[GitHub] [spark] rithwik-db commented on a diff in pull request #39369: [SPARK-41775][PYTHON][ML] Adding support for PyTorch functions
rithwik-db commented on code in PR #39369:
URL: https://github.com/apache/spark/pull/39369#discussion_r1082896210
##
python/pyspark/ml/torch/tests/test_distributor.py:
##
@@ -349,6 +434,13 @@ def test_get_num_tasks_distributed(self) -> None:
self.spark.sparkContext._conf.set("spark.task.resource.gpu.amount",
"1")
+# def test_end_to_end_run_distributedly(self) -> None:
Review Comment:
Sorry, that shouldn't have been commented out. Will quickly update adding
that test back in
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] lu-wang-dl commented on a diff in pull request #39369: [SPARK-41775][PYTHON][ML] Adding support for PyTorch functions
lu-wang-dl commented on code in PR #39369:
URL: https://github.com/apache/spark/pull/39369#discussion_r1082894756
##
python/pyspark/ml/torch/tests/test_distributor.py:
##
@@ -349,6 +434,13 @@ def test_get_num_tasks_distributed(self) -> None:
self.spark.sparkContext._conf.set("spark.task.resource.gpu.amount",
"1")
+# def test_end_to_end_run_distributedly(self) -> None:
Review Comment:
Clean up this?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39671: [SPARK-40303][DOCS] Deprecate old Java 8 versions prior to 8u362
dongjoon-hyun commented on PR #39671: URL: https://github.com/apache/spark/pull/39671#issuecomment-1398718941 FYI, GitHub Action is currently on the old version but `jdk8u362` will be automatically applied in one or two weeks. I'll keep monitoring the version change. https://user-images.githubusercontent.com/9700541/213764829-44ae3b35-54e1-4420-8741-9f10e720eec0.png;> -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #39677: [SPARK-42043][CONNECT][TEST][FOLLOWUP] Better env var and a few bug fixes
dongjoon-hyun commented on code in PR #39677:
URL: https://github.com/apache/spark/pull/39677#discussion_r1082842120
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/connect/client/util/RemoteSparkSession.scala:
##
@@ -121,14 +117,14 @@ object SparkConnectServerUtils {
s"Fail to locate the spark connect server target folder:
'${parentDir.getCanonicalPath}'. " +
s"SPARK_HOME='${new File(sparkHome).getCanonicalPath}'. " +
"Make sure the spark connect server jar has been built " +
-"and the system property `SPARK_HOME` is set correctly.")
+"and the env variable `SPARK_HOME` is set correctly.")
val jars = recursiveListFiles(parentDir).filter { f =>
// SBT jar
(f.getParentFile.getName.startsWith("scala-") &&
-f.getName.startsWith("spark-connect-assembly") &&
f.getName.endsWith("SNAPSHOT.jar")) ||
+f.getName.startsWith("spark-connect-assembly") &&
f.getName.endsWith(".jar")) ||
Review Comment:
Thank you for the fix.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39677: [SPARK-42043][CONNECT][TEST][FOLLOWUP] Better env var and a few bug fixes
dongjoon-hyun commented on PR #39677: URL: https://github.com/apache/spark/pull/39677#issuecomment-1398677709 Hi, @zhenlineo . When we use the same JIRA id, we need to add `[FOLLOWUP]` in the PR title. I added at this time. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #39671: [SPARK-40303][DOCS] Deprecate old Java 8 versions prior to 8u362
dongjoon-hyun closed pull request #39671: [SPARK-40303][DOCS] Deprecate old Java 8 versions prior to 8u362 URL: https://github.com/apache/spark/pull/39671 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39671: [SPARK-40303][DOCS] Deprecate old Java 8 versions prior to 8u362
dongjoon-hyun commented on PR #39671: URL: https://github.com/apache/spark/pull/39671#issuecomment-1398671949 Now, both Zulu and Adoptiun(Temurin) are available. Thank you all. Merged to master. https://user-images.githubusercontent.com/9700541/213759635-e5163f33-ab6e-4f02-a981-d2044cd171b2.png;> -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on pull request #39190: [SPARK-41683][CORE] Fix issue of getting incorrect property numActiveStages in jobs API
srowen commented on PR #39190: URL: https://github.com/apache/spark/pull/39190#issuecomment-1398662080 FWIW, this part was last changed in https://issues.apache.org/jira/browse/SPARK-24415 to fix a different bug (CC @ankuriitg ) It might be worth re-running the simple example there to see if this retains the 'fix', but, evidently the tests added in that old change still pass here. While I'm always wary of touching this core code and I myself don't know it well, this seems fairly convincing. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sunchao commented on pull request #39633: [SPARK-42038][SQL] SPJ: Support partially clustered distribution
sunchao commented on PR #39633: URL: https://github.com/apache/spark/pull/39633#issuecomment-1398661965 @cloud-fan the idea is similar to skew join but for v2 sources, let me try to split the code into a separate rule following your idea. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhenlineo commented on pull request #39677: [SPARK-42043][CONNECT][TEST] Better env var and a few bug fixes
zhenlineo commented on PR #39677: URL: https://github.com/apache/spark/pull/39677#issuecomment-1398630857 cc @HyukjinKwon @LuciferYang Thanks for the review. I address the immediate fix in this PR. For other improvements, I've created tickets and we can add as follow ups. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhenlineo commented on a diff in pull request #39541: [SPARK-42043][CONNECT] Scala Client Result with E2E Tests
zhenlineo commented on code in PR #39541:
URL: https://github.com/apache/spark/pull/39541#discussion_r1082775554
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/connect/client/util/RemoteSparkSession.scala:
##
@@ -0,0 +1,198 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.connect.client.util
+
+import java.io.{BufferedOutputStream, File}
+
+import scala.io.Source
+
+import org.scalatest.BeforeAndAfterAll
+import sys.process._
+
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.connect.client.SparkConnectClient
+import org.apache.spark.sql.connect.common.config.ConnectCommon
+
+/**
+ * An util class to start a local spark connect server in a different process
for local E2E tests.
+ * It is designed to start the server once but shared by all tests. It is
equivalent to use the
+ * following command to start the connect server via command line:
+ *
+ * {{{
+ * bin/spark-shell \
+ * --jars `ls connector/connect/server/target/**/spark-connect*SNAPSHOT.jar |
paste -sd ',' -` \
+ * --conf spark.plugins=org.apache.spark.sql.connect.SparkConnectPlugin
+ * }}}
+ *
+ * Set system property `SPARK_HOME` if the test is not executed from the Spark
project top folder.
+ * Set system property `DEBUG_SC_JVM_CLIENT=true` to print the server process
output in the
+ * console to debug server start stop problems.
+ */
+object SparkConnectServerUtils {
+ // System properties used for testing and debugging
+ private val SPARK_HOME = "SPARK_HOME"
+ private val ENV_DEBUG_SC_JVM_CLIENT = "DEBUG_SC_JVM_CLIENT"
+
+ private val sparkHome = System.getProperty(SPARK_HOME, fileSparkHome())
+ private val isDebug = System.getProperty(ENV_DEBUG_SC_JVM_CLIENT,
"false").toBoolean
+
+ // Log server start stop debug info into console
+ // scalastyle:off println
+ private[connect] def debug(msg: String): Unit = if (isDebug) println(msg)
+ // scalastyle:on println
+ private[connect] def debug(error: Throwable): Unit = if (isDebug)
error.printStackTrace()
+
+ // Server port
+ private[connect] val port = ConnectCommon.CONNECT_GRPC_BINDING_PORT +
util.Random.nextInt(1000)
+
+ @volatile private var stopped = false
+
+ private lazy val sparkConnect: Process = {
+debug("Starting the Spark Connect Server...")
+val jar = findSparkConnectJar
+val builder = Process(
+ new File(sparkHome, "bin/spark-shell").getCanonicalPath,
+ Seq(
+"--jars",
+jar,
+"--driver-class-path",
+jar,
+"--conf",
+"spark.plugins=org.apache.spark.sql.connect.SparkConnectPlugin",
+"--conf",
+s"spark.connect.grpc.binding.port=$port"))
+
+val io = new ProcessIO(
+ // Hold the input channel to the spark console to keep the console open
+ in => new BufferedOutputStream(in),
+ // Only redirect output if debug to avoid channel interruption error on
process termination.
+ out => if (isDebug) Source.fromInputStream(out).getLines.foreach(debug),
+ err => if (isDebug) Source.fromInputStream(err).getLines.foreach(debug))
+val process = builder.run(io)
+
+// Adding JVM shutdown hook
+sys.addShutdownHook(kill())
+process
+ }
+
+ def start(): Unit = {
+assert(!stopped)
+sparkConnect
Review Comment:
I tried to stop the server properly by sending `:quit` to the shell process,
but it works 20% of the runs. As it is too unreliable I has to use the kill. Do
you know some better way to stop the shell properly? Thanks a lot.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhenlineo commented on a diff in pull request #39541: [SPARK-42043][CONNECT] Scala Client Result with E2E Tests
zhenlineo commented on code in PR #39541:
URL: https://github.com/apache/spark/pull/39541#discussion_r1082771233
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/connect/client/util/RemoteSparkSession.scala:
##
@@ -0,0 +1,198 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.connect.client.util
+
+import java.io.{BufferedOutputStream, File}
+
+import scala.io.Source
+
+import org.scalatest.BeforeAndAfterAll
+import sys.process._
+
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.connect.client.SparkConnectClient
+import org.apache.spark.sql.connect.common.config.ConnectCommon
+
+/**
+ * An util class to start a local spark connect server in a different process
for local E2E tests.
+ * It is designed to start the server once but shared by all tests. It is
equivalent to use the
+ * following command to start the connect server via command line:
+ *
+ * {{{
+ * bin/spark-shell \
+ * --jars `ls connector/connect/server/target/**/spark-connect*SNAPSHOT.jar |
paste -sd ',' -` \
+ * --conf spark.plugins=org.apache.spark.sql.connect.SparkConnectPlugin
+ * }}}
+ *
+ * Set system property `SPARK_HOME` if the test is not executed from the Spark
project top folder.
+ * Set system property `DEBUG_SC_JVM_CLIENT=true` to print the server process
output in the
+ * console to debug server start stop problems.
+ */
+object SparkConnectServerUtils {
+ // System properties used for testing and debugging
+ private val SPARK_HOME = "SPARK_HOME"
+ private val ENV_DEBUG_SC_JVM_CLIENT = "DEBUG_SC_JVM_CLIENT"
+
+ private val sparkHome = System.getProperty(SPARK_HOME, fileSparkHome())
+ private val isDebug = System.getProperty(ENV_DEBUG_SC_JVM_CLIENT,
"false").toBoolean
+
+ // Log server start stop debug info into console
+ // scalastyle:off println
+ private[connect] def debug(msg: String): Unit = if (isDebug) println(msg)
Review Comment:
In normal runs, we shall not print anything out. The prints are merely added
for me to quick debugging any server start errors when setting up the tests.
The Scala client needs a new logging system, which we will add in a
follow-up PR. Let me know if it is a recommendation to use log4j for all test
outputs. Then I will migrate these tests together.
https://issues.apache.org/jira/browse/SPARK-42135
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] peter-toth commented on pull request #38038: [SPARK-42136] Refactor BroadcastHashJoinExec output partitioning calculation
peter-toth commented on PR #38038: URL: https://github.com/apache/spark/pull/38038#issuecomment-1398625037 cc @cloud-fan -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhenlineo commented on a diff in pull request #39541: [SPARK-42043][CONNECT] Scala Client Result with E2E Tests
zhenlineo commented on code in PR #39541:
URL: https://github.com/apache/spark/pull/39541#discussion_r1082763118
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/connect/client/util/RemoteSparkSession.scala:
##
@@ -0,0 +1,198 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.connect.client.util
+
+import java.io.{BufferedOutputStream, File}
+
+import scala.io.Source
+
+import org.scalatest.BeforeAndAfterAll
+import sys.process._
+
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.connect.client.SparkConnectClient
+import org.apache.spark.sql.connect.common.config.ConnectCommon
+
+/**
+ * An util class to start a local spark connect server in a different process
for local E2E tests.
+ * It is designed to start the server once but shared by all tests. It is
equivalent to use the
+ * following command to start the connect server via command line:
+ *
+ * {{{
+ * bin/spark-shell \
+ * --jars `ls connector/connect/server/target/**/spark-connect*SNAPSHOT.jar |
paste -sd ',' -` \
+ * --conf spark.plugins=org.apache.spark.sql.connect.SparkConnectPlugin
+ * }}}
+ *
+ * Set system property `SPARK_HOME` if the test is not executed from the Spark
project top folder.
+ * Set system property `DEBUG_SC_JVM_CLIENT=true` to print the server process
output in the
+ * console to debug server start stop problems.
+ */
+object SparkConnectServerUtils {
+ // System properties used for testing and debugging
+ private val SPARK_HOME = "SPARK_HOME"
+ private val ENV_DEBUG_SC_JVM_CLIENT = "DEBUG_SC_JVM_CLIENT"
+
+ private val sparkHome = System.getProperty(SPARK_HOME, fileSparkHome())
Review Comment:
Oh, thanks so much. I cannot depends on code in catalyst plan. But the code
was really helpful so I copied the code to use here.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhenlineo opened a new pull request, #39677: [SPARK-42043][CONNECT][TEST] Better env var and a few bug fixes
zhenlineo opened a new pull request, #39677: URL: https://github.com/apache/spark/pull/39677 ### What changes were proposed in this pull request? Use a better env var to find the spark home in E2E tests. Fixed the jar finding bug for RC builds. Use Nano instead of MS for elapsed time measurement. ### Why are the changes needed? Bug fix and improvements. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Existing tests. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] itholic commented on pull request #39505: [SPARK-41979][SQL] Add missing dots for error messages in error classes.
itholic commented on PR #39505: URL: https://github.com/apache/spark/pull/39505#issuecomment-1398592475 Test paseed. cc @MaxGekk @cloud-fan -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] kuwii commented on pull request #39190: [SPARK-41683][CORE] Fix issue of getting incorrect property numActiveStages in jobs API
kuwii commented on PR #39190:
URL: https://github.com/apache/spark/pull/39190#issuecomment-1398579998
I'm not familiar with how Spark creates and runs jobs and stages for a
query, but I think it may be related to this case. I can reproduce this locally
using Spark on Yarn mode with this code:
```python
from pyspark import SparkConf, SparkContext
from pyspark.sql import SQLContext
from pyspark.sql.functions import countDistinct, col, count, when
import time
conf = SparkConf().setAppName('test')
sc = SparkContext(conf = conf)
spark = SQLContext(sc).sparkSession
spark.range(1, 100).count()
```
The execution for `count` creates 2 jobs: job 0 with stage 0 and job 1 with
stage 1, 2.
