[GitHub] spark pull request #23050: [SPARK-26079][sql] Ensure listener event delivery...
Github user asfgit closed the pull request at: https://github.com/apache/spark/pull/23050 --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23063: [SPARK-26033][PYTHON][TESTS] Break large ml/tests.py fil...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/23063 Will merge this one tomorrow if this is not merged till then. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23050: [SPARK-26079][sql] Ensure listener event delivery in Str...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/23050 Merged to master and branch-2.4. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23048: transform DenseVector x DenseVector sqdist from i...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/23048#discussion_r234399421
--- Diff:
mllib-local/src/main/scala/org/apache/spark/ml/linalg/Vectors.scala ---
@@ -370,14 +370,19 @@ object Vectors {
case (v1: DenseVector, v2: SparseVector) =>
squaredDistance = sqdist(v2, v1)
- case (DenseVector(vv1), DenseVector(vv2)) =>
-var kv = 0
+ case (DenseVector(vv1), DenseVector(vv2)) => {
val sz = vv1.length
-while (kv < sz) {
- val score = vv1(kv) - vv2(kv)
- squaredDistance += score * score
- kv += 1
+@annotation.tailrec
--- End diff --
FWIW, I did an experimental by myself before because someone proposed
similar change (turning `while` to tail recursive one). There was no virtual
difference. If this change is only tail recursion vs `while`, I doubt how much
it can improve. I believe the benchmark steps should be clarified.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23049: [SPARK-26076][Build][Minor] Revise ambiguous error messa...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23049 **[Test build #98954 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98954/testReport)** for PR 23049 at commit [`07cd7f5`](https://github.com/apache/spark/commit/07cd7f592a2c15707706ca720ea220be267c1b75). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23049: [SPARK-26076][Build][Minor] Revise ambiguous error messa...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23049 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23049: [SPARK-26076][Build][Minor] Revise ambiguous error messa...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23049 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/5103/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23038: [SPARK-25451][CORE][WEBUI]Aggregated metrics tabl...
Github user shahidki31 commented on a diff in the pull request:
https://github.com/apache/spark/pull/23038#discussion_r234399022
--- Diff:
core/src/test/scala/org/apache/spark/status/AppStatusListenerSuite.scala ---
@@ -1275,6 +1275,49 @@ class AppStatusListenerSuite extends SparkFunSuite
with BeforeAndAfter {
assert(allJobs.head.numFailedStages == 1)
}
+ test("SPARK-25451: total tasks in the executor summary should match
total stage tasks") {
+val testConf = conf.clone()
+ .set("spark.ui.liveUpdate.period", s"${Int.MaxValue}s")
+
+val listener = new AppStatusListener(store, testConf, true)
+
+val stage = new StageInfo(1, 0, "stage", 4, Nil, Nil, "details")
+listener.onJobStart(SparkListenerJobStart(1, time, Seq(stage), null))
+listener.onStageSubmitted(SparkListenerStageSubmitted(stage, new
Properties()))
+
+val tasks = createTasks(4, Array("1", "2"))
+tasks.foreach { task =>
+ listener.onTaskStart(SparkListenerTaskStart(stage.stageId,
stage.attemptNumber, task))
+}
+
+tasks.filter(_.index < 2).foreach { task =>
+time += 1
+var execId = (task.index % 2 + 1).toString
+tasks(task.index).markFinished(TaskState.FAILED, time)
+listener.onTaskEnd(
+ SparkListenerTaskEnd(stage.stageId, stage.attemptId, "taskType",
+ExecutorLostFailure(execId, true, Some("Lost executor")),
tasks(task.index), null))
+}
+
+stage.failureReason = Some("Failed")
+listener.onStageCompleted(SparkListenerStageCompleted(stage))
+time += 1
+listener.onJobEnd(SparkListenerJobEnd(1, time, JobFailed(new
RuntimeException("Bad Executor"
+
+tasks.filter(_.index >= 2).foreach { task =>
+time += 1
+var execId = (task.index % 2 + 1).toString
+tasks(task.index).markFinished(TaskState.FAILED, time)
+listener.onTaskEnd(SparkListenerTaskEnd(stage.stageId,
stage.attemptId, "taskType",
+ ExecutorLostFailure(execId, true, Some("Lost executor")),
tasks(task.index), null))
+}
+
+val esummary =
store.view(classOf[ExecutorStageSummaryWrapper]).asScala.map(_.info)
+esummary.foreach {
+ execSummary => assert(execSummary.failedTasks == 2)
--- End diff --
Done
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23038: [SPARK-25451][CORE][WEBUI]Aggregated metrics tabl...
