECTED_METHOD_NAME = "requestBufferBlocking"; + static final String EXPECTED_METHOD_NAME = "requestBufferBuilderBlocking"; --- End diff -- Requires a follow up ticket to make it less fragile. > Port JobVertexBackPressureHandler to REST endpoint > -- > > Key: FLINK-7856 > URL: https://issues.apache.org/jira/browse/FLINK-7856 > Project: Flink > Issue Type: Sub-task > Components: Distributed Coordination, REST, Webfrontend >Reporter: Fang Yong >Assignee: Gary Yao >Priority: Major > > Port JobVertexBackPressureHandler to REST endpoint -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink pull request #5397: [FLINK-7856][flip6] WIP
Github user GJL commented on a diff in the pull request: https://github.com/apache/flink/pull/5397#discussion_r165155912 --- Diff: flink-runtime/src/main/java/org/apache/flink/runtime/rest/handler/legacy/backpressure/BackPressureStatsTracker.java --- @@ -74,7 +74,7 @@ static final String EXPECTED_CLASS_NAME = "org.apache.flink.runtime.io.network.buffer.LocalBufferPool"; /** Expected method name for back pressure indicating stack trace element. */ - static final String EXPECTED_METHOD_NAME = "requestBufferBlocking"; + static final String EXPECTED_METHOD_NAME = "requestBufferBuilderBlocking"; --- End diff -- Requires a follow up ticket to make it less fragile. ---
[jira] [Commented] (FLINK-7856) Port JobVertexBackPressureHandler to REST endpoint
[
https://issues.apache.org/jira/browse/FLINK-7856?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347417#comment-16347417
]
ASF GitHub Bot commented on FLINK-7856:
---
Github user GJL commented on a diff in the pull request:
https://github.com/apache/flink/pull/5397#discussion_r165155639
--- Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/rest/messages/JobVertexBackPressureInfo.java
---
@@ -0,0 +1,184 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.rest.messages;
+
+import
org.apache.flink.runtime.rest.handler.job.JobVertexBackPressureHandler;
+
+import
org.apache.flink.shaded.jackson2.com.fasterxml.jackson.annotation.JsonCreator;
+import
org.apache.flink.shaded.jackson2.com.fasterxml.jackson.annotation.JsonInclude;
+import
org.apache.flink.shaded.jackson2.com.fasterxml.jackson.annotation.JsonProperty;
+import
org.apache.flink.shaded.jackson2.com.fasterxml.jackson.annotation.JsonValue;
+
+import java.util.List;
+import java.util.Objects;
+
+import static org.apache.flink.util.Preconditions.checkNotNull;
+
+/**
+ * Response type of the {@link JobVertexBackPressureHandler}.
+ */
+@JsonInclude(JsonInclude.Include.NON_NULL)
+public class JobVertexBackPressureInfo implements ResponseBody {
+
+ public static final String FIELD_NAME_STATUS = "status";
+ public static final String FIELD_NAME_BACKPRESSURE_LEVEL =
"backpressure-level";
+ public static final String FIELD_NAME_END_TIMESTAMP = "end-timestamp";
+ public static final String FIELD_NAME_SUBTASKS = "subtasks";
+
+ @JsonProperty(FIELD_NAME_STATUS)
+ private final VertexBackPressureStatus status;
+
+ @JsonProperty(FIELD_NAME_BACKPRESSURE_LEVEL)
+ private final VertexBackPressureLevel backpressureLevel;
+
+ @JsonProperty(FIELD_NAME_END_TIMESTAMP)
+ private final Long endTimestamp;
+
+ @JsonProperty(FIELD_NAME_SUBTASKS)
+ protected final List subtasks;
+
+ @JsonCreator
+ public JobVertexBackPressureInfo(
+ @JsonProperty(FIELD_NAME_STATUS) VertexBackPressureStatus
status,
+ @JsonProperty(FIELD_NAME_BACKPRESSURE_LEVEL)
VertexBackPressureLevel backpressureLevel,
+ @JsonProperty(FIELD_NAME_END_TIMESTAMP) Long endTimestamp,
+ @JsonProperty(FIELD_NAME_SUBTASKS)
List subtasks) {
+ this.status = status;
+ this.backpressureLevel = backpressureLevel;
+ this.endTimestamp = endTimestamp;
+ this.subtasks = subtasks;
+ }
+
+ public static JobVertexBackPressureInfo deprecated() {
+ return new JobVertexBackPressureInfo(
+ VertexBackPressureStatus.DEPRECATED,
+ null,
+ null,
+ null);
+ }
+
+ @Override
+ public boolean equals(Object o) {
+ if (this == o) {
+ return true;
+ }
+ if (o == null || getClass() != o.getClass()) {
+ return false;
+ }
+ JobVertexBackPressureInfo that = (JobVertexBackPressureInfo) o;
+ return Objects.equals(status, that.status) &&
+ Objects.equals(backpressureLevel,
that.backpressureLevel) &&
+ Objects.equals(endTimestamp, that.endTimestamp) &&
+ Objects.equals(subtasks, that.subtasks);
+ }
+
+ @Override
+ public int hashCode() {
+ return Objects.hash(status, backpressureLevel, endTimestamp,
subtasks);
+ }
+
+
//-
+ // Static helper classes
+
//-
+
+ /**
+* Nested class to encapsulate the sub tasks back
[GitHub] flink pull request #5397: [FLINK-7856][flip6] WIP
Github user GJL commented on a diff in the pull request:
https://github.com/apache/flink/pull/5397#discussion_r165155639
--- Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/rest/messages/JobVertexBackPressureInfo.java
---
@@ -0,0 +1,184 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.runtime.rest.messages;
+
+import
org.apache.flink.runtime.rest.handler.job.JobVertexBackPressureHandler;
+
+import
org.apache.flink.shaded.jackson2.com.fasterxml.jackson.annotation.JsonCreator;
+import
org.apache.flink.shaded.jackson2.com.fasterxml.jackson.annotation.JsonInclude;
+import
org.apache.flink.shaded.jackson2.com.fasterxml.jackson.annotation.JsonProperty;
+import
org.apache.flink.shaded.jackson2.com.fasterxml.jackson.annotation.JsonValue;
+
+import java.util.List;
+import java.util.Objects;
+
+import static org.apache.flink.util.Preconditions.checkNotNull;
+
+/**
+ * Response type of the {@link JobVertexBackPressureHandler}.
+ */
+@JsonInclude(JsonInclude.Include.NON_NULL)
+public class JobVertexBackPressureInfo implements ResponseBody {
+
+ public static final String FIELD_NAME_STATUS = "status";
+ public static final String FIELD_NAME_BACKPRESSURE_LEVEL =
"backpressure-level";
+ public static final String FIELD_NAME_END_TIMESTAMP = "end-timestamp";
+ public static final String FIELD_NAME_SUBTASKS = "subtasks";
+
+ @JsonProperty(FIELD_NAME_STATUS)
+ private final VertexBackPressureStatus status;
+
+ @JsonProperty(FIELD_NAME_BACKPRESSURE_LEVEL)
+ private final VertexBackPressureLevel backpressureLevel;
+
+ @JsonProperty(FIELD_NAME_END_TIMESTAMP)
+ private final Long endTimestamp;
+
+ @JsonProperty(FIELD_NAME_SUBTASKS)
+ protected final List subtasks;
+
+ @JsonCreator
+ public JobVertexBackPressureInfo(
+ @JsonProperty(FIELD_NAME_STATUS) VertexBackPressureStatus
status,
+ @JsonProperty(FIELD_NAME_BACKPRESSURE_LEVEL)
VertexBackPressureLevel backpressureLevel,
+ @JsonProperty(FIELD_NAME_END_TIMESTAMP) Long endTimestamp,
+ @JsonProperty(FIELD_NAME_SUBTASKS)
List subtasks) {
+ this.status = status;
+ this.backpressureLevel = backpressureLevel;
+ this.endTimestamp = endTimestamp;
+ this.subtasks = subtasks;
+ }
+
+ public static JobVertexBackPressureInfo deprecated() {
+ return new JobVertexBackPressureInfo(
+ VertexBackPressureStatus.DEPRECATED,
+ null,
+ null,
+ null);
+ }
+
+ @Override
+ public boolean equals(Object o) {
+ if (this == o) {
+ return true;
+ }
+ if (o == null || getClass() != o.getClass()) {
+ return false;
+ }
+ JobVertexBackPressureInfo that = (JobVertexBackPressureInfo) o;
+ return Objects.equals(status, that.status) &&
+ Objects.equals(backpressureLevel,
that.backpressureLevel) &&
+ Objects.equals(endTimestamp, that.endTimestamp) &&
+ Objects.equals(subtasks, that.subtasks);
+ }
+
+ @Override
+ public int hashCode() {
+ return Objects.hash(status, backpressureLevel, endTimestamp,
subtasks);
+ }
+
+
//-
+ // Static helper classes
+
//-
+
+ /**
+* Nested class to encapsulate the sub tasks back pressure.
+*/
+ public static final class SubtaskBackPressureInfo {
+
+ public static final String FIELD_NAME_SUBTASK = "subtask";
+ public static final String FIELD_NAME_BACKPRESSURE_LEVEL =
"backpressure-lev
[jira] [Commented] (FLINK-7856) Port JobVertexBackPressureHandler to REST endpoint
[ https://issues.apache.org/jira/browse/FLINK-7856?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347414#comment-16347414 ] ASF GitHub Bot commented on FLINK-7856: --- Github user GJL commented on a diff in the pull request: https://github.com/apache/flink/pull/5397#discussion_r165155368 --- Diff: flink-runtime/src/test/java/org/apache/flink/runtime/taskexecutor/TestingTaskExecutorGateway.java --- @@ -75,6 +76,17 @@ public void setDisconnectJobManagerConsumer(Consumer> d return CompletableFuture.completedFuture(Acknowledge.get()); } + @Override + public CompletableFuture requestStackTraceSample( --- End diff -- Needs to be implemented > Port JobVertexBackPressureHandler to REST endpoint > -- > > Key: FLINK-7856 > URL: https://issues.apache.org/jira/browse/FLINK-7856 > Project: Flink > Issue Type: Sub-task > Components: Distributed Coordination, REST, Webfrontend >Reporter: Fang Yong >Assignee: Gary Yao >Priority: Major > > Port JobVertexBackPressureHandler to REST endpoint -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink pull request #5397: [FLINK-7856][flip6] WIP
Github user GJL commented on a diff in the pull request: https://github.com/apache/flink/pull/5397#discussion_r165155368 --- Diff: flink-runtime/src/test/java/org/apache/flink/runtime/taskexecutor/TestingTaskExecutorGateway.java --- @@ -75,6 +76,17 @@ public void setDisconnectJobManagerConsumer(Consumer> d return CompletableFuture.completedFuture(Acknowledge.get()); } + @Override + public CompletableFuture requestStackTraceSample( --- End diff -- Needs to be implemented ---
[jira] [Commented] (FLINK-7856) Port JobVertexBackPressureHandler to REST endpoint
[ https://issues.apache.org/jira/browse/FLINK-7856?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347413#comment-16347413 ] ASF GitHub Bot commented on FLINK-7856: --- GitHub user GJL opened a pull request: https://github.com/apache/flink/pull/5397 [FLINK-7856][flip6] WIP WIP PR is based on #4893 @tillrohrmann You can merge this pull request into a Git repository by running: $ git pull https://github.com/GJL/flink FLINK-7856-3 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/5397.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5397 commit bea6bf16b2cac1a8da1f3d28432798965b64cea9 Author: zjureel Date: 2017-11-15T05:55:28Z [FLINK-7856][flip6] Port JobVertexBackPressureHandler to REST endpoint commit 968f0dfe8a3c6832b0e6a83c5c61eaa1fd886c1b Author: gyao Date: 2018-01-31T19:01:24Z [hotfix][tests] Add Javadocs to JobMasterTest Add Javadocs to JobMasterTest. Remove debug print. commit 6140fa6f460491bbe0eaf19d15b8a2f5d81622a0 Author: gyao Date: 2018-01-31T19:02:59Z [FLINK-7856][flip6] Implement JobVertexBackPressureHandler commit 4625a637fa0a17a0ea0a3a48952d562a29fa5c06 Author: gyao Date: 2018-01-31T19:06:09Z [hotfix] Log swallowed exception in JobMaster > Port JobVertexBackPressureHandler to REST endpoint > -- > > Key: FLINK-7856 > URL: https://issues.apache.org/jira/browse/FLINK-7856 > Project: Flink > Issue Type: Sub-task > Components: Distributed Coordination, REST, Webfrontend >Reporter: Fang Yong >Assignee: Gary Yao >Priority: Major > > Port JobVertexBackPressureHandler to REST endpoint -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink pull request #5397: [FLINK-7856][flip6] WIP
GitHub user GJL opened a pull request: https://github.com/apache/flink/pull/5397 [FLINK-7856][flip6] WIP WIP PR is based on #4893 @tillrohrmann You can merge this pull request into a Git repository by running: $ git pull https://github.com/GJL/flink FLINK-7856-3 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/5397.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5397 commit bea6bf16b2cac1a8da1f3d28432798965b64cea9 Author: zjureel Date: 2017-11-15T05:55:28Z [FLINK-7856][flip6] Port JobVertexBackPressureHandler to REST endpoint commit 968f0dfe8a3c6832b0e6a83c5c61eaa1fd886c1b Author: gyao Date: 2018-01-31T19:01:24Z [hotfix][tests] Add Javadocs to JobMasterTest Add Javadocs to JobMasterTest. Remove debug print. commit 6140fa6f460491bbe0eaf19d15b8a2f5d81622a0 Author: gyao Date: 2018-01-31T19:02:59Z [FLINK-7856][flip6] Implement JobVertexBackPressureHandler commit 4625a637fa0a17a0ea0a3a48952d562a29fa5c06 Author: gyao Date: 2018-01-31T19:06:09Z [hotfix] Log swallowed exception in JobMaster ---
[GitHub] flink issue #5395: [FLINK-8308] Remove explicit yajl-ruby dependency, update...