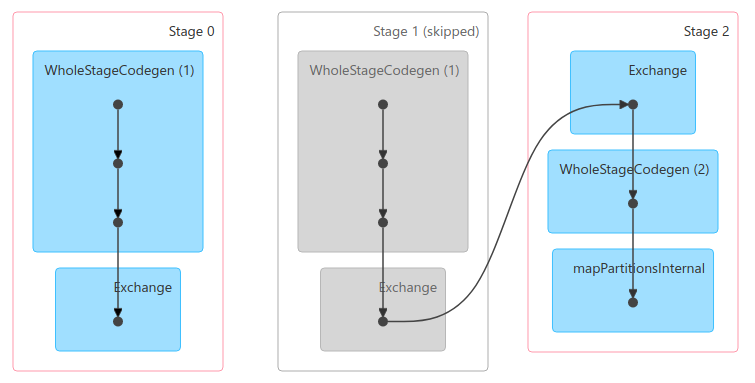
Because of some logic, stage 1 will always be skipped, not even submitted.
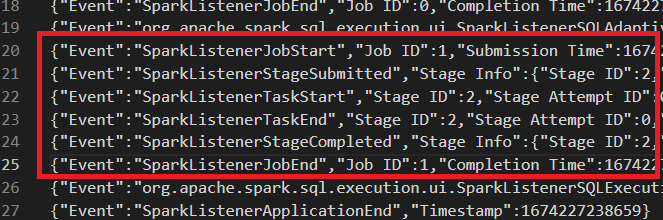
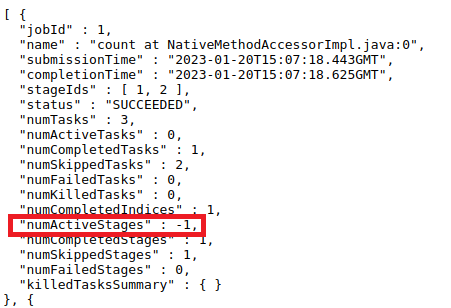
This is the case that is mentioned in the PR's description. And because the
incorrect logic of updating `numActiveStages`, it will be `-1` in jobs API.
This PR can fix it.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhenlineo commented on a diff in pull request #39541: [SPARK-42043][CONNECT] Scala Client Result with E2E Tests
zhenlineo commented on code in PR #39541:
URL: https://github.com/apache/spark/pull/39541#discussion_r1082698957
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/connect/client/SparkConnectClientSuite.scala:
##
@@ -78,7 +78,7 @@ class SparkConnectClientSuite
}
test("Test connection") {
-val testPort = 16000
+val testPort = 16001
Review Comment:
Two tests uses 16000 and cause some flakiness when running in parallel.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhenlineo commented on a diff in pull request #39541: [SPARK-42043][CONNECT] Scala Client Result with E2E Tests
zhenlineo commented on code in PR #39541:
URL: https://github.com/apache/spark/pull/39541#discussion_r1082698009
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/connect/client/util/Cleaner.scala:
##
@@ -0,0 +1,113 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.connect.client.util
+
+import java.lang.ref.{ReferenceQueue, WeakReference}
+import java.util.Collections
+import java.util.concurrent.ConcurrentHashMap
+
+import scala.collection.mutable
+import scala.util.control.NonFatal
+
+/**
+ * Helper class for cleaning up an object's resources after the object itself
has been garbage
+ * collected.
+ *
+ * When we move to Java 9+ we should replace this class by
[[java.lang.ref.Cleaner]].
+ */
+private[sql] class Cleaner {
+ class Ref(pin: AnyRef, val resource: AutoCloseable)
+ extends WeakReference[AnyRef](pin, referenceQueue)
+ with AutoCloseable {
+override def close(): Unit = resource.close()
+ }
+
+ def register(pin: Cleanable): Unit = {
+register(pin, pin.cleaner)
+ }
+
+ /**
+ * Register an objects' resources for clean-up. Note that it is absolutely
pivotal that resource
+ * itself does not contain any reference to the object, if it does the
object will never be
+ * garbage collected and the clean-up will never be performed.
+ *
+ * @param pin
+ * who's resources need to be cleaned up after GC.
+ * @param resource
+ * to clean-up.
+ */
+ def register(pin: AnyRef, resource: AutoCloseable): Unit = {
+referenceBuffer.add(new Ref(pin, resource))
+ }
+
+ @volatile private var stopped = false
+ private val referenceBuffer = Collections.newSetFromMap[Ref](new
ConcurrentHashMap)
+ private val referenceQueue = new ReferenceQueue[AnyRef]
+
+ private val cleanerThread = {
+val thread = new Thread(() => cleanUp())
+thread.setName("cleaner")
+thread.setDaemon(true)
+thread
+ }
+
+ def start(): Unit = {
+require(!stopped)
+cleanerThread.start()
+ }
+
+ def stop(): Unit = {
+stopped = true
+cleanerThread.interrupt()
+ }
+
+ private def cleanUp(): Unit = {
+while (!stopped) {
+ try {
+val ref = referenceQueue.remove().asInstanceOf[Ref]
+referenceBuffer.remove(ref)
+ref.close()
+ } catch {
+case NonFatal(e) =>
+ // Perhaps log this?
+ e.printStackTrace()
Review Comment:
https://issues.apache.org/jira/browse/SPARK-42135
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on a diff in pull request #39660: [SPARK-42128][SQL] Support TOP (N) for MS SQL Server dialect as an alternative to Limit pushdown
srowen commented on code in PR #39660: URL: https://github.com/apache/spark/pull/39660#discussion_r1082695284 ## sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/jdbc/JDBCRDD.scala: ## @@ -307,11 +307,12 @@ private[jdbc] class JDBCRDD( "" } +val myTopExpression: String = dialect.getTopExpression(limit) // SQL Server Limit alternative Review Comment: Yeah, feels like this belongs all in the MySQL dialect, one way or the other. Is it not just an alternative LIMIT clause? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] tgravescs commented on a diff in pull request #39674: [DON'T MERGE] Test remove SPARK_USE_CONC_INCR_GC
tgravescs commented on code in PR #39674:
URL: https://github.com/apache/spark/pull/39674#discussion_r1082615175
##
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala:
##
@@ -1005,26 +1005,6 @@ private[spark] class Client(
val tmpDir = new Path(Environment.PWD.$$(),
YarnConfiguration.DEFAULT_CONTAINER_TEMP_DIR)
javaOpts += "-Djava.io.tmpdir=" + tmpDir
-// TODO: Remove once cpuset version is pushed out.
-// The context is, default gc for server class machines ends up using all
cores to do gc -
-// hence if there are multiple containers in same node, Spark GC affects
all other containers'
-// performance (which can be that of other Spark containers)
-// Instead of using this, rely on cpusets by YARN to enforce "proper"
Spark behavior in
-// multi-tenant environments. Not sure how default Java GC behaves if it
is limited to subset
-// of cores on a node.
-val useConcurrentAndIncrementalGC =
launchEnv.get("SPARK_USE_CONC_INCR_GC").exists(_.toBoolean)
Review Comment:
yeah this is pretty old, not sure if anyone is using it anymore. Personally
think its ok to remove since users can set themselves.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] grundprinzip commented on a diff in pull request #39585: [SPARK-42124][PYTHON][CONNECT] Scalar Inline Python UDF in Spark Connect
grundprinzip commented on code in PR #39585:
URL: https://github.com/apache/spark/pull/39585#discussion_r1082600958
##
connector/connect/common/src/main/protobuf/spark/connect/expressions.proto:
##
@@ -217,6 +218,28 @@ message Expression {
bool is_user_defined_function = 4;
}
+ message ScalarInlineUserDefinedFunction {
Review Comment:
I had a discussion with @hvanhovell and we agreed that the message type
should be moved out of the expression message because we want to use the same
message at the end of the day for registered and inline function.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] ggershinsky commented on pull request #39665: [SPARK-42114][SQL][TESTS] Add uniform parquet encryption test case
ggershinsky commented on PR #39665: URL: https://github.com/apache/spark/pull/39665#issuecomment-1398455770 Thanks Dongjoon. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] peter-toth commented on pull request #39676: [SPARK-42134][SQL] Fix getPartitionFiltersAndDataFilters() to handle filters without referenced attributes
peter-toth commented on PR #39676: URL: https://github.com/apache/spark/pull/39676#issuecomment-1398437534 cc @cloud-fan, @huaxingao -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] peter-toth opened a new pull request, #39676: [SPARK-42134][SQL] Fix getPartitionFiltersAndDataFilters() to handle filters without referenced attributes
peter-toth opened a new pull request, #39676:
URL: https://github.com/apache/spark/pull/39676
### What changes were proposed in this pull request?
This is a small correctness fix to
`DataSourceUtils.getPartitionFiltersAndDataFilters()` to handle filters without
any referenced attributes correctly. E.g. without the fix the following query
on ParquetV2 source:
```
spark.conf.set("spark.sql.sources.useV1SourceList", "")
spark.range(1).write.mode("overwrite").format("parquet").save(path)
df = spark.read.parquet(path).toDF("i")
f = udf(lambda x: False, "boolean")(lit(1))
val r = df.filter(f)
r.show()
```
returns
```
+---+
| i|
+---+
| 0|
+---+
```
but it should return with empty results.
The root cause of the issue is that during `V2ScanRelationPushDown` a filter
that doesn't reference any column incorrectly identified as partition filter.
### Why are the changes needed?
To fix a correctness issue.
### Does this PR introduce _any_ user-facing change?
Yes, fixes a correctness issue.
### How was this patch tested?
Added new UT.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] srowen commented on pull request #39190: [SPARK-41683][CORE] Fix issue of getting incorrect property numActiveStages in jobs API
srowen commented on PR #39190: URL: https://github.com/apache/spark/pull/39190#issuecomment-1398393768 Yeah but do you know how it happens, or have a theory? Just want to see if the change seems to match with some theory of how it arises. Or does this change definitely change the output above? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #39671: [SPARK-40303][DOCS] Deprecate old Java 8 versions prior to 8u362
LuciferYang commented on PR #39671: URL: https://github.com/apache/spark/pull/39671#issuecomment-1398388671 Ok, plenty of time. I am fine to make this change -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #39675: [MINOR][DOCS] Update the doc of arrow & kubernetes
dongjoon-hyun commented on code in PR #39675: URL: https://github.com/apache/spark/pull/39675#discussion_r1082534577 ## docs/running-on-kubernetes.md: ## @@ -34,13 +34,13 @@ Please see [Spark Security](security.html) and the specific security sections in Images built from the project provided Dockerfiles contain a default [`USER`](https://docs.docker.com/engine/reference/builder/#user) directive with a default UID of `185`. This means that the resulting images will be running the Spark processes as this UID inside the container. Security conscious deployments should consider providing custom images with `USER` directives specifying their desired unprivileged UID and GID. The resulting UID should include the root group in its supplementary groups in order to be able to run the Spark executables. Users building their own images with the provided `docker-image-tool.sh` script can use the `-u ` option to specify the desired UID. -Alternatively the [Pod Template](#pod-template) feature can be used to add a [Security Context](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/#volumes-and-file-systems) with a `runAsUser` to the pods that Spark submits. This can be used to override the `USER` directives in the images themselves. Please bear in mind that this requires cooperation from your users and as such may not be a suitable solution for shared environments. Cluster administrators should use [Pod Security Policies](https://kubernetes.io/docs/concepts/policy/pod-security-policy/#users-and-groups) if they wish to limit the users that pods may run as. +Alternatively the [Pod Template](#pod-template) feature can be used to add a [Security Context](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/#volumes-and-file-systems) with a `runAsUser` to the pods that Spark submits. This can be used to override the `USER` directives in the images themselves. Please bear in mind that this requires cooperation from your users and as such may not be a suitable solution for shared environments. Cluster administrators should use [Pod Security Admission](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/#set-the-security-context-for-a-pod) if they wish to limit the users that pods may run as. ## Volume Mounts As described later in this document under [Using Kubernetes Volumes](#using-kubernetes-volumes) Spark on K8S provides configuration options that allow for mounting certain volume types into the driver and executor pods. In particular it allows for [`hostPath`](https://kubernetes.io/docs/concepts/storage/volumes/#hostpath) volumes which as described in the Kubernetes documentation have known security vulnerabilities. -Cluster administrators should use [Pod Security Policies](https://kubernetes.io/docs/concepts/policy/pod-security-policy/) to limit the ability to mount `hostPath` volumes appropriately for their environments. +Cluster administrators should use [Pod Security Admission](https://kubernetes.io/docs/concepts/security/pod-security-admission/) to limit the ability to mount `hostPath` volumes appropriately for their environments. Review Comment: Ditto. `Pod Security Admission` is still beta in v1.23 and 1.24. I'd not put the beta into the recommendation. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #39674: [DON'T MERGE] Test remove SPARK_USE_CONC_INCR_GC
LuciferYang commented on code in PR #39674:
URL: https://github.com/apache/spark/pull/39674#discussion_r1082533145
##
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala:
##
@@ -1005,26 +1005,6 @@ private[spark] class Client(
val tmpDir = new Path(Environment.PWD.$$(),
YarnConfiguration.DEFAULT_CONTAINER_TEMP_DIR)
javaOpts += "-Djava.io.tmpdir=" + tmpDir
-// TODO: Remove once cpuset version is pushed out.
-// The context is, default gc for server class machines ends up using all
cores to do gc -
-// hence if there are multiple containers in same node, Spark GC affects
all other containers'
-// performance (which can be that of other Spark containers)
-// Instead of using this, rely on cpusets by YARN to enforce "proper"
Spark behavior in
-// multi-tenant environments. Not sure how default Java GC behaves if it
is limited to subset
-// of cores on a node.
