[GitHub] spark issue #21009: [SPARK-23905][SQL] Add UDF weekday
Github user gatorsmile commented on the issue: https://github.com/apache/spark/pull/21009 Thanks! Merged to master. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21009: [SPARK-23905][SQL] Add UDF weekday
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/21009 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21004: [SPARK-23896][SQL]Improve PartitioningAwareFileIndex
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21004 **[Test build #89315 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89315/testReport)** for PR 21004 at commit [`12ac191`](https://github.com/apache/spark/commit/12ac191cb29f4ba1f817abffc8c7422efe837b38). * This patch **fails due to an unknown error code, -9**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21004: [SPARK-23896][SQL]Improve PartitioningAwareFileIndex
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21004 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/89315/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21004: [SPARK-23896][SQL]Improve PartitioningAwareFileIndex
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21004 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21052: [SPARK-23799] FilterEstimation.evaluateInSet produces de...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21052 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/89316/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21057: 2 Improvements to Pyspark docs
Github user HyukjinKwon commented on a diff in the pull request: https://github.com/apache/spark/pull/21057#discussion_r181299329 --- Diff: python/pyspark/streaming/kafka.py --- @@ -104,7 +104,7 @@ def createDirectStream(ssc, topics, kafkaParams, fromOffsets=None, :param topics: list of topic_name to consume. :param kafkaParams: Additional params for Kafka. :param fromOffsets: Per-topic/partition Kafka offsets defining the (inclusive) starting -point of the stream. +point of the stream (Dict with keys of type TopicAndPartition and int values). --- End diff -- I would say sth like ``a dictionary containing `TopicAndPartition` to integers.``. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21052: [SPARK-23799] FilterEstimation.evaluateInSet produces de...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21052 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21037: [SPARK-23919][SQL] Add array_position function
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21037 **[Test build #89314 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89314/testReport)** for PR 21037 at commit [`16ae59c`](https://github.com/apache/spark/commit/16ae59cf02da2cf0cd2e9a311b348bd82b452bff). * This patch **fails due to an unknown error code, -9**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21024: [SPARK-23917][SQL] Add array_max function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21024 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/89318/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21053: [SPARK-23924][SQL] Add element_at function
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21053 **[Test build #89313 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89313/testReport)** for PR 21053 at commit [`bb0ab45`](https://github.com/apache/spark/commit/bb0ab45b4a9bbf1155dbb9513508bbef3685b3f6). * This patch **fails due to an unknown error code, -9**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21052: [SPARK-23799] FilterEstimation.evaluateInSet produces de...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21052 **[Test build #89316 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89316/testReport)** for PR 21052 at commit [`74b6ebd`](https://github.com/apache/spark/commit/74b6ebdc2cd8a91944cc6159946f560ba7212a6a). * This patch **fails due to an unknown error code, -9**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21024: [SPARK-23917][SQL] Add array_max function
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21024 **[Test build #89318 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89318/testReport)** for PR 21024 at commit [`e739a0a`](https://github.com/apache/spark/commit/e739a0a247bc3782ee4348246eff921c86f83e13). * This patch **fails due to an unknown error code, -9**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21060: [SPARK-23942][PYTHON][SQL][BRANCH-2.3] Makes collect in ...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21060 **[Test build #89312 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89312/testReport)** for PR 21060 at commit [`4656724`](https://github.com/apache/spark/commit/4656724d27c208d794f99691cfbf93b4bb118d93). * This patch **fails due to an unknown error code, -9**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21024: [SPARK-23917][SQL] Add array_max function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21024 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21053: [SPARK-23924][SQL] Add element_at function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21053 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/89313/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21037: [SPARK-23919][SQL] Add array_position function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21037 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/89314/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21037: [SPARK-23919][SQL] Add array_position function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21037 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21053: [SPARK-23924][SQL] Add element_at function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21053 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21060: [SPARK-23942][PYTHON][SQL][BRANCH-2.3] Makes collect in ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21060 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21060: [SPARK-23942][PYTHON][SQL][BRANCH-2.3] Makes collect in ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21060 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/89312/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21004: [SPARK-23896][SQL]Improve PartitioningAwareFileIndex
Github user gengliangwang commented on the issue: https://github.com/apache/spark/pull/21004 retest this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21004: [SPARK-23896][SQL]Improve PartitioningAwareFileIndex
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21004 **[Test build #89319 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89319/testReport)** for PR 21004 at commit [`12ac191`](https://github.com/apache/spark/commit/12ac191cb29f4ba1f817abffc8c7422efe837b38). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21004: [SPARK-23896][SQL]Improve PartitioningAwareFileIndex
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21004 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21004: [SPARK-23896][SQL]Improve PartitioningAwareFileIndex
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21004 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/2300/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21053: [SPARK-23924][SQL] Add element_at function
Github user kiszk commented on the issue: https://github.com/apache/spark/pull/21053 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21037: [SPARK-23919][SQL] Add array_position function
Github user kiszk commented on the issue: https://github.com/apache/spark/pull/21037 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21053: [SPARK-23924][SQL] Add element_at function
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21053 **[Test build #89321 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89321/testReport)** for PR 21053 at commit [`bb0ab45`](https://github.com/apache/spark/commit/bb0ab45b4a9bbf1155dbb9513508bbef3685b3f6). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21037: [SPARK-23919][SQL] Add array_position function
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21037 **[Test build #89322 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89322/testReport)** for PR 21037 at commit [`16ae59c`](https://github.com/apache/spark/commit/16ae59cf02da2cf0cd2e9a311b348bd82b452bff). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21061: [SPARK-23914][SQL] Add array_union function
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21061 **[Test build #89320 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89320/testReport)** for PR 21061 at commit [`29c9b92`](https://github.com/apache/spark/commit/29c9b92e32766a3a79eabb9040e25c368020fa65). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21061: [SPARK-23914][SQL] Add array_union function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21061 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/2301/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21061: [SPARK-23914][SQL] Add array_union function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21061 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20953: [SPARK-23822][SQL] Improve error message for Parq...
