[GitHub] [spark] AmplabJenkins removed a comment on issue #24092: [SPARK-27160][SQL] Fix DecimalType literal casting
AmplabJenkins removed a comment on issue #24092: [SPARK-27160][SQL] Fix DecimalType literal casting URL: https://github.com/apache/spark/pull/24092#issuecomment-473132048 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/103517/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24101: [CORE][MINOR] Correct the comment to show heartbeat interval is configurable
AmplabJenkins removed a comment on issue #24101: [CORE][MINOR] Correct the comment to show heartbeat interval is configurable URL: https://github.com/apache/spark/pull/24101#issuecomment-473133416 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] vanzin commented on issue #23380: [SPARK-26343][KUBERNETES] Try to speed up running local k8s integration tests
vanzin commented on issue #23380: [SPARK-26343][KUBERNETES] Try to speed up running local k8s integration tests URL: https://github.com/apache/spark/pull/23380#issuecomment-473137259 Merging to master. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24072: [SPARK-27112] : Create a resource ordering between threads to resolve the deadlocks encountered …
SparkQA commented on issue #24072: [SPARK-27112] : Create a resource ordering between threads to resolve the deadlocks encountered … URL: https://github.com/apache/spark/pull/24072#issuecomment-473085987 **[Test build #103519 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/103519/testReport)** for PR 24072 at commit [`09f9b47`](https://github.com/apache/spark/commit/09f9b4767b3f8b94b8ef1ae956d46e7158d50b9d). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24092: [SPARK-27160][SQL] Fix DecimalType literal casting
dongjoon-hyun commented on a change in pull request #24092: [SPARK-27160][SQL]
Fix DecimalType literal casting
URL: https://github.com/apache/spark/pull/24092#discussion_r265782742
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/orc/OrcFilters.scala
##
@@ -136,10 +137,7 @@ private[sql] object OrcFilters {
case FloatType | DoubleType =>
value.asInstanceOf[Number].doubleValue()
case _: DecimalType =>
- val decimal = value.asInstanceOf[java.math.BigDecimal]
- val decimalWritable = new HiveDecimalWritable(decimal.longValue)
- decimalWritable.mutateEnforcePrecisionScale(decimal.precision,
decimal.scale)
Review comment:
@sadhen and @cloud-fan .
Yes, Line 140 was the bug and `mutateEnforcePrecisionScale` just amended the
scale and precision for the `HiveDecimalWriter(long)` case. We can remove this
in the new code.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #24097: [SPARK-27165][SPARK-27107][BRANCH-2.4][BUILD][SQL] Upgrade Apache ORC to 1.5.5
dongjoon-hyun commented on issue #24097: [SPARK-27165][SPARK-27107][BRANCH-2.4][BUILD][SQL] Upgrade Apache ORC to 1.5.5 URL: https://github.com/apache/spark/pull/24097#issuecomment-473099201 Thanks a lot, @HyukjinKwon ! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level
SparkQA commented on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level URL: https://github.com/apache/spark/pull/24098#issuecomment-473100183 **[Test build #103522 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/103522/testReport)** for PR 24098 at commit [`9263218`](https://github.com/apache/spark/commit/9263218ae5436b3fb780b6e733876ff92c7d81a5). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level
AmplabJenkins commented on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level URL: https://github.com/apache/spark/pull/24098#issuecomment-473099805 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/8933/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level
AmplabJenkins removed a comment on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level URL: https://github.com/apache/spark/pull/24098#issuecomment-473099805 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/8933/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level
AmplabJenkins removed a comment on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level URL: https://github.com/apache/spark/pull/24098#issuecomment-473099801 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon closed pull request #24089: [SPARK-27158][BUILD] dev/mima and dev/scalastyle support dynamic profiles
HyukjinKwon closed pull request #24089: [SPARK-27158][BUILD] dev/mima and dev/scalastyle support dynamic profiles URL: https://github.com/apache/spark/pull/24089 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #24075: [SPARK-26176][SQL] Invalid column names validation is been added when we create a table using the Hive serde "STORED AS"
dongjoon-hyun commented on issue #24075: [SPARK-26176][SQL] Invalid column names validation is been added when we create a table using the Hive serde "STORED AS" URL: https://github.com/apache/spark/pull/24075#issuecomment-473109791 Thank you for pinging me, @sujith71955 . I updated the PR description slightly. I also take a look at this tonight. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level
dongjoon-hyun commented on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level URL: https://github.com/apache/spark/pull/24098#issuecomment-473112224 Thank you for review and approval, @dbtsai ! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24091: [SPARK-27159][SQL]update mssql server dialect to support binary type
AmplabJenkins commented on issue #24091: [SPARK-27159][SQL]update mssql server dialect to support binary type URL: https://github.com/apache/spark/pull/24091#issuecomment-473112366 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/103523/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24091: [SPARK-27159][SQL]update mssql server dialect to support binary type
AmplabJenkins commented on issue #24091: [SPARK-27159][SQL]update mssql server dialect to support binary type URL: https://github.com/apache/spark/pull/24091#issuecomment-473112363 Merged build finished. Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24091: [SPARK-27159][SQL]update mssql server dialect to support binary type
SparkQA commented on issue #24091: [SPARK-27159][SQL]update mssql server dialect to support binary type URL: https://github.com/apache/spark/pull/24091#issuecomment-473111857 **[Test build #103523 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/103523/testReport)** for PR 24091 at commit [`fb6493e`](https://github.com/apache/spark/commit/fb6493e8f85f08c55901c9e817c82babb79ee176). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24091: [SPARK-27159][SQL]update mssql server dialect to support binary type
SparkQA commented on issue #24091: [SPARK-27159][SQL]update mssql server dialect to support binary type URL: https://github.com/apache/spark/pull/24091#issuecomment-473112357 **[Test build #103523 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/103523/testReport)** for PR 24091 at commit [`fb6493e`](https://github.com/apache/spark/commit/fb6493e8f85f08c55901c9e817c82babb79ee176). * This patch **fails Scala style tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #23882: [SPARK-26979][PYTHON] Add missing string column name support for some SQL functions
HyukjinKwon commented on a change in pull request #23882: [SPARK-26979][PYTHON]
Add missing string column name support for some SQL functions
URL: https://github.com/apache/spark/pull/23882#discussion_r265816244
##
File path: python/pyspark/sql/functions.py
##
@@ -85,13 +96,16 @@ def _():
>>> df.select(lit(5).alias('height')).withColumn('spark_user',
lit(True)).take(1)
[Row(height=5, spark_user=True)]
"""
-_functions = {
+_name_functions = {
+# name functions take a column name as their argument
'lit': _lit_doc,
Review comment:
Does `lit` takes the string as column names? how do we create string literal?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24095: [SPARK-27163][PYTHON] Cleanup and consolidate Pandas UDF functionality
AmplabJenkins removed a comment on issue #24095: [SPARK-27163][PYTHON] Cleanup and consolidate Pandas UDF functionality URL: https://github.com/apache/spark/pull/24095#issuecomment-473121000 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/103508/ Test FAILed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24088: [SPARK-27122][core] Jetty classes must not be return via getters in org.apache.spark.ui.WebUI
AmplabJenkins commented on issue #24088: [SPARK-27122][core] Jetty classes must not be return via getters in org.apache.spark.ui.WebUI URL: https://github.com/apache/spark/pull/24088#issuecomment-473123941 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/8936/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24088: [SPARK-27122][core] Jetty classes must not be return via getters in org.apache.spark.ui.WebUI
AmplabJenkins commented on issue #24088: [SPARK-27122][core] Jetty classes must not be return via getters in org.apache.spark.ui.WebUI URL: https://github.com/apache/spark/pull/24088#issuecomment-473123935 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #20793: [SPARK-23643][CORE][SQL][ML] Shrinking the buffer in hashSeed up to size of the seed parameter
SparkQA commented on issue #20793: [SPARK-23643][CORE][SQL][ML] Shrinking the buffer in hashSeed up to size of the seed parameter URL: https://github.com/apache/spark/pull/20793#issuecomment-473123981 **[Test build #103513 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/103513/testReport)** for PR 20793 at commit [`47151b1`](https://github.com/apache/spark/commit/47151b171222a661ff6c9d5948426bf0c5d7165b). * This patch **fails PySpark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #23964: [SPARK-26975][SQL] Support nested-column pruning over limit/sample/repartition
SparkQA commented on issue #23964: [SPARK-26975][SQL] Support nested-column pruning over limit/sample/repartition URL: https://github.com/apache/spark/pull/23964#issuecomment-473126408 **[Test build #103511 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/103511/testReport)** for PR 23964 at commit [`033d172`](https://github.com/apache/spark/commit/033d1721e7021525e66406c7e0c436d9eb49e7e1). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24099: Add docker integration test for MsSql server
AmplabJenkins commented on issue #24099: Add docker integration test for MsSql server URL: https://github.com/apache/spark/pull/24099#issuecomment-473127273 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] lipzhu commented on issue #24091: [SPARK-27159][SQL]update mssql server dialect to support binary type