-val useConcurrentAndIncrementalGC =
launchEnv.get("SPARK_USE_CONC_INCR_GC").exists(_.toBoolean)
Review Comment:
Thanks @dongjoon-hyun
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #39675: [MINOR][DOCS] Update the doc of arrow & kubernetes
dongjoon-hyun commented on code in PR #39675: URL: https://github.com/apache/spark/pull/39675#discussion_r1082532817 ## docs/running-on-kubernetes.md: ## @@ -34,13 +34,13 @@ Please see [Spark Security](security.html) and the specific security sections in Images built from the project provided Dockerfiles contain a default [`USER`](https://docs.docker.com/engine/reference/builder/#user) directive with a default UID of `185`. This means that the resulting images will be running the Spark processes as this UID inside the container. Security conscious deployments should consider providing custom images with `USER` directives specifying their desired unprivileged UID and GID. The resulting UID should include the root group in its supplementary groups in order to be able to run the Spark executables. Users building their own images with the provided `docker-image-tool.sh` script can use the `-u ` option to specify the desired UID. -Alternatively the [Pod Template](#pod-template) feature can be used to add a [Security Context](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/#volumes-and-file-systems) with a `runAsUser` to the pods that Spark submits. This can be used to override the `USER` directives in the images themselves. Please bear in mind that this requires cooperation from your users and as such may not be a suitable solution for shared environments. Cluster administrators should use [Pod Security Policies](https://kubernetes.io/docs/concepts/policy/pod-security-policy/#users-and-groups) if they wish to limit the users that pods may run as. +Alternatively the [Pod Template](#pod-template) feature can be used to add a [Security Context](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/#volumes-and-file-systems) with a `runAsUser` to the pods that Spark submits. This can be used to override the `USER` directives in the images themselves. Please bear in mind that this requires cooperation from your users and as such may not be a suitable solution for shared environments. Cluster administrators should use [Pod Security Admission](https://kubernetes.io/docs/tasks/configure-pod-container/security-context/#set-the-security-context-for-a-pod) if they wish to limit the users that pods may run as. Review Comment: I'm not sure about this part because K8s 1.25 is not available in EKS environment yet. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #39675: [MINOR][DOCS] Update the doc of arrow & kubernetes
dongjoon-hyun commented on code in PR #39675: URL: https://github.com/apache/spark/pull/39675#discussion_r1082529696 ## docs/index.md: ## @@ -45,7 +45,6 @@ Java 8 prior to version 8u201 support is deprecated as of Spark 3.2.0. When using the Scala API, it is necessary for applications to use the same version of Scala that Spark was compiled for. For example, when using Scala 2.13, use Spark compiled for 2.13, and compile code/applications for Scala 2.13 as well. -For Python 3.9, Arrow optimization and pandas UDFs might not work due to the supported Python versions in Apache Arrow. Please refer to the latest [Python Compatibility](https://arrow.apache.org/docs/python/install.html#python-compatibility) page. Review Comment: +1 for the removal. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #39674: [DON'T MERGE] Test remove SPARK_USE_CONC_INCR_GC
dongjoon-hyun commented on code in PR #39674:
URL: https://github.com/apache/spark/pull/39674#discussion_r1082528460
##
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala:
##
@@ -1005,26 +1005,6 @@ private[spark] class Client(
val tmpDir = new Path(Environment.PWD.$$(),
YarnConfiguration.DEFAULT_CONTAINER_TEMP_DIR)
javaOpts += "-Djava.io.tmpdir=" + tmpDir
-// TODO: Remove once cpuset version is pushed out.
-// The context is, default gc for server class machines ends up using all
cores to do gc -
-// hence if there are multiple containers in same node, Spark GC affects
all other containers'
-// performance (which can be that of other Spark containers)
-// Instead of using this, rely on cpusets by YARN to enforce "proper"
Spark behavior in
-// multi-tenant environments. Not sure how default Java GC behaves if it
is limited to subset
-// of cores on a node.
-val useConcurrentAndIncrementalGC =
launchEnv.get("SPARK_USE_CONC_INCR_GC").exists(_.toBoolean)
Review Comment:
For the YARN code, @mridulm and @tgravescs knows better~
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39671: [SPARK-40303][DOCS] Deprecate old Java 8 versions prior to 8u362
dongjoon-hyun commented on PR #39671: URL: https://github.com/apache/spark/pull/39671#issuecomment-1398367056 BTW, we didn't cut the branch yet and we still have one month for Apache Spark 3.4.0 release. I'm considering that time period for this decision, @LuciferYang . You are also correct and being conservative is better if we don't have a room like that. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39671: [SPARK-40303][DOCS] Deprecate old Java 8 versions prior to 8u362
dongjoon-hyun commented on PR #39671: URL: https://github.com/apache/spark/pull/39671#issuecomment-1398362594 Timezone issues are inevitably which we need to adjust the code in a regular basis, @LuciferYang . -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #39671: [SPARK-40303][DOCS] Deprecate old Java 8 versions prior to 8u362
LuciferYang commented on PR #39671: URL: https://github.com/apache/spark/pull/39671#issuecomment-1398356049 @dongjoon-hyun Hmm...do you remember SPARK-40846? When we upgrade from 8u345 to 8u352 for GA testing, there are some time zone issue that need to be solved by changing the code, so I am not sure whether it is the right time to directly recommend a Java version without GA verification in the document. But maybe I'm too conservative. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #39663: [SPARK-42129][BUILD] Upgrade rocksdbjni to 7.9.2
LuciferYang commented on PR #39663: URL: https://github.com/apache/spark/pull/39663#issuecomment-1398346083 Thanks @dongjoon-hyun -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #39674: [DON'T MERGE] Test remove SPARK_USE_CONC_INCR_GC
LuciferYang commented on code in PR #39674:
URL: https://github.com/apache/spark/pull/39674#discussion_r1082496069
##
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala:
##
@@ -1005,26 +1005,6 @@ private[spark] class Client(
val tmpDir = new Path(Environment.PWD.$$(),
YarnConfiguration.DEFAULT_CONTAINER_TEMP_DIR)
javaOpts += "-Djava.io.tmpdir=" + tmpDir
-// TODO: Remove once cpuset version is pushed out.
-// The context is, default gc for server class machines ends up using all
cores to do gc -
-// hence if there are multiple containers in same node, Spark GC affects
all other containers'
-// performance (which can be that of other Spark containers)
-// Instead of using this, rely on cpusets by YARN to enforce "proper"
Spark behavior in
-// multi-tenant environments. Not sure how default Java GC behaves if it
is limited to subset
-// of cores on a node.
-val useConcurrentAndIncrementalGC =
launchEnv.get("SPARK_USE_CONC_INCR_GC").exists(_.toBoolean)
Review Comment:
Java 14 starts to remove support for
CMS([JEP-363](https://openjdk.org/jeps/363)). So when we use Java 17 to run
Spark and set `SPARK_USE_CONC_INCR_GC=true`, CMS will not take effect (No error
will be reported due to `-XX:+IgnoreUnrecognizedVMOptions` is configured by
default).
It seems that `SPARK_USE_CONC_INCR_GC` is only use by Yarn AppMaster. We can
also achieve the same goal by directly configuring
`spark.driver.extraJavaOptions(cluster mode)` or
`spark.yarn.am.extraJavaOptions(client mode)`. At the same time, I found that
`SPARK_USE_CONC_INCR_GC` is not exposed to users in any user documents, so I
think we might be able to clean up this env.
But because I lack some context for this env, so I wonder if we can remove
it? @srowen @dongjoon-hyun @HyukjinKwon
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #39674: [DON'T MERGE] Test remove SPARK_USE_CONC_INCR_GC
LuciferYang commented on code in PR #39674:
URL: https://github.com/apache/spark/pull/39674#discussion_r1082496069
##
resource-managers/yarn/src/main/scala/org/apache/spark/deploy/yarn/Client.scala:
##
@@ -1005,26 +1005,6 @@ private[spark] class Client(
val tmpDir = new Path(Environment.PWD.$$(),
YarnConfiguration.DEFAULT_CONTAINER_TEMP_DIR)
javaOpts += "-Djava.io.tmpdir=" + tmpDir
-// TODO: Remove once cpuset version is pushed out.
-// The context is, default gc for server class machines ends up using all
cores to do gc -
-// hence if there are multiple containers in same node, Spark GC affects
all other containers'
-// performance (which can be that of other Spark containers)
-// Instead of using this, rely on cpusets by YARN to enforce "proper"
Spark behavior in
-// multi-tenant environments. Not sure how default Java GC behaves if it
is limited to subset
-// of cores on a node.
-val useConcurrentAndIncrementalGC =
launchEnv.get("SPARK_USE_CONC_INCR_GC").exists(_.toBoolean)
Review Comment:
Java 14 starts to remove support for
CMS([JEP-363](https://openjdk.org/jeps/363)). So when we use Java 17 to run
Spark and set `SPARK_USE_CONC_INCR_GC=true`, CMS will not take effect (No error
will be reported due to `-XX:+IgnoreUnrecognizedVMOptions` is configured by
default).
It seems that `SPARK_USE_CONC_INCR_GC` is only use by Yarn AppMaster. We can
also achieve the same goal by directly configuring
`spark.driver.extraJavaOptions(cluster mode)` or
`spark.yarn.am.extraJavaOptions(client mode)`. At the same time, I found that
`SPARK_USE_CONC_INCR_GC` is not exposed to users in any user documents, so I
think we can clean up this environment variable.
But because I lack some context for this env, so I wonder if we can remove
it? @srowen @dongjoon-hyun @HyukjinKwon
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] panbingkun opened a new pull request, #39675: [MINOR][DOCS] Update the doc of arrow & kubernetes
panbingkun opened a new pull request, #39675: URL: https://github.com/apache/spark/pull/39675 ### What changes were proposed in this pull request? The pr aims to update the doc of arrow & kubernetes. ### Why are the changes needed? 1.https://arrow.apache.org/docs/python/install.html#python-compatibility https://user-images.githubusercontent.com/15246973/213697081-18ee63f7-9db6-4ba7-9351-213d40ddf980.png;> 2. https://user-images.githubusercontent.com/15246973/213697245-cee6b6c8-9d0f-4253-8954-775227df8991.png;> ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Manual test. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang opened a new pull request, #39674: [DON'T MERGE] Test remove SPARK_USE_CONC_INCR_GC
LuciferYang opened a new pull request, #39674: URL: https://github.com/apache/spark/pull/39674 ### What changes were proposed in this pull request? ### Why are the changes needed? ### Does this PR introduce _any_ user-facing change? ### How was this patch tested? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #39663: [SPARK-42129][BUILD] Upgrade rocksdbjni to 7.9.2
dongjoon-hyun closed pull request #39663: [SPARK-42129][BUILD] Upgrade rocksdbjni to 7.9.2 URL: https://github.com/apache/spark/pull/39663 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39671: [SPARK-40303][DOCS] Deprecate old Java 8 versions prior to 8u362
dongjoon-hyun commented on PR #39671: URL: https://github.com/apache/spark/pull/39671#issuecomment-1398319998 To @LuciferYang , I don't think this is a compatibility or any failure. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39541: [SPARK-42043][CONNECT] Scala Client Result with E2E Tests
dongjoon-hyun commented on PR #39541: URL: https://github.com/apache/spark/pull/39541#issuecomment-1398317390 As @HyukjinKwon pointed out, this causes a failure for RC and official release. - https://github.com/apache/spark/pull/39668#issuecomment-1398314758  Please fix it ASAP, @zhenlineo . -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #39671: [SPARK-40303][DOCS] Deprecate old Java 8 versions prior to 8u362
LuciferYang commented on PR #39671: URL: https://github.com/apache/spark/pull/39671#issuecomment-1398316727 Could you use 8u362 to run full UTs offline to check compatibility? Thanks ~ @wangyum -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39668: [WIP] Test 3.4.0 tagging
dongjoon-hyun commented on PR #39668: URL: https://github.com/apache/spark/pull/39668#issuecomment-1398314758 It seems that we have only one failure.  -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #39671: [SPARK-40303][DOCS] Deprecate old Java 8 versions prior to 8u362
LuciferYang commented on PR #39671: URL: https://github.com/apache/spark/pull/39671#issuecomment-1398314217 One problem is that GA is still using Temurin 8u352 for build and test. We need to wait for a while before running GA tasks using 8u362. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] WeichenXu123 commented on a diff in pull request #39369: [SPARK-41775][PYTHON][ML] Adding support for PyForch functions
WeichenXu123 commented on code in PR #39369:
URL: https://github.com/apache/spark/pull/39369#discussion_r1082450887
##
python/pyspark/ml/torch/tests/test_distributor.py:
##
@@ -224,8 +293,10 @@ def setUp(self) -> None:
self.sc = SparkContext("local-cluster[2,2,1024]", class_name,
conf=conf)
self.spark = SparkSession(self.sc)
+self.mnist_dir_path = tempfile.mkdtemp()
def tearDown(self) -> None:
+shutil.rmtree(self.mnist_dir_path)
os.unlink(self.tempFile.name)
Review Comment:
Nit: refine the variable name: `tempFile` --> `gpu_discovery_script_file`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wecharyu commented on pull request #39115: [SPARK-41563][SQL] Support partition filter in MSCK REPAIR TABLE statement
wecharyu commented on PR #39115: URL: https://github.com/apache/spark/pull/39115#issuecomment-1398308497 > Can you tune the config spark.sql.addPartitionInBatch.size? Setting it to a larger number can reduce the number of RPCs. It does not help in `RepairTableCommand`, when enable dropping partitions the driver will first request all partitions: https://github.com/apache/spark/blob/e1c630a98c45ae07c43c8cf95979532b51bf59ec/sql/core/src/main/scala/org/apache/spark/sql/execution/command/ddl.scala#L854-L856 > if you know exactly which partition(s) to add/drop, why not use the ALTER TABLE ... ADD/DROP PARTITION command? `ADD/DROP PARTITION` needs to specify the full partition name for each partition, it will be more convenient if we can specify partial partition values in `MSCK REPAIR TABLE`. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] WeichenXu123 commented on a diff in pull request #39369: [SPARK-41775][PYTHON][ML] Adding support for PyForch functions
WeichenXu123 commented on code in PR #39369:
URL: https://github.com/apache/spark/pull/39369#discussion_r1082443370
##
python/pyspark/ml/torch/distributor.py:
##
@@ -495,32 +546,119 @@ def set_gpus(context: "BarrierTaskContext") -> None:
def _run_distributed_training(
self,
-framework_wrapper_fn: Optional[Callable],
+framework_wrapper_fn: Callable,
train_object: Union[Callable, str],
*args: Any,
) -> Optional[Any]:
if not framework_wrapper_fn:
raise RuntimeError("Unknown combination of parameters")
+
+log_streaming_server = LogStreamingServer()
+self.driver_address = get_driver_host(self.sc)
+log_streaming_server.start()
+time.sleep(1) # wait for the server to start
+self.log_streaming_server_port = log_streaming_server.port
+
spark_task_function = self._get_spark_task_function(
framework_wrapper_fn, train_object, *args
)
self._check_encryption()
-result = (
-self.sc.parallelize(range(self.num_tasks), self.num_tasks)
-.barrier()
-.mapPartitions(spark_task_function)
-.collect()[0]
+self.logger.info(
+f"Started distributed training with {self.num_processes} executor
proceses"
+)
+try:
+result = (
+self.sc.parallelize(range(self.num_tasks), self.num_tasks)
+.barrier()
+.mapPartitions(spark_task_function)
+.collect()[0]
+)
+finally:
+log_streaming_server.shutdown()
+self.logger.info(
+f"Finished distributed training with {self.num_processes} executor
proceses"
)
return result
@staticmethod
def _run_training_on_pytorch_file(
input_params: Dict[str, Any], train_path: str, *args: Any
) -> None:
+log_streaming_client = input_params.get("log_streaming_client", None)
training_command = TorchDistributor._create_torchrun_command(
input_params, train_path, *args
)
-TorchDistributor._execute_command(training_command)
+TorchDistributor._execute_command(
+training_command, log_streaming_client=log_streaming_client
+)
+
+@contextmanager
+@staticmethod
+def _setup_files(train_fn: Callable, *args: Any) -> Tuple[str, str]:
+save_dir = TorchDistributor._create_save_dir()
+pickle_file_path = TorchDistributor._save_pickled_function(save_dir,
train_fn, *args)
+output_file_path = os.path.join(save_dir,
TorchDistributor.PICKLED_OUTPUT_FILE)
+train_file_path = TorchDistributor._create_torchrun_train_file(
+save_dir, pickle_file_path, output_file_path
+)
+try:
+yield (train_file_path, output_file_path)
+finally:
+TorchDistributor._cleanup_files(save_dir)
+
+@staticmethod
+def _run_training_on_pytorch_function(
+input_params: dict[str, Any], train_fn: Callable, *args: Any # TODO:
change dict to Dict
+) -> Any:
+with TorchDistributor._setup_files(train_fn, *args) as
(train_file_path, output_file_path):
+args = [] # type: ignore
+TorchDistributor._run_training_on_pytorch_file(input_params,
train_file_path, *args)
+output = TorchDistributor._get_pickled_output(output_file_path)
+return output
+
+@staticmethod
+def _create_save_dir() -> str:
+# TODO: need to do this in a safe way to avoid issues during
concurrent runs
+return tempfile.mkdtemp()
+
+@staticmethod
+def _cleanup_files(save_dir: str) -> None:
+shutil.rmtree(save_dir)
Review Comment:
pls add argument `ignore_errors=True`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] WeichenXu123 commented on a diff in pull request #39299: [WIP][SPARK-41593][PYTHON][ML] Adding logging from executors
WeichenXu123 commented on code in PR #39299:
URL: https://github.com/apache/spark/pull/39299#discussion_r1082428873
##
python/pyspark/ml/torch/log_communication.py:
##
@@ -0,0 +1,201 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+#http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+# type: ignore
+
+from contextlib import closing
+import time
+import socket
+import socketserver
+from struct import pack, unpack
+import sys
+import threading
+import traceback
+from typing import Optional, Generator
+import warnings
+from pyspark.context import SparkContext
+
+# Use b'\x00' as separator instead of b'\n', because the bytes are encoded in
utf-8
+_SERVER_POLL_INTERVAL = 0.1
+_TRUNCATE_MSG_LEN = 4000
+
+
+def get_driver_host(sc: SparkContext) -> Optional[str]:
+return sc.getConf().get("spark.driver.host")
+
+
+_log_print_lock = threading.Lock() # pylint: disable=invalid-name
+
+
+def _get_log_print_lock() -> threading.Lock:
+return _log_print_lock
+
+
+class WriteLogToStdout(socketserver.StreamRequestHandler):
+def _read_bline(self) -> Generator[bytes, None, None]:
+while self.server.is_active:
+packed_number_bytes = self.rfile.read1(4)
Review Comment:
We should use `rfile.read` instead of `rfile.read1`
`rfile.read(nbytes)` runs in blocking mode and ensures nbytes data are read
unless it reads until EOF.