Github user yuchenhuo commented on a diff in the pull request:
https://github.com/apache/spark/pull/20953#discussion_r181306071
--- Diff:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/FileScanRDD.scala
---
@@ -179,7 +182,23 @@ class FileScanRDD(
currentIterator = readCurrentFile()
}
- hasNext
+ try {
+hasNext
+ } catch {
+case e: SchemaColumnConvertNotSupportedException =>
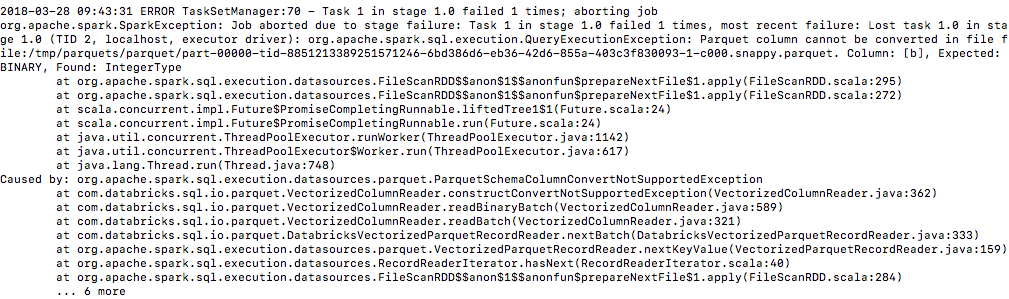
+ val message = "Parquet column cannot be converted in " +
+s"file ${currentFile.filePath}. Column: ${e.getColumn}, " +
+s"Expected: ${e.getLogicalType}, Found:
${e.getPhysicalType}"
+ throw new QueryExecutionException(message, e)
--- End diff --
Yes, you are right. Sorry, I shouldn't say "use QueryExecutionException
instead of the original SparkException". The final exception would still be
wrapped with a SparkException. Inside the SparkException would be
QueryExecutionException. But the reason is still the same, they don't want to
throw too many different Exceptions which might be hard to capture and display.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21053: [SPARK-23924][SQL] Add element_at function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21053 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21053: [SPARK-23924][SQL] Add element_at function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21053 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/2302/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21037: [SPARK-23919][SQL] Add array_position function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21037 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21037: [SPARK-23919][SQL] Add array_position function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21037 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/2303/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20078: [SPARK-22900] [Spark-Streaming] Remove unnecessary restr...
Github user vc60er commented on the issue: https://github.com/apache/spark/pull/20078 by set spark.streaming.dynamicAllocation.minExecutors also has same issue .https://issues.apache.org/jira/browse/SPARK-14788 @felixcheung --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21040: [SPARK-23930][SQL] Add slice function
Github user kiszk commented on a diff in the pull request:
https://github.com/apache/spark/pull/21040#discussion_r181313290
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
---
@@ -287,3 +287,101 @@ case class ArrayContains(left: Expression, right:
Expression)
override def prettyName: String = "array_contains"
}
+
+
+/**
+ * Slices an array according to the requested start index and length
+ */
+// scalastyle:off line.size.limit
+@ExpressionDescription(
+ usage = "_FUNC_(a1, a2) - Subsets array x starting from index start (or
starting from the end if start is negative) with the specified length.",
+ examples = """
+Examples:
+ > SELECT _FUNC_(array(1, 2, 3, 4), 2, 2);
+ [2,3]
+ > SELECT _FUNC_(array(1, 2, 3, 4), -2, 2);
+ [3,4]
+ """, since = "2.4.0")
+// scalastyle:on line.size.limit
+case class Slice(x: Expression, start: Expression, length: Expression)
+ extends TernaryExpression with ImplicitCastInputTypes {
+
+ override def dataType: DataType = x.dataType
+
+ override def inputTypes: Seq[AbstractDataType] = Seq(ArrayType,
IntegerType, IntegerType)
+
+ override def nullable: Boolean = children.exists(_.nullable)
+
+ override def foldable: Boolean = children.forall(_.foldable)
+
+ override def children: Seq[Expression] = Seq(x, start, length)
+
+ override def nullSafeEval(xVal: Any, startVal: Any, lengthVal: Any): Any
= {
+val startInt = startVal.asInstanceOf[Int]
+val lengthInt = lengthVal.asInstanceOf[Int]
+val arr = xVal.asInstanceOf[ArrayData]
+val startIndex = if (startInt == 0) {
+ throw new RuntimeException(
+s"Unexpected value for start in function $prettyName: SQL array
indices start at 1.")
+} else if (startInt < 0) {
+ startInt + arr.numElements()
+} else {
+ startInt - 1
+}
+if (lengthInt < 0) {
+ throw new RuntimeException(s"Unexpected value for length in function
$prettyName: " +
+s"length must be greater than or equal to 0.")