lipzhu commented on issue #24091: [SPARK-27159][SQL]update mssql server dialect to support binary type URL: https://github.com/apache/spark/pull/24091#issuecomment-473127184 > What's the difference in SQL Server? I'm just wondering if there are any compatibility problems with older versions, or whether there's an upside to changing the type? > What's the difference in SQL Server? I'm just wondering if there are any compatibility problems with older versions, or whether there's an upside to changing the type? @srowen This is a bug fix for writing binary data back to MsSql Server. #24099 https://github.com/apache/spark/blob/9ee60a6fe0eed6e6d4e1b4387f51849bda0c6b9c/external/docker-integration-tests/src/test/scala/org/apache/spark/sql/jdbc/MsSqlServerIntegrationSuite.scala#L170 `= FINISHED o.a.s.sql.jdbc.MsSqlServerIntegrationSuite: 'Basic write test' = - Basic write test *** FAILED *** com.microsoft.sqlserver.jdbc.SQLServerException: Column, parameter, or variable #5: Cannot find data type BLOB. at com.microsoft.sqlserver.jdbc.SQLServerException.makeFromDatabaseError(SQLServerException.java:256) at com.microsoft.sqlserver.jdbc.SQLServerStatement.getNextResult(SQLServerStatement.java:1621) at com.microsoft.sqlserver.jdbc.SQLServerStatement.doExecuteStatement(SQLServerStatement.java:868) at com.microsoft.sqlserver.jdbc.SQLServerStatement$StmtExecCmd.doExecute(SQLServerStatement.java:768) at com.microsoft.sqlserver.jdbc.TDSCommand.execute(IOBuffer.java:7194) at com.microsoft.sqlserver.jdbc.SQLServerConnection.executeCommand(SQLServerConnection.java:2930) at com.microsoft.sqlserver.jdbc.SQLServerStatement.executeCommand(SQLServerStatement.java:248) at com.microsoft.sqlserver.jdbc.SQLServerStatement.executeStatement(SQLServerStatement.java:223) at com.microsoft.sqlserver.jdbc.SQLServerStatement.executeUpdate(SQLServerStatement.java:711) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.createTable(JdbcUtils.scala:868)` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] lipzhu edited a comment on issue #24091: [SPARK-27159][SQL]update mssql server dialect to support binary type
lipzhu edited a comment on issue #24091: [SPARK-27159][SQL]update mssql server dialect to support binary type URL: https://github.com/apache/spark/pull/24091#issuecomment-473127184 > What's the difference in SQL Server? I'm just wondering if there are any compatibility problems with older versions, or whether there's an upside to changing the type? > What's the difference in SQL Server? I'm just wondering if there are any compatibility problems with older versions, or whether there's an upside to changing the type? @srowen This is a bug fix for writing binary data back to MsSql Server. #24099 https://github.com/apache/spark/blob/9ee60a6fe0eed6e6d4e1b4387f51849bda0c6b9c/external/docker-integration-tests/src/test/scala/org/apache/spark/sql/jdbc/MsSqlServerIntegrationSuite.scala#L170 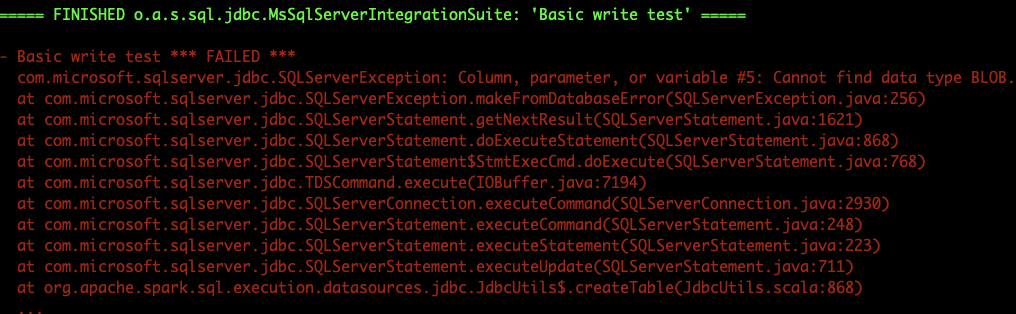 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24012: [SPARK-26811][SQL] Add capabilities to v2.Table
SparkQA commented on issue #24012: [SPARK-26811][SQL] Add capabilities to v2.Table URL: https://github.com/apache/spark/pull/24012#issuecomment-473127301 **[Test build #103510 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/103510/testReport)** for PR 24012 at commit [`93c77f5`](https://github.com/apache/spark/commit/93c77f5c6f2a06bc2cf8fe27fd16ff8f42a891da). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24099: Add docker integration test for MsSql server
AmplabJenkins removed a comment on issue #24099: Add docker integration test for MsSql server URL: https://github.com/apache/spark/pull/24099#issuecomment-473126837 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #23964: [SPARK-26975][SQL] Support nested-column pruning over limit/sample/repartition
AmplabJenkins removed a comment on issue #23964: [SPARK-26975][SQL] Support nested-column pruning over limit/sample/repartition URL: https://github.com/apache/spark/pull/23964#issuecomment-473126938 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/103511/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24099: Add docker integration test for MsSql server
AmplabJenkins removed a comment on issue #24099: Add docker integration test for MsSql server URL: https://github.com/apache/spark/pull/24099#issuecomment-473126921 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on issue #23942: [SPARK-27033][SQL]Add Optimize rule RewriteArithmeticFiltersOnIntegralColumn
maropu commented on issue #23942: [SPARK-27033][SQL]Add Optimize rule RewriteArithmeticFiltersOnIntegralColumn URL: https://github.com/apache/spark/pull/23942#issuecomment-473130097 Ah, I see. If we could follow the ANSI standard, this optimization (comparison rewriting) looks reasonable. Anyway, in this pr, we need to narrow down the optimization target to `eq` only. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24091: [SPARK-27159][SQL]update mssql server dialect to support binary type
AmplabJenkins commented on issue #24091: [SPARK-27159][SQL]update mssql server dialect to support binary type URL: https://github.com/apache/spark/pull/24091#issuecomment-473130197 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #22758: [SPARK-25332][SQL] Instead of broadcast hash join , Sort merge join node is added in the plan for the join queries executed i
HyukjinKwon commented on a change in pull request #22758: [SPARK-25332][SQL]
Instead of broadcast hash join ,Sort merge join node is added in the plan for
the join queries executed in a new spark session/context
URL: https://github.com/apache/spark/pull/22758#discussion_r265827554
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveMetastoreCatalog.scala
##
@@ -193,6 +193,16 @@ private[hive] class HiveMetastoreCatalog(sparkSession:
SparkSession) extends Log
None)
val logicalRelation = cached.getOrElse {
val updatedTable = inferIfNeeded(relation, options, fileFormat)
+ // Intialize the catalogTable stats if its not defined.An intial
value has to be defined
+ // so that the hive statistics will be updated after each insert
command.
+ val withStats = {
+if (updatedTable.stats == None) {
Review comment:
@wangyum, so it is basically subset of #22721? It's funny that Hive tables
should set the initial stats alone here, which is supposed to be set somewhere
else.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu removed a comment on issue #23942: [SPARK-27033][SQL]Add Optimize rule RewriteArithmeticFiltersOnIntegralColumn
maropu removed a comment on issue #23942: [SPARK-27033][SQL]Add Optimize rule RewriteArithmeticFiltersOnIntegralColumn URL: https://github.com/apache/spark/pull/23942#issuecomment-473130097 Ah, I see. If we could follow the ANSI standard, this optimization (comparison rewriting) looks reasonable. Anyway, in this pr, we need to narrow down the optimization target to `eq` only. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24100: [SPARK-27164] RDD.countApprox on empty RDDs schedules jobs which never complete
AmplabJenkins commented on issue #24100: [SPARK-27164] RDD.countApprox on empty RDDs schedules jobs which never complete URL: https://github.com/apache/spark/pull/24100#issuecomment-473131516 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24100: [SPARK-27164] RDD.countApprox on empty RDDs schedules jobs which never complete
AmplabJenkins commented on issue #24100: [SPARK-27164] RDD.countApprox on empty RDDs schedules jobs which never complete URL: https://github.com/apache/spark/pull/24100#issuecomment-473131600 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24092: [SPARK-27160][SQL] Fix DecimalType literal casting
SparkQA commented on issue #24092: [SPARK-27160][SQL] Fix DecimalType literal casting URL: https://github.com/apache/spark/pull/24092#issuecomment-473131623 **[Test build #103517 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/103517/testReport)** for PR 24092 at commit [`591c3f4`](https://github.com/apache/spark/commit/591c3f4b0b75798c94bef365872abbff6ed098eb). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24072: [SPARK-27112] : Create a resource ordering between threads to resolve the deadlocks encountered …
SparkQA commented on issue #24072: [SPARK-27112] : Create a resource ordering between threads to resolve the deadlocks encountered … URL: https://github.com/apache/spark/pull/24072#issuecomment-473131548 **[Test build #103518 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/103518/testReport)** for PR 24072 at commit [`47448b7`](https://github.com/apache/spark/commit/47448b794b9521a638ba44b3396e27a42c580362). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a change in pull request #19082: [SPARK-21870][SQL] Split aggregation code into small functions
HyukjinKwon commented on a change in pull request #19082: [SPARK-21870][SQL]
Split aggregation code into small functions
URL: https://github.com/apache/spark/pull/19082#discussion_r265828011
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/expressions/codegen/CodeGenerator.scala
##
@@ -944,6 +945,24 @@ class CodegenContext {
}
}
+object CodegenContext {
+
+ private val javaKeywords = Set(
Review comment:
enum looks over kill for now
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24101: [CORE][MINOR] Correct the comment to show heartbeat interval is configurable
AmplabJenkins commented on issue #24101: [CORE][MINOR] Correct the comment to show heartbeat interval is configurable URL: https://github.com/apache/spark/pull/24101#issuecomment-473133863 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #24072: [SPARK-27112] : Create a resource ordering between threads to resolve the deadlocks encountered …
SparkQA removed a comment on issue #24072: [SPARK-27112] : Create a resource ordering between threads to resolve the deadlocks encountered … URL: https://github.com/apache/spark/pull/24072#issuecomment-473072242 **[Test build #103514 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/103514/testReport)** for PR 24072 at commit [`2b4f226`](https://github.com/apache/spark/commit/2b4f226f365dc769562e0c0e99b048201f1e398f). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #24028: [SPARK-26917][SQL] Further reduce locks in CacheManager
cloud-fan closed pull request #24028: [SPARK-26917][SQL] Further reduce locks in CacheManager URL: https://github.com/apache/spark/pull/24028 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24073: [SPARK-27134][SQL] array_distinct function does not work correctly with columns containing array of array
AmplabJenkins commented on issue #24073: [SPARK-27134][SQL] array_distinct function does not work correctly with columns containing array of array URL: https://github.com/apache/spark/pull/24073#issuecomment-473133516 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/103515/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24072: [SPARK-27112] : Create a resource ordering between threads to resolve the deadlocks encountered …