Github user shahidki31 commented on a diff in the pull request:
https://github.com/apache/spark/pull/23038#discussion_r234399018
--- Diff:
core/src/test/scala/org/apache/spark/status/AppStatusListenerSuite.scala ---
@@ -1275,6 +1275,49 @@ class AppStatusListenerSuite extends SparkFunSuite
with BeforeAndAfter {
assert(allJobs.head.numFailedStages == 1)
}
+ test("SPARK-25451: total tasks in the executor summary should match
total stage tasks") {
+val testConf = conf.clone()
+ .set("spark.ui.liveUpdate.period", s"${Int.MaxValue}s")
+
+val listener = new AppStatusListener(store, testConf, true)
+
+val stage = new StageInfo(1, 0, "stage", 4, Nil, Nil, "details")
+listener.onJobStart(SparkListenerJobStart(1, time, Seq(stage), null))
+listener.onStageSubmitted(SparkListenerStageSubmitted(stage, new
Properties()))
+
+val tasks = createTasks(4, Array("1", "2"))
+tasks.foreach { task =>
+ listener.onTaskStart(SparkListenerTaskStart(stage.stageId,
stage.attemptNumber, task))
+}
+
+tasks.filter(_.index < 2).foreach { task =>
+time += 1
+var execId = (task.index % 2 + 1).toString
+tasks(task.index).markFinished(TaskState.FAILED, time)
+listener.onTaskEnd(
+ SparkListenerTaskEnd(stage.stageId, stage.attemptId, "taskType",
+ExecutorLostFailure(execId, true, Some("Lost executor")),
tasks(task.index), null))
+}
+
+stage.failureReason = Some("Failed")
+listener.onStageCompleted(SparkListenerStageCompleted(stage))
+time += 1
+listener.onJobEnd(SparkListenerJobEnd(1, time, JobFailed(new
RuntimeException("Bad Executor"
+
+tasks.filter(_.index >= 2).foreach { task =>
+time += 1
--- End diff --
Updated
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23038: [SPARK-25451][CORE][WEBUI]Aggregated metrics tabl...
Github user shahidki31 commented on a diff in the pull request:
https://github.com/apache/spark/pull/23038#discussion_r234399010
--- Diff:
core/src/test/scala/org/apache/spark/status/AppStatusListenerSuite.scala ---
@@ -1275,6 +1275,49 @@ class AppStatusListenerSuite extends SparkFunSuite
with BeforeAndAfter {
assert(allJobs.head.numFailedStages == 1)
}
+ test("SPARK-25451: total tasks in the executor summary should match
total stage tasks") {
+val testConf = conf.clone()
+ .set("spark.ui.liveUpdate.period", s"${Int.MaxValue}s")
+
+val listener = new AppStatusListener(store, testConf, true)
+
+val stage = new StageInfo(1, 0, "stage", 4, Nil, Nil, "details")
+listener.onJobStart(SparkListenerJobStart(1, time, Seq(stage), null))
+listener.onStageSubmitted(SparkListenerStageSubmitted(stage, new
Properties()))
+
+val tasks = createTasks(4, Array("1", "2"))
+tasks.foreach { task =>
+ listener.onTaskStart(SparkListenerTaskStart(stage.stageId,
stage.attemptNumber, task))
+}
+
+tasks.filter(_.index < 2).foreach { task =>
+time += 1
--- End diff --
Updated the code
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23038: [SPARK-25451][CORE][WEBUI]Aggregated metrics table doesn...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23038 **[Test build #98953 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98953/testReport)** for PR 23038 at commit [`4385035`](https://github.com/apache/spark/commit/43850357b086796368532dc70f7adacccfa23b45). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23038: [SPARK-25451][CORE][WEBUI]Aggregated metrics tabl...
Github user shahidki31 commented on a diff in the pull request:
https://github.com/apache/spark/pull/23038#discussion_r234399006
--- Diff:
core/src/test/scala/org/apache/spark/status/AppStatusListenerSuite.scala ---
@@ -1275,6 +1275,49 @@ class AppStatusListenerSuite extends SparkFunSuite
with BeforeAndAfter {
assert(allJobs.head.numFailedStages == 1)
}
+ test("SPARK-25451: total tasks in the executor summary should match
total stage tasks") {
+val testConf = conf.clone()
+ .set("spark.ui.liveUpdate.period", s"${Int.MaxValue}s")
--- End diff --
Done.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23055: [SPARK-26080][PYTHON] Disable 'spark.executor.pyspark.me...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23055 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/5102/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23055: [SPARK-26080][PYTHON] Disable 'spark.executor.pyspark.me...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23055 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23055: [SPARK-26080][PYTHON] Disable 'spark.executor.pyspark.me...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23055 **[Test build #98952 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98952/testReport)** for PR 23055 at commit [`52a91cc`](https://github.com/apache/spark/commit/52a91cc887462227caf65eb85c0f01d5e8fd0485). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23065: [SPARK-26090][CORE][SQL][ML] Resolve most miscellaneous ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23065 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23065: [SPARK-26090][CORE][SQL][ML] Resolve most miscellaneous ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23065 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/98948/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23065: [SPARK-26090][CORE][SQL][ML] Resolve most miscellaneous ...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23065 **[Test build #98948 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98948/testReport)** for PR 23065 at commit [`e2e375b`](https://github.com/apache/spark/commit/e2e375b592ccbbf2e468736fb2ee00b33787c58e). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23055: [SPARK-26080][PYTHON] Disable 'spark.executor.pys...
Github user HyukjinKwon commented on a diff in the pull request:
https://github.com/apache/spark/pull/23055#discussion_r234398745
--- Diff:
core/src/main/scala/org/apache/spark/api/python/PythonRunner.scala ---
@@ -74,8 +74,13 @@ private[spark] abstract class BasePythonRunner[IN, OUT](
private val reuseWorker = conf.getBoolean("spark.python.worker.reuse",
true)
// each python worker gets an equal part of the allocation. the worker
pool will grow to the
// number of concurrent tasks, which is determined by the number of
cores in this executor.
- private val memoryMb = conf.get(PYSPARK_EXECUTOR_MEMORY)
+ private val memoryMb = if (Utils.isWindows) {
--- End diff --
> My point is that if resource can't be loaded for any reason, the code
shouldn't fail. As it is, if resource can't be loaded then that is handled, but
if the memory limit is set then the worker will still try to use it. That's
what I think is brittle. There should be a flag for whether to attempt to use
the resource API, based on whether it was loaded.
Ah, so the point is that the condition for the existence `resource` might
not be clear - so we should have the flag to make it not failed in case. Yup,
makes sense. Let me add a flag.