Github user StevenLangbroek commented on the issue: https://github.com/apache/flink/pull/5395 https://github.com/apache/calcite/tree/master/site#setup ---
[jira] [Commented] (FLINK-8308) Update yajl-ruby dependency to 1.3.1 or higher
[ https://issues.apache.org/jira/browse/FLINK-8308?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347348#comment-16347348 ] ASF GitHub Bot commented on FLINK-8308: --- Github user StevenLangbroek commented on the issue: https://github.com/apache/flink/pull/5395 https://github.com/apache/calcite/tree/master/site#setup > Update yajl-ruby dependency to 1.3.1 or higher > -- > > Key: FLINK-8308 > URL: https://issues.apache.org/jira/browse/FLINK-8308 > Project: Flink > Issue Type: Task > Components: Project Website >Reporter: Fabian Hueske >Assignee: Steven Langbroek >Priority: Critical > Fix For: 1.5.0, 1.4.1 > > > We got notified that yajl-ruby < 1.3.1, a dependency which is used to build > the Flink website, has a security vulnerability of high severity. > We should update yajl-ruby to 1.3.1 or higher. > Since the website is built offline and served as static HTML, I don't think > this is a super critical issue (please correct me if I'm wrong), but we > should resolve this soon. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-8308) Update yajl-ruby dependency to 1.3.1 or higher
[ https://issues.apache.org/jira/browse/FLINK-8308?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347314#comment-16347314 ] ASF GitHub Bot commented on FLINK-8308: --- Github user alpinegizmo commented on the issue: https://github.com/apache/flink/pull/5395 It would be lovely to ditch ruby 1.9. However, if I understand correctly, we don't fully control the environment that builds the docs, and the last time we tried this we couldn't get a newer ruby there. But it has been a while, and maybe the ASF infrastructure folks have seen the light. @rmetzger Can we somehow determine what ruby version is running on the build machines? > Update yajl-ruby dependency to 1.3.1 or higher > -- > > Key: FLINK-8308 > URL: https://issues.apache.org/jira/browse/FLINK-8308 > Project: Flink > Issue Type: Task > Components: Project Website >Reporter: Fabian Hueske >Assignee: Steven Langbroek >Priority: Critical > Fix For: 1.5.0, 1.4.1 > > > We got notified that yajl-ruby < 1.3.1, a dependency which is used to build > the Flink website, has a security vulnerability of high severity. > We should update yajl-ruby to 1.3.1 or higher. > Since the website is built offline and served as static HTML, I don't think > this is a super critical issue (please correct me if I'm wrong), but we > should resolve this soon. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-8357) enable rolling in default log settings
[
https://issues.apache.org/jira/browse/FLINK-8357?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347312#comment-16347312
]
ASF GitHub Bot commented on FLINK-8357:
---
Github user XuMingmin commented on a diff in the pull request:
https://github.com/apache/flink/pull/5371#discussion_r165141492
--- Diff: flink-dist/src/main/flink-bin/conf/logback.xml ---
@@ -17,8 +17,14 @@
-->
-
+
${log.file}
+
+
+
logFile.%d{-MM-dd}.log
--- End diff --
ditto
> enable rolling in default log settings
> --
>
> Key: FLINK-8357
> URL: https://issues.apache.org/jira/browse/FLINK-8357
> Project: Flink
> Issue Type: Improvement
> Components: Logging
>Reporter: Xu Mingmin
>Assignee: mingleizhang
>Priority: Major
> Fix For: 1.5.0
>
>
> The release packages uses {{org.apache.log4j.FileAppender}} for log4j and
> {{ch.qos.logback.core.FileAppender}} for logback, which could results in very
> large log files.
> For most cases, if not all, we need to enable rotation in a production
> cluster, and I suppose it's a good idea to make rotation as default.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-8357) enable rolling in default log settings
[
https://issues.apache.org/jira/browse/FLINK-8357?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347311#comment-16347311
]
ASF GitHub Bot commented on FLINK-8357:
---
Github user XuMingmin commented on a diff in the pull request:
https://github.com/apache/flink/pull/5371#discussion_r165141378
--- Diff: flink-dist/src/main/flink-bin/conf/logback-yarn.xml ---
@@ -17,8 +17,14 @@
-->
-
+
${log.file}
+
+
+
logFile.%d{-MM-dd}.log
--- End diff --
should it be
`${log.file}.%d{-MM-dd}`?
> enable rolling in default log settings
> --
>
> Key: FLINK-8357
> URL: https://issues.apache.org/jira/browse/FLINK-8357
> Project: Flink
> Issue Type: Improvement
> Components: Logging
>Reporter: Xu Mingmin
>Assignee: mingleizhang
>Priority: Major
> Fix For: 1.5.0
>
>
> The release packages uses {{org.apache.log4j.FileAppender}} for log4j and
> {{ch.qos.logback.core.FileAppender}} for logback, which could results in very
> large log files.
> For most cases, if not all, we need to enable rotation in a production
> cluster, and I suppose it's a good idea to make rotation as default.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink issue #5395: [FLINK-8308] Remove explicit yajl-ruby dependency, update...
Github user alpinegizmo commented on the issue: https://github.com/apache/flink/pull/5395 It would be lovely to ditch ruby 1.9. However, if I understand correctly, we don't fully control the environment that builds the docs, and the last time we tried this we couldn't get a newer ruby there. But it has been a while, and maybe the ASF infrastructure folks have seen the light. @rmetzger Can we somehow determine what ruby version is running on the build machines? ---
[GitHub] flink pull request #5371: [FLINK-8357] [conf] Enable rolling in default log ...
Github user XuMingmin commented on a diff in the pull request:
https://github.com/apache/flink/pull/5371#discussion_r165141492
--- Diff: flink-dist/src/main/flink-bin/conf/logback.xml ---
@@ -17,8 +17,14 @@
-->
-
+
${log.file}
+
+
+
logFile.%d{-MM-dd}.log
--- End diff --
ditto
---
[GitHub] flink pull request #5371: [FLINK-8357] [conf] Enable rolling in default log ...
Github user XuMingmin commented on a diff in the pull request:
https://github.com/apache/flink/pull/5371#discussion_r165141378
--- Diff: flink-dist/src/main/flink-bin/conf/logback-yarn.xml ---
@@ -17,8 +17,14 @@
-->
-
+
${log.file}
+
+
+
logFile.%d{-MM-dd}.log
--- End diff --
should it be
`${log.file}.%d{-MM-dd}`?
---
[jira] [Commented] (FLINK-8534) if insert too much BucketEntry into one bucket in join of iteration will cause a error (Caused : java.io.FileNotFoundException release file error)
[ https://issues.apache.org/jira/browse/FLINK-8534?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347155#comment-16347155 ] zhu.qing commented on FLINK-8534: - And Code is attached as a BFS in graph use native flink api. > if insert too much BucketEntry into one bucket in join of iteration will > cause a error (Caused : java.io.FileNotFoundException release file error) > -- > > Key: FLINK-8534 > URL: https://issues.apache.org/jira/browse/FLINK-8534 > Project: Flink > Issue Type: Bug > Components: Local Runtime > Environment: windows, intellij idea, 8g ram, 4core i5 cpu, Flink > 1.4.0, and parallelism = 2 will cause problem and others will not. >Reporter: zhu.qing >Priority: Major > Attachments: T2AdjSetBfs.java > > > When insert too much entry into bucket (MutableHashTable insertBucketEntry() > line 1054 more than 255) will cause spillPartition() (HashPartition line > 317). So > this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, > bufferReturnQueue); > And in > prepareNextPartition() of ReOpenableMutableHashTable (line 156) > furtherPartitioning = true; > so in > finalizeProbePhase() in HashPartition (line 367) > this.probeSideChannel.close(); > //the file will be delete > this.buildSideChannel.deleteChannel(); > this.probeSideChannel.deleteChannel(); > after deleteChannel the next iteartion will fail. > > And I use web-google(SNAP) as dataset. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (FLINK-8534) if insert too much BucketEntry into one bucket in join of iteration will cause a error (Caused : java.io.FileNotFoundException release file error)
[ https://issues.apache.org/jira/browse/FLINK-8534?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] zhu.qing updated FLINK-8534: Description: When insert too much entry into bucket (MutableHashTable insertBucketEntry() line 1054 more than 255) will cause spillPartition() (HashPartition line 317). So this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, bufferReturnQueue); And in prepareNextPartition() of ReOpenableMutableHashTable (line 156) furtherPartitioning = true; so in finalizeProbePhase() in HashPartition (line 367) this.probeSideChannel.close(); //the file will be delete this.buildSideChannel.deleteChannel(); this.probeSideChannel.deleteChannel(); after deleteChannel the next iteartion will fail. And I use web-google(SNAP) as dataset. was: When insert too much entry into bucket (MutableHashTable line 1054 more than 255 ) will cause spillPartition() (HashPartition line 317). So this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, bufferReturnQueue); And in prepareNextPartition() of ReOpenableMutableHashTable (line 156) furtherPartitioning = true; so in finalizeProbePhase() in HashPartition (line 367) this.probeSideChannel.close(); //the file will be delete this.buildSideChannel.deleteChannel(); this.probeSideChannel.deleteChannel(); after deleteChannel the next iteartion will fail. And I use web-google(SNAP) as dataset. > if insert too much BucketEntry into one bucket in join of iteration will > cause a error (Caused : java.io.FileNotFoundException release file error) > -- > > Key: FLINK-8534 > URL: https://issues.apache.org/jira/browse/FLINK-8534 > Project: Flink > Issue Type: Bug > Components: Local Runtime > Environment: windows, intellij idea, 8g ram, 4core i5 cpu, Flink > 1.4.0, and parallelism = 2 will cause problem and others will not. >Reporter: zhu.qing >Priority: Major > Attachments: T2AdjSetBfs.java > > > When insert too much entry into bucket (MutableHashTable insertBucketEntry() > line 1054 more than 255) will cause spillPartition() (HashPartition line > 317). So > this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, > bufferReturnQueue); > And in > prepareNextPartition() of ReOpenableMutableHashTable (line 156) > furtherPartitioning = true; > so in > finalizeProbePhase() in HashPartition (line 367) > this.probeSideChannel.close(); > //the file will be delete > this.buildSideChannel.deleteChannel(); > this.probeSideChannel.deleteChannel(); > after deleteChannel the next iteartion will fail. > > And I use web-google(SNAP) as dataset. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (FLINK-8534) if insert too much BucketEntry into one bucket in join of iteration will cause a error (Caused : java.io.FileNotFoundException release file error)
[ https://issues.apache.org/jira/browse/FLINK-8534?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] zhu.qing updated FLINK-8534: Description: When insert too much entry into bucket (MutableHashTable line 1054 more than 255 ) will cause spillPartition() (HashPartition line 317). So this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, bufferReturnQueue); And in prepareNextPartition() of ReOpenableMutableHashTable (line 156) furtherPartitioning = true; so in finalizeProbePhase() in HashPartition (line 367) this.probeSideChannel.close(); //the file will be delete this.buildSideChannel.deleteChannel(); this.probeSideChannel.deleteChannel(); after deleteChannel the next iteartion will fail. And I use web-google(SNAP) as dataset. was: When insert too much entry into bucket (MutableHashTable line 1054 more than 255 ) will cause spillPartition() (HashPartition line 317). So this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, bufferReturnQueue); And in prepareNextPartition() of ReOpenableMutableHashTable (line 156) furtherPartitioning = true; so in finalizeProbePhase() in HashPartition (line 367) this.probeSideChannel.close(); //the file will be delete this.buildSideChannel.deleteChannel(); this.probeSideChannel.deleteChannel(); after deleteChannel the next iteartion will fail. And I use web-google as dataset(SNAP). > if insert too much BucketEntry into one bucket in join of iteration will > cause a error (Caused : java.io.FileNotFoundException release file error) > -- > > Key: FLINK-8534 > URL: https://issues.apache.org/jira/browse/FLINK-8534 > Project: Flink > Issue Type: Bug > Components: Local Runtime > Environment: windows, intellij idea, 8g ram, 4core i5 cpu, Flink > 1.4.0, and parallelism = 2 will cause problem and others will not. >Reporter: zhu.qing >Priority: Major > Attachments: T2AdjSetBfs.java > > > When insert too much entry into bucket (MutableHashTable line 1054 more than > 255 ) will cause spillPartition() (HashPartition line 317). So > this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, > bufferReturnQueue); > And in > prepareNextPartition() of ReOpenableMutableHashTable (line 156) > furtherPartitioning = true; > so in > finalizeProbePhase() in HashPartition (line 367) > this.probeSideChannel.close(); > //the file will be delete > this.buildSideChannel.deleteChannel(); > this.probeSideChannel.deleteChannel(); > after deleteChannel the next iteartion will fail. > > And I use web-google(SNAP) as dataset. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-8360) Implement task-local state recovery
[
https://issues.apache.org/jira/browse/FLINK-8360?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347147#comment-16347147
]
ASF GitHub Bot commented on FLINK-8360:
---
Github user tillrohrmann commented on a diff in the pull request:
https://github.com/apache/flink/pull/5239#discussion_r165112749
--- Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/state/StateSnapshotContextSynchronousImpl.java
---
@@ -130,7 +136,7 @@ public OperatorStateCheckpointOutputStream
getRawOperatorStateOutput() throws Ex
}
private void closeAndUnregisterStream(
- NonClosingCheckpointOutputStream stream) throws IOException {
+ NonClosingCheckpointOutputStream stream) throws
IOException {
--- End diff --
Should be sufficient to have `NonClosingCheckpointOutputStream`
> Implement task-local state recovery
> ---
>
> Key: FLINK-8360
> URL: https://issues.apache.org/jira/browse/FLINK-8360
> Project: Flink
> Issue Type: New Feature
> Components: State Backends, Checkpointing
>Reporter: Stefan Richter
>Assignee: Stefan Richter
>Priority: Major
> Fix For: 1.5.0
>
>
> This issue tracks the development of recovery from task-local state. The main
> idea is to have a secondary, local copy of the checkpointed state, while
> there is still a primary copy in DFS that we report to the checkpoint
> coordinator.