SparkQA commented on issue #24072: [SPARK-27112] : Create a resource ordering between threads to resolve the deadlocks encountered … URL: https://github.com/apache/spark/pull/24072#issuecomment-473133635 **[Test build #103514 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/103514/testReport)** for PR 24072 at commit [`2b4f226`](https://github.com/apache/spark/commit/2b4f226f365dc769562e0c0e99b048201f1e398f). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24073: [SPARK-27134][SQL] array_distinct function does not work correctly with columns containing array of array
AmplabJenkins removed a comment on issue #24073: [SPARK-27134][SQL] array_distinct function does not work correctly with columns containing array of array URL: https://github.com/apache/spark/pull/24073#issuecomment-473133516 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/103515/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24101: [CORE][MINOR] Correct the comment to show heartbeat interval is configurable
AmplabJenkins commented on issue #24101: [CORE][MINOR] Correct the comment to show heartbeat interval is configurable URL: https://github.com/apache/spark/pull/24101#issuecomment-473133416 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24073: [SPARK-27134][SQL] array_distinct function does not work correctly with columns containing array of array
AmplabJenkins removed a comment on issue #24073: [SPARK-27134][SQL] array_distinct function does not work correctly with columns containing array of array URL: https://github.com/apache/spark/pull/24073#issuecomment-473133512 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24101: [CORE][MINOR] Correct the comment to show heartbeat interval is configurable
AmplabJenkins removed a comment on issue #24101: [CORE][MINOR] Correct the comment to show heartbeat interval is configurable URL: https://github.com/apache/spark/pull/24101#issuecomment-473133322 Can one of the admins verify this patch? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #24093: [SPARK-27161][SQL] improve the document of SQL keywords
maropu commented on a change in pull request #24093: [SPARK-27161][SQL] improve the document of SQL keywords URL: https://github.com/apache/spark/pull/24093#discussion_r265828436 ## File path: docs/sql-keywords.md ## @@ -1,16 +1,20 @@ --- layout: global -title: SQL Reserved/Non-Reserved Keywords -displayTitle: SQL Reserved/Non-Reserved Keywords +title: Spark SQL Keywords +displayTitle: Spark SQL Keywords --- -In Spark SQL, there are 2 kinds of keywords: non-reserved and reserved. Non-reserved keywords have a -special meaning only in particular contexts and can be used as identifiers (e.g., table names, view names, -column names, column aliases, table aliases) in other contexts. Reserved keywords can't be used as -table alias, but can be used as other identifiers. +When `spark.sql.parser.ansi.enabled` is true, Spark SQL has two kinds of keywords: +* Reserved keywords: Keywords that reserved and can't be used as identifiers for table, view, column, alias, etc. +* Non-reserved keywords: Keywords that have a special meaning only in particular contexts and can be used as identifiers in other contexts. -The list of reserved and non-reserved keywords can change according to the config -`spark.sql.parser.ansi.enabled`, which is false by default. +When `spark.sql.parser.ansi.enabled` is false, Spark SQL has two kinds of keywords: +* Non-reserved keywords: Keywords that have a special meaning only in particular contexts and can be used as identifiers in other contexts. +* Strict-non-reserved keywords: A strict version of non-reserved keywords, which can not be used as table alias. + +By default `spark.sql.parser.ansi.enabled` is false. + +Below is a list of all the keywords in Spark SQL. Review comment: ok, I'll check and fix as followup. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #24093: [SPARK-27161][SQL] improve the document of SQL keywords
maropu commented on a change in pull request #24093: [SPARK-27161][SQL] improve the document of SQL keywords URL: https://github.com/apache/spark/pull/24093#discussion_r265830237 ## File path: docs/sql-keywords.md ## @@ -1,16 +1,20 @@ --- layout: global -title: SQL Reserved/Non-Reserved Keywords -displayTitle: SQL Reserved/Non-Reserved Keywords +title: Spark SQL Keywords +displayTitle: Spark SQL Keywords --- -In Spark SQL, there are 2 kinds of keywords: non-reserved and reserved. Non-reserved keywords have a -special meaning only in particular contexts and can be used as identifiers (e.g., table names, view names, -column names, column aliases, table aliases) in other contexts. Reserved keywords can't be used as -table alias, but can be used as other identifiers. +When `spark.sql.parser.ansi.enabled` is true, Spark SQL has two kinds of keywords: +* Reserved keywords: Keywords that reserved and can't be used as identifiers for table, view, column, alias, etc. +* Non-reserved keywords: Keywords that have a special meaning only in particular contexts and can be used as identifiers in other contexts. -The list of reserved and non-reserved keywords can change according to the config -`spark.sql.parser.ansi.enabled`, which is false by default. +When `spark.sql.parser.ansi.enabled` is false, Spark SQL has two kinds of keywords: +* Non-reserved keywords: Keywords that have a special meaning only in particular contexts and can be used as identifiers in other contexts. +* Strict-non-reserved keywords: A strict version of non-reserved keywords, which can not be used as table alias. Review comment: Great and this new group is easy-to-understand. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #24093: [SPARK-27161][SQL] improve the document of SQL keywords
maropu commented on a change in pull request #24093: [SPARK-27161][SQL] improve the document of SQL keywords URL: https://github.com/apache/spark/pull/24093#discussion_r265830090 ## File path: docs/sql-keywords.md ## @@ -1,16 +1,20 @@ --- layout: global -title: SQL Reserved/Non-Reserved Keywords -displayTitle: SQL Reserved/Non-Reserved Keywords +title: Spark SQL Keywords +displayTitle: Spark SQL Keywords Review comment: `spark.sql.parser.ansi.enabled` affects parsing behaviours, too, e.g., when true, it makes `interval` optional. In future, we could change the behaivour of overflow handling in execution for the more strict ANSI compliance. These behaivour changes affected by the ANSI option should be documented not in this document but in another document? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #24093: [SPARK-27161][SQL] improve the document of SQL keywords
maropu commented on a change in pull request #24093: [SPARK-27161][SQL] improve the document of SQL keywords URL: https://github.com/apache/spark/pull/24093#discussion_r265824998 ## File path: docs/sql-keywords.md ## @@ -1,16 +1,20 @@ --- layout: global -title: SQL Reserved/Non-Reserved Keywords -displayTitle: SQL Reserved/Non-Reserved Keywords +title: Spark SQL Keywords +displayTitle: Spark SQL Keywords --- -In Spark SQL, there are 2 kinds of keywords: non-reserved and reserved. Non-reserved keywords have a -special meaning only in particular contexts and can be used as identifiers (e.g., table names, view names, -column names, column aliases, table aliases) in other contexts. Reserved keywords can't be used as -table alias, but can be used as other identifiers. +When `spark.sql.parser.ansi.enabled` is true, Spark SQL has two kinds of keywords: +* Reserved keywords: Keywords that reserved and can't be used as identifiers for table, view, column, alias, etc. Review comment: nit: `* Reserved keywords: Keywords that are reserved and can't be used as identifiers for tables, views, columns, aliases, etc.`? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #24093: [SPARK-27161][SQL] improve the document of SQL keywords
maropu commented on a change in pull request #24093: [SPARK-27161][SQL] improve the document of SQL keywords URL: https://github.com/apache/spark/pull/24093#discussion_r265825069 ## File path: docs/sql-keywords.md ## @@ -1,16 +1,20 @@ --- layout: global -title: SQL Reserved/Non-Reserved Keywords -displayTitle: SQL Reserved/Non-Reserved Keywords +title: Spark SQL Keywords +displayTitle: Spark SQL Keywords --- -In Spark SQL, there are 2 kinds of keywords: non-reserved and reserved. Non-reserved keywords have a -special meaning only in particular contexts and can be used as identifiers (e.g., table names, view names, -column names, column aliases, table aliases) in other contexts. Reserved keywords can't be used as -table alias, but can be used as other identifiers. +When `spark.sql.parser.ansi.enabled` is true, Spark SQL has two kinds of keywords: +* Reserved keywords: Keywords that reserved and can't be used as identifiers for table, view, column, alias, etc. +* Non-reserved keywords: Keywords that have a special meaning only in particular contexts and can be used as identifiers in other contexts. Review comment: nit: `in other contexts.` -> `in the other contexts, e.g., SELECT 1 WEEK means interval type data, but WEEK can be used as identifiers`? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #24093: [SPARK-27161][SQL] improve the document of SQL keywords
maropu commented on a change in pull request #24093: [SPARK-27161][SQL] improve the document of SQL keywords URL: https://github.com/apache/spark/pull/24093#discussion_r265828883 ## File path: sql/catalyst/src/main/antlr4/org/apache/spark/sql/catalyst/parser/SqlBase.g4 ## @@ -1215,6 +1232,9 @@ nonReserved | YEARS ; +// +// Start of the keywords list +// SELECT: 'SELECT'; Review comment: +1 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan closed pull request #24069: [SPARK-27136][SQL] Remove data source option check_files_exist
cloud-fan closed pull request #24069: [SPARK-27136][SQL] Remove data source option check_files_exist URL: https://github.com/apache/spark/pull/24069 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #24092: [SPARK-27160][SQL] Fix DecimalType literal casting
dongjoon-hyun commented on issue #24092: [SPARK-27160][SQL] Fix DecimalType literal casting URL: https://github.com/apache/spark/pull/24092#issuecomment-473138559 +1 for @cloud-fan 's opinion. @sadhen , could you add another test case for that? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24072: [SPARK-27112] : Create a resource ordering between threads to resolve the deadlocks encountered …
AmplabJenkins commented on issue #24072: [SPARK-27112] : Create a resource ordering between threads to resolve the deadlocks encountered … URL: https://github.com/apache/spark/pull/24072#issuecomment-473140844 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer edited a comment on issue #23950: [SPARK-27140][SQL]The feature is 'insert overwrite local directory' has an inconsistent behavior in different environment.