> If the worker operates as I described, then why make any changes on the
JVM side?
I am making some changes on the JVM side so that we can explicitly disable
on a certain condition For instance, if we don't make a change in JVM side, and
only make the changes in Python `worker`. Later, we can have some other changes
in JVM side referring this configuration - which can be problematic.
If we keep the configuration somehow in JVM side, it basically means we
could have another status for this configuration, rather then just being
disabled or enabled which we should take care of.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23059: [SPARK-26091][SQL] Upgrade to 2.3.4 for Hive Metastore C...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/23059 Looks good. Adding @gatorsmile and @wangyum --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23063: [SPARK-26033][PYTHON][TESTS] Break large ml/tests.py fil...
Github user HyukjinKwon commented on the issue: https://github.com/apache/spark/pull/23063 Let me leave a cc for @holdenk, @MLnick, @jkbradley and @mengxr FYI. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23063: [SPARK-26033][PYTHON][TESTS] Break large ml/tests.py fil...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23063 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/98945/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23063: [SPARK-26033][PYTHON][TESTS] Break large ml/tests.py fil...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23063 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23063: [SPARK-26033][PYTHON][TESTS] Break large ml/tests.py fil...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23063 **[Test build #98945 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98945/testReport)** for PR 23063 at commit [`a4f8f12`](https://github.com/apache/spark/commit/a4f8f12f6357861572ffbf34190947983545ba98). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23016: [SPARK-26006][mllib] unpersist 'dataInternalRepr' in the...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23016 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23016: [SPARK-26006][mllib] unpersist 'dataInternalRepr' in the...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23016 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/98951/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23016: [SPARK-26006][mllib] unpersist 'dataInternalRepr' in the...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23016 **[Test build #98951 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98951/testReport)** for PR 23016 at commit [`a4c5597`](https://github.com/apache/spark/commit/a4c55974a04878dfa92cdbb636823bbac10c8f64). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23016: [SPARK-26006][mllib] unpersist 'dataInternalRepr' in the...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23016 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/98950/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23016: [SPARK-26006][mllib] unpersist 'dataInternalRepr' in the...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23016 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23016: [SPARK-26006][mllib] unpersist 'dataInternalRepr' in the...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23016 **[Test build #98950 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98950/testReport)** for PR 23016 at commit [`7a4ede8`](https://github.com/apache/spark/commit/7a4ede8da3076892a9302d5d1e11bf6dcc77ff05). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23049: [SPARK-26076][Build][Minor] Revise ambiguous error messa...
Github user gengliangwang commented on the issue: https://github.com/apache/spark/pull/23049 @vanzin I see your point. I will add a link to https://spark.apache.org/docs/latest/configuration.html. Thanks for the suggestion. In my case, I didn't know where to find or edit `spark-env.sh` at that time. I tried run `find . -name spark-env.sh` and got nothing. The script will only print `spark-env.sh` without its location only if SPARK_ENV_LOADED is not set. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23064: [MINOR][SQL] Fix typo in CTAS plan database string
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23064 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23064: [MINOR][SQL] Fix typo in CTAS plan database string
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23064 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/98947/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23064: [MINOR][SQL] Fix typo in CTAS plan database string