But `rfile.read1` runs in non-blocking mode and might return any number
bytes result.
##
python/pyspark/ml/torch/log_communication.py:
##
@@ -0,0 +1,201 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+#http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+# type: ignore
+
+from contextlib import closing
+import time
+import socket
+import socketserver
+from struct import pack, unpack
+import sys
+import threading
+import traceback
+from typing import Optional, Generator
+import warnings
+from pyspark.context import SparkContext
+
+# Use b'\x00' as separator instead of b'\n', because the bytes are encoded in
utf-8
+_SERVER_POLL_INTERVAL = 0.1
+_TRUNCATE_MSG_LEN = 4000
+
+
+def get_driver_host(sc: SparkContext) -> Optional[str]:
+return sc.getConf().get("spark.driver.host")
+
+
+_log_print_lock = threading.Lock() # pylint: disable=invalid-name
+
+
+def _get_log_print_lock() -> threading.Lock:
+return _log_print_lock
+
+
+class WriteLogToStdout(socketserver.StreamRequestHandler):
+def _read_bline(self) -> Generator[bytes, None, None]:
+while self.server.is_active:
+packed_number_bytes = self.rfile.read1(4)
+if not packed_number_bytes:
+time.sleep(_SERVER_POLL_INTERVAL)
+continue
+number_bytes = unpack("@i", packed_number_bytes)[0]
+message = self.rfile.read1(number_bytes)
Review Comment:
Same with https://github.com/apache/spark/pull/39299/files#r1082428873
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #39666: [SPARK-42130][UI] Handle null string values in AccumulableInfo and ProcessSummary
LuciferYang commented on code in PR #39666:
URL: https://github.com/apache/spark/pull/39666#discussion_r1082425788
##
core/src/main/scala/org/apache/spark/status/protobuf/Utils.scala:
##
@@ -17,10 +17,24 @@
package org.apache.spark.status.protobuf
+import com.google.protobuf.MessageOrBuilder
+
object Utils {
def getOptional[T](condition: Boolean, result: () => T): Option[T] = if
(condition) {
Some(result())
} else {
None
}
+
+ def setStringField(input: String, f: String => MessageOrBuilder): Unit = {
Review Comment:
Agree with you
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] WeichenXu123 commented on a diff in pull request #39299: [WIP][SPARK-41593][PYTHON][ML] Adding logging from executors
WeichenXu123 commented on code in PR #39299:
URL: https://github.com/apache/spark/pull/39299#discussion_r1082420774
##
python/pyspark/ml/torch/log_communication.py:
##
@@ -0,0 +1,201 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+#http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+# type: ignore
+
+from contextlib import closing
+import time
+import socket
+import socketserver
+from struct import pack, unpack
+import sys
+import threading
+import traceback
+from typing import Optional, Generator
+import warnings
+from pyspark.context import SparkContext
+
+# Use b'\x00' as separator instead of b'\n', because the bytes are encoded in
utf-8
+_SERVER_POLL_INTERVAL = 0.1
+_TRUNCATE_MSG_LEN = 4000
+
+
+def get_driver_host(sc: SparkContext) -> Optional[str]:
+return sc.getConf().get("spark.driver.host")
+
+
+_log_print_lock = threading.Lock() # pylint: disable=invalid-name
+
+
+def _get_log_print_lock() -> threading.Lock:
+return _log_print_lock
+
+
+class WriteLogToStdout(socketserver.StreamRequestHandler):
+def _read_bline(self) -> Generator[bytes, None, None]:
+while self.server.is_active:
+packed_number_bytes = self.rfile.read1(4)
+if not packed_number_bytes:
+time.sleep(_SERVER_POLL_INTERVAL)
+continue
+number_bytes = unpack("@i", packed_number_bytes)[0]
+message = self.rfile.read1(number_bytes)
+yield message
+
+def handle(self) -> None:
+self.request.setblocking(0) # non-blocking mode
+for bline in self._read_bline():
+with _get_log_print_lock():
+sys.stderr.write(bline.decode("utf-8") + "\n")
+sys.stderr.flush()
+
+
+# What is run on the local driver
+class LogStreamingServer:
+def __init__(self) -> None:
+self.server = None
+self.serve_thread = None
+self.port = None
+
+@staticmethod
+def _get_free_port() -> int:
+with closing(socket.socket(socket.AF_INET, socket.SOCK_STREAM)) as tcp:
+tcp.bind(("", 0))
+_, port = tcp.getsockname()
+return port
+
+def start(self) -> None:
+if self.server:
+raise RuntimeError("Cannot start the server twice.")
+
+def serve_task(port: int) -> None:
+with socketserver.ThreadingTCPServer(("0.0.0.0", port),
WriteLogToStdout) as server:
+self.server = server
+server.is_active = True
+server.serve_forever(poll_interval=_SERVER_POLL_INTERVAL)
+
+self.port = LogStreamingServer._get_free_port()
+self.serve_thread = threading.Thread(target=serve_task,
args=(self.port,))
+self.serve_thread.setDaemon(True)
+self.serve_thread.start()
+
+def shutdown(self) -> None:
+if self.server:
+# Sleep to ensure all log has been received and printed.
+time.sleep(_SERVER_POLL_INTERVAL * 2)
+# Before close we need flush to ensure all stdout buffer were
printed.
+sys.stdout.flush()
+self.server.is_active = False
+self.server.shutdown()
+self.serve_thread.join()
+self.server = None
+self.serve_thread = None
+
+
+class LogStreamingClientBase:
+@staticmethod
+def _maybe_truncate_msg(message: str) -> str:
+if len(message) > _TRUNCATE_MSG_LEN:
+message = message[:_TRUNCATE_MSG_LEN]
+return message + "...(truncated)"
+else:
+return message
+
+def send(self, message: str) -> None:
+pass
+
+def close(self) -> None:
+pass
+
+
+class LogStreamingClient(LogStreamingClientBase):
+"""
+A client that streams log messages to :class:`LogStreamingServer`.
+In case of failures, the client will skip messages instead of raising an
error.
+"""
+
+_log_callback_client = None
+_server_address = None
+_singleton_lock = threading.Lock()
+
+@staticmethod
+def _init(address: str, port: int) -> None:
+LogStreamingClient._server_address = (address, port)
+
+@staticmethod
+def _destroy() -> None:
+LogStreamingClient._server_address = None
+if
[GitHub] [spark] WeichenXu123 commented on a diff in pull request #39299: [WIP][SPARK-41593][PYTHON][ML] Adding logging from executors
WeichenXu123 commented on code in PR #39299:
URL: https://github.com/apache/spark/pull/39299#discussion_r1082420394
##
python/pyspark/ml/torch/log_communication.py:
##
@@ -0,0 +1,201 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+#http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+# type: ignore
+
+from contextlib import closing
+import time
+import socket
+import socketserver
+from struct import pack, unpack
+import sys
+import threading
+import traceback
+from typing import Optional, Generator
+import warnings
+from pyspark.context import SparkContext
+
+# Use b'\x00' as separator instead of b'\n', because the bytes are encoded in
utf-8
+_SERVER_POLL_INTERVAL = 0.1
+_TRUNCATE_MSG_LEN = 4000
+
+
+def get_driver_host(sc: SparkContext) -> Optional[str]:
+return sc.getConf().get("spark.driver.host")
+
+
+_log_print_lock = threading.Lock() # pylint: disable=invalid-name
+
+
+def _get_log_print_lock() -> threading.Lock:
+return _log_print_lock
+
+
+class WriteLogToStdout(socketserver.StreamRequestHandler):
+def _read_bline(self) -> Generator[bytes, None, None]:
+while self.server.is_active:
+packed_number_bytes = self.rfile.read1(4)
+if not packed_number_bytes:
+time.sleep(_SERVER_POLL_INTERVAL)
+continue
+number_bytes = unpack("@i", packed_number_bytes)[0]
Review Comment:
Pls use `>i` instead of `@i`, `@` means native order that might be different
on different platform
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] EnricoMi commented on pull request #39640: [SPARK-38591][SQL] Add flatMapSortedGroups and cogroupSorted
EnricoMi commented on PR #39640:
URL: https://github.com/apache/spark/pull/39640#issuecomment-1398282605
@cloud-fan following issue: `ds.groupByKey` adds key columns to the plan:
```
def groupByKey[K: Encoder](func: T => K): KeyValueGroupedDataset[K, T] = {
val withGroupingKey = AppendColumns(func, logicalPlan)
val executed = sparkSession.sessionState.executePlan(withGroupingKey)
new KeyValueGroupedDataset(
encoderFor[K],
encoderFor[T],
executed,
logicalPlan.output,
withGroupingKey.newColumns)
}
```
Here, `[key#10, seq#11, value#12]` are the group value columns, whereas
`[value#17]` represents the group key columns. User defined `$"value"` for
group sorting, which cannot be resolved in this situation:
```
'MapGroups [value#17], [key#10, seq#11, value#12], ['seq ASC NULLS FIRST,
'length('key) ASC NULLS FIRST, 'value ASC NULLS FIRST], obj#19: java.lang.String
+- AppendColumns [value#17]
+- Project [_1#3 AS key#10, _2#4 AS seq#11, _3#5 AS value#12]
+- LocalRelation [_1#3, _2#4, _3#5]
```
The group sort columns should reference only the original value columns (not
the `AppendColumns` column), we get an ambiguous reference otherwise:
```
val ds = Seq(("a", 1, 10), ("a", 2, 20), ("b", 2, 1), ("b", 1, 2), ("c", 1,
1))
.toDF("key", "seq", "value")
// groupByKey Row => String adds key columns `value` to the dataframe
val grouped = ds.groupByKey(v => v.getString(0))
// $"value" here is expected to not reference the key column
val aggregated = grouped.flatMapSortedGroups($"seq", expr("length(key)"),
$"value") {
(g, iter) => Iterator(g, iter.mkString(", "))
}
```
[AMBIGUOUS_REFERENCE] Reference `value` is ambiguous, could be:
[`value`, `value`].
How can I modify the `dataOrder: Seq[SortOrder]` in such a way that
`$"value"` is resolved against the `AppendColumns.child` / `[key#10, seq#11,
value#12]`?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] WeichenXu123 commented on a diff in pull request #39299: [WIP][SPARK-41593][PYTHON][ML] Adding logging from executors
WeichenXu123 commented on code in PR #39299:
URL: https://github.com/apache/spark/pull/39299#discussion_r1082416985
##
python/pyspark/ml/torch/log_communication.py:
##
@@ -0,0 +1,201 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+#http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+# type: ignore
+
+from contextlib import closing
+import time
+import socket
+import socketserver
+from struct import pack, unpack
+import sys
+import threading
+import traceback
+from typing import Optional, Generator
+import warnings
+from pyspark.context import SparkContext
+
+# Use b'\x00' as separator instead of b'\n', because the bytes are encoded in
utf-8
+_SERVER_POLL_INTERVAL = 0.1
+_TRUNCATE_MSG_LEN = 4000
+
+
+def get_driver_host(sc: SparkContext) -> Optional[str]:
+return sc.getConf().get("spark.driver.host")
+
+
+_log_print_lock = threading.Lock() # pylint: disable=invalid-name
+
+
+def _get_log_print_lock() -> threading.Lock:
+return _log_print_lock
+
+
+class WriteLogToStdout(socketserver.StreamRequestHandler):
+def _read_bline(self) -> Generator[bytes, None, None]:
+while self.server.is_active:
+packed_number_bytes = self.rfile.read1(4)
+if not packed_number_bytes:
+time.sleep(_SERVER_POLL_INTERVAL)
+continue
+number_bytes = unpack("@i", packed_number_bytes)[0]
+message = self.rfile.read1(number_bytes)
+yield message
+
+def handle(self) -> None:
+self.request.setblocking(0) # non-blocking mode
+for bline in self._read_bline():
+with _get_log_print_lock():
+sys.stderr.write(bline.decode("utf-8") + "\n")
+sys.stderr.flush()
+
+
+# What is run on the local driver
+class LogStreamingServer:
+def __init__(self) -> None:
+self.server = None
+self.serve_thread = None
+self.port = None
+
+@staticmethod
+def _get_free_port() -> int:
+with closing(socket.socket(socket.AF_INET, socket.SOCK_STREAM)) as tcp:
+tcp.bind(("", 0))
+_, port = tcp.getsockname()
+return port
+
+def start(self) -> None:
+if self.server:
+raise RuntimeError("Cannot start the server twice.")