beliefer edited a comment on issue #23950: [SPARK-27140][SQL]The feature is 'insert overwrite local directory' has an inconsistent behavior in different environment. URL: https://github.com/apache/spark/pull/23950#issuecomment-472740651 cc @maropu @gatorsmile @dongjoon-hyun @janewangfb @cloud-fan Please help me,to find the reason.Thanks a lot! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24072: [SPARK-27112] : Create a resource ordering between threads to resolve the deadlocks encountered …
AmplabJenkins removed a comment on issue #24072: [SPARK-27112] : Create a resource ordering between threads to resolve the deadlocks encountered … URL: https://github.com/apache/spark/pull/24072#issuecomment-473140850 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/103519/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on issue #24094: [SPARK-27162][SQL] Add new method getOriginalMap in CaseInsensitiveStringMap
cloud-fan commented on issue #24094: [SPARK-27162][SQL] Add new method getOriginalMap in CaseInsensitiveStringMap URL: https://github.com/apache/spark/pull/24094#issuecomment-473142525 AFAIK hadoop conf can be set in 3 ways: 1. global level, via `SparkContext.hadoopConfiguration` 2. session level, via `SparkSession.conf` 3. operation level, via `DataFrameReader/Writer.option` 1 and 2 are fine, as they are case sensitive. The problem is 3, as data source v2 treats options as case-insensitive. There are 2 solutions I can think of 1. Do not support operation level hadoop conf for data source v2. 2. Keep the original case sensitive map. I think 2 is more reasonable, which is this PR trying to do. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #24097: [SPARK-27165][SPARK-27107][BRANCH-2.4][BUILD][SQL] Upgrade Apache ORC to 1.5.5
dongjoon-hyun closed pull request #24097: [SPARK-27165][SPARK-27107][BRANCH-2.4][BUILD][SQL] Upgrade Apache ORC to 1.5.5 URL: https://github.com/apache/spark/pull/24097 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24097: [SPARK-27165][SPARK-27107][BRANCH-2.4][BUILD][SQL] Upgrade Apache ORC to 1.5.5
AmplabJenkins removed a comment on issue #24097: [SPARK-27165][SPARK-27107][BRANCH-2.4][BUILD][SQL] Upgrade Apache ORC to 1.5.5 URL: https://github.com/apache/spark/pull/24097#issuecomment-473144293 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24097: [SPARK-27165][SPARK-27107][BRANCH-2.4][BUILD][SQL] Upgrade Apache ORC to 1.5.5
AmplabJenkins commented on issue #24097: [SPARK-27165][SPARK-27107][BRANCH-2.4][BUILD][SQL] Upgrade Apache ORC to 1.5.5 URL: https://github.com/apache/spark/pull/24097#issuecomment-473144293 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level
dongjoon-hyun closed pull request #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level URL: https://github.com/apache/spark/pull/24098 This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #24092: [SPARK-27160][SQL] Fix DecimalType literal casting
dongjoon-hyun commented on issue #24092: [SPARK-27160][SQL] Fix DecimalType literal casting URL: https://github.com/apache/spark/pull/24092#issuecomment-473145953 Yes, right, @sadhen . This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on issue #23680: [SPARK-26756][SQL] Support session conf for thriftserver
HyukjinKwon commented on issue #23680: [SPARK-26756][SQL] Support session conf for thriftserver URL: https://github.com/apache/spark/pull/23680#issuecomment-473146948 ?? do you mean we cannot set the configuration by `set ...` via Spark thriftserver if we use `beeline`? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on issue #23680: [SPARK-26756][SQL] Support session conf for thriftserver
HyukjinKwon commented on issue #23680: [SPARK-26756][SQL] Support session conf for thriftserver URL: https://github.com/apache/spark/pull/23680#issuecomment-473146980 Can you provide reproducible steps? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a change in pull request #24094: [SPARK-27162][SQL] Add new method getOriginalMap in CaseInsensitiveStringMap
gengliangwang commented on a change in pull request #24094: [SPARK-27162][SQL]
Add new method getOriginalMap in CaseInsensitiveStringMap
URL: https://github.com/apache/spark/pull/24094#discussion_r265840525
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/internal/SessionState.scala
##
@@ -96,6 +98,11 @@ private[sql] class SessionState(
hadoopConf
}
+ def newHadoopConfWithCaseInsensitiveOptions(options:
CaseInsensitiveStringMap): Configuration = {
Review comment:
Otherwise, developers might not be aware of using `.getOriginalMap` if they
want to create Hadoop configuration from CaseInsensitiveStringMap.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24047: [SPARK-25196][SQL] Extends Analyze commands for cached tables
dongjoon-hyun commented on a change in pull request #24047: [SPARK-25196][SQL]
Extends Analyze commands for cached tables
URL: https://github.com/apache/spark/pull/24047#discussion_r265842727
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/StatisticsCollectionSuite.scala
##
@@ -470,4 +471,34 @@ class StatisticsCollectionSuite extends
StatisticsCollectionTestBase with Shared
}
}
}
+
+ test("analyzes column statistics in cached query") {
+withTempView("cachedTempView", "tempView") {
+ spark.sql(
+"""CACHE TABLE cachedTempView AS
+ | SELECT c0, avg(c1) AS v1, avg(c2) AS v2
+ | FROM (SELECT id % 3 AS c0, id % 5 AS c1, 2 AS c2 FROM range(1,
30))
+ | GROUP BY c0
+""".stripMargin)
+
+ // Analyzes one column in the cached logical plan
+ spark.sql("ANALYZE TABLE cachedTempView COMPUTE STATISTICS FOR COLUMNS
v1")
+ val queryStats1 = spark.table("cachedTempView").queryExecution
+.optimizedPlan.stats.attributeStats
+ assert(queryStats1.map(_._1.name).toSet === Set("v1"))
+
+ // Analyzes two more columns
+ spark.sql("ANALYZE TABLE cachedTempView COMPUTE STATISTICS FOR COLUMNS
c0, v2")
+ val queryStats2 = spark.table("cachedTempView").queryExecution
+.optimizedPlan.stats.attributeStats
+ assert(queryStats2.map(_._1.name).toSet === Set("c0", "v1", "v2"))
+
+ // Analyzes in a temporary table
+ spark.sql("CREATE TEMPORARY VIEW tempView AS SELECT * FROM range(1, 30)")
+ val errMsg = intercept[NoSuchTableException] {
+spark.sql("ANALYZE TABLE tempView COMPUTE STATISTICS FOR COLUMNS id")
+ }.getMessage
+ assert(errMsg.contains("Table or view 'tempView' not found in database
'default'"))
+}
Review comment:
Also, please add a test coverage on the global temp view.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #24094: [SPARK-27162][SQL] Add new method getOriginalMap in CaseInsensitiveStringMap
cloud-fan commented on a change in pull request #24094: [SPARK-27162][SQL] Add
new method getOriginalMap in CaseInsensitiveStringMap
URL: https://github.com/apache/spark/pull/24094#discussion_r265842993
##
File path:
sql/catalyst/src/main/java/org/apache/spark/sql/util/CaseInsensitiveStringMap.java
##
@@ -78,11 +81,13 @@ public String get(Object key) {
@Override
public String put(String key, String value) {
+original.put(key, value);
Review comment:
The thing worries me most is the inconsistency between the case insensitive
map and the original map. I think we should either fail or keep the latter
entry if `a -> 1, A -> 2` appears together.