> Recovery can attempt to restore from the secondary local copy, if available,
> to save network bandwidth. This requires that the assignment from tasks to
> slots is as sticky is possible.
> For starters, we will implement this feature for all managed keyed states and
> can easily enhance it to all other state types (e.g. operator state) later.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #5239: [FLINK-8360] Implement task-local state recovery
Github user tillrohrmann commented on a diff in the pull request:
https://github.com/apache/flink/pull/5239#discussion_r165112749
--- Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/state/StateSnapshotContextSynchronousImpl.java
---
@@ -130,7 +136,7 @@ public OperatorStateCheckpointOutputStream
getRawOperatorStateOutput() throws Ex
}
private void closeAndUnregisterStream(
- NonClosingCheckpointOutputStream stream) throws IOException {
+ NonClosingCheckpointOutputStream stream) throws
IOException {
--- End diff --
Should be sufficient to have `NonClosingCheckpointOutputStream`
---
[jira] [Commented] (FLINK-8101) Elasticsearch 6.x support
[
https://issues.apache.org/jira/browse/FLINK-8101?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347137#comment-16347137
]
ASF GitHub Bot commented on FLINK-8101:
---
Github user cjolif commented on a diff in the pull request:
https://github.com/apache/flink/pull/5374#discussion_r165109918
--- Diff:
flink-connectors/flink-connector-elasticsearch5.3/src/main/java/org/apache/flink/streaming/connectors/elasticsearch53/Elasticsearch53ApiCallBridge.java
---
@@ -0,0 +1,138 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.streaming.connectors.elasticsearch53;
+
+import
org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchApiCallBridge;
+import
org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkBase;
+import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
+import
org.apache.flink.streaming.connectors.elasticsearch.util.ElasticsearchUtils;
+import org.apache.flink.util.Preconditions;
+
+import org.elasticsearch.action.bulk.BackoffPolicy;
+import org.elasticsearch.action.bulk.BulkItemResponse;
+import org.elasticsearch.action.bulk.BulkProcessor;
+import org.elasticsearch.client.Client;
+import org.elasticsearch.client.transport.TransportClient;
+import org.elasticsearch.common.network.NetworkModule;
+import org.elasticsearch.common.settings.Settings;
+import org.elasticsearch.common.transport.TransportAddress;
+import org.elasticsearch.common.unit.TimeValue;
+import org.elasticsearch.transport.Netty3Plugin;
+import org.elasticsearch.transport.client.PreBuiltTransportClient;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nullable;
+
+import java.net.InetSocketAddress;
+import java.util.List;
+import java.util.Map;
+import java.util.concurrent.atomic.AtomicLong;
+
+/**
+ * Implementation of {@link ElasticsearchApiCallBridge} for Elasticsearch
5.3 and later versions.
+ */
+public class Elasticsearch53ApiCallBridge extends
ElasticsearchApiCallBridge {
+
+ private static final long serialVersionUID = -5222683870097809633L;
+
+ private static final Logger LOG =
LoggerFactory.getLogger(Elasticsearch53ApiCallBridge.class);
+
+ /**
+* User-provided transport addresses.
+*
+* We are using {@link InetSocketAddress} because {@link
TransportAddress} is not serializable in Elasticsearch 5.x.
+*/
+ private final List transportAddresses;
+
+ Elasticsearch53ApiCallBridge(List
transportAddresses) {
+ Preconditions.checkArgument(transportAddresses != null &&
!transportAddresses.isEmpty());
+ this.transportAddresses = transportAddresses;
+ }
+
+ @Override
+ public AutoCloseable createClient(Map clientConfig) {
+ Settings settings = Settings.builder().put(clientConfig)
+ .put(NetworkModule.HTTP_TYPE_KEY,
Netty3Plugin.NETTY_HTTP_TRANSPORT_NAME)
+ .put(NetworkModule.TRANSPORT_TYPE_KEY,
Netty3Plugin.NETTY_TRANSPORT_NAME)
+ .build();
+
+ TransportClient transportClient = new
PreBuiltTransportClient(settings);
+ for (TransportAddress transport :
ElasticsearchUtils.convertInetSocketAddresses(transportAddresses)) {
+ transportClient.addTransportAddress(transport);
+ }
+
+ // verify that we actually are connected to a cluster
+ if (transportClient.connectedNodes().isEmpty()) {
+ throw new RuntimeException("Elasticsearch client is not
connected to any Elasticsearch nodes!");
+ }
+
+ if (LOG.isInfoEnabled()) {
--- End diff --
I think this is just a copy/paste of the practices in the other
pre-exisiting bridges ;) But that should be fixed now.
> Elasticsearch 6.x support
> --
[GitHub] flink pull request #5374: [FLINK-8101][flink-connectors] Elasticsearch 5.3+ ...
Github user cjolif commented on a diff in the pull request:
https://github.com/apache/flink/pull/5374#discussion_r165109918
--- Diff:
flink-connectors/flink-connector-elasticsearch5.3/src/main/java/org/apache/flink/streaming/connectors/elasticsearch53/Elasticsearch53ApiCallBridge.java
---
@@ -0,0 +1,138 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.flink.streaming.connectors.elasticsearch53;
+
+import
org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchApiCallBridge;
+import
org.apache.flink.streaming.connectors.elasticsearch.ElasticsearchSinkBase;
+import org.apache.flink.streaming.connectors.elasticsearch.RequestIndexer;
+import
org.apache.flink.streaming.connectors.elasticsearch.util.ElasticsearchUtils;
+import org.apache.flink.util.Preconditions;
+
+import org.elasticsearch.action.bulk.BackoffPolicy;
+import org.elasticsearch.action.bulk.BulkItemResponse;
+import org.elasticsearch.action.bulk.BulkProcessor;
+import org.elasticsearch.client.Client;
+import org.elasticsearch.client.transport.TransportClient;
+import org.elasticsearch.common.network.NetworkModule;
+import org.elasticsearch.common.settings.Settings;
+import org.elasticsearch.common.transport.TransportAddress;
+import org.elasticsearch.common.unit.TimeValue;
+import org.elasticsearch.transport.Netty3Plugin;
+import org.elasticsearch.transport.client.PreBuiltTransportClient;
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import javax.annotation.Nullable;
+
+import java.net.InetSocketAddress;
+import java.util.List;
+import java.util.Map;
+import java.util.concurrent.atomic.AtomicLong;
+
+/**
+ * Implementation of {@link ElasticsearchApiCallBridge} for Elasticsearch
5.3 and later versions.
+ */
+public class Elasticsearch53ApiCallBridge extends
ElasticsearchApiCallBridge {
+
+ private static final long serialVersionUID = -5222683870097809633L;
+
+ private static final Logger LOG =
LoggerFactory.getLogger(Elasticsearch53ApiCallBridge.class);
+
+ /**
+* User-provided transport addresses.
+*
+* We are using {@link InetSocketAddress} because {@link
TransportAddress} is not serializable in Elasticsearch 5.x.
+*/
+ private final List transportAddresses;
+
+ Elasticsearch53ApiCallBridge(List
transportAddresses) {
+ Preconditions.checkArgument(transportAddresses != null &&
!transportAddresses.isEmpty());
+ this.transportAddresses = transportAddresses;
+ }
+
+ @Override
+ public AutoCloseable createClient(Map clientConfig) {
+ Settings settings = Settings.builder().put(clientConfig)
+ .put(NetworkModule.HTTP_TYPE_KEY,
Netty3Plugin.NETTY_HTTP_TRANSPORT_NAME)
+ .put(NetworkModule.TRANSPORT_TYPE_KEY,
Netty3Plugin.NETTY_TRANSPORT_NAME)
+ .build();
+
+ TransportClient transportClient = new
PreBuiltTransportClient(settings);
+ for (TransportAddress transport :
ElasticsearchUtils.convertInetSocketAddresses(transportAddresses)) {
+ transportClient.addTransportAddress(transport);
+ }
+
+ // verify that we actually are connected to a cluster
+ if (transportClient.connectedNodes().isEmpty()) {
+ throw new RuntimeException("Elasticsearch client is not
connected to any Elasticsearch nodes!");
+ }
+
+ if (LOG.isInfoEnabled()) {
--- End diff --
I think this is just a copy/paste of the practices in the other
pre-exisiting bridges ;) But that should be fixed now.
---
[jira] [Commented] (FLINK-5820) Extend State Backend Abstraction to support Global Cleanup Hooks
[ https://issues.apache.org/jira/browse/FLINK-5820?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347136#comment-16347136 ] ASF GitHub Bot commented on FLINK-5820: --- GitHub user StephanEwen opened a pull request: https://github.com/apache/flink/pull/5396 [FLINK-5820] [state backends] Split shared/exclusive state and properly handle disposal ## What is the purpose of the change This PR contains the final changes needed for [FLINK-5820]. Disposal of checkpoint directories happens properly across all file system types (previously did not work properly for some S3 connectors) with reduced calls to the file systems. Shared and exclusive state are split into different directories, to help implement cleanup safety nets. ## Brief change log 1. TaskManagers use the `CheckpointStorage` to create `CheckpointStreamFactories`. Previously, these stream factories were created by the `StateBackend`. This completes the separating out the "storage" aspect of the `StateBackend` into the `CheckpointStorage`. 2. The location where to store state is communicated between the `CheckpointCoordinator` (instantiating the original `CheckpointStorageLocation` for a checkpoint/savepoint) and the Tasks in a unified manner. Tasks transparently obtain their `CheckpointStreamFactories` always in the same way, regardless of whether writing state for checkpoints or savepoints. 3. Checkpoint state now has the scope `EXCLUSIVE` or `SHARED`, which may be stored differently. The current file system based backends put shared state into a */shared* directory, while exclusive state goes into the */chk-1234* directory. 4. Tasks can directly write *task-owned state* to a checkpoint storage. That state neither belongs specifically to one checkpoint, nor is it shared and eventually released by the Checkpoint Coordinator. Only the tasks themselves may release the state. An example for that type of state are the *write ahead logs* created by some sinks. 5. When a checkpoint is finalized, its storage is described by a `CompletedCheckpointStorageLocation`. That object gives access to addressing, metadata, and handles location disposal. This allows us to drop the *"delete parent if empty"* logic in File State Handles and fixes the issue that checkpoint directories are currently left over on S3. **Future Work** - In the future, the `CompletedCheckpointStorageLocation` should also be used as a way to handle relative addressing of checkpoints, to allow users to move them to different directories without breaking the internal paths. - We can now implement disposal fast paths, like drop directory as a whole, rather than dropping each state object separately. However, one would still need to release drop shared state objects individually. Finishing these fast paths is currently blocked on some rework of the shared state handles, to make their selective release easier and more robust. ## Verifying this change This change can be verified by running a Flink cluster with a checkpointed program and This PR also adds and adjusts various unit tests to guard the new behavior. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / no) - The serializers: (yes / no / don't know) - The runtime per-record code paths (performance sensitive): (yes / no / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: (yes / no / don't know) - The S3 file system connector: (yes / no / don't know) ## Documentation - Does this pull request introduce a new feature? *Somewhat* (it changes the state backend directory layouts) - If yes, how is the feature documented? (not applicable / docs / **JavaDocs** / not documented) You can merge this pull request into a Git repository by running: $ git pull https://github.com/StephanEwen/incubator-flink locations Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/5396.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5396 commit ec8e552a7b50b8c605bb2609713cb2dd50245118 Author: Stephan Ewen Date: 2018-01-30T14:53:46Z [hotfix] [checkpointing] Cleanup: Fix Nullability and names in checkpoint stats. commit cf18831b69bd909d6491eb73d3294d3295ddd930 Author: Stephan Ewen Date: 2018-01-30T10:57:30Z [hotfix] [tests] Drop obsolete CheckpointExternalResumeTest. Because all checkpoi
[jira] [Updated] (FLINK-8534) if insert too much BucketEntry into one bucket in join of iteration will cause a error (Caused : java.io.FileNotFoundException release file error)
[ https://issues.apache.org/jira/browse/FLINK-8534?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] zhu.qing updated FLINK-8534: Environment: windows, intellij idea, 8g ram, 4core i5 cpu, Flink 1.4.0, and parallelism = 2 will cause problem and others will not. (was: windows intellij idea 8g ram 4core i5 cpu. Flink 1.4.0) > if insert too much BucketEntry into one bucket in join of iteration will > cause a error (Caused : java.io.FileNotFoundException release file error) > -- > > Key: FLINK-8534 > URL: https://issues.apache.org/jira/browse/FLINK-8534 > Project: Flink > Issue Type: Bug > Components: Local Runtime > Environment: windows, intellij idea, 8g ram, 4core i5 cpu, Flink > 1.4.0, and parallelism = 2 will cause problem and others will not. >Reporter: zhu.qing >Priority: Major > Attachments: T2AdjSetBfs.java > > > When insert too much entry into bucket (MutableHashTable line 1054 more than > 255 ) will cause spillPartition() (HashPartition line 317). So > this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, > bufferReturnQueue); > And in > prepareNextPartition() of ReOpenableMutableHashTable (line 156) > furtherPartitioning = true; > so in > finalizeProbePhase() in HashPartition (line 367) > this.probeSideChannel.close(); > //the file will be delete > this.buildSideChannel.deleteChannel(); > this.probeSideChannel.deleteChannel(); > after deleteChannel the next iteartion will fail. > > And I use web-google as dataset(SNAP). -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-8308) Update yajl-ruby dependency to 1.3.1 or higher
[ https://issues.apache.org/jira/browse/FLINK-8308?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347135#comment-16347135 ] ASF GitHub Bot commented on FLINK-8308: --- GitHub user StevenLangbroek opened a pull request: https://github.com/apache/flink/pull/5395 [FLINK-8308] Remove explicit yajl-ruby dependency, update Jekyll to 3+ ## What is the purpose of the change The docs dependend on `yajl-ruby` 1.2, which had a security defect. Although we don't rely on ruby in our hosting infrastructure, it's best not to have contributors uninstall unsafe software. This PR updates Jekyll, and removes some explicit dependencies in favour of relying on built-in Jekyll dependencies. ## Brief change log * Update Jekyll to 3.7.2 * Remove ruby2 distinction. Docs now depend on ruby 2.1+. Ruby 1.9 is over 10 years old, and OS X ships with 2.3. Maintaining backwards compatibility seems undesirable to me. If you disagree with this assumption, please let me know and let's discuss how to move forward. ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. You can merge this pull request into a Git repository by running: $ git pull https://github.com/StevenLangbroek/flink flink_8308_yajl_ruby_dependency Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/5395.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5395 commit 51713d207dd266479029d5847df1b4731612b540 Author: Steven Langbroek Date: 2018-01-31T16:26:28Z [FLINK-8308] Remove explicit yajl-ruby dependency, update Jekyll to 3+ > Update yajl-ruby dependency to 1.3.1 or higher > -- > > Key: FLINK-8308 > URL: https://issues.apache.org/jira/browse/FLINK-8308 > Project: Flink > Issue Type: Task > Components: Project Website >Reporter: Fabian Hueske >Assignee: Steven Langbroek >Priority: Critical > Fix For: 1.5.0, 1.4.1 > > > We got notified that yajl-ruby < 1.3.1, a dependency which is used to build > the Flink website, has a security vulnerability of high severity. > We should update yajl-ruby to 1.3.1 or higher. > Since the website is built offline and served as static HTML, I don't think > this is a super critical issue (please correct me if I'm wrong), but we > should resolve this soon. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink pull request #5396: [FLINK-5820] [state backends] Split shared/exclusi...