+}
+// this can happen if start is negative and its absolute value is
greater than the
+// number of elements in the array
+if (startIndex < 0) {
+ return new GenericArrayData(Array.empty[AnyRef])
+}
+val elementType = x.dataType.asInstanceOf[ArrayType].elementType
+val data = arr.toArray[AnyRef](elementType)
+new GenericArrayData(data.slice(startIndex, startIndex + lengthInt))
+ }
+
+ override def doGenCode(ctx: CodegenContext, ev: ExprCode): ExprCode = {
+val elementType = x.dataType.asInstanceOf[ArrayType].elementType
+nullSafeCodeGen(ctx, ev, (x, start, length) => {
+ val arrayClass = classOf[GenericArrayData].getName
+ val values = ctx.freshName("values")
+ val i = ctx.freshName("i")
+ val startIdx = ctx.freshName("startIdx")
+ val resLength = ctx.freshName("resLength")
+ val defaultIntValue =
CodeGenerator.defaultValue(CodeGenerator.JAVA_INT, false)
+ s"""
+ |${CodeGenerator.JAVA_INT} $startIdx = $defaultIntValue;
+ |${CodeGenerator.JAVA_INT} $resLength = $defaultIntValue;
+ |if ($start == 0) {
+ | throw new RuntimeException("Unexpected value for start in
function $prettyName: "
+ |+ "SQL array indices start at 1.");
+ |} else if ($start < 0) {
+ | $startIdx = $start + $x.numElements();
+ |} else {
+ | // arrays in SQL are 1-based instead of 0-based
+ | $startIdx = $start - 1;
+ |}
+ |if ($length < 0) {
+ | throw new RuntimeException("Unexpected value for length in
function $prettyName: "
+ |+ "length must be greater than or equal to 0.");
+ |} else if ($length > $x.numElements() - $startIdx) {
+ | $resLength = $x.numElements() - $startIdx;
+ |} else {
+ | $resLength = $length;
+ |}
+ |Object[] $values;
+ |if ($startIdx < 0) {
+ | $values = new Object[0];
+ |} else {
+ | $values = new Object[$resLength];
+ | for (int $i = 0; $i < $resLength; $i ++) {
+ |$values[$i] = ${CodeGenerator.getValue(x, elementType, s"$i
+ $startIdx")};
--- End diff --
For the future, I agree that this is the right way to generate Java code
since we can avoid boxing.
On the other hand, you are proposing to postpone specialization. In `eval`
and generated code, `GenericArrayData` is generated by using `Object[]`.
I may misunderstand `for coherency` since I may not find the target of the
coh
[GitHub] spark issue #20858: [SPARK-23736][SQL] Extending the concat function to supp...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20858 **[Test build #89323 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89323/testReport)** for PR 20858 at commit [`7f5124b`](https://github.com/apache/spark/commit/7f5124ba8752387b3e1d6c0922b551a2cba98356). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20983: [SPARK-23747][Structured Streaming] Add EpochCoordinator...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20983 **[Test build #89324 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89324/testReport)** for PR 20983 at commit [`8fa609c`](https://github.com/apache/spark/commit/8fa609cd8ad6130aa16b9bf624fe5b5e0f5ef256). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20888: [SPARK-23775][TEST] Make DataFrameRangeSuite not ...
Github user gaborgsomogyi commented on a diff in the pull request:
https://github.com/apache/spark/pull/20888#discussion_r181326106
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/DataFrameRangeSuite.scala ---
@@ -152,22 +154,28 @@ class DataFrameRangeSuite extends QueryTest with
SharedSQLContext with Eventuall
}
test("Cancelling stage in a query with Range.") {
+val slices = 10
+
val listener = new SparkListener {
- override def onJobStart(jobStart: SparkListenerJobStart): Unit = {
-eventually(timeout(10.seconds), interval(1.millis)) {
- assert(DataFrameRangeSuite.stageToKill > 0)
+ override def onTaskStart(taskStart: SparkListenerTaskStart): Unit = {
+eventually(timeout(10.seconds)) {
+ assert(DataFrameRangeSuite.isTaskStarted)
}
-sparkContext.cancelStage(DataFrameRangeSuite.stageToKill)
+sparkContext.cancelStage(taskStart.stageId)
+DataFrameRangeSuite.semaphore.release(slices)
--- End diff --
I see your point and tried similar things before. How do you think it's
possible to wait on anything in the task's code without having
`NotSerializableException`? That's a quite hard limitation.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20874: [SPARK-23763][SQL] OffHeapColumnVector uses MemoryBlock
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20874 **[Test build #89325 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89325/testReport)** for PR 20874 at commit [`088ac7d`](https://github.com/apache/spark/commit/088ac7dbc8e9bb651be8044a83569de6871a67bf). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21024: [SPARK-23917][SQL] Add array_max function
Github user ueshin commented on the issue: https://github.com/apache/spark/pull/21024 Jenkins, retest this please. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21024: [SPARK-23917][SQL] Add array_max function
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21024 **[Test build #89326 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89326/testReport)** for PR 21024 at commit [`e739a0a`](https://github.com/apache/spark/commit/e739a0a247bc3782ee4348246eff921c86f83e13). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21024: [SPARK-23917][SQL] Add array_max function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21024 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21024: [SPARK-23917][SQL] Add array_max function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21024 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/2304/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20874: [SPARK-23763][SQL] OffHeapColumnVector uses MemoryBlock
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20874 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20874: [SPARK-23763][SQL] OffHeapColumnVector uses MemoryBlock
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20874 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/2305/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21059: [SPARK-23974][CORE] fix when numExecutorsTarget equals m...