One thing we can simplify is, `CaseInsensitiveStringMap` is read by data
source and can be read-only. Then it can be easier to resolve conflicting
entries at the beginning.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #24093: [SPARK-27161][SQL] improve the document of SQL keywords
cloud-fan commented on a change in pull request #24093: [SPARK-27161][SQL] improve the document of SQL keywords URL: https://github.com/apache/spark/pull/24093#discussion_r265845089 ## File path: docs/sql-keywords.md ## @@ -1,16 +1,20 @@ --- layout: global -title: SQL Reserved/Non-Reserved Keywords -displayTitle: SQL Reserved/Non-Reserved Keywords +title: Spark SQL Keywords +displayTitle: Spark SQL Keywords Review comment: Yea, this document is about keywords, not everything about the ansi mode. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level
AmplabJenkins commented on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level URL: https://github.com/apache/spark/pull/24098#issuecomment-473154849 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung commented on a change in pull request #24087: [SPARK-27096][SQL][FOLLOWUP] Do the correct validation of join types in R side and fix join docs for scala, python and r
felixcheung commented on a change in pull request #24087:
[SPARK-27096][SQL][FOLLOWUP] Do the correct validation of join types in R side
and fix join docs for scala, python and r
URL: https://github.com/apache/spark/pull/24087#discussion_r265847869
##
File path: R/pkg/R/DataFrame.R
##
@@ -2553,14 +2554,14 @@ setMethod("join",
"outer", "full", "fullouter", "full_outer",
"left", "leftouter", "left_outer",
"right", "rightouter", "right_outer",
-"left_semi", "leftsemi", "left_anti", "leftanti")) {
+"semi", "left_semi", "leftsemi", "anti", "left_anti",
"leftanti")) {
joinType <- gsub("_", "", joinType)
sdf <- callJMethod(x@sdf, "join", y@sdf, joinExpr@jc,
joinType)
} else {
- stop("joinType must be one of the following types: ",
- "'inner', 'cross', 'outer', 'full', 'full_outer',",
- "'left', 'left_outer', 'right', 'right_outer',",
- "'left_semi', or 'left_anti'.")
+ stop(paste("joinType must be one of the following types: ",
Review comment:
remove the space at the end of `types: ` - paste adds space
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung commented on a change in pull request #24087: [SPARK-27096][SQL][FOLLOWUP] Do the correct validation of join types in R side and fix join docs for scala, python and r
felixcheung commented on a change in pull request #24087:
[SPARK-27096][SQL][FOLLOWUP] Do the correct validation of join types in R side
and fix join docs for scala, python and r
URL: https://github.com/apache/spark/pull/24087#discussion_r265848085
##
File path: R/pkg/tests/fulltests/test_sparkSQL.R
##
@@ -2356,40 +2356,96 @@ test_that("join(), crossJoin() and merge() on a
DataFrame", {
expect_equal(names(joined2), c("age", "name", "name", "test"))
expect_equal(count(joined2), 3)
- joined3 <- join(df, df2, df$name == df2$name, "rightouter")
+ joined3 <- join(df, df2, df$name == df2$name, "right")
expect_equal(names(joined3), c("age", "name", "name", "test"))
expect_equal(count(joined3), 4)
expect_true(is.na(collect(orderBy(joined3, joined3$age))$age[2]))
-
- joined4 <- select(join(df, df2, df$name == df2$name, "outer"),
-alias(df$age + 5, "newAge"), df$name, df2$test)
- expect_equal(names(joined4), c("newAge", "name", "test"))
+
+ joined4 <- join(df, df2, df$name == df2$name, "right_outer")
+ expect_equal(names(joined4), c("age", "name", "name", "test"))
expect_equal(count(joined4), 4)
- expect_equal(collect(orderBy(joined4, joined4$name))$newAge[3], 24)
+ expect_true(is.na(collect(orderBy(joined4, joined4$age))$age[2]))
- joined5 <- join(df, df2, df$name == df2$name, "leftouter")
+ joined5 <- join(df, df2, df$name == df2$name, "rightouter")
expect_equal(names(joined5), c("age", "name", "name", "test"))
- expect_equal(count(joined5), 3)
- expect_true(is.na(collect(orderBy(joined5, joined5$age))$age[1]))
-
- joined6 <- join(df, df2, df$name == df2$name, "inner")
- expect_equal(names(joined6), c("age", "name", "name", "test"))
- expect_equal(count(joined6), 3)
+ expect_equal(count(joined5), 4)
+ expect_true(is.na(collect(orderBy(joined5, joined5$age))$age[2]))
- joined7 <- join(df, df2, df$name == df2$name, "leftsemi")
- expect_equal(names(joined7), c("age", "name"))
- expect_equal(count(joined7), 3)
- joined8 <- join(df, df2, df$name == df2$name, "left_outer")
- expect_equal(names(joined8), c("age", "name", "name", "test"))
- expect_equal(count(joined8), 3)
- expect_true(is.na(collect(orderBy(joined8, joined8$age))$age[1]))
-
- joined9 <- join(df, df2, df$name == df2$name, "right_outer")
- expect_equal(names(joined9), c("age", "name", "name", "test"))
+ joined6 <- select(join(df, df2, df$name == df2$name, "outer"),
+alias(df$age + 5, "newAge"), df$name, df2$test)
+ expect_equal(names(joined6), c("newAge", "name", "test"))
+ expect_equal(count(joined6), 4)
+ expect_equal(collect(orderBy(joined6, joined6$name))$newAge[3], 24)
+
+ joined7 <- select(join(df, df2, df$name == df2$name, "full"),
+alias(df$age + 5, "newAge"), df$name, df2$test)
+ expect_equal(names(joined7), c("newAge", "name", "test"))
+ expect_equal(count(joined7), 4)
+ expect_equal(collect(orderBy(joined7, joined7$name))$newAge[3], 24)
+
+ joined8 <- select(join(df, df2, df$name == df2$name, "fullouter"),
+alias(df$age + 5, "newAge"), df$name, df2$test)
+ expect_equal(names(joined8), c("newAge", "name", "test"))
+ expect_equal(count(joined8), 4)
+ expect_equal(collect(orderBy(joined8, joined8$name))$newAge[3], 24)
+
+ joined9 <- select(join(df, df2, df$name == df2$name, "full_outer"),
+alias(df$age + 5, "newAge"), df$name, df2$test)
+ expect_equal(names(joined9), c("newAge", "name", "test"))
expect_equal(count(joined9), 4)
- expect_true(is.na(collect(orderBy(joined9, joined9$age))$age[2]))
-
+ expect_equal(collect(orderBy(joined9, joined9$name))$newAge[3], 24)
+
+ joined10 <- join(df, df2, df$name == df2$name, "left")
+ expect_equal(names(joined10), c("age", "name", "name", "test"))
+ expect_equal(count(joined10), 3)
+ expect_true(is.na(collect(orderBy(joined10, joined10$age))$age[1]))
+
+ joined11 <- join(df, df2, df$name == df2$name, "leftouter")
+ expect_equal(names(joined11), c("age", "name", "name", "test"))
+ expect_equal(count(joined11), 3)
+ expect_true(is.na(collect(orderBy(joined11, joined11$age))$age[1]))
+
+ joined12 <- join(df, df2, df$name == df2$name, "left_outer")
+ expect_equal(names(joined12), c("age", "name", "name", "test"))
+ expect_equal(count(joined12), 3)
+ expect_true(is.na(collect(orderBy(joined12, joined12$age))$age[1]))
+
+ joined13 <- join(df, df2, df$name == df2$name, "inner")
+ expect_equal(names(joined13), c("age", "name", "name", "test"))
+ expect_equal(count(joined13), 3)
+
+ joined14 <- join(df, df2, df$name == df2$name, "semi")
+ expect_equal(names(joined14), c("age", "name"))
+ expect_equal(count(joined14), 3)
+
+ joined14 <- join(df, df2, df$name == df2$name, "leftsemi")
+ expect_equal(names(joined14), c("age", "name"))
+ expect_equal(count(joined14), 3)
+
+ joined15 <- join(df, df2, df$name == df2$name, "left_semi")
+ expect_equal(names(joined15), c("age", "name"))
+
[GitHub] [spark] felixcheung commented on a change in pull request #24087: [SPARK-27096][SQL][FOLLOWUP] Do the correct validation of join types in R side and fix join docs for scala, python and r
felixcheung commented on a change in pull request #24087:
[SPARK-27096][SQL][FOLLOWUP] Do the correct validation of join types in R side
and fix join docs for scala, python and r
URL: https://github.com/apache/spark/pull/24087#discussion_r265847681
##
File path: R/pkg/R/DataFrame.R
##
@@ -2520,8 +2520,9 @@ setMethod("dropDuplicates",
#' Column expression. If joinExpr is omitted, the default, inner join is
attempted and an error is
#' thrown if it would be a Cartesian Product. For Cartesian join, use
crossJoin instead.
#' @param joinType The type of join to perform, default 'inner'.
-#' Must be one of: 'inner', 'cross', 'outer', 'full', 'full_outer',
-#' 'left', 'left_outer', 'right', 'right_outer', 'left_semi', or 'left_anti'.
+#' Must be one of: 'inner', 'cross', 'outer', 'full', 'fullouter',
'full_outer',
+#' 'left', 'leftouter', 'left_outer', 'right', 'rightouter', 'right_outer',
'semi',
+# 'leftsemi', 'left_semi', 'anti', 'leftanti', 'left_anti'.