GitHub user StephanEwen opened a pull request: https://github.com/apache/flink/pull/5396 [FLINK-5820] [state backends] Split shared/exclusive state and properly handle disposal ## What is the purpose of the change This PR contains the final changes needed for [FLINK-5820]. Disposal of checkpoint directories happens properly across all file system types (previously did not work properly for some S3 connectors) with reduced calls to the file systems. Shared and exclusive state are split into different directories, to help implement cleanup safety nets. ## Brief change log 1. TaskManagers use the `CheckpointStorage` to create `CheckpointStreamFactories`. Previously, these stream factories were created by the `StateBackend`. This completes the separating out the "storage" aspect of the `StateBackend` into the `CheckpointStorage`. 2. The location where to store state is communicated between the `CheckpointCoordinator` (instantiating the original `CheckpointStorageLocation` for a checkpoint/savepoint) and the Tasks in a unified manner. Tasks transparently obtain their `CheckpointStreamFactories` always in the same way, regardless of whether writing state for checkpoints or savepoints. 3. Checkpoint state now has the scope `EXCLUSIVE` or `SHARED`, which may be stored differently. The current file system based backends put shared state into a */shared* directory, while exclusive state goes into the */chk-1234* directory. 4. Tasks can directly write *task-owned state* to a checkpoint storage. That state neither belongs specifically to one checkpoint, nor is it shared and eventually released by the Checkpoint Coordinator. Only the tasks themselves may release the state. An example for that type of state are the *write ahead logs* created by some sinks. 5. When a checkpoint is finalized, its storage is described by a `CompletedCheckpointStorageLocation`. That object gives access to addressing, metadata, and handles location disposal. This allows us to drop the *"delete parent if empty"* logic in File State Handles and fixes the issue that checkpoint directories are currently left over on S3. **Future Work** - In the future, the `CompletedCheckpointStorageLocation` should also be used as a way to handle relative addressing of checkpoints, to allow users to move them to different directories without breaking the internal paths. - We can now implement disposal fast paths, like drop directory as a whole, rather than dropping each state object separately. However, one would still need to release drop shared state objects individually. Finishing these fast paths is currently blocked on some rework of the shared state handles, to make their selective release easier and more robust. ## Verifying this change This change can be verified by running a Flink cluster with a checkpointed program and This PR also adds and adjusts various unit tests to guard the new behavior. ## Does this pull request potentially affect one of the following parts: - Dependencies (does it add or upgrade a dependency): (yes / no) - The public API, i.e., is any changed class annotated with `@Public(Evolving)`: (yes / no) - The serializers: (yes / no / don't know) - The runtime per-record code paths (performance sensitive): (yes / no / don't know) - Anything that affects deployment or recovery: JobManager (and its components), Checkpointing, Yarn/Mesos, ZooKeeper: (yes / no / don't know) - The S3 file system connector: (yes / no / don't know) ## Documentation - Does this pull request introduce a new feature? *Somewhat* (it changes the state backend directory layouts) - If yes, how is the feature documented? (not applicable / docs / **JavaDocs** / not documented) You can merge this pull request into a Git repository by running: $ git pull https://github.com/StephanEwen/incubator-flink locations Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/5396.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5396 commit ec8e552a7b50b8c605bb2609713cb2dd50245118 Author: Stephan Ewen Date: 2018-01-30T14:53:46Z [hotfix] [checkpointing] Cleanup: Fix Nullability and names in checkpoint stats. commit cf18831b69bd909d6491eb73d3294d3295ddd930 Author: Stephan Ewen Date: 2018-01-30T10:57:30Z [hotfix] [tests] Drop obsolete CheckpointExternalResumeTest. Because all checkpoints are now externalized (write their metadata) this is an obsolete test. commit a46acdd0f7142e40eee8c742e17eefaa6c7da3da Author: Stephan Ewen Date: 2018-01-29T22:24:24Z [hotfix] [checkpoints] Clean up CompletedCheckpoint, grouping related metho
[GitHub] flink pull request #5395: [FLINK-8308] Remove explicit yajl-ruby dependency,...
GitHub user StevenLangbroek opened a pull request: https://github.com/apache/flink/pull/5395 [FLINK-8308] Remove explicit yajl-ruby dependency, update Jekyll to 3+ ## What is the purpose of the change The docs dependend on `yajl-ruby` 1.2, which had a security defect. Although we don't rely on ruby in our hosting infrastructure, it's best not to have contributors uninstall unsafe software. This PR updates Jekyll, and removes some explicit dependencies in favour of relying on built-in Jekyll dependencies. ## Brief change log * Update Jekyll to 3.7.2 * Remove ruby2 distinction. Docs now depend on ruby 2.1+. Ruby 1.9 is over 10 years old, and OS X ships with 2.3. Maintaining backwards compatibility seems undesirable to me. If you disagree with this assumption, please let me know and let's discuss how to move forward. ## Verifying this change This change is a trivial rework / code cleanup without any test coverage. You can merge this pull request into a Git repository by running: $ git pull https://github.com/StevenLangbroek/flink flink_8308_yajl_ruby_dependency Alternatively you can review and apply these changes as the patch at: https://github.com/apache/flink/pull/5395.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #5395 commit 51713d207dd266479029d5847df1b4731612b540 Author: Steven Langbroek Date: 2018-01-31T16:26:28Z [FLINK-8308] Remove explicit yajl-ruby dependency, update Jekyll to 3+ ---
[jira] [Updated] (FLINK-8534) if insert too much BucketEntry into one bucket in join of iteration will cause a error (Caused : java.io.FileNotFoundException release file error)
[ https://issues.apache.org/jira/browse/FLINK-8534?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] zhu.qing updated FLINK-8534: Environment: windows intellij idea 8g ram 4core i5 cpu. Flink 1.4.0 (was: windows ideal 8g ram 4core i5 cpu. Flink 1.4.0) > if insert too much BucketEntry into one bucket in join of iteration will > cause a error (Caused : java.io.FileNotFoundException release file error) > -- > > Key: FLINK-8534 > URL: https://issues.apache.org/jira/browse/FLINK-8534 > Project: Flink > Issue Type: Bug > Components: Local Runtime > Environment: windows intellij idea 8g ram 4core i5 cpu. Flink 1.4.0 >Reporter: zhu.qing >Priority: Major > Attachments: T2AdjSetBfs.java > > > When insert too much entry into bucket (MutableHashTable line 1054 more than > 255 ) will cause spillPartition() (HashPartition line 317). So > this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, > bufferReturnQueue); > And in > prepareNextPartition() of ReOpenableMutableHashTable (line 156) > furtherPartitioning = true; > so in > finalizeProbePhase() in HashPartition (line 367) > this.probeSideChannel.close(); > //the file will be delete > this.buildSideChannel.deleteChannel(); > this.probeSideChannel.deleteChannel(); > after deleteChannel the next iteartion will fail. > > And I use web-google as dataset(SNAP). -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-3089) State API Should Support Data Expiration (State TTL)
[ https://issues.apache.org/jira/browse/FLINK-3089?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347125#comment-16347125 ] Xavier Fournet commented on FLINK-3089: --- Thanks [~phoenixjiangnan] for the design documentation. I made some comments on it. > State API Should Support Data Expiration (State TTL) > > > Key: FLINK-3089 > URL: https://issues.apache.org/jira/browse/FLINK-3089 > Project: Flink > Issue Type: New Feature > Components: DataStream API, State Backends, Checkpointing >Reporter: Niels Basjes >Assignee: Bowen Li >Priority: Major > > In some usecases (webanalytics) there is a need to have a state per visitor > on a website (i.e. keyBy(sessionid) ). > At some point the visitor simply leaves and no longer creates new events (so > a special 'end of session' event will not occur). > The only way to determine that a visitor has left is by choosing a timeout, > like "After 30 minutes no events we consider the visitor 'gone'". > Only after this (chosen) timeout has expired should we discard this state. > In the Trigger part of Windows we can set a timer and close/discard this kind > of information. But that introduces the buffering effect of the window (which > in some scenarios is unwanted). > What I would like is to be able to set a timeout on a specific state which I > can update afterwards. > This makes it possible to create a map function that assigns the right value > and that discards the state automatically. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-8360) Implement task-local state recovery
[
https://issues.apache.org/jira/browse/FLINK-8360?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347095#comment-16347095
]
ASF GitHub Bot commented on FLINK-8360:
---
Github user tillrohrmann commented on a diff in the pull request:
https://github.com/apache/flink/pull/5239#discussion_r165107880
--- Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/state/SnapshotResult.java
---
@@ -0,0 +1,83 @@
+package org.apache.flink.runtime.state;/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+import org.apache.flink.util.ExceptionUtils;
+
+/**
+ *
+ */
+public class SnapshotResult implements StateObject {
--- End diff --
That way we would also get rid of all the null checks.
> Implement task-local state recovery
> ---
>
> Key: FLINK-8360
> URL: https://issues.apache.org/jira/browse/FLINK-8360
> Project: Flink
> Issue Type: New Feature
> Components: State Backends, Checkpointing
>Reporter: Stefan Richter
>Assignee: Stefan Richter
>Priority: Major
> Fix For: 1.5.0
>
>
> This issue tracks the development of recovery from task-local state. The main
> idea is to have a secondary, local copy of the checkpointed state, while
> there is still a primary copy in DFS that we report to the checkpoint
> coordinator.
> Recovery can attempt to restore from the secondary local copy, if available,
> to save network bandwidth. This requires that the assignment from tasks to
> slots is as sticky is possible.
> For starters, we will implement this feature for all managed keyed states and
> can easily enhance it to all other state types (e.g. operator state) later.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-8534) if insert too much BucketEntry into one bucket in join of iteration will cause a error (Caused : java.io.FileNotFoundException release file error)
[ https://issues.apache.org/jira/browse/FLINK-8534?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] zhu.qing updated FLINK-8534: Description: When insert too much entry into bucket (MutableHashTable line 1054 more than 255 ) will cause spillPartition() (HashPartition line 317). So this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, bufferReturnQueue); And in prepareNextPartition() of ReOpenableMutableHashTable (line 156) furtherPartitioning = true; so in finalizeProbePhase() in HashPartition (line 367) this.probeSideChannel.close(); //the file will be delete this.buildSideChannel.deleteChannel(); this.probeSideChannel.deleteChannel(); after deleteChannel the next iteartion will fail. And I use web-google as dataset(SNAP). was: When insert too much entry into bucket (more than 255 )will cause spillPartition(). So this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, bufferReturnQueue); And in prepareNextPartition() of reopenablemutable hash table furtherPartitioning = true; so in finalizeProbePhase() in HashPartition (line 367) this.probeSideChannel.close(); //the file will be delete this.buildSideChannel.deleteChannel(); this.probeSideChannel.deleteChannel(); after deleteChannel the next iteartion will fail. And I use web-google as dataset(SNAP). > if insert too much BucketEntry into one bucket in join of iteration will > cause a error (Caused : java.io.FileNotFoundException release file error) > -- > > Key: FLINK-8534 > URL: https://issues.apache.org/jira/browse/FLINK-8534 > Project: Flink > Issue Type: Bug > Components: Local Runtime > Environment: windows ideal 8g ram 4core i5 cpu. Flink 1.4.0 >Reporter: zhu.qing >Priority: Major > Attachments: T2AdjSetBfs.java > > > When insert too much entry into bucket (MutableHashTable line 1054 more than > 255 ) will cause spillPartition() (HashPartition line 317). So > this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, > bufferReturnQueue); > And in > prepareNextPartition() of ReOpenableMutableHashTable (line 156) > furtherPartitioning = true; > so in > finalizeProbePhase() in HashPartition (line 367) > this.probeSideChannel.close(); > //the file will be delete > this.buildSideChannel.deleteChannel(); > this.probeSideChannel.deleteChannel(); > after deleteChannel the next iteartion will fail. > > And I use web-google as dataset(SNAP). -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-8484) Kinesis consumer re-reads closed shards on job restart
[ https://issues.apache.org/jira/browse/FLINK-8484?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347093#comment-16347093 ] ASF GitHub Bot commented on FLINK-8484: --- Github user tzulitai commented on the issue: https://github.com/apache/flink/pull/5337 Great, thanks for the update! As a side note, I will be making some additional changes to the code regarding the not-so-nice iteration across the `sequenceNumsToRestore` map. It would make sense to have a "equivalence wrapper" class around `StreamShardMetadata`, that only checks equivalence of the stream name and shard id. That wrapper class can then be used as the key of the `sequenceNumsToRestore` map. No tests you added would be touched, so I assume it'll work just as fine for you. > Kinesis consumer re-reads closed shards on job restart > -- > > Key: FLINK-8484 > URL: https://issues.apache.org/jira/browse/FLINK-8484 > Project: Flink > Issue Type: Bug > Components: Kinesis Connector >Affects Versions: 1.4.0, 1.3.2 >Reporter: Philip Luppens >Assignee: Philip Luppens >Priority: Blocker > Labels: bug, flink, kinesis > Fix For: 1.3.3, 1.5.0, 1.4.1 > > > We’re using the connector to subscribe to streams varying from 1 to a 100 > shards, and used the kinesis-scaling-utils to dynamically scale the Kinesis > stream up and down during peak times. What we’ve noticed is that, while we > were having closed shards, any Flink job restart with check- or save-point > would result in shards being re-read from the event horizon, duplicating our > events. > > We started checking the checkpoint state, and found that the shards were > stored correctly with the proper sequence number (including for closed > shards), but that upon restarts, the older closed shards would be read from > the event horizon, as if their restored state would be ignored. > > In the end, we believe that we found the problem: in the > FlinkKinesisConsumer’s run() method, we’re trying to find the shard returned > from the KinesisDataFetcher against the shards’ metadata from the restoration > point, but we do this via a containsKey() call, which means we’ll use the > StreamShardMetadata’s equals() method. However, this checks for all > properties, including the endingSequenceNumber, which might have changed > between the restored state’s checkpoint and our data fetch, thus failing the > equality check, failing the containsKey() check, and resulting in the shard > being re-read from the event horizon, even though it was present in the > restored state. > > We’ve created a workaround where we only check for the shardId and stream > name to restore the state of the shards we’ve already seen, and this seems to > work correctly. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-8360) Implement task-local state recovery
[
https://issues.apache.org/jira/browse/FLINK-8360?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347094#comment-16347094
]
ASF GitHub Bot commented on FLINK-8360:
---
Github user tillrohrmann commented on a diff in the pull request:
https://github.com/apache/flink/pull/5239#discussion_r165107698
--- Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/state/SnapshotResult.java
---
@@ -0,0 +1,83 @@
+package org.apache.flink.runtime.state;/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+import org.apache.flink.util.ExceptionUtils;
+
+/**
+ *
+ */
+public class SnapshotResult implements StateObject {
--- End diff --
I'm wondering whether it wouldn't make sense to have a `SnapshotResult` and
a subclass `SnapshotResultWithLocalSnapshot`. The latter has an additional
field for the `taskLocalSnapshot`. That way it's much clearer how to initialize
these structures. Ideally the arguments are both not null.