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23064 **[Test build #98947 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98947/testReport)** for PR 23064 at commit [`ad971b6`](https://github.com/apache/spark/commit/ad971b668e05b93d54263ed87c9845d646085751). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23067: [SPARK-26097][Web UI] Add the new partitioning descripti...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23067 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23067: [SPARK-26097][Web UI] Add the new partitioning descripti...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23067 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23067: [SPARK-26097][Web UI] Add the new partitioning descripti...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23067 Can one of the admins verify this patch? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23067: [SPARK-26097][Web UI] Add the new partitioning de...
GitHub user idanz opened a pull request: https://github.com/apache/spark/pull/23067 [SPARK-26097][Web UI] Add the new partitioning description to the exchange node name ## What changes were proposed in this pull request? small change in the node name of the Exchange node to add in the string representation of the partitioning, this is just to have this information propagate to the DAG UI and help with join skew investigation for example. ## How was this patch tested? tested manually to see the UI impact and regression to see nothing is broken 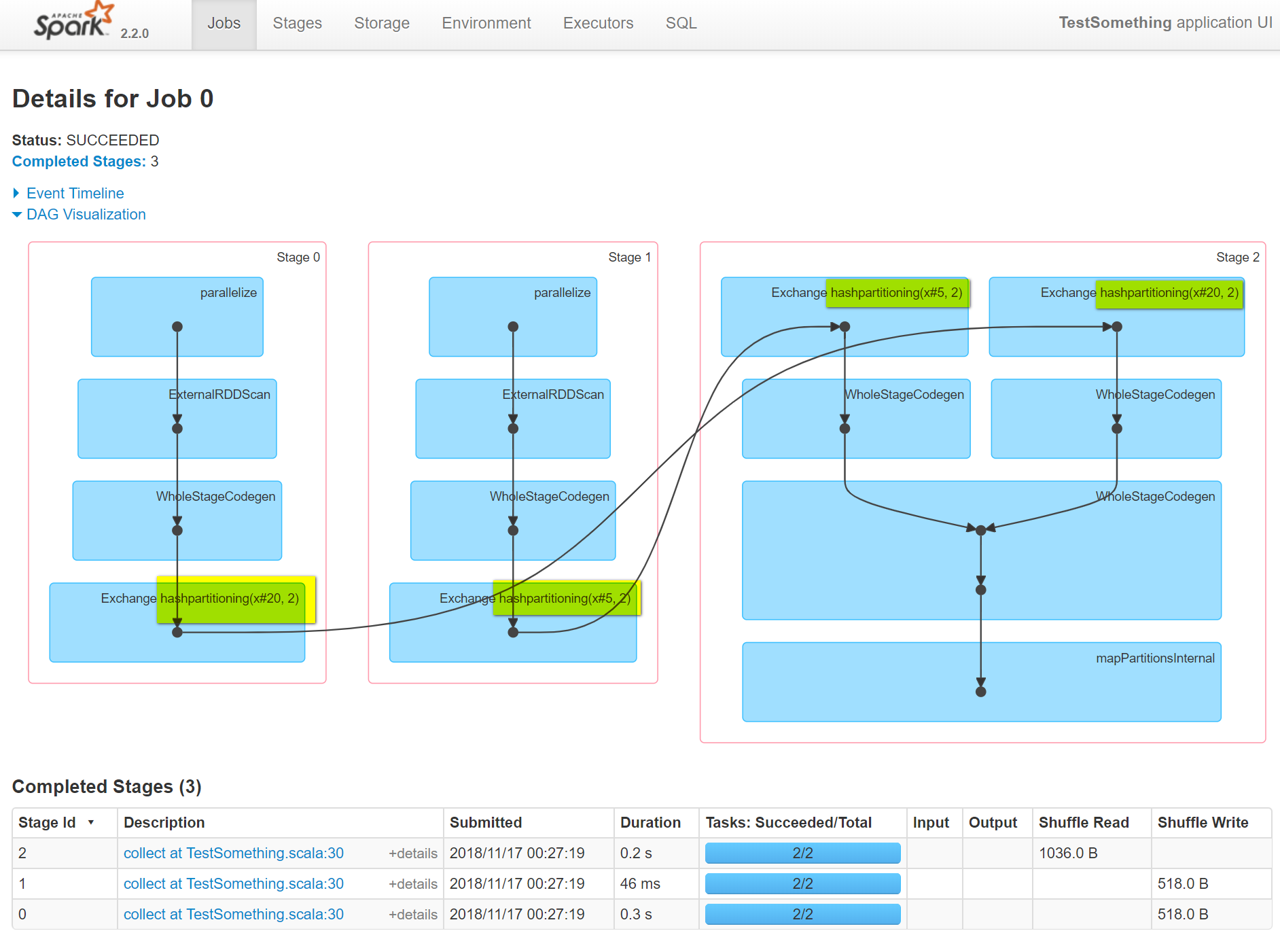 Please review http://spark.apache.org/contributing.html before opening a pull request. You can merge this pull request into a Git repository by running: $ git pull https://github.com/idanz/spark patch-3 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/23067.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #23067 commit 74898fda77f255a13981907aa5b9b6b78406aa1d Author: Idan Zalzberg Date: 2018-11-17T05:05:03Z Add the new partitioning description to the exchange node name --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23053: [SPARK-25957][K8S] Add ability to skip building optional...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23053 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23053: [SPARK-25957][K8S] Add ability to skip building optional...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23053 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/98941/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23053: [SPARK-25957][K8S] Add ability to skip building optional...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23053 **[Test build #98941 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98941/testReport)** for PR 23053 at commit [`8887b5a`](https://github.com/apache/spark/commit/8887b5abd426f61d004e03918445187ccc836a46). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23016: [SPARK-26006][mllib] unpersist 'dataInternalRepr' in the...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23016 **[Test build #98951 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98951/testReport)** for PR 23016 at commit [`a4c5597`](https://github.com/apache/spark/commit/a4c55974a04878dfa92cdbb636823bbac10c8f64). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23016: [SPARK-26006][mllib] unpersist 'dataInternalRepr' in the...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23016 **[Test build #98950 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98950/testReport)** for PR 23016 at commit [`7a4ede8`](https://github.com/apache/spark/commit/7a4ede8da3076892a9302d5d1e11bf6dcc77ff05). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23066: [SPARK-26043][CORE] Make SparkHadoopUtil private to Spar...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23066 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23066: [SPARK-26043][CORE] Make SparkHadoopUtil private to Spar...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23066 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/5101/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23016: [SPARK-26006][mllib] unpersist 'dataInternalRepr'...
Github user shahidki31 commented on a diff in the pull request:
https://github.com/apache/spark/pull/23016#discussion_r234396276
--- Diff: mllib/src/main/scala/org/apache/spark/mllib/fpm/PrefixSpan.scala
---
@@ -174,6 +174,10 @@ class PrefixSpan private (
val freqSequences = results.map { case (seq: Array[Int], count: Long)
=>
new FreqSequence(toPublicRepr(seq), count)
}
+// Cache the final RDD to the same storage level as input
+freqSequences.persist(data.getStorageLevel)
--- End diff --
@srowen Yes. That is the correct approach. I updated the code. Thanks
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23066: [SPARK-26043][CORE] Make SparkHadoopUtil private to Spar...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23066 **[Test build #98949 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98949/testReport)** for PR 23066 at commit [`5a79b2e`](https://github.com/apache/spark/commit/5a79b2e73a658b5fffd6b605b109b63cd1c887e2). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23066: [SPARK-26043][CORE] Make SparkHadoopUtil private to Spar...
Github user srowen commented on the issue: https://github.com/apache/spark/pull/23066 CC @vanzin . I took the liberty of simplifying a few other bits of the file too. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23066: [SPARK-26043][CORE] Make SparkHadoopUtil private ...