Review comment:
missing `'` in `#'`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung commented on a change in pull request #24087: [SPARK-27096][SQL][FOLLOWUP] Do the correct validation of join types in R side and fix join docs for scala, python and r
felixcheung commented on a change in pull request #24087:
[SPARK-27096][SQL][FOLLOWUP] Do the correct validation of join types in R side
and fix join docs for scala, python and r
URL: https://github.com/apache/spark/pull/24087#discussion_r265848033
##
File path: R/pkg/tests/fulltests/test_sparkSQL.R
##
@@ -2356,40 +2356,96 @@ test_that("join(), crossJoin() and merge() on a
DataFrame", {
expect_equal(names(joined2), c("age", "name", "name", "test"))
expect_equal(count(joined2), 3)
- joined3 <- join(df, df2, df$name == df2$name, "rightouter")
+ joined3 <- join(df, df2, df$name == df2$name, "right")
expect_equal(names(joined3), c("age", "name", "name", "test"))
expect_equal(count(joined3), 4)
expect_true(is.na(collect(orderBy(joined3, joined3$age))$age[2]))
-
- joined4 <- select(join(df, df2, df$name == df2$name, "outer"),
-alias(df$age + 5, "newAge"), df$name, df2$test)
- expect_equal(names(joined4), c("newAge", "name", "test"))
+
+ joined4 <- join(df, df2, df$name == df2$name, "right_outer")
+ expect_equal(names(joined4), c("age", "name", "name", "test"))
expect_equal(count(joined4), 4)
- expect_equal(collect(orderBy(joined4, joined4$name))$newAge[3], 24)
+ expect_true(is.na(collect(orderBy(joined4, joined4$age))$age[2]))
- joined5 <- join(df, df2, df$name == df2$name, "leftouter")
+ joined5 <- join(df, df2, df$name == df2$name, "rightouter")
expect_equal(names(joined5), c("age", "name", "name", "test"))
- expect_equal(count(joined5), 3)
- expect_true(is.na(collect(orderBy(joined5, joined5$age))$age[1]))
-
- joined6 <- join(df, df2, df$name == df2$name, "inner")
- expect_equal(names(joined6), c("age", "name", "name", "test"))
- expect_equal(count(joined6), 3)
+ expect_equal(count(joined5), 4)
+ expect_true(is.na(collect(orderBy(joined5, joined5$age))$age[2]))
- joined7 <- join(df, df2, df$name == df2$name, "leftsemi")
- expect_equal(names(joined7), c("age", "name"))
- expect_equal(count(joined7), 3)
- joined8 <- join(df, df2, df$name == df2$name, "left_outer")
- expect_equal(names(joined8), c("age", "name", "name", "test"))
- expect_equal(count(joined8), 3)
- expect_true(is.na(collect(orderBy(joined8, joined8$age))$age[1]))
-
- joined9 <- join(df, df2, df$name == df2$name, "right_outer")
- expect_equal(names(joined9), c("age", "name", "name", "test"))
+ joined6 <- select(join(df, df2, df$name == df2$name, "outer"),
+alias(df$age + 5, "newAge"), df$name, df2$test)
+ expect_equal(names(joined6), c("newAge", "name", "test"))
+ expect_equal(count(joined6), 4)
+ expect_equal(collect(orderBy(joined6, joined6$name))$newAge[3], 24)
+
+ joined7 <- select(join(df, df2, df$name == df2$name, "full"),
+alias(df$age + 5, "newAge"), df$name, df2$test)
+ expect_equal(names(joined7), c("newAge", "name", "test"))
+ expect_equal(count(joined7), 4)
+ expect_equal(collect(orderBy(joined7, joined7$name))$newAge[3], 24)
+
+ joined8 <- select(join(df, df2, df$name == df2$name, "fullouter"),
+alias(df$age + 5, "newAge"), df$name, df2$test)
+ expect_equal(names(joined8), c("newAge", "name", "test"))
+ expect_equal(count(joined8), 4)
+ expect_equal(collect(orderBy(joined8, joined8$name))$newAge[3], 24)
+
+ joined9 <- select(join(df, df2, df$name == df2$name, "full_outer"),
+alias(df$age + 5, "newAge"), df$name, df2$test)
+ expect_equal(names(joined9), c("newAge", "name", "test"))
expect_equal(count(joined9), 4)
- expect_true(is.na(collect(orderBy(joined9, joined9$age))$age[2]))
-
+ expect_equal(collect(orderBy(joined9, joined9$name))$newAge[3], 24)
+
+ joined10 <- join(df, df2, df$name == df2$name, "left")
+ expect_equal(names(joined10), c("age", "name", "name", "test"))
+ expect_equal(count(joined10), 3)
+ expect_true(is.na(collect(orderBy(joined10, joined10$age))$age[1]))
+
+ joined11 <- join(df, df2, df$name == df2$name, "leftouter")
+ expect_equal(names(joined11), c("age", "name", "name", "test"))
+ expect_equal(count(joined11), 3)
+ expect_true(is.na(collect(orderBy(joined11, joined11$age))$age[1]))
+
+ joined12 <- join(df, df2, df$name == df2$name, "left_outer")
+ expect_equal(names(joined12), c("age", "name", "name", "test"))
+ expect_equal(count(joined12), 3)
+ expect_true(is.na(collect(orderBy(joined12, joined12$age))$age[1]))
+
+ joined13 <- join(df, df2, df$name == df2$name, "inner")
+ expect_equal(names(joined13), c("age", "name", "name", "test"))
+ expect_equal(count(joined13), 3)
+
+ joined14 <- join(df, df2, df$name == df2$name, "semi")
+ expect_equal(names(joined14), c("age", "name"))
+ expect_equal(count(joined14), 3)
+
+ joined14 <- join(df, df2, df$name == df2$name, "leftsemi")
+ expect_equal(names(joined14), c("age", "name"))
+ expect_equal(count(joined14), 3)
+
+ joined15 <- join(df, df2, df$name == df2$name, "left_semi")
+ expect_equal(names(joined15), c("age", "name"))
+
[GitHub] [spark] felixcheung commented on a change in pull request #24086: [SPARK-27155][Build]update oracle docker image name
felixcheung commented on a change in pull request #24086:
[SPARK-27155][Build]update oracle docker image name
URL: https://github.com/apache/spark/pull/24086#discussion_r265849492
##
File path:
external/docker-integration-tests/src/test/scala/org/apache/spark/sql/jdbc/OracleIntegrationSuite.scala
##
@@ -55,7 +56,7 @@ class OracleIntegrationSuite extends
DockerJDBCIntegrationSuite with SharedSQLCo
import testImplicits._
override val db = new DatabaseOnDocker {
-override val imageName = "wnameless/oracle-xe-11g:16.04"
+override val imageName = "deepdiver/docker-oracle-xe-11g:2.0"
Review comment:
agreed there..
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dilipbiswal commented on a change in pull request #24087: [SPARK-27096][SQL][FOLLOWUP] Do the correct validation of join types in R side and fix join docs for scala, python and r
dilipbiswal commented on a change in pull request #24087:
[SPARK-27096][SQL][FOLLOWUP] Do the correct validation of join types in R side
and fix join docs for scala, python and r
URL: https://github.com/apache/spark/pull/24087#discussion_r265849362
##
File path: R/pkg/R/DataFrame.R
##
@@ -2520,8 +2520,9 @@ setMethod("dropDuplicates",
#' Column expression. If joinExpr is omitted, the default, inner join is
attempted and an error is
#' thrown if it would be a Cartesian Product. For Cartesian join, use
crossJoin instead.
#' @param joinType The type of join to perform, default 'inner'.
-#' Must be one of: 'inner', 'cross', 'outer', 'full', 'full_outer',
-#' 'left', 'left_outer', 'right', 'right_outer', 'left_semi', or 'left_anti'.
+#' Must be one of: 'inner', 'cross', 'outer', 'full', 'fullouter',
'full_outer',
+#' 'left', 'leftouter', 'left_outer', 'right', 'rightouter', 'right_outer',
'semi',
+# 'leftsemi', 'left_semi', 'anti', 'leftanti', 'left_anti'.
Review comment:
@felixcheung Thanks a lot. Will fix.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dilipbiswal commented on a change in pull request #24087: [SPARK-27096][SQL][FOLLOWUP] Do the correct validation of join types in R side and fix join docs for scala, python and r
dilipbiswal commented on a change in pull request #24087:
[SPARK-27096][SQL][FOLLOWUP] Do the correct validation of join types in R side
and fix join docs for scala, python and r
URL: https://github.com/apache/spark/pull/24087#discussion_r265849398
##
File path: R/pkg/R/DataFrame.R
##
@@ -2553,14 +2554,14 @@ setMethod("join",
"outer", "full", "fullouter", "full_outer",
"left", "leftouter", "left_outer",
"right", "rightouter", "right_outer",
-"left_semi", "leftsemi", "left_anti", "leftanti")) {
+"semi", "left_semi", "leftsemi", "anti", "left_anti",
"leftanti")) {
joinType <- gsub("_", "", joinType)
sdf <- callJMethod(x@sdf, "join", y@sdf, joinExpr@jc,
joinType)
} else {
- stop("joinType must be one of the following types: ",
- "'inner', 'cross', 'outer', 'full', 'full_outer',",
- "'left', 'left_outer', 'right', 'right_outer',",
- "'left_semi', or 'left_anti'.")