> Implement task-local state recovery
> ---
>
> Key: FLINK-8360
> URL: https://issues.apache.org/jira/browse/FLINK-8360
> Project: Flink
> Issue Type: New Feature
> Components: State Backends, Checkpointing
>Reporter: Stefan Richter
>Assignee: Stefan Richter
>Priority: Major
> Fix For: 1.5.0
>
>
> This issue tracks the development of recovery from task-local state. The main
> idea is to have a secondary, local copy of the checkpointed state, while
> there is still a primary copy in DFS that we report to the checkpoint
> coordinator.
> Recovery can attempt to restore from the secondary local copy, if available,
> to save network bandwidth. This requires that the assignment from tasks to
> slots is as sticky is possible.
> For starters, we will implement this feature for all managed keyed states and
> can easily enhance it to all other state types (e.g. operator state) later.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #5239: [FLINK-8360] Implement task-local state recovery
Github user tillrohrmann commented on a diff in the pull request:
https://github.com/apache/flink/pull/5239#discussion_r165107880
--- Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/state/SnapshotResult.java
---
@@ -0,0 +1,83 @@
+package org.apache.flink.runtime.state;/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+import org.apache.flink.util.ExceptionUtils;
+
+/**
+ *
+ */
+public class SnapshotResult implements StateObject {
--- End diff --
That way we would also get rid of all the null checks.
---
[GitHub] flink issue #5337: [FLINK-8484][flink-kinesis-connector] Ensure a Kinesis co...
Github user tzulitai commented on the issue: https://github.com/apache/flink/pull/5337 Great, thanks for the update! As a side note, I will be making some additional changes to the code regarding the not-so-nice iteration across the `sequenceNumsToRestore` map. It would make sense to have a "equivalence wrapper" class around `StreamShardMetadata`, that only checks equivalence of the stream name and shard id. That wrapper class can then be used as the key of the `sequenceNumsToRestore` map. No tests you added would be touched, so I assume it'll work just as fine for you. ---
[GitHub] flink pull request #5239: [FLINK-8360] Implement task-local state recovery
Github user tillrohrmann commented on a diff in the pull request:
https://github.com/apache/flink/pull/5239#discussion_r165107698
--- Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/state/SnapshotResult.java
---
@@ -0,0 +1,83 @@
+package org.apache.flink.runtime.state;/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+import org.apache.flink.util.ExceptionUtils;
+
+/**
+ *
+ */
+public class SnapshotResult implements StateObject {
--- End diff --
I'm wondering whether it wouldn't make sense to have a `SnapshotResult` and
a subclass `SnapshotResultWithLocalSnapshot`. The latter has an additional
field for the `taskLocalSnapshot`. That way it's much clearer how to initialize
these structures. Ideally the arguments are both not null.
---
[jira] [Updated] (FLINK-8534) if insert too much BucketEntry into one bucket in join of iteration will cause a error (Caused : java.io.FileNotFoundException release file error)
[ https://issues.apache.org/jira/browse/FLINK-8534?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] zhu.qing updated FLINK-8534: Description: When insert too much entry into bucket (more than 255 )will cause spillPartition(). So this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, bufferReturnQueue); And in prepareNextPartition() of reopenablemutable hash table furtherPartitioning = true; so in finalizeProbePhase() in HashPartition (line 367) this.probeSideChannel.close(); //the file will be delete this.buildSideChannel.deleteChannel(); this.probeSideChannel.deleteChannel(); after deleteChannel the next iteartion will fail. And I use web-google as dataset(SNAP). was: When insert too much entry into bucket (more than 255 )will cause spillPartition(). So this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, bufferReturnQueue); And in prepareNextPartition() of reopenablemutable hash table furtherPartitioning = true; so in finalizeProbePhase() in HashPartition this.probeSideChannel.close(); //the file will be delete this.buildSideChannel.deleteChannel(); this.probeSideChannel.deleteChannel(); after deleteChannel the next iteartion will fail. And I use web-google as dataset(SNAP). > if insert too much BucketEntry into one bucket in join of iteration will > cause a error (Caused : java.io.FileNotFoundException release file error) > -- > > Key: FLINK-8534 > URL: https://issues.apache.org/jira/browse/FLINK-8534 > Project: Flink > Issue Type: Bug > Components: Local Runtime > Environment: windows ideal 8g ram 4core i5 cpu. Flink 1.4.0 >Reporter: zhu.qing >Priority: Major > Attachments: T2AdjSetBfs.java > > > When insert too much entry into bucket (more than 255 )will cause > spillPartition(). So > this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, > bufferReturnQueue); > And in > prepareNextPartition() of reopenablemutable hash table > furtherPartitioning = true; > so in > finalizeProbePhase() in HashPartition (line 367) > this.probeSideChannel.close(); > //the file will be delete > this.buildSideChannel.deleteChannel(); > this.probeSideChannel.deleteChannel(); > after deleteChannel the next iteartion will fail. > > And I use web-google as dataset(SNAP). -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-8360) Implement task-local state recovery
[
https://issues.apache.org/jira/browse/FLINK-8360?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347090#comment-16347090
]
ASF GitHub Bot commented on FLINK-8360:
---
Github user tillrohrmann commented on a diff in the pull request:
https://github.com/apache/flink/pull/5239#discussion_r165106582
--- Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/state/SnapshotResult.java
---
@@ -0,0 +1,83 @@
+package org.apache.flink.runtime.state;/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+import org.apache.flink.util.ExceptionUtils;
+
+/**
+ *
+ */
+public class SnapshotResult implements StateObject {
+
+ private static final long serialVersionUID = 1L;
+
+ private final T jobManagerOwnedSnapshot;
+ private final T taskLocalSnapshot;
--- End diff --
Maybe annotate as `Nullable`.
> Implement task-local state recovery
> ---
>
> Key: FLINK-8360
> URL: https://issues.apache.org/jira/browse/FLINK-8360
> Project: Flink
> Issue Type: New Feature
> Components: State Backends, Checkpointing
>Reporter: Stefan Richter
>Assignee: Stefan Richter
>Priority: Major
> Fix For: 1.5.0
>
>
> This issue tracks the development of recovery from task-local state. The main
> idea is to have a secondary, local copy of the checkpointed state, while
> there is still a primary copy in DFS that we report to the checkpoint
> coordinator.
> Recovery can attempt to restore from the secondary local copy, if available,
> to save network bandwidth. This requires that the assignment from tasks to
> slots is as sticky is possible.
> For starters, we will implement this feature for all managed keyed states and
> can easily enhance it to all other state types (e.g. operator state) later.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #5239: [FLINK-8360] Implement task-local state recovery
Github user tillrohrmann commented on a diff in the pull request:
https://github.com/apache/flink/pull/5239#discussion_r165106582
--- Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/state/SnapshotResult.java
---
@@ -0,0 +1,83 @@
+package org.apache.flink.runtime.state;/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+import org.apache.flink.util.ExceptionUtils;
+
+/**
+ *
+ */
+public class SnapshotResult implements StateObject {
+
+ private static final long serialVersionUID = 1L;
+
+ private final T jobManagerOwnedSnapshot;
+ private final T taskLocalSnapshot;
--- End diff --
Maybe annotate as `Nullable`.
---
[jira] [Commented] (FLINK-8534) if insert too much BucketEntry into one bucket in join of iteration will cause a error (Caused : java.io.FileNotFoundException release file error)
[ https://issues.apache.org/jira/browse/FLINK-8534?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347086#comment-16347086 ] zhu.qing commented on FLINK-8534: - And I failed to use 16g laptop to reproduce the bug. The key to the bug is that you need insert enough entry in function insertBucketEntry upto 256 and that cause spillPartition(). But in 8g desktop it will always reproduce > if insert too much BucketEntry into one bucket in join of iteration will > cause a error (Caused : java.io.FileNotFoundException release file error) > -- > > Key: FLINK-8534 > URL: https://issues.apache.org/jira/browse/FLINK-8534 > Project: Flink > Issue Type: Bug > Components: Local Runtime > Environment: windows ideal 8g ram 4core i5 cpu. Flink 1.4.0 >Reporter: zhu.qing >Priority: Major > Attachments: T2AdjSetBfs.java > > > When insert too much entry into bucket (more than 255 )will cause > spillPartition(). So > this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, > bufferReturnQueue); > And in > prepareNextPartition() of reopenablemutable hash table > furtherPartitioning = true; > so in > finalizeProbePhase() in HashPartition > this.probeSideChannel.close(); > //the file will be delete > this.buildSideChannel.deleteChannel(); > this.probeSideChannel.deleteChannel(); > after deleteChannel the next iteartion will fail. > > And I use web-google as dataset(SNAP). -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-8484) Kinesis consumer re-reads closed shards on job restart
[ https://issues.apache.org/jira/browse/FLINK-8484?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347085#comment-16347085 ] ASF GitHub Bot commented on FLINK-8484: --- Github user pluppens commented on the issue: https://github.com/apache/flink/pull/5337 Thanks - we've been running it in production for the last 5 days without issues, so it seems to work fine. We'll be enabling autoscaling of the streams in the coming hours, so if anything is amiss, it should pop up on our radar in the coming days. > Kinesis consumer re-reads closed shards on job restart > -- > > Key: FLINK-8484 > URL: https://issues.apache.org/jira/browse/FLINK-8484 > Project: Flink > Issue Type: Bug > Components: Kinesis Connector >Affects Versions: 1.4.0, 1.3.2 >Reporter: Philip Luppens >Assignee: Philip Luppens >Priority: Blocker > Labels: bug, flink, kinesis > Fix For: 1.3.3, 1.5.0, 1.4.1 > > > We’re using the connector to subscribe to streams varying from 1 to a 100 > shards, and used the kinesis-scaling-utils to dynamically scale the Kinesis > stream up and down during peak times. What we’ve noticed is that, while we > were having closed shards, any Flink job restart with check- or save-point > would result in shards being re-read from the event horizon, duplicating our > events. > > We started checking the checkpoint state, and found that the shards were > stored correctly with the proper sequence number (including for closed > shards), but that upon restarts, the older closed shards would be read from > the event horizon, as if their restored state would be ignored. > > In the end, we believe that we found the problem: in the > FlinkKinesisConsumer’s run() method, we’re trying to find the shard returned > from the KinesisDataFetcher against the shards’ metadata from the restoration > point, but we do this via a containsKey() call, which means we’ll use the > StreamShardMetadata’s equals() method. However, this checks for all > properties, including the endingSequenceNumber, which might have changed > between the restored state’s checkpoint and our data fetch, thus failing the > equality check, failing the containsKey() check, and resulting in the shard > being re-read from the event horizon, even though it was present in the > restored state. > > We’ve created a workaround where we only check for the shardId and stream > name to restore the state of the shards we’ve already seen, and this seems to > work correctly. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (FLINK-8534) if insert too much BucketEntry into one bucket in join of iteration will cause a error (Caused : java.io.FileNotFoundException release file error)
[ https://issues.apache.org/jira/browse/FLINK-8534?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel ] zhu.qing updated FLINK-8534: Description: When insert too much entry into bucket (more than 255 )will cause spillPartition(). So this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, bufferReturnQueue); And in prepareNextPartition() of reopenablemutable hash table furtherPartitioning = true; so in finalizeProbePhase() in HashPartition this.probeSideChannel.close(); //the file will be delete this.buildSideChannel.deleteChannel(); this.probeSideChannel.deleteChannel(); after deleteChannel the next iteartion will fail. And I use web-google as dataset(SNAP). was: When insert too much entry into bucket (more than 255 )will cause spillPartition(). So this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, bufferReturnQueue); And in prepareNextPartition() of reopenablemutable hash table furtherPartitioning = true; so in finalizeProbePhase() in HashPartition this.probeSideChannel.close(); //the file will be delete this.buildSideChannel.deleteChannel(); this.probeSideChannel.deleteChannel(); after deleteChannel the next iteartion will fail. And I use web-google as dataset(SNAP). And I failed to use 16g laptop to reproduce the bug. The key to the bug is that you need insert enough entry in function insertBucketEntry upto 256 and that cause spillPartition(). > if insert too much BucketEntry into one bucket in join of iteration will > cause a error (Caused : java.io.FileNotFoundException release file error) > -- > > Key: FLINK-8534 > URL: https://issues.apache.org/jira/browse/FLINK-8534 > Project: Flink > Issue Type: Bug > Components: Local Runtime > Environment: windows ideal 8g ram 4core i5 cpu. Flink 1.4.0 >Reporter: zhu.qing >Priority: Major > Attachments: T2AdjSetBfs.java > > > When insert too much entry into bucket (more than 255 )will cause > spillPartition(). So > this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel, > bufferReturnQueue); > And in > prepareNextPartition() of reopenablemutable hash table > furtherPartitioning = true; > so in > finalizeProbePhase() in HashPartition > this.probeSideChannel.close(); > //the file will be delete > this.buildSideChannel.deleteChannel(); > this.probeSideChannel.deleteChannel(); > after deleteChannel the next iteartion will fail. > > And I use web-google as dataset(SNAP). -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink issue #5337: [FLINK-8484][flink-kinesis-connector] Ensure a Kinesis co...