+
+def serve_task(port: int) -> None:
+with socketserver.ThreadingTCPServer(("0.0.0.0", port),
WriteLogToStdout) as server:
+self.server = server
+server.is_active = True
+server.serve_forever(poll_interval=_SERVER_POLL_INTERVAL)
+
+self.port = LogStreamingServer._get_free_port()
+self.serve_thread = threading.Thread(target=serve_task,
args=(self.port,))
+self.serve_thread.setDaemon(True)
+self.serve_thread.start()
+
+def shutdown(self) -> None:
+if self.server:
+# Sleep to ensure all log has been received and printed.
+time.sleep(_SERVER_POLL_INTERVAL * 2)
+# Before close we need flush to ensure all stdout buffer were
printed.
+sys.stdout.flush()
+self.server.is_active = False
+self.server.shutdown()
+self.serve_thread.join()
+self.server = None
+self.serve_thread = None
+
+
+class LogStreamingClientBase:
+@staticmethod
+def _maybe_truncate_msg(message: str) -> str:
+if len(message) > _TRUNCATE_MSG_LEN:
+message = message[:_TRUNCATE_MSG_LEN]
+return message + "...(truncated)"
+else:
+return message
+
+def send(self, message: str) -> None:
+pass
+
+def close(self) -> None:
+pass
+
+
+class LogStreamingClient(LogStreamingClientBase):
+"""
+A client that streams log messages to :class:`LogStreamingServer`.
+In case of failures, the client will skip messages instead of raising an
error.
+"""
+
+_log_callback_client = None
+_server_address = None
+_singleton_lock = threading.Lock()
+
+@staticmethod
+def _init(address: str, port: int) -> None:
+LogStreamingClient._server_address = (address, port)
+
+@staticmethod
+def _destroy() -> None:
+LogStreamingClient._server_address = None
+if
[GitHub] [spark] WeichenXu123 commented on a diff in pull request #39299: [WIP][SPARK-41593][PYTHON][ML] Adding logging from executors
WeichenXu123 commented on code in PR #39299:
URL: https://github.com/apache/spark/pull/39299#discussion_r1082414835
##
python/pyspark/ml/torch/log_communication.py:
##
@@ -0,0 +1,201 @@
+#
+# Licensed to the Apache Software Foundation (ASF) under one or more
+# contributor license agreements. See the NOTICE file distributed with
+# this work for additional information regarding copyright ownership.
+# The ASF licenses this file to You under the Apache License, Version 2.0
+# (the "License"); you may not use this file except in compliance with
+# the License. You may obtain a copy of the License at
+#
+#http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+#
+# type: ignore
+
+from contextlib import closing
+import time
+import socket
+import socketserver
+from struct import pack, unpack
+import sys
+import threading
+import traceback
+from typing import Optional, Generator
+import warnings
+from pyspark.context import SparkContext
+
+# Use b'\x00' as separator instead of b'\n', because the bytes are encoded in
utf-8
+_SERVER_POLL_INTERVAL = 0.1
+_TRUNCATE_MSG_LEN = 4000
+
+
+def get_driver_host(sc: SparkContext) -> Optional[str]:
+return sc.getConf().get("spark.driver.host")
+
+
+_log_print_lock = threading.Lock() # pylint: disable=invalid-name
+
+
+def _get_log_print_lock() -> threading.Lock:
+return _log_print_lock
+
+
+class WriteLogToStdout(socketserver.StreamRequestHandler):
+def _read_bline(self) -> Generator[bytes, None, None]:
+while self.server.is_active:
+packed_number_bytes = self.rfile.read1(4)
+if not packed_number_bytes:
+time.sleep(_SERVER_POLL_INTERVAL)
+continue
+number_bytes = unpack("@i", packed_number_bytes)[0]
+message = self.rfile.read1(number_bytes)
+yield message
+
+def handle(self) -> None:
+self.request.setblocking(0) # non-blocking mode
+for bline in self._read_bline():
+with _get_log_print_lock():
+sys.stderr.write(bline.decode("utf-8") + "\n")
+sys.stderr.flush()
+
+
+# What is run on the local driver
+class LogStreamingServer:
+def __init__(self) -> None:
+self.server = None
+self.serve_thread = None
+self.port = None
+
+@staticmethod
+def _get_free_port() -> int:
+with closing(socket.socket(socket.AF_INET, socket.SOCK_STREAM)) as tcp:
+tcp.bind(("", 0))
Review Comment:
Let's explicitly use `spark.driver.host` as the hostname part of the address
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum commented on pull request #39671: [SPARK-40303][DOCS] Recommends users to use JDK 8u362 and later versions
wangyum commented on PR #39671: URL: https://github.com/apache/spark/pull/39671#issuecomment-1398267365 > Oh, does `Zulu` only have that released version, @wangyum ? > > * https://bugs.openjdk.org/browse/JDK-8296506 > > I cannot find docker image and Adoptium (Temurin) Java yet. > > * https://hub.docker.com/_/openjdk/tags?page=1=8u > * https://adoptium.net/temurin/archive/?version=8 It is in progress: https://user-images.githubusercontent.com/5399861/213687652-369ff146-3e8b-4ee5-b57b-42c4c78ad1c8.png;> -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] kuwii commented on pull request #39190: [SPARK-41683][CORE] Fix issue of getting incorrect property numActiveStages in jobs API
kuwii commented on PR #39190: URL: https://github.com/apache/spark/pull/39190#issuecomment-1398263751 @srowen We found this issue in some of Spark applications. Here's the event log of an example, which can be loaded through history server: [application_1671519030791_0001_1.zip](https://github.com/apache/spark/files/10465796/application_1671519030791_0001_1.zip) In `/api/v1/applications/application_1671519030791_0001/1/jobs`, `numActiveStages` of job 3, 4, 5, 8 are less than 0. 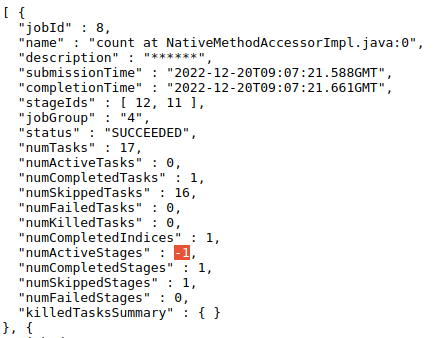 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] EnricoMi commented on pull request #39673: [SPARK-42132][SQL] Deduplicate attributes in groupByKey.cogroup
EnricoMi commented on PR #39673:
URL: https://github.com/apache/spark/pull/39673#issuecomment-1398246138
Ideally, `QueryPlan.rewriteAttrs` would not replace occurrences `id#0L#`
with `id#13L` in all fields of `CoGroup`, but only in `rightDeserializer`,
`rightGroup`, `rightAttr`, `rightOrder`:
```
case class CoGroup(
func: (Any, Iterator[Any], Iterator[Any]) => TraversableOnce[Any],
keyDeserializer: Expression,
leftDeserializer: Expression,
rightDeserializer: Expression,
leftGroup: Seq[Attribute],
rightGroup: Seq[Attribute],
leftAttr: Seq[Attribute],
rightAttr: Seq[Attribute],
leftOrder: Seq[SortOrder],
rightOrder: Seq[SortOrder],
outputObjAttr: Attribute,
left: LogicalPlan,
right: LogicalPlan) extends BinaryNode with ObjectProducer { ... }
```
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] EnricoMi opened a new pull request, #39673: [SPARK-42132][SQL] Deduplicate attributes in groupByKey.cogroup
EnricoMi opened a new pull request, #39673:
URL: https://github.com/apache/spark/pull/39673
### What changes were proposed in this pull request?
This deduplicate attributes that exist on both sides of a `CoGroup` by
aliasing the occurrence on the right side.
### Why are the changes needed?
Usually, DeduplicateRelations rule does exactly this. But the generic
`QueryPlan.rewriteAttrs` replaces all occurrences of the duplicate reference
with the new reference, but `CoGroup` uses the old reference for left and right
group attributes, value attributes, and group order. Only the occurrences in
the right attributes must be replaced.
Further, the right deserialization expression is not touched at all.
The following DataFrame cannot be evaluated:
```scala
val df = spark.range(3)
val left_grouped_df = df.groupBy("id").as[Long, Long]
val right_grouped_df = df.groupBy("id").as[Long, Long]
val cogroup_df = left_grouped_df.cogroup(right_grouped_df) {
case (key, left, right) => left
}
```
The query plan:
```
== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- SerializeFromObject [input[0, bigint, false] AS value#12L]
+- CoGroup, id#0: bigint, id#0: bigint, id#0: bigint, [id#13L], [id#13L],
[id#13L], [id#13L], obj#11: bigint
:- !Sort [id#13L ASC NULLS FIRST], false, 0
: +- !Exchange hashpartitioning(id#13L, 200), ENSURE_REQUIREMENTS,
[plan_id=16]
: +- Range (0, 3, step=1, splits=16)
+- Sort [id#13L ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(id#13L, 200), ENSURE_REQUIREMENTS,
[plan_id=17]
+- Range (0, 3, step=1, splits=16)
```
### Does this PR introduce _any_ user-facing change?
This fixes correctness.
### How was this patch tested?
Unit test in `DataFrameSuite`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] vicennial opened a new pull request, #39672: [SPARK-42133] Add basic Dataset API methods to Spark Connect Scala Client
vicennial opened a new pull request, #39672: URL: https://github.com/apache/spark/pull/39672 ### What changes were proposed in this pull request? Adds the following methods: - Dataframe API methods - project - filter - limit - SparkSession - range (and its variations) This PR also introduces `Column` and `functions` to support the above changes. ### Why are the changes needed? Incremental development of Spark Connect Scala Client. ### Does this PR introduce _any_ user-facing change? Yes, users may now use the proposed API methods. Example: `val df = sparkSession.range(5).limit(3)` ### How was this patch tested? Unit tests + simple E2E test. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39671: [SPARK-40303][DOCS] Recommends users to use JDK 8u362 and later versions
dongjoon-hyun commented on PR #39671: URL: https://github.com/apache/spark/pull/39671#issuecomment-1398234989 Oh, is `Zulu` only have that released version, @wangyum ? - https://bugs.openjdk.org/browse/JDK-8296506 I cannot find docker image and Adoptium (Temurin) Java yet. - https://hub.docker.com/_/openjdk/tags?page=1=8u -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #38376: [SPARK-40817][K8S] `spark.files` should preserve remote files
dongjoon-hyun commented on PR #38376: URL: https://github.com/apache/spark/pull/38376#issuecomment-1398224853 Perfect, @antonipp ! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] wangyum opened a new pull request, #39671: [SPARK-40303][DOCS] Recommends users to use JDK 8u362 and later versions
wangyum opened a new pull request, #39671:
URL: https://github.com/apache/spark/pull/39671
### What changes were proposed in this pull request?
This PR update document recommends users to use JDK 8u362 and later versions.
### Why are the changes needed?
8u362 fixed a performance issue:
https://github.com/openjdk/jdk8u-dev/pull/161
Benchmark code:
```scala
val dir = "/tmp/spark/benchmark"
val N = 200
val columns = Range(0, 100).map(i => s"id % $i AS id$i")
spark.range(N).selectExpr(columns: _*).write.mode("Overwrite").parquet(dir)
val cnt = 60
val selectExps = columns.take(cnt).map(_.split(" ").last).map(c =>
s"count(distinct $c)")
val start = System.currentTimeMillis()
spark.read.parquet(dir).selectExpr(selectExps: _*).collect()
println(s"Benchmark result. Java version:
${System.getProperty("java.version")}. Time(ms): ${System.currentTimeMillis() -
start}")
```
8u352 benchmark result:
```shell
export
JAVA_HOME=/Users/yumwang/Downloads/zulu8.66.0.15-ca-jdk8.0.352-macosx_x64
export PATH=${JAVA_HOME}/bin:${PATH}
bin/spark-shell --master "local[2]" -i benchmark.scala
Benchmark result. Java version: 1.8.0_352. Time(ms): 641155
```
8u362 benchmark result:
```shell
export
JAVA_HOME=/Users/yumwang/Downloads/zulu8.68.0.19-ca-jdk8.0.362-macosx_x64
export PATH=${JAVA_HOME}/bin:${PATH}
bin/spark-shell --master "local[2]" -i benchmark.scala
Benchmark result. Java version: 1.8.0_362. Time(ms): 79360
```
### Does this PR introduce _any_ user-facing change?
No.
### How was this patch tested?
N/A.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] antonipp commented on pull request #38376: [SPARK-40817][K8S] `spark.files` should preserve remote files
antonipp commented on PR #38376: URL: https://github.com/apache/spark/pull/38376#issuecomment-1398209302 Thank you for the reviews and for the merge! I am not 100% sure what is the backport process but I opened 2 PRs (for 3.3 and 3.2) since I believe both are still supported based on the [versioning policy](https://spark.apache.org/versioning-policy.html). - 3.3: https://github.com/apache/spark/pull/39669 - 3.2: https://github.com/apache/spark/pull/39670 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] antonipp opened a new pull request, #39669: [SPARK-40817][K8S][3.3] `spark.files` should preserve remote files
antonipp opened a new pull request, #39669:
URL: https://github.com/apache/spark/pull/39669
### What changes were proposed in this pull request?
Backport https://github.com/apache/spark/pull/38376 to `branch-3.3`
You can find a detailed description of the issue and an example reproduction
on the Jira card: https://issues.apache.org/jira/browse/SPARK-40817
The idea for this fix is to update the logic which uploads user-specified
files (via `spark.jars`, `spark.files`, etc) to
`spark.kubernetes.file.upload.path`. After uploading local files, it used to
overwrite the initial list of URIs passed by the user and it would thus erase
all remote URIs which were specified there.
Small example of this behaviour:
1. User set the value of `spark.jars` to
`s3a://some-bucket/my-application.jar,/tmp/some-local-jar.jar` when running
`spark-submit` in cluster mode
2. `BasicDriverFeatureStep.getAdditionalPodSystemProperties()` gets called
at one point while running `spark-submit`
3. This function would set `spark.jars` to a new value of
`${SPARK_KUBERNETES_UPLOAD_PATH}/spark-upload-${RANDOM_STRING}/some-local-jar.jar`.
Note that `s3a://some-bucket/my-application.jar` has been discarded.
With the logic proposed in this PR, the new value of `spark.jars` would be
`s3a://some-bucket/my-application.jar,${SPARK_KUBERNETES_UPLOAD_PATH}/spark-upload-${RANDOM_STRING}/some-local-jar.jar`,
so in other words we are making sure that remote URIs are no longer discarded.
### Why are the changes needed?
We encountered this issue in production when trying to launch Spark on
Kubernetes jobs in cluster mode with a fix of local and remote dependencies.
### Does this PR introduce _any_ user-facing change?
Yes, see description of the new behaviour above.
### How was this patch tested?
- Added a unit test for the new behaviour
- Added an integration test for the new behaviour
- Tried this patch in our Kubernetes environment with `SparkPi`:
```
spark-submit \
--master k8s://https://$KUBERNETES_API_SERVER_URL:443 \
--deploy-mode cluster \
--name=spark-submit-test \
--class org.apache.spark.examples.SparkPi \
--conf
spark.jars=/opt/my-local-jar.jar,s3a://$BUCKET_NAME/my-remote-jar.jar \
--conf
spark.kubernetes.file.upload.path=s3a://$BUCKET_NAME/my-upload-path/ \
[...]