Github user sadhen commented on the issue: https://github.com/apache/spark/pull/21059 @jiangxb1987 I re-investigated the logs and find that there must be bugs in the yarn scheduler backend. And this PR is not the right way to fix the issue. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21059: [SPARK-23974][CORE] fix when numExecutorsTarget e...
Github user sadhen closed the pull request at: https://github.com/apache/spark/pull/21059 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21060: [SPARK-23942][PYTHON][SQL][BRANCH-2.3] Makes collect in ...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/21060 retest this please --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21060: [SPARK-23942][PYTHON][SQL][BRANCH-2.3] Makes collect in ...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21060 **[Test build #89327 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89327/testReport)** for PR 21060 at commit [`4656724`](https://github.com/apache/spark/commit/4656724d27c208d794f99691cfbf93b4bb118d93). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21040: [SPARK-23930][SQL] Add slice function
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21040#discussion_r181338128
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
---
@@ -287,3 +287,101 @@ case class ArrayContains(left: Expression, right:
Expression)
override def prettyName: String = "array_contains"
}
+
+
+/**
+ * Slices an array according to the requested start index and length
+ */
+// scalastyle:off line.size.limit
+@ExpressionDescription(
+ usage = "_FUNC_(a1, a2) - Subsets array x starting from index start (or
starting from the end if start is negative) with the specified length.",
+ examples = """
+Examples:
+ > SELECT _FUNC_(array(1, 2, 3, 4), 2, 2);
+ [2,3]
+ > SELECT _FUNC_(array(1, 2, 3, 4), -2, 2);
+ [3,4]
+ """, since = "2.4.0")
+// scalastyle:on line.size.limit
+case class Slice(x: Expression, start: Expression, length: Expression)
+ extends TernaryExpression with ImplicitCastInputTypes {
+
+ override def dataType: DataType = x.dataType
+
+ override def inputTypes: Seq[AbstractDataType] = Seq(ArrayType,
IntegerType, IntegerType)
+
+ override def nullable: Boolean = children.exists(_.nullable)
+
+ override def foldable: Boolean = children.forall(_.foldable)
+
+ override def children: Seq[Expression] = Seq(x, start, length)
+
+ override def nullSafeEval(xVal: Any, startVal: Any, lengthVal: Any): Any
= {
+val startInt = startVal.asInstanceOf[Int]
+val lengthInt = lengthVal.asInstanceOf[Int]
+val arr = xVal.asInstanceOf[ArrayData]
+val startIndex = if (startInt == 0) {
+ throw new RuntimeException(
+s"Unexpected value for start in function $prettyName: SQL array
indices start at 1.")
+} else if (startInt < 0) {
+ startInt + arr.numElements()
+} else {
+ startInt - 1
+}
+if (lengthInt < 0) {
+ throw new RuntimeException(s"Unexpected value for length in function
$prettyName: " +
+s"length must be greater than or equal to 0.")
+}
+// this can happen if start is negative and its absolute value is
greater than the
+// number of elements in the array
+if (startIndex < 0) {
+ return new GenericArrayData(Array.empty[AnyRef])
+}
+val elementType = x.dataType.asInstanceOf[ArrayType].elementType
+val data = arr.toArray[AnyRef](elementType)
+new GenericArrayData(data.slice(startIndex, startIndex + lengthInt))
+ }
+
+ override def doGenCode(ctx: CodegenContext, ev: ExprCode): ExprCode = {
+val elementType = x.dataType.asInstanceOf[ArrayType].elementType
+nullSafeCodeGen(ctx, ev, (x, start, length) => {
+ val arrayClass = classOf[GenericArrayData].getName
+ val values = ctx.freshName("values")
+ val i = ctx.freshName("i")
+ val startIdx = ctx.freshName("startIdx")
+ val resLength = ctx.freshName("resLength")
+ val defaultIntValue =
CodeGenerator.defaultValue(CodeGenerator.JAVA_INT, false)
+ s"""
+ |${CodeGenerator.JAVA_INT} $startIdx = $defaultIntValue;
+ |${CodeGenerator.JAVA_INT} $resLength = $defaultIntValue;
+ |if ($start == 0) {
+ | throw new RuntimeException("Unexpected value for start in
function $prettyName: "
+ |+ "SQL array indices start at 1.");
+ |} else if ($start < 0) {
+ | $startIdx = $start + $x.numElements();
+ |} else {
+ | // arrays in SQL are 1-based instead of 0-based
+ | $startIdx = $start - 1;
+ |}
+ |if ($length < 0) {
+ | throw new RuntimeException("Unexpected value for length in
function $prettyName: "
+ |+ "length must be greater than or equal to 0.");
+ |} else if ($length > $x.numElements() - $startIdx) {
+ | $resLength = $x.numElements() - $startIdx;
+ |} else {
+ | $resLength = $length;
+ |}
+ |Object[] $values;
+ |if ($startIdx < 0) {
+ | $values = new Object[0];
+ |} else {
+ | $values = new Object[$resLength];
+ | for (int $i = 0; $i < $resLength; $i ++) {
+ |$values[$i] = ${CodeGenerator.getValue(x, elementType, s"$i
+ $startIdx")};
--- End diff --
My target of coherency was the `CreateArray` operator and the code
generated in `GenerateSafeProjection`.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21025: [SPARK-23918][SQL] Add array_min function
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21025 **[Test build #89328 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89328/testReport)** for PR 21025 at commit [`a7d3a2e`](https://github.com/apache/spark/commit/a7d3a2e28719daf4a49614887d2aa79d090aab69). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21024: [SPARK-23917][SQL] Add array_max function
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21024 **[Test build #89329 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89329/testReport)** for PR 21024 at commit [`1cde795`](https://github.com/apache/spark/commit/1cde795fe96b915f7b322ea1746c436d51391528). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21060: [SPARK-23942][PYTHON][SQL][BRANCH-2.3] Makes collect in ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21060 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21060: [SPARK-23942][PYTHON][SQL][BRANCH-2.3] Makes collect in ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21060 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/2306/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20981: [SPARK-23873][SQL] Use accessors in interpreted LambdaVa...