Github user pluppens commented on the issue: https://github.com/apache/flink/pull/5337 Thanks - we've been running it in production for the last 5 days without issues, so it seems to work fine. We'll be enabling autoscaling of the streams in the coming hours, so if anything is amiss, it should pop up on our radar in the coming days. ---
[jira] [Commented] (FLINK-8360) Implement task-local state recovery
[ https://issues.apache.org/jira/browse/FLINK-8360?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347082#comment-16347082 ] ASF GitHub Bot commented on FLINK-8360: --- Github user tillrohrmann commented on a diff in the pull request: https://github.com/apache/flink/pull/5239#discussion_r165105360 --- Diff: flink-runtime/src/main/java/org/apache/flink/runtime/state/SnapshotResult.java --- @@ -0,0 +1,83 @@ +package org.apache.flink.runtime.state;/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ --- End diff -- License and package seem in the wrong order. > Implement task-local state recovery > --- > > Key: FLINK-8360 > URL: https://issues.apache.org/jira/browse/FLINK-8360 > Project: Flink > Issue Type: New Feature > Components: State Backends, Checkpointing >Reporter: Stefan Richter >Assignee: Stefan Richter >Priority: Major > Fix For: 1.5.0 > > > This issue tracks the development of recovery from task-local state. The main > idea is to have a secondary, local copy of the checkpointed state, while > there is still a primary copy in DFS that we report to the checkpoint > coordinator. > Recovery can attempt to restore from the secondary local copy, if available, > to save network bandwidth. This requires that the assignment from tasks to > slots is as sticky is possible. > For starters, we will implement this feature for all managed keyed states and > can easily enhance it to all other state types (e.g. operator state) later. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink pull request #5239: [FLINK-8360] Implement task-local state recovery
Github user tillrohrmann commented on a diff in the pull request: https://github.com/apache/flink/pull/5239#discussion_r165105360 --- Diff: flink-runtime/src/main/java/org/apache/flink/runtime/state/SnapshotResult.java --- @@ -0,0 +1,83 @@ +package org.apache.flink.runtime.state;/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ --- End diff -- License and package seem in the wrong order. ---
[jira] [Commented] (FLINK-8360) Implement task-local state recovery
[ https://issues.apache.org/jira/browse/FLINK-8360?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347080#comment-16347080 ] ASF GitHub Bot commented on FLINK-8360: --- Github user tillrohrmann commented on a diff in the pull request: https://github.com/apache/flink/pull/5239#discussion_r165104909 --- Diff: flink-runtime/src/main/java/org/apache/flink/runtime/state/SnapshotResult.java --- @@ -0,0 +1,83 @@ +package org.apache.flink.runtime.state;/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +import org.apache.flink.util.ExceptionUtils; + +/** + * --- End diff -- Missing JavaDocs. > Implement task-local state recovery > --- > > Key: FLINK-8360 > URL: https://issues.apache.org/jira/browse/FLINK-8360 > Project: Flink > Issue Type: New Feature > Components: State Backends, Checkpointing >Reporter: Stefan Richter >Assignee: Stefan Richter >Priority: Major > Fix For: 1.5.0 > > > This issue tracks the development of recovery from task-local state. The main > idea is to have a secondary, local copy of the checkpointed state, while > there is still a primary copy in DFS that we report to the checkpoint > coordinator. > Recovery can attempt to restore from the secondary local copy, if available, > to save network bandwidth. This requires that the assignment from tasks to > slots is as sticky is possible. > For starters, we will implement this feature for all managed keyed states and > can easily enhance it to all other state types (e.g. operator state) later. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink pull request #5239: [FLINK-8360] Implement task-local state recovery
Github user tillrohrmann commented on a diff in the pull request: https://github.com/apache/flink/pull/5239#discussion_r165104909 --- Diff: flink-runtime/src/main/java/org/apache/flink/runtime/state/SnapshotResult.java --- @@ -0,0 +1,83 @@ +package org.apache.flink.runtime.state;/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +import org.apache.flink.util.ExceptionUtils; + +/** + * --- End diff -- Missing JavaDocs. ---
[jira] [Commented] (FLINK-8360) Implement task-local state recovery
[ https://issues.apache.org/jira/browse/FLINK-8360?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347074#comment-16347074 ] ASF GitHub Bot commented on FLINK-8360: --- Github user tillrohrmann commented on a diff in the pull request: https://github.com/apache/flink/pull/5239#discussion_r165103361 --- Diff: flink-runtime/src/main/java/org/apache/flink/runtime/state/Snapshotable.java --- @@ -54,5 +54,5 @@ * * @param state the old state to restore. */ - void restore(Collection state) throws Exception; + void restore(R state) throws Exception; --- End diff -- To me it is not really clear, why you've made this change here? Code wise it does not seem necessary. > Implement task-local state recovery > --- > > Key: FLINK-8360 > URL: https://issues.apache.org/jira/browse/FLINK-8360 > Project: Flink > Issue Type: New Feature > Components: State Backends, Checkpointing >Reporter: Stefan Richter >Assignee: Stefan Richter >Priority: Major > Fix For: 1.5.0 > > > This issue tracks the development of recovery from task-local state. The main > idea is to have a secondary, local copy of the checkpointed state, while > there is still a primary copy in DFS that we report to the checkpoint > coordinator. > Recovery can attempt to restore from the secondary local copy, if available, > to save network bandwidth. This requires that the assignment from tasks to > slots is as sticky is possible. > For starters, we will implement this feature for all managed keyed states and > can easily enhance it to all other state types (e.g. operator state) later. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink pull request #5239: [FLINK-8360] Implement task-local state recovery
Github user tillrohrmann commented on a diff in the pull request: https://github.com/apache/flink/pull/5239#discussion_r165103361 --- Diff: flink-runtime/src/main/java/org/apache/flink/runtime/state/Snapshotable.java --- @@ -54,5 +54,5 @@ * * @param state the old state to restore. */ - void restore(Collection state) throws Exception; + void restore(R state) throws Exception; --- End diff -- To me it is not really clear, why you've made this change here? Code wise it does not seem necessary. ---
[jira] [Commented] (FLINK-8360) Implement task-local state recovery
[
https://issues.apache.org/jira/browse/FLINK-8360?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347073#comment-16347073
]
ASF GitHub Bot commented on FLINK-8360:
---
Github user StefanRRichter commented on a diff in the pull request:
https://github.com/apache/flink/pull/5239#discussion_r165103021
--- Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/state/DefaultOperatorStateBackend.java
---
@@ -325,8 +325,7 @@ public OperatorStateHandle performOperation() throws
Exception {
return task;
}
- @Override
- public void restore(Collection restoreSnapshots)
throws Exception {
+ public void restore(StateObjectCollection
restoreSnapshots) throws Exception {
--- End diff --
Ok, if you just talk about this particular usage, I might double-check if
the interface is enough.
> Implement task-local state recovery
> ---
>
> Key: FLINK-8360
> URL: https://issues.apache.org/jira/browse/FLINK-8360
> Project: Flink
> Issue Type: New Feature
> Components: State Backends, Checkpointing
>Reporter: Stefan Richter
>Assignee: Stefan Richter
>Priority: Major
> Fix For: 1.5.0
>
>
> This issue tracks the development of recovery from task-local state. The main
> idea is to have a secondary, local copy of the checkpointed state, while
> there is still a primary copy in DFS that we report to the checkpoint
> coordinator.
> Recovery can attempt to restore from the secondary local copy, if available,
> to save network bandwidth. This requires that the assignment from tasks to
> slots is as sticky is possible.
> For starters, we will implement this feature for all managed keyed states and
> can easily enhance it to all other state types (e.g. operator state) later.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #5239: [FLINK-8360] Implement task-local state recovery
Github user StefanRRichter commented on a diff in the pull request:
https://github.com/apache/flink/pull/5239#discussion_r165103021
--- Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/state/DefaultOperatorStateBackend.java
---
@@ -325,8 +325,7 @@ public OperatorStateHandle performOperation() throws
Exception {
return task;
}
- @Override
- public void restore(Collection restoreSnapshots)
throws Exception {
+ public void restore(StateObjectCollection
restoreSnapshots) throws Exception {
--- End diff --
Ok, if you just talk about this particular usage, I might double-check if
the interface is enough.
---
[jira] [Commented] (FLINK-8360) Implement task-local state recovery
[
https://issues.apache.org/jira/browse/FLINK-8360?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347072#comment-16347072
]
ASF GitHub Bot commented on FLINK-8360:
---
Github user StefanRRichter commented on a diff in the pull request:
https://github.com/apache/flink/pull/5239#discussion_r165102741
--- Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/state/DefaultOperatorStateBackend.java
---
@@ -325,8 +325,7 @@ public OperatorStateHandle performOperation() throws
Exception {
return task;
}
- @Override
- public void restore(Collection restoreSnapshots)
throws Exception {
+ public void restore(StateObjectCollection
restoreSnapshots) throws Exception {
--- End diff --
Because there where a couple of static helper methods operating on those
collections, e.g. disposing a collection of state handles or checking if the
collection as a whole has any state. IMO those things should go to a separate
class and not be static helpers over a generic collection.
> Implement task-local state recovery
> ---
>
> Key: FLINK-8360
> URL: https://issues.apache.org/jira/browse/FLINK-8360
> Project: Flink
> Issue Type: New Feature
> Components: State Backends, Checkpointing
>Reporter: Stefan Richter
>Assignee: Stefan Richter
>Priority: Major
> Fix For: 1.5.0
>
>
> This issue tracks the development of recovery from task-local state. The main
> idea is to have a secondary, local copy of the checkpointed state, while
> there is still a primary copy in DFS that we report to the checkpoint
> coordinator.
> Recovery can attempt to restore from the secondary local copy, if available,
> to save network bandwidth. This requires that the assignment from tasks to
> slots is as sticky is possible.
> For starters, we will implement this feature for all managed keyed states and
> can easily enhance it to all other state types (e.g. operator state) later.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #5239: [FLINK-8360] Implement task-local state recovery
Github user StefanRRichter commented on a diff in the pull request:
https://github.com/apache/flink/pull/5239#discussion_r165102741
--- Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/state/DefaultOperatorStateBackend.java
---
@@ -325,8 +325,7 @@ public OperatorStateHandle performOperation() throws
Exception {
return task;
}
- @Override
- public void restore(Collection restoreSnapshots)
throws Exception {
+ public void restore(StateObjectCollection
restoreSnapshots) throws Exception {
--- End diff --
Because there where a couple of static helper methods operating on those
collections, e.g. disposing a collection of state handles or checking if the
collection as a whole has any state. IMO those things should go to a separate
class and not be static helpers over a generic collection.
---
[jira] [Commented] (FLINK-8360) Implement task-local state recovery
[
https://issues.apache.org/jira/browse/FLINK-8360?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347070#comment-16347070
]
ASF GitHub Bot commented on FLINK-8360:
---
Github user tillrohrmann commented on a diff in the pull request:
https://github.com/apache/flink/pull/5239#discussion_r165102131
--- Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/state/DefaultOperatorStateBackend.java
---
@@ -325,8 +325,7 @@ public OperatorStateHandle performOperation() throws
Exception {
return task;
}
- @Override
- public void restore(Collection restoreSnapshots)
throws Exception {
+ public void restore(StateObjectCollection
restoreSnapshots) throws Exception {
--- End diff --
Why can't it remain a `Collection`?
> Implement task-local state recovery
> ---
>
> Key: FLINK-8360
> URL: https://issues.apache.org/jira/browse/FLINK-8360
> Project: Flink
> Issue Type: New Feature
> Components: State Backends, Checkpointing
>Reporter: Stefan Richter
>Assignee: Stefan Richter
>Priority: Major
> Fix For: 1.5.0
>
>
> This issue tracks the development of recovery from task-local state. The main
> idea is to have a secondary, local copy of the checkpointed state, while
> there is still a primary copy in DFS that we report to the checkpoint
> coordinator.
> Recovery can attempt to restore from the secondary local copy, if available,
> to save network bandwidth. This requires that the assignment from tasks to
> slots is as sticky is possible.