/opt/spark/examples/jars/spark-examples_2.12-3.1.3.jar
```
Before applying the patch, `s3a://$BUCKET_NAME/my-remote-jar.jar` was
discarded from the final value of `spark.jars`. After applying the patch and
launching the job again, I confirmed that
`s3a://$BUCKET_NAME/my-remote-jar.jar` was no longer discarded by looking at
the Spark config for the running job.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] antonipp opened a new pull request, #39670: [SPARK-40817][K8S][3.2] `spark.files` should preserve remote files
antonipp opened a new pull request, #39670:
URL: https://github.com/apache/spark/pull/39670
### What changes were proposed in this pull request?
Backport https://github.com/apache/spark/pull/38376 to `branch-3.2`
You can find a detailed description of the issue and an example reproduction
on the Jira card: https://issues.apache.org/jira/browse/SPARK-40817
The idea for this fix is to update the logic which uploads user-specified
files (via `spark.jars`, `spark.files`, etc) to
`spark.kubernetes.file.upload.path`. After uploading local files, it used to
overwrite the initial list of URIs passed by the user and it would thus erase
all remote URIs which were specified there.
Small example of this behaviour:
1. User set the value of `spark.jars` to
`s3a://some-bucket/my-application.jar,/tmp/some-local-jar.jar` when running
`spark-submit` in cluster mode
2. `BasicDriverFeatureStep.getAdditionalPodSystemProperties()` gets called
at one point while running `spark-submit`
3. This function would set `spark.jars` to a new value of
`${SPARK_KUBERNETES_UPLOAD_PATH}/spark-upload-${RANDOM_STRING}/some-local-jar.jar`.
Note that `s3a://some-bucket/my-application.jar` has been discarded.
With the logic proposed in this PR, the new value of `spark.jars` would be
`s3a://some-bucket/my-application.jar,${SPARK_KUBERNETES_UPLOAD_PATH}/spark-upload-${RANDOM_STRING}/some-local-jar.jar`,
so in other words we are making sure that remote URIs are no longer discarded.
### Why are the changes needed?
We encountered this issue in production when trying to launch Spark on
Kubernetes jobs in cluster mode with a fix of local and remote dependencies.
### Does this PR introduce _any_ user-facing change?
Yes, see description of the new behaviour above.
### How was this patch tested?
- Added a unit test for the new behaviour
- Added an integration test for the new behaviour
- Tried this patch in our Kubernetes environment with `SparkPi`:
```
spark-submit \
--master k8s://https://$KUBERNETES_API_SERVER_URL:443 \
--deploy-mode cluster \
--name=spark-submit-test \
--class org.apache.spark.examples.SparkPi \
--conf
spark.jars=/opt/my-local-jar.jar,s3a://$BUCKET_NAME/my-remote-jar.jar \
--conf
spark.kubernetes.file.upload.path=s3a://$BUCKET_NAME/my-upload-path/ \
[...]
/opt/spark/examples/jars/spark-examples_2.12-3.1.3.jar
```
Before applying the patch, `s3a://$BUCKET_NAME/my-remote-jar.jar` was
discarded from the final value of `spark.jars`. After applying the patch and
launching the job again, I confirmed that
`s3a://$BUCKET_NAME/my-remote-jar.jar` was no longer discarded by looking at
the Spark config for the running job.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on pull request #39668: [WIP] Test 3.4.0 tagging
HyukjinKwon commented on PR #39668: URL: https://github.com/apache/spark/pull/39668#issuecomment-1398189235 cc @xinrong-meng FYI -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #39541: [SPARK-42043][CONNECT] Scala Client Result with E2E Tests
HyukjinKwon commented on code in PR #39541:
URL: https://github.com/apache/spark/pull/39541#discussion_r1082329957
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/ClientE2ETestSuite.scala:
##
@@ -0,0 +1,43 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql
+
+import org.apache.spark.sql.connect.client.util.RemoteSparkSession
+import org.apache.spark.sql.types.{StringType, StructField, StructType}
+
+class ClientE2ETestSuite extends RemoteSparkSession { // scalastyle:ignore
funsuite
+
+ // Spark Result
+ test("test spark result schema") {
+val df = spark.sql("select val from (values ('Hello'), ('World')) as
t(val)")
+val schema = df.collectResult().schema
+assert(schema == StructType(StructField("val", StringType, false) :: Nil))
+ }
+
+ test("test spark result array") {
+val df = spark.sql("select val from (values ('Hello'), ('World')) as
t(val)")
+val result = df.collectResult()
+assert(result.length == 2)
+val array = result.toArray
+assert(array.length == 2)
+assert(array(0).getString(0) == "Hello")
+assert(array(1).getString(0) == "World")
+ }
+
+ // TODO test large result when we can create table or view
Review Comment:
Please file a JIRA.
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/ClientE2ETestSuite.scala:
##
@@ -0,0 +1,43 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql
+
+import org.apache.spark.sql.connect.client.util.RemoteSparkSession
+import org.apache.spark.sql.types.{StringType, StructField, StructType}
+
+class ClientE2ETestSuite extends RemoteSparkSession { // scalastyle:ignore
funsuite
Review Comment:
Seems like we don't need ` // scalastyle:ignore funsuite`.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #39541: [SPARK-42043][CONNECT] Scala Client Result with E2E Tests
HyukjinKwon commented on code in PR #39541:
URL: https://github.com/apache/spark/pull/39541#discussion_r1082329724
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/connect/client/SparkConnectClientSuite.scala:
##
@@ -78,7 +78,7 @@ class SparkConnectClientSuite
}
test("Test connection") {
-val testPort = 16000
+val testPort = 16001
Review Comment:
Why did we change this?
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #39541: [SPARK-42043][CONNECT] Scala Client Result with E2E Tests
HyukjinKwon commented on code in PR #39541:
URL: https://github.com/apache/spark/pull/39541#discussion_r1082329225
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/connect/client/util/RemoteSparkSession.scala:
##
@@ -0,0 +1,198 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.connect.client.util
+
+import java.io.{BufferedOutputStream, File}
+
+import scala.io.Source
+
+import org.scalatest.BeforeAndAfterAll
+import sys.process._
+
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.connect.client.SparkConnectClient
+import org.apache.spark.sql.connect.common.config.ConnectCommon
+
+/**
+ * An util class to start a local spark connect server in a different process
for local E2E tests.
+ * It is designed to start the server once but shared by all tests. It is
equivalent to use the
+ * following command to start the connect server via command line:
+ *
+ * {{{
+ * bin/spark-shell \
+ * --jars `ls connector/connect/server/target/**/spark-connect*SNAPSHOT.jar |
paste -sd ',' -` \
+ * --conf spark.plugins=org.apache.spark.sql.connect.SparkConnectPlugin
+ * }}}
+ *
+ * Set system property `SPARK_HOME` if the test is not executed from the Spark
project top folder.
+ * Set system property `DEBUG_SC_JVM_CLIENT=true` to print the server process
output in the
+ * console to debug server start stop problems.
+ */
+object SparkConnectServerUtils {
+ // System properties used for testing and debugging
+ private val SPARK_HOME = "SPARK_HOME"
+ private val ENV_DEBUG_SC_JVM_CLIENT = "DEBUG_SC_JVM_CLIENT"
+
+ private val sparkHome = System.getProperty(SPARK_HOME, fileSparkHome())
+ private val isDebug = System.getProperty(ENV_DEBUG_SC_JVM_CLIENT,
"false").toBoolean
+
+ // Log server start stop debug info into console
+ // scalastyle:off println
+ private[connect] def debug(msg: String): Unit = if (isDebug) println(msg)
+ // scalastyle:on println
+ private[connect] def debug(error: Throwable): Unit = if (isDebug)
error.printStackTrace()
+
+ // Server port
+ private[connect] val port = ConnectCommon.CONNECT_GRPC_BINDING_PORT +
util.Random.nextInt(1000)
+
+ @volatile private var stopped = false
+
+ private lazy val sparkConnect: Process = {
+debug("Starting the Spark Connect Server...")
+val jar = findSparkConnectJar
+val builder = Process(
+ new File(sparkHome, "bin/spark-shell").getCanonicalPath,
+ Seq(
+"--jars",
+jar,
+"--driver-class-path",
+jar,
+"--conf",
+"spark.plugins=org.apache.spark.sql.connect.SparkConnectPlugin",
+"--conf",
+s"spark.connect.grpc.binding.port=$port"))
+
+val io = new ProcessIO(
+ // Hold the input channel to the spark console to keep the console open
+ in => new BufferedOutputStream(in),
+ // Only redirect output if debug to avoid channel interruption error on
process termination.
+ out => if (isDebug) Source.fromInputStream(out).getLines.foreach(debug),
+ err => if (isDebug) Source.fromInputStream(err).getLines.foreach(debug))
+val process = builder.run(io)
+
+// Adding JVM shutdown hook
+sys.addShutdownHook(kill())
+process
+ }
+
+ def start(): Unit = {
+assert(!stopped)
+sparkConnect
+ }
+
+ def kill(): Int = {
+stopped = true
+debug("Stopping the Spark Connect Server...")
+sparkConnect.destroy()
+val code = sparkConnect.exitValue()
+debug(s"Spark Connect Server is stopped with exit code: $code")
+code
+ }
+
+ private def fileSparkHome(): String = {
+val path = new File("./").getCanonicalPath
+if (path.endsWith("connector/connect/client/jvm")) {
+ // the current folder is the client project folder
+ new File("../../../../").getCanonicalPath
+} else {
+ path
+}
+ }
+
+ private def findSparkConnectJar: String = {
+val target = "connector/connect/server/target"
+val parentDir = new File(sparkHome, target)
+assert(
+ parentDir.exists(),
+ s"Fail to locate the spark connect target folder:
'${parentDir.getCanonicalPath}'. " +
+s"SPARK_HOME='${new File(sparkHome).getCanonicalPath}'. " +
+"Make sure
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #39541: [SPARK-42043][CONNECT] Scala Client Result with E2E Tests
HyukjinKwon commented on code in PR #39541:
URL: https://github.com/apache/spark/pull/39541#discussion_r1082319733
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/connect/client/util/RemoteSparkSession.scala:
##
@@ -0,0 +1,198 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.connect.client.util
+
+import java.io.{BufferedOutputStream, File}
+
+import scala.io.Source
+
+import org.scalatest.BeforeAndAfterAll
+import sys.process._
+
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.connect.client.SparkConnectClient
+import org.apache.spark.sql.connect.common.config.ConnectCommon
+
+/**
+ * An util class to start a local spark connect server in a different process
for local E2E tests.
+ * It is designed to start the server once but shared by all tests. It is
equivalent to use the
+ * following command to start the connect server via command line:
+ *
+ * {{{
+ * bin/spark-shell \
+ * --jars `ls connector/connect/server/target/**/spark-connect*SNAPSHOT.jar |
paste -sd ',' -` \
+ * --conf spark.plugins=org.apache.spark.sql.connect.SparkConnectPlugin
+ * }}}
+ *
+ * Set system property `SPARK_HOME` if the test is not executed from the Spark
project top folder.
+ * Set system property `DEBUG_SC_JVM_CLIENT=true` to print the server process
output in the
+ * console to debug server start stop problems.
+ */
+object SparkConnectServerUtils {
Review Comment:
Is this an API? Would be great to either document that this package is an
internal API, or properly give the accessor.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #39541: [SPARK-42043][CONNECT] Scala Client Result with E2E Tests
HyukjinKwon commented on code in PR #39541:
URL: https://github.com/apache/spark/pull/39541#discussion_r1082327967
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/connect/client/util/RemoteSparkSession.scala:
##
@@ -0,0 +1,198 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.connect.client.util
+
+import java.io.{BufferedOutputStream, File}
+
+import scala.io.Source
+
+import org.scalatest.BeforeAndAfterAll
+import sys.process._
+
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.connect.client.SparkConnectClient
+import org.apache.spark.sql.connect.common.config.ConnectCommon
+
+/**
+ * An util class to start a local spark connect server in a different process
for local E2E tests.
+ * It is designed to start the server once but shared by all tests. It is
equivalent to use the
+ * following command to start the connect server via command line:
+ *
+ * {{{
+ * bin/spark-shell \
+ * --jars `ls connector/connect/server/target/**/spark-connect*SNAPSHOT.jar |
paste -sd ',' -` \
+ * --conf spark.plugins=org.apache.spark.sql.connect.SparkConnectPlugin
+ * }}}
+ *
+ * Set system property `SPARK_HOME` if the test is not executed from the Spark
project top folder.
+ * Set system property `DEBUG_SC_JVM_CLIENT=true` to print the server process
output in the
+ * console to debug server start stop problems.
+ */
+object SparkConnectServerUtils {
+ // System properties used for testing and debugging
+ private val SPARK_HOME = "SPARK_HOME"
+ private val ENV_DEBUG_SC_JVM_CLIENT = "DEBUG_SC_JVM_CLIENT"
+
+ private val sparkHome = System.getProperty(SPARK_HOME, fileSparkHome())
+ private val isDebug = System.getProperty(ENV_DEBUG_SC_JVM_CLIENT,
"false").toBoolean
+
+ // Log server start stop debug info into console
+ // scalastyle:off println
+ private[connect] def debug(msg: String): Unit = if (isDebug) println(msg)
+ // scalastyle:on println
+ private[connect] def debug(error: Throwable): Unit = if (isDebug)
error.printStackTrace()
+
+ // Server port
+ private[connect] val port = ConnectCommon.CONNECT_GRPC_BINDING_PORT +
util.Random.nextInt(1000)
+
+ @volatile private var stopped = false
+
+ private lazy val sparkConnect: Process = {
+debug("Starting the Spark Connect Server...")
+val jar = findSparkConnectJar
+val builder = Process(
+ new File(sparkHome, "bin/spark-shell").getCanonicalPath,
+ Seq(
+"--jars",
+jar,
+"--driver-class-path",
+jar,
+"--conf",
+"spark.plugins=org.apache.spark.sql.connect.SparkConnectPlugin",
+"--conf",
+s"spark.connect.grpc.binding.port=$port"))
+
+val io = new ProcessIO(
+ // Hold the input channel to the spark console to keep the console open
+ in => new BufferedOutputStream(in),
+ // Only redirect output if debug to avoid channel interruption error on
process termination.