Github user viirya commented on the issue: https://github.com/apache/spark/pull/20981 ping @hvanhovell --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21025: [SPARK-23918][SQL] Add array_min function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21025 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/2307/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21025: [SPARK-23918][SQL] Add array_min function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21025 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20560: [SPARK-23375][SQL] Eliminate unneeded Sort in Optimizer
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20560 **[Test build #89330 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89330/testReport)** for PR 20560 at commit [`6c5f04c`](https://github.com/apache/spark/commit/6c5f04cb989736ced5d7c8695a0740e512df36c6). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20984: [SPARK-23875][SQL] Add IndexedSeq wrapper for Arr...
Github user viirya commented on a diff in the pull request:
https://github.com/apache/spark/pull/20984#discussion_r181339660
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/util/ArrayData.scala
---
@@ -164,3 +167,46 @@ abstract class ArrayData extends SpecializedGetters
with Serializable {
}
}
}
+
+/**
+ * Implements an `IndexedSeq` interface for `ArrayData`. Notice that if
the original `ArrayData`
+ * is a primitive array and contains null elements, it is better to ask
for `IndexedSeq[Any]`,
+ * instead of `IndexedSeq[Int]`, in order to keep the null elements.
+ */
+class ArrayDataIndexedSeq[T](arrayData: ArrayData, dataType: DataType)
extends IndexedSeq[T] {
+
+ private def getAccessor(dataType: DataType): (Int) => Any = dataType
match {
+case BooleanType => (idx: Int) => arrayData.getBoolean(idx)
+case ByteType => (idx: Int) => arrayData.getByte(idx)
+case ShortType => (idx: Int) => arrayData.getShort(idx)
+case IntegerType => (idx: Int) => arrayData.getInt(idx)
--- End diff --
I'd like to reuse the access getter in #20981 which covers `DateType` and
`TimestampType`.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21024: [SPARK-23917][SQL] Add array_max function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21024 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/2308/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21024: [SPARK-23917][SQL] Add array_max function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21024 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20560: [SPARK-23375][SQL] Eliminate unneeded Sort in Optimizer
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20560 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/2309/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20560: [SPARK-23375][SQL] Eliminate unneeded Sort in Optimizer
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20560 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21031: [SPARK-23923][SQL] Add cardinality function
Github user mgaido91 commented on a diff in the pull request:
https://github.com/apache/spark/pull/21031#discussion_r181340756
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/functions.scala ---
@@ -3282,6 +3282,14 @@ object functions {
*/
def size(e: Column): Column = withExpr { Size(e.expr) }
+ /**
+ * Returns length of array or map as BigInt.
--- End diff --
BigInt -> long
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20923: [SPARK-23807][BUILD] Add Hadoop 3.1 profile with relevan...
Github user steveloughran commented on the issue: https://github.com/apache/spark/pull/20923 @jerryshao comments? I know without the patched hive or mutant hadoop build Spark doesn't work with Hadoop 3, but this sets everything up to build consistently, which is a prerequisite to fixing up the semi-official spark hive JAR. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20695: [SPARK-21741][ML][PySpark] Python API for DataFrame-base...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20695 **[Test build #89331 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89331/testReport)** for PR 20695 at commit [`20968c1`](https://github.com/apache/spark/commit/20968c1101d7c19bd81bf561e47e6b477fe0a19a). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20695: [SPARK-21741][ML][PySpark] Python API for DataFrame-base...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20695 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/2310/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20695: [SPARK-21741][ML][PySpark] Python API for DataFrame-base...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20695 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20695: [SPARK-21741][ML][PySpark] Python API for DataFrame-base...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20695 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/89331/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20695: [SPARK-21741][ML][PySpark] Python API for DataFrame-base...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20695 **[Test build #89331 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89331/testReport)** for PR 20695 at commit [`20968c1`](https://github.com/apache/spark/commit/20968c1101d7c19bd81bf561e47e6b477fe0a19a). * This patch **fails Python style tests**. * This patch merges cleanly. * This patch adds the following public classes _(experimental)_: * `class SummaryBuilder(JavaWrapper):` --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20695: [SPARK-21741][ML][PySpark] Python API for DataFrame-base...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20695 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21031: [SPARK-23923][SQL] Add cardinality function
Github user kiszk commented on a diff in the pull request:
https://github.com/apache/spark/pull/21031#discussion_r181344225
--- Diff: sql/core/src/main/scala/org/apache/spark/sql/functions.scala ---
@@ -3282,6 +3282,14 @@ object functions {
*/
def size(e: Column): Column = withExpr { Size(e.expr) }
+ /**
+ * Returns length of array or map as BigInt.