> For starters, we will implement this feature for all managed keyed states and
> can easily enhance it to all other state types (e.g. operator state) later.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-8534) if insert too much BucketEntry into one bucket in join of iteration will cause a error (Caused : java.io.FileNotFoundException release file error)
[
https://issues.apache.org/jira/browse/FLINK-8534?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
zhu.qing updated FLINK-8534:
Description:
When insert too much entry into bucket (more than 255 )will cause
spillPartition(). So
this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel,
bufferReturnQueue);
And in
prepareNextPartition() of reopenablemutable hash table
furtherPartitioning = true;
so in
finalizeProbePhase() in HashPartition
this.probeSideChannel.close();
//the file will be delete
this.buildSideChannel.deleteChannel();
this.probeSideChannel.deleteChannel();
after deleteChannel the next iteartion will fail.
And I use web-google as dataset(SNAP). And I failed to use 16g laptop to
reproduce the bug. The key to the bug is that you need insert enough entry in
function insertBucketEntry upto 256 and that cause spillPartition().
was:
When insert too much entry into bucket will cause
spillPartition(). So
this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel,
bufferReturnQueue);
And in
prepareNextPartition() of reopenablemutable hash table
furtherPartitioning = true;
so in
finalizeProbePhase()
freeMemory.add(this.probeSideBuffer.getCurrentSegment());
// delete the spill files
this.probeSideChannel.close();
System.out.println("HashPartition probeSideRecordCounter Delete");
this.buildSideChannel.deleteChannel();
this.probeSideChannel.deleteChannel();
after deleteChannel the next iteartion will fail.
And I use web-google as dataset(SNAP). And I failed to use 16g laptop to
reproduce the bug. The key to the bug is that you need insert enough entry in
function insertBucketEntry upto 256 and that cause spillPartition().
> if insert too much BucketEntry into one bucket in join of iteration will
> cause a error (Caused : java.io.FileNotFoundException release file error)
> --
>
> Key: FLINK-8534
> URL: https://issues.apache.org/jira/browse/FLINK-8534
> Project: Flink
> Issue Type: Bug
> Components: Local Runtime
> Environment: windows ideal 8g ram 4core i5 cpu. Flink 1.4.0
>Reporter: zhu.qing
>Priority: Major
> Attachments: T2AdjSetBfs.java
>
>
> When insert too much entry into bucket (more than 255 )will cause
> spillPartition(). So
> this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel,
> bufferReturnQueue);
> And in
> prepareNextPartition() of reopenablemutable hash table
> furtherPartitioning = true;
> so in
> finalizeProbePhase() in HashPartition
> this.probeSideChannel.close();
> //the file will be delete
> this.buildSideChannel.deleteChannel();
> this.probeSideChannel.deleteChannel();
> after deleteChannel the next iteartion will fail.
>
> And I use web-google as dataset(SNAP). And I failed to use 16g laptop to
> reproduce the bug. The key to the bug is that you need insert enough entry in
> function insertBucketEntry upto 256 and that cause spillPartition().
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-8360) Implement task-local state recovery
[
https://issues.apache.org/jira/browse/FLINK-8360?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347068#comment-16347068
]
ASF GitHub Bot commented on FLINK-8360:
---
Github user tillrohrmann commented on a diff in the pull request:
https://github.com/apache/flink/pull/5239#discussion_r165101966
--- Diff:
flink-contrib/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBKeyedStateBackend.java
---
@@ -1016,7 +1017,7 @@ void releaseResources(boolean canceled) {
}
@Override
- public void restore(Collection restoreState) throws
Exception {
+ public void restore(StateObjectCollection
restoreState) throws Exception {
--- End diff --
Why is this necessary?
> Implement task-local state recovery
> ---
>
> Key: FLINK-8360
> URL: https://issues.apache.org/jira/browse/FLINK-8360
> Project: Flink
> Issue Type: New Feature
> Components: State Backends, Checkpointing
>Reporter: Stefan Richter
>Assignee: Stefan Richter
>Priority: Major
> Fix For: 1.5.0
>
>
> This issue tracks the development of recovery from task-local state. The main
> idea is to have a secondary, local copy of the checkpointed state, while
> there is still a primary copy in DFS that we report to the checkpoint
> coordinator.
> Recovery can attempt to restore from the secondary local copy, if available,
> to save network bandwidth. This requires that the assignment from tasks to
> slots is as sticky is possible.
> For starters, we will implement this feature for all managed keyed states and
> can easily enhance it to all other state types (e.g. operator state) later.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink pull request #5239: [FLINK-8360] Implement task-local state recovery
Github user tillrohrmann commented on a diff in the pull request:
https://github.com/apache/flink/pull/5239#discussion_r165102131
--- Diff:
flink-runtime/src/main/java/org/apache/flink/runtime/state/DefaultOperatorStateBackend.java
---
@@ -325,8 +325,7 @@ public OperatorStateHandle performOperation() throws
Exception {
return task;
}
- @Override
- public void restore(Collection restoreSnapshots)
throws Exception {
+ public void restore(StateObjectCollection
restoreSnapshots) throws Exception {
--- End diff --
Why can't it remain a `Collection`?
---
[GitHub] flink pull request #5239: [FLINK-8360] Implement task-local state recovery
Github user tillrohrmann commented on a diff in the pull request:
https://github.com/apache/flink/pull/5239#discussion_r165101966
--- Diff:
flink-contrib/flink-statebackend-rocksdb/src/main/java/org/apache/flink/contrib/streaming/state/RocksDBKeyedStateBackend.java
---
@@ -1016,7 +1017,7 @@ void releaseResources(boolean canceled) {
}
@Override
- public void restore(Collection restoreState) throws
Exception {
+ public void restore(StateObjectCollection
restoreState) throws Exception {
--- End diff --
Why is this necessary?
---
[jira] [Updated] (FLINK-8534) if insert too much BucketEntry into one bucket in join of iteration will cause a error (Caused : java.io.FileNotFoundException release file error)
[
https://issues.apache.org/jira/browse/FLINK-8534?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
Fabian Hueske updated FLINK-8534:
-
Component/s: Local Runtime
> if insert too much BucketEntry into one bucket in join of iteration will
> cause a error (Caused : java.io.FileNotFoundException release file error)
> --
>
> Key: FLINK-8534
> URL: https://issues.apache.org/jira/browse/FLINK-8534
> Project: Flink
> Issue Type: Bug
> Components: Local Runtime
> Environment: windows ideal 8g ram 4core i5 cpu. Flink 1.4.0
>Reporter: zhu.qing
>Priority: Major
> Attachments: T2AdjSetBfs.java
>
>
> When insert too much entry into bucket will cause
> spillPartition(). So
> this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel,
> bufferReturnQueue);
> And in
> prepareNextPartition() of reopenablemutable hash table
> furtherPartitioning = true;
> so in
> finalizeProbePhase()
> freeMemory.add(this.probeSideBuffer.getCurrentSegment());
> // delete the spill files
> this.probeSideChannel.close();
> System.out.println("HashPartition probeSideRecordCounter Delete");
> this.buildSideChannel.deleteChannel();
> this.probeSideChannel.deleteChannel();
> after deleteChannel the next iteartion will fail.
>
> And I use web-google as dataset(SNAP). And I failed to use 16g laptop to
> reproduce the bug. The key to the bug is that you need insert enough entry in
> function insertBucketEntry upto 256 and that cause spillPartition().
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-8360) Implement task-local state recovery
[ https://issues.apache.org/jira/browse/FLINK-8360?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347063#comment-16347063 ] ASF GitHub Bot commented on FLINK-8360: --- Github user tillrohrmann commented on a diff in the pull request: https://github.com/apache/flink/pull/5239#discussion_r165098878 --- Diff: flink-runtime/src/main/java/org/apache/flink/runtime/checkpoint/StateObjectCollection.java --- @@ -0,0 +1,179 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.flink.runtime.checkpoint; + +import org.apache.flink.runtime.state.StateObject; +import org.apache.flink.runtime.state.StateUtil; + +import java.util.ArrayList; +import java.util.Collection; +import java.util.Collections; +import java.util.Iterator; +import java.util.function.Predicate; + +/** + * @param type of the contained state objects. --- End diff -- JavaDoc not complete. > Implement task-local state recovery > --- > > Key: FLINK-8360 > URL: https://issues.apache.org/jira/browse/FLINK-8360 > Project: Flink > Issue Type: New Feature > Components: State Backends, Checkpointing >Reporter: Stefan Richter >Assignee: Stefan Richter >Priority: Major > Fix For: 1.5.0 > > > This issue tracks the development of recovery from task-local state. The main > idea is to have a secondary, local copy of the checkpointed state, while > there is still a primary copy in DFS that we report to the checkpoint > coordinator. > Recovery can attempt to restore from the secondary local copy, if available, > to save network bandwidth. This requires that the assignment from tasks to > slots is as sticky is possible. > For starters, we will implement this feature for all managed keyed states and > can easily enhance it to all other state types (e.g. operator state) later. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[GitHub] flink pull request #5239: [FLINK-8360] Implement task-local state recovery
Github user tillrohrmann commented on a diff in the pull request: https://github.com/apache/flink/pull/5239#discussion_r165098878 --- Diff: flink-runtime/src/main/java/org/apache/flink/runtime/checkpoint/StateObjectCollection.java --- @@ -0,0 +1,179 @@ +/* + * Licensed to the Apache Software Foundation (ASF) under one + * or more contributor license agreements. See the NOTICE file + * distributed with this work for additional information + * regarding copyright ownership. The ASF licenses this file + * to you under the Apache License, Version 2.0 (the + * "License"); you may not use this file except in compliance + * with the License. You may obtain a copy of the License at + * + * http://www.apache.org/licenses/LICENSE-2.0 + * + * Unless required by applicable law or agreed to in writing, software + * distributed under the License is distributed on an "AS IS" BASIS, + * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. + * See the License for the specific language governing permissions and + * limitations under the License. + */ + +package org.apache.flink.runtime.checkpoint; + +import org.apache.flink.runtime.state.StateObject; +import org.apache.flink.runtime.state.StateUtil; + +import java.util.ArrayList; +import java.util.Collection; +import java.util.Collections; +import java.util.Iterator; +import java.util.function.Predicate; + +/** + * @param type of the contained state objects. --- End diff -- JavaDoc not complete. ---
[jira] [Created] (FLINK-8540) FileStateHandles must not attempt to delete their parent directory.
Stephan Ewen created FLINK-8540: --- Summary: FileStateHandles must not attempt to delete their parent directory. Key: FLINK-8540 URL: https://issues.apache.org/jira/browse/FLINK-8540 Project: Flink Issue Type: Sub-task Components: State Backends, Checkpointing Reporter: Stephan Ewen Assignee: Stephan Ewen Fix For: 1.5.0 Currently, every file disposal checks if the parent directory is now empty, and deletes it if that is the case. That is not only inefficient, but prohibitively expensive on some systems, like Amazon S3. With the resolution of [FLINK-8539], this will no longer be necessary. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Created] (FLINK-8539) Introduce "CompletedCheckpointStorageLocation" to explicitly handle disposal of checkpoint storage locations
Stephan Ewen created FLINK-8539:
---
Summary: Introduce "CompletedCheckpointStorageLocation" to
explicitly handle disposal of checkpoint storage locations
Key: FLINK-8539
URL: https://issues.apache.org/jira/browse/FLINK-8539
Project: Flink
Issue Type: Sub-task
Components: State Backends, Checkpointing
Reporter: Stephan Ewen
Assignee: Stephan Ewen
Fix For: 1.5.0
The storage location of completed checkpoints misses a proper representation.
Because of that, there is no place that can handle the deletion of a checkpoint
directory, or the dropping of a checkpoint specific table.
Current workaround for file systems is, for example, that every file disposal
checks if the parent directory is now empty, and deletes it if that is the
case. That is not only inefficient, but prohibitively expensive on some
systems, like Amazon S3.
Properly representing the storage location for completed checkpoints allows us
to add a disposal call for that location.
That {{CompletedCheckpointStorageLocation}} can also be used to capture
"external pointers", metadata, and even allow us to use custom serialization
and deserialization of the metadata in the future, making the abstraction more
extensible by allowing users to introduce new types of state handles.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-8534) if insert too much BucketEntry into one bucket in join of iteration will cause a error (Caused : java.io.FileNotFoundException release file error)
[
https://issues.apache.org/jira/browse/FLINK-8534?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
zhu.qing updated FLINK-8534:
Description:
When insert too much entry into bucket will cause
spillPartition(). So
this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel,
bufferReturnQueue);
And in
prepareNextPartition() of reopenablemutable hash table
furtherPartitioning = true;
so in
finalizeProbePhase()
freeMemory.add(this.probeSideBuffer.getCurrentSegment());
// delete the spill files
this.probeSideChannel.close();
System.out.println("HashPartition probeSideRecordCounter Delete");
this.buildSideChannel.deleteChannel();
this.probeSideChannel.deleteChannel();
after deleteChannel the next iteartion will fail.
And I use web-google as dataset(SNAP). And I failed to use 16g laptop to
reproduce the bug. The key to the bug is that you need insert enough entry in
function insertBucketEntry upto 256 and that cause spillPartition().
was:
When insert too much entry into bucket will cause
spillPartition(). So
this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel,
bufferReturnQueue);
And in
prepareNextPartition() of reopenablemutable hash table
furtherPartitioning = true;
so in
finalizeProbePhase()
freeMemory.add(this.probeSideBuffer.getCurrentSegment());
// delete the spill files
this.probeSideChannel.close();
System.out.println("HashPartition probeSideRecordCounter Delete");
this.buildSideChannel.deleteChannel();
this.probeSideChannel.deleteChannel();
after deleteChannel the next iteartion will fail.
And I use web google as dataset(SNAP). And I failed to use 16g laptop to
reproduce the bug. The key to the bug is that you need insert enough entry in
function insertBucketEntry upto 256 and that cause spillPartition().