+ stop(paste("joinType must be one of the following types: ",
Review comment:
@felixcheung Sure.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dilipbiswal commented on issue #24087: [SPARK-27096][SQL][FOLLOWUP] Do the correct validation of join types in R side and fix join docs for scala, python and r
dilipbiswal commented on issue #24087: [SPARK-27096][SQL][FOLLOWUP] Do the correct validation of join types in R side and fix join docs for scala, python and r URL: https://github.com/apache/spark/pull/24087#issuecomment-473158056 @felixcheung > I would prefer expect_error as well Yeah.. i had already made the change after @HyukjinKwon 's comment :-). I was running the test to make sure. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] felixcheung commented on issue #24087: [SPARK-27096][SQL][FOLLOWUP] Do the correct validation of join types in R side and fix join docs for scala, python and r
felixcheung commented on issue #24087: [SPARK-27096][SQL][FOLLOWUP] Do the correct validation of join types in R side and fix join docs for scala, python and r URL: https://github.com/apache/spark/pull/24087#issuecomment-473159139 so personally my preference is not have the hardcoded list of join type and checks in R, as you imagine it's problematic to keep it up to date. problem is often time an error in SQL is not readable in R. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ueshin edited a comment on issue #24073: [SPARK-27134][SQL] array_distinct function does not work correctly with columns containing array of array
ueshin edited a comment on issue #24073: [SPARK-27134][SQL] array_distinct function does not work correctly with columns containing array of array URL: https://github.com/apache/spark/pull/24073#issuecomment-473164953 ~LGTM.~ I rethought after https://github.com/apache/spark/pull/24073#discussion_r265854866, I agree with @kiszk to skip traversing the arraybuffer after null found. @srowen Could you take another look please? Thanks! This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #24094: [SPARK-27162][SQL] Add new method getOriginalMap in CaseInsensitiveStringMap
cloud-fan commented on a change in pull request #24094: [SPARK-27162][SQL] Add
new method getOriginalMap in CaseInsensitiveStringMap
URL: https://github.com/apache/spark/pull/24094#discussion_r265837236
##
File path:
sql/catalyst/src/main/java/org/apache/spark/sql/util/CaseInsensitiveStringMap.java
##
@@ -40,9 +40,12 @@ public static CaseInsensitiveStringMap empty() {
return new CaseInsensitiveStringMap(new HashMap<>(0));
}
+ private final Map original;
+
private final Map delegate;
public CaseInsensitiveStringMap(Map originalMap) {
+this.original = new HashMap<>(originalMap);
Review comment:
this should be `new HashMap<>(originalMap.size);`, otherwise we add data to
it twice.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LantaoJin commented on issue #24090: [SPARK-27157][DOCS] Add Executor level metrics to monitoring docs
LantaoJin commented on issue #24090: [SPARK-27157][DOCS] Add Executor level metrics to monitoring docs URL: https://github.com/apache/spark/pull/24090#issuecomment-473143954 > This is probably OK, but are these metrics things that Spark generates or that are generated automatically by Ganglia et al? that is, do we need to document them or point at existing external docs? @srowen They are generated by Spark, see `ExecutorMetricType` This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA commented on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level
SparkQA commented on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level URL: https://github.com/apache/spark/pull/24098#issuecomment-473145100 **[Test build #103522 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/103522/testReport)** for PR 24098 at commit [`9263218`](https://github.com/apache/spark/commit/9263218ae5436b3fb780b6e733876ff92c7d81a5). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] SparkQA removed a comment on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level
SparkQA removed a comment on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level URL: https://github.com/apache/spark/pull/24098#issuecomment-473100183 **[Test build #103522 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/103522/testReport)** for PR 24098 at commit [`9263218`](https://github.com/apache/spark/commit/9263218ae5436b3fb780b6e733876ff92c7d81a5). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24096: [SPARK-27165][SPARK-27107][BUILD][SQL] Upgrade Apache ORC to 1.5.5
AmplabJenkins removed a comment on issue #24096: [SPARK-27165][SPARK-27107][BUILD][SQL] Upgrade Apache ORC to 1.5.5 URL: https://github.com/apache/spark/pull/24096#issuecomment-473149230 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/103521/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a change in pull request #24047: [SPARK-25196][SQL] Extends Analyze commands for cached tables
dongjoon-hyun commented on a change in pull request #24047: [SPARK-25196][SQL]
Extends Analyze commands for cached tables
URL: https://github.com/apache/spark/pull/24047#discussion_r265842545
##
File path:
sql/core/src/test/scala/org/apache/spark/sql/StatisticsCollectionSuite.scala
##
@@ -470,4 +471,34 @@ class StatisticsCollectionSuite extends
StatisticsCollectionTestBase with Shared
}
}
}
+
+ test("analyzes column statistics in cached query") {
+withTempView("cachedTempView", "tempView") {
+ spark.sql(
+"""CACHE TABLE cachedTempView AS
Review comment:
Maybe, `cachedQuery` is better than `cachedTempView`?
For me, `cachedTempView` sounds like the following.
```sql
CREATE TEMPORARY VIEW tempView AS ...
CACHE TABLE tempView
```
We can rename this from `cachedTempView` to `cachedQuery` first. Then, we
can add a new test case for the real cached temp views of the above SQL case
before line 496.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #24094: [SPARK-27162][SQL] Add new method getOriginalMap in CaseInsensitiveStringMap
cloud-fan commented on a change in pull request #24094: [SPARK-27162][SQL] Add
new method getOriginalMap in CaseInsensitiveStringMap
URL: https://github.com/apache/spark/pull/24094#discussion_r265843483
##
File path:
sql/core/src/main/scala/org/apache/spark/sql/internal/SessionState.scala
##
@@ -96,6 +98,11 @@ private[sql] class SessionState(
hadoopConf
}
+ def newHadoopConfWithCaseInsensitiveOptions(options:
CaseInsensitiveStringMap): Configuration = {
Review comment:
Then we should document it in `CaseInsensitiveMap`. data source developers
can't access `SessionState`
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on issue #23964: [SPARK-26975][SQL] Support nested-column pruning over limit/sample/repartition
dongjoon-hyun commented on issue #23964: [SPARK-26975][SQL] Support nested-column pruning over limit/sample/repartition URL: https://github.com/apache/spark/pull/23964#issuecomment-473152043 Do you have any other concerns, @maropu and @viirya ? This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun edited a comment on issue #23964: [SPARK-26975][SQL] Support nested-column pruning over limit/sample/repartition
dongjoon-hyun edited a comment on issue #23964: [SPARK-26975][SQL] Support nested-column pruning over limit/sample/repartition URL: https://github.com/apache/spark/pull/23964#issuecomment-473152043 Do you have any other concerns, @maropu and @viirya ? Every comments are welcome. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] cloud-fan commented on a change in pull request #24075: [SPARK-26176][SQL] Verify column names for CTAS with `STORED AS`
cloud-fan commented on a change in pull request #24075: [SPARK-26176][SQL]
Verify column names for CTAS with `STORED AS`
URL: https://github.com/apache/spark/pull/24075#discussion_r265844898
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveStrategies.scala
##
@@ -155,7 +155,7 @@ object HiveAnalysis extends Rule[LogicalPlan] {
CreateTableCommand(tableDesc, ignoreIfExists = mode == SaveMode.Ignore)
case CreateTable(tableDesc, mode, Some(query)) if
DDLUtils.isHiveTable(tableDesc) =>
- DDLUtils.checkDataColNames(tableDesc)
+ DDLUtils.checkDataColNames(tableDesc.copy(schema = query.schema))
Review comment:
can we unify this check for both data source table and hive serde table?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sujith71955 commented on a change in pull request #24075: [SPARK-26176][SQL] Verify column names for CTAS with `STORED AS`
sujith71955 commented on a change in pull request #24075: [SPARK-26176][SQL]
Verify column names for CTAS with `STORED AS`
URL: https://github.com/apache/spark/pull/24075#discussion_r265847163
##
File path:
sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveStrategies.scala
##
@@ -155,7 +155,7 @@ object HiveAnalysis extends Rule[LogicalPlan] {
CreateTableCommand(tableDesc, ignoreIfExists = mode == SaveMode.Ignore)
case CreateTable(tableDesc, mode, Some(query)) if
DDLUtils.isHiveTable(tableDesc) =>
- DDLUtils.checkDataColNames(tableDesc)
+ DDLUtils.checkDataColNames(tableDesc.copy(schema = query.schema))
Review comment:
sure, let me check. thanks for your input.
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level
AmplabJenkins removed a comment on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level URL: https://github.com/apache/spark/pull/24098#issuecomment-473155058 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/103522/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins commented on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level
AmplabJenkins commented on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level URL: https://github.com/apache/spark/pull/24098#issuecomment-473155058 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/103522/ Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] AmplabJenkins removed a comment on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level
AmplabJenkins removed a comment on issue #24098: [SPARK-27166][SQL] Improve `printSchema` to print up to the given level URL: https://github.com/apache/spark/pull/24098#issuecomment-473154849 Merged build finished. Test PASSed. This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #23964: [SPARK-26975][SQL] Support nested-column pruning over limit/sample/repartition
maropu commented on a change in pull request #23964: [SPARK-26975][SQL] Support
nested-column pruning over limit/sample/repartition
URL: https://github.com/apache/spark/pull/23964#discussion_r265848830
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala
##
@@ -647,6 +647,10 @@ object ColumnPruning extends Rule[LogicalPlan] {
// Can't prune the columns on LeafNode
case p @ Project(_, _: LeafNode) => p
+case p @ NestedColumnAliasing(nestedFieldToAlias, attrToAliases)
Review comment:
We don't need to compute `getAliasSubMap` in `NestedColumnAliasing` if
`nestedSchemaPruningEnabled` is false, right?