GitHub user srowen opened a pull request: https://github.com/apache/spark/pull/23066 [SPARK-26043][CORE] Make SparkHadoopUtil private to Spark ## What changes were proposed in this pull request? Make SparkHadoopUtil private to Spark ## How was this patch tested? Existing tests. You can merge this pull request into a Git repository by running: $ git pull https://github.com/srowen/spark SPARK-26043 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/23066.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #23066 commit 5a79b2e73a658b5fffd6b605b109b63cd1c887e2 Author: Sean Owen Date: 2018-11-17T04:22:52Z Make SparkHadoopUtil private --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #22995: [SPARK-25998] [CORE] Change TorrentBroadcast to h...
Github user srowen commented on a diff in the pull request:
https://github.com/apache/spark/pull/22995#discussion_r234396107
--- Diff:
core/src/main/scala/org/apache/spark/broadcast/TorrentBroadcast.scala ---
@@ -93,7 +96,14 @@ private[spark] class TorrentBroadcast[T: ClassTag](obj:
T, id: Long)
private var checksums: Array[Int] = _
override protected def getValue() = {
-_value
+val memoized: T = if (_value == null) null.asInstanceOf[T] else
_value.get
--- End diff --
I suppose there is a race condition here, in that several threads could end
up simultaneously setting the reference. It won't be incorrect as the data
ought to be the same. I am not sure of the access pattern for this object;
maybe it's always single-threaded. But if lots are reading, you can imagine
them all causing a call to `readBroadcastBlock()` simultaneously.
Introducing another object to lock on is safe and not too much extra
legwork. Might be worth it.
Isn't WeakReference cleared on any GC? would SoftReference be better to
hold out until memory is exhausted? to avoid re-reading. There's a tradeoff
there.
Good idea, just surprisingly full of possible gotchas.
Nit: isn't `val memoized = if (_value == null) null else _value.get`
sufficient?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23038: [SPARK-25451][CORE][WEBUI]Aggregated metrics table doesn...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23038 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23038: [SPARK-25451][CORE][WEBUI]Aggregated metrics table doesn...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23038 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/98939/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23038: [SPARK-25451][CORE][WEBUI]Aggregated metrics table doesn...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23038 **[Test build #98939 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98939/testReport)** for PR 23038 at commit [`50cc762`](https://github.com/apache/spark/commit/50cc7620b3459589bf8a027a71d9197ee1e269e8). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23016: [SPARK-26006][mllib] unpersist 'dataInternalRepr'...
Github user srowen commented on a diff in the pull request:
https://github.com/apache/spark/pull/23016#discussion_r234395721
--- Diff: mllib/src/main/scala/org/apache/spark/mllib/fpm/PrefixSpan.scala
---
@@ -174,6 +174,10 @@ class PrefixSpan private (
val freqSequences = results.map { case (seq: Array[Int], count: Long)
=>
new FreqSequence(toPublicRepr(seq), count)
}
+// Cache the final RDD to the same storage level as input
+freqSequences.persist(data.getStorageLevel)
--- End diff --
The problem here is that it won't get persisted until something
materializes it, and at that point its dependent RDD dataInternalRepr is
already unpersisted.
I'd say that _if_ the input's storage level isn't NONE, then persist
freqSequences at the same level and .count() it to materialize it. Then
unpersist dataInternalRepr in all events.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23040: [SPARK-26068][Core]ChunkedByteBufferInputStream should h...
Github user cloud-fan commented on the issue: https://github.com/apache/spark/pull/23040 also cc @jiangxb1987 @zsxwing --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23040: [SPARK-26068][Core]ChunkedByteBufferInputStream should h...
Github user cloud-fan commented on the issue: https://github.com/apache/spark/pull/23040 LGTM except one comment --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23040: [SPARK-26068][Core]ChunkedByteBufferInputStream s...
Github user cloud-fan commented on a diff in the pull request:
https://github.com/apache/spark/pull/23040#discussion_r234395227
--- Diff:
core/src/main/scala/org/apache/spark/util/io/ChunkedByteBuffer.scala ---
@@ -222,7 +222,7 @@ private[spark] class ChunkedByteBufferInputStream(
dispose: Boolean)
extends InputStream {
- private[this] var chunks = chunkedByteBuffer.getChunks().iterator
+ private[this] var chunks =
chunkedByteBuffer.getChunks().filter(_.hasRemaining).iterator
--- End diff --
can you add a comment above, saying that we do this filter because `read`
assumes `chunks` has no empty chunk?
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23062: [SPARK-8288][SQL] ScalaReflection can use companion obje...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23062 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/98940/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23062: [SPARK-8288][SQL] ScalaReflection can use companion obje...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23062 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23062: [SPARK-8288][SQL] ScalaReflection can use companion obje...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23062 **[Test build #98940 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98940/testReport)** for PR 23062 at commit [`e27f933`](https://github.com/apache/spark/commit/e27f933710c289d5bc1ddcad38eecde0e555ac60). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23017: [SPARK-26015][K8S] Set a default UID for Spark on K8S Im...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23017 Test FAILed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/98943/ Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23017: [SPARK-26015][K8S] Set a default UID for Spark on K8S Im...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23017 Merged build finished. Test FAILed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23017: [SPARK-26015][K8S] Set a default UID for Spark on K8S Im...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23017 **[Test build #98943 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98943/testReport)** for PR 23017 at commit [`8f4fd19`](https://github.com/apache/spark/commit/8f4fd194e89a5062fc694cf917e1c2f744294495). * This patch **fails Spark unit tests**. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23038: [SPARK-25451][CORE][WEBUI]Aggregated metrics table doesn...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23038 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23038: [SPARK-25451][CORE][WEBUI]Aggregated metrics table doesn...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23038 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/98938/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23038: [SPARK-25451][CORE][WEBUI]Aggregated metrics table doesn...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23038 **[Test build #98938 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98938/testReport)** for PR 23038 at commit [`8109396`](https://github.com/apache/spark/commit/81093961bdf83f68e8685640ea5103e44f2696d7). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23043: [SPARK-26021][SQL] replace minus zero with zero in Unsaf...