+ out => if (isDebug) Source.fromInputStream(out).getLines.foreach(debug),
+ err => if (isDebug) Source.fromInputStream(err).getLines.foreach(debug))
+val process = builder.run(io)
+
+// Adding JVM shutdown hook
+sys.addShutdownHook(kill())
+process
+ }
+
+ def start(): Unit = {
+assert(!stopped)
+sparkConnect
Review Comment:
Can we do this w/ a proper `start` and `stop`? For example, if you call
`kill`, then it will start a process, and then kill.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #39541: [SPARK-42043][CONNECT] Scala Client Result with E2E Tests
HyukjinKwon commented on code in PR #39541:
URL: https://github.com/apache/spark/pull/39541#discussion_r1082326873
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/connect/client/util/RemoteSparkSession.scala:
##
@@ -0,0 +1,198 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.connect.client.util
+
+import java.io.{BufferedOutputStream, File}
+
+import scala.io.Source
+
+import org.scalatest.BeforeAndAfterAll
+import sys.process._
+
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.connect.client.SparkConnectClient
+import org.apache.spark.sql.connect.common.config.ConnectCommon
+
+/**
+ * An util class to start a local spark connect server in a different process
for local E2E tests.
+ * It is designed to start the server once but shared by all tests. It is
equivalent to use the
+ * following command to start the connect server via command line:
+ *
+ * {{{
+ * bin/spark-shell \
+ * --jars `ls connector/connect/server/target/**/spark-connect*SNAPSHOT.jar |
paste -sd ',' -` \
+ * --conf spark.plugins=org.apache.spark.sql.connect.SparkConnectPlugin
+ * }}}
+ *
+ * Set system property `SPARK_HOME` if the test is not executed from the Spark
project top folder.
+ * Set system property `DEBUG_SC_JVM_CLIENT=true` to print the server process
output in the
+ * console to debug server start stop problems.
+ */
+object SparkConnectServerUtils {
+ // System properties used for testing and debugging
+ private val SPARK_HOME = "SPARK_HOME"
+ private val ENV_DEBUG_SC_JVM_CLIENT = "DEBUG_SC_JVM_CLIENT"
+
+ private val sparkHome = System.getProperty(SPARK_HOME, fileSparkHome())
+ private val isDebug = System.getProperty(ENV_DEBUG_SC_JVM_CLIENT,
"false").toBoolean
Review Comment:
Can we use either environment variable or make the name consistent with what
we;re using in Spark? e.g., `spark.debug.sc.jvm.client`
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/connect/client/util/RemoteSparkSession.scala:
##
@@ -0,0 +1,198 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.connect.client.util
+
+import java.io.{BufferedOutputStream, File}
+
+import scala.io.Source
+
+import org.scalatest.BeforeAndAfterAll
+import sys.process._
+
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.connect.client.SparkConnectClient
+import org.apache.spark.sql.connect.common.config.ConnectCommon
+
+/**
+ * An util class to start a local spark connect server in a different process
for local E2E tests.
+ * It is designed to start the server once but shared by all tests. It is
equivalent to use the
+ * following command to start the connect server via command line:
+ *
+ * {{{
+ * bin/spark-shell \
+ * --jars `ls connector/connect/server/target/**/spark-connect*SNAPSHOT.jar |
paste -sd ',' -` \
+ * --conf spark.plugins=org.apache.spark.sql.connect.SparkConnectPlugin
+ * }}}
+ *
+ * Set system property `SPARK_HOME` if the test is not executed from the Spark
project top folder.
+ * Set system property `DEBUG_SC_JVM_CLIENT=true` to print the server process
output in the
+ * console to debug server start stop problems.
+ */
+object SparkConnectServerUtils {
+ // System properties used for testing and debugging
+ private val SPARK_HOME = "SPARK_HOME"
+ private val ENV_DEBUG_SC_JVM_CLIENT = "DEBUG_SC_JVM_CLIENT"
+
+ private val sparkHome =
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #39541: [SPARK-42043][CONNECT] Scala Client Result with E2E Tests
HyukjinKwon commented on code in PR #39541:
URL: https://github.com/apache/spark/pull/39541#discussion_r1082326160
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/connect/client/util/RemoteSparkSession.scala:
##
@@ -0,0 +1,198 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.connect.client.util
+
+import java.io.{BufferedOutputStream, File}
+
+import scala.io.Source
+
+import org.scalatest.BeforeAndAfterAll
+import sys.process._
+
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.connect.client.SparkConnectClient
+import org.apache.spark.sql.connect.common.config.ConnectCommon
+
+/**
+ * An util class to start a local spark connect server in a different process
for local E2E tests.
+ * It is designed to start the server once but shared by all tests. It is
equivalent to use the
+ * following command to start the connect server via command line:
+ *
+ * {{{
+ * bin/spark-shell \
+ * --jars `ls connector/connect/server/target/**/spark-connect*SNAPSHOT.jar |
paste -sd ',' -` \
+ * --conf spark.plugins=org.apache.spark.sql.connect.SparkConnectPlugin
+ * }}}
+ *
+ * Set system property `SPARK_HOME` if the test is not executed from the Spark
project top folder.
+ * Set system property `DEBUG_SC_JVM_CLIENT=true` to print the server process
output in the
+ * console to debug server start stop problems.
+ */
+object SparkConnectServerUtils {
+ // System properties used for testing and debugging
+ private val SPARK_HOME = "SPARK_HOME"
+ private val ENV_DEBUG_SC_JVM_CLIENT = "DEBUG_SC_JVM_CLIENT"
+
+ private val sparkHome = System.getProperty(SPARK_HOME, fileSparkHome())
Review Comment:
Should get the Spark home from local property too. See `SQLHelper.sparkHome`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] EnricoMi commented on pull request #39640: [SPARK-38591][SQL] Add flatMapSortedGroups and cogroupSorted
EnricoMi commented on PR #39640: URL: https://github.com/apache/spark/pull/39640#issuecomment-1398179550 Thanks for your time! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39541: [SPARK-42043][CONNECT] Scala Client Result with E2E Tests
dongjoon-hyun commented on PR #39541: URL: https://github.com/apache/spark/pull/39541#issuecomment-1398177490 BTW, while I was reviewing this PR, I felt the necessity to open an official PR to test any potential test cases on tagging. Here is the general PR to detect any `SNAPSHOT` string issue. - https://github.com/apache/spark/pull/39668 Also, cc @xinrong-meng since she is the release manager. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #39541: [SPARK-42043][CONNECT] Scala Client Result with E2E Tests
HyukjinKwon commented on code in PR #39541:
URL: https://github.com/apache/spark/pull/39541#discussion_r1082323765
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/connect/client/util/RemoteSparkSession.scala:
##
@@ -0,0 +1,198 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.connect.client.util
+
+import java.io.{BufferedOutputStream, File}
+
+import scala.io.Source
+
+import org.scalatest.BeforeAndAfterAll
+import sys.process._
+
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.connect.client.SparkConnectClient
+import org.apache.spark.sql.connect.common.config.ConnectCommon
+
+/**
+ * An util class to start a local spark connect server in a different process
for local E2E tests.
+ * It is designed to start the server once but shared by all tests. It is
equivalent to use the
+ * following command to start the connect server via command line:
+ *
+ * {{{
+ * bin/spark-shell \
+ * --jars `ls connector/connect/server/target/**/spark-connect*SNAPSHOT.jar |
paste -sd ',' -` \
+ * --conf spark.plugins=org.apache.spark.sql.connect.SparkConnectPlugin
+ * }}}
+ *
+ * Set system property `SPARK_HOME` if the test is not executed from the Spark
project top folder.
+ * Set system property `DEBUG_SC_JVM_CLIENT=true` to print the server process
output in the
+ * console to debug server start stop problems.
+ */
+object SparkConnectServerUtils {
+ // System properties used for testing and debugging
+ private val SPARK_HOME = "SPARK_HOME"
+ private val ENV_DEBUG_SC_JVM_CLIENT = "DEBUG_SC_JVM_CLIENT"
+
+ private val sparkHome = System.getProperty(SPARK_HOME, fileSparkHome())
+ private val isDebug = System.getProperty(ENV_DEBUG_SC_JVM_CLIENT,
"false").toBoolean
+
+ // Log server start stop debug info into console
+ // scalastyle:off println
+ private[connect] def debug(msg: String): Unit = if (isDebug) println(msg)
+ // scalastyle:on println
+ private[connect] def debug(error: Throwable): Unit = if (isDebug)
error.printStackTrace()
+
+ // Server port
+ private[connect] val port = ConnectCommon.CONNECT_GRPC_BINDING_PORT +
util.Random.nextInt(1000)
+
+ @volatile private var stopped = false
+
+ private lazy val sparkConnect: Process = {
+debug("Starting the Spark Connect Server...")
+val jar = findSparkConnectJar
+val builder = Process(
+ new File(sparkHome, "bin/spark-shell").getCanonicalPath,
+ Seq(
+"--jars",
+jar,
+"--driver-class-path",
+jar,
+"--conf",
+"spark.plugins=org.apache.spark.sql.connect.SparkConnectPlugin",
+"--conf",
+s"spark.connect.grpc.binding.port=$port"))
+
+val io = new ProcessIO(
+ // Hold the input channel to the spark console to keep the console open
+ in => new BufferedOutputStream(in),
+ // Only redirect output if debug to avoid channel interruption error on
process termination.
+ out => if (isDebug) Source.fromInputStream(out).getLines.foreach(debug),
+ err => if (isDebug) Source.fromInputStream(err).getLines.foreach(debug))
+val process = builder.run(io)
+
+// Adding JVM shutdown hook
+sys.addShutdownHook(kill())
+process
+ }
+
+ def start(): Unit = {
+assert(!stopped)
+sparkConnect
+ }
+
+ def kill(): Int = {
+stopped = true
+debug("Stopping the Spark Connect Server...")
+sparkConnect.destroy()
+val code = sparkConnect.exitValue()
+debug(s"Spark Connect Server is stopped with exit code: $code")
+code
+ }
+
+ private def fileSparkHome(): String = {
+val path = new File("./").getCanonicalPath
+if (path.endsWith("connector/connect/client/jvm")) {
+ // the current folder is the client project folder
+ new File("../../../../").getCanonicalPath
+} else {
+ path
+}
+ }
+
+ private def findSparkConnectJar: String = {
+val target = "connector/connect/server/target"
+val parentDir = new File(sparkHome, target)
+assert(
+ parentDir.exists(),
+ s"Fail to locate the spark connect target folder:
'${parentDir.getCanonicalPath}'. " +
+s"SPARK_HOME='${new File(sparkHome).getCanonicalPath}'. " +
+"Make sure
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #39541: [SPARK-42043][CONNECT] Scala Client Result with E2E Tests
HyukjinKwon commented on code in PR #39541:
URL: https://github.com/apache/spark/pull/39541#discussion_r1082319733
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/connect/client/util/RemoteSparkSession.scala:
##
@@ -0,0 +1,198 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.connect.client.util
+
+import java.io.{BufferedOutputStream, File}
+
+import scala.io.Source
+
+import org.scalatest.BeforeAndAfterAll
+import sys.process._
+
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.connect.client.SparkConnectClient
+import org.apache.spark.sql.connect.common.config.ConnectCommon
+
+/**
+ * An util class to start a local spark connect server in a different process
for local E2E tests.
+ * It is designed to start the server once but shared by all tests. It is
equivalent to use the
+ * following command to start the connect server via command line:
+ *
+ * {{{
+ * bin/spark-shell \
+ * --jars `ls connector/connect/server/target/**/spark-connect*SNAPSHOT.jar |
paste -sd ',' -` \
+ * --conf spark.plugins=org.apache.spark.sql.connect.SparkConnectPlugin
+ * }}}
+ *
+ * Set system property `SPARK_HOME` if the test is not executed from the Spark
project top folder.
+ * Set system property `DEBUG_SC_JVM_CLIENT=true` to print the server process
output in the
+ * console to debug server start stop problems.
+ */
+object SparkConnectServerUtils {
Review Comment:
Is this an API? Would be great to either document that this package is an
internal API, or properly give the accessor.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #39541: [SPARK-42043][CONNECT] Scala Client Result with E2E Tests
HyukjinKwon commented on code in PR #39541:
URL: https://github.com/apache/spark/pull/39541#discussion_r1082320316
##
connector/connect/client/jvm/src/test/scala/org/apache/spark/sql/connect/client/util/RemoteSparkSession.scala:
##
@@ -0,0 +1,198 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql.connect.client.util
+
+import java.io.{BufferedOutputStream, File}
+
+import scala.io.Source
+
+import org.scalatest.BeforeAndAfterAll
+import sys.process._
+
+import org.apache.spark.sql.SparkSession
+import org.apache.spark.sql.connect.client.SparkConnectClient
+import org.apache.spark.sql.connect.common.config.ConnectCommon
+
+/**
+ * An util class to start a local spark connect server in a different process
for local E2E tests.
+ * It is designed to start the server once but shared by all tests. It is
equivalent to use the
+ * following command to start the connect server via command line:
+ *
+ * {{{
+ * bin/spark-shell \
+ * --jars `ls connector/connect/server/target/**/spark-connect*SNAPSHOT.jar |
paste -sd ',' -` \
+ * --conf spark.plugins=org.apache.spark.sql.connect.SparkConnectPlugin
+ * }}}
+ *
+ * Set system property `SPARK_HOME` if the test is not executed from the Spark
project top folder.
+ * Set system property `DEBUG_SC_JVM_CLIENT=true` to print the server process
output in the
+ * console to debug server start stop problems.
+ */
+object SparkConnectServerUtils {
+ // System properties used for testing and debugging
+ private val SPARK_HOME = "SPARK_HOME"
+ private val ENV_DEBUG_SC_JVM_CLIENT = "DEBUG_SC_JVM_CLIENT"
+
+ private val sparkHome = System.getProperty(SPARK_HOME, fileSparkHome())
+ private val isDebug = System.getProperty(ENV_DEBUG_SC_JVM_CLIENT,
"false").toBoolean
+
+ // Log server start stop debug info into console
+ // scalastyle:off println
+ private[connect] def debug(msg: String): Unit = if (isDebug) println(msg)
+ // scalastyle:on println
+ private[connect] def debug(error: Throwable): Unit = if (isDebug)
error.printStackTrace()
+
+ // Server port
+ private[connect] val port = ConnectCommon.CONNECT_GRPC_BINDING_PORT +
util.Random.nextInt(1000)
+
+ @volatile private var stopped = false
+
+ private lazy val sparkConnect: Process = {
+debug("Starting the Spark Connect Server...")
Review Comment:
nit but `...` -> `.`
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun opened a new pull request, #39668: [WIP] Test 3.4.0 tagging
dongjoon-hyun opened a new pull request, #39668: URL: https://github.com/apache/spark/pull/39668 This aims to test the possible test failures on Spark 3.4.0 RC tag. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] HyukjinKwon commented on a diff in pull request #39541: [SPARK-42043][CONNECT] Scala Client Result with E2E Tests
HyukjinKwon commented on code in PR #39541:
URL: https://github.com/apache/spark/pull/39541#discussion_r1082316930
##
connector/connect/client/jvm/src/main/scala/org/apache/spark/sql/SparkSession.scala:
##
@@ -0,0 +1,103 @@
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one or more
+ * contributor license agreements. See the NOTICE file distributed with
+ * this work for additional information regarding copyright ownership.