--- End diff --
Good catch, thanks
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21031: [SPARK-23923][SQL] Add cardinality function
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21031 **[Test build #89332 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89332/testReport)** for PR 21031 at commit [`a21f85b`](https://github.com/apache/spark/commit/a21f85ba2bd4c2f3ee33ac0499a4f92fe2e54629). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21031: [SPARK-23923][SQL] Add cardinality function
Github user mgaido91 commented on the issue: https://github.com/apache/spark/pull/21031 LGTM --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21062: Branch 1.2
GitHub user androidbestcoder opened a pull request: https://github.com/apache/spark/pull/21062 Branch 1.2 ## What changes were proposed in this pull request? (Please fill in changes proposed in this fix) ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/apache/spark branch-1.2 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/21062.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #21062 commit e7f9dd5cd10d18d0b712916750ac1643df169b4f Author: Ernest Date: 2014-12-18T23:42:26Z [SPARK-4880] remove spark.locality.wait in Analytics spark.locality.wait set to 10 in examples/graphx/Analytics.scala. Should be left to the user. Author: Ernest Closes #3730 from Earne/SPARK-4880 and squashes the following commits: d79ed04 [Ernest] remove spark.locality.wait in Analytics (cherry picked from commit a7ed6f3cc537f57de87d28e8466ca88fbfff53b5) Signed-off-by: Reynold Xin commit 61c9b89d84c868e9ecf5cffb9718c46753c9996e Author: Madhu Siddalingaiah Date: 2014-12-19T00:00:53Z [SPARK-4884]: Improve Partition docs Rewording was based on this discussion: http://apache-spark-developers-list.1001551.n3.nabble.com/RDD-data-flow-td9804.html This is the associated JIRA ticket: https://issues.apache.org/jira/browse/SPARK-4884 Author: Madhu Siddalingaiah Closes #3722 from msiddalingaiah/master and squashes the following commits: 79e679f [Madhu Siddalingaiah] [DOC]: improve documentation 51d14b9 [Madhu Siddalingaiah] Merge remote-tracking branch 'upstream/master' 38faca4 [Madhu Siddalingaiah] Merge remote-tracking branch 'upstream/master' cbccbfe [Madhu Siddalingaiah] Documentation: replace with (again) 332f7a2 [Madhu Siddalingaiah] Documentation: replace with cd2b05a [Madhu Siddalingaiah] Merge remote-tracking branch 'upstream/master' 0fc12d7 [Madhu Siddalingaiah] Documentation: add description for repartitionAndSortWithinPartitions (cherry picked from commit d5a596d4188bfa85ff49ee85039f54255c19a4de) Signed-off-by: Josh Rosen commit 075b399c59b508251f4fb259e7b0c13b79ff5883 Author: Aaron Davidson Date: 2014-12-19T00:43:16Z [SPARK-4837] NettyBlockTransferService should use spark.blockManager.port config This is used in NioBlockTransferService here: https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/network/nio/NioBlockTransferService.scala#L66 Author: Aaron Davidson Closes #3688 from aarondav/SPARK-4837 and squashes the following commits: ebd2007 [Aaron Davidson] [SPARK-4837] NettyBlockTransferService should use spark.blockManager.port config (cherry picked from commit 105293a7d06b26e7b179a0447eb802074ee9c218) Signed-off-by: Josh Rosen commit ca37639aa1b537d0f9b56bf1362bf293635e235c Author: Andrew Or Date: 2014-12-19T01:37:42Z [SPARK-4754] Refactor SparkContext into ExecutorAllocationClient This is such that the `ExecutorAllocationManager` does not take in the `SparkContext` with all of its dependencies as an argument. This prevents future developers of this class to tie down this class further with the `SparkContext`, which has really become quite a monstrous object. cc'ing pwendell who originally suggested this, and JoshRosen who may have thoughts about the trait mix-in style of `SparkContext`. Author: Andrew Or Closes #3614 from andrewor14/dynamic-allocation-sc and squashes the following commits: 187070d [Andrew Or] Merge branch 'master' of github.com:apache/spark into dynamic-allocation-sc 59baf6c [Andrew Or] Merge branch 'master' of github.com:apache/spark into dynamic-allocation-sc 347a348 [Andrew Or] Refactor SparkContext into ExecutorAllocationClient (cherry picked from commit 9804a759b68f56eceb8a2f4ea90f76a92b5f9f67) Signed-off-by: Andrew Or Conflicts: core/src/main/scala/org/apache/spark/SparkContext.scala commit fd7bb9d9728fa2b4fc6f26ae6a31cfa60d560ad4 Author: Sandy Ryza Date: 2014-12-19T06:40:44Z SPARK-3428. TaskMetrics for running tasks is missing GC time metrics Author: Sandy Ryza Closes #3684 from sryza/sandy-spark-3428 and squashes the following commits: cb827fe [Sandy Ryza] SPARK-3428. TaskMetrics for running tasks is missing GC time metrics (cherry picke
[GitHub] spark issue #21062: Branch 1.2
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21062 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21053: [SPARK-23924][SQL] Add element_at function
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21053 **[Test build #89321 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89321/testReport)** for PR 21053 at commit [`bb0ab45`](https://github.com/apache/spark/commit/bb0ab45b4a9bbf1155dbb9513508bbef3685b3f6). * This patch **fails PySpark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21062: Branch 1.2
Github user androidbestcoder closed the pull request at: https://github.com/apache/spark/pull/21062 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21031: [SPARK-23923][SQL] Add cardinality function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21031 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution/2311/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21053: [SPARK-23924][SQL] Add element_at function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21053 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21031: [SPARK-23923][SQL] Add cardinality function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21031 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21053: [SPARK-23924][SQL] Add element_at function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21053 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/89321/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20858: [SPARK-23736][SQL] Extending the concat function to supp...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/20858 **[Test build #89323 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89323/testReport)** for PR 20858 at commit [`7f5124b`](https://github.com/apache/spark/commit/7f5124ba8752387b3e1d6c0922b551a2cba98356). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20858: [SPARK-23736][SQL] Extending the concat function to supp...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20858 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/89323/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #21063: [SPARK-23886][Structured Streaming][WIP] Update q...