> if insert too much BucketEntry into one bucket in join of iteration will
> cause a error (Caused : java.io.FileNotFoundException release file error)
> --
>
> Key: FLINK-8534
> URL: https://issues.apache.org/jira/browse/FLINK-8534
> Project: Flink
> Issue Type: Bug
> Environment: windows ideal 8g ram 4core i5 cpu. Flink 1.4.0
>Reporter: zhu.qing
>Priority: Major
> Attachments: T2AdjSetBfs.java
>
>
> When insert too much entry into bucket will cause
> spillPartition(). So
> this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel,
> bufferReturnQueue);
> And in
> prepareNextPartition() of reopenablemutable hash table
> furtherPartitioning = true;
> so in
> finalizeProbePhase()
> freeMemory.add(this.probeSideBuffer.getCurrentSegment());
> // delete the spill files
> this.probeSideChannel.close();
> System.out.println("HashPartition probeSideRecordCounter Delete");
> this.buildSideChannel.deleteChannel();
> this.probeSideChannel.deleteChannel();
> after deleteChannel the next iteartion will fail.
>
> And I use web-google as dataset(SNAP). And I failed to use 16g laptop to
> reproduce the bug. The key to the bug is that you need insert enough entry in
> function insertBucketEntry upto 256 and that cause spillPartition().
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Updated] (FLINK-8534) if insert too much BucketEntry into one bucket in join of iteration will cause a error (Caused : java.io.FileNotFoundException release file error)
[
https://issues.apache.org/jira/browse/FLINK-8534?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
zhu.qing updated FLINK-8534:
Description:
When insert too much entry into bucket will cause
spillPartition(). So
this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel,
bufferReturnQueue);
And in
prepareNextPartition() of reopenablemutable hash table
furtherPartitioning = true;
so in
finalizeProbePhase()
freeMemory.add(this.probeSideBuffer.getCurrentSegment());
// delete the spill files
this.probeSideChannel.close();
System.out.println("HashPartition probeSideRecordCounter Delete");
this.buildSideChannel.deleteChannel();
this.probeSideChannel.deleteChannel();
after deleteChannel the next iteartion will fail.
And I use web google as dataset(SNAP). And I failed to use 16g laptop to
reproduce the bug. The key to the bug is that you need insert enough entry in
function insertBucketEntry upto 256 and that cause spillPartition().
was:
When insert too much entry into bucket will cause
spillPartition(). So
this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel,
bufferReturnQueue);
And in
prepareNextPartition() of reopenablemutable hash table
furtherPartitioning = true;
so in
finalizeProbePhase()
freeMemory.add(this.probeSideBuffer.getCurrentSegment());
// delete the spill files
this.probeSideChannel.close();
System.out.println("HashPartition probeSideRecordCounter Delete");
this.buildSideChannel.deleteChannel();
this.probeSideChannel.deleteChannel();
after deleteChannel the next iteartion will fail.
> if insert too much BucketEntry into one bucket in join of iteration will
> cause a error (Caused : java.io.FileNotFoundException release file error)
> --
>
> Key: FLINK-8534
> URL: https://issues.apache.org/jira/browse/FLINK-8534
> Project: Flink
> Issue Type: Bug
> Environment: windows ideal 8g ram 4core i5 cpu. Flink 1.4.0
>Reporter: zhu.qing
>Priority: Major
> Attachments: T2AdjSetBfs.java
>
>
> When insert too much entry into bucket will cause
> spillPartition(). So
> this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel,
> bufferReturnQueue);
> And in
> prepareNextPartition() of reopenablemutable hash table
> furtherPartitioning = true;
> so in
> finalizeProbePhase()
> freeMemory.add(this.probeSideBuffer.getCurrentSegment());
> // delete the spill files
> this.probeSideChannel.close();
> System.out.println("HashPartition probeSideRecordCounter Delete");
> this.buildSideChannel.deleteChannel();
> this.probeSideChannel.deleteChannel();
> after deleteChannel the next iteartion will fail.
>
> And I use web google as dataset(SNAP). And I failed to use 16g laptop to
> reproduce the bug. The key to the bug is that you need insert enough entry in
> function insertBucketEntry upto 256 and that cause spillPartition().
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Commented] (FLINK-8308) Update yajl-ruby dependency to 1.3.1 or higher
[ https://issues.apache.org/jira/browse/FLINK-8308?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347033#comment-16347033 ] Ufuk Celebi commented on FLINK-8308: I don't know how many people use it but we have a Docker image that can build and serve the docs. That one requires Ruby. (1) https://github.com/apache/flink/tree/master/docs (2) https://github.com/apache/flink/blob/master/docs/docker/Dockerfile > Update yajl-ruby dependency to 1.3.1 or higher > -- > > Key: FLINK-8308 > URL: https://issues.apache.org/jira/browse/FLINK-8308 > Project: Flink > Issue Type: Task > Components: Project Website >Reporter: Fabian Hueske >Assignee: Steven Langbroek >Priority: Critical > Fix For: 1.5.0, 1.4.1 > > > We got notified that yajl-ruby < 1.3.1, a dependency which is used to build > the Flink website, has a security vulnerability of high severity. > We should update yajl-ruby to 1.3.1 or higher. > Since the website is built offline and served as static HTML, I don't think > this is a super critical issue (please correct me if I'm wrong), but we > should resolve this soon. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-8526) When use parallelism equals to half of the number of cpu, join and shuffle operators will easly cause deadlock.
[ https://issues.apache.org/jira/browse/FLINK-8526?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347027#comment-16347027 ] zhu.qing commented on FLINK-8526: - link there is more information in https://issues.apache.org/jira/browse/FLINK-8534 > When use parallelism equals to half of the number of cpu, join and shuffle > operators will easly cause deadlock. > --- > > Key: FLINK-8526 > URL: https://issues.apache.org/jira/browse/FLINK-8526 > Project: Flink > Issue Type: Bug > Components: DataSet API, Local Runtime >Affects Versions: 1.4.0 > Environment: 8 machines(96GB and 24 cores) and 20 taskslot per > taskmanager. twitter-2010 dataset. And parallelism setting to 80. I run my > code in standalone mode. >Reporter: zhu.qing >Priority: Major > Attachments: T2AdjActiveV.java, T2AdjMessage.java > > Original Estimate: 72h > Remaining Estimate: 72h > > The next program attached will stuck at some special parallelism in some > situation. When parallelism is 80 in previous setting, The program will > always stuck. And when parallelism is 100, everything goes well. According > to my research I found when the parallelism equals to number of taskslots. > The program is not fastest and probably caused network buffer not enough. How > networker buffer related to parallelism and how parallelism relate to > running task (In other words we have 160 taskslots but running task can be > far more than taskslots). > Parallelism cannot be equals to half of the cpu. > Or will casuse "java.io.FileNotFoundException". You can repeat exception on > your pc and set your parallelism equals to half of your cpu core. -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Commented] (FLINK-8384) Session Window Assigner with Dynamic Gaps
[ https://issues.apache.org/jira/browse/FLINK-8384?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347020#comment-16347020 ] ASF GitHub Bot commented on FLINK-8384: --- Github user dyanarose commented on the issue: https://github.com/apache/flink/pull/5295 Ah, I hadn't thought to keep both in place. So unless the Dynamic SessionWindow classes had withDynamicGap made package private, you would then be able to instantiate them from two different classes. That could feel a bit iffy, however someone else would call it a convenience method. I'll get the change in for the Trigger cast, that should clean up the PR a fair bit > Session Window Assigner with Dynamic Gaps > - > > Key: FLINK-8384 > URL: https://issues.apache.org/jira/browse/FLINK-8384 > Project: Flink > Issue Type: Improvement > Components: Streaming >Reporter: Dyana Rose >Priority: Minor > > *Reason for Improvement* > Currently both Session Window assigners only allow a static inactivity gap. > Given the following scenario, this is too restrictive: > * Given a stream of IoT events from many device types > * Assume each device type could have a different inactivity gap > * Assume each device type gap could change while sessions are in flight > By allowing dynamic inactivity gaps, the correct gap can be determined in the > [assignWindows > function|https://github.com/apache/flink/blob/master/flink-streaming-java/src/main/java/org/apache/flink/streaming/api/windowing/assigners/EventTimeSessionWindows.java#L59] > by passing the element currently under consideration, the timestamp, and the > context to a user defined function. This eliminates the need to create > unwieldy work arounds if you only have static gaps. > Dynamic Session Window gaps should be available for both Event Time and > Processing Time streams. > (short preliminary discussion: > https://lists.apache.org/thread.html/08a011c0039e826343e9be0b1bb4ecfc2e12976bc65f8a43ee88@%3Cdev.flink.apache.org%3E) -- This message was sent by Atlassian JIRA (v7.6.3#76005)
[jira] [Updated] (FLINK-8534) if insert too much BucketEntry into one bucket in join of iteration will cause a error (Caused : java.io.FileNotFoundException release file error)
[
https://issues.apache.org/jira/browse/FLINK-8534?page=com.atlassian.jira.plugin.system.issuetabpanels:all-tabpanel
]
zhu.qing updated FLINK-8534:
Attachment: T2AdjSetBfs.java
> if insert too much BucketEntry into one bucket in join of iteration will
> cause a error (Caused : java.io.FileNotFoundException release file error)
> --
>
> Key: FLINK-8534
> URL: https://issues.apache.org/jira/browse/FLINK-8534
> Project: Flink
> Issue Type: Bug
> Environment: windows ideal 8g ram 4core i5 cpu. Flink 1.4.0
>Reporter: zhu.qing
>Priority: Major
> Attachments: T2AdjSetBfs.java
>
>
> When insert too much entry into bucket will cause
> spillPartition(). So
> this.buildSideChannel = ioAccess.createBlockChannelWriter(targetChannel,
> bufferReturnQueue);
> And in
> prepareNextPartition() of reopenablemutable hash table
> furtherPartitioning = true;
> so in
> finalizeProbePhase()
> freeMemory.add(this.probeSideBuffer.getCurrentSegment());
> // delete the spill files
> this.probeSideChannel.close();
> System.out.println("HashPartition probeSideRecordCounter Delete");
> this.buildSideChannel.deleteChannel();
> this.probeSideChannel.deleteChannel();
> after deleteChannel the next iteartion will fail.
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[GitHub] flink issue #5295: [FLINK-8384] [streaming] Session Window Assigner with Dyn...
Github user dyanarose commented on the issue: https://github.com/apache/flink/pull/5295 Ah, I hadn't thought to keep both in place. So unless the Dynamic SessionWindow classes had withDynamicGap made package private, you would then be able to instantiate them from two different classes. That could feel a bit iffy, however someone else would call it a convenience method. I'll get the change in for the Trigger cast, that should clean up the PR a fair bit ---
[jira] [Commented] (FLINK-8500) Get the timestamp of the Kafka message from kafka consumer(Kafka010Fetcher)
[
https://issues.apache.org/jira/browse/FLINK-8500?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347008#comment-16347008
]
Aljoscha Krettek commented on FLINK-8500:
-
Yes, no I feel stupid. 😅 You analysed it exactly right: we do get the timestamp
from Kafka but then all of the builtin timestamp extractors
({{AscendingTimestampExtractor}} and
{{BoundedOutOfOrdernessTimestampExtractor}}) don't take that into account and
overwrite it.
You can get around that by writing a completely custom
{{AssignerWithPeriodicWatermarks}} but it's not a good situation.
> Get the timestamp of the Kafka message from kafka consumer(Kafka010Fetcher)
> ---
>
> Key: FLINK-8500
> URL: https://issues.apache.org/jira/browse/FLINK-8500
> Project: Flink
> Issue Type: Improvement
> Components: Kafka Connector
>Affects Versions: 1.4.0
>Reporter: yanxiaobin
>Priority: Blocker
> Fix For: 1.5.0, 1.4.1
>
> Attachments: image-2018-01-30-14-58-58-167.png,
> image-2018-01-31-10-48-59-633.png
>
>
> The method deserialize of KeyedDeserializationSchema needs a parameter
> 'kafka message timestamp' (from ConsumerRecord) .In some business scenarios,
> this is useful!
>
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)
[jira] [Comment Edited] (FLINK-8500) Get the timestamp of the Kafka message from kafka consumer(Kafka010Fetcher)
[
https://issues.apache.org/jira/browse/FLINK-8500?page=com.atlassian.jira.plugin.system.issuetabpanels:comment-tabpanel&focusedCommentId=16347008#comment-16347008
]
Aljoscha Krettek edited comment on FLINK-8500 at 1/31/18 3:26 PM:
--
Yes, now I feel stupid. 😅 You analysed it exactly right: we do get the
timestamp from Kafka but then all of the builtin timestamp extractors
({{AscendingTimestampExtractor}} and
{{BoundedOutOfOrdernessTimestampExtractor}}) don't take that into account and
overwrite it.
You can get around that by writing a completely custom
{{AssignerWithPeriodicWatermarks}} but it's not a good situation.
was (Author: aljoscha):
Yes, no I feel stupid. 😅 You analysed it exactly right: we do get the timestamp
from Kafka but then all of the builtin timestamp extractors
({{AscendingTimestampExtractor}} and
{{BoundedOutOfOrdernessTimestampExtractor}}) don't take that into account and
overwrite it.
You can get around that by writing a completely custom
{{AssignerWithPeriodicWatermarks}} but it's not a good situation.
> Get the timestamp of the Kafka message from kafka consumer(Kafka010Fetcher)
> ---
>
> Key: FLINK-8500
> URL: https://issues.apache.org/jira/browse/FLINK-8500
> Project: Flink
> Issue Type: Improvement
> Components: Kafka Connector
>Affects Versions: 1.4.0
>Reporter: yanxiaobin
>Priority: Blocker
> Fix For: 1.5.0, 1.4.1
>
> Attachments: image-2018-01-30-14-58-58-167.png,
> image-2018-01-31-10-48-59-633.png
>
>
> The method deserialize of KeyedDeserializationSchema needs a parameter
> 'kafka message timestamp' (from ConsumerRecord) .In some business scenarios,
> this is useful!
>
--
This message was sent by Atlassian JIRA
(v7.6.3#76005)