+ * The ASF licenses this file to You under the Apache License, Version 2.0
+ * (the "License"); you may not use this file except in compliance with
+ * the License. You may obtain a copy of the License at
+ *
+ *http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing, software
+ * distributed under the License is distributed on an "AS IS" BASIS,
+ * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ * See the License for the specific language governing permissions and
+ * limitations under the License.
+ */
+package org.apache.spark.sql
+
+import org.apache.arrow.memory.RootAllocator
+
+import org.apache.spark.connect.proto
+import org.apache.spark.sql.connect.client.{SparkConnectClient, SparkResult}
+import org.apache.spark.sql.connect.client.util.Cleaner
+
+/**
+ * The entry point to programming Spark with the Dataset and DataFrame API.
+ *
+ * In environments that this has been created upfront (e.g. REPL, notebooks),
use the builder to
+ * get an existing session:
+ *
+ * {{{
+ * SparkSession.builder().getOrCreate()
+ * }}}
+ *
+ * The builder can also be used to create a new session:
+ *
+ * {{{
+ * SparkSession.builder
+ * .master("local")
+ * .appName("Word Count")
+ * .config("spark.some.config.option", "some-value")
+ * .getOrCreate()
+ * }}}
+ */
+class SparkSession(private val client: SparkConnectClient, private val
cleaner: Cleaner)
+extends AutoCloseable {
+
+ private[this] val allocator = new RootAllocator()
+
+ /**
+ * Executes a SQL query using Spark, returning the result as a `DataFrame`.
This API eagerly
+ * runs DDL/DML commands, but not for SELECT queries.
+ *
+ * @since 3.4.0
+ */
+ def sql(query: String): Dataset = newDataset { builder =>
+builder.setSql(proto.SQL.newBuilder().setQuery(query))
+ }
+
+ private[sql] def newDataset(f: proto.Relation.Builder => Unit): Dataset = {
+val builder = proto.Relation.newBuilder()
+f(builder)
+val plan = proto.Plan.newBuilder().setRoot(builder).build()
+new Dataset(this, plan)
+ }
+
+ private[sql] def execute(plan: proto.Plan): SparkResult = {
+val value = client.execute(plan)
+val result = new SparkResult(value, allocator)
+cleaner.register(result)
+result
+ }
+
+ override def close(): Unit = {
+client.shutdown()
+allocator.close()
+ }
+}
+
+// The minimal builder needed to create a spark session.
+// TODO: implements all methods mentioned in the scaladoc of [[SparkSession]]
Review Comment:
Please file a JIRA for a TODO.
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39665: [SPARK-42114][SQL][TESTS] Add uniform parquet encryption test case
dongjoon-hyun commented on PR #39665: URL: https://github.com/apache/spark/pull/39665#issuecomment-1398167017 I fixed the `Affected Version` from 3.3.1 to 3.4.0 because this fails in `branch-3.3`. ``` [info] ParquetEncryptionSuite: [info] - SPARK-34990: Write and read an encrypted parquet (2 seconds, 461 milliseconds) [info] - SPARK-37117: Can't read files in Parquet encryption external key material mode (476 milliseconds) [info] - SPARK-42114: Test of uniform parquet encryption *** FAILED *** (184 milliseconds) [info] "PAR[E]" did not equal "PAR[1]" (ParquetEncryptionSuite.scala:140) [info] Analysis: [info] "PAR[E]" -> "PAR[1]" ``` -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39664: [SPARK-42114][SQL] Test of uniform parquet encryption
dongjoon-hyun commented on PR #39664: URL: https://github.com/apache/spark/pull/39664#issuecomment-1398159305 I merged the newer PR, @ggershinsky . :) - https://github.com/apache/spark/commit/e1c630a98c45ae07c43c8cf95979532b51bf59ec -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #39666: [SPARK-42130][UI] Handle null string values in AccumulableInfo and ProcessSummary
dongjoon-hyun commented on code in PR #39666: URL: https://github.com/apache/spark/pull/39666#discussion_r1082308565 ## core/src/main/protobuf/org/apache/spark/status/protobuf/store_types.proto: ## @@ -22,7 +22,12 @@ package org.apache.spark.status.protobuf; * Developer guides: * - Coding style: https://developers.google.com/protocol-buffers/docs/style * - Use int64 for job/stage IDs, in case of future extension in Spark core. - * - Use `weakIntern` on string values in create new objects during deserialization. + * - For string fields: + * - use `optional string` for protobuf definition + * - on serialization, check if the string is null to avoid NPE + * - on deserialization, set string fields as null if it is not set. Also, use `weakIntern` on + * string values in create new objects during deserialization. + * - add tests with null string inputs Review Comment: Just a question. Is there a way to automate this checking in `store_types.proto` file? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #39666: [SPARK-42130][UI] Handle null string values in AccumulableInfo and ProcessSummary
dongjoon-hyun commented on code in PR #39666: URL: https://github.com/apache/spark/pull/39666#discussion_r1082308565 ## core/src/main/protobuf/org/apache/spark/status/protobuf/store_types.proto: ## @@ -22,7 +22,12 @@ package org.apache.spark.status.protobuf; * Developer guides: * - Coding style: https://developers.google.com/protocol-buffers/docs/style * - Use int64 for job/stage IDs, in case of future extension in Spark core. - * - Use `weakIntern` on string values in create new objects during deserialization. + * - For string fields: + * - use `optional string` for protobuf definition + * - on serialization, check if the string is null to avoid NPE + * - on deserialization, set string fields as null if it is not set. Also, use `weakIntern` on + * string values in create new objects during deserialization. + * - add tests with null string inputs Review Comment: Just a question. Is there a way to automate this in `store_types.proto` file? -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on a diff in pull request #39666: [SPARK-42130][UI] Handle null string values in AccumulableInfo and ProcessSummary
dongjoon-hyun commented on code in PR #39666: URL: https://github.com/apache/spark/pull/39666#discussion_r1082307793 ## core/src/main/protobuf/org/apache/spark/status/protobuf/store_types.proto: ## @@ -22,7 +22,12 @@ package org.apache.spark.status.protobuf; * Developer guides: * - Coding style: https://developers.google.com/protocol-buffers/docs/style * - Use int64 for job/stage IDs, in case of future extension in Spark core. - * - Use `weakIntern` on string values in create new objects during deserialization. + * - For string fields: + * - use `optional string` for protobuf definition Review Comment: Thank you for adding this. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun commented on pull request #39665: [SPARK-42114][SQL][TESTS] Add uniform parquet encryption test case
dongjoon-hyun commented on PR #39665: URL: https://github.com/apache/spark/pull/39665#issuecomment-1398155059 BTW, please add `ggershin...@apple.com` to your GitHub profile as the secondary email. ``` $ git log -n1 commit e1c630a98c45ae07c43c8cf95979532b51bf59ec (HEAD -> master, apache/master, apache/HEAD) Author: Gidon Gershinsky ``` Then, the GitHub commit list will show your profile image correctly, @ggershinsky .  -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] dongjoon-hyun closed pull request #39665: [SPARK-42114][SQL][TESTS] Add uniform parquet encryption test case
dongjoon-hyun closed pull request #39665: [SPARK-42114][SQL][TESTS] Add uniform parquet encryption test case URL: https://github.com/apache/spark/pull/39665 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a diff in pull request #39666: [SPARK-42130][UI] Handle null string values in AccumulableInfo and ProcessSummary
gengliangwang commented on code in PR #39666:
URL: https://github.com/apache/spark/pull/39666#discussion_r1082286371
##
core/src/main/scala/org/apache/spark/status/protobuf/Utils.scala:
##
@@ -17,10 +17,24 @@
package org.apache.spark.status.protobuf
+import com.google.protobuf.MessageOrBuilder
+
object Utils {
def getOptional[T](condition: Boolean, result: () => T): Option[T] = if
(condition) {
Some(result())
} else {
None
}
+
+ def setStringField(input: String, f: String => MessageOrBuilder): Unit = {
Review Comment:
On second thought, there is no convenient way for getting optional map. As
per your suggestion, there will be `setField` and `getStringField`, which
become asymmetrical.
I will keep the current code
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a diff in pull request #39666: [SPARK-42130][UI] Handle null string values in AccumulableInfo and ProcessSummary
gengliangwang commented on code in PR #39666:
URL: https://github.com/apache/spark/pull/39666#discussion_r1082251439
##
core/src/main/scala/org/apache/spark/status/protobuf/Utils.scala:
##
@@ -17,10 +17,24 @@
package org.apache.spark.status.protobuf
+import com.google.protobuf.MessageOrBuilder
+
object Utils {
def getOptional[T](condition: Boolean, result: () => T): Option[T] = if
(condition) {
Some(result())
} else {
None
}
+
+ def setStringField(input: String, f: String => MessageOrBuilder): Unit = {
Review Comment:
Sure
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] zhengruifeng commented on pull request #39661: [SPARK-41884][CONNECT] Support naive tuple as a nested row
zhengruifeng commented on PR #39661: URL: https://github.com/apache/spark/pull/39661#issuecomment-1398122520 LGTM, thanks! -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer commented on a diff in pull request #39660: [SPARK-42128][SQL] Support TOP (N) for MS SQL Server dialect as an alternative to Limit pushdown
beliefer commented on code in PR #39660:
URL: https://github.com/apache/spark/pull/39660#discussion_r1082270560
##
sql/core/src/main/scala/org/apache/spark/sql/jdbc/JdbcDialects.scala:
##
@@ -544,6 +544,14 @@ abstract class JdbcDialect extends Serializable with
Logging {
if (limit > 0 ) s"LIMIT $limit" else ""
}
+ /**
+ * MS SQL Server version of `getLimitClause`.
+ * This is only supported by SQL Server as it uses TOP (N) instead.
+ */
+ def getTopExpression(limit: Integer): String = {
Review Comment:
This API looks a little hack.
https://github.com/apache/spark/pull/39667 refactor the API and this PR
could override getSQLText.
cc @cloud-fan @huaxingao
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] beliefer opened a new pull request, #39667: [SPARK-42131][SQL] Extract the function that construct the select statement for JDBC dialect.
beliefer opened a new pull request, #39667:
URL: https://github.com/apache/spark/pull/39667
### What changes were proposed in this pull request?
Currently, JDBCRDD uses fixed format for SELECT statement.
```
val sqlText = options.prepareQuery +
s"SELECT $columnList FROM ${options.tableOrQuery}
$myTableSampleClause" +
s" $myWhereClause $getGroupByClause $getOrderByClause $myLimitClause
$myOffsetClause"
```
But some databases have different syntax that uses different keyword or
sort. For example, MS SQL Server uses keyword TOP to describe LIMIT clause or
Top N.
The LIMIT clause of MS SQL Server.
```
SELECT TOP(1) Model, Color, Price
FROM dbo.Cars
WHERE Color = 'blue'
```
The Top N of MS SQL Server.
```
SELECT TOP(1) Model, Color, Price
FROM dbo.Cars
WHERE Color = 'blue'
ORDER BY Price ASC
```
Their PR will let JDBC dialect could define the special syntax own.
### Why are the changes needed?
Extract the function that construct the select statement for JDBC dialect.
### Does this PR introduce _any_ user-facing change?
'No'.
New feature.
### How was this patch tested?
N/A
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] sadikovi commented on pull request #39660: [SPARK-42128][SQL] Support TOP (N) for MS SQL Server dialect as an alternative to Limit pushdown
sadikovi commented on PR #39660: URL: https://github.com/apache/spark/pull/39660#issuecomment-1398098578 Thanks @dongjoon-hyun. I will address your comments soon-ish . @beliefer, Yes, you are right. The documentation describes TOP (N) returning the N top rows when used together with ORDER BY but when it is by itself, it behaves just like LIMIT - no particular order is guaranteed. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] gengliangwang commented on a diff in pull request #39666: [SPARK-42130][UI] Handle null string values in AccumulableInfo and ProcessSummary
gengliangwang commented on code in PR #39666:
URL: https://github.com/apache/spark/pull/39666#discussion_r1082251439
##
core/src/main/scala/org/apache/spark/status/protobuf/Utils.scala:
##
@@ -17,10 +17,24 @@
package org.apache.spark.status.protobuf
+import com.google.protobuf.MessageOrBuilder
+
object Utils {
def getOptional[T](condition: Boolean, result: () => T): Option[T] = if
(condition) {
Some(result())
} else {
None
}
+
+ def setStringField(input: String, f: String => MessageOrBuilder): Unit = {
Review Comment:
Sure
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on a diff in pull request #39666: [SPARK-42130][UI] Handle null string values in AccumulableInfo and ProcessSummary
LuciferYang commented on code in PR #39666:
URL: https://github.com/apache/spark/pull/39666#discussion_r1082248889
##
core/src/main/scala/org/apache/spark/status/protobuf/Utils.scala:
##
@@ -17,10 +17,24 @@
package org.apache.spark.status.protobuf
+import com.google.protobuf.MessageOrBuilder
+
object Utils {
def getOptional[T](condition: Boolean, result: () => T): Option[T] = if
(condition) {
Some(result())
} else {
None
}
+
+ def setStringField(input: String, f: String => MessageOrBuilder): Unit = {
Review Comment:
Should we make this function more general? Such as
```
def setField[T](input: T, f: T => MessageOrBuilder): Unit = {
if (input != null) {
f(input)
}
}
```
Other types of input may also be null, such as map.
https://github.com/apache/spark/blob/ec424c5b0e392acc57e825fb94a21d6963ebece9/sql/core/src/main/scala/org/apache/spark/status/protobuf/sql/SQLExecutionUIDataSerializer.scala#L37-L41
--
This is an automated message from the Apache Git Service.
To respond to the message, please log on to GitHub and use the
URL above to go to the specific comment.
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For queries about this service, please contact Infrastructure at:
us...@infra.apache.org
-
To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org
For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] EnricoMi closed pull request #37551: [SPARK-38591][SQL] Add sortWithinGroups to KeyValueGroupedDataset
EnricoMi closed pull request #37551: [SPARK-38591][SQL] Add sortWithinGroups to KeyValueGroupedDataset URL: https://github.com/apache/spark/pull/37551 -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] EnricoMi commented on pull request #37551: [SPARK-38591][SQL] Add sortWithinGroups to KeyValueGroupedDataset
EnricoMi commented on PR #37551: URL: https://github.com/apache/spark/pull/37551#issuecomment-1398081395 Closing as #39640 has been merged. -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org
[GitHub] [spark] LuciferYang commented on pull request #39642: [SPARK-41677][CORE][SQL][SS][UI] Add Protobuf serializer for `StreamingQueryProgressWrapper`
LuciferYang commented on PR #39642: URL: https://github.com/apache/spark/pull/39642#issuecomment-1398075391 Will refactor after https://github.com/apache/spark/pull/39666 merged -- This is an automated message from the Apache Git Service. To respond to the message, please log on to GitHub and use the URL above to go to the specific comment. To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For queries about this service, please contact Infrastructure at: us...@infra.apache.org - To unsubscribe, e-mail: reviews-unsubscr...@spark.apache.org For additional commands, e-mail: reviews-h...@spark.apache.org