GitHub user efimpoberezkin opened a pull request: https://github.com/apache/spark/pull/21063 [SPARK-23886][Structured Streaming][WIP] Update query status for ContinuousExecution ## What changes were proposed in this pull request? Added query status updates to ContinuousExecution ## How was this patch tested? Existing tests in ContinuousSuite You can merge this pull request into a Git repository by running: $ git pull https://github.com/efimpoberezkin/spark pr/update-query-status Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/21063.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #21063 commit 8fa7d9f1f1f804e2c75819cb27c67f841c688cdc Author: Efim Poberezkin Date: 2018-04-13T10:20:59Z Added query status update messages --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #20858: [SPARK-23736][SQL] Extending the concat function to supp...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/20858 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21063: [SPARK-23886][Structured Streaming][WIP] Update query st...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21063 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21063: [SPARK-23886][Structured Streaming][WIP] Update query st...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21063 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20938: [SPARK-23821][SQL] Collection function: flatten
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/20938#discussion_r181342596
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
---
@@ -287,3 +289,160 @@ case class ArrayContains(left: Expression, right:
Expression)
override def prettyName: String = "array_contains"
}
+
+/**
+ * Transforms an array of arrays into a single array.
+ */
+@ExpressionDescription(
+ usage = "_FUNC_(arrayOfArrays) - Transforms an array of arrays into a
single array.",
+ examples = """
+Examples:
+ > SELECT _FUNC_(array(array(1, 2), array(3, 4));
+ [1,2,3,4]
+ """,
+ since = "2.4.0")
+case class Flatten(child: Expression) extends UnaryExpression {
+
+ override def nullable: Boolean = child.nullable || dataType.containsNull
--- End diff --
`child.nullable || child.dataType.asInstanceOf[ArrayType].containsNull`?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20938: [SPARK-23821][SQL] Collection function: flatten
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/20938#discussion_r181345710
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
---
@@ -287,3 +289,160 @@ case class ArrayContains(left: Expression, right:
Expression)
override def prettyName: String = "array_contains"
}
+
+/**
+ * Transforms an array of arrays into a single array.
+ */
+@ExpressionDescription(
+ usage = "_FUNC_(arrayOfArrays) - Transforms an array of arrays into a
single array.",
+ examples = """
+Examples:
+ > SELECT _FUNC_(array(array(1, 2), array(3, 4));
+ [1,2,3,4]
+ """,
+ since = "2.4.0")
+case class Flatten(child: Expression) extends UnaryExpression {
+
+ override def nullable: Boolean = child.nullable || dataType.containsNull
+
+ override def dataType: ArrayType = {
+child
+ .dataType.asInstanceOf[ArrayType]
+ .elementType.asInstanceOf[ArrayType]
+ }
+
+ override def checkInputDataTypes(): TypeCheckResult = child.dataType
match {
+case ArrayType(_: ArrayType, _) =>
+ TypeCheckResult.TypeCheckSuccess
+case _ =>
+ TypeCheckResult.TypeCheckFailure(
+s"The argument should be an array of arrays, " +
+s"but '${child.sql}' is of ${child.dataType.simpleString} type."
+ )
+ }
+
+ override def nullSafeEval(array: Any): Any = {
+val elements = array.asInstanceOf[ArrayData].toObjectArray(dataType)
+
+if (elements.contains(null)) {
+ null
+} else {
+ val flattened = elements.flatMap(
+_.asInstanceOf[ArrayData].toObjectArray(dataType.elementType)
+ )
+ new GenericArrayData(flattened)
+}
+ }
+
+ override def doGenCode(ctx: CodegenContext, ev: ExprCode): ExprCode = {
+nullSafeCodeGen(ctx, ev, c => {
+ val code = if (CodeGenerator.isPrimitiveType(dataType.elementType)) {
+ genCodeForConcatOfPrimitiveElements(ctx, c, ev.value)
+} else {
+ genCodeForConcatOfComplexElements(ctx, c, ev.value)
--- End diff --
I'm wondering if we say "complex" for non-primitive types?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20938: [SPARK-23821][SQL] Collection function: flatten
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/20938#discussion_r181347402
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
---
@@ -287,3 +289,160 @@ case class ArrayContains(left: Expression, right:
Expression)
override def prettyName: String = "array_contains"
}
+
+/**
+ * Transforms an array of arrays into a single array.