Github user cloud-fan commented on the issue: https://github.com/apache/spark/pull/23043 `UnsafeRow.set` is not the only place to write float/double as binary data, can you check other places like UnsafeWriter? --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23061: [SPARK-26095][build] Disable parallelization in make-dis...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23061 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/98934/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23061: [SPARK-26095][build] Disable parallelization in make-dis...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23061 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23061: [SPARK-26095][build] Disable parallelization in make-dis...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23061 **[Test build #98934 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98934/testReport)** for PR 23061 at commit [`2bf6e61`](https://github.com/apache/spark/commit/2bf6e61d390ad3f4abc28a141bbdf11f71fbd08f). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23038: [SPARK-25451][CORE][WEBUI]Aggregated metrics table doesn...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23038 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23038: [SPARK-25451][CORE][WEBUI]Aggregated metrics table doesn...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23038 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/98936/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23038: [SPARK-25451][CORE][WEBUI]Aggregated metrics table doesn...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23038 **[Test build #98936 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98936/testReport)** for PR 23038 at commit [`5b13b77`](https://github.com/apache/spark/commit/5b13b7725cc6dff0e6caed1229c05efcf89d9eff). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23030: [MINOR][YARN] Make memLimitExceededLogMessage more clean
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23030 **[Test build #98946 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98946/testReport)** for PR 23030 at commit [`ca008cd`](https://github.com/apache/spark/commit/ca008cd6bb16a4b5c3156b572bb4f05034230912). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23030: [MINOR][YARN] Make memLimitExceededLogMessage more clean
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23030 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23030: [MINOR][YARN] Make memLimitExceededLogMessage more clean
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23030 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/98946/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23065: [SPARK-26090][CORE][SQL][ML] Resolve most miscell...
Github user srowen commented on a diff in the pull request: https://github.com/apache/spark/pull/23065#discussion_r234393692 --- Diff: common/unsafe/pom.xml --- @@ -89,6 +89,11 @@ commons-lang3 test + + org.apache.commons + commons-text --- End diff -- LevenshteinDistance moved here from commons lang --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23065: [SPARK-26090][CORE][SQL][ML] Resolve most miscell...
Github user srowen commented on a diff in the pull request:
https://github.com/apache/spark/pull/23065#discussion_r234393727
--- Diff:
external/avro/src/test/scala/org/apache/spark/sql/avro/AvroSuite.scala ---
@@ -138,7 +138,7 @@ class AvroSuite extends QueryTest with SharedSQLContext
with SQLTestUtils {
test("test NULL avro type") {
withTempPath { dir =>
val fields =
-Seq(new Field("null", Schema.create(Type.NULL), "doc",
null)).asJava
+Seq(new Field("null", Schema.create(Type.NULL), "doc",
null.asInstanceOf[AnyVal])).asJava
--- End diff --
Should be an exact workalike invocation here, just works around a
deprecation
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23065: [SPARK-26090][CORE][SQL][ML] Resolve most miscell...
Github user srowen commented on a diff in the pull request:
https://github.com/apache/spark/pull/23065#discussion_r234393870
--- Diff:
sql/core/src/test/scala/org/apache/spark/sql/execution/streaming/ProcessingTimeExecutorSuite.scala
---
@@ -48,7 +45,7 @@ class ProcessingTimeExecutorSuite extends SparkFunSuite
with TimeLimits {
}
test("trigger timing") {
-val triggerTimes = new ConcurrentHashSet[Int]
+val triggerTimes = ConcurrentHashMap.newKeySet[Int]()
--- End diff --
Yes, this is the recommended way to get a concurrent Set in the JDK
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23065: [SPARK-26090][CORE][SQL][ML] Resolve most miscell...
Github user srowen commented on a diff in the pull request:
https://github.com/apache/spark/pull/23065#discussion_r234393768
--- Diff:
mllib/src/main/scala/org/apache/spark/ml/feature/LabeledPoint.scala ---
@@ -30,8 +28,12 @@ import org.apache.spark.ml.linalg.Vector
* @param features List of features for this data point.
*/
@Since("2.0.0")
-@BeanInfo
case class LabeledPoint(@Since("2.0.0") label: Double, @Since("2.0.0")
features: Vector) {
+
+ def getLabel: Double = label
--- End diff --
These are added to explicitly add what the companion BeanInfo class was
implicitly adding
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23065: [SPARK-26090][CORE][SQL][ML] Resolve most miscell...
Github user srowen commented on a diff in the pull request:
https://github.com/apache/spark/pull/23065#discussion_r234393704
--- Diff: core/src/main/scala/org/apache/spark/scheduler/StageInfo.scala ---
@@ -30,7 +30,7 @@ import org.apache.spark.storage.RDDInfo
@DeveloperApi
class StageInfo(
val stageId: Int,
-@deprecated("Use attemptNumber instead", "2.3.0") val attemptId: Int,
+private val attemptId: Int,
--- End diff --
Funny, MiMa didn't warn about this, but will go in release notes
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23065: [SPARK-26090][CORE][SQL][ML] Resolve most miscell...