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
With regards,
Apache Git Services
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] maropu commented on a change in pull request #23964: [SPARK-26975][SQL] Support nested-column pruning over limit/sample/repartition
maropu commented on a change in pull request #23964: [SPARK-26975][SQL] Support
nested-column pruning over limit/sample/repartition
URL: https://github.com/apache/spark/pull/23964#discussion_r265849055
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/NestedColumnAliasing.scala
##
@@ -0,0 +1,150 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions._
+import org.apache.spark.sql.catalyst.plans.logical._
+import org.apache.spark.sql.types._
+
+/**
+ * This aims to handle a nested column aliasing pattern inside the
`ColumnPruning` optimizer rule.
+ * If a project or its child references to nested fields, and not all the
fields
+ * in a nested attribute are used, we can substitute them by alias attributes;
then a project
+ * of the nested fields as aliases on the children of the child will be
created.
+ */
+object NestedColumnAliasing {
+
+ def unapply(plan: LogicalPlan)
+: Option[(Map[GetStructField, Alias], Map[ExprId, Seq[Alias]])] = plan
match {
+case Project(_, child) if canProjectPushThrough(child) =>
+ getAliasSubMap(plan, child)
+case _ => None
+ }
+
+ /**
+ * Replace nested columns to prune unused nested columns later.
+ */
+ def replaceToAliases(
+ plan: LogicalPlan,
+ nestedFieldToAlias: Map[GetStructField, Alias],
+ attrToAliases: Map[ExprId, Seq[Alias]]): LogicalPlan = plan match {
+case Project(projectList, child) =>
+ Project(
+getNewProjectList(projectList, nestedFieldToAlias),
+replaceChildrenWithAliases(child, attrToAliases))
+ }
+
+ /**
+ * Return a replaced project list.
+ */
+ private def getNewProjectList(
+ projectList: Seq[NamedExpression],
+ nestedFieldToAlias: Map[GetStructField, Alias]): Seq[NamedExpression] = {
+projectList.map(_.transform {
+ case f: GetStructField if nestedFieldToAlias.contains(f) =>
+nestedFieldToAlias(f).toAttribute
+}.asInstanceOf[NamedExpression])
+ }
+
+ /**
+ * Return a plan with new childen replaced with aliases.
+ */
+ private def replaceChildrenWithAliases(
+ plan: LogicalPlan,
+ attrToAliases: Map[ExprId, Seq[Alias]]): LogicalPlan = {
+plan.withNewChildren(plan.children.map { plan =>
+ Project(plan.output.flatMap(a => attrToAliases.getOrElse(a.exprId,
Seq(a))), plan)
+})
+ }
+
+ /**
+ * Returns true for those operators that project can be pushed through.
+ */
+ private def canProjectPushThrough(plan: LogicalPlan) = plan match {
+case _: GlobalLimit => true
+case _: LocalLimit => true
+case _: Repartition => true
+case _: Sample => true
+case _ => false
+ }
+
+ /**
+ * Return root references that are individually accessed as a whole, and
`GetStructField`s.
+ */
+ private def collectRootReferenceAndGetStructField(plan: LogicalPlan):
Seq[Expression] = {
+def helper(e: Expression): Seq[Expression] = e match {
+ case _: AttributeReference | _: GetStructField => Seq(e)
+ case es if es.children.nonEmpty => es.children.flatMap(helper)
+ case _ => Seq.empty
+}
+plan.expressions.flatMap(helper)
+ }
+
+ /**
+ * Return two maps in order to replace nested fields to aliases.
+ *
+ * 1. GetStructField -> Alias: A new alias is created for each nested field.
+ * 2. ExprId -> Seq[Alias]: A reference attribute has multiple aliases
pointing it.
+ */
+ private def getAliasSubMap(plans: LogicalPlan*)
+: Option[(Map[GetStructField, Alias], Map[ExprId, Seq[Alias]])] = {
+val (nestedFieldReferences, otherRootReferences) = plans
+ .map(collectRootReferenceAndGetStructField).reduce(_ ++ _).partition {
+case _: GetStructField => true
+case _ => false
+ }
+
+val aliasSub = nestedFieldReferences.asInstanceOf[Seq[GetStructField]]
+ .filter(!_.references.subsetOf(AttributeSet(otherRootReferences)))
+ .groupBy(_.references.head)
+ .flatMap { case (attr: Attribute, nestedFields: Seq[GetStructField]) =>
+// Each expression can contain multiple nested fields.
+// Note that we keep the original
[GitHub] [spark] maropu commented on a change in pull request #23964: [SPARK-26975][SQL] Support nested-column pruning over limit/sample/repartition
maropu commented on a change in pull request #23964: [SPARK-26975][SQL] Support
nested-column pruning over limit/sample/repartition
URL: https://github.com/apache/spark/pull/23964#discussion_r265850994
##
File path:
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/NestedColumnAliasing.scala
##
@@ -0,0 +1,150 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+
+package org.apache.spark.sql.catalyst.optimizer
+
+import org.apache.spark.sql.catalyst.expressions._
+import org.apache.spark.sql.catalyst.plans.logical._
+import org.apache.spark.sql.types._
+
+/**
+ * This aims to handle a nested column aliasing pattern inside the
`ColumnPruning` optimizer rule.
+ * If a project or its child references to nested fields, and not all the
fields
+ * in a nested attribute are used, we can substitute them by alias attributes;
then a project
+ * of the nested fields as aliases on the children of the child will be
created.
+ */
+object NestedColumnAliasing {
+
+ def unapply(plan: LogicalPlan)
+: Option[(Map[GetStructField, Alias], Map[ExprId, Seq[Alias]])] = plan
match {
+case Project(_, child) if canProjectPushThrough(child) =>
+ getAliasSubMap(plan, child)
+case _ => None
+ }
+
+ /**
+ * Replace nested columns to prune unused nested columns later.
+ */
+ def replaceToAliases(
+ plan: LogicalPlan,
+ nestedFieldToAlias: Map[GetStructField, Alias],
+ attrToAliases: Map[ExprId, Seq[Alias]]): LogicalPlan = plan match {
+case Project(projectList, child) =>
+ Project(
+getNewProjectList(projectList, nestedFieldToAlias),
+replaceChildrenWithAliases(child, attrToAliases))
+ }
+
+ /**
+ * Return a replaced project list.
+ */
+ private def getNewProjectList(
+ projectList: Seq[NamedExpression],
+ nestedFieldToAlias: Map[GetStructField, Alias]): Seq[NamedExpression] = {
+projectList.map(_.transform {
+ case f: GetStructField if nestedFieldToAlias.contains(f) =>
+nestedFieldToAlias(f).toAttribute
+}.asInstanceOf[NamedExpression])
+ }
+
+ /**
+ * Return a plan with new childen replaced with aliases.
+ */
+ private def replaceChildrenWithAliases(
+ plan: LogicalPlan,
+ attrToAliases: Map[ExprId, Seq[Alias]]): LogicalPlan = {
+plan.withNewChildren(plan.children.map { plan =>
+ Project(plan.output.flatMap(a => attrToAliases.getOrElse(a.exprId,
Seq(a))), plan)
+})
+ }
+
+ /**
+ * Returns true for those operators that project can be pushed through.
+ */
+ private def canProjectPushThrough(plan: LogicalPlan) = plan match {
+case _: GlobalLimit => true
+case _: LocalLimit => true
+case _: Repartition => true
+case _: Sample => true
+case _ => false
+ }
+
+ /**
+ * Return root references that are individually accessed as a whole, and
`GetStructField`s.
+ */
+ private def collectRootReferenceAndGetStructField(plan: LogicalPlan):
Seq[Expression] = {
+def helper(e: Expression): Seq[Expression] = e match {
+ case _: AttributeReference | _: GetStructField => Seq(e)
+ case es if es.children.nonEmpty => es.children.flatMap(helper)
+ case _ => Seq.empty
+}
+plan.expressions.flatMap(helper)
+ }
+
+ /**
+ * Return two maps in order to replace nested fields to aliases.
+ *
+ * 1. GetStructField -> Alias: A new alias is created for each nested field.
+ * 2. ExprId -> Seq[Alias]: A reference attribute has multiple aliases
pointing it.
+ */
+ private def getAliasSubMap(plans: LogicalPlan*)
+: Option[(Map[GetStructField, Alias], Map[ExprId, Seq[Alias]])] = {
+val (nestedFieldReferences, otherRootReferences) = plans
+ .map(collectRootReferenceAndGetStructField).reduce(_ ++ _).partition {
+case _: GetStructField => true
+case _ => false
+ }
+
+val aliasSub = nestedFieldReferences.asInstanceOf[Seq[GetStructField]]
+ .filter(!_.references.subsetOf(AttributeSet(otherRootReferences)))
+ .groupBy(_.references.head)
+ .flatMap { case (attr: Attribute, nestedFields: Seq[GetStructField]) =>
Review comment:
nit: `.flatMap { case (attr, nestedFields: Seq[GetStructField]) =>`
[GitHub] [spark] SparkQA removed a comment on issue #24096: [SPARK-27165][SPARK-27107][BUILD][SQL] Upgrade Apache ORC to 1.5.5
SparkQA removed a comment on issue #24096: [SPARK-27165][SPARK-27107][BUILD][SQL] Upgrade Apache ORC to 1.5.5 URL: https://github.com/apache/spark/pull/24096#issuecomment-473090853 **[Test build #103521 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/103521/testReport)** for PR 24096 at commit [`91536da`](https://github.com/apache/spark/commit/91536da18f3d01ea9820b64b38ad54320337151b). This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. For queries about this service, please contact Infrastructure at: us...@infra.apache.org With regards, Apache Git Services - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org