+ */
+@ExpressionDescription(
+ usage = "_FUNC_(arrayOfArrays) - Transforms an array of arrays into a
single array.",
+ examples = """
+Examples:
+ > SELECT _FUNC_(array(array(1, 2), array(3, 4));
+ [1,2,3,4]
+ """,
+ since = "2.4.0")
+case class Flatten(child: Expression) extends UnaryExpression {
+
+ override def nullable: Boolean = child.nullable || dataType.containsNull
+
+ override def dataType: ArrayType = {
+child
+ .dataType.asInstanceOf[ArrayType]
+ .elementType.asInstanceOf[ArrayType]
+ }
+
+ override def checkInputDataTypes(): TypeCheckResult = child.dataType
match {
+case ArrayType(_: ArrayType, _) =>
+ TypeCheckResult.TypeCheckSuccess
+case _ =>
+ TypeCheckResult.TypeCheckFailure(
+s"The argument should be an array of arrays, " +
+s"but '${child.sql}' is of ${child.dataType.simpleString} type."
+ )
+ }
+
+ override def nullSafeEval(array: Any): Any = {
+val elements = array.asInstanceOf[ArrayData].toObjectArray(dataType)
+
+if (elements.contains(null)) {
+ null
+} else {
+ val flattened = elements.flatMap(
+_.asInstanceOf[ArrayData].toObjectArray(dataType.elementType)
+ )
+ new GenericArrayData(flattened)
+}
+ }
+
+ override def doGenCode(ctx: CodegenContext, ev: ExprCode): ExprCode = {
+nullSafeCodeGen(ctx, ev, c => {
+ val code = if (CodeGenerator.isPrimitiveType(dataType.elementType)) {
+ genCodeForConcatOfPrimitiveElements(ctx, c, ev.value)
--- End diff --
nit: indent.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #20938: [SPARK-23821][SQL] Collection function: flatten
Github user ueshin commented on a diff in the pull request:
https://github.com/apache/spark/pull/20938#discussion_r181333291
--- Diff:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/collectionOperations.scala
---
@@ -287,3 +289,160 @@ case class ArrayContains(left: Expression, right:
Expression)
override def prettyName: String = "array_contains"
}
+
+/**
+ * Transforms an array of arrays into a single array.
+ */
+@ExpressionDescription(
+ usage = "_FUNC_(arrayOfArrays) - Transforms an array of arrays into a
single array.",
+ examples = """
+Examples:
+ > SELECT _FUNC_(array(array(1, 2), array(3, 4));
+ [1,2,3,4]
+ """,
+ since = "2.4.0")
+case class Flatten(child: Expression) extends UnaryExpression {
+
+ override def nullable: Boolean = child.nullable || dataType.containsNull
+
+ override def dataType: ArrayType = {
+child
+ .dataType.asInstanceOf[ArrayType]
+ .elementType.asInstanceOf[ArrayType]
+ }
+
+ override def checkInputDataTypes(): TypeCheckResult = child.dataType
match {
+case ArrayType(_: ArrayType, _) =>
+ TypeCheckResult.TypeCheckSuccess
+case _ =>
+ TypeCheckResult.TypeCheckFailure(
+s"The argument should be an array of arrays, " +
+s"but '${child.sql}' is of ${child.dataType.simpleString} type."
+ )
+ }
+
+ override def nullSafeEval(array: Any): Any = {
+val elements = array.asInstanceOf[ArrayData].toObjectArray(dataType)
+
+if (elements.contains(null)) {
+ null
+} else {
+ val flattened = elements.flatMap(
+_.asInstanceOf[ArrayData].toObjectArray(dataType.elementType)
+ )
+ new GenericArrayData(flattened)
+}
+ }
+
+ override def doGenCode(ctx: CodegenContext, ev: ExprCode): ExprCode = {
+nullSafeCodeGen(ctx, ev, c => {
+ val code = if (CodeGenerator.isPrimitiveType(dataType.elementType)) {
+ genCodeForConcatOfPrimitiveElements(ctx, c, ev.value)
+} else {
+ genCodeForConcatOfComplexElements(ctx, c, ev.value)
+}
+ nullElementsProtection(ev, c, code)
+})
+ }
+
+ private def nullElementsProtection(
+ ev: ExprCode,
+ childVariableName: String,
+ coreLogic: String): String = {
+s"""
+|for(int z=0; z < $childVariableName.numElements(); z++) {
+| ${ev.isNull} |= $childVariableName.isNullAt(z);
--- End diff --
How about breaking when `null` is found?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21061: [SPARK-23914][SQL] Add array_union function
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/21061 **[Test build #89320 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89320/testReport)** for PR 21061 at commit [`29c9b92`](https://github.com/apache/spark/commit/29c9b92e32766a3a79eabb9040e25c368020fa65). * This patch **fails PySpark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21061: [SPARK-23914][SQL] Add array_union function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21061 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #19627: [SPARK-21088][ML] CrossValidator, TrainValidationSplit s...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/19627 **[Test build #89334 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/89334/testReport)** for PR 19627 at commit [`80f07fb`](https://github.com/apache/spark/commit/80f07fb93a00e2cda402d312e5c6e915bb400c12). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #21061: [SPARK-23914][SQL] Add array_union function
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/21061 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/89320/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org