Github user srowen commented on a diff in the pull request:
https://github.com/apache/spark/pull/23065#discussion_r234393743
--- Diff:
external/kinesis-asl/src/main/java/org/apache/spark/examples/streaming/JavaKinesisWordCountASL.java
---
@@ -105,25 +105,22 @@ public static void main(String[] args) throws
Exception {
String endpointUrl = args[2];
// Create a Kinesis client in order to determine the number of shards
for the given stream
-AmazonKinesisClient kinesisClient =
-new AmazonKinesisClient(new DefaultAWSCredentialsProviderChain());
-kinesisClient.setEndpoint(endpointUrl);
-int numShards =
-
kinesisClient.describeStream(streamName).getStreamDescription().getShards().size();
-
+AmazonKinesis kinesisClient = AmazonKinesisClientBuilder.standard()
--- End diff --
Most of the Kinesis changes are of this form, to use the new client
builder, with the same argument going in as far as I can tell. The rest are
Java 8 cleanups.
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23065: [SPARK-26090][CORE][SQL][ML] Resolve most miscellaneous ...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23065 **[Test build #98948 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98948/testReport)** for PR 23065 at commit [`e2e375b`](https://github.com/apache/spark/commit/e2e375b592ccbbf2e468736fb2ee00b33787c58e). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23065: [SPARK-26090][CORE][SQL][ML] Resolve most miscell...
Github user srowen commented on a diff in the pull request:
https://github.com/apache/spark/pull/23065#discussion_r234393799
--- Diff:
mllib/src/test/scala/org/apache/spark/ml/feature/QuantileDiscretizerSuite.scala
---
@@ -276,10 +276,10 @@ class QuantileDiscretizerSuite extends MLTest with
DefaultReadWriteTest {
1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0)
val data2 = Array.range(1, 40, 2).map(_.toDouble)
val expected2 = Array (0.0, 0.0, 0.0, 1.0, 1.0, 1.0, 1.0, 2.0, 2.0,
2.0,
- 2.0, 2.0, 3.0, 3.0, 3.0, 4.0, 4.0, 4.0, 4.0, 4.0)
+ 2.0, 3.0, 3.0, 3.0, 3.0, 4.0, 4.0, 4.0, 4.0, 4.0)
--- End diff --
Interestingly, avoiding double Ranges actually fixed the code here. You can
see the bucketing before didn't quite make sense. Now it's even. It's because
of...
```
scala> (0.0 to 1.0 by 1.0 / 10).toList
:12: warning: method to in trait FractionalProxy is deprecated
(since 2.12.6): use BigDecimal range instead
(0.0 to 1.0 by 1.0 / 10).toList
^
res5: List[Double] = List(0.0, 0.1, 0.2, 0.30004, 0.4, 0.5,
0.6, 0.7, 0.7999, 0.8999, 0.)
scala> (0 to 10).map(_.toDouble / 10).toList
res6: List[Double] = List(0.0, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9,
1.0)
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23065: [SPARK-26090][CORE][SQL][ML] Resolve most miscell...
Github user srowen commented on a diff in the pull request:
https://github.com/apache/spark/pull/23065#discussion_r234393720
--- Diff:
external/kafka-0-10-sql/src/test/scala/org/apache/spark/sql/kafka010/KafkaContinuousTest.scala
---
@@ -56,7 +56,7 @@ trait KafkaContinuousTest extends KafkaSourceTest {
}
// Continuous processing tasks end asynchronously, so test that they
actually end.
- private val tasksEndedListener = new SparkListener() {
+ private class TasksEndedListener extends SparkListener {
--- End diff --
Complains about existential types if you access a method in an anonymous
inner class
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23065: [SPARK-26090][CORE][SQL][ML] Resolve most miscell...
Github user srowen commented on a diff in the pull request:
https://github.com/apache/spark/pull/23065#discussion_r234393826
--- Diff:
mllib/src/test/scala/org/apache/spark/ml/recommendation/ALSSuite.scala ---
@@ -601,7 +601,7 @@ class ALSSuite extends MLTest with DefaultReadWriteTest
with Logging {
val df = maybeDf.get._2
val expected = estimator.fit(df)
-val actuals = dfs.filter(_ != baseType).map(t => (t,
estimator.fit(t._2)))
+val actuals = dfs.map(t => (t, estimator.fit(t._2)))
--- End diff --
The filter here was nonsensical, comparing a value to type. Removed it as
it's always true
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23065: [SPARK-26090][CORE][SQL][ML] Resolve most miscell...
Github user srowen commented on a diff in the pull request:
https://github.com/apache/spark/pull/23065#discussion_r234393755
--- Diff:
external/kinesis-asl/src/test/java/org/apache/spark/streaming/kinesis/JavaKinesisInputDStreamBuilderSuite.java
---
@@ -49,13 +51,14 @@ public void testJavaKinesisDStreamBuilder() {
.checkpointInterval(checkpointInterval)
.storageLevel(storageLevel)
.build();
-assert(kinesisDStream.streamName() == streamName);
-assert(kinesisDStream.endpointUrl() == endpointUrl);
-assert(kinesisDStream.regionName() == region);
-assert(kinesisDStream.initialPosition().getPosition() ==
initialPosition.getPosition());
-assert(kinesisDStream.checkpointAppName() == appName);
-assert(kinesisDStream.checkpointInterval() == checkpointInterval);
-assert(kinesisDStream._storageLevel() == storageLevel);
+Assert.assertEquals(streamName, kinesisDStream.streamName());
--- End diff --
These assertions were wrong in two ways: == and assert
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23065: [SPARK-26090][CORE][SQL][ML] Resolve most miscellaneous ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23065 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23065: [SPARK-26090][CORE][SQL][ML] Resolve most miscellaneous ...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23065 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/5100/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23065: [SPARK-26090][CORE][SQL][ML] Resolve most miscell...
GitHub user srowen opened a pull request: https://github.com/apache/spark/pull/23065 [SPARK-26090][CORE][SQL][ML] Resolve most miscellaneous deprecation and build warnings for Spark 3 ## What changes were proposed in this pull request? The build has a lot of deprecation warnings. Some are new in Scala 2.12 and Java 11. We've fixed some, but I wanted to take a pass at fixing lots of easy miscellaneous ones here. They're too numerous and small to list here; see the pull request. Some highlights: - `@BeanInfo` is deprecated in 2.12, and BeanInfo classes are pretty ancient in Java. Instead, case classes can explicitly declare getters - Lots of work in the Kinesis examples to update and avoid deprecation - Eta expansion of zero-arg methods; foo() becomes () => foo() in many cases - Floating-point Range is inexact and deprecated, like 0.0 to 100.0 by 1.0 - finalize() is finally deprecated (just needs to be suppressed) - StageInfo.attempId was deprecated and easiest to remove here I'm not now going to touch some chunks of deprecation warnings: - Parquet deprecations - Hive deprecations (particularly serde2 classes) - Deprecations in generated code (mostly Thriftserver CLI) - ProcessingTime deprecations (we may need to revive this class as internal) - many MLlib deprecations because they concern methods that may be removed anyway - a few Kinesis deprecations I couldn't figure out - Mesos get/setRole, which I don't know well - Kafka/ZK deprecations (e.g. poll()) - a few other ones that will probably resolve by deleting a deprecated method ## How was this patch tested? Existing tests, including manual testing with the 2.11 build and Java 11. You can merge this pull request into a Git repository by running: $ git pull https://github.com/srowen/spark SPARK-26090 Alternatively you can review and apply these changes as the patch at: https://github.com/apache/spark/pull/23065.patch To close this pull request, make a commit to your master/trunk branch with (at least) the following in the commit message: This closes #23065 commit e2e375b592ccbbf2e468736fb2ee00b33787c58e Author: Sean Owen Date: 2018-11-17T02:50:57Z Resolve most miscellaneous deprecations and some build warnings --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23064: [MINOR][SQL] Fix typo in CTAS plan database string
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23064 **[Test build #98947 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98947/testReport)** for PR 23064 at commit [`ad971b6`](https://github.com/apache/spark/commit/ad971b668e05b93d54263ed87c9845d646085751). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23064: [MINOR][SQL] Fix typo in CTAS plan database string
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23064 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/5099/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23064: [MINOR][SQL] Fix typo in CTAS plan database string
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23064 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark pull request #23064: [MINOR][SQL] Fix typo in CTAS plan database strin...
GitHub user dongjoon-hyun opened a pull request:
https://github.com/apache/spark/pull/23064
[MINOR][SQL] Fix typo in CTAS plan database string
## What changes were proposed in this pull request?
Since Spark 1.6.0, there was a redundant '}' character in CTAS string
plan's database argument string; `default}`. This PR aims to fix it.
```scala
scala> sc.version
res1: String = 1.6.0
scala> sql("create table t as select 1").explain
== Physical Plan ==
ExecutedCommand CreateTableAsSelect [Database:default}, TableName: t,
InsertIntoHiveTable]
+- Project [1 AS _c0#3]
+- OneRowRelation$
```
## How was this patch tested?
Manual.
You can merge this pull request into a Git repository by running:
$ git pull https://github.com/dongjoon-hyun/spark SPARK-FIX
Alternatively you can review and apply these changes as the patch at:
https://github.com/apache/spark/pull/23064.patch
To close this pull request, make a commit to your master/trunk branch
with (at least) the following in the commit message:
This closes #23064
commit ad971b668e05b93d54263ed87c9845d646085751
Author: Dongjoon Hyun
Date: 2018-11-17T02:37:21Z
[MINOR][SQL] Fix typo in CTAS plan argString
```
scala> sql("create table t as select 1").explain
== Physical Plan ==
ExecutedCommand CreateTableAsSelect [Database:default}, TableName: t,
InsertIntoHiveTable]
+- Project [1 AS _c0#3]
+- OneRowRelation$
scala> sc.version
res1: String = 1.6.0
```
---
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23030: [MINOR][YARN] Make memLimitExceededLogMessage more clean
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23030 **[Test build #98946 has started](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98946/testReport)** for PR 23030 at commit [`ca008cd`](https://github.com/apache/spark/commit/ca008cd6bb16a4b5c3156b572bb4f05034230912). --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23030: [MINOR][YARN] Make memLimitExceededLogMessage more clean
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23030 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/testing-k8s-prb-make-spark-distribution-unified/5098/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23030: [MINOR][YARN] Make memLimitExceededLogMessage more clean
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23030 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23061: [SPARK-26095][build] Disable parallelization in make-dis...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23061 Merged build finished. Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23061: [SPARK-26095][build] Disable parallelization in make-dis...
Github user AmplabJenkins commented on the issue: https://github.com/apache/spark/pull/23061 Test PASSed. Refer to this link for build results (access rights to CI server needed): https://amplab.cs.berkeley.edu/jenkins//job/SparkPullRequestBuilder/98933/ Test PASSed. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] spark issue #23061: [SPARK-26095][build] Disable parallelization in make-dis...
Github user SparkQA commented on the issue: https://github.com/apache/spark/pull/23061 **[Test build #98933 has finished](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/98933/testReport)** for PR 23061 at commit [`2bf6e61`](https://github.com/apache/spark/commit/2bf6e61d390ad3f4abc28a141bbdf11f71fbd08f). * This patch passes all tests. * This patch merges cleanly. * This patch adds no public classes. --